
Abstract
This paper studies the robot-written character identification problem under an end-to-end semi-supervised deep learning framework consisting of semi-supervised learning and deep learning modules. The learning framework allows a deep neural network to be trained on labeled and pseudo-labeled samples where pseudo-labeled samples refer to the samples with labels predicted by the semi-supervised learning module. Moreover, to guarantee the feasibility of the learning framework, a two-stage strategy is proposed for training the deep neural network. Specifically, the two-stage training strategy adopts pseudo-labeled samples firstly to train a deep neural network, then the deep neural network is refined using labeled samples one more time. As a result, more samples can be used for training a deep neural network, which is significant to the performance improvement of a deep neural network in the case of inadequate labeled samples. More importantly, the deep neural networks trained under the proposed learning framework perform better than the famous deep neural networks in a robot-written character identification experiment.
Introduction
Industrial products have always painted a series of characters by robots on their surface as identity. However, the characters written by robots are unique in font and shape, always different from the characters written by hands. The images of the characters written by a robot may lie on a complicated low-dimensional manifold. A feasible technical road map for recognizing industrial products is to learn the patterns of the character images and fit the complicated manifold of the images by a model. Therefore, the high-capacity models, such as deep neural networks, have been applied to the recognition of industrial products. Deep neural networks, especially convolutional neural networks, are perfect candidate models for learning the patterns of images[1–5]. By stacking a huge quantity of neurons layer by layer, a deep neural network can tackle a lot of complicated problems, such as image classification and speech recognition [6–9]. The progress in the computing capability of computers since the 1990s makes it possible to build a large-scale neural network and train a neural network with the aid of a GPU [10]. Over the past decades, a great number of famous deep network models were proposed. For example, Simonyan et al. [11] designed a deep convolutional network, called VGG, for large-scale image recognition where VGG consists of 16-19 layers with very small (3×3) convolution filters. Chollet found that the Inception modules in convolutional neural networks can be interpreted as an intermediate step between regular convolution and depthwise separable convolution. Then, inspired by Inception, Chollet [12] proposed a new deep convolutional neural network, called Xception, where Inception modules are replaced with depthwise separable convolutions. He et al. [13] train deeper neural networks by reformulating the layers as learning residual functions with reference to the layer inputs. A network becomes its residual version by inserting shortcut connections into a plain network. Computational efficiency and low parameter count are the main concerns for various application scenarios, such as mobile vision and big data. Szegedy et al. explained the benefit of Inception modules of convolutional neural networks in terms of the computational cost. Huang et al. [14] proposed a new Dense Convolutional Network (DenseNet), which connects each layer to every other layer in a feed-forward fashion. DenseNets have several advantages in terms of alleviating the vanishing gradient, strengthening feature propagation, encouraging feature reuse, and substantially reducing the number of parameters. Tan et al. [15] proposed a new scaling approach for uniformly scaling the depth, width, and resolution of convolutional neural networks. They evaluated their method of scaling up MobileNets and ResNet. Deep neural networks have been applied to a variety of industrial fields. For example, Chen et al. [34] proposed a semisupervised recurrent convolutional attention model for human activity recognition. Luo et al. [35] proposed an adaptive semisupervised feature analysis method for video semantic recognition. Zhang et al. [36] applied the spatio-temporal preserving representations for EEG-based human intention recognition. Liu et al. [37], Fang et al. [38], He et al. [39] and Du et al. [40] studied scene text detection problem with the semi-supervised learning theory. Bhunia et al. [41] studied a handwritten text recognition problem with a novel meta-learning framework.
Although deep neural networks show great priority compared with the traditional machine learning models, a huge number of labeled samples are required for training a deep neural network [16]. When labeled samples are adequate for model training, then deep neural networks have been proven to be superior to the traditional supervised models in real-world applications, such as image identification and speech recognition. However, labeled samples are inadequate in most real-world application scenarios. As a result, if unlabeled samples can play an important role in model training, then a deep neural network can get a performance boost. To allow a deep learning framework to take advantage of unlabeled samples for model training is a challenging problem. A possible solution is to assign pseudo labels for unlabeled samples and use the pseudo-labeled samples for model training.
To improve the learning ability of a deep neural network in the case of inadequate labeled samples, we construct a learning framework such that a deep neural network can get well-trained with the aid of unlabeled samples. The deep learning framework contains a semi-supervised learning module that is responsible for predicting the true labels of unlabeled samples. After unlabeled samples become pseudo-labeled samples, we then achieve the purpose of training sample set extension by constructing a training sample set of labeled and pseudo-labeled samples. More training samples allow a neural network to avoid the over-fitting problem. The innovations and contributions of this paper are summarized as follows:
1) The first contribution of this paper is to construct a deep learning framework consisted of two modules, including a semi-supervised learning module and a deep neural network module. The learning framework allows a deep neural network to avoid overfitting problem by extending the training sample set with unlabeled samples.
