
Abstract
Short-term energy consumption prediction of buildings is crucial for developing model-based predictive control, fault detection, and diagnosis methods. This study takes a university library in Xi’an as the research object. First, a time-by-time energy consumption prediction model is established under the supervised learning approach, which uses a long short-term memory (LSTM) network and a Multi-Input Multi-Output (MIMO) strategy. The experimental results validate the model’s validity, which is close enough to physical reality for engineering purposes. Second, the potential of the people flows factor in energy consumption prediction models is explored. The results show that people flow has great potential in predicting building energy consumption and can effectively improve the prediction model performance. Third, a diagnostic method, which can recognize abnormal energy consumption data is used to diagnose the unreasonable use of the building during each hour of operation. The method is based on differences between actual and predicted energy consumption data derived from a short-term energy consumption prediction model. Based on actual building operation data, this work is enlightening and can serve as a reference for building energy efficiency management and operation.
Introduction
As China’s economy grows, it has become a market that has a huge impact on the structure of world energy supply and demand [1]. In the medium-to-long-term outlook for global energy supply and demand, China’s economy will continue to rise significantly, as will its energy need. Excessive energy consumption not only leads to the depletion of fossil fuels like oil and coal, which seriously threatens the sustainability of natural resource use but also leads to massive greenhouse gas emissions and hasten the process of global warming [2]. Therefore, promoting efforts to ensure stable energy supply and demand and to address energy and environmental issues will be key to world energy security.
Currently, the building sector accounts for 39 percent of total global energy consumption and 38 percent of total global greenhouse gas emissions, respectively [3]. Compared to the transportation and industrial sectors, buildings have much greater energy-saving potential [4]. At the same time, with the gradual rise in floor space and energy consumption in recent years [5], energy efficiency research has become an important research direction, and fast and accurate energy consumption forecasting can provide data to optimize operational efficiency and help achieve China’s peak CO2 emissions by 2030.
In the process of building utilization, energy consumption is influenced by occupant behavior and external conditions such as climate and is regular and cyclical [6]. To reduce the waste of energy consumption in buildings, there is an urgent need to establish scientific predictive and diagnostic models based on in-depth analysis of the influencing factors and to take practical measures.
The goal of this research is first to develop a short-term prediction model for building energy consumption based on deep learning algorithms and to investigate the effect of the people flows factor on prediction performance. Then, based on the prediction model, an abnormal energy consumption diagnosis model is established to compare the predicted energy consumption values with the measured energy consumption values to determine the abnormal energy consumption and diagnose the unreasonable usage phenomena in building operations. Finally, the diagnostic results are applied to building operations and energy efficiency management.
The remainder of this paper is structured as follows: Section 2 reviews the literature relevant to this study. Section 3 presents the theoretical foundations of the algorithms and strategies used in this paper. Section 4 provides a detailed study of the case. A discussion of the case results is presented in Section 5. Section 6 summarizes the conclusions.
Literature review
For a long time, the industry has undertaken a comprehensive and in-depth study on building energy consumption prediction and achieved remarkable results. The existing methods are classified into two main categories: physical methods and data-driven methods. The prediction accuracy of physical methods relies heavily on detailed information about the building system [7] and the model performance may be inconsistent if the assumptions of physical principles are not satisfied [8]. In contrast, data-driven methods, which obtain historical building energy consumption sample data through sensing and communication technologies [9] and establish nonlinear mapping relationships between energy consumption samples, have been widely used in building energy consumption prediction due to their practicality, adaptability, and high prediction accuracy [10]. Previous studies have shown that prediction techniques in machine learning and artificial intelligence, such as artificial neural networks (ANN) [11] and support vector regression (SVR) [12, 13], work well in building energy consumption prediction. Data-driven approaches are gaining popularity in the building sector as modern building automation systems (BAS) provide more and more data on building operations. The rapid development of big data analytics opens up possibilities for making effective use of BAS data. A prominent and promising example is deep learning, which has achieved great success in the field of pattern recognition [14]. Deep learning can be developed both in a supervised manner for deep neural networks (DNN) models for prediction and in an unsupervised manner for deep autoencoder models for feature extraction [15]. Lee et al. [16] used a deep learning approach to integrate the advantages of supervised and unsupervised learning to build prediction models and improve the prediction efficiency of heating ventilation and air conditioning (HVAC) systems.
In general, time series and regression are the most often utilized data-driven methods for building energy consumption prediction. The former predict building energy consumption over time by identifying interdependencies and correlations between variables and time; the latter predict building energy consumption through building models based on the correlation between numerous attributes and energy consumption data [17]. Traditional machine learning techniques treat each input variable as an independent variable and therefore ignore the inherent temporal dependence between successive measures. Recurrent neural networks (RNN) use a continuous approach to input data, and therefore, the temporal dependence between continuous data can be well captured [18]. It has been shown that recurrent models achieve superior accuracy in energy prediction relative to other popular machine learning techniques [19, 20].
The role of energy consumption forecasting varies depending on the forecasting period. Long-term forecasts (e.g., more than one year) are typically used for energy maintenance planning [21]and power distribution [22]; medium-term forecasts (e.g., monthly, annually) are mainly used for component operation mode determination [23] and predictive maintenance [24]; and short-term forecasts (e.g., sub-hourly, hourly, or daily) are typically used for predictive model control [25], fault detection [26], and control optimization [27]. Short-term building energy consumption forecasting has attracted a great deal of interest among building professionals because of its close relevance to the daily operation of various service systems [28, 29]. Accurate prediction of building electricity consumption enables smooth integration of individual buildings with smart grid infrastructure [30], identifies abnormal operating behavior [31, 32], and optimizes the operation strategy of building renewable systems [33]. Shan et al. [34] developed a robust chiller sequence control strategy based on predicted building cooling load. The strategy was validated to be 3% more energy efficient than the conventional strategy. The predicted cold load was used directly or indirectly as an indicator for fault detection and diagnosis (FDD). Ben et al. [35] used ANN to predict the next day’s cold load and optimize the HVAC thermal storage system operation. The results showed that the optimal control strategy can reduce operating costs while improving operational flexibility. Wang et al. [36] proposed a method for predicting power consumption and detecting anomalies based on long short-term memory (LSTM) neural network, which resulted in a significant improvement in power theft identification compared with previous unsupervised algorithms. One of the studies’ underlying assumptions is that reliable short-term building load forecasting is available.
A data-driven dynamic energy diagnostic approach based on data has received increasing attention because it can provide accurate results by comparing current energy performance with historical data. The key to using a data-driven approach for energy consumption anomaly diagnosis is to build a reasonable and effective energy consumption prediction model that compares predicted values with historical energy consumption values to diagnose a building’s energy use and help operators identify abnormal energy use and inefficient operating conditions. Examples include Energy Star in the US [37], Demonstrated Energy Certificate (DEC) in the UK [38], and Leadership in Energy and Environmental Design (LEED) in Chicago [39]. Park et al. [40] use three data mining techniques (correlation analysis, decision tree analysis, and variance analysis) to propose an energy benchmark for improving the operational rating system of 1072 office buildings in Korea. Lin et al. [41] propose a temperature-based approach with simulation tests to detect abnormal energy failures in building operations. Yan et al. [42] propose a multi-level energy performance diagnosis method for buildings where energy information is scarce and energy use data is very limited. Li et al. [43] proposed a simplified method for energy benchmarking of HVAC systems in large commercial buildings based on detailed data from sub-metering systems and overall building operation. Liu et al. [44] proposed a support vector machine method for predicting and diagnosing energy consumption in large public buildings based on 11 input parameters such as historical energy consumption data, meteorological data, and time-period data. Traditional building energy diagnostic methods are based on benchmarks identified in national or local codes and compare the energy performance of reference buildings by building thermodynamic models. However, the results of such diagnostic methods are often difficult to interpret, while failing to provide targeted observations.
The application of building energy prediction in energy diagnosis was discussed previously, and the following information was obtained from a literature review. The use of deep learning algorithms for building energy consumption prediction and diagnosis has been less studied in applications. Previous studies on building energy consumption prediction only took the number of people inside the building as an input parameter and did not consider the impact of entrance and exit personnel flow on the building energy prediction model. Existing building abnormal energy consumption diagnosis usually uses a daily or monthly benchmark, which is challenging at smaller time scales.
