
Abstract
Background:
Image semantic segmentation can be understood as the allocation of a predefined category label to each pixel in the image to achieve the region segmentation of the image. Different categories in the image are identified with different colors. While achieving pixel classification, the position information of pixel points of different categories in the image is retained.
Purpose:
Due to the influence of background and complex environment, the traditional semantic segmentation methods have low accuracy. To alleviate the above problems, this paper proposes a new real-time image semantic segmentation framework based on a lightweight deep convolutional encoder-decoder architecture for robotic environment sensing.
Methodology:
This new framework is divided into three stages: encoding stage, decoding stage and dimension reduction stage. In the coding stage, a cross-layer feature map fusion (CLFMF) method is proposed to improve the effect of feature extraction. In the decoding stage, a new lightweight decoder (LD) structure is designed to reduce the number of convolutional layers to speed up model training and prediction. In the dimension reduction stage, the convolution dimension reduction method (CDR) is presented to connect the encoder and decoder layer by layer to enhance the decoder effect.
Results:
Compared with other state-of-the-art image semantic segmentation methods, we conduct comparison experiments on datasets Cityscapes, SUN RGB-D, CamVid, KITTI. The Category iIoU combined with the proposed method is more than 70%, and the Category IoU is as high as 89.7%.
Conclusion:
The results reflect that the new method can achieve the better semantic segmentation effect.
Keywords
Introduction
Environment sensing is one of the most basic and critical technologies in the research of intelligent autonomous mobile robot [1, 2]. It can identify obstacles and passable areas in the environment, which provides an important basis for intelligent decision-making planning and control implementation. According to the different sensors, the common methods of environmental sensing can be roughly divided into the following categories: the method based on ultrasonic wave radar [3], the method based on millimeter wave radar [4], the method based on infrared [5], the method based on laser radar, the method based on vision [6], and the method based on multi-sensor information fusion [7], etc,. Visual-based environmental sensing method is an important branch of environmental sensing research. Therein, image semantic segmentation based on deep learning is the frontier of visual-based environmental sensing, which is more difficult than image recognition and object detection [8].
Related works
Semantic segmentation requires that the fine edge of the object should be given, and the category of the object should be accurate recognized. Compared with image recognition and object detection [9, 10], the information provided by semantic segmentation is more accurate and rich, which can provide more comprehensive guidance for intelligent decision-making planning and control execution of the robot [11].
In 2015, Shelhamer et al. proposed a full convolutional network (FCN) for semantic segmentation [12]. Deep learning is applied to image semantic segmentation for the first time. The main idea is to remove the full connection layer in the classification task and replace it with full convolution. And it uses up-sampling to restore the feature map as the original size of the image to complete the end-to-end training. The idea of end-to-end training by up-sampling and restoring feature map has been widely used by semantic segmentation based on deep learning. This model is evolved from the early VGG (Visual Geometry-Group) model [13] with large model, many parameters, and unrefined segmentation edge. In the same year, Badrinarayanan et al. [14] proposed a more elegant network structure (SegNet), which divided image semantic segmentation into encoding stage and symmetric decoding stage. The features can be restored to the original position more accurately by using the records saved in the process of up-sampling and down-sampling in the coding stage. Unlike FCNs, SegNet also has a large number of learnable parameters at the decoding stage. Segnet has achieved good results in qualitative analysis and numerical accuracy in indoor and outdoor scenes, but the symmetric structure of the model determines the number of model parameters.
In 2018, Chen et al. [15] proposed a DeepLab image semantic segmentation model. In this model, features were extracted roughly through FCN, and then optimized by constructing full connection Conditional random field (CRF). Finally, the accurate segmentation results were obtained. DeepLab proposed a convolution operation called “Atrous Convolution", which increased the receptive field and improved the segmentation effect while the number of parameters remained unchanged. Although the idea of deep learning-based extraction feature and CRF optimization has greatly improved the segmentation accuracy, the two-stage operation leads to slow running speed and cannot achieve the effect of real-time segmentation. In 2017, Lin et al. [16] proposed the RefineNet model and designed the multi-path feature extraction structure to enhance the feature extraction effect and improve the semantic segmentation accuracy. Guo et al. [17] proposed a residual network model with full resolution. The model divided the input image into two input streams, one carried out ordinary pooling operation to enhance the recognition effect, and the other maintained full resolution to enhance the positioning effect. In 2019, Silberman et al. [18] improved the DeeplLab model and proposed the Deeplabv3+ model, which introduced the improved Xception structure [19] into the new model and adopted the hierarchical “Atrous convolution” to further improve the segmentation accuracy of the model. Gao et al. [20] proposed a Fast Bilateral Symmetrical Network (FBSNet) to alleviate the above challenges. Specifically, FBSNet employed a symmetrical encoder-decoder structure with two branches, semantic information branch and spatial detail branch. The Semantic Information Branch (SIB) was the main branch with semantic architecture to acquire the contextual information of the input image and meanwhile acquire sufficient receptive field. While the Spatial Detail Branch (SDB) was a shallow and simple network used to establish local dependencies of each pixel for preserving details, which was essential for restoring the original resolution during the decoding phase. Meanwhile, a Feature Aggregation Module (FAM) was designed to effectively combine the output of these two branches. It has the same structure of encoder-decoder. However, we have lightened the decoder. At the same time, we also add a dimension reduction module to reduce the amount of computation. Hu et al. [21] proposed a joint feature pyramid (JFP) module, which could combine multiple network stages with learning multi-scale feature representations with strong semantic information, hence improving pixel classification performance. Second, a spatial detail extraction (SDE) module was built to capture the shallow network multi-level local features and make up for the geometric information lost in the down-sampling stage. Finally, a bilateral feature fusion (BFF) module was designed, which properly integrated spatial information and semantic information through a hybrid attention mechanism in spatial dimensions and channel dimensions, making full use of the correspondence between high-level features and low-level features. This method did reduce the efficiency of computation, but the accuracy was affected. Gu et al. [22] proposed high-resolution vision transformer (HRViT) for semantic segmentation. It balanced the model performance and efficiency of HRViT by various branch-block co-optimization techniques. Specifically, it explored heterogeneous branch designs, reduced the redundancy in linear layers, and augmented the attention block with enhanced expressiveness. However, for dense prediction vision tasks, it did not perform very well. Liu et al. [23] adopted class-level feature alignment for conditional distribution alignment, as well as two simple yet effective methods to rectify the classifier bias from source to target by remolding the classifier predictions. This novel approach could undo the damage of the label shift problem in cross-domain semantic segmentation. But this work mainly focused on the close-set crossdomain semantic segmentation task. The open-set domain adaptation and partial domain adaptation setting were not considered.
