
Abstract
With the rapid development of cloud computing, there are more and more large-scale data centers, which makes the energy management of data centers more complex. In order to achieve better energy-saving effect, it is necessary to solve the problems of concurrent management and interdependence of IT, refrigeration, storage, and network equipment. Reinforcement learning learns by interacting with the environment, which is a good way to realize the independent management of the data center. In this paper, a overall energy consumption method for data center based on deep reinforcement learning is proposed to achieve collaborative energy saving of data center task scheduling and refrigeration equipment. A new multi-agent architecture is proposed to separate the training process from the execution process, simplify the interaction process during system operation and improve the operation effect. In the deep learning stage, a hybrid deep Q network algorithm is proposed to optimize the joint action value function of the data center and obtain the optimal strategy. Experiments show that compared with other reinforcement learning methods, our method can not only reduce the energy consumption of the data center, but also reduce the frequency of hot spots.
Keywords
Introduction
The data center is an important component of data processing and storage in the high-tech era, and is a crucial resource to promote the development of the new Internet industry. With the continuous development of artificial intelligence and cloud computing, the scale of the data center is expanding to meet the requirements of the times.At the same time, the rapid development of data centers has brought great energy consumption. According to a Natural Resources Defense Council report [1], data centers currently consume about 7% of global electricity. The energy consumption of data centers is expected to exceed 140 billion kilowatt-hours each year. Huge energy consumption not only increases the economic cost, but also brings great pressure to the environment [2]. Energy conservation is an urgent problem to be solved in the data center.
IT equipment and cooling equipment are the main energy sources of the data center, and their energy consumption usually accounts for 85% of the total energy consumption of the data center. Therefore, the research on energy saving technology of data center mainly focuses on improving the energy efficiency of IT equipment and cooling equipment. Dynamic Voltage and Frequency Scaling (DVFS) [3] and “processor main memory” coordinated frequency modulation technology CoScale [4] and other technologies have realized the energy conservation of IT equipment hardware layer. They allow the processor core to place itself in a low voltage and low frequency state when the load is low, thereby reducing energy consumption. In the cluster layer, reasonable job scheduling is usually used to make all IT equipment at the best energy consumption [5]. The other is to move jobs on low load IT devices to other IT devices, and then turn off the emptied IT devices or enter low power standby mode [6].The energy-saving technology of cooling equipment mainly focuses on the research of cooling technology, machine room layout and intelligent refrigeration. Based on fluid mechanics and material science, new cooling medium, new cooling means and cooling transmission efficiency are studied. The intelligent cooling system mainly controls the CRAC equipment automatically to avoid excessive cooling on the premise of ensuring the thermal safety of IT equipment. Boucher et al. [7] studied the influence of CRAC cooling temperature setting, CRAC fan speed, and the switch of the bottom air supply floor on the cooling effect. Zhou et al. [8] proposed an algorithm to dynamically control the opening and closing state of the bottom air supply floor, reducing the cooling energy consumption by about 20%.
However, in the data center, due to the complex interaction between air conditioning and IT equipment, controlling one aspect alone cannot achieve excellent energy saving effect. At present, a small number of studies have considered the control of IT equipment and cooling equipment at the same time. They are based on the prior knowledge of thermodynamics and the thermal modeling of the computer room structure to study the control strategy. Shine et al. [9] proposed a Dynamic thermal Management (DTM) technology for energy consumption, which reduces the total power consumption of calculation and cooling by taking Thermal resistance as a control variable. But this method is from the perspective of CPU heat control, which is too granular compared with the energy saving of the entire data center. Chisca et al. [10] proposed a nonlinear equation to characterize the integrated heat, power and load model, and then used the local search method to search the optimal solution. Wan et al. [11] proposed a multi-layer algorithm based on mixed integer nonlinear programming. The algorithm controls different devices through different control layers, and reduces overall energy consumption through cross layer collaboration. The above methods depend on the specific machine room structure and many assumptions, which is inconvenient to use in practice. Wei et al. [12] developed an algorithm based on heuristic DRL. The HVAC control and data center workload scheduling are combined to optimize the total cost, which can maintain the ideal room temperature and meet the data center workload deadline constraints; Hayato [13] and others proposed a dynamic scheduling algorithm based on power prediction. Migrate the load from the server with low airflow speed to the server with high airflow speed, and seek the lowest point of global energy consumption through load migration prediction. Because there are many physical and virtual machines in the cloud data center, the search space of this method is too large, and the algorithm time complexity is very high. Although the heuristic algorithm can reduce the time cost, it is easy to fall into a local minimum, and cannot achieve the best overall placement effect.
