
Abstract
Human-computer interaction(HCI) has broad range of applications. One particular application domain is rehabilitation devices. Several bioelectric signals can potentially be used in HCI systems in general and rehabilitation devices in particular. Surface ElectroMyoGraphic(sEMG) signal is one of the more important bioelectric signals in this context. The sEMG signal is formed by muscle activation although the details are rather complex. Applications of sEMG are referred is commonly referred to as myoelectric control since the dominant use of this signal is to activate a device even if (as the term control may imply) feedback is not always used in the process. With the development of deep neural networks, various deep learning architectures are used for sEMG-based gesture recognition with many researchers having reported good performance. Nevertheless, challenges remain in accurately recognizing sEMG patterns generated by gestures produced by hand or the upper arm. For instance one of the difficulties in hand gesture recognition is the influence of limb positions. Several papers have shown that the accuracy of gesture classification decreases when the limb position changes even if the gesture remains the same. Prior work by our team has shown that dynamic gesture recognition is in principle more reliable in detecting human intent, which is often the underlying idea of gesture recognition. In this paper, a Convolutional Neural Network (CNN) with Long Short-Term Memory or LSTM (CNN-LSTM) is proposed to classify five common dynamic gestures. Each dynamic gesture would be performed in five different limb positions as well. The trained neural network model is then used to enable a human subject to control a 6 DoF (Degree of Freedom) robotic arm with 1 DoF gripper. The results show a high level of accurate performance achieved with the proposed approach. In particular, the overall accuracy of the dynamic gesture recognition is 84.2%. The accuracies vary across subjects but remain at approximately 90%for some subjects.
Introduction
Human-computer interaction (HCI) is an important technology in conjunction with intelligent mechatronic devices [1]. A number of biosignals are used in HCI applications as the linkage between computers and humans. Surface electromyography (sEMG) signal has found its niche in this realm as it is evident in the literature [2–5]. sEMG is generated by various ions that are present in the muscles during flexion and contraction movements [6]. Many classifiers are employed in the process of recognition of sEMG siganls such as as Support Vector Machines (SVM) [7], k-Nearest Neighbors (kNN) [8] and Decision Trees [9]. In addition, deep learning methods, which have been used in a broad range of applciation [10–13], are also applied to sEMG signals. For instance a 50-layer Convolutional Neural Network (CNN) based on Residual Networks (ResNet) architecture [14] has achieved 99.59%accuracy at recognizing 7 categories of gestures. An attention-based Bidirectional Convolutional Gated Recurrent Unit (Bi-CGRU) model [15] has demonstrated a 88.73%accuracy on 17 hand gestures. However, while good performance using various models has been achieved, we still face challenges in sEMG-based gesture recognition.
Mukhopadhyay and Samui [16] explored a Deep Neural Network (DNN) based classification system for the upper limb position invariant myoelectric signal. The results show that the average accuracy of test data based on the DNN model trained by the same limb positions as the test data is over 95%while the average accuracy of independent test data could only reach about 70%. In addition, the DNN model trained by all positions produced approximately 75%accuracy on test data for every position. In other words, limb position has a significant impact on gesture recognition. Campbell et al have explained how the limb position influences the results in detail. For instance, muscular activity that maintains the limb positions against the gravitational force is dependent on the position of the limb [17]. When the limb positions is changed, the supplemental muscle activity varies as well. Additionally, while in different limb positions the underlying topography of muscle fibers may shift relative to the electrodes and this also impacts the accuracy of the sEMG gesture recognition process [17].
According to Mitra and Acharya [18], gestures can be divided into static and dynamic categories. A static motion is represented by repeated and constant multi-dimensional sEMG features. In contrast, a dynamic motion is expressed by a temporal sequence of multiple sEMG features that vary during the respective motion. A previous member of our team, Shin [19], proposed a sequence-based pattern recognition model to classify dynamic sEMG hand gestures. Based on his research, the classification of dynamic gestures achieved higher accuracy compared to the result of static gestures when limb position was changed. He also explored the potential for dynamic gestures classification at different limb positions and showed high recognition accuracy at different limb positions by using cross-validation but did not demonstrate a real-time recognition system for dynamic gestures at different limb positions. The present work uses some dynamic gestures but at more common limb positions than those used in Shin’s work. A real-time system then recognizes all the gestures at all different limb positions. Because the limb positions used are common in people’s daily lives, the proposed approach enhances the potential for gesture recognition to handle real-world problems.
In this paper, five dynamic gestures are chosen. A Convolutional Neural Network (CNN) with Long Short-Term Memory, or LSTM (CNN-LSTM) is used to classify the resulting dynamic gestures so as to train an HCI system involving interaction with a robotic arm based on a trained CNN-LSTM model in Section 2. Then, two experiments involving the model itself and the HCI system are presented in Section 3. Section 4 analyses the results from Section 3 and gives the conclusion.
Method
In this section, A CNN-LSTM neural network is introduced. Then based on this neural network, we would describe an HCI system.
CNN-LSTM neural network
Convolutional Neural Network . The convolutional neural network known as CNN is commonly used in image processing [20, 21] due to its strong feature extraction function. In the convolutional layer, a kernel containing a batch of parameters connects the current layer and input data of the previous layer. The kernel has a smaller size than the input matrix. Every time, the kernel would move along a specific direction in a predefined step on the input data until it moved through the whole input matrix. In the training process, the parameters in the kernel would update constantly [22]. Therefore, the special local information from the input data would be captured. There are three kinds of convolutional layers: 1D, 2D, 3D (where D means dimension). The 1D convolutional layer is commonly used in time series data since the kernel only moves along the time axis which preserves important temporal information. The input data in our case is 2D but only one of the dimensions is spatial. We employ a 1D convolutional layer with multiple channels as in Fig. 1 1ddcnn to preserve the important temporal information.
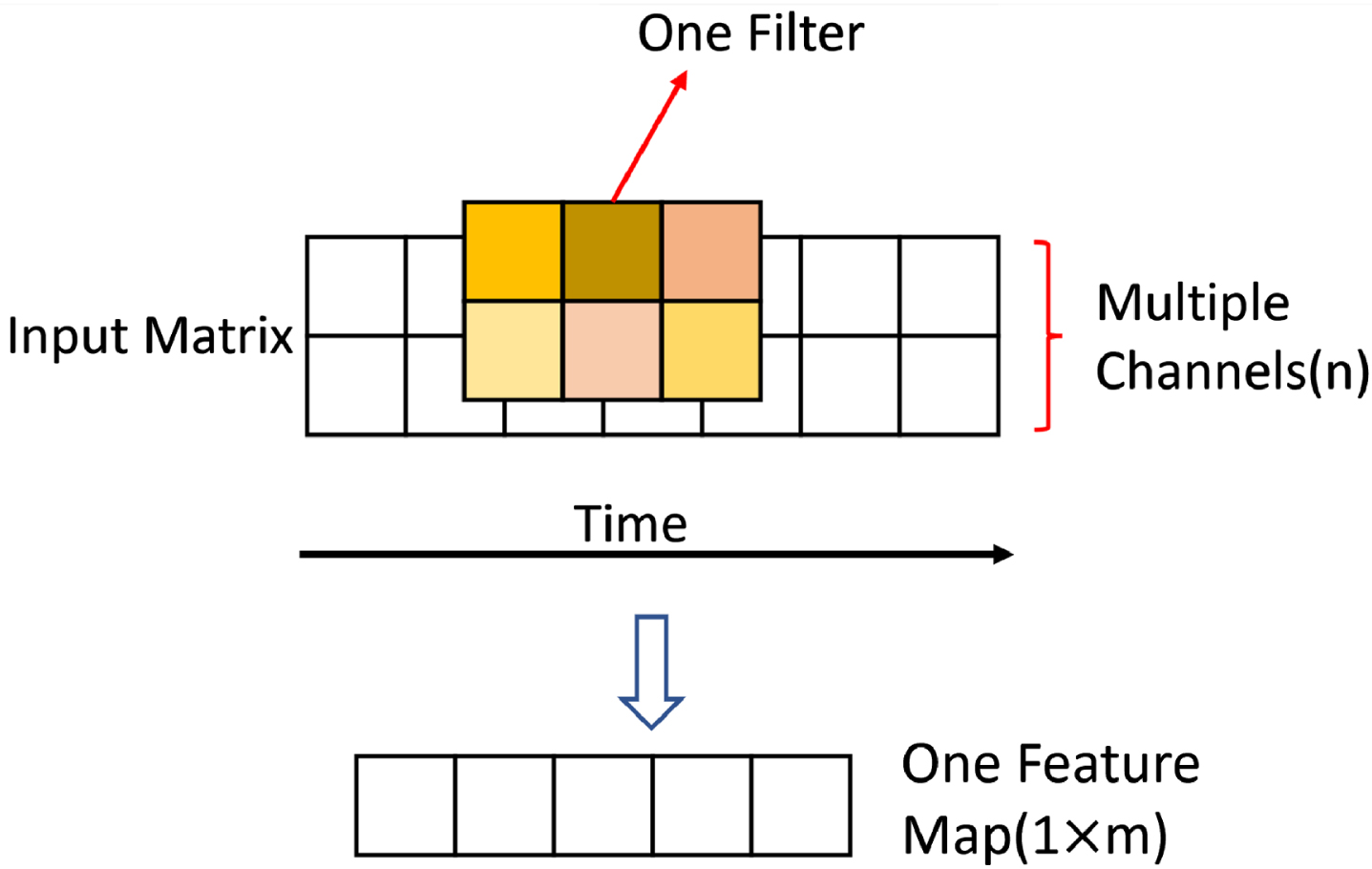
1D convolution with multiple channel.
