
Abstract
The advent use of smart devices has enabled the emergence of many applications that facilitate user interaction through speech. However, speech reveals private and sensitive information about the user’s identity, posing several security risks. For example, a speaker’s speech can be acquired and used in speech synthesis systems to generate fake speech recordings that can be used to attack that speaker’s verification system. One solution is to anonymize the speaker’s identity from speech before using it. Existing anonymization schemes rely on using a pool of real speakers’ identities for anonymization, which may result in associating a speaker’s speech with an existing speaker. Hence, this paper investigates the use of Generative Adversarial Networks (GAN) to generate a pool of fake identities that are used for anonymization. Several GAN types were considered for this purpose, and the Conditional Tabular GAN (CTGAN) showed the best performance among all GAN types according to different metrics that measure the naturalness of the anonymized speech and its linguistic content.
Introduction
In the past decade, digitization has revolutionized the world by bringing new possibilities and innovations that ease daily activities. Among these innovations are the applications that understand natural language voice commands and complete tasks for the user. These products are called Smart Personal Assistants (SPA) [13] or Virtual Assistants. A typical virtual assistant system can interpret human speech, deduce the intent, perform an action and/or respond via synthesized speech. Actions might include asking questions, controlling home devices, or managing tasks such as writing an email, playing a song, calling someone, or setting a reminder.
SPA systems rely heavily on emerging technologies such as artificial intelligence, natural language processing, and speech recognition which have witnessed unprecedented development lately, facilitating the offering of many reliable and commercial SPAs such are Google’s Assistant and Amazon’s Alexa. These SPAs are being widely adopted by users. According to Google, 27% of the global online population is using voice search on mobile phones [14]. Moreover, TechCrunch reports that over two billion devices have voice assistants installed in 2020 [17].
The operation of SPAs in different systems such as smartphones, watches, televisions, and smart cars involves the use of different modules such as automatic speech recognition (ASR), natural language understanding (NLU), dialog manager (DM), and text-to-speech (TTS). These modules are usually deployed on the cloud, which implies that the user’s speech, which embeds his private information and identity, is transferred to the cloud via the network. Hence, there is a great risk of exposing the personal privacy of the speech data and the speaker’s identity. Accordingly, adequate privacy preservation is essential to ensure that sensitive bio-metric data, including voice recordings or speech data, are properly protected from misuse. This is a huge concern, especially with the recent EU General Data Protection Regulation [26] that demands giving control to individuals over their personal data.
Generally, speech privacy includes the privacy of the linguistic content and the speaker’s identity. Protecting the speaker’s identity is crucial as it can be used for verification and authentication. Hence, speaker anonymization or de-identification techniques are usually employed. These techniques refer to the process of suppressing the speaker’s identity (timbre, pitch, speaking rate, and speaking style) by modifying the original speech signal to make it sound like an anonymous speaker while maintaining linguistic content, speech quality, and naturalness.
The baseline for such technology was first provided by The INTERSPEECH 2020 VoicePrivacy challenge [6], in an attempt to gather effort in the research community to facilitate the development of voice privacy preservation technology that suppresses speaker-discriminative information, promote effective anonymization techniques, provide benchmarking techniques and to investigate the proper evaluation metrics in anonymization. The challenge provided a baseline system for concealing speaker identity by separating the linguistic content from the speaker’s identifiable information. The baseline performs anonymization by replacing the speaker identity that is modeled as an x-vector, which is a neural network-based latent representation, with a pseudo-identity that is derived from a pool of real speakers’ identities. The problem with this approach is the use of real speaker identities in the anonymization process, in which it can be argued that the anonymized speech can protect the identity of one user at the expense of exposing another identity and/or associating it with a different speaker.
The work presented in this paper addresses the speaker anonymization problem formulated by The VoicePrivacy Challenge by proposing a novel speaker anonymization model through the use of Generative Adversarial Networks (GANs) to generate a pool of synthesized human identities that can be used in the anonymization pipeline provided by the challenge. We believe this is the first attempt to synthesize human speaker identities using GANs. Several GAN types were investigated for this purpose, and the conditional tabular GAN (CTGAN) showed the best performance among all GAN types based on different metrics. Experimental results proved the ability of the proposed anonymization approach to producing diverse synthesized speaker identities (an average of 0.75 for cross-cosine similarity) that are close to real identities (an average of 0.49 for the Kolmogorov-Smirnov measure). Also, the proposed approach resulted in the lowest word error rate of 6.39% when assessed using an external ASR system.
The rest of the paper is organized as follows. In Section 2, anonymization technology and some related work including the baseline system provided by the VoicePrivacy Challenge are presented. Section 3 discusses the proposed anonymization model. Section 4 outlines the process of GAN selection, training, and the performance metrics used to evaluate different GAN designs. In Section 5, the findings of the conducted experiments are discussed. Finally, Section 6 summarizes the main findings of this paper and discusses some of the possible future directions.
Related work
As mentioned earlier, speaker anonymization is the process of masking the identity of an original speech signal while preserving the linguistic content and speech quality. Speaker anonymization differs from speech anonymization which targets hiding the linguistic content of speech. Speaker anonymization can be performed physically by introducing some sort of disturbance or noise to the original speech signal [9, 21]. Alternatively, speaker anonymization can be performed logically by manipulating the speaker identity [11]. The anonymization technique presented in the paper falls in the logical category.
Alegre et al. [1] investigated the so-called speaker evasion and hiding using voice conversion techniques to avoid surveillance systems. The system evaluated only how the approach could degrade ASV performance and did not consider degradation to speech quality.
Jin et al. [11] proposed a voice transformation (VT) system to change the speaker identity into a special speaker. In [15] and [18], the authors improved the convenience of the VT-based method to enable the user to select an approximate transformation from a pool of pre-trained VT models for speaker anonymization. A convolutional neural network was also employed as a VT system in [3] where different transformations were averaged to obtain the anonymized speech. Justin et al. [12] performed speaker anonymization by first recognizing the diphones in the input speech using an ASR system and then synthesizing speech from the recognized diphone sequence. The synthesized speech differs from the original one in speaker identity because the synthesizer is speaker-dependent and was trained using the data of different speakers.
To spread the efforts toward developing speech privacy solutions in the form of a competitive challenge, the VoicePrivacy challenge was introduced as part of The Interspeech 2020 special sessions and challenges [24]. In this challenge, participants are required to anonymize speech datasets while preserving the linguistic content and naturalness of the speech.
The VoicePrivacy challenge provided a baseline system for anonymization. The main assumption in the baseline system is that a speech waveform can be decomposed into two sets of features. The first set contains the sequence of spoken words while the second set includes the acoustic features that represent the speaker identity, which are the target to be modified in an anonymization process.
The baseline system is shown in Fig. 1 [6]. It includes three blocks to extract the two sets of features mentioned previously. The first block (F0 Extractor) extracts the fundamental frequency (F0) or pitch of the speech. F0 is a widely adopted feature in ASR systems as it determines the perceived relative loudness of speech and plays an important role in perceived para-linguistic and prosodic information in speech [5]. The second block is an automatic speech recognition (ASR) system that is based on deep neural networks (DNN) and is responsible for extracting the phonemes posteriogram (PPG) that encodes the linguistic content of speech.
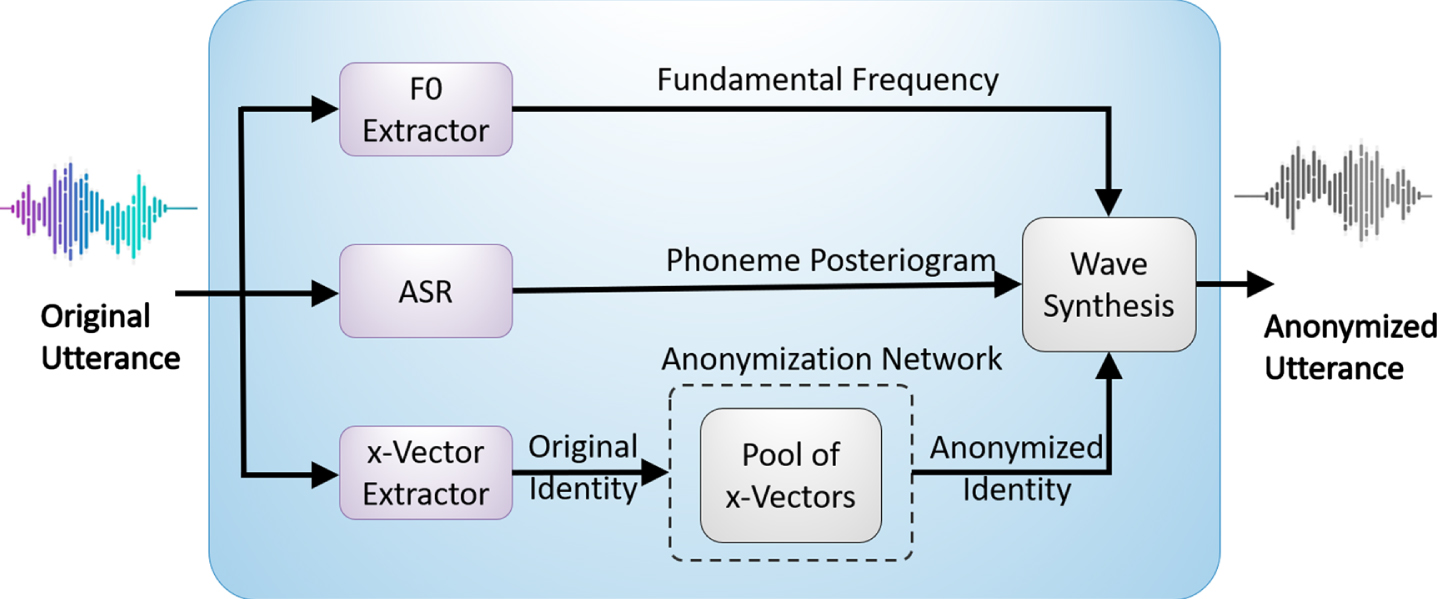
Speaker anonymization pipeline [6].
