
Abstract
Compared with other facial expression recognition, classroom facial expression recognition should pay more attention to the feature extraction of a specific region to reflect the attention of students. However, most features are extracted with complete facial images by deep neural networks. In this paper, we proposed a new expression recognition based on attention mechanism, where more attention would be paid in the channel information which have much relationship with the expression classification instead of depending on all channel information. A new classroom expression classification has also been concluded with considering the concentration. Moreover, activation function is modified to reduce the number of parameters and computations, at the same time, dropout regularization is added after the pool layer to prevent overfitting of the model. The experiments show that the accuracy of our method named Ixception has an maximize improvement of 5.25% than other algorithms. It can well meet the requirements of the analysis of classroom concentration.
Keywords
Introduction
Classroom facial expression is an important way to reflect the listening state of students. However, the division of students’ emotions while in a classroom is the key factor to judge the state of listening [1, 2]. Researchers have analyzed different situations based on different definitions of emotion. The basic emotions proposed by Ekman have been widely recognized and studied by the academic community, but these emotions are somewhat different from those emphasized in learning situations [3, 4]. Thus, a new classification of emotional states need to be defined with considering learning situation.
Most existing facial expression methods are based on the six basic emotions of psychologist Ekman [5], namely happiness, anger, boredom, sadness, fear, and surprise. Ekman proposed a facial action unit (AU) coding system (FACS). The facial action unit includes six upper facial muscle features and nine lower facial features [6]. FACS has been widely used for emotion recognition and has become a very effective tool for emotion analysis. Bu not all of the emotions Ekman described are applicable to the classroom. At present, there is no unified concept for the division of students’ emotions while in a classroom. Researchers have analyzed different situations based on different definitions of emotion. Mello [7] of the University of Memphis monitored the mood changes in students who were learning basic computer skills under the Auto Tutor system. It was found that the six emotional factors mentioned by Ekman were not completely applicable to the analysis of students’ classroom states. Happiness, surprise, boredom, confusion, and frustration occurred more frequently in a classroom, with happiness and surprise occurring more frequently.
The method of face detection is another issue would to be considered. Intuitive observation is a directly method for teacher to know the learning state of students, which limited by the number of students, classroom size and other factors. Therefore, it is particularly important to use artificial intelligence technology to develop an efficient method for detecting students’ emotional states while learning in a classroom environment. Since face detection is a relatively mature technology, which can analyze the features of students’ facial expressions so as to accurately explore their emotional states and to effectively detect their current learning states.
Chen et al. [8] proposed an intelligent human-computer interaction system based on the online classroom, where position algorithm was used to estimate head posture, Haar-like features was used to recognize facial expression, and multi-modal information was adopted to identify learners’ emotional states. Based on the displacement of facial feature points and local texture differences, a support vector machine was used to recognize facial expressions. However, support vector machines are difficult to implement on large-scale training samples. By identifying students’ classroom behaviors,locating facial feature points and estimating head pose angles, Huang et al. [9] proposed a deep convolutional neural network (D-CNN) combined with cascaded facial feature point location method to analyze and recognize head poses and facial expressions. That means the initial position of the facial feature was estimated and the feature information was extracted with extracting the head pose. Lee et al. [10] proposed a process-focused assessment (PFA) method where a deep neural network model was used to learn facial expressions in order to conduct real-time assessments of students’ learning and learning processes. The concept of machine learning based on a DNN model was adopted, and the open library Keras was used to implement the network. Adaboost and Haar-based methods were used to extract facial features. Summarizing the above convolutional neural networks, the recognition of facial expressions were divided into three categories: simple, neutral, and difficult, whose efficiency was low.
