
Abstract
The purpose of facial expression recognition is to capture facial expression features from static pictures or videos and to provide the most intuitive information about human emotion changes for artificial intelligence devices to use effectively for human-computer interaction. Among the factors, the excessive loss of locally valid information and the irreversible degradation trend of the information at different expression semantic scales with increasing network depth are the main challenges faced currently. To address such problems, an enhanced pyramidal network model combining with triple attention mechanisms is designed in this paper. Firstly, three attention mechanism modules, i.e. CBAM, SK, and SE, are embedded into the backbone network model in stages, and the key features are sensed by using spatial or channel information mining, which effectively reduces the effective information loss caused by the network depth. Then, the pyramid network is used as an extension of the backbone network to obtain the semantic information of expression features across scales. The recognition accuracy reaches 96.25% and 73.61% in the CK+ and Fer2013 expression change datasets, respectively. Furthermore, by comparing with other current advanced methods, it is shown that the proposed network architecture combining with the triple attention mechanism and multi-scale cross-information fusion can simultaneously maintain and improve the information mining ability and recognition accuracy of the facial expression recognition model.
Introduction
The research by psychologist Mehrabian [1] shows that 55% of human emotional expressions are embodied by facial expressions, and facial expressions [2–6] are the most direct expression of emotional changes. Facial expression recognition is to capture the facial expression features from static pictures or videos for artificial intelligence devices to obtain the most intuitive information about human emotional changes. Currently, facial expression recognition has been widely used in many fields. Face expression recognition generally includes four steps, image acquisition, pre-processing, feature extraction, and classification recognition. Since the accuracy of image recognition is limited by the original image size, angle, and other information, feature extraction is the key technology that needs to be addressed in the process of facial expression recognition to effectively extract the abstract detail information inside the image and perform information mining to the maximum extent.
Traditional feature extraction methods include local binary pattern (LBP) [7], principal component analysis [8], statistical histogram [9], etc., but they are all easily constrained by background noise, angle, and other factors. In addition, in the process of image recognition, the effective information is not uniformly distributed, but a large amount of key information is distributed in some local areas of the image, so the traditional algorithm has only limited feature extraction ability and is difficult to always extract the key interest effectively. In addition, the generalization ability and robustness of the algorithm model are not strong as well. In recent years, convolutional neural networks (CNN) based on deep learning have been widely used in the field of computer vision. Compared with traditional methods, convolutional neural networks can map the information of each channel of the image into the deep network structure by convolution and pooling operations, thus enhancing the network feature representation capability and improving the performance of the detection vision tasks.
Although the traditional CNN model makes up for the shortcomings of traditional methods to a certain extent, because it extracts a large number of invalid features when performing image feature extraction, it increases the number of model parameters and reduces the training efficiency, which deteriorates the network recognition accuracy. In addition, the traditional CNN model does not consider the feature information of different hierarchical structures, resulting in the extracted features lacking contextual information of different scales. Therefore, in practical classification tasks such as face expression recognition, there still exist two main challenging problems: first, too much effective information is lost in the convolution and pooling process as the network depth increases; second, the information at different expression semantic scales shows an irreversible degradation trend in the spatial downsampling process. These problems lead to a certain deviation of the inherent prior knowledge related to expression recognition from the real image, and many network models rely heavily on the quality of the working datasets, which makes it difficult to fully exploit the detailed information and thus affects the accuracy of the expression classification recognition.
In the deep CNN structure, the shallow convolutional layer extracts the texture features of the image which are more general, and as the depth of the network increases the extracted features become more abstract and complex, and their characterization ability is more unique. For the network model, the attention mechanism is an effective means of information extraction to obtain rich feature representation without affecting the structure of the CNN model, which especially helps to extract key local information. Among the various types of attention mechanisms in the existing modules, the channel attention is more concerned with the semantic information of images and the spatial attention is more concerned with the location information of images. Therefore, incorporating suitable attention mechanism modules in different convolutional layers of the network can be an effective means to extract local key information in the image. In addition, since images have higher resolution and more comprehensive information in the shallow layer of the network, as the network deepens, the resolution will become lower, the semantic information will become stronger, and the perception of details will become worse. Therefore, the reasonable use of shallow and deep information to achieve effective feature fusion and improve network recognition is a key task in network model construction.