The third block (x-vector Extractor) is used to extract the x-vector of the speaker, which is a speaker embedding that has been lately and widely used to model the speaker identity irrespective of the speech content. x-vectors have shown impressive performance in speech verification and recognition applications compared to other types of features such as the d-vectors and i-vectors [23]. Basically, The x-vector extractor is a deep neural network (DNN) that performs speaker recognition from frame-by-frame speaker labels to utterance-level speaker labels through an aggregation process. The general structure of the x-vector network is shown in Fig. 2. In this network, time-delay layers are first used to extract frame-level embeddings of an utterance. Afterward, the mean and standard deviation of the frame-level embeddings are concatenated as a segment-level feature using a statistical pooling layer. The generated segment-level features are then used to train a feedforward network that classifies the speaker. All the layers are trained jointly. Once the network is trained, the x-vector is defined as the speaker-level embedding produced by the second to last hidden layer, i.e., embedding a that is shown in Fig. 2, which is a 512-dimensional vector. The trained model can then generate the x-vector for the input utterances.
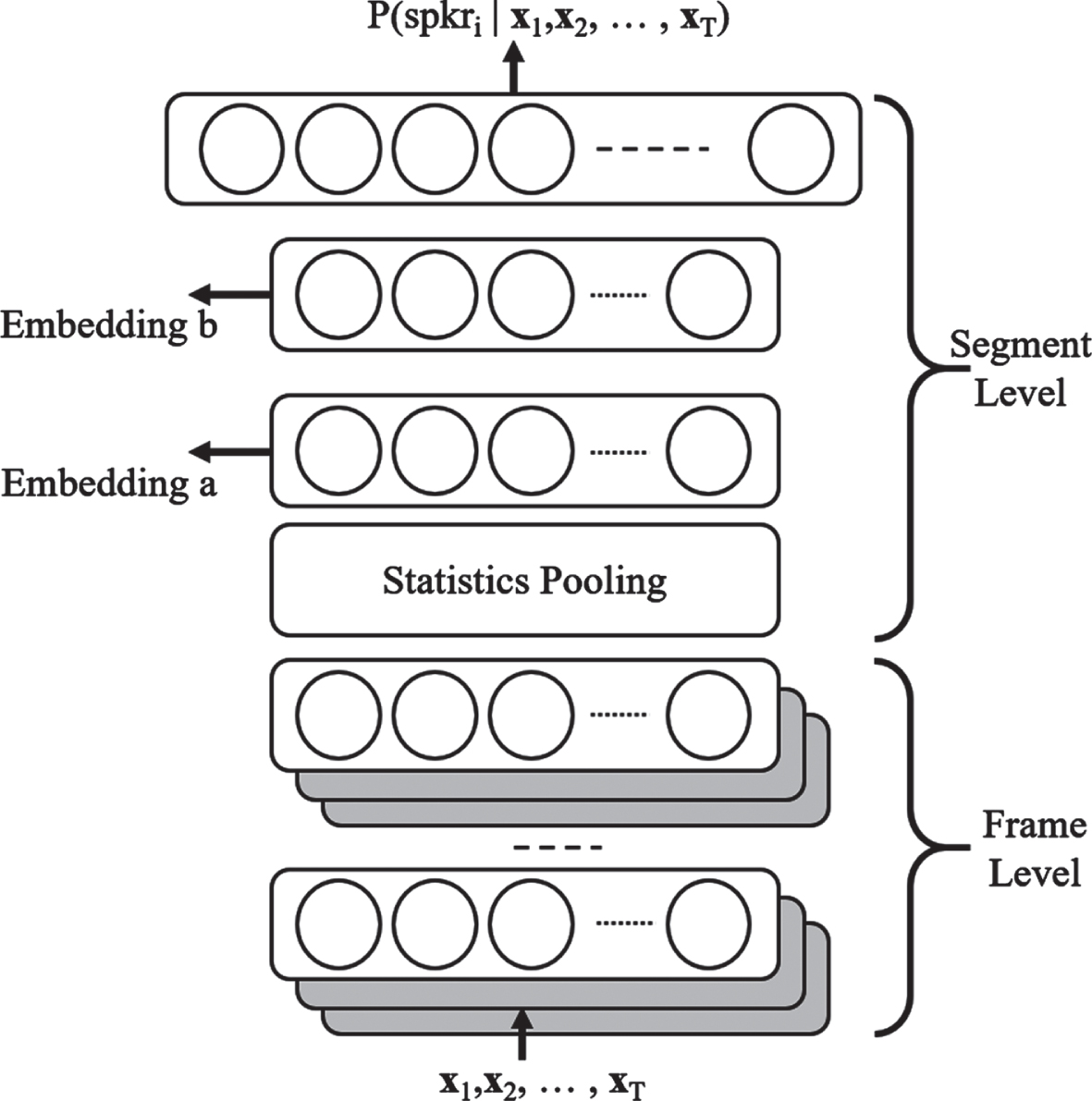
x-vector network [23].
In addition to the feature extraction blocks, the baseline has an anonymization block that consists of a pool of real x-vectors, i.e., x-vectors for real speaker identities, and an anonymization scheme based on using a similarity metric to select a subset of the pool then compute it’s average to create a new synthetic x-vector representing a new speaker identity.
With these features (F0, PPGs, and anonymized x-vector) in hand, the baseline model synthesizes the speech waveform using an acoustic model and a neural waveform model. The baseline system suffers from poor linguistic preservation highlighted in the high word error rate (WER) for largely distant anonymized x-vectors, in addition to the fact that it uses real identities in anonymization, which may result in privacy issues, as discussed earlier. The work in this paper attempts to mitigate such issues by generating fake identities that can be used in anonymization.
In [25], Turner et al. modified the anonymization process of the baseline by using a distribution-preserving voice anonymization technique to generate x-vectors that approximate the original distribution of x-vectors and their intra-similarities using Gaussian Mixture Models (GMM). To anonymize an utterance, the GMM is randomly sampled to obtain a fake x-vector. The distance between the original x-vector and the fake vector is calculated to exclude the fake vector if the distance is less than a predefined threshold. This is an optional step that can be used to mitigate the risk of the fake x-vector being similar to the original one. The proposed model resulted in higher word error rates (WER) compared to the baseline. Additionally, the proposed model did not produce consistent, equal error rate (EER) values and failed to supersede the baseline model for some datasets.
Champion et al. [5] modified the baseline by including the pitch (F0) in the anonymization process. This was based on their analysis of the impact of this modification across gender which showed that it can always improve the anonymization process. They linearly transformed the log-scaled version of the F0 using
As discussed in Section 2, the baseline system provided by the VoicePrivacy Challenge uses a pool of real x-vectors to anonymize a given speech signal. The proposed anonymization system is basically similar to the baseline system except for the fact that the pool of real x-vectors is replaced with a pool of fake x-vectors that are generated using adversarial generative networks (GANs). In this section, a swift overview of GANs is presented. Then the architecture of the proposed anonymization model and the process of GAN network selection are discussed.
Generative adversarial networks
Generative adversarial networks were first proposed in [7] as a framework to estimate and approximate generative models via an adversarial process. The basic GAN architecture comprises two networks; the generator network (G) and the discriminator network (D). As the names imply, the generator network generates data following a desired distribution from some latent representation (usually noise). On the other hand, the discriminator network attempts to distinguish between the data produced by the generator, i.e., fake data, and the data sampled from the real distribution. The training objective in GANs is to fool the discriminator network into misidentifying fake data as real, which indicates that the generator network learned the distribution of the real data. Backpropagation is applied in both networks so that the generator produces better samples while the discriminator becomes more skilled at flagging synthetic samples.
The original GAN [7] is known as the vanilla GAN, and it was benchmarked in imaging applications using relatively simple image data sets. Several GAN architectures have been proposed in the literature such as the conditional GAN (CGAN) [16], the Wasserstein GAN (WGAN) [2] and the conditional tabular GANs (CTGAN) [28]. Different GAN types attempted to address issues related to the training of GANs and their accuracy and stability in approximating real data distributions for different data types such as images and tabular data. Despite the theoretical existence of unique solutions in the training of GANs, the training of GANs is challenging as the generator network may converge to a state where it is generating the same data for different inputs; a phenomenon known as mode collapse in GANs [22]. In general, different GAN types were used in image applications such as de-noising, image generation, and style transfer. This paper is concerned with investigating the use of GANs in generating speaker identities that can be used in the anonymization baseline in [6] instead of the real x-vectors.
