
Abstract
In order to solve the problems of high computational complexity, poor dimensionality reduction, and reduced clustering effect when the clustering task faces a large amount of big data, the application of a large data adaptive semi-supervised clustering method based on deep learning is proposed. Through the self-encoder of the deep clustering network, the analysis of the confrontation network is generated, and the semi-supervised deep clustering algorithm and algorithm of the adaptive strategy are optimized. Through the encoder layer structure of the deep coding network, different parameters are set for all data sets for algorithm experimental analysis. The results show that the data obtained by this method is faster, more accurate and more optimized than the traditional clustering method, which proves the effectiveness of the method.
Introduction
In the real world, there are a lot of data in various fields. In order to find valuable information from data, machine learning and data mining technologies came into being. Among them, cluster analysis is an important technology in machine learning and data mining research [1, 2, 3]. The purpose of clustering is to divide a group of objects into different classes according to their characteristics, so that the objects in the same class are highly similar and the objects in different classes are obviously different. Since the 1990s, in order to improve the performance of classifiers, many scholars have tried to combine supervised learning and unsupervised learning, and make comprehensive use of labeled samples and unlabeled samples to better train classifiers. However, it was not until the beginning of the 21st century that SSL began to form a theory and algorithm system independent of traditional supervised learning and unsupervised learning, and became a new type of machine learning method [4]. In practical applications, obtaining fully labeled data is usually very expensive and time-consuming, while obtaining unlabeled data is much easier. As shown in Fig. 1, SSL is an effective method to improve classifier learning performance by using a small amount of labeled data and a large amount of unlabeled data, which has been deeply studied in many fields.
Example of semi supervised learning.
Clustering task is a basic problem in machine learning, computer vision, data compression and other fields. Traditional clustering methods have developed more mature, but the geometric increase of human activities leads to the increase of the amount and complexity of stored data, the connection between data and the characteristics of data itself have become more and more complex, and the difficulty of clustering task has also increased. It has been faced with the problems of high computational complexity, poor dimensionality reduction effect and reduced clustering effect. The significance of data lies not only in the data itself, but also in a series of analysis activities based on data to help people explore potential information and produce valuable deep information.
In recent years, due to the powerful ability of feature extraction and representation, the combination of deep learning and clustering task has attracted extensive attention. Clustering based on deep learning, also known as deep clustering, is gradually rising. Deep clustering is essentially a leading clustering method that uses the powerful representation capabilities of deep learning to improve the clustering results. The key is that the expression of the extracted data requires both the use of neural networks to learn low-dimensional expressions of data suitable for clustering, And can reflect the information and structural characteristics of the original data, so as to achieve better clustering effects. Literature [5] analyzes and summarizes big data clustering and small data clustering on the basis of the development of traditional clustering. Literature [6] summarizes some effective representative algorithms in the early stage of deep clustering combined with the development of recent years, but it lacks the research on deep clustering of graph neural network. With the continuous penetration of artificial intelligence technology, graph neural network machine learning has attracted more and more attention of researchers and practitioners, and is more and more widely used in tasks such as classification, clustering, link prediction and so on.
Cluster analysis is one of the most basic tasks in the fields of data mining, machine learning, pattern recognition and so on. Its goal is to divide the data set into several clusters so that the data in the same cluster are as similar as possible. Although many classical clustering algorithms have been published, such as k-means and Gaussian mixture model, affected by the disaster of dimension, the traditional clustering algorithms can not effectively deal with high-dimensional data sets [7]. In order to solve this problem, dimensionality reduction algorithms are often applied to data pre-processing before clustering. The principle is to map the original high-dimensional data to a low-dimensional latent space so that the transformed data can be easily distinguished. Classical dimensionality reduction algorithms include principal component analysis, independent component analysis, Laplacian feature mapping, and local linear embedding.
Semi supervised clustering method is an improvement on the traditional clustering method based on the fusion of a small amount of supervised information [8]. Semi supervised clustering method uses a small amount of prior information to guide the clustering process, and optimizes the clustering results to the greatest extent, so that it can meet the expectations of researchers. Through the research of semi supervised clustering method, a small amount of supervision information can be used to effectively improve the clustering performance. Because the research of semi supervised clustering method is conducive to the management of massive data and better mining effective information from massive data, the research of semi supervised clustering algorithm has high research and practical significance. Therefore, how to make use of these monitoring information more effectively to improve the performance of semi supervised clustering method is the main content of this paper. Based on this research background and significance, this paper proposes semi supervised clustering algorithms based on pairwise constraints of label information. Experiments on benchmark data sets verify that the algorithm in this paper is true and effective, which has certain research significance for the development of semi-supervised clustering.
