
Abstract
Essentially, the problem solving of attribute reduction can be regarded as a process of reduct searching which will be terminated if a pre-defined restriction is achieved. Presently, among a variety of searching strategies, meta-heuristic searching has been widely accepted. Nevertheless, it should be emphasized that the iterative procedures in most meta-heuristic algorithms rely heavily on the random generation of initial population, such a type of generation is naturally associated with the limitations of inferior stability and performance. Therefore, a constraint score guidance is proposed before carrying out meta-heuristic searching and then a novel framework to seek out reduct is developed. Firstly, for each attribute and each label in data, the index called local constraint score is calculated. Secondly, the qualified attributes are identified by those constraint scores, which consist of the foundation of initial population. Finally, the meta-heuristic searching can be further employed to achieve the required restriction in attribute reduction. Note that most existing meta-heuristic searchings and popular measures (evaluate the significance of attributes) can be embedded into our framework. Comprehensive experiments over 20 public datasets clearly validated the effectiveness of our framework: it is beneficial to reduct with superior stabilities, and the derived reduct may further contribute to the improvement of classification performance.
Introduction
With the rapid advancements of modern communication technologies, the scale and volume of data have brought huge challenges to data processing and problem solving in various real-world applications. Note that among those challenges, the curse of dimensionality is essentially serious [6, 49]. Therefore, how to reduce the dimension of data without causing a significant information loss has become a critical task.
Importantly, attribute reduction [8, 58], a key topic in the field of rough set theory [38, 52], has been demonstrated to be a developed technology for dimension reduction or the so-called feature selection in machine learning. Generally speaking, the objective of attribute reduction is to select a subset of qualified attributes from raw data and then construct the expected reduct based on a pre-defined restriction. Neighborhood rough set [23, 54], which employs neighborhood relation to partition the universe, has a decent advantage in analyzing data with continuous or even mixed values. Therefore, as a common dimension reduction method, attribute reduction based on neighborhood rough set has been paid much attention to. Since the neighborhood rough set model was proposed to reveal the uncertainty or inconsistency in data, those uncertainty or inconsistency-based measures provide us fundamental basis and broad thinking for exploring attribute reduction related studies, e.g., the definitions of restriction, the principle of selecting attribute, and so on.
Presently, two key factors have been mainly addressed in attribute reduction: (1) evaluation criterion; (2) searching process. For the first case, the criterions based on supervised [21, 47], semi-supervised [13, 30] and even unsupervised [27, 33] measures have been respectively designed, which characterize the significance of attributes in terms of different views and then successfully implement the evaluation. For the second case, by examining the inherent limitations of exhaustive searching in expensive computational cost, heuristic searching has been especially favored in recent researches [35, 53].
Note that one of the widely accepted heuristic searchings in the problem solving of attribute reduction is greedy search [7, 22]. In such a searching, the greedy principle is applied to select the optimal attribute for each iteration until the pre-defined restriction is achieved. Obviously, the performance of greedy searching is easily limited by a local optimum. That is why an efficient global searching is frequently required. Fortunately, meta-heuristic searching has attracted great attention recently due to the advantage of its global searching ability [19, 24].
Without loss of generality, a meta-heuristic searching is an algorithm designed by considering human experience or natural law and is capable of identifying optimal or suboptimal solutions by taking a global view. The population generation mechanisms in meta-heuristic searching produce multiple solutions/individuals in each iteration. Up to now, various effective meta-heuristic searchings have been applied to the task of attribute reduction, e.g., the genetic algorithm [3, 11], the forest optimization algorithm [18, 48], the fish swarm algorithm [9, 32], the particle swarm optimization [40, 45], the ant colony optimization [12, 44] and the bat algorithm [1, 2].
As an effective approach to solve attribute reduction task, many improved algorithms based on meta-heuristic searching have been proposed. For instance, Zhou et al. [61] proposed a correlation-guided genetic algorithm, which checks the quality of the potential solutions to reduce the possibility of producing inferior solutions; Rashno et al. [41] developed a multi-objective particle swarm optimization method, which updates velocity and position of particles by particle and feature ranks to guide particles moving toward the best solutions; Ma et al. [34] presented a two-stage hybrid ant colony optimization, which uses the features’ inherent relevance attributes and the classification performance to guide the optimal feature subset searching.
