
Abstract
The Copula concept has long been used in many applications, especially in the financial field. This concept was first used in 1959 by Sklar in his mathematical work and greatly assisted in the applications of financial and insurance areas. The copula functions have been widely used in dependence modeling. In this study, we look at how the copula began to develop from a basic form to a more advanced form through studies that previous researchers have made. Throughout this study, we find various types of the copula, and each exhibits its own characteristics lying under two main families, Elliptical and Archimedean copulas. Our findings suggest that copula is vital in solving problems in statistical dependence measures and joint marginal distribution functions. This comprehensive study served as a review paper on the development of copulas from their initial existence to their latest evolution.
Introduction
The financial field involves managing money and how an individual, company, or government agency acquires and spends money. This leads to financial services that allow consumers and businesses to acquire financial goods from money management. For instance, a payment system provider is a financial service when it accepts and transfers funds between payers and recipients. The financial services sector is one of the most critical segments of the economy. It helps drive a nation’s economy, providing the free flow of capital and liquidity in the marketplace.Financial modeling is the process of creating a model of a scenario in which a financial choice must be made. Financial modeling is being utilized by an increasing number of businesses these days for purposes such as risk assessment, strategy planning, and review of capital budgeting since it offers numerous benefits to both managers and end users. Therefore, financial modeling is a crucial process in the finance industry. However, the recent recession has necessitated a re-evaluation of modeling in the financial services industry [50]. Moreover, aggregating individual risks is one of the most pressing problems in risk management. For example, assume the random variables modeling individual risks are either independent or dependent on a common factor that allows the reduction of independent variables case. This can be done by eventually adding one new variable (describing the common factor) to the set of risks, effectively solving or at least discarding the problem. The task becomes considerably more complicated when modeling fully dependent random variables or when one does not know the exact joint distribution to construct a huge dependency set between the provided individual risks.
Prior to the above problem, a common approach is to assume that the vector of risks has Gaussian behavior (with some specific covariance matrix), but this is unlikely to be the case since not all threats are normally distributed. Consider the extremely asymmetric loss distribution of a pool of credit, or the normal joint distribution may fail to capture some important unique elements of the dependency of the examined risks, such as tail dependence. In addition, we emphasize that we frequently lack as much information about the joint distribution as we do about each individual risk [49]. Therefore, the idea of a copula that provides a robust and approachable framework for describing risks is introduced. Copula also provides a robust and user-friendly mechanism for risk analysis in risk management. Copula is derived from the Latin noun copula, meaning ”link, tie, bond,” and refers to uniting two things. This word was first used in 1959 in Abe Sklar’s mathematical work [81], but it has recently gained favor in financial applications. A copula is a multivariate distribution function that joins or links univariate marginal distribution functions. A distribution function distributes probabilities as a function of outcomes; that is, the distribution function offers the probability for each outcome [8].
In the 1950s, the idea of a copula was first established, with its discovery linked to the works of [28, 31, 81]. Fréchet first introduced a distribution with a specified marginal [31]. For random variables Y1 and Y2 specified on [0, 1] probability space, he worked on a problem involving the bivariate distribution functions F1 (y1) and F2 (y2). The distribution function F (y1, y2) = F (y1) F (y2) is a member of the set
In this regard, our focus shifted to the interplay between random variables. Since the behavior of a univariate marginal distribution function can be determined, we can use multivariate distributions to learn more about marginal distributions’ interaction or gain a more thorough understanding of their dependencies. We will look at why copulas are replacing linear correlation as the go-to tool for solving financial problems because they are much more accurate and popular. The financial industry is well-known for misusing techniques. Correlation has been labeled a "minefield for the unwary" due to the frequency with which it is inappropriately applied to problems. Because correlation is not a universal dependency measure in risk management, this will not work. For instance, if we want to represent the relationship or reliance between two risky variables X and Y, we will likely employ linear correlation. When our random variables follow a multivariate normal distribution, a correlation of +1 tells us that the two variables are positively dependent (rises or falls together), a correlation of -1 tells us that they are negatively dependent (one rises and the other falls), and a correlation of 0 tells us that the two variables are independent. Furthermore, correlation is restricted in a normal or elliptical universe since it cannot model asymmetries. Regarding financing, there is a much stronger relationship between significant losses than between significant gains. The correlation cannot be assumed invariant by any modifications of the variables it is based on. For example, the correlation between variable X and variable Y is not the same as that between log(X) and log(Y). As a result, the transformations we apply to our data can affect the correlation estimations we obtained [64]. In light of these limitations, copula, introduced at the outset as an alternative to correlation as a measure of reliance, becomes more appealing. Unlike correlation, copulas benefit from invariance under strictly increasing random variable transformations. Copula is superior to correlation since it remains unchanged when the units of measurement are changed, for as, when going from X to log(X). Rather than using a single statistic, like correlation, to summarise the dependence structure, we can utilise a model for the dependence structure that reflects our in-depth understanding of the risk management challenge at hand. In order to establish marginal models for individual risk factors and copula models for their dependence structure, we can use the copula as a multivariate distribution function.
A copula can be used to suggest an appropriate form for the joint distribution if the marginal distributions are known. For this purpose, we have access to numerous copula families from which to choose. This allows us to select a specific copula family based on the random variables of the multivariate data we are attempting to model. This means we can generate multivariate distribution functions by combining arbitrary marginal distributions and extracting copulas from well-known multivariate distribution functions. Knowing the right copula to use when modeling random variables will help determine the right dependence structure. Since each copula has a totally different dependence structure, it is necessary to choose a copula that describes the true dependence structure as well as possible [64]. Derived from distribution functions, more advanced copulas allow us to select the most appropriate model for a given problem from various parametric families. Elliptical copulas and Archimedean copulas are the two main kinds of copulas [23]. These families share a standard structure in their two arguments, making them a valuable part of both bivariate and multivariate copulas. Implicit copulas, which belong to the class of Elliptical copulas, are frequently used as a standard. However, Elliptical copulas can only have radial asymmetry; thus, they have no closed-form expression. It makes sense that in many financial applications, the correlation between extremely large losses would be higher than between extremely large earnings. This kind of asymmetry cannot be modeled using Elliptical copulas. Gaussian copula and Student-t copula are examples of Elliptical copulas. In the study conducted by [79], they recommended using a copula regression to analyse multivariate, longitudinal claims data to account for the unique features of insurance premiums at the policy level. To analyse the semi-continuous claim costs for each coverage type, the model employs the Tweedie double generalised linear model and a Gaussian copula to account for cross-sectional and temporal dependence among the multilevel claims. Then, the second kind of copula is Archimedean copulas. These copulas are also known as explicit copulas and are widely used thanks to their simplicity of construction. This class has many copula families, many of which share desirable qualities. Due to their attractive features and relatively straightforward construction, they use extensively in financial and insurance-related applications [25]. Example of Archimedean copulas is Clayton, Gumbel, and Frank copulas. Genest and Mackay’s [34] study demonstrated that Archimedean copulas could have only a single component in certain circumstances regarding Kendall’s measure of association. However, we will go through many other developments on copula in this study and their unique characteristics.
Motivated by the literature gap discussed above, this paper intends to deepen understanding of copulas’ role in solving a finance-related problem. Many queries will arise when we explore the theory of copulas; for example, why are copulas significant for research and analysis in this financial field? To answer this question, there are two significant reasons for this study. First, it may be used to learn statistical dependence measures with its application in finance, and second, it can be used to create different types of joint distributions. To establish joint distributions, we can use copula to couple marginal distributions of data used in research. The beauty of copula is that it allows us to extract the dependence structure from marginal distributions jointly. It is useful when studying many variables as it is a multivariate dependence structure [12].
This research makes the following key contributions. First, this research can serve as a valuable, comprehensive review for those who intend to gain more knowledge and information on copula, especially regarding the applications in finance. Second, there needs to be more research made on this topic. We noticed that most of the review papers only focused on the copula itself and not on the applications in the financial field. So, this paper also contributes as a guideline to other researchers in assisting their understanding of copula in the financial field.
