
Abstract
MobileBert is a generic lightweight model suffering from a large network depth and parameter cardinality. Therefore, this paper proposes a secondary lightweight model entitled LightMobileBert, which retains the bottom 12 Transformers structure of the pre-trained MobileBert and utilizes the tensor decomposition technique to process the model to skip pre-training and further reduce the parameters. At the same time, the joint loss function is constructed based on the improved Supervised Contrastive Learning loss function and the Cross-Entropy loss function to improve performance and stability. Finally, the LMBert_Adam optimizer, an improved Bert_Adam optimizer, is used to optimize the model. The experimental results demonstrate that LightMobileBert has a comparatively higher performance than MobileBert and other popular models while requiring 57% fewer network parameters than MobileBert, confirming that LightMobileBert retains a higher performance while being lightweight.
Keywords
Introduction
Large-scale pre-trained language models (PTMs) can capture the general language knowledge from some large language corpora and have become the backbone model for many natural language processing (NLP) tasks. Especially BERT [1] and its variants [2, 3] have been proven very effective. However, these models typically suffer from an enormous parameter cardinality, slow response speed, and difficulty in deploying on hardware-constrained edge devices. Therefore, lightweight NLP models have emerged.
Currently, popular lightweight methods for PTMs include model pruning [4–7], model quantization [8–11], low-rank decomposition, parameters sharing [12–14] and knowledge distillation [15–19]. Model pruning considers tailoring parts that have an insignificant impact on the model’s performance. Model quantification properly deals with the model’s precision. The process of decomposing a large tensor into several smaller tensors is called low-rank decomposition. In addition, parameter sharing is usually involved in this process. Finally, knowledge distillation refers to transferring knowledge from the teacher model to the student model. The abovementioned methods aim to obtain small model network parameters, a highly efficient reasoning time, and a relatively appealing performance.
Although these methods have achieved noticeable results by compressing the original models, current research suggests that comparatively few methods achieve secondary lightweight models based on the existing lightweight models. Considering that MobileBert [19] is more general than other lightweight models (described in Section 2.4), we developed a secondary lightweight model based on MobileBert that attains an appealing performance with a more visible lightweight. The first step involves halving the Transformers structure of MobileBert to retain the bottom structures as pruned MobileBert. In the second step, the tensor decomposition technology application solves the mismatch between the pre-trained MobileBert network and the LightMobileBert model. Specifically, step two is divided into the following two phases. In the first, the pruned MobileBert is used to load the pre-trained MobileBert network, and in the second, the Candecamp Parafac (CP) tensor decomposition scheme is used to process the structure of the pruned MobileBert. These operations optimize the model’s structure, avoid training the model from scratch, and save pre-training resources. In the third step, the Supervised Contrastive Learning [20–22] (SCL) loss function is migrated to NLP from the image processing domain, and its improvement is combined with the Cross-Entropy (CE) loss function to construct a joint loss function for fitting-training the LightMobileBert model. Therefore, the distance between the same category is closer, and the distance between different categories is longer, so the model has better performance and stability. Finally, the LMBert_Adam optimizer based on Bert_Adam [23] is proposed to improve and stabilize our model’s performance. Extensive experiments on the seven classification corpora of GLUE [24] verify that although the proposed LightMobileBert has fewer parameters than other models, it maintains a relatively high performance.
This paper conducts some work in secondary lightweight models, which applies deep learning models to edge devices. Overall, the contributions of this paper are as follows: We propose a secondary lightweight model entitled LightMobileBert that is based on MobileBert. LightMobileBert is one of the rare secondary lightweight models in the field of NLP, with its success representing a further reduction in the threshold of deep learning deployment on resource-constrained edge devices and secondary innovation about lightweight models. Specifically, our proposed method has the following innovations. First, the size of the MobileBert model is reduced directly by reducing the Transformers layer. Second, the tensor decomposition technique used to process the model realizes the change in the internal structure without requiring a pre-training process. Third, the SCL loss function is extended and improved from the image process domain and combined with the CE loss function to enhance our model’s performance and stability. Finally, the LMBert_Adam optimizer based on Bert_Adam is proposed to improve and stabilize the model’s performance on different corpora. Compared with MobileBert, the number of network parameters of LightMobileBert is 57% the MobileBert’s and only 14.47M. In the experiments involving seven corpora of GLUE, the average performance is improved by 2.06% compared to MobileBert. At the same time, our model attains higher performance and is more lightweight than other lightweight models, proving the effectiveness of the LightMobileBert model. The code is available at https://github.com/DeguangChen/LightMobileBert.
Related work
This section reviews the most related works in NLP Lightweight modeling. Primarily, this paper is based on MobileBert conducting secondary lightweight research (MobileBert is a general and lightweight model based on BERT). Therefore, this section makes the necessary introduction to the representative lightweight models and the applicable technologies.