Nevertheless, it should be stressed that one primary limitation of meta-heuristic searching is the low stability of the derived result. Low stability indicates that a searching algorithm will output a very different solution if data varies slightly, which will cause ambiguity and unreliability in the subsequent learning tasks. The reason should be mainly contributed to the random initialized generation of the population in meta-heuristic searching. The importance of stability is frequently overlooked in high-dimensional data processing [10, 37]. Furthermore, we also observe that though the random initialization mechanism can guarantee the diversity of individuals in the population to a certain extent, some individuals are inevitably equipped with poor fitness. It follows that the performance of the derived result will also be easily affected by those poor individuals.
Inspired by the above analyses, new initialization of the population has become necessary. In this research, we develop a new initialization mechanism guided by an effective index called constraint score [31, 41]. Following such novel initialization of the population, a general framework to perform meta-heuristic searching can then be further constructed. Different from the random initialization of the population in conventional meta-heuristic searching, the function of the constraint score is to identify attributes with better discrimination ability among samples. Immediately, those attributes are regarded as the foundation of producing the initial population.
The main contributions of this paper can then be summarized as follows. A constraint score with the local view is used. The traditional constraint score is proposed by considering all samples in data, which ignores the discrimination ability in terms of samples with specific labels [51, 55]. Therefore, the conventional constraint score is replaced by a local constraint score in our strategy, which aims to comprehensively reveal the distinguishability of attributes for different labels. A simple but effective plug-and-play framework is developed. The distinguishing feature of our study is to present a general framework, and most existing meta-heuristic searchings to attribute reduction can be embedded into it to improve their performance further.
The rest of this paper is organized as follows. In Section 2, we review basic concepts related to this study. In Section 3, we introduce some popular meta-heuristic searchings. In Section 4, a constraint-guided meta-heuristic searching framework is formally elaborated. Section 5 shows the performance evaluation of the proposed framework over extensive datasets. Finally, in Section 6, we draw conclusions and future plans.
Preliminaries
Neighborhood rough set
In general, a training data can be represented by an decision system such that
Obviously, by d, an indiscernibility relation can be formed over U: IND (d) = {(x i , x j ) ∈ U × U|d (x i ) = d (x j )}. Immediately, universe U is partitioned into serval disjoint decision classes such as U/IND (d) = {X1, X2, ⋯ , X q }. ∀X p ∈ U/IND (d), X p is referred to as the p-th decision class, it is the collection of samples which possess the p-th label. Especially, ∀x i ∈ U, the decision class which contains x i is denoted by [x i ] d in the context of this study.
From the perspective of Granular Computing (GrC) [15, 28], information granulation plays a crucial role in various data analyses. The objective of information granulation is to granulate either samples in U or condition attributes in AT, which can effectively reduce the volume of data or reveal the inherent structure of data. Among various information granulation techniques, the neighborhood strategy is widely accepted because of not only its clear explanation but also its simple implementation. In addition, it should also be emphasized that the flexible radius used in the neighborhood also provides us a meaningful characterization of the multi-granularity structure of data [25, 29]. The general form of the neighborhood is then presented as follows.
Following Definition 1, the set of all neighborhoods, i.e., {δ
A
(x
i
) | ∀ x
i
∈ U}, forms the result of information granulation over U based on the information provided by A. Furthermore, suppose that δ ≥ δ′, we then obtain
Following Section 2.1, one of the important tasks is to sketch the power of characterizing decisions by condition attributes. In view of this, various measures have been explored with respect to different requirements. We mainly concentrate on the three following frequently used measures in the context of this study.
Dependency shown in Definition 3 is the percentage of those samples that certainly belong to one of the decision classes. A higher value of dependency indicates that the performance of characterizing decision classes by neighborhood is better. Obviously, 0 ≤ γ A (d) ≤1 holds.
Condition entropy shown in Definition 4 measures the discriminating ability of a condition attribute subset A for decision d. The smaller the value of such a condition entropy is, the more powerful the discriminating ability of A for d is. Obviously, 0 ≤ E A (d) ≤ |U|/e holds.
Discrimination index shown in Definition 5 characterizes the ability of a condition attribute subset A to distinguish samples with different labels. The smaller the value of discrimination index is, the greater the distinguishing ability of A is. Obviously, 0 ≤ H A (d) ≤ log |U| holds.
