
Abstract
With the prevailing development of the internet and sensors, various streaming raw data are generated continually. However, traditional clustering algorithms are unfavorable for discovering the underlying patterns of incremental data in time; clustering accuracy cannot be assured if fixed parameters clustering algorithms are used to handle incremental data. In this paper, an Incremental-Density-Micro-Clustering (IDMC) framework is proposed to address this concern. To reduce the succeeding clustering computation, we design the Dynamic-microlocal-clustering method to merge samples from streaming data into dynamic microlocal clusters. Beyond that, the Density-center-based neighborhood search method is proposed for periodically merging microlocal clusters to global clusters automatically; at the same time, these global clusters are updated by the Dynamic-cluster-increasing method with data streaming in each period. In this way, IDMC processes sensor data with less computational time and memory, improves the clustering performance, and simplifies the parameter choosing in conventional and stream data clustering. Finally, experiments are conducted to validate the proposed clustering framework on UCI datasets and streaming data generated by IoT sensors. As a result, this work advances the state-of-the-art of incremental clustering algorithms in the field of sensors’ streaming data analysis.
Introduction
With the rapid development of sensors and network technology, mega data have been collected from social network platforms, intelligent manufacturing, autopilot systems, and e-commercial websites. However, having only large data is not enough, and how to use this crude data effectively is the key to data mining. Therefore, more attention should be given to discovering the valuable information hidden in the data, such as rules, insights, and patterns. Moreover, these pristine data have no labels, which falls under the category of unsupervised learning. Clustering is an effective unsupervised machine-learning algorithm for data mining [1]. It judges the similarity of data according to their predefined attributes and gathers similar samples in the same category. No prior knowledge is required in this process, where only the similarity among the data serves as criteria for clustering. In addition, clustering is a multivariate statistical analysis method [2, 3]. It can show the global distribution of datasets and figure out the relationship among the attributes of data [4].
Information spreading rapidly in the network has become a new form of data flow [5, 6], and this continuous flow of data is on the web all the time. For most enterprises and units, it is impossible to intercept all the network data and save it in the storage medium for unified analysis. On the one hand, hardware resource requirements are very high. On the other hand, network data have a certain timeliness, so the results and knowledge obtained after.
Storing and analyzing the data may be outdated. Discovering the underlying patterns of incremental data in time is an urgent problem to be solved. However, in the face of streaming data, the traditional global clustering algorithm is no longer applicable. An efficient data stream clustering algorithm is needed to analyze the data and feedback on the analysis results in real time [7]. In addition, clustering accuracy cannot be assured if fixed parameter clustering algorithms are used to handle these incremental data [8]. Therefore, clustering methods with fewer or more convenient tuning parameters become more necessary.
Based on this situation, researchers are keen on improving clustering algorithms to cope with the dynamic data environment [9]. For example, the incremental K-means algorithm [10, 11], the incremental clustering algorithm based on Mahalanobis distance [12], and other algorithms have been successively proposed. Guha et al. proposed the stream algorithm [13] to process evolutionary data streams. According to the principle of divide-and-conquer, it uses an iterative process to achieve k-means clustering of data streams in a limited space. Aggarwal et al. proposed a data stream clustering framework Clu-stream [13, 14] based on summarizing the essential defects of the above methods, whose core idea is to divide the clustering process into online and offline stages. Since their core algorithms are still based on K-means, they can only find spherical clusters, and their shortcomings will be exposed when facing nonspherical clusters.
To deal with nonlinear data, especially the arbitrary shape of clusters, a Den-stream clustering algorithm based on density was proposed by Cao et al. [16]. To address this issue, Zhao et al. focused on incremental clustering by extending the clustering by fast search and find of density peaks (DPC) method [17] to incrementally handle large-scale dynamic data [18]. An enhanced version of the incremental Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm was introduced by Bakr et al. [22] for incremental building and updating arbitrary-shaped clusters in large datasets. Bao et al. proposed a boundary-profile-based incremental clustering method to find arbitrarily shaped clusters with dynamically growing datasets [24]. These pure density-based methods have difficulty dealing with inhomogeneous density data, and the adjustment process of multiple parameters is coupled.
In addition, the D-Stream algorithm based on the data flow grid model was proposed by Chen et al. [19]. Chen et al. presented a new type of incremental clustering algorithm [20], which is based on swarm intelligence theory. Suárez et al. introduced a new algorithm for incremental overlapped clustering [21] called Incremental Clustering by Strength Decision. Yu et al. introduced a new incremental soft clustering approach based on three-way decision theory to combat data changes [22]. Nentwig et al. presented new scalable approaches for incremental entity clustering that support the continuous addition of link data [23]. These methods provide a good direction for incremental clustering, but the clustering effect is uneven, and the operation process is complex, which limits their application and promotion.
However, in addition to the computational efficiency that needs to be improved, these algorithms with fixed parameters are unfavorable for discovering patterns from incremental data. To overcome this problem, we propose a two-stage incremental clustering framework Incremental-Density-Micro-Clustering (IDMC), as shown in Fig. 1, which investigates automatic incremental clustering on streaming data from sensors.
