
Abstract
Sentiment analysis is the contextual analysis of words to retrieve the social opinion of a brand which aids the business firms/institutions to know the impact of their products/services. It is habitual that users may express different opinions regarding various aspects of the same entity. Therefore, there is a strong demand to extract all the opinion targets may those be explicitly mentioned aspects or implicit aspects which are not directly specified in the reviews. In this context, comparatively less amount of work has been carried out concerning implicit aspect detection. The proposed work has been dedicated solely to extracting the implicit aspects using a dynamic approach based on the type of sentence containing the clues for implicit aspect. A novel aspect pointer compendium (APC) has been developed that catalyzes the task of finding implicit aspects to the maximum extent possible. The APC incorporates the usage of different types of clues such as synonym clues, context clues, phrase clues, and partially implicit aspects that aid in the detection of hidden aspects. Based on this idea, the proposed work classifies the implicit aspect sentences into six types and proceeds with the task in an efficient manner. To strengthen the task of implicit aspect detection, the proposed work utilizes a hybrid technique encompassing APC, domain-specific adjective-noun collocation list (DSANCL), and the explicit aspect-opinion word pairs extracted from the reviews. The experimentation and results reveal that the proposed hybrid approach shows a good improvement in terms of the efficacy of extracting the implicit aspects as compared to the existing baseline models.
Introduction
Sentiment analysis is an active field of research in recent years. It analyses the sentiments expressed in the text at different levels (document-level, sentence-level, and aspect-level) and also identifying sentiment in Cloud Computing and Internet of Things. Out of these three levels, aspect- level analysis of sentiments proves to be a more fine-grained level of analysis. The bulk of research work executed so far focuses on detecting explicit aspects but ignored implicit aspects, which are insinuated by other existing words and articulates of the sentence [13]. As a reasonable percent of aspects present in user reviews are implicit, it is worth detecting them and finding their associated sentiment. Due to the wide availability of the Internet, and rapid growth of web applications people tend to increasingly share their views and opinions regarding various entities such as goods, services, or organizations through social network platforms. It is difficult to extract relevant concepts from huge amounts of data [19]. In the pre-web era, whenever we decide to buy a product or use a service, most of us discuss with our friends regarding their opinion or experience with the particular brand, and based on these premises decision-making is carried out. Now, in the presence of the ever-growing web, there are a lot of opportunities to go through the reviews/opinions of several people who are geographically distributed. The IoT industry is encouraged by modern business intelligence to benefit from ubiquitous sentiment polarity of public moods and pertinent data provided in form of text using context aware integrated data management, through opinion mining through pervasive hybrid applications based on social media [27]. Optimization techniques are used to locate the sentiment in clouds in order to enhance the detection performance and load balancing of a machine learning model [26]. The immense advancements in this field urged the researchers to devise new techniques and approaches that could mitigate the raising issues and multiplex scenarios of Aspect-based Sentiment Analysis (ABSA) [15].
ABSA is a prominent and challenging issue in natural language processing tasks. It aims to analyze the emotion of the aspect words in given subjective sentences [28]. World Wide Web has given an opportunity for customers to share their views and opinion on products that they have purchased [17]. E-commerce giants like Amazon, Flipkart, etc provide customers with a forum to share their experience and provide potential consumers with true evidence of the product’s outcomes [18]. Similarly, in the domain of higher education, nowadays students and parents make a careful choice of Institution by giving weightage to the opinions and feedback of the students and alumni of various Institutions. Student feedback has been an essential part of many universities. The feedback could be about teaching quality, infrastructure, curriculum, and how to improve them. Students also use online platforms to share their opinion about the various aspects of their Institutions. This information if carefully analyzed can reveal several useful insights using which Institutions can take relevant measures to strengthen them in the appropriate sectors. On the other hand, carrying out ABSA on student reviews, stakeholders come to know about the pros and cons of the university concerning the individual aspects such as Lectures, facilities, sports, etc., Referring to the public opinion is a well-known method of decision making in human society. In general, humans tend to ask for the opinion of family and friends before opting to use a service. With the rapid development of blogs and online forums, people share their views on several subjects such as politics, services, and education. Implicit aspect detection can be done by extracting useful information from the corpus, and by using the domain knowledge from the web. Due to users’ free style of writing, the reviews tend to be implicit. While extensive research has identified explicit aspects, little effort has been put forward on implicit aspect extraction due to the complexity of the problem [3]. The ABSA task aims to associate a piece of text with a set of aspects and also infer their respective sentimental polarities. Unfortunately, the aspect is often expressed implicitly through a set of representations. Implicit aspect detection is one of the challenging NLP tasks in practice but has not received sufficient attention from the research community [4].