Autoencoder
The autoencoder is a typical deep learning model of the encoder-decoder architecture. In an unsupervised way, the original input is transformed into an intermediate representation to capture the potential feature representation of the input. This type of neural network learns the representation of data from the input layer and attempts to reproduce the original data at the output layer. By doing this, the autoencoder model can learn its potential distribution from incomplete data and generate new credible estimates [9, 10, 11]. Autoencoders have been widely used in many fields, including dimensionality reduction, image recognition and text classification. Figure 2 shows the typical structure of the autoencoder.
Autoencoder network structure.
The autoencoder is composed of input layer, hidden layer and output layer, in which the input layer and hidden layer constitute the encoder, and the hidden layer and output layer constitute the decoder. The input layer obtains the original input, the middle hidden layer encodes the input into a compact hidden representation, and the output layer reconstructs the original input. The encoder part of AE maps the input vector x to the hidden representation Z through nonlinear transformation. The calculation process is as follows:
In which
There are many variants of the autoencoder, among which the more classic is the Denoising Autoencoder (DAE), as shown in Fig. 3. The goal of this variant is to extract and encode robust features from the noisy data
Network structure of noise reduction automatic encoder.
Generative Adversarial Network (GAN) is a deep learning method that has emerged in recent years. GAN does not require supervision information during the learning process, and the generator and discriminator among them compete with each other in a zero-sum game [15, 16, 17]. Both the generator and the discriminator can gradually obtain better performance and better representation during their respective training process. For example, in the case of an image generation problem, the generator generates an image from Gaussian noise, and the discriminator determines the quality of the generated image. This process continues until the output of the generator can be close to the actual input sample.
Generative adversarial network structure.
The generation network takes random noise z as input and outputs the generated fake data
The network structure of the adaptive semi-supervised deep clustering algorithm.
The objective of GAN is stated as follows:
Based on the GAN framework, information maximizing generic advantageous networks can decompose discrete and continuous potential factors and expand them to complex data sets [18, 19]. The high efficiency of InfoGAN in the clustering effect mainly comes from maximizing the mutual information between the fixed small subset of the noise variable and the observation data. The optimization algorithm based on the generative adversarial network can impose multiple types of a priori on the basic framework, making the framework more flexible and diversified, but it has shortcomings such as modal collapse and difficulty in convergence.
Semi-supervised depth clustering algorithm based on adaptive strategy. The network structure of the algorithm is shown in Fig. 5. The algorithm maps the data from the original space to the feature space through the deep coding network, and obtains the feature representation results suitable for the clustering task. By learning the low-dimensional representation of the original data, it can alleviate the degradation of the performance of the traditional semi supervised clustering method in the face of high-dimensional data, and effectively alleviate the dimension disaster of data in the original space. At the same time, the algorithm also proposes a label adaptive strategy to correct the problem of label drift in cluster assignment. This strategy can not only improve the utilization of label information, but also weaken the excessive impact of deep coding network on cluster center. Finally, the algorithm designs a semi supervised joint learning framework to integrate label loss and clustering loss to adjust the potential representation and clustering center, and finally improve the performance of the clustering method in this chapter.
Data in the original space often shows the characteristics of too high dimension and more redundant information, resulting in its important features are not prominent enough, and it is difficult to effectively measure the similarity between data samples. To overcome the curse of dimensionality of the original data, the algorithm uses a stacked autoencoder network to construct a latent space of high-dimensional data, and learns a low-dimensional representation of the original data by minimizing the reconstruction loss. Autoencoder belongs to an unsupervised deep learning method. It realizes the purpose of automatic feature extraction through the process of encoding input data and decoding the result after dimensionality reduction it is often used to learn more essential representations of raw data. The deep coding network learns the latent features of the data in the low-dimensional space on the basis of the auto-encoder network, that is, calculates the hidden representations of the data samples, and uses these hidden representations to reconstruct the data samples, so as to minimize the loss between raw data and reconstructed data.
The adaptive semi-supervised deep clustering algorithm uses stacked autoencoders as a deep encoding network that learns the latent feature space of the initial data, and initializes it layer-wise by denoising autoencoders. Given a dataset
where Dropout(
After obtaining the latent representation of each data sample, the deep encoding network will decode the latent representation of the data by the following reconstruction function:
Among them,
Deep clustering of variational autoencoders
There are not many researches based on variational autoencoders, and the most representative algorithms are VaDE and GMVAE. The VaDE [7] algorithm assumes that the prior distribution of the hidden variable z obeys a Gaussian mixture model (GMM):
In which
In the above formula, the first term is the reconstruction loss (i.e. network loss), and the second term represents the KL divergence between the variational posterior distribution
After sampling from the Gaussian distribution
Note that
Among them,
The difference from VaDE is that GMVAE believes that the mean and variance of the Gaussian prior are also random variables, which are approximated by a neural network with a parameter of
The label information (positive label and negative label) reflects the membership relationship between the data object and the class label. The partition matrix
The process of transforming a matrix into a pair-wise relationship matrix.