Model pruning
As a naive lightweight method, pruning has a wide range of applications in NLP. In general, model pruning is the tailoring of some parts that have a limited impact on model performance.
Compressing BERT [4] is dedicated to exploring the influence of weight pruning in BERT’s pre-training stage on the performance of subsequent tasks. The model discusses three different level pruning strategies and draws the corresponding conclusions. Precisely, the Reweighted Proximal Pruning [5] (RPP) for BERT has been proposed, with the experimental results revealing that proximal pruning maintains high performance for both the pre-trained tasks and subsequent multiple fine-tuned tasks. At the same time, the model can be deployed on some edge devices. The LayerDrop model [6], a form of a structured dropout, has a regularization effect during training and permits pruning at inference time. Experimental results reveal that it is possible to select subnetworks of some depth from a large network without fine-tuning them while posing a limited impact on performance. The BERT-OF-THESEUS model [7] adopts the Theseus concept to perform an inter-layer replacement of Transformers, decreasing the parameters while avoiding pre-training and substantially saving computational power. However, our model and existing methods have verified that similar effects are possible by directly exploiting the bottom layers of the Transformers.
Model pruning is a simple but practical method that can reduce the model size and accelerate model convergence without significantly affecting the model’s performance. At present, this kind of method is relatively mature and has many applications in the NLP domain.
Model quantization
As an essential part of lightweight NLP, quantization is commonly an effective method. As a general rule, model quantization aims to handle the model’s parameters’ precision properly.
For instance, the Q8Bert model [8] quantizes the General Matrix Multiply (GMM) in the BERT’s fully connected and embedded layers. Simultaneously, quantization-aware training is executed in subsequent tasks, so the model parameters are one-fourth of the BERT model while minimizing the performance penalty. Similar to this method is Q-Bert [9]. Moreover, the TernaryBert model [10] splits the quantization on the Bert model into weight layer and activation layer quantization. In this work, to terrorize the BERT weight, the author uses both the approximation-based ternary weight networks [25] (TWN) and the loss-aware transition [26] (LAT). Therefore, the method has achieved noticeable compression results. FQ-BERT [11] fully quantizes the BERT model and quantifies the weights, activations, softmax, layer normalization, and all the intermediate results of the BERT model. Experiments have demonstrated that the FQ-BERT model achieves noticeable compression for weights with negligible performance loss.
The principle of model pruning is to reduce the model’s parameters to compress the model. However, model quantization compresses the model with low precision instead of high precision. However, in essence, the model’s parameter cardinality is not reduced. Currently, mixed precision methods are popular to deal with lightweight models, which is essentially model quantification.
Low-rank decomposition, parameter sharing
Due to the difficult knowledge of matrix decomposition, low-rank decomposition is seldom used in lightweight NLP. However, almost all low-rank decomposition models about NLP have high popularity. In short, decomposing a large tensor into several small tensors is called low-rank decomposition, and parameter sharing is usually involved in this process.
Among the successful models, Albert [12] is a model in terms of low-rank decomposition and parameter sharing. The model adopts word vector decomposition techniques, sentence-order prediction techniques, and several good-quality corpora to train, considerably reducing the number of model parameters while improving its performance relative to BERT. At the same time, the parameter sharing technology significantly reduces the number of model parameters. However, this method’s computational complexity is not reduced. The Y-Tuning model [13] also adapts frozen large-scale PTMs to specific downstream tasks. Without tuning the features of input text and model parameters, the model is both parameter-efficient and training-efficient. Moreover, the YOCO-BERT model [14] constructed an enormous search space that covers almost all configurations in the BERT model. Then, a novel stochastic nature gradient optimization method guided the generation of optimal candidate architectures, which balanced exploration and exploitation.
Low-rank decomposition is supported by appropriate mathematical knowledge, but pruning and quantification relatively lack this theory. However, finding a suitable mathematical formula is challenging, which may be one reason why low-rank decomposition is less used.
Knowledge distillation
Distillation is the most widely used method in model compression, which is the transfer of knowledge from the teacher model to the student model.
The Distilbert model [15] compressed BERT’s 12 Transformers layers to six, sacrificing 3% performance in exchange for 40% parameter compression. However, compared with the current popular distillation models, the parameter cardinality is comparatively large. Tinybert [16] adopted the two-stage training method and calculated the loss function between the teacher and the student models in multiple intermediate processes that aligned them as much as possible to facilitate the knowledge transfer from the teacher model to the student model. At the same time, the corpora have been considerably enhanced, and thus the model has made more significant progress in both lightweight size and performance. However, TinyBert has many hyper-parameters increasing its adjustment complexity. Moreover, it is not fair to compare with models such as BERT after applying the corpora enhancement technique. Similar models are the Simplified TinyBert [17] and the CatBert [18].