Aspect-level opinion mining detects detailed sentiments about features of products [5]. It is necessary to mine opinions towards aspects instead of the whole entity. The capability of distinguishing whether an input is subjective or objective, in particular, can be highly beneficial for a more effective sentiment classification [24]. Due to the cost of manual annotation, researchers focus on unsupervised implicit aspect identification. Indeed, when a document or a sentence evaluates a single entity, it does not mean that this evaluation is true for all aspects of the entity [7]. An aspect is a concept on which the author expresses his/her opinion in the document. Within the next few years, sentiment analysis or opinion mining is set to become an important component of real-world applications for manufacturers, e- commerce companies, and potential customers [8]. The need for a better understanding of t opinions paved the way to novel approaches that focus on the analysis of the sentiment related to specific features of a product [1], giving birth to the field of ABSA [16].
At a more fine-grained level, ABSA focuses on the targets of users’ opinions and determining the sentiment orientation of these opinions. Due to the complexity of implicit aspects, not much effort has been put forward to solve the problem while explicit aspects have been studied extensively. Existing approaches for implicit aspect extraction have focused on the specific type of aspects and have neglected the actual problem. The proposed work focuses on the efficient extraction of implicit aspects by giving a dedicated treatment to the reviews depending on the type of implicit sentence. The sentence that does not contain any explicitly mentioned aspect is referred to as an implicit sentence in our work. Treating all the implicit sentences, in the same way, may not yield effective results in terms of implicit aspect extraction. A deep study of implicit sentences in user reviews revealed several useful insights that can be better exploited in detecting the hidden aspects. It was found that various types of clues such as synonym clues, sole clues, phrase clues, context clues, etc. are present in the reviews that serve as a promising sign for detecting the hidden aspects. With these insights, the proposed hybrid approach incorporating APC, DSANCL, and explicit aspect-opinion word pairs works efficiently in detecting the implicit aspects that can contribute to the overall improvement in the aspect extraction task of ABSA.
Related work
The problem of grasping implicit features in microblog posts is solved in a hierarchical way using a knowledge-based topic model and support vector machine [1]. The authors proposed an implicit feature detection algorithm to identify the implicit aspects hidden in the posts. They used the topic model to accomplish this task. They have used word pairs of high frequency and lexicons to detect implicit emotions. Association rules are created using the word pairs of high probabilities. With this setup, they fill in the missing emotions in the forthcoming implicit sentences. The work in [2] uses a taxonomy-based approach for the identification of explicit aspects and implicit aspects. A financial expert was employed to conceive the taxonomy involving the aspects related to trade following a hierarchy of general to more specific. They formed a total of seven aspect classes. The taxonomy was used to calculate the relativity between taxonomy labels and textual candidates. The work in [3] deploys a multi-level knowledge engineering approach for identifying implicit aspects in the movie domain. Their approach is to first detect the explicit aspects by utilizing the BiLSTM-CRF method. It acts as input to manipulate the dependent phrases to identify implicit aspects. Their model can detect implicit aspects from four types of sentences comprising three types of dependent sentences and one type of independent sentences. The annotation phase carries out the pre- processing tasks on the movie reviews. The explicit aspects identification phase extracts aspects from explicit sentences using the supervised BiLSTM-CRF method. These explicit aspects serve as the source for finding the implicit aspects of independent and dependent sentences.
