
Abstract
This paper proposes that the task of single-image low-light enhancement can be accomplished by a straightforward method named Opt2Ada. It contains a series of pixel-level operations, including an
Introduction
In real world, most cameras capture images from sub-optimal lighting conditions including back-lit, non-uniform illumination, weak or extremely low-lighting, color cast, and intensive noise. These images usually suffer multiple degradation that is detrimental for high-level machine vision tasks, such as object detection [1], segmentation [2], and recognition [3]. Because high quality imaging is critical to these applications, low-light image enhancement (LLIE) is one of the fundamental tasks in image processing pipelines. In this domain, methods are versatile some of these are based on the histogram equalization [4, 5] and others may depend on the Retinex theory [6]. Recent years, the deep-learning (DL) based LLIE methods are prosperous since the first seminal work [7]. Due to fact that the convolutional neural networks (CNNs) can automatically learn intricate patterns from the input images, it is a good candidate for LLIE tasks. Traditional methods usually depend on particular hand-craft priors which limit their performance and flexibility. The performances of DL based methods heavily rely on their elaborately designed CNN architectures and carefully selected paired/unpaired large-scale training data. Moreover, learning-based methods may be regarded as the fitting of data which would be inevitably suffered from a lack of interpretability. This could bring difficulties in analyzing the nature of the LLIE itself so as to find potential cue for improvement. As a result, most of these existing CNN-based methods give rise to unsatisfactory visual results, when presented with real-world images with various light intensities and intensive noises [8].
To address the above issues, this work proposes Opt2Ada, an universal method to enhance low-light images. The method is traditional and is not data-driven. By integrating a series of procedures including an In contrast to existing CNN-based LLIE methods, the present method dose not contain any trainable parameters. Therefore, Opt2Ada will not be biased to specific training data. The quantitative and qualitative evaluations guarantee the universality of the present method with superior performance with DL algorithms. We propose a low-light image dataset that contains photos captured by different mobile devices under diverse illumination conditions to evaluate the generalization of Opt2Ada. The comparisons are also made between Opt2Ada and the existing methods. We deploy Opt2Ada on various mobile devices and test it in the wild. Although multiple pixel-wise operations are involved, the algorithm can also achieve 3 to 9 frames per second (FPS).
The remainder of this paper is organized as follows. Section 2 summarizes the recent literature on progresses of LLIE including both conventional and DL methods. Section 3 presents the overall algorithms design. After the experimental results described in Section 4, the algorithm is deployed and tested on mobile devices. The conclusions are drawn in the final section.
Related works
Nowadays, algorithms for LLIE can be divided into two categories. The first category which has received relatively more attention is built upon the decomposing and reassembling the input image pixels. In this aspect, the illumination component is decomposed from the input image by properly enforced priori or regularization. After improving the illuminance part and recombining it with the remaining parts, the image with enhanced brightness is obtained. Most of these decomposition regularization are based on the Retinex theory [6], which assumes that an image is composed of a reflection component with an illumination component. In this way, the proposed algorithms include traditional methods such as, HSV consistent model [9], SRIE [10], LIME [11], BIMEF [12], and LR3M [13] as well as the DL methods such as, RetinexNet [14], RUAS [8], RetinexDIP [15]. Instead of the Retinex theory, there are also certain DL methods that directly use sophisticatedly designed CNNs to separate and enhance the illumination component simultaneously. In an end-to-end manner, the input image can be decomposed, enhanced, and reconstituted by auto-encoder [7], multiple branch CNNs [16], generative adversarial networks [17], and U-net based Retinex decomposition [18]. Furthermore, efforts are also devoted to design new attention model and learning paradigm, such as signal-to-noise-ratio awareness network [19] and the self-calibrated illumination learning framework [20].