Wu et al. [11] designed a program to analyze students’ facial expressions. Opencv software was used for face capture, two different CNN models were integrated to recognize students’ facial expressions, and the EMQX message protocol was used to transmit the facial expression information. Talegaonkar et al. [12] proposed a facial expression recognition system developed by CNN, which could classify facial expressions in real time through a webcam. The image was preprocessed by gray transform, normalization, and image size adjustment. The Haar cascade classifier was used for face detection, and a convolutional neural network was used to recognize facial expressions. Wang et al. [13] proposed a framework combining a compact deep learning model based on the architecture of CNN with an online course platform. Students’ facial expressions were analyzed from the perspective of computer simulation. The facial expression recognition (FER) algorithm was used to analyze the students’ facial expressions and to divide them into eight emotions. Pabba et al. [14] proposed a real-time monitoring system for student group participation using convolutional neural networks to recognize students’ facial expressions, which included two modules: offline and online. The offline module was a CNN-based trained FER model, while the online module ran in real time to estimate students’ engagement using the CNN model trained in the offline module. Multiple FER models needed to be trained for different populations. The above methods are all belong to standard convolution, where features are extracted from the complete face image rather than the regional characteristics that should be observed. Moreover, large amount of calculations and large number of parameters are also needed.
Different from the above, Li et al. [15] proposed a novel end-to-end automatic facial expression recognition network with an attention mechanism. This method combined local binary pattern (LBP) and convolution features with the attention mechanism to improve the performance of the network. The LBP feature can improve network performance by extracting texture information from images and capturing tiny movements of faces. The attention mechanism can make the neural network pay more attention to useful features. They combined the LBP characteristics with the attention mechanism to enhance the attention model in order to obtain better results. Minaee et al. [16] gave an over-view of modern augmented reality technology from application-level and technical perspectives, including about 100 promising machine learning-based work systems developed for AR. AR-based education platforms are in high demand after the COVID-19 pandemic, and augmented reality can serve as a great tool in education.
Taking into account six basic emotions and foreign studies on classroom emotions, this paper defines students’ facial expressions as listening, thinking, understanding, yawning and wandering [17, 18]. This definition was more in line with teaching practices. Based on Xception [19, 20], this paper adopt deep separable convolution to reduce the number of model parameters and improves the efficiency of model parameters [21, 22]. In addition, the rational use of attention mechanism module plays an important role in improving students’ expression recognition in class [23]. We introduces attention mechanism module to improve channel information, suppress useless information, solve the loss problem caused by different importance ratio of channel information, and improve the activation function and accuracy of network identification.
The contributions of this paper are as follows: The Xception convolutional neural network with a high recognition rate was selected as the basic model. The classification of facial expressions in a classroom is put forward. The attention mechanism module was added to the model to focus on useful information. The activation function was improved, the number of parameters and amount of calculations of the model were reduced, and dropout regularization was used during training to simplify the network structure and to prevent overfitting of the model. The accuracy of the proposed method in this paper was improved by 5.25% compared to Resnet50 [24], 3.11% compared to Inceptionv3 [25], 2.71% compared to MobileNet v1 [26], and 2.22% compared to Xception. The recall rate and F1 score were also improved. The accuracy has also improved in the public datasets FER2013, CK+, AffectNet, RaFD. The algorithm effectively improved the accuracy of expression recognition.
Related works
Xception
The Xception network is an improvement to Inception v3 [27] proposed by Google, which is divided into three parts: entry, middle, and exit. The input layer is mainly used for continuous down sampling to reduce the spatial dimension. The middle constantly learns correlations and optimizes the features. The final output is the summary and collation of features, which are used to express for the full connection layer. Feature extraction is based on 36 convolution layers, which are structured into 14 modules, including 4 for entry flow, 8 for middle flow, and 2 for exit flow. All modules except the first and last modules have linear residual connections [28] around them. The specific structure is shown in Fig. 1.
