
Abstract
Breast cancer can be successfully treated if diagnosed at its earliest, though it is considered as a fatal disease among women. The histopathology slide turned images are the gold standard for tumor diagnosis. However, the manual diagnosis is still tedious due to its structural complexity. With the advent of computer-aided diagnosis, time and computation intensive manual procedure can be managed with the development of an automated classification system. The feature extraction and classification are quite challenging as these images involve complex structures and overlapping nuclei. A novel nuclei-based patch extraction method is proposed for the extraction of non-overlapping nuclei patches obtained from the breast tumor dataset. An ensemble of pre-trained models is used to extract the discriminating features from the identified and augmented non-overlapping nuclei patches. The discriminative features are further fused using p-norm pooling technique and are classified using a LightGBM classifier with 10-fold cross-validation. The obtained results showed an increase in the overall performance in terms of accuracy, sensitivity, specificity, and precision. The proposed framework yielded an accuracy of 98.3% for binary class classification and 95.1% for multi-class classification on ICIAR 2018 dataset.
Introduction
In India, National Cancer Registry Programme (NCRP) extrapolated a surge in the number of cases from 13.9 lakh in 2020 to 15.7 lakh by 2025. Despite the surge, one-third of these cancers are preventable and curable. Global Breast Cancer Initiative (GBCI), an establishment of the World Health Organization (WHO) targeted to curtail the overall death rate of breast cancer across the globe by 2.5% per year, deterring the mortality of breast cancer nearly 2.5 million between 2020 and 2040, thereby reduce 25% of breast cancer deaths by 2030 and 40% by 2040 [1].
Though the initial screening of breast tumor is done using non-invasive imaging modalities [2], the type of the tumor is determined by biopsy, an invasive procedure for tissue extraction [3]. Further, to visualize the nuclei and cytoplasm, the tissues are stained with Hematoxylin and Eosin (H & E) stains. In digital pathology, the manual assessment of the images is quite strenuous as they are complex and disparate in nature. Hence, the Computer-Assisted Diagnosis systems (CADs) are used as the decision support systems by the pathologists for an automatic detection and diagnosis of tumors [4]. Recently, the amelioration of high computing and deep models such as Convolutional Neural Networks (CNNs) are intertwined with the CADs, have shown a remarkable performance compared to conventional methods for localization, segmentation, feature extraction and classification tasks [5–10]. However, there are certain shortcomings in employing CNNs directly on the histopathology images leading to a poor performance in the classification process. Amongst the several factors, the variations due to the staining process leads to improper classification. Hence, the images must be prepared and standardized such that the nuclei in the images are made evident to attain a better classification accuracy. The preprocessing involves two phases, stain normalization and patch extraction. The stain normalization has gathered considerable interest among the researchers for past few decades as it has shown noticeable increase in the classification performance [6]. Amongst the significant approaches, the normalization technique proposed in [11] is employed in majority of the research contributions [8–10, 12]. The histopathological images encompass cell structures which are intricate and overlapping. In the above research works, it is observed that stain normalization alone does not guarantee to capture the clear edges of the nuclei for an extraction of discriminative features. Better visualization of the nuclei and its structure can be obtained by using certain image enhancement techniques along with stain normalization method.
In general, the histopathology images are large and computation intensive. However, resizing the input size for CNN leads to loss of crucial information. Hence, the patch extraction method is employed to extract significant patches from histopathology images which encompasses essential discriminative information for classification. The prevailing method for patch extraction is sliding window approach which is used in majority of the research works [8–10, 12–18]. This method involves limitations as the discriminative nuclei are present in only certain areas of the tissues. In paper [12], the patch sizes considered for extraction are 400×400 and 650×650 where most of the patches have irrelevant information. Whereas the patch size of 512×512 is used in [8–9, 17] and 128×128 is used in [8–10, 19]. However, these patches are further resized to 32×32 and the Principal Component Analysis [8] and Autoencoders [9] are applied prior to K-means clustering to cluster the patches based on the phenotypes. This process is both computation and time intensive. On the other hand, some research works are more focused on the patch extraction through segmentation guided approach [7, 16], where the informative regions are targeted for a less computation intensive process. However, in many of the extracted patches, there are fewer nuclei and more cytoplasm leading to degradation in the classification performance [8]. This issue can be addressed using a novel method which focuses on extracting the nuclei features, which motivated to propose a nuclei-based patch extraction approach, where each patch obtained possess a non-overlapping individual nucleus.