Motivation
In summary, the above methods have the following problems: 1) the model is a sequential structure, there is no correlation between layers, and feature extraction is not sufficient, which affects the segmentation accuracy; 2) the model has complex structure, large number of parameters, difficult model training and slow prediction speed, which makes it impossible to achieve real-time segmentation effect; 3) The decoder and encoder are basically separated, and the shallow features cannot realize their values,which results in inaccurate pixel positioning and unrefined edge segmentation.
Aiming at the above problems, our motivation is as follows: a new neural network architecture RT-SegNet (Real-time Segmentation Network) is designed based on SegNet (deep convolutional encoder-decoder architecture), which realizes the end-to-end training and prediction from the original image to the semantic segmentation map. To solve the problem, we give the contributions for this paper. (1), a cross-layer fusion feature map (CLFFM) method is proposed to improve the effect of feature extraction. Firstly, the feature map size and the number of feature map channels are balanced across layers by pooling and 1×1 convolutional layer, and then the feature map is superimposed on channel dimensions. To solve the problem (2), the decoder is improved and a lightweight decoder (LD) structure is proposed to remove unnecessary convolutional layers, reduce the number of convolutional layers and output feature maps of decoder. Thus, the number of model parameters and the amount of calculation are greatly reduced, the speed of training and prediction is improved, and the difficulty of model training is reduced. To solve the problem (3), we design the convolution dimension reduction (CDR) method. It uses the convolution method with the three convolution layers to gradually reduce the channel of output feature graph. It connects the encoder and decoder for layer-by-layer. The high level feature and the low level feature are fused, so the decoder performance is enhanced, the semantic segmentation effect is improved, and the segmentation edge is refined.
Organization
This paper is organized as follows. In section 2, we introduce the traditional convolutional encoder-decoder architecture. Section 3 detailed states the proposed image semantic segmentation model. Experiments are conducted on section 4. There is a conclusion in section 5.
Traditional deep convolutional encoder-decoder architecture model
SegNet (deep convolutional encoder-decoder architecture) is a symmetric image semantic segmentation model based on deep learning proposed by Machine Intelligence Laboratory of University of Cambridge. Based on the VGG16 model [24], the model directly removes the full connection layer, and only retains the first 13 convolution layers. A symmetric up-sampling structure is designed to replace the original full connection layer. Figure 1 shows the overall architecture of the SegNet model. Figure 2 shows the implementation details of each layer.
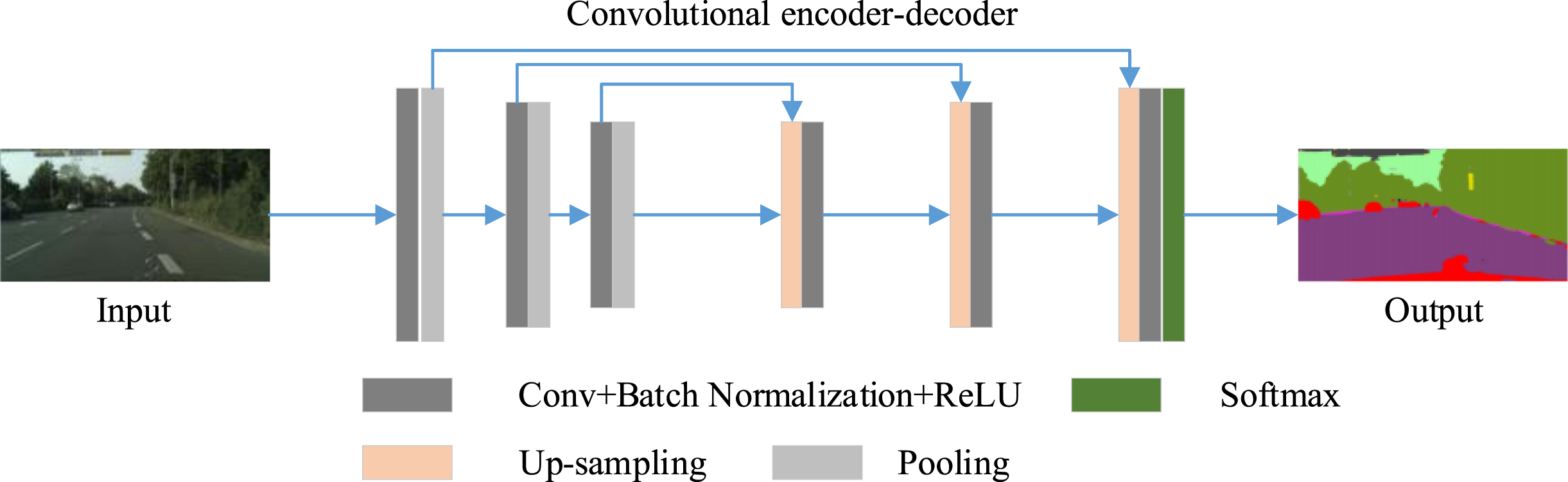
Original SegNet model.