The remaining of this paper is presented in 6 sections. In the upcoming section, the theory of copula is presented. Then, we will go through the families of the copula in the third section, the elliptical and Archimedean copulas. After that, in the fourth section, a shift from general copula to pair copula construction which is the PCC, is discussed. Furthermore, more information about PCC is presented in the fifth section, and a discussion is made in the sixth section. Lastly, we presented an overall conclusion of this study in the seventh section.
Theory of copulas
This section will explain the theory that is related to copulas. First, we will look through Sklar’s theorem. Then we will proceed to the following theory, a d-dimensional copula followed by Fréchet-Hoeffding bound inequality and the independent copula.
Sklar’s theorem
Sklar’s theorem makes copulas crucial [81]. Any multivariate joint distribution can be described by its marginal distribution, according to this theorem. Let J be d-dimensional distribution function with marginals F1, F2, …, F d . Then, there exists d-copula C d such that, J (x1, x2, …, x d ) = C d (F1 (x1) , F2 (x2) … F d (x d )) for all x ∈ R d . The copula is uniquely determined, if F1, F2, …, F d are continuous. Otherwise, C d is uniquely determined on (range of F1), x (range of F2), x … x (range of F d ). Contrarily, if C d is a d-copula, and F1, F2, …, F d are distribution functions, then the function J in (1) is d-dimensional cdf with marginals F1, F2, …, F d [11].
A d-dimensional copula
A d-dimensional copula is a function “C” from I
d
= [0, 1]
d
to I = [0, 1] if and only if it satisfies the following conditions: For every m in I
d
, C (m1, m2, dotsi, m
d
) =0 if at least one of m is equal to zero. If all m’s are set to one then for every k ∈ 1, 2, dotsi, d, C (m) = m
k
. C is d-increasing, for all (a1, …, a
d
), (b1, …, b
d
) in I
d
such that a
i
≤ b
i
, V
c
([a, b]) ≥0,
Fréchet-Hoeffding bound inequality
Fréchet-Hoeffding theorem establishes the minimal and maximal bounds on the set of copulas. For every d-copula, the Fréchet-Hoeffding bound inequality is given by:
Independence copula
The independence copula is the copula that results from a dependency structure in which each individual variable is independent of the other. If the random variables are independent, then copula density is equal to the product of the marginal distribution of the random variables. Let all m in the unit interval, and then the copula is independent if and only if, C d (m) = m1, m2, . . . , m d . For all d ≥ 2, the continuous random variables X1, X2, …, X d are independent if and only if their d-copula is C d (m).
Copula families
Elliptical and Archimedean copulas are the two types of copulas that exist. We are interested in bivariate one-parameter copula families that are continuous, interpolate between independence and the Fréchet upper bound, and support all of (0, 1) 2. These families are symmetric in both arguments and can be utilised for both bivariate and multivariate copulas [65].
Elliptical copulas
Copulas having elliptical distributions are known as elliptical copulas. The t-student, logistic, and Gaussian (normal) distributions are all examples of distributions. Implicit copulas are a class of elliptical copulas commonly used as a benchmark model. Elliptical copulas have the disadvantage of not having closed-form expressions and being limited to radial asymmetry. With elliptical copulas, such asymmetries are impossible to simulate. It appears reasonable to anticipate that significant losses are more correlated than large gains in many insurance and financial applications. The upper and lower tail dependence factors are equal because elliptical distributions are radially symmetric. They are simply the distribution functions of component-wise converted elliptically distributed random vectors [64].
A normal (Gaussian) copula is an example of an Elliptical copula. The Gaussian copula is the most popular for modeling the association in finance and insurance risk problems [26]. It is the multivariate normal distribution’s copula. The copula of n-variate normal distribution is,
Gaussian copulas have no upper or lower tail dependence, and they are the most commonly employed in finance since they are the copula of a log-normal vector. It conveys dependence in the same way as a multivariate normal distribution does, but for variables with arbitrary marginals. If n = 2, by expression above we have
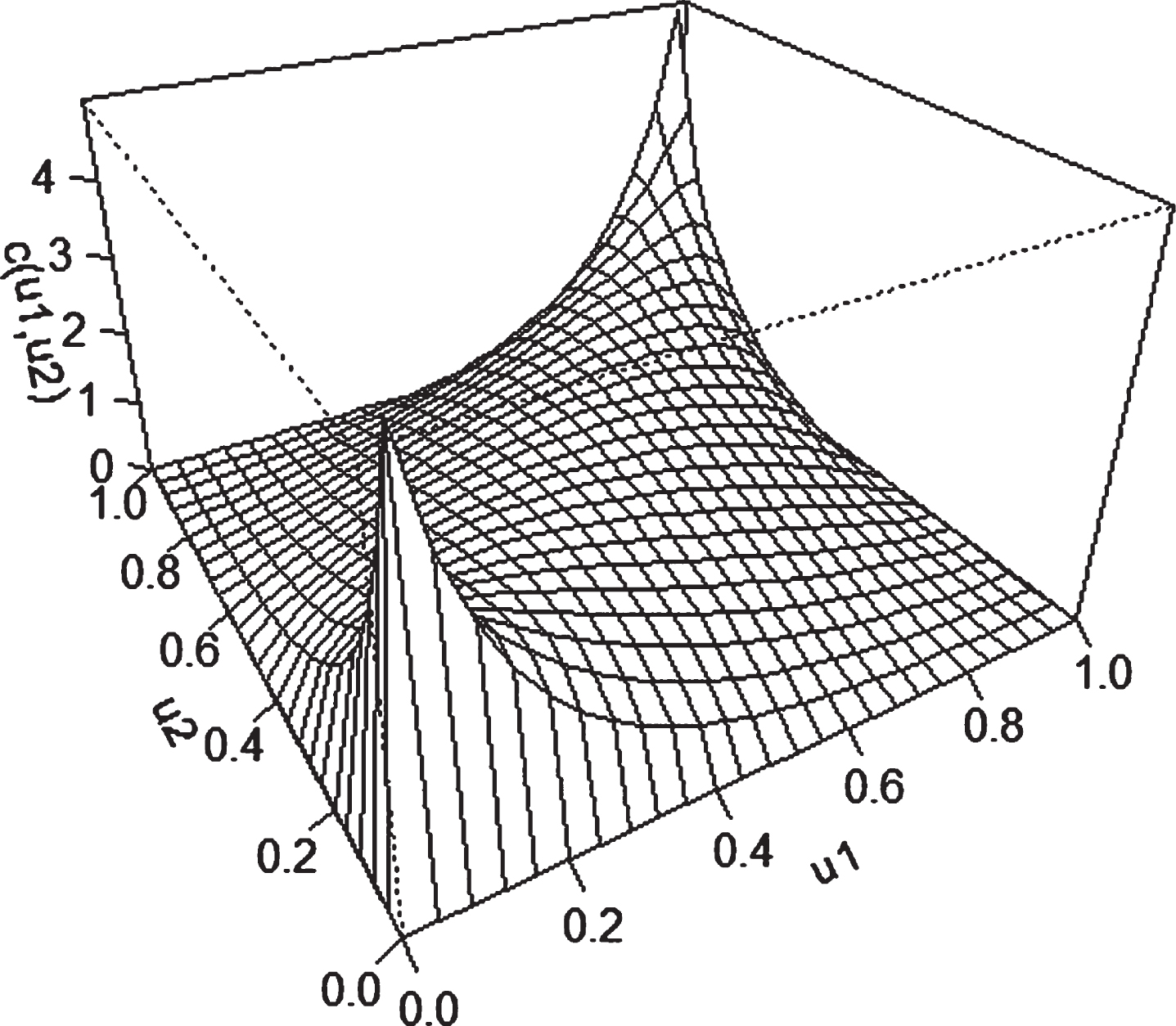
Gaussian copula density.
