
Abstract
The dynamic gesture trajectory recognition results are low accurate and poor real-time due to the problems of occlusion, complex background and fast gesture movement. In this paper, we take advantage of the advantages of machine vision to extract the video keyframes by the three-frame differential method and use the annotation software to produce the dataset. The you only look once 4 (YOLOv4) algorithm is improved to reduce the redundancy of the network structure and enhance the applicability of the feature map for hand gesture recognition. Combined with the Deep-sort real-time tracking feature, the hand motion trajectory is obtained by introducing the epiphenomenal features to effectively avoid the situation that the object is not tracked when it is obscured. To avoid the problem of gradient disappearance during deep network training, the DenseNet-BC-169 network is used to balance the recognition rate and training time for gesture trajectory classification. Compared with FLIXT, the winner of the dynamic gesture recognition challenge, the final results showed a 6.13% improvement in accuracy and video processing with the IsoGD dataset reached 31fps, validating the effectiveness of this method.
Introduction
In the development of human-computer interaction, gesture recognition technology has gradually become the focus of attention of scholars. The gesture recognition technology is widely used in real-life applications such as smart home, smart driving and virtual reality due to its high flexibility and convenience [1]. Dynamic gesture recognition technology has gone through two key stages [2]. In the first stage, dynamic gestures are detected with the help of an intermediary (data gloves). The data glove is used to obtain the spatial position information of the finger joints, and then the spatial position coordinates are analyzed to achieve dynamic gesture recognition. Scholars such as Wu [3] applied Cyber Glove to recognize some common sentences in the Chinese sign language database. Subsequently, some new types of sensors have been used in gesture recognition. Gehrig [4] used optical sensors to capture 3D information of dynamic gestures to recognize dynamic gestures. Gupta [5] used inertial sensors to collect 6-axis spatial position changes of dynamic gestures to identify continuous dynamic gestures. In 2020, Ge’s team [6] studied the virtual human hand motion modeling system based on WiseGlove7S data gloves, completed the virtual human hand gesture modeling and motion modeling. Dynamic gesture recognition with data gloves has achieved satisfactory results in terms of accuracy and speed, but the comfort and convenience of the operator wearing data gloves or corresponding sensors is not conducive to widespread use in everyday life. In the second stage, scholars focus on the research of dynamic gesture recognition technology in the field of computer vision. The Dynamic Time Warping (DTW) algorithm and the Hidden Markov Model (HMM) are the two feature classification methods frequently used in the traditional dynamic gesture recognition process. The Massachusetts Institute of Technology used the DTW algorithm [7] to achieve dynamic gesture recognition, but the algorithm relies on the consistency of the actions and recognition degrades when the actions differentiation is large. By combining a HMM with a fuzzy neural network, Wang [8] made the model for dynamic gesture recognition with both temporal capability and fuzzy inference capability. Liu [9] try to combine HMM with recurrent neural networks to perform static gesture recognition, but again could not handle the recognition of a large variety of gestures with complex movements. Two Stream Network, LongSortTerm Memory Network (LSTM) and 3D Convolutional Neural Network are all dynamic gesture recognition networks designed using deep learning methods, which have good recognition results. Chung [10] used the hand as the region of interest for real-time tracking, applies skin color detection and noise processing to remove unwanted background information from the image. And AlexNet [11] and VGGnet [12, 13] were used to identify specific hand gestures with high accuracy. Simonyan [14] proposed a two-stream network, consisting of a spatial network and a temporal network. The spatial features of the images and the motion information of several consecutive frames are focused on separately, after which the information is fused to complete the behavior recognition task. The algorithm only understands spatial information through a single frame of the image, which is difficult to cope with movements that vary greatly between frames, and the optical flow information operation will occupy a large amount of memory. Zhang [15] proposed a 3D separable convolutional and LSTM-based network for dynamic gesture recognition, which reduces network redundancy and serializes the extracted features with an accuracy of 52.21% on the ISOGD validation set. Yifan [16] proposed an end-to-end deeply deformed 3D convolution that increased the sampling position of the 3D convolution and focused on the offset of the feature map, which achieved an accuracy of 55.8% on the IsoGD dataset. Furthermore, several other algorithms are also employed feature fusion to get dynamic gesture recognition. The literature [17] investigates fusion methods for multimodal data and designs a two-stream 3D convolutional neural network to process multimodal data simultaneously to complete gesture recognition. Therefore, convolutional neural network recognition of dynamic gestures currently has both breakthrough and great upside. To address the problems of low recognition accuracy and slow speed of convolutional neural network algorithm in the field of dynamic gesture recognition, this paper proposes a combination of Yolov4 and Deep-sort to recognize and track gestures, and Dense-Net to classify trajectories. The structure flow chart is shown in Fig. 1. The combination of Yolov4, Deep-sort and Dense-Net has improved the accuracy and speed of dynamic gesture detection by taking advantage of the good real-time performance of Yolov4, the fast-tracking speed of Deep-sort, and the improved real-time gesture detection and tracking capability.