A batch normalization layer is applied after the convolutional layer. This layer is responsible for stabilizing the distribution over a minibatch of inputs to a given network layer during training. The first two moments of each activation distribution (mean and variance) are set to zero and one, respectively, as part of additional layers of the network. The batch normalized inputs are then scaled and shifted to preserve model expressivity based on trainable parameters [23]. Dropout is a common method to prevent overfitting, and it offers a probability to combine different neural network structures. In the dropout process, the neurons are chosen randomly. The chosen neurons, the neurons themselves and their in and out connections would be removed temporarily, which are shown in Fig. 2 [24]. The whole CNN part would be expressed in the Fig. 3.
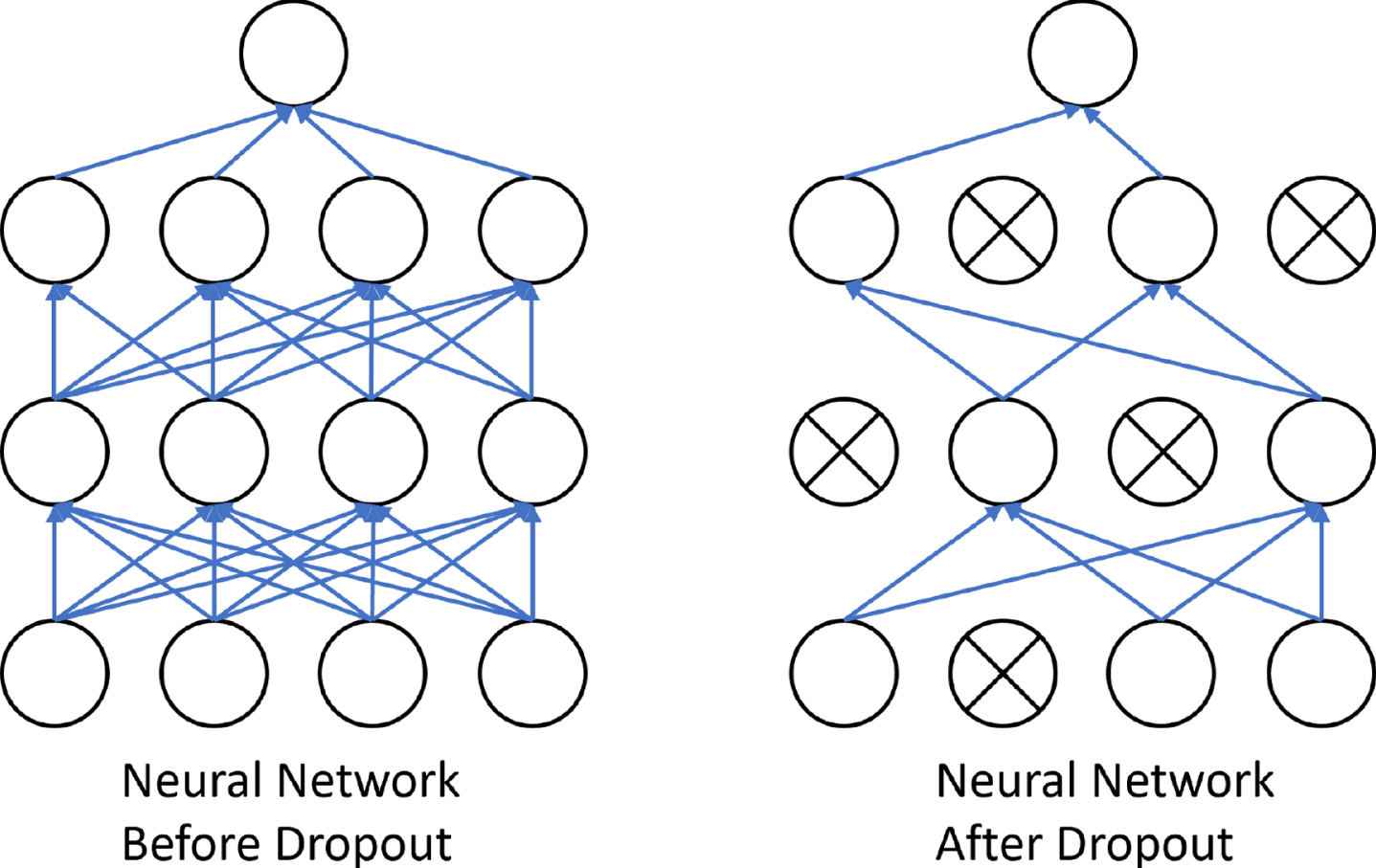
Dropout. Adapted from “Dropout: a simple way to prevent neural networks from overfitting” by Srivastava et al., 2014, Journal of Machine Learning Research, Volume:15, pp 1929-1958.
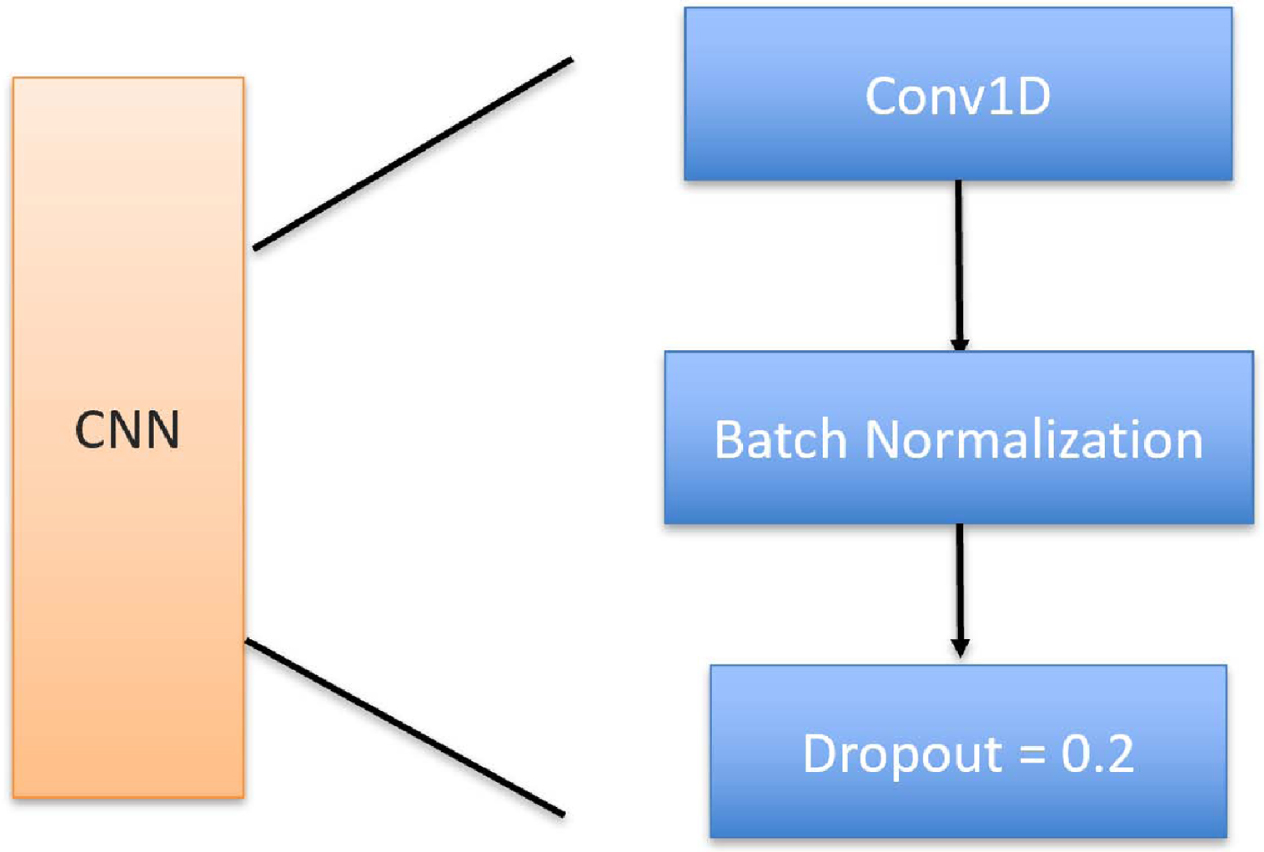
CNN architecture.
Long Short-Term Memory Neural Network. Long Short-Term Memory neural network known as an LSTM neural network is a type of Recurrent Neural Network (RNN). RNNs are wildly adopted in research areas concerned with sequential data such as text, audio, and video [25]. Figure 4 represents a recurrent neural network structure whose internal memory can store information. This enables the RNN to learn the relevant information when the gap between the relevant information is not large even if this information is sequential in some sense.
