
Abstract
Feature Selection (FS) for Sentiment Analysis (SA) becomes a complex problem because of the large-sized learning datasets. However, to reduce the data dimensionality, researchers have focused on FS using swarm intelligence approaches that reflect the best classification performance. Crocodiles Hunting Strategy (CHS), a novel swarm-based meta-heuristic that simulates the crocodiles’ hunting behaviour, has demonstrated excellent optimization results. Hence, in this work, two FS algorithms, i.e., Binary CHS (BCHS) and Improved BCHS (IBCHS) based on original CHS were applied for FS in the SA field. In IBCHS, the opposition-based learning technique is applied in the initialization and displacement phases to enhance the search space exploration ability of the IBCHS. The two proposed approaches were evaluated using six well-known corpora in the SA area (Semeval-2016, Semeval-2017, Sanders, Stanford, PMD, and MRD). The obtained result showed that IBCHS outperformed BCHS regarding search capability and convergence speed. The comparison results of IBCHS to several recent state-of-the-art approaches show that IBCHS surpassed other approaches in almost all used corpora. The comprehensive results reveal that the use of OBL in BCHS greatly impacts the performance of BCHS by enhancing the diversity of the population and the exploitation ability, which improves the convergence of the IBCHS.
Keywords
Introduction
Sentiment analysis, also called opinion mining is a branch in Natural Language Processing (NLP) domain. It recently attracted researchers ‘attention because of the development and the prosperity of social media. SA aims to detect the sentiment polarity towards a specific subject in a given source of information [1]. It can be applied in several areas, including the analysis of emotions, analysis of public opinion trends, customer feedback, and others [2].
SA from Text (SAT) can be viewed as a text classification problem that classifies different instances (texts) into several predefined classes [1]. SAT consists of four main tasks; text pre-processing, Feature Extraction (FE), Feature Selection (FS), and classification [3]. Generally, data obtained from the Internet, especially social media, is highly unstructured, making SA difficult for machines, which require a pre-processing stage including tokenization, stop word removal, POS tagging, etc. [4]. Because the machine does not understand the text in its original form, the FE serves to convert the pre-processed text to value vectors using several techniques, including bag of words, word embedding, Term Frequency-Inverse Document Frequency (TFIDF), and others. The FS task aims to reduce the dimensionality of data [5], i.e., decreasing the number of features in the feature vector extracted from the original text that may improve the SA performance. Finally, each text is annotated with a sentiment class (positive or negative) and used for learning a classification model. The obtained model will be subsequently used to recognize the text’s sentiment class. In this work, we focus on swarm intelligence-based FS in SA.
The popularity and reach of social media have facilitated the way to generate vast and ever-growing information, generally in the form of comments. Therefore, SAT and other text analysis tasks generally depend on datasets collected from social media with high dimensionality (a large number of features)(many features). Some of these features are irrelevant, redundant, or noisy [5], influencing the classifier quality and decreasing the speed of the learning process. Therefore, dimensionality reduction is the main challenge in SAT that may improve their performance by selecting the most significant features related to the sentiment polarity. Moreover, an efficient FS method can help remove irrelevant and redundant features that may give quick classifier learning and better performance.
FS methods are classified into three main categories, namely filter (feature ranking), wrapper (subset feature selection), and hybrid methods [6]. Filter methods aim to assign scores to features using information theory and distance measurement and remove all features that did not get enough scores. In the wrapper methods, the space of possible subsets of features is explored to search for the best subset. Wrapper methods are generally computationally expensive compared to filter methods but can usually obtain better performance [7]. In this paper, we focused on a wrapper method, in which we consider the feature selection as a combinatorial optimization problem that is an NP-hard optimization problem [8]. This problem can be resolved using meta-heuristic algorithms that can find satisfactory solutions over a reasonable time [9]. Many researchers have applied swarm intelligence-based algorithms to address the FS problem in several areas [8], but no FS technique can tackle various FS problems. Hence, this work needs to develop a new efficient swarm-based algorithm for FS in the SA domain.
Several studies have been carried out for the using of swarm intelligence methods to improve the performance of the optimization algorithms. However, in most cases the researchers are interested in improving the exploitation and exploration phases, Crocodiles behaviors consist of encircling and hunting the prey [10]. the exploration (global Search) and exploitation (local search) phases of the (CHS) are inspired by the encircling mechanisms, These mechanisms are mathematically modelled to present the CHS and perform the optimization processes. CHS is a population-based and gradient-free method, so it can be used to address complicated or straightforward optimization problems subject to specific constraints [10]. The convergence of the CHS algorithm is ensured by the Balancing between exploration and exploitation in two phases. So in our work we used the Crocodile Hunting Strategy (CHS) which is a recently introduced swarm-based optimization algorithm. It has a promising optimization capability in resolving the feature-clustering problem [11]. With the few tuned parameters of CHS, their simplicity, and their flexibility, we are motivated to propose a binary CHS to tackle the FS problem in SA as a binary optimization problem. We also proposed an improved binary CHS using the Opposition-Based Learning strategy (OBL) to improve the performance.
In this work, the main contributions are (1) the introduction of a BCHS for FS problem in SA. (2) the application of OBL strategy in the Improved binary CHS (IBCHS) to improve the exploration capability and the convergence rate of the IBCHS (3) The comparison of the IBCH to other recent FS approaches based on six well-known corpora in the SA area (Semeval-2016, Semeval-2017, Sanders, Stanford, PMD, and MRD).
The rest of the paper has been organized as follows. Section 2 presents some preliminary details. Related works are presented in section 3. Section 4 and Section 5 present the proposed BCHS and IBCHS algorithms, respectively, and describe their application in FS for SA. The experimental results are discussed in Section 6. Section 7 concludes the paper and presents the future scopes of this study.
Related works
FS is an important research problem in SA because it influences the SA algorithms’ accuracy and efficiency [12]. Several works have been made for FS in SA using different approaches. The FS approaches can be classified into two main categories: statistical-based approaches and population-based intelligence approaches.
Statistical methods, also called filter methods, measure a score for each feature in the text based on statistical equations. Then using this score, the top-ranked features are selected, and the selected feature number must be initially predefined [13]. Many statistical methods are used for FS in text classification and SA, including Mutual Information (MI) [14], Information Gain (IG) [15], Chi-square (CHI) [16], Document Frequency (DF) [16], Gini Index (GI) [17]. And Minimum Redundancy Maximum Relevance (MRMR) [18]. The mathematical equations of several statistical methods are presented in [12].
