
Abstract
False information is becoming more frequent in distributing disinformation by distorting people’s awareness and decision-making by altering their views or knowledge. The propagation of disinformation has been aided by the proliferation of social media and online forums. Allowing it to readily blend in with true information. Parody news and rumors are the most common types of misleading and unverified information, and they should be caught as soon as possible to avoid their disastrous consequences. As a result, in recent years, there has been a surge in interest in effective detection approaches. For this study, a customized dataset was built that included both real and parody tweets from Pakistan and India. This study proposes a two-step strategy for detecting parody tweets. In the first stage of the approach the unstructured data is converted into structured data set. In the second step, multiple supervised artificial intelligence algorithms were employed. An experimental assessment of the different classification methods inside a customized dataset was undertaken in this study, and these classification models were compared using evaluation metrics. Our results showed accuracy of 92%.
Introduction
Due to quick access to the latest news, trends, and major events happening around the world, the use of social sites (such as Twitter and Facebook) has exploded in recent years [1]. Newspapers, tabloids, and journals gave way to online news platforms, blogs, social media feeds, and other digital media formats as the news medium changed [2]. Consumers now have access to information about any topic from any corner of the world at their fingertips. Users of social media platforms can share their feelings and opinions, and they can discuss and chat about any issue they desire, such as democracy, education, healthcare, and finance. However, not all the news on social media platforms is true and genuine. Majority of fake and parody news scattered in emergency situations [3, 4].
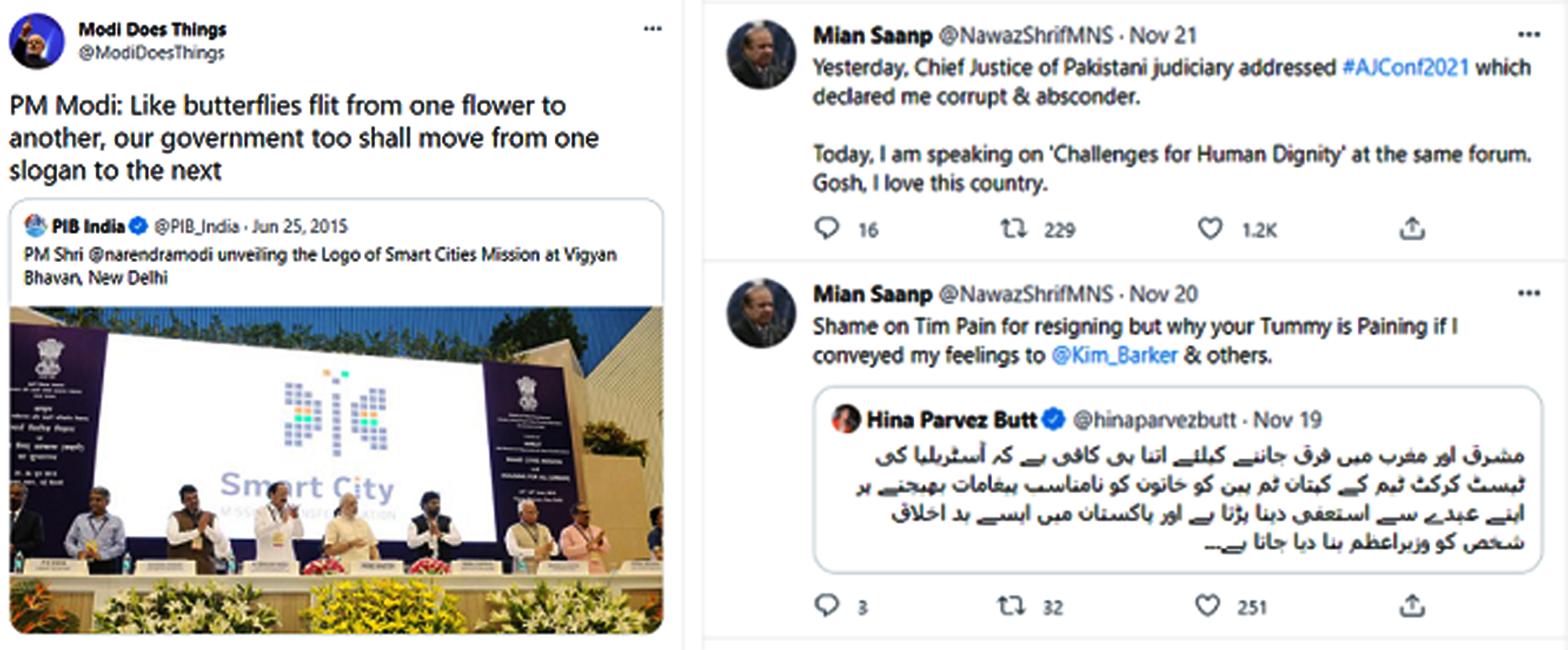
Examples of tweets from parody accounts.