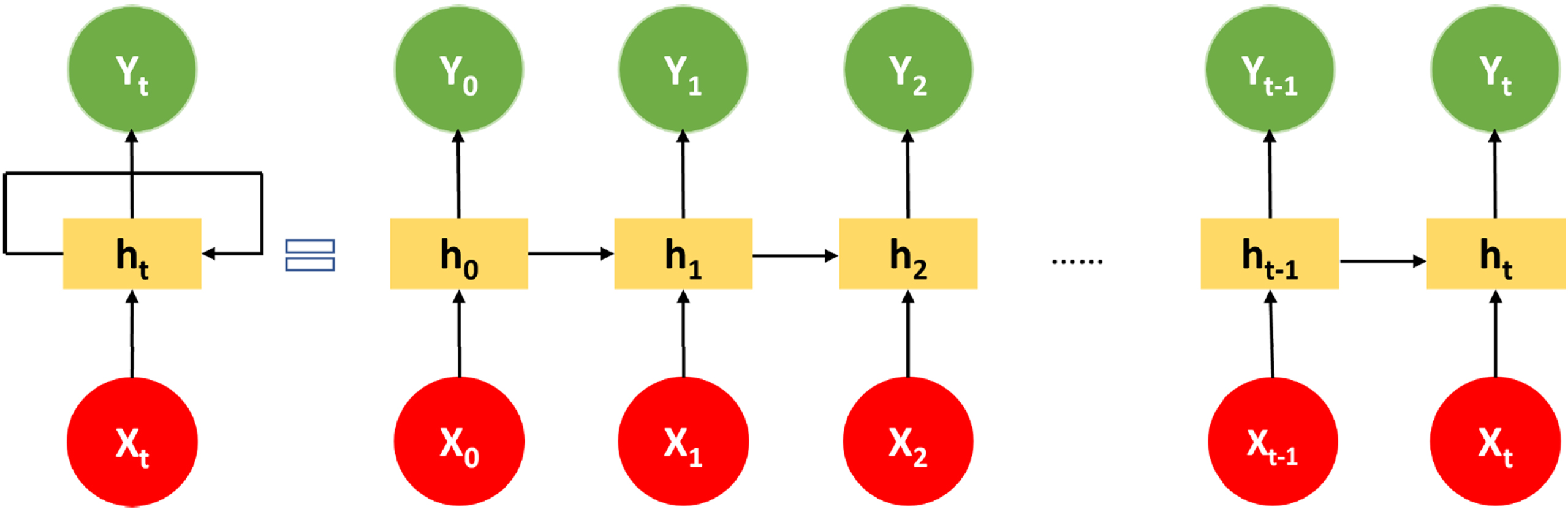
RNN Structure. Adapted from “What is not where: the challenge of integrating spatial representations into deep learning architectures” by Kelleher and Dobnik, 2017, In CLASP Papers in Computational Linguistics Volume 1: Proceedings of the Conference on Logic and Machine Learning in Natural Language (LaML 2017), Gothenburg, Sweden.
RNNs face the vanishing problem when the input data is long. Therefore, the LSTM architecture [26] was proposed to handle “long-term dependencies” [25]. LSTM networks have many successful applications such as COVID prediction [27], video captioning [28], translation [29]. An LSTM unit includes three gates that enable the network to handle long-term dependencies as shown in Fig. 5.
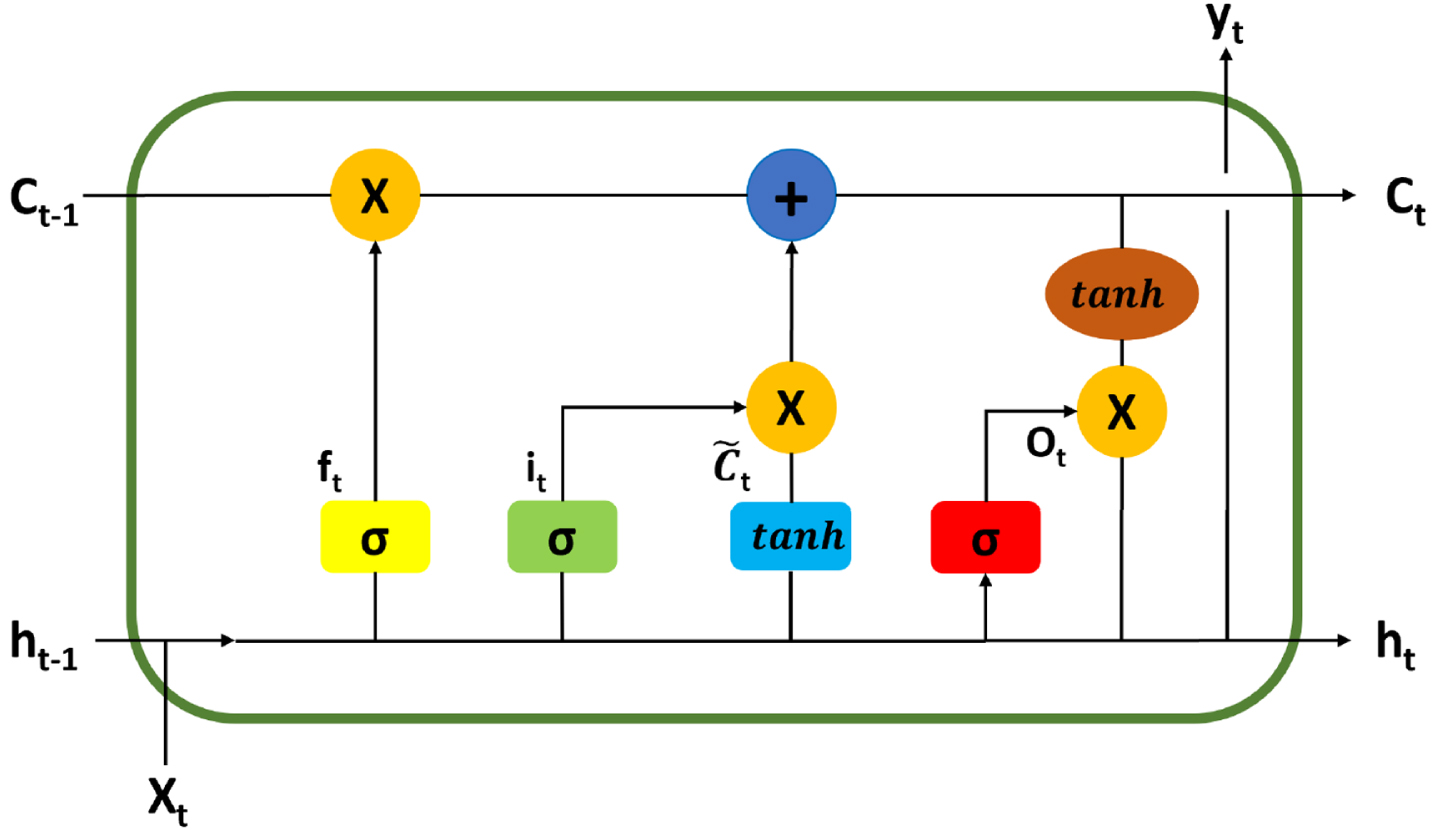
LSTM Unit. Adapted from “Emotion Analysis: Bimodal Fusion of Facial Expressions and EEG” by Jiang et al., 2021, Computers, Materials and Continua, pp 2315-2327.
The figure illustrates the details of one LSTM unit at time t, where X t is the input, h t and ht-1 represent the hidden units which are short-term memories. h t could be calculated in the following formula:
The value of the gate controls the flow of information.The range of the value is between 0 to 1. When the gate approaches 0, the information through that gate would be deleted, and when the gate is close to 1, the information through the gate would be saved. For example, if the information is relevant, the forget gate would be close to 0, and the input gate would be close to 1. Therefore, the new information would be stored in the current cell while the old information is forgotten. Consequently, the entire network can easily learn long-term dependencies between sequences [30].
CNN-LSTM Neural Network. Based on the previous introduction, the CNN-LSTM in Fig. 6 is used in the present study. This type of hybrid neural network has already been employed in many types of research [31, 32]. The hybrid CNN-LSTM neural network is employed for sEMG-based dynamic gesture recognition where the gestures are performed in different limb positions in this paper. The input is the raw EMG sequences of multiple channels. The CNN would extract local features of the raw data, which is then input into the LSTM neural network where the temporal information is used. Finally, a dense layer with neurons which is the same as the number of gestures categories, and a softmax layer are followed. Note that the notion of a dense layer refers to a type of layer in neural network. This does not relate to the data scale. The neurons of one dense layer are connected with every neurons of its previous layer.

CNN-LSTM neural network.
For a real-time gesture recognition system, there are two parts to be focused. The first is data acquisition. In this paper, a MYO armband1 shown in Fig. 7 is used for raw EMG data collection. It has eight EMG sensors with a sampling rate of 200hz. In this research, we only consider the influence of arm positions. Therefore, only right handed human subjects were recruited and each human subject wears the armband on their right forearm.

MYO armband.