Obviously, the measures presented in section 2.2 can be used to measure the performance of attributes. Nevertheless, they do not take the labels of samples into account. In view of this, the constraint score proposed by Sun et al. [43] is presented as follows, which can quantitatively characterize the distinguishing ability among samples.
By Equation (10), a smaller value of τ (A, d) implies a higher ability of distinguishing samples by information provided by attributes in A. The reasons can be attributed to the following facts: (1) a smaller value of τ (A, d) can be obtained by a smaller value of ∑(x
i
,x
j
)∈
Attribute reduction
Similar to the case in conventional rough set, attribute reduction is also a key in exploiting neighborhood rough set. Without loss of generality, the objective of attribute reduction is to remove redundant or irreverent attributes from raw data. Therefore, it can not only reduce the volume of data but also provide qualified attributes for subsequent learning tasks.
Up to now, note that various forms of attribute reduction have been explored through different measures. Nevertheless, most attribute reductions possess similar structures, i.e., a form of defining a minimal subset of attributes that satisfies a measure-based restriction. From this point of view, Yao et al. [57] have presented the following general definition of attribute reduction.
A achieves the restriction ∀A′ ⊂ A, A′ does not achieve the restriction
In Definition 7, the measure ρ can be calculated by dependency γ
A
(d), condition entropy E
A
(d) and discrimination index H
A
(d) shown in Definitions 3, 4 and 5, respectively. Note that γ
A
(d) is positive preference while both E
A
(d) and H
A
(d) are negative preference. We then know that constraint
Following Definition 7, how to seek out the corresponding reduct is then a challenge. Up to now, various searching strategies have been developed with respect to different perspectives, e.g., from the perspective of searching efficiency or searching objective. Among those strategies, the fitness function based searching is especially popular because of its lower complexity. Specifically, as a representative way of fitness function based searching, meta-heuristic searching has drawn much attention in recent years. Generally, a meta-heuristic searching can be regarded as the combination of randomly searching and heuristic searching. For example, the genetic algorithm, forest optimization algorithm, fish swarm algorithm and bat algorithm have been successfully introduced into the search of reduct.
Notations used in the above algorithms are listed as follows. At the beginning of these algorithms, a population consisting of k individuals is randomly positioned, which represents the random generation of initial solutions of reducts. For instance, the population is represented by The fitness function is used to measure the adaptability of individuals in the population. Given a solution, it should be evaluated by using fitness function, which reveals the power or performance of such a solution. A higher value of fitness function implies a better solution has been obtained. Generally, the fitness of the solution can be represented by various ways, e.g., the dependency, condition entropy, discrimination index and so on. t is a variable that indicates the number of iterations in the procedure of the algorithm.
Genetic algorithm
Genetic Algorithm (GA) is a widely known meta-heuristic searching mechanism. It is inspired by the evolution theory to simulate the natural evolution process [20, 62]. Following this principle, the best individuals are the ones most likely to survive for subsequent reproduction. A population derived by such a way is usually superior to that of the previous generation. Without loss of generality, the generation of a new population is conducted by following three specific operators. Selection operator. Generally, the selection operator adopts the roulette wheel method. The basic thinking is to make each selected individual’s probability and fitness proportional, that is, a selection strategy based on the fitness ratio. We put these individuals into a line segment ranging from 0 to 1 in proportion, and the length of the line segment represents the selection probability of each individual. Randomly generate a number in the interval [0, 1] and the falling interval represents the selected individual. Crossover operator. The crossover operator is the core of the genetic algorithm, which directly determines the algorithm’s performance. It is a mechanism in which a new generation is created by exchanging entries (values in binary vector) between two individuals (attribute subsets) based on the result of the previous iteration. Mutation operator. In the mutation operator, one or more previous individuals (attribute subsets) are selected randomly based on mutation probability, and one or more attributes in those subsets are exchanged. In other words, an attribute is randomly added into or removed from an attribute subset. Therefore, new individuals can also be obtained.
Immediately, we know that in GA, the parent population generates a new offspring population for the next evolution by the above three operators. The following Algorithm 1 shows a detailed pseudo-code of GA.