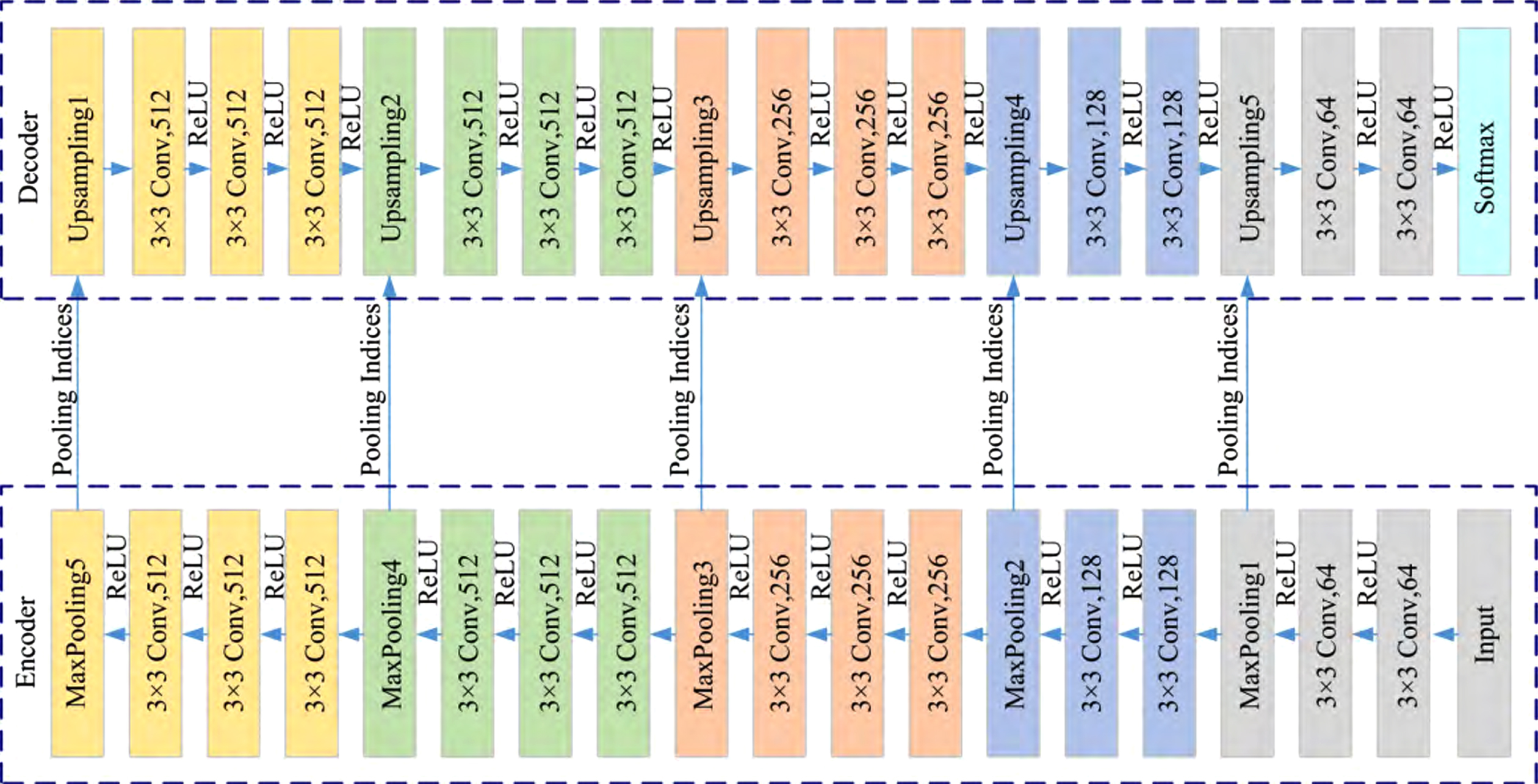
Detailed architecture of SegNet.
On the whole, the SegNet model is divided into two symmetrical parts: encoder and decoder. Each encoder layer corresponds to one decoder layer. There are a large number of parameters that can be learned at both encoding and decoding stages. The output of the decoder is eventually sent to the Softmax classifier for per-pixel C classification (C is the total number of categories). The category with the highest classification probability is taken as the current pixel category in the prediction. It can be seen from Fig. 1, each convolution layer is followed by a Batch normalization layer (BN) [25] and Rectified-linear unit (ReLU). This model executes five max-pooling operations with window size = 2×2 and stride = 2. Each pooling retains a pool token (Indices) that records the location of the obtained maximum value. At up-sampling, the corresponding values are restored to their respective locations using the Pooling Indices.
The overall framework of RT-SegNet is shown in Fig. 3. The model consists of 35 convolution layers, each of which is followed by a BN layer, a ReLU layer or a Parametric Rectified Linear Unit (PRELU) layer. In particular, the convolution layer before the Regularization layer omits the BN layer, since the Regularization layer has served as a normalization function. The regularization layer adopts the Spatial dropout method for regularization, the dropout rate p is set as 0.5, and the model can be divided into five modules as a whole, which are divided by color in Fig. 3. The original three modules are completely redesigned. The fourth and fifth module use the corresponding parts of the object recognition model in VGG16. Then the lightweight decoder and dimensionality reduction module are designed. Through an asymmetric up-sampling process, the feature map is restored to the original input size, thus achieving an end-to-end pixel-level segmentation. The new model not only ensures the accuracy, but also greatly improves the prediction speed.
