
Abstract
Considering the heterogeneity, diffusive shape, and complex background of tumors, automatic segmentation of hepatic lesions in computed tomography (CT) images has been considered a challenging task. The performance of existing methods remains subject to segmentation uncertainties, especially in tumor boundary regions. The pixel information in these regions will be affected by both sides, thereby exposing the segmentation results to missing marks. To this end, a new network architecture named Two Direction Segmentation U-Net (TDS-U-Net) is hereby designed based on the classic Attention U-Net to tackle this problem. As the most important blocks of the Attention U-Net network, attention gates (AGs) focus on the target structures of different shapes and sizes. In the last layer of TDS-U-Net, two dichotomous convolutional networks are applied to obtain the segmentation maps of the liver and the tumor respectively. Superimposing two segmented maps to obtain the final image addresses the above problems. The entire structure has been verified on two widely accepted public CT datasets, LiTS17 and KiTS19. Compared with the state of the art, this method exhibits superior performance and excellent shape extractions with high detection sensitivity, perfectly demonstrating its effectiveness in medical image segmentation.
Introduction
Liver cancer, known as one of the most common cancers with a high mortality rate in the modern world, has caused a serious threat to the health and lives of contemporary humans. Generally, computed tomography (CT) is applied to tumor diagnosis and treatment. Manual liver lesion segmentation on CT is time-consuming, difficult to reproduce, and easy to be influenced by personal subjective experiences. In this case, a fully automatic method for liver lesion segmentation should be urgently developed. Although the liver segmenting task has achieved favorable results due to CNN, localization of liver tumors remains a demanding task to be further improved. One of the main issues in the segmentation task lies in the low contrast between liver and tumor tissues, high variation in size, shape, and number of lesions, and the similarity of nearby organs. Besides, the imaging noise makes it difficult to segment the lesions, thus making automatic liver lesion segmentation a challenging task.
To address the above-mentioned issues, numerous methods based on the deep learning technology have been proposed for the liver lesion segmentation task in recent years, which can be generally divided into two categories:
1) 2D models, e.g., Cascaded-FCN [1] train and cascade two FCNs for a combined segmentation of the liver and its lesions, FCN based on VGG-16 [2] achieved semantic level segmentation of the image by combining the deep abstract feature and shallow feature in depth by building the duplicate channel;
2) 3D models, e.g., densely connected volumetric ConvNets [3] proposed a novel 3D convolutional neural network with densely-connected layers to automatically segment the prostate from Magnetic Resonance(MR) images, which consisted of a 2D DenseUNet for efficiently extracting intra-slice features and a 3D counterpart for hierarchically aggregating volumetric contexts (H-DenseUNet) [4], a 3D patch-based fully dense and fully convolutional network (FD-FCN) [5]. The previous methods have exhibited much-improved performance, but still have considerable potential for further optimization. For example, previous 2D networks fail to fully utilize the depth information of the CT images, and the segmentation accuracy is quite low. Meanwhile, 3D networks are computationally expensive and have high requirements for hardware configurations. Under the same computing resources, large amounts of parameters and heavy computation jointly limit the depth and complexity of the 3D networks.
The traditional U-Net based method has achieved great success in medical image classification, but is still subject to certain limitations: firstly, the feature map of U-Net convolution lacks a targeted refining process of feature information; secondly, most CT files in the dataset present tumors, but the pixel area of the tumor is much smaller than that of the liver, thereby leading to a smaller number of tumor categories than liver categories. This results in a category imbalance that could easily lead to errors in small liver regions, discontinuous liver regions, and blurred liver boundaries; thirdly, the process of gradual down-sampling of the U-Net network may reduce the resolution of the image, thus decreasing the segmentation accuracy; lastly, the deepening of the network depth can easily induce degradation problems.
Considering the aforementioned facts, a Two Direction Segmentation U-Net (TDS-U-Net) based 2D model was hereby proposed for image segmentation, and the main contributions of this work are listed as follows:
1. A novel feature fusion method is proposed, which has four feature fusion channels to fuse the four-layer features of the decoder based on the original encoder-decoder layer, and thus obtain the low-level features;
2. The transition layer and the final output layer of the decoder are replaced by Atrous Spatial Pyramid Pooling (ASPP) to extract richer multi-scale feature information;
3. One new method is proposed to separately segment the liver and tumor.
Related work
In 2017, Christ et al. [1] trained two cascaded U-Net type FCNs: the first FCN segmented a liver from the rest of the inner body tissues, while the second FCN segmented lesions from the ROIs (regions-of-interest) predicated from the first FCN. Indeed, there is a remarkable overlap between liver and lesion intensities, which leads to low overall contrast. Paper [1] proved that the intensity of liver and lesion significantly overlap in the data set, thus resulting in the low overall contrast and segmenting difficulties. To successively segment the liver and the tumor within the liver region, two segmentation networks should be designed.