Anonymization model architecture
The architecture of the proposed anonymization model is essentially similar to the baseline system depicted in Fig. 1 in terms of having the feature extraction blocks for F0, PPG, and x-vector of the input utterance, as well as the speech synthesis block that generates the anonymized speech waveform out of F0, PPG, and the anonymized x-vector. The main difference is in the nature of the x-vector pool used for anonymization. The proposed system uses fake x-vectors generated using GANs, which is the major contribution of the paper. In general, we seek to design and train a suitable GAN that can generate pseudo identities in the form of x-vectors. When these fake identities are used to anonymize some input speech waveform, they should produce an anonymized speech that is not only natural but also has a minimal change in the linguistic content of the original speech waveform.
The general architecture of the GAN to be designed and trained is shown in Fig. 3. In this network, the generator network (G) is trained to generate fake 512-dimensional x-vectors based on 100-dimensional input noise vectors Z derived from a uniform distribution. The training of the two networks is performed in an alternating fashion such that the discriminator (D) network is trained on real and fake samples to maximize its classification accuracy in terms of identifying real and fake samples. The gradients of the loss function of the discriminator are calculated and backpropagated through the D network only. Afterward, the G network is trained to generate a new set of x-vectors that are fed into D along with real samples in an attempt to minimize the classification accuracy of D. The gradients of the loss function of G are then calculated through the D and G networks, and only the weights of G are updated.
This process is repeated for a number of epochs during which the generator performance is expected to improve in terms of its ability to generate better fake samples that the discriminator cannot identify as fake. Meanwhile, the discriminator performance is expected to improve to create an environment of adversarial training. More details on GAN training and loss functions can be found in [23].
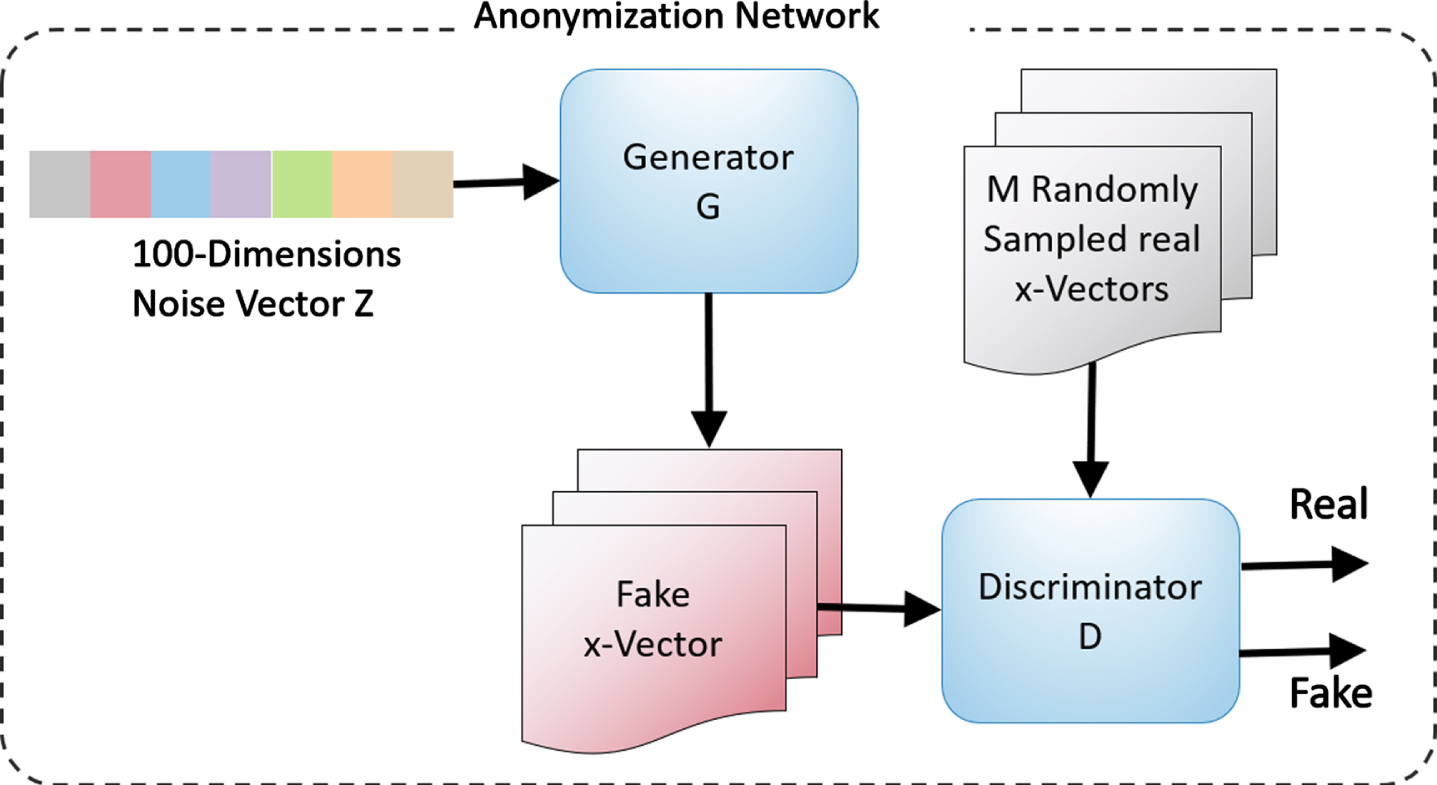
GAN-Based architecture for generating anonymized x-vectors
As mentioned in Section 3.1, there are many types of GANs in the literature. In this paper, the performance of the vanilla GAN, CGAN, WGAN, and CTGAN in generating fake x-vectors is investigated. The first three types of these GANs are popular in image applications while the CTGAN is suitable for tabular data, which is the case of x-vectors. Table 1 presents the architecture and hyperparameters used in implementing and evaluating each of the four GAN designs in this paper.
The four GAN architectures and their hyperparameters
The four GAN architectures and their hyperparameters
Different architectures and parameters for the four GAN types were investigated and evaluated in terms of their ability to generate a suitable pool of fake x-vectors for speech anonymization. Grid search was considered in the valuation to search for the best architecture and hyperparameters. The architecture and the hyperparameters with the best performance in terms of their generalization capabilities to generate x-vectors with a distribution similar to real x-vectors were selected for each of the four GAN types. Several evaluation metrics were used for this purpose as discussed in Section 5. Table 1 shows the architecture and hyperparameters selected for implementing and evaluating each of the four GAN designs in anonymization.
It is worth mentioning here that designing the architectures of the vanilla GAN, CGAN, and WGAN; is considered an adaption of these networks to work with the 512-dimensional x-vectors as they are originally tailored to work with images. This included changes in the network size, activation functions, and the type of layers. For example, the use of convolutional layers degraded the performance significantly as the discriminator network dominated the performance of the generator. Alternatively, dense layers are used in different architectures which showed better performance as they are more suitable for approximating and modeling structured data such as x-vectors.
In this section, the evaluation strategy and the performance metrics used to select the best GAN are discussed. The selection process was performed in two phases. In the first phase, the ability of the considered GANs to generate x-vectors with a distribution similar to real x-vectors distributions is evaluated (subsection 4.1. In the second phase, the GANs that produced the best distribution of x-vectors were used to generate pools of fake x-vectors used in the anonymization system. The GAN that provides the best-anonymized speech quality is selected as the generator for the pool of fake x-vectors in the proposed system (subsection 4.2). Also, a brief description of the datasets used in the evaluation is presented in the last subsection.
Phase I: Generative model evaluation
As discussed earlier, most of the GAN networks were employed in image applications where the evaluation of the GAN output is pretty straightforward through assessing the quality of the generated images. In this case, the GAN is used to generate the 512-dimensional x-vectors. Evaluating the quality of the generated x-vectors requires using them to synthesize the anonymized speech waveform. However, this approach involves several cascaded models, which would imply the possibility of introducing a cascaded error that may compromise the whole evaluation process. Moreover, one of the most common problems in training GANs is mode collapse, where the generator gets stuck in producing one or a few distinct samples rather than capturing the training data distribution and producing diverse samples within that distribution.
As a first phase for GAN selection and to eliminate possible errors in the synthesis system, the ability of the considered GANs to generate x-vectors with the proper distribution is evaluated. For this purpose, two performance metrics are used to quantify the generation quality of the GANs. The first metric is the cross-cosine similarity which is defined by
The other metric that is used to evaluate the generative capability of the GANs is the Kolmogorov-Smirnov (KS) score which is used to measure the similarity between two data distributions. In this case, this allows measuring the similarity between the distributions of real x-vectors and the generated x-vectors. A GAN with a higher KS score implies its inability to model the distribution of the real data, i.e., its synthesized identities don’t follow the distribution of the real identities. Such GAN is excluded in from the experiments conducted in the second phase. More details about this evaluation are provided in Section 5.