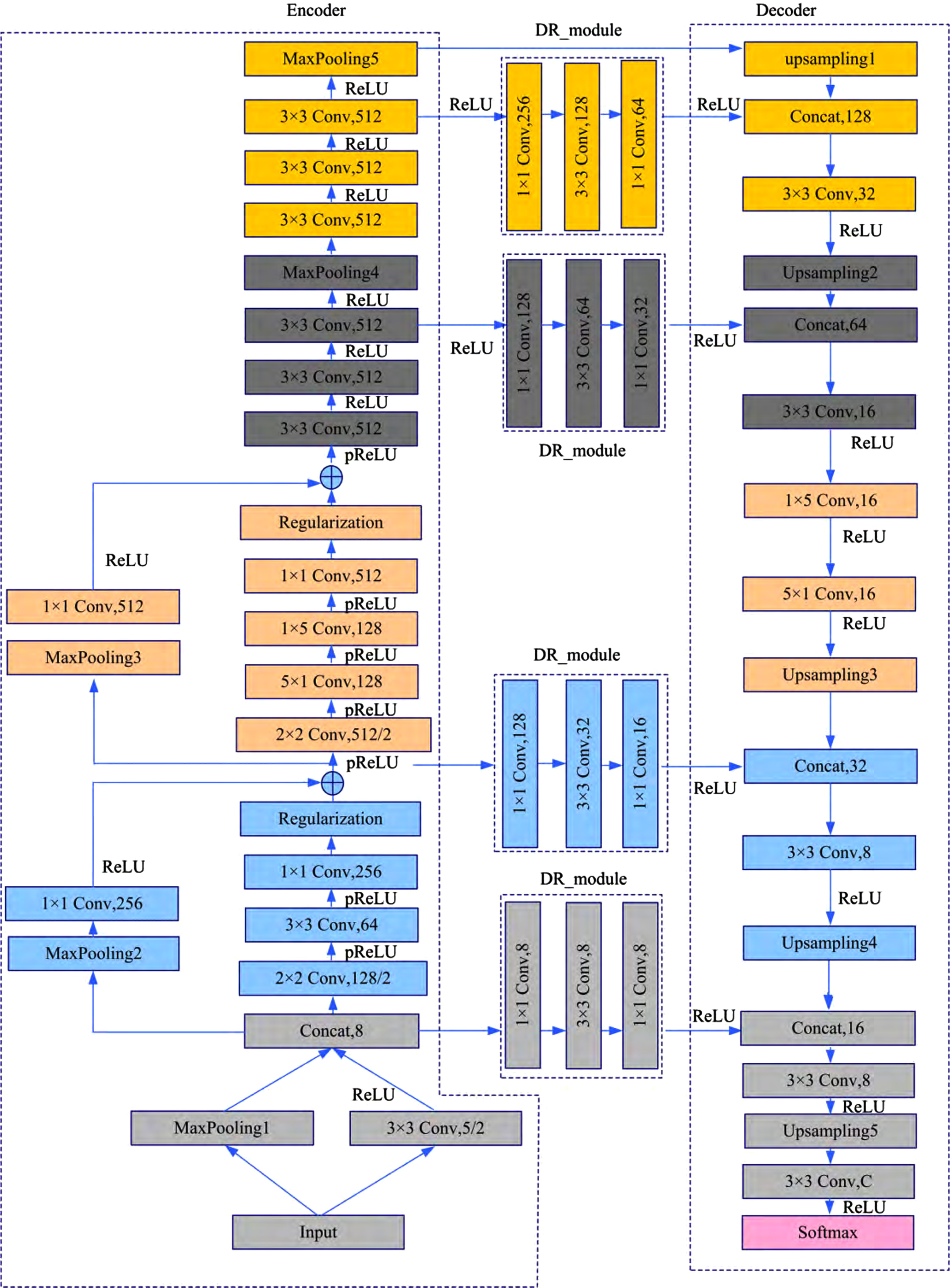
Proposed RT-SegNet structure.
In order to match the size of the feature graph, the necessary zero-padding operation is carried out on the convolution operation in some layers. In the image, the adjacent pixels have a high similarity and contain a lot of redundant information. Therefore, in the early stage of the model, the size of the image can be greatly compressed to extract smaller feature images, which can immensely reduce the amount of floating point calculation of the model while maintaining the accuracy, then it accelerates the model training and prediction. Therefore, in the early stage of the model, RT-SegNet directly makes a convolution and max-pooling for the input of the model with a step size of 2. Then, the obtained feature graphs from the two parts are fused together, and it reduces the size of the input image by 1/4 with only one layer.
For the deep neural network, the larger receptive field contains more context information, and the extracted features are more conducive to classification. It is same as the semantic segmentation. Therefore, enlarging the range of receptive field is important to improve the segmentation accuracy. However, larger receptive field often needs large convolution kernels, which means the increase of parameter numbers, it will further increase the training and prediction time in deep neural network, so it is difficult to meet the real-time requirements [26]. In order to solve this problem, we use an asymmetric convolution technique, which enlarges the receptive field while keeping the parameter number approximately equal to the original convolution parameter number.
A N×N convolution kernel can be decomposed into two consecutive N×1 and 1×N convolution kernels under the condition that the output size remains unchanged. As shown in Fig. 4, for a input with size 4×4, Fig. 4(a) directly uses a 3×3 convolution kernel for convolution, and the obtained size of the output feature graph is 2×2. Figure 4(b) first uses a 3×1 convolution kernel for convolution, and then uses a 1×3 convolution. The final output is also a 2×2 feature graph. However, a 3×3 convolution kernel contains 9 parameters, while a 3×1 and a 1×3 convolution kernel only contain 6 parameters in total, and the number of parameters is reduced by 1/3. For a N×N convolution kernel, the parameter compression ratio of this decomposition satisfies formula (1):
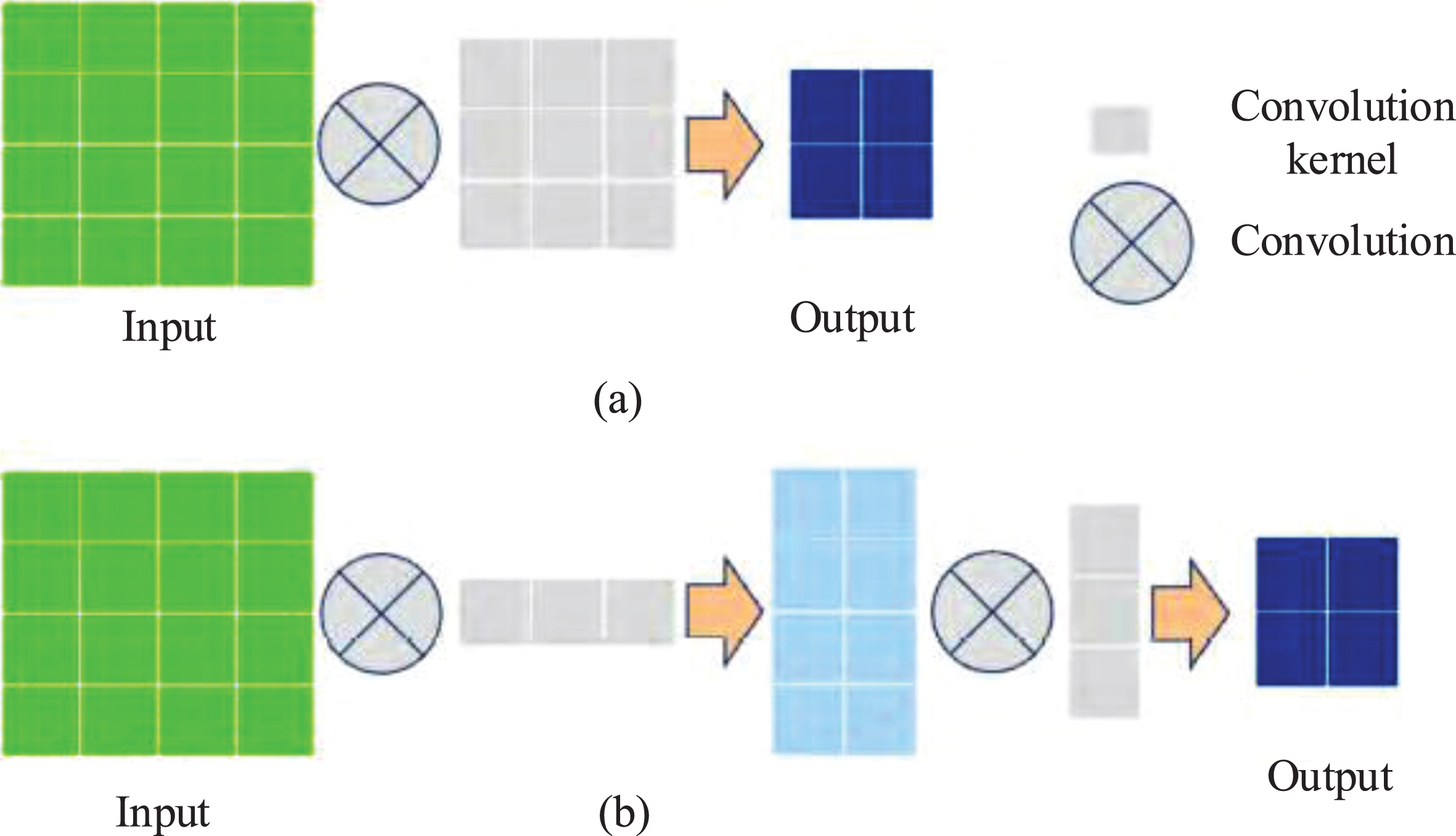
(a) normal convolution, (b) asymmetric convolution.
It can be clearly seen from Equation (1) that, with the increase of the convolution kernel, the parameter compression effect generated by the decomposition becomes more obvious. In the overall model architecture, in order to increase the receptive field and improve the classification accuracy, a 5×5 convolution kernel is used to replace 3×3 convolution kernel in the third module of the proposed model. In order to ensure the running speed of the model, a 5×5 convolution kernel is replaced by an asymmetric convolution kernel n = 5, which effectively controls the increase of the model parameter numbers.
