
Abstract
Aiming at the problems of traditional text abstract extraction algorithms for processing long text of Chinese patents and unsatisfactory results of long abstract generation, the PatBertSum algorithm is proposed, which enables the algorithm to process long (more than 1500 words) patent text with high efficiency and generate high-quality long (more than 200 words) text summaries. The method is based on the improved BertSum algorithm model, using the new CLTPDS patented text dataset, processing long texts by Head-Tail, transforming Chinese input representations, generating sentence vectors using a pre-trained model, and capturing internal text features and text structure features to extract summaries. Experimentally, this paper demonstrates that the method has improved the recall and F-value of ROUGE by more than 8 percentage points compared with existing methods.
Introduction
The explosive development of the modern Internet has produced a huge amount of data information, but the proportion of valuable information in more data information is reduced, among which the effective use of text information is a major problem. Text summarization technology extracts, summarize, or refines the key information in the text data information, to summarize and display the main content or key points of the original text information, thus greatly improving the efficiency of users to obtain the required information from a large amount of text data. The traditional way of extracting text summaries by hand takes a lot of time and effort and requires a high degree of professionalism from the practitioner, which is not possible to be applied on a large scale. Therefore, automatic text summarization technology has emerged and combined with the rapid development of deep learning, summarization technology has been growing rapidly in recent years.
Research on automatic text summarization techniques started in 1958 when Luhn [1] first proposed that core sentences could be extracted from high-frequency words and scored to generate text summaries. Mihalcea and Tarau [2] proposed a TextRank network by calculating the similarity between sentences, performing iterative calculations to finally obtain sentence weights, and ranking them to obtain text summaries using the TextRank algorithm. Sutskever, Vinyals et al. [3] proposed the sequence-to-sequence (seq2seq) model, which maps one sequence to another sequence utilizing a neural network. Dai and Le [4] first proposed the pre-trained language model (PTLM), which has been confirmed to have good results in various domain tasks. Vaswani, Shazeer, et al. [5] proposed the Transformer model based on RNN’s seq2seq model framework, which built the whole model framework with an attention mechanism instead of RNN. The BERT model (Devlin, Chang, et al. [6]) pretrains the deep bidirectional representation by jointly adjusting the contexts in all layers, and after pre-training, it can be widely applied to various natural language tasks by only fine-tuning its additional output layers. Liu [7] used the BERT model for pre-training and fine-tuned it toward summary extraction, and proposed the BertSum model that uses BERT to obtain sentence vectors and captures document-level features for summary extraction.
Meanwhile, we noticed that differences in language significantly affect sentence extraction for summarizing English and Chinese documents (Wang & Yang [8]). However, Chinese is one of the six working languages of the United Nations and the primary language is spoken by more than one-fifth of the world’s population. So the Chinese automatic text summarization model has high research value and research difficulty. Qiu, Shu, et al. [9] use an improved TextRank algorithm with sentence weight to extract key sentences from multiple documents, generating summary sentences from key sentence sequences based on the Seq2seq model. This model cannot handle long texts or generate long abstracts, unsuitable for patent texts. Trappey, Wu, et al. [10] used a combined ontology-based and TF-IDF concept clustering approach for summarization. This traditional method is insufficient for achieving state-of-the-art performance and is only applicable to English patents, not Chinese patents.
At present, text abstracts are mainly studied in fields such as news. Compared with news, scientific documents (such as patents) are harder to extract core ideas and key innovations due to their size, obscurity, and professionalism. Abstracts in the patent field are generally 100 to 300 words, while previous models can only generate abstracts of less than 100 words.
To address the above problems, this paper explores the pattern of the location and frequency of abstracts of patent articles in the original text by studying the line structure and organization scale of Chinese patent articles, and then builds an automatic abstract extraction model that considers the characteristics of patent texts and their abstracts. In this paper, we argue that BertSum is well suited for automatic abstraction of long-text patents by virtue of its pre-training method on a large Chinese dataset and its powerful architecture for learning complex features of abstracts. Therefore, this paper improves the BertSum algorithm model based on the new CLTPDS patent text dataset, processes long texts by Head-Tail, transforms Chinese input representations, generates sentence vectors using the pre-training model, and captures internal text features and text structure features of sentences to extract abstracts. Combining the textual and structural features of the abstracts of patent documents, the patented features inside the sentences are captured for abstract extraction.