Illustration of our present framework. Dynamic microlocal clustering is the preceding (first) stage of IDMC. With streaming data flowing in, it generates microlocal clusters in real time. Density-center-based neighborhood search and Dynamic-cluster-increasing make up the subsequent (second) stage of IDMC, which integrates all microlocal clusters into final clusters in their ways. In contrast to the other IDMC processes, which run continuously, the density-center-based neighborhood search process runs only after the Dynamic-cluster-increasing given each trigger signal.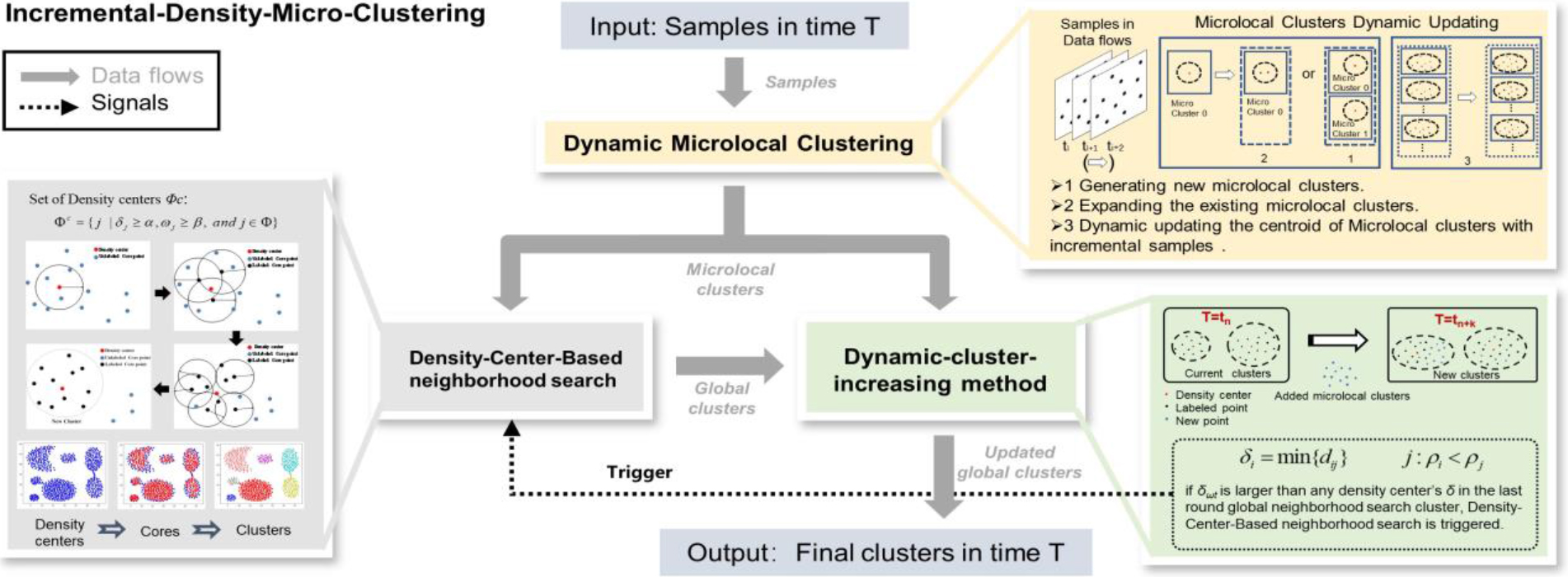
In the first stage, we give a novel definition of density to measure the consistency of each microlocal cluster, and the parameters are adjusted autonomously according to current samples in the streaming dataset. For the incremental clustering setting, we present a dynamic microlocal cluster method in which the centroid is upgraded by the incoming points. Beyond that, an additional parameter is used to enhance the weights and joining degree of the dynamic microlocal cluster. In this way, massive data can be transformed into finite microlocal clusters according to the demands at this step, which can effectively lower the workload in the next stage. At the same time, the new dynamic class cluster data are more accurate than the previous data.
In the second stage, Density-center-based neighborhood searching and Dynamic-cluster-increasing alternate with the incoming microlocal clusters to integrate the final clusters automatically. Density-center based neighborhood searching works as follows. After the density centers of microlocal clusters are selected by their “Megalopolis distance” and density, neighborhood search starts from the highest density one, and all points in its neighbors are classified into the same cluster. This cluster is enlarged by including the neighborhood of merged points until no new neighbor is found. In dynamic clusters increasing, to be specific, the coming microlocal clusters are used for generating new clusters, merging, or dividing existing clusters. After a preset condition is triggered, all microlocal clusters execute another global clustering. These methods make the tuning procedure more convenient and robust, with fewer parameters. Extensive experimental results on eight public datasets and streaming sensor datasets demonstrate the superiority of our framework.
The main contributions of this work are summarized as follows:
As the first step of IDMC, this paper presents a novel Dynamic-microlocal-clustering method in which microlocal clusters are described by dynamic centroids in the data stream, which can effectively lower the workload in the next stage. The Density-center-based neighborhood search method is utilized as the second stage of IDMC to integrate microlocal clusters to obtain the final clusters automatically. Furthermore, the tuning procedure becomes more convenient and robust with fewer parameters. We present a Dynamic-cluster-increasing approach that saves time and resources by reclustering fresh samples from the data flow alongside the original data and improving the efficiency of updating real-time global clusters.
The rest of this paper is organized as follows. The preliminary knowledge is introduced in Section 2. We provide the main principles and steps of the IDMC in Section 3. To investigate the performance of the proposed clustering framework, experiments on both UCI real datasets and IoT sensors’ streaming data are presented in Section 4. Finally, conclusions and future studies are discussed in Section 5.
In this section, we introduce some basic principles of related work, including one-pass clustering and DBSCAN clustering. All definitions are based on dataset
One-pass clustering
For one-pass clustering, the dataset must be scanned once to accomplish the clustering [24]. It performs well in identifying data with hyper-spherical distributions but poorly in identifying data with convex distributions. Furthermore, it can demonstrate its characteristics of high efficiency and simplicity in large-scale data, secondary clustering, or combination with other algorithms.
The framework is divided into two stages: micro-clustering and ultimate clustering [25]. It constructs an initial local cluster, that is, a micro-cluster reflecting the raw data summary after processing, during the micro-clustering stage. The ultimate clustering is made up of a sequence of interconnected micro-clusters throughout the clustering process.
Micro-clustering is the process of assigning a data point to a micro-cluster. Finding the local cluster all at once creates a micro-cluster with a specific form as the local cluster’s smallest unit. The data points are then assigned successively to micro-clusters to build local clusters.
Concepts of density clustering
DBSCAN, as a classic density clustering algorithm, gives some essential concepts, especially the definition of density. In it, outlier detection, backbone identification, and density definition depend on the notion of Eps (the cutoff distance) and
Neighborhood: If point
Density Connected: Two points
Core point:
Border point: Given two points
Noise point: If point
Method
Dynamic microlocal cluster
Given a sequential dataset
Microlocal cluster
Let
As the distances between the incoming point and all microlocal clusters are computed for each data point during the microlocal clusters assignment, we can use this information to find adjacent microlocal clusters for final clustering without recomputing the distance between the microlocal clusters. Using the notion of joined microlocal clusters as defined below, the computed distances can continuously track adjacent microlocal clusters.
For the incremental clustering setting, we present a dynamic microlocal cluster. The centroid
The centroid
In this way, the late points adding to microlocal clusters can contribute more significantly to their centroids.
In order to lay a foundation for final clustering in the following part, we propose a microlocal cluster density calculation. The basic equation is a typical Gaussian kernel and an exponential fading function Date point
Here we give a novel definition of density to measure the consistency of each microlocal cluster, all the parameters are adjusted autonomously according to current microlocal cluster in streaming dataset [29].