To address the above problems, this paper proposes an enhanced pyramid network model incorporating triple attention mechanisms, i.e. CBAM, SE, and SK, by embedding channel and spatial attention modules in the deep backbone model in a phased manner. Compared with the traditional CNN model, this model has the ability to focus on extracting important spatial and channel information in local regions and eliminate invalid and redundant information without affecting the network structure. In addition, in order to alleviate the problem of irreversible loss of partial information caused by the deep network when extracting higher semantic features, a pyramidal network model is introduced to obtain the cross-scale semantic features, so that the feature extraction part of the network can still obtain effective shallow feature information while ensuring information flow. This paper is arranged as follows. In the feature extraction methods based on the three attention modules, i.e. CBAM, SE, and SK, the three modules are embedded into the appropriate convolutional layers of the backbone network with taking into account the channels of key features of expression images, as well as the effective extraction of spatial information. A weight-sharing fusion structure is used to fuse the convolutional layers containing the three attention mechanism modules layer by layer, simplifying the connection of networks combined with the pyramidal attention mechanisms and enabling each convolutional layer of network to make more reasonable use of shallow and intermediate layer features in the recognition process, thus effectively fusing the features and spatial information from different semantic scales. Using the complementarity between the triple attention modules and the pyramid network model, the fused features are secured with less redundancy and paying more attention to the differences, which significantly improves the network generalization and robustness by combining the information extraction advantages covering different features.
Related work
The attention mechanism
For facial expression features extraction, the information related to the expression change mainly comes from a few face regions such as eyes and mouth, and the correlation between other face regions and the expression change is less or even negligible. Face expression recognition needs to focus on the face regions closely related to the expression change to avoid disturbance by irrelevant information and ensure recognition accuracy and efficiency. The attention mechanisms can extract the feature channels and regions that highly correlate with the expression changes [10–12] and remove the irrelevant information. At present, the research of facial expression recognition based on attention mechanisms mainly adopts the single type of attention mechanism method.
Li et al. [13] used partially occluded faces as research objects to extract feature channel information from facial expression images and proposed a convolutional neural network with attention (ACNN) that senses the occluded face regions and focuses the attention on the most discriminative non-occluded face regions. ACNN is an end-to-end learning framework that unites feature channel information from multiple face representations on regions of interest (ROI). Each representation is weighted by a set gate unit that computes a corresponding adaptive weight based on the changing features captured by the attention mechanism of each region. Considering different regions of interest (ROI) of the face, two types of ACNNs are designed: a block-based ACNN (pACNN) and a global ACNN (gACNN). The pACNN only pays attention to local facial regions and the gACNN integrates each local region, and both structures use the aforementioned gate unit to perform adaptive weight computation on the features captured by the spatial attention mechanisms of each region. The authors evaluated the proposed ACNN in both real and synthetic occlusion environments, including a homemade dataset of real facial expressions, and two largest datasets of facial expressions in the field (RAF-DB and AffectNet). The experimental results show that the ACNN network improves facial expression recognition accuracy for both non-occluded and occluded faces. ACNN also outperforms other state-of-the-art methods on several other widely used laboratory facial expression datasets. The above results illustrate that the ACNN network, which uses a gating unit to perform adaptive weight calculation on the features captured by the attention mechanisms, takes full advantages of the attention mechanisms ability to fully extract important information, thus improving the reliability of facial expression recognition.
Li et al. [14] used the channel attention mechanism to provide feature channel information and proposed an attention mechanism for an end-to-end network for facial expression recognition, which consists of four parts, namely, a feature extraction module, an attention module, a reconstruction module, and a classification module. LBP features extract image texture information and then capture minute movements of faces, which can improve the network performance. The attention mechanism can make the neural network pay more attention on useful features. The LBP features and attention mechanism are combined to form an enhanced attention model to obtain better results. This method is applied to our dataset and other four representative expression datasets, namely, JAFFE, CK+, FER2013, and Oulu-CASIA. The experimental results demonstrate the feasibility and effectiveness of this method.