Structure flow diagram.
Dynamic gesture data set
Wan [18] from the Institute of Automation of the Chinese Academy of Sciences compiled the CGD2011 [19] dynamic gesture data set and released the IsoGD dynamic gesture data set in 2016. The data set contains a total of more than 47,000 dynamic gesture videos. Each video is taken with the KinectTM camera. The data format is RGB and RGB-D, and the resolution of each frame is 320×240. The selected IsoGD dataset was filtered to identify gestures with high gesture differentiation, a high proportion of gestures, and gestures with high applicability in daily life. The filtered dynamic gesture video sequences were then edited. By comparing the dynamic gesture keyframes, it is verified that the three-frame difference method extracts keyframes better than the clustering method and the two-frame difference method.
The extracted keyframes are shown in Fig. 2. The extracted gesture keyframes were annotated with the Lableme annotation software, and the gestures of 12 people were annotated with a total of 1600 data sets. This was used as the training and testing data for Yolov4 to recognize different gestures.

Example of screened samples.
Alexey Bochkovskiy published YOLOv4 in April 2020 [20]. The YOLOv4 target detection algorithm divides the input picture into S × S grids. The center point of the detected object will fall in one of the grids, and the grid will perform target detection, as shown in Fig. 3. After obtaining the position of the detection frame center point of the dynamic gesture, the trajectory information during the gesture movement is finally obtained by using the Deep-sort tracking network.
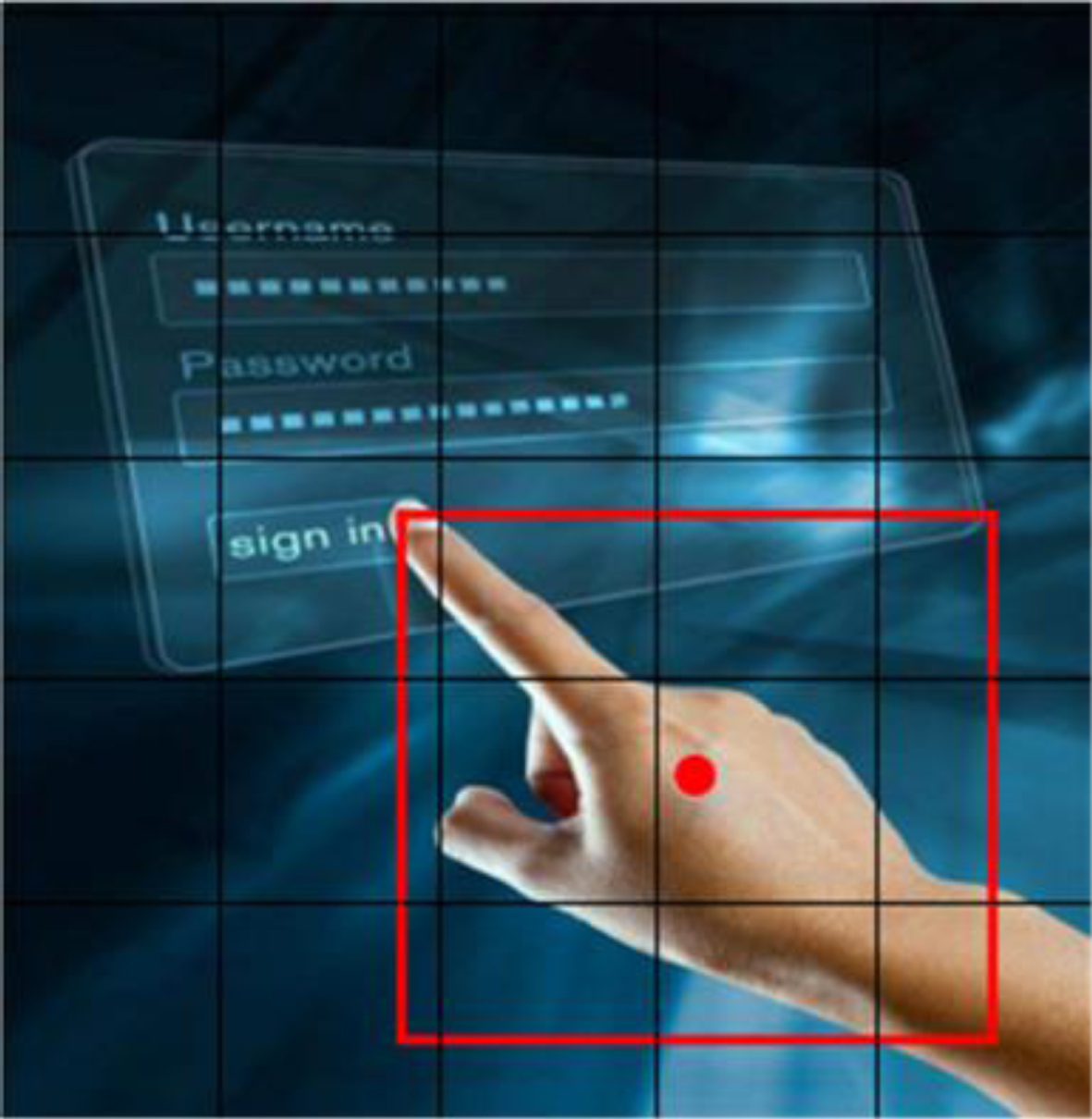
Detection schematic.