Model
Long text data processing
A complete Chinese patent specification contains a title page, claims, specification, and accompanying drawings. And following the real patent requirements, the text of the patent invention is usually over 1500 words and the text of the patent abstract is over 200 words, so it needs to be processed for the text structure and scale characteristics of the patent article.
In the real patent text, the main innovation key content of the patent is contained in the invention content column of the specification. Therefore, after collecting the data, this paper extracts the invention content and abstract of the data, corresponds to the patent text and it’s abstract, removes errors and duplicates, and organizes them into a Chinese long text patent dataset CLTPDS. The longest token is 512 tokens, and the longest token will lead to memory overflow. To solve the above problems encountered when using Bert to process long patent text, this paper proposes to use the Head-Tail method. The current long text research mainly adopts Head-Tail interception, RNN (recur-rent method), and Sliding Window to deal with long text.
Head-Tail interception means truncating the long text and selecting the important tokens for input into the model. The most common method is to pick the top N tokens of the article and the top K tokens at the end of the article to ensure that N + K < = 510, based on the assumption that the first and last information of the article best represents the global summary of the chapter.
BERT specifies a maximum input length for MLM pre-training, resulting in a maximum length limit, while for RNN-like networks there is no sentence length limit (for k tokens it goes through k NN calculations). The disadvantage of RNN (recurrent method) is that RNN is less effective compared to Transformer. Sliding Window is mainly seen in various reading comprehension tasks (e.g. Stanford’s SQuAD). This means that the document is divided into overlapping segments, and each segment is sent to BERT as a separate document for processing. Finally, the results obtained from these separate documents are integrated. Based on the characteristic that the core content of the patent text is concentrated in the head and tail of the text, this paper adopts the Head-Tail method, which focuses on the head and tail core sentences and consumes low computational resources, and cuts the head and tail core sentences of the invention contained in the patent specification in the ratio of 128:328, and then cuts and discards the sentences with less than 4 words directly.
The experimental results demonstrate that the addition of Head-Tail can significantly improve the summary quality with relatively minimum complexity.
Text data input representation
An input representation can explicitly characterize a single text sentence or a pair of text sentences in a sequence of word chunks. For a given block of words, its input representation is constructed by summing the block embeddings, segment embeddings, and bit embeddings of the corresponding blocks of words. The first-word block of each sequence is always the special classification embed-ding ([CLS]). The final hidden state corresponding to this word block is used as the aggregated sequence representation for the classification task. For non-classification tasks, this vector will be ignored.
Sentence pairs are packed into individual sequences and distinguish sentences in two ways. First, they are separated using special word blocks ([SEP]). Second, a learning sentence A is added to embed into each word of the first sentence, and sentence B is embedded into each word block of the second sentence. Assuming a single sentence input, only sentence A embedding is used.
As shown in Fig. 1, after Head-Tail text processing, based on the demand of Chinese patent direction, this paper carries out the optimization of Chinese text adaptation based on Liu [7]’s Bertsum model. For the input sequence of sentences, PatBertsum model splits the sequence into Chinese words for processing, instead of conventional processing with pairs of words, which improves the reliability of the algorithm results.