However, these methods require a threshold value for the selected feature number, which is not easy to determine initially. In addition, it does not eliminate the redundancy features. Because of the growth of generated content in social media, client reviews, and comments, redetermination of the selected features’ threshold becomes difficult and can decrease the SA performance. Thus, intelligent FS methods, which select features without predefined threshold values, are essential.
Swarm Intelligence (SI) based methods [19] can be solutions for this purpose. SI algorithms are inspired by the collective intelligence that emerges through many agents’ cooperation in the space of solutions [20]. The intelligent comportment of SI is provided by the communication between agents and their environment to resolve large-scale optimization problems [21]. These algorithms search for the solution of each optimization problem in several iterations and take advantage of knowledge from previous iterations at each new iteration. The FS in SA is a global optimization problem because it searches a subset of features in a big size features set, which opens the path for using SI algorithms to reduce the selected features number and increase the SA performance.
In recent years, SI algorithms have succeeded in solving FS problem in various domains. However, that is no algorithm can tackle the FS in all domains. Hence, few swarm-based algorithms are used for FS in SA [22]. In [23], the authors used the Genetic Algorithms (GA) as optimizers in FS, tested their proposition on the product reviews corpus, and obtained an accuracy of 85%. Chen and al. [24] propose a chaos genetic algorithm for FS optimization in text classification. It considers the text as a bag of words, and a classification method is used to evaluate the selected feature subset. This approach outperforms all other compared methods in terms of accuracy.
In [25], Jin et al. propose an improved Particle Swarm Optimization (PSO) with SVM to FS in Chinese text classification. The improved PSO is applied in the FS step along with classifier SVM. Fudan University Chinese text classification balanced corpus is used to evaluate this approach. Chantar et al. [26] propose a binary PSO to select a feature set in an Arabic-language document. The obtained text classification results in accuracy using KNN is 94 %, which is more accurate than other approaches. In [27], the authors resolve the FS by applying GA and PSO in IG and Chi-square. They evaluate their propositions on the Reuters-21578 corpus, and the results show that the PSO-based algorithm outperforms all other approaches in classification precision.
Ahmed et al. proposed in [28] an FS method for text data using the ACO meta-heuristic. The proposed method was tested on a customer reviews corpus, and the KNN classifier was used for the selected feature evaluation. Kumar et al. [29] studied tweets from two benchmarked Twitter corpora (SemEval 2016 and SemEval 2017). It uses two swarm intelligence algorithms, namely, Binary Moth Flame (BMF) and Binary Grey Wolf (BGW), for FS in tweets categorization. The results show an improvement of 9.4% and 10.6 % in accuracy for BGW and BMF, respectively. In [30], the authors proposed a multi-objective-grey wolf-optimization algorithm for decreasing the error of KNN in the FS stage, and the neural network is the classifier stage. They evaluate this approach on three corpora, Polarity Movie Dataset (PMD), Sentiment140, and Sentiment140-2.
Kumar and Khorwal [31] used the firefly meta-heuristic for FS optimization and the SVM classifier to evaluate the selected sub-set of features on four Movie review and Twitter datasets. The obtained results indicate that the proposed approach outperforms the GA method. However, most of these algorithms, also has its own drawbacks such as the slow convergence and the ease of falling into the local optimum. For example in Ant colony algorithm initial pheromone is deficient and generally require a longer search times, and this method is prone to stagnation, namely search proceeds to a certain extent. The solution is almost identical for all individuals found. [32] another example, in drosophila algorithm is not suitable for solving the problem of the argument which is negative, because the taste density determination function can only process the argument which is positive. And in Firefly optimization algorithm the shortcomings of the low peak detection, slow convergence, solution inaccurate remains. To avoid these problems the researchers have interested in improving the exploitation and exploration phases,
CHS is a recent swarm-based optimizer; it shows good optimization capability compared to ACO, GA, PSO, and FA [33]. Therefore, in this current work, enjoying the benefits of CHS, we have applied the binary version of CHS to the FS problem in SA. An improved CHS is also proposed using the OBL to accelerate his convergence speed.
Background
This section presents the FS problem, the original CHS algorithm, and the OBL strategy.
Feature selection
In classification problems, the generated model is trained on a training dataset and evaluated on a test dataset. The training dataset consists of samples (rows) defined by the features number (columns) and a class feature. Some of these features are irrelevant, redundant, or noisy, which decreases the classification performance. FS aims to select a subset of features by removing irrelevant features to decrease the learning time and increase the classification performance. FS can significantly improve the comprehensibility of the SA models by generating reduced models [34].
Searching an optimal subset of features (combination of relevant features) from the original set of features is a combinatorial optimization problem described as an NP-hard problem [35].
The wrapper process for FS is an iterative procedure with two main steps: subset generation and subset evaluation. Intelligent optimization methods are required for the subset generation, while classifiers such as SVM, KNN, and others are used for the evaluation step.
Original CHS
The CHS is a recent population-based meta-heuristic proposed by Alireza Balavand [11] for resolving the feature clustering problem. It can solve optimization problems using swarm intelligence. The original CHS is inspired by the crocodile’s behaviour in nature that mimics the encircling mechanics (local search) and the hunting processes (global search) of crocodiles [11]. In CHS, Crocodiles are divided into two subsets when hunting; big crocodiles called chasers, and small crocodiles called ambushers. The chasers follow and chase fish toward the shore without catching them, whereas the ambushers wait in the shallow and try to snatch fish [11].
As with all swarm-based meta-heuristics, in CHS population (population of crocodiles) is randomly initialized for constructing the initial solutions. After the agents’ evaluation using a fitness function, the population is divided into chasers (50 percent of the population) and ambushers (50 percent of the population) according to their fitness value. The best agent is considered the leader chaser (Prey). Next, all agents start moving towards the target, but the chasers’ movement is different from the ambushers’ movement. The chasers move by using the chasing prey principle to explore the space of solutions. In contrast, the ambushers move by using the attacking prey principle to exploit the space of solutions.
Chasing the prey
The chasers follow the prey and direct it to the shallow area. The position of each chaser agent is denoted Xchaser and moves according the Equations (2).
Where dis is a distance between the prey and the i
th
chaser at iteration t,
The ambushers are waiting in the attacking area to catch the prey, followed by the chasers. Equations (3), and (5) simulate the movement of the ambusher agent for attacking the prey.
Where dis is a distance between the prey and the i
th
ambusher at iteration t,
Where apc is the average of chasers positions, and apa is the average of ambushers positions.