Another example of an Elliptical copula is the Student-t copula. It is a copula of the multivariate Student-t distribution. Let X be a vector with n variate Student-t distribution with v degrees of freedom, mean vector μ (of μ > 1) and covariance matrix v/(v - 2) ∑, for v > 2 since if v ≤ 2, the covariance matrix is not defined. Then X can be represented as
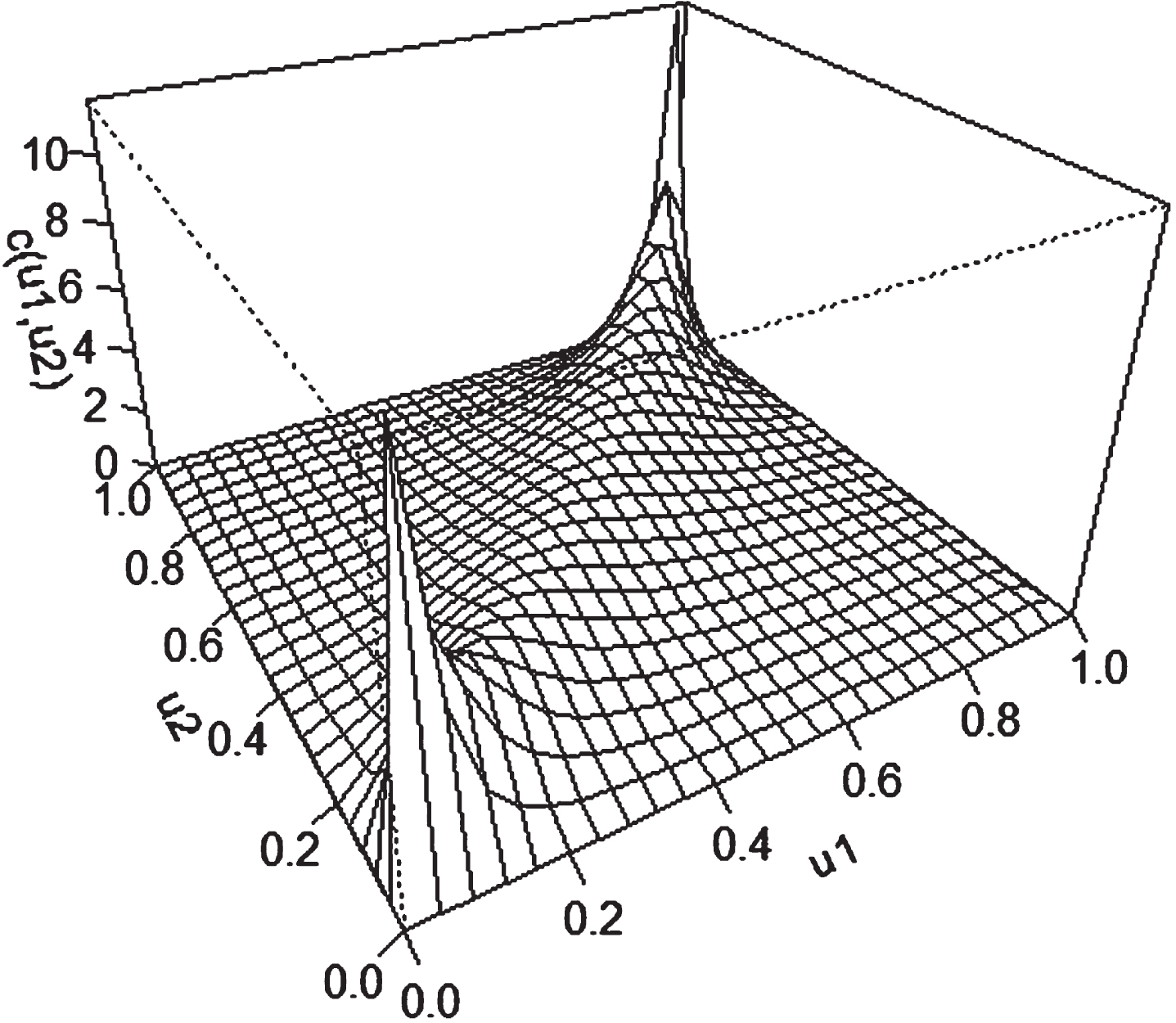
Student-t copula density.
Archimedean copulas, also known as explicit copulas, have a wide range of applications due to their ease of construction. Members of this class have a wide range of desirable characteristics, and they belong to a large number of copula families. Because of their simple shape and pleasant qualities are often utilised in financial and insurance applications [64].
There are various examples of Archimedean copula. One example is Clayton copula. It is an asymmetric Archimedean copula in which the negative tail is more dependent than the positive tail. This copula is given by: letting X and Y be random variables with joint distribution functions. Then the Clayton copula is,
The Frank copula is symmetric, which means the dependence between positive and negative returns is correlated. The parameter θ ∈ (- ∞ , ∞) ∖ {0} controls the degree of dependence between u and v [64].
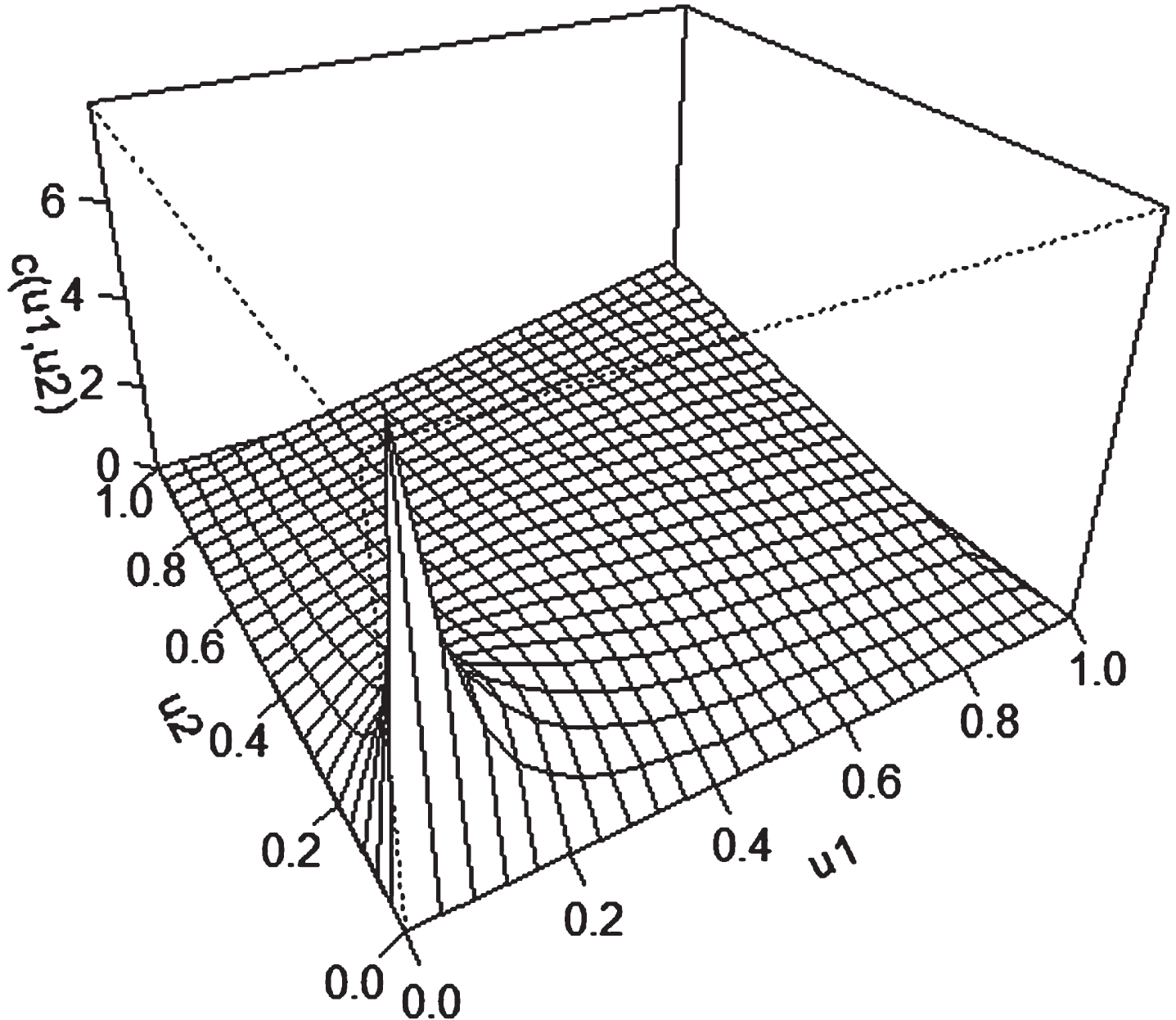
Clayton copula density.