The renaissance of deep learning along with high performance computation has achieved significant success in medical imaging domain. The deep learning techniques have achieved substantial progress in several tasks such as medical image reconstruction, enhancement, registration, segmentation, and diagnosis of the disease. The new progress of deep learning technology involves several strategies such as deeper the network, there is an increased discrimination knowledge. The involvement of the adversarial and attention models assists in an automated identification of “where” and “what” for a comprehensive decision making. For channel attention mechanisms, squeeze and excite networks are incorporated. An architecture design can be automated using the Neural architecture search (NAS) for a better performance. The limited data condition in the medical imaging domain has also prompted to explore techniques to scale up the dataset. This is achieved through data augmentation using conventional approach called affine transformations, which comprises rotation, scaling, translation, flipping and other geometric transformations [20, 21]. However, these affine transformations include occupancy of supplementary memory and at times some operations such as cropping, or translation which needs extra observation to keep a check for any alteration in the images. Especially in medical imaging domain, the affine transformation has a limitation as the discrimination between the training and the testing data are highly complex in positional and translational variance. Now, researchers have profound insights on augmentation of images using deep learning approaches like neural style transfer, adversarial training, and Generative adversarial networks [21] to obtain the synthetic image. These synthetic data obtained through deep learning approaches represents a solution for the medical image data scarcity challenge. The other challenge addressed by the deep learning methods is the segmentation of Region of Interest (RoIs) in medical images. The tissues which contribute more to the disease are identified and marked as the RoIs. Though several traditional approaches such as edge based, threshold based, region based, watershed based, clustering based. The deep method includes CNNs which typically use an encoder-decoder based architecture such as SegNet, UNet, DeepLab, Mask-RCNN.
For classification tasks, training deep models from scratch are usually highly intensive and need more expertise. However, these advent CNNs are capable to produce an excellent classification at the cost of high memory and computing usage. To overcome this, transfer learning approaches are used for feature extraction and classification [8–10, 13–18]. Despite the contributions of the researchers, there is indeed a demand for an efficient algorithm that could be used for multiple datasets for a better classification performance [22]. The pretrained models can be easily finetuned and are simple to infer and extract the high-level features from the extracted patches. In majority of the research contributions, the VGG [23], ResNet [24], Inception [25] are used as the promising feature extraction approaches. Nonetheless, some approaches yield an efficient result on one dataset but an average result on another depending on the features. This challenge can be addressed by combining pretrained models or ensemble of best models for a better identification of the class labels [26–29].
Especially, training an ensemble of pretrained networks on the nuclei patches assists to extract more discriminative features that contribute towards an enhanced classification. From the literature, it is evident that there is a lot of limitations with respect to the existing grid-based patch extraction as most of the extracted patches includes irrelevant information leading to a suboptimal training process. Hence the proposed model aims in the extraction of appropriate features for an optimal classification of breast tumors through feature fusion and decision trees.
Key contributions
Rather than the traditional approaches for patch extraction such as random sampling or grid sampling, the proposed method of direct extraction of nuclei patches will streamline the feature extraction process. Amongst several deep learning models, the well-established pretrained models adapted in the medical imaging domain for feature extraction are VGG16, Inception, and ResNet models where the features are fused to obtain a fused model. Further, the classification of the extracted features is achieved using a LightGBM models.
The key contributions of this paper are summarized as follows: The nuclei whose features contribute more to tumor detection are highlighted using a combination of two image pre-processing techniques, stain normalization and gamma correction. A novel nuclei-based patch extraction algorithm is proposed for the selection of non-overlapping nuclei, which eradicates the redundancy in feature extraction and results in the extraction of better features. An ensemble of transfer learning algorithms is used for an efficient discriminative feature extraction from the nuclei-based patches. LightGBM, a robust algorithm based on The Gradient Boosting Decision Tree (GBDT) is employed on the obtained features for classification.
Materials and methods
In this section, the materials and methods used in this work are discussed in detail. Figure 1 illustrates the schematic representation of the proposed system.
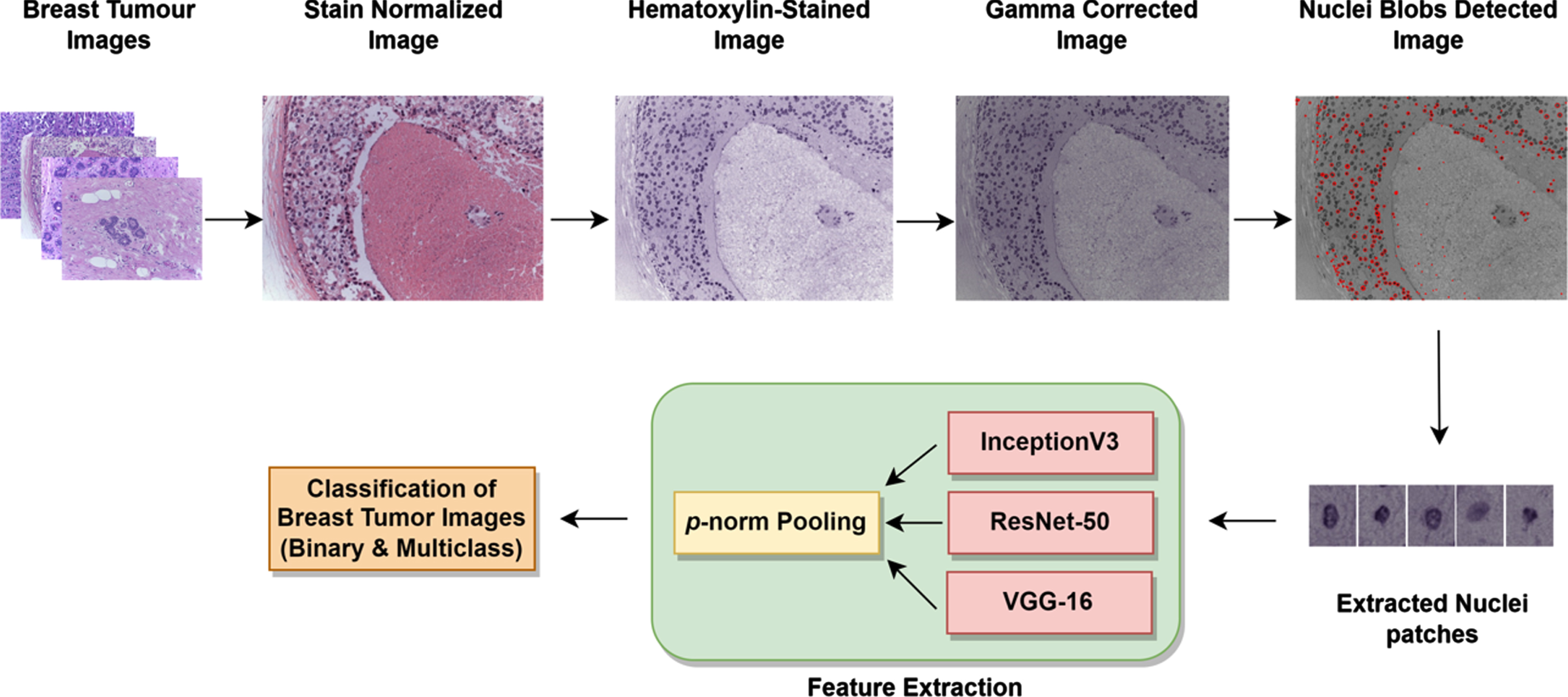
Schematic representation of the proposed system.