Minaee et al. [15] used a maximum pooling spatial attention mechanism to extract spatial information considering less classification for facial expression recognition [16] and proposed an attention-based lightweight convolutional network with less than 10 layers. The backbone network consists of four convolutional layers with a maximum pooling layer after every two convolutional layers and a linear unit (ReLU) activation function, which can focus on regions rich in facial features, followed by a discarded layer and two fully connected layers. The hopping network is a localization network, consisting of two convolutional layers (each followed by a maximum pooling layer and a ReLU layer) and two fully connected layers. The results show that even an attentional convolutional network with only a few layers (less than 10 layers) can equally adequately represent the features and the spatial information of facial expressions to achieve very high accuracy rates.
Gan et al. [17] used a densely connected convolutional neural network with hierarchical spatial attention mechanisms to extract spatial information and eliminate the influence of redundant information from emotionally irrelevant regions on expression recognition and proposed a convolutional neural network with densely connected spatial attention mechanisms at each level. The network can adaptively locate emotionally relevant and important regions to represent facial expressions more effectively. Experimental results show that this method distinguishes facial expressions more accurately than other existing state-of-the-art methods.
Nan et al. [18] proposed a lightweight A-MobileNet model by using a convolutional block attention mechanism (CBAM) to extract feature channel information and spatial information in the feature channel information. First, the CBAM attention module with spatial attention mechanism and channel attention mechanism in tandem is introduced into the MobileNetV1 model to enhance the local feature extraction of facial expressions. Then, the center loss and softmax loss are combined to optimize the model parameters to reduce intra-class variance and increase inter-class distance. The test results of facial expression recognition on FERPlus and RAF-DB datasets illustrate that the method significantly improves the recognition accuracy without increasing the number of model parameters.
The attention mechanisms in the above expression recognition studies mainly include two types of spatial attention mechanisms and channel feature attention mechanisms, which can act on both backbone networks and hopping networks, and both use pooling modules to simplify the parameters and realize the lightweight of the networks. However, in order to ensure the important information of expression recognition comprehensively, research on the optimal combination of different types of attention mechanisms of each convolutional layer, position placement, etc. is needed to obtain the complete cross-scale semantic information of face expressions from both the shallow and deep layers of the network.
Pyramid module
To further improve the accuracy of face expression recognition, sufficient hierarchical features need to be collected from each convolutional layer to comprehensively extract the semantic scale information of expression images, so that the detailed reconstruction of the features and the spatial information can achieve the desired effect. The network model combining with the pyramid network with the attention mechanism links the information extracted by the attention mechanism of each convolutional layer to comprehensively represent the semantic information of the image, allowing fast and accurate recognition of crowd size [19–22], person recognition [23], human pose and activity recognition [24–26], various object recognition [27–30], and image classification [31–34]. Compared with these applications, the variation of face region information and feature information related to face expressions is with more details and abstract and not easily distinguishable, and the combination of pyramidal networks and attention mechanisms can enable comprehensive and accurate extraction of important expression information for each convolutional layer.
Liu et al. [35] proposed a pyramid model combining with a hierarchical scale attention mechanism to extract the regions most relevant to facial expressions from each convolutional layer and select the most informative scale in each convolutional layer to learn the expression recognition task. Farzaneh et al. [36] used an attention mechanism in a pyramid network to extract the spatial feature map of the middle convolutional layer of the CNN network as the background that estimates the attention weights associated with the feature importance to ensure that important expression recognition feature information is not missed [37]. However, these methods failed to comprehensively fuse the expression recognition-related information of each convolutional layer, which are not conducive to providing the features and spatial information required for complete expression recognition. Huang et al. [38] pointed out that due to a large number of convolutional layers in the CNN network, information such as images is prone to distortion during propagation, which causes long-range bias between different facial regions in each convolutional layer, resulting in that the inability of the convolutional layer to process the features and spatial information. The features and spatial information required for complete expression recognition are thus not accurately recognized by the convolutional layers. To solve this problem, a novel convolutional neural network model for facial recognition is proposed in this paper, which embeds a lattice-based attention mechanism in low-level feature learning to capture the correlation of different regions in facial expression images and regulate the parameter updates of the convolutional kernel in low-level feature learning. In the high-level semantic representation, the visual transformer attention mechanism uses a sequence of visual semantic tokens (generated from pyramidal features of high convolutional layer blocks) to learn the global representation. And all layers are fully connected to fuse the face expression recognition image information collected by the attention mechanisms to classify the expressions.
