
Abstract
The traditional Ordered Weighting Average (OWA) operator is suitable for aggregating numerical attributes. However, this method fails when the attribute values are given in a linguistic form. In this paper, a novel aggregating method named Entropy and Probability based Fuzzy Induced Ordered Weighted Averaging (EPFIOWA) is proposed for Gaussian-fuzzy-number-based linguistic attributes. A method is first designed to obtain a reasonable weighting vector based on probability distribution and maximal entropy. Such optimal weighting vectors can be obtained under any given level of optimism, and the symmetric properties of the proposed model are proven. The linguistic attributes of EPFIOWA are represented by Gaussian fuzzy numbers because of their concise form and good operational properties. In particular, the arithmetic operations and distance measures of Gaussian fuzzy numbers required by EPFIOWA are given systematically. A novel method to obtain the order-inducing variables of linguistic attribute values is proposed in the EPFIOWA operators by calculating the distances between any Gaussian fuzzy number and a set of ordered grades. Finally, two numerical examples are used to illustrate the proposed approach, with evaluation results consistent with the observed situation.
Keywords
Introduction
Multiple attribute comprehensive evaluation refers to an evaluation process of ranking a number of alternatives (objects) based on particular attribute values. As a solution for multiple attribute evaluation, Ordered Weighted Averaging (OWA) operators were first proposed by Yager in 1988 [1], with the output of an OWA operator being defined as the dot product of a weighting vector and an attribute value vector wherein any attribute values are rearranged in non-decreasing order. OWA rapidly attracted significant attention among researchers, and has since been applied across multiple fields, including risk assessment [2], project planning [3], industry scheduling [4], book recommendation technique [5], safety evaluation [6]. Several surveys on the field, as noted in [7, 8] and [9], have been undertaken to summarize the development of OWA. And across the relevant literature, the generalization of OWA operators and the optimization of the OWA weighting vector have emerged as two equally important issues.
With respect to the first issue, several generalization methods have been proposed since the advent of OWA, such as the Generalized WOA (GOWA) [10], Ordered Weighted Geometric Averaging (OWGA) [11], Probabilistic OWA (POWA) [12], Weighted OWA (WOWA) [13], and Olympic type OWA [14]. These improvements provide a parameterized family of comprehensive evaluation methods, which includes the most commonly used evaluation operators such as the maximum, the minimum and the average evaluation.
Yager and Filev generalized OWA operator theory further by proposing a method known as the Induced OWA (IOWA) operator [15]. They introduced another type of variables to the IOWA operator named the associated order-inducing variables, such that the ordered position of the attributes is no longer determined by the attribute values, but by these order-inducing variables. IOWA has grown in popularity in recent years [16–20], because this method permits the use of linguistic values that may have no inherent order as attribute values, as long as these linguistic values are associated with appropriate order-inducing variables. However, this method cannot be used when the order-induced variables are unknown.
Linguistic values are now commonly used across various evaluation fields [21, 22], as many researchers find it more reasonable to adopt unspecified linguistic values that are more consistent with human cognition than numerical data. Due to the ground-breaking work of Zadeh et al. [23], fuzzy logic based linguistic values have become efficient tools for modelling uncertain information about the performance of attributes, and, in recent years, several significant developments have occurred in the modelling of uncertainty, incomplete information and subjective views in OWA and IOWA formats [24–27]. However, the operational laws and distance measures of fuzzy linguistic variables still require further analysis for the effective use of IOWA, especially when order-inducing variables are not provided initially.
With respect to the second issue, there are numerous papers dealing with the optimization of OWA weighting vectors. The survey given in [28] summarizes many of them. One direct way to generate OWA weights is to utilize the normal probability distribution [29], which assumes that attributes of unduly high and low preference should be assigned very low weights, while non-preferential attributes should be assigned high weights. This basic and direct method can also be generalized to cover other types of probability distribution and multiple OWA weight forms, as in [30, 31] and [32]. However, the obtained weighting vectors may be susceptible to subjective judgments with respect to evaluators.