The second part of the system is the recognition process, a trained CNN-LSTM model gives the gesture result using the EMG signals. A fist motion is added before a gesture in the system. This motion could be considered as a trigger mechanism that informs the programming to capture the gesture signals. For the trigger mechanism, a specific value as a threshold is set to identify if the sum of the absolute values of each channel is higher than the threshold, which indicates muscle activity. After the fist motion, the armband vibrates. Then gesture signals would be recorded in the following 3 seconds. Compared to no trigger mechanism, the system with the fist offers the programming a clear start to capture pieces of signals and less noise. The real-time recognition system is shown in Fig. 8
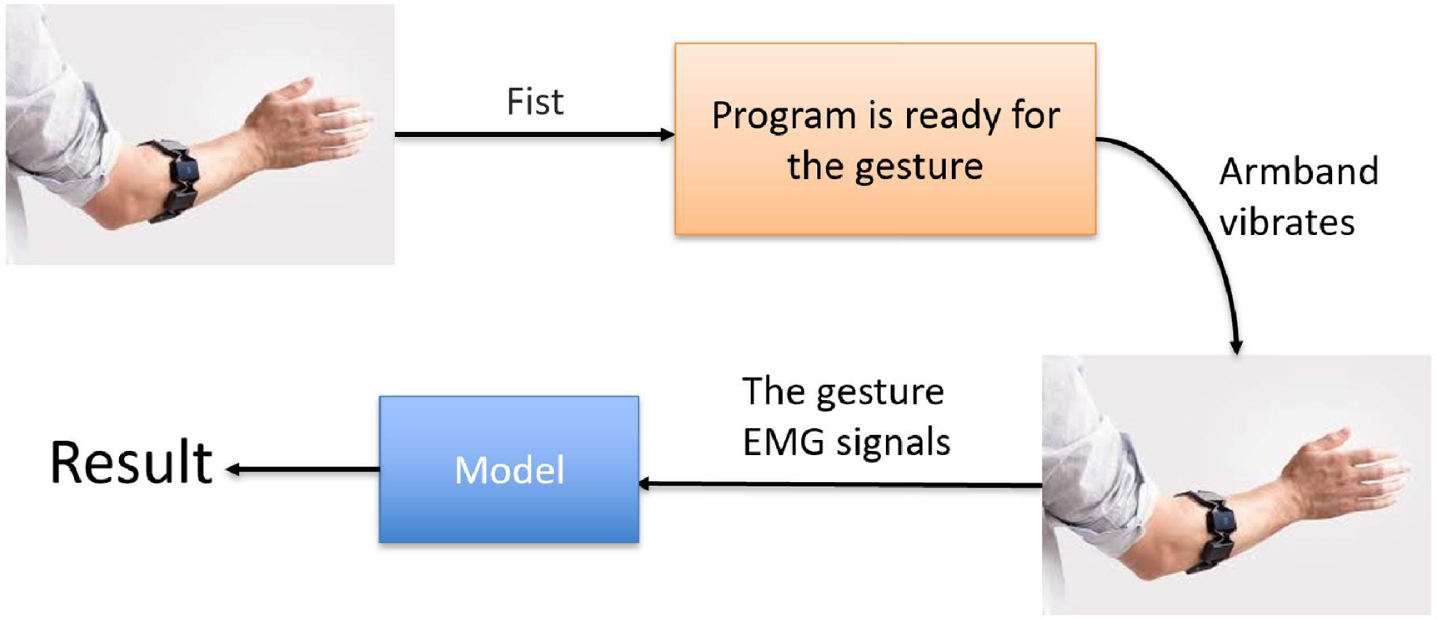
Real-time gesture recognition.
For the HCI system, a 6-DoF Kinova robot arm with 1-DoF gripper shown in Fig. 9 is used here. The HCI system enables human subjects to manipulate the robot arm via their gestures. The HCI system shown in Fig. 10 is proposed based on the gesture recognition system. After the real-time recognition, the results would be sent to a control algorithm where one gesture would correspond to one trajectory.
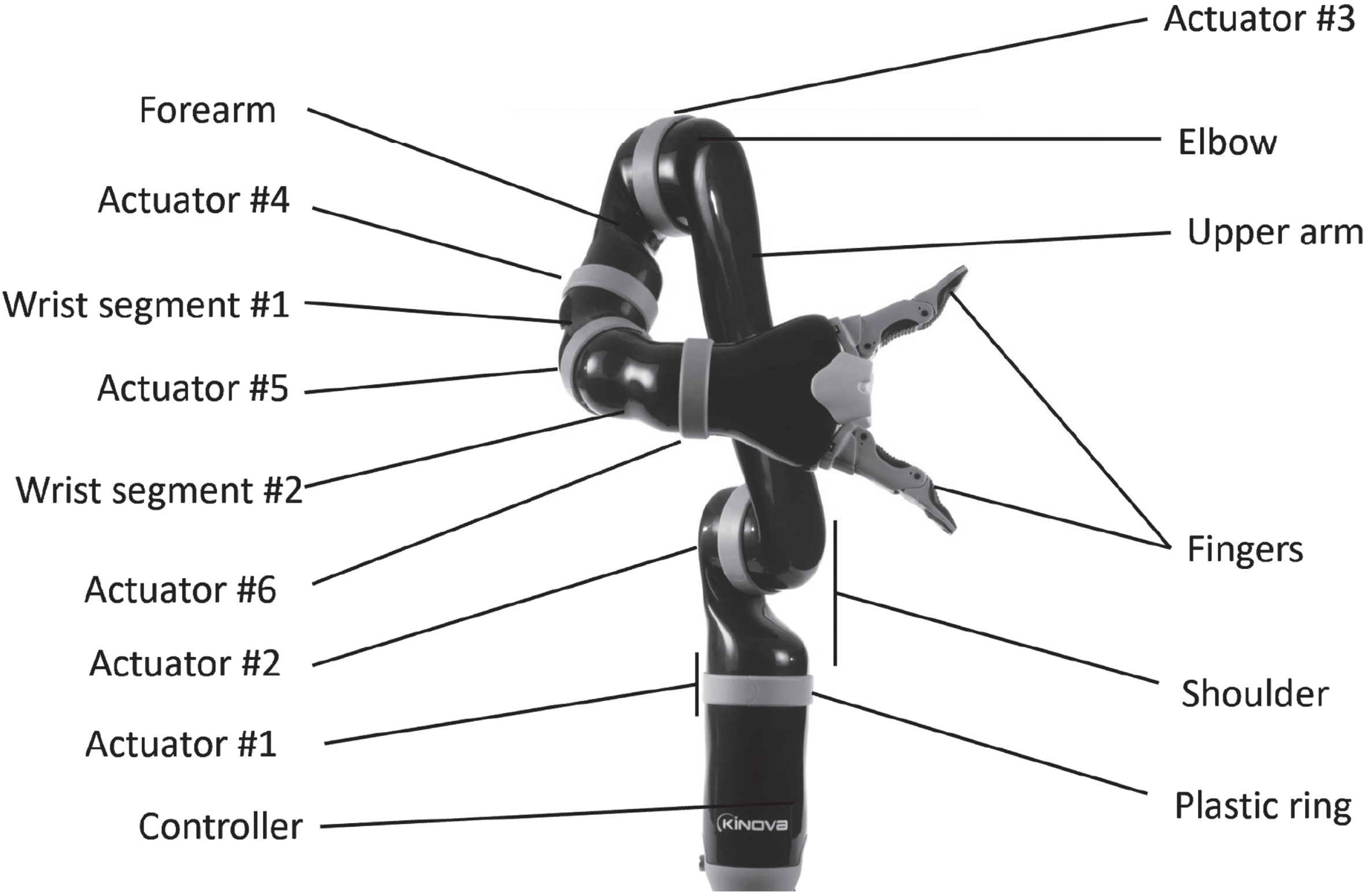
Kinova robot arm.
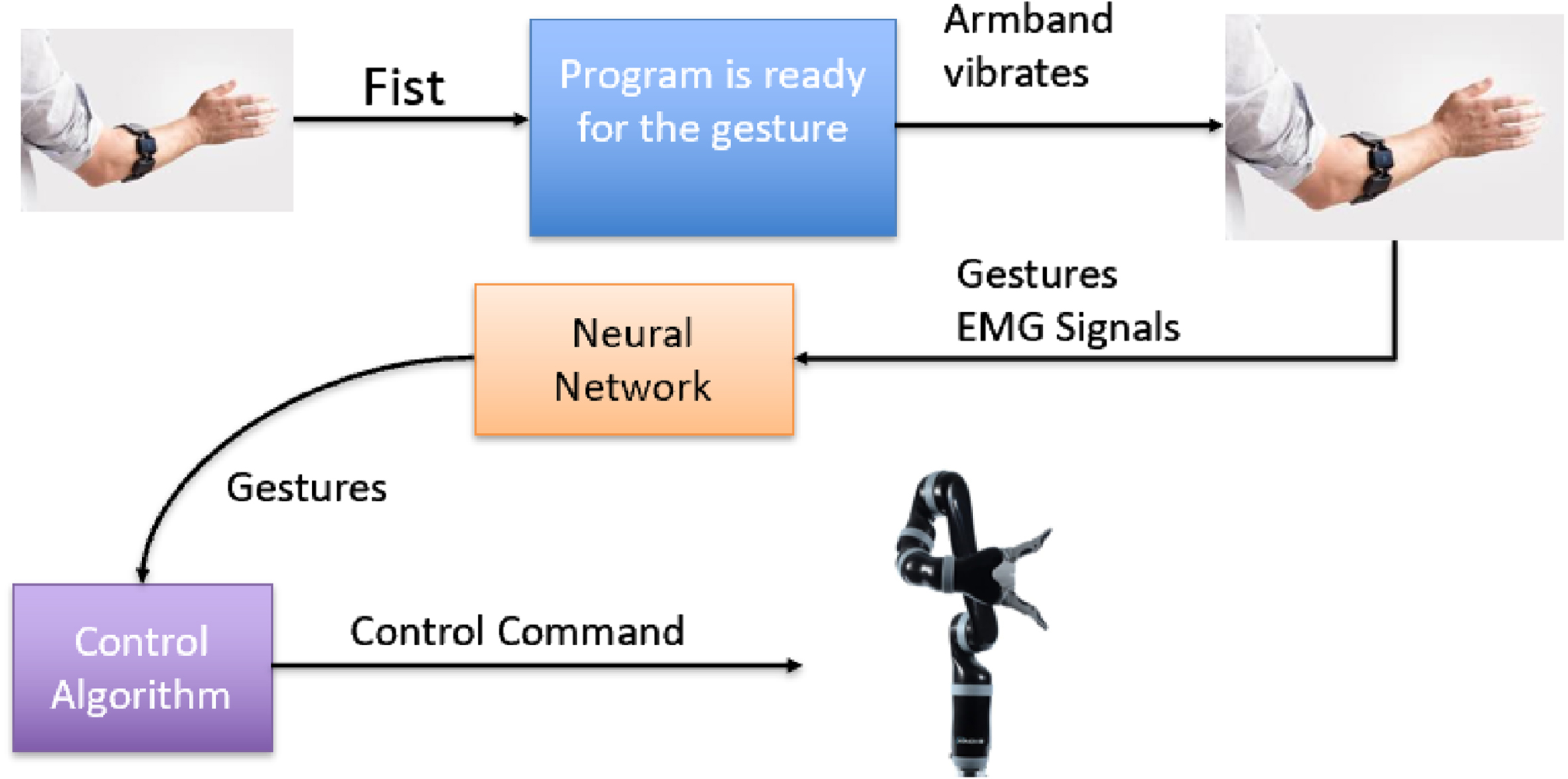
HCI system.