Following the first phase of selection, the GANs that showed the best performance in terms of generating reasonable distributions for x-vectors are evaluated in terms of the quality of the anonymized speech. Effectively, these GANs are used to generate anonymized speech utterances, which are then evaluated using an automatic speaker verification system (ASVeval and an automatic speech recognition system (ASReval). Both systems are trained on the LibriSpeech-train-clean-360 dataset using Kaldi speech recognition toolkit [19] as described in the challenge’s evaluation plan [24].
The ASVeval system is used to test whether the anonymized identity matches the original identity of the speaker. Effectively, the ASVeval system is used to verify multiple anonymized and real speakers. In addition, the rejection rates are calculated. The equal error rate (EER) metric measures the verification ability. In anonymization, a typical value of 50% for the EER is desired as it indicates a perfect anonymization scenario where the speaker’s identity is truly hidden. In addition to the EER metric, the log-likelihood-ratio cost function (Cllr) that is proposed in [4] is used as an application-independent evaluation objective. The Cllr metric can be decomposed into a (1) discrimination loss (
The ASVeval system is based on state-of-the-art x-vector speaker embeddings with a probabilistic linear discriminant analysis (PLDA) backend [10]. Experiments conducted in this work followed the VoicePrivacy Challenge plan such that [24]: Compute PLDA (LLR) scores for (a) clean enrollment data and (b) anonymized trial data. Compute PLDA (LLR) scores for (a) anonymized enrollment data and (b) anonymized trial data. For steps 1 and 2, calculate equal error rate (EER) and log-likelihood-ratio cost function (Cllr).
On the other hand, the ASReval system is used to measure the quality of the linguistic content in the anonymized utterance using the word error rate (WER) metric; which is basically the ratio of the wrong words in the anonymized utterance to the total number of words in the original utterance. Lower WER values indicate better matching in the linguistic content between the original and anonymized utterances.
Datasets
A number of publicly available datasets are used for training, validation, and testing of the proposed speaker anonymization system. A detailed description of the data used for training, validation, and testing in our experiments is given in the following subsections. They generally comprise subsets from the corpora as in Table 2.
Datasets statistics
Datasets statistics
The training in the proposed system refers to GAN training only since all other models in the system are pre-trained based on the setting given in Table 3. The Vox-Celeb1,2 & LibriTTS train-other-100 corpora were used to train the anonymization model, i.e., the GAN model. A more detailed description of the data is provided in Table 4. It can be seen that these two datasets combine roughly more than 3000 hours and close to 1.5 million utterances. The utterances are slightly biased with male voices, especially in the VoxCeleb dataset.
Training settings for the pre-trained models in the proposed anonymization architecture
Training settings for the pre-trained models in the proposed anonymization architecture
A validation set is usually used to evaluate the design of different models and to fine-tune the hyperparameters of the model. As stated by the challenge organizers in their evaluation plan [24], anonymized utterances are referred to as trial utterances. In contrast, enrollment utterances are several utterances for each speaker, which may or may not have been anonymized.
Table 5 highlights some details about the validation datasets. The vctk-dev dataset has roughly five times the utterances of the LibriSpeech-dev dataset. For the LibriSpeech-dev dataset, the speakers in the enrollment set are a subset of those in the trial set. For the vctk-dev dataset, two subsets were created of trial utterances, denoted as common parts and different parts. Both include trials from the same set of speakers but from disjoint subsets of utterances. The common part of the trials is composed of utterances # 1 - 24 in the vctk corpus, which is identical for all speakers: the elicitation paragraph6 (utterances # 1 - 5) and rainbow passage7 (utterances # 6 - 24). The enrollment subset and the different parts of the trials are composed of distinct utterances for all speakers (utterances with indexes ≥25).
Statistics of the training datasets for the proposed anonymization architecture
Statistics of the training datasets for the proposed anonymization architecture
Statistics of the validation datasets [24]
Similar to the validation data, the test subsets from two different corpora (LibriSpeech and vctk) are used for testing. Those datasets are split into enrollment and trial subsets as summarized in Table 6. It can be seen that the number of trial utterances is roughly balanced in both datasets. While speakers in enrollment and the enrollment utterances are slightly more biased with females in the LibriSpeech test dataset.
Statistics of the test datasets [24]
Statistics of the test datasets [24]
In this section, the experimental setup and the results for evaluating both the generative models and the anonymization quality are presented and discussed.
Experimental setup
Experiments were performed on a Lenovo IdeaPad L340 Gaming 9th Gen Intel Core i7 4.5GHz 12M Cash 6-Cores, 8GB RAM, 256GB SSD +1 TB HDD, Nvidia GTX 1650 4GB, and Ubuntu 20.04 operating system.
All experiments were based on the challenge publicly available baseline [6]. Software packages involved: Python 3.6 for training the GAN models, Kaldi toolkit [19] for the pre-trained models. The GAN, CGAN, and WGAN were implemented using Keras python framework, whereas the CTGAN was implemented using PyTorch framework. The training, validation, and test sets are those discussed in Section 4.3. The pool of external speakers on which x-vectors are computed to train the GAN model is composed of the LibriTTS train-other-500 and VoxCeleb1,2. Additional information on the number of speakers and the gender distributions can be found in Table 4.
Generative model evaluation results
This is the first phase of GAN selection in which GANs are assessed in terms of their generation ability of fake x-vectors. Figure 4 shows the KS values for the different types of GANs for both genders. The KS metric measures the approximate distance between synthesized (fake) and real distributions of x-vectors. High values for KS (max. of 1) indicate dissimilar distributions. In other words, they indicate that the synthesized speakers’ distribution is far from the real speakers’ distribution, which is undesired. Based on the results depicted in Fig. 4, the CGAN has the highest KS statistic score for both genders; therefore it can be ruled out. However, the KS statistic scores are inconclusive for the GAN, WGAN, and CTGAN.
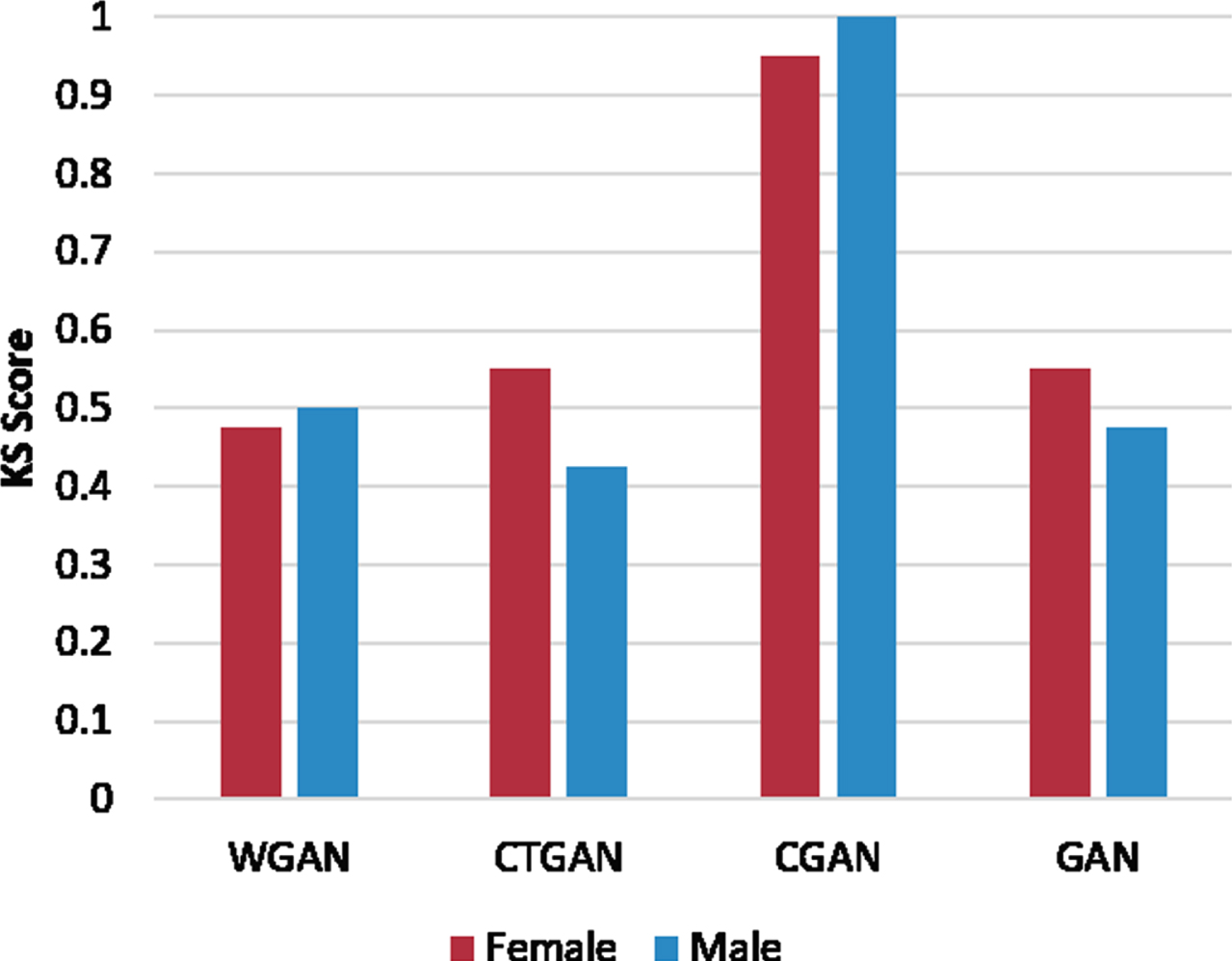
KS score results for different GAN designs
To further assess the GANS, the cross-cosine similarity measure was used to further assess the diversity of the generated x-vectors by computing the cross-cosine similarity between x-vector pairs. Figure 5 compares the cross-cosine similarity distribution for the four GAN designs. Compared to the original data distribution for both males and females, the x-vectors generated by the vanilla GAN appear to have a slightly similar distribution but with some undesired density above 0.8. On the other hand, the CTGAN’s data distribution is good enough to indicate diverse identities, while in the case of a WGAN and CGAN, the results show a dominating state of mode collapse. Hence, this leaves the GAN and CTGAN as the potential candidates that learned the distribution of real x-vectors. Choosing between the GAN and CTGAN is performed by considering their effect on the quality of the anonymized speech, as discussed in the following subsection.