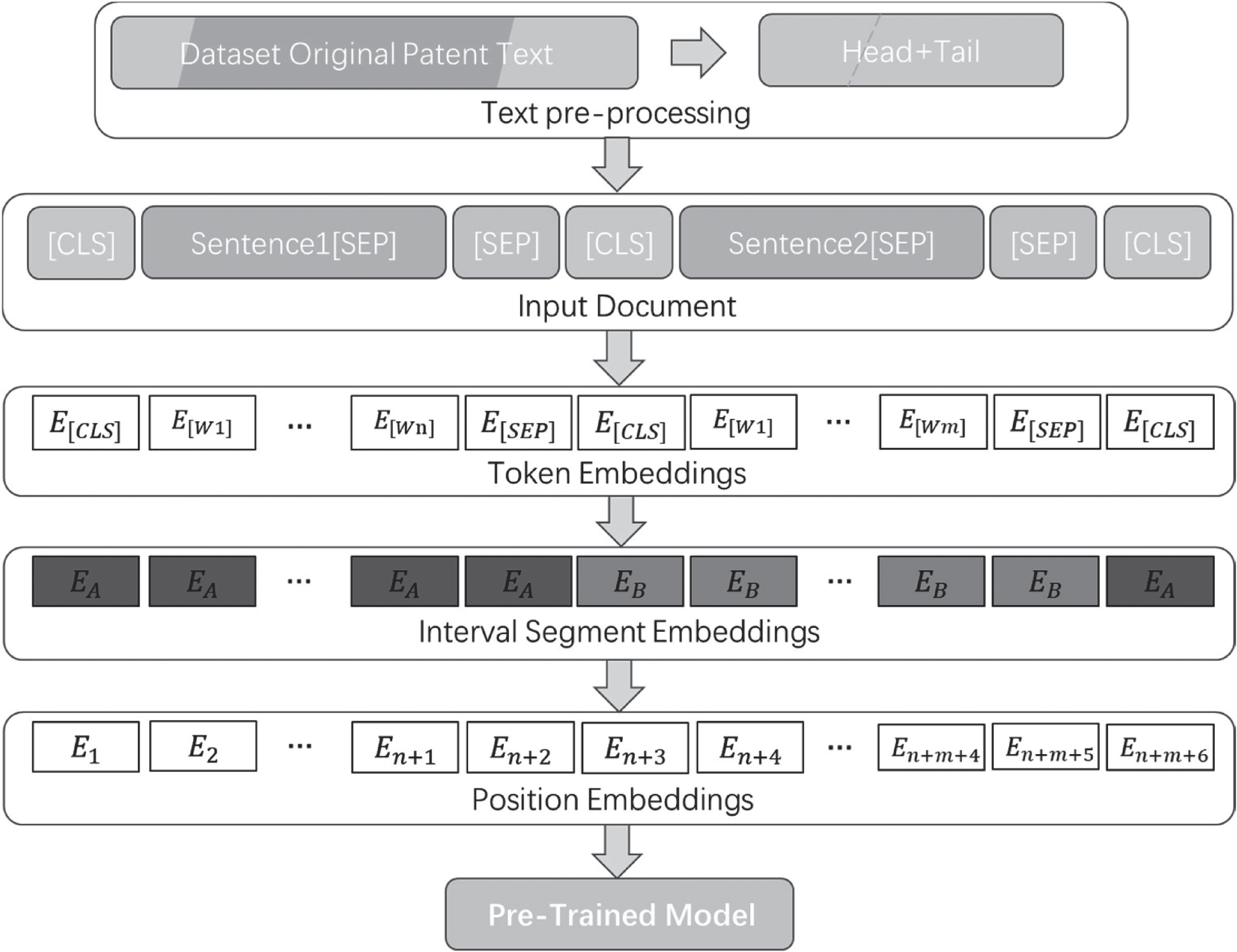
Schematic diagram of vector embedding.
In the next step, the input data is Token transformed, and the [CLS] flag bit is set at the beginning of the input data sentence to determine whether it is a summary sentence, and [SEP] is set at the end of the sentence to separate the sentences. Multiple embedding calculations are performed to obtain sentence vectors containing inter-sentence and intra-sentence features as the input to the pre-trained model. In addition, the pre-training model of the PatBertsum model is Bert-wwm-Ext model(Cui, Che, et al. [11]), which is a Chinese pre-training language model released by Xunfei Joint Laboratory of HUST. Compared with the Bert-base used in the Bertsum model of Liu [7] and other pre-training Bert models, the pre-training dataset of this model is done to increase the number of 5.4B; the number of training steps is increased, 1M steps in the first stage of training and 400K steps in the second stage of training, which has better performance in the field of Chinese text summarization.
To achieve the goal of generating excellent long text summaries, the PatBertsum model additionally considers the effects of sentence length, sentence text structure, and other factors in the summary judgment. After obtaining the sentence vectors from the output of the pre-trained model, several summary-specific layers are constructed on top of it to capture the document-level features used to extract the summaries.