However, the connection of each convolutional layer of the pyramid model increases the complexity and parameters of the structure, and a model optimization study to simplify the model connection and reduce the parameters of the model with taking into account the accuracy and recognition efficiency of expression recognition needs to be conducted in conjunction with the optimal combination of the attention mechanisms.
Proposed approach
Overview
Firstly, this paper selects three modules, i.e. CBAM, SE, and SK for the network construction. Among them, the CBAM module connects channel attention and spatial attention in series and introduces a global pool to utilize global information for comprehensive extraction of the important channel and spatial information [39]. The SE module increases the weight value of corresponding feature channels to enhance feature response, and for useless or interference features, the SE module decreases the weight value of the corresponding feature channel to weaken the feature response [40]. The SK attention module fuses the information from all branches by summing the elements through three processes, i.e. segmentation, fusion, and selection, and finally obtains the output feature map by aggregating all the branch feature maps [41]. In this paper, we combine these three attention mechanisms to further suppress the information not useful for expression recognition and improve the expression recognition accuracy while simultaneously extracting the important spatial and channel information.
The model architecture of this paper is shown in Fig. 1. ResNet-50 and FPN are used as the network backbone. Among them, three attention modules, i.e. CBAM, SE, and SK, are embedded in the deep backbone network in a phased manner, and the cross-scale pyramid network is used as an extension of the backbone network to capture cross-scale semantic information using a simplified connection with shared weights. The number of feature channels and pixels output by the attention mechanism of each convolutional layer involved in the fusion is kept consistent by 1×1 convolution as well as upsampling module. In addition, to better achieve cross-fusion of the cross-scale information, the enhanced convolutional network module (single stage headless or SSH) is used as post-processing to refine the aggregated features, further enhance the useful information in the aggregated features, suppress the useless information, and effectively improve the feature representation capability. Finally, Softmax function is used to classify the output images by expression.

The network architecture of FPN with attention mechanism.
The structure diagram of the triple attention mechanisms is shown in Fig. 1. In this paper, the backbone network consists of multiple convolutional and pooling layers alternately stacked on top of each other. As the number of layers increases, the network extracts multi-level features from local to global. In the initial stage of the network, the image information is more comprehensive and sufficient, but there is also more redundant information. When performing the information extraction in the initial stage of the network, global attention needs to be determined by effectively capturing the large range of information. The channel attention identifies the important information on the image channel, and spatial attention, as a complement to the channel attention, finds the location where most information is gathered in the channel-based direction. If the channel or the spatial attention is used alone for the information extraction, it may result in inadequate extraction of local effective information, and in order not to lose the spatial and channel information, this paper first embeds the CBAM module into the network for information extraction. The CBAM includes the channel attention module (CAM)) and the spatial attention module (SAM), and the two modules extract the image feature channels containing expression changes and image regions, respectively [38]. This structural feature makes the network retain the global information of facial expression images while eliminating redundant information so that the obtained expression features have strong integrity. After the CBAM feature extraction, the network has initially obtained the focused regions of the pictures at the spatial and channel levels, and in the mid-level stage of the backbone network, the features need to be further streamlined, and the information screening at the channel location level is more capable of mining the key information compared with the spatial location; and to further improve the feature representation, the SE attention mechanism is embedded into the mid-level position of the network, and the SE (squeeze and stimulated) attention mechanism can be considered as a channel attention mechanism with feature channel weighting, and the weights of each feature channel containing expression change information are calculated by global average pooling (GAP) to achieve accurate comparison of the importance of feature channels. The difficulty of expression recognition comes from the data anomalies caused by the diversity of expression images. Based on the rich information on human faces, the changes in expressions have great randomness, which increases the difficulty of the network recognition of abnormal samples and affects the generalizability of the network model. To address the above problems, this paper adds the SK attention mechanism module to the terminal position of the network model. The SK module can dynamically generate corresponding convolutional kernels for extracting the image regions of face expression change information at different scales, and generate corresponding weights for each convolutional kernel to reflect the importance of image regions containing the facial expression change at various scales [9], so that objects of different sizes can get deep features of the same scale to obtain better results.