The Mobilebert model [19] is relatively standard in the current distillation field. This model uses the same depth as Bertlarge (24 layers) and is a thin version of Bertlarge while equipped with bottleneck structures and a designed balance between Multi-Head Attention (MHA) and Feed-Forward Networks (FFN). A specially designed teacher model, namely an inverted-bottleneck incorporated Bertlarge model (IB-Bert), is trained first. Then the knowledge is transferred from IB-Bert to MobileBert. The most prominent feature of the IB-Bert model is that the linear mechanism, namely the inverted bottleneck, is added to the basic Transformer to increase the dimension of the corresponding network structure (because the deep and narrow model is difficult to train). In this way, the IB-Bert model obtains a high performance. To achieve a lightweight structure, Mobilebert has a linear mechanism to reduce the corresponding network’s dimension. A problem introduced by the linear mechanism structure of MobileBert is that the balance between the MHA and the FFN modules is broken. To solve this problem, the stacked feed-forward networks are used in MobileBERT to rebalance the relative size between MHA and FFN. Each MobileBert’s Transformer layer contains one MHA but several stacked FFN. Thus, the teacher model can smoothly transfer knowledge to the student model and successfully compress it.
In the conventional distillation compression process, the student models are always trained based on the mature teacher model, limiting the student model’s performance to a certain extent. MobileBert puts knowledge distillation first and then designs the teacher and student models. Therefore, the student model of this method is more versatile and has a higher performance. For the above reasons, this paper chooses the MobileBert as the basic model for innovation.
LightMobileBert model
The LightMobileBert model comprises Embedding, Transformers, joint loss function optimization, and classification layers. Among them, the Transformer layer comprises linear mapping, multi-head attention, some feed-forward neural network, and multiple regularization layers. The LightMobileBert model structure is illustrated in Fig. 1, and since it inherits the structure of MobileBert, it inherits the structure of BERT. Hence, the structure of LightMobileBert does not need to be introduced. We only introduce the improved and optimized parts of the LightMobilebert model, namely the layers reduction, tensor decomposition, joint loss functions, and optimizer, highlighted in Fig. 1 in red color.
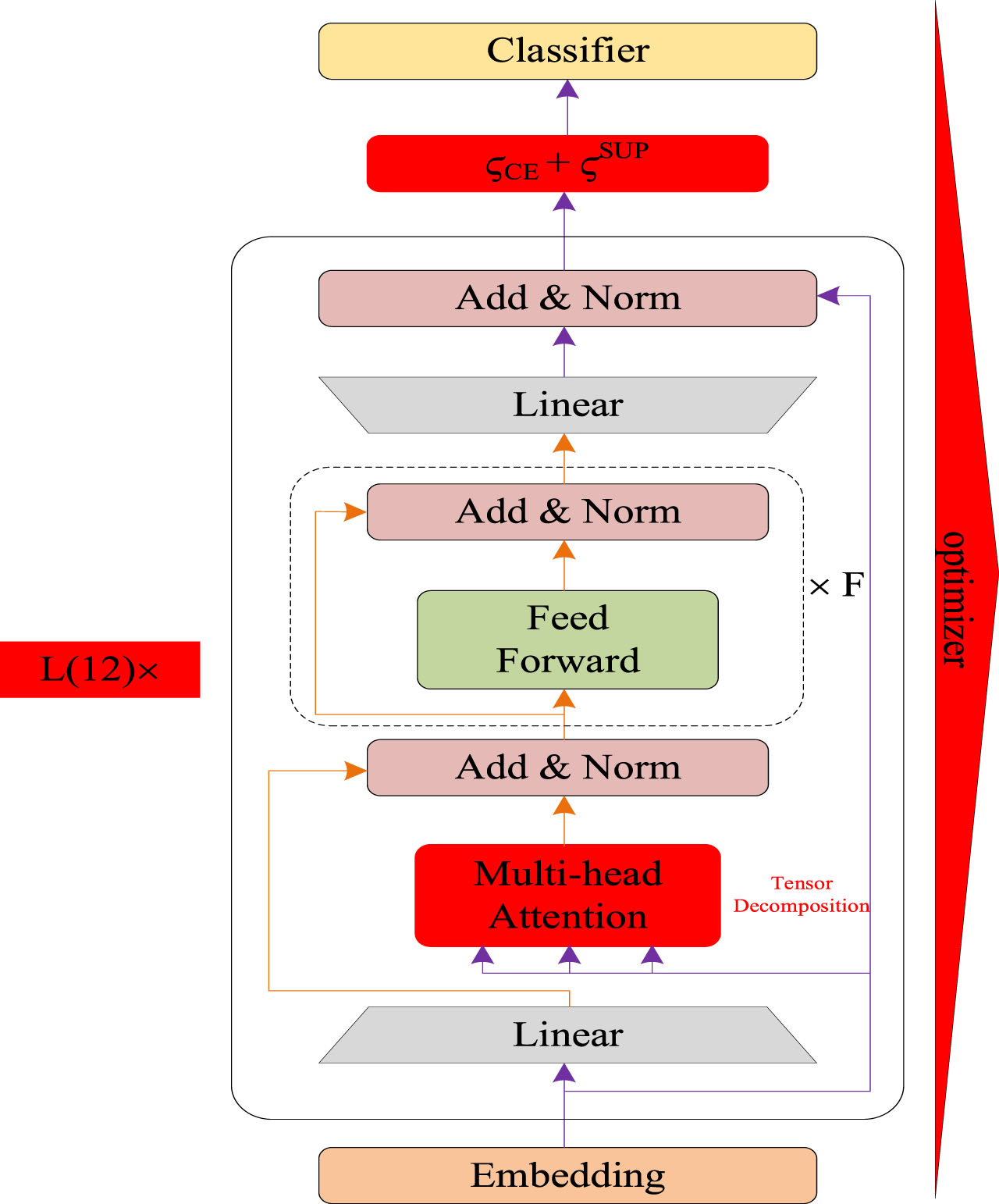
LightMobileBert model structure.
