
Abstract
The wind power is considered as a potential renewable energy resource which requires less management cost and effort than the others like as tidal, geothermal, etc. However, the natural randomization and volatility aspects of wind in different regions have brought several challenges for efficiently as well as reliably operating the wind-based power supply grid. Thus, it is necessary to have centralized monitoring centers for managing as well as optimizing the performance of wind power farms. Among different management task, wind speed prediction is considered as an important task which directly support for further wind-based power supply resource planning/optimization, hence towards power shortage risk and operating cost reductions. Normally, considering as traditional time-series based prediction problem, most of previous deep learning-based models have demonstrated significant improvement in accuracy performance of wind speed prediction problem. However, most of recurrent neural network (RNN) as well as sequential auto-encoding (AE) based architectures still suffered several limitations related to the capability of sufficient preserving the spatiotemporal and long-range time dependent information of complex time-series based wind datasets. Moreover, previous RNN-based wind speed predictive models also perform poor prediction results within high-complex/noised time-series based wind speed datasets. Thus, in order to overcome these limitations, in this paper we proposed a novel integrated convolutional neural network (CNN)-based spatiotemporal randomization mechanism with transformer-based architecture for wind speed prediction problem, called as: RTrans-WP. Within our RTrans-WP model, we integrated the deep neural encoding component with a randomized CNN learning mechanism to softy align temporal feature within the long-range time-dependent learning context. The utilization of randomized CNN component at the data encoding part also enables to reduce noises and time-series based observation uncertainties which are occurred during the data representation learning and wind speed prediction-driven fine-tuning processes.
Introduction
Time series based data analysis and forecasting is considered as a primitive problem which has been widely studied in multiple disciplines [1, 2]. For very recent years, our world has been shifted into a new generation of low-CO2 and environmental protection towards greener energy production [3, 4], consumption as well as manufacturing. Within the direction, low-carbon emission and better living environment, renewable energy resources have been widely taken in consideration for reducing and further completely substituting the usage of fossil fuel/non-renewable resources in power production. Among well-known natural resources, the wind power is considered as a potential, unlimited and efficient energy supply which can be utilized in different regions of our world. In other words, the wind energy source, is currently booming with the multiple supports from governments and organizations. Thus, the development of wind energy production as well as it associated aspects (e.g., facility manufacturing, material science, management system, etc. for wind power production) have been attracting more and more attention from the international research communities to towards smart wind farm/power management and production [5] (as illustrated in Fig. 1). It’s needless to say that the wind power production and consumption can be considered as a common energy-shifting mainstream in multiple developing/developed countries. However, the wind power production is known as a challenging process which require advanced achievements in both technical/material manufacturing as well as management. Within the wind power production management aspect, as we all known that, most of wind resources around the world are frequently influenced by different natural factors (e.g., temperature, humidity, geography, climate, sessions, etc.). Thus, these intermittent and random characteristics of wind have made this type of renewable energy supply unstable. This challenge also carries great burdensome to monitor and optimize of overall power grid systems. To achieve better efficiency in managing wind power farms, wind speed prediction is considered as the most effective way to deal with the randomization and volatility aspects of natural wind resources. Therefore, most of recent researches in wind power production domain are mainly focused on focus on the enhancement of wind speed as well as power prediction approaches which provide better forecasting results.
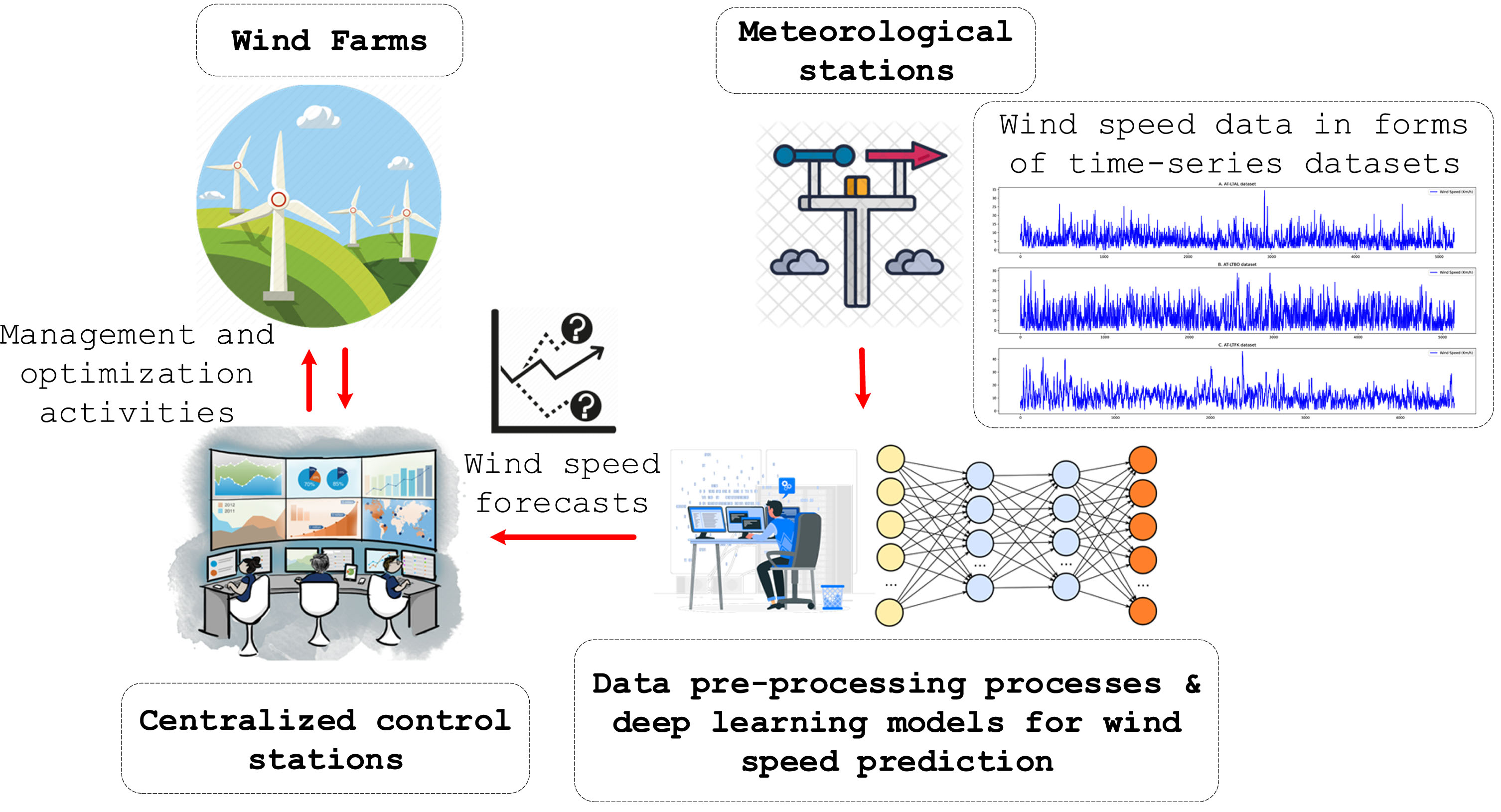
The illustration of smart/deep learning-based wind farm management and optimization through wind speed forecasting approach.