As shown in Fig. 2, the feature information of the sequence recorded after the [CLS] tag of the input representation is processed by the pre-training model to calculate the sentence vector, which is obtained by the multiple self-attentive mechanisms of the pre-training model, including the relationship of the sequence with other sequences and the relationship of the words within the sequence. For each sentence, the final prediction score will be calculated. The loss of the whole model is the binary classification entropy of the gold label. These summary layers will be fine-tuned together with the Bert-wwm-ext pre-training model.

Schematic diagram of sentence vector feature classification.
A composite classifier is added to the output of the pre-trained model and a sigmoid function is used to obtain the prediction scores.
Where σ is the sigmoid function, W o is the internal sentence association weight of the output sentence vector, obtained by training the multi-headed self-attention mechanism of the Transformer model, and there are two structural weights of sentences in the text, where W l is the length weight of the sentence and W s is the position weight of the sentence in the text. The experiments prove that the parameters α, β and γ have the best results with the values of 0.7, 0.2 and 0.1, respectively. The experiments are shown in Fig. 3.

Experimental results of model parameters taking values.
Firstly, we set β, γ to 0.1 in equation (2) and try different values to compare the experimental results, and the maximum ROUGE value is 59.56 when taking 0.7. Similarly, we obtain the best experimental results when setting α,γ to 0.7, 0.1 and α, β to 0.7, 0.2, respectively. The experimental results in Fig. 3 show that the best experimental results are obtained when the values of the parameters α, β and γ are 0.7, 0.2, and 0.1, respectively.
The length of the abstract text must be appropriate based on real patent requirements, and sentences above or below the median sentence length will receive a lower score.
The position of the sentence in the text is a key element in determining whether it is a summary sentence, with sentences near the beginning and end receiving a higher score.
The experimental results demonstrate that adding a classifier based on the patent text structure to the original model significantly improves the summary quality.
The most common evaluation method currently used in text summarization tasks is ROUGE (Recall-Oriented Understudy for Gisting Evaluation (Lin & Hovy [12])) ROUGE-1 is to evaluate the match between the standard text and the generated text in terms of unary grammar, ROUGE-2 is to evaluate the binary grammar match, and ROUGE-L is to calculate the longest common word length match between the standard text and the generated text. In this paper, ROUGE-L, the most distinguished one, is chosen as the main reference score.
The calculation is as follows.
In this paper, we use the CLTPDS patent text dataset crawled and integrated by the crawler to train, using the Pytorch deep learning platform, with the help of pandas, transformers, Numpy, and other class libraries, based on industry-leading pre-training models such as Bert-base-Chinese and Bert-wwm-ext. The joint fine-tuning using BERT and summary layers largely improve the differentiation. The Adam optimization algorithm (Kingma & Ba [13]) parameters used for fine-tuning are β1 = 0.9, β2 = 0.999, s = 10-8. The learning rate plan for the first 1,000 steps is as follows.
The models were all trained on the GPU (GTX 2080) for 42,000 steps with gradient accumulation every three steps. the size of the Batch was 600. model checkpoints were saved and evaluated on the validation set every 2,000 steps. The top 3 checkpoints are selected based on their evaluation loss on the validation set, and the average results are reported on the test set. When predicting the summary of a new document, the model is first used to obtain a score for each sentence. These sentences are then ranked ac-cording to their scores from highest to lowest and the top n sentences are dynamically selected as summaries, with n being selected based on a total word count of no less than 100 words and no more than 300 words.
Since there is no large-scale Chinese patent text dataset on the Internet, the dataset used in this paper is the real patent data collected from public patent websites such as Patent Star, which consists of patent texts ranging from 1,500 to 3,000 words and the corresponding text abstracts ranging from 150 to 300 words. The data were used for the actual experiment. The data is divided into 38,000 training sets, 3,300 validation sets, and 800 test sets after data pre-processing with python, which are organized into the Chinese long-text patent dataset CLTPDS(See attachment:dataset example.xlsx). 24,000 short-text Chinese abstracts are obtained by using the abstract data generated by the Oracle algorithm, which is only used for testing the feasibility of the algorithm.
To demonstrate the superiority of the Chinese long-text proprietary dataset CLTPDS, the Chinese single-document corpus TTNews provided by NLPCC2018 Shared Task 3 is selected for comparison. TTNews is a long-text summary dataset containing 50,000 training data, 2,000 validation sets, and 2,000 test sets. Compared with the classical LCSTS Chinese short text summarization dataset, the comparison experimental effect of TTNews is more convincing.