To address the current research gaps, the main objectives of this study are as follows.
A multi-step ahead short-term building energy consumption prediction model is developed based on 10 input parameters including historical energy consumption data, people flow, meteorological factors, and temporal factors. This model is performed under a supervised learning approach using LSTM networks and the Multi-Input Multi-Output (MIMO) strategy.
Classify people flows into three categories according to the movement of people and analyze the impact on the performance of the building energy consumption prediction model.
The abnormal energy consumption diagnosis method is developed on a smaller time scale (per hour) based on a short-term energy consumption prediction model. Then, based on the diagnosis results, an in-depth analysis of abnormal energy consumption is conducted.
Theoretical background
Long short-term memory
For sequential problems, recurrent neural networks can be used, which have been successfully applied to many problems such as neuro-linguistic programming, speech recognition, and machine translation [18]. In theory, RNN can make use of information in arbitrarily long sequences. However, in practice, the deepening of the network structure makes the model lose the ability to learn prior information and is limited to looking back only a few steps. A typical RNN is depicted in Fig. 1.
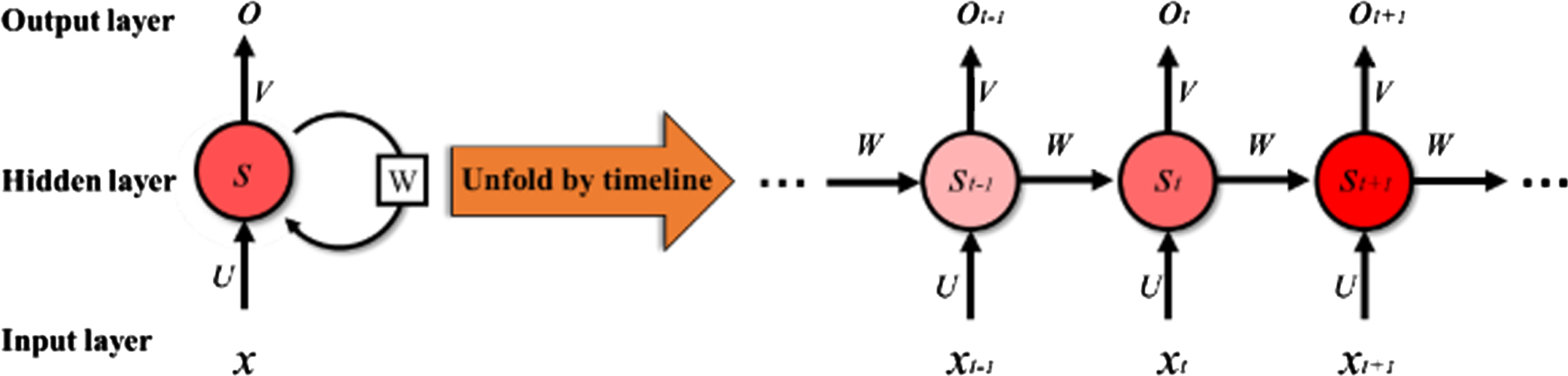
RNN network structure.
One of the most popular solutions is called the long short-term memory neural network. LSTM was first proposed by Hochreiter & Schmidhuber in 1997 [45], which can effectively solve the problem of long-term dependence of information and avoid gradient disappearance or explosion. Broadly speaking, LSTM is a special model in RNN, which also has the recursive property of RNN. Narrowly speaking, it is again a modified model of RNN with a distinct memory and forgetting pattern that can be flexibly adapted to the timing characteristics of network learning tasks. Compared to the traditional RNN, the hidden layer of LSTM is no longer an ordinary neural unit, but rather an LSTM unit with a distinct memory pattern. The cell of the LSTM model is depicted in Fig. 2. The LSTM model uses the sigmoid function and the tanh function to process the data. They are expressed as:
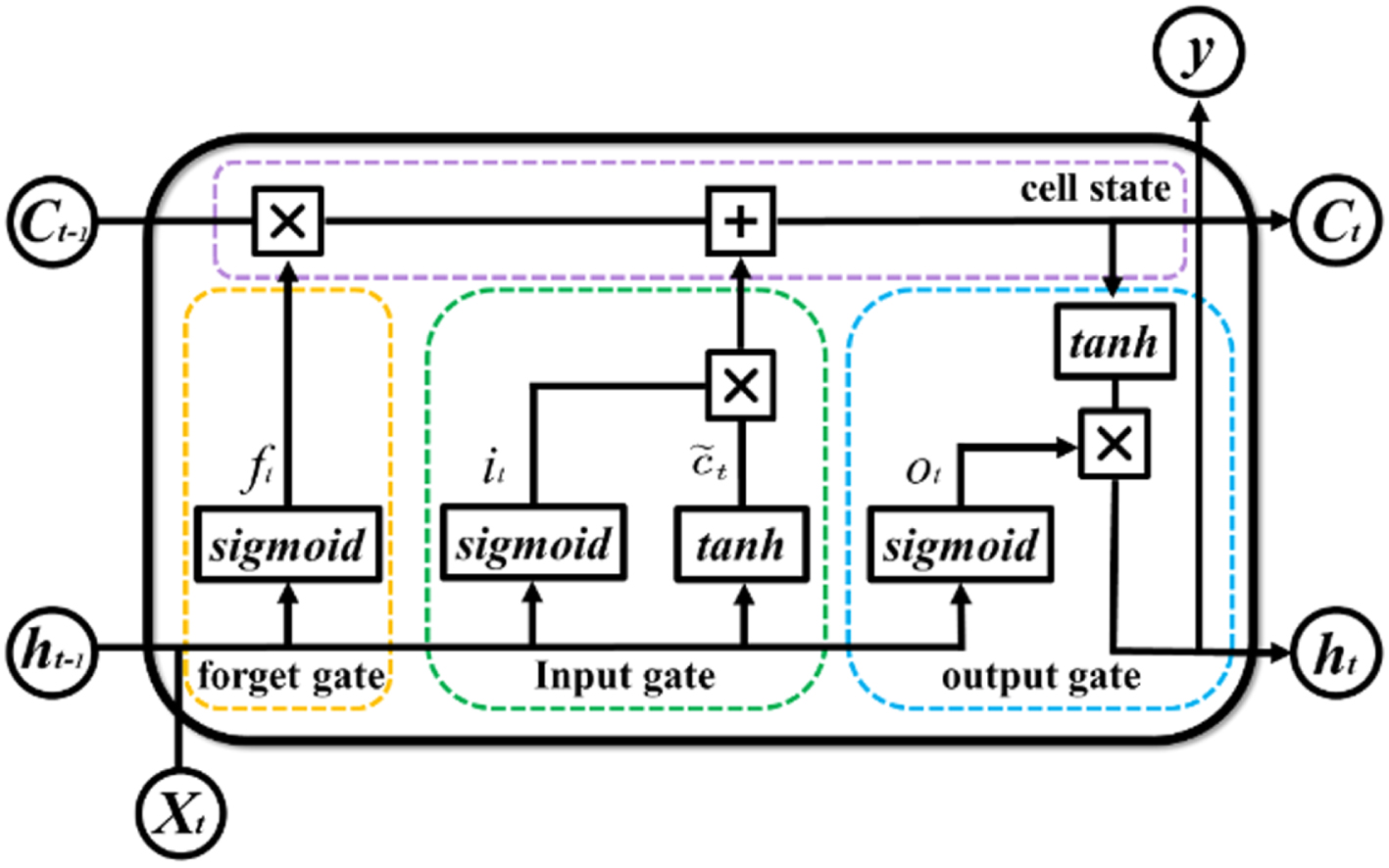
LSTM structure.
The function of the forget gate is to decide which relevant information from the previous step should be discarded or retained. The information from the previous hidden layer and the current input are passed to the sigmoid function at the same time, and the output value ranges between 0 and 1. The closer it is to 0, the more it should be discarded, and the closer it is to 1, the more it should be kept.
The function of the input gate is to determine which information is important in the current input. Firstly, the previous hidden layer’s information and the current input are passed to the sigmoid function, and the value is adjusted to a value between 0 and 1 to determine which information to update. Next, the previous hidden layer’s information and the current input are passed to the tanh function to generate a new marquee vector. Finally, the output value of the sigmoid function is multiplied by the output value of the tanh function.