Remark1:
The details of the dynamic microlocal clustering process are shown in Algorithm 3.1.3. First, data points arrive one by one, and the first point
1em [h] Dynamic microlocal clusteringInputInput InitializationInitialization OutputOutput
Density center selection
In this part, we use a novel method based on density center for executing the clustering process In our work, referred to as “Megalopolis distance”
Let us use the megalopolis in Fig. 2 as an analogy to explain the distance
Urban distribution in some megalopolises of China and America.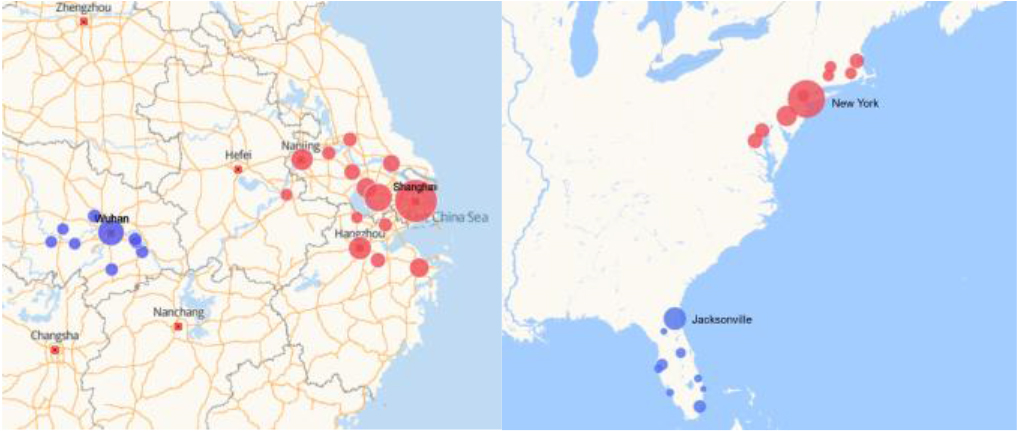
In order to become the central metropolis of a megalopolis, the city must be large enough and far enough away from other larger cities. Shanghai and New York are the central cities of their megalopolis, and there are also many big cities around them, such as Hangzhou and Philadelphia. Because they are adjacent to larger cities, Hangzhou and Philadelphia cannot become the central cities of the megalopolis. However, cities like Wuhan and Jacksonville, comparable in size but far removed from Shanghai and New York, have built megalopoleis around themselves. Therefore, the distance from other larger cities becomes the key to becoming a metropolis. For samples in clustering, megalopolis distance
Where
Outlier detection is used on the “Megalopolis distance” of all microlocal clusters. The outlier points can be regarded as preliminary density centers, as shown in Fig. 6c the red points. When we execute the process of neighborhood searching, the appropriate steps will only run with core points, and the core points refer to centroids whose weight are greater than a certain threshold, i.e.,
Identifying density centers is one of the most significant procedures in the neighborhood search of microlocal clusters. If they were not well selected, the final clustering accuracy would be reduced, even leading to a clustering failure. Here, we select the microlocal clusters with large
In DPC, cluster centers determine the number of clusters strictly [30]. Hence choosing the parameters of a decision graph is essential. Furthermore, it is extremely difficult to identify cluster centers without previous knowledge of the number of clusters. Because there is no discernible distinction between cluster centers and other nodes on the decision graph, cluster centers should be chosen manually by an expert. These difficulties described above, however, do not bother our algorithm. Furthermore, density centers have the following characteristics:
Density-center-based neighborhood searchInputInput InitializationInitialization OutputOutput
Density centers contain cluster centers. The number of density centers is not less than the number of clusters. A density center may be located in the neighborhood of other density centers.
The selection of alpha and beta in Fig. 3 further demonstrates the Density-center-based neighborhood search algorithm’s robustness. It is worth mentioning that the performance of our model is quite stable when alpha and beta is less than 3.5 and 1.5. In practice, selecting parameters should be guided by the simple principle,i.e., produce as many density centers by keeping alpha and beta values as low as possible. In this case, the clustering accuracies reach a plateau, and the resulting time expenditure is negligible, as shown in Fig. 3(a)–(b). In this way, all these parameter combinations are appropriate.
The effect of parameters 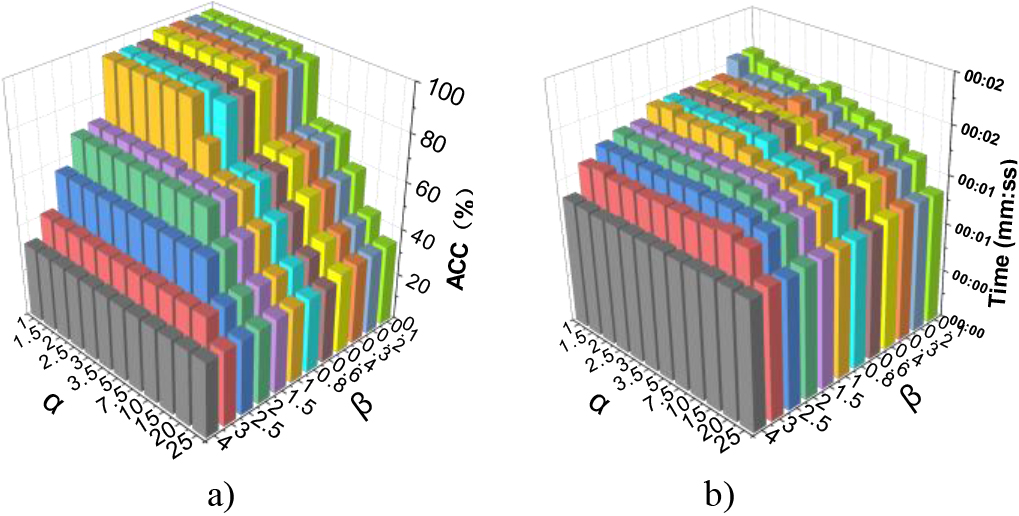
Processes of neighborhood searching: Starting from the point with the highest density, all the points in the neighborhood are divided into the same cluster. Expand the cluster by merging the neighborhoods of the previously merged points until no new neighbor is found. At this point, we have our first cluster.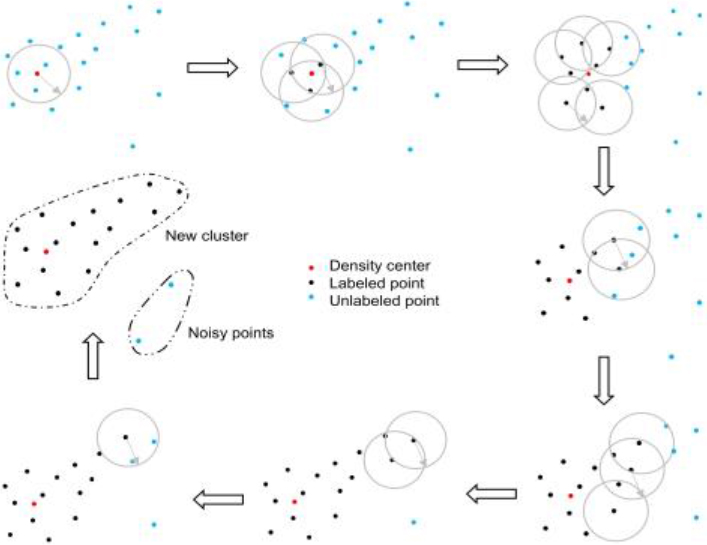
Coalescing by neighborhood search is another crucial step in a clustering process, as shown in Fig. 4. First, the selected density centers are arranged by density. Second, neighborhood search starts from the highest density point, and all points in its neighbors are classified into the same cluster. Third, this cluster is enlarged by including the neighborhood of merged points until no new neighbor is found. Thus, we got the first cluster. In the next round, the following density center will be selected to coalesce the unmerged rest points for seeking another cluster until all density centers are classified. If a point is not merged into any clusters, we regard it as a noise point.