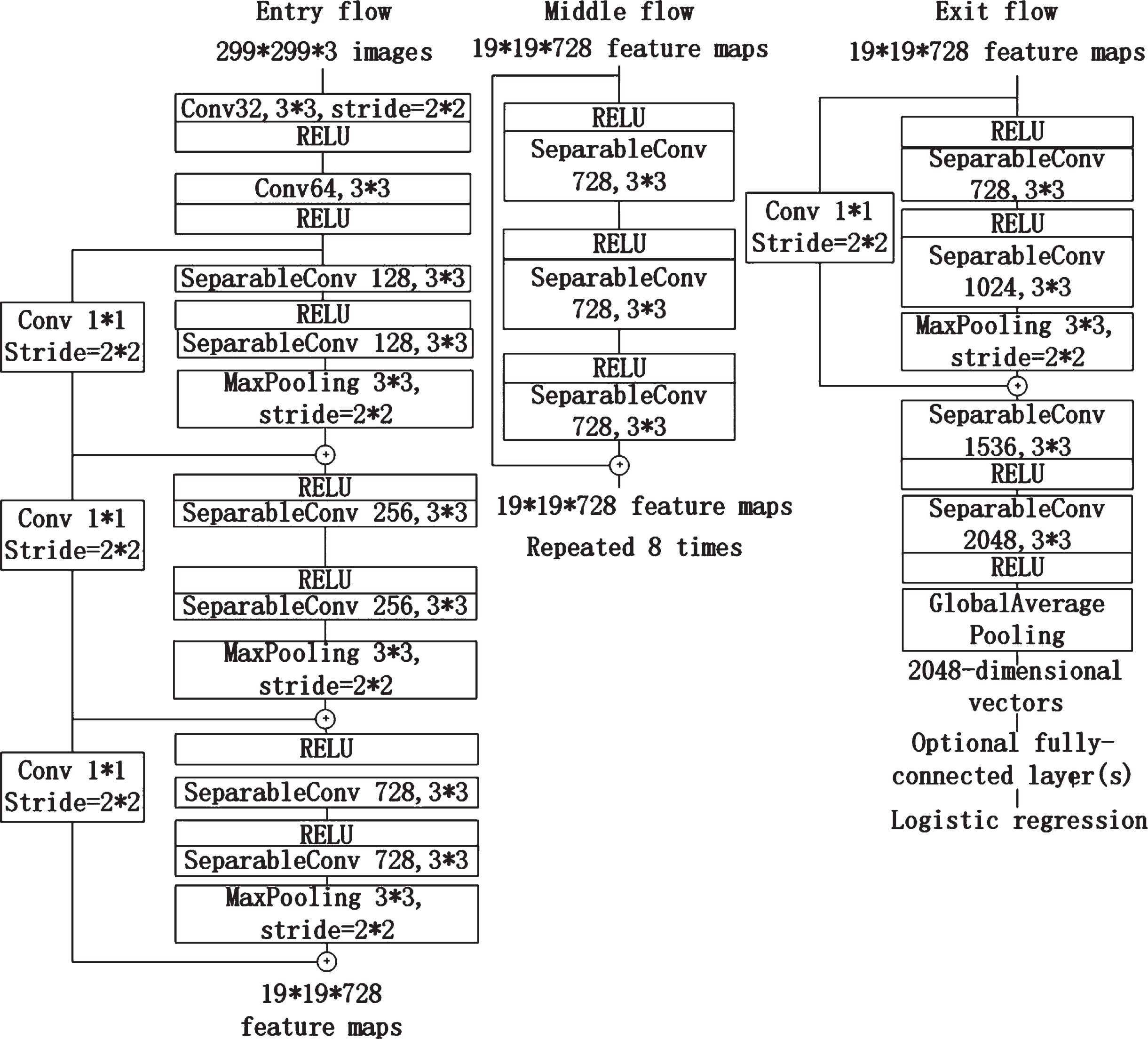
The architecture of Xception.
The Xception network is a kind of convolutional neural network based on depthwise separable convolution. At the same time, the residual structure is introduced to reduce the difficulty of network training, to accelerate convergence of the network, and to solve the problem of disappearance of the gradient in the deep network. Depthwise separable convolution can be decomposed into two smaller operations: depthwise convolution and pointwise convolution [29]. Deep convolution carries out the convolution operation on each channel without changing the depth of the input feature image, so as to obtain the output feature graph with the same number of channels as the input feature image. Point-by-point convolution carries out the convolution by raising and lowering the dimensions of the feature graph. Depthwise separable convolution has lower parameters and operational costs than conventional convolution [30]. An example of depthwise separable convolution is shown in Fig. 2.