The main innovation of the BERT-OF-THESEUS model is that every two or three consecutive Transformer layers are randomly reserved, and then the downstream tasks are fitted. This method is relatively complex, and obtaining inconsistent corpora feature information results in a particular performance penalty. Nonetheless, this method brings some inspiration to our model.
Considering the pruning strategy presented in Section 2.1 and the main innovation of the BERT-OF-THESEUS model, the LightMobileBert model is improved. As already known, in image processing and NLP, the bottom model structures obtain more general feature information, while the high-level model structures obtain more specific features. Based on this, the LightMobileBert intercepts the bottom 12 Transformers of MobileBert as the basic model one. At the same time, using the idea of the BERT-OF-THESEUS model, i.e. every two consecutive transformer layers of MobileBert are randomly reserved as the basic model two. The experiments reveal that the performance of the two basic models is roughly the same. Therefore, according to the simple principle, this paper selects the basic model one to be the
Through the above operations, the basic structure of LightMobileBert is constructed. However, this basic structure has many parameters and poor performance compared to other well-performing models. Therefore, it is necessary to optimize the basic LightMobileBert further.
Tensor decomposition
Since models such as BERT and MobileBert are two-stage models and require very high-performance hardware equipment during pre-training, it is difficult for general research institutions to pay the high pre-trained costs. Therefore, for research utilizing BERT and its related models, most researchers do not alter the structure of the pre-trained parts and only deal with the subsequent tasks to improve the model’s performance.
LightMobileBert is a secondary lightweight model based on MobileBert. To effectively use the existing pre-trained parameters of MobileBert and the basic LightMobileBert, after the operations presented in Section 3.1, we use the Candecamp Parafac (CP) decomposition scheme for tensor decomposition to process the network’s structure. This strategy optimizes the model’s structure, avoids training the model from scratch, and largely saves pre-training resources.
CP decomposition is a special case of Tucker decomposition. The main difference is that there is a core tensor after the Tucker decomposition, while there is no core tensor after CP decomposition. CP decomposition decomposes a large tensor into a series of unit tensors. For a tensor χ of size n1×n2×n3, as illustrated in Fig. 2, the CP decomposition formula is:
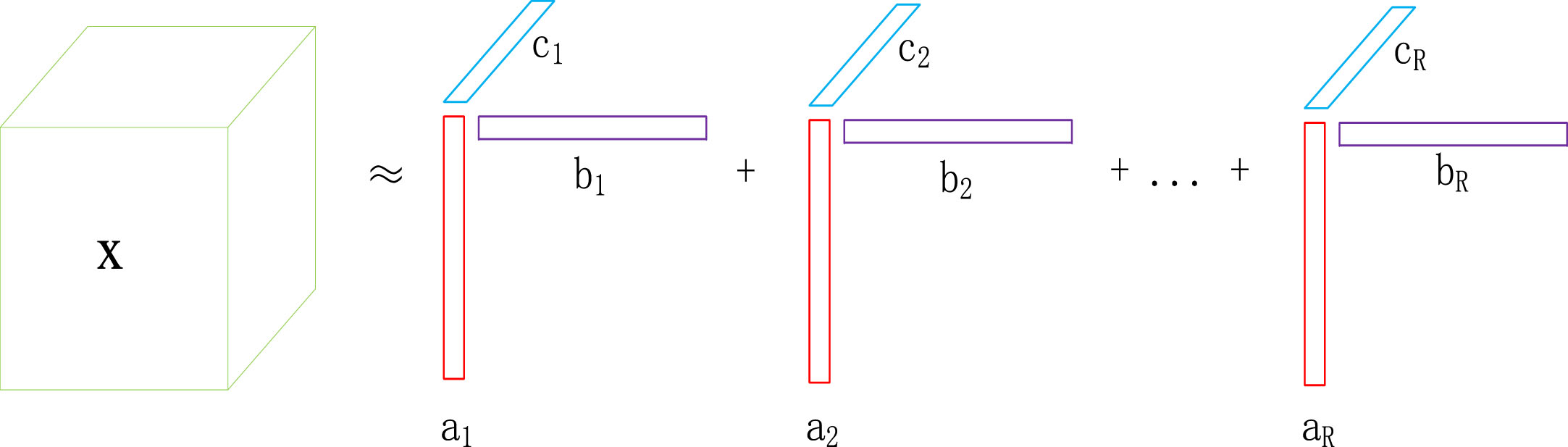
CP decomposition form.