2) The learning framework consists of a semi-supervised learning module for predicting the labels of unlabeled samples so that unlabeled samples can become pseudo-labeled samples. Then, we obtain an extended training sample set of labeled and pseudo-labeled samples, and a deep neural network is allowed to be trained on the extended training sample set.
3) To guarantee the feasibility of the learning framework, a two-stage training strategy is proposed for training a deep neural network. The two-stage strategy allows a deep neural network to be trained on the pseudo-labeled first and labeled samples one more time. The two-stage training strategy allows the deep neural network to learn from the pseudo-labeled samples roughly and then to refine the deep neural network using the labeled samples.
4) We implemented an experiment on robot-written character identification to demonstrate the advantages of the proposed learning framework. The experimental results showed that the deep neural network trained under the proposed learning framework outperforms a couple of well-known deep neural networks in terms of identification accuracy.
The remainder of this article is organized as follows. Section 2 will introduce the learning strategy taken by the proposed learning framework and two important modules of the learning framework. In Section 3, an experiment will be implemented to evaluate the performance of the proposed learning framework. At last, conclusions are drawn.
The proposed end-to-end semi-supervised deep learning framework
There are two important modules, including a semi-supervised learning module and a deep neural network module, in the proposed learning framework. The layout of the proposed deep learning framework is depicted in Fig. 2. Under the deep learning framework, the whole sample set will be split into two parts, including a group of labeled samples, and a group of unlabeled and labeled samples. Then, the semi-supervised learning module will be used for predicting the labels of unlabeled samples so that unlabeled samples become pseudo-labeled samples. Finally, the deep neural network is allowed to be trained on both pseudo-labeled and labeled samples with the aid of a two-stage training strategy.
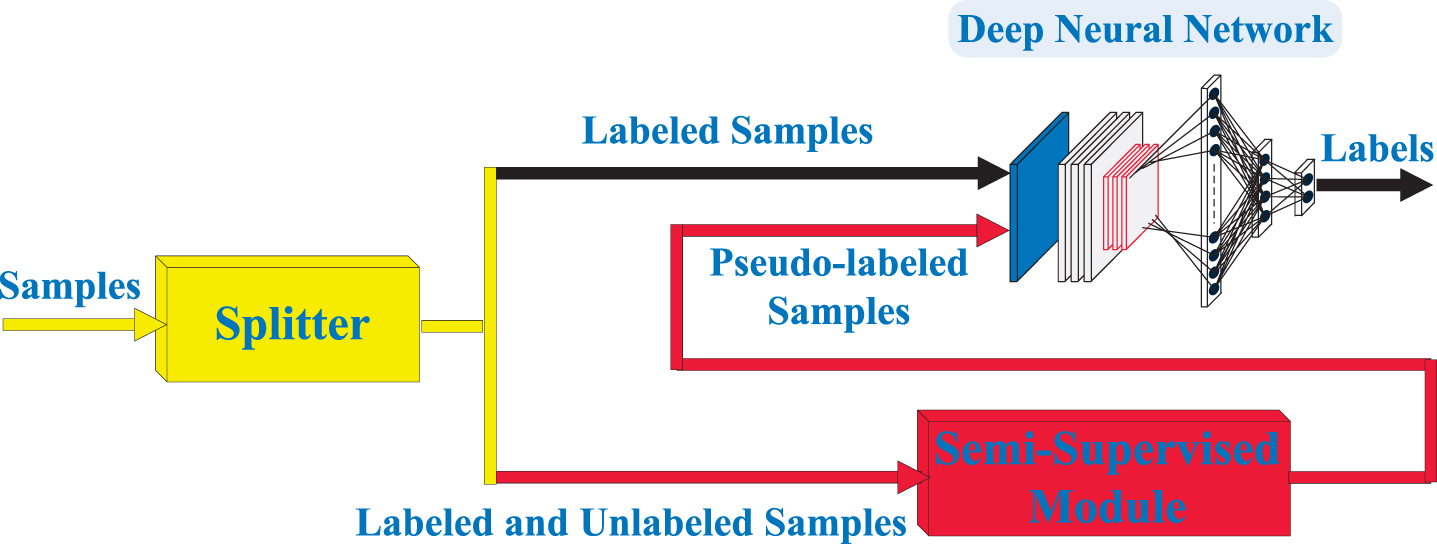
Illustration of the proposed semi-supervised deep learning framework.
The purpose of supervised learning frameworks is to infer the labels of unlabeled samples using a model that is well-trained on labeled samples. However, inferring the labels of unlabeled samples is not the ultimate goal of the proposed deep learning framework, but for training sample extension so that a deep neural network can be trained on more samples. The two-module learning framework allows a deep neural network to take advantage of pseudo-labeled samples for model training firstly. Then, labeled samples are used to refine the deep neural network.