People, companies, and media outlets utilise Twitter more than any other social media network to share and inform their subscribers about current events and news. Twitter has seen a huge increase in subscribers in recent years, owing to the fact that most politicians, athletes, media outlets, and businesses have official Twitter accounts [5]. Subscribers can simply obtain the most recent news in near real time and easily communicate their negative and positive reactions to that news 1
Almost all prominent and influential people in Pakistan and India have official Twitter accounts that they use to keep their followers up to date on the newest news. However, many parody and false accounts have been formed in the name of notable people and companies. These accounts are used to criticize and create a negative picture of a person or company. These accounts are used to create unfavorable and biased alternatives against a specific entity, and one of the reasons for these accounts is financial reward [6, 7]. Many parody accounts with a large following operate on Twitter in Pakistan and India. Tweets from these accounts are used to criticize political opponents, and these accounts are used to criticize entities in a humorous manner. Since there is a history of animosity between Pakistan and India, these accounts are also used to tweet against each other in order to build a particular narrative for their audience. In Table 1 mentioned some of the real and parody twitter usernames. Maryam Nawaz is the vice president of Pakistan’s PML-N. She routinely tweets about party ideology, condemns government decisions, and critics of her political opponents. Her genuine verified Twitter username is
Parody tweets are frequently misinterpreted as genuine, despite the fact that Twitter only allows parody accounts if they are clearly labelled as such and the image does not have the intent to mislead 2 . Figure 2 shows an example of tweets from parody accounts that appear to be real because the writing style of these tweets seems to be very similar to those of real accounts. These tweets frequently efficaciously duped a large number of users and harmed the narrative of a real person or organization.
Example of real accounts and parody accounts
Recently, many researchers have been working on detecting fake news using various machine learning and deep learning techniques. The majority of the datasets used to train the models are publicly available. Many researchers have not addressed the domain of detecting parody tweets on specific country regions.
Our contribution in this domain is the creation of a previously unavailable region-based tweet dataset. Trained various machine learning and deep learning models on datasets and then evaluated model performance in various scenarios such as (Pakistan training dataset and test on Indian dataset). This work focuses on the use of advanced NLP techniques known as Transformers and compare their performance to traditional machine learning models such as logistic Regression. Proposed solution was assessed by using various performance metrics.
Review of literature
Parody was invented by Aristotle in ancient Greece. Who turned awesome poems in to laughable by faintly changing the wording in famous poems. Parody studied as different subject in linguistics [8]. Typically, verbal parody entails a highly placed, purposeful, and conventional speaking act [8] that includes both a harsh judgments and a sort of pretense or echoic remark [9] in which an entity is copied or imitated with the goal of critiquing it in a comic manner. As a result, parody has an intrinsic quality of imitative creation for amusement purposes [10]. The parodist purposefully re-presents the object of the parody and proudly displays it [8]. Parody has different forms and different purpose [11]. Author explains in study [11] about the different forms of the parody and what are the aim of spreading parody. Different forms of parody may be a lie and fake news. Parody can be used to make fun of someone or something in a humorous fashion. It can be used to distribute fake news and cause social unrest. People must be educated to understand why parody is employed and how it affects society in both positive and negative ways.
Because social media is so easy to use, it has grown in popularity over the previous decade. This ease of access led to erroneous use of social media. It has become quite simple to disseminate fake information and create parodic content about entities. Parody is now widely regarded as a vital and integral aspect of social media, particularly on Twitter [12]. Customers can create spoof accounts on Twitter, but there are some limitations. This parody issue has recently piqued the interest of many scholars who want to learn more about this area of social media. Previous studies on parody in social media focused on evaluating how these accounts contribute to topical discussions [13] and the relationship between identity, deception, and legitimacy [12].