Another way to generate OWA weights is to use the well-known concept “orness” introduced by Yager in [1]. As a linear combination of weighting vectors, orness can reflect the optimism level of an evaluator. Evaluators often need to rank alternatives under a predefined level of optimism. Unsurprisingly, many papers investigate the optimization of weighting vectors under a given orness level. Some orness-based methods obtain optimal weighting vectors by maximizing the entropy of the relevant OWA weights. O’Hagan was probably the first to suggest a maximal entropy model subject to a given level of orness [33], and this model had been proven to have an analytical solution [34]. In [35], the authors maximized Bayesian entropy under a given orness level. By using the Lagrange multiplier method, this model had also been proven to have an analytic solution [36]. A model based on Rényi entropy was proposed in [37]. Other researches on entropy-based models can be found in [38, 39] and so on. Another kind of orness-based models obtain optimal weighting vectors by minimizing the differences among weights. Such models include the least square deviation model [40], the minimax disparity model [41, 42], the equidifferent OWA operator [43], the χ2 method [40] and so on. Other kinds of orness-based methods can be found in a recent survey [28]. It is also worth mentioning that there exist papers where the optimal weighting vector is derived to obtain the desired evaluation result of the evaluator [44].
In order to design reasonable OWA weights which integrate subjective and objective factors, and to use linguistic attribute variables in IOWA when their associated order-inducing variables are not provided, this paper focuses on developing a novel Entropy and Probability based Fuzzy Induced Ordered Weighted Averaging (EPFIOWA) model based on the methods discussed above. We mainly carry out the following work in this study. A new method that combines subjective and objective criteria to determine the weights of OWA is proposed. An initial probability distribution and an optimism level are given subjectively by the evaluator, while the optimal weights are objectively determined by using a maximal entropy programming model. The symmetric properties of the optimal weights are proven. Arithmetic operation properties and distance measurements for Gaussian fuzzy numbers are proposed. Based on these results, the similarity of two Gaussian-fuzzy-number-based linguistic values can be calculated. A novel method to obtain the order-inducing variables is proposed for IOWA operators. When Gaussian fuzzy numbers are used as linguistic attribute values, their order-inducing variables can be obtained by calculating the similarities between any Gaussian fuzzy number and a set of ordered grades as provided by the evaluator. Finally, an EPFIOWA method is proposed for multiple attribute comprehensive evaluation using linguistic values, with evaluation results consistent with the observed situation.
The rest of this paper is organized as follows. Section 2 briefly reviews OWA theory and the relevant IOWA operators. In Section 3, a novel optimization model to obtain the OWA weights based on probability, entropy and orness level is proposed, and symmetric properties of this model are proven. The arithmetic system and distance measures used for Gaussian fuzzy numbers are also introduced in this section. In Section 4, an EPFIOWA method based on Gaussian fuzzy numbers is proposed. In Section 5, two examples are given to illustrate how to use the proposed EPFIOWA operators.
Ordered weighted average operators
This section offers the necessary preliminaries regarding the OWA theory.
OWA theory
An OWA operator is an aggregation operator for multi-attribute decision-making.
OWA W is a useful decision-making method due to the fact that it takes the optimism level of the evaluator into account [21]. An optimistic evaluator would select a weighting vector Wmax = (1, 0, ⋯ , 0) to retrieve the largest attribute,
Yager and Filev proposed a more general type of OWA operator known as the IOWA operator [15]. IOWA is an extension of OWA, with the difference being that the ordering step of the IOWA operator is not sorted by the attribute values, but rather by a set of order-inducing variables associated with the attribute values.
where b i is the attribute value of the two-tuple with the ith largest value of order-inducing variable (u1, u2, ⋯ , u n ).