The semi-supervised learning module of the proposed deep learning framework is important to the overall performance of a deep neural network. We propose a high-performance semi-supervised learning module with manifold learning and kernel learning theories. Next, we start to introduce the semi-supervised learning module. Suppose that samples are drawn from a probability distribution P on
According to the Representer theorem [17], the solution to optimization problem (1) exists in
Inspired by the above semi-supervised learning theory, the proposed semi-supervised learning module is
Because the labels of labeled samples are already known, thus label matrix
Because
For optimization problem (6), we define the following objective function to be minimized
where
For above constrained optimization problem, a Lagrange function can be defined as follows
where Φ and Ψ are two matrices of Lagrangian multipliers.
The partial derivative of L (
According to the Karush-Kuhn-Tucher (KKT) condition
Φ
ij
(
The partial derivative of L (
According to the KKT condition Ψ
ij
The algorithm for searching the label matrix
For above algorithm, we have the following conclusions: 1) for a fixed
Given a nonnegative matrix
as an auxiliary function of J (
If the nonnegative matrix
The inequalities in (19) inspire us to compute the partial derivative of G (
Similarly, given a nonnegative matrix
as an auxiliary function of J (
Obviously, the following inequality holds
If the nonnegative matrix
The partial derivative of F (
Then
In conclusion, the multiplicative update rules (13) and (15) can not only guarantee the convergence but also guarantee the nonnegativity of matrices
A deep neural network can be competent for classification tasks only when it gets well-trained on a group of labeled training samples. Model training is to search a set of parameters using an optimization algorithm such that the deep neural network can output a correct label
In the proposed end-to-end semi-supervised learning framework, the output layer of the deep neural network is a soft-max activation layer. As a result, given an input sample, the output of the deep neural network is a label vector
The cross-entropy loss function defined as follows is used for model training
Given an one-hot label vector
Applying (29) to (27), we can obtain a well-defined loss function for model training. Next, we will introduce the two-stage strategy for training a deep neural network using pseudo-labeled and labeled samples, separately. The pseudo-labeled samples are responsible for pre-training the deep neural network, while the labeled samples are responsible for fine-tuning the deep neural network.
The first stage of the two-stage training strategy is to minimize the loss function on pseudo-labeled samples using a numerical optimization algorithm as follows
The second stage of the two-stage training strategy is to train the deep neural network using labeled samples. In this stage, a numerical optimization algorithm as follows is adopted to search a set of model parameters
After model training is finished, we then obtain a well-trained deep neural network. The procedures for training a deep neural network are summarized in Table
The procedures for training a deep neural network
In this section, we will implement an experiment to evaluate the performance of the semi-supervised deep learning framework. Moreover, we will compare the deep neural network trained under the semi-supervised learning framework with both traditional machine learning models (not deep neural networks) and famous deep neural networks in the experiment. Traditional machine learning models include decision tree (DT) [31], k-nearest neighbors (KNN) [27–30], support vector machine (SVM) [20–23], and kernel support vector machine (KSVM) [24–26]. Deep neural network models include Vgg16 [11], DenseNet [14], Xception [12], ResNet [13], EfficientNet [15]. In this experiment, each model will confront a robot-written character identification task where the characters were written by a robot on the surface of steel coils. The images of the working robot are shown in Fig. 2. The sample images of the characters written by the robot are shown in Fig. 3.

Images of the working robot.

Two sample images of the characters written by the robot.
We take several steps for solving the robot-written character identification problem, such as model selection, image preprocessing, model training, and model evaluation. The first step is to design the architecture of the deep neural network. The deep neural network for the character identification task is a convolutional neural network (CNN), as shown in Fig. 4. The CNN consists of three blocks where the first and second blocks include convolutional layers and max-pooling layers, respectively, and the third block consists of a set of fully-connected layers. Specifically, the convolutional layer in the first block has a kernel size=5, filters=9, padding=same, and the max-pooling layer in the first block has a pool-size=2, a batch normalization, and a ReLU activation. The second block of the CNN consists of convolutional layers with kernel-size=5, filters=27, and padding=same, and the max-pooling layers in the second block have a pool-size=2, a batch normalization, and a ReLU activation. The third block of the CNN consists of a flattened layer and three fully-connected layers where the numbers of the neurons in the fully-connected layers are 215, 75, and 15, respectively. Finally, the output of the CNN comes from the last fully-connected layer with a softmax activation.