In general, most of recent wind speed data modelling and forecasting methods can be categorized into three main approaches, including: physical, statistical and machine learning based approaches. Within the physical approach, wind speed forecasting techniques are designed to analysis region-specific geographical as well as operation conditions of wind farms to conduct predictions. Due to the main reliance on unique aspects of different wind farms in different regions, the generalization of models in this approach is quite poor and might be unable to flexibly applied in different conditions. For the statistical approach, it is considered as more generalized in comparing with physical approach in which it doesn’t require much information of geographical characteristics around the wind farms to conduct predictions. Within this approach, the proposed wind speed predictive models utilize different statistical (Naïve Bayes, Gaussian process regression, exponential smoothing, etc.) and auto-regressive (e.g., ARIMA, ARX, etc.) methods to efficiently model and learn the temporal moving patterns of the time-series [6] based wind speed datasets. However, many recent researches have demonstrated that statistical/auto-regression techniques such as ARIMA [7, 8] might be unable to sufficiently preserve the complex and long-ranged time-dependent features to deliver accuracy predictions. On the machine learning based approach, it can be classified into two main trends. The first main trend of this approach is to use traditional machine learning based techniques with out-of-shelf algorithms, such as: support vector machine (SVM) [9, 10], support vector regression (SVR) [11, 12], etc. or shallow artificial neural network architectures [13–15], such as: multi-layered perceptron (MLP) [16], Boltzmann machine [17], etc. to efficiently model complex time-dependent data of wind speed and learn to conduct future predictions. Within the machine learning based paradigm, artificial neural network is popularly used due to its advanced characteristics in characteristics non-linear data modelling, automatically feature extraction, fitting, adaptation as well as prediction task-driven training. Thus, different neural network architectures have been proposed at that time to be suitable for handling wind speed forecasting problem. However, traditional show neural architectures are considered as so simple to model the complex non-linear and long-term temporal patterns from time series-based wind speed datasets. Thus, they can’t achieve better accuracy performance for range-varied wind speed prediction task within large-scaled datasets.
In recent years, the dramatic progresses of deep learning in multiple disciplines, such as: natural language process (NLP) [18], computer vision (CV), etc. have provided potential directions for leveraging the performance of wind forecasting task in forms of short/long-term time-series based prediction problem. Recent advanced deep learning-based architectures like as RNN, CNN, sequential auto-encoding (a.k.a. Seq2Seq) [19], etc. have been utilized in modelling and capturing complex time-dependent features from the input historical observations to deliver more accurate wind speed prediction than previous traditional machine learning based techniques. The common RNN-based architectures like as: gated recurrent unit (GRU), long short-term memory (LSTM), etc. have been widely used to learn the temporal features from time-series based datasets in forms of layer-to-layer aggregation learning through passing hidden states between recurrent neural cells. However, RNN-based architectures for wind speed forecasting problem like as LSTM [20–22] or Bidirectional LSTM (Bi-LSTM) [23] are still limited in sufficiently modelling high-complex and noisy time-series based wind datasets which include a large number of abnormal and lagged consecutive observations. Moreover, they might also fail to proper internet the time-dependent embeddings of input sequences into prediction outputs in forms of next hidden state generation. To overcome these limitations, in recent times, majorly inspired from great achievements of advanced sequential auto-encoding and transformer [24] based architectures, AE/transformer-based techniques have shown superior performances in capturing long-range dependency from time-series based datasets than classical RNN-based architectures. However, following our best knowledge there is no work have been dedicated to deal with the wind speed prediction problem. Moreover, with limitations of intermittent and random characteristics of wind data in nature, the large number of occurred noises and abnormal fluctuations within wind speed datasets might challenge existing sequential AE/transformer-based techniques to produce high-accurate prediction results.
Our motivations & contributions
Mainly inspired from wonderful ideas of applying transformer-based architectures for time-series based prediction task, in this paper we formulate the wind speed forecasting problem as sequential data embedding and transformation, called as: RTrans-WP (as illustrated in Fig. 2). Our proposed RTrans-WP supports to achieve better prediction results within complex and large-scaled wind datasets. In our proposed RTrans-WP model, we integrated the transformer-based architecture with a custom regularization mechanism through weighting randomization within a multi-layered convolutional network architecture. The CNN-based randomization mechanism enables to softly transform the initial input sequences into a regularized representation spaces before feeding into the encoding component of the given transformer-based architecture. By doing this, we can reduce the effects of abnormal/lagged input observations in the initial wind speed dataset which might lead to disturbances for the transformer during the temporal latent representation learning process. Then, the regularized input sequences are passed into the encoder to extract time-dependent temporal embeddings that carry rich-semantic structural relationships between consecutive input sequences. The, learnt latent embeddings from the encoding component are fed into self-attention mechanism to produce contextual information of corresponding input sequences. For the implementation of attention mechanism in our proposed RTrans-WP model, we utilized the multi-headed attention architecture which are mainly adopted from previous studies [24, 25]. In order to speed up the contextual information learning process, we adopted the probabilistic sparse multi-head self-attention mechanism of recent works [26]. Then, the incorporated encoder’s embeddings and contextual information are fed into the decoding component to interpret the corresponding sequences which are also known as the embedding reconstruction process. For dealing with the wind speed prediction problem, the output sequence representations of the decoder are incorporated with task-driven full-connected layer to conduct predictions. To sum up, our contributions in this paper can be summarized as three-folds, including: First of all, we present an approach of applying modified transformer-based architecture with the probabilistic sparse multi-head self-attention mechanism to effectively model, extract and learn rich-semantic temporal information from the given time-series based wind speed dataset. The given sequential auto-encoding with self-attention mechanism enables to sufficiently transform and interpret the term-varied representations of the historical observations into rich-semantic embedding vectors which are later utilized to fine-tune for prediction task at the end. Secondly, to effectively deal with noise/lagged input sequences within the given time-series dataset, we apply a custom regularization with a CNN-based randomization layer in which initial variables of the input sequences are softly transformed into unified and noise-reduced embedding spaces before feeding into the encoding part. The utilization of random weighting transform through a multi-layered CNN architecture can directly support to improve both quality of generated input sequence embeddings as well as prediction outputs in the end. Finally, to demonstrate the effectiveness of our proposed RTrans-WP model for wind speed prediction task, we conduct extensive experiments as well as comparative studies between our model with recent state-of-the-art deep learning baselines in real-world wind speed datasets. The experimental outputs present the outperformance as well as necessary of our proposed ideas in this paper in which the integrated CNN-based regularization mechanism with transformer-based architecture can explicitly produce better wind speed data representation as well as prediction.