Forest optimization algorithm
Forest optimization algorithm (FOA) is a meta-heuristic method motivated by the growth and development of trees in a forest [17]. In FOA, trees use the seeding strategy to implement propagation, which includes the transfer and deployment of the seeds of trees. Generally, there are two representative methods of seeding: (1) local seeding: seeds near the parent trees can grow smoothly; (2) global seeding: sometimes, by considering external factors such as animals, wind and water, seeds travel long distances and are placed in entirely new locations [36]. Based on the explanations of local and global seedings, FOA creates exploration and exploitation mechanisms, which can identify the most appropriate surroundings for tree evolution in the problem space. The detailed phases of FOA are elaborated as follows. Initializing trees. Similar to other popular meta-heuristic algorithms, the forest is initialized by randomly generating trees. Firstly, each variable of each tree is initialized randomly with either 0 or 1. For instance, if a data possesses |AT| attributes, the size of each tree will be |AT|+1, where the last variable denotes the “Age” of such a tree. Particularly, the “Age” is set to be 0 in the initialization of the algorithm. Note that the local seeding in each iteration of the algorithm will increase the “Age” of all trees except newly generated ones in the local seeding stage. Local seeding. This stage adds some neighbors of each tree with “Age” 0 into the forest. Some variables are selected randomly (the parameter “LSC” determines the number of the selected variables). Then the values of the selected variables are changed from 0 to 1 or vice versa. After performing the local seeding stage, the “Ages” of all trees, except newly generated ones, are increased by 1, respectively. Population limiting. In this stage, two series of trees will be removed from the forest, which form the candidate population: (i) “Age” of a tree is older than a parameter called “life time”; (ii) the extra trees that exceed the “area limit” parameter after sorting the trees by their fitness values. This stage forms the candidate population and a pre-defined percentage of the candidate population, which can be used in the following global seeding. Global seeding. To perform the global seeding in FOA, for each tree in the candidate population, some of the variables are selected randomly. The number of the selected variables is determined by a parameter called “GSC”. Immediately, the value of each selected variable will be changed from 0 to 1 or vice versa. Updating the best tree. In this stage, after ranking the trees by their fitness values, the tree with the best fitness value will be identified as the best one and its “Age” will set to be 0.
Note that stages (2)-(5) are performed iteratively until the stop condition is satisfied, i.e., the objective of attribute reduction is satisifed. The following Algorithm 2 presents a detailed process of FOA to attribute reduction.
Fish swarm algorithm
Fish swarm algorithm (FSA) is an optimization method through considering fish’s behavior of seeking food [5, 60]. The hamming distance between two fish indicates their relationship. Besides, there are some other parameters including visual distances of fish, maximum step length and crowd factor. In FSA, all fish try to identify locations that satisfy their food requirements by using the following three distinct behaviors: preying, swarming and following behaviors. Preying behavior. In FSA, preying is the fundamental biological behavior of looking for food. It can be simulated by randomly searching with a tendency toward food concentration. In such a procedure, each artificial fish in the initial population tries their best within its exploration range visual to search for the qualified position where food resources are richer. Generally speaking, we randomly give the fish a new position within its visual. If the fitness of the new position is better than that of the current one, then the fish moves to such a new position. To avoid expansive time-consuming, note that if the condition is not satisfied after numerous tries, then a random position within the step range will be directly given to the fish. Swarming behavior. In the natural environment, fish prefer to assemble in several swarms, which aims to minimize dangers. The common objectives of swarm include satisfying food intake requirements and attracting new population members. In FSA, the swarm consists of fish within the current fish’s visual. The central position of a swarm is then calculated by the arithmetic average of all swarm members’ positions over each dimension. If the swarm center possesses a better fitness value than the current positions of fish and the swarm center is not overly crowded, then fish will move from the current positions to the next positions toward the center. Otherwise, preying behavior is employed to identify the next position for fish. Following behavior. Based on the consideration of visual, some fish may be able to find a greater amount of food than others can. Therefore, fish will naturally try to follow the best one to gain relatively more food and less crowding. In other words, in FSA, if a fish in the neighborhood can find a better fitness value by comparing with its current position, and if the swarm of the neighbor is not overly crowded, then it will move towards the position of this neighbor. It should be emphasized that the preying behavior commences if the following behavior is not able to determine the next position of a fish.
Based on the fish behaviors described above, Algorithm 3 shows the pseudocode of FSA to search for a reduct.