To solve the above problems, this paper uses the Deep Q Network (DQN) to solve the collaborative optimization problem in the data center. DQN combines the advantages of deep learning and reinforcement learning. This type of algorithm has the characteristics of self-learning and adaptive [14, 15]. It requires few parameters and has better global search ability, which is very suitable for the control of complex systems.
The main contributions of this paper are summarized as follows: An method based on hybrid depth Q network is proposed to optimize the joint action value function of the data center and extract the optimal distributed strategy. The convolutional neural network is used to extract the two-dimensional IT equipment status, and the full connected network is used to extract the one-dimensional environment status, which is combined with the action information and provided to the Q learning algorithm to fit the value function of the mixed status. Compared with the original DQN method which directly merges multiple states, it has better learning effect. A global energy consumption optimization model based on heterogeneous multi-agent reinforcement learning is designed. The model designs independent agent modules for job scheduling and temperature control. Each module has an act agent (ActNet) using local data and an evaluation agent (EvalNet) using global data. The algorithm adopts centralized training and decentralized execution. During training, all networks run at the same time, making the act agent approach the effect of the evaluation agent; At runtime, only act agents are used. This simplifies the interaction process between agents, improves the running speed, and has better scalability.
Related work
At present, there are a lot of IT equipment in the data center, and the layout of the computer room is also very complex, which makes it difficult to use the traditional expert system to control. And Deep Reinforcement Learning (DRL) is a data-driven method, which is very suitable for the control of complex systems and has been applied in various aspects of energy consumption optimization in the data center [16–18].
In terms of energy consumption optimization of servers: Yuan J et al. [19] applies reinforcement learning to resource management of uncertain job flow data center, and proposes a resource automatic control algorithm based on energy consumption awareness to improve energy consumption of data center. Shaw et al. [20] and Wang et al. [21] uses reinforcement learning algorithm to dynamically optimize virtual machine layout. There is no need to create environment models and workload information. Energy consumption and SLA conflicts can be considered while controlling, and the physical servers with insufficient load can be switched to sleep mode to reduce energy consumption. Xue et al. [22] proposed a data center power management framework based on reinforcement learning, which does not rely on any given static assumptions of job arrival and job service process. By designing sophisticated state action space and reward function, the goal of reducing server energy consumption and ensuring reasonable average job response time is achieved.
In terms of energy saving of refrigeration equipment: Li et al. [23] provides an end-to-end cooling control algorithm (CCA) through the offline version of the Deep Deterministic Policy Gradient (DDPG) algorithm. In this algorithm, the Evalue network is used to predict the data center energy cost and the resulting cooling effect, and the policy network is used to generate control strategies. In addition, there are also some researches on job scheduling based on temperature sensing to optimize the load distribution and avoid hot spots so as to reduce energy consumption.
However, due to dynamic factors such as the workload of the data center, the impact between servers and cooling equipment, and the changing outdoor environment, only reducing energy consumption in one aspect can not cope with the dynamic changes of the environment, so the optimization strategy of joint IT equipment and cooling equipment came into being. Ran et al. [24] proposed an optimization framework DeepEE based on deep reinforcement learning, which solved the problem of mixed action space through a parameterized action space Deep Q Network (PADQN) algorithm, and jointly optimized the job scheduling of IT system and air volume regulation of cooling system. This kind of method does not consider the complex changes within the data center environment, and does not require any prior knowledge. It is a simple and easy to understand method. In addition, it only considers the CPU limit and does not consider the limit of incompressible resource memory when allocating load, which may be difficult in practical application.