As the histopathology images are prone to variations due to staining procedures, there is a need to eliminate the differences and highlight the nuclei for a better classification. The nuclei in the histopathology images are extracted using the approach illustrated in Algorithm 1 and Fig. 2. In this work, the normalization strategy [11] is employed to normalize the stained images and separate the hematoxylin (I
h
) and eosin (I
h
) components. Since there is a nonlinear relationship between light intensity and stain concentration, the RGB intensity data cannot be used directly for stain separation. Hence, the color intensities of the RGB present in the H&E-stained images are transformed to optical density (OD) space by employing logarithmic transformation using Eq. (1), where I represent a vectorized matrix of the image and I0 is the incident light intensity set to 255 as each channel is of 8 bits [6]. The OD is a linear combination of the stain vectors and the saturation matrices for each stain.
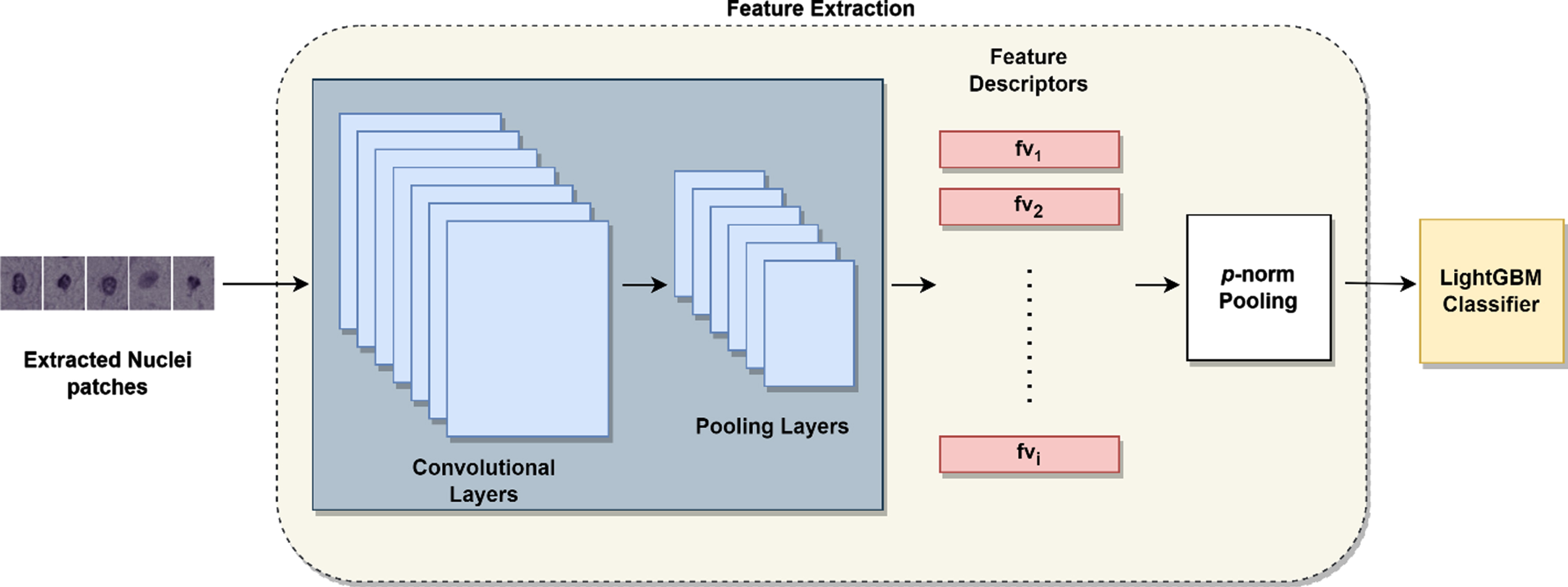
Feature Extraction and classification process.