The IOWA is especially useful when the attribute values are expressed as linguistic values which have no explicit order relationship. In such case, these linguistic values can be sorted by their corresponding order-inducing variables; however, it remains difficult to sort the linguistic attribute values if the corresponding associated order-inducing variables are missing.
Orness levels
As a linear combination of the OWA weights, the orness level associated with the OWA operator [45] is defined as follows.
The orness level α (W) ∈ [0, 1] is a parameter that can be used to determine the optimism level of the evaluator. If α (W) = 1, we have
Entropy and probability based weights and gaussian fuzzy numbers
This section introduces a novel programming model to determine a weighting vector based on entropy and probability density function. Some symmetric properties of this model are then proven. And then the arithmetic operations and distance measure of Gaussian fuzzy numbers are proposed.
An OWA weight generation model using entropy and probability distribution
Xu [29] proposed a Gaussian probability density function to generate OWA weights. The Gaussian distribution is one of the most important two-parameter probability distributions in statistics, as many data sets drawn from nature display similar bell-shaped curves. For a n-attribute alternative to be aggregated, weights based on a Gaussian density function can thus be computed as
As shown in Fig. 1, in order to analyze the effect of the parameter K, different OWA weights are generated using (3) and (6) under different values of K∈ { 1/2, 2/3, 1, 3/2, 2 }, where the OWA dimension n = 7. Obviously, the larger the K value, the more similar these weights are. Therefore, K can reflect the attitude of the evaluator towards the maximum and minimum evaluation values. If K approaches 0, the unduly high and low evaluation values are assigned very low weights.
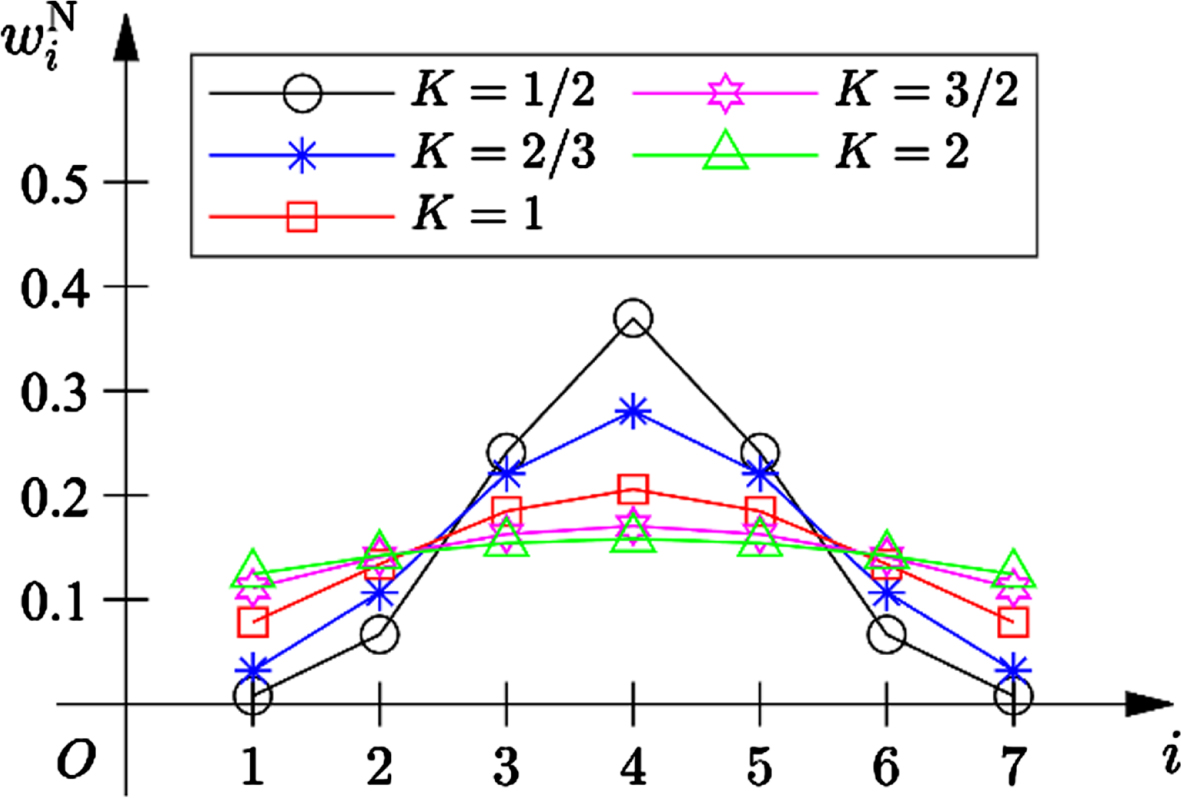
OWA weights generated using a Gaussian distribution.