With the development of reinforcement learning algorithms, Masoumzadeh et al. [25] proposes a cooperative multi-agent learning method to increase the scalability of distributed systems by making host nodes become management entities in hierarchical system architecture. Each host node promotes the dynamic virtual machine consolidation process through self-management, so as to avoid performance degradation under overload and insufficient load. Ryan et al. [26] proposed a multi-agent data center energy consumption optimization algorithm. In this algorithm, each agent adopts DDPG structure and has an Actor network and a Critical network to realize the collaborative control of the data center. However, the existing data center multi-agent system belongs to the same kind of multi-agent system. Due to the interaction of data center, air conditioner and IT equipment, it has strong instability, so it can be seen as a very complex multi-agent system. Its air conditioning agent and IT equipment agent interact with the environment in different ways and contents, so heterogeneous multi-agent design is more suitable for actual needs [27]. Therefore, the existing multi-agent reinforcement learning methods cannot be simply applied to the data center environment.
Multi agent system is a dynamic and unstable system, because the optimal strategy of each agent in this system not only depends on the interaction with the environment, but also depends on the strategy adopted by other agents. In this paper, we propose a method for optimizing the overall energy consumption of the data center based on deep reinforcement learning. The training process optimizes the action agent by learning the joint action value function, and the running process obtains an excellent distributed strategy by observing the local state. Through centralized training and decentralized execution, the interaction process between multi-agent is simplified, and the stability and scalability of the system are improved.
Data center overall energy consumption method algorithm based on heterogeneous multi-agent reinforcement learning
In order to deal with the problem of mixed action space caused by different devices and the interaction between devices in the data center, this paper proposes a global energy optimization algorithm MADDQN based on heterogeneous multi-agent reinforcement learning.
MADDQN data center multi-agent system
MADDQN data center multi-agent system consists of scheduling agent (schedule_agent), cooling agent (AC_agent) and data center environment. The interaction between the two agents and the environment is shown in Fig. 1. The schedule_agent and AC_agent are dual DQN networks [28, 29], including the main network (MainNet) and the target network (TargetNet). Each agent has its own reward function, and has an independent action network (ActNet) and evaluation network EvalNet. ActNet is used to make decisions and select the optimal behavior, and EvalNet is used to evaluate whether the current agent’s behavior can reach the global optimal.
