
Abstract
Clustering plays a fundamental task in the process of data mining, which remains more demanding due to the ever-increasing dimension of accessible datasets. Big data is considered more populous as it has the ability to handle various sources and formats of data under numerous highly developed technologies. This paper devises a robust and effective optimization-based Internet of Things (IoT) routing technique, named Student Psychology Based Optimization (SPBO) -based routing for the big data clustering. When the routing phase is done, big data clustering is carried out using the Deep Fractional Calculus-Improved Invasive Weed Optimization fuzzy clustering (Deep FC-IIWO fuzzy clustering) approach. Here, the Mapreduce framework is used to minimizing the over fitting issues during big data clustering. The process of feature selection is performed in the mapper phase in order to select the major features using Minkowski distance, whereas the clustering procedure is carried out in the reducer phase by Deep FC-IIWO fuzzy clustering, where the FC-IIWO technique is designed by the hybridization of Improved Invasive Weed Optimizer (IIWO) and Fractional Calculus (FC). The developed SPBO-based routing approach achieved effective performance in terms of energy, clustering accuracy, jaccard coefficient, rand coefficient, computational time and space complexity of 0.605 J, 0.935, 0.947, 0.954, 2100.6 s and 72KB respectively.
Introduction
IoT plays an ever-increasing imperative role in the day-to-day life of humans, as it provides superior service quality through continuous data gathering [1]. It is also a system of organized smart mechanical machines, digital machines, objects, and computing devices with the potential of transferring data packets on an IoT network of linked intermediate nodes. Due to the progressive growth of communication ability and computing power of IoT, there are still many issues and shortcomings that need to be addressed because of the intrinsic features of the big data from IoT, such as inadequate energy supply, restricted communication range, data redundancy, node failure, and limited node computing capability. Moreover, the big data gathered in the IoT is mainly utilized for performing monitoring services in a real-time environment. The expected environmental data can be estimated using this composed data in advance. The correlations among the data are not so significant because of the prevalent loss in the gathered data. The data incompleteness may cause certain deviations in estimation outcomes, thereby affecting the decisions of the overall monitoring system potentially. Precise estimation has a significant part in any type of domain. Researchers show that the data gathered can completely enhance the performance accuracy effectively. Therefore, it is very essential to guarantee the completeness of gathered data in IoT [2].
The growth of big data expands every year due to emergent technologies and applications. The revolution in science and technology affects the size of the data, which increases rapidly with an idea for enhancing commercial actions. Big data is a massive dataset that is typically more difficult to capture, gather, and filter using traditional methods [3]. In general, data is created at a higher rate in numerous ranges of domains, which has been subjected to the users in a structured, non-structured, and semi-structured form with the recent expansion and development in information technology. Advanced technologies are essential so that valuable information can be stored and extracted from massive collections of data. Nevertheless, the process of extracting and identifying the necessary information and understanding from big data is more difficult, and hence various conventional relational databases cannot satisfy the requirements of the user [4]. Clustering can be used for identifying the unusual patterns in big data [5], and also for executing different pattern identification and unsupervised machine learning tasks. The clustering process is an unsupervised learning technique for identifying the highest similarity in a cluster and the minimum similarity among the clusters, which are comparable to each other. Furthermore, numerous studies have generally focused on developing competent clustering techniques in order to provide quick and consistent decision-making models in real-world systems.
The aim of the current work is to devise a route-based big data clustering technique using the SPBO algorithm. The reason for selecting the SPBO algorithm is that the SPBO-based routing approach achieves effective performance in terms of energy, clustering accuracy, jaccard coefficient, rand coefficient, computational time and space complexity. The main motivation for selecting the SPBO optimization is the numerous existing big data clustering approaches in IoT fields along with their merits and drawbacks that encourage the experts to devise the proposed SPBO-based routing technique for performing big data clustering in IoT. The optimization algorithm named SPBO is used here to route sensed data using effective fitness measures, namely energy and distance.
The SPBO-based routing is accomplished for routing the sensed information to BS for performing the clustering process. Besides, the Mapreduce framework is employed to minimise the over-fitting issues during data clustering. The process of clustering mainly consists of two phases, namely feature selection and clustering. Firstly, the input data is gathered from the dataset, and it is presented to the mapper phase for selecting significant features using the Minkowski distance measure. Meanwhile, the process of clustering is performed in the reducer phase using the Deep FC-IIWO fuzzy clustering algorithm. However, the FC-IIWO model is devised by the hybridization of the IIWO algorithm and FC.
The key part of the work is portrayed as follows,
The proposed SPBO-based routing is an effective SPBO-based routing technique is devised for performing the big data clustering in IoT fields. This paper devises a robust and effective optimization-based Internet of Things (IoT) routing technique, named Student Psychology Based Optimization (SPBO) -based routing for the big data clustering. The proposed SPBO algorithm is depends on the Student Psychology who are attempting to put forth more effort to enhance their performance in the exam up to the level for becoming the best student in the class.
The current research paper is arranged as follows: section 2 reviews the different approaches employed for big data clustering in IoT, the system model of IoT is illustrated in section 3. Section 4 describes the proposed IoT-based routing approach for big data clustering, the experimental outcomes are portrayed in section 5, and finally section 6 concludes the paper.
Literature survey
The different existing big data clustering approaches in IoT are reviewed in this section. Amit K. Shukla and Pranab K. Muhuri introduced an Interval Type-2 fuzzy Set (Interval T2FS) approach for clustering big data [6]. Here, the Fuzzy C-Means (FCM) strategy was employed for performing the process of clustering. This approach effectively reduces the computational complexities. However, this technique failed to utilise large datasets as FCM does not execute powerfully with very large datasets. Fanyu Bu et al. developed a High-Order Possibility C-Means technique using a Double-Layer Deep Computation Model (HOPCM-DCM) for clustering big data [7]. Here, an asymmetric tensor auto-encoder mechanism was employed for training the DCM. This method improved the training effectiveness of DCM, but it was still ineffective in resolving outlier problems. F. Safara et al. devised a priority-enabled and energy-efficient routing (PriNergy) mechanism for improving routing performance in IoT systems [8]. This method effectively improves the routing protocol efficiency and ultimately prevents overcrowding issues. However, this approach failed to consider novel optimization algorithms in order to achieve effective results. Q. Zhang et al. [9] developed two HOPCM algorithms, namely canonical polyadic decomposition (CP-HOPCM) and the tensor train network (TT-HOPCM) in order to cluster large data. This technique effectively saved the memory space without any drop in the clustering accuracy, but the major challenge lies in minimising the over-fitting issues.
The numerous challenges confronted by the big data clustering approaches in IoT are elaborated below as follows.
The interval T2FS algorithm was designed for big data clustering, but this technique failed to utilise fuzzy uncertainty modelling mechanisms for demanding objectives like dimensionality reduction for multi-variate big datasets. The HOPCM-DCM technique was introduced in for clustering big data based on multi-modal data, and this technique achieved less time for clustering. However, the major challenge lies in establishing the optimum initialization approach for improving clustering performance.
PriNergy routing was presented for IoT systems, but the major challenge lies in considering meta-heuristic algorithms for controlling the routing process in the IoT nodes. The method designed in [10] was devised for large data clustering. However, this method does not consider effective clustering approaches like spectral clustering for improving the clustering accuracy. CP-HOPCM and TT-HOPCM were introduced for clustering big data in IoT, but the major challenge lies in utilising the big data clustering concept in the real-time applications of IoT with low-end devices for enhanced outcomes.
Ayomi Sasmito and Asri Bekti Pratiwi developed a SPBO algorithm for scheduling problems. This algorithm utilised many parameters for better performance [11]. The NP-hard problem is the principle of the optimization in this algorithm. The advantage of this work is high compatibility and better performance. The disadvantage of the work is the high space complexity for the searching operation. Zhanqiu Yu implemented the Big Data Clustering Analysis Algorithm for RFID IOT application with the help of the K-Means algorithm [12]. The work is more efficient in clustering compared with other techniques. The drawback is that work is needed to improve the feasibility. Tripathi et al. execute the Military-Dog-Based Algorithm for Clustering. The MapReduce concepts are involved in solving the problem [13]. The work is extremely precise. The cons of the work are the high computation time for the completion. The original SPBO classifies students according to their efforts in improving their performances. In this paper, we use chaotic maps to enhance student efforts in each category and present different strategic approaches. Logistic, iterative, sine, tent, and singer maps are integrated using proposed strategies to find the best map and also its strategy, named CSPBO.