[4] proposes a unified framework addressing aspect categorization and aspect-based sentiment subtasks. First, auxiliary sentences are constructed for implicit aspects by using semantic and syntactic information. Subsequently, BERT is encouraged to learn the aspect-specific representation as an outcome for the auto- computed auxiliary sentence. The BERT-based approach contributes to fine-tuning the ABSA subtask. [5] proposed a novel implicit aspect identification approach based on non-negative matrix factorization. First, product aspects are clustered by combining the co-occurrence information with intra-relations of aspects and opinion words. Then, the context information of aspects is collected and the review sentences are represented by word vectors. Ultimately, a classifier is used to predict the hidden aspects. The highlight of this approach is transforming the problem of implicit aspect detection into a text classification problem. For a new review sentence input, the model predicts the highly probable aspect category. A feature-centroid classifier is used to detect the target aspect. [6] uses an approach of corpus-based and wordnet dictionary-based model for implicit aspect term extraction. In implicit aspect detection, the Naïve Bayes classifier is used to identify the final latent aspects. [7] proposed a hybrid model based on wordnet relations and term-weighting for detecting implicit aspect sentences and thereby identifying the hidden aspects. They evaluated the performance using Naïve Bayes, a support vector machine, and a random forest with three crime datasets. Their approach involves a hybrid implicit aspect representation model. It encompasses three subtasks: creating a list of document adjectives and verbs, generating the term document vector representation, computing the document term frequency vectors for each document, and finally improving the training data. [8] proposes a hybrid model combining semantic relations and a frequency-based approach with supervised classifiers for implicit aspect detection. Their model addresses aspect term extraction and aggregation involving adjectives and verbs. In the Implicit aspect term aggregation step, their model deals with fine and coarse granularity levels. [9] proposed a multi-level approach that identifies implicit aspects using co-occurrence and similarity- based techniques. This approach focuses on the identification of clues for hidden targets of opinions. They have handcrafted several rules to detect implicit aspect clues. In addition to extracting clues, their model can allocate clues to the sentiment words if no association could be identified. This aids in detecting implicit aspects irrespective of their co-occurrence with sentiment words. [10] focused on the recognition of fact- implied implicit sentiment at the sentence level. The authors proposed a method for representation learning.
APC developed as part of the proposed work
APC developed as part of the proposed work
In [11], the rule grammar method is used to detect the hidden aspects with explicitly associated sentiments. The work deals with four types of sentence models namely simple, compound, complex and compound- complex. In this study, authors have used a hybrid approach of several techniques such as Elmo, Term frequency - Inverse cluster frequency (TF-ICF), wordnet, and semantic similarity. Elmo is an advanced NLP technique to denote words in the form of vectors or embedding. Elmo can create separate vectors for the same word depending on the context of the sentence which contains the specific word. For implementing the Elmo process, TensorFlow tools were used. Wordnet is employed to categorize the aspects and sentiment words based on their synonyms and antonyms. TF-ICF is used to compute the term frequency on each cluster in the document. An implicit aspect corpus is used to find the aspect categories for handling implicit sentences. The words are determined based on the semantics concepts and context. The method starts by pre- processing the reviews to filter less relevant terms. The pre-processed reviews are fed as input to the aspect categorization module. Using Elmo, aspect keywords from Wikipedia links are also input to the module. Following this task, aspect and sentiment words are extracted using the hybrid approach. Through grammatical rule extraction, pair of aspect terms and sentiment terms are extracted. This is accomplished using the basic dependency parser and enhanced dependency parser of Stanford NLP. The review sentences are categorized into four types of models. After splitting into four types of sentence models, the next task is to find the aspect-opinion pairs from each sentence structure. The study has proposed two generalized rules for the aspect parser, rules for review sentences containing noun phrases and rules for the review sentences without nouns but containing an adjective phrase. The algorithm for expanding keywords starts by fetching the keywords from Wikipedia and pre-processing those terms. The synonyms and antonyms of keyword terms are fetched from the wordnet. As the next step, the algorithm calculates ICF and TF-ICF. The first ten largest similarity-valued words are compared with lexicons. The highest valued word is chosen as the expanded keyword term. The evaluation results show that the hybrid approach yields a better F1 measure of 82% when compared to the baseline methods. In [12], the authors proposed a novel approach using conditional random fields (CRF) for finding implicit aspect indicators(IAI) that denote the implicit aspects. It uses a supervised learning approach of sequential labeling with CRF to achieve the goal. In this study, a corpus was developed for the task of IAI extraction. This is accomplished by manually labeling the IAI and its associated aspects. The corpus is openly accessible for research purposes. For IAI extraction, only opinionated sentences are considered. Each word in the opinionated sentence is labeled as “I” or “O”. Those words which are labeled with “I” are the implicit aspect indicators, whereas the words labeled with “O” are interpreted as other words which do not contribute to the IAI task. The labeling task is implemented using the technique of sequential labeling based on CRF. The data to train the sequence labeler is taken from the dataset. The NERFeatureFactory class implemented in the stanfordNER provides various feature extraction methods out of which the required feature extractors alone can be enabled to use with the CRF classifier so that feature vector can be built. For a given word sequence, a feature vector is constructed for every term which is to be labeled. The constituents of the feature vector are word features, n-gram features, POS features, context features, class sequence features, and word bi-gram features. Word features are used to denote the type of word instance that is to be labeled. N-gram features which are very useful in named entity recognition tasks indicate whether a substring is present in a word. POS features indicate the POS tag of each word that is present in the sentence. Context features are the tags of the preceding and following words of the current word to be labeled. Class sequence features are the association of a specific word with the labels given to the preceding words. A label window of size 2 is used for this task. [20] proposed a framework based on span-level aspect term extraction. They used a tag data augmentation module to generate training samples for multi-aspect samples. To get contextual token representations, a pre-trained model is used that acts a feature extractor. [21] proposed a BERT-based attentive representation learning for detecting aspect category in an unsupervised manner. BERT generates meaningful sentence representation that aids in effective learning of aspect categories. [22] proposed an effective and novel method using attention mechanism and graph convolutional network for aspect-based sentiment classification. [23] focuses on the various techniques used for classifying the given portion of natural language text, audio and video according to the thoughts, feelings or opinions expressed in it, i.e., whether the general attitude is Neutral, Positive or Negative. [25] proposed a meta-based self-training method for ABSA by framing a generalizable model through appropriate symbolic representation selection and effective learning control in a neural system.