On the other hand, the second category includes methods that enhance the images in a pixel-wise manner without decomposing and reassembling operations. The most representative conventional methods, such as DHECI [21] and LDR [22], are built upon the well-known histogram equalization and they also include additional priors and constraints. Adaptive histogram equalization method intends to improve the contrast [23], and an advanced version of it, i.e. contrast limited adaptive histogram equalization method, is proposed afterward [24]. The weighted bi-histogram equalization uses the decomposed tiles based on the distributed area ratio [25]. In addition to natural image LLIE, alpha-rooting is one of the more sound histogram-based method for medical image enhancement [26]. Nevertheless, after the image has been manipulated, the gray-level of the enhanced image is reduced and certain details would be blurred. If certain images have peaks in the histogram, the contrast is unnaturally over-enhanced after the operation. Moreover, the intensity slicing algorithm is more restrictive to the lighting condition. It cannot be applied to all types of low-light images and different lighting conditions may need different procedures. There are also frequency domain enhancement methods, such as DCT [27]. Since the Fourier transformation is used, the frequency domain algorithms are complex and computationally slow. Visually, they may also lead to the loss of edges, blurring details, and creating ringing effect. As a result, both of these methods have obvious disadvantages and they are extremely sensitive to hand-craft super-parameters. For DL methods, CNNs can be designed to learn the curves for pixel value amplification. In this case, the proposed methods include ExCNet [28], Zero-DCE [29], and Zero-DCE++ [30].
Methodology
To provide a comprehensive understanding of our methodology, the pipeline of the proposed method can be divided into three successive procedures: an

(Color online) Sketch of Opt2Ada. The method is composed by a series of operations which sequentially act on the input image.
In our method, instead of using the Retinex theory [6] or a CNN [14], we use a linear transformation to do the illuminance channel decomposition. The input data is converted from its original format to a floating point representation of linear RGB values and normalized to [0, 1]. Since the real scene illuminance condition is usually unknown, we assume that a D65 white point to convert tristimulus values between RGB and CIE XYZ format as the illuminance channel decomposition. The mapping of decomposition is denoted as
Here, r
ij
, g
ij
, and b
ij
are the normalized pixel value in RGB channels with i, j being the location of the pixel, and
After the decomposition of the illuminance component according to Equation (1), the illuminance of the input image is enhanced according to an adaptive logarithmic mapping [31]:
To explore the behavior of Equation (3), we plot it for various values of b and
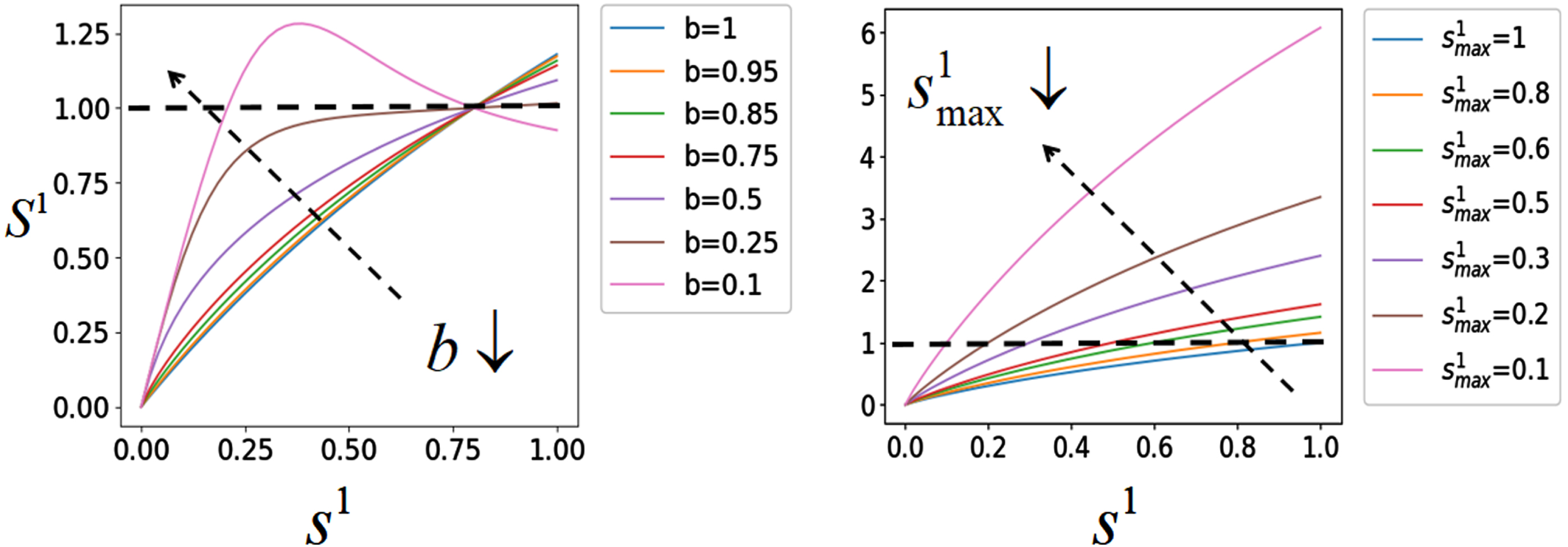
(Color online) Visualization of Equation (3) for various values of b in the left panel and various values of
The image can be transformed from the XYZ format back to the conventional RGB format via the following equation,
In Equation (5),
By experiments, it is found that if we only use the operation present in the previous section to amplify the brightness, the resulting image will be suffered by inevitably overexposure and boosted noise. As shown in middle panel of Fig. 3, although the brightness is greatly improved, the visual quality of the enhanced image is not satisfied. It can also be seen from the first line in Fig. 3 that the brightness of the area in the red box is relatively high due to the presence of a street lamp. After the adaptive illuminance enhancement, although the formula is adaptive, the red box area is still enhanced. This leads to an overexposure that makes the enhanced image visually unsatisfactory. In addition, nighttime images usually contain large noise domains and strong noise intensity. From the second line of Fig. 3, we can also see that if the input image contains a large noise region, the adaptive illuminance enhancement will also amplify the noise giving rise to a large artifact block.