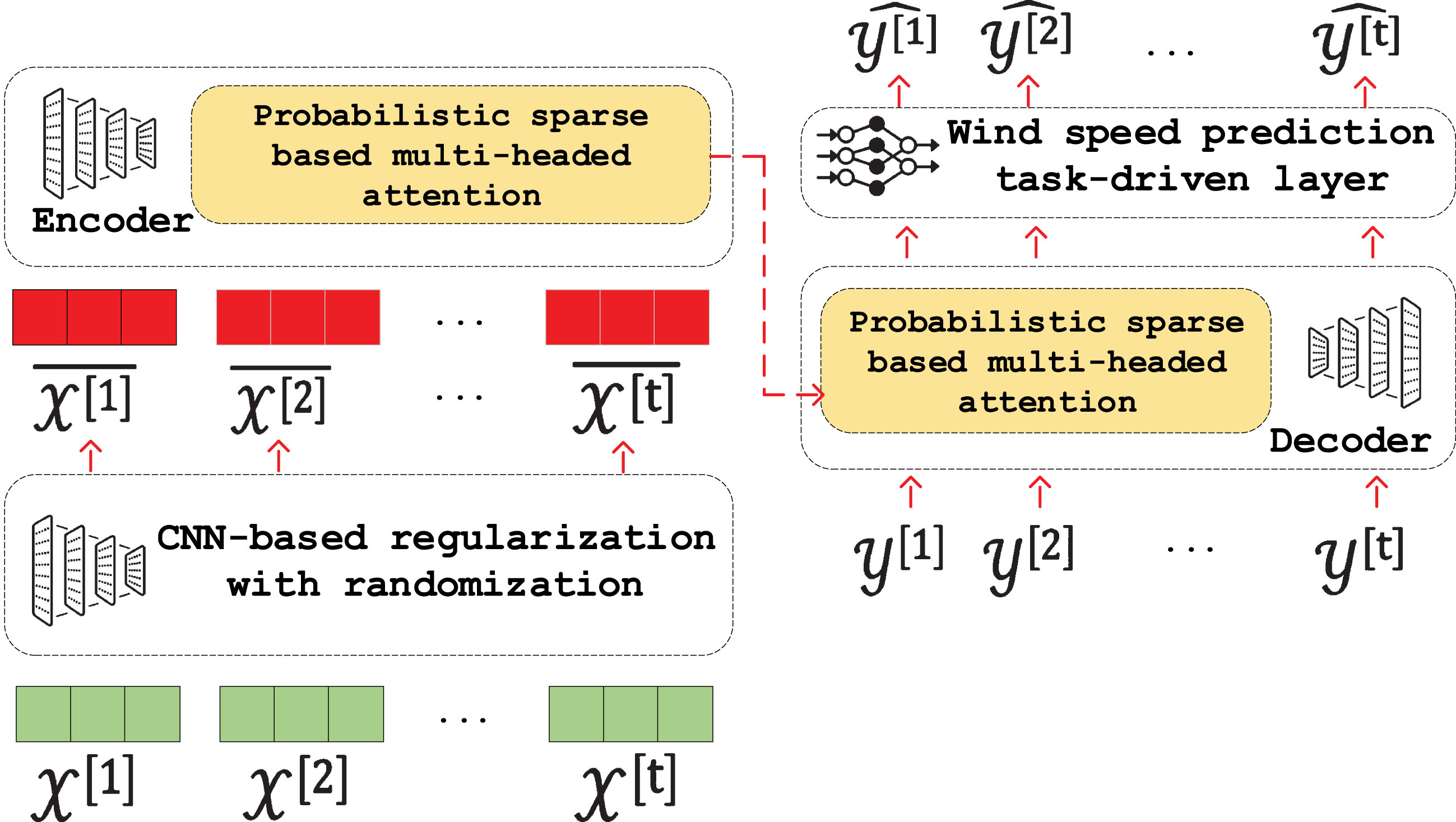
The illustration of overall architecture of our proposed RTrans-WP model in this paper.
In the next section, we briefly review about recent attempts for wind speed prediction task in both traditional machine learning and deep learning-based approaches. Next, in the third section we formally present about the methodology and detailed implementations of our proposed RTrans-WP model for handling with wind speed prediction task. In the fourth section, we show extensive experiments and thorough performance comparisons between our proposed RTrans-WP model with other state-of-the-art baselines in real-world datasets. Finally, we conclude our works as well as highlight some future improvements for this researching direction in the last section. Table 1 shows the list of notations/mathematical symbols and their corresponding explanations which are commonly used in the rest contents of our paper.
List of notations and descriptions which are used in our paper
In this section, we briefly review about recent studies which are mainly focused on the time-series based wind speed forecasting problem. Generally, for recent decades, there are an amplified number of researches have been conducted in order to seek better accuracy performances for the wind speed prediction problem. The accurate wind speed forecasting results play an important role in centralized wind farm monitoring and optimization systems. Most of recent studies in area can be categorized into two main trends, the traditional mathematical/regression-based and deep learning-based approaches. The proposed techniques in each approach have their own common pros/cons. The remained limitations of these previous works played as important motivations for our works in this paper.
Traditional approach in wind speed forecasting
From the past, there are several statistical techniques for time-series based analysis and evaluation, such as SVR, ARIMA, etc. These regression-based methods have been utilized to extract temporal patterns from input sequential wind speed records, then delivered predictions. In this well-known work [7], Cadenas, E., et al. have proposed the utilization of integrated multivariate NARX model within univariate ARIMA framework. This integration enables to efficiently deal with the temporal information preserving from complex time-series based wind speed datasets. This proposed model has been considered a remarkable prediction technique for this problem at that time. In recent time, Sim, S. K. et al. [8] proposed a novel nested ARIMA model which can support to handle non-stationary temporal features from wind speed datasets to achieve better prediction results. In this approach, the wind speed temporal changing patterns [8] in different time-steps are sufficiently modelled. In order do this, critical temporal patterns within a wind speed dataset have been sufficiently captured by integrating parameter variation and stochastic processes between different input sequences, thus achieve better results for longer-ranged wind speed prediction problems.
On the other hand, there are other researchers have also demonstrated the utilization of traditional machine learning based algorithms to efficiently deal with the wind speed forecasting task. Such as recent works of Li, Z. et al. [9] and Natarajan, Y. J. et al. [10] in applying different modified SVM techniques to preserve the temporal latent features from the input time-series wind datasets. Similar to that, in a very recent attempt [10], the integrated SVM with different techniques such as: singular spectrum analysis (SSA) and variational mode decomposition (VMD). These methods have assisted to properly eliminate the noised/lagged observations from dataset and retrieve the approximate temporal behavior wind speed. Thus, they can directly help to improve the forecasting performance. There are other researchers have dedicated their studies [13–15] on the application of traditional neural network architectures such as linear full-connected neural network architecture. These classical neural architectures enable to effectively model and capture the short-term dynamic temporal patterns from time-series based wind speed dataset. Such as notable efforts of Zhang, Y. et al. [14] and Bre, F., et al. [15] in applying different multi-layered neural network architectures to learn and transform the non-linear representations of time-dependent wind speed reported data entries. Thus, the learnt temporal patterns of input sequences are sufficiently captured and transformed into prediction-friendly embedding forms. These recent studies have presented that neural network architectures can be considered as a potential direction for further improvement in both wind speed data representation learning and forecasting problem. Even these traditional techniques have delivered significant performances on producing acceptable accurate prediction outputs, they still suffered several challenges. These challenges are majorly related to the capability of preserving long-range dependency between consecutive input observations. Moreover, they are also considered as unable to deal with lagged/noised sequences which are normally occurred within complex wind speed datasets.
Deep learning-based wind speed prediction approach
In recent years, there are tremendous raises of deep learning-based architectures in multiple domains of computer science. The rapid developments of deep neural models have provided potential and promising solutions for existing challenges of traditional approaches for wind speed prediction problem. In fact, most of well-known RNN-based architectures, such as: GRU, LSTM, Bi-LSTM, etc. have become the mainstream for most of deep learning-based wind speed forecasting systems. Such as in the recent attempts of Ghaderi, A. et al. [20], Yu, C. et al. [21] and Geng, D. et al. [22], they have in utilized the LSTM-based architecture for sufficiently preserving the dynamic long-term patterns of reported wind speed entries. These extracted dynamic patterns are later utilized to produce better forecasting results. In this work [22], Geng, D. et al. proposed a novel integrated principal concept analysis (PCA) with LSTM architecture to efficiently restructure the input sequences before feeding to LSTM. Thus, it can effectively support to reduce the occurred noises within given wind speed datasets.