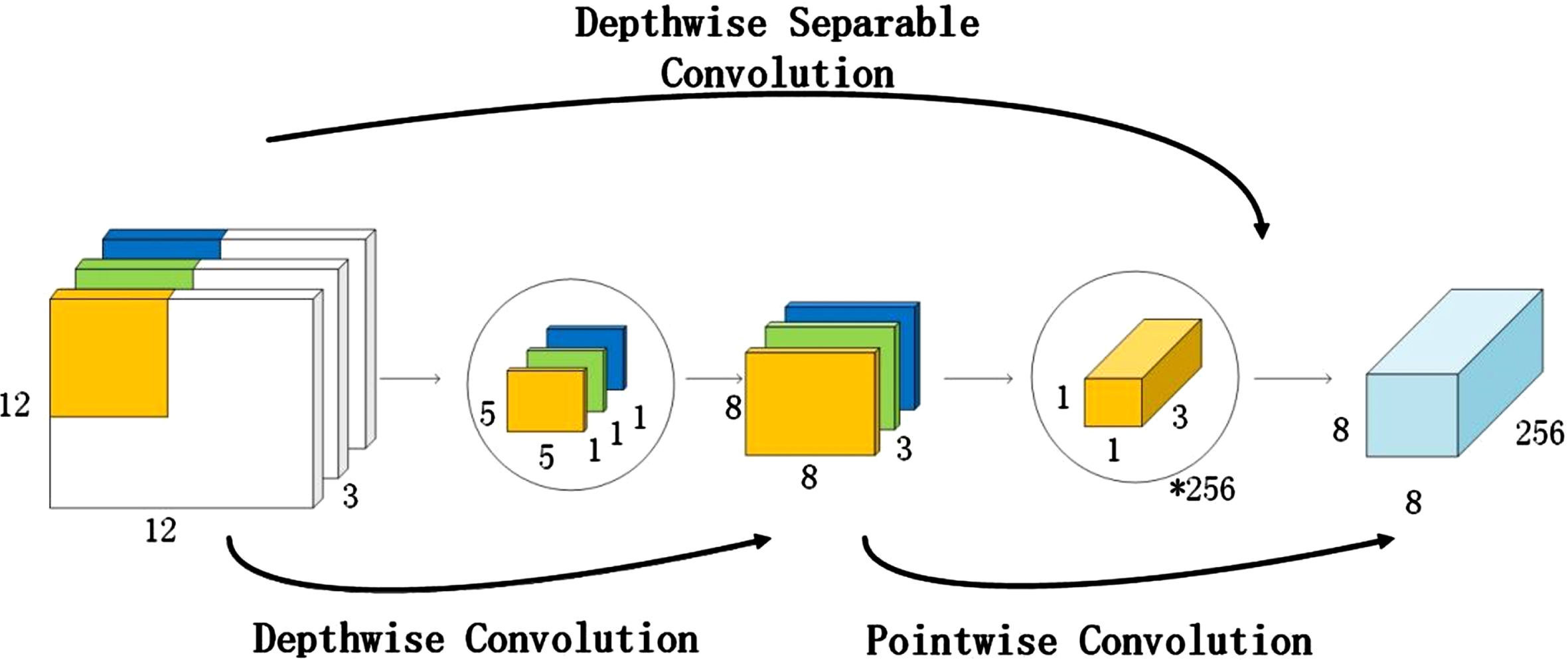
Depthwise separable convolution.
The main function of the squeeze and excitation block (SE Block) is to allocate each channel and to help the network to learn important feature information. The block is divided into three steps: squeeze operation, excitation operation, and fusion operation. The squeeze operation makes use of global pooling, carries out feature compression along the spatial dimension, and turns each two-dimensional feature channel into a real number [31].