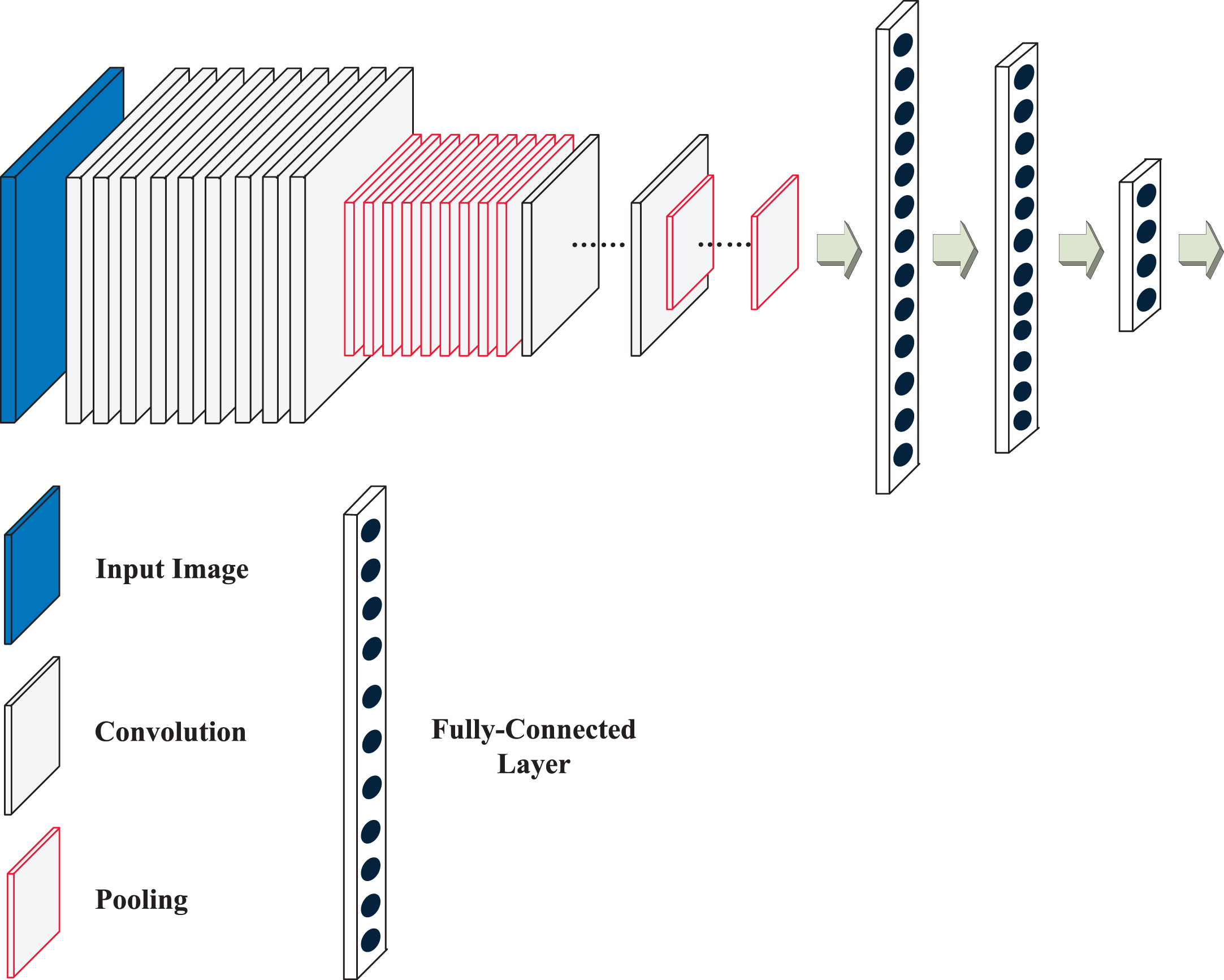
Illustration of the architecture of the CNN for robot-written character identification. The CNN will serve as a classifier whose input is an image, and output is a vector, i.e., classification result of the input image.
The second step is image preprocessing. The whole image set consists of a total of 285 images. Image preprocessing includes image resizing, binary image transformation, de-noising, and gray image transformation, where gray image transformation is responsible for transforming the original images into grayscale images, and image resizing is responsible for transforming the grayscale images into new images with the size of 40×80 pixels, de-noising is responsible for removing noises from the images by a median filter, and binary image transformation is to transform the images into binary images. The sample images after image preprocessing are shown in Fig. 5. Moreover, the visualization result of these images in a two-dimensional space by t-SNE is given by Fig. 6 [32].

Preprocessed images of the characters.

Visualization result of the preprocessed images by t-SNE. Each type of the processed character images is mapped onto a two-dimensional plane and represented by dots in different colors and sizes.
The third step is model training. In this step, we split the whole image set into three parts, including a set of labeled images, a set of unlabeled images, and a set of images for the test. Then we take the semi-supervised learning module to predict the labels of unlabeled images so that unlabeled images become pseudo-labeled images. Finally, we take the two-stage training strategy to train the CNN on the labeled and pseudo-labeled images, separately.