In the picture, each small cell will predict B bounding box and the confidence score of the bounding box. Confidence contains two pieces of information. First, the probability that the bounding box contains the detection object is represented by Pr(object). When there is a detection object in the bounding box, Pr(object)=1, otherwise Pr(object)=0.
Second, the accuracy of the bounding box can be represented by IOU (the intersection ratio of the candidate bound and the ground truth bound). So the confidence is equal to Pr(object) × IOU. The value (x, y, w, h) is used to represent the position and size of the YOLO bounding box, (x,y) represents the center point coordinates, w represents the width of the bounding box, and h represents the height of the bounding box. The range of the four values of (x, y, w, h) is between [0, 1]. It is finally used to represent the predicted value of the bounding box, where c represents the confidence. For the classification problem, each small cell needs to predict c categories, it is judged which of the C categories the target belongs to. This judgment is based on the confidence of each bounding box. The predictive value of each small cell is (B × 5+C). When the picture is divided into cells, the total prediction amount is S × S × (B× 5+C). Finally, the YOLOv4 model is trained by the mean square and loss function of Eq. (1).
In the formula,
Many training techniques have been added to the network structure to improve the accuracy of network recognition. The optimal value of hyperparameters was selected by using the method of Mosaic data enhancement and the use of the GA algorithm. Among them, Mosaic data enhancement is to randomly select four pictures during the detection, and perform a series of operations such as flipping, mirroring, and zooming on them. In this way, the background for detecting gestures can be expanded.
The overall structure of YOLO is divided into four major sections: Input, BackBone, Neck, and Prediction. The backbone network CSPDarknet53 contains a total of five residual modules. The CSPDarknet53 adds CSPNet to the five large residual modules of Darknet53 and completes the integration of the feature map through the change of gradient. The feature map is divided into two parts, and part of the function is to perform convolution operations. The other part of the role is to combine the results of the previous convolution. When doing target detection, CSP can not only improve the learning ability of the convolutional neural network but also reduce the difficulty of calculation. PANet makes full use of the feature fusion method to increase the network’s ability to accurately detect targets. The overall structure of the network is shown in Fig. 4.
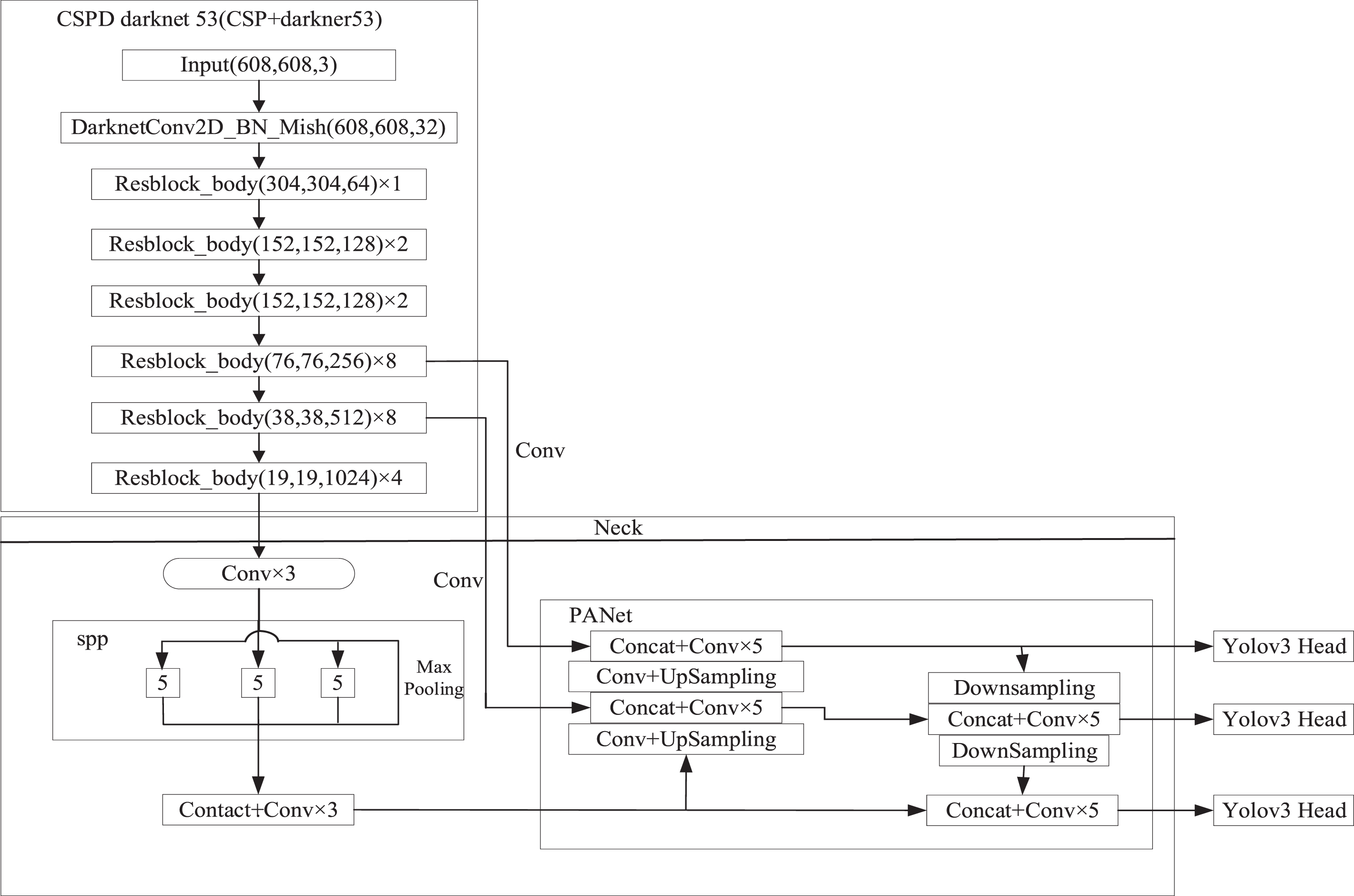
YOLOv4 general structure diagram.