Based on the robust set of rules and patterns framed in our previous work ERBA-DSL [14], the explicit aspect-opinion word pairs are extracted from the opinionated reviews with explicit aspects. This serves as one of the sources for detecting the implicit aspects. The proposed model detects the implicit aspects by employing a hybrid approach whose primary components are the APC, domain-specific adjective-noun collocation list, and the source of explicit aspect-opinion word pairs extracted using the ERBA-DSL model. An in-depth study was carried out to explore the possible ways by which the implicit aspects hidden in the review sentences can be dug out. Natural language linguistics reveals several interesting sources that can aid in finding the latent aspects that have associated opinions. For example, the terms that are present before or after the adjective/adverb(opinion) serve as valuable clues to identify the hidden target of the opinion. Figure 1 shows the APC developed as part of the proposed work which serves as the primary component of the implicit aspect detection task.
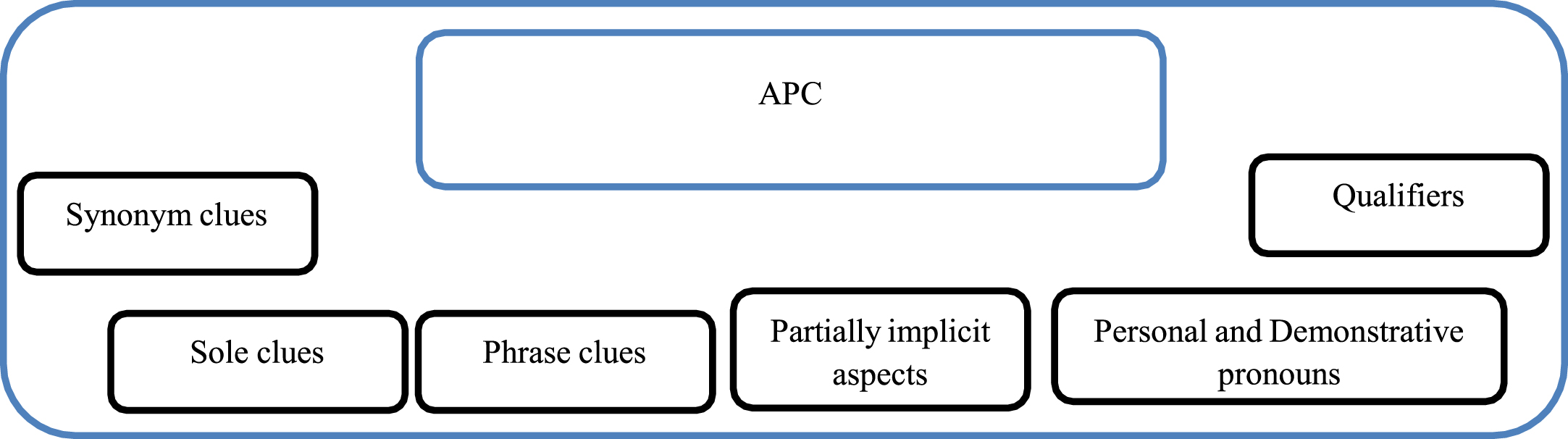
APC developed as part of the proposed work.
We have categorized the implicit aspect clues into three types namely synonym clues, sole clues, and phrase clues.
Synonym clues are one form of context clues that denote the hidden opinion target. In this case, the user review contains a word with the same meaning as that of the implicit aspect. For example, the term “Rink” means “Covering over an acre in extent”. Consider the review sentence, “Largely covered rink”. In this example, “rink” serves as a synonym clue denoting the implicit aspect “playground” about which the user has expressed an opinion “largely covered”.