After the squeeze operation, the network only obtains a global description, but this description cannot be used as the weight of the channel. Therefore, the excitation operation is proposed, which can obtain channel-level dependence and satisfy the ability to learn non-exclusive emphasis.
After the excitation operation, the weights of each channel in the input feature graph U are obtained, and then, the weights are fused with the initial features.
The module structure is shown in Fig. 3. The feature map size is H × W × C. Fsq (·), which is representative of the squeeze operation. Fex (· , W) represents the excitation operation. Fscale (· , ·) represents the fusion operation.
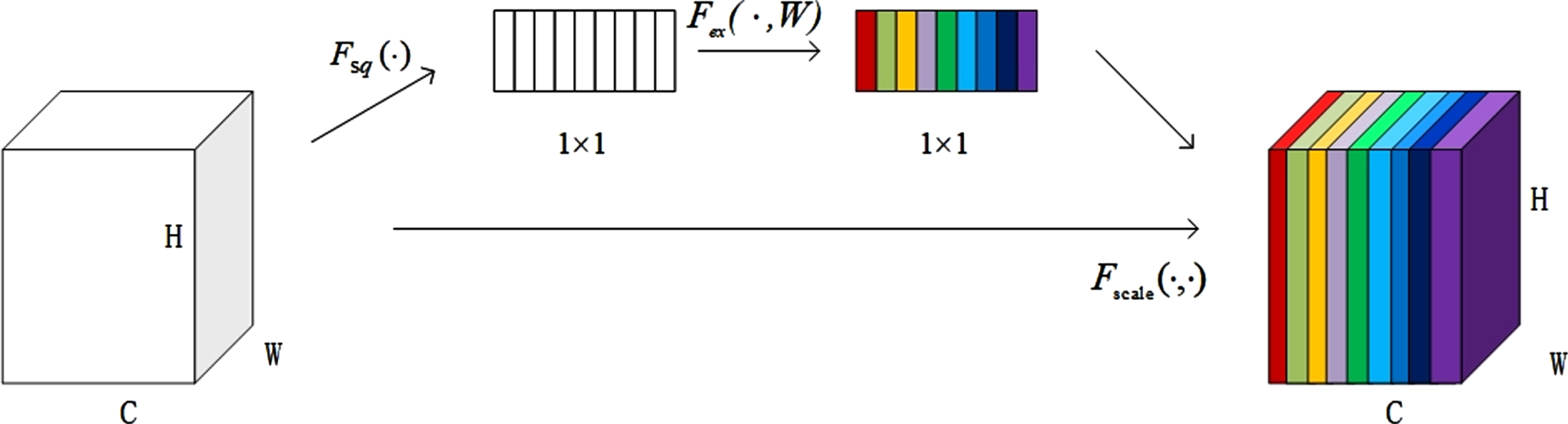
SE block architecture.
An activation function is usually introduced to enhance the nonlinear function of the convolutional neural network. The Mish function [24] is mathematically defined as follows:
The ReLU activation [32] function has the problem of a disappearing gradient when the input is negative, while the Mish function is a smooth, non-monotone activation function, which can make gradient descent smoother and can improve the recognition accuracy at the same time.
At present, most mainstream CNNs extract expression features from the whole face image and treat all regions in the image uniformly. They cannot focus on the input image to classify relevant regional features of the image, which will result in a waste of information processing resources and weakens the expression ability of the features. SE-Net integrates channel attention into the convolutional module, which significantly improves the performance of multiple deep CNNs. To prevent excessive network parameters from affecting network performance, SE blocks were only added to the first three parts of the network. The ReLU activation function was replaced by the Mish activation function, and the linear operation was used to strengthen the feature representation and to reduce the number of parameters and computations of the model.