The geodesic path is the shortest route between any two unit-norm color vectors. The OD transformed pixels can be projected onto this geodesic direction in stain vectors. The plane is determined with vectors which correlate to the largest singular values obtained because of singular value decomposition of the OD converted pixels. Thus, the optimal stain vectors are identified, and their individual stain concentrations are calculated. The normalized image I norm is obtained from where the hematoxylin component I h and eosin component I e are separated which is illustrated in Fig. 4.
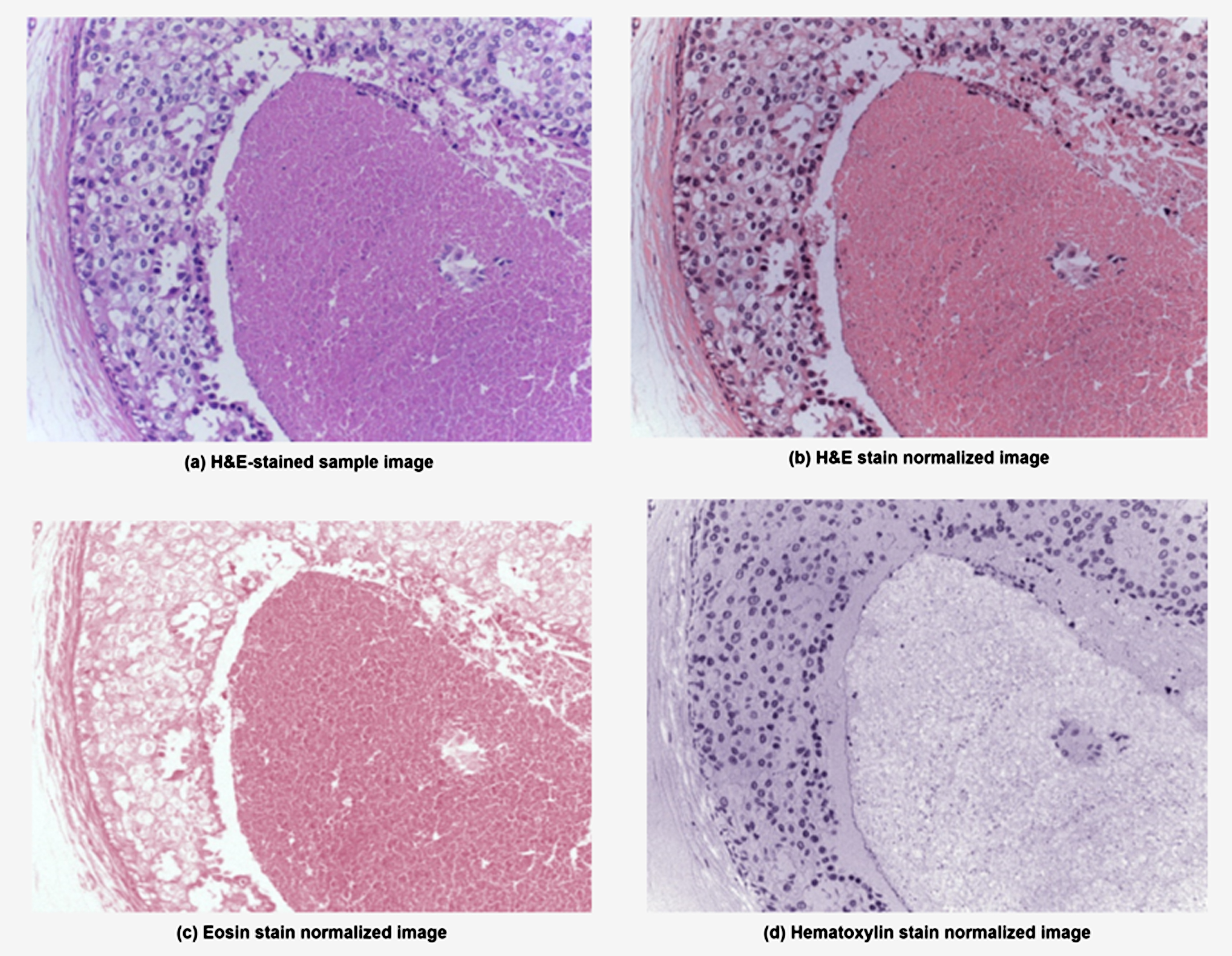
Results of stain normalization of the H&E-stained images.
The key markers for the diagnosis of tumor include variations in the morphological and textural features of nuclei. As hematoxylin binds with nuclei-based components and eosin highlights the other components. the hematoxylin-stained image, I h is separated from the I norm for a better selection of features depicted in Fig. 4(d). Consequently, involving non-overlapping nucleus patches directly rather than using grid sampled patches can assists the pretrained CNNs to extract the appropriate features pertaining to the nuclei. Hence, the I h images are further subjected to gamma correction in order to highlight the nuclei edges and removal of noise. The output gamma corrected image is obtained using Equation (2). The I gc is the gamma corrected image, and γ represents gamma value considered between 0.9 < γ< 1. A sample of the gamma corrected image is depicted in Fig. 5(a).

(a) denotes the gamma corrected images (b) The nuclei blobs are identified using LoG (c) sample of non-overlapping nuclei (d) Sample of overlapping images.