System model of IoT model
The IoT model comprise of numerous sensor nodes, which are connected to the internet in a wireless manner. In IoT network, the data processing and transmission are performed through the IoT network devices. Figure 1 presents the structure of IoT model. The IoT model is contains one Base Station (BS), Cluster Head (CH), and numerous nodes. The direct communication is done within the particular radio range of wireless communication. Each IoT nodes in the wireless network has its maximum radio range of communication that is equivalently distributed within the dimension of A w and B w meters. Every nodes present in the IoT network has its distinct ID for interconnecting the nodes in order to create clusters in the network of IoT. The optimum location of sink node in the IoT network is illustrated as {0.5Y w , 0.5Z w }. In addition, the IoT nodes act as sensor as well as router. After creating the nodes, the source node transfers the data packets to BS using chosen optimal path. The sink node is employed for collecting all the data packets from the IoT nodes. Consequently, CH mechanism is utilized for transmitting data packets to BS through IoT nodes.
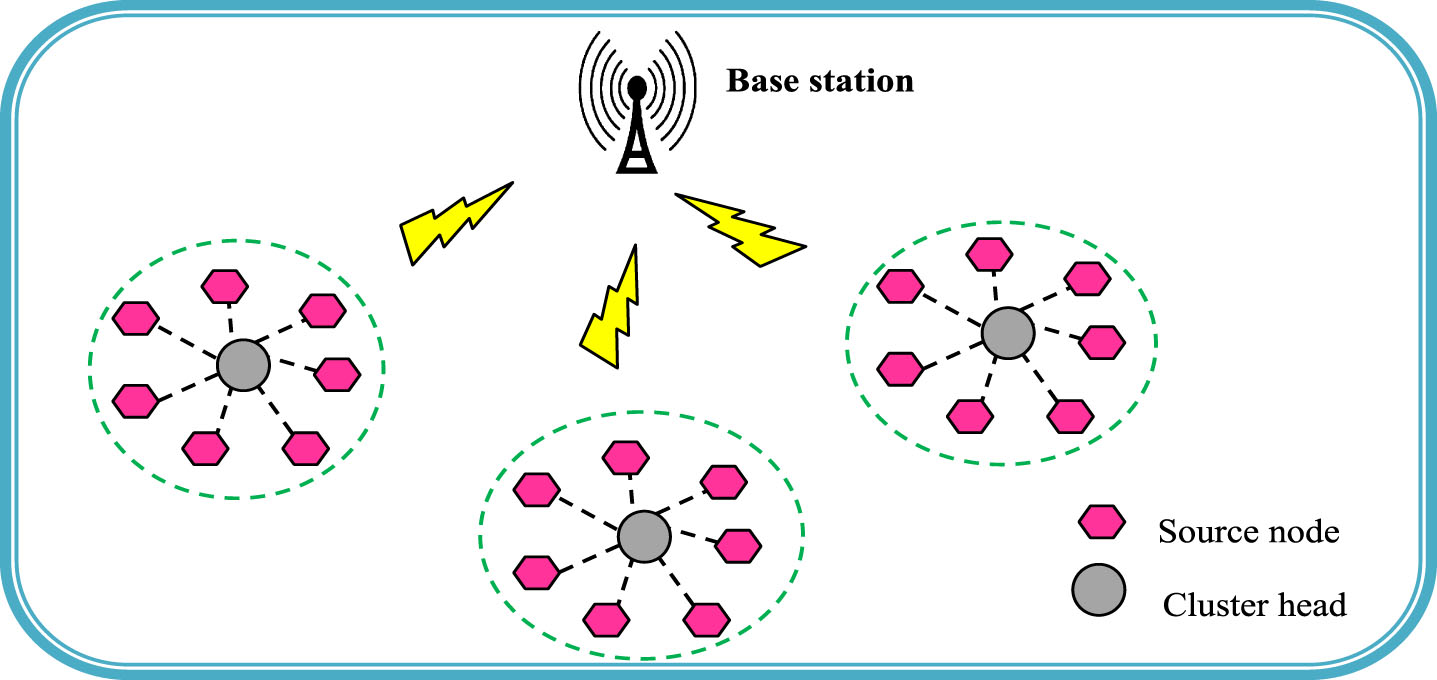
System model of IoT.
Each node comprise of initial energy H0 where the energy of the nodes is not rechargeable during transmission [14–16]. However, the loss of energy while transmitting the packets from i
th
nodes to r
th
CH performs multi path fading and free space model. The transmitter dissipates the energy using power amplifier and the radio electronics, whereas the receiver dissipates the energy using radio electronics. However, the dissipated energy of the nodes while transferring h bytes of data is given as Equation (1) and (2),
The energy value of the individual node and CH gets updated after receiving or transmitting b bytes of data is formulated as Equations (5) and (6),
This section describes the Optimization-based routing approach for performing the big data clustering in IoT fields. Initially, the IoT simulation is done such that the simulated IoT nodes are allowed to collect the sensed information and are routed to BS for performing the big data clustering process. The process of routing is done using the optimization algorithm, named SPBO [17–19] with the fitness objectives. After the process of routing, the data clustering is done using Deep FC-IIWO fuzzy clustering approach in a MapReduce framework and this framework comprises of a mapper and a reducer phase for performing the following process: Initially, the input data is acquired from the database, and then the acquired data is partitioned. Once the data partitioning is done, the partitioned data is presented to the mapper phase for selecting the significant features using Minkowski distance measure. Thereafter, the chosen features are given to the reducer where the process of clustering is performed by Deep FC-IIWO fuzzy clustering technique. Meanwhile, FC-IIWO technique is employed for finding the parameters in deep fuzzy clustering model [20]. However, the FC-IIWO algorithm is newly devised by the incorporation of FC concept and IIWO model [21, 22]. Figure 2 depicts the schematic representation of the developed technique.

Schematic view of developed SPBO-based routing approach for big data clustering in IoT.
The IoT nodes that collect the sensed information are routed to the BS, where the process of routing is done by the SPBO algorithm. Let us assume the dataset as D with ω number of attributes G and it is given as Equation (7),
Routing is the significant process of choosing finest paths in the network in such a way that the data packets are forwarded from the sender to the receiver in a secure way. This process effectively improves the superiority of the network related services. However, the optimal path selection depends on some major fitness factors, such as energy and distance.
The solution vector is represented based on the solution encoding function. Here, the solution vector is used for determining the routing path for transferring the sensed information to the destination for the big data clustering process. Moreover, the solution vector is in the dimension of 1 × n and the index of m number of nodes lies within the range from 1 ≤ q ≤ m. The solution encoding representation is depicted in Fig. 3.

Representation of solution encoding.
The fitness measure is utilized for determining optimal solution with respect to the fitness objectives, namely energy and distance. The routing path with the least fitness value is regarded as the finest paths for sensing data packets. Furthermore, the equation for the fitness function is given below as Equation (8),
SPBO is used for performing the routing process where the concept of SPBO depends on the psychology of student’s who is giving numerous attempts in order to become the finest student of class [23, 24]. Accordingly, student with the maximum marks is regarded as the best student. In order to become the best student of class, students have to attain higher marks than the remaining students in the class. The algorithmic phases of the SPBO-based routing approach are portrayed below as follows:
i) Initialization: The student population Z is initialized in the solution space T, which is given as Equation (9),
Here, Z represents the student, and Z d signifies the d th student, respectively.
ii) Fitness measure: The fitness function is utilized for determining the fitness value of every solution, and the equation is expressed.
iii) Update solution: The update equation of best, average and good students is mathematically formulated as follows:
a) Best student: The student having higher grade in examination is regarded as best student. In addition, the best student in class always tries to keep their position by attaining maximum marks in class. The performance enhancement of the best student is formulated using the equation given below as Equation (10),
b) Good student: The student tries to give more effort if finds interest in any of the subject in such a way that the complete performance of student gets enhanced. This type of student is considered as the good student. This type of student selection is a arbitrary procedure as the psychology of students are different. This type of students is expressed using the equation given as Equation (11),
Likewise, the students who strive to give extra efforts than the effort taken by the average student is given as Equation (12),
c) Average student: The attempt taken by the student is based on their interest towards that specific subject. Accordingly, the student will give average effort if they have less interest in any subjects. Depending on the psychology of student, this category of student is randomly selected and their performance is represented as Equation (13),
d) Students try to progress at random: Except the above mentioned three categories of students, some students strive to boost their performance in the exam by their own. Thus, the performance of this sort of student is given as Equation (14),
iv) Evaluating feasibility: The solution with the fitness value is computed for finding the optimal values of the network parameter.
v) Termination: All the above illustrated steps are iterated until best solution is achieved. Table 1 presents the pseudo code of SPBO-based routing approach.