According to public relations studies, parody accounts have an impact on organizations during crises [14] and can represent a threat to their credibility [7]. Author in [7] studied how parody accounts come in to play in crisis situation and what are the impacts of these parody accounts on people and overall society. The research also looks at how these accounts behave and how they reinforce negative impressions and sabotage an organization’s efforts and initiatives and gave suggestions to organizations how to tackle these parody accounts effectively.
Many researchers studied how to find parody and fake accounts on twitter. One of the study conducted by researchers was [15] in which activity based approach is used to identify fake accounts. In this study, researchers looked at 62 million publicly available Twitter user profiles and devised a system for detecting automatically generated bogus profiles in the future. A very reliable subset of false user accounts was found using a pattern-matching algorithm on screen names combined with an examination of tweet update times. The fake users’ conduct was exposed by examining the profile creation times and URLs of these false accounts in comparison to a ground truth data set. There are also multiple ways to find parody and fake profiles automatically from twitter. For example [16] identify fake profile by using public information like "how many number of following and how many number of followers". In [17] authors looked into the idea of using text mining to create an algorithm that automatically determines a user’s identity on Twitter. It validated the owners of social media profiles in order to reduce the impact of false accounts on public perception. The method was based on write-print, a bio-metric for writing style. Imitation detection [18] seeks to distinguish between an original text and a text authored by someone attempting to emulate the original author’s style in order to impersonate them.
In the context of recognizing disinformation, satire has been briefly examined as one of multiple prediction goals in NLP [19]. Authors proposed a method to detect satire from the articles by using text-mining and features extraction. Dataset used by the researchers came from different news web portals and 71% f1-score achieved by applying different classifiers on real news articles to detect satire. To detect linguistic elements of parody, [20] compare the language of true news with that of sarcasm, forgeries, and propaganda. They show how stylistic features might aid in determining the text’s truthfulness. Satire detection is always a challenging task due to its wide range of text features and satire contains seriously spoken words which cause difficulty to detect. Researches studied to detect satire in different languages as well. One of the research to detect satire in Spanish language was conducted by authors [21]. In this study author suggested a method for detection of satire from twitter text. Dataset was categorised into two classes (satire and non-satire). The propose of this research was to focus on the style of the tweets rather than the context written in the post. [22, 23] another studies conducted for satire detection containing from news articles, tweets, customers reviews. As satire and parodies are categorized as a type of disinformation with "no intent to inflict damage but has the ability to fool," the study of parody is pertinent to this topic [24].
In [25] authors did research into detecting sarcasm in text automatically. The sentiment analysis community reacted positively to this study. This paper is a collection of previous work in the field of automatic sarcasm detection. The authors mention three research achievements: semi-supervised trend extraction to identify underlying sentiment, hashtag-based monitoring, and context beyond target text inclusion. They also go through datasets, techniques, trends, and problems with detecting sarcasm. In this research study [26] two different approaches were suggested for the detection of sarcasm from the twitter tweets. The first approach was parsing-based lexicon generation algorithm (PBLGA) and the second approach to detect sarcasm from the frequency of interjection words from the twitter text. In this study 89% precision was achieved by using first approach and 85% precision was accomplished from second approach. In [27] the goal was to tackle the difficult task of detecting sarcasm on Twitter by using behavioural factors unique to people who express sarcasm.
On the detection of misleading and false content on social media, research has been undertaken. The authors [28] conducted a study for identification of irony and satire using data-mining and ensemble feature selection from the news articles. A series of classification models were applied on news dataset including Logistic regression (LR), Support vector machine (SVM), Linear Model tree (LMT) and C4.5. A 95.8% precision was achieved from the experiment.
Another study conducted by authors [21] to identify whether the tweet is satirical or non-satirical. Researchers collected all the satirical and non-satirical tweets in Spanish language and applied different machine learning approaches for the recognition of satirical tweets. They model each tweet’s text using a collection of linguistically driven attributes aimed at capturing the text’s style rather than its content.
Automatically irony detection in tweets research carried out by researchers in study [29] where they proposed a method for this task. They offered a unique model that investigates the usage of subjective elements based on a diverse set of lexical resources for English that express various aspects of affect. Sentimental information aids in discriminating between ironic and non-ironic tweets, according to classification trials conducted across a variety of corpora.