The number of asymmetric convolution parameters with n = 5 is 2/5 of the number of convolution parameters with 5×5 and 10/9 of the number of convolution parameters with 3×3, but the receptive field is the same as the 5×5 convolution and 25/9 times of the 3×3 convolution, which is more conducive to improving the classification accuracy. The RT-SegNet model is generally divided into two stages, namely, the encoder stage on the left and the decoder stage on the right as shown in Fig. 3. In the encoder stage, this paper proposes a CLFMF method to improve the feature extraction effect. In the decoder stage, an asymmetric structure is adopted, and a lightweight decoder is designed to effectively reduce the number of parameters and speed up the model prediction. Finally, between the encoder and the decoder, the model builds a dimensionality reduction module, which fuses the high-dimensional features of the bottom layer with the low-dimensional features of the top layer to improve the segmentation accuracy.
As shown in the left part of Fig. 3, in the encoder stage, the model contains 16 convolution layers and 5 maximum pooling layers. At this stage, the feature “level” becomes more and more abstract with the increase of depth, the size of feature map becomes smaller and smaller. In this stage, the same structural module can often be shared with object recognition model [27]. The existing open models are used to initialize model parameters and conduct fine-tuning, which can accelerate the convergence speed of the model. In deep learning, the depth of the model determines the performance of the network. The deeper model denotes the stronger fitting ability. However, with the depth increase of the network model, gradient diffusion and gradient disappearance will occur, and the difficulty of training optimization will increase, so the model will be difficult to converge. Moreover, even if the model is converged by some regularization methods, the degradation phenomenon will occur, that is, with the increase of network depth, the accuracy of convergence will eventually decline. In order to solve the above two problems, RT-Segnet model proposes a cross-layer feature map fusion (CLFMF) method.
As shown in Fig. 5, two branches are extracted from the initial input. The main branch is convolved in multiple layers, while the secondary branch is only pooled and convolved once, then the feature graphs of the two branches are fused. Here, the multi-layer convolution of the main branch mainly plays the role of feature extraction, and the pooling of the secondary branch is to match the size of the feature graph with that of the main branch. The main function of the secondary branch convolution is to match the channel number in the feature graph with the channel number in the main branch and balance the feature ratio. The fusion method adopts channel dimension superposition, that is, the main branch feature map channel and the secondary branch feature map channel are fused. Before fusion, the feature map size of the main branch is w × h × c m , and the feature map size of the secondary branch is w × h × c s , then the feature map size after fusion will become w × h × (c m + c s ). In this way, the fused feature map not only contains the features extracted by convolution, but also is directly enhanced by the initial features. So it can effectively improve the optimization efficiency and avoid degradation.