Similar to that, in very recent times, Liang, T. et al. proposed the utilization of Bi-LSTM architecture [23] with the application of transfer learning/pre-training paradigm of NLP and CV fields. This pre-trained predictive model assists to achieve remarkable improvements in the wind speed forecasting problem. Specifically, the given Bi-LSTM based architecture is pre-trained with the existing historical data of different wind farms in typical geographical locations. Then, the pre-trained Bi-LSTM model is utilized to fine-tuning for predicting the wind speeds of other wind farms which are located nearby (similar geographical characteristics). The experimental results within real-world datasets show previous LSTM/Bi-LSTM based techniques have remarkably enhance the accuracy performance of wind speed forecasting task Moreover, it also enables the capability of generalization and supervised learning manners within the wind speed forecasting problem. However, looking at the temporal representation learning side for time-series based prediction problem, most of recent RNN-based wind speed predictive models still suffered several limitations. These limitations are mainly related to the capability of incorporating with long-ranged sequences of large-scaled datasets. Moreover, these previous models are also considered as unable to concentrate on important temporal feature of the long-ranged input wind speed sequences during the representation learning process. Therefore, in case of handling complex wind speed datasets with high frequency of noises and lagged observations, most of traditional deep learning-based prediction techniques might tend to perform poor prediction outputs.
Methodology
In this section, we formally present the background concepts and methodology of our proposed RTrans-WP model. The RTrans-WP model is designed as a sequential auto-encoding mechanism with a modified multi-head attention mechanism to efficiently learn and capture dynamic temporal patterns from the time-series based wind speed datasets. Then, the learnt sequential embeddings of reported wind speed sequences which are generated at the decoding component are utilized to fine-tune for prediction through a full-connected task driven layer. To deal with abnormal/noised historical observations from the time-series dataset, we implement a custom CNN-based regularization through randomization strategy to transform the variables of input sequences into stable representation forms before feeding them into the encoding component.
Transformer-based architecture for time-series based wind speed data representation learning
Long-range sequential wind speed data embedding
In general, the wind speed forecasting task is normally formulated as a time-series based prediction problem with the given input sequence of fixed (L) window-size at a specific (tth) time-step, denoted as:
In this equation, the (Θenc) and (Θdec) are the sets of trainable parameters of encoding and decoding components, respectively. The ultimate goal of any sequential auto-encoding/transformer-based architecture is to extract temporal latent feature from the input to jointly optimized the original data representation reconstruction and the task-specific fine-tuning processes. By doing like this, the rich-semantic and long-range dependencies within the input sequences can be properly extracted, transformed and interpreted through the layer-to-layer neural aggregation mechanisms in both encoder and decoder. This sequential representation learning paradigm have been widely applied and proved the effectiveness in multiple NLP problems, especially in machine translation and machine reading comprehension tasks.
For the wind speed prediction task-driven learning objective, the output hidden states which are produced by the decoder, denoted as: (
In general, the decoding component of our given is worked as a sequential embedding interpretation mechanism which supports to transform the previous embedding states of the encoder into the unified and better friendly prediction task-driven representation forms. To better achieve global positional context as well as local temporal context of the unified sequential embedding forms, we utilized a modified multi-head attention mechanism within our transformer-based architecture which are mainly inspired from previous studies [24–26].
Then, from the calculated sparsity score of all queries in (Q), we only selected top-(u) dominant queries to update the attention weights (as shown in Equation 4). In this equation the (
In this section, we present the proposal of applying regularization mechanism within the CNN-based feature embedding mechanism. In general, the proposed random-based regularization mechanism supports to not only softly reduce the occurred noise from the given wind speed dataset but also transform the input time series in to a better prediction-friendly embedding space. As a time-series based prediction problem, within complex datasets, there is a large number of noise and abnormal fluctuations. These fluctuations might be frequently occurred due to different reasons. These reasons might be related to problems in data collection process, the influences of external aspects, etc. Therefore, in order to eliminate these challenges which are tightly related to the occurred noises and disturbances, we apply a multi-layered convolutional neural architecture with an initial randomized CNN-based weighting layer at the beginning. Then, a traditional CNN-based architecture is placed after to in charge for the time-series wind speed data representation learning process. In more specific, the given CNN-based regularization mechanism which is implemented in our RTrans-WP model takes the initial variables of the sequences (
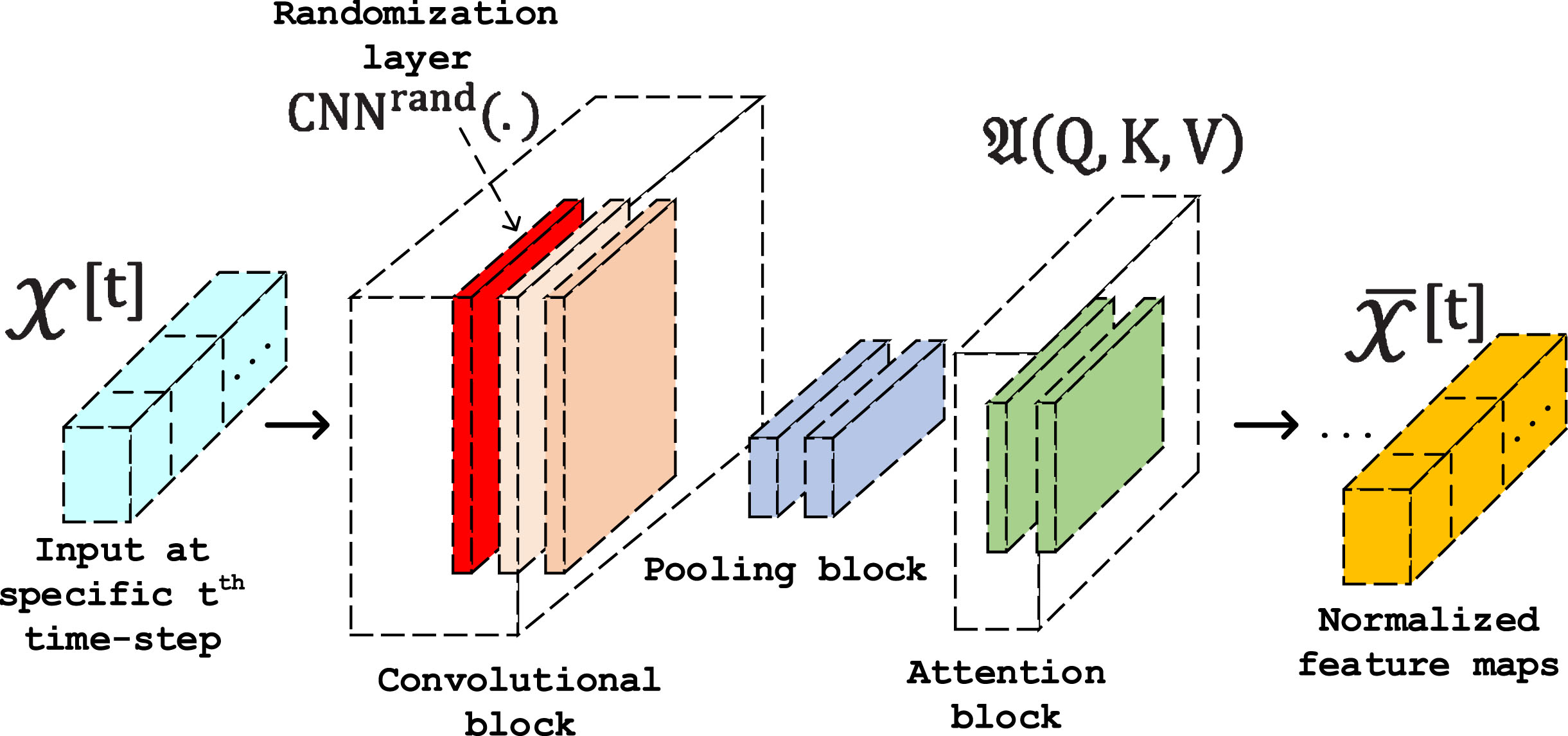
The illustration of CNN-based architecture with regularization for time-series based feature extraction through randomization strategy.