Paired constraints include must-link and cannot-link, which reflect the relationship between data objects. Let
Among them,
According to the definition of the pairwise relationship matrix, we redefine the cost function
Among them,
In this paper, stochastic gradient descent (SGD) and back propagation are used to optimize the joint objective function Eq. (13). It is worth noting that the parameters to be optimized or updated include two parts: The feature space
Clustering results of ACC metrics
Clustering results of NMI metric
The gradient of the loss function L relative to the cluster center
In the back propagation process, the parameter
Clustering results of labeled data with different proportions
Classification accuracy of three data sets
The accuracy of labeling data at different scales on MNIST, USPS, REUTERS-10K.
Experimental parameter settings
The encoder layer structure of the deep coding network is set to d-500-500-2000-10 for all data sets, in which d is the dimension of the input data. All layers are fully connected, and the internal layers (except the input layer, embedded layer and output layer) are activated by Re LU nonlinear function. For each data set, a sample label list A will be dynamically generated according to whether there is label information in the data set. The length of the list is consistent with the size of the batch data obtained each time. If the sample point has a real label, its corresponding element value in list A is 1; If there is no real label, its corresponding element value is 0. The learning rate of SGD is 0.01. The convergence threshold tol% is set to 0.1%. After experimental testing, the trade-off parameter
The trend of accuracy and model loss with the number of iterations.
The impact of the trade-off parameter 
This section presents experimental results on three representative data sets. Tables 1 and 2 report the results of the experimental results on the two evaluation indexes of ACC and NMI respectively. The label data selected in this article accounted for 30% of the total data. The best performance results are highlighted in bold in the table. Compared with the traditional K-means and SMKL methods, the method in this paper can learn more representative features through the deep coding network. Moreover, K-means is an unsupervised method, which can not use label information in the clustering process, which further leads to performance degradation. It can be seen that the method proposed in this paper has achieved the best effect.
Runtime analysis.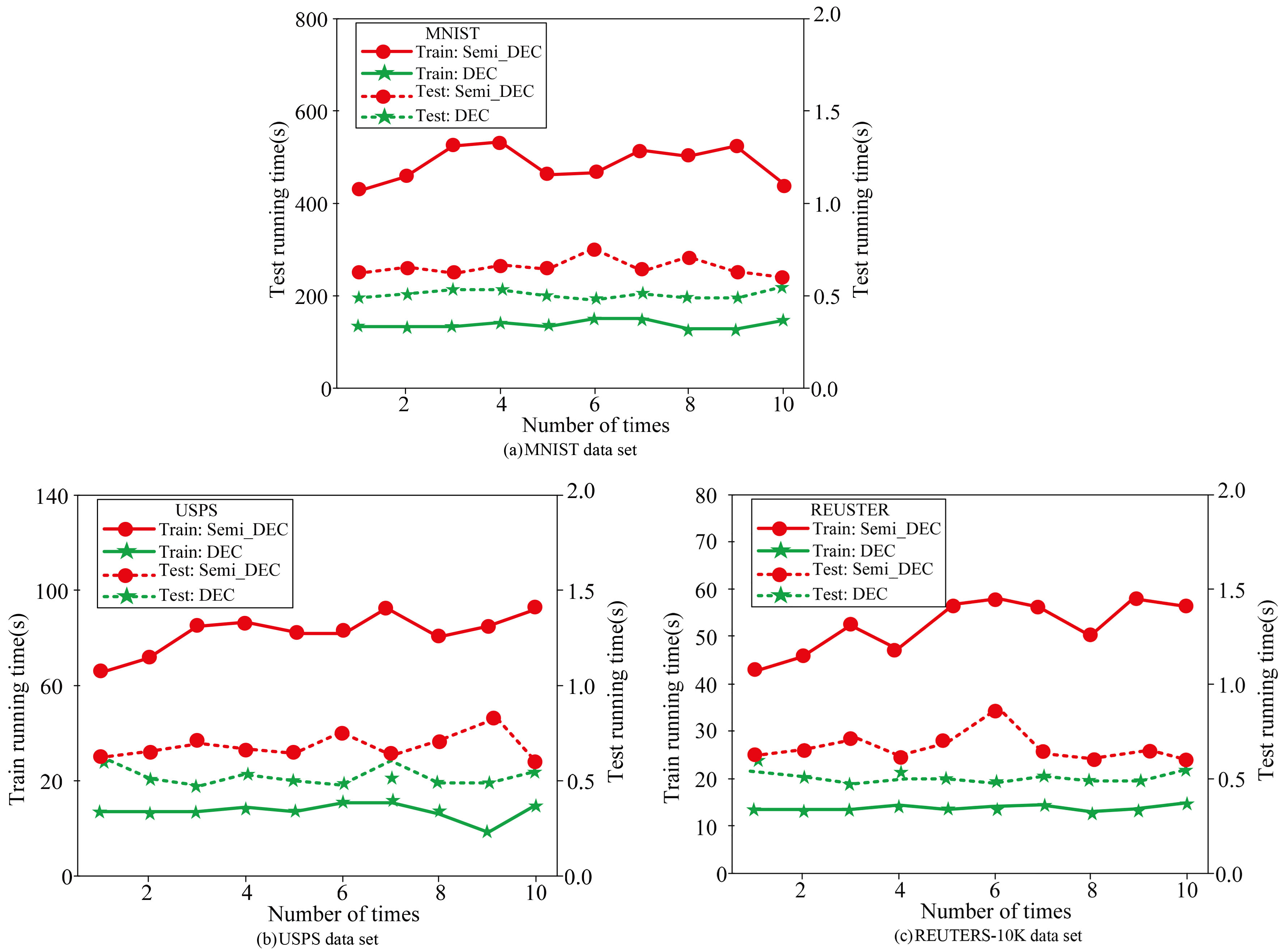
Similarly, in order to evaluate the impact of prior knowledge on the performance of Semi-DEC, the proportion of labeled data in the training sample is increased from 1% to 50%.
Each experiment was conducted 10 times, and the average results are shown in Table 3. Table 4 shows the results of the classification task when using the same network structure as Semi-DEC. As shown in Table 3 and Fig. 4, two conclusions can be drawn in this chapter. Firstly, with the increase of the number of labeled samples, the results of ACC and NMI on the three data sets increase. Especially on MNIST dataset with 50% labeled data, ACC and NMI can reach 97.5% and 95.2% respectively. Secondly, when the proportion of labeled data can reach 50%, the clustering performance of Semi-DEC on the three data sets can roughly reach the classification accuracy. This also further proves the superior performance of Semi-DEC.