This paper focuses on the Xception network architecture. After each depthwise separable convolution, an extrusion excitation module was added to the entry flow. After depthwise separable convolution, the input image was first pooled and calculated as follows:
Next comes the excitation operation, which consists of two fully connected layers and the Sigmoid activation function. The calculation is as follows:
After the above operations, the weights of each channel in the input feature graph U were obtained. Finally, the weights and original features were fused. The calculation is as follows:
Finally, the feature map was obtained and passed into the next layer. The middle flow received the incoming feature graph of the entry flow for three convolution operations. After eight middle flow processing operations were repeated, the exit flow received the processed feature graph. After adjusting the number of channels through two depthwise separable convolution operations, maximum pooling was performed to change the size. The fusion structure was passed into the global pooling layer using the residual network. Figure 4 shows the entry flow in this paper. As can be seen from Fig. 4, the output of the depthwise separable convolutional layer was input into the SE module, and the output was then sent to the batch normalization layer, which can help the network to further focus on and select information conducive to facial expression classification.

Entry flow in this paper.
Data set
FER2013 consisted of 35886 images of faces with different expressions, each 48 by 48 pixels in size. We collected images from FER2013 that fit the classification. The data set in this paper divided expressions into five categories, including listening, thinking, understanding, mind wandering and yawning. For these five categories of emotional states in a classroom, their simple facial expression features and corresponding classroom behaviors were given, as shown in Table 1. In the process of model training, a data set with a large amount of data can suppress the overfitting phenomenon, so we extended the dataset by traditional data enhancement, including rotation and mirroring, as shown in Fig. 5. After data enhancement, listening had 688 images, thinking had 150 images, understanding had 594 images, yawning had 204 images, and mind wandering had 342 images. Finally, 1978 images were obtained and divided into the training and test sets according to a ratio of 8 : 2.
Classroom emotional state classification
Classroom emotional state classification

Data set facial expression examples.
The experimental environment of the algorithm in this paper included: a 64-bit Windows 10 operating system, a Python3.8 programming language experiment, a TensorFlow2.6.2 deep learning framework, and an Nvidia GeForce RTX 2080Ti graphics card. The batch-size was set as 16 in the training stage, and Adam was used as the optimizer. Five rounds of pre-training were conducted, with a learning rate of 10–3. A total of 150 rounds of training were conducted, and the initial learning rate was 10–4. In order to accelerate network convergence and to prevent network overfitting, dropout regularization was added to the network. The network was pre-trained using the ImageNet data set.
To verify the effectiveness of the proposed algorithm, a comparison experiment was conducted with other algorithms on the data set. The comparison results are shown in Table 2.
The identification results of different methods on the data set
The identification results of different methods on the data set
By analyzing Table 2, we can see that compared with other methods, the method proposed in this paper achieved a good recognition effect. The accuracy of the proposed algorithm was improved by 5.25% compared to Resnet50, 3.11% compared to Inceptionv3, 2.71% compared to MobileNet v1, and 2.22% compared to Xception. Compared with the other algorithms, the recall rate and F1 score were also improved. It can be seen that the method proposed in this paper could learn facial features well and had higher recognition accuracy.
To verify the network’s performance, ablation experiments were performed on the data set. The methods of the ablation experiments are shown in Table 3, including whether the SE module was added into Xception network and whether the activation function was improved. By adding the SE module to the model and improving the activation function, key information in the facial features could be effectively selected so as to improve the recognition accuracy of the network model to a certain extent. Table 2 shows that Acc, Recall and F1_score of the Ixception network model were 95.48%, 0.9546, and 0.9546, respectively, which were 2.22%, 0.0212, and 0.0212 higher than those of the Xception network model. Table 4 shows after the SE module was added to the Xception network model, ACC, Recall and F1_score were increased by 1.31%, 0.0128, and 0.0128, respectively, which had the greatest impact on the performance of the network model. After improving the activation function, the network model was improved by 0.91%, 0.0084, and 0.0084, respectively. Therefore, the addition of the SE module and improvement in the activation function greatly contributed to the improvement in the network model’s recognition performance.