The cell state runs through the entire process. Firstly, the cell states of the previous layer are multiplied point by point with the oblivion vector. Finally, the value is added point by point with the output value of the input gate to update the neural network’s new information into the cell state.
The output gate’s function is to determine the value of the next hidden layer. Firstly, the previously hidden layer and the current input information are passed to the sigmoid function, and the newly obtained cell state is passed to the tanh function. Finally, the sigmoid function output is multiplied by the tanh function to determine the information that the hidden state should carry and pass to the next time step.
Where W f , W i , W c , W o and b f , b i , b c , b o are the corresponding weights and biases, respectively.
A Multi-step ahead time series forecasting implies applying historical time series [y1, y2, . . . , y N ] to predict the subsequent H-step series [yN+1, yN+2, . . . , yN+H], where N denotes the number of observed data and H≥1 denotes the prediction range [46, 47]. It can be generated by iterating a single-step ahead model or directly using a specific model for each period. It has been widely used for short-term building energy forecasting due to the strong time dependence of building energy consumption between each time step [48].
Good forecasting is an important basis for people to make decisions. This paper examines the performance of three primary strategies for multi-step ahead time series forecasting: the Recursive strategy, the Direct strategy, and the Multi-Input Multi-Output (MIMO) strategy. The recursive strategy is the most traditional and intuitive multi-step ahead prediction strategy [49]. For historical time series [y1, y2, . . . , y
N
], The prediction model can be expressed as:
When we forecast H steps ahead, the first step is predicted by the model, then the next step (use the same one-step-ahead prediction mode) is predicted using the value just predicted as part of the input variable, and so on until the full horizon is forecasted. The prediction process is as follows:
Since the recursive strategy relies on a one-step prediction model throughout the training cycle, there is a high possibility of error accumulation when the prediction time horizon is long and all model inputs are predicted values. For the error accumulation problem of the recursive strategy, the direct strategy develops a separate model (Eq. (11)) for each time step in the prediction time horizon and does not use any predicted values for the next prediction step, so it is not affected by the error accumulation.
The entire prediction process of the direct strategy can be defined as:
Since multiple models are developed, a large computational load is generated. In addition, since the prediction models are generated independently of each other, the complex temporal correlation between the predictions is ignored, thus affecting the overall prediction accuracy. Considering the complex dependencies between variables, one possible solution is to move from modeling single-output mappings to modeling multiple outputs.
MIMO strategy, as the name implies, is a process of multiple target output. As shown in Fig. 3, it avoids the Direct strategy’s conditional independence assumption as well as the Recursive strategy’s error accumulation. The prediction model can be expressed as:
The prediction process can be defined as:

The inference mechanism of MIMO strategy.
To evaluate the prediction model’s accuracy, residuals (ɛ) are used to reflect the prediction accuracy of each time step, while mean absolute error (MAE) shows the overall accuracy. ɛ and MAE can be expressed as below:
Similarly, root mean squared error (RMSE) and MAE are scale-dependent metrics that describe the error between the predicted value and the actual value. The RMSE is most sensitive to anomalous data because it geometrically amplifies the error and can be expressed using:
The coefficient of variation of the root mean squared error (CV-RMSE) is a scale-independent index that indicates the relative size of the error.
The coefficient of determination (R2) measures the degree of fit of the prediction model. A larger R2 indicates a better prediction performance. The R2 is defined by the formula:
Research outline
The structure of a short-term building energy consumption prediction and diagnosis using deep learning algorithms is shown in Fig. 4. It consists of two phases: prediction and diagnosis. The goal of the first phase is to develop a supervised short-term energy consumption prediction model that uses an LSTM network optimized for MIMO strategies. The model is applied to a real building to evaluate the prediction performance and to investigate the effect of people flow factors on the performance of the energy prediction model. In the second phase, based on the short-term energy consumption prediction model, the predicted values of each step are compared with the actual values to determine the abnormal energy consumption diagnosis criteria. The established abnormal energy consumption diagnostic criteria are applied to actual buildings to detect unreasonable use and improve energy use efficiency.
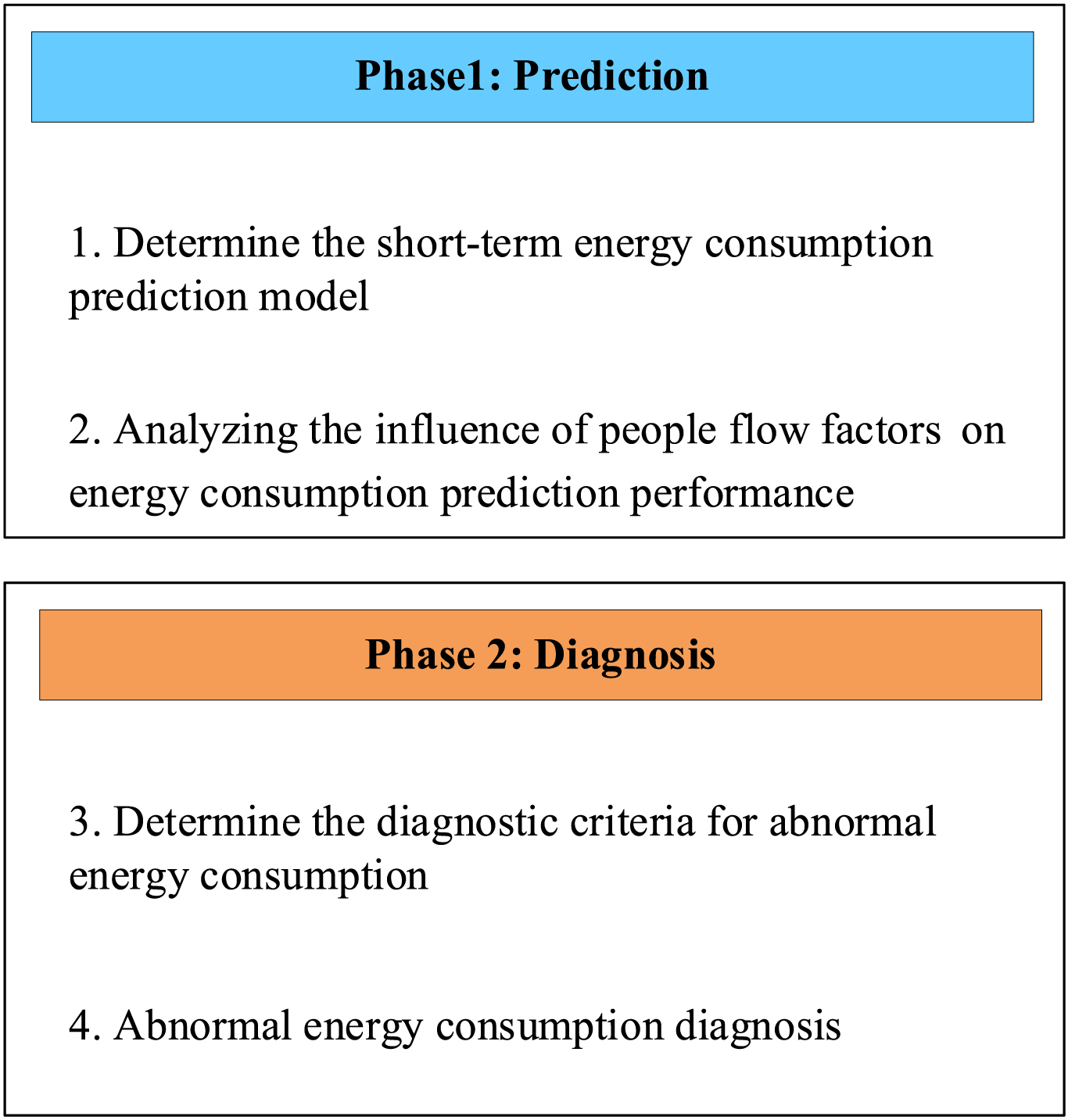
Research outline.
In this paper, we selected the Yanta Campus Library of Xi’an University of Architecture and Technology, China, as the simulated building. As shown in Fig. 5, the library is a five-story building which has a floor area of 12,700m2 and 1,200 reading seats. It is mainly divided into book stacks, reading rooms, lecture halls, study areas, office areas, etc.
Library floor plan.