The nuclei in the Ih image are highlighted than its respective background. Due to the inconsistent staining process, there are certain intensity discontinuities observed in the boundary of the nucleus and in certain cases it is multi-modal. However, with appropriate gaussian blurring effect, these intensity distributions can be witnessed as unimodal. Thus, the profile of the nucleus appears as a ridge with smooth change. In order to obtain a blob, the ridge pattern can be rotated around its central axis. By rotating a Gaussian’s second derivative around its axis, the nucleus can be modelled as a blob along with some additive gaussian noise. This approach is called LoGFilter. Thus, the Laplacian of Gaussian blob detection method [30] is used to extract the potential nuclei. The preprocessed image is convolved with the gaussian filter at different scales and the extrema is captured in the resultant scale space. For the given image at a point(x,y), the gaussian filter is generated using Equation (3).
The variable σ is the standard deviation of the kernel which defines the scale of the filter. Typically, the value corresponds to the size of the nuclei to be detected. In this scenario, we consider the nuclei as a blob and tune the parameters of the Laplacian of the gaussian (LoG) in order to detect the blobs at a particular scale. Nucleus varies between 5–10μm and hence the initial value of σ is considered as 2 to identify the smallest nuclei and the scale levels are chosen such that the final sigma is obtained to detect the largest blob in the given image. The scales obtained as a result of convolution is termed as scale sigma, σ1. However, increased σ1 value leads to a decreased response. Hence, a scale normalized LoG is applied by multiplying the LoG with σ2to find the nucleus. A multiplying scale factor of 1.414 i.e
Further, the local maxima are detected in the scale space using non-maximum suppression which tends to identify pixels compared to its 26 scale-space neighbors [30]. The centroids of the nucleus are approximated where the neighbors of a recognized pixel within a coverage of less than 25 pixels are ignored for the consideration of non-overlapping nuclei. If the blobs are extracted as such with the intricate edges, they are prone to overfitting. Hence, the patches are selected in such a way where all the nuclei can be accommodated. Once the centroids of the blobs are detected, a nucleus centered square patch of 33×33 is considered. The nuclei square patches of size 33×33 will cover most of the non-overlapping nuclei using Algorithm 2, depicted in Fig. 5.
Transfer Learning includes fine-tuning, training the model is quicker and easier when compared to building a model from scratch with random weights. In our work, the pre-trained State Of The Art (SOTA) models VGG16 [20], ResNet50 [21] and InceptionV3 [22] are used for feature extraction process.
These pretrained networks are utilized as they have yielded better performance with both natural and medical images. VGG16 models when applied on medical data have shown promising results and it is quite simple to implement. Simonyan et al. [20] proposed VGG16, composed of 13 convolutional layers, five maxpooling layers and three fully connected layers or dense layers. The convolutional and dense layer involves learning weights and are considered as the learnable layers. In convolutional layers, the model utilizes filters or kernels of 3×3 with Rectified Linear Units (ReLU) as activation function. The activations in the dense layers extract the trainable parameters with 4096 nodes. As the network grows deeper for a better precision it is quite tedious to optimize. With its defined architecture, ResNet50 addresses this limitation with its 50 layered CNN devised by He et al. [21] to classify the images in ImageNet dataset. The input size of images for ResNet is 224×224, with 64 filters in the convolutional layer of size 7×7 along with a stride of 2. This is followed by a maxpooling layer of 3×3 with stride of 2. The blocks comprise of three convolutional layers with residual connections, which sum up the actual input to output of the convolutional block. The architecture has 1000 neurons in its dense connected layer for a better classification. Amongst the several versions of Inception, InceptionV3 is an optimized model proposed by Christian Szegedy et al. [22] includes factorized convolutions, smaller convolutions, asymmetric convolutions, auxillary classifier and grid size reduction to develop the architecture. The 1×1, 3×3 or 5×5 convolutions assists feature pooling to extract the maximum number of features from each convolution layer. However, in all the models, dense layers are replaced with a Global Average Pooling (GAP) layer, thereby control overfitting by reducing the number of network parameters. Breast histopathology images comprises a variety of textures, shapes, and histology elements including cytoplasm and nuclei. Hence, the nuclei patches are extracted from the images and in order to extract deep representative features from the patches, an ensemble of three algorithms are employed. The nuclei feature extraction and classification process is illustrated in Fig. 2.
Nuclei feature fusion and classification
As a result of feature extraction, the feature maps of each nucleus patch extracted from the image are combined to form a single vector using p-norm pooling [8, 12] using Equation (4).
Several pooling strategies such as are tested on the obtained features. In general, the pooling strategy assists to reduce the training intricacies while employing the classifier. Further, the obtained feature vectors are further classified using a LightGBM [31] classifier, an open-source framework based on gradient boosting decision tree algorithm (GBDT).
Datasets
The ICIAR 2018 Grand challenge on Breast Cancer Histology images is an extended dataset [32] and the distribution of the images are tabulated in Table 1 and the sample images are depicted in Fig. 3.