Where
OBL was firstly introduced by Tizhoosh [36]. It is a machine intelligence strategy that is used by artificial intelligence. It aims to get a better approximation for a current solution and its opposite by simultaneously calculating the solution and the opposite solution. More precisely, the OBL generates the opposite position of each agent in the population. Then, it replaces it with its opposite if the fitness of this later is better. Therefore, the OBL strategy has been successfully utilized to improve the performance of the population-based algorithm in several works [37], like PSO [38, 39], Ant Colony Optimization (ACO) [40], and ABC [41]. The excellence of OBL schemes is shown through mathematical proof in [42].
The OBL strategy [36] is defined for an optimization problem P as follows. Let a solution x ∈ [lb, ub] of the problem P, and a fitness function f() to evaluate each solution. The OBL is defined as follows: Generate the opposite Calculate f(x) and f( If f(
The opposite of a real value x is defined by the Equation (6) [36].
As presented above, the FS problem is considered a binary optimization problem, in which the features take only zero or one, therefore, lb = 0 and ub = 1. Thus, we defined the opposite of a binary value as in Equation (7).
The opposite of a binary vector is defined as follows. Let V=(x1, x2, . . . xd), d > 1, a d-dimensional binary vector, the opposite of V is denoted
SAT, modeled as Sentiment Classification (SC), categorizes the input text into two or more classes, generally (positive and negative). The proposed SC model has four phases: data pre-processing, FS using BCHS, and classification model generation using a selected supervised classification algorithm. Figure 1 represents the proposed approach steps.

General diagram of the proposed approach for FS in SA.
The pre-processing phase includes a crucial process that helps clean the dataset from noisy data, reducing the document size [43]. In this work, this phase consists of the following operations: tokenization, stop words removal and stemming.
Preliminary data cleaning phase
In this phase, we got rid of unnecessary parts of the data, converting all characters to lower case and removing punctuation marks.
Tokenization
During the tokenization process, the tokenizer splits the textual documents into smaller units, i.e., the tokens. Tokens can take the form of words, numbers, or punctuation marks. The NLTK library has been used in this work for tokenization of all tested corpora.
Stop words removal
Stop words are common words in a language without sentiment polarity information. After the tokenization step, the words obtained can be deleted if they exist in the stop words list. By removing these words, we remove the low-level information from our text in order to focus on the vital information. Thus eliminating these words can help to simplify the word vector space without affecting the sentiment polarity of the document. The English NLTK’s list of stop words is used in this work.
Stemming
Stemming is a NLP technique that lowers inflection in words to its word stem [44]. The importance of stemming is that the different forms of a word together with their stem share, usually, the same sentiment orientation in a given context. The Porter stemmer is used in this work.
Feature extraction
The FE phase is among the important phases in SA that transform an unstructured text document into a structured one, i.e., a set of features. So, the structured document can be easily processed by the classification algorithms [45]. Term Frequency Inverse Document Frequency (TF-IDF) [42] is a good technique for text FE by converting the text into a vector space representation [46]. It evaluates the weight (importance) of a word W in a text document D based on word statistics calculated using the three following equations.
Where TFW,D is calculated using Equation (10), which refers to the frequency of the term W in document D, and IDFW,D denotes the inverse document frequency of the word w and is calculated using Equation (11).
The CHS is a recent algorithm that finds good results in solving the feature clustering problem, which motivates us to introduce a binary version of the CHS and use it to resolve the FS problem in SA. To the best of our knowledge, CHS has not yet been applied to the FS problems. In this subsection, we present our proposed Binary CHS (BCHS) and all the required details of its application to the FS problem.
Because the original CHS is designed to deal with the continuous problem, and the FS in SA is considered a binary optimization problem, CHS should be adapted to the FS problem by converting it to binary form. Two issues should be considered for applying any meta-heuristic algorithm for binary optimization problems: the agent’s position (solution) coding in binary space with the adaptation of the position’s update equations. Second is the definition of a fitness function to evaluate agents’ positions.
Binary CHS solution encoding and position’s updates
In the original CHS algorithm, the crocodile’s positions are randomly and uniformly distributed between the lower and upper bound values. Then, each agent moves in the solutions’ space through continuous-valued positions. For the FS problem in SA, the lower and upper bound are zero and one, respectively. However, in the FS problem case, since the problem is to select or not a given feature, then the solutions’ space is modeled as a D-dimensional binary-valued, where D is the feature’s number in the TF-IDF dataset (Matrix). In this paper, a binary vector V with a length D represents an FS solution (sub-set of features). If V[i] is equal to one, the i th feature will be selected; otherwise, it is not selected. Therefore, a transformation of continuous values to binary ones is necessary after the agent’s position initialization and after the position updates.
One of the most known methods to convert a continuous algorithm to a binary version without modifying its structure is to use Transfer Functions (TFn) [47]. There are several S-shaped and V-shaped functions used in the literature. The sigmoid TFn (S-shaped) shows the best results in converting the original PSO to binary PSO [48] and in several recent algorithms [47] that motivate us to use it in this paper to transform the continuous CHS algorithm to binary CHS. The sigmoid TFn presented in Equation (12) serves to define a probability for updating a real value
Where
After that, the new real position is calculated using Equation (2) for chasers and Equation (5) for ambushers. By using sigmoid TFn, a binary value of each real element in the new position can be calculated by using Equation (13).
Where
Therefore, Equation (13) can provide a binary vector from a real vector position of each crocodile (agent) which stands for the features’ presence or absence. An example of encoding; agent, real vector, and binary vector is presented in Fig. 2.