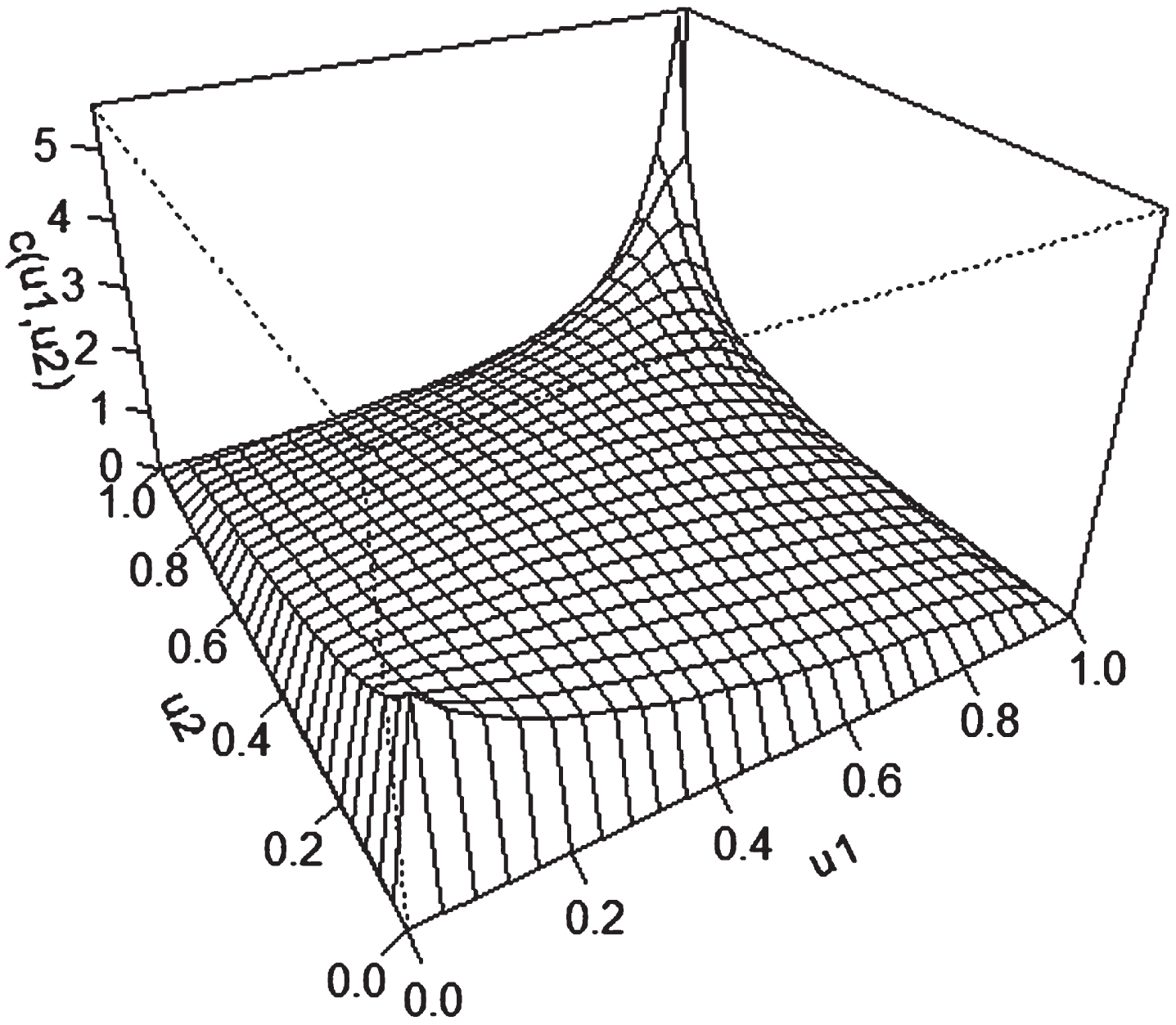
Gumbel copula density.
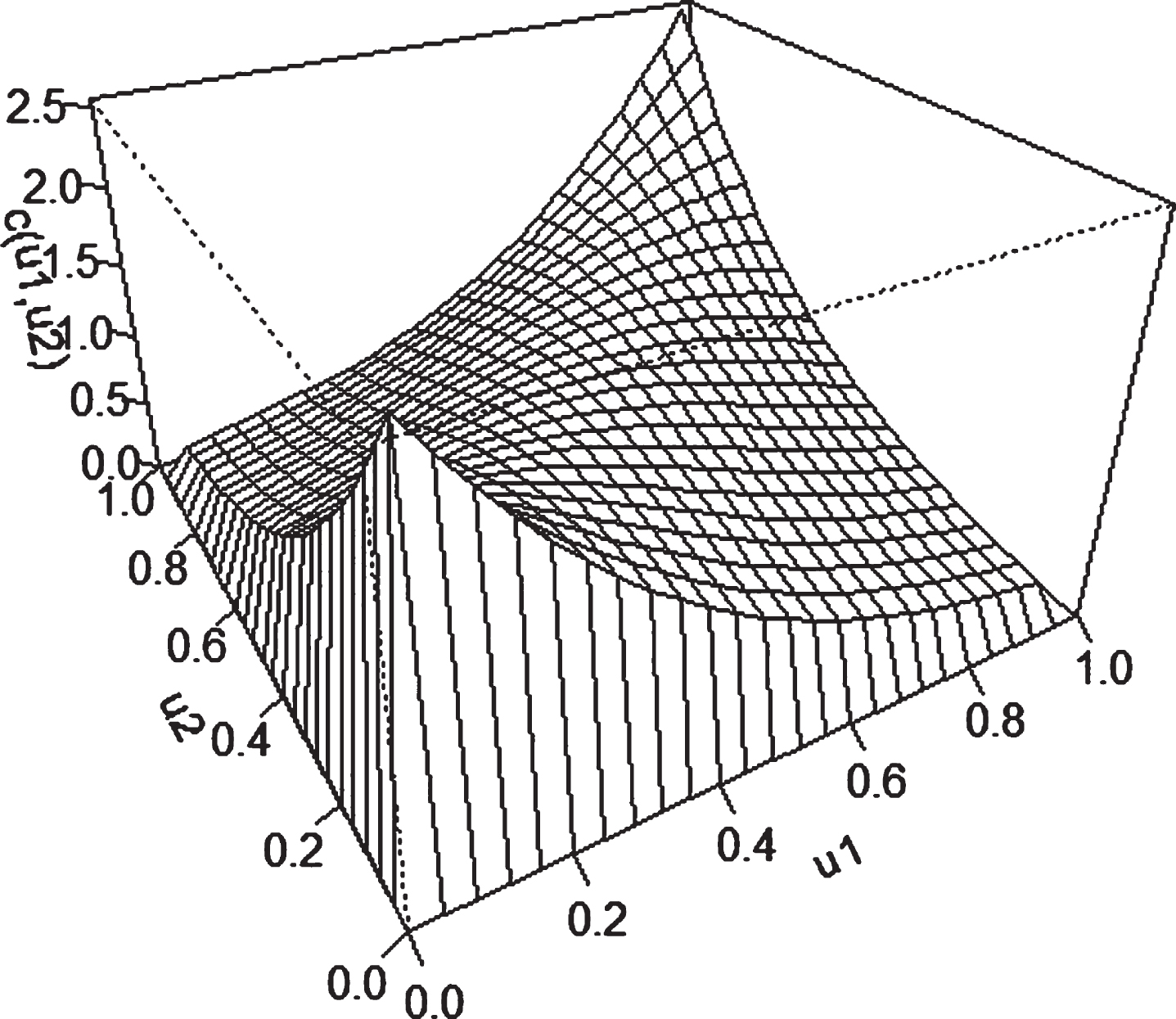
Frank copula density.