As can be seen from Table 1, compared with the TTNews dataset, the average length of text in the CLTPDS dataset is three times longer than the former, reaching over 1500, while the average length of the abstract text is six times longer than the former, reaching over 150. And to better compare the CLTPDS dataset with the TTNews dataset, we put the two datasets into the PatBertSum model for training and tested them with 3675 test data, and the results are as follows:
Comparison of text lengths of data sets
Comparison of text lengths of data sets
As shown in Fig. 4, the horizontal coordinate is the value of ROUGE-L, and the vertical coordinate is the number of this taken value. In the test for automatic abstraction of long patent texts, the CLTPDS dataset has steadily more high scores (ROUGE-L greater than 0.5) than the TTNews dataset, indicating that the CLTPDS dataset is better in processing long Chinese text abstracts. Meanwhile, the data of CLTPDS dataset is based on multi-domain patent texts, which can reflect the current needs of patent texts and their abstracts more realistically and is more suitable for the objectives to be achieved by the study.
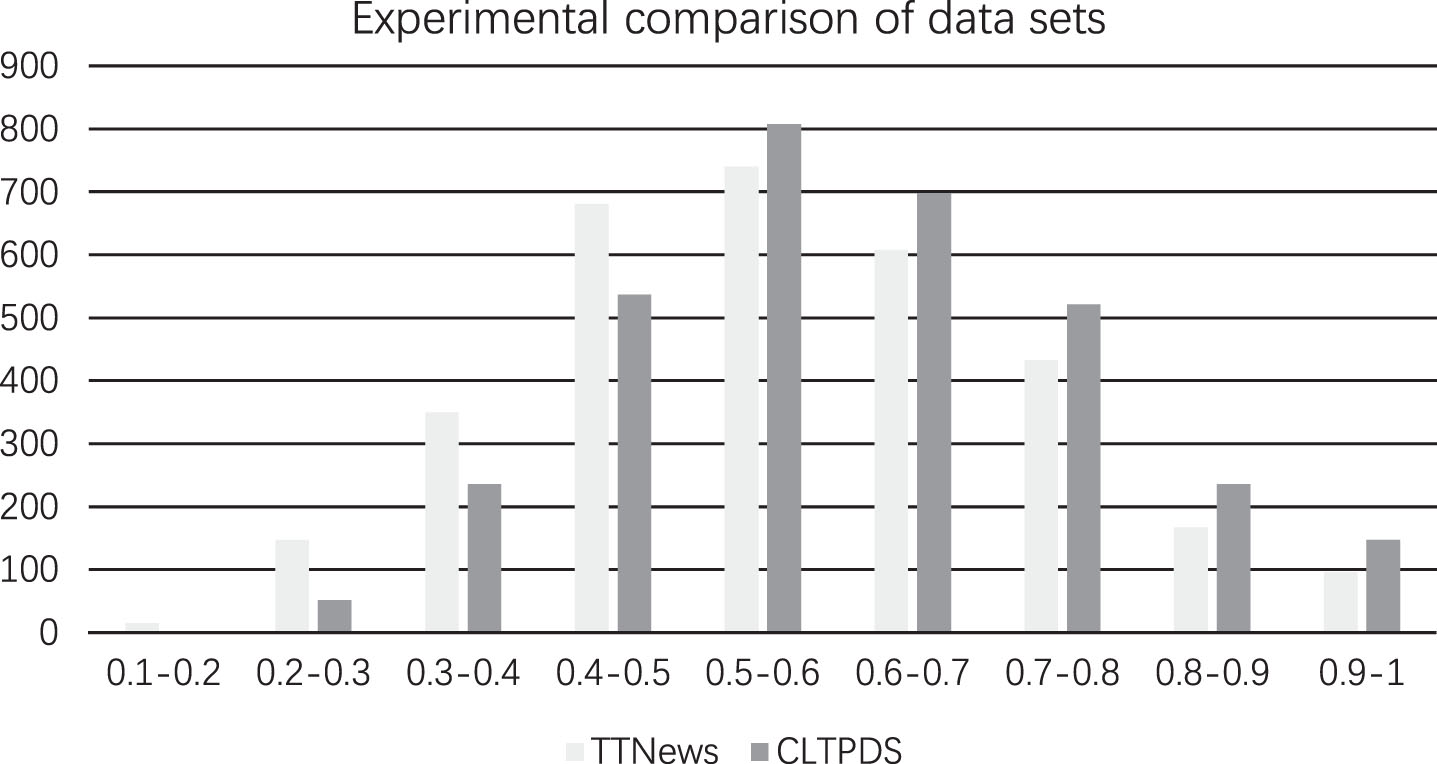
Experimental comparison of data sets.