Comparative discussion
The Deep FC-IIWO fuzzy clustering approach is employed for the process of big data clustering in the MapReduce framework. Here, the parameters of deep fuzzy clustering are identified optimally using FC-IIWO algorithm [25]. However, FC-IIWO is devised by the incorporation of IIWO and FC concept. IIWO algorithm is a population-driven evolutionary optimization method inspired by the weed colony behaviours. This algorithm performs the global searches more speedily so that the diversity of the population gets enhanced in an effective way. On the other hand, FC technique is used for resolving the problems based on the integral and the derivative equations. Furthermore, the integration of FC with IIWO attains optimal solution with minimum computational time and improved accuracy as Equation (15),
The implementation results of the developed SPBO-based routing approach for big data clustering in IoT is illustrated in this section. The experimentation of developed SPBO-based routing technique is performed using PYTHON tool Windows 10 OS, 8GB RAM with Intel core-i3 processor. The implementation of the developed SPBO-based routing approach is carried out using Bitcoin Heist Ransomware Address dataset [26] and Iris dataset from UC Irvine Machine Learning Repository. The description of the dataset employed are elucidated below as follows,
Bitcoin heist ransomware address data is taken from UCI machine learning database, which consists of 10 attributes and 2916697 instances. This datasets consists of address features on the heterogenous Bitcoin network inorder to identify ransomware payments. The features of this database are multivariate and time series, whereas the attribute characteristics is real and integer. The dimension of this dataset is 2916697 × 10 that is 10 columns with 2916697 rows. Iris dataset is a small classic and earliest datasets utilized mainly for the purpose of classification methods. It has multivariate characteristics. These datasets are mainly associated with classification purposes. The iris data [27–30] is acquired from the UCI machine learning database, which comprise of 4 attributes and 150 instances. The dimension of the dataset is 150 × 5 that is 5 columns with 150 rows. The attributes contains sepal length, width, petal length and width and class.
The clustering output is shown in Fig. 4) in which, the data points are divided into three groups. In the Fig. 4) the iris dataset is divided into three clusters which is shown in three different colors, blue, orange, and green respectively. The dataset is grouped into three class labels such as Iris-setosa, Iris-versicolor, Iris- virginica.
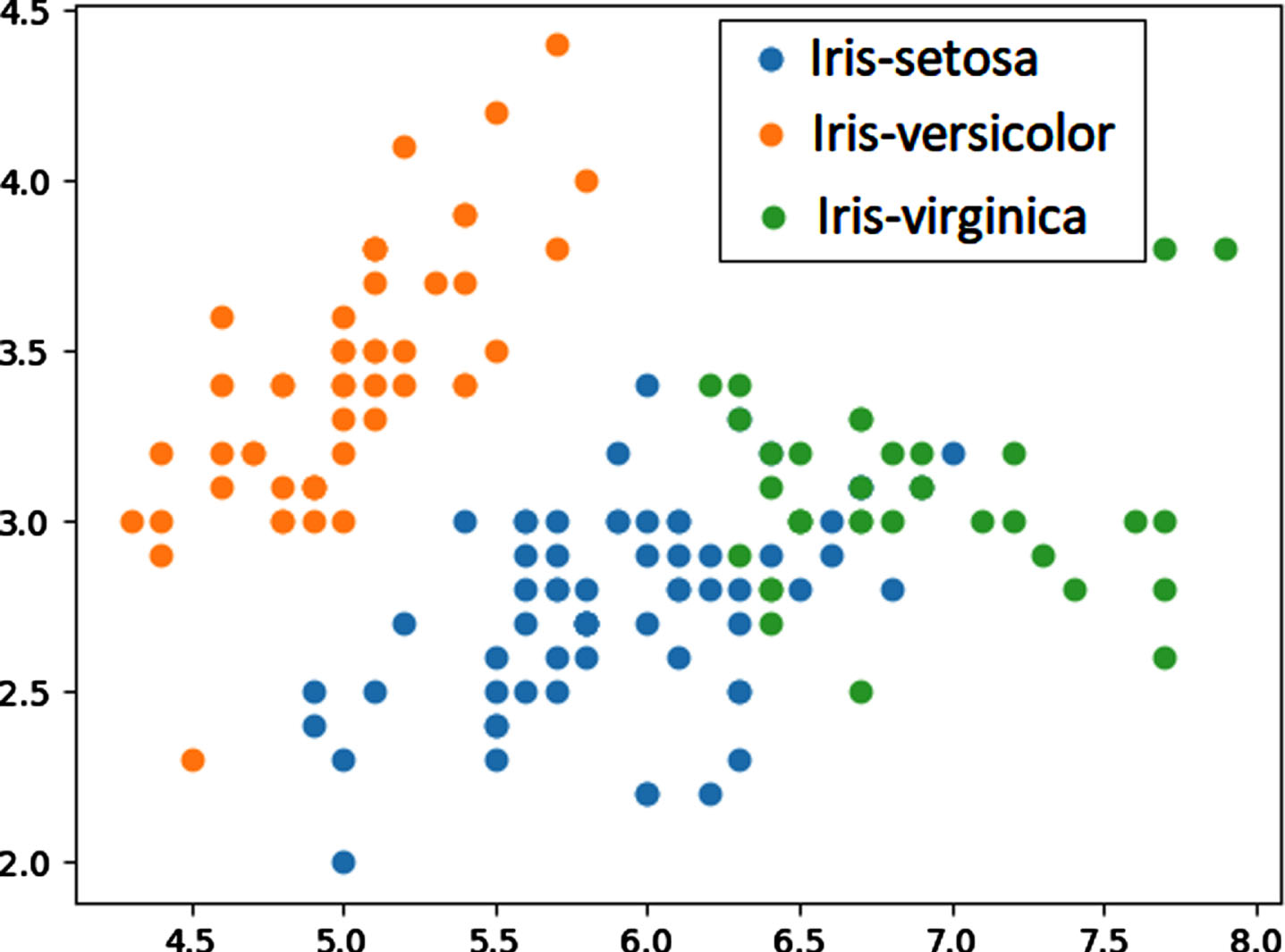
Cluster output.
The performance of developed SPBO-based routing approach is analyzed using evaluation metrics, such as energy, clustering accuracy, jaccard coefficient and rand coefficient.
Energy: It is a measure which defines the energy consumed by the nodes for broadcasting the data packets to destination end.
Clustering accuracy: Accuracy defines the measure of appropriateness of clustering data, which is expressed as Equation (16),
5.3.3 Jaccard similarity: Jaccard coefficient (JC) is used for computing the similarity between two data’s, which is given as Equation (17),
The comparative assessment of the developed SPBO-based routing technique is done by comparing the developed method with different existing techniques, such as PriNergy routing+T2FCS, PriNergyrouting+PCM algorithm, PriNergyrouting+K-means technique, PriNergyrouting+Mapreduce+Clustering, and Deep FC-IIWO fuzzy clustering.
The comparative assessment of the developed SPBO-based routing approach is carried out using dataset-1 and dataset-2 with respect to the metrics, namely energy, clustering accuracy, jaccard coefficient, and rand coefficient.
Figure 5 illustrates the comparative assessment of the developed technique based on dataset-1 with respect to the metrics, such as energy, clustering accuracy, Jaccard coefficient, and rand coefficient. The analysis based on energy is depicted in Fig. 5. By considering the round as 800, the developed SPBO-based routing technique measured an energy value of 0.681J, whereas the energy value measured by the existing techniques, such as PriNergy routing+T2FCS is 0.424 J, PriNergyrouting+PCM is 0.476J, PriNergyrouting+K-means technique is 0.536J, PriNergyrouting+Mapreduce+Clustering is 0.586 J, and Deep FC-IIWO fuzzy clustering is 0.588J.