In this Equation (5), the
To prove the effectiveness of our proposed RTrans-WP model for wind speed prediction task, we conducted extensive experiments in real-world datasets. For comparative analysis, we also compared our model with different deep learning-based baselines for handling time-series based prediction problem. In addition, we also conducted several ablation studies to evaluate the effectiveness of applying CNN-based regularization mechanism in our RTrans-WP model for the wind speed data temporal representation/forecasting problem as well as sensitivity of some model’s hyper-parameters.
Dataset descriptions & experimental setups
To evaluate the performance of different techniques for wind speed prediction problem, we used a real-world dataset which have been constructed by collecting wind speed data which is reported from 66 stations in Assos, Turkey. This dataset is retrieved from the data repository of Iowa Environmental Mesonet (IEM) 1 , Iowa State University. This is a quite large dataset with over 1.15M data entries which are reported from different meteorological stations within periods of January 01, 2016 to December 06, 2017. Each data entry presents for the reported wind speed value (in kilometer/hours) at a specific time-step within the approximate 1-minute interval. For the experiments in this paper, we mainly used the wind speed data which is collected from three stations, named as: LTAL, LTBO and LTFK (as illustrated in Fig. 4). The general information about these data collections is described in the Table 2.
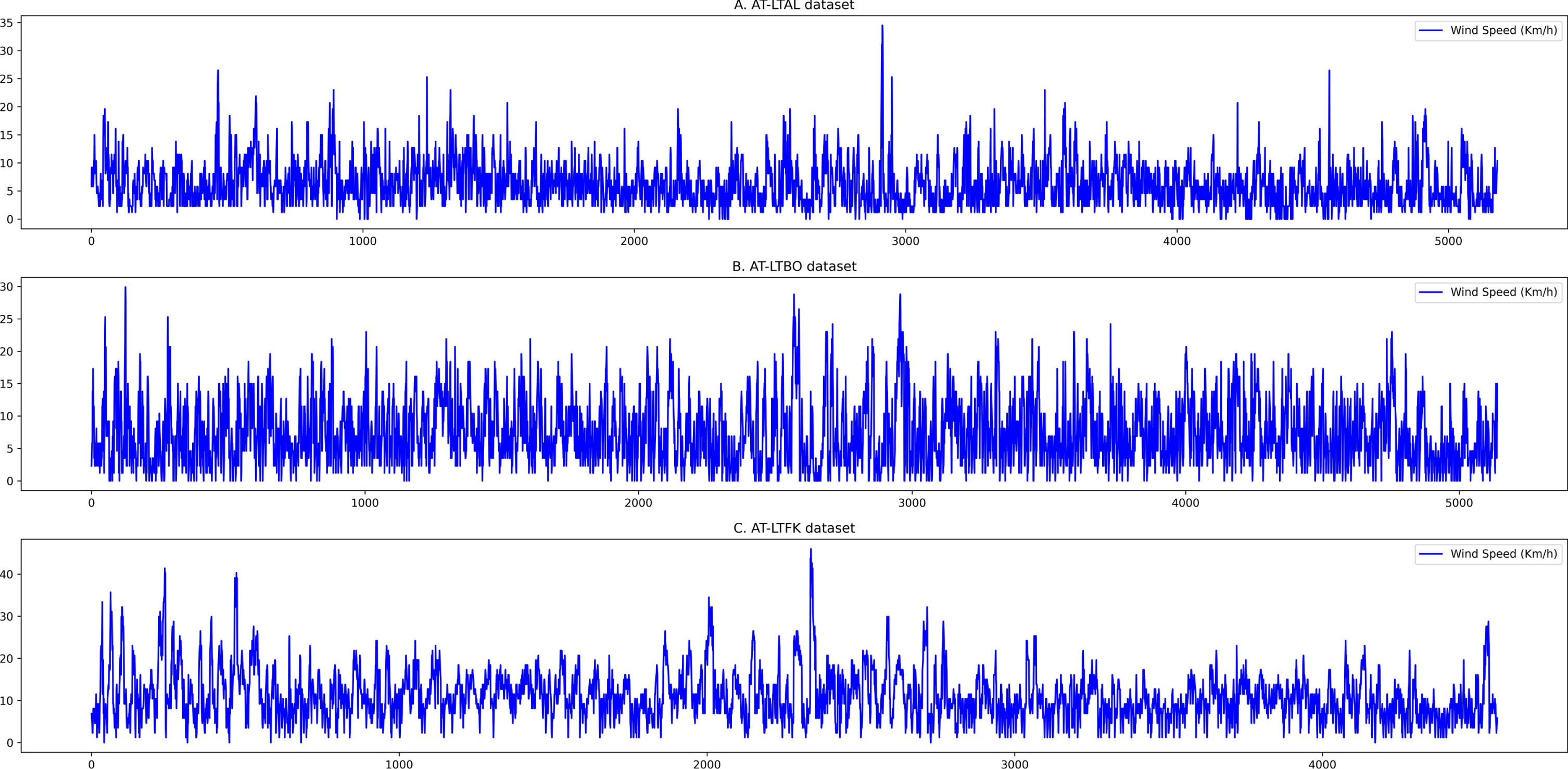
The visualization of wind speed fluctuations in (Km/h) of three real-world datasets, including: AT-LTAL, AT-LTBO and AT-LTFK.
General information about datasets which are used in our experiments
Detailed configurations of the proposed RTrans-WP model for all experiments in this paper
In order to standardly evaluate the accuracy performance for wind speed forecasting task of different techniques, we mainly used two benchmark evaluation methods, including: mean absolute errors (MAE) and root mean squared errors (RMSE). The wind speed forecasting outputs of each method in three described above real-world datasets are identified as shown in Equation (6).
In this equation, the (T), (
To compare the accuracy performance of our proposed RTrans-WP model with other baselines, we also implemented several deep learning-based techniques for deal with time-series based prediction problem. The comparative baseline techniques include the traditional implementation of GRU, LSTM/Bi-LSTM which are set up under the supports of PyTorch framework. In general, for the setups of GRU, LSTM and Bi-LSTM architectures, we used them to model and extract temporal features from three real-world wind speed datasets then the aggregated hidden states at different time-steps are incorporated with a prediction task-driven full-connected layer to deliver next predicted values. The number of hidden neural cells as well as other training strategy configurations for these RNN-based architectures are setup as the same as described in Table 3.
For recent state-of-the-art deep learning baselines, we implemented the Multi-LSTM architecture of Ghaderi, A. et al. in this work [20], the sequential AE (Seq2Seq) [19] and transformer architecture [25] with multi-headed attention mechanism for time series prediction. In more specifics, in this work [20], a.k.a. as Deep-Forecast, Ghaderi, A. et al. proposed a novel integrated multiple RNN architecture to extract richer spatiotemporal information from the time-series based datasets in order to improve accuracy performance of the prediction task in multiple forecasting problem. To setup the Deep-Forecast model, we utilized the original implementation as well as configurations of this paper in which the model achieved the highest accuracy performances. For the implementation of sequential auto-encoding and multi-headed transformer architectures for time-series based prediction problem, we followed the best practices of Sutskever, I. et al. [19] and Vaswani, Ashish, et al. [25] in their original works. Similar to the approach in our proposed RTrans-WP model, for these advanced deep neural architectures, a full-connected prediction task-driven layer is placed at the decoder’s output layer to conduct wind speed predictions. All the initial configurations for the Seq2Seq-WP and Transformer-WP models to handle the wind speed prediction problem are configured as the same as shown in Table 3.