Statistical researchers have been given various new prospects due to exceptional technical advancements in recent decades. The increasing availability of massive data sets and the emergence of enormous databases have necessitated the development of multivariate analysis methodologies. Many of them are based on the assumption of a multivariate parametric distribution. The multivariate normal distribution has been the most popular due to its numerous appealing qualities. Though it has numerous natural applications, it cannot account for heavy tails, skewness, nonlinear dependence, or severe joint events. As a result, varieties of alternatives, including multivariate extensions of well-known univariate distributions, have been offered.
The justifications of shifting
Due to its advantages, we know that the multivariate normal distribution is the most popular multivariate analysis method researchers widely use. Even though they are a helpful method, they also have the bad trait that their flexibility reduces as the dimension increases, limiting the spectrum of dependence they may portray. Furthermore, their univariate marginal distributions are all of the same types and have a similar shape. In the multivariate t-student distribution, for example, each variable has its own location and scale parameters, and each pair has its correlation. However, all share the degrees of freedom parameter, which affects the frequently essential tails. One way to deal with these issues is to change the original variables into a more tractable mathematical distribution. Using the cumulative distribution function (cdf) for each variable [41].
For bivariate models (d = 2), there exists a long and varied list of copula families [41]. As soon as d ≥ 3, the catalog of available copula is significantly reduced [36]. Several well-known Archimedean copulae generalize to higher dimensions [56]. However, they are exchangeable. As a result, all pairwise dependencies are the same, making them unsuitable for data with more diverse dependency patterns. Furthermore, as d increases, the constraints on their parameters, and hence the spectrum of dependency they can represent, become increasingly severe. An Elliptical copula, most likely the Gaussian or t-student, is another common option in higher dimensions. When pairwise dependencies are fairly symmetric and, more critically, extremes do not appear to occur simultaneously, the former may be a good alternative. The t-student copula is desirable if the data appear to be tail dependent. Although each pair of variables correlates, the degrees of freedom parameter is shared. The Student-t, like the multivariate Archimedean copula, is best suited when the tail behavior of all pairings is comparable [41]. Therefore, a flexible and more versatile method is introduced by [46], which is the pair copula constructions (PCC).
Pair copula constructions (PCC)
The growing availability of multidimensional data for complex systems has rekindled interest in multivariate modeling, particularly copula. As a result, there is now a broad and diverse list of the parametric bivariate copula, all fully suitable for bivariate models. In larger dimensions, however, the choice of parametric copula is still limited [36]. Recent research has tended to favor hierarchical, copula-based systems. The pair copula (PCC) architecture is perhaps their most promising. Initially proposed by [46], it has been further explored and discussed by [5, 15] and in an inferential context by [3]. Recently, there have been many papers on PCC in the literature, particularly in financial applications. Bayesian inference on PCC is the topic of [59], while [48] explores tail dependence in such constructions. [83] present a non-parametric petroleum-related application of PCC. The combination of its basic construction and high adaptability is likely the reason for the PCC’s rising popularity. They can model various complicated dependencies despite being created entirely from pair copula. PCC often minimizes dimension by pairing the variable set and creating a versatile dependency structure. Regarding the number of copula functions that could be used in the construction, PCC is more versatile [24]. D-Vine (drawable vine copula), C-Vine (canonical vine copula), and R-Vine (regular vine copula) are the three structures that make up the PCC system.
The PCC
In this section, we will look further into the PCC, the pair copula construction, to study their usage and advantages. Recent improvements in high-dimensional copula models have favored hierarchical structures based on the pair copula construction model (PCC), commonly known as vine copulas. It is a revolutionary new approach to building complex multivariate highly dependent models similar to traditional hierarchical modeling. The PCC’s growing popularity is likely due to its simple structure and high adaptability. Despite being constructed entirely of pair copula, they can model many complex dependencies [42]. The decomposition of a multivariate density into a cascade of pair copula is used to model the original variables and their conditional and unconditional distribution functions [3]. The following is a representation of an n-dimensional vine: (n - 1) trees (T); The tree j has (n - 1 + j) nodes and (n - j) edges; Each edge corresponds to a bivariate copula density; The borders of the tree j become nodes of the tree j + 1; Complete decomposition is defined by n (n - 1)/2 edges and marginal densities of each variable, that is, n (n - 1)/2 bivariate copula densities and N marginal.
Using pair-copula constructions, the joint copula density c can be expressed as a product of several bivariate pair-copulas. Let f be the joint density function of n random variables X = (X1, …, X
n
),
For high-dimensional distributions, there are a significant number of possible pair copula constructions. A graphical model has been introduced and is denoted as the regular vines (R-vines) [5, 6]. In addition, a new automated model selection and estimation technique based on graph theoretical considerations is presented, evaluated in a large simulation study, and applied to a 16-dimensional financial data set of international equity, fixed income, and commodity indices observed over the last decade, particularly during the financial crisis in 2012 [22]. The class of R-vines is still very general and embraces a large number of possible pair copula decompositions. Two special cases of R-vines are the Canonical Vine (C-vine) and Drawable Vine (D-vine). Figure 6 shows the R-vine structure and the inference on R-vines consists of three tasks: Structure selection: The number of possible R-vines on d varibles is Choosing copula families: Gaussian, t, Gumbel, and Clayton are just a few examples of possible pair copula families. A model selection criterion, such as the Akaike information criterion (AIC), the Bayesian information criterion (BIC), or the copula information criterion (CIC) [39], or a copula goodness-of-fit test, is often used to choose the copula types one by one. Besides, four different strategies are compared, among them AIC and the goodness-of-fit test based on the Cramer-von Mises statistic [54]. In this study, the AIC was the most reliable selection criterion. Estimating the parameters of each pair copula: The pair-copula construction is a multivariate copula by definition. As a result, any multivariate copula estimator, such as the inference function for margins (IFM) approach [47] or the maximum pseudo-likelihood (MPL) estimator [33, 80], can be used to determine the parameters of a given PCC. Alternatives to the standard maximum likelihood estimators have been proposed. Bayesian techniques to select the pair-copula families for D-vines are covered by [18, 59, 60], while [43, 63, 72, 73] discuss vines with non-parametric pair-copulae.