The input variables include historical energy consumption data, people flow, meteorological factors (e.g., outdoor temperature, relative humidity), and temporal factors (e.g., time of day, workday type), as shown in Table 1. The energy consumption data came from the school’s energy monitoring platform, which captures energy use in all school buildings. The authors downloaded the library energy use from this system on average every hour. It is important to emphasize that electricity is considered the only source of energy for the library, except for the use of municipal heating from November 15 to March 15 of each year. People flow data came from the library’s Access Control Information Query Statistics System (ACIQSS). All people entering and leaving the library must pass through face recognition and are allowed to pass one person at a time. Based on the information provided by ACIQSS, it was converted into the data type required for the experiment. Meteorological data were obtained from local weather stations. In addition, the workday type was presented, which was derived from the academic calendar of the University.
Summary of input variables
The output variables are the electricity consumption of the library, covering electricity for lighting sockets, electricity for air conditioning, electricity for power, etc. Figure 6 depicts in detail the hourly electricity consumption of the library from September 2020 to October 2021.
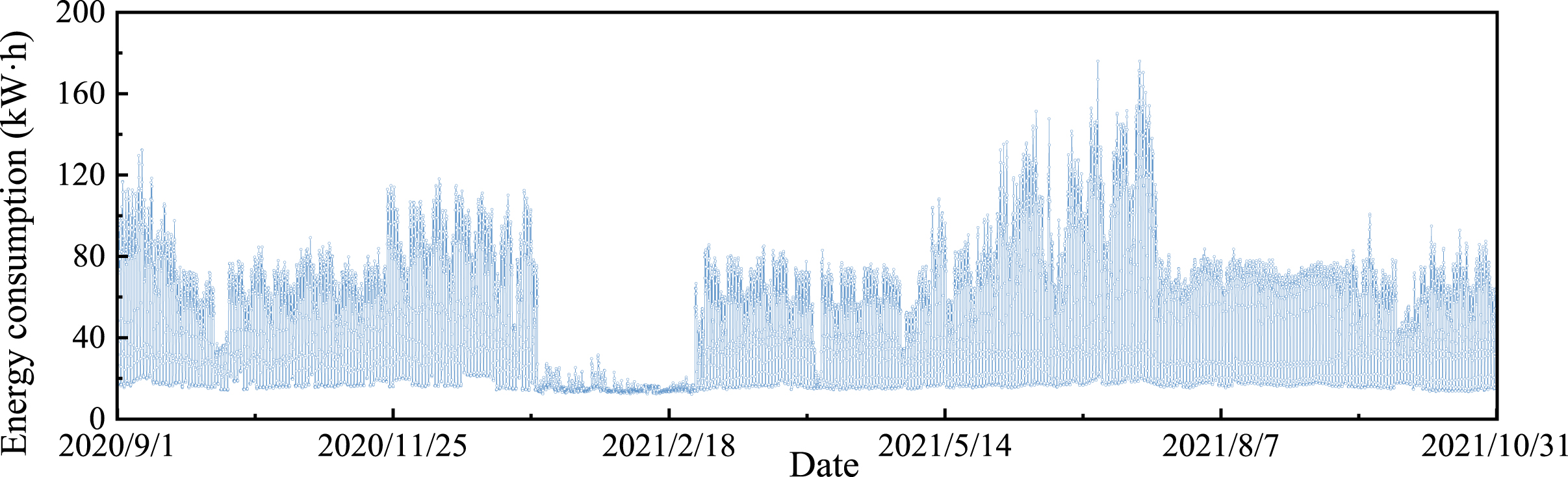
Power consumption per hour.
Before the model is trained and tested, the raw data is initially analyzed and pre-processed to understand the relationship between input and output variables, and the most important variables are selected to reduce the complexity of model training and improve prediction accuracy. Of course, using multiple inputs is well connected to the predicted reality, however, introducing too many variables can make the model more complex and introduce uncertainty into the system by over-relying on known variables. Objectively, this connection is made to justify the use of fewer input parameters to achieve satisfactory prediction performance and accuracy.
Figure 7 shows the results of the Pearson correlation analysis between the different features and energy consumption in the collected raw data set. The results show that: outdoor temperature, visitors flow into the library, and in-library flow have a strong correlation with the energy consumption of the library; in-library flow has the strongest correlation with the energy consumption, and the wind speed has the lowest correlation with the energy consumption.
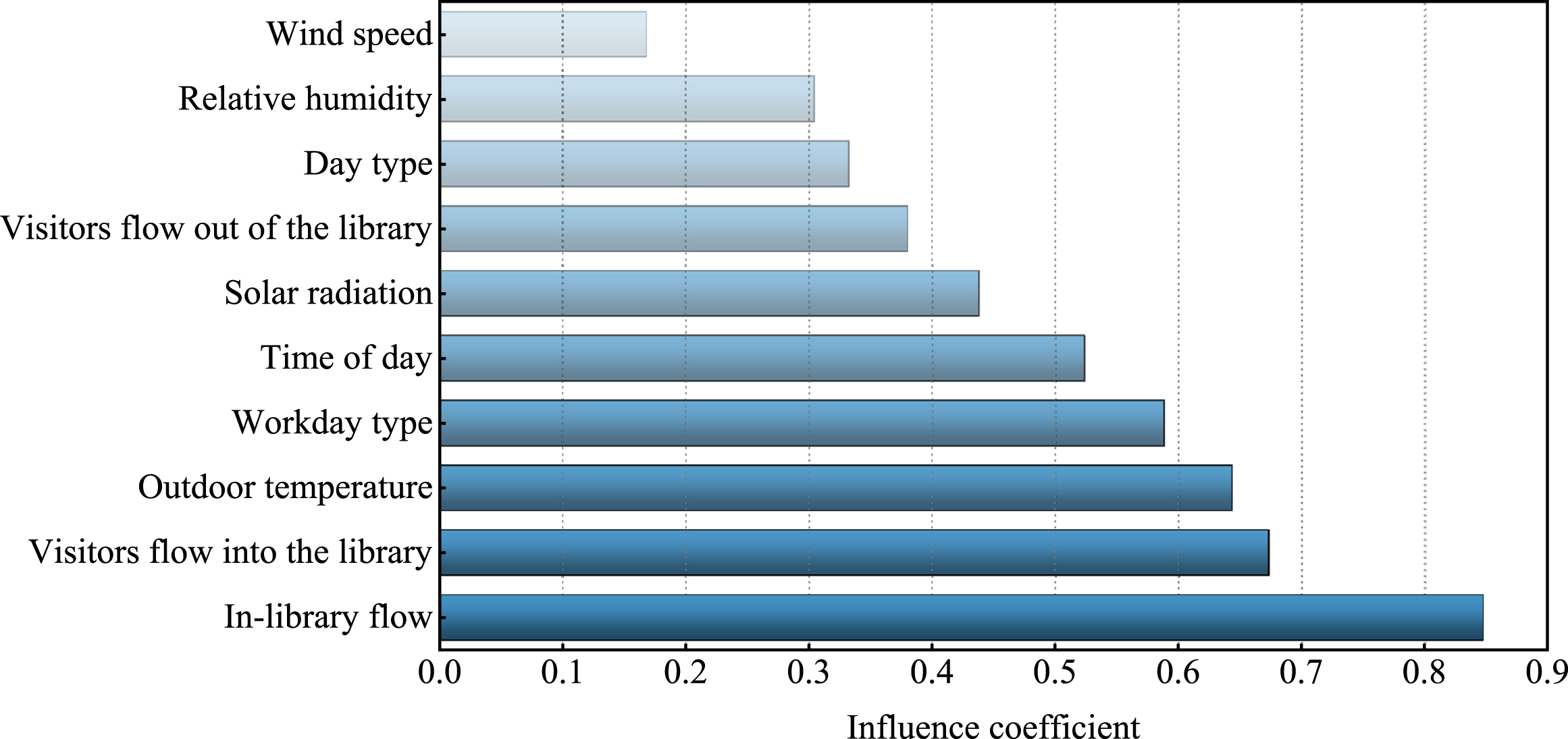
Variable correlation.
According to the Pearson correlation significance criteria, the features with correlation coefficients greater than 0.3 were selected as the input parameters of the prediction model. Therefore, 10 parameters such as historical building energy consumption, in-library flow, visitors flow into the library, and outdoor temperature with correlation coefficients greater than 0.3 were used as inputs to the building energy consumption prediction model for model learning and testing.