Bat algorithm
Bat Algorithm (BA) is an optimization algorithm based on the echolocation behavior of bats. In the world of nature, bats identify their targets by varying the loudness and pulse rate. Bats emit a very loud sound pulse and then listen for the echo that bounces back from the surrounding objects. The correlation between the bounced and the reflected pulses determines the obstacle type. Their pulses vary in properties and can be correlated with their hunting strategies, depending on the species. In BA, bats adjust their positions by using the following mechanisms. Update velocity, position and frequency. Firstly, some parameters such as the position P
ind
, velocity V
ind
, and frequency F
ind
are initialized for each bat. The movement of the virtual bats is given by updating their velocity and position through the following equations:
Random flight. A strategy called random walk can be employed to improve the variability of the possible solutions. That is, one best bat is primarily selected among the current solutions, and then the random walk is applied to generate a new solution. This bat accepts the condition as the following equation:
The Algorithm 4 shows the pseudocode of the bat algorithm to search the reduct.
As what has been addressed in subsection 3.1, each individual in the population represents a reduct pool, and each position in the individual represents an attribute. If an attribute is identified and added into the corresponding reduct pool, the position of such an attribute in the individual will be set to 1, otherwise, it will be set to 0.
Obviously, if a meta-heuristic algorithm is carried out, the initial population is generated randomly. Such a random initialization strategy possesses the advantage of ensuring the diversity in the population. However, some limitations will emerge in the problem solving of attribute reduction, which can be illustrated as follows.
The performance of a meta-heuristic algorithm is especially influenced by the quality of the initial population. For example, though a random initialization strategy can ensure the diversity of individuals, the initial individuals may be equipped with poor fitness values due to the randomness mechanism. Consequently, those individuals, i.e., the candidate solutions or the so-called reduct pools, are modified constantly in the whole process of the meta-heuristic algorithm. From this point of view, an initial population with poor fitness values of individuals will inevitably influence the searching efficiency of an algorithm. Furthermore, it should also be emphasized that most common adjustments are realized by using the random addition or removal of attributes, e.g., the mutation operator, “LSC” parameter, “GSC” parameter, etc., which also limit the individuals’ movement within a certain range.
To fill the above gaps, in this research, a framework called constraint-guided meta-heuristic searching will be develop to the problem solving of attribute reduction. In such a framework, the basic thinking of constraint score shown in section 2.3 is employed. Generally, our method is inspired by the following facts. The purpose of designing a constraint guidance is to present a new initialization strategy, which makes the initial population possess good quality. In other words, not only to ensure the diversity of individuals in population, but also to make the individuals in the initial population better. The importance of attributes is evaluated by a local view instead of the global view of a constraint score. In other words, not only a new form of constraint score is defined, but also such a new form of constraint score is equipped with the distinguishing ability which is similar to that described in section 2.3.
From the discussions above, the main principle of our strategy is:
Before carrying out the meta-heuristic search procedure, a local constraint score which is related to each label in the data is defined. Such a local constraint score can possess the distinguishing ability among samples with respect to specific samples over a label.
Similar to what have been addressed in Equation (10), by Equation (15), a smaller value of τ (a
r
, l
p
) implies a greater ability of distinguishing samples related to label l
p
over the attribute a
r
. Immediately, it is not difficult to obtain a matrix such that
Obviously, in our initialization strategy, the number of labels plays a key role, and it straightly affects the quality of the initial population. From this point of view, a specific limit parameter is adopted as follow. Pseudo_threshold, it extends the number of labels in data, that is, generating a specified number of labels such as L′ = {l p |1 ≤ p ≤ q′} (q′ ≥ 2) by pseudo-label strategy [54], which will avoid the difficulty of insufficient labels in raw data.
The above algorithm elaborates our initialization strategy: the constraint score matrix is used to identify qualified attributes which are regarded as the foundation of the individuals in the population. In other words, constraint score offers a population preprocessing before the search. Consequently, not only the evaluations of attributes is more comprehensive and substantial because the local view of the discrimination ability of attributes is taken into account, but also the searching space of the population is compressed. Note that in steps 12-15, a random mechanism is also employed which is useful in further expanding individuals and can then guarantee the diversities among individuals.