In 2018, Li et al. [4] developed a hybrid densely connected UNet (H-DenseUNet) that worked in an end-to-end manner, which consisted of a 2D DenseUNet and a 3D counterpart. In H-DenseUNet, the intra-slice representations and inter-slice features could be optimized jointly through a hybrid feature fusion (HFF) layer for accurate liver and lesion segmentation. It was trained on the MICCAI 2017 Liver Tumor Segmentation (LiTS) dataset [6], validated on the 3DIRCADb dataset, and achieved a liver DICE = 98.2% and a tumor DICE = 93.7%. Notably, exclusive experiments were also conducted on the 3DIRCADb dataset through cross-validation, and achieved a liver segmentation DICE = 94.7% and a tumor segmentation DICE = 65%.
Siriapisith et al. [7] adopted the concept of variable neighborhood and proposed a 2D segmentation method that could be searched by iteratively alternating the search through intensity and gradient spaces. They claimed that they had attained the segmentation performance with a DSC of 84.48±5.84% and 76.93±8.24% for large and small liver tumors, respectively.
Zettler et al. [8] presented a study mainly focusing on comparing 2D U-Nets and 3D U-Net counterparts, and the initial results indicated a Dice improvement of about 6% at most. Unexpectedly, liver and kidney problems, for instance, were significantly better tackled by applying the faster and GPU-memory saving 2D U-Nets. Besides, there were no remarkable differences in other abdominal key organs, but 2D U-Net was observed to have a remarkable advantage in GPU computation for all the studied organs. To conclude, the improved network based on 2D U-net is endowed with more advantages.
Xi et al. [9] proposed an integrated Yolov5-Deeplabv3 + real-time segmentation network (YDRSNet) for gear pitting measurement. This very two-stage network was constructed by using Yolov5 and an improved Deeplabv3+, and could be applied to processing the video samples in real time and overcoming the problem of sample imbalance.
Qin et al. [10] proposed an efficient architecture by distilling knowledge from well-trained medical image segmentation networks to train another lightweight network. A novel distillation module tailored for medical image segmentation was further devised to transfer semantic region information from the teacher to the student network. The lightweight network was improved up to 32.6% in the present experiment while maintaining its portability in the inference phase. The entire structure was verified on two widely accepted public CT datasets of LiTS17 and KiTS19.
Generally, the attention gates (AGs) are commonly applied to the language processing (NLP) for image captioning [11]. In the image analysis, trainable attention is categorized into hard attention and soft attention via feature map sampling. Soft attention is parameterized and learns weights depending on the relationship between features. Hence, it is derivable and could be embedded into the model for direct training. Gradients could be propagated back to other parts of the model via the attention mechanism module. In [12], additive soft attention is applied to sentence-to-sentence translation, while channel-wise attention is applied to channel highlighting in [13]. In [14], the author proposed SENet, the top-performer in the ILSVRC 2017 image classification challenge, which could be regarded as the attention mechanism of the channel dimension.
Besides, hard attention mainly conducts the crop random process in local feature areas, and samples a portion of the hidden state of the inputs based on the probability rather than that of the entire encoder. To realize the backpropagation of gradients, the monte Carlo sampling method was applied to the estimation of the gradient of modules.
Methodology
The hereby proposed TDS-U-Net network consists of an encoder responsible for feature extraction and a decoder for feature location, which constitute the symmetric structure (Fig. 2).
The whole architecture consists of 8 residual blocks, 4 pooling layers, 4 attention gates(AGs), 1 atrous spatial pyramid pooling (ASPP) block, 4 upsampling blocks, 1 deep network composite blocks, and 2 classification convolution blocks. The convolution kernel size is 3×3, the pooling layer size is 2×2, and that of the input image is 512×512×1. After a series of operations like convolution, feature extraction, and pooling, two 512×512 binary segmentation images are obtained for each feature image, i.e., the segmentation image of the liver and that of the tumor.
Uneven edge segmentation at the intersection of the liver and tumor segmentation.