(Color online) Outputs of adaptive illuminance enhancement procedure (middle panel) and adaptive global scaling (right panel).
To make further adjustment, we propose an adaptive global scaling operation which allows processing of the enhanced image in the previous section to eliminate overexposure and noise improving the visual quality. The essence of the adaptive global scaling is to assume that the regions with pixel value close to 1 correspond to the overexposure region, while the regions with pixel value close to 0 are regarded as the noise region. The pixels in these two regions should be cutoff, and then the remaining pixel values of the whole image are stretched to re-populate the whole range between 0 to 1. To this end, we first manually set the high and low ratios Lhigh∖low ∈ [0, 1] for the input image pixel truncation. For example, if we set L
high
= 0.8, the upper 20% pixel values will be scaled. The selection of these ratios are empirical, which needs to be determined by experiments. When L
high
and L
low
are selected, the pixel values of the original image are truncated accordingly. Then the truncated image is scaled by following steps. The overall scaling is denoted by

(Color online) Sketch of adaptive global scaling.
In this section, we are in a position to verify the universality and effectiveness of Opt2Ada on real nighttime images via intensive experiments. For datasets, we chose the well known toy dataset LOL, as well as a custom real scene dataset collected and arranged by authors. For the comparison with existing methods, we select a state-of-the-art traditional algorithm LIME [11], a zero-shot-learning DL algorithm (Zero-DCE++) [30], and a non-reference DL algorithm (RetinexDIP) [15]. In the evaluation, both quantitative comparisons and qualitative visualizations are made. In quantitative comparisons, various metrics are used including full-reference metrics: SSIM (structural similarity index measurement), PSNR (peak signal-to-noise ratio), MSE (mean square error), and MAE (mean absolute error), non-reference metrics: NIQE (naturalness image quality evaluator), PI (perceptual index), and AB (average brightness), and semantic metrics: SPAQ (Smartphone Photography Attribute and Quality).
Dataset and Metrics
The datasets used in this paper are elaborated as follows:

(Color online) Several images sampled from the proposed Real-Scene dataset. The images are taken by different mobile devices under diverse lighting conditions and scenes.
Quantitative evaluation of a LLIE algorithm is more intricate then evaluating a high-level task and one can not get a conclusion from a single indicator such as mean average precision for object detection algorithms. Therefore, various metrics are used including full-reference metrics: SSIM, PSNR, MSE, and MAE, non-reference metrics: NIQE [33], PI [34], and AB, and semantic metrics: SPAQ [35]. The SPAQ includes three factors which stand for baseline model (SPAQ-BL), image attributes (SPAQ-IA), and scene semantics (SPAQ-SS) [35]. The details of these indicator are elaborated in a recent survey [32], and we do not intend to reproduce them here.
In the experimental evaluation, Opt2Ada is realized by python-3.6 with numpy-1.18.4 for matrix manipulation and opencv-4.2.0 for image reading and writing. The experiment is performed on a computer with ubuntu16.04, Intel i5-9400F CPU, and 8GB memory. We use a same set of parameters in which b = 0.25, L high = 0.98, and L low = 0.02 over all of our experiments. The input images keep their original resolutions. The pseudo-code for implement Opt2Ada is provided in Algorithm 1.