The Self-Attention mechanism is the most pivotal part of Transformer about the basic LightMobileBert model. The parameters account for a large proportion of the basic LightMobileBert model. Hence, compressing the key parts can better reflect the effectiveness of CP decomposition. Therefore, CP decomposition is used to process the Self-Attention in the basic LightMobileBert. All tensors with a size of [–1,128] are processed as [–1,64]. Compared with MobileBert, after the operations presented in Sections 3.1 and 3.2, the LightMobileBert becomes more lightweight while saving the pre-training costs and as
The same source images indicate multiple images formed by an image after different types of transformation, such as rotation, clipping, and affine transformation. The same category images indicate a group of images with the same label. Self-supervised Contrastive Learning [20] only distinguishes the same source images but can not distinguish the same category images. Therefore, the image process has proposed the Supervised Contrastive Learning [21, 22] (SCL) loss function. The SCL method incorporates labels to bring the image features of the same category close to each other and decline the image features of different categories as far away as possible to achieve better classification results. The SCL formula is:
Formula (2) reveals that SCL requires an augmented dataset. Hence, we used Glove [27] and Easy Data Augmentation technologies [28] to augment the corpora for the experiments but found that the performance of our model was not significantly improved. In addition, it is unfair to compare the model trained with augmented corpora with the models without augmentation technologies. So, in this paper, all original corpora are kept unchanged, and we change formula (2) to make it applicable for the NLP task. The improved SCL loss function is given by:
The CE loss function (ς
CE
) is a loss function commonly used in neural network classification models. Due to its good performance, it is widely used. It is formulated as:
The joint loss function is more aggregated intra-class and dispersed inter-class than the CE loss function. The comparison of their classification effects is illustrated in Fig. 3.
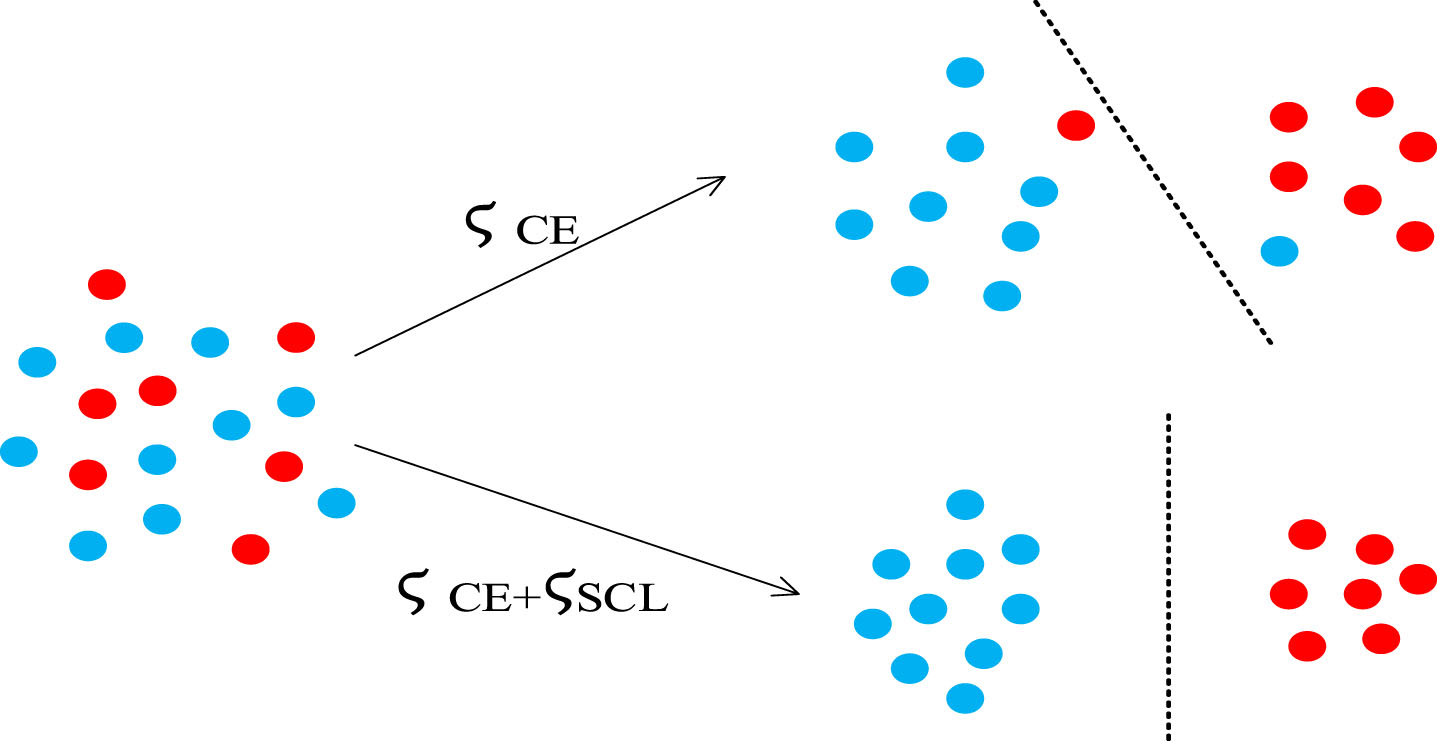
The classification effects comparison.