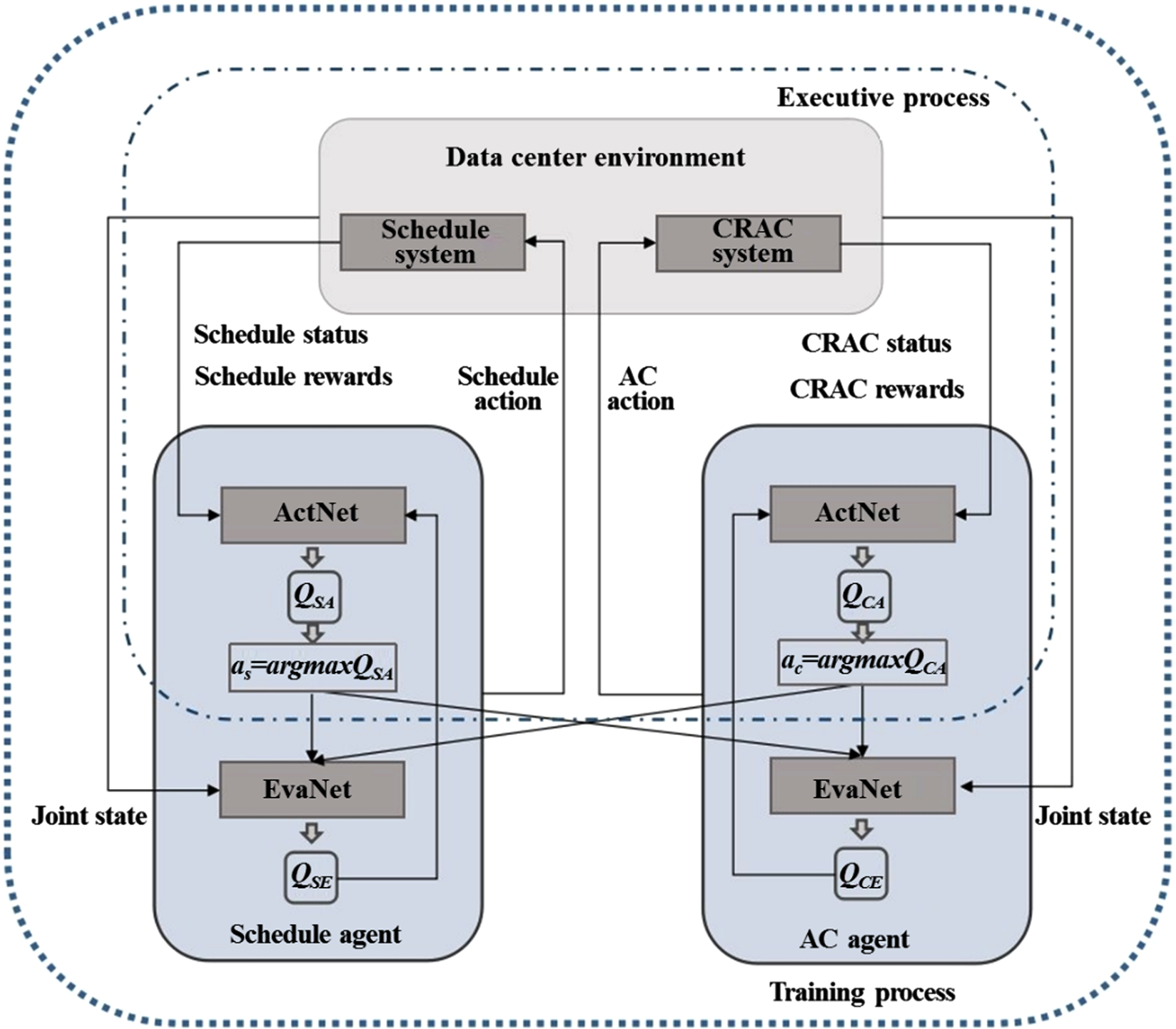
MADDQN data center multi-agent system interaction diagram.
In the training process, all networks of schedule_agent and AC_agent participate. ActNet observes the state and rewards of the subsystem, uses DQN to fit the action value function, selects the optimal value function as the selected action, and applies it to the data center environment to obtain the next environmental state. EvalNet observes the global state and the actions of the two agents, and evaluates the joint strategy of the two agents. In this way, EvalNet can obtain the global optimal value function, and use this value function to update the parameters of ActNet and EvalNet. Through EvalNet, two agents can jointly consider each other’s states and actions, and interact with each other in a simple way. At the same time, our dual network structure also improves the accuracy and stability of the algorithm.
After training, schedule_agent and AC_agent does not need to observe the global information any more. Each agent only needs to obtain the state of the corresponding subsystem and formulate control strategies according to their respective reward functions to achieve the overall collaborative control.
Because each agent interacts with different objects, the schedule_agent and AC_agent has different network structure. The IT state input by schedule_agent is two-dimensional, so its ActNet is a depth convolution neural network. The temperature information observed by AC_agent is one-dimensional, so its ActNet is a full connection depth neural network. The input information of EvalNet is the global state and the action of two networks, so the two agents EvalNet have the same input layer and hidden layer structure. However, the output action value function Q is related to their respective action networks, so their output layers are different, so the EvalNet of the two agents has different network structures.
This algorithm has very good scalability. When the scale of the data center increases, the data center can be partitioned, and more dispatching and air conditioning agents can be added to the system. Each agent can observe the state of the local state, and achieve the global optimization through EvalNet, which can be easily integrated with little change to the original agent.
In the multi-agent reinforcement learning method, agents interact with the environment and make decisions. Schedule_agent is responsible for assigning tasks to appropriate servers, which is the core of the whole algorithm. The key of schedule_agent is the design of state space, action space, reward function and network structure.