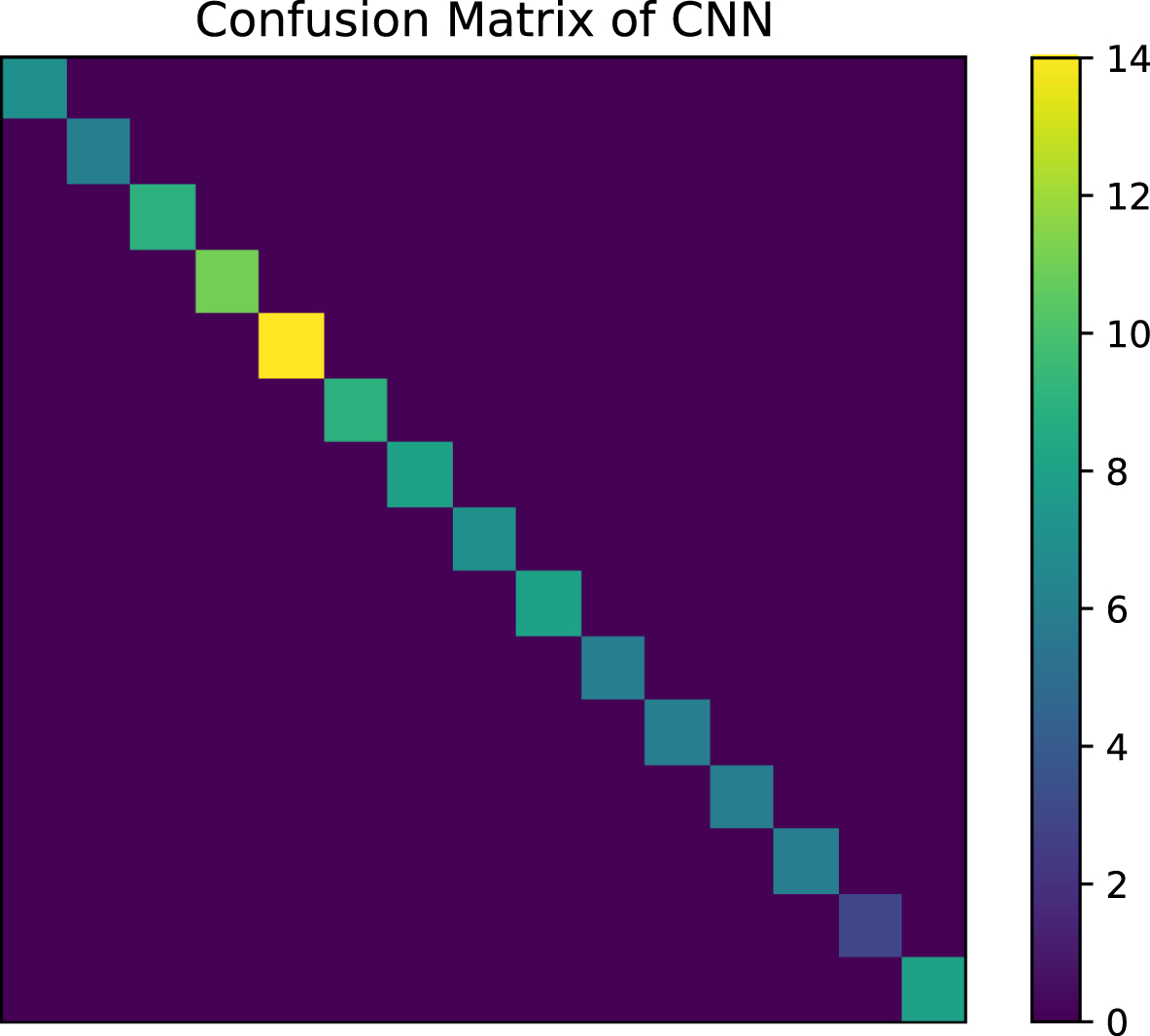
The last step is to launch the well-trained CNN and evaluate its performance on the test images. Moreover, the compared models were trained on the labeled images. The strategy taken by SVM and KSVM for this multi-classes image identification task is one-vs-rest. To evaluate the performance of each model quantitatively, we selected the accuracy of image identification as the performance metric where accuracy can be derived from the confusion matrices about test images. Confusion matrices computed by the models are shown in Figs. 7 and 8 in the case of 20% labeled images. Compared with Figs. 7 and 8, one can conclude that the CNN performs better than traditional models in terms of accuracy.