Algorithm 1
Results and discussions
We provide the evaluation results of the present method on the LOL-test set in Fig. 6 and Table 1. From visualizations shown in Fig. 6, one can see that Opt2Ada gives rise to the output images closest to the ground truth (GT) images visually. The quantitative results of full-reference metrics and non-reference metrics mentioned in Section 4.1 are given in Table 1. As can be seen from full-reference metrics as provided in Table 1, Zero-DCE++ is the best of all whose MAE, MSE and PSNR outperform other methods by a wide margin. Except for Zero-DCE++, MAE, MSE and PSNR of LIME is slightly better than RetinexDIP and Opt2Ada. Whereas, Opt2Ada outperforms LIME and RetinexDIP in terms of SSIM and AB. Especially in the aspect of brightness improvement, the AB of the output images of Opt2Ada is closest to that of GT images (122.2). For the non-reference metrics: NIQE, PI, and SPAQ, a different picture is shown. The NIQE of Opt2Ada is better than other methods by 12.9%, 12.1%, and 8.3% for LIME, Zero-DCE++, and RetinexDIP, respectively. For PI, RetinexDIP gives rise to the lowest value. For SPAQ, there are three sub-indexes: SPAQ-BL, SPAQ-IA, and SPAQ-SS. Here, SPAQ-BL estimates image quality by a baseline model (residual network 50), SPAQ-IA works for by input image attributes, and SPAQ-SS accounts for input image semantic information. It is shown that Opt2Ada better than other methods in SPAQ-BL and SPAQ-SS, and achieves a nearly equal performance in SPAQ-IA.

(Color online) Visual results of different methods on LOL-test.
Quantitative comparisons on LOL-test in terms of SSIM, PSNR, MSE, MAE, NIQE, PI, SPAQ, and AB
In Fig. 7, and Tables 3, we provide the quantitative comparison and visualization results between various methods on the Real-Scene dataset. Different from the previous toy dataset LOL, note from Table 2 that Opt2Ada shows promoting performance in NIQE, PI, SPAQ, and AB. To be specific, NIQE of our method is reduced by 42%, 0.4%, 2.5%, 4.7% relative to the input image, LIME, Zero-DCE++, and RetinexDIP, respectively. Moreover, we also find that PI of the enhanced image obtained by both the present and the existing algorithms is higher than the input image. This means that the increase in brightness inevitably leads to a degeneration in PI. It is found that both LIME and Opt2Ada outperform the DL methods. The SPAQ-BL, SPAQ-IA, and SPAQ-SS for Opt2Ada are increased by 0.4%, 0.37%, and 0.7% with respect to RetinexDIP, while 5.3%, 8.5%, and 6.9% with respect to input images. This means that the proposed method can obtain a nearly equal SPAQ with respect to RetinexDIP, while the evidently improvement is achieved with respect to input images. Compared with LIME, indicators SPAQ-BL and SPAQ-IA have decreased, but SPAQ-SS of Opt2Ada is still the highest of all. Therefore, Opt2Ada outperforms other algorithms in restoring semantic information of images. This is also consistent with the results on LOL-test set. For the brightness, the proposed method can achieve a AB that is closest to the normal lighting scene, while the AB obtained by other algorithms can only achieve about half of the normal light AB value.

(Color online) Visual results of different methods on Real-Scene dataset.
Quantitative comparisons on Real-Scene dataset in terms of NIQE, PI, SPAQ, and AB
Quantitative comparisons on Real-Scene dataset in terms of EME, AME, SDME, Visibility, TDME
Moreover, one notes from Table 3 that Opt2Ada also shows promoting performance in EME, AME, SDME, Visibility, TDME. The definition of these metrics can be found in Ref. [36] and we would not reproduce them here. EME of our method is reduced by 33%, 8.3%, 7.9%, 3.2% relative to the input image, LIME, Zero-DCE++, and RetinexDIP, respectively. Since in Table 2 we have found that Opt2Ada outperforms in restoring semantic information of images, it may also effective in restoring image details. The AME, SDME, and Visibility for Opt2Ada are increased by 0.4%, 0.6%, and 2.2% with respect to RetinexDIP, while 26%, 33%, and 24% with respect to input images. Compared with RetinexDIP, indicators TDME have decreased, but EME, AME, SDME and Visibility is still the highest of all. This means that the proposed method can achieve almost the same detail enhancement performance as RetinexDIP, while the evidently improvement is achieved with respect to input images.