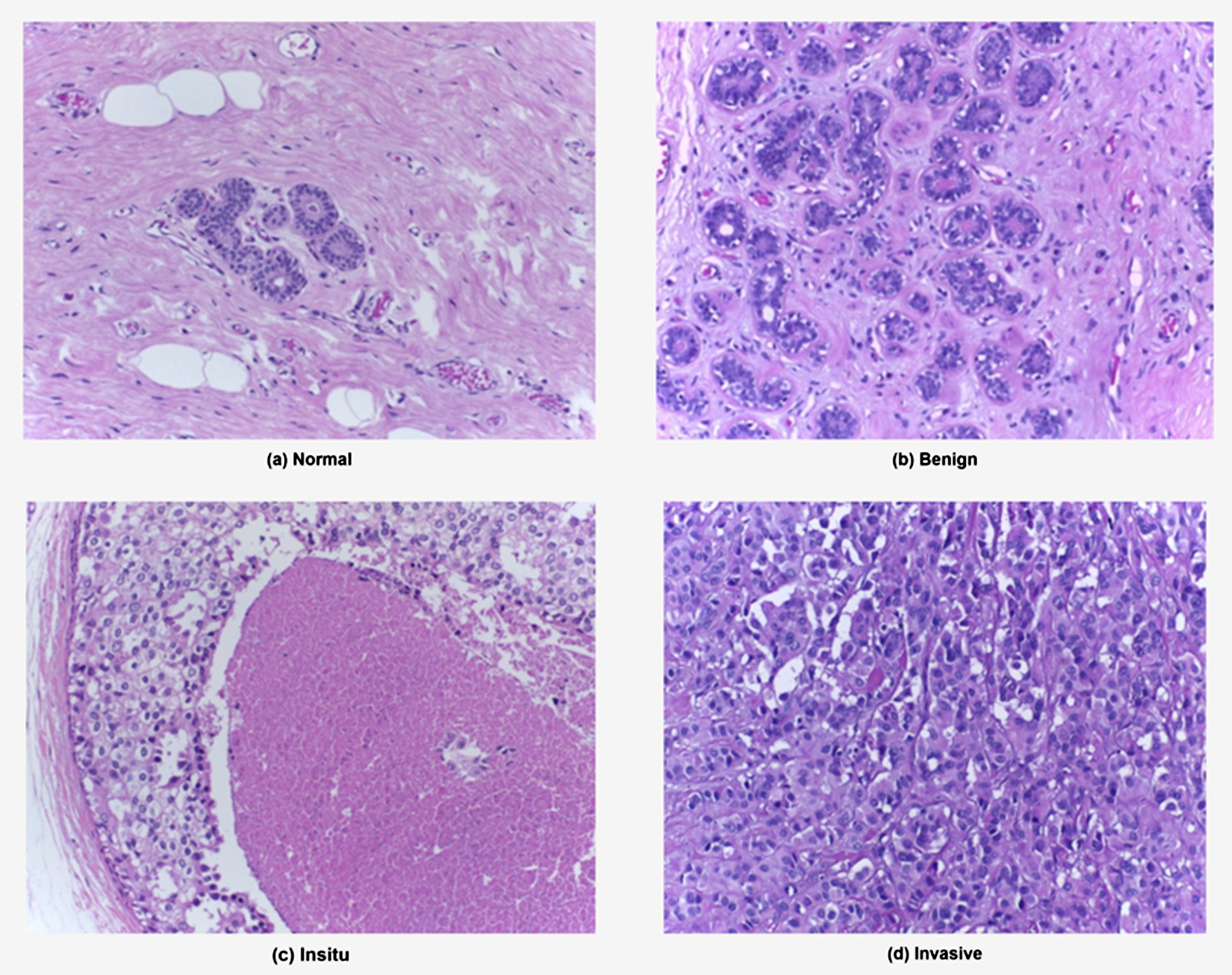
Illustration of samples from ICIAR 2018 dataset, (a) & (b) belong to non-carcinoma and (c) & (d) to carcinoma classes.
ICIAR 2018 dataset
The proposed model is executed on a workstation with six core Intel processor of 3.9GHZ, 32GB DDR4 RAM and NVIDIA GEFORCE RTX 11GB GPU. The proposed work is evaluated on ICIAR2018, a benchmark dataset for breast histopathological images. From the ICIAR2018 dataset, there are a total of 22,105 non-overlapping nuclei patches are extracted, out of which carcinoma nuclei patches are 13,185 and non-carcinoma patches are 8,920. The data augmentation is an indispensable task where the patches are rotated in X-Y plane with
The performance of the proposed model to classify the breast histopathology images into four classes as normal, benign, insitu and invasive are empirically analyzed using metrics such as accuracy, precision, sensitivity, and specificity.
The formulae for the performance metrics are given in Equation (5–8).
Finally, the confusion matrix is a contingency table representation between the actual and the predicted outcome which provide a better visualization of the model performance.
The hematoxylin stain normalized image, Ih is obtained from the image for a better nuclei extraction and depicted in Fig. 4.
The edges of the nuclei are highlighted in the obtained images using gamma correction method. The nuclei are captured prominently if the images are preprocessed using gamma correction which is illustrated in Fig. 5(a). Using our nuclei blob detection algorithm, the non-overlapping nuclei patches are extracted for feature extraction using non maximum suppression technique. The detected blobs are illustrated in Fig. 5(b). A sample of the overlapped and non-overlapped nuclei blobs are shown in Fig. 5(c) & 5(d) .