The specific calculation process for information extraction is as follows:
In order not to miss information about the expression changes, it is necessary to fuse important feature channel information and spatial information from the triple attention mechanisms embedded in the Resnet-50 backbone network to different convolutional layers. The pyramid structure is a typical fusion structure that can fuse the feature channel information and spatial information from different convolutional layers [48], which helps to enhance the feature representation of the network and improve the detection and recognition performance of visual tasks such as expression recognition [23], and is suitable for fusing the output information of each attention of the triple attention mechanisms. However, there are semantic gaps and similarities between the output information of each convolutional layer, and weight combinations corresponding to the information of different convolutional layers need to be established [49], so the triple attention mechanisms fusion in this paper requires the establishment of weight combinations of CBAM, SE, and SK. In this paper, we further introduce a pyramid structure on the bottom-up path to extract multi-scale global contextual information and merge it. The pyramid fusion structure usually uses a weight-sharing approach to achieve full fusion of convolutional layers by summation fusion of multiple partial convolutional layers with the same combination of weight coefficients for partial convolutional kernel summation fusion, thus replacing the fusion of fully connected convolutional layers, which reduces the complexity of network connectivity and ensures no loss of information in each convolutional layer [39]. In this paper, the CBAM module and the SE module, and the SE module and the SK module, are summed and fused, respectively, with the same combination of weight coefficients. The feature fusion pyramid structure with shared weights in this paper is shown in Fig. 2. The output P1 of the CBAM module is summed and fused with the output P3 of the SE module, and the SK module is summed and fused with the SE module, and the above two outputs are summed and fused with the output of the SK module. Among them, the 1×1 convolution module ensures that the number of feature channels output by each convolutional layer attention mechanism involved in fusion is the same. The upsampling module makes it consistent for the output feature image elements of the attention mechanisms of the convolutional layers involved in the fusion.
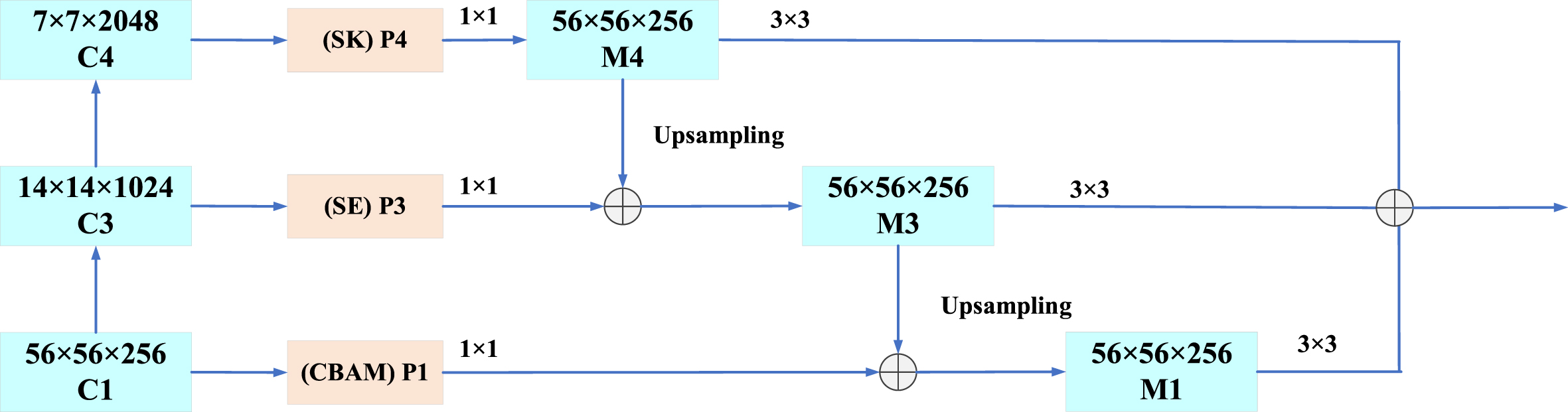
The network architecture of pyramid feature fusion module.