The time complexity of algorithm 5 mainly comprises of three components: calculating the constraint matrix in steps 3-7, the cost of the calculation for each label and each attribute is
The following Fig. 1 visually illustrates the process of Algorithm 5.
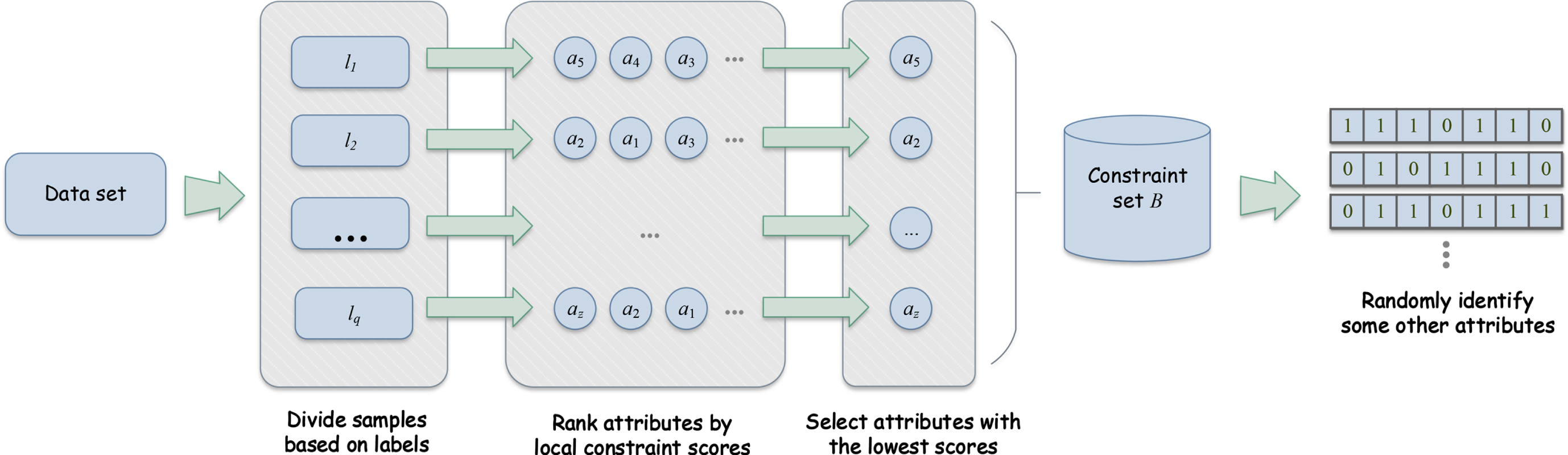
A general framework of population initialization guided by constraint score.
To facilitate the further understanding of our initialization strategy, a toy example is presented as follows.
An example of decision system
Calculate the constraint matrix derived by each label and each attribute via Definition 7, then we can obtain
Following the above result, for label l1, we have τ (a3, l1) < τ (a1, l1) < τ (a2, l1) < τ (a4, l1) < τ (a5, l1) < τ (a6, l1). By Algorithm 5, attribute a1 satisfies τ (a3, l1) = min {τ (a
r
, l1) |1 ≤ r ≤ 6}, which should be added into set B. Similarly, for label l2, attribute a4 is identified and added into set B. We finally obtain B = {a3, a4}.
Following Algorithm 5 which initializes the population, the following Algorithm 6 is then designed to further expand the selection of qualified attributes until the restriction in attribute reduction is achieved.
The time complexity of algorithm 6 mainly comprises of two components: the cost of initializing the population by Algorithm 5, which has been calculated above, is
Note that if the meta-heuristic searching used in Algorithm 6 is genetic algorithm, forest optimization algorithm, fish swarm algorithm and bat algorithm, then the corresponding searchings are named as “CG-GA”, “CG-FOA”, “CG-FSA” and “CG-BA”, respectively (“CG” is short for “Constraint Guide”).
Data descriptions
In this section, to validate the effectiveness of our framework, we perform it over 20 datasets. The details of these datasets are presented in the following Table 2. The programming language is Matlab R2017b. All the experiments have been carried out on a personal computer with Windows 10, Intel Core i5-8265U CPU (1.60 GHz) and 16.00 GB memory.