Consider another review sentence, “Uni provides strange free rooms”. In this sentence, the term “rooms” serves as a synonym clue denoting the implicit aspect “Hostel/Accommodation” about which the user has expressed an opinion “strange-free”.
Sole clues are the specific single-word hints that denote an implicit aspect. As a subtask of the proposed work, an extensive study was carried out with thousands of reviews from the University reviews domain to reveal the various aspects /features of the university reviews. As a by-product of this study, a set of single- word clues that could identify the hidden aspects was framed. For example, consider the review sentence, “Brilliant methodology”. In this sentence, the user has expressed an opinion “Brilliant” about an aspect that is not directly mentioned in the review, but it is possible to reveal the hidden aspect using the sole clue “methodology”. The term “methodology” serves as a sole clue that denotes the aspect “Teaching pedagogy” concerning the domain of university reviews. Similarly, in the review sentence, “paper evaluation by professors are justified” it is clear that the user expresses a positive opinion, “justified”, about an aspect that is not directly mentioned in the sentence. In this case, the term “evaluation” serves as a sole clue that helps in identifying the target implicit aspect “Assessment”.
Certain review sentences contain a set of words (phrase) that together serves as a promising clue to detect the target implicit aspect. For instance, “staff possesses high teaching skills”. In this review sentence, the set of words “Teaching skills” serves as a phrase clue to identify the implicit aspect “teaching pedagogy”. The APC built in the proposed work contains the set of all possible phrase clues and their respective aspects for the university reviews domain.
Pronouns that act as a substitute for nouns or noun phrases serve as good indicators of the implicit aspects. Pronouns can indicate the contextual references in a sentence. Considering the value of pronouns in the task of implicit aspect detection, an in-depth study was carried out regarding the various types of pronouns that can be utilized in this task. The sole limitation of a pronoun is that it becomes meaningless in the absence of prior information about a noun. The noun that is replaced by a pronoun is called the antecedent. For example, consider the following review sentences,
Review sentence 1: “I love my university, it is amazing”
Review sentence 2: “Library is good, it is open 24 × 7”
In the review sentence1, the pronoun “it” denotes the noun “university” in the preceding phrase.
Similarly, in the review sentence2, the pronoun “it” denotes the preceding noun “Library”.
Users tend to use pronouns as a way of avoiding repetition of the same noun again and more impressively pronouns are very short.
The following types of pronouns are found in the review sentences:
(i) Personal pronouns are terms including but not limited to “it”, “he”, “she”, “I”, “we”, “who”, ”him”, “them”, “whoever”, “anyone”, “something”, “nobody” etc.
Consider the review sentence, “my staffs are friendly. I like them”
In the first phrase, the user has expressed an opinion “friendly” about the aspect “staffs”. Thus, the explicit aspect-opinion word pair is extracted as “staff-friendly”. In the subsequent phrase, the user wishes to express something more about the same aspect “staff” without repeating the noun. In this context, a personal pronoun, “them” is used to denote the implicit aspect “staffs” and another opinion “like” is expressed about the same aspect. This example demonstrates the use of the personal pronoun in identifying the implicit aspect.
(ii) Demonstrative pronouns are used to point to specific things that are being referred to. Some examples of demonstrative pronouns are this, that, these, those, etc. Consider the review sentence, “Lab equipment is not working properly. These are nonfunctional”.
Partially implicit aspects –target implicit aspect mapping using context clues
In the first sentence of the above review text, the user mentions the status of lab equipment as “not working”. Here, the explicit aspect is “lab equipment” and the opinion is “not working”. In the second sentence of the review, the user expresses another opinion “nonfunctional”, but the aspect is not explicitly mentioned, instead, a demonstrative pronoun “these” is used that denotes the preceding noun “Lab equipment”.
Qualifiers are a group of words that gives more information about a noun. While qualifiers of time tell how often an event occurs, qualifiers of quantity convey how much action has happened. The study utilizes both types of qualifiers in identifying the implicit aspects. For example, consider the review sentence, “lot of societies, some are hard to fit in”. In this review text, the user conveys that even though there are a lot of societies in the university, some of the societies are hard to associate with. Here, the qualifier of quantity, “some” indicates the aspect “societies” in the preceding phrase. This aids in detecting the implicit aspect “societies” which is the target of the opinion “hard to fit”. To understand the usage of the qualifier of quantity, let us go through another review text, “Uni has many sports clubs. All are fine”. In this example, the qualifier of quantity, “all”, denotes the implicit aspect “sports clubs” that is the target of the opinion “fine”.