State space design
The state of the IT system s
s
is represented by a binary matrix, including the current state of the server resources and the job request resources in the queue. Suppose there are m servers in the cluster, the waiting queue length is q, and the backlog queue length is b. The two-dimensional matrix of c*t is used to represent the state of a certain type of resources,
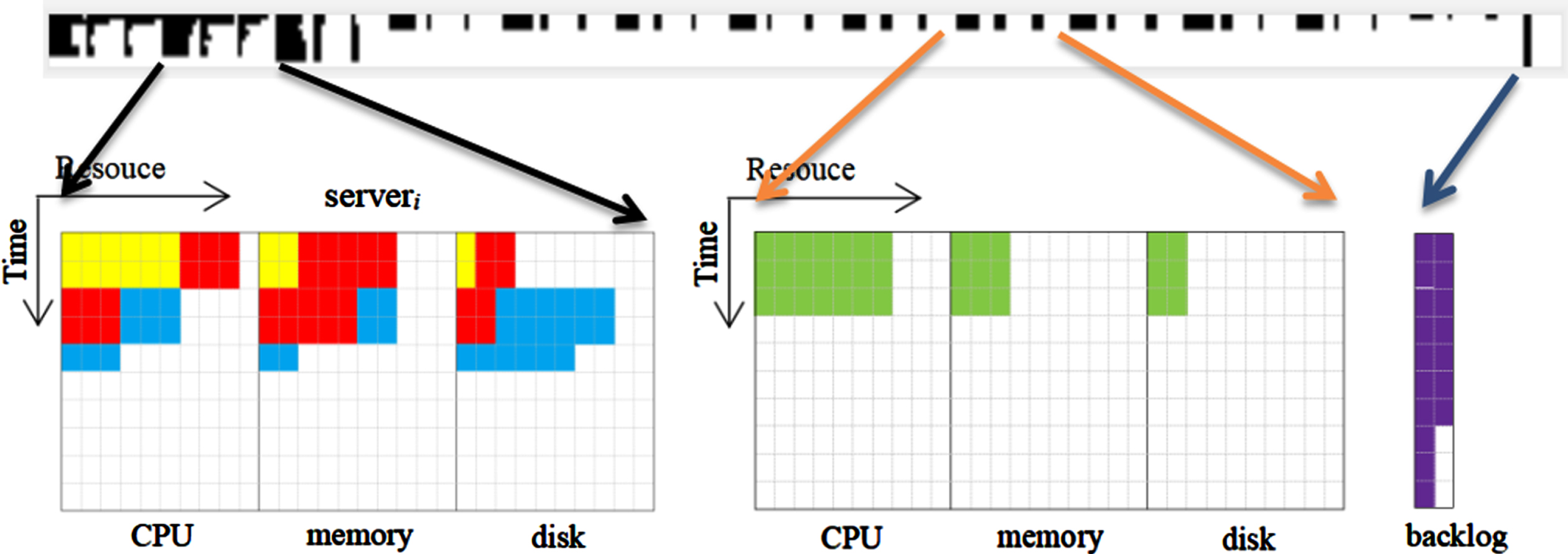
State space diagram of IT system.
On the left is the resource utilization status chart of the server i (i = 0, 1, ⋯ , m), which indicates that the current node is about to process three jobs, and yellow jobs and red jobs are being executed synchronously. Among them, yellow jobs occupy six units of CPU resources, two units of memory resources, and one unit of disk resources, and need to execute two time units. In the middle is the resource request status chart of the job j (j = 0, 1, …, q) in the waiting queue, indicating that the job requests 7 CPU resources, 3 memory resources, and 2 disk resources, and needs to execute 4 time units. On the right is a graph of the squeeze queue, which shows the number of subsequent jobs arriving when the waiting queue is full. The graph shows that there are 17 jobs in the current backlog queue. Because the size of the cluster in the data center is often very large and constantly expanding, the state space of the scheduling system is dynamic, and the two-dimensional matrix will change with the change of the cluster size.
a s refers to job scheduling action, action a s is defined as a s = i * q + j, and refers to assigning job j in the queue to server i. i ∈ {0, 1, ⋯ , m} refers to index a of the selected server, and j ∈ {0, 1, ⋯ , q} refers to the location index of the selected job in the waiting queue. The action space size is m * q + 1, including an invalid operation, and indicates that the agent has not scheduled at the current time.
Design of reward function
In the MADDQN data center multi-agent system, the agent of the scheduling system has its own independent reward function. The optimization goal of the scheduling system is to minimize the energy consumption of the server on the premise of avoiding hot spots. In the scheduling system, hot spots will appear when the server is overloaded. Therefore, the power limit is used to represent the temperature limit. This paper selects the server energy consumption model based on system utilization proposed by Yao et al. [30] to establish a super linear energy consumption model, as shown in Formula 3-1.