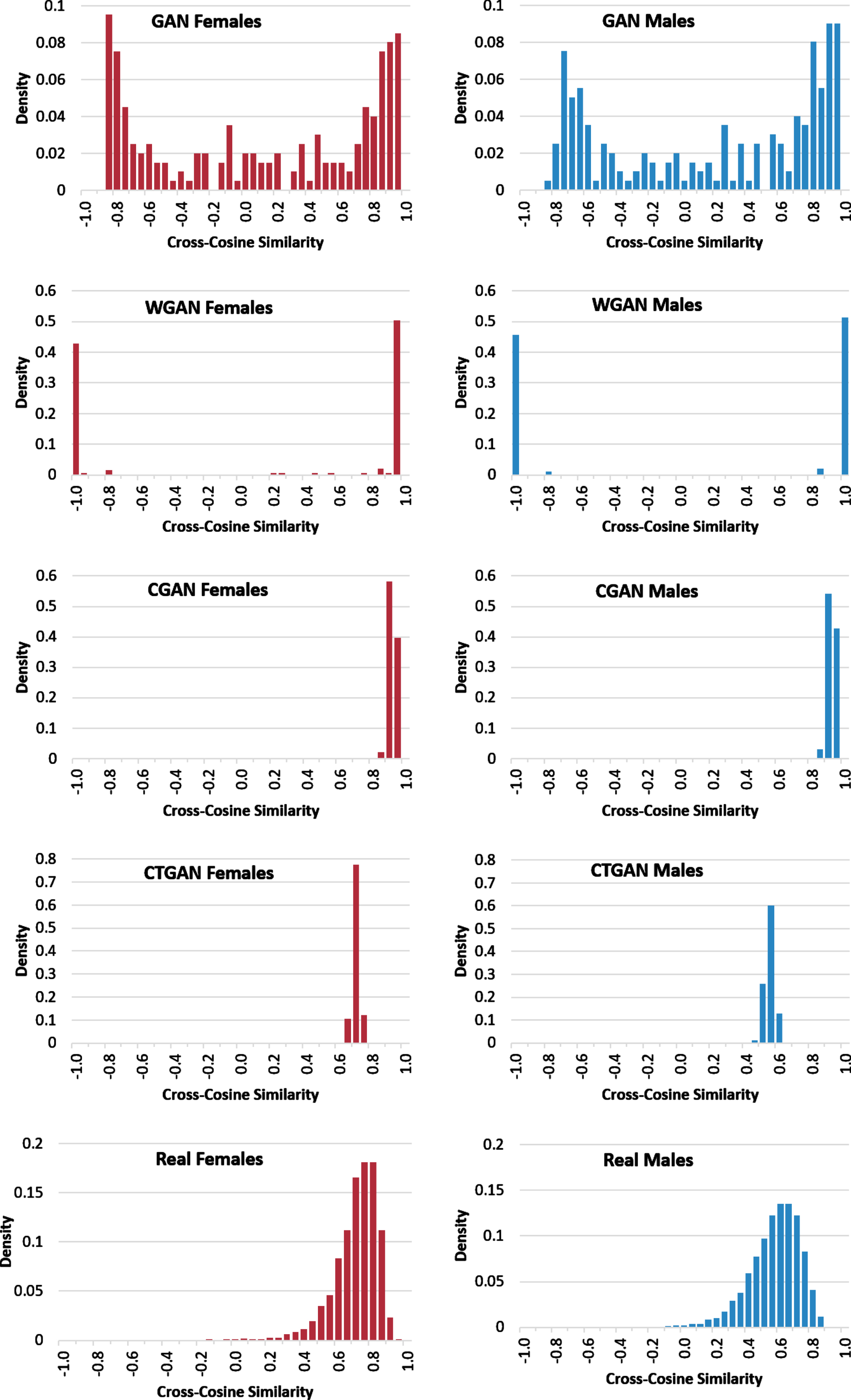
Cross-cosine similarity distribution for the four GAN designs
As a second phase for GAN selection, the performance of the GAN and CTGAN is assessed in terms of anonymization quality. The evaluation considered varying the pool size as well as the distance measure. As mentioned in Section 4, an ASVeval system is used to evaluate the speaker verification ability of the proposed anonymization system. Similar to the evaluation carried out for the baseline [6], the ASV system in [20] is used, as implemented in Kaldi speech recognition toolkit [19], which is trained on the VoxCeleb dataset and then adapted to the vctk domain using 2580 utterances from 20 unused speakers in the vctk corpus. On the other hand, to assess the quality of speech after anonymization, DeepSpeech [8] that is pre-trained on clean external data as the ASReval system is used.
GAN pool evaluation
Table 7 shows the anonymization evaluation results for the GAN-generated pool in terms of WER when the pool size is 1 K. It is evident how the GAN scored an extremely high WER. Effectively, more than 90% of the transcribed anonymization utterances are wrong compared to the same non-anonymized utterances. This indicates the poor quality of the anonymized waveform and its failure to maintain linguistic content.
ASR results for vanilla GAN using validation data
ASR results for vanilla GAN using validation data
Note that a language model (LM) is a probability distribution over sequences of words, which is trained on a large text corpus. A probability distribution is learned over the proper sequencing of words in a spoken language. The LM is used to enhance the output of the ASR models by correcting its mistakes according to the LM’s learned contextual probability of the language. The size of the corpora used to train the LM highly contributes to the model’s accuracy. In this work, two models
In addition, a subjective evaluation through listening to a large subset of the anonymized utterances using the GAN pool revealed significant corruption in the anonymized voice with a bee-like nature. This violates the objective of anonymization, which is to produce a human-like voice. Based on this, the use of vanilla GAN for x-vector generation was dropped, and no further experiments were conducted.
The evaluation conducted in the previous two subsections makes the CTGAN the network of choice for the proposed model to generate the pool of fake x-vectors. In this experiment, the effect of varying the pool size of speaker identities in the anonymization process is studied when the CTGAN is considered. Results are reported in terms of speaker verifiability metrics (EER,C llr ) and speech quality metric (WER) for various pool sizes (1K, 3K, 5K) for both genders, and on multiple test datasets.
In Fig. 6, steady performance of the CTGAN is observed over various pool sizes and multiple datasets in terms of EER and C llr . This indicates that the speaker verifiability metrics don’t depend on the size of the anonymization pool. It is also noticed that EER and C llr values are lower in the case of (a-a), i.e., both utterances are anonymized. This results from the anonymization projecting the utterances to relatively similar speaker identities. In Fig. 7, it can be noticed that there is minimal difference in WER values due to varying the pool size for different datasets. However, the results of large language models tend to be better as the larger LM contributes more to correcting the ASR output mistakes. As a result of the varying pool size experiment, the smaller pool size was used throughout the rest of the experiments to shrink the size of the whole anonymization system.