Comparative results & discussions
Wind speed prediction task & comparative studies
For the wind speed performance evaluation through different deep learning-based techniques, we conducted the experiments in three real-world datasets. The Figs. 5 and 6 showed the performance comparisons in terms of MAE and RMSE evaluation metrics between different techniques within AT-LTAL, AT-LTBO and AT-LTFK datasets, respectively. In general, as shown from the experimental outputs, our proposed RTrans-WP model outperforms all traditional as well as state-of-the-art deep learning-based techniques for the wind speed forecasting problem in all datasets. Moreover, as shown from the experimental results, it is obvious that all the transformer-based techniques including our proposed model and Transformer-WP have achieved explicitly better results than previous deep learning-based methods. Therefore, these results have generally proved the effectiveness of applying sequential auto-encoding architecture with complex self-attention mechanism. The application of self-attention mechanism within RNN/AE-based architecture can effectively facilitate both long-ranged temporal feature representation learning and prediction task-driven fine-tuning, especially in wind prediction problem.

Comparative studies for wind speed forecasting task in terms of MAE metric between different deep learning-based techniques within the AT-LTAL, AT-LTBO and AT-LTFK datasets.
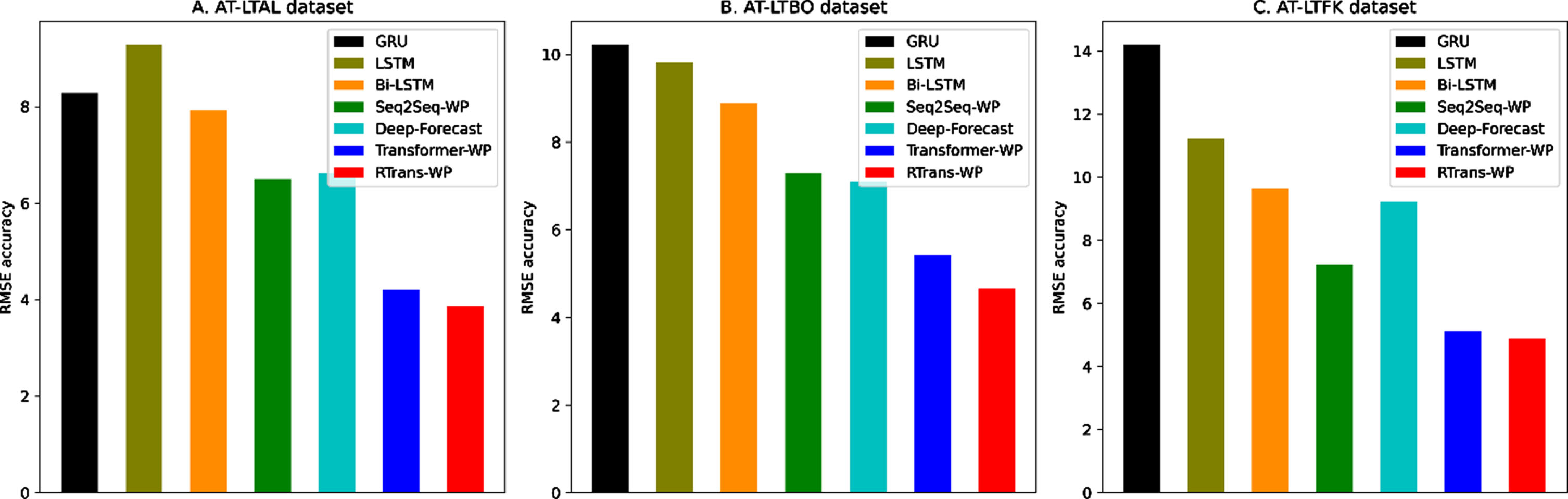
Comparative studies for wind speed forecasting task in terms of RMSE metric between different deep learning-based techniques within the AT-LTAL, AT-LTBO and AT-LTFK datasets.
In more specifics, averaging the prediction outputs in all three datasets, in comparing with traditional deep learning-based techniques, including GRU, LSTM and Bi-LSTM, our proposed RTrans-WP model remarkably improves the accuracy performance about 166.84% /141.75%, 147.81% /127.05% and 125.1% /97.66% in terms of MAE/RMSE evaluation metrics, respectively. By comparing different classical and well-known RNN-based architectures for the wind speed prediction task, we can figure out that while dealing with complex/long-ranged wind speed datasets, these classical RNN-based architectures are quite limited. Beside problems related to the variant vanishing during the training processes, the capability of concentrating on important dynamic patterns of the input sequences is also a major limitation of previous RNN-based architectures.
Similar to that, the experimental results also indicated the outperformances of our proposed RTrans-WP in comparing with recent state-of-the-art baselines, including: Seq2Seq-WP, Deep-Forecast and Transformer-WP techniques. These techniques are considered as our main competitors in this paper. Specifically, in comparing with these deep learning-based techniques, our model about slightly leverages the accuracy performances in terms of MAE/RMSE evaluation methods, approximately 70.45% /57.54%, 93.59% /71.03% and 22.1% and 10.15%, respectively. In comparing with the most recent time-series based analysis and prediction techniques like as Transformer-WP, our proposed model demonstrated the better prediction results as well as model’s reliability in which input sequences are softly regularized during the temporal feature learning processes. These experimental outputs have presented the effectiveness of integrating the sequential auto-encoding mechanism with multi-layered CNN-based regularization through randomization mechanism which directly supports to achieve richer temporal structures and semantics of wind speed data representations which are later used to significantly improve the performance of forecasting task.
In this paper, we mainly focused on dealing with the wind speed prediction task in forms of time series-based analysis and forecasting problem. In general, considering as an important principle which most of time-series based techniques are relied on, the correlations within a given time-series dataset present for the relationships between the current evaluated and historical observation entries. The Fig. 7 shows the correlations within different used wind speed datasets, including AT-LTAL, AT-LTBO and AT-LTFK which are mainly used in our experiments. Generally, this figure shows the strength of the correlation between wind speed observations and their corresponding lags by applying autocorrelation evaluation strategy in which correlation coefficients are identified for each observation and their lag values. Specifically, as shown from the Fig. 7, in each dataset (AT-LTAL in Fig. 7-A, AT-LTBO in Fig. 7-B and AT-LTFK in Fig. 7-C) we can see the relationships between each observation at a specific (tth) time-step and its corresponding lag of that observation at the previous time (t - 1th) time-step. As can be seen, the point cluster along the diagonal line is increasing from the top-left to the bottom-right in which the strong correlations between historical observation entries are shown. Thus, these extensive analyses indicate that these time series-based wind speed datasets are predictable.