To test our HCI system, a task is designed. Once the task is fixed, we would have specific trajectories for completing the task by using the HCI system. As an example, a task with four trajectories is designed. Each trajectory corresponds to a set of control commands: control commands 1(C1), control commands 2(C2), control commands 3(C3) and control commands 4(C4). If duplicate commands are sent to the robot, the task will fail. For instance, if C3 is sent twice, the robot would never complete the task even if it finally receives all four commands. Since the classification accuracy is not 100%, there will be wrong recognition results which lead to wrong commands. To avoid the issue, a control algorithm for the task is shown in Fig. 12.control. Each gesture corresponds to a control command. The mechanism is to produce a certain order for the commands. If there is a wrong classification because the output which represents the command and i do not match, no command would be sent. Human subjects need to repeat the gestures in the order list until the robot moves, then perform the next motions. A state machine explains how the HCI system runs and the state changes of the robot arm as shown in Fig. 11. 0 represents a wrong command and 1 represents the correct command; q0 is an initial state for the task that the robot arm is in a home position. The state would change every time the correct commands are generated. On the contrary, the state would remain in its current status and does not change if a wrong command is generated. When the first correct command is generated, the robot arm will move to the first position, and the system will be at the q1 state. Then the system would be at the q2 state after the second correct command is generated. Next, the system would be at the q3 state after generating the third correct command. The last state would be q4 after the fourth correct command is generated. The control algorithm could be extended when more trajectory pieces are needed for a task.

Finite state machine for the task.

Control algorithm.
Experiment protocols
Two experiments approved by IRB2021-0194D are conducted in this research. One was designed to test the gesture recognition system and the other was to test the HCI system.
First experiment: Gesture recognition
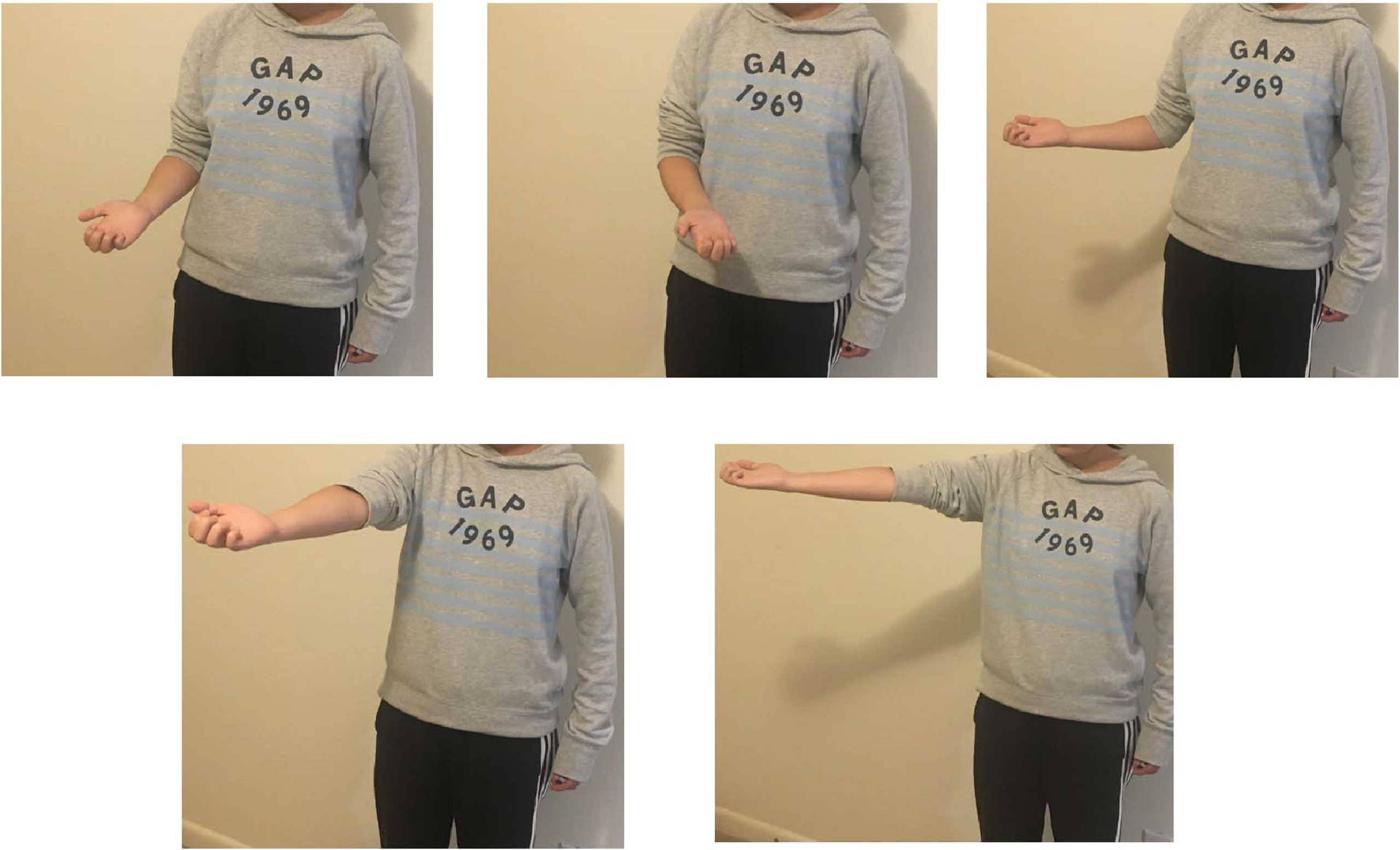
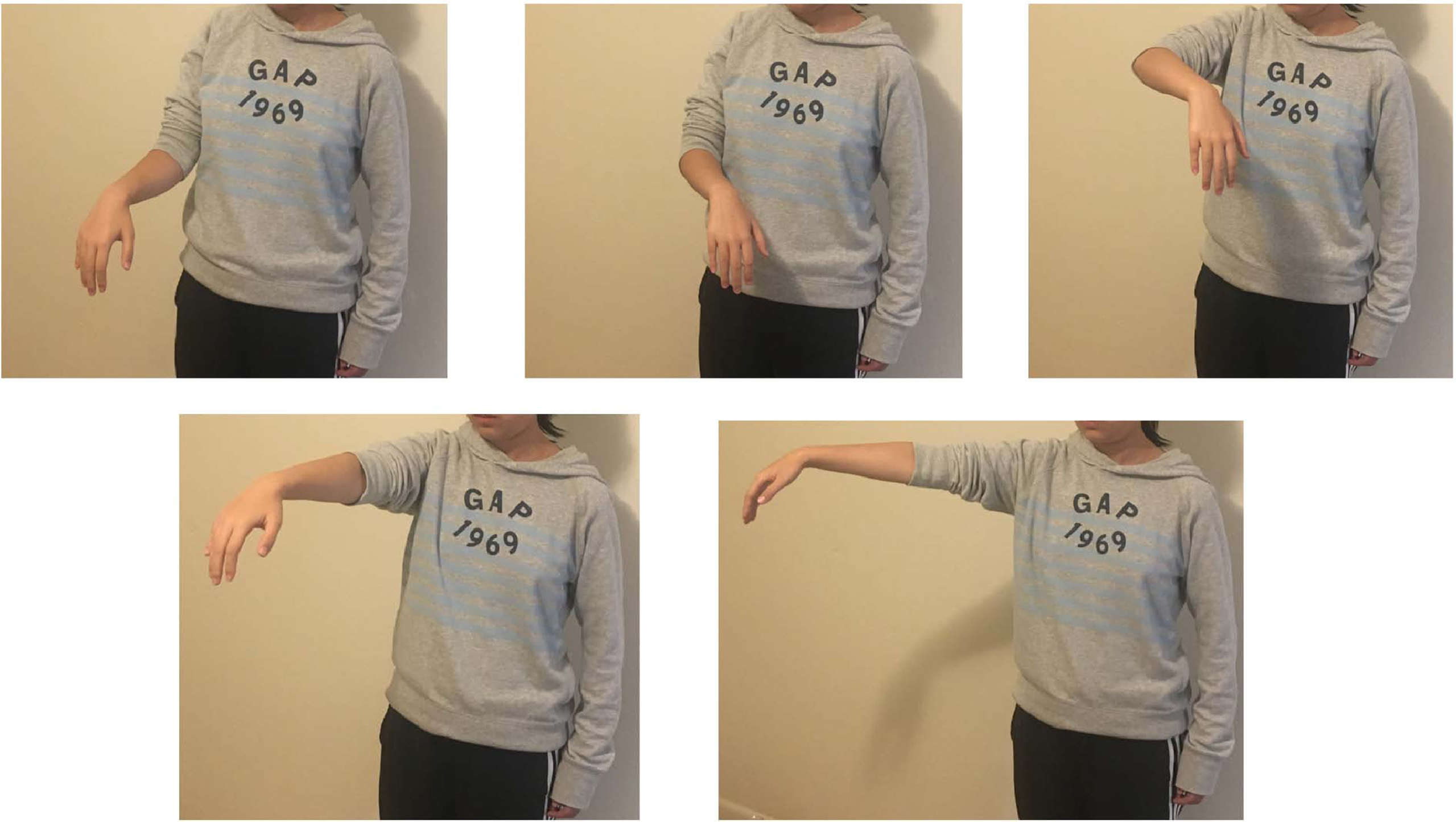
The first experiment was designed to test the performance of the CNN-LSTM model to classify the five dynamic gestures shown in Fig. 13.The gestures and positions would be performed in front of every subjects. Also, subjects would be watched and notified when they are performing the movements to make sure the motions are right. For each gesture, the human subject was asked to perform these at five limb positions. The limb positions of each gesture could be found in Appendix A.