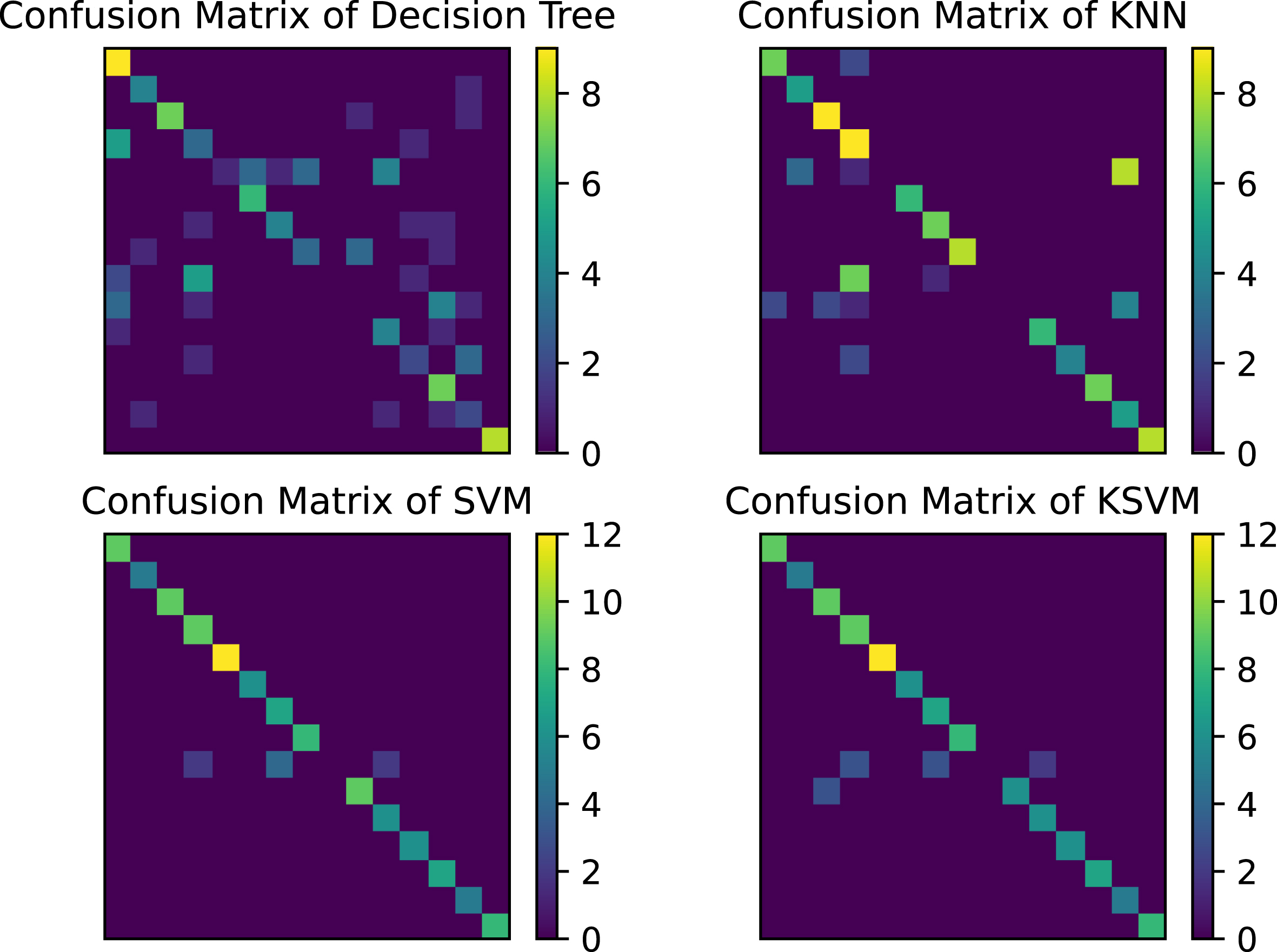
Confusion matrices of DT, KNN, SVM, and KSVM with 20% labeled training images where the confusion matrix closing to a diagonal matrix indicates a higher accuracy.
We also evaluated the performance of each model with different numbers of labeled training images. Therefore, we increase the number of labeled training images gradually to observe the performance change of each model. When the number of labeled images increases from 15% to 35% with an interval of 5%, the performance change of each model is summarized in Table 2. Table shows that the CNN trained under the semi-supervised deep neural network performs best when the number of labeled images is small. Moreover, the performance of the CNN keeps at a high level with the number of labeled images increasing. In conclusion, the CNN trained under the new semi-supervised deep learning framework almost outperforms the traditional models no matter how the number of labeled images changes, as shown in Fig. 9.