P
th
represents the set power threshold, which is determined according to the configuration of different servers. The goal of schedule_agent is to learn to minimize the server energy consumption and reduce the emergence of hot spots. The learning process of the agent is to maximize the cumulative reward, so the main part of the reward function is the negative value of the server energy consumption. When the energy consumption is minimum, the reward is maximum. At the same time, in order to prevent hot spots due to server overload, the softplus function is used to construct a penalty item. In the process of dispatching system regulation, the penalty should be increased if the power exceeds the rated power; For the agent, it should get a smaller feedback to reduce the probability of making this action next time. Therefore, if the punishment item is reversed, the punishment will be increased if the action is invalid. In this paper, the reward function of schedule_agent is set as Formula 3-4.
The optimization goal is to achieve a balance between minimizing the average power and preventing the server from overheating. The first part in parentheses is the average energy consumption with the goal of minimizing, and the second part is the penalty function for overheating, λ It represents the penalty factor. When the server power exceeds the rated power, the penalty will be increased, so as to feedback a smaller reward value.
In the MADDQN data center multi-agent system, The schedule_agent has two DQN networks, one of which is used to make decisions, expressed as ActNet. To ensure the schedule_agent. For the stability of learning, ActNet is designed as a dual network structure, including the MainNet and the TargetNet. The two networks have the same network structure but different parameters. The parameters of the MainNet are updated in real time, while the parameters of the TargetNet are reproduced from the parameters of the main network at regular intervals.
ActNet is responsible for receiving the state and reward value of IT system in the environment. Since the state space is a two-dimensional matrix, the network structure of ActNet is a multi-layer deep neural network with convolutional network as the input layer. As shown in Fig. 3.
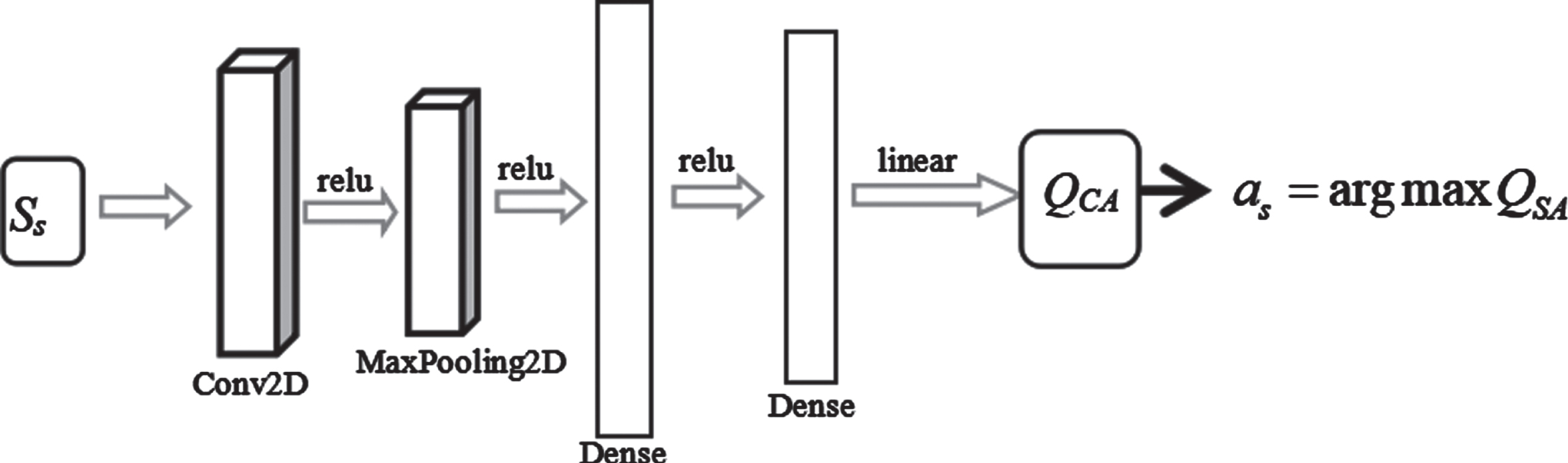
ActNet network structure of a.
The input layer size of ActNet is the image observed by schedule_agent, and the output layer size is the action space size m * q + 1. ActNet fits the optimal value function QSA of IT system status and scheduling actions, and selects the optimal actions to act on the IT system according to the QSA value, thus changing the entire data center environment.