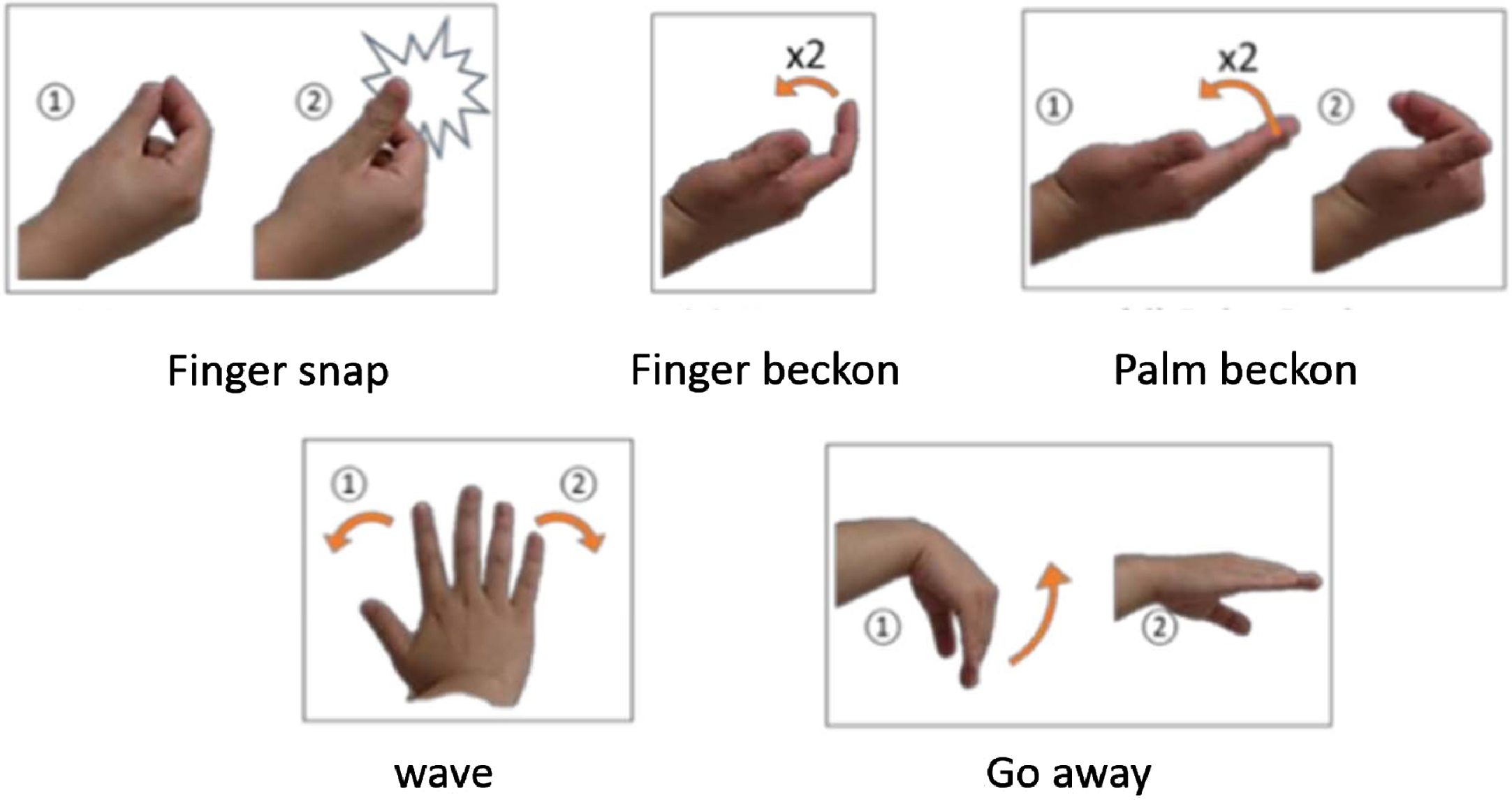
Five dynamic gestures. Adapted from “Myoelectric human computer interaction using reliable temporal sequence based myoelectric classification for dynamic hand gestures” by Shin, 2016, Doctoral dissertation, Texas A & M university.
The training dataset is obtained from 7 human subjects. Every gesture at each arm position was repeated 10 times. In order to increase the data size, augmentation was used. The orders of channels are changed which is displayed in Fig. 14. Augmentation is a way to enlarge the available dataset artificially for deep learning model training. For example, flipping the images in the image dataset is one augmentation operation. Here, since the armband would be worn in a certain place, channels 1 to 8 should represent seven areas in the forearm. When you change the input order, the operation would have the same effect as changing places where the MYO armband is located. For example, in the first lines, this is the same as you rotate the armband.
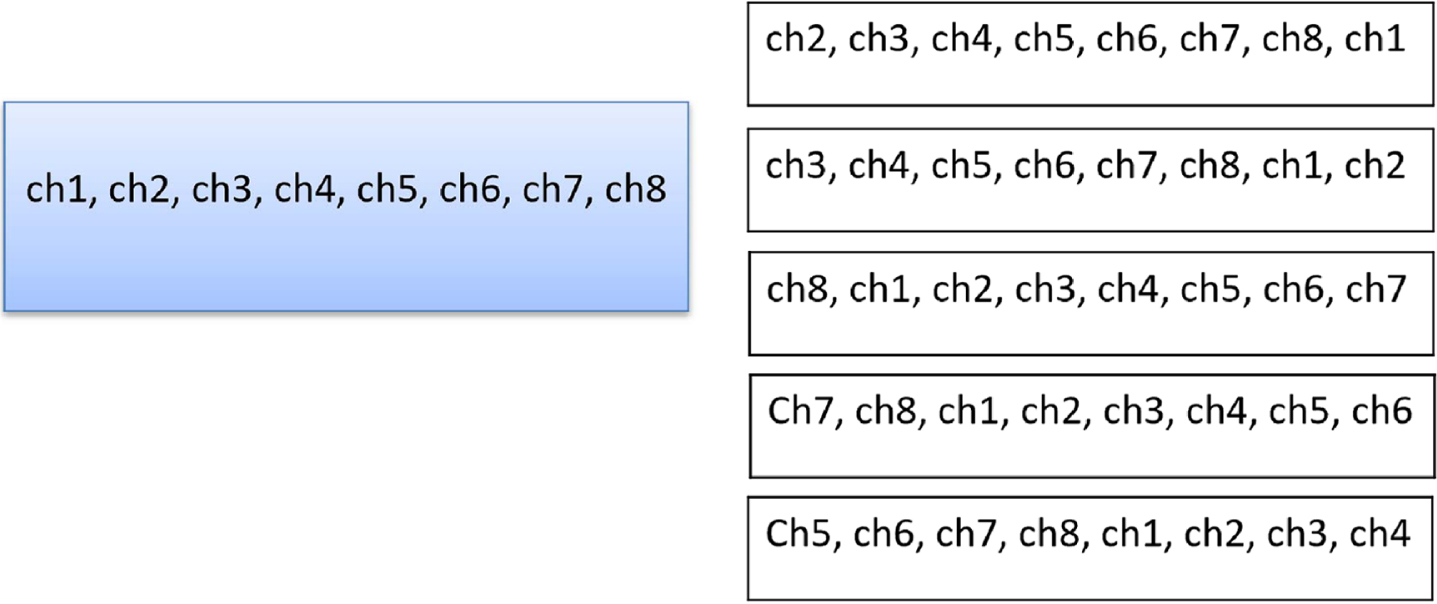
Augmentation.
After the CNN-LSTM model was trained by the above training dataset, the model was applied to the real-time gesture recognition system mentioned before to test its accuracy. The test dataset was from 12 human subjects. We chose 7 people for the training dataset so as to enable the validation accuracy could reach over 90%, and small tests on subjects perform well. We used 12 people for the test. Human subjects for the test have two parts, one part includes people who contributed to the training dataset, one part includes people who were not in the training dataset. This gives us a view to see if its contribution to the training dataset would influence the accuracy of a subject test.
The second experiment is to evaluate the performance of the HCI system. To measure the performance, we design a go and grasp task. A water bottle is put at a certain point where it is reachable by the robot arm. The robot arm starts from its home position, approaches the bottle, and closes its gripper to grab it. Then the robot moves back to its home position with the bottle. The experiment is set up as shown in Fig.15.