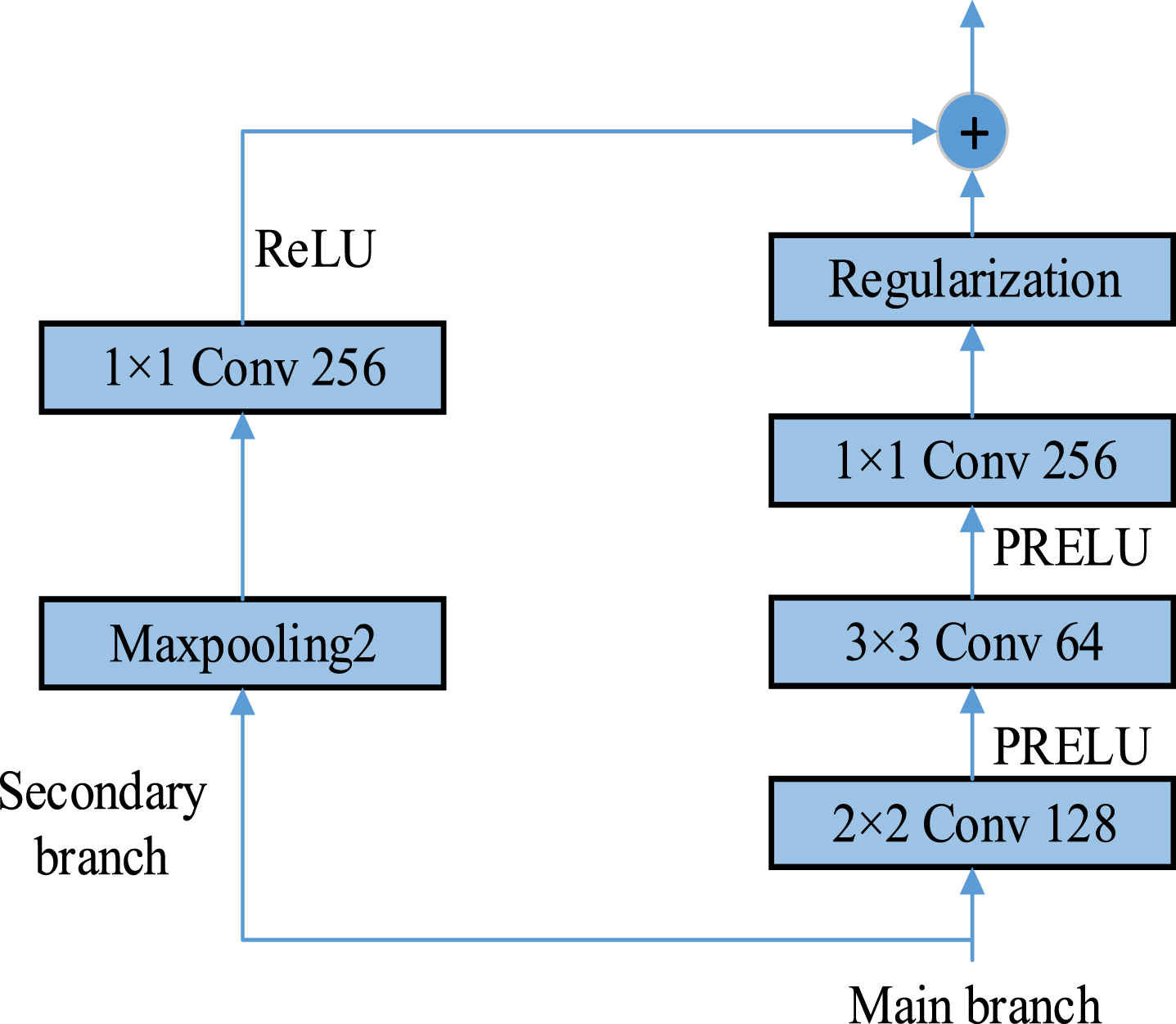
Schematic diagram of CLFMF.
Different from the original SegNet, the decoder process is actually a re-understanding of features, so in the decoder process, the dimension of the up-sampling does not need to be set exactly the same as that of the encoder process. The dimension can become smaller as the increasing of the up-sampling level. As shown in Fig. 3, in the decoder stage, a Lightweight Decoder (LD) structure is designed, which only contains 6 convolution layers and corresponds to 5 sub-samples in the encoder stage. Through five up-sampling processes, LD gradually restores the smaller feature map in the encoder stage to the size of the input image, so as to achieve the effect of one-to-one correspondence with the label and realize end-to-end training. The initial up-sampling dimension of LD structure is 64, and the number of up-sampling channels is reduced by half each time, and becomes 8 after 3 times. In addition, the number of convolution layers between each two up-sampling layers is no longer corresponding to the decoder, and only one convolution layer is retained between the two up-sampling layers. This design greatly reduces the number of parameters in the decoder stage.
Dimension reduction module
In the deep neural network, the convolutional layer not only has good feature extraction function, but also has translation invariance characteristic, which is beneficial to the image classification task. However, this property of convolution is actually equivalent to removing part of the position-related information in the image. Moreover, with the depth increase of the network, the information loss will be more serious, which will have a negative impact on the pixel-level semantic segmentation. Because in the pixel level image semantic segmentation, the classification of the pixels is not only associated with the pixel values, pixel position can also provide a lot of information. For example, suddenly appearing a piece of the sky in the middle of the road is impossible, it does not accord with common sense, accordingly, it will not suddenly appears a piece of the road in the sky.
In order to solve the above problem in pixel-level image semantic segmentation, inspired by Sharpmask [27] and FCN, a high-level feature and low-level feature fusion method is proposed. By the nature of the CNN [28], the layer of network is more closer to the bottom layer (input), it contains more rich location information, so it will be benefit for the fusion. It can not only ensure the accuracy of semantic segmentation and classification, but also improve the accuracy of pixel positioning, and refine each classification edge of semantic segmentation. However, the dimension of the feature graph up-sampling on the decoderin the lightweight decoder is much smaller than that in the encoder process. If the fusion is carried out directly, the features of the up-sampling will be covered due to the small proportion and cannot be fully expressed. In this paper, a dimension reduction module (DRM) is proposed. Firstly, the feature graph in the encoder process is reduced to the same dimension as the up-sampled feature graph through the dimension reduction module, and then the feature image is fused to ensure the dimension balance between the up-sampled feature graph on the decoder and the feature image in the encoder process.