The specific process of the pyramid structure feature extraction is as follows:
Let F
CBAM
be the output of the CBAM attention mechanism and F
SE
the output of the SE attention mechanism. The whole fusion process is shown in Equation (8),
The output features of the SK attention module are summed and fused with the SE module, and the fusion process is shown in Equation (9)
Each of the output vectors F1, F2, and the output vector F
SK
of the SK module after 1×1×256 convolutional layers passes through the corresponding 3×3 convolutional kernels, and gets summed and fused, and the output vector is set to F. The output is the fused output of the triple attention mechanisms. The activation function of the convolution kernel is the ReLu process, as shown in Equation (10).

Examples of the cropped image in databases: (a) anger (b) disgust (c) fear (d) happy (e) neutral (f) sad (g) surprise.
The experiment is based on Keras framework with TensorFlow framework as the backend, the programming language is Python 3.7 in PyCharm IDE, on Windows 8 of 64-bit OS, hardware platform is GPU-NVIDIA-2080-Ti, and the graphics memory is 11 GB. In the experiment, Adam is used to optimize loss, learning rate of 0.0001, decay rate of 1×10-5, training period of 100, batch size of 64. Using CK+(surprised, angry, disgust, fear, happy, contempt, and sad) and Fer2013 (surprised, angry, disgust, fear, happy, neural, and sad) expression change datasets, and the sample sizes of the two datasets are shown in Tables 1 2, respectively.
Number of expression samples in CK+ and Fer2013
Number of expression samples in CK+ and Fer2013
Ablation experiment with attention mechanism in Fer2013
Firstly, the recognition ability of the network embedded with different attention mechanism modules is evaluated. The recognition results are shown in Tables 2 3, where three attentions acting separately means that each attention is placed in the three convolutional layers with outputs P1, P2, and P4, respectively, as shown in Fig. 1. Acting together means that these three attentions are placed in the three convolutional layers with outputs P1, P2 and P4, respectively, in the order from left to right.
Ablation experiment with attention mechanism in CK+
Ablation experiment with attention mechanism in CK+
As can be seen from the table, the highest accuracy case of Fer2013 and CK+ datasets is the combination of Resnet50 + Cbam+Se+Sk, which reaches 63.32% and 96.75%, respectively, whereas the number of parameters is less than 4M, higher than the combination of Resnet50 + Se+Sk+Cbam, which has the least number of parameters, indicating that the combination has a good balance of computing efficiency and accuracy. The above results demonstrate that the triple attention mechanisms have the best effect on expression recognition works by first extracting important channel features and spatial information for facial expression recognition, and then compare the importance of feature information and region information in turn. The reason is that both CBAM, SE, and SK are used with CBAM adopting both the CAM module and the SAM module to accurately extract the feature channels and image regions that most fully reflect the expression changes and remove regions and features less relevant to the expression recognition, with SE adopting global maximum pooling to achieve accurate comparison of feature channel importance and strengthen the extraction of feature channel information, and with SK comparing the image regions corresponding to the face expression changes at different scales by comparing the importance of such image regions by the weights of convolution kernels to strengthen the extraction of spatial information of image regions so that expression recognition can avoid the interference of useless information to the maximum extent, improving the efficiency of the algorithm and enhancing the generalization ability of the model.