There is a particular situation: a density center
Finally, the rest points in
Density-center-based neighborhood search in IDMC shows strong robustness in choosing density centers. In Fig. 5, we use three different schemes (a)-(c) to select density centers. For each operation, such as the scheme of selecting 16 density centers in (a). Ordinary microlocal clusters are dark blue dots and the density centers selected preliminary are shown as red ones in the first graph, wathet dots in the second graph are noisy points, and the clustering result will be shown in the third graph. We can see that the three schemes obtained the same clustering result. Thus, the Density-center-based neighborhood search method has excellent flexibility in selecting density centers. To ensure the accuracy of clustering, it is appropriate to select relatively more density centers at the expense of slightly increased time to execute this approach.
Three different schemes of density center selection.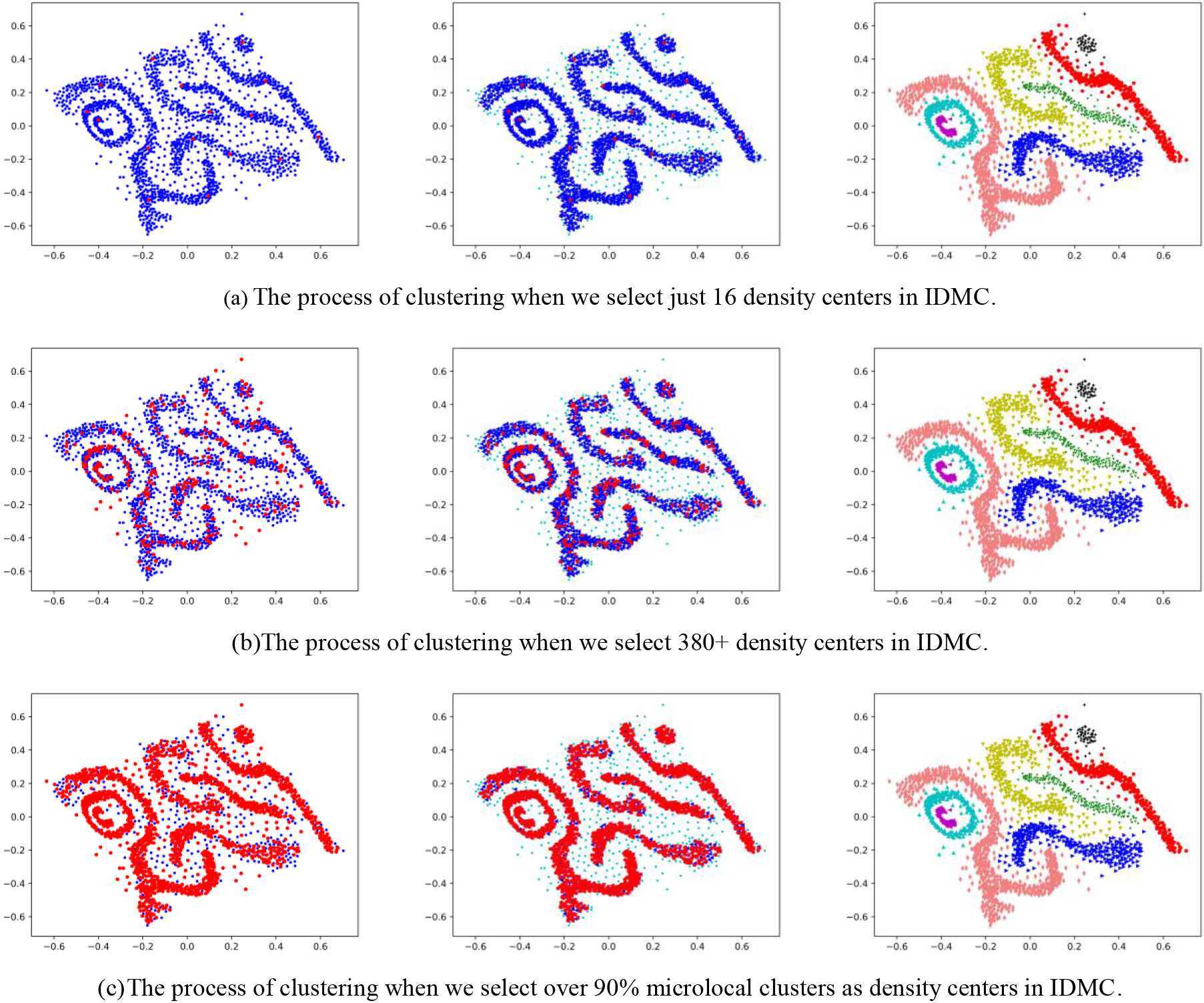
In this part, each microlocal cluster is coming into global clusters continuously according to their timestamp. To update real-time global clusters and improve our method’s efficiency, we propose a “quantity breeds quality” way to execute the dynamic clusters increase. Specifically, the coming microlocal clusters are usually merged into existing clusters or considered noisy points. After a preset condition is triggered, all microlocal clusters execute Algorithm 2.