As shown in Fig. 6, DRM consists of three successive convolutional layers that progressively reduce the dimensions to those that match the decoder process. The module first reduces the encoder feature graph dimension to 1/2 or 1/4 of the original size through a 1×1 convolution, and then extracts the feature once through a 3×3 convolution kernel. Finally, a 1×1 convolution is used to adjust the feature graph size to the same dimension as the decoder. Since the output feature dimension of convolution can be set by itself, it is also feasible to directly use a 1×1 convolution kernel to reduce the dimension of the encoder’s feature graph to the dimension matching the decoder stage, but this method has too much loss and the effect is not good. Different from the original SegNet, which only transmits the pooling marks to the top layer, the DRM module not only transmits the location information, but also has certain feature enhancement ability, which can improve the accuracy of the model for pixel-level classification.

Schematic diagram of high level features and low level features fusion.
Data sets
As shown in Table 1, the experiment uses CamVid [29], Cityscapes [30], Sun RGB-D [31], and Kitti [32] to train and test RT-SegNet.
Data sets introduction
Data sets introduction
The CamVid dataset from the University of Cambridge is the first video set with complete target classification semantic tags and metadata, providing 32-category images with pixel-level labeling. Unlike most CCTV type cameras, which capture video from a fixed position, this data set captures video from the perspective of a moving car, which increases the number and heterogeneity of the observed target categories. The data set contains a total of 710 semantically segmented images per pixel, including 370 training sets, 100 evaluation sets and 240 testing sets. During training, the data set is roughly divided into 11 categories, which are the sky, buildings, trees, streets, sidewalks, traffic signs, poles, pedestrians, bicycles, fences, and vehicles.
Cityscapes is a dataset focusing on semantic understanding of city streetscapes. It contains 5000 fine-tuned labeled images (including 3000 training sets, 500 evaluation sets, and 1500 testing sets) and 20000 roughly labeled images. The dataset defines 30 visual categories, grouped into eight large groups: flat land, buildings, nature, vehicles, sky, objects, people, and space. Only the top 19 of the total number of pixels are considered for evaluation.
The Sun RGB-D dataset is an indoor scene dataset. Compared to outdoor scenes such as CamVid and Cityscapes, the Sun RGB-D dataset is more complex and has 397 categories, so the segmentation is more difficult. The complexity of indoor environment is closer to the real application environment of robot, so the segmentation effect on this data set is also more meaningful for robot environment sensing. The actual experiment uses the fixed 37 categories.
The KITTI dataset is a computer vision dataset provided by the Institute of Technology at the Karlsruhe Institute of Technology and the Toyota Institute of Technology in Chicago for challenging the real world. It covers visual tasks such as stereo matching, optical flow, visual range, 3D target detection and tracking. The KITTI dataset is similar to the CamVid scene. Although no labeled segmented samples are provided by the authorities, there are a large number of labeled segmented images by volunteers. In the experiment, the data sets contributed by these volunteers are unified into the rough classification of the KITTI data set with 1202 images.
In the evaluation of experiment results, three evaluation indexes are used, namely Global accuracy rate (GAR), Classification accuracy rate (CAR) and Mean inter-over union (MIoU) [33]. The specific formulas are as follows:
Where m is the sample number in the test set. TP
i
is the number of pixels correctly classified in the i-th sample. total
i
is the total pixel number of the i-th sample.
In the formula, n is the classification category.
Where
In this paper, the Stochastic Gradient Descent (SGD) method with momentum attenuation is used to train the network. In terms of hardware configuration, the used servers are equipped with two Xeon E5-2683V3 CPU, four Titan X GPUs with 12G video memory, and 128G memory. In software configuration, the server installs Ubuntu 4.04 operating system with Caffe deep learning framework. The programming language is C++ and Python with CuDNNv5, Cuda7.5, OpenCV2.3.11, ProtoBuffer, Atlas, IMDB and other third party dependent libraries.
Cross-entropy is a measure of the difference between two probability distributions for a given random variable or set of events. You might recall that information quantifies the number of bits required to encode and transmit an event. Lower probability events have more information, higher probability events have less information.
In the experiment, the momentum coefficient is set as 0.9, the attenuation coefficient is 0.0005. The maximum iteration number is 4×104, and the batch size is 24. The fourth and fifth module are initialized with the parameters corresponding to the VGG-D model. The other layers are randomly initialized by Gaussian distribution with mean 0 and standard deviation 0.01. The cross entropy loss function is used. In order to balance the proportion of pixels in each category, the loss function adopts the median frequency balance method [34] to add weight in each category. Here we discuss the effect of learning rate on the error rate value.
From Table 2, we can see that when learning rate is 0.1, the error rate is 2.1%, which is the best value compared with other learning rates. So in the next experiments, we select the initial learning rate as 0.1.
Segmentation efficiency change curve with learning rate/%
Segmentation efficiency change curve with learning rate/%
As shown in Table 3, in terms of the parameter number, although the parameter number of RT-SegNet is slightly increased compared with that of SegNet in the encoder stage, the parameter number of RT-SegNet is significantly reduced in the decoder stage due to the asymmetric structural design. The parameter number in the decoder stage is reduced by 20 times compared with that of SegNet. The total parameter number is about 1/2 of the total parameter number of the SegNet model. Figure 7 is the result with SegNet and RT-SegNet. We find that employing RT-SegNet is better than using SegNet.
Parameter comparison with SegNet model
Parameter comparison with SegNet model

The comparison results.
As shown in Table 4, the decrease of the parameter number is also directly reflected in the prediction time of the model. RT-SegNet can reach 3.8 fps with the image resolution 1440×1080, 7.7 fps with the image resolution 960×720. However, with the image resolution 480×360, RT-SegNet only needs 43 ms to perform a prediction, reaching 23.3 fps, which is similar to the human visual frame rate (24 fps).