For the problem of missing data, the average value of this data for 2 similar days in the vicinity is taken to fill in. If the data suddenly becomes abnormally large or suddenly becomes 0, the data is replaced by the data of the time period before and after the time of this data and the data of similar days. Quantifies the type of weekday (e.g., weekdays are set to 1 and weekends are set to –1).
When multivariate time series are used for energy consumption forecasting, the magnitudes differ between variables and the values vary widely. Considering the range of inputs and outputs of the nonlinear activation function in the model, to avoid saturation of neurons and to consider equally the role of each variable on building energy consumption, Eq. (20) was used to normalize the raw data to the interval [–1, 1].
The predicted building energy consumption data obtained by the prediction model is then inverse normalized to make it physically meaningful, and the inverse normalization is calculated by the formula:
The energy consumption prediction model was implemented on an Intel(R) Core (TM) i7-10870 H CPU @ 2.20 GHz system, using PyCharm professional edition 2021.2 and the Anaconda3 development environment, built on the TensorFlow framework and Python 3.7.
Traditional prediction models split the data set into two parts: the training set (about 70%) and the test set (about 30%). To be able to select the model with the best effect and generalization ability. In this study, the entire dataset is divided into training set (about 60%), validation set (about 20%), and test set (about 20%). The training set is used for model training; the validation set is used to determine the model hyperparameters and select the optimal model, and the test set is used for prediction result verification and anomaly diagnosis.
In this paper, we use the LSTM algorithm and MIMO strategy with a supervised learning method for short-term energy consumption prediction, and the design process is shown in Fig. 8. Seven types of hyperparameters were optimized by grid search, including Hidden size, Epochs, Dropout, Batch size, Optimization method, Activation function, and Loss function. Grid search settings are shown in Table 2. Among them, Input size and Output size are determined by the model structure.
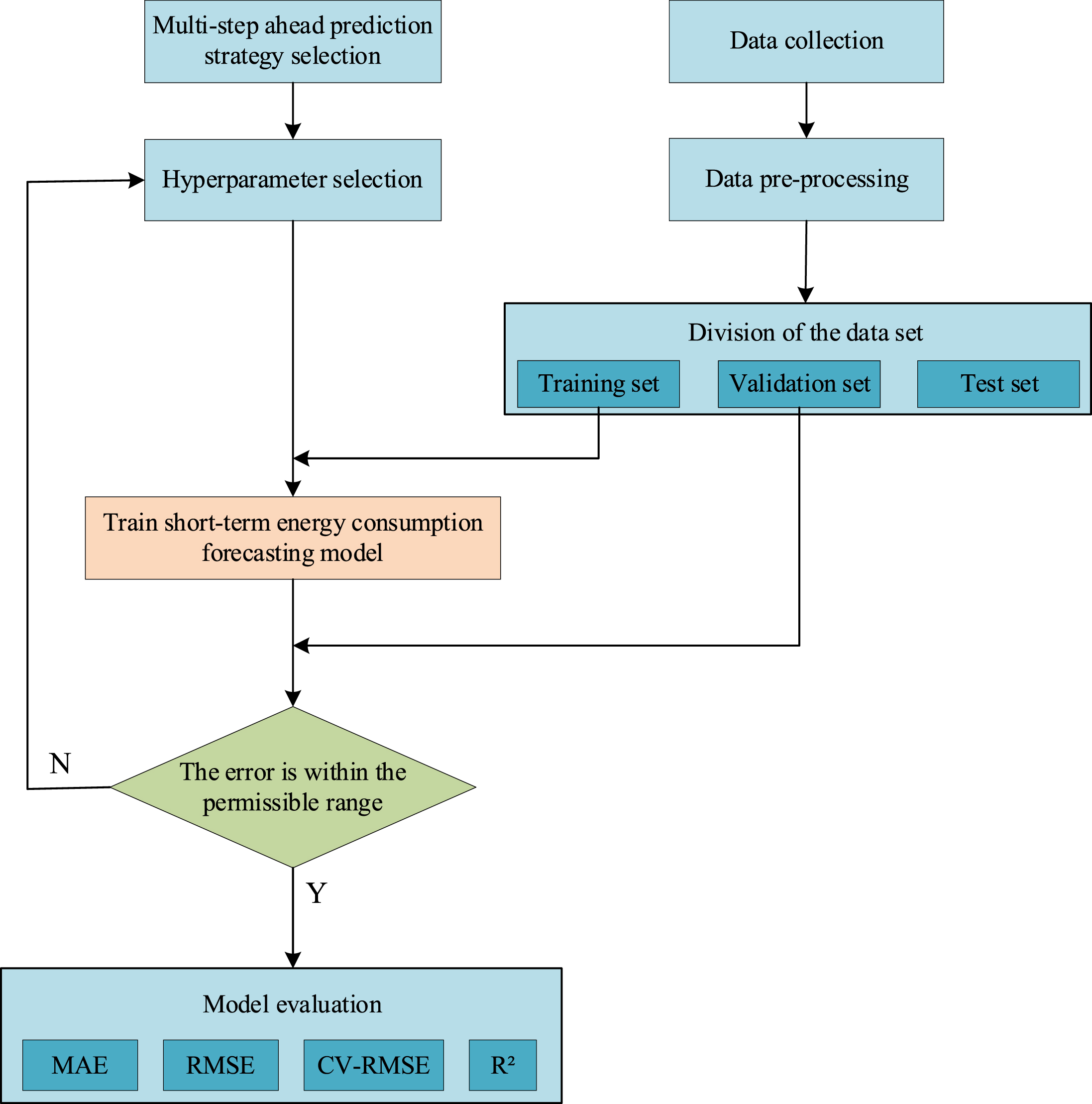
Flow chart of energy consumption prediction.
Hyperparameter settings
The criteria for judging energy consumption anomalies are mainly based on the error value between energy-saving data and non-energy-saving data (the data obtained from the prediction model is energy-saving data and the actual data is non-energy-saving data), while the ideal situation is that the two are the same, or the actual energy consumption is less than the predicted energy consumption, indicating that the current energy consumption is reasonable and in an energy-saving state. Usually, the gap between actual energy consumption and predicted energy consumption is inevitable due to the perturbation of various uncertainties.
A simple and practical diagnosis method for abnormal energy consumption in buildings is essential for building energy efficiency. Traditional diagnosis methods have complicated processes, so this paper proposes an abnormal energy consumption diagnosis method based on a prediction model, which uses the deviation between the predicted energy consumption and the actual value and has the advantages of fast diagnosis, high diagnostic accuracy, and practicality. The established short-term energy prediction model is used as a benchmark for energy consumption anomaly diagnosis to evaluate the energy consumption at each time step, and the design process is shown in Fig. 9. ɛ is used to indicate the difference between the actual energy consumption and the predicted value in the diagnostic data. MAE indicates the mean absolute error of the predicted data with the actual value greater than the predicted value. As is shown in Fig. 10, when ɛ is less than or equal to 0, it is considered an energy-saving state at this time; when ɛ is greater than 0 and less than or equal to MAE, it is considered an attention state at this time, and there may be a non-energy-saving situation; when ɛ is greater than MAE, it is considered as a non-energy-saving state at this time, and there is the non-energy-saving situation, which needs to be analyzed and managed to eliminate abnormalities.