At the same time, an exponential fading function
When a new point does not update a microlocal cluster, its weight will gradually decrease. If the weight of any microlocal cluster is less than a preset threshold, it is removed from the microlocal cluster space
[h] Dynamic clusters increasingInputInput InitializationInitialization OutputOutput
IDMC’s vital clustering processes of dataset D6.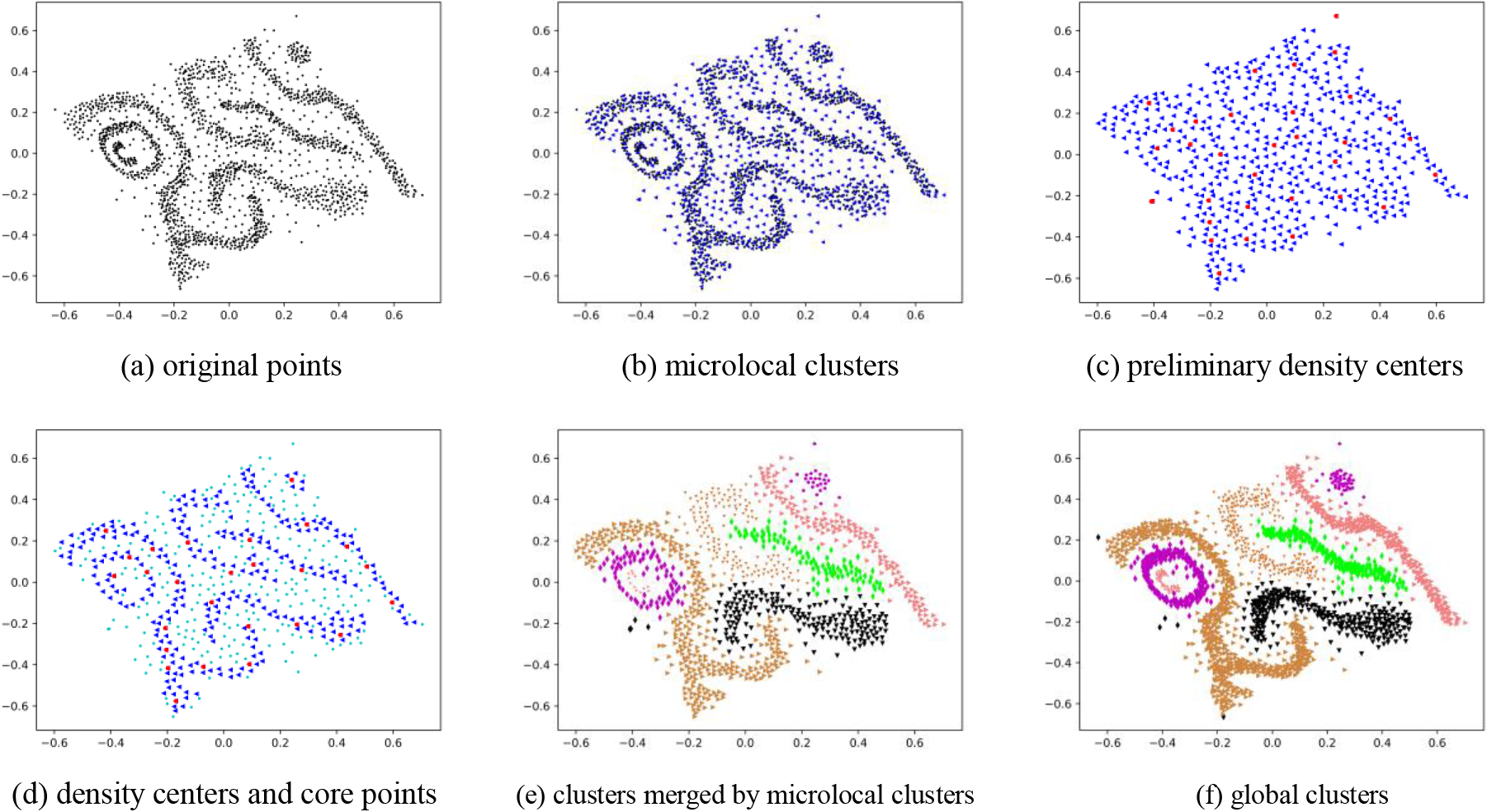
The details of the Dynamic-clusters-increasing process are shown in Algorithm 3.3. First, the distances between incoming microlocal cluster
To facilitate the demonstration of the clusters, we adjusted the decay rate
For the computational complexity, our framework mainly consists of 3 parts, i.e., Dynamic microlocal clustering, Density-center-based neighborhood search and Dynamic-cluster-increasing. In the first stage,
Synthetic datasets
Synthetic datasets
Representative dynamic clusters of D6 at different times.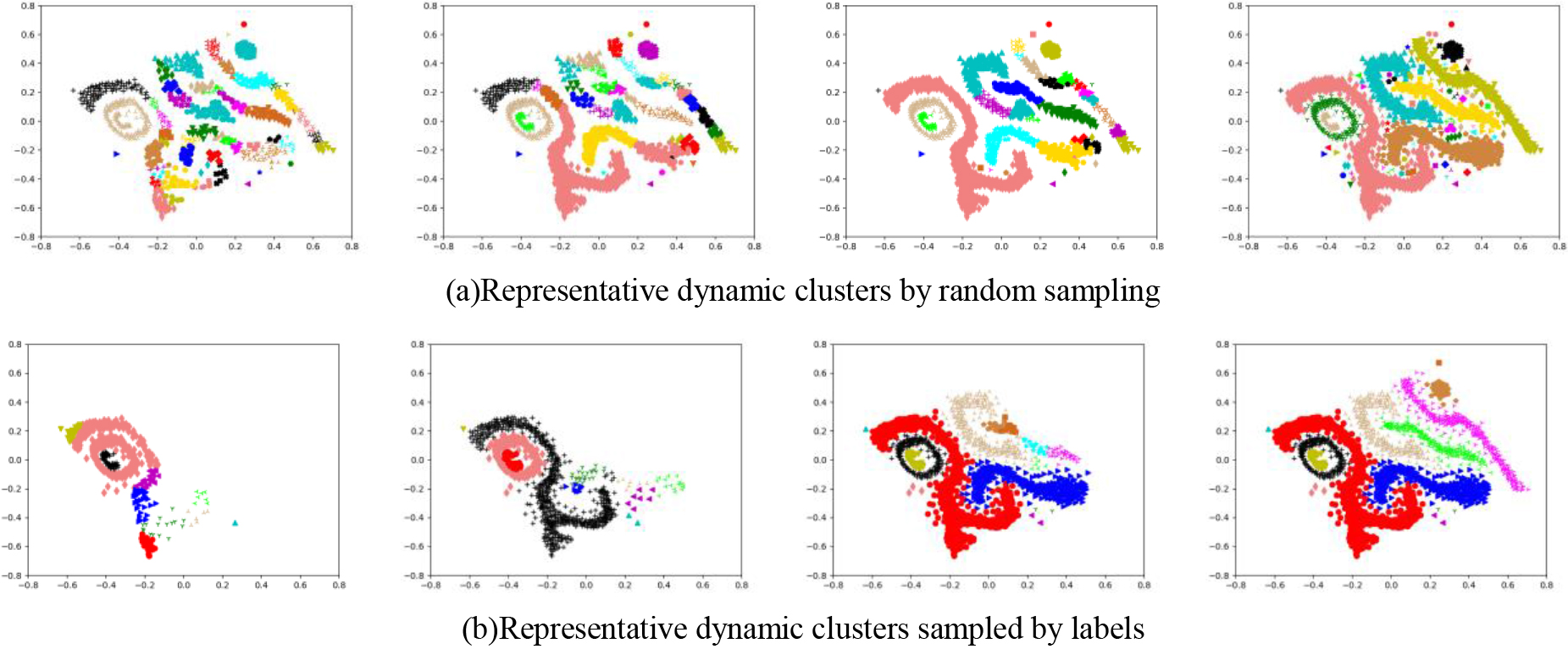
In this section, four synthetic and eight UCI real datasets, including mega ones, and streaming data generated by IoT sensors are selected to evaluate the accuracy, efficiency, and adaptability of IDMC with the baselines. Normalized mutual information (NMI) [31], Rand index (RI) [31], and Adjusted Rand index (ARI) [32] were employed as performance indices in all of the studies. The three indices have values ranging from 0 to 1. The higher the values, the greater similarity between the clustering findings and the ground truth. To maintain the values of all characteristics on the same scale across all datasets in the trials, min-max normalization was used to rescale all of the attributes to values between 0 and 1. Besides, all experiments run on Python 3.7 on a laptop with 64-bit Windows, core i5 CPU, and 16 GB of memory.