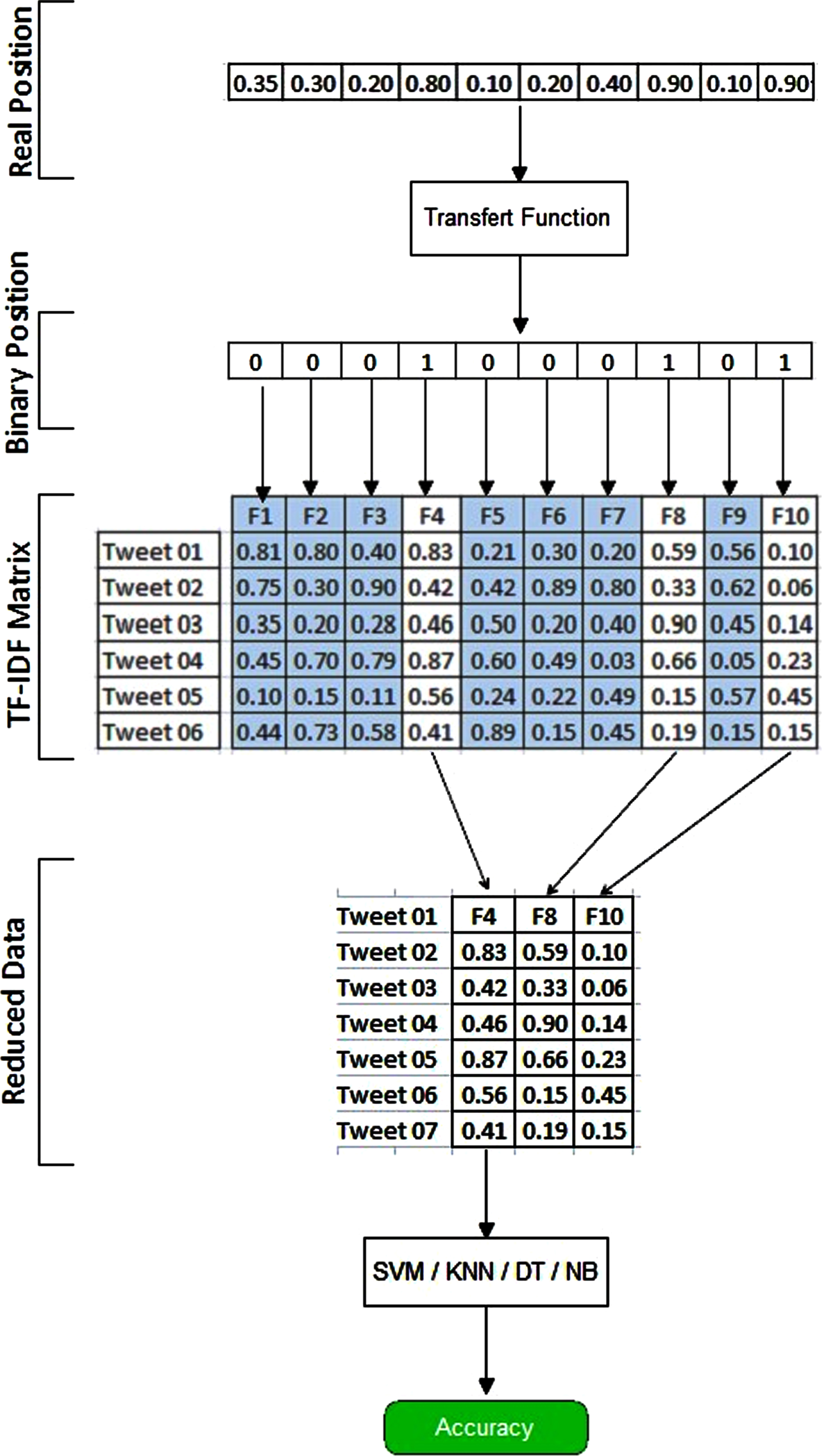
Example of encoding agent.
To propose any binary meta-heuristic for the FS problem, it should define the fitness function to evaluate the quality of each solution (feature sub-set).
In this work, a classification algorithm is called for feature subset evaluation. Several classification algorithms can be used for the solution evaluation, but in the comparison of the proposed approach to state-of-the-art approaches, we choose SVM because it is commonly used and has great success in text classification [12].
Because the objective of any FS method is to maximize the accuracy and minimize the number of selected features, we have used these two objectives in the fitness function design as presented in Equation (14).
Where Acc represents the accuracy while using a feature subset X, SF is the selected features number, D is the total number of features in the original TF-IDF dataset, and α is a number in the range [0,1] used to represent the weighting of the two objectives in the fitness function.
The pseudo-code in Fig. 3 presents the outlines of the FS approach in SA based on the BCHS algorithm.

Pseudo-code of the BCHS algorithm with TFn.
After the algorithm’s parameters initialization, the initial agents’ positions are randomly generated in line (7). After that, their binary value and the fitness are calculated in the main loop of the algorithm in lines (8-11). In lines (12-14), the population is divided into; chasers (the best 50% of crocodiles) and ambushers (the remaining 50%). The fittest crocodile (agent) in the chasers is the prey agent. The main loop is repeated according to the iterations’ number of the algorithm (line 15). In this loop, α is a randomly generated number between 0 and 1. Afterward, the position of each chaser agent is updated in lines (17-23). The same process is repeated for the ambusher agents in lines (24-30). In line 31, the two sub-populations (chasers and ambushers) are grouped to form the new population of the current iteration of the algorithm. The binary value and the fitness of all agents in the new population are calculated in lines (32-35). In lines (36-38), the new population is redevised into the chaser population (the fittest 50% of agents), and the ambusher population (the remaining 50% of agents), the fittest agent in the chaser population is the prey. Finally, in line 40, the algorithm returns the fittest agent as the solution to the FS problem.
When the BCHS algorithm is called to the FS problem, we notice that the obtained accuracy is acceptable, but the algorithm converges slowly to the best solution. On another side, OBL has been recently called in many population-based optimization algorithms to increase their convergence speed [49–51]. The convergence speed and global searching performance of each swarm-based algorithm are affected principally by two main properties: the quality of initial solutions and the displacement strategy [52]. Therefore, according to the promising results obtained by the combination of OBL with these population-based optimization algorithms, and to enhance the BCHS’s convergence, an Improved BCHS (IBCHS) is proposed based on the OBL strategy to enhance the classification accuracy on the one hand and the convergence speed on the other hand. To achieve this aim, the OBL strategy is called in the two phases of the IBCHS algorithm: initialization and displacement.
OBL-based initialization
Since the BCHS generates the initial population randomly, the population diversity becomes low, which decreases the exploration property. Therefore, we have called the OBL strategy in the initialization phase to overcome this shortcoming by improving the initial population’s diversity.
The main steps of the IBCHS initialization proceeds in three steps, as follows:
Step 1: generate N agents randomly.
Step 2: calculate the opposite of each agent using Equation (8).
Step 3: evaluate the fitness of each agent and their opposite. Afterward, the fittest one is selected and added to the initial population.
OBL-based displacement
The call of the OBL in the displacement phase in IBCHS may enhance his exploration ability, which helps it avoid trapping in local optimum. We distinguish two cases in each new iteration of BCHS: Firstly, if the best agent (prey) improves its fitness, then the IBCHS proceeds with the same principle of BCHS for agent displacement strategy. Whereas, in the case where the prey does not improve his fitness, we propose to modify the ambushers’ displacement strategy as follows: Because the ambushers are responsible for the exploitation, then the exploitation of ambushers of a non-improved position makes no sense. For this, we have introduced a new displacement strategy of ambushes by calling the OBL strategy to make a possible effective displacement and explore another search space. Then, the ambusher’s OBL-based displacement may increase the algorithm’s exploration and prevent it from falling into the local optimum. The pseudo-code of IBCHS is described in Fig. 4, where Xi denotes the ith original agent’s position and

Pseudo-code of the IBCHS algorithm.