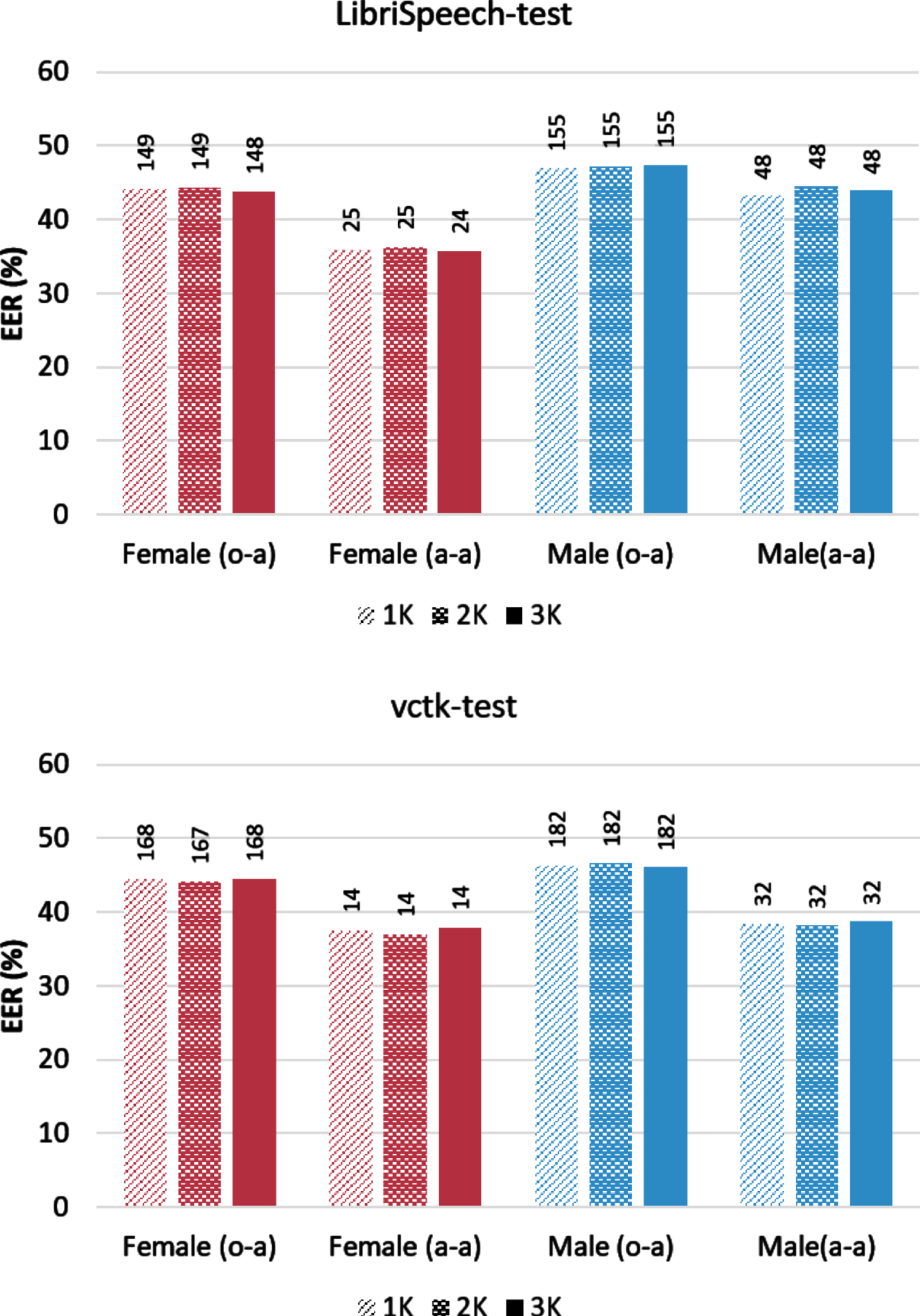
ASV results (EER) for CTGAN-generated pool on Test Sets, with C llr score on top of each bar.
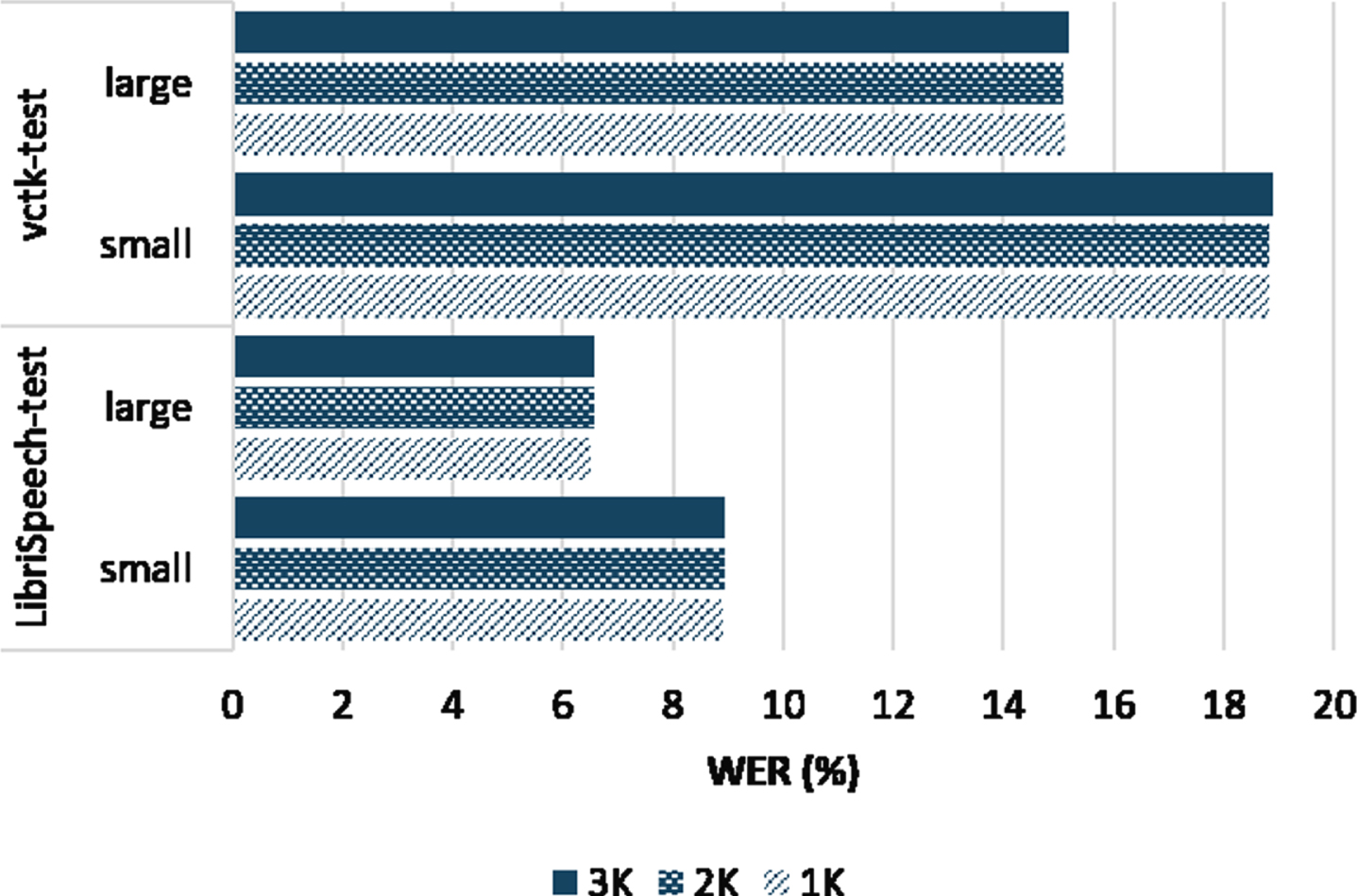
ASR results for CTGAN-generated pool with different pool sizes. Small/Large refers to the language model size.
As discussed earlier, the x-vector selection process from the pool relies on calculating a distance measure, which could be the PLDA distance or the cross-cosine score. The following experiment studies the effect of the choice of the distance metric on anonymization performance. Figure 8 shows the EER and C llr scores for the anonymization system when PLDA and cross-cosine similarity distance metrics are used to select the x-vector from the synthesized pool. The average EER score for both test datasets was 42.2 and 43.03 for the PLDA and cross-cosine similarity, respectively. On the other hand, the PLDA and cross-cosine distance metrics scored an average C llr score of 96.47 and 95.1, respectively. These results imply that the choice of distance metric has no significant impact on the performance of the anonymization system in terms of speaker verification.
Regarding the effect of the distance metric on the quality of anonymized speech, Fig. 9 shows that both distance metrics (Cosine and PLDA) result in comparable WER scores for different datasets and using different language models. Hence, it can be concluded that there is no significant difference between the two distance metrics on the performance of the anonymization system.