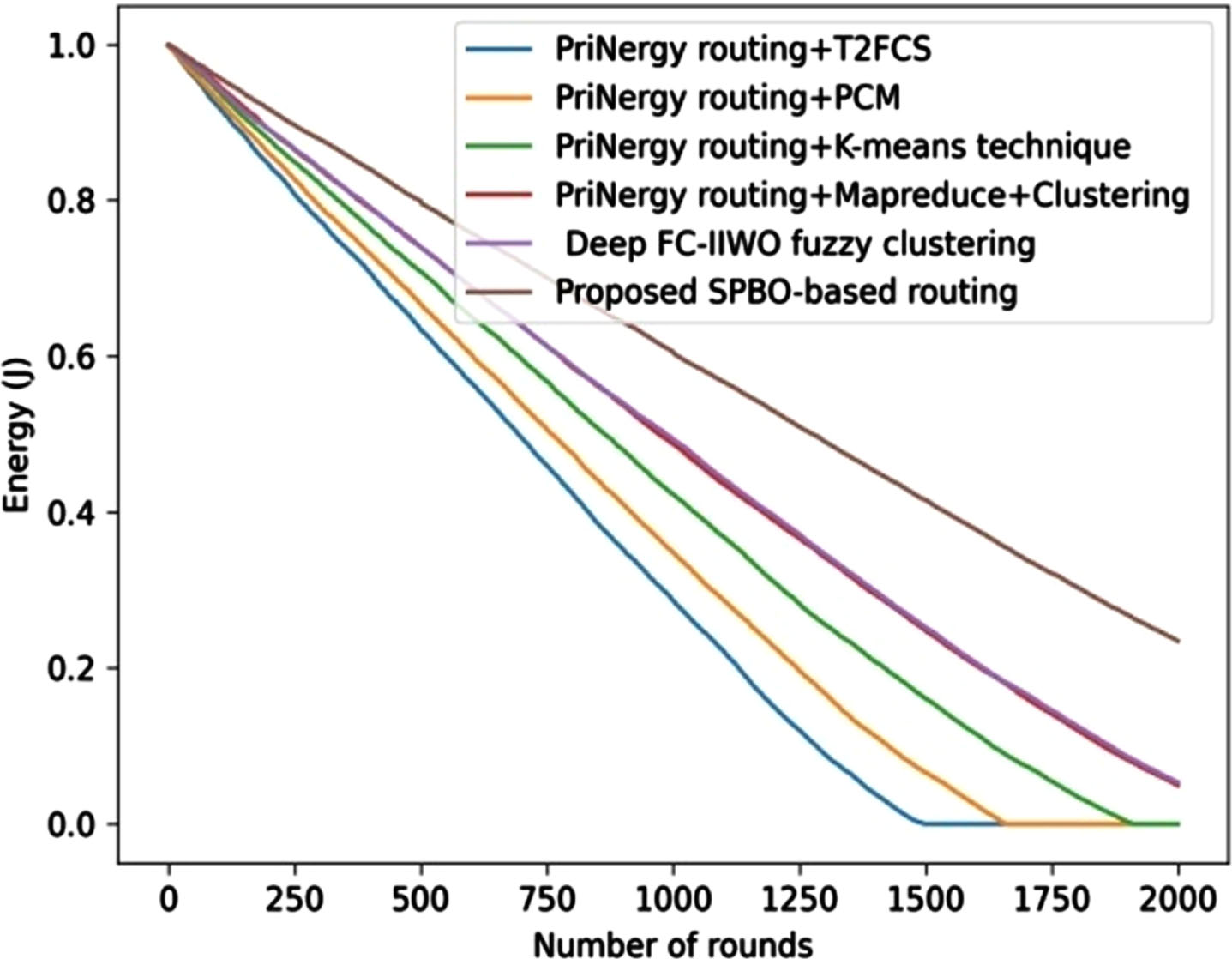
Comparative assessment of proposed SPBO-based routing approach using dataset-1 with respect to energy.
The assessment using clustering accuracy is shown in Fig. 6. The clustering accuracy achieved by techniques, such as PriNergy routing+T2FCS, PriNergyrouting+PCM, PriNergyrouting+K-means technique, PriNergyrouting+Mapreduce+Clustering, Deep FC-IIWO fuzzy clustering, and the proposed SPBO-based routing is 0.695, 0.704, 0.758, 0.775, 0.854, and 0.875 for the round 800.
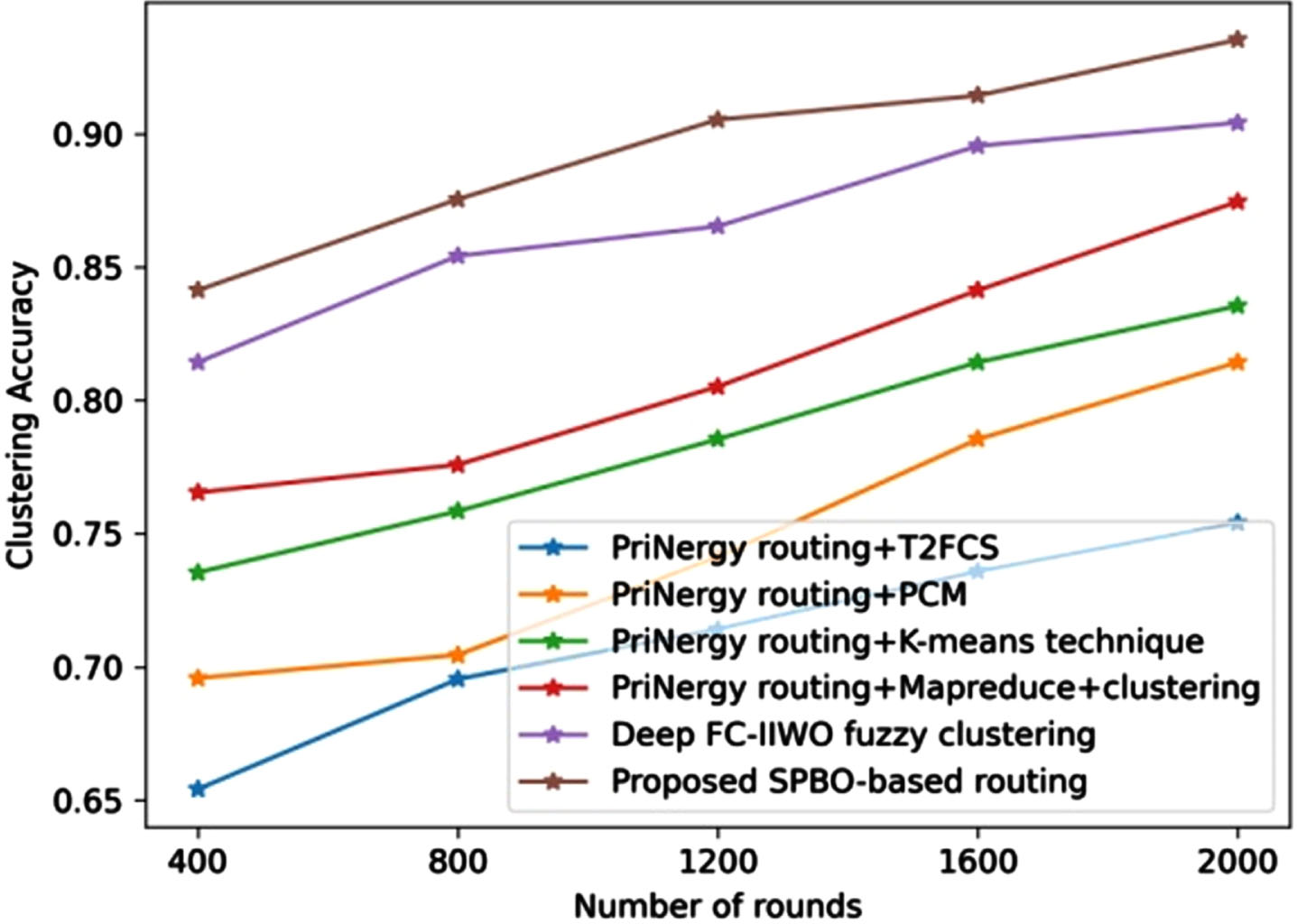
Comparative assessment of proposed SPBO-based routing approach using dataset-1 with respect to clustering accuracy.
The analysis using jaccard coefficient is presented in Fig. 7. The developed SPBO-based routing approach obtained a jaccard coefficient value of 0.895, while the existing techniques, such as PriNergy routing+T2FCS, PriNergyrouting+PCM, PriNergyrouting+K-means technique, PriNergyrouting+Mapreduce+Clustering, and Deep FC-IIWO fuzzy clustering measured a jaccard coefficient value of 0.704, 0.735, 0.774, 0.795, and 0.874 for the round 800.