The first loop in lines (6 to 12) generates the initial population randomly. First, a population is randomly generated in line (7). Then the opposite position, the binary value, and each agent’s fitness in the initial population are calculated in lines (8,9, and 10), respectively. Next, in line (11), the algorithm selects the best between the agent’s position and its opposite position. The variable previous_fitness is used to store the prey agent’s fitness in the previous iteration and initialized by zero in line (13). In the main loop of IBCHS, lines 14 to 43 serve to generate a new generation at each iteration; First, in lines (15-16), the population is divided into chasers (the best 50% of the population) and ambushers (the remaining agents).
In lines (17-18), the fittest agent is the prey, and its fitness is stored in the variable fitness(X_Prey). A random number α is generated in the range [0, 1] in line (19). The inner loop in lines (20 to 26) updates the chaser’s positions. After calculating the distance between the chaser agent and the prey, the new chaser’s position is generated according to this distance using Equations (2.1) and (2.2).
The second inner loop in lines (27 to 36) begins by measuring the distance between the ambusher agent and the prey, and then updates its position as follows: if the calculated distance is less than α, it updates its position according to the Equation (5.1). Otherwise, it compares the fitness value of the prey in the current iteration and the previous iteration (previous _fitness). If the prey improves his fitness compared to the previous iteration line (32), it uses Equation (5.2) to update his position. Otherwise, the prey is considered as fallen into local optimum; then, the ambusher updates his position using the OBL of his current position for eventual new space exploration. In line (37), the variable previous_fitness is updated. Then in line (38), the two sub-populations, chasers and ambushers, are grouped into one population. The binary value and the fitness of each agent in this population are calculated in lines (40 and 41), respectively. Finally, in line (44), the algorithm returns the fittest agent as the best solution.
This section is divided into four main subsections. The first subsection describes the used datasets. The second subsection presents the used evaluation metrics for evaluating the proposed and the compared approaches. The third subsection studies the comparison between the BCHS and IBCHS proposed approaches. The last subsection compares the proposed approach and other state-of-the-art FS approaches.
Datasets description
There are several datasets for SA studies. To evaluate the two proposed algorithms, six datasets have been used. The used datasets were selected due to their common use in literature. All dataset’s instances are randomly divided into 80% as the training sub-set and 20% as the subtest set. A brief presentation of these datasets is provided as follows.
SemEval2016 and SemEval2017
SemEval (Semantic Evaluation) is an ongoing series of international research workshops on natural language processing [53]. Its primary mission is the evaluation of semantic analysis systems. It is developed from the Senseval word meaning assessment series. Each year the workshop presents a collection of shared tasks in which different teams design computational semantic analysis systems. In the current work, we use the SemEval2016-Task4 [53] and SemEval2017-Task4 [53] because they are frequently used in several researches in the SA field [54].
Sanders Dataset
The Sanders Dataset [55], presented by Niek Sanders, contains approximately 5513 manually categorized tweets with four labels: 654 negative, 2503 neutral, 570 positive, and 1786 irrelevant. The Twitter API is used with four search terms: #apple, #google, #Microsoft, and #twitter. In our experiments, we are only interested in #apple tweets labeled positive and negative, i.e., about 163 positive tweets and 315 negative.
Stanford Dataset
The Stanford Twitter Sentiment Corpus [56] contains approximately 1.6 million tweets (800000 positive and 800000 negative) collected by a scrapper that calls the Twitter API for specific requests. In this paper, we only used sample data with 3000 tweets (1500 positive and 1500 negative tweets).
PMD
The Polarity Movie Dataset (PMD) [30] is composed of 1000 reviews, 500 positives, and 500 negatives. This data set is designed for SA studies. Their reviews are extracted from IMDB (Cornell movie review [57]).
Movie review data
The Movie Review Data (MRD) [58] was a collection of movie reviews taken from the website https://www.imdb.com/. It was collected originally in 202 by Bo Pang and Lillian Lee in their research on NLP. Nevertheless, it was updated and cleaned in 2004 and referred as v2.0. The MRD contains 1000 positive movie reviews and 1000 negative movie reviews. In Table 1, we present the characteristics of the datasets.
Datasets details
Datasets details
Three well-known metrics for data classification are used to evaluate the proposed approach, including accuracy, precision, and recall. Accuracy: is the ratio between the correctly classified texts and the total number of texts in the corpus. It is calculated as in Equation (15).
Where CCT is the correctly classified texts by the classifier, and TNT is the total number of texts in the corpus. Precision: measure the proportion of true positives with respect to both true positive and false positive rates combined. The precision value is calculated according to Equation (16).
Recall: measure the true positive rate. The recall value is calculated according to Equation (17).
Where TP (true positive) is text instances correctly identified as positive comments. FP (false positive) is the instances wrongly identified as positive comments. FN (false negative), is the instances wrongly identified as negative comments.
For the experimental setting, the particles number is set to 100. The parameter α in the objective function is set as 0.8. The proposed algorithms are implemented using python environment on 5th generation Intel® core ™ with a processor at 1.6 GHz and RAM of 8 GB.
Python was used for its suitability for intense mathematical programming (open and free), tremendous community support, and numerous open-source packages. Various python libraries were used: scikit-learn is used to implement various supervised classification algorithms on which the accuracy is determined after FS, NumPy (this library has mathematical functions that support the manipulation of large arrays and matrices). It is optimized to reduce the computation time required to manipulate large matrices. Its implementation involved large matrices for extracting features (with and without TFIDF), Pandas is the library used for data manipulation and analysis, and NLTK is a comprehensive collection of programs and libraries aimed at statistical and symbolic NLP for the English language. It has many inbuilt functions like Tokenization, Stemming, Lemmatization, etc.
The first experiment aims to compare the proposed BCHS-based FS and IBCHS-based FS, and highlight the influence of the OBL strategy-based improvement in the IBCHS. Then, the IBCHS is compared to some other approaches in subsection 6.4.
Figure 5 illustrates the convergence curve of the proposed methods on the six used datasets. The fitness of each solution is calculated using Equation (14) which incorporates the two essential criteria (accuracy and number of selected features). Generally, a best FS approach obtains a low number of features and a high accuracy value. In this experiment, the SVM is used to evaluate the fitness of the subset of selected features.