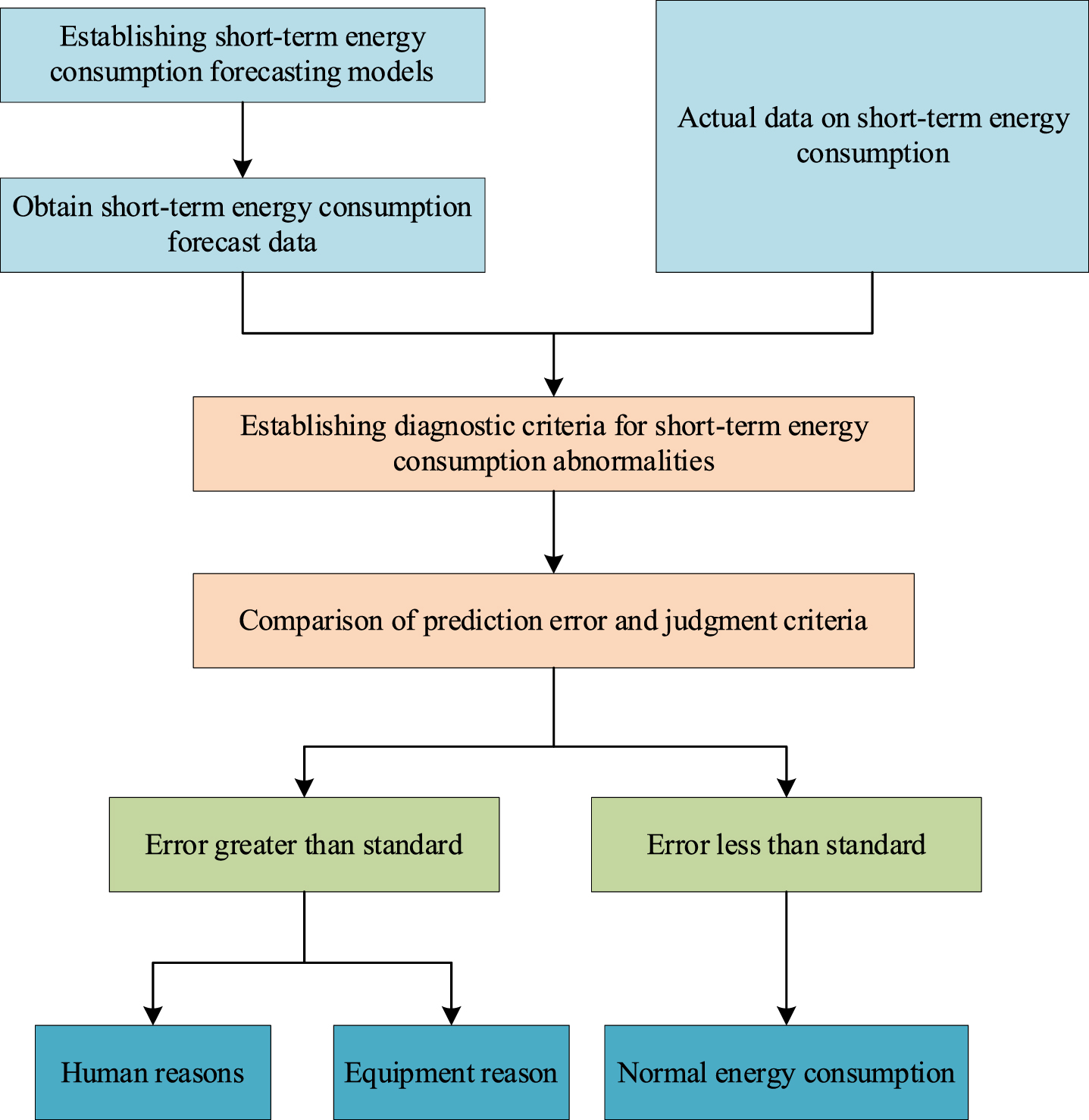
Flow chart of abnormal energy consumption diagnosis.
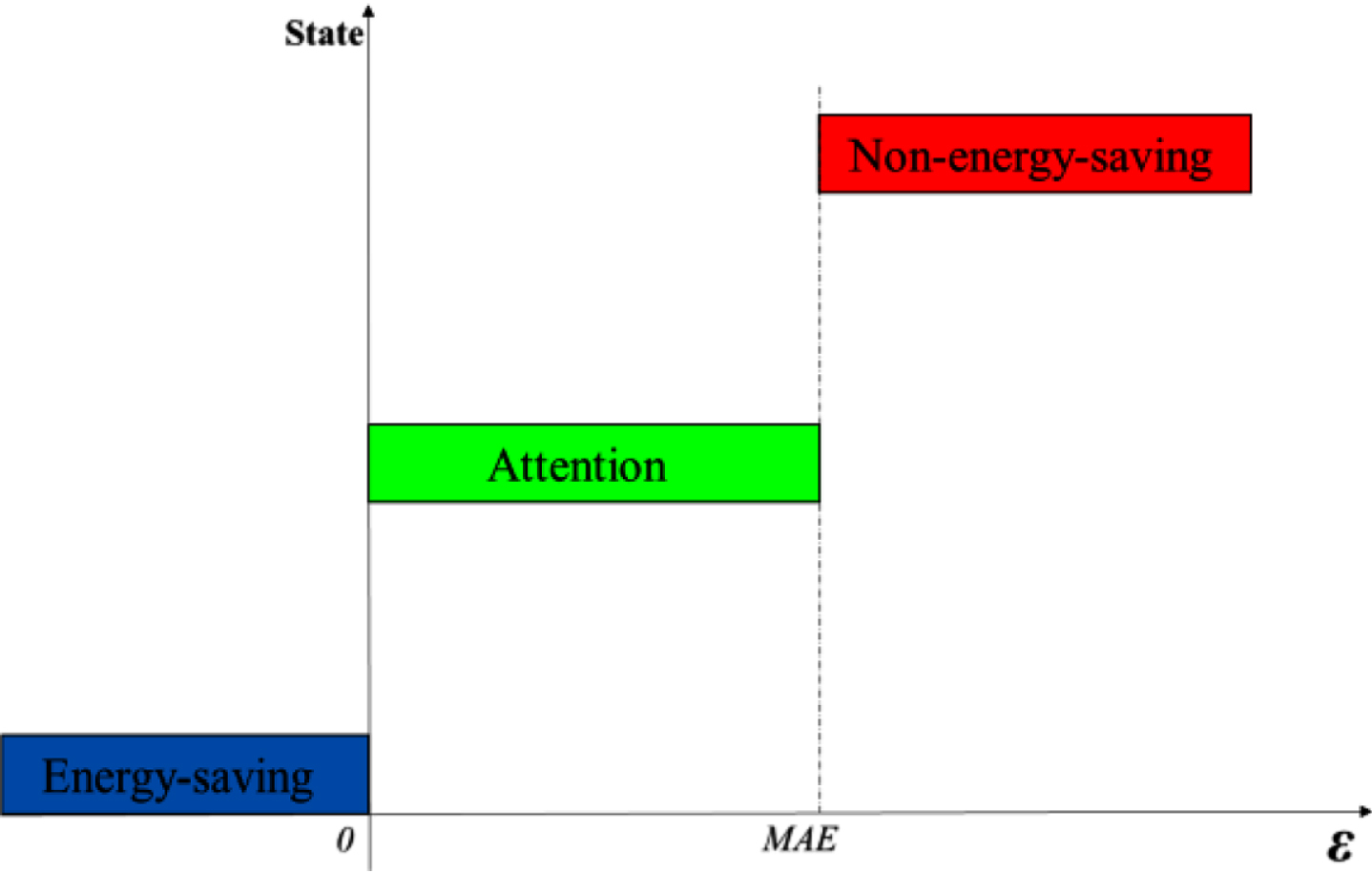
Energy consumption state determination standard.
Short-term energy prediction results
In this study, data related to energy consumption from September 2020 to April 2021 were selected to train the model, data from May to July 2021 were used as the validation data, data from August and September were used as the prediction data, and finally, data from October were selected to diagnose abnormal energy consumption.
Figure 11 shows the building energy consumption predicted 24 hours in advance versus the actual energy consumption for the period from August to September 2021, and the model had a good predictive performance overall, except for the peak prediction. To verify the effectiveness of the model proposed in this paper, it is compared with traditional machine learning methods, as shown in Table 3, and the MIMO-LSTM model outperforms other models in all performance indexes. According to the literature, if the CV-RMSE is less than 30% when using hourly data, the model is sufficiently close to the physical reality for engineering purposes [50]. As listed in Table 3, the CV-RMSE of the model proposed in this paper is 0.1434, which was far below the 30% threshold, indicating that the predictive performance of the model was reliable for subsequent energy consumption anomaly diagnosis.