Twitter is the main social media platform on which different political parties run their election campaigns, so many parody accounts created to damage opposition party narrative by tweeting fake tweets which cause real political damage. M. S. Looijenga [30] explored how fake tweets impact during the Dutch election of 2012. Eight different supervised machine learning models were used on tweets dataset including Decision Trees (DT), Bernoulli Naive Bayes(B-NB), Linear Support Vector Machine (LSVM), Gaussian Nai ve Bayes (G-NB) and Multinomial Naive Bayes(M-NB), ExtraTrees (ET), Stochastic Gradient Descent (SGD) and Random Forests (RF). Bag of Words representation model was used for data tokenization, normalization and vectorisation.
Kaliyar et al. [31] presented the method to identify fake news using a deep neural network approach. The dataset used was fake and real news propagated during the time of the U.S. General Presidential Election-2016. In this paper author proposed a model called "FakeBERT" which is the combination of NLP pre-trained model called BERT(Bidirectional Encoder Representations from Transformers) along with deep learning approach. Very promising results were obtained by applying suggested model on dataset. Author achieved 98.90% accuracy.
Parody account were used to spread fake news in crisis situation. Many researcher studied how parody accounts influenced society and organization in a crisis situation [7, 32]. Different machine learing and deep learning techniques were used by the researchers for the detection of parody news. Ajao et al. [33] proposed the mechanism to automatically identify fake news originated from a Twitter post. Hybrid CNN and RNN models was used in this research paper and LSTM was used for the evaluation of models.
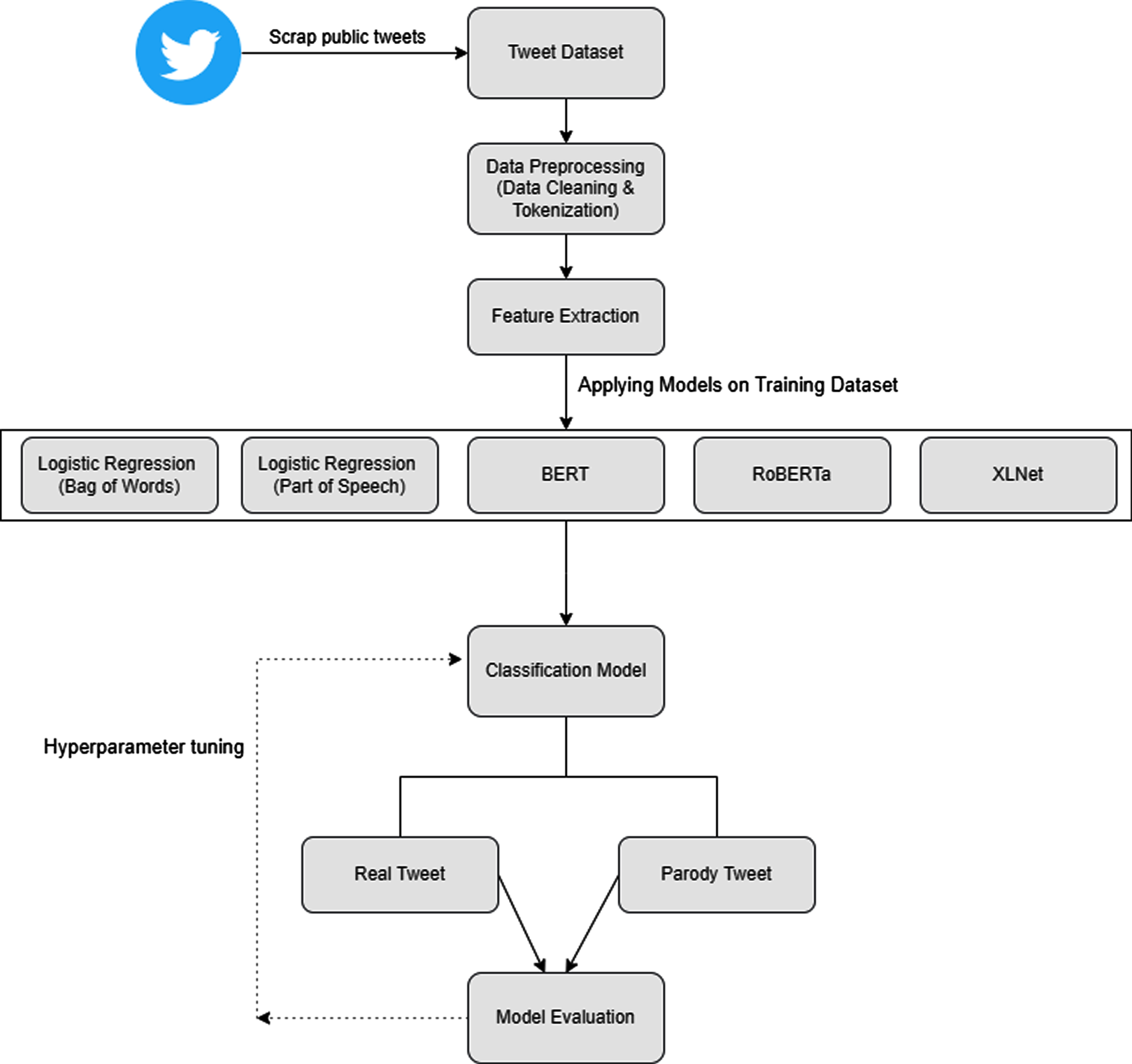
Proposed methodology for classification of parody tweets.