In the process of studying the possible clues that may denote the hidden aspects, it was possible to explore a novel kind of implicit aspects known as partially implicit aspects. To the best of our knowledge, the proposed work is the first to identify a new kind of aspect in ABSA. So far, all the existing works have dealt with only two types of aspects, namely, explicit aspects and implicit aspects. An in-depth study of the review sentences reveals the possibility of the occurrence of partially implicit aspects too. In general, the aspects that do not directly occur in a review sentence are defined as implicit aspects. But, in certain cases, the noun present in a review sentence acts as part of the opinion target, which can be exploited to identify the target implicit aspect. For example, consider the review sentence, “Professors are bit speedy”. Here, “speedy” is the opinion expressed about an implicit aspect that is connected with the noun (Professors) in the sentence. The noun “Professors” together with the context clue “bit speedy” is looked up in the APC developed in the proposed work. The result of the look-up in APC finalizes the target implicit aspect as “staff behavior”. It was found that a reasonable percentage of review sentences are found to contain partially implicit aspects(PIA).
Class 1 sentences are represented as below:
Consider the sample review sentence, “uni has vast high-tech rink”
The Table 3 shows the synonym clue and opinion words corresponding to the above review sentence.
In the above review sentence, the synonym clue “rink” denotes the implicit aspect “playground” that is the target of the two opinion words “vast” and “high-tech”. The target implicit aspect associated with the specified synonym clue is fetched from the APC developed in the proposed work.
Implicit sentence containing synonym clue
Implicit sentence containing synonym clue
Class 2 sentences are represented as below:
Consider the sample review sentence, “Brilliant Methodology”
Table 4 shows the sole clue and opinion word tags for the sample review sentence under consideration.
In the above review sentence, the sole clue “methodology” denotes the implicit aspect “teaching pedagogy” that is the target of the opinion “brilliant”.
Implicit sentence containing synonym clue Term1 Term2
Class 3 sentences are represented as below:
Consider the sample review sentence, “taste feels very long on tongue”. Table 5 shows the phrase clue and the opinion words specified in the review sentence. Table 5 shows the phrase clue and the opinion word specified in the sample review sentence.
Implicit sentence containing phrase clue
In the above example, the phrase clue is composed of two terms “teaching” and “skills” which together denotes the implicit aspect “pedagogy”.
Class 4 sentences are represented as below:
Let ea denote explicit aspect.
Let pp denote the personal pronoun.
Let S1 denotes the review sentence composed of terms x1 to xn
Let S2 denotes the review sentence composed of terms y1 to yn
The personal pronoun(
Personal pronoun and opinion words in the review sentence
In the above example, the personal pronoun “it” in the second sentence denotes the implicit aspect “university” which is the noun in the preceding sentence, sentence1.
Class 5 sentences are represented as below:
Let ea denote explicit aspect.
Let dp denote the demonstrative pronoun.
Let S1 denotes the review sentence composed of terms x1 to xn
Let S2 denotes the review sentence composed of terms y1 to yn
The demonstrative pronoun(
Demonstrative pronoun and opinion words in the review sentence
In the above example, the demonstrative pronoun “those” in the second sentence denotes the implicit aspect “furniture” which is the noun in the preceding sentence 1.
Class 6 sentences are represented as below:
Consider the sample review sentence, “Professors encourages students”. Table 8 shows the partially implicit aspect and the opinion word present in the sample review sentence.
Partially implicit aspect and opinion words in the review sentence
In the above example, the partial implicit aspect
The algorithm developed for identifying the target implicit aspect using the APC, DSANCL, and the explicit aspect-opinion word pairs are presented below.
Let R be the set of review sentences
Let R_OSE denote the set of opinion holding reviews with explicit aspects.
Let R_OSI denote the set of opinion holding reviews with implicit aspects.
Let sw denote the sentiment word

Proposed hybrid architecture for implicit aspect detection.
The proposed approach carries out the task of implicit aspect detection using the novel APC developed in this work. It also makes use of the IAD source1 and IAD source2 developed in our previous work ERBA- DSL. The explicit aspect-opinion word pairs extracted in the ERBA-DSL model serve as IADsource1 and the domain-specific adjective-noun collocation list(DSANCL) in the said model serves as IAD source2. First, the opinionated reviews which do not contain any explicit opinion target are collected from the dataset. Such reviews are said to contain implicit aspects and are denoted by R_OSI, opinionated sentences with implicit aspects. In each iteration of the set of reviews, R_OSI, a review is fetched. First, the number of sentences in a review is determined. If the review contains only a single sentence and the word or words present in the sentence are all same as the sentiment word(sw), then the only possible candidate for the opinion target would be the overall entity corresponding to the domain(in our case, the university domain). On the other hand, if the single review sentence is of type class1(sentence with synonym clue), then the APC is looked up for the presence of the synonym clue, and the corresponding target implicit aspect(tia) is fetched from the APC.