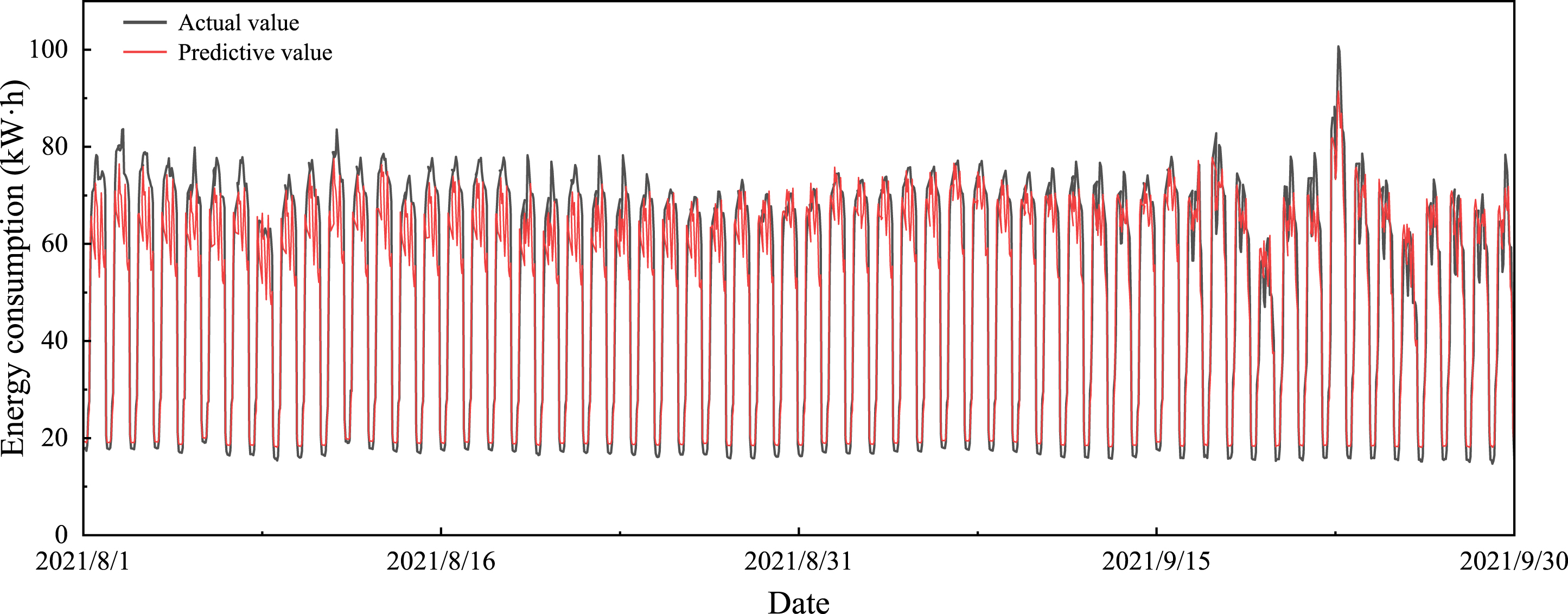
Predicted results of the prediction set.
Summary of prediction results of different models
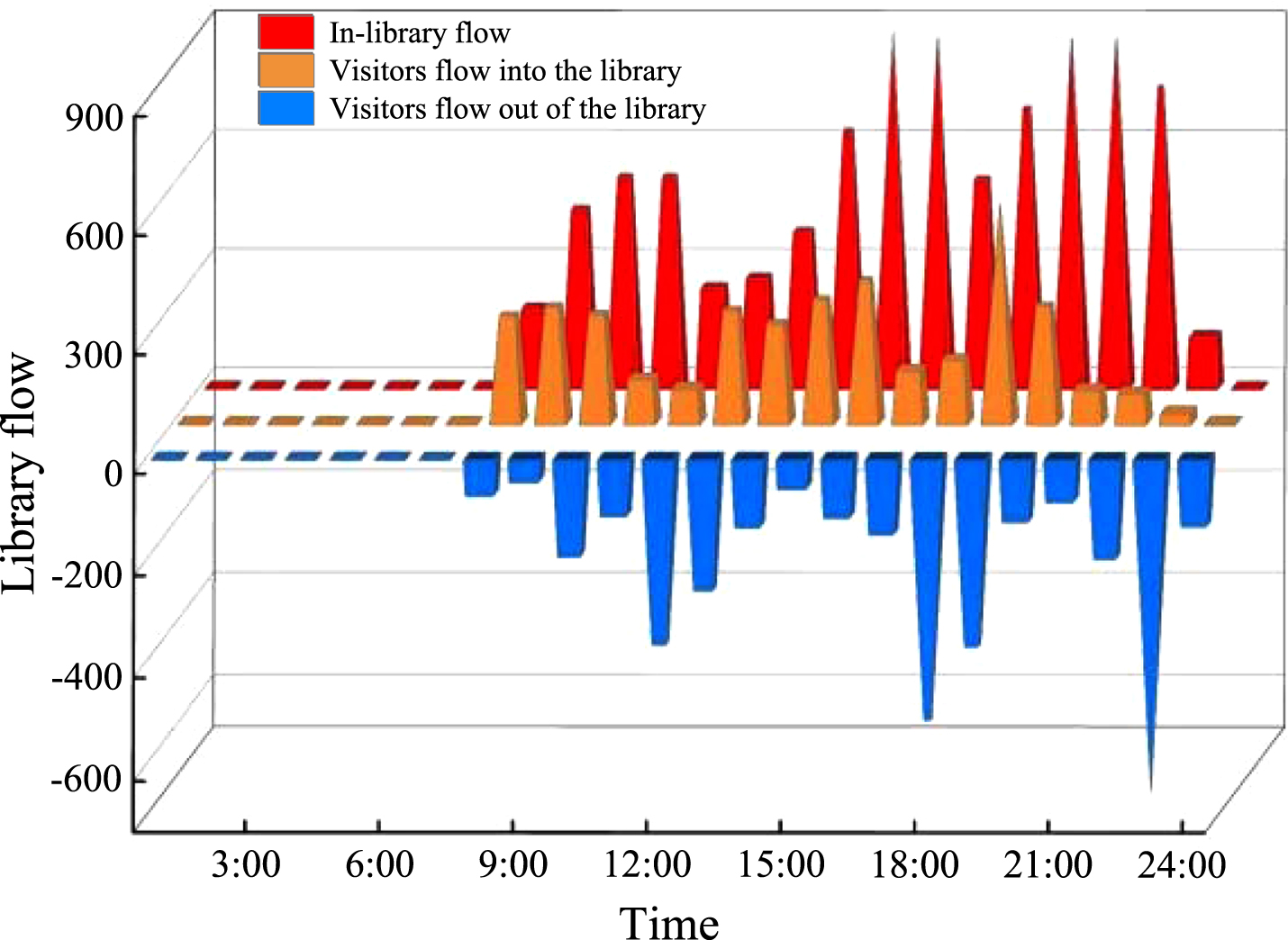
To further explore the effect of people flow factors on the predicted performance of library energy consumption, people flow factors were divided into three categories: in-library flow, visitors flow out of the library, and visitors flow into the library. As shown in Fig. 12, during the library opening hours (7 a.m. to 11 p.m.), the number of people in the library shows three peaks, which occur at 10 a.m., 4 p.m. and 8 p.m.; differently, the number of people leaving the library peaks at 12 a.m., 6 p.m. and 11 p.m., respectively.

Fluctuating library population change.
Figure 13 shows the actual energy consumption on September 15, 2021, versus the projected energy consumption with different input characteristics. Unlike the change in the number of people, there were two peaks in actual energy consumption, at 11:00 a.m. and 4:00 p.m. There was no significant increase in energy consumption at 8:00 p.m. when the number of people peaked for the third time. The main reason for this is that the nights are cooler in autumn and the demand for air conditioning does not increase significantly when the number of people increases, and there was a difference in time between the peak number of people and the peak energy consumption due to the lagging nature of the air conditioning system. As can be seen from Fig. 13, the best prediction performance was achieved when all three features (visitors flow into the library, visitors flow out of the library, and In-library flow) are input, while the worst prediction performance was achieved when only visitors flow out of the library was available.
Forecast results for different input features.
As shown in Table 4, the evaluation metrics of the model prediction under different input features are shown in detail. Compared with single input features, the prediction performance of the model with multiple input features is significantly improved. For a single feature, the in-library flow has the greatest impact on the improvement of prediction performance, followed by the visitors flow into the library, and the least impact is the visitors flow out of the library. Table 4 also shows that people flow had great potential for predicting building energy consumption. With all three features input, the prediction model is optimal for all indicators.
Prediction accuracy with different input features
People flow is a major source of uncertainty in building energy prediction models. In this study, relatively static data on changes in the number of people over one hour are used; whereas occupant behavior is dynamic, stochastic, and influenced by various factors. Nonetheless, the expected results are still achieved in this study.