With the introduction of pre-trained models, practical applications of natural language processing have been fundamentally transformed. It has not only democratised the development of machine learning applications by allowing amateurs to create them, but it has also aided specialists in achieving better outcomes without having to train a model from scratch. Pre-trained models have also proven to be a valuable resource for amateur experts looking to learn from an established framework that can then be fine-tuned to generate new applications. Pre-trained models are simple to implement and do not require a lot of labelled data to work with, making them useful for a wide range of business challenges, including prediction, transfer learning, and feature extraction. Lots of already pre-trained models are available publicly which are trained on text including Wikipedia and books. Researcher used these pre-trained models for classification binary as well as multi labeled classes. Performance of models enhanced by using these transformers [31, 35].
Past study was related to this research for recognizing parody tweets from real ones. In [35] authors study to identify parody from Twitter exclusively pertaining to political themes tweeted by US and UK politicians. Another study [34] was recently conducted on the Pakistani tweets dataset to detect parody tweets using various machine learning and deep learning techniques.
For this work, we suggest a framework in the following section, followed by explanation of dataset creation, data preprocessing and algorithms that were applied in this research work. Figure 3 illustrates the suggested composition of predicting parody tweets.
We define social media parody recognition as a binary classification problem conducted at the post level. Let assume twitter post as T, defined as the series of tokens. The target is to classify which tweet is real and which one is parody.
Initially we have built a customized dataset for this study and has tested a segment of users from Pakistan and India who come from a variety of backgrounds, including politicians, athletes, media outlets, and well-known corporations. We picked Twitter as our social media platform of choice since most politicians, sportsmen, and businesses have Twitter accounts. They kept their followers up to date with the newest news, government pronouncements, and their reactions to the most recent occurrence. The supporters may simply share their opinions on any well-known entity’s statements, as well as critique its policies. We selected Pakistan and India from the South-Asian area for this study since the political climates in both nations are nearly identical, and the sports played in each region are also nearly identical. Twitter permit to create parody account with some restriction, mention clearly specific terms like
Dataset generation
This sub-section explains how real and parody accounts were collected and procedure to developed tweets dataset of Pakistan and India tweets.
Gathering parody and real accounts
Using the Twitter API [36], users can retrieve public information from Twitter. To locate parody accounts, we use the Twitter API with keywords such as
The accounts with tweets in different languages other than English, and accounts that were blacklisted were also deleted from list of user. If numerous parody profiles are found, we only retain one.
We were able to distinguish parody accounts of prominent people, sportsmen, and media houses from both India and Pakistan after following all of the above methods. Following that, we acquired all of the real accounts related with the parody accounts entities.
Gathering parody and real tweets
Following the gathering of all parody and real user accounts, we use the publicly available Twitter API to collect all of the tweets posted by the users. According to Twitter’s API rules, each account is limited to 3200 tweets. We collected up to 1000 tweets from each account for this study. A total of 34620 tweets we collected, with 19185 Indian tweets and 15435 Pakistani tweets. After that we, classify tweets as real or parody by assigning a 1 to actual tweets and a 0 to parody tweets based on the type of Twitter account from which they were originated.