The other DQN network is used to evaluate the current action, which is represented as EvalNet. EvalNet is also a dual network structure with different parameters but the same structure. EvalNet observes the overall status of the current data center, including temperature, server status, and the actions of two agents, as the input information of the network. EvalNet adopts a hybrid network structure, as shown in Fig. 4. Output layer is consistent with schedule_agent, which is the action space m * q + 1.
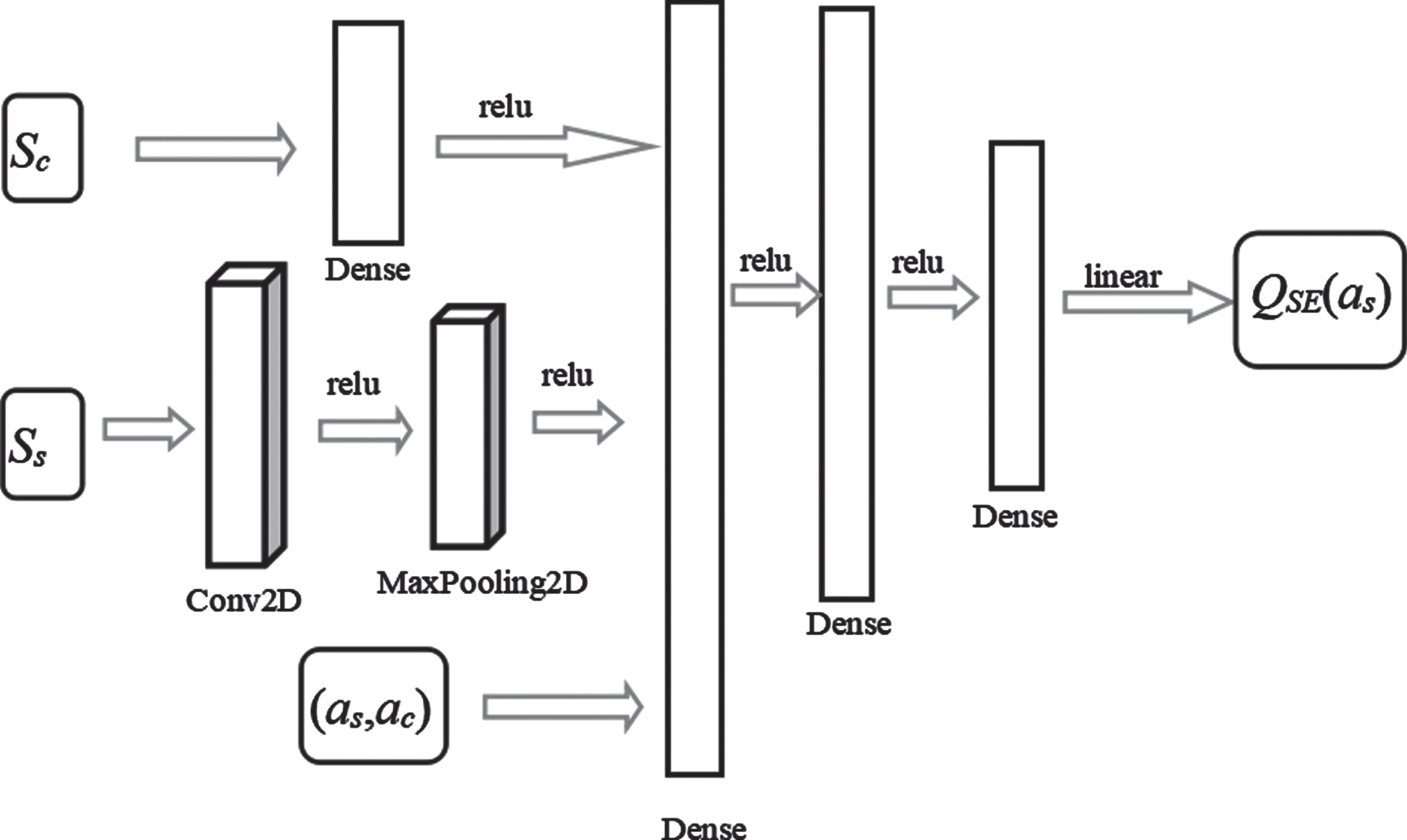
EvalNet network structure of schedule_agent.