Apparently, OWA weights based on Gaussian function are symmetrical about the center position. Weighting vectors generated from such probability functions are very common, because the weights of extreme evaluation values are relatively small compared with those of moderate evaluation values, and such systems belong to the broader class of OWA operators that are averaging around the center. However, in such method, weights on the left of the center are mirrors of weights on the right of the center, causing such systems to be unable to measure the level of optimism of a given evaluator.
Unlike Xu’s method, which gives the weighting vector directly from the Gaussian distribution, this paper uses the a more comprehensive model to determine the OWA weights based on considering probability distributions of any given type and the weight entropy under a predefined level of optimism.
The first term of the objective function in (7) makes w
i
equal to
It can be shown that if the given probability distribution is symmetric, such that
And
is correct since
Now, we show that
For the other thing, because
Thus,
In real-life applications, attribute values are sometimes given using linguistic values. Thus, just as Gaussian distributions are important in statistics and are often used in the natural and social sciences, Gaussian fuzzy numbers are used as a very common and remarkably useful way of expressing linguistic attribute values, based on their ability to represent membership degrees in a natural way.
Such linguistic values may be estimated by using (historical) numerical evaluation scores, or Gaussian fuzzy numbers that are given by some experts in the field, who do not necessarily include the evaluator. However, it may be difficult for the evaluator to sort such linguistic values. To resolve this problem, this section introduces the arithmetic operations and distance measures used with Gaussian fuzzy numbers. By applying distance measurements, an evaluator can determine the ranking of linguistic values based on a comparison of these values with a set of ordered grades given by the evaluator.
Arithmetic operations of Gaussian fuzzy numbers
Gaussian fuzzy numbers are basic concepts in fuzzy theory, being useful tools for modeling the uncertainty of attribute information. A Gaussian fuzzy number in R is defined as a special type of fuzzy set whose membership function f (x) is
The following example describes how to use evaluation data to construct a Gaussian-fuzzy-number-based linguistic value and the comparison of two Gaussian fuzzy numbers.