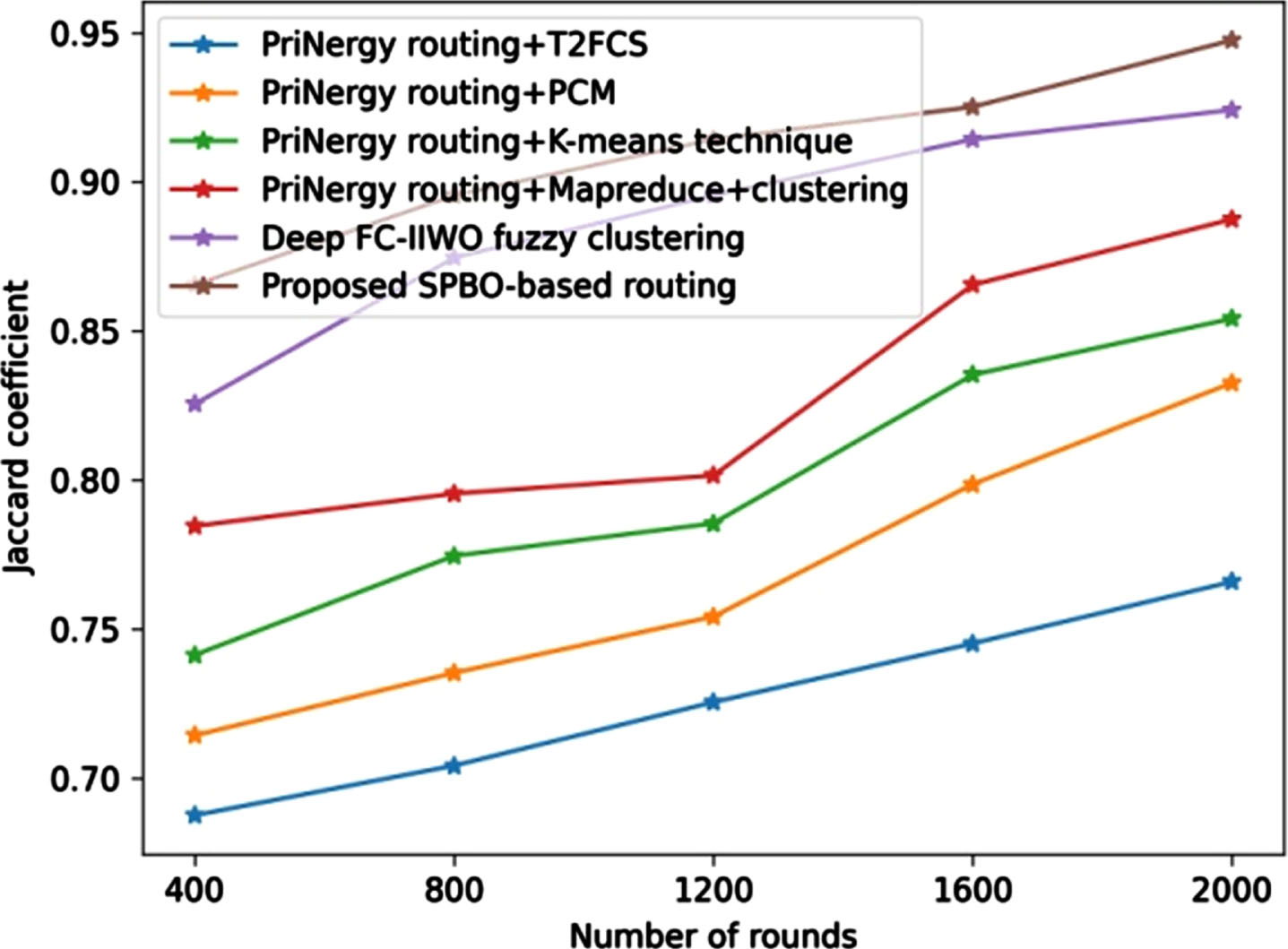
Comparative assessment of proposed SPBO-based routing approach using dataset-1 with respect to jaccard coefficient.
Figure 8 illustrates the analysis using rand coefficient. The value of rand coefficient obtained by the PriNergy routing+T2FCS is 0.705, PriNergyrouting+PCM is 0.736, PriNergyrouting+K-means technique is 0.784, PriNergyrouting+Mapreduce+Clustering is 0.814, Deep FC-IIWO fuzzy clustering is 0.835, and proposed SPBO-based routing is 0.854 for the round 400.
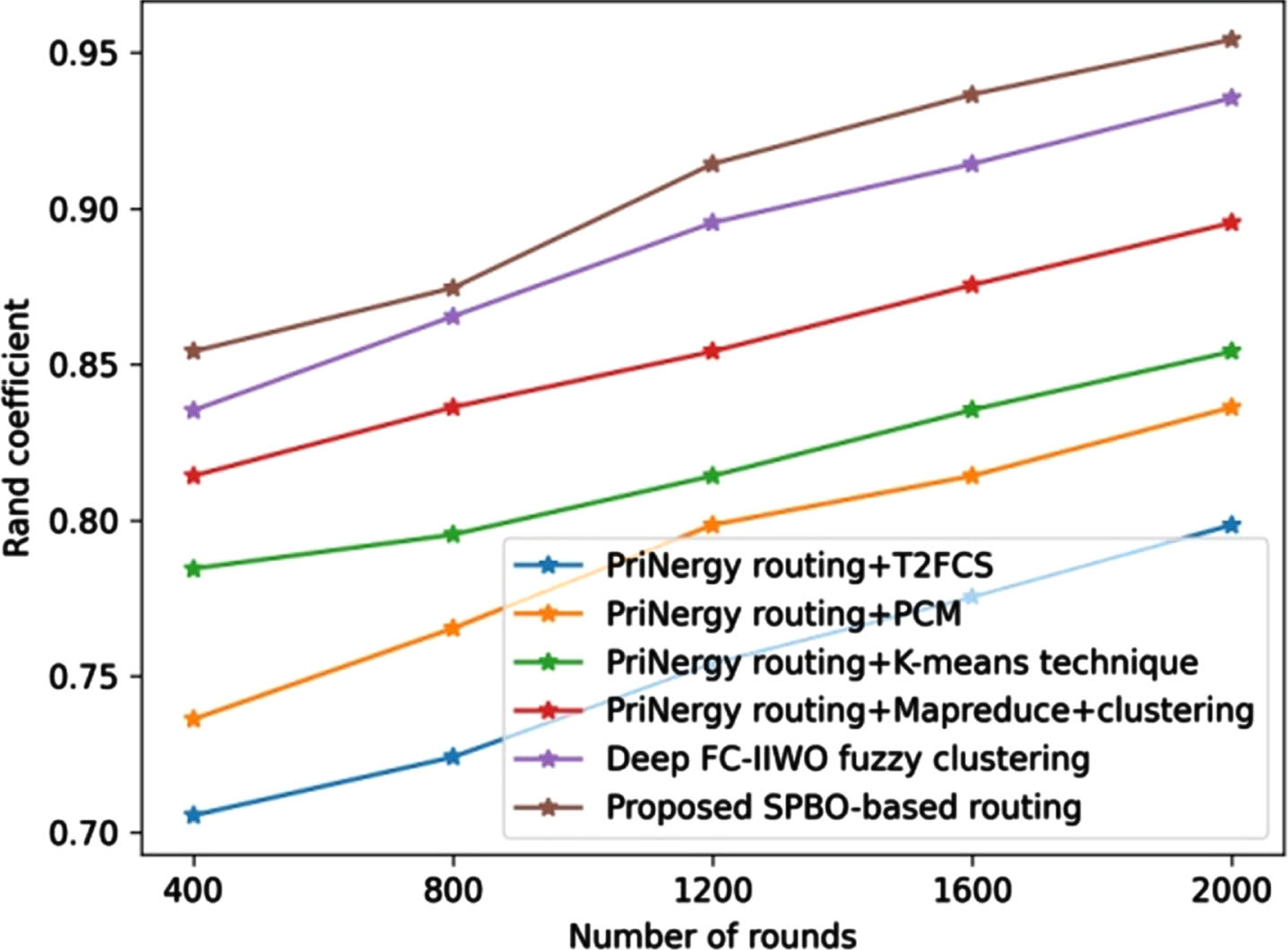
Comparative assessment of proposed SPBO-based routing approach using dataset-1 with respect to rand coefficient.
Figure 9 illustrates the performance evaluation based on time complexity. The developed SPBO-based routing has computational time of 1980 s, while the existing techniques, such as PriNergy routing+T2FCS, PriNergyrouting+PCM, PriNergyrouting+K-means technique, PriNergyrouting+Mapreduce+Clustering, and Deep FC-IIWO fuzzy clustering measured computational time of 2051 s, 2020, 2000 s, 1997 s, and 1990 s for the round 800.