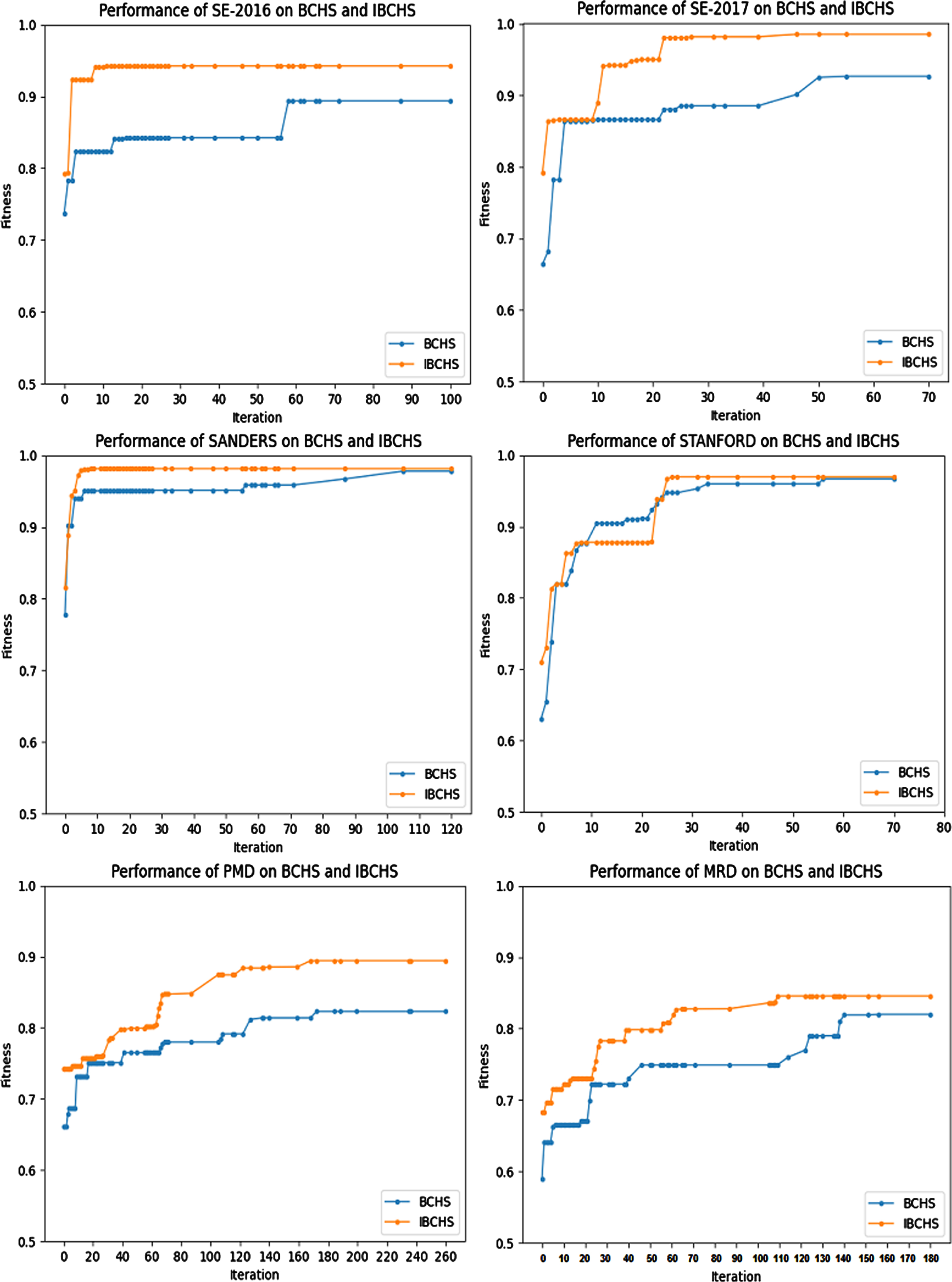
Comparison results between BCHS and IBCHS.
From Fig. 5, it is clear that IBCHS converged faster for all datasets. On Sanders and Stanford datasets, the CHS and IBCHS converged towards the same fitness result. However, in the four remaining datasets (SE-2016, SE-2017, PMD, and MRD), the IBCHS converged towards better fitness results than BCHS. This convergence may be interpreted by the trapping of the BCHS in the local optimum, which results poor fitness value. The good exploration ability of IBCHS is owing to the diversity of particles in the solutions space, which keeps IBCHS tracking for the global optimum.
To show the effectiveness of the IBCHS-based FS approach in comparison to BCHS-based FS, Tables 2 3 show their results based on various datasets. Notice that the best result is bolded and underlined.
BCHS and IBCHS results for different datasets
Selected features using BCHS and IBCHS for different datasets
In Table 2, we display accuracy (Acc), Recall (Rec), precision (Pr), and fitness (Fit) values of the proposed FS approaches on the six used datasets.
It is clear from Table 2 that the accuracy values and the fitness values showed significant improvement by applying IBCHS compared to BCHS. The FS using IBCHS achieved the best accuracy in three of six datasets and yielded the same accuracy in the remaining three. For the fitness measure, the FS using IBCHS achieved the best values in four datasets, whereas it shows the same values in the remaining two. IBCHS showed an average improvement of 6% in accuracy on the three datasets (SE-2016, PMD, and MRD) and 3.8% in fitness on the five datasets (all datasets except Stanford).
The good performance of the IBCHS can be explained by the fact that IBCHS well explores the space of solutions, guiding it to select the relevant features, thus improving the accuracy and the fitness values.
Table 3 presents the Number of Selected Features (NFS) results and the percentage of Features Selected (% FS) of the BCHS-based FS and IBCHS-based FS on the six used datasets. In Table 3, the best values are bolded and underlined. From Table 3, it is clear that the IBCHS-based FS achieved the smallest NFS and the % FS in all datasets. For all test datasets, BCHS and IBCHS obtain an average % FS of 27.41% and 10.61%, respectively. Then, IBCHS-based FS selects 16.8% smaller NFS compared to BCHS-based FS.
The results in Tables 2, 3 and Fig. 6 confirmed that the IBCHS-based FS reduces the feature number and improves the accuracy. Then it optimizes the FS problem in the two directions, feature size and classification accuracy, which demonstrate the effectiveness of IBCHS at selecting the relevant features. This result can be explained by the improvement of IBCHS in the exploration ability (global search) using the OBL strategy, which helps explore high-quality regions in the solution’s space.