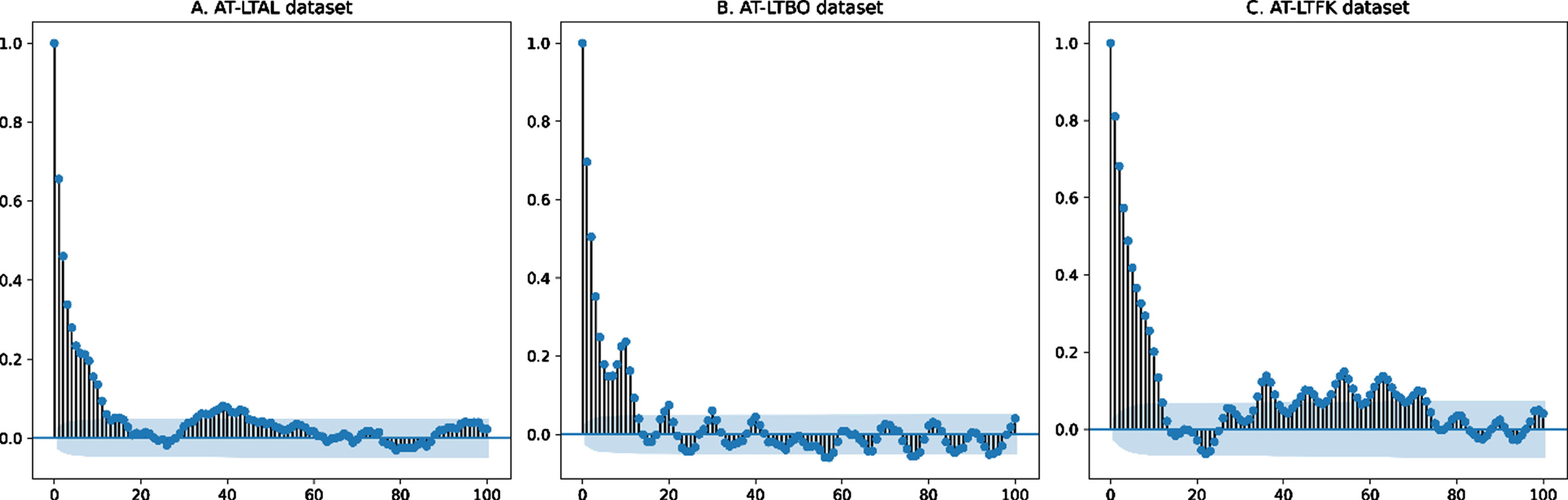
Analysis on the autocorrelation factor of AT-LTAL, AT-LTBO and AT-LTFK datasets.
To demonstrate the reliability and robustness of our proposed RTrans-WP model for dealing with the daily wind speed forecasting problem, we further validate the predicted results of our model against the ground-truth values within 24-hours interval. The Fig. 8 shows the prediction outputs of our proposed RTrans-WP model which are validated against the true wind speed values in the last batch of testing sets within the AT-LTAL, AT-LTBO and AT-LTFK datasets. As shown from the experimental outputs, our proposed RTrans-WP model delivered great fits with the recorded ground-truth wind speed values in different datasets, especially within the AT-LTBO and AT-LTFK datasets where the predicted lines are nearly fit with the true observations.
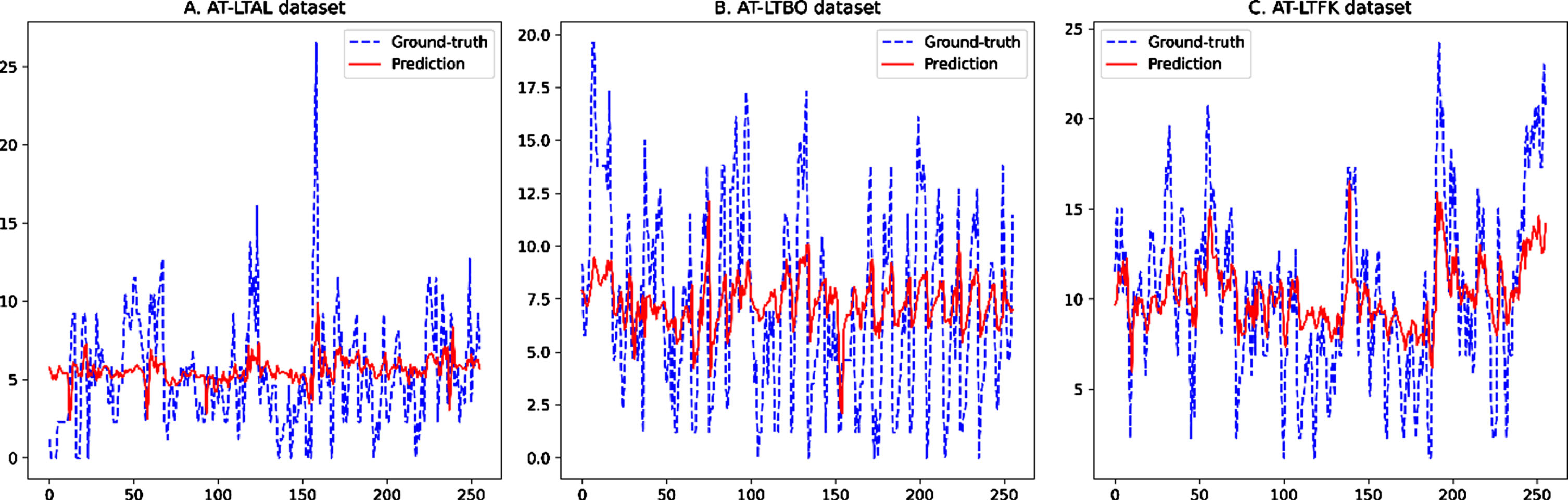
Illustration of the wind speed prediction performance against the ground-truth values of our proposed RTrans-WP model in the last data batch of each dataset.
For further evaluation on the performance of our proposed RTrans-WP model in stability and model’s parameter/component sensitivity aspects. We conducted further experiments to study the model’s stability with size-varied training set as well as the influences of embedding vector dimensionality (dAE, the transformer-based architecture as described in sub-section 3.1), number of CNN-based layers (kREG) and the effectives of the randomized regularization mechanism which are utilized in our RTrans-WP model (as described in sub-section 3.2).
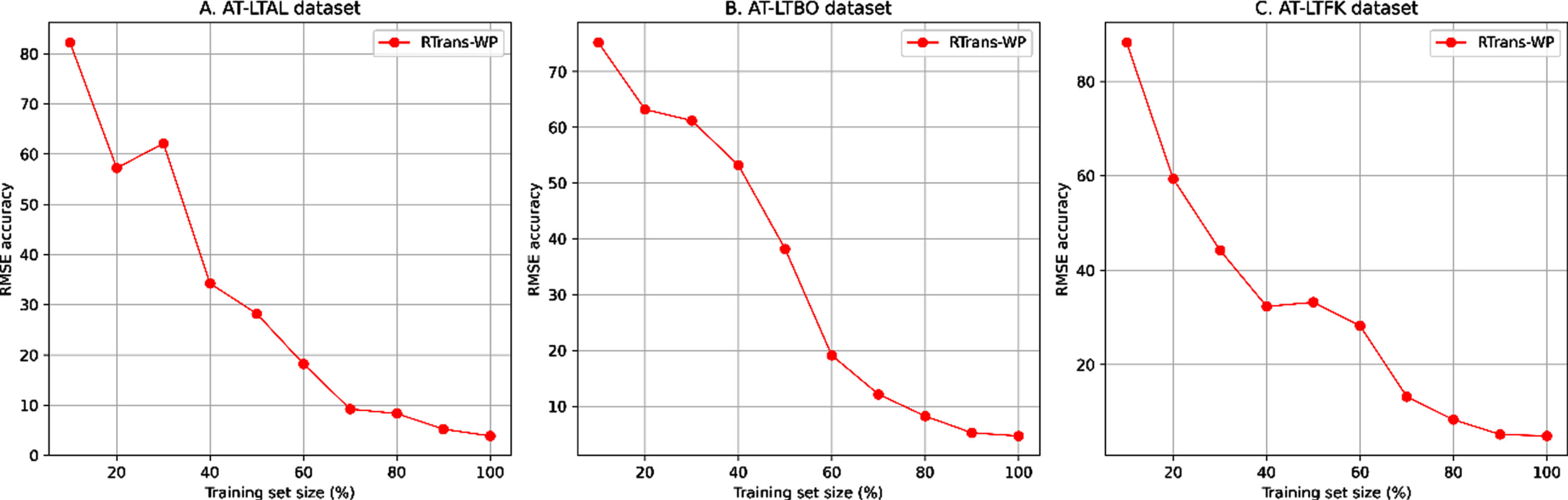
Studies on the stability of our proposed RTrans-WP model for wind speed prediction task with different training set size (%) of AT-LTAL, AT-LTBO and AT-LTFK datasets.