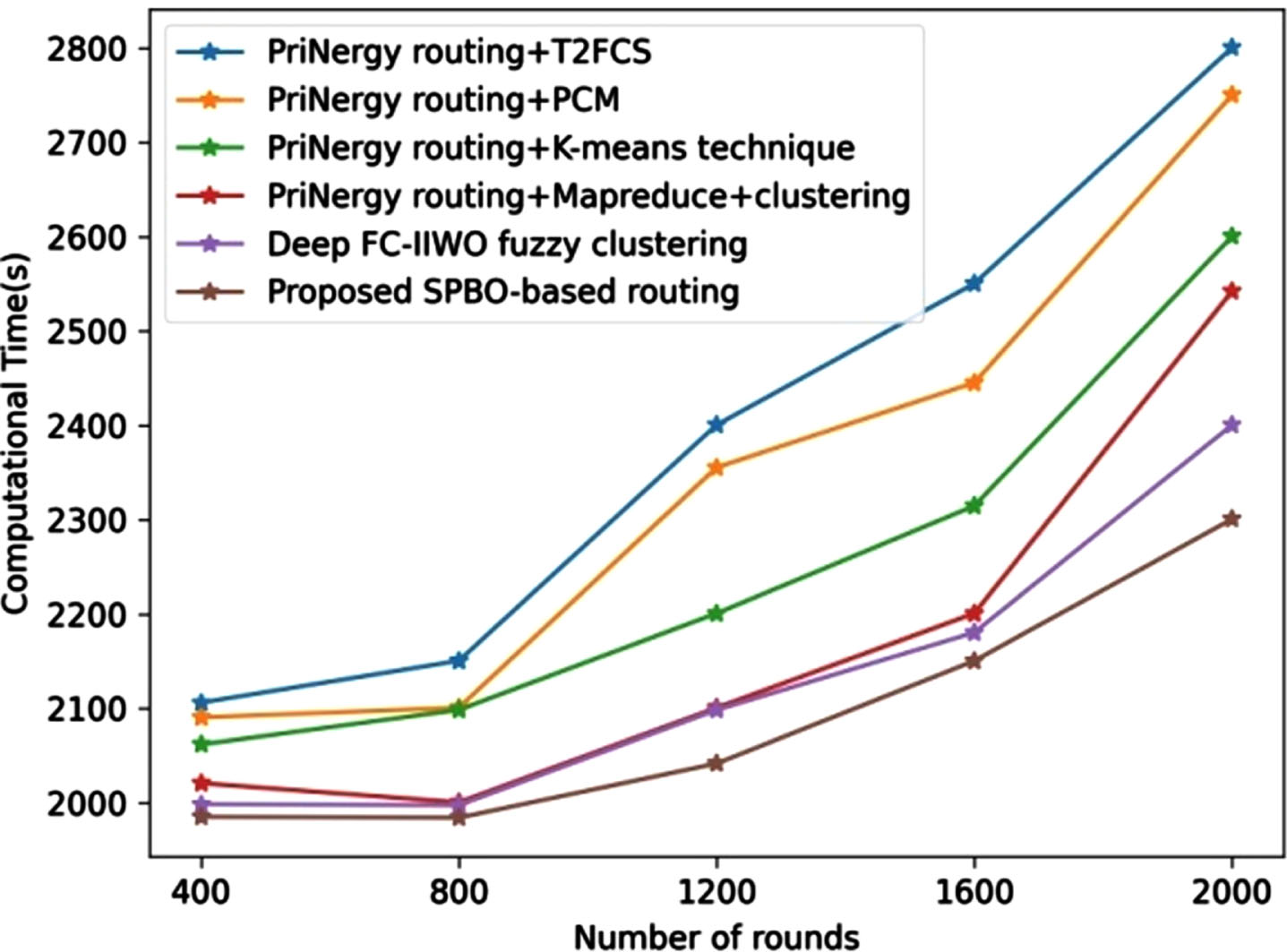
Comparative assessment of proposed SPBO-based routing approach using dataset-1 with respect to computational time.
Figure 10 illustrates the performance evaluation based on space complexity. The developed SPBO-based routing has space complexity of 68KB, while the existing techniques, such as PriNergy routing+T2FCS, PriNergyrouting+PCM, PriNergyrouting+K-means technique, PriNergyrouting+Mapreduce+Clustering, and Deep FC-IIWO fuzzy clustering measured space complexity of 69.8KB, 69.1KB, 69KB, 68.7KB, and 68.3KB for the round 800.

Comparative assessment of proposed SPBO-based routing approach using dataset-1 with respect to space complexity.
The comparative assessment of developed SPBO-based routing technique using dataset-2 with respect to the evaluation metrics. The analysis using energy is presented in Fig. 11. The developed SPBO-based routing approach obtained an energy value of 0.647 J, while the existing techniques, such as PriNergy routing+T2FCS, PriNergyrouting+PCM, PriNergyrouting+K-means technique, PriNergyrouting+Mapreduce+Clustering, and Deep FC-IIWO fuzzy clustering measured energy value of 0.541 J, 0.591 J, 0.602 J, 0.596 J, and 0.639 J for the round 700.
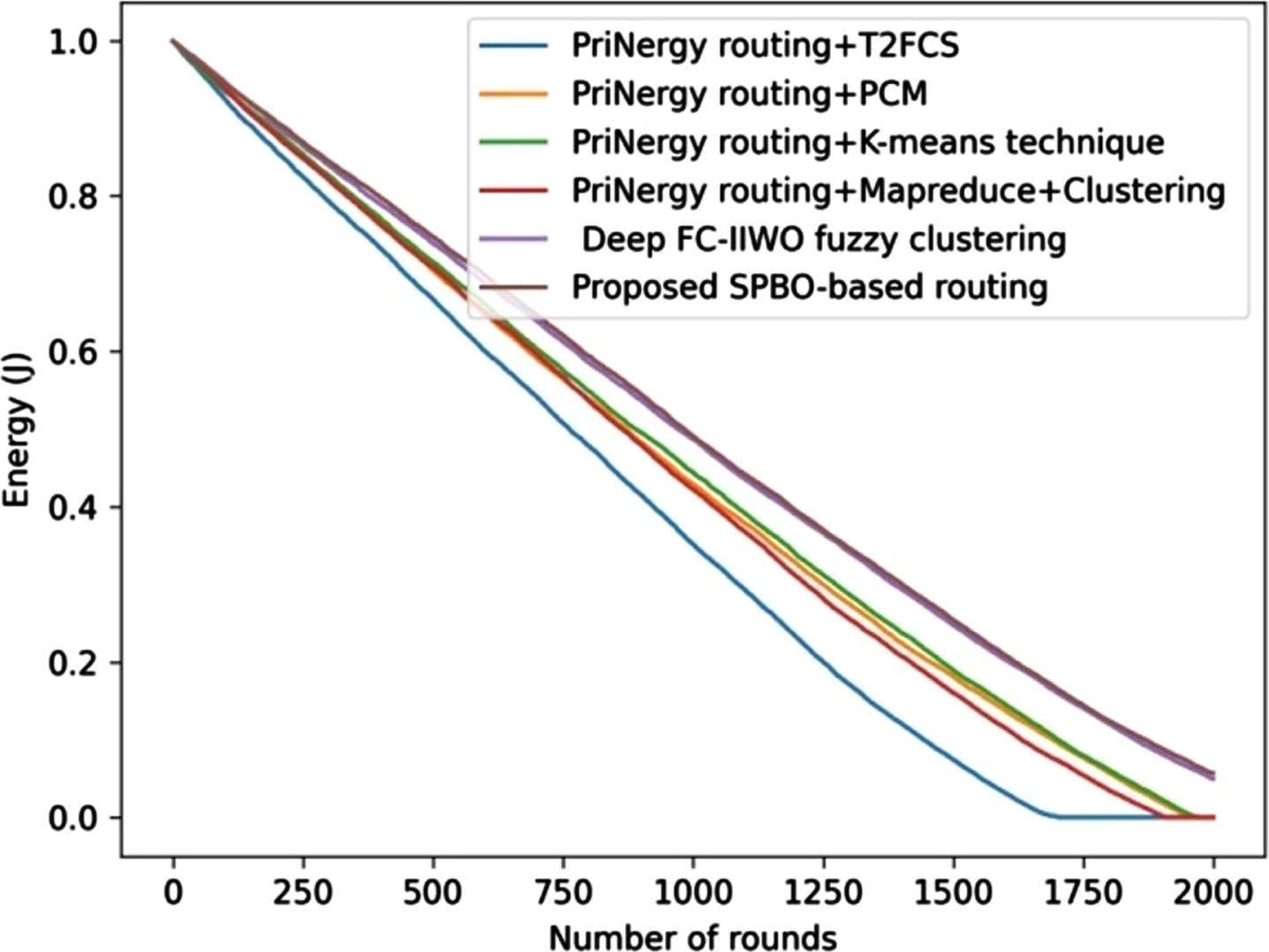
Comparative assessment of proposed SPBO-based routing approach using dataset-2 with respect to energy.