Experiment with synthetic datasets
In this part, we show the clustering results of synthetic datasets, IDMC’s outstanding performance in static and incremental data through two-dimensional data with good visibility is highlighted here.
These datasets contain points ranging from 399 to 8000 in two dimensions, representing some intractable clustering instances because they contain clusters with widely different shapes, sizes, and varying densities: 1) Aggregation (Agg) represents a dataset containing arbitrary shaped clusters with uniform density; 2) Compound (Com) represents datasets containing arbitrary shaped clusters with various densities; 3) D8 represents datasets containing concave clusters; 4) Chameleon T4.8K (without labels) represents dataset containing clusters banded non-spherical with shapes. Since T4.8K has no label, the clustering accuracy of this dataset is not presented in Table 2, and only the results of IDMC are given in Fig. 8.
The clustering results of IDMC on the rest synthetic datasets, as shown in Table 2 and Fig. 8 too, show IDMC’s advantages in terms of accuracy and robustness.
Final clustering results of IDMC on synthetic datasets
Final clustering results of IDMC on synthetic datasets
Representative dynamic clusters of aggregation compound and chameleon T4.8K.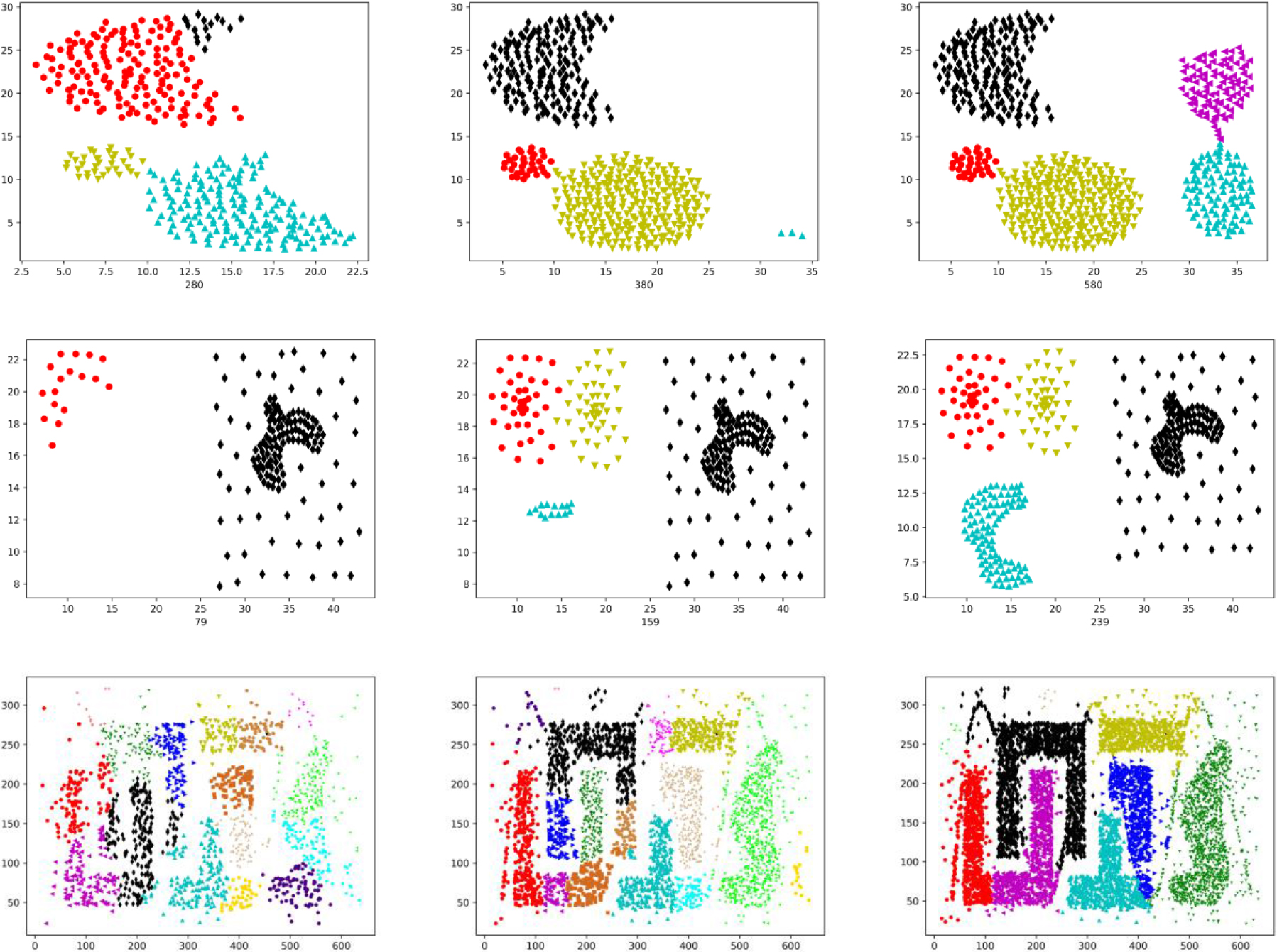
The second section of the experiment is the performance of IDMC on the static dataset of UCI. Because the upper limit of the accuracy of the performance of the incremental clustering algorithm is static clustering, that is, the accuracy of the dataset when it is read into the clustering algorithm all at once is higher than that when the data is read into the clustering algorithm in batches. Therefore, after obtaining its remarkable clustering effect on synthetic datasets, we continue to use IDMC on UCI real datasets and compare it with other state-of-the-art traditional clustering algorithms, including DBSCAN [26], HDBSCAN [33], DPC [17], SNN-DPC [34], FKNN-DPC [35], and EvolveCluster [36]. The experimental data are taken from seven different datasets in the UCI database (
Real datasets for evaluating clustering performance with traditional clustering algorithms
Real datasets for evaluating clustering performance with traditional clustering algorithms
The cluster accuracy results of IDMC in this set of experiments are shown in Table 4. The clustering accuracy of the comparison algorithm FIDC comes from [37]. One of the input parameters of the DPC family algorithms, including EvolveCluster, DPC, SNN-DPC, and FKNN-DPC was the number of clusters. As a result, the total number of final and ground truth clusters must always be the same. This might give these algorithms a leg up on their competition.
Comparison of clustering performances on real datasets
In Table 4, in most datasets, IDMC yields the best performance indices than its peers. It generates the best performance indices for the majority of datasets except for Multiple features and Waveform-noise. These two data sets contain a large number of noise points, so the compactness of various clusters is not enough, and the boundary between classes is not apparent, which leads to the difficulty of IDMC in neighborhood search and reduces the accuracy of clustering. Nevertheless, fuzzy local clustering is employed in FIDC to reduce clustering inconsistencies so that it surpasses the compared algorithms in these two datasets. DBSCAN and HDBSCAN rejected more than half of the Waveform (noise) datasets as outliers. Consequently, these two methods are considered to fail to handle these datasets.