The complexity of the algorithm is related to the calculation amount and parameter amount of the network. The calculation amount of a single convolution network is Formula 3-5.
Where, C
i
represents the number of input channels, C
o
represents the number of output channels, k represents the side length of the convolution kernel, and W and H represent the length and width of the feature graph. The parameter quantity of a single convolution network is Formula 3-6.
Brackets indicate the parameter quantity of a convolution kernel, C
o
× indicates that the layer has C
o
convolution kernels, and +1 indicates bias. The pooled layer has no parameters. For a single full connection layer, the parameter amount is equal to the calculation amount, which is expressed in Formula 3-7.
C
in
and C
out
are the number of input and output channels of the full connection layer. From the above three formulas, we can see that the calculation amount of the deep neural network including a convolution network and multiple fully connected networks is Formula 3-8, and the parameter amount is Formula 3-9.
l represents the number of layers of the full connection layer. For the l -th full connection layer, the number of input channels C in is the number of output channels Cl-1 of the (l-1) full connection layer. For the EvalNet network structure diagram, the value of D is 2, and the value of C i is the size of the black and white image in Figure 3-2. Corresponding to the input of scheduling state, the number of input channels of the first full connection layer is m + 2, that is, the state space of the cooling system; Corresponding to the input of cooling state, the size of output layer is the size of the scheduling action space.
State space design
The thermal interaction process in the data center environment is very complex, and the reinforcement learning method does not need to consider the detailed temperature transformation. Agent and environment interaction can directly observe the temperature information through the temperature sensor, and make decisions according to the observation state. This paper focuses on temperature change and regulation. Assuming that a cluster corresponds to a CRAC system, the status of the CRAC can be expressed as Formula 3-10.
Where, T
return
represents the return air temperature of the air conditioner and T
set
represents the set temperature of the CRAC. The cooling state in the data environment can be expressed as Formula 3-11.
Where
a c represents the temperature regulation action, and action a c is defined as a c = Δt, indicating the temperature adjustment range. The temperature adjustment in the actual environment is generally accurate to 1°C, and the temperature adjustment range should not be too large, so the value range of action a c is discrete as [-2,-1,0,1,2], and the size of action space is 5.
Design of reward function
In the data center multi-agent system, the agent of the cooling system has an independent reward function. The optimization goal of the cooling system is to minimize the cooling energy consumption while ensuring the safe operation of the server. According to the thermodynamic law, the cooling power of CRAC should be expressed as the heat of the air in the compressor cooled in unit time [31–33], which can be expressed as the linear relationship of the temperature difference between the inlet and outlet of CRAC. The power consumption model of CRAC is shown in Formula 3-13.
Where w1 is a constant, determined by the air density ρ. The air flow rate f and the specific heat capacity c are determined. w2 is also a constant, representing the inherent energy consumption of other components. According to the computer room management standard, the optimal temperature range of the data center is 18°C∼28°C, and the set temperature of the air conditioner should also be kept within a reasonable range. If the temperature is too high, the cooling demand will not be met. If the temperature is too low, the service life of the air conditioner will be affected. Therefore, the set temperature in this paper is based on Formula 3-14.
Tmin is the lowest temperature threshold and Tmax is the highest temperature threshold, both of which are constants, with different values depending on the season. The goal of cooling system control is to minimize the energy consumption of CRAC. Therefore, the reward function takes the negative value of server energy consumption. When the cooling energy consumption is minimum, the reward is maximum. In order to prevent excessive temperature fluctuation, two penalty terms are constructed with softplus function. When the set temperature is higher than the maximum value or lower than the minimum value, a penalty will be imposed. The reward function of AC_agent is designed as shown in Formula 3-15.
The first item in the bracket indicates the optimization goal of AC_agent is to reduce the energy consumption of CRAC. The second and third terms represent the penalty function. β1 and β2 represent penalty factors. When the temperature exceeds the limit, the penalty will be increased and a smaller reward value will be returned.
In MADDQN’s data center multi-agent system, The AC_agent also has two DQN networks, ActNet and EvalNet, both of them are dual network structures. The ActNet of the AC_agent is responsible for receiving the status and reward value of the cooling system in the environment. The cooling state of the cooling system is one-dimensional information, so ActNet is designed as a deep neural network composed of multiple full connection layers. As shown in Fig. 5.