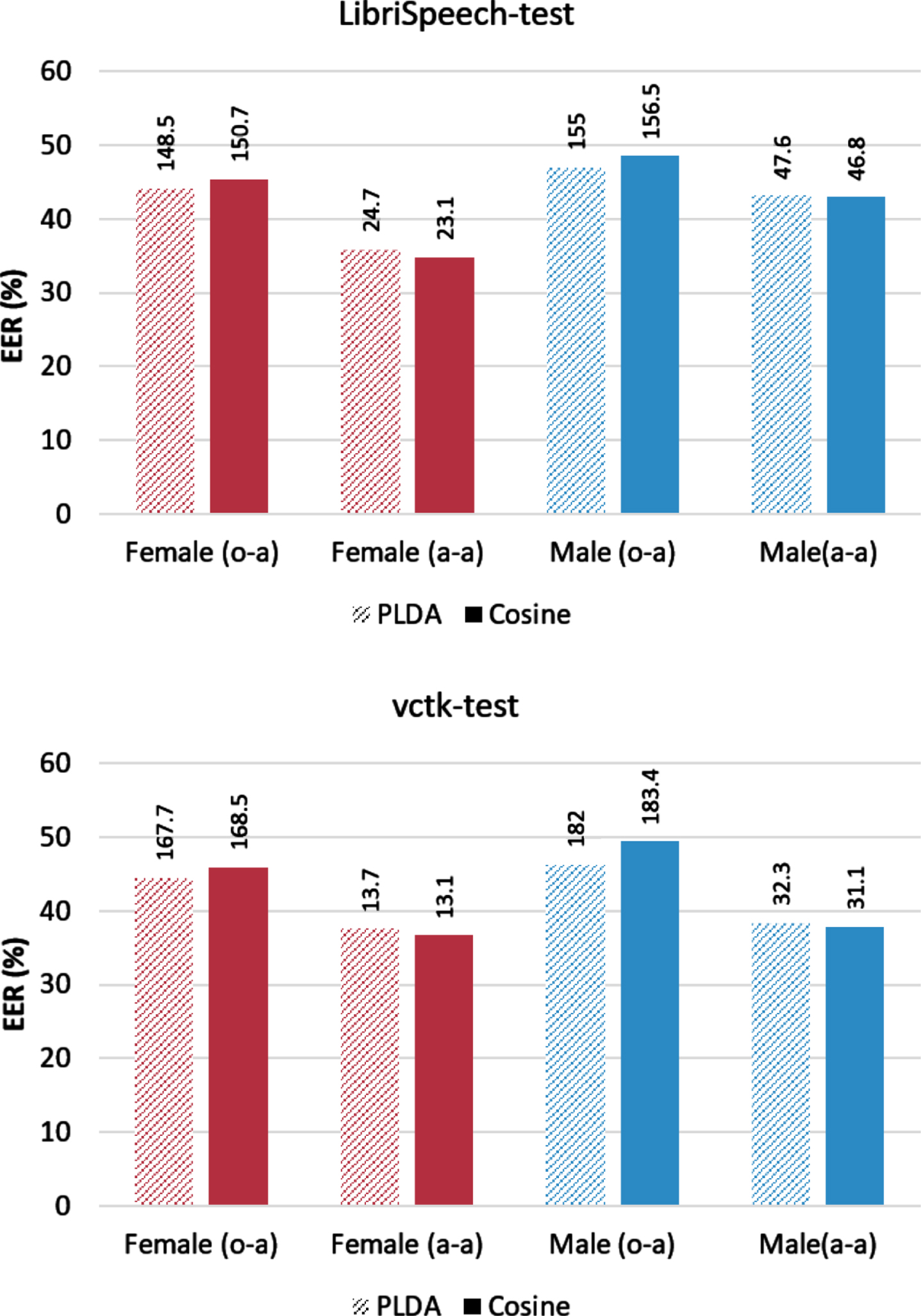
ASV Results using PLDA and Cross-Cosine distances on test sets. The C llr score is shown on top of each bar.
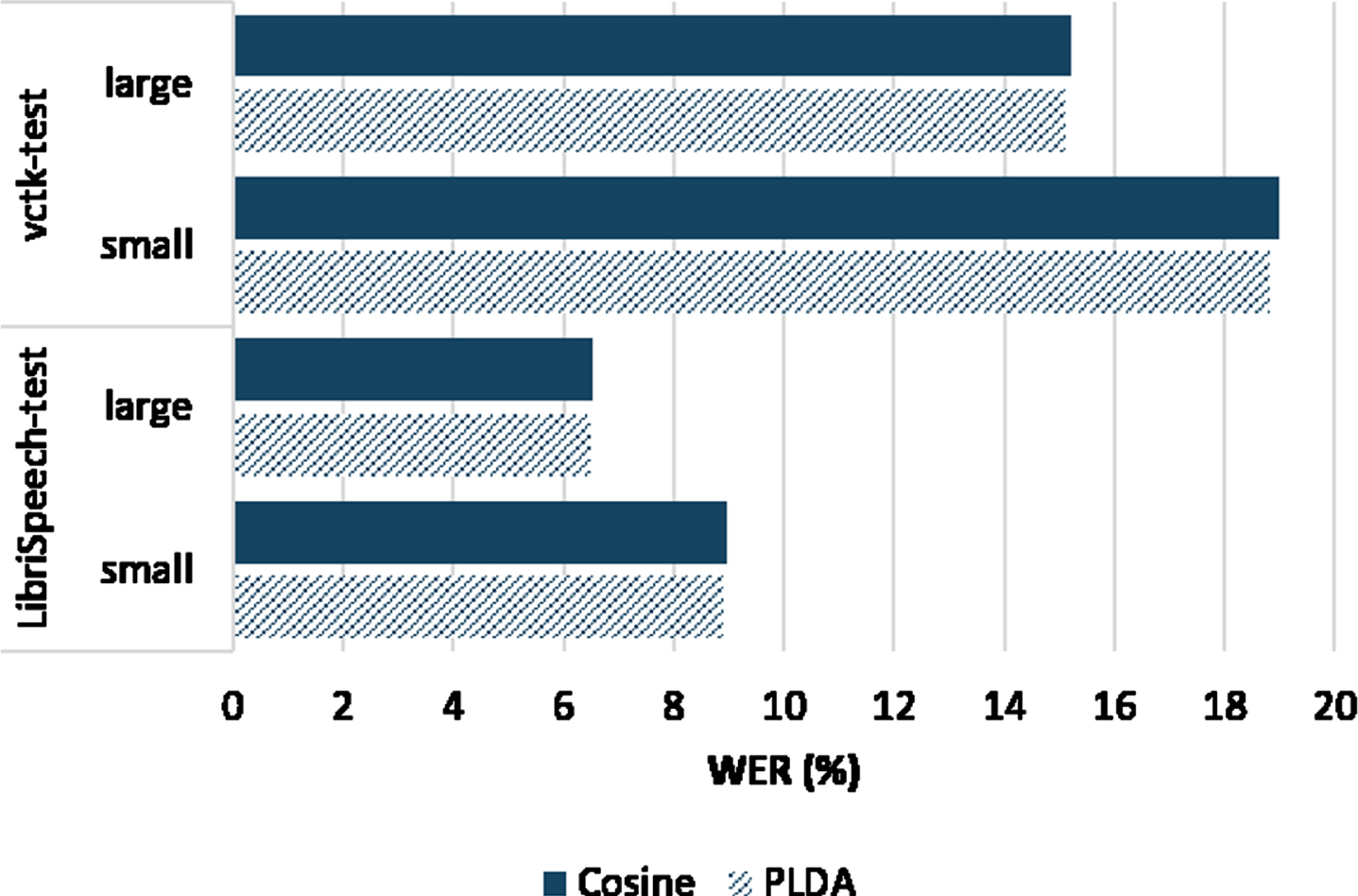
ASR results using the PLDA and Cross-Cosine distances on test sets. Small/Large refers to the language model size.
In this section, the performance of the proposed anonymization system is compared with the baseline anonymization system [6] and the enhanced system in [25] which uses Gaussian Mixture Models (GMM) to generate the pool of x-vectors.