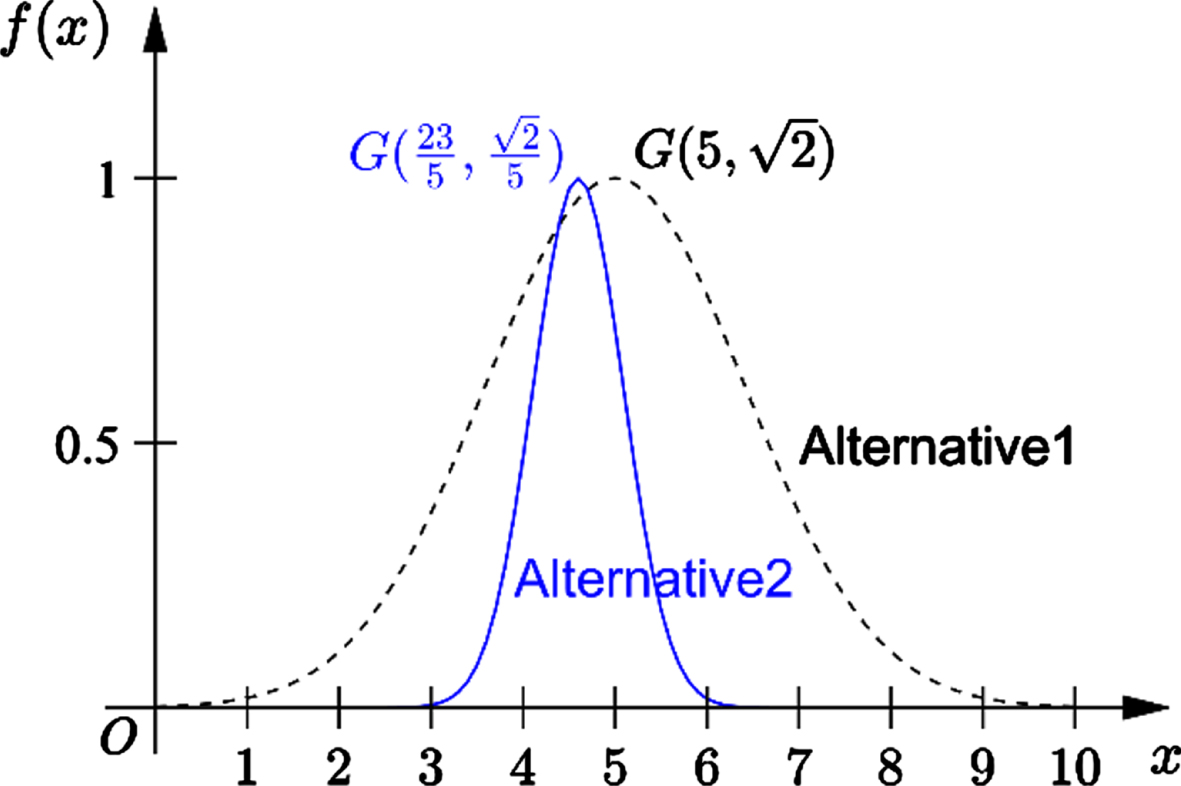
Membership function of a Gaussian fuzzy number.
One advantage of using Gaussian fuzzy numbers to represent linguistic values is that: the arithmetic operations and distance measures of Gaussian fuzzy numbers have simple forms that are similar to those of real numbers. Thus, for n Gaussian fuzzy numbers G (μ i , σ i ) , i = 1, 2, ⋯ , n, and n real numbers w1, w2, ⋯ , w n ∈ R, according to the extension principle [46], we have
An evaluator may have several ordered evaluation grades
It is possible to obtain the order-inducing variable of {G
j
} by calculating any similarity between a linguistic value G
j
and an evaluation grade
Substituting (17) into (16) gives the L1-type Hausdorff distance of G1and G2
□
The Fuzzy Induced OWA (FIOWA) operator is an extension of the IOWA operator, with the difference that the attribute values of FIOWA are not numerical numbers, but instead more general linguistic values represented by fuzzy sets.
Gaussian fuzzy numbers are suitable for representing fuzzy linguistic values. For one thing, Gaussian fuzzy numbers are easy to understand, and are commonly used as in social sciences; for another thing, they have excellent operation properties as shown in Theorem 2 and Theorem 3. Based on these considerations, Gaussian fuzzy numbers are used as linguistic values in the following Gaussian fuzzy number based FIOWA operator.
Synthesizing all the methods mentioned above, this work develops an EPFIOWA approach based on the Gaussian-fuzzy-number based FIOWA, the maximal entropy OWA model, and probabilistic OWA weighting vectors for multi-attribute evaluation problems. This EPFIOWA can be accomplished by implementing the following steps:
Given the required optimism level (orness level) α, and a probability density-based weighting vector WPro, the programming model Model (α, WPro) in (7) is utilized to determine the necessary IOWA weighting vector W.