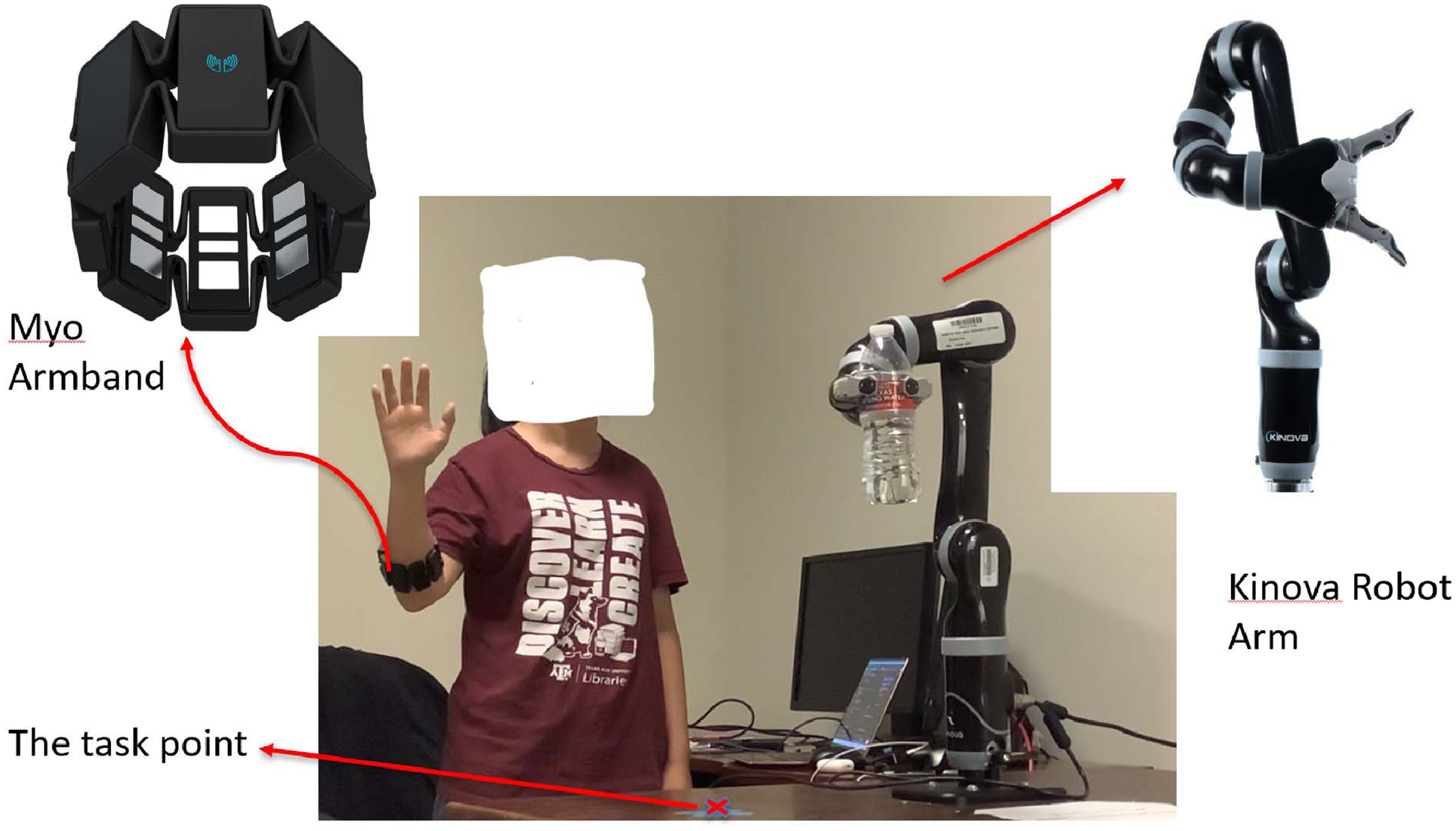
Task setup.
Human subjects repeat the task three times and the period of performace of every task is recorded. In addition, a joystick shown in Fig. 16 joystick is used as a comparison device as a relatively well-developed technology in robot control. It allows users to send a direct command to the robot arm compared to the HCI system which requires time to recognize a gesture and to perform the required command. Human subjects need to finish the same go and grasp task via the joystick three times and their time to complete the task is recorded. Human subjects are given ten minutes to get familiar with the joystick before performing the task. If the water bottle were to be knocked down by the manipulator during one task, the task execution would continue and the time to reset the bottle would be included in the task execution time.
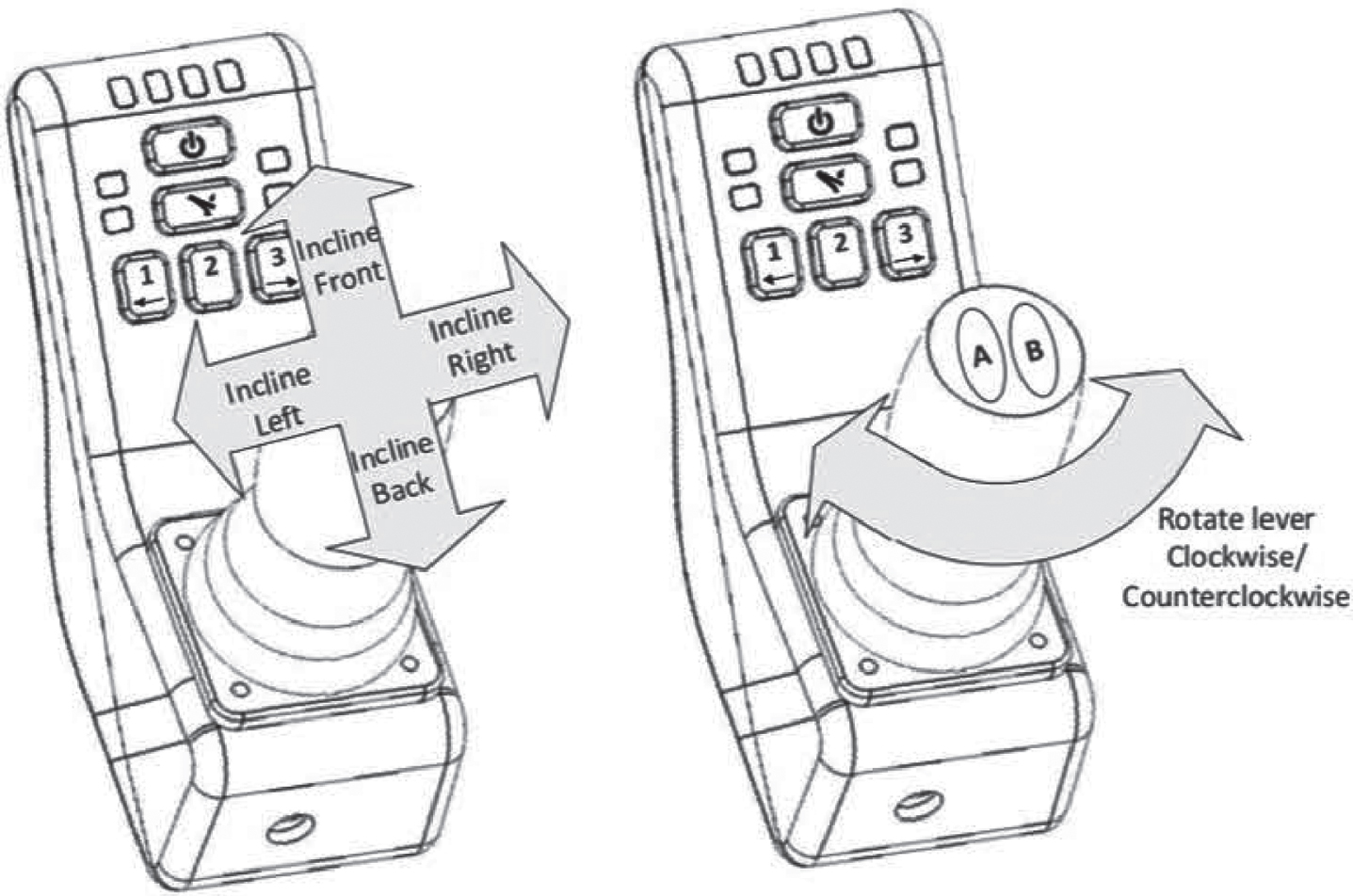
Joystick. Reprinted from “compliant control of the Kinova Robot for surface polishing” by Ochoa, 2019.
Results of the first experiment
This section presents the results obtained by applying the first experiment on 12 human subjects. There are five gestures and each gesture had five arm positions. The human subjects repeated each gesture at each arm position ten times. The total amount of test gestures is 3000. There are gestures from subjects who contributed to the training dataset(SC) and gestures from subjects who did not contribute to the training dataset(SN). But the accuracy of two groups does not reflect a significant law which means there is no guarantee that SC has better accuracy than SN. The overall accuracy was 84.2%, which shows the comprehensive condition for these 3000 gesture data. To show the influence of limb positions on each gesture, the accuracy for each position is depicted in Table 1.
Accuracy in each limb position
Accuracy in each limb position
From Table 1, the accuracy varies in a small range among different arm positions. The distribution of accuracy at different positions(Position 1: P1, Position 2: P2, Position 3: P3, Position 4: P4, Position 5: P5) for each different gestures is given in Fig. 17.
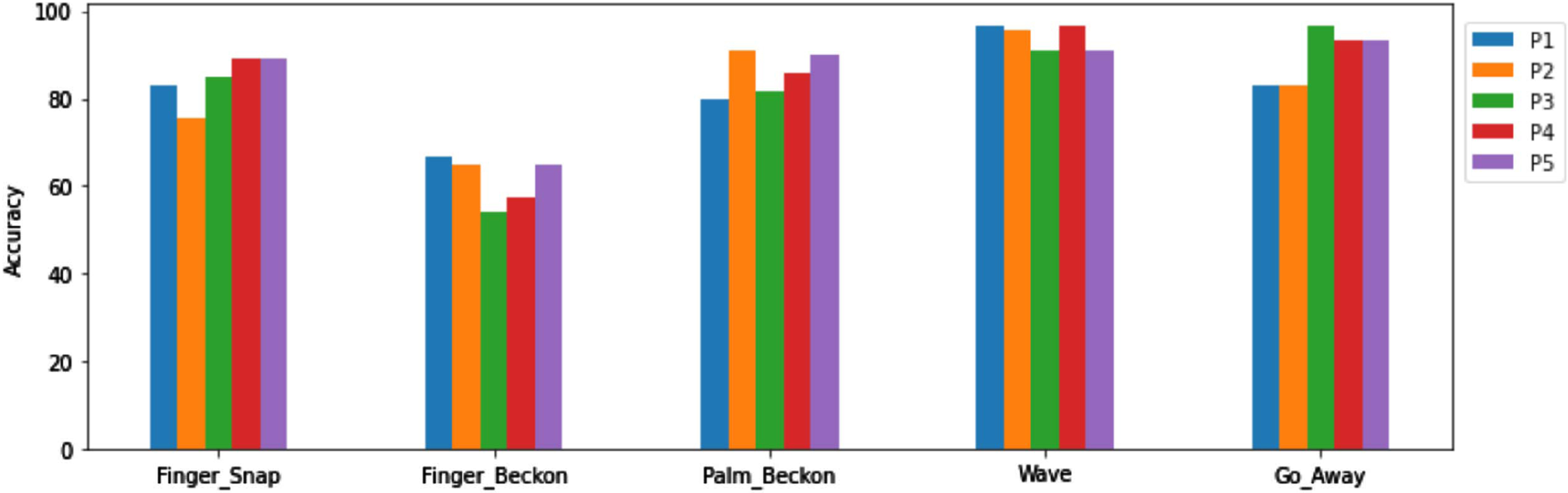
Accuracy distribution.