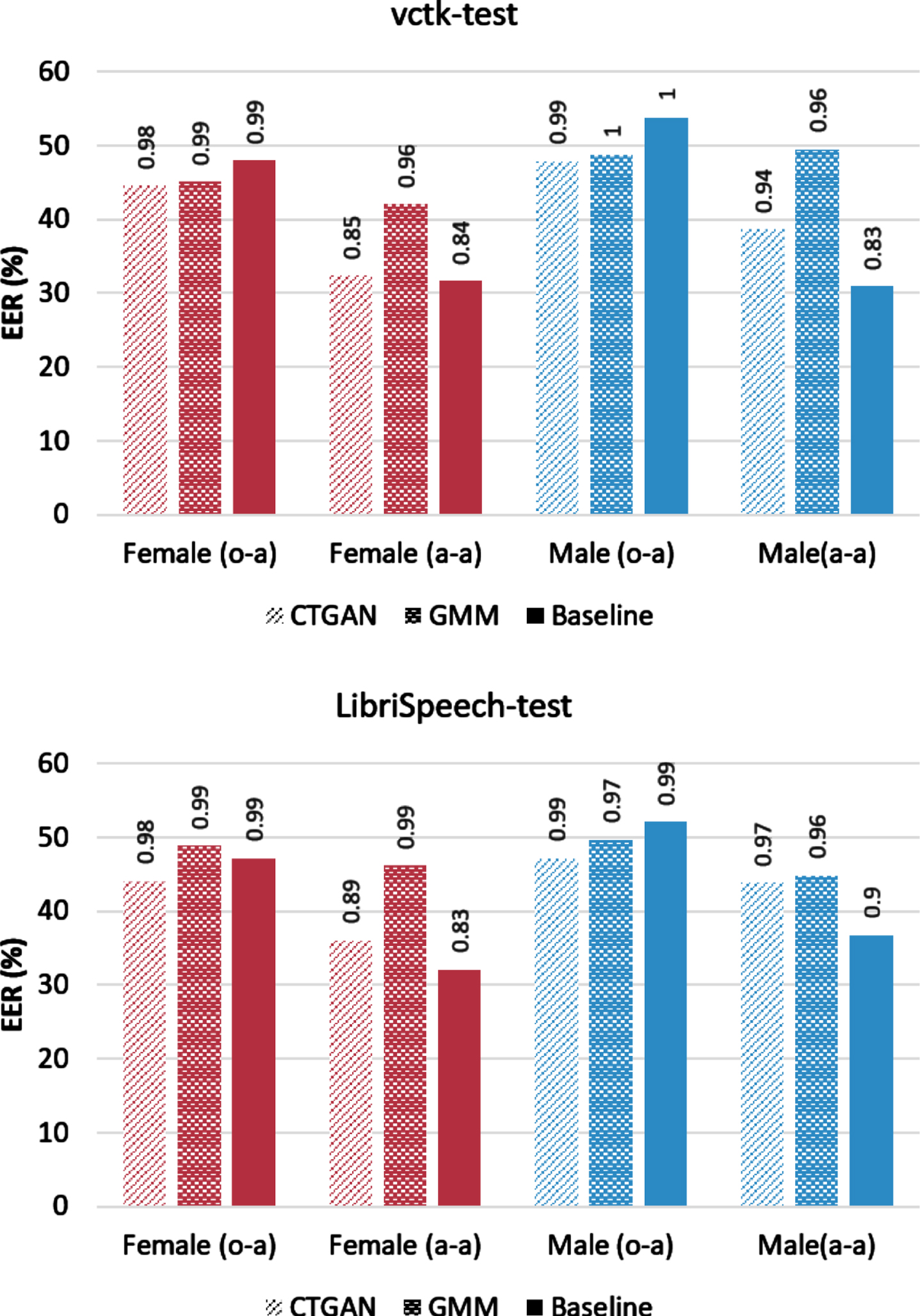
In terms of the ASV performance, Fig. 10 shows the EER (y-axis) and C llr (bar tops) values for the three systems under consideration on the vctk-test and LibriSpeech-test subsets. A state-of-the-art ASV system with cosine backend has EER around 10% [29]. For ASV, this value indicates that the false acceptance and false rejection rates are equal to 10%, which matches the objective of a general ASV system which is to be able to verify speakers accurately. In other other words, to minimize false rejection and false acceptance rates. However, in the anonymization case, values around 50% indicate that 50% of the time, the system miss-identifies a given speaker as another speaker as if it’s tossing a coin, indicating that the ASV system is completely fooled and fails to verify the identity of the speaker given an original sample and an anonymized one. This indicates that the two compared speakers are different from each other, which is the exact goal of anonymization. Furthermore, as displayed in the figure, the average EER for all systems in the (original - anonymized) case tends to be larger than the (anonymized- anonymized case) as in the latter case all speakers are sampled from the same distribution and synthesized artificially thus are more similar as compared to the former case.
The
As for the performance of the three systems in terms of ASR, Fig. 11 shows the WER scores where it is clear how the proposed anonymization system achieves the highest performance. This implies that the proposed solution can better preserve the linguistic content of the anonymized speech and make it sound more intelligible. This is an essential aspect of anonymization as this data is needed for training and personalization purposes; therefore, good speech quality is critical for the data to still be valuable.
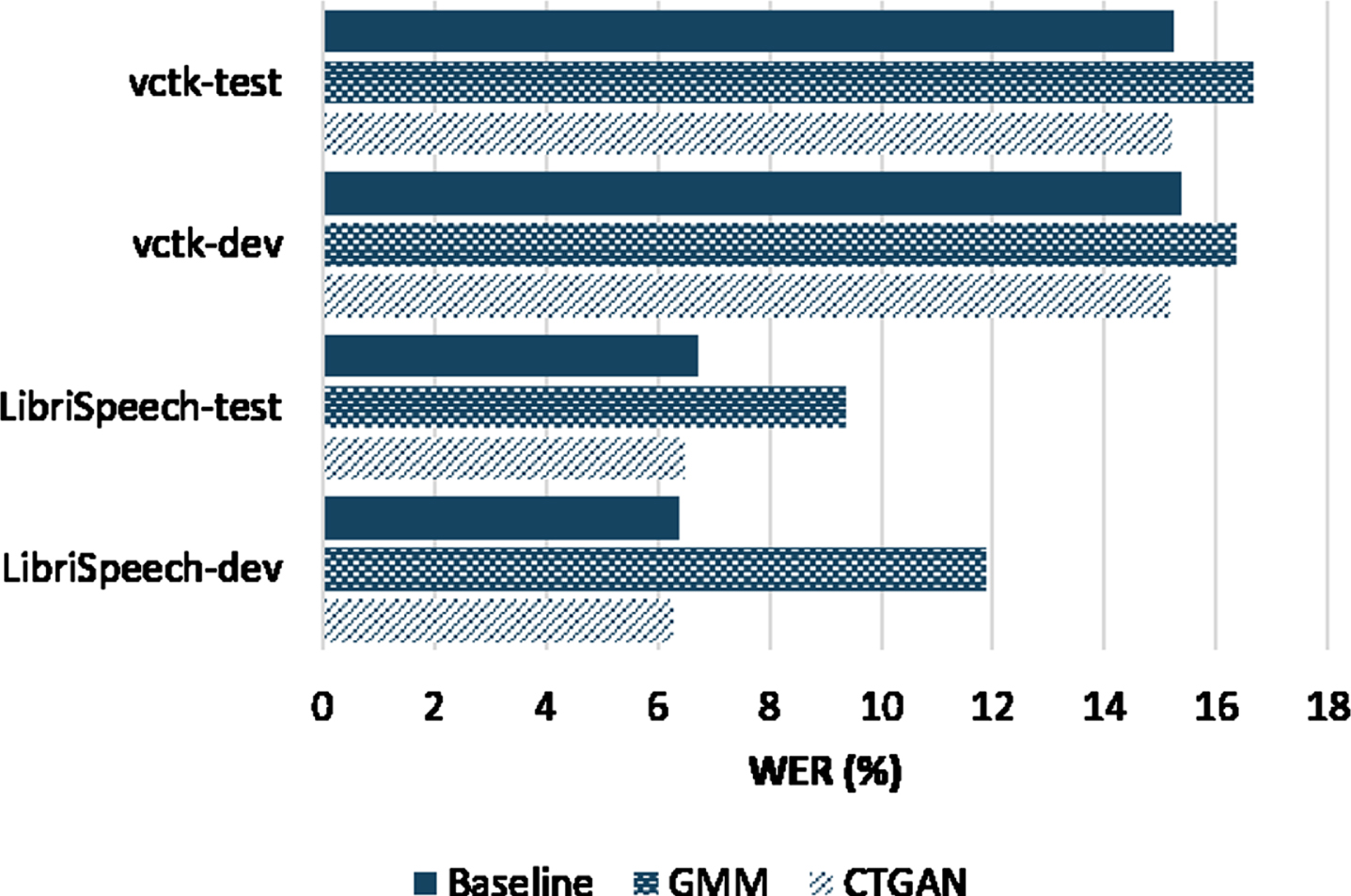
In summary, the proposed anonymization system resulted in similar results in terms of speaker verifiability metrics (EER,C llr ) and relatively lower WER. However, this was achieved by using fake speaker identities, unlike the other two systems which relied on real identities, which is the main contribution of this work.
The speaker anonymization problem aims to suppress the personally identifiable information in a speech signal, leaving all other aspects intact. This issue has been raised by the Interspeech VoicePrivacy Challenge [6] which served as an initiative to spread the effort of developing speech privacy-preserving solutions amongst the research community. The challenge provided a baseline model for the anonymization task that targets anonymizing speech utterances using a pool of real x-vectors. This poses a security risk as anonymized speech using these real speaker identities in the form of x-vectors violates the privacy of the real speaker.
In this paper, we attempted to address this issue by examining the opportunity of using generative adversarial networks (GANs) to generate a pool of synthetic x-vectors that can be used instead of the real pool in the baseline system. Performing speaker anonymization using this approach guarantees the extreme difficulty of reversing the anonymized utterances back to the original speaker by the use of sophisticated attacker systems as the pseudo identities are synthesized artificially, thus adding an extra anonymization layer to the whole process and ensuring better quality for the anonymized utterances, making them more real and close to being natural.
Basically, we evaluated four different types of GANs to generate the x-vectors. The performance of these four alternatives was assessed using proper metrics to measure their ability to generate a distribution close to the distribution of real x-vectors in addition to speaker verifiability and speech intelligibility and quality. The conditional tabular GAN (CTGAN) showed the best performance in this regard. Specifically, the CTGAN achieved a WER of 6.27% and 6.5% on LibriSpeech dev and test datasets, respectively, with comparable EER and C llr values compared to the baseline. These results highlight that artificially synthesized speaker identities perform better than original x-vectors.
Generally, we believe this is the first attempt at synthesizing human speaker identities using GANs. The scope of use for such a model extends beyond just anonymization. For example, text-to-speech systems and data augmentation for creating speech corpora to train different models.
Footnotes
Conflict of interest
The authors do not have any conflict of interest to declare related to any material discussed in this article.
Data availability statement
The datasets used during the current study for training and evaluation are available in the public domain. The links to these datasets are available in the references section. The data generated by this work (Synthesized Identities) can be made available upon request.