Figure 12 depicts the analysis based on clustering accuracy. By considering the round as 1600, the developed SPBO-based routing technique measured an clustering accuracy of 0.854, whereas the clustering accuracy measured by the existing techniques, such as PriNergy routing+T2FCS is 0.704, PriNergyrouting+PCM is 0.736, PriNergyrouting+K-means technique is 0.754, PriNergyrouting+Mapreduce+clustering is 0.798, and Deep FC-IIWO fuzzy clustering is 0.825. Figure 13 illustrates the analysis using jaccard coefficient. The value of jaccard coefficient obtained by the PriNergy routing+T2FCS is 0.725, PriNergyrouting+PCM is 0.754, PriNergyrouting+K-means technique is 0.784, PriNergyrouting+Mapreduce+Clustering is 0.804, Deep FC-IIWO fuzzy clustering is 0.836, and proposed SPBO-based routing is 0.854 for the round 800.
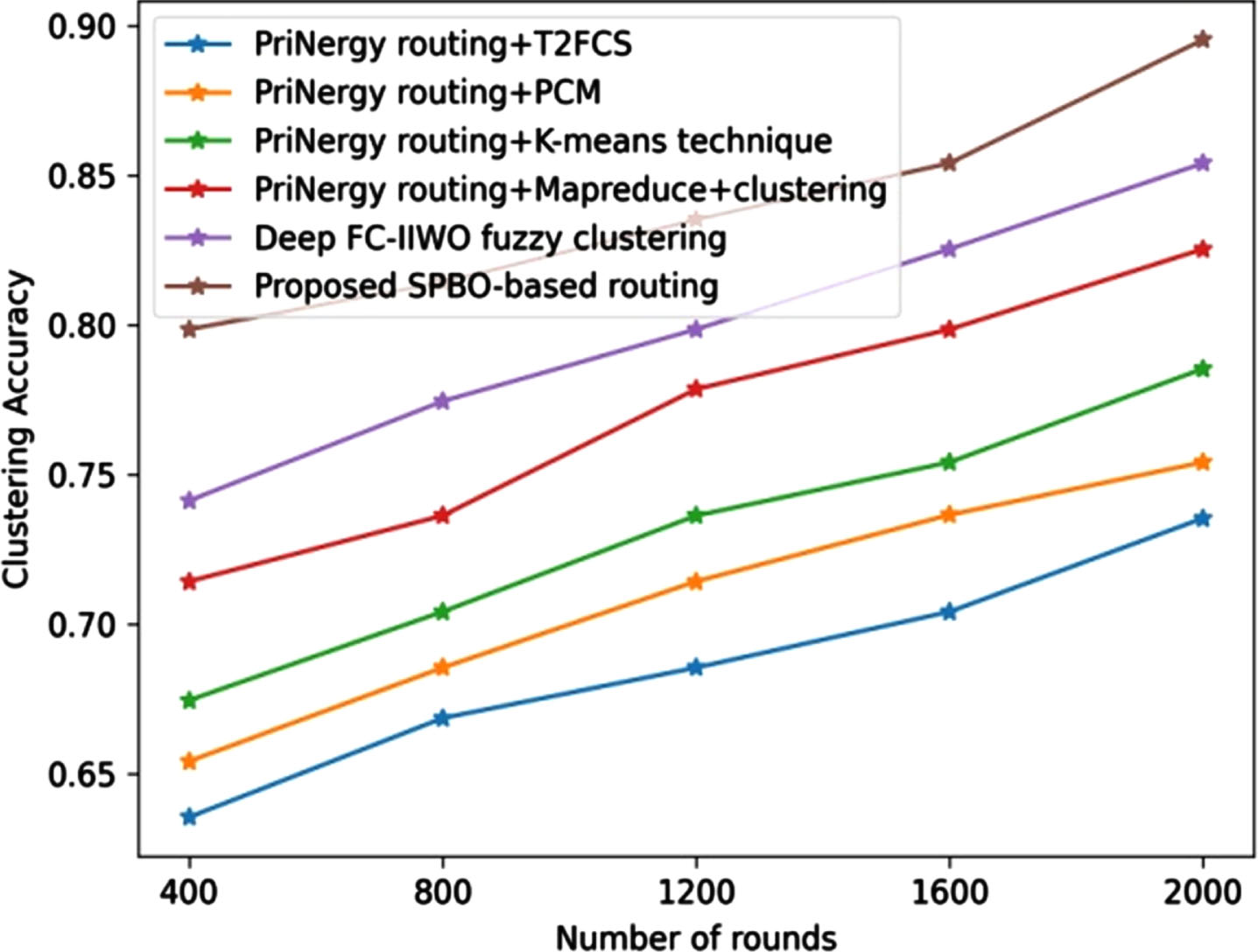
Comparative assessment of proposed SPBO-based routing approach using dataset-2 with respect to clustering accuracy.
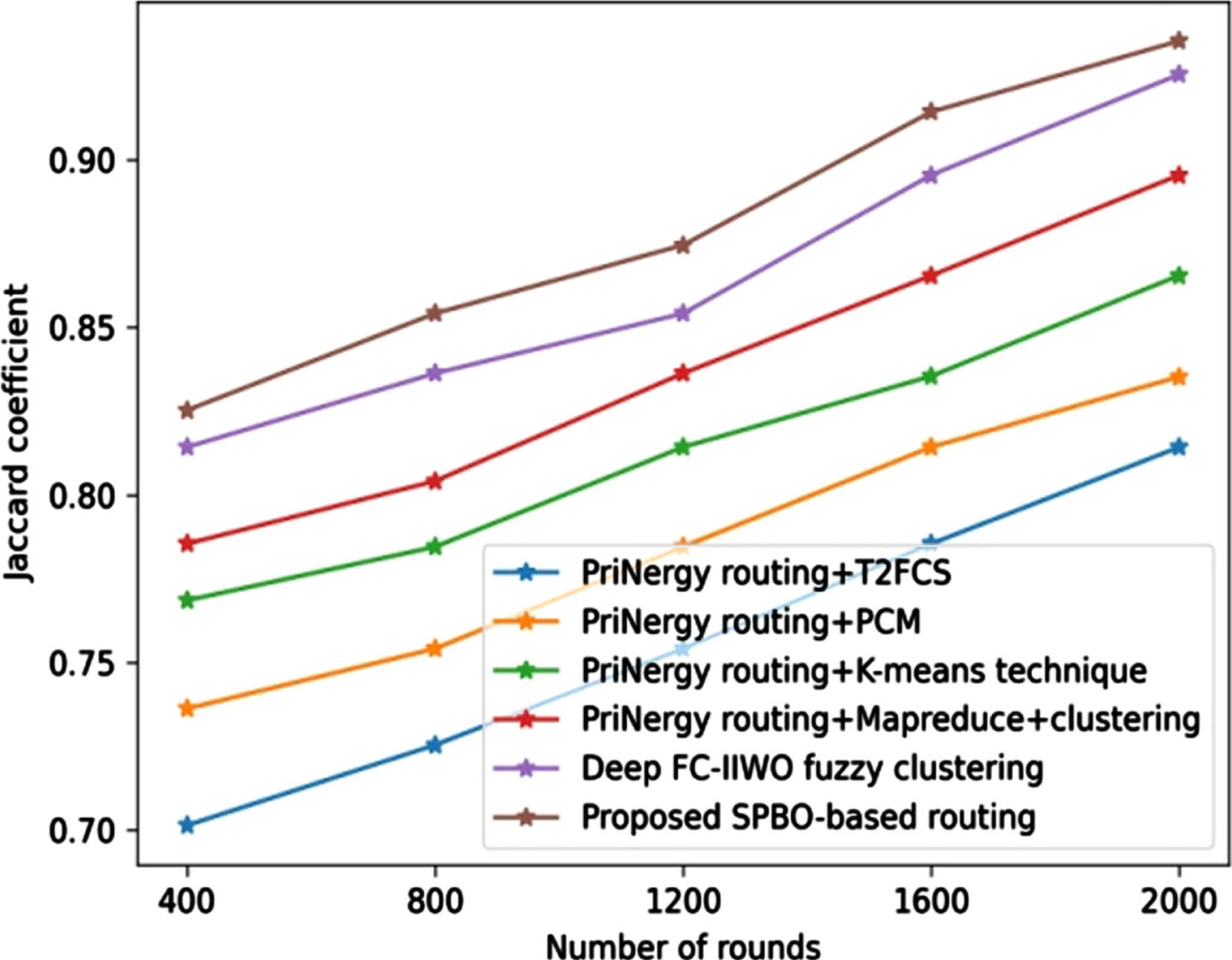
Comparative assessment of proposed SPBO-based routing approach using dataset-2 with respect to jaccard coefficient.