The YOLOv4 convolutional neural network algorithm structure uses CSPDarknet53 as the main structure, and the connection method using the residual network is the inter-layer connection. This structure reduces the problem of gradient disappearance during backpropagation of the convolutional neural network, and reduces the amount of parameters. After tensor stitching, multiple label classification can be supported by the Logistic classifier.
The YOLOv4 algorithm, like other series of YOLO algorithms, is more suitable for multi-target detection and classification. For the detection of a single target in the gesture detection task, the YOLOv4 network structure has some redundancy and complexity, which not only increase the training time and reduce the training efficiency, but also increase the amount of data during training, reduce the real-time performance, and increase the difficulty of training. In response to the above problems, our research improved the YOLOv4 network structure, so that the network guarantees accuracy when doing target detection, and improves the detection speed and the real-time performance of the network. The improved network improves the residuals in the main feature extraction network The network structure of the module is improved by adjusting the convolutional layer and adding a linear activation function. The improved YOLOv4 network structure model is shown in Table 1.
Improved YOLOv4 network structure
The improvement method: 1. Add a convolution kernel after each residual module in the original YOLOv4 network to reduce the dimensionality of the output. 2. In order to avoid the problem of the loss of feature images in the convolutional layer due to the reduction of the output dimension after the addition of the 1*1 convolution kernel, a linear activation function is used in the first convolutional layer. 3. Adjust the number of layers of the residual network in the residual module to increase the connection performance between the residual modules. It not only improves the reusability of the feature map but also reduces the loss of feature transfer between modules.
The number on the right side of the Output column is the number of network layers of each Residual module.
The Simple Online and Real time Tracking(SORT) algorithm [21] is a very simple and effective practical target tracking algorithm. The SORT is matched according to the IOU value, and the matching speed is very fast, but the ID Switch is very large. The Deep-sort tracking algorithm is improved on the basis of the s algorithm. By introducing apparent features, it effectively avoids the situation that the object cannot be tracked when it is occluded, and the ID Switch is significantly reduced. The Deep-sort flow chart is shown in Fig. 5. Compared with the Sort process, it has two parts: cascade matching and confirmation letter trajectory. The Kalman filter predicts a new trajectory, and the Hungarian algorithm performs cascade matching and IOU matching through the predicted trajectory and the current frame detection trajectory, and then the Kalman filter performs trajectory update.