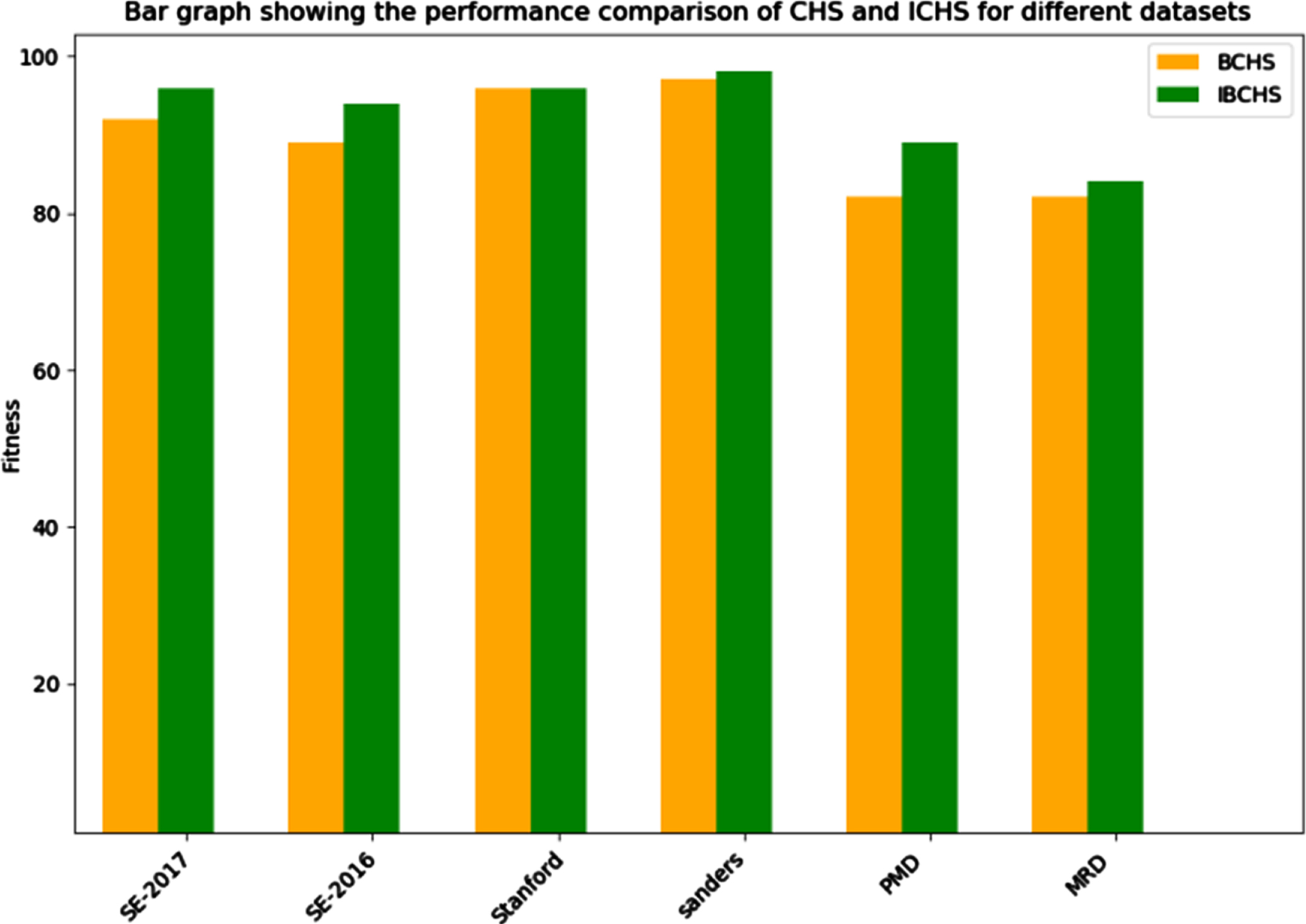
The performance comparison of CHS and IBCHS for different datasets.
To further evaluate the IBCHS performance, their convergence rates in terms of fitness value using four classifiers (SVM, KNN, NB, and DT) are depicted in Fig. 7. The convergence curves of different Table 4 shows the results of various sentiment classification algorithms (SVM, NB, KNN, and DT). These classifiers are used for evaluating the quality of the features selected subset by the IBCHS on all used datasets in this study. The results indicate that the value of the accuracy calculated with SVM is always greater than or equal to the best accuracy obtained by other classifiers.
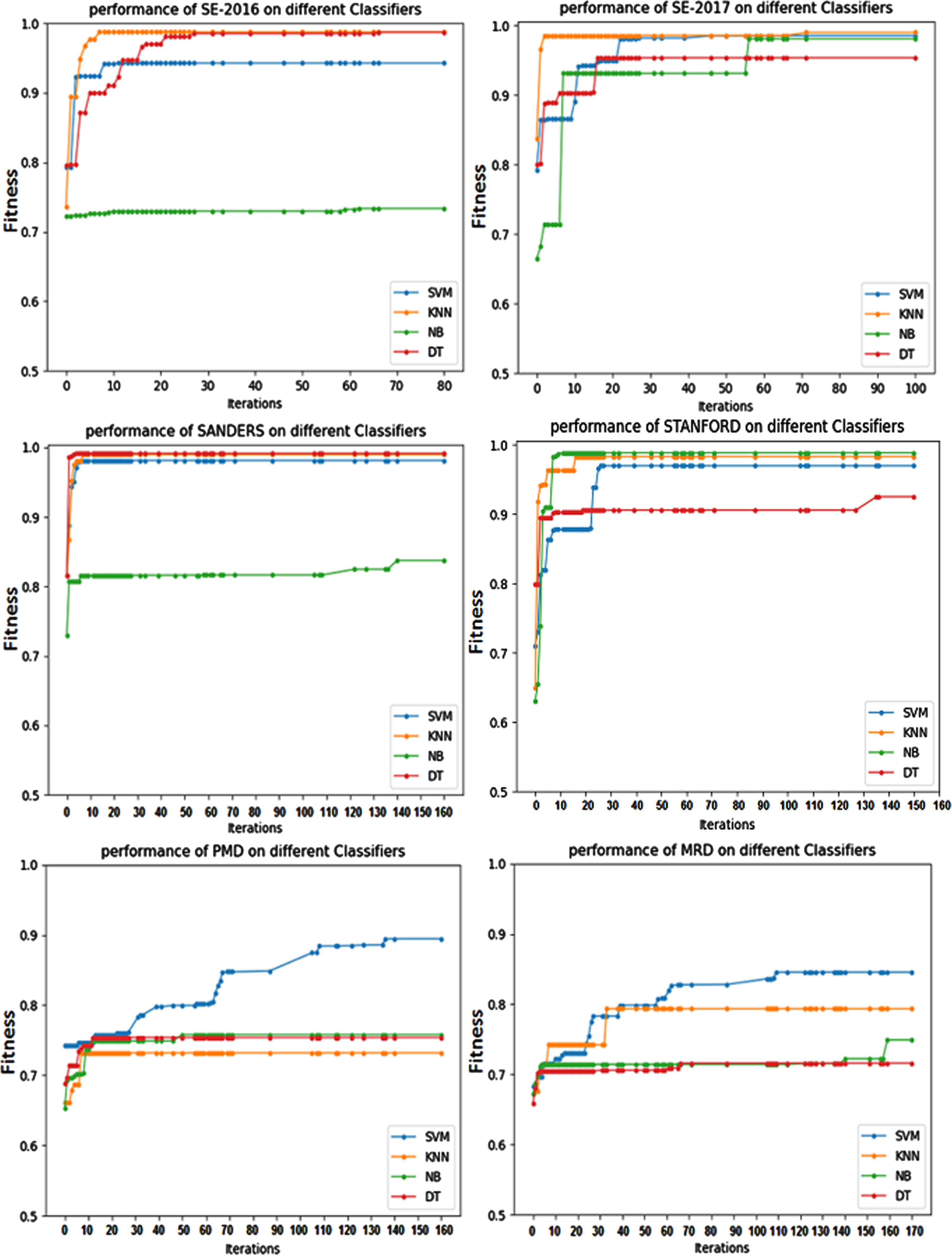
Convergence study of IBCHS-based FS using different classifier algorithms.