The optimizer has a significant impact on the model’s performance. Tianyi et al. [29] argued that one of the main factors of the BERT model instability is that the Bert_Adam optimizer omits the offset correction term compared to the standard Adam optimizer. When the corpus is smaller, the model’s performance will suffer some losses and large fluctuations.
Based on the above findings rthis paper proposes the LMBert_Adam optimizer and emphasizes its innovation ri.e. rdifferent aspects from Bert_Adam. Specifically rfirst rwe restore the optimizer to the standard Adam optimizer (the red parts in Table 1 are the omitted parts of the Bert_Adam optimizer). This way rthe model’s performance is stabilized and improved on the small corpora. Furthermore ran additional γ attenuation coefficient is set on the standard Adam optimizer to act on the current gradient θ (the purple part in the 11th row). It should be noted that adding γ is convenient for the optimizer to fine-tune based on parameter adjustment and obtain better performance to a certain extent. The LMBert_Adamoptimization algorithm is presented in Table 1.
LMBert_Adam optimization algorithm
LMBert_Adam optimization algorithm
This section introduces the experimental environments and corpora and conducts detailed experiments and analyses. These experiments prove that LightMobileBert has reduced the number of parameters and achieves relatively higher performance than other lightweight models.
Experimental environment
The experiments are conducted on two systems using a Windows 10 platform. One of the systems uses an Inter (R) Xeon (R) Gold 6154 CPU with 256GB memory ran Nvidia TITAN V graphics card rPython version 3.6.8 rand Torch version 1.1.1. On this system rwe mainly train the large corpora. The second system has an Inter (R) Xeon (R) E5-1620 v3 3.5 GHz CPU with 8GB memory ran NVIDIA RTX 2080 graphic card rPython version 3.6.8 rand Torch version 1.1. 1. This system is used for training small corpora.
Corpora composition
Based on the above findings, this paper proposes the LMBert_Adam optimizer and emphasizes its innovation, i.e., different aspects from Bert_Adam. Specifically, first, we restore the optimizer to the standard Adam optimizer. This way, the model’s performance is stabilized and improved on the small corpora. Furthermore, an additional γ attenuation coefficient is set on the standard Adam optimizer to act on the current gradient θ. It should be noted that adding γ is convenient for the optimizer to fine-tune based on parameter adjustment and obtain better performance to a certain extent. The LMBert_Adamoptimization algorithm is presented in Table 1.
Following BERT and MobileBert, we do not consider the controversial WNLI corpus. We utilize accuracy as the metric for SST-2, MNLI, QNLI, QQP, RTE, MNLI and MNLI-mm. CoLA is evaluated on Matthew’s correlation, and in terms of MRPC, the F1 is evaluated. In this paper, if not explicitly mentioned, the experimental data is the default development set of GLUE.
GLUE classification corpora
GLUE classification corpora
Due to the significant difference in the size of each corpus, setting a uniform batch size is not conducive to the performance of the LightMobileBert model. Therefore, this section explores the optimal batch size corresponding to the different corpora.