On the other hand, a similar tendency can be found from the visualization results in Fig. 7. In the Real-Scene dataset, we can see that Zero-DCE++ can achieve almost similar enhancement results to LIME, and RetinexDIP gives rise to enhancement results which are featured by lower brightness, color blocks, and artifacts. In Fig. 8, we present several test results for the high-contrast images in Real-Scene dataset. It is shown that the present method also outperforms other method on these images. Therefore, the proposed method not only enhances the brightness to an appropriate level without introducing non-existent color blocks, but also reveals certain details that exist in the original image and not clearly seen before.

(Color online) Several visual results of high-contrast images for different methods.
For evaluating the running speed of Opt2Ada and testing its performance in the wild, we implement Zero-DCE++ and Opt2Ada using C++ and deploy on mobile phones. We use Android Studio with NDK to compile C++ code, and only realized a CPU version of the code. Tencent’s NCNN library is used when decode the image reading from mobile phone camera [37]. For Zero-DCE++, we first convert the pytorch model to the ONNX (Open Neural Network Exchange) format [38], then deploy it using NCNN library. As a matter of fact, Opt2Ada includes six pixel-wise operations so that it will be very time consuming without parallel computation or non-using graphics processing unit (GPU). The results are provided in Table 4 in which FPS is measured when the application runs stably for five minutes. It can be seen that the value of FPS varies significantly from 3.60 to 9.14 with different computation capacity of CPUs on these devices. For example, the Huawei’s Nova 4e has only achieved 3.6 FPS, while the Honor 60 can nearly double the running speed of the Nova 4E. Compared with Zero-DCE++, Opt2Ada can run 2 to 4 times faster. As a result, for all types of modern mobile phone, the running speed of Opt2Ada can reach nearly real-time. A video demonstration of Opt2Ada on mobile device is provided on-line and the application will be public available soon 3 .
FPS of Zero-DCE++ and Opt2Ada on various mobile devices
FPS of Zero-DCE++ and Opt2Ada on various mobile devices
Visual results of Zero-DCE++ and Opt2Ada tested on various mobile devices are provided in Fig. 9. Here, we test using images captured in real time from the cell phone’s camera, rather than using stored images. It is shown that when algorithms are tested in the real environment, the visual results are closed to those on Real-Scene dataset but quite different from those on LOL dataset. Although the qualities of image captured by different cell phones are different, the brightness enhancement of Opt2Ada is significant than that of Zero-DCE++. A stable performance across different scenario and device is achieved. These testing results not only illustrate the superior of Opt2Ada, but also tell us that toy datasets have great limitations in the evaluation of LLIE algorithms, that is, methods or models that perform well on toy datasets may not perform well in the wild.

(Color online) Visual results of Zero-DCE++ and Opt2Ada on various mobile devices.
In this study, a new LLIE algorithm, Opt2Ada, is proposed by integrating an optimized illuminance channel decomposition, an adaptive illuminance enhancement, and an adaptive global scaling. Without using the Retinex theory, we first establish the illumination map by a transformation matrix which directly isolates the illuminance channel from the RGB channels. Then we adapt a pixel-dependent log shape curve that enhance the illumination map adaptively. Finally, the enhanced illumination map is reunion with the other part of the input image by an inverse transformation matrix. To eliminate overexposure, noise, and artifacts, the image is further scaled by an adaptive global scaling. Our experiments are performed on an existing benchmark dataset LOL as well as on an custom dataset. Various metrics are included and comparison are also made among traditional and DL methods. It is shown that the proposed algorithm outperforms traditional and DL algorithms in both toy dataset and real dataset resulting not only state-of-the-art quantitative results but also applicable visualizations. Additionally, the proposed algorithm is not data-driven and its parameters are universal. This has given rise to a generalization capability better than that of the data-driven methods. As a result, it can be straightforwardly integrated into the pre-processing subroutine for advanced machine vision tasks. For running speed evaluation, we deploy Opt2Ada on various mobile devices. Without parallel computation, Opt2Ada can run on CPU with 3.60 to 9.14 FPS. When tested in the wild, Opt2Ada shows a stable and effective performance better than DL models over various mobile devices and scenarios. There is also a large space for optimization. In the future, we are going to make use of Vulkan [39] to accelerate the algorithm by utilizing the GPUs of the mobile phone.
Disclosures statement
No conflict of interest exists in the submission, and it is approved by all authors for publication. We declare that the work presented is original research that has not been published previously and is not under consideration for publication elsewhere, in whole or in part.
Acknowledgments
This work is supported by the National Natural Science Foundation of China (No. 11604240) and the Scientific Research Project of Tianjin Municipal Education Commission under Grant (No. 2019KJ231).