Data description
Data description
In experiment, we use 10-folds cross-validation to calculate reducts. This mechanism divides all samples into 10 disjoint groups. For each round of computation, we choose one group of samples, which is regarded as the test data to perform classification. The combination of rest samples is regarded as train data to derive reducts by different algorithms. The above process is repeated 10 times. Therefore, the mean values of compared metrics are recorded.
In the context of this experiment, we have used 10 different radii to conduct the experiment, they are 0.04, 0.08, ⋯, 0.40. To avoid adding too many redundant attributes into reducts, the length of each individual in initial population is set to be 10 % × |AT| if the 4 meta-heuristic searchings shown in Section 3 are employed.
Comparisons of stabilities of reducts
In this section, the stabilities of reducts derived by different types of searching will be compared. Given a decision system
in which A g is the reduct derived over U - U g .
Obviously, Sta R ∈ [0, 1] holds. If A g ∩ Ag′ = ∅, then Sta R achieves the minimal value 0, which means that the obtained reduct is completely unstable. If A g = Ag′, then Sta R achieves the maximal value 1, which means that the obtained reduct is completely stable. The detailed comparisons are reported in the following Tables 3–5.
Stabilities of reducts w.r.t. dependency
Stabilities of reducts w.r.t. condition entropy
Stabilities of reducts w.r.t. discrimination index
With a thorough investigation of Tables 3–5, it is not difficult to list the following items. Compared with the reducts derived by 4 conventional meta-heuristic searchings (GA, FOA, FSA, BA), if our constraint score guided initialization of population is used, then the corresponding revised searching will generate reducts with superior stabilities. Taking data “LSVT Voice Rehabilitation (ID: 8)” as an example, if the measure of dependency shown in Equation (7) is used, then the stability related to “GA” is 0.0567 while that related to “CG-GA” is 0.1177; the stability related to “FOA” is 0.0629 while that related to “CG-FOA” is 0.1171. Such an observation has demonstrated that our constraint score guided initialization of population does offer better initialized population than conventional meta-heuristic searching can. No matter which measure is used to evaluate attributes and search reducts, our framework also shows significant advantages. By a comparison between “GA” and “CG-GA”, in Table 3 (the measure is dependency defined in Equation (7)), the average stabilities related to “GA” and “CG-GA” are 0.2045 and 0.2674, respectively; in Table 4 (the measure is condition entropy defined in Equation (8)), the average stabilities related to “GA” and “CG-GA” with condition entropy are 0.2904 and 0.3420, respectively. Similar cases can also be observed in Table 5. Such an observation has also demonstrated that our constraint score guided initialization of population is independent to the used measure in the problem solving of attribute reduction. In addition, it can be observed that our superiority is also significant over large-scale datasets. Taking data “Statlog (Landsat Satellite) (ID: 17)” as an example, if the measure of dependency shown in Equation (7) is used, then the stability related to “GA” is 0.3540 while that related to “CG-GA” is 0.1038; the stability related to “FOA” is 0.2531 while that related to “CG-FOA” is 0.1248.
From discussions above, we can conclude that based on our study, the constraint score guided initialization of population is not only effective in improving the stabilities of reducts derived by various meta-heuristic searchings, but also is adaptive to search reducts with respect to different measures. Not only in common datasets, but also in big scale datasets. That is why our strategy is equipped with the characteristic of plug-and-play.
In this section, the classification stabilities [51] related to different types of reduct will be compared. The classifiers called CART (Classification And Regression Tree) and KNN (K-Nearest Neighbor, K=3) are used to derive classification results over test samples.
Similar to the stability of reduct shown above, given a decision system
In Table 6, Pre A g (x i ) is the predicted label of test sample x i by using reduct A g , and ξ1, ξ2, ξ3 and ξ4 are numbers of samples which satisfy the corresponding conditions shown in Table 6, respectively. Therefore, the agreement of classification results, i.e., Agg (A g , Ag′) is
An example of decision system
The comparisons among classification stabilities based on 2 classifiers in terms of 3 measures are presented in the following Tables 7–9.