The encoder part increases the number of filters by 1×1 convolution, performs 3×3 convolution, restores the number of filters by 1×1 convolution, and reduces the feature size by max-pooling. The decoder part combines the upsampling with the 3x3 convolution.
In the encoder convolution unit, ordinary units are replaced by block structures, and batch normalization and ReLU activation operations are performed after each convolution. The introduction of batch normalization not only reduces the sensitivity of the model to initialization parameters, but also imposes a regularization effect to a certain extent. In the ReLU function, its ability to effectively avert gradient disappearance problems makes it extensively applied to the activation. To better obtain information from the feature mapping of the encoder, AGs are added to the decoder to adaptively extract image features.
Thus, the network could focus on specific segmentation tasks by virtue of the channel attention mechanism (see Fig. 2). The specific operations of the AGs module are as follows. During the upsampling process of the decoder, even if the features of the fusion encoder cannot make the compensation, some features will be cut by the maximum pooling module. The extraction module is dense convolution, i.e., a combination of convolution and upsampling that aims to change the channel and size of features. The features of the four directions are combined with concatenation, and the final feature size is 512×512×1.
The network could be formulated as follows:
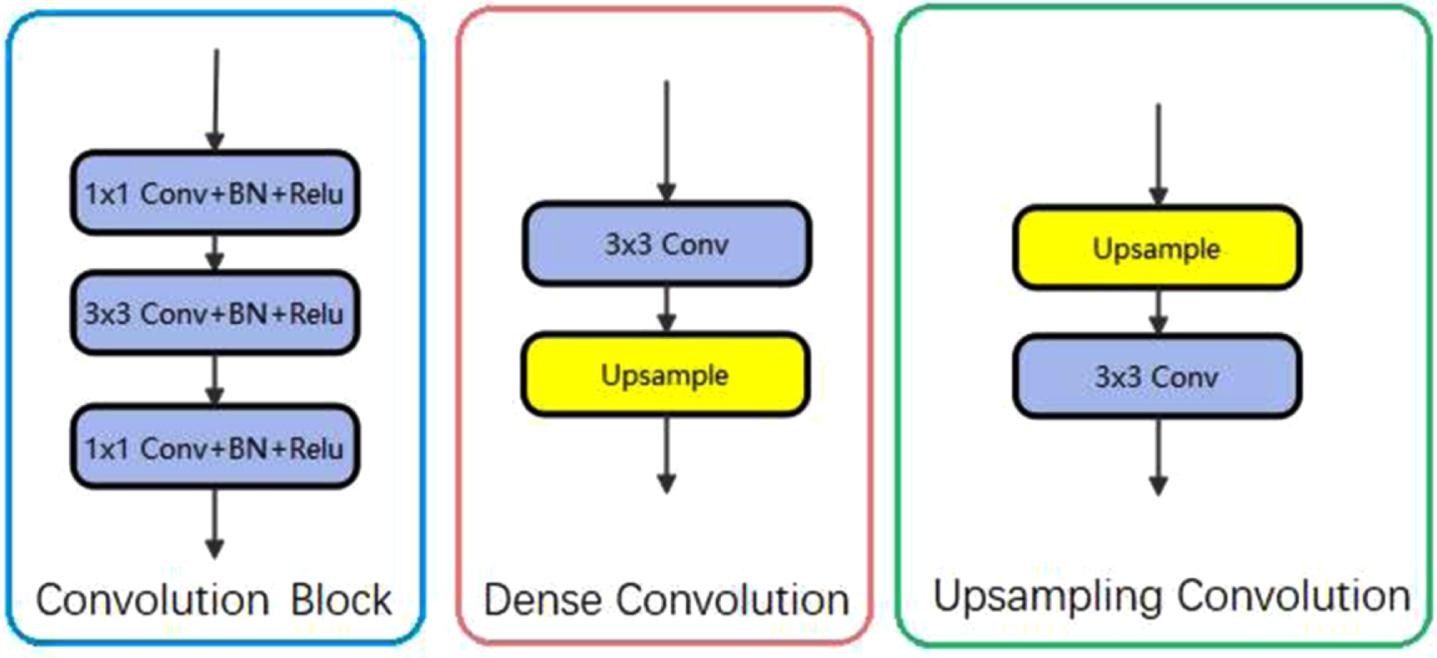
The structure of Convolution Block, Dense Convolution, and Upsampling Convolution.