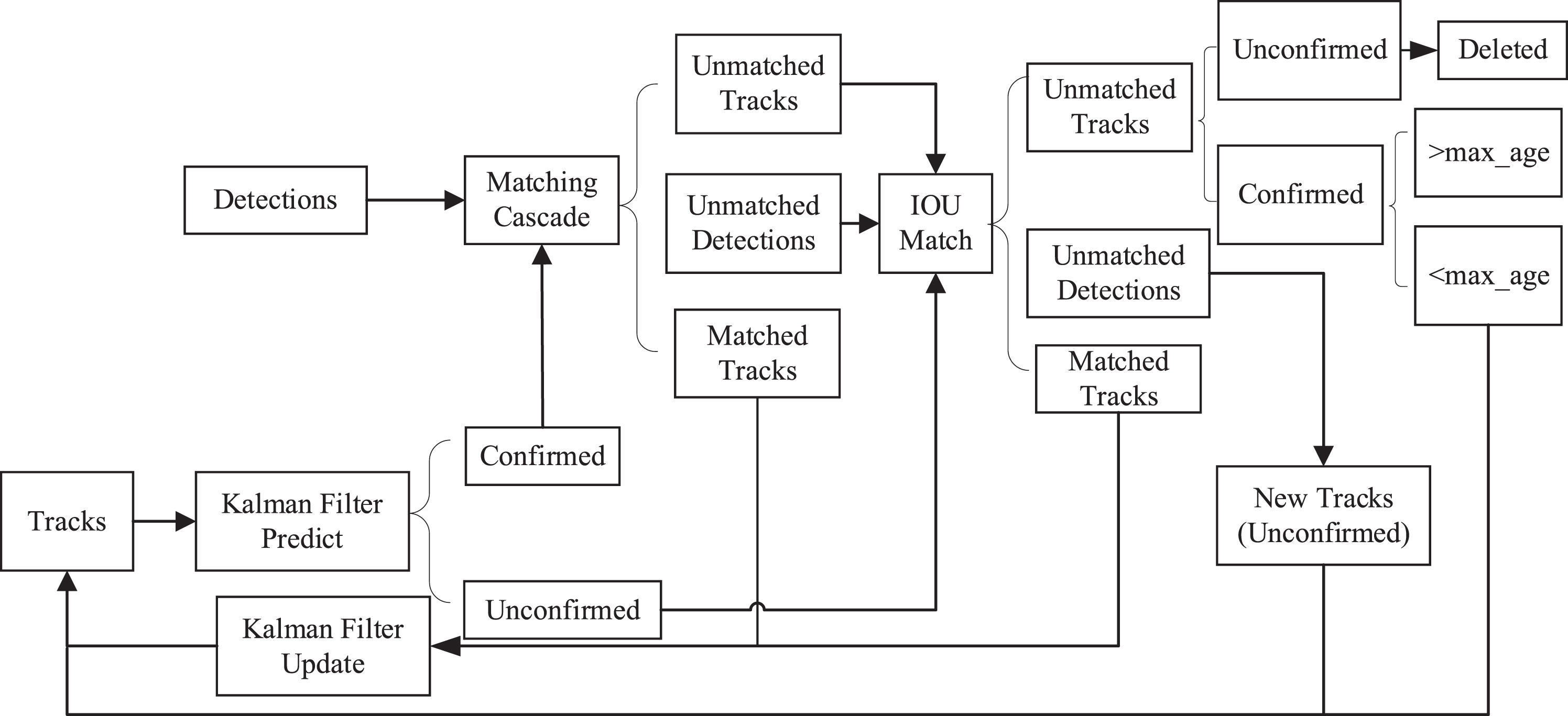
The process Deep-sort.
For gesture trajectories, the DenseNet [22] series network is used for target classification in our research. This network can avoid the problem of the disappearance of the gradient of the deep neural network during training. Through its unique inter-module connection method, feature propagation and feature reuse are increased. Its model parameters are less convenient for training and calculation. After obtaining the hand movement trajectory through YOLOv4 detection and Deep-sort tracking algorithm, the experiment compares the DenseNet network of different depths, balances the accuracy and time of training, and determines the DenseNet-BC-169 target classification model to complete the gesture trajectory classification.
In order to verify the detection effectiveness of the improved YOLOv4 proposed in this paper, the algorithm is first compared with the YOLOv4 algorithm in the IsoGD dynamic gesture data set, and then compared with other classical detection algorithms.
The change of the loss function during the training process is shown in Fig. 6. After 4000 iterations, it shows that the model has converged.