Linguistic attribute values {G i |i = 1, 2, ⋯ , n} are collected from experts or constructed from numerical evaluation data with respective to n attributes, where every G i is represented by a Gaussian fuzzy number.
The evaluator defines m ordered grades within a dimensionless domain (such as [0, 1]), which are expressed by m two-tuples
As shown in Fig. 3, the corresponding Gaussian fuzzy numbers

Gaussian fuzzy numbers.
In this step, the order-inducing variables {u
i
|i = 1, 2, ⋯ , n} that are associated with the linguistic values {G
i
|i = 1, 2, ⋯ , n} are determined by calculating the distance between every element in {G
i
|i = 1, 2, ⋯ , n} as given by the historical data or experts, and every element in
Thus, the linguistic attribute value for each attribute is obtained by the evaluator.
Aggregate the linguistic attribute values <u i , G i >, i = 1, 2, ⋯ , n, obtained in Step 3 according to the Gaussian fuzzy number based FIOWA operator (18), then denote the aggregation result as Z.
Based on Theorem 2, the aggregation result Z obtained in Step 4 is also a Gaussian fuzzy number. However, in general,
This section offers two experiments to illustrate the use of the proposed EPFIOWA approach in dealing with linguistic multi-attribute evaluation problems. Section 5.1 uses a simple example to calculate the evaluation results at different optimism levels to analyze the parameters α (Orness level) in the EPFIOWA method. Section 5.2 discusses a problem related to the battery recycling process, two classical OWA methods are used as comparative methods to verify the effectiveness of the proposed method.
An illustrative example
Assume that an object to be evaluated has n = 4 attributes. The attribute values given by some experts for these four attributes are
According to (3) and (6), the obtained OWA weighting vector W via Model (α, W
Pro
) is thus
As
Repeating this experiment under different levels of optimism α
i
= 0, 0.1, 0.2, ⋯ , 1, gives the evaluation results Z
i
= G (μ
i
, σ
i
) as shown in Fig. 4. The mean value of the evaluation result increases gradually with the increase in α. While, the variance shows no obvious change. The reason for this is that a large difference emerges in the mean value of the linguistic attribute values {G
i
|i = 1, 2, 3, 4}, while the difference in variance remains relatively small. As α increases, the evaluation result thus gives higher weights to those terms with better attribute values. Consequently, if the alternative has some attributes with good evaluation grades (near

Evaluation Results under different value of orness level α.
This section discusses a problem related to the battery recycling process. The aim is to select an appropriate third-party reverse logistics supplier to carry out reverse logistics activities, with the example adapted from [50] and [25]. In order to verify the effectiveness of the proposed method, two classic evaluation methods mentioned above, namely, OWA and IOWA, are used as comparison methods and applied to the same problem.
In this example, the evaluator needs to evaluate five potential suppliers by considering seven factors (attributes). These attributes are: (1) F1 : quality; (2) F2 : delivery; (3) F3 : cost; (4) F4 : rejection rate; (5) F5 : technological capability; (6) F6 : development potential; and (7) F7 : Service attitude. Five suppliers X i , i = 1, 2, ⋯ , 5, are offered as potential suppliers, and several experts are invited to evaluate the competencies of these five suppliers in these areas. The numerical attribute values from these experts are then converted into Gaussian fuzzy number-based linguistic values in the interval [0,1], the resulting means and standard deviations of these Gaussian fuzzy numbers are listed in Table 1. Based on these statistical results, the linguistic value G ij of candidate X i for any attribute F j can thus be obtained. For example, the linguistic value of X1 in F2 is expressed by the Gaussian fuzzy number G12 = G (0.5, 0.02). Note that G42 and G45 have extremely large variances, which indicates that there are considerable differences in the experts’ evaluation.
Linguistic values collected from experts
Linguistic values collected from experts
*Data adapted from [25]. Values in bold indicate that the linguistic values have large variances.