In Fig. 2, after concatenation, the two feature maps are the segmentation of the liver and tumor. In both images, there are only two colors of pixels, the white is the result of the segmentation, and the black is the background. Take the white pixel position in the tumor segmentation image and set it to gray in the liver segmentation image to obtain the final image. Gray is the tumor, white is the liver, and black is the background.
Furthermore, to alleviate the problem of resolution degradation caused by multiple down-sampling, ASPP [15] is utilized as the transition layer of the network, as presented in Fig. 4. The ASPP module could capture the contextual information of the image at multiple scales, which promotes the inclusion of multi-scale semantic information in the extracted feature map. Similarly, the ASPP module is introduced to the output of the decoder part, thereby increasing the accuracy together with the transition layer.
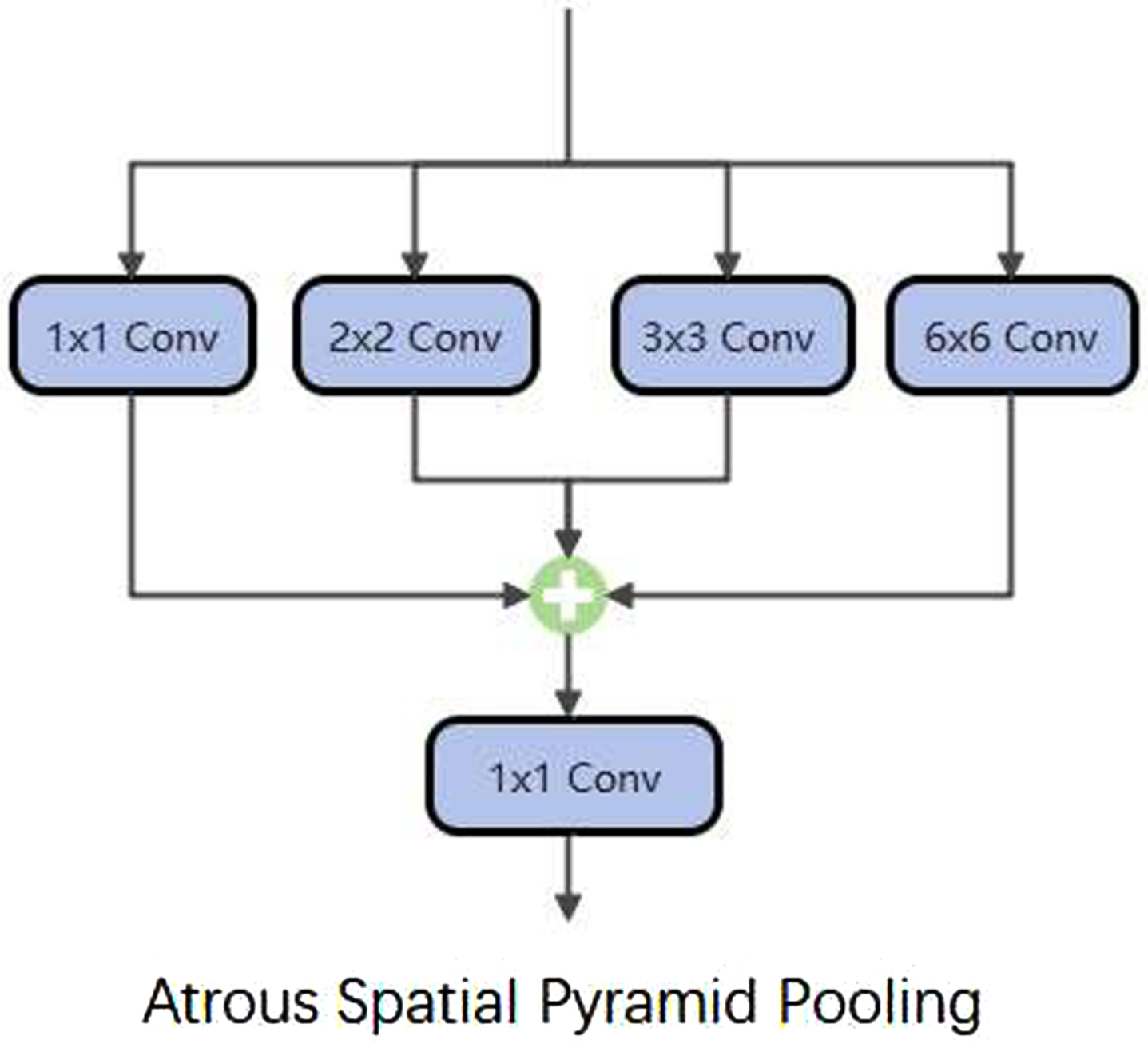
The structure of ASPP.