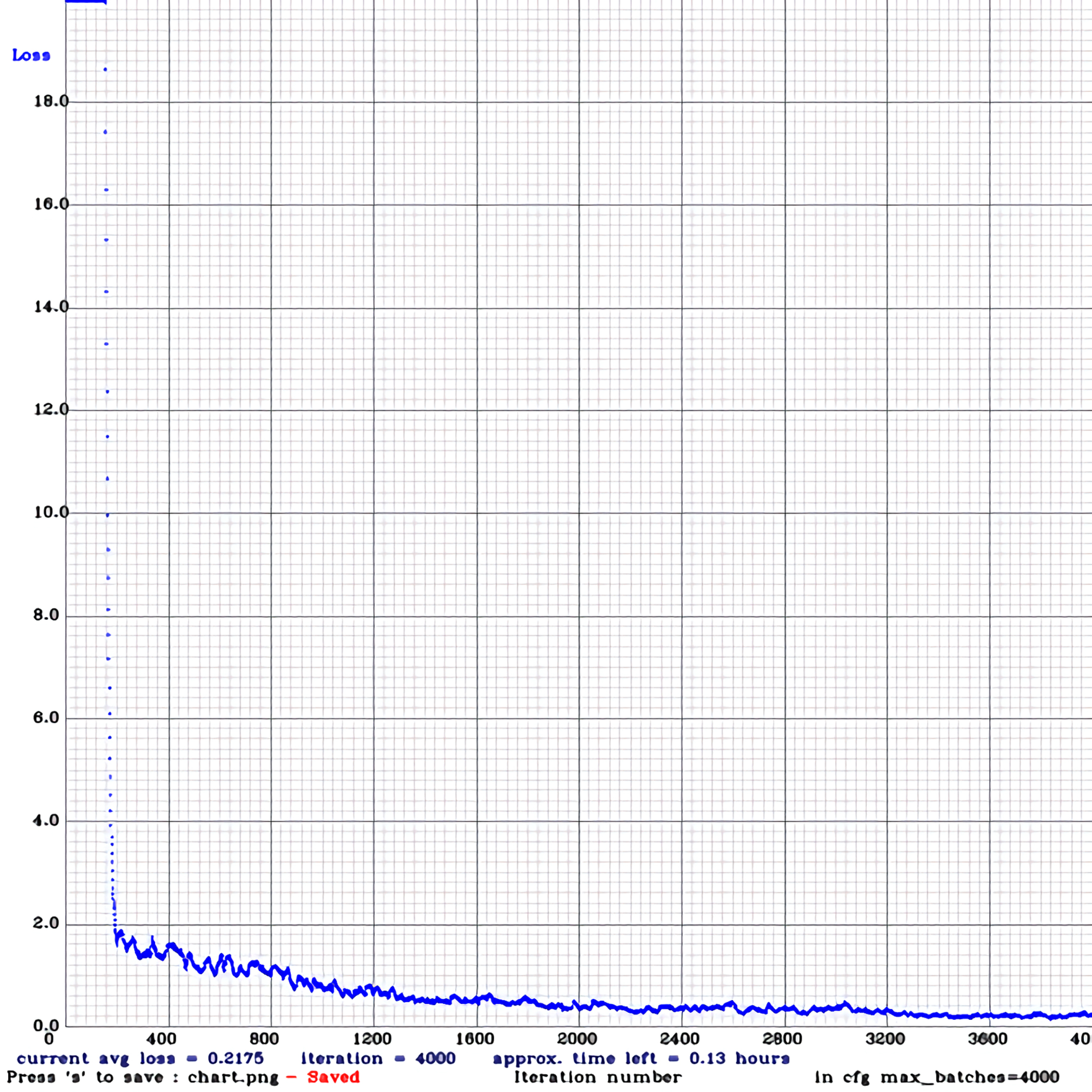
Variation of loss function.
The training and testing environment is completed under Windows, the hardware conditions are CPU i7-9750H, GPU NVIDIA GTX 1050. Set each batch of training samples to 16. The number of times is set to max batches=4000, steps=3200, 3600. The initial learning rate is 0.001, and the classes in the layer are set to 1, filters=(category+5)*3=18, height=608, width=608.
YOLOv4 and the improved YOLOv4 were applied to 200 test sets of data for comparison, and the results are shown in Table 2. compared to the YOLOv4 algorithm, The improved YOLOv4 algorithm improved the accuracy by 2.68%, the recall by 1.53%, and the final average accuracy by 2.36%. YOLOv4 improves the indexes by adjusting the network structure and improves the detection speed by 3 fps. It meets the real-time requirement of dynamic detection.
Comparison of the indicators of the two algorithms
Comparison of the indicators of the two algorithms
In the comparison with SSD [23], R-CNN [24], and CornerNet [25] algorithms, 30 dynamic gesture videos were selected in the dataset, and the accuracy and recall statistics were performed for the above four algorithms. From the PR curves in Fig. 7, we can see that the improved YOLOv4 has the largest image area enclosed by the horizontal and vertical coordinates, i.e., the largest mAP value, and the highest recognition accuracy.