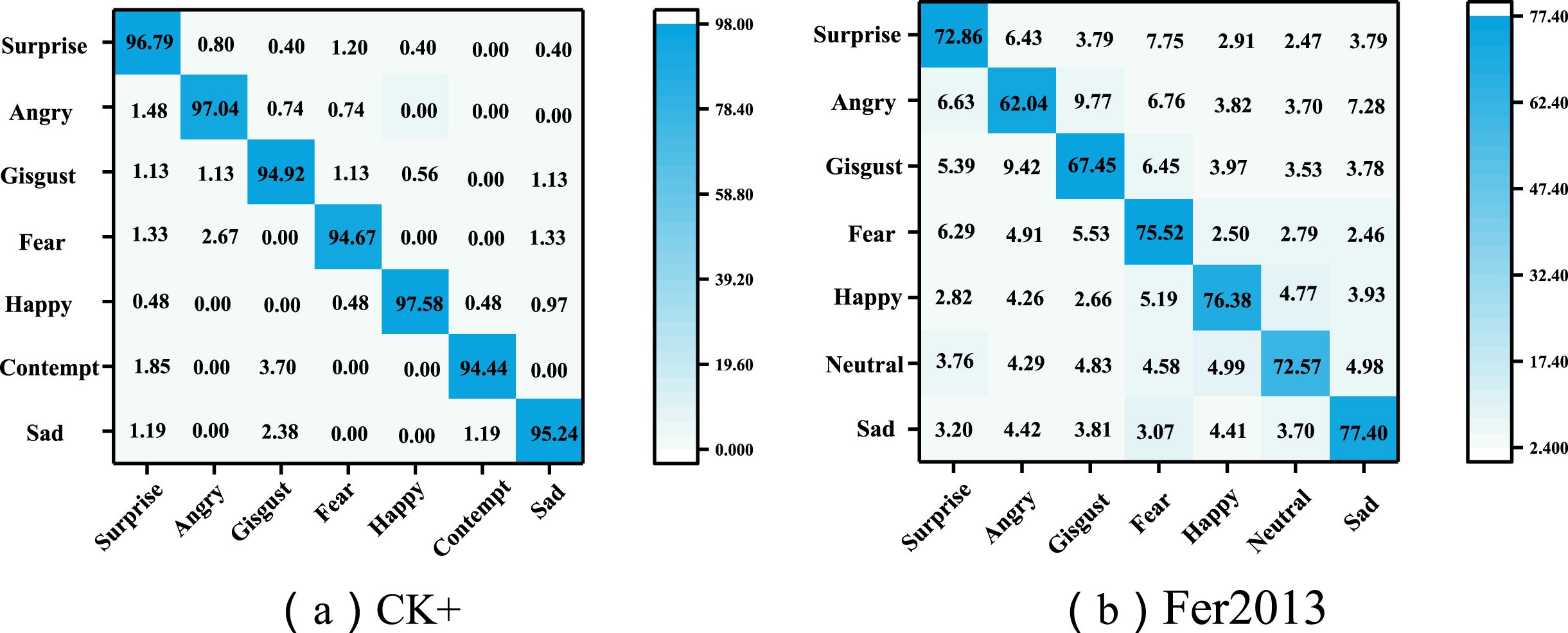
The confusion matrix.
By the feature extraction order of CBAM, SE, and SK attention mechanisms, this paper performs the analysis of expression recognition with two fusion connection methods. The fusion method 1 represents the fusion of the three convolutional modules P1, P2, and P4; and the fusion method 2 represents the fusion of the three convolutional modules P1, P3, and P4. To verify the model generalization, this paper uses both STO and 5-fold cross-validation methods for the training, and the results are shown in Tables 4 5.
Ablation experiment with FPN, SSH and attention mechanism in Fer2013
Ablation experiment with FPN, SSH and attention mechanism in Fer2013
Ablation experiment with FPN, SSH and attention mechanism in CK+
From the expression recognition results, it can be seen that not only the accuracy of STO and 5-fold is similar, with combining the enhancement module, the attention mechanism, and the pyramid fusion of fusion method 1, it is also the highest among all the combination methods including others, and the accuracy of Fer2013 and CK+ datasets with cross-validation training by the model is 73.61% and 96.25%, respectively, indicating that the selection of intermediate convolutional layers involved in the fusion is one of the important factors to determine the accuracy of expression recognition and the number of parameters, because the semantic information of the image output of convolutional layers at different positions is very different, and the semantic information of the image of the convolutional layer whose output is P3 cannot well reflect the changes of the expression recognition, which causes interference to the expression recognition and reduces the degree of reduction of the number of parameters to a certain extent, and characterizes the effectiveness of a reasonable fusion approach combined with the enhancement module to extract the expression recognition information.

Classification results of the model for the pictures.
The results of the cross-validation confusion matrix calculation for the Fer2013 dataset and the CK+ dataset expressions are shown in Fig. 4. Taking the Fer2013 dataset as an example, the highest recognition accuracy is for the expression of sad and happy, probably because this expression is more feature-rich and easier to distinguish than other expressions, whereas anger and disgust are easily misidentified. The problem arises firstly because the number of different expressions in the dataset is unbalanced, and secondly because anger and disgust itself has some similarity and is not easy to distinguish.