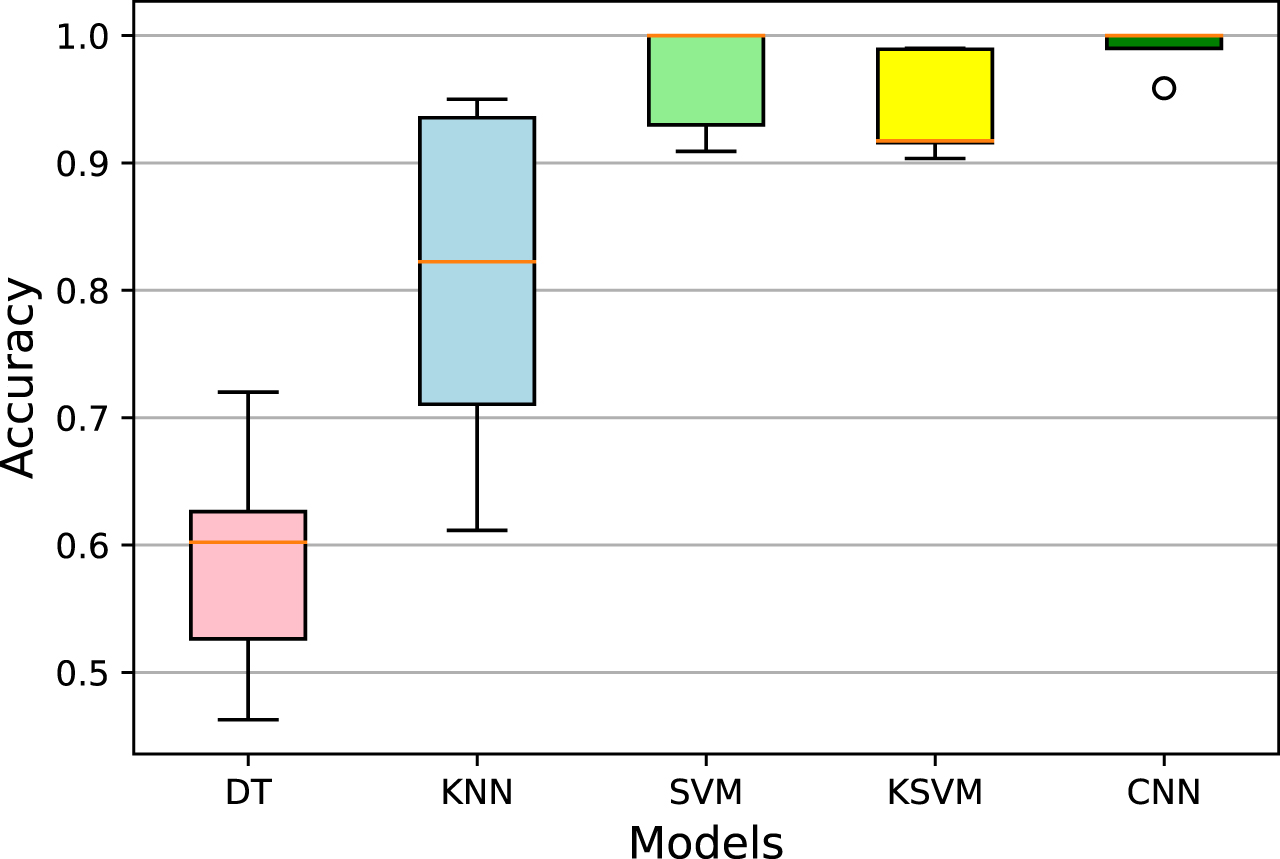
Identification accuracy distributions of the traditional models with different numbers of labeled training image.
Identification accuracies of the traditional models with different numbers of labeled images (LI)
The identification accuracies of the deep models with different numbers of labeled images are depicted in Fig. 10. Moreover, the identification accuracy of each deep model is listed in Table 3. Compared with the identification accuracy of the CNN, Table 3 indicates that the deep models yield lower identification accuracy and do not competent to the image identification with a small number of labeled training images, which agrees with the conclusions we conclude previous sections of this paper, i.e., the performance of deep neural networks highly depend on the quantity of labeled training samples.