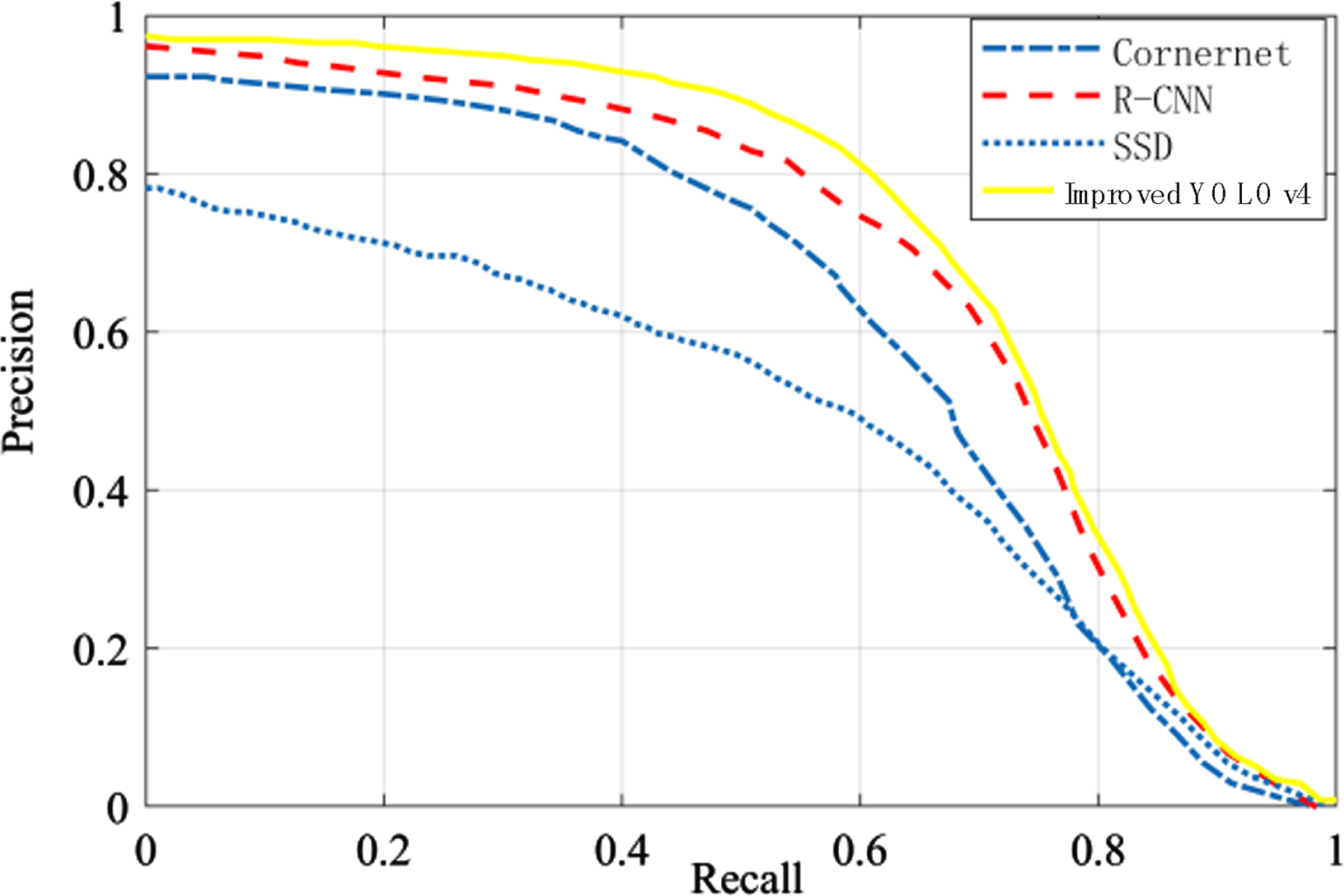
Accuracy/recall curve.
The gestures were changed in different video scenes, and the success rate was counted. The statistical results are shown in Table 3. The success rate of the improved YOLOv4 algorithm in detecting gestures in different scenes is higher than other algorithms.
Success rate of different scenarios
Figure 8 illustrates the comparison of the detection results of different algorithms. In the process of gesture detection with a complex background, Fig. 8(a) shows that the improved YOLOv4 algorithm can still detect the target accurately when the background is complex. Figure 8(b) shows that CornerNet has multiple detection frames in complex scenes, but cannot detect the specific location of the gesture. Figure 8(c) shows that although the SSD algorithm detects the gesture target in complex scenes, it fails to detect all the information of the gesture. Figure 8(d) shows that although the R-CNN is able to detect all the information of the hand and locate it accurately, it runs slowly at 25fps, which cannot meet the real-time requirement of dynamic detection. As shown in Fig. 8(e), the improved algorithm can still detect hand when part of the gesture target is blocked, while the other algorithms cannot. As shown in Fig. 8(f), CornerNet shows a delay in the detection process when the hand movement is fast.