Three methods of ablation experiments
Evaluation of different ablation methods on the data set
The experimental environment of the algorithm in this paper included: a 64-bit Windows 10 operating system, a Python3.8 programming language experiment, a TensorFlow2.6.2 deep learning framework, and an Nvidia GeForce RTX 2080Ti graphics card. The batch-size was set as 16 in the training stage, and Adam was used as the optimizer. Five rounds of pre-training were conducted, with a learning rate of 10–3. A total of 150 rounds of training were conducted, and the initial learning rate was 10–4. In order to accelerate network convergence and to prevent network overfitting, dropout regularization was added to the network. The network was pre-trained using the ImageNet data set.
To verify the effectiveness of the proposed algorithm, a comparison experiment was conducted with other algorithms on the data set. The comparison results are shown in Table 2.
By analyzing Table 2, we can see that compared with other methods, the method proposed in this paper achieved a good recognition effect. The accuracy of the proposed algorithm was improved by 5.25% compared to Resnet50, 3.11% compared to Inceptionv3, 2.71% compared to MobileNet v1, and 2.22% compared to Xception. Compared with the other algorithms, the recall rate and F1 score were also improved. It can be seen that the method proposed in this paper could learn facial features well and had higher recognition accuracy.
In order to verify the effectiveness of the proposed algorithm, the experimental results of Xception and Ixception on AffectNet, FER2013 and CK+ are compared. Compared with the Xception algorithm, the accuracy of expression recognition obtained by the Ixception algorithm proposed in this paper are all improved to some extent.As shown in Table 5, the effectiveness of the proposed algorithm is verified by experiments.
Results on public datasets
Results on public datasets
The confusion matrix can reflect the recognition accuracy of each type of expression and the misclassification of other types. The confusion matrices obtained by the Xception and Ixception networks through the test experiment on the data set are shown in Figs. 6 and 7, where the rows of the matrix represent the real recognition results and the columns represent the predicted recognition results.

Evaluation index of different ablation methods on data set.

The confusion matrix of Xception.