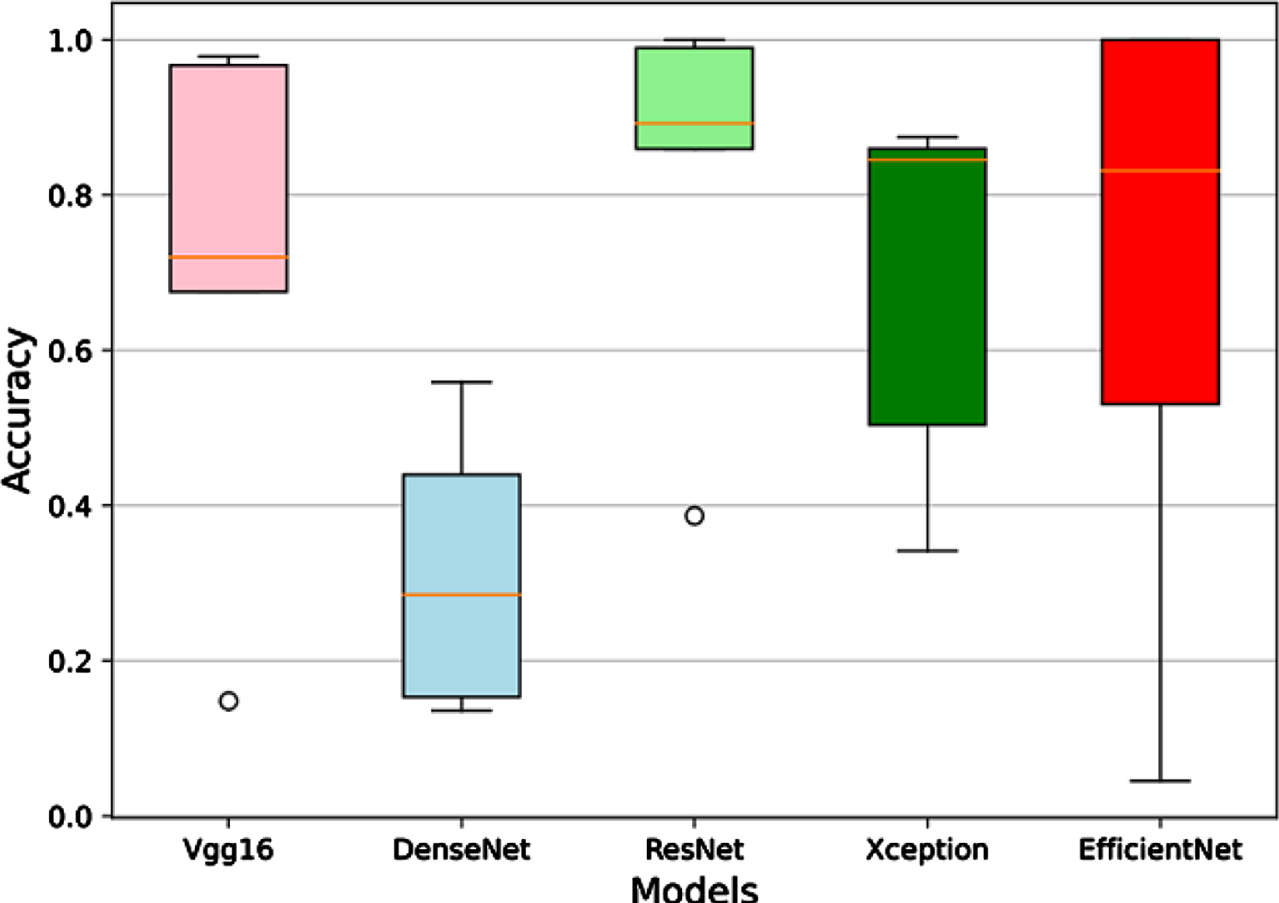
Identification accuracy distributions of the deep models with different numbers of labeled training image.
Identification accuracies of the deep models with different numbers of labeled images (LI)
To evaluate the computation efficiency of each model, we summarize the time spent on each model for identifying the test images. Tables 4 and 5 show the computation efficiency of the traditional models and deep models, respectively. The computation was tested with a laptop with an I7-CPU and RTX-2060 GPU.
Computation efficiency of the traditional models for identifying testing images
Computation efficiency of the deep models for identifying testing images
We have presented an end-to-end semi-supervised deep learning framework for training a deep neural network when labeled samples are inadequate. By assigning pseudo labels for unlabeled samples, a deep neural network is allowed to be trained on an extended sample set consisting of pseudo-labeled samples and labeled samples. The proposed learning framework consists of two modules, including a semi-supervised learning module and a deep neural network module, where the semi-supervised learning module is responsible for predicting the labels of unlabeled samples so that the unlabeled samples can become pseudo-labeled samples, and the deep neural network serves as an interface of the learning framework for out-of-sample identification. To guarantee the feasibility of the learning framework, we then developed a two-stage strategy for training a deep neural network.
We have drawn some important conclusions from the experiment. The first conclusion is that gigantic deep neural networks are incapable of the robot-written character identification task since they need more labeled images for model training. The second conclusion is that some traditional tiny machine learning models, such as KNN and SVM, show better performance because they need fewer labeled images for model training. The third conclusion is that even though few labeled images are available for model training, we can still train a high-performance deep neural network with the efficient use of unlabeled images. More importantly, we proved that the model trained under the new learning framework is superior to the well-known models, including decision tree, k-nearest neighbors, support vector machine, kernel support vector machine, Vgg16, Xception, ResNet, DenseNet, and EfficientNet, through an experiment on the robot-written character identification.
Footnotes
Acknowledgment
This work was supported by the Fundamental Research Funds for the Central Universities (3132022138).