Classification stabilities based on CART and KNN w.r.t. dependency
Classification stabilities based on CART and KNN w.r.t. condition entropy
Classification stabilities based on CART and KNN w.r.t. discrimination index
With a deep investigation of Tables 7–9, it is not difficult to list the following items. If our constraint score guidance based initialization of population is introduced into “GA”, “FOA”, “FSA” and “BA”, the derived reducts can provide us with better classification stabilities over most datasets. Taking “Urban Land Cover (ID: 19)” in Table 7 (the measure is dependency mentioned in Equation (7)) as an example, the classification stability related to “FSA” is 0.6815 while that related to “CG-FSA” is 0.7342; the classification stability related to “BA” is 0.6917 while that related to “CG-BA” is 0.7704. Such significant improvements of classification stabilities should be contributed to increasing the stabilities of reducts shown in Tables 3–5. From the perspective of the average value, it can also be observed that our framework shows significant advantages for all 3 measures mentioned in Equations (7)-(9), respectively. For example, if the measure “dependency” and the classifier CART are employed (see Table 7), the average classification stabilities related to “GA” and “CG-GA” are 0.6706 and 0.7028, respectively; if the measure “condition entropy” and the classifier CART are used (see Table 8), the average classification stabilities related to “GA” and “CG-GA” are 0.6821 and 0.7238, respectively. Furthermore, no matter which measure is used to evaluate the importance of attributes in the process of searching reducts, it can also be observed that the improvements of classification stabilities based on classifier CART are better than those based on KNN. Taking Table 7 (the measure is “dependency”) as an example, if “BA” is compared with “CG-BA”, the average classification stability is increased by about 6.54% based on CART, but only by 4.39% based on KNN
From discussions above, we can conclude that the constraint score guided initialization of population is effective in producing reducts which provide better stabilities of classification results. Additionally, similar to the case of stability of reduct, from the perspective of the classification stability, our framework is also adaptive to different measures.
In this section, the classification accuracies related to different types of reduct will be compared. The comparisons among classification accuracies based on 2 classifiers in terms of 3 measures are presented in the above Tables 10–12.
Classification accuracies based on CART and KNN w.r.t. dependency
Classification accuracies based on CART and KNN w.r.t. dependency
Classification accuracies based on CART and KNN w.r.t. condition entropy
Classification accuracies based on CART and KNN w.r.t. discrimination index
With a deep investigation of Tables 10–12, it is not difficult to conclude that the explanations about the results of classification accuracies are similar to those about the results of classification stabilities shown in the above subsection. In other words, the reducts derived by our framework can also provide better classification accuracies over most datasets. Taking “Madelon (ID:9)” in Table 10 (the measure is “dependency”) as an example, if the classifier CART is employed, then the classification accuracy related “GA” is 0.5392 while that related to “CG-GA” is 0.7192.
Furthermore, it is interesting to note that the classification accuracies are improved more significant over some high-dimensional data such as “Leukemia (ID:6)”, “Madelon (ID:9)”, “MLL (ID:10)”, etc. Take “Leukemia (ID:6)” in Tab 12 (the measure is “discrimination index”) as an example, if the classifier CART is employed, then the classification accuracy related to “FSA” is 0.5929 while that related to “CG-FSA” is 0.8600. The classification accuracy has been increased by about 45%.
In this paper, through considering the limitations of meta-heuristic searching for problem solving of attribute reduction, a novel framework based on the guidance of constraint score is developed. By constraint score, potential attributes with better distinguishability can be revealed, which initializes the population for subsequent meta-heuristic searching. Note that our used constraint score is designed via a local view, which can capture the distinguishable ability of attributes over each label. Therefore, the evaluation of attributes by our local constraint score is more comprehensive than that by conventional constraint score.
Moreover, it is worth pointing out that our method shows a simple but effective two-stages of searching, in which mostly meta-heuristic algorithms can be easily embedded into it. Following the substantial experimental comparisons, our framework is competitive in both stability of the derived reduct and the related classification performance, i.e., classification stability and classification accuracy.
The following topics deserve our further investigations: (1) how to take the redundancy among features into account by considering the diversity, which aims to obtain a higher quality initial population; (2) the proposed framework in this study only from the perspective of initial population, therefore, we can explore some new strategies by considering the efficiency and effectiveness of the subsequent searching, e.g., pruning and boosting mechanisms.
Footnotes
Acknowledgments
This work was supported by National Natural Science Foundation of China (Nos. 62076111, 62176107) and the Postgraduate Research & Practice Innovation Program of Jiangsu Province (No. SJCX22_1902).