Data division
The dataset was split into 80% training and 20% testing part. Different machine learning and deep learning algorithms were applied to classify parody tweets in a novel way. The data divisions that were applied to the dataset to automatically detect parody tweets were as follows:
Overall tweet dataset
The combined dataset contains 34620 real and parody tweets of both India and Pakistan (see Table 1).
Pakistani tweet dataset
In second experiment, we took the same dataset from study [34]. We divide Pakistani tweet dataset holding 15435 tweets into training and testing part as shown in Table 1.
Indian tweets dataset
In third phase, we took Indian tweet dataset which contains 19185 records having both real and parody tweets as shown in Table 2.
Different dataset splits
Different dataset splits
Finally, we split the dataset according to region. First we took Pakistani tweet dataset as training and Indian tweet dataset as testing and used Indian tweet dataset as training and Pakistani tweet dataset as testing as well shown in Table 2.
Data preprocessing
As raw data is incomprehensible to models, data cannot be supplied straight to them for classification. Models accept integers and double values, but the data we collected from tweets is of the string format. Therefore, preprocessing techniques must be used on the dataset in order for machine learning and deep learning models to accept the data.
Following steps were performed while preprocessing the tweet text.
Replace contraction
As the first step, we replace contraction.
Region-Based Data-Split
Region-Based Data-Split
As the second step, we covert all text into lower case for the symmetry.
Remove URLs & HTML tags
As the third step, all the unnecessary URLs and the HTML tags from the tweet text were removed.
Stop stopwords
As the fourth step, all the stopwords from the text tokens were removed using stopwords list from python library NLTK.
Text tokenization
For tokenization of the cleaned dataset, Differential Language Analysis ToolKit (DLATK) was employed 4 .
Classification models
We ran a number of experiments on the dataset using a variety of machine learning and deep learning algorithms, including simple logistic regression, recurrent neural networks, and transformers, which are pre-trained NLP models to predict parody from tweets dataset. Following are the algorithms were used in this study:
Logistic regression model
The first model used on the dataset was logistic regression model that extracted features from text data using the Bag of Words approach [37].
In the second part, we use Part-of-Speech (POS) tagging to extend LR with Bag-of-Words [38]. Initially we tagged all of the text with POS, then used BoW to automatically extract from the text, with each word being connected with a Part-of-Speech tag 5 .
Bi-directional long short term memory (Bi-LSTM)
The recurrent neural network (RNN) used in this study is Bi-LSTM. Bi-LSTM is the extension of standard LSTM [39]. To protect future and previous knowledge, make the input flow in both directions in Bi-LSTM. The GloVe 200-Dimensional Word Vectors [40], which had already been trained on tweets, were used for embedding 6 .
Pre-trained models
The advance techniques used are pre-trained NLP transformers models for the prediction of real and parody tweet. In natural language processing, the Transformer is a unique design that seeks to solve sequence-to-sequence tasks while also resolving long-range dependencies. It does not use sequence-aligned RNNs or convolution to compute representations of its input and output, instead relying solely on self-attention [41].
With the introduction of pre-trained models, practical applications of natural language processing have been fundamentally transformed. It has not only democratised the development of machine learning applications by allowing amateurs to create them, but it has also aided specialists in achieving better outcomes without having to train a model from scratch.
Pre-trained models have also proven to be a valuable resource for amateur experts looking to learn from an established framework that can then be fine-tuned to generate new applications. Pre-trained models are simple to implement and don’t require a lot of labelled data to work with, making them useful for a wide range of business challenges, including prediction, transfer learning, and feature extraction.
BERT
First pre-trained model used in this research is BERT (Bidirectional Encoder Representations from Transformers) [42] which is trained on un-labeled English words over 800M words and around 2500M words of English Wikipedia [42]. To learn bidirectional embedding for input tokens, the model employs several multi-head attention layers. It’s been trained for masked language modelling, which involves masking a portion of the input tokens in a sequence and predicting a masked word given its context. BERT employs word pieces that are summed with positional and segment embeddings after passing through an embedding layer. We added an output dense layer for binary classification and feed it the ’classification’ token to fine-tune the BERT-base model for predicting parody tweets.