To further explore the accuracy of the model, we analyzed the same gesture at the same arm positions performed by different subjects. In Fig. 18, we represent the performance of the finger snap gesture from two subjects. The accuracy of the finger snap for the two subjects is slightly different. As is shown in Fig. 18, the accuracy of Subject 1(S1) on P1, P2 and P3 is higher than that of Subject 2(S2). In addition, the accuracy of S1 on P2 and P5 are equal to that of S2. Therefore, the overall accuracy of S1 is 98%which is higher than 84%of S2.
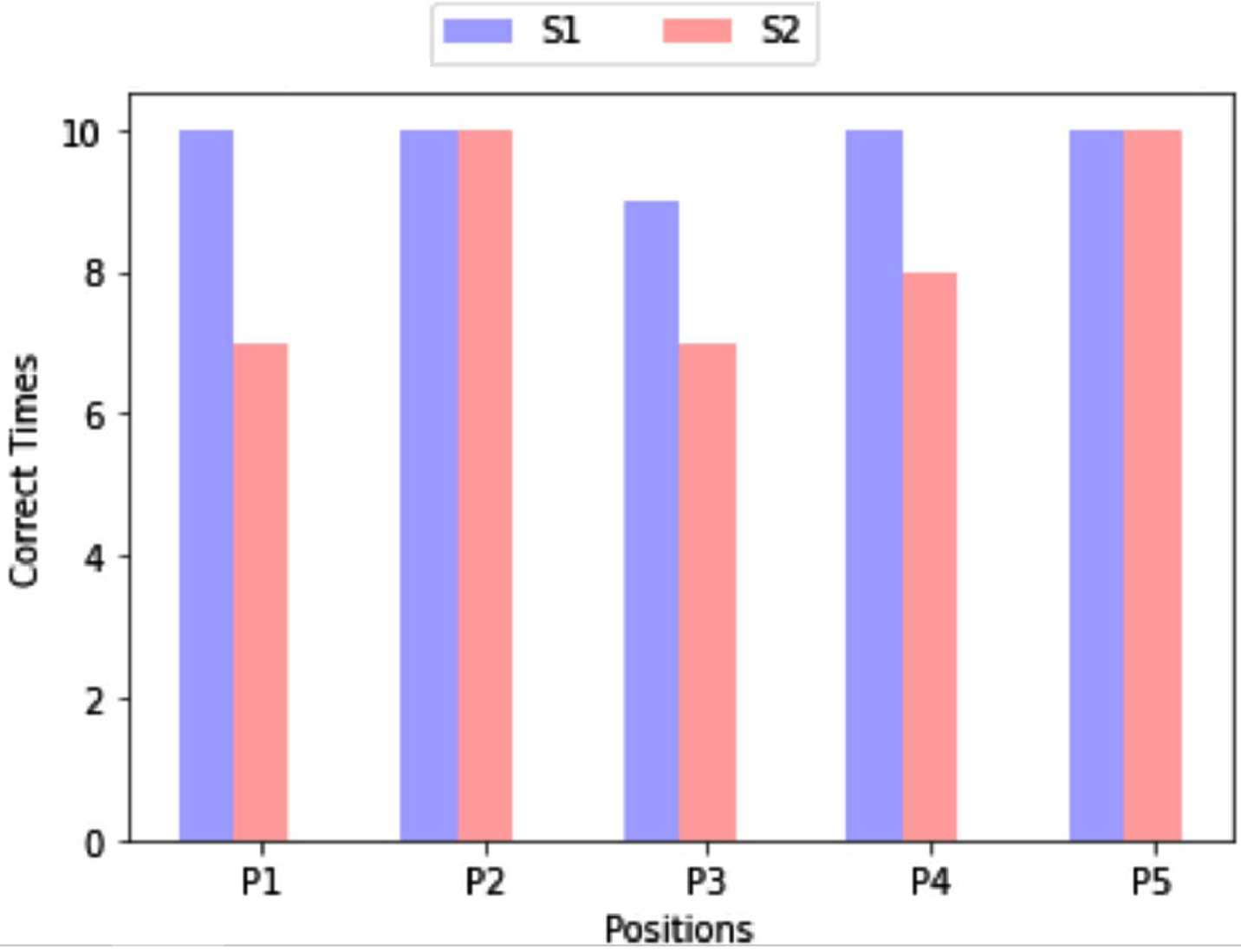
Finger snap at five different limb positions for two different subjects.
In this section, we represent, analyze and compare the performance of myoelectric control and joystick control modes. Each human subject performed each control mode three times. The operation time is used to evaluate the feasibility of myoelectric control in this application by comparing it with joystick control which is more mature in this field. The average time of task of 12 human subjects for two control modes is depicted in Table 2.
Average time for joystick control(JC) and myoelectric control(MC)
Average time for joystick control(JC) and myoelectric control(MC)
From Table 2, most subjects like subject 5 use much less average time on joystick control than myoelectric control. The data of three tests for subject 5 is shown in Table 3. For some subjects like subject 6, the average time of the two control methods is similar. The data of three tests for subject 6 is shown in Table 4. For subjects like subject 10, the average time of joystick control is more prolonged than myoelectric control. The data of three tests for subject 10 is shown in Table 5.
Task time of subject 5
Task time of subject 6
Task time of subject 10
For the first experiment in Section 3, Table 1 gives a brief idea of how limb position impacts the gesture classification accuracy. The average accuracy of the 12 human subjects at each limb position is close; the largest difference is 3.98%, which means the model could classify five dynamic gestures effectively when the limb positions changes. Figure 17 provides the details for the accuracy of every gesture at different limb positions. As we can see, there is no major difference between accuracy at five different limb positions for each gesture. This further proves that the model is relatively position-invariant for the five dynamic gestures. But Fig. 17 also indicates that the dynamic gesture itself could influence the accuracy where the accuracy of the wave gesture is over 90%and the accuracy of finger beckon is around 70%. Additionally, Fig. 18 shows that different human subjects have an impact on accuracy where the accuracy varies across different subjects performing the same gesture in the same position. In short, the model is relatively position-independent, but the accuracy is slightly influenced by the dynamic gesture selection and human subjects’ performing proficiency.
For the second experiment in Section 3, most human subjects spent more time using myoelectric control than joystick control. But for some subjects such as Subject 6, the time for the two control modes is similar. In addition, the myoelectric control execution time is smaller than that of joystick control for Subject 10. The majority results of the human subjects fit the assumption that myoelectric control would use longer time to execute than the joystick control. But time differences are not huge. Considering the extra processing time of executing the motions, catching the motions, wrong classification and recognition, the differences are acceptable. Moreover, the fixed trajectory makes it impossible for the myoelectric control algorithm here to complete other task unless the commands are modified according to the specific requirements. But this helps the control system perform in a stable manner in every task. During the experiments, myoelectric control is able to grab the bottled water successfully without knocking it down. But it happened when using joystick control. Because the trajectory of myoelectric control method is fixed. And the path by using joystick changes every time. In addition, the myoelectric control mode is easier to start than joystick control. Human subjects do not need to learn the rules and practice the task. Based on the discussion before, myoelectric control establish a potential in human computer interaction.
Conclusion
This paper proposed a CNN-LSTM neural network to classify five dynamic gestures. Based on the daily life habits of most people, five limb positions were chosen for each gesture. In the tests, motions were performed in the pre-defined limb positions. The model is able to recognize every gesture when it is under different limb positions, although the differences in accuracy on different positions still exist as shown in Table 1. After the proposed model is applied successfully to reduce the effect of limb positions for gesture recognition, an HCI system is designed based on the trained model. To use the system, human subjects need to wear a MYO myoelectric armband for EMG signal collection. The gesture data would be input into the system and be recognized by the trained model. Then a command would be sent according to the corresponding relationship between gestures and commands. This system enables human subjects to manipulate a robot arm using pre-defined gestures.
Future work needs to concentrate on the following directions: the tiger mechanism in the real-time recognition system needs to be removed, the classification accuracy needs to be improved and the classification system needs to be more robust. Many neural networks achieve good results on classification work, like the Bidirectional LSTM neural network. In addition, methods like transfer learning which enable us to employ the knowledge from large public datasets, may improve the accuracy. However, the specific method needs to be further determined.
Footnotes
Appendix
Five Limb Positions of Finger Snap. Five Limb Positions of Finger Beckon. Five Limb Positions of Palm Beckon. Five Limb Positions of Wave. Five Limb Positions of Go Away.


The manufacturer of MYO armband is Thalmic Labs.