IBCHS’s results using SVM, KNN, NB and DT classifiers on the used datasets
Classifiers, show that the IBCHS-based FS approach is approximately converged after 66, 71, 140, 136, 140, and 159 iterations for SE-2016, SE-2017, Sanders, Stanford, PMD, and MRD datasets, respectively. Thus, the maximum iterations number can be set to 200 iterations in the rest experiments.
Thus, it is clear that the IBCHS can provide good results whatever the used classification algorithm with a slight outperformance of SVM. For this, the IBCHS with SVM is used compared to other FS approaches in the following subsection.
In this experiment, we aim to evaluate the competitiveness of the IBCHS for solving the FS problem in SA by comparing its performance against previous approaches on each test dataset. In the following experiments, the iterations number and the agents’ number of the IBCHS are set to 200 and 60, respectively.
Table 5 shows the accuracy (Acc), the % SF, and the increase in Acc and % SF of the IBCHS compared with BGW and BMF [19] over SE-2016 and SE-2017 corpora. The proposed IBCHS selects almost 15% of the total features and achieves 98% and 99% in accuracy for SE-2016 and SE-2017, respectively, outperforming BGW and BMF. More precisely, IBCHS increases the accuracy by 21.5% and 24.5% in SE-2016 and SE-2017, respectively. On the other hand, it reduces the % SF by 45.01% and 37.79% on SE-2016 and SE-2017 corpora, respectively. This considerable improvement can be explained mainly by the good exploration ability of the IBCHS by using the OBL strategy compared to BGW and BMF, which are apparently trapped in the local optimum.
Performance of the IBCHS-based FS compared to BGW and BFM for the SE-2016 and SE-2017 datasets
Performance of the IBCHS-based FS compared to BGW and BFM for the SE-2016 and SE-2017 datasets
Table 6 presents the accuracy (Acc) and % SF achieved values by the IBCHS-based FS approach and the IG-based FS approach [15] for the two datasets, Sanders and Stanford. The IBCHS obtain better results than IG, with 98% and 99% accuracy for Sanders and Stanford, respectively. As seen in the resulting values, our approach improved the accuracy by about 4% for Sanders and 19% for Stanford. Moreover, the improvement in the percentage of selected features is significant by about 45% and 37% for Sanders and Stanford, respectively.
Performance of IBCHS-based FS compared to IG for the Sanders and Stanford datasets
Table 7 depicts the obtained result by the IBCHS compared against the FFSVM, FS-BPSO, and MOWGOKB [30] on the PMD dataset. From this table, we remark that the IBCHS does not obtain the best accuracy; however, it achieved a good reduction in the selected features number by an increase of about 33%. This increase can be explained by the fact that the IBCHS uses the fitness function that combined the two objectives (accuracy and selected feature number). Thus, the IBCHS outperforms MOWGOKB in fitness value.
Performance of IBCHS-based FS compared to FFSVM, FS-BPSO and MOWGOKB approaches for the PMD dataset
Performance of IBCHS-based FS compared to Genetic-SVM and Firefly-SVM approaches for the MRD dataset
The accuracy performance on the MRD dataset is shown in Table 5, where the IBCHS outperforms the two compared approaches, Genetic-SVM and Firefly-SVM [31], by a slight improvement of 0,71%.
In summary, the results presented in this subsection show that the IBCHS-based FS approach has the best accuracies in five datasets from six and has the best-selected features number on all tested datasets compared to state-of-the-art FS approaches. These results provide evidence of the competitiveness of the IBCHS.
This good performance of IBCHS is due to the optimization ability of the original CHS [11] and the improvement applied to the BCHS. More precisely, the new population initialization method leads to good dispersion of the particles in the solutions space, which explore it well. In addition, the called OBL strategy in the update position may prevent the algorithm from tramping in the local optimum.
In this paper, we introduced two new binary variants of the CHS meta-heuristic, BCHS, and IBCHS, to tackle the FS problem in the SA field. A sigmoid transfer function was used to convert real vectors to binary ones in BCHS. The OBL strategy was used in the IBCHS algorithm to overcome its convergence to local optimum and improve its global convergence rate.
The proposed approaches have been evaluated using six well-known benchmark corpora in the SA field. In the first experiment, a comparison was made between the two proposed approaches to show the efficiency of the IBCHS. The IBCHS was compared to several state-of-the-art FS approaches in the second experiment.
Overall, the comparison results confirm that the IBCHS exhibit significant improvements in selected subset features and solution quality (accuracy) on almost all used corpora. Therefore, the IBCHS may be applied as a promising alternative to the FS problem and all other binary optimization problems. However, some improvements could be employed to IBCHS to further performance improvement, for example, combining the IBCHS with other meta-heuristics to tackle their advantages in the exploration and exploitation abilities.
Statements and declarations
Competing interests
The authors declare that they have no competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.