In [16], the author presented a new Dual Gradient-Color U-Net (DGCU–Net) model that contains two encoders and a single decoder paths. Additionally, the atrous spatial pyramid pooling (ASPP) block is utilized in the bridge stage between the encoder and decoder sub-networks. The proposed network architecture significantly improves the skin lesion segmentation results of the baseline U-Net model, and the ASPP module has a significant effect in the field of image segmentation.
A novel attentional gates (AGs) model was proposed for medical imaging in the paper [17], which automatically learns to focus on target structures of different shapes and sizes. The location information of the model features its shallowness, and the model can learn the characteristics of implicit learning with the AG training model in the inhibition of the input image not related to the area, while highlighting remarkable characteristics used for specific tasks. Similar low-level features will not keep repeating all models in the cascade extraction, thus reducing computational resources and model parameters. The AG automatic learning focuses on the target structure without additional supervision.
The attention coefficients,
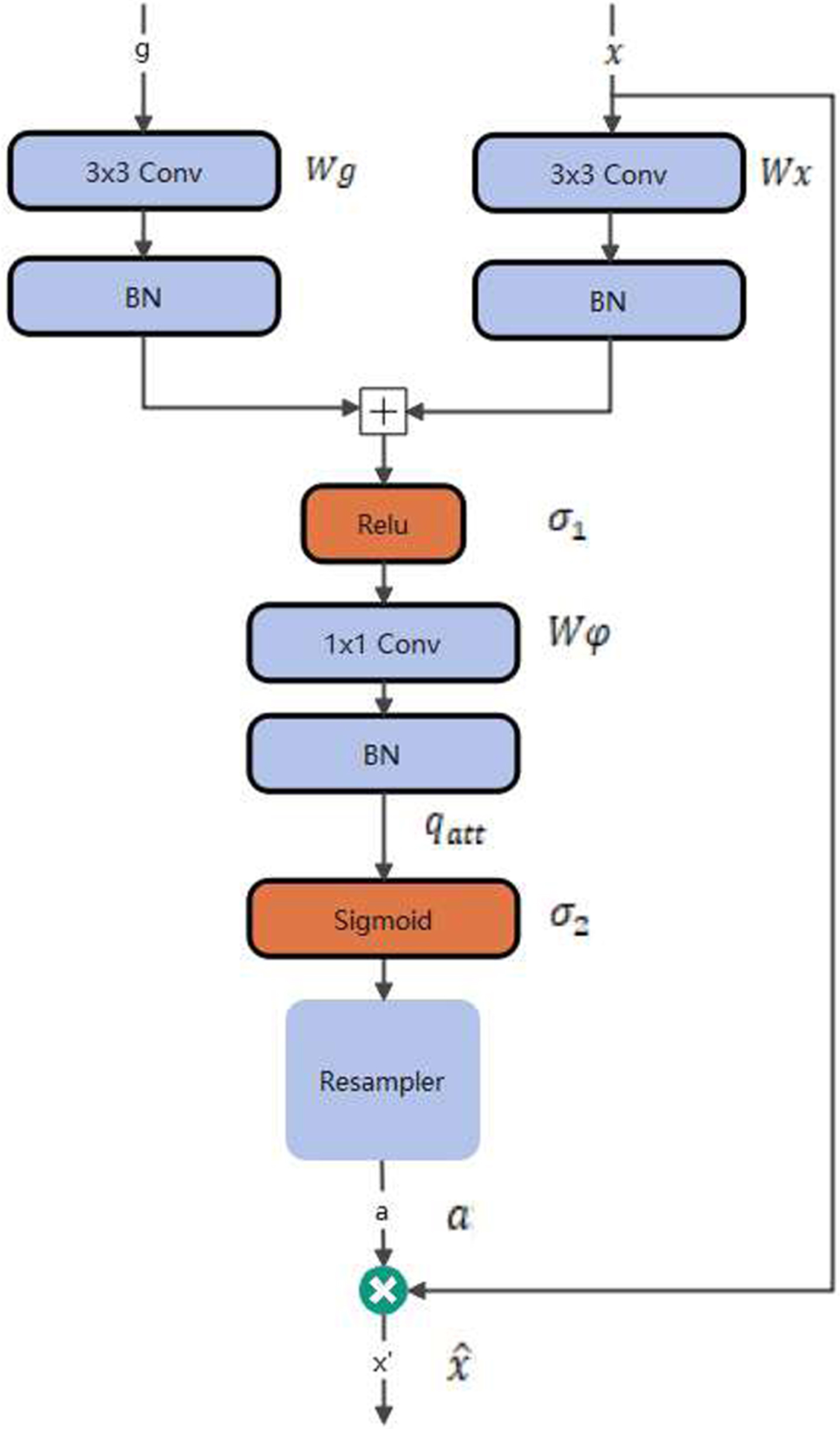
The structure of AGs.