The features of the nuclei patches are extracted using pretrained SOTA models InceptionV3, ResNet50 and VGG16 using transfer learning approach. The fully connected layers are removed in all pre-trained SOTAs, and the global average pooling technique is introduced for accepting images of arbitrary sizes and average of each feature map is generated. It also provides a determined size of feature vector of length equivalent to number of channels of the feature map. Thus, the InceptionV3, ResNet50 exhibits one dimensional feature vector of 2048 and VGG16 of 1408. The obtained feature descriptors are merged to form descriptors for each image using p-norm pooling technique, where p is 3. The data are again processed with five different seeds, thereby training around 150 gradient boosting models (10 number of folds×5seeds×3 CNNs).
Further, a FusedModel is obtained by combining the predictions of three different pre-trained models, seeds and are cross validated across all the 10 folds for multi-class classification. The comparative study of binary and multi-class classification of the images using the proposed model are studied.
Figures 6 & 7 showcase the trends in the performance of the binary and multi-class classification across all 10 folds.
The confusion matrix for the image-wise classification of binary and multiclass classification is depicted in Fig. 8. The binary classification comprises of carcinoma and non-carcinoma classes, whereas the multi-class involves normal, benign, Insitu and Invasive classes.

Represents the performance metrics of binary class classification for all 10 folds using cross validation.
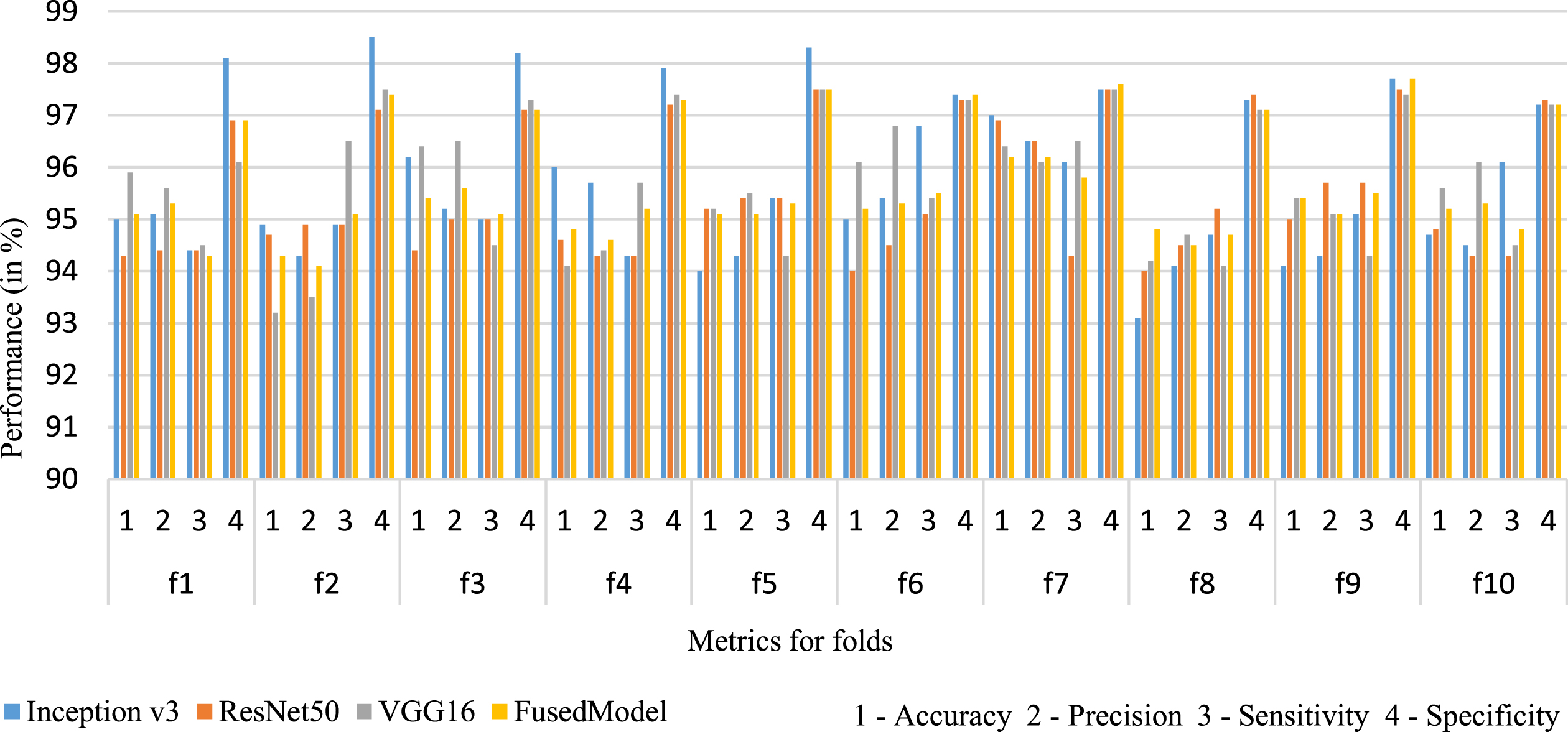
Represents the performance metrics of multi class classification for all 10 folds using cross validation.

Confusion matrix of binary class and multi-class classification.
The classification accuracy for binary classification is 98.3%. For multi-class classification, the average classification accuracy across all folds is 95.1%.