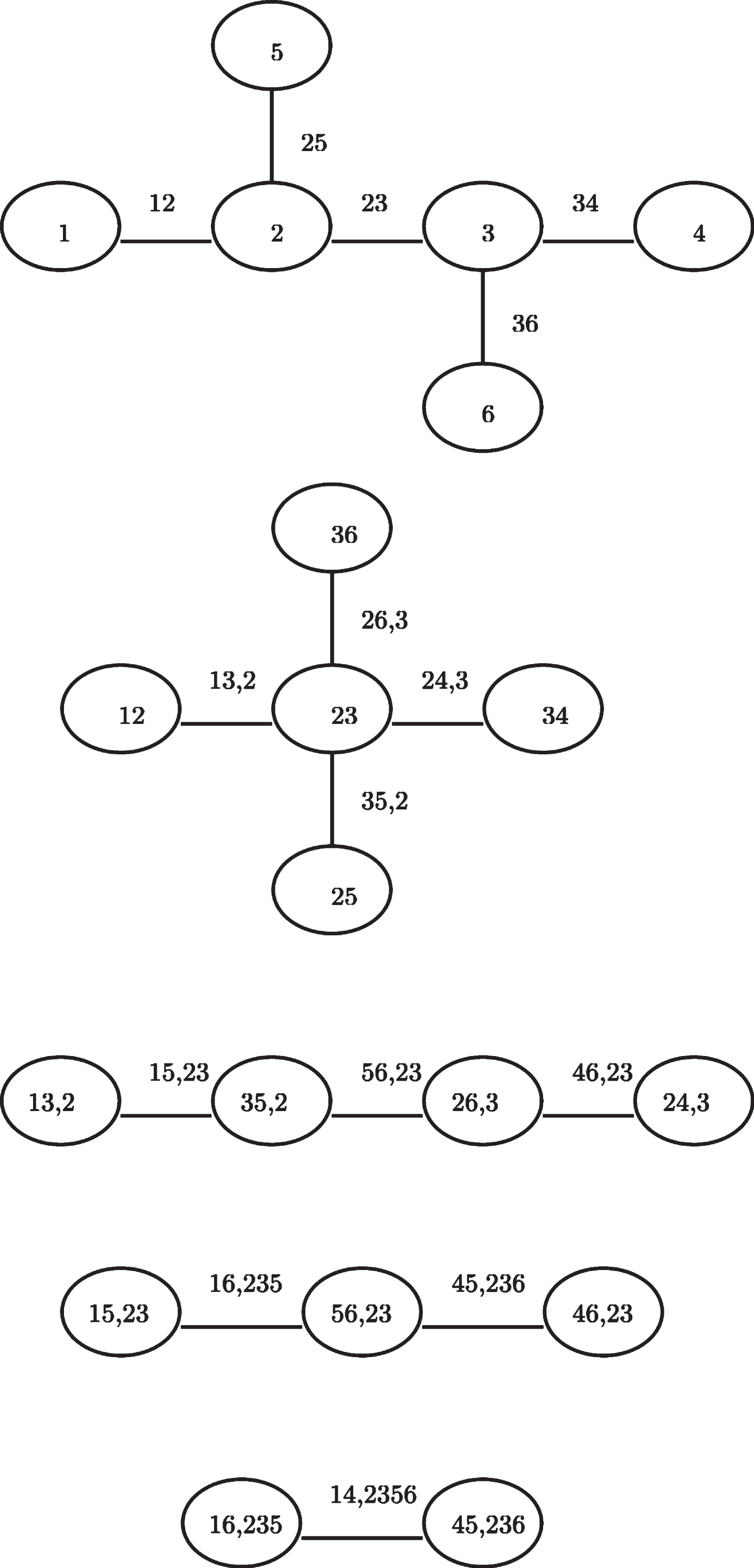
R-vines structure.
The density composition of Fig. 6 is
An R package for CDVine software includes functions and tools for statistical inference of C-vine and D-vine copulas. It includes bivariate exploratory data analysis methods, bivariate copula selection, and pair-copula family selection in a vine [74]. Furthermore, [4] has examined the dependence risk characteristics of three 20-stock portfolios from the retail, manufacturing, and gold-mining equity sectors of the Australian market in periods before, during, and after the 2008–2009 global financial crisis (GFS) using R-vine, C-vine, and D-vine. Moreover, as an extension to prior contributions in quantitative risk management, modeling non-life insurance risks in a multivariate framework was investigated. This research analyses the influence of explicit dependence modeling on capital requirements for non-life insurance losses using a D-vine copula [57]. Figure 7 shows the tree structure of the C-vine, while Fig. 8 shows the tree structure of the D-vine.
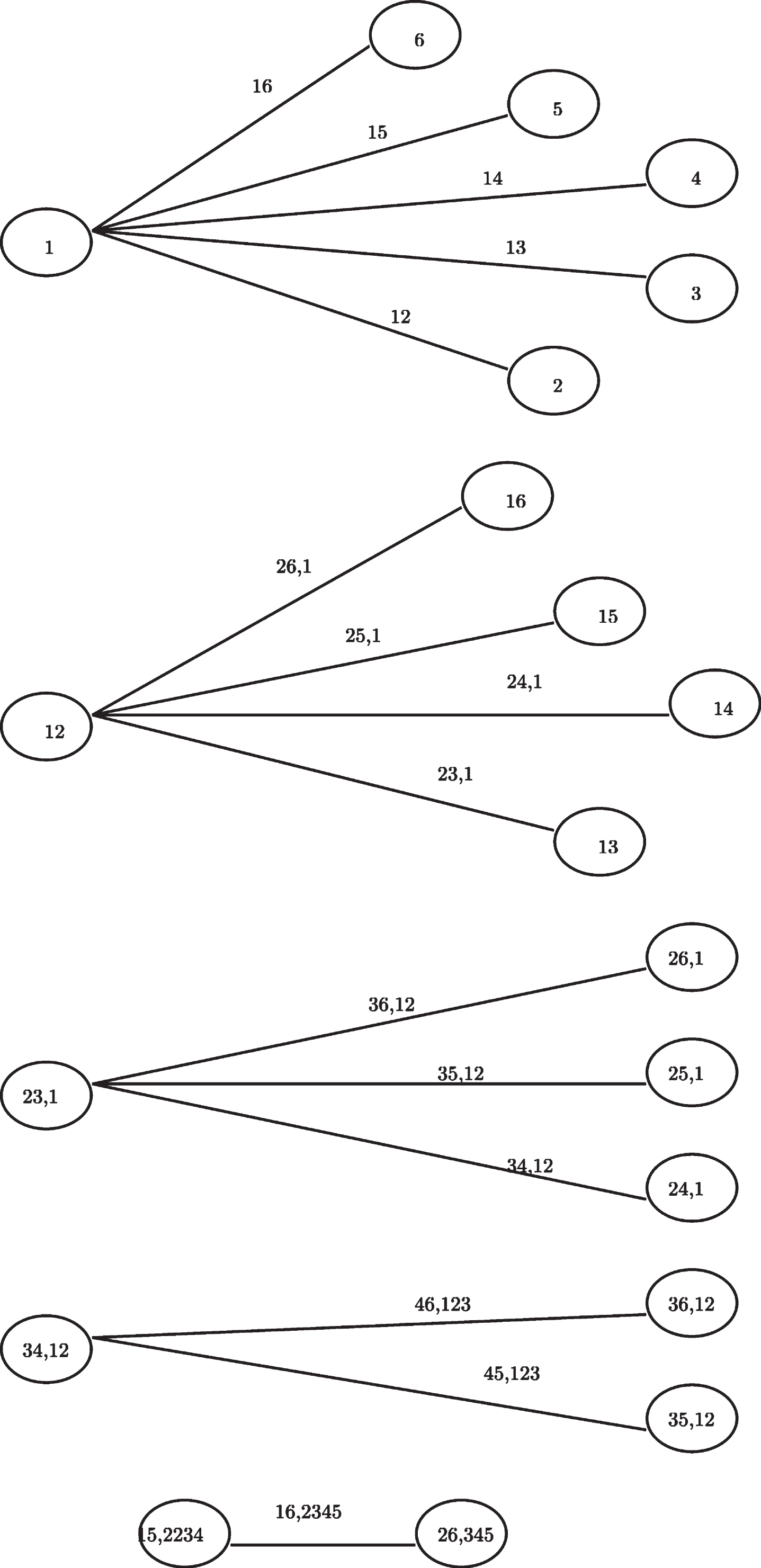
C-vines structure.