A fixed initial learning rate and training batch are set for each corpus. The fixed learning rate remains unchanged for the first third of the total training steps. For the final two-thirds of the training steps,the learning rate decreases linearly and finally decreases to one-third of the initial learning rate:
Setting of hyper-parameters corresponding to various corpora in the model
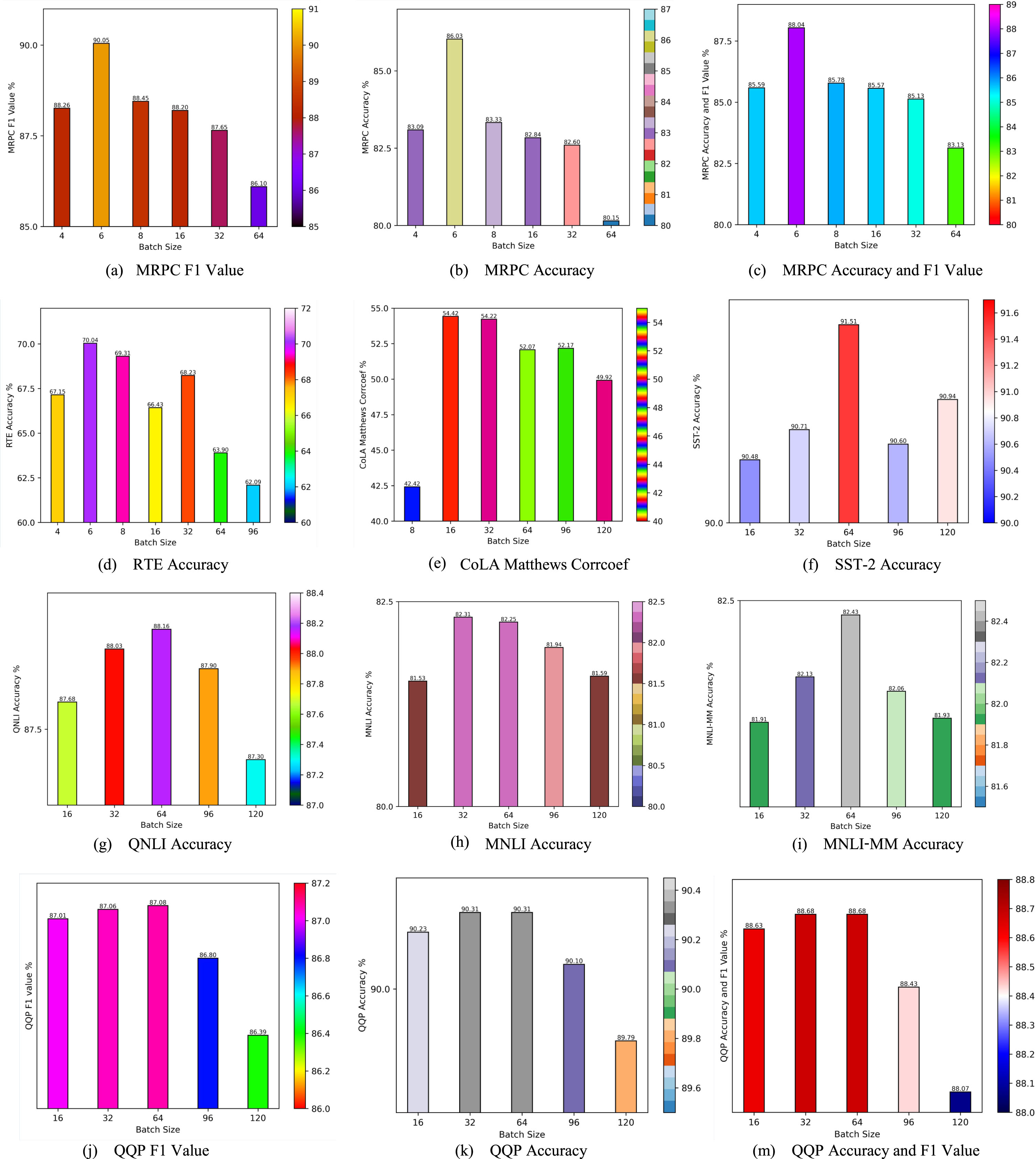
Effects of batch sizes on model performance.
Figure 4 highlights that: (1) LightMobileBert obtains the best performance with different batch sizes on different corpora. This is caused by the difference in the size of the corpora and the difficulty of the corpora itself. (2) The smaller the corpus size, the smaller the optimal batch size required. It is proved that under the same model conditions, the relatively small batch size of a relatively small corpus can promote the model to learn subtler corpus characteristics, which is convenient for the optimization of the neural network model. (3). As the size of the corpora increases, the influence of the batch size on model performance gradually decreases to a specific range. This is because the larger the corpora, after a certain period of training, the characteristics of acquired corpora improved (no over-fitting and under-fitting problems), thereby the effects of different batch sizes on model performance become smaller. The experiment mainly demonstrated that the smaller the corpora, the greater the impact of the change in batch size on model performance.
This section compares the test results obtained under the best batch size of Section 4.3 against the performance of currently popular lightweight models. The corresponding results are reported in Table 4.