Similarly, if the single review sentence is of type class2(sentence with a sole clue) or class3(sentence with phrase clue) or class4(sentence with context clue), the same lookup procedure in APC is followed to fetch the corresponding target implicit aspect. Suppose if the review under analysis contains more than one sentence, then fetch all the nouns in the first sentence in a set, cia denoting candidate implicit aspects. The number of nouns in the set is denoted by cia_count. If a personal pronoun or demonstrative pronoun is present in the second sentence, then check the cia_count, if only a single candidate is present in the set, then declare it as the target implicit aspect. On the other hand, if multiple candidates are present, then find the weight of each candidate based on IAD source1 and IAD source2. All the candidates are ranked based on their total weight score calculated based on both the IAD sources. The candidate with the largest weight is chosen as the target implicit aspect.
Around 4254 reviews were taken for analysis. Out of these reviews, nearly 94.92% of reviews, that is, around 4038 were sentiment-bearing reviews and 5.07% of the reviews were not bearing any sentiment. The Table 9 and Fig. 3 shows the statistics related to the dataset. The distribution of explicit and implicit aspects in the sentiment-bearing reviews is shown in the Table 10 and Fig. 4. The statistics about the sentiment- bearing reviews with implicit aspects is shown in the Table 11.

Dataset statistics.
Statistics of the dataset

Distribution of explicit and implicit aspects in the sentiment-bearing reviews.
Distribution of explicit and implicit aspects in the sentiment-bearing reviews
Among the 1049 sentiment-bearing reviews with more than one sentence, 618 reviews had only a single candidate implicit aspect and 431 reviews contained multiple candidate implicit aspects. The class-wise distribution of implicit aspects is shown in Table 12 and Fig. 5. The table also shows the number of implicit aspects extracted class-wise by the baseline and the proposed model. It is found that the hybrid model involving ERBA-DSL and the APC yields better results in terms of implicit aspect detection. The performance metrics of the baseline model and the proposed hybrid model are compared and the results are shown in Table 13 and Fig. 6. The results reveal the effectiveness of the hybrid model with the novel APC component works well in the extraction of implicit aspects and the precision, and f1-score are improved to nearly 88% whereas the recall has seen a relatively good improvement of around 90%.
Statistics about sentiment-bearing reviews with implicit aspects. Let R_OSI denote the set of sentiment-bearing reviews with implicit aspects

Comparison of implicit aspects extracted by ERBA-DSL, APC and ERBA-DSL+APC.
Class-wise distribution of implicit aspects and the number of implicit aspects extracted by ERBA-DSL, APC and ERBA-DSL+APC models
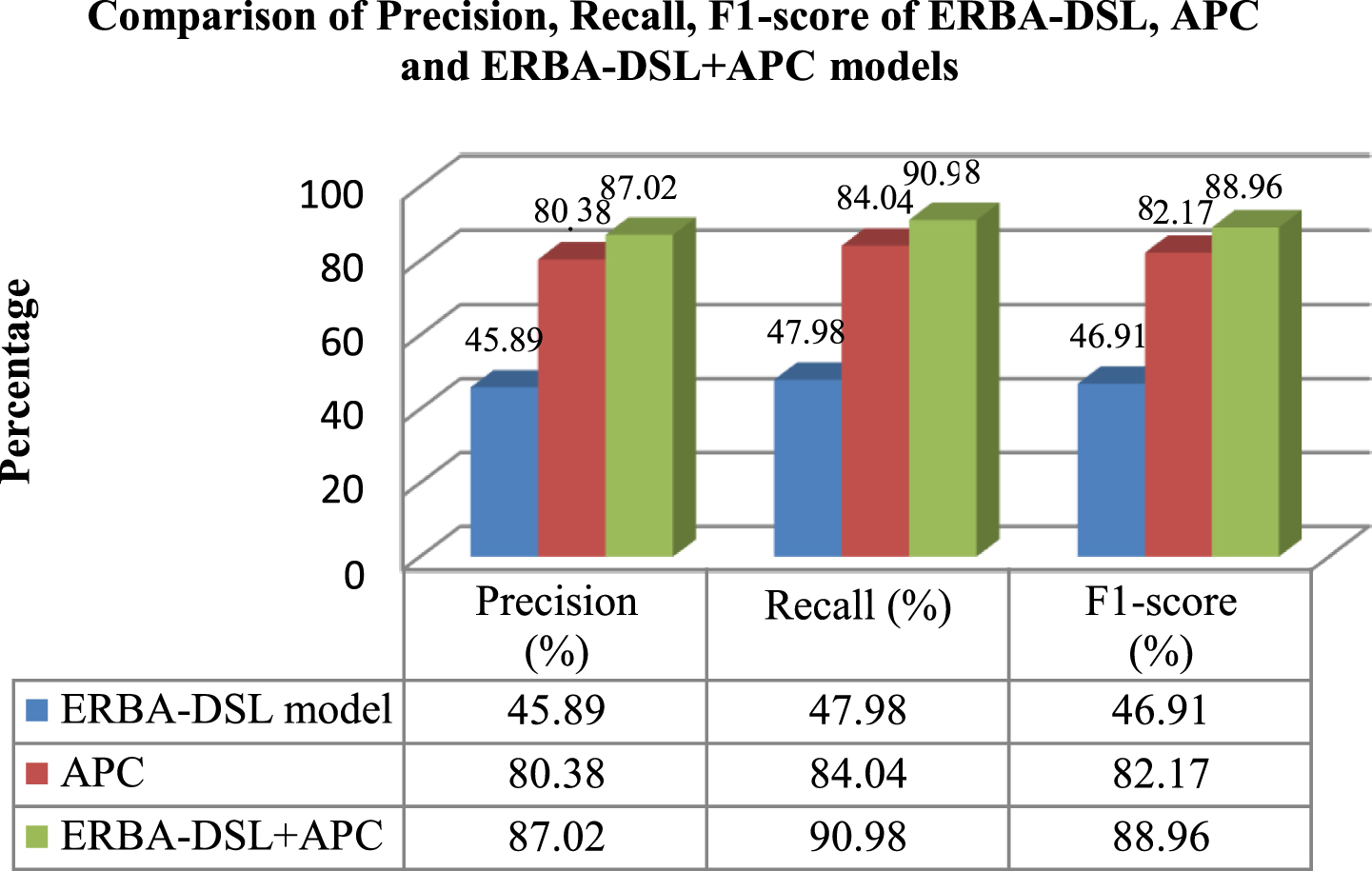