The assessment using rand coefficient is shown in Fig. 14. For the round 800, the value of coefficient achieved by techniques, such as PriNergy routing+T2FCS, PriNergyrouting+PCM, PriNergyrouting+K-means technique, PriNergyrouting+Mapreduce+Clustering, Deep FC-IIWO fuzzy clustering, and the proposed SPBO-based routing is 0.741, 0.765, 0.785, 0.814, 0.838, and 0865. Figure 15 illustrates the performance evaluation based on time complexity. The developed SPBO-based routing has computational time of 1984 s, while the existing techniques, such as PriNergy routing+T2FCS, PriNergyrouting+PCM, PriNergyrouting+K-means technique, PriNergyrouting+Mapreduce+Clustering, and Deep FC-IIWO fuzzy clustering measured computational time of 2150 s, 2100, 2098 s, 2000 s, and 1997 s for the round 800.
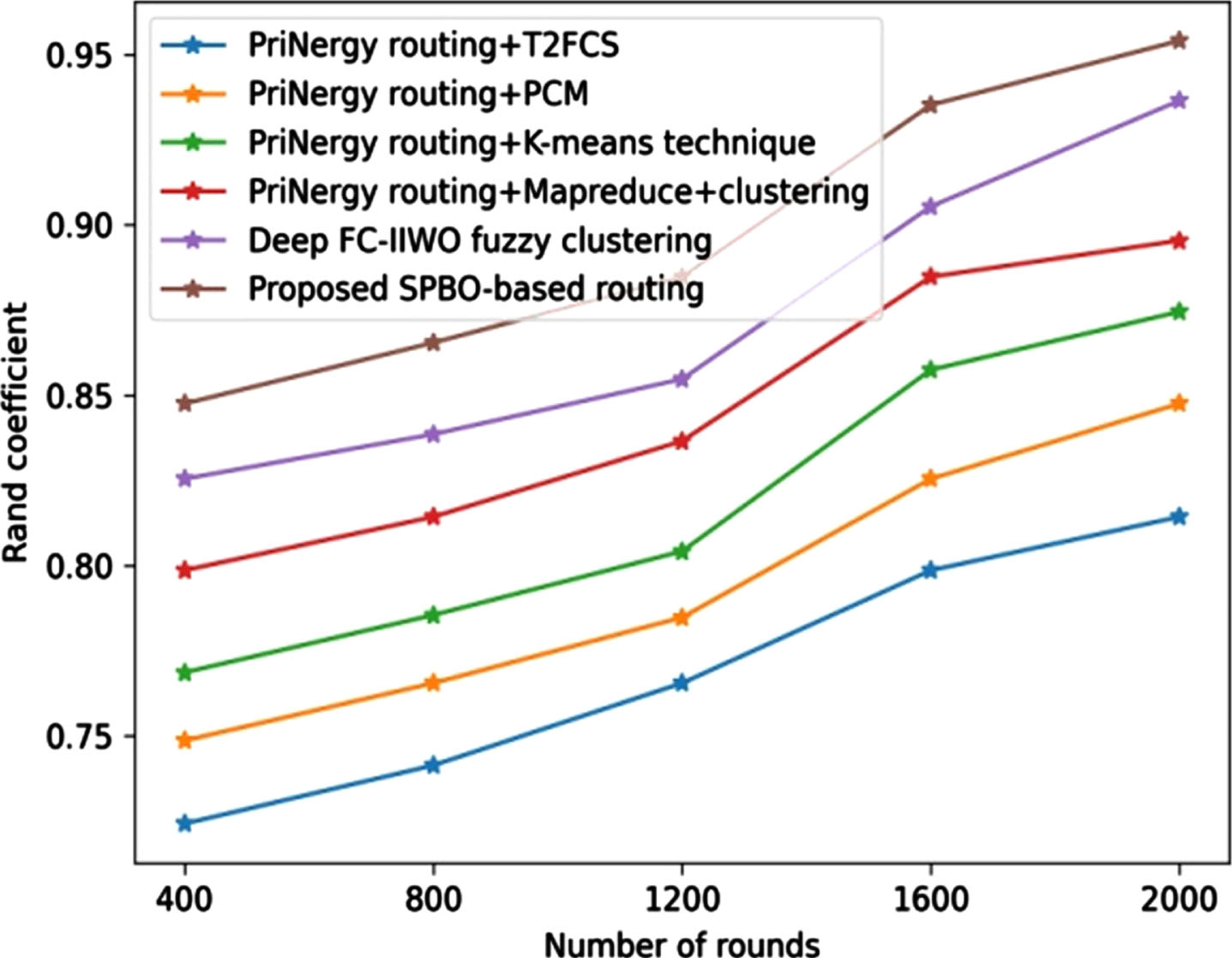
Comparative assessment of proposed SPBO-based routing approach using dataset-2 with respect to rand coefficient.

Comparative assessment of proposed SPBO-based routing approach using dataset-2 with respect to computational time.
Figure 16 illustrates the performance evaluation based on space complexity. The developed SPBO-based routing has space complexity of 69.1KB, while the existing techniques, such as PriNergy routing+T2FCS, PriNergyrouting+PCM, PriNergyrouting+K-means technique, PriNergyrouting+Mapreduce+Clustering, and Deep FC-IIWO fuzzy clustering measured space complexity of 71.6KB, 71.4KB, 71.1KB, 69.8KB, and 69.5KB for the round 800.

Comparative assessment of proposed SPBO-based routing approach using dataset-2 with respect to space complexity.
Table 1 illustrates the comparative discussion of developed SPBO-based routing approach in comparison with the existing techniques using dataset-1 and dataset-2 for the round 2000. The developed SPBO-based routing measured a clustering accuracy of 0.935, while the clustering accuracy measured by the existing techniques. The developed SPBO-based routing technique measured a jaccard coefficient of 0.947, whereas the jaccard coefficient measured by the existing techniques. The value of rand coefficient measured by the PriNergy routing+T2FCS is 0.798, PriNergyrouting+PCM is 0.836, PriNergyrouting+K-means technique is 0.854, PriNergyrouting+Mapreduce+clustering is 0.895, Deep FC-IIWO fuzzy clustering is 0.935, and the proposed SPBO-based routing technique is 0.954.
The developed SPBO-based routing technique measured a computational time of 2100.6 s, whereas the time taken by the existing techniques. The developed SPBO-based routing technique evaluated storage complexity of 72KB, whereas the time taken by the existing techniques. It is evidently stated that the proposed method attained a maximum energy of 0.605 J, maximum clustering accuracy of 0.935, maximum jaccard coefficient of 0.947, maximum rand coefficient of 0.954, reduced computational time to 2100.6 s and space complexity is reduced to 72KB.
Conclusion
Efficient big data clustering is a requirement for immense data processing in this digitalized connected world. Conventional clustering algorithms are incapable of handling extremely large amounts of unstructured big data. Thus, to achieve robustness and efficiency in clustering big data, this research work presents an effective SPBO-based routing approach. The proposed routing method allows IoT node simulation to perform data clustering. The IoT nodes gather the sensed information and broadcast it to the BS by the process of routing, which is carried out using the optimization algorithm named SPBO. The input data is partitioned more effectively and then presented to the MapReduce framework. Here, the significant features are selected in the mapper phase using Minkowski distance, whereas the clustering process is done using Deep FC-IIWO fuzzy clustering. However, the proposed technique attained superior performance on the basis of energy, clustering accuracy, jaccard coefficient, rand coefficient, computational time and space complexity of 0.605 J, 0.935, 0.947, 0.954, 2100.6 s and 72KB respectively. The approach is found to be proficient and reliable in performing the tasks based on clustering. The future work would be focused on devising more novel deep learning classifiers for enhancing the effectiveness of the big data clustering process.