In order to verify the superiority of IDMC, a statistical test for the comparison in Table 4 was performed using nonparametric tests for multiple comparisons. Friedman test [38] is a nonparametric equivalent of the repeated-measures ANOVA, and it is a commonly used test to compare the overall performance of
Ranks and
Iman and Davenport [39] showed that Friedman’s
Friedman test can only give the conclusion of whether there is a difference in the performance of
With the development of the Internet of Things, the number of sensors increases, which puts forward higher requirements for the algorithm’s computing power on large-scale data. We validate the efficiency of IDMC by comparing it with the traditional clustering method, by selecting the Phones-accelerometer dataset, a sub dataset of “Heterogeneity Activity Recognition,” to verify the arithmetic speed of IDMC on a mega dataset. It contains the readings of two motion sensors commonly found in smartphones. Readings were recorded while users executed activities scripted in no specific order carrying smartwatches and smartphones. It contains 1,048,576 samples, eight attributes, and seven classes.
Comparison of computation time on large scale datasets
Comparison of computation time on large scale datasets
Comparison of execution time on the large-scale dataset.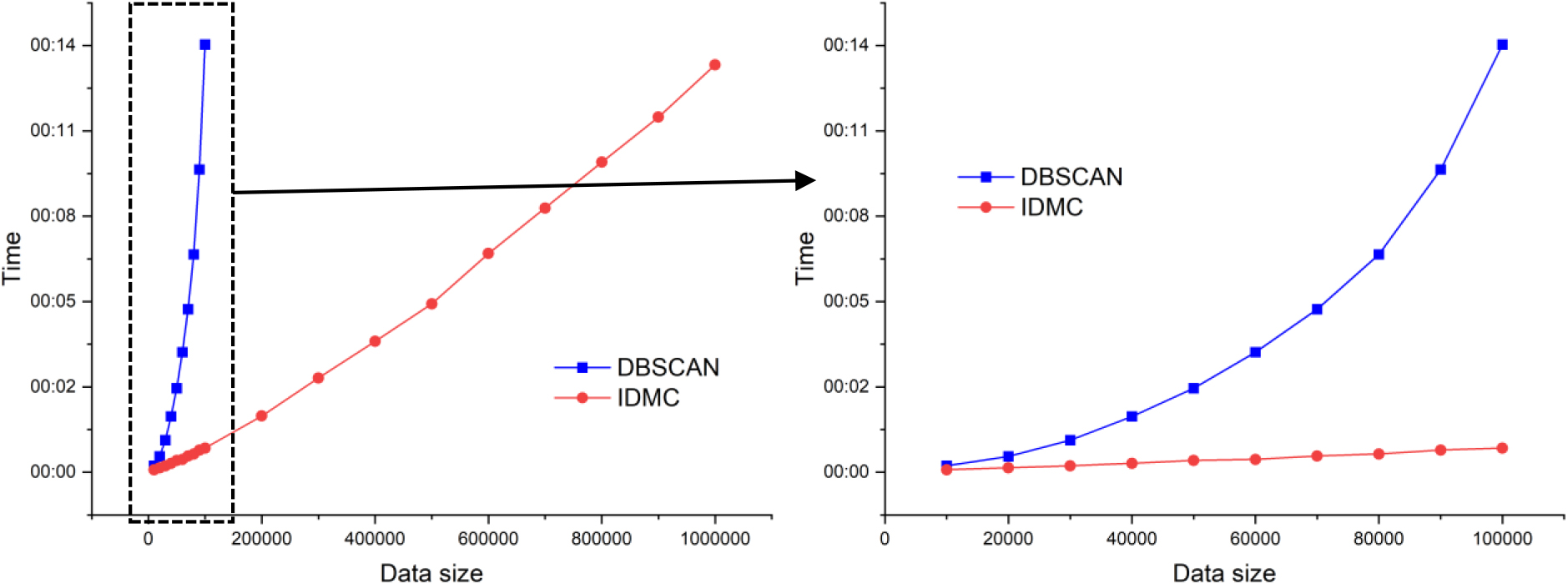
Photovoltaic generation system and sensors.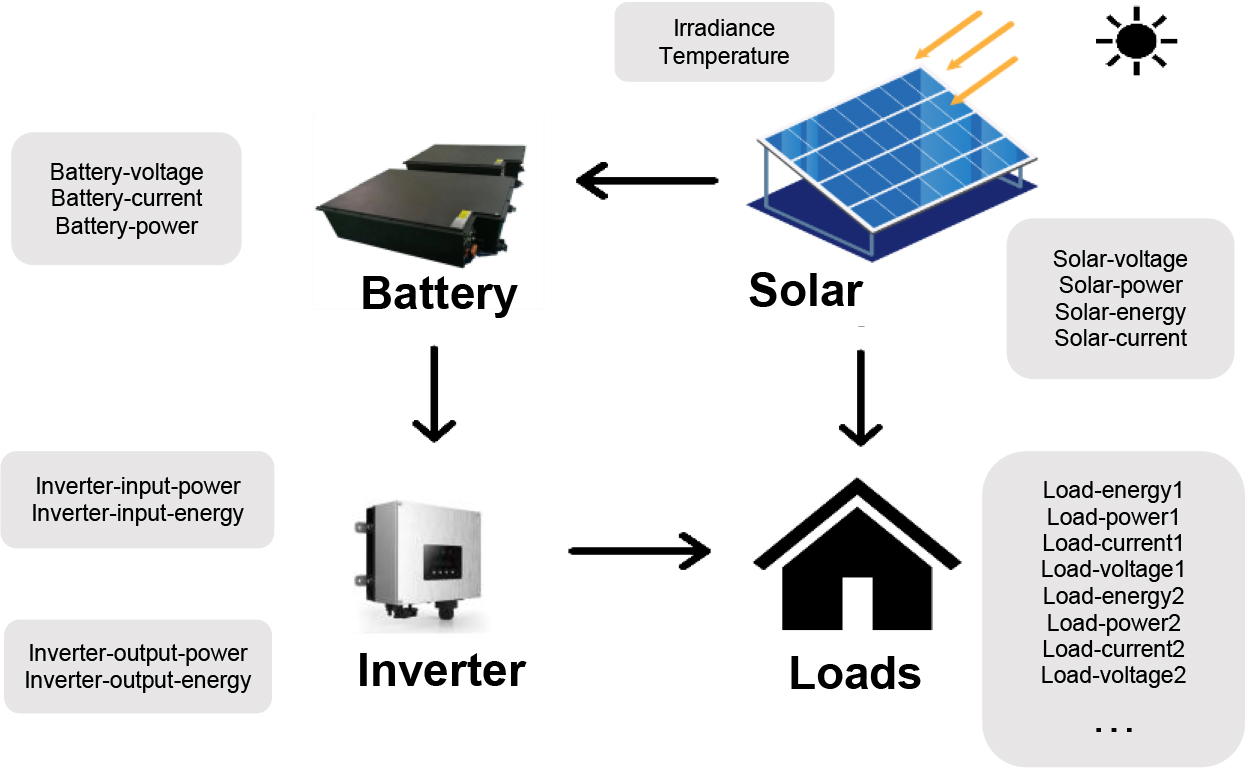
Because DPC-family algorithms are incapable of handling datasets larger than 10,000 samples, we did not use them for experiments. As HDBSCAN is also incapable of dealing with large datasets, DBSCAN is the only method to handle large datasets efficiently. We randomly selected 100,000 to 1,000,000 samples without replacement from the phones-accelerometer dataset. The computation time and performance indices for each algorithm are kept track. For each sample size, Table 6 displays the average findings of 10 repetitions.