To further investigate the computational complexity of the model, this paper discusses the number of model parameters and the running time from two perspectives. It can be seen in Table 6 that by adding the attention mechanism module, the number of model parameters and training efficiency can be effectively reduced. The model training time is reduced from 308.8 to 211.4 mins, which indicates that the model lightweight effect can be achieved to a certain extent by adding the attention mechanism modules and the pyramid fusion.
Participants and Train time
To demonstrate the classification results of the model specifically for different pictures, one picture from each expression of netural, sad, happiness, fear, disgust, contemp, and angry is randomly selected for classification and recognition in this paper, and the results are shown in Fig. 5. The recognition accuracy of the model for netural, sad, happiness, fear, disgust, contemp, and angry are 87.5%, 92.7%, 98.6%, 95%, 92.3%, 89.9%, and 91.7%, respectively.
Table 7 indicates the results by comparing the proposed method with others in the literatures. The relatively low accuracy in the CK+ dataset is by the W-HOG method [42], which uses a traditional manual feature extraction method with lower expression recognition performance than the convolutional neural network method, proving that the expression recognition method of the convolutional neural network is better than the traditional expression recognition methods such as manual feature extraction. Attention D [43] combined with a convolutional neural network and attention mechanism and proposed a densely connected convolutional neural network with hierarchical spatial attention that can adaptively locate salient regions and focus on emotion-related features with higher accuracy than inception methods that do not employ an attention mechanism, reflecting the role of attention mechanism on important region information extraction for improving the expression recognition. The method used in this paper incorporates the important information of attention and performs comprehensive expression change space and feature channel information extraction, and adopts a pyramid fusion method that takes into account comprehensively the information extraction and simplicity of network structure, so the accuracy of facial expression change recognition in the CK+ dataset is higher than several other methods. The method in the literature [43] has a higher recognition rate of facial expression changes for the Fer2013 dataset than the VGG+SVM [42] and GoogleNet [44] methods that do not employ any attention mechanisms, again demonstrating the irreplaceable role of the attention mechanism for extracting information that requires very precise differentiation such as expression changes. The network architecture of the literature [14] uses LBP features to extract image texture information and then captures the minute movements of faces with higher expression recognition accuracy than the above three methods, proving the higher performance of the network with the addition of the attention mechanism.
Performance comparison on CK+ and Fer2013
In this paper, we combine different attention mechanism modules together to regulate the network learning process by using spatial and channel attentions and convolutional sizes on different network stages to target more local area information extraction. The modules of spatial attention and channel attention are matched to perceive key features using different information mining approaches to streamline feature information on the one hand, and reduce the loss of effective information due to network depth on the other. In deep learning networks, the higher the network level, the more features are based on abstraction, and the semantic features at different levels have different characteristics, with higher level features containing more semantics but lacking details. The bottom-level features have high resolution and contain more details, which helps in fine-grained recognition but lacks sufficient semantic information. Cross-fusion of high and low-level features of different sizes through a pyramid network structure contains not only enough semantic information but also enough resolution and detail information, which is beneficial for multi-scale fine-grained expression recognition. In the real face recognition domain, the diversity of face information poses a challenge to the recognition model accuracy as well as generalization, which indicates that sufficient information extraction, local detail filtering, and cross-fusion of different semantic features are key techniques need to be addressed in the network learning, and the method in this paper can address this challenge to a certain extent, indicating that the enhanced pyramid fusion structure combined with the triple attention mechanism is an effective way to explore key factors of face recognition.
This paper takes the Resnet-50 network as the backbone and proposes a triple attention mechanism with the CBAM, SE, and SK attention mechanisms acting together. It incorporates spatial and channel information into the early layer of the network and further extracts network feature information at the channel feature level, and combines with the feature fusion pyramid structure to extract multi-scale information and integrates the information advantages of different features to improve the network recognition capability. The highest recognition accuracy on the CK+ and Fer2013 expression change datasets reaches 96.25% and 73.61%, respectively. In addition, compared with other current advanced methods, it is proved that the approach of this paper has achieved significant improvement in the recognition accuracy and feature fusion. Future work will explore better ways to integrate the semantic features and extend the current network architecture, as well as further improve the recognition capability of the network model across various datasets.
Conflicts of interest
There are no conflicts to declare.
Footnotes
Acknowledgments
This paper was supported by the Jilin Provincial Department of science and technology (212556SF010191444).