Evaluations on the influences of dimensionality of embedding vector (d AE ) of the given transformer-based architecture of our proposed RTrans-WP model.
Thus, to evaluate on how this mechanism can support to improve the accuracy performance for wind speed prediction task within different datasets, we implemented two separated versions of our model, the original one (RTrans-WP) and no-regularization version, named as: RTrans-WP (NoReg). The Fig. 11 shows the comparative studies between two versions within AT-LTAL, AT-LTBO and AT-LTFK datasets. The experimental outputs explicitly proved the effectiveness of integrating CNN-based regularization mechanism within the transformer-based architecture for leveraging the accuracy performance of wind speed prediction task within high-complex/noise time-series based datasets.
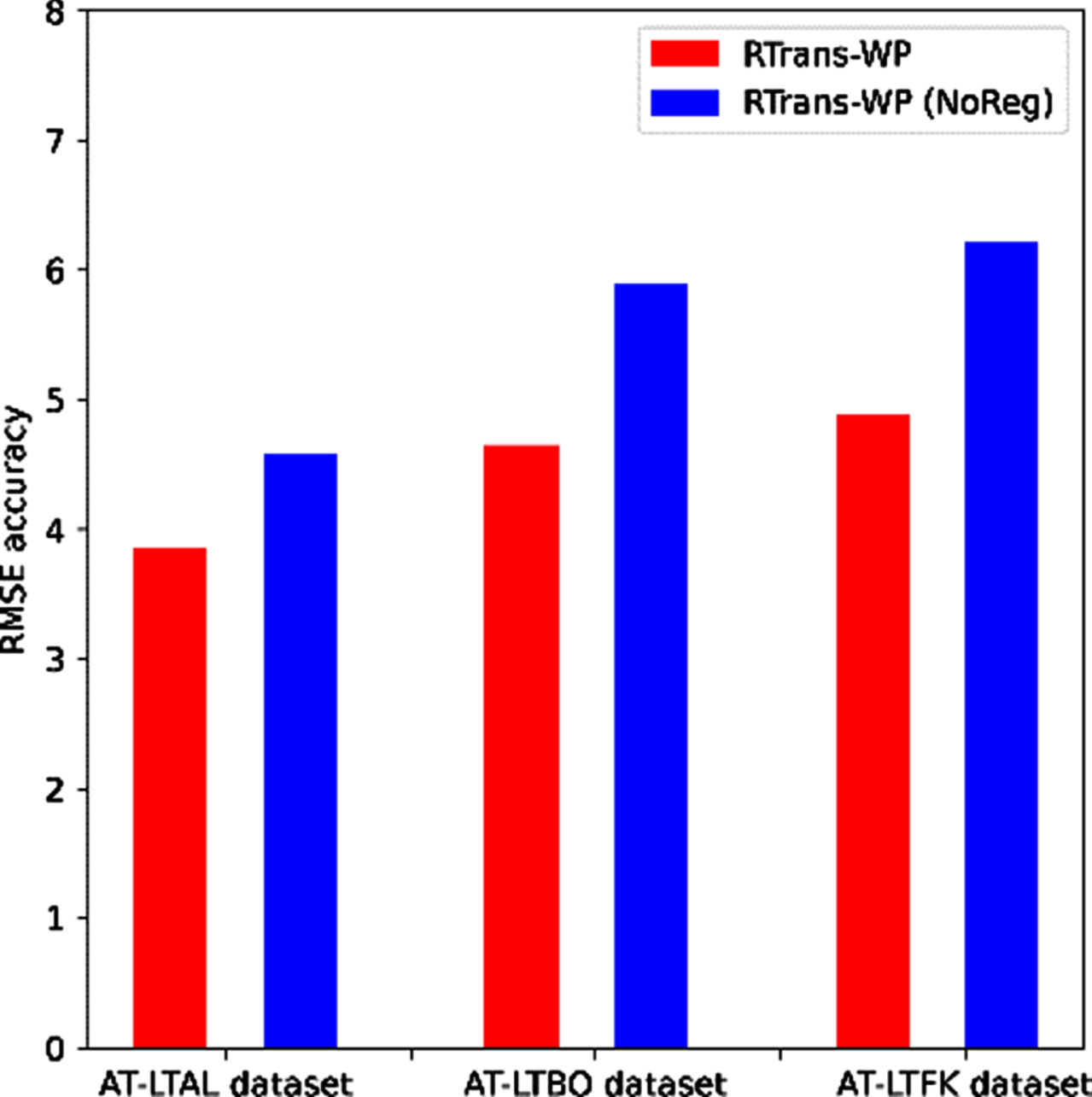
Studies on the effectiveness of applying CNN-based regularization with randomization within the sequential representation learning process of our proposed RTrans-WP model.
Finally, we also conducted extensive empirical studies on how the number of CNN-based layers (kREG) within the randomized regularization mechanism can influence the model’s performance. To do this, we varied the value of (kREG) parameter from 1 to 5 and then reported the changes on the overall model’s RMSE-based accuracy performance. As shown from experimental outputs in Fig. 12, this parameter is quite insensitive with the AT-LTBO and AT-LTFK datasets in which it stably achieved reasonable RMSE-based accuracy performances with kREG ⩾ 2, whereas it showed oscillations with kREG = 1 and kREG ⩾ 4, however the accuracy performance fluctuation range is not quite large. for future implementation within different wind speed datasets, this parameter should be carefully evaluated to find suitable configurations in which our proposed RTrans-WP model can achieve highest accuracy performance.

Studies on the influences of number of CNN-based layers (k REG ) for the randomization regularization mechanism within our proposed RTrans-WP model.
In this paper, we proposed a novel integrated CNN-based regularization with transformer-based architecture for dealing with the wind speed prediction task, called as: RTrans-WP. In this model, we implement a transformer-based architecture with the modified multi-headed attention mechanism for speeding up the sequential embedding contextual information extraction. Through a sequential auto-encoding mechanism, the rich structural and semantic temporal features from complex time-series based wind speed datasets which are later utilized to remarkably improve the accuracy performance of wind speed forecasting problem. In addition, to deal with challenges related to noises and disturbances which are occurred within wind speed historical observations, we proposed the utilization of a CNN-based regularization mechanism with the layered randomized weighting strategy to efficiently transform the initial variables of input sequences into stable and noise-reduced representation forms before feeding into transformer-based architecture.
Extensive experiments within benchmark datasets have demonstrated the necessary of our proposed ideas in this paper in which our proposed RTrans-WP explicitly achieved better accuracy performance then other state-of-the-art deep learning-based techniques for wind speed prediction task. For our future works, we intend to incorporate the advanced RNN-based architectures such as recurrent highway network (RHN) into the transformer-based architecture to facilitate for the integration of exogenous information resources into the sequential representation process of our RTrans-WP model to improve the wind speed forecasting performance.