AG is characterized by a set of parameters θ att including linear transformations Wx ∈ RFl*Fint, Wg ∈ RFg*Fint, Wg ∈ RFint*1, and bias terms b φ ∈ R and b g ∈ R Fint . The linear transformations were computed by applying channel-wise 1×1×1 convolutions to the input tensors, and a sigmoid activation function was adopted. The experimental results indicate better training convergence for the AG parameters.
In [18], all models were found to be subject to a tendency of missing small targets when trained with BCE or Focal Loss. Moreover, the developed losses handle not the imbalance between lesion sizes but that between classes. Herein, a simple methodology was proposed to reweight loss functions in the way that all targets contribute equally, that is, small targets have greater weights. The Universal Loss and Dice Loss formulas are as follows:
At the training stage, a tensor of weights was formed for each incoming patch by splitting the corresponding ground-truth patch into K + 1 connected componentsL0,..., L k , among which,L0 denotes the non-lesion component (background), and K represents the number of lesions in the current patch. Afterward, a weight inversely proportional to the volume of the component was assigned to each component.
In the formula, Wi denotes the weight assigned to each voxel inside the corresponding component L j . The constant in the denominator ensures that the sum of the weights equals that of the unit tensors of the same size (see derivation details in Supplementary Materials). This method was named inverse weighting (iW).
Dataset information
The publicly available dataset of the MICCAI 2017 LiTS [6] Challenge was applied to the training of the hereby proposed method. The LiTS dataset contains 131 and 70 contrast-enhanced 3D abdominal CT scans for training and testing, respectively. This method was tested on the 70 LiTS challenge test cases. The dataset was acquired from numerous different clinical sites with different scanners and protocols. Each slice in all CT scans has a fixed size of 512×512 pixels with the number of slices per scan varying between 42 and 1026, whereas the image resolutions differ from scan to scan.
LiTS Liver is an open-source dataset initially developed for liver lesion segmentation of CT scans, and a total of 131 CT images were hereby split into three sets of 70/30/31.
The publicly accessible KiTS19 [19] dataset embraces 210 intact abdominal CT scans labeled with manual segmentation masks of kidney and kidney tumor. There are no pre-operative arterial phase data, and the slice thickness is from 1 mm to 5 mm. The image resolution ranges from 0.4 mm to 1.0 mm in axial, and the longitudinal fields of view range from 20 to 140. The volume of most tumors varies between 9.6 cm3 to 109.7 cm3. Organizers emphasize that every patient selected into this dataset has one or more kidney tumors.
Experiments and results
Results
Figure 6 presents the effect picture of the present network in the LiTS dataset. The proposed model exhibits a relatively high robustness while dealing with difficult segmentation problems, e.g., small liver regions, discontinuous liver areas, and blurred liver boundaries.