RoBERTa
RoBERTa [43] is also used in this research work, RoBERTa is the extension of BERT with more pre-trained data injected in this model. RoBERTa showed promising performance as compared to BERT.
XLNET
Third pre-trained model used is XLNet [44] based on transformers network. XLNet is an auto-regressive pretrained model. The structure wise XLNet is alike BERT but differ from BERT in the training process.
Hyperparameters
We optimize all model parameters on the development set for each data split shown in Table 4.
All models parameters and configurations
All models parameters and configurations
A variety of indicators were employed to evaluate the algorithm’s performance. Multiple performance metrics are used for this purpose. There are lot of model evaluation metrics to access the performance of models on test dataset. Following are the performance metrics use in this research Confusion Matrix Accuracy Precision Recall F1-Measure
Confusion matrix
The confusion matrix is a table showing of the effectiveness of a classification algorithm on the test set, with four parameters: True Positive False Positive True Negative False Negative True Positive (TP): Tweet predicted real which is labeled as a real tweet True Negative (TN): Tweet predicted parody which is labeled as parody tweet False Negative (FN): Tweet predicted real which is labeled as parody tweet False Positive (FP): Tweet predicted parody which is labeled as a real tweet
In this research, predicting whether tweet is real or parody in the task. Above indicators represents the following meaning of parameters used in confusion matrix:
Accuracy
Accuracy is one of the mostly utilize performance indicator for the classification. Accuracy is the ratio of the correct predicted values either true or false to the whole predicted values. Formula Accuracy is used to calculate the accuracy.
Precision is used to find the positive predicted values. Precision is the ratio of accurately predicted positive instances divided by the total number of true positives predicted is used to compute it [45]. Equation Precision shown below describe the formula for the calculation of precision.
Recall is a ratio that measures how many correct positive predictions were produced out of all possible positive predictions [45]. Unlike precision, which only considers the correct positive predictions out of all true positives, recall evaluates the positive predictions that were missed. Formula for the calculation of recall is shown in equation .
The F1-Score is a method of combining precision and recall into a single metric that encompasses both features [45]. F1-Score can be calculated by using formula shown in equation 4 F1-Score by using precision and recall values. Equation display the formula for the calculation of f1-score by using predicted values.
Classification models performance on different datasets. Highest result are in bolds
This part of research paper contains all of the results obtained by using various classification models on multiple dataset samples as explained in the subsection . We evaluate our algorithms methods using different evaluating metrics like accuracy, recall, f1-score and precision [46].
Overall dataset
The complete dataset result is presented in the Table . Both RNN and basic logistic regression models are outperformed by pre-trained models. Among all the models, BERT was the best performing model.
Pakistani tweet dataset
This work is an extension of a study [34], the results obtained on the Pakistani tweet dataset are identical to those acquired in earlier study. Results are shown in Table 1-results. On the RoBERTa model, 92% accuracy was attained on the Pakistani tweet dataset.
Indian tweets dataset
Table shows the result obtained on Indian tweets dataset. In this case logistic regression model perform good as compared to other models. 86% accuracy achieved on Indian tweets dataset.
Region based Dataset
Region based Dataset
Table 1 shows the accuracy and precision acquired on the region based split. Train on Pakistan based tweets and test on Indian tweets data. Train on Indian tweet data and test on Pakistani tweets data.
When comparing pre-trained models to logistic models and neural networks, the results obtained in both scenarios suggest that pre-trained models outperform them. RoBERTa outperforms pre-trained models, achieving 75% in the first scenario and 73.40% in the second.
Outcome and way-forward
We suggested a method to discover parody from a twitter dataset based on the Pakistan and India regions in this paper. This research builds on the findings of a previous study undertaken by the authors [34]. For this study, we created a data set of both nations’ tweets, which was previously unavailable. There are 34620 tweets in this dataset, both actual and parody. We run multiple algorithms on the dataset on different data. On the test dataset, we produced very promising results, with up to 86.70% accuracy. On Pakistani and Indian tweets, accuracy was 92% and 86%, respectively.
In future, we plan to extend the research by enhancing the tweets dataset and optimize parameters to attain better accuracy on unseen data.
Footnotes
India has 24.45 million number of Twitter users as of October 2021, https://www.statista.com/statistics/242606/number-of-active-twitter-users-in-selected-countries/ 46.00 million social media users in Pakistan in January 2021 ![]()