During the experiment, we discovered that DBSCAN’s operating speed is one order of magnitude slower than IDMC. So, we chose the data volume of DBSCAN from 10000 to 100000, as in Table 6 and Fig. 9, to better compare the running time of the display method. Moreover, we discovered that the running time of IDMC is basically linearly proportional to the quantity of data, while that of DBSCAN is exponential. Because we used dynamic microlocal clusters to represent the uniformly distributed but numerous samples in the first stage of IDMC; in the second stage, we used a “quantity breeds quality” principle to reduce the number of Epochs on microlocal clusters. As a consequence, our algorithm has a significant advantage when dealing with large-scale data. Furthermore, despite more data to process, IDMC’s clustering accuracy is higher.
In this part, we apply IDMC to data stream from a photovoltaic power system for comparison with Clu-stream [13], DenStream [40], DBSTREAM [41], StreamKM++ [42], and Dstream [19], not only to compare the running speed, but also the real-time clustering accuracy. This data is acquired by sensors as part of each working operation and is timestamped. All dataset in this section is derived from [25]. Photovoltaic power generation is a burgeoning industry that is widely promoted as a sustainable energy alternative. The batteries, inverter, and other equipment are connected to the solar panels as shown in Fig. 10. They charge batteries and power load devices on sunny days. At night and on overcast days, batteries provide electricity to loads.
Sensors are installed above and below solar panels, as well as in the batteries, inverter, and load subsystems. They record the voltage, instantaneous power, and current of the solar panels, batteries, and each load. Sensors placed above the solar panels record the temperature and irradiance of the panels (sun exposure). There are 119266 rows and 23 columns in this dataset. Except for “date-time” and “location,” all variables are numeric. Solar panels, batteries, inverters, and loads are the four components. The samples of this dataset are recorded every one minute.
Comparison of results on solar panel sensors
Comparison of results on solar panel sensors
Comparison of clustering results on streaming data of solar panel sensors. Comparison of clustering results on streaming data of loads sensors.
Comparison of results on loads sensors
For the photovoltaic power system, we perform a cluster comparison using the sensor data of solar panels. It has five characteristics; all samples are periodically and significantly correlated with solar activity. The evaluation window for the performance indices is set at 10,000 points. The computation time and accuracy are averaged from the results of 10 experiments. From Fig. 12, we find the NMI of four algorithms can reach 80% in the first batch and maintained at that level throughout, which indicates the data from solar panels sensors are in periodic variation and static modes. As a result, all algorithms can detect hidden patterns and distinguish them using distinct clusters. Apart from that, IDMC surpasses the comparison method in every performance metric. The clustering accuracy is more stable and will not vary significantly with the increase of the number of samples.
We implement cluster comparison on additional data collected by load sensors. It contains six characteristics, and the pattern is more intricate and unpredictable, changing with the season, time, weather, and other factors. The evaluation window for performance indices is also set at 10,000 points. In Fig. 12(a), the time spent by IDMC increases in a conventional linear manner as the data volume increases. The computation time of the other three algorithms, on the other hand, is much higher than that of IDMC, Dstream’s execution time, in particular, does not follow a traditional linear relationship with data size. Because the data instances are so distributed, the resulting clusters exhibit a low degree of homogeneity, as seen in Fig. 12(b)–(d). However, IDMC surpasses the other algorithms in all performance indexes. Overall, IDMC outperforms its competitors in robustness, execution speed, and accuracy.
All of the above are the four main parts of the experiment. Part A shows IDMC’ outstanding performance on artificial datasets. IDMC’s outstanding performance in static and incremental data through two-dimensional data with good visibility is highlighted here. The second part of the experiment is the performance of IDMC on the static dataset of UCI. Because the upper limit of the accuracy of the performance of the incremental clustering algorithm is static clustering, that is, the accuracy of the dataset when it is read into the clustering algorithm all at once is higher than that when the data is read into the clustering algorithm in batches. Therefore, in this part, we compare the accuracy of the IDMC algorithm with the classic and efficient clustering baselines, which proves that IDMC has strength over the traditional static clustering algorithm when dealing with static data. The third section of the experiment is to compare the speed of IDMC and traditional clustering algorithms. With the development of the Internet of Things, the number of sensors increases, which puts forward higher requirements for the algorithm’s computing power on large-scale data. DBSCAN is a traditional clustering algorithm and its ability to deal with large-scale data is the best, so in this part, we compare it with IDMC for operation speed, and the results can see the advantages of our algorithm on large-scale datasets. The fourth section is the comparison experiment between IDMC and dynamic clustering algorithms. We compare IDMC with three excellent dynamic clustering algorithms. From the tables and pictures, we can see that our method can not only compare the running speed but also the real-time clustering accuracy. As a result, our IDMC framework advances the state-of-the-art of incremental clustering algorithms in the field of sensors’ streaming data analysis.
Conclusion
For streaming sensor data, we suggested an incremental density clustering framework based on dynamic microlocal clusters. As the foundational step of IDMC, we use a novel Dynamic microlocal clustering method in which microlocal clusters are described by dynamic centroids in the data stream. Then, Density-center-based neighborhood searching and Dynamic cluster increasing methods alternate with the incoming microlocal clusters to integrate microlocal clusters to get the final clusters automatically. IDMC processed sensor data with less computational time and memory, improved the clustering performance, and simplified the parameter choosing in conventional and stream data clustering. Furthermore, parameters tuning procedures become more convenient and robust. Extensive experiment results on eight public datasets and streaming sensors dataset demonstrate the superiority of our framework. In future work, we plan to extend IDMC in three respects. Firstly, a built-in feature reduction algorithm will be integrated into the algorithm to perform feature reduction and clustering simultaneously. Secondly, solving other tasks, such as classification, fusion, regression, etc. [43, 44] is an interesting future work. Besides, we will operate IMDC in a distributed clustering environment [45] to accommodate very larger volume datasets.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China (61991413) and Science Fund for Creative Research Groups of the National Natural Science Foundation of China (61821005) and Supported by the Joint Funds of the National Natural Science Foundation of China (U22B2041) and National Natural Science Foundation of China (91948303) and the Local science and technology projects guided by the central government of Liaoning Province (2022JH6/100100009).