In order to further verify the effectiveness of this method, we carried out experiments from many aspects, using the impact of different proportions of labeled data on performance, the change process of loss function and accuracy, weighing the impact of parameters on clustering performance and run-time analysis. As shown in Fig. 7.
For the different effects of different labeled data on performance, Fig. 7 shows the change trend of clustering result accuracy on MNIST, USPS and reuster-10k data sets. The dotted line represents the classification accuracy results obtained through multiple experiments when the classification model uses the same network structure as the Semi-DEC algorithm. It can be seen more intuitively from Fig. 6 that on MNIST data set and REUSTER-10k data set, with the gradual increase of the proportion of labeled data, the clustering effect of Semi-DEC method can be very close to that of the classification model using all label information under the same network structure. Although there are some gaps between the clustering effect of Semi- DEC and that of classification model under network structure on USPS data set, it can be seen that the difference is not large, which is enough to reflect the effectiveness of this method in improving clustering performance.
From Fig. 8, we can see the process record that the loss function and accuracy change with the increase of training times. It can be seen from the Figureure that after reaching a certain number of iterations, the loss value of the data set or the clustering accuracy will gradually tend to be stable, which also proves the robustness of the method in this paper.
In order to get a more accurate and clear understanding of the specific impact of the label loss trade-off parameter
Regarding the running time, Figs 9 and 10 records the running time comparison between the Semi-DEC method and the DEC method in this paper. Since the method in this paper is further researched and improved on the basis of the DEC method, only the DEC method is selected for comparison in terms of running time. It can be seen that the method in this paper consumes relatively more time than the DEC algorithm in the training process. This is because the label adaptive strategy is added to the Semi-DEC method, and the label loss needs to be calculated after each round of clustering assignment is completed in the training process, so more time is required. However, this paper believes that it is worthwhile to increase the limited training time, because the clustering performance of this method has been significantly improved.
In order to be able to quickly retrieve the massive amounts of big data, and filter out the tasks that represent the feature representation space and clustering assignment of deep learning, the application of a big data adaptive semi-supervised algorithm based on deep learning is proposed. Based on the clustering network structure, the autoencoder network is analyzed, and the autoencoder network is deepened, the semi-supervised algorithm analysis of the generative confrontation network is carried out, and the adaptive clustering algorithm is further proposed, and then the algorithm is optimized, Different data sets are set as experimental parameters. Finally, different data sets MNIST, USPS and reuster-10k are compared, The results show that this method has better performance than the traditional clustering methods, and has important significance and reference value for the research of clustering.