The density composition of Fig. 7 is
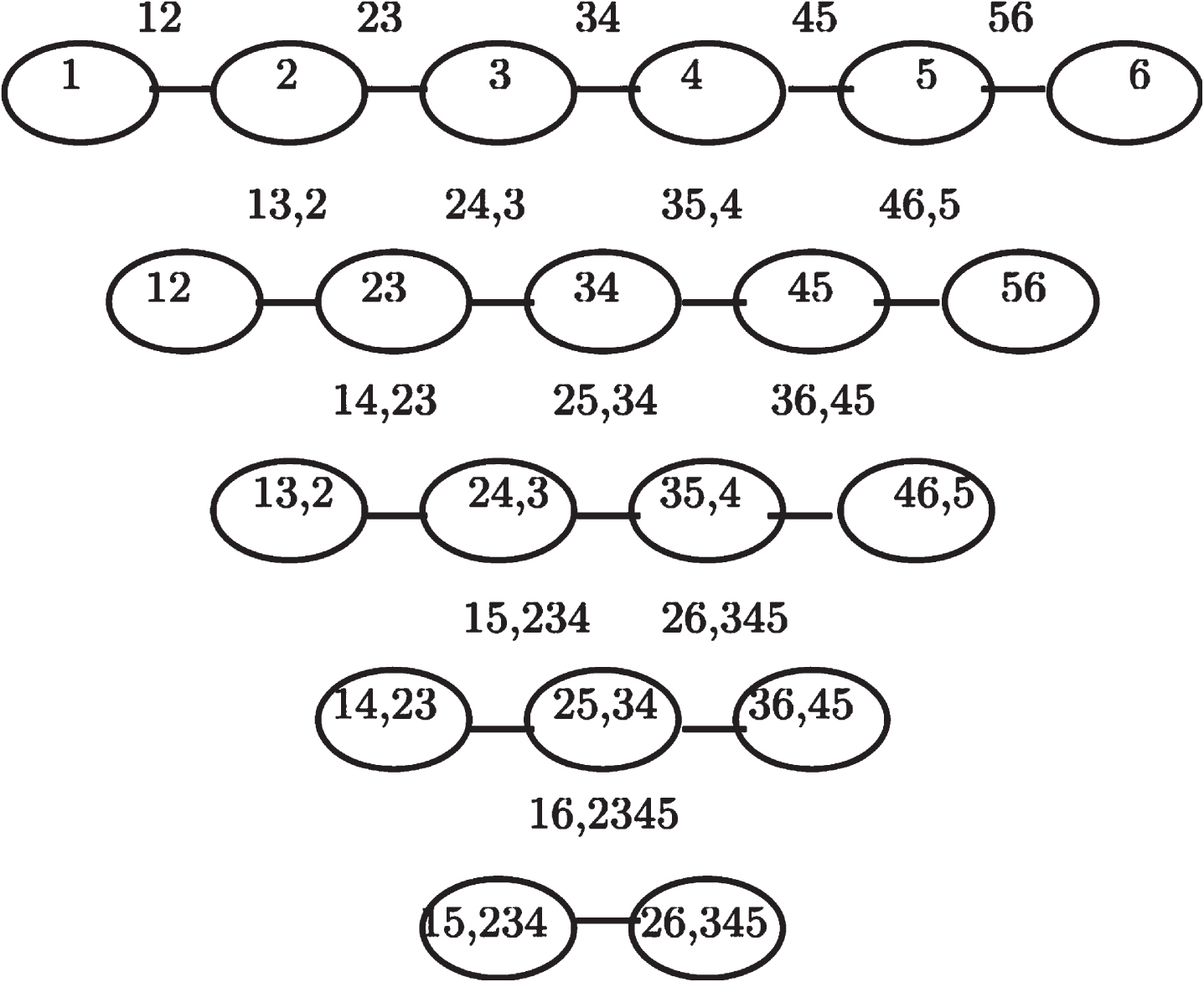
D-vines structure.
The density composition of Fig. 8 is
Maximum likelihood estimation (CML) is often used in C-vine and D-vine copula models. It is critical to have good starting values for the optimization since it will require optimization with at least n(n 1)/2 parameters. The CML approach employs the empirical probability integral transform [0,1] [33] to obtain uniform margins. This approach can be broken down into two steps: Transform margins Estimate the parameters of the copula:
The goodness-of-fit (GOF) test is used to determine whether a copula or copula construction fits the data correctly. The probability integral transform (PIT) [70] and a transformation was used to create a goodness-of-fit test was introduced [10]. Two approaches based on the empirical copula and Kendall’s process, which were originally proposed by [3] for standard multivariate copula, were used in this paper [27, 35]. In the financial services industry, the recent crisis has prompted a re-evaluation of modeling. Experts in the modeling industry have released a manifesto for responsible modeling, which they are enthusiastically supporting, but the financial crisis is not the primary reason for the widespread use of financial modeling. between empirical copula
Discussion
There are two families of copula: elliptical copulas and Archimedean copulas. Both of these copulas are applied to different types of problems. For example, elliptical copulas, the Gaussian copula, are often popular in finance as they do not have upper or lower tail dependence. It is applied in a higher dimensions problem when pairwise dependencies are relatively symmetric and, more critically, extremes do not appear to occur simultaneously. As for the Archimedean copulas, they are best suited to the problem when the tail behavior of all pairings is comparable. However, as mentioned in the previous section, the elliptical and Archimedean copulas have their drawbacks. Therefore, studies were made in the previous years on how to encounter those drawbacks, resulting in more versatile and flexible approaches to copula, such as pair constructions copula, which is the PCC.
Furthermore, there exists a time frame where a general form of copula is then developed into a more flexible and versatile structure to corporate with more complex data. The literature on copula theory dates back to 1959 when Sklar used the word "copula" statistically. He derives the word copula for multivariate joint distribution that links to its one-dimensional marginal distribution. The concept of copula was introduced in the 1950’s decade, and the discovery of copula is associated with the three seminal research papers of Sklar, Fréchet, and Féron. Fréchet introduced distributions with the given marginal, which was further developed by his students, Féron and Sklar. Féron provided certain functions that coupled three-dimensional distributions with corresponding one-dimensional marginal distributions, defined on the unit cube [0, 1]. Then, in 1959, Sklar introduced functions on the unit d-a cube that relates d-dimensional distributions to their one-dimensional marginal distributions for any d > 2. Sklar also focused on the fundamental properties of these functions. Sklar then introduces the copula notion, which he names Sklar’s Theorem after.
In the 1990s, research on copulas and their applications grew primarily. The important monographs by [46] appeared in this decade and now become standard references on articles related to copula theory. The theory is about A class of m-variate distributions with given margins and m (m - 1)/2 dependence parameters, which is based on iteratively mixing conditional distributions, which is derived. At the end of this decade, the interest in the copula theory grew markedly. The growing interest is due to its applications in finance, insurance,, and risk analysis, as seen by the the frequency of published papers. With the turn of the new century, copula theory research and applications grew enormously. [5, 6] introduced the notion of a vine-dependent distribution and demonstrated the existence of such distributions. A vine is a visual representation of data that may be used to decrease the conditional independence property of Markov trees and belief nets. A vine allows the expert to specify conditional rank correlations, or more generally, conditional copula, so the information is never inconsistent.
Further significant developments and applications in the new century are rapidly building. Even though, unlike the c-vine and d-vines, the form of the r-vines can change widely based on the statistical characteristics of the structured multivariate distributions, [15] developed an analytical model to break down multivariate densities and estimating the inference of r-vines structures. [3] describes how multivariate datasets with complicated structures of dependence in the tails may be described using a chain of pair-copula acting on two variables simultaneously. Despite the above developments, the application of copulas in many fields of sciences and finance grew enormously in the second decade of the 21st century. [59] presents a Bayesian analysis of pair-copula constructions (PCCs), which outperformed several previous multivariate copula structures in modeling financial data relationships. To enable extreme events in bivariate margins independently, they use bivariate t-copulas as building pieces in a PCC.