Comparison of precision, recall and F1-score of ERBA-DSL, APC and ERBA-DSL+APC models.
Comparison of Precision, Recall and F1-score of baseline models with the proposed hybrid model
The proposed approach is dedicated to accomplishing the task of implicit aspect extraction which is a highly focused area in the domain of ABSA. Even though a lot of research work was done in the area of explicit aspect extraction, only a very few works have dealt with hidden aspects. A thorough study revealed the fact that even though the number of implicit aspects present in user reviews is far lesser than the number of explicit aspects, extraction of implicit aspects reasonably contributes to the overall improvement of aspect extraction efficiency. This is the motivation for carrying out this research work on implicit aspect detection and finding out the various mechanisms that can aid in the efficient accomplishment of the said task.
In this regard, the proposed work has made novel contributions to detecting the hidden aspects in the reviews by developing an APC and classifying the implicit aspect sentences into six classes based on the type of clues and pronouns present in these sentences. A detailed study of the reviews in the dataset revealed the fact that the reviews consist of certain clue words that serve as a valuable hint to identify the hidden aspects. The notion of using clues to identify hidden aspects together with the knowledge of the natural language leads us to categorize the types of clues present in the reviews. The idea is to categorize the sentences containing implicit aspects based on synonym clues, sole clues, phrase clues, context clues, personal pronouns, and demonstrative pronouns. Moreover, an APC has been developed as part of the research work that contains the data regarding each type of clue and the associated target implicit aspect denoted by the clue. The APC has been specifically developed for the university reviews domain. It can be tailored to suit other domains too. The experimentation on the university reviews dataset clearly indicates the effectiveness of the proposed hybrid model with the novel APC component. The performance metrics achieved by the hybrid model is very promising and shows a reasonable improvement over the baseline models.
Future work will be focused on enhancing the APC with other types of clues and web resources. Moreover, the number of classes of implicit aspect sentences can be extended further. The integration of APC with other promising approaches for implicit aspect extraction will be given due consideration.
Footnotes
Acknowledgments
We would like to extend our sincere thanks to the authors of the reference papers for their valuable ideas and the recommended methods in the area of sentiment analysis. We also thank the reviewers for their useful comments and suggestions.
Funding statement
The authors received no funding for this study.
Conflict of interest
The authors declare that they have no conflicts of interest to report regarding the present study.