The performance metrics of the image-based classification for four classes using the fused model are tabulated in Table 2. From the table, it is inferred, the fused model achieved an accuracy of 95.1% and outperformed other state of the art methods. Similarly, the binary classification is performed and are tabulated in Table 3. From Tables 2 and 3, the average performance metrics of binary classification is high when compared to multi-class classification. This is due to the indistinguishable features between the normal and the benign classes.
Performance metrics (in %) for four class image level classification using proposed method
Performance metrics (in %) for two class image level classification using proposed method
Hence, it is evident from the multi-class confusion matrix, that the normal image was labelled as benign. Among the multi-class classification, the insitu and invasive showed a better performance when compared to the benign and normal. However, in binary class classification there is an increased performance as both the normal and benign are of same noncarcinoma class.
The experiments of the proposed nuclei-based patch extraction model using three different pretrained CNN networks in ombination with LightGBM are performed. The mean percentage of accuracy, precision, sensitivity, and specificity are tabulated in Table 4 and Table 5 for both the binary and multiclass classification of the individual models. While employing the pretrained CNNs on the extracted nuclei patches, InceptionV3 have outperformed the other two models with 93.9% and 97.1% accuracy for multiclass and binary class respectively. VGG16 is made of simple structure has achieved significant performance in extracting the low-level representations. However, with complex medical images, learning the underlying patterns and extracting high level features needs at most care. Hence, InceptionV3 involves pointwise convolutions along with different filter sizes in the convolutional layers assists to learn the complex patterns of the nuclei patches. ResNet50 achieved a better performance compared to VGG16 and extracted the features which contributed for a better classification of the nuclei patches. Hence, the features extracted by all three pretrained models are fused together to achieve an improved classification accuracy.
Performance comparison of the different pretrained models on image level multi class classification
Performance comparison of the different pretrained models on image level multi class classification
Performance comparison of the different pretrained models on image level binary class classification
Comparison of the proposed method with SOTA’s on ICIAR 2018 dataset
As InceptionV3 achieved better performance compared to the other models, this model is used to experiment different feature pooling strategies on the extracted nuclei patches. Figure 9 compares the accuracy of average pooling, square pooling, and the 3-norm pooling approaches. The relative accuracies are plotted as a bar graph and from the graph it is evident that the 3-norm pooling approach achieved the best accuracy with 93.9%. Thus, the p-norm pooling approach with p as 3 is considered for feature fusion across all the experiments. In disease diagnosis, even a slight increase in accuracy is essential. While designing a classification model for breast tumor diagnosis, it is essential to avoid misdiagnosing a benign as malignant or vice versa. Thus, to achieve a better result, it is indeed worth to employ feature fusion and use a fused model though there is an acceptable increased computation time.

Accuracy comparison of different pooling approaches for binary and multiclass classification.
For grid-based selection method, the images are stain normalized using [11] and preprocessed using gamma correction. The grid-based sampling is applied and patches of 512×512 are extracted from the images. Approximately 35 patches are extracted from each image with overlap. Data augmentation explained in section 3.1 is applied on these images. The augmented images are further fed to pretrained models and features are extracted. The extracted features are fused and classified using the techniques discussed in 2.3. The accuracy obtained as a result of grid-based sampling for binary and multi class classification are 94.5% and 91.5%. whereas the nuclei-based patch selection approach using Algorithm 1 and Algorithm 2 was improved by 3.8% and 3.6% compared to grid-based approach. The precision obtained by the nuclei-based patch extraction for binary and multi class is 98.5% and 95% which is 4.5% and 3.5% enhanced than the grid-based models. This evidently showcase that the features extracted from the nuclei-based patches contribute more towards the discrimination of the tumor. The processing time for nuclei-based technique is observed to be lesser than the grid-based approach.
Comparison of proposed method with SOTAs on ICIAR 2018 dataset
The proposed approach is compared with the existing SOTAs and is illustrated in Table 5. From the table, it is evident that majority of the works have considered grid-based patch extraction. Amongst the existing works, the highest accuracy for binary classification at image level is 93.8% [12] and 90% for multi class classification [14]. In paper [7], the authors employed a smart patch technique by choosing patches with high density nuclei and achieved an accuracy of 84% for binary classification. The proposed model outperforms the existing works with an accuracy of 98.3% for binary and 95.1% for multiclass classification proving that the feature extraction from the nuclei-based patches is successful.
Conclusion
CADs play a remarkable role in an accurate and precise diagnosis of medical images. With respect to histopathology images, accurate classification assists to identify the type of the cancer. Deep learning automatically infers and learn feature representations for classification of breast tissues. However, there are certain constraints which have a great impact on the accuracy and the time taken for processing the tissues. To address these issues, this research work proposes a novel nucleus-based patch extraction for an accurate automated classification of the histopathology images. The cancer diagnosis and their types are purely based on the characteristics of the nucleus. The highlighted nuclei patches which are obtained because of the pre-processing the histopathological images are fed to the pre-trained models for the extraction of discriminative features. The LightGBM is employed on the obtained features from three different pre-trained models and has achieved an accuracy of 98.3% for binary class and 95.1% for multi-class classification. In future, the model can be experimented on different tumor histopathological datasets. With the advancement of computation resources and deep learning techniques, data augmentation of the images can be achieved using Generative Adversarial Networks (GANs) and can further be extended to study the impact of attention models on these histopathological images.