The evaluation tool in this paper is ROUGE, and the abstract in the patent specification is used as the evaluation criterion, and the abstract generated by the algorithm in this paper is used as the evaluation content. The text abstract evaluation is obtained by calculating the F-value of ROUGE-L, where ROUGE-L is calculated as the longest common word length match between the standard text and the generated text.
After experimenting and comparing the existing models by implementing them on the in-extra-long text abstract dataset, the results are shown below. All models use the Chinese long text patent dataset CLTPDS. TextRank: TextRank algorithm is an algorithm for ranking words and sentences by constructing a topological structure graph of the text. In this paper, we first partition the patent text into several constituent sentences to build a node connection graph, then calculate the similarity between sentences to generate the edge weight value, and then calculate the TextRank value of sentences by circular iteration, and finally extract the top three sentences of TextRank value to combine them into a text summary according to the original text order to obtain a summary with relatively smooth logical order. Transformer: As proposed by Vaswani et al. [5] in 2017, the Transformer model is a model based entirely on a multi-headed attention mechanism, this paper uses this model with a baseline of 6 layers, a hidden layer size of 512, and a feedforward filter size of 2048. the generated results obtain a score of the top three combinations to become abstract. PatBertsum-a: The Bertsum model with the Head-Tail technique is added, and the results generated obtain a score of the first three combinations to become the summary. PatBertsum-b: A Bertsum model based on a classifier with a patented text structure is added, and the results calculated based on the Bertsum model are summarized after this classifier. PatBertsum: Both Head-Tail technology and the classifier based on the patented text structure are added. The text is processed by Head-Tail and then calculated based on the classical Bertsum model, and the results are generated by the classifier based on the patented structure.
As shown in Table 2, Bertsum also has a decisive advantage over other generic models in the field of patent summarization, and PatBertsum achieves the best results in all three metrics simultaneously. The addition of the Head-Tail technique and the patent text structure-based classifier, respectively, has significantly improved the performance of the PatBertsum model compared to itself, and the addition of the patent text structure-based classifier to the former has achieved an excellent result.
Evaluation table of the results of each model
Evaluation table of the results of each model
To more clearly demonstrate the specificity of the PatBertsum model and the Bert-sum model in specific automatic patent text summarization work, this paper prepared an additional 3371 test data (including patent text and corresponding abstracts) to test the two models separately, and the ROUGE-L scores of the results were normalized for a more distinguishable graphical performance The results are as follows.
As shown in Fig. 5, the overall distribution shows that the Bertsum model produces more result scores before the 0.5 intervals, while PatBertsum has a significant ad-vantage after the score results reach 0.6 and above. That is, the PatBertsum model not only reduces the number of low-quality text summaries but also produces more high-quality text summaries, while the model has stability. In terms of specific values, the ROUGE-L expectation of Bertsum is 60.93 and the ROUGE-L expectation of PatBertsum’s model is 66.78, which is a 9.6 percent improvement for this test alone. In conclusion, PatBertsum’s model has significantly higher expectations than the original model, and the overall distribution is more biased toward high scores, which can consistently produce high-quality patent text abstracts compared to Bertsum’s model.