Performance of different models on GLUE
Performance of different models on GLUE
According to Table 4, (1) The average performance of the LightMobileBert model on the seven corpora is 2.06% higher than that of MobileBert, while the parameter is only 57% of MobileBert. It has been proven that the LightMobileBert model has apparent advantages over MobileBert. (2) The LightMobileBert model has almost the same number of parameters as the TinyBert and BARTen-yT models, but the average performance is improved by 4.52% and 3.76% over that of TinyBert and BARTen-yT. (3) Compared with other models with large parameters, such as YOCO-Bert (searchedB) and Bert-of-Theseus model, LightMobileBert has absolute advantages in model size and slight advantages in performance. (4) Compared with the LightMobileBertbasic model, the performance of LightMobileBert is improved by 4.66%, proving the optimization measures’ effectiveness. (5) Compared with the Bertbase model, the performance of our model is slightly short, but the network parameters are only 13.15% of that of the Bertbase model, which proves the effectiveness of the LightMobileBert model. Through the above experiments, the LightMobileBert model has proved to have higher accuracy, decreased number of parameters, and computational cost in contrast to other popular models.
The advantages of the LightMobileBert model over its competitor models have already been demonstrated. In this section, we investigate the effects of the loss function, the optimizer, and the CP decomposition on the performance of the LightMobileBert model. In addition, the idea of the layer reduction operation on transformers of Section 3.1 is similar to the BERT-OF-THESEUS model. Therefore, the ablation experiments of the layer reduction operation on transformers were neglected. For further details on the related ablation experiments, please refer to [7].
Loss function ablation experiments
Loss function ablation experiments
According to Table 5, (1) On each corpus, the model’s performance using the joint loss function is better than that solely using the CE loss function. Additionally, the average performance of the joint loss function is 0.85% higher than the CE loss function, proving the importance of the joint loss function. (2) When the corpus is relatively small, the joint loss function can accelerate convergence and improve the model’s performance more than in a relatively large corpus. (3) When the corpus is relatively large, the improvement of the joint loss function on the model’s performance is relatively weak. Therefore, we use the joint loss function to train the LightMobileBert based on these conclusions.
Optimizer ablation experiments
According to Table 6, (1) On each corpus, the model’s performance using the LMBert_Adam optimizer is better than solely using the Bert_Adam optimizer. Additionally, the average performance of the LMBert_Adam optimizer is 2.37% higher than the Bert_Adam optimizer, demonstrating the importance of the former optimizer. (2) The LMBert_Adam optimizer can more effectively improve the model’s performance on small corpora. (3) According to the corresponding comparison between Tables 5 and 6, it can be found that with the increase in the corpora size, the joint loss function and LMBert_Adam optimizer have similar enhancement effects on the LightMobilebert model. Hence, this paper applies the LMBert_Adam optimizer to achieve an appealing performance.
CP decomposition ablation experiments
According to Table 7, the average performance when neglecting CP decomposition is 0.77% higher than when using CP decomposition, proving that CP decomposition has a slightly negative influence on the performance of the LightMobileBert model. However, the CP decomposition technique can effectively compress the LightMobileBert model and avoid pre-training the model. Therefore, we use the CP decomposition in our method.
This paper proposes the LightMobileBert model, an extension of MobileBert, which utilizes the layer reduction operation on Transformers to reduce the model size. Then CP decomposition technology is adopted to reduce the model’s size further and avoid pre-training the model. After that, the improved SCL and the CE functions are used to construct a joint loss function to enhance the performance of the LightMobileBert model. Finally, the LMBert_Adam optimizer is constructed based on the Bert_Adam optimizer to improve the LightMobileBert model’s performance further. The experimental results on the seven classification corpora of GLUE demonstrate that compared with the MobileBert, LightMobileBert’s overall performance is improved, and the model size is significantly reduced. The experimental results prove the effectiveness of the proposed model, providing a theoretical basis and practical significance for the lightweight model to be deployed on edge devices.
However, there are still some problems to be solved. First, this paper only explores the classification problem and does not cover more complicated problems such as question-and-answer (QA). Second, compared with designing and pre-training a new model, the LightMobileBert model is processed directly by reducing the number of the transformers’ layers and relies on tensor decomposition technology, resulting in a certain extent of performance loss. For the first problem, since the improved SCL and CE loss functions are suitable for classification algorithms, it is very interesting to study the general loss function. For the second problem, designing and pre-training a new model requires a lot of hardware and software resources, which is challenging for general research institutions and individuals. Therefore, exploring a method to reduce the model size and its corresponding pre-trained network with a small performance loss is meaningful.
Footnotes
Acknowledgments
This research was supported through National Natural Science Foundation of China (No. 62273219, 62006149, 62003203, 62102239, 61862001); Natural Science Foundation of Shaanxi Province (No. 2021JM-206, 2021JQ-314); Fundamental Research Funds For the Central Universities (No.2021CSLY023, 2021TS035, GK202205038); Center for Applied Mathematics of Inner Mongolian (ZZYJZD2022003); the Shaanxi Key Science and Technology Innovation Team Project (No. 2022TD-26).