Performance comparison with SegNet at different resolutions
Note: t is the prediction time. F is the decoding rate.
Cityscapes is a data set of city streetscapes, as shown in Table 5. According to the evaluation methods on the Cityscapes data set, the results are analyzed at two granularity levels, namely the Category level and the fine-grained classification level. In here, we also select other state-of-the-art semantic segmentation methods, i.e., C3Net [35], JSNet [36], WeGleNet [37].
Cityscapes test set results/%
Where IoU represents the cross-joint measurement over the entire test set, and iIoU represents the weighted average of the cross-joint measurement for each category. The Fine-grained IoU, Fine-grained iIoU, IoU and iIoU values with SegNet achieve 56.1%, 34.2%, 71.8% and 63.5% respectively. Compared with SegNet, C3Net, JSNet, WeGleNet, RT-SegNet achieves better results in the four indicators. In the fine-grained classification level, RT-SegNet improves by 17.1%, 12%, 7.4% and 2.6% than SegNet, C3Net, JSNet, WeGleNet on IoU, and RT-SegNet improves by 11.6%, 9.9%, 8.6% and 4.3% than SegNet, C3Net, JSNet, WeGleNet on iIoU respectively. In the Category level, RT-SegNet improves by 17.9%, 13.3%, 8.8% and 4.4% than SegNet, C3Net, JSNet, WeGleNet on IoU, and RT-SegNet improves by 7.3%, 6.1%, 5.7% and 5.1% than SegNet, C3Net, JSNet, WeGleNet on iIoU respectively. This indicates that the early dimension reduction does not have a negative impact on the accuracy, while the jump join and asymmetric convolution help to improve the performance of the model. In addition, the parameter compression in the decoder stage has little effect on the segmentation accuracy, which verifies that the decoder is mainly the interpretation for the features extraction of the encoder. Because at the fine-grained classification level, some fine-grained classifications are merged together to improve the accuracy, and the improvement of the segmentation effect at the Category level is greater than that at the fine-grained classification level. Meanwhile, the dimensionality reduction module is added to the new method in this paper. The fusion of the high-level features and the low-level features can make the semantic segmentation more refined and significantly improve the segmentation accuracy of each class.
As shown in Table 6, for the SUN RGB-D data sets, RT-SegNet improves the GAR by 19.4%, 18.2%, 17.5%, 5.1%, the CAR by 11.2%, 10.4%, 9.3%, 4.9%, the MIoU by 9.5%, 8.6%, 7.7%, 4.4% than that of SegNet, C3Net, JSNet, WeGleNet. It shows that the jump connection and asymmetric convolution can deepen the network and produce the positive classification accuracy. After adding dimension reduction module and integrating high-level features with low-level features, the better semantic segmentation effect with RT-SegNet can be achieved. The processing time of RT-SegNet is 1.5 s, which is lower than C3Net, JSNet, WeGleNet. However, it is higher than SegNet with 1.2 s due to its slightly complex model. In summary, the proposed method has relatively little running time while ensuring accuracy.
SUN RGB-D test set results/%
CamVid and KITTI are both road and street view data sets, and the class types of the two data sets are relatively similar. During the experiment, the two data sets are uniformly processed into 11 categories (excluding the “unknown” category) for training respectively. The experiment results are shown in Tables 7 and 8. As can be seen from Tables 7, 8, the accuracy of RT-SegNet is significantly improved compared with the other methods.
On the whole, the GAR of RT-SegNet is improved by 13%, 10.7%, 4.7% and 2.1% than SegNet, C3Net, JSNet, WeGleNet on CamVid data set, the CAR of RT-SegNet is improved by 25.3%, 21.2%, 15.7% and 2.4% than SegNet, C3Net, JSNet, WeGleNet on CamVid data set, the MIoU of RT-SegNet is improved by 22.8%, 15.7%, 9.5% and 5% than SegNet, C3Net, JSNet, WeGleNetC on CamVid data set, respectively. The similar results are shown in Table 8. For the detailed class, the RT-SegNet demonstrates the better results. Figure 8 shows the visualization results. Figure 8 shows that the segmentation predictions made by our proposed lightweight SegNet is more accurate on classes such as traffic light, traffic sign and road.
The CamVid test set results
The KITTI test set results

Visualization result of semantic segmentation with different methods.
In this paper, the robot environment sensing technology based on deep learning for image semantic segmentation is studied, this paper proposes a new real-time image semantic segmentation framework based on a lightweight SegNet for robotic environment sensing. It realizes the end-to-end training and prediction from the original image to the semantic segmentation graph. In the decoder stage, RT-SegNet uses the proposed CLFFM to improve the feature extraction effect. Then the decoder is reconstructed and the LD structure is designed to reduce the convolutional layer number of the decoder, which greatly reduces the number of model parameters and accelerates the speed of model training and prediction. Finally, the RT-SegNet model uses the convolution method to design a dimensionality reduction module (DRM), which connects the high-dimensional low-level features of the encoder and the low-dimensional high-level features of the decoder to enhance the decoder performance and improve the segmentation accuracy. Experimental results show that RT-SegNet achieves better results than original other methods on CamVid, Cityscapes, SUN RGB-D, and KITTI datasets. The classification accuracy is over 95% on Sky, Building, Tree, Transportation, GAR and CAR, and over 99% on Road and Sidewalk. The final MIoU is 88.6% with proposed method. Each category achieves an optimal result. If the proposed method encounters more complex scenes with serious background overlap, the segmentation effect will be poor, and the time complexity will also increase. In the further works, more complex scenes will be labeled, and the robustness of RT-SegNet will be further improved by increasing the training data. It will provide more accurate discriminant basis for robot intelligent decision planning and intelligent control.
Footnotes
Acknowledgments
This work was supported by the Project (Name: Research on road scene segmentation technology based on convolutional neural network; Project Number:222102210318). And 2023 International Science and Technology Cooperation Project of Henan Province: Research on Human Behavior recognition technology based on semi-supervised transfer learning in video detection, Project number: 232102520007.