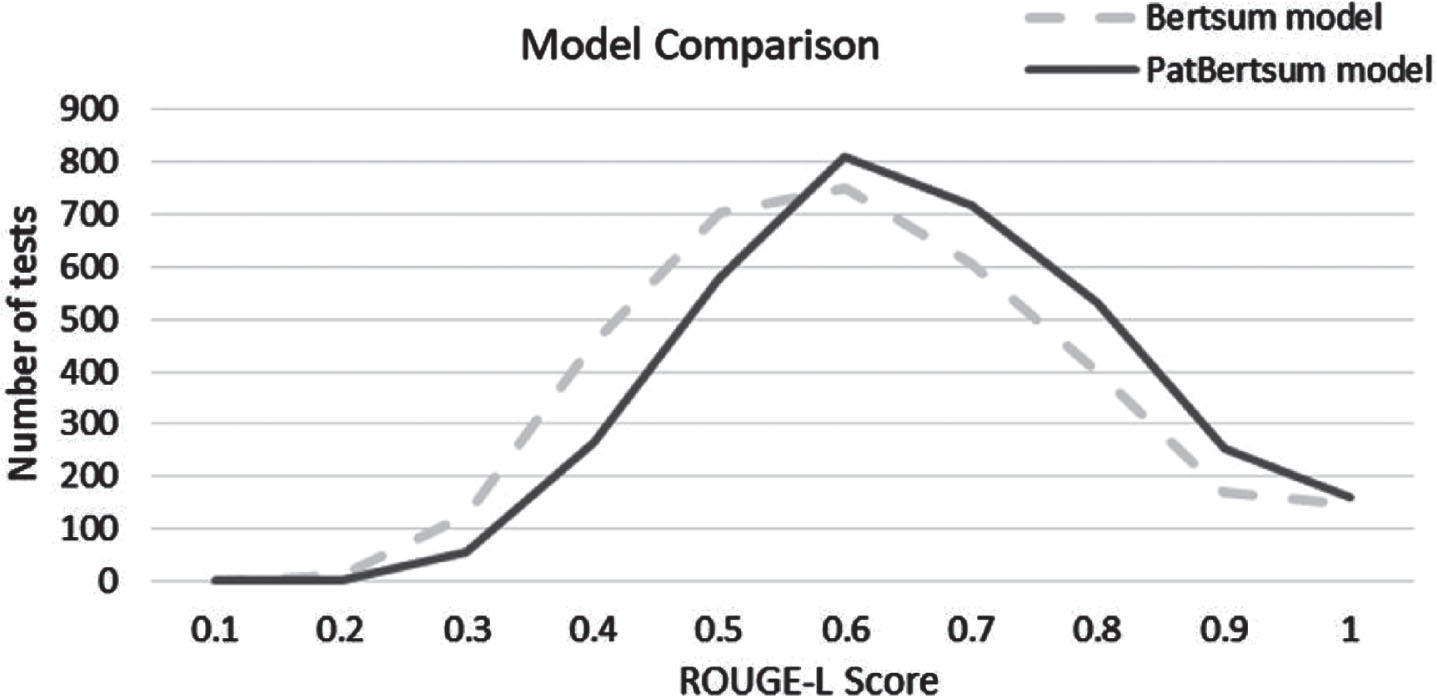
Detailed comparison of Bert-Sum algorithm and PatBertsum algorithm.
This paper proposes a method for automatic summarization of very long Chinese patent texts based on the PatBertsum algorithm, which is based on the Bertsum model of automatic patent text summarization, using the Chinese long-text patent dataset CLTPDS, and solves the problem of how to extract the very long patent texts The problem of extracting the abstracts and generating high-quality long texts is solved by introducing the Head-Tail technique and optimizing the classifier based on the Bertsum model. Through experiments on a real large Chinese patent text abstract data set, adding the Head-Tail technique and the classifier based on the structure of the patent text can significantly improve the abstract level are found respectively, and the PatBertsum model based on the two techniques can obtain the best performance in handling the very long patent text and generating long abstracts, and the experiments show that the model can reasonably handle very long patent texts and obtain comprehensive and fluent long text abstracts, so the model can be applied to various abstracting tasks of real patent texts in Chinese. In future work, we will combine the generative abstract model with a small amount of core text extraction and text generation on this basis to improve the accuracy of abstracts and reduce the text redundancy problem of long abstracts, making the abstracting effect go further.
Footnotes
Acknowledgments
The authors thank the referees for their thorough review and valuable suggestions that helped improve the quality of the paper. This research was supported by a Cooperation project between Lanzhou University of Technology and ScienBiZip Intellectual Property Agency Co. LTD (Grant Nos. H2111cc004), and Lanzhou University of Technology Higher Education Research Project (Grant Nos. 202102001). Please send all inquiries to the corresponding author, Peng Qin.