The assessment of market risk has been the primary application area of PCC in finance. Market risk is typically measured in terms of value-at-risk (VaR) or conditional value-at-risk (cVaR). Both measures are intended to estimate the likelihood of large losses, creating a need for flexible dependency models such as pair-copula constructions. In the seminal paper [3], the PCC was used to simulate the dependency structure of a portfolio comprising two stock return indices and two bond return indices. Since then, these constructions have been used for equities [2, 9, 30, 84, 87], interest rates [9, 59, 69], exchange rates [19, 30, 52, 61, 88], electricity prices and other commodities [30, 38, 58, 68, 78, 82] and housing prices [90]. In the majority of these studies, the PCC outperforms alternative dependency models.
From a methodological standpoint, a misunderstanding of credit risk contributed to the 2008 financial crisis [17]. The Gaussian copula has conventionally been used to model the correlation structure of a credit portfolio, which has earned much condemnation, even in a non-academic context [71]. The works in [14, 29, 32] demonstrate how vine copula can generate a more consistent and precise forecast of a loan portfolio’s economic capital. In [20], a different credit risk application uses the pair-copula construction. This paper aims to calculate the probability of default (PD) for businesses. They consider a relation to a particular model based on balance sheet data, in which the equity dynamics are modeled using the D-vine.
Dalla Valle et al., [22] published a paper that described a new automated model selection and estimating approach based on graph theoretical principles. This comprehensive search approach is tested and implemented in a massive simulation study of a 16-dimensional financial data set, including international equities, fixed income, and commodity indexes. Schweizer and Sklar [74] present the R package CDVine, which includes functions and methods for statistical inference of C-vine and D-vine copulas, in a separate paper from 2013. It includes bivariate exploratory data analysis methods, bivariate copula selection, and pair-copula family selection in a vine. Shi et al., [79] proposed a copula regression for multivariate longitudinal claims to capture the distinctive aspects of policy-level insurance costs. The Tweedie double generalised linear model is used in the model to look at the semi-continuous claim costs of every coverage type, and a Gaussian copula is used to account for cross-sectional and temporal dependence among the multilevel claims.
Aside from that, portfolio optimization has made great strides since Markowitz’s [55] seminal work. After demonstrated it citerockafellar2000optimization that linear programming techniques can be used for cVaR optimization, this approach has become quite popular. Typically, scenarios are fed into the cVaR optimization. As a result, the returns on the portfolio’s instruments can have any multivariate distribution. In [53], individual asset returns are assumed to be distributed according to the skewed Student t-distribution of [44]. At the same time, a canonical vine copula is used to model their dependency structure. Compared to other models with elliptical or symmetric dependence frameworks, this model produces the best results across various statistical and economic metrics. Other papers demonstrating pair-copula constructions’ utility for portfolio optimization are [7, 21, 45]
The impact of explicit dependence modeling on capital requirements among non-life insurance losses is investigated in this paper. Throughout the process of development of copula, Regular vine (R-vine), canonical vine (C-vine), and drawable vine (D-vine) copulas were used by [4] to examine the dependence risk characteristics of three 20-stock portfolios from the retail, manufacturing, and gold-mining equity sectors of the Australian market in periods before, during, and after the global financial crisis (GFC) in 2008. In addition, [57] extends recent contributions in quantitative risk management by modeling non-life insurance risks in a multivariate framework. The latest study, which is by [16], describes how rank-based procedures for inference in copula models for continuous responses whose behavior does not depend on covariates can be adapted to the broader framework in which (possibly non-linear) regression models for the marginal responses are linked by a copula that does not depend on covariates.
Consistent with the result of other studies, [13] developed a new time-varying mixed copula in which a two-stratum process sets the dynamic weights of four unique copulas to study the extent of tail dependency in four independent quadrants. The weight of each copula is established in the two-stratum process by the relative importance of positive and negative dependence systems, followed by its historical values and adjustment processes. Each stratum’s weighting mechanism changes over time. The asymmetric tail dependencies between the stock and exchange rate markets are examined using this revised formulation. As for the latest study made last two years, Quatto et al., [67] proposed a new copula for modeling higher-order dependencies between pairs of portfolio assets, employing orthogonal polynomials to model symmetric co-kurtoses. The Gram–Charlier expansion of the Normal distribution or Gram–Charlier-like expansions of leptokurtic laws are used to describe skewness and leptokurtosis of portfolio margins.
In another study produced in 2021, the general C-vine copula can characterise the dependence structure among collateral return series and has greater predictive accuracy over the multivariate normal distribution and other copulas, according to [89]. The general C-vine copula was proposed as a component of portfolio methods that financial inventory providers may use to reduce default risks and improve their risk profile. Therefore, it is shown that copula has grown these past decades vigorously, and remarkably it is an essential tool for solving problems related to finance and insurance.
Conclusion
This paper can comprehensively review the development of copulas that focus on the financial field. Based on our study, various previous research supports that copulas have undergone a significant development process over these past decades. The main research findings are as follows: On the one hand, the concept of copula leads to determining the best way to solve the problem with more than one marginal distribution since it connects the marginal distribution functions. Besides, problems associated with dependence measures can also be solved efficiently using the copulas function as they are much more accurate and popular [64]. Furthermore, many copulas can help researchers determine the suitable model for solving their financial problems based on their characteristics, such as R-Vine, C-Vine, and D-Vine copulas. This will give them options to calibrate the maximum usage of the copula model to achieve the best analysis outcome.
Our paper’s findings have important implications. Our paper reveals that the development of copulas has successfully assisted financial problems that involve complicated dependence measures. For example, to study the correlation structure of a credit portfolio, researchers should consider using the Gaussian copula due to its radially symmetric factor, and it is the most popular copula for modeling association. Furthermore, to solve the market risk problem, it is recommended to use the PCC. This is because PCC can minimize dimension by pairing the variable set and creating a versatile dependency structure. This information helps future researchers to choose the appropriate copula related to the financial field. Besides that, our paper also provides knowledgeable remarks on copula from its first existence, which was first introduced by Sklar [81] when he tried to solve problems related to fundamental features of connecting d-dimensional distributions with one-dimensional marginal distributions. He then discovered that there exists a task of identifying a link between those two distributions. As a result, he introduced a copula function, which is a statistical function connecting n-dimensional distributions to their one-dimensional margins. This copula function was put under his name, which is known as Sklar’s theorem. In the first decade of the 21st century, copula keeps evolving, especially in the financial field. This is shown in the paper [3], which indicates that the extended copula, the PCC, is used to simulate the dependency structure of a portfolio of different stocks. The latest study, by Zhi et al., [89], revealed that the general C-Vine copula could characterize the dependence structure among collateral return series. This shows that the copula has grown these past decades rapidly. As an initial attempt at reviewing the development of copulas in finance, this work can be extended in several directions. First, instead of focusing on the applications in finance, this study could include the applications of copulas in other fields, such as medicine and education. For instance, in the medical research paper of [86], he discussed the simple modifications that maintain the probit assumption for marginal distributions while introducing non-normal dependence using copulas. The paper’s findings show that the Frank copula outperforms the standard bivariate probit model on the effect of insurance status on the absence of ambulatory health care expenditure. Moreover, in the education field, Gilenko and Chernova [37] discovered that to secure the positive effect of financial literacy on financial well-being, specifically via saving more actively, appropriate programs should be introduced at the early stages of education. They employed a copula-based bivariate probit-regression approach and found that the studied magnitude is substantially greater when the endogeneity effect is appropriately controlled for. Furthermore, in line with the rapid development of copula, a new update on research on copula and its application can also be included in the paper.
Footnotes
Acknowledgment
We acknowledge financial support from the Ministry of Higher Education Malaysia under the Fundamental Research Grant Scheme (FRGS) FRGS/1/2020/ STG06/UTHM/03/5.