The established model was applied to the energy consumption forecast for October. Based on forecast results, the deviation of the predicted energy consumption from the actual energy consumption was calculated for each step. Figure 10 shows the proposed energy consumption judgment criteria, which were divided into three cases: energy-saving state, attention state, and non-energy-saving state. As shown in Fig. 14, when the deviation between the actual value and the predicted value is less than or equal to 0, the state of energy-saving is considered; when the deviation is greater than 0 and less than or equal to 7.8253 (the average absolute error of the test set in the non-energy saving state), the state of attention is considered; when the deviation is greater than 7.8253, the state of non-energy saving is considered.
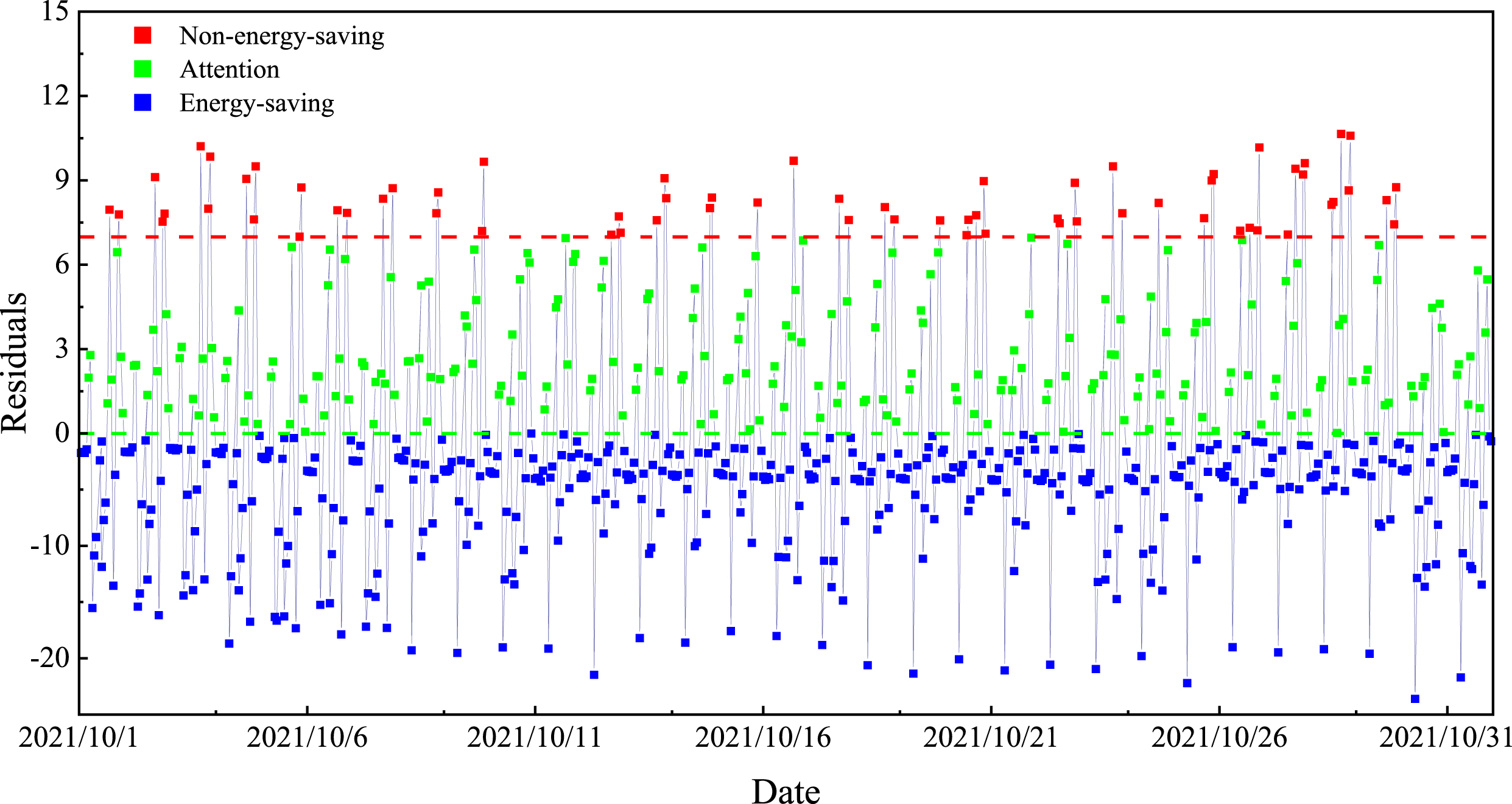
Energy consumption diagnosis results.
Table 5 provides statistics on the distribution of diagnostic results among the three states. Among the 744 data in October, 67 data were diagnosed as non-energy-saving status, accounting for 9.01% of the total data in October; 220 data were diagnosed as attention status, accounting for 29.57% of the total data; and 457 data were diagnosed as energy-saving status, accounting for 61.42% of the total data. Table A1 shows in detail the results of energy consumption in a non-energy saving state in October. Among the 67 non-energy-saving states, they are mainly concentrated at 5 p.m., 9 p.m., and 10 p.m. and a small number of them occurred at 11 a.m. and 12 a.m. Three of these time points had a relative error of 20% or more.
Statistics of diagnosis results of three states
After diagnosing the energy consumption anomaly, the reasons for the anomaly were analyzed. The possible reasons were twofold: first, there were problems with the equipment itself, such as old equipment, which reduced the operating efficiency; second, human factors led to insufficient management and use, such as the air conditioner not being turned off in time, the operating temperature setting being too low, etc.
The causes of abnormal energy consumption, in this case, are analyzed as follows: There is serious energy waste in the use and management of the library. It is mainly manifested in the unreasonable switching off air conditioning systems and lighting systems; some digital devices in the library have a low utilization rate and are in standby mode for a long time; patrons who bring their own devices do not turn off the devices in time when they leave the library; drinking fountains run 24 hours a day.
The emphasis on energy-saving technology and the neglect of energy-saving management is a long-standing and prominent problem in China’s building energy-saving work. From this study, there is significant energy waste in the building’s use and maintenance due to a lack of energy-saving awareness among users, management, and maintenance. We hope that more readers, library managers, universities, and government departments will pay attention to the environmental sustainability of libraries, establish the concept of low-carbon operation and green development, and contribute to the global fight against climate change.
This paper contributes to the existing literature on building energy consumption prediction from several aspects. Firstly, an LSTM model based on 10 input parameters such as historical energy consumption data, people flow factors, meteorological factors, and temporal factors are proposed. The model uses the MIMO strategy to predict the building’s hourly energy consumption under supervised learning.
Secondly, the impact of people flow factors on improving the performance of the energy consumption prediction model is investigated using a university library as an example. The people flow factors are divided into three characteristics: visitors flow into the library, visitors flow out of the library, and in-library flow. The experimental results show that the largest influence is the in-library flow and the smallest is visitors flow out of the library; the prediction model performance is optimal when the three features are input. The superiority of people flow for improving the building energy consumption prediction model is demonstrated, and the results contribute to further research on building energy consumption prediction based on people flows.
Finally, based on the prediction model, an energy consumption diagnosis method for each time step of the building is proposed. The experimental results show that out of 744 data in October, 67 data were diagnosed as non-energy efficient, and the relative errors at three of the time points were above 20%. The non-energy-saving time in building operation was successfully diagnosed, and the diagnosis method is based on the mathematical relationship between the predicted and actual values, so it has good generality and practicality in practical applications.
The simplicity and practicality of the diagnostic method for building energy consumption anomalies are crucial to building energy efficiency. In the future, we will continue to strengthen the applied research on building energy consumption prediction, propose effective diagnostic methods, improve the energy efficiency of buildings, and ultimately achieve energy savings.
Non-energy-saving state
Footnotes
Acknowledgments
The authors would like to express their gratitude to the teachers of the Energy Station and Library Information Technology Department of Xi’an University of Architecture and Technology for their great support to this study, and also sincerely thank the Green Energy Station System Intelligent Control Consulting and Advisory Project of Xianyang Airport Phase III Expansion Project (No: 20210103) and Shaanxi Province Key Research and Development Program Project(No: 2018ZDCXL-SF-03-02) for their fund support to this study. Appendix A. Abnormal energy consumption diagnosis results.