As can be seen from Figs. 7 and 8, the accuracy of detecting each type of facial expression was improved by the algorithm in this paper. As can be seen from the above figure, each type of facial expression was slightly confused with the others, but listening, understanding, and yawning could be easily distinguished with an accuracy of more than 95%.
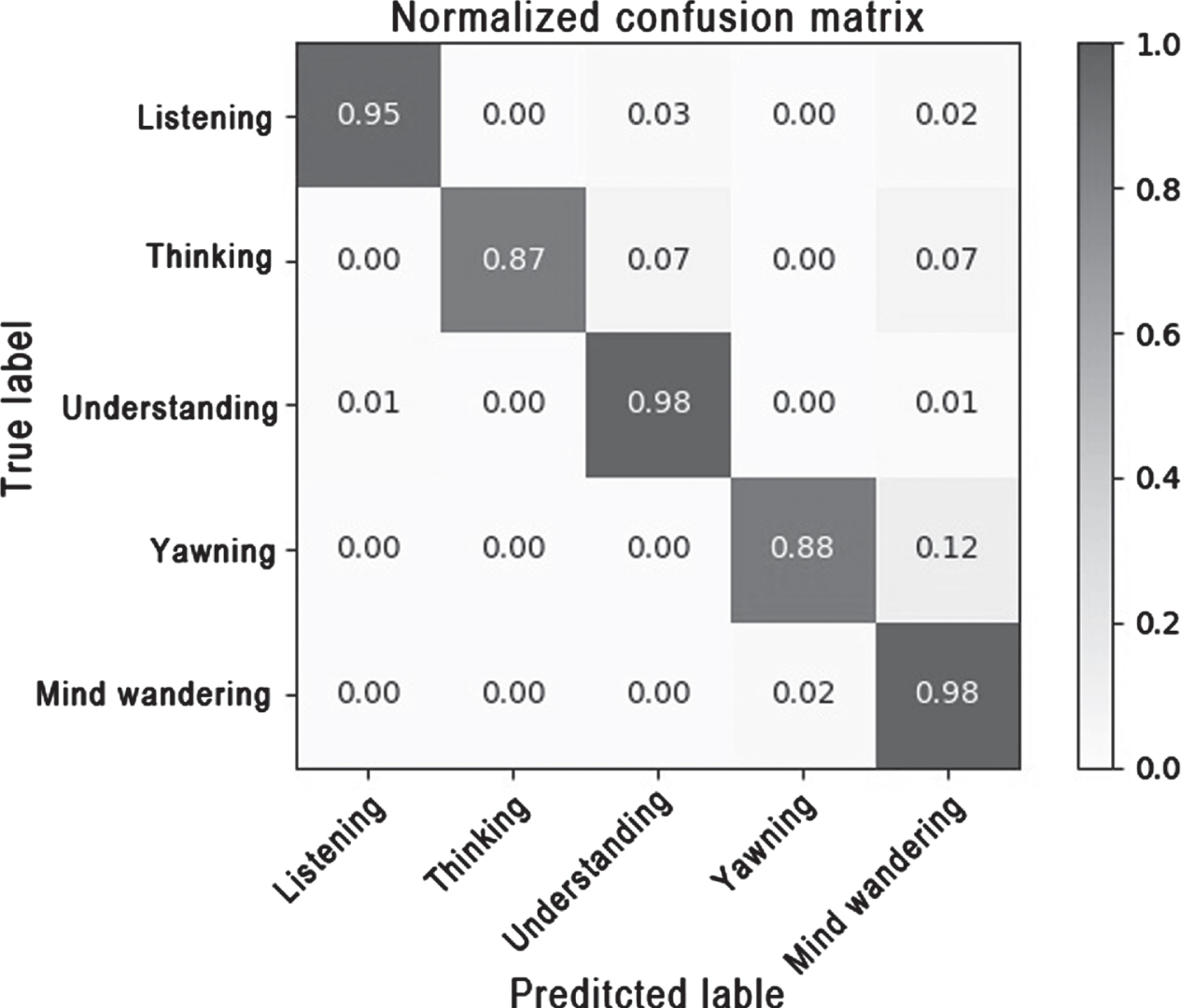
The confusion matrix of our method.
The recognition rates for thinking and yawning were low, and some pictures were assigned to the wrong category. These features were based on the eyes, while the rest of the facial features were more subtle, which led to the prediction being misclassified as understanding and mind wandering. Yawning and mind wandering share some similar characteristics. Students will occasionally hold their faces in their hands when they are distracted and they also easily cover their mouths with their hands when yawning, leading to confusion. Another reason for this phenomenon is that there were fewer training pictures of thinking and yawning, and the samples to learn were limited, so their recognition rates were lower than the those of the other three types.
In order to solve the problem that convolutional neural networks cannot focus on the regional features of students’ facial expressions in a classroom from images, this paper proposed an attention-mechanism-based facial expression recognition method based on the Xception network. The attention mechanism was introduced to adjust the proportion of channel information, to improve the ability of the network to extract important features from students’ facial expressions, and to learn the features of students’ facial expressions more resonably. During training, dropout regularization was used to simplify the network structure and to prevent overfitting of the model. The experimental results on the data set presented in this paper showed that, compared with the benchmark network model and other classical networks, the proposed method effectively improved the performance of classroom students’ facial expression recognition. In future work, the problem of sample imbalance in the experimental data and how to optimize the algorithm more suitably for students’ facial expression recognition will be further studied.
Footnotes
Acknowledgments
This work is supported by Guangxi Key Laboratory of Trusted Software (KX202315); Industry-University-Research Innovation Foundation of Chinese Universty (2021LDA06003); Provincial Graduate Student Innovation Ability Training Funding Project of Hebei Provincial Education Department (CXZZSS2023058). Hebei Normal University Teaching Reform Project (2023XJJG049).