Schematic diagram of different algorithms for detection.
The results of gesture tracking are shown in Fig. 9. There are eight types of trajectories, which are counterclockwise circle, clockwise circle, inward, outward, right, left, downward and upward. The trajectory curves represent the trajectory of the hand tracked by Deep-sort, and the detection frame is an improved YOLOv4 detection frame for gestures.

Gesture tracking effect.
The overall test of the model is shown in Fig. 10, and the four plots show the tracking effect. The red and blue lines show the trajectory of the center point of the gesture detection box for Deep-sort tracking. The green box shows the prediction box for Deep-sort tracking, and the purple box shows the detection box for YOLOv4 gesture detection. Deep-sort can track a specific hand when tracking, and different numbers above the detection box represent different trajectories. (a) shows the tracking state of the gesture before it is completely blocked; (b) shows the state when the hand is completely blocked and there is no gesture detection frame and the trajectory cannot be seen; (c) shows the tracking effect when the gesture appears again. It is proved that the dynamic gesture recognition system designed in this paper will continue tracking when the tracking target is completely blocked for a short time and reappears; (d) indicates the trajectory of the hand when there is no object occlusion, and the number 2 on the detection box indicates the second gesture type. That is, the final output of the dynamic gesture recognition model in this paper is the digital information on the detection box.

Gesture detection tracking results.
The overall performance of the algorithm is evaluated by comparing the recognition rate of the proposed scheme with several other groups of schemes. The datasets chosen for these sets of solutions were all IsoGD. And the algorithms that had won the top three places at the IsoGD competition were FLIXT [26], AMRL [27], and XDETVP-TRIMPS [28]. The main idea of FLIXT algorithm is to first process the original dynamic gesture video to get the video features, then input the original RGB sequence and the processed video sequence together into the network, and classify the gestures by the classifier. The final recognition rate of FLIX is 56.9%, which is currently ranked first. The AMRL algorithm uses the idea of ranking pooling and uses a two-dimensional convolutional neural network to perform the recognition, with a tested recognition rate of 55.57%. The XDETVP-TRIMPS algorithm first divides the RGB video sequences and RGB-D video sequences into several segments, and then feeds them into the 3D convolutional neural network, and the final recognition rate is 50.93%. There are other methods [15, 16] from the last two years that have yielded good results. But there are no identification results on the IsoGD test set. The statistical analysis of the recognition rate of the above methods and the algorithm of this paper on the validation and test sets is shown in Table 4.
Recognition rates of different algorithms in IsoGD dataset
Our algorithm improves 6.13% over FLIXT, the winner of the dynamic gesture recognition challenge. The final processed video frame rate is 30fps, which meets the real-time video processing requirement and proves the feasibility of this algorithm.
In this paper, we propose a computer vision-based approach to dynamic gesture recognition. The main idea is to integrate the best-performing vision algorithms at this stage and make full use of the advantages of different algorithms in the field of dynamic gesture recognition. By improving the structure of the Yolov4 target detection algorithm, the impact of the gesture recognition algorithm on the accuracy of dynamic gestures is overcome for problems such as complex gestures, the large amplitude of motion and fast speed. Combined with Deep-sort for real-time tracking of motion gestures, the problem of gestures being easily lost by occlusion is solved, and finally DenseNet-BC-169 classifies the obtained multiple gesture trajectories. The three methods with different characteristics are applied to each stage of dynamic gestures to build a holistic gesture recognition scheme, and the effectiveness of the scheme is verified against other algorithms. The accuracy of 63.03% was achieved with the IsoGD dataset, and the stability was good in complex environments. Future work will focus on exploring superior gesture recognition networks to improve detection accuracy. This can be done by using the Generative Adversarial Networks (GAN) approach to predict and restore obscured gestures, and by using Neural Architecture Search (NAS) to search for the best network structure solution. At the same time, we can lighten the processing model, reducing the amount of computation, speeding up the training and detection of the model, and making it easier to apply to embedded devices. On the other hand, the modal fusion and robustness of the model can be improved to detect multiple hands and gestures of multiple people in different perspectives, and further improve the practical application of the solution in various fields.
Footnotes
Acknowledgments
This research was supported by Special Fund for Basic Scientific Research Operations of General Universities in Heilongjiang Province (Project number: LGYC2018JQ017).