Assuming there are seven evaluation grades within the cognitive scope of the evaluator, as listed in (19), with corresponding Gaussian fuzzy numbers as shown in Fig. 3. The optimistic evaluator selects an orness level of α = 0.6. The initial weighting vector
The final linguistic evaluation results for all five candidates are listed in Table 2. This highlights that X3 and X4 are the two best suppliers based on the proposed model, with linguistic evaluation values
Linguistic evaluation results for all candidates
From the perspective of mean value alone, Z4 appears better than Z3 as μ4 > μ3. However, in terms of standard deviation, σ3 ⪡ σ4, which means the uncertainty of result Z4 is very large. The order-inducing variable calculated by (20) are given in Table 2, from which one can see that Z3 is slightly better than Z4, consistent with the fact that suppliers with stable evaluation results may be preferred over highly variable suppliers.
The membership functions of Z3 and Z4 are shown in Fig. 5.

Comparison of evaluation results for X3 and X4.
In order to verify the effectiveness of the proposed method, two classic OWA and IOWA methods are applied to the same evaluation problem. In the OWA method, the weighting vector is the same as that used in the EPFIOWA, the mean value information in Table 1 is used as numerical attribute values, and the standard deviation information in Table 1 is ignored. In the IOWA method, the weighting vector is set to (1/7, 1/7, ⋯ , 1/7), and the other calculation steps are the same as those in EPFIOWA. The evaluation results of the three methods are shown in Table 3. As the standard deviation information is not fully considered, the OWA method regards X4 as the best supplier, which has the largest difference in attribute values in F2 and F5. The IOWA method also regards X4 as the best supplier due to the fact that the optimism level of the evaluator is not fully considered. In this example, therefore, the EPFIOWA method proposed in this paper can get more reasonable results than the other methods.
Evaluation results for different methods
The traditional induced OWA operator is suitable for aggregating the information in the form of numerical values. However, it cannot handle problems in which the attribute values are given in a linguistic format, especially when these linguistic attribute values are difficult to sort. This paper thus introduces a frequently used representation type for linguistic values, i.e. the Gaussian fuzzy numbers, to allow the arithmetic operations and distance measures required for IOWA to be deduced. Based on this, a Gaussian-fuzzy-number-based IOWA operator is defined that takes argument pairs as its inputs, of which one component is the Gaussian-fuzzy-number-based attribute value, and the other is an order-inducing variable associated with the Gaussian fuzzy number.
A critical step in developing an OWA operator is the determination of OWA operator weights. In order to obtain a reasonable weighting vector for the proposed FIOWA operator, a novel programming method is thus proposed to determine the OWA weights according to the optimism level of the evaluator and an initial probability distribution. Some of the desired properties of the proposed method, such as its symmetry property, are examined in this study.
The research results show that in the proposed model, if an alternative has some good attributes, the evaluation results of the proposed EPFIOWA method will be significantly improved with the improvement of the optimistic level. The proposed EPFIOWA operator can obtain reasonable evaluation results that are consistent with the observed situation because the proposed method fully takes into account the uncertainty of attribute values and the optimistic level of the evaluator.
The extension and application of the developed EPFIOWA to more fields is a problem worthy of further study.
Footnotes
Acknowledgment
This research is supported by the Science and Technology Programs of Quanzhou (2021CT0010, 2022N002S), the Fujian Natural Science Foundation Project (2021J01001), and Fujian Key Laboratory of Financial Information Processing (Putian University, JXC202205).
The authors would like to thank the editors and the anonymous reviewers for their insightful and constructive comments and suggestions, which improved the quality of this article. The authors would like to acknowledge the support by Fujian provincial key laboratory of data-intensive computing, Fujian university laboratory of intelligent computing and information processing, Fujian provincial big data research institute of intelligent manufacturing.
Conflicts of interest
The authors declare no conflicts of interest.