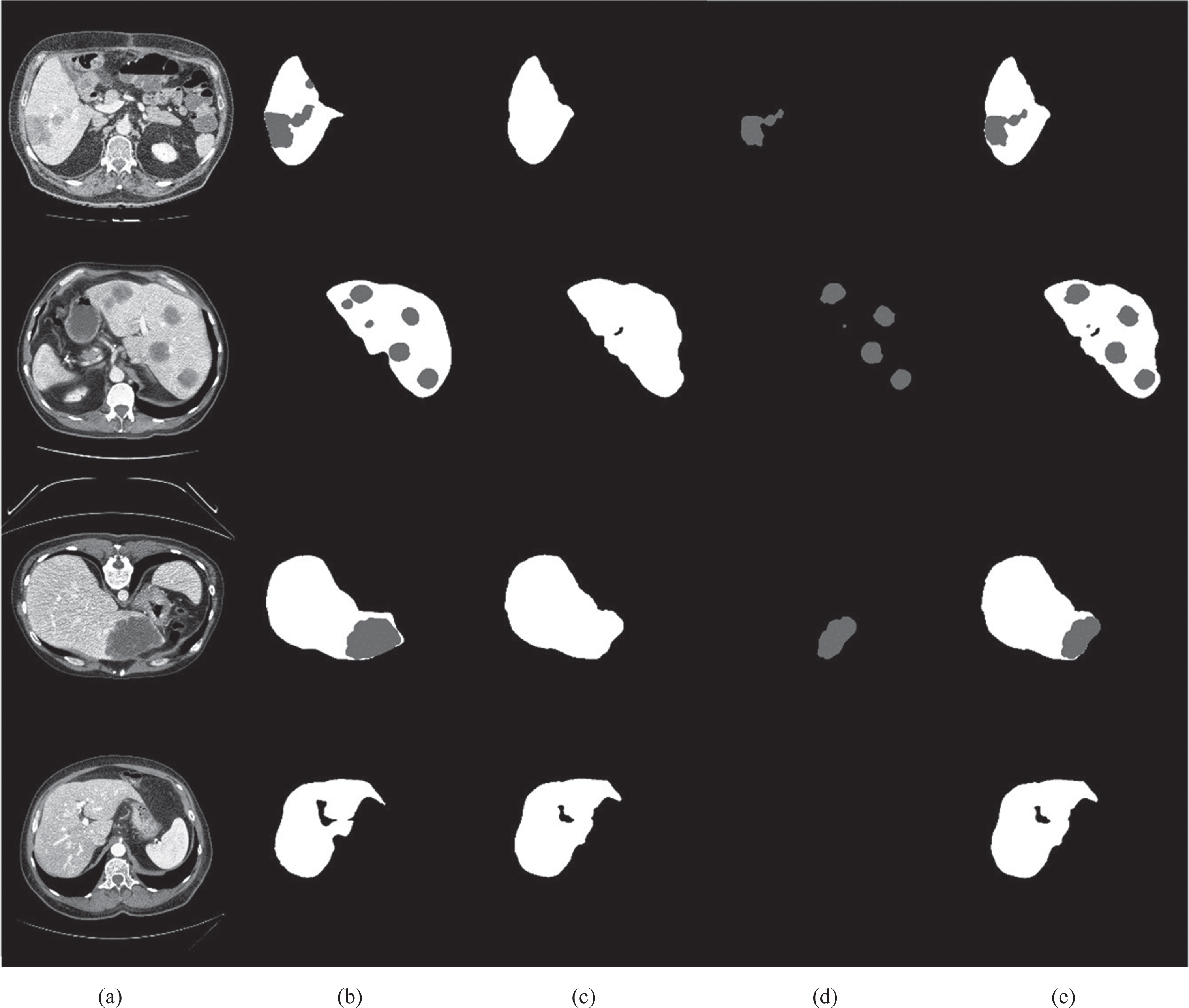
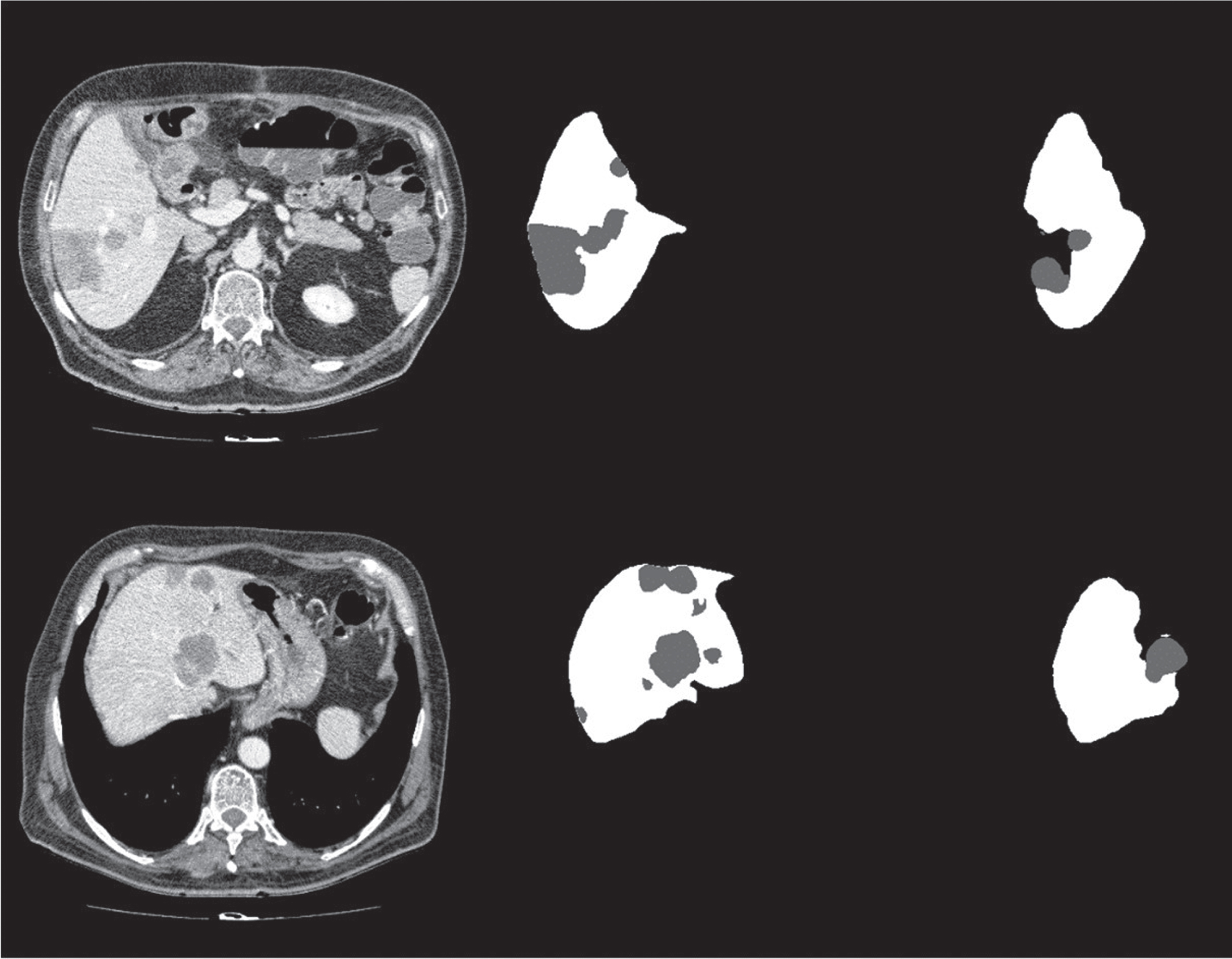
The remarkable effect of the proposed network segmentation, which separates the liver from the tumor and then fuses it. (a) Data; (b) Label; (c) The liver cut from the network; (d) The tumor cut from the network; (e) Results.
Table 1 depicts the quantitative comparison results of the four models. It can be observed from Table 1 that the hereby proposed model is provided with significant advantages in the comparisons on three evaluation metrics, especially for the Dice. This very method obtains the highest accuracy of 97.21±0.55. Compared with SAR-U-Net [20] and Attention U-Net [17], the Dice of the proposed model has been greatly improved.
The results of the proposed networks on LiTS17
Figure 7 presents the effect picture of this network in the KiTS19 dataset. Due to the shape characteristics of the liver organ, the label of the liver data is rather complete, and the pixel areas of the liver are connected together. The kidney is shaped like a bow. There is always a label with a space in the middle that does not belong to any organ. It is difficult for the network to segment such a shape, and the real area is not of this shape, which belongs to the label error information.

(a) Data; (b) Label; (c) The kidney cut from the network; (d) The tumor cut from the network; (e) Results.
Table 2 shows the quantitative comparison results of the three models, where it can be observed that in the KiTS19 dataset, tumor segmentation is not as favorable as kidney segmentation regardless of the network. This is determined by the characteristics of the dataset. The labeling accuracy of the label in the KiTS19 is lower than that in the LiTS17.
The results of this networks in the KiTS19 dataset
This paper presents a new TDS-U-Net network for CT liver segmentation. Based on the U-Net framework, an attention mechanism was added, and the branch network was applied to the final output step to separate the liver and the tumor and then fuse them. First, the AGS-based attention mechanism was adopted to adaptively extract image features and suppress irrelevant areas. Hence, the network focused on relevant features of the liver segmentation task. Afterward, ASPP technology was utilized as the transition layer and output layer of the network to realize multi-scale extraction of feature images. Compared with related classic methods, this method exhibits superior performance on the quantitative metrics. Specifically, the proposed method presents a remarkable improvement and robustness in handling small liver regions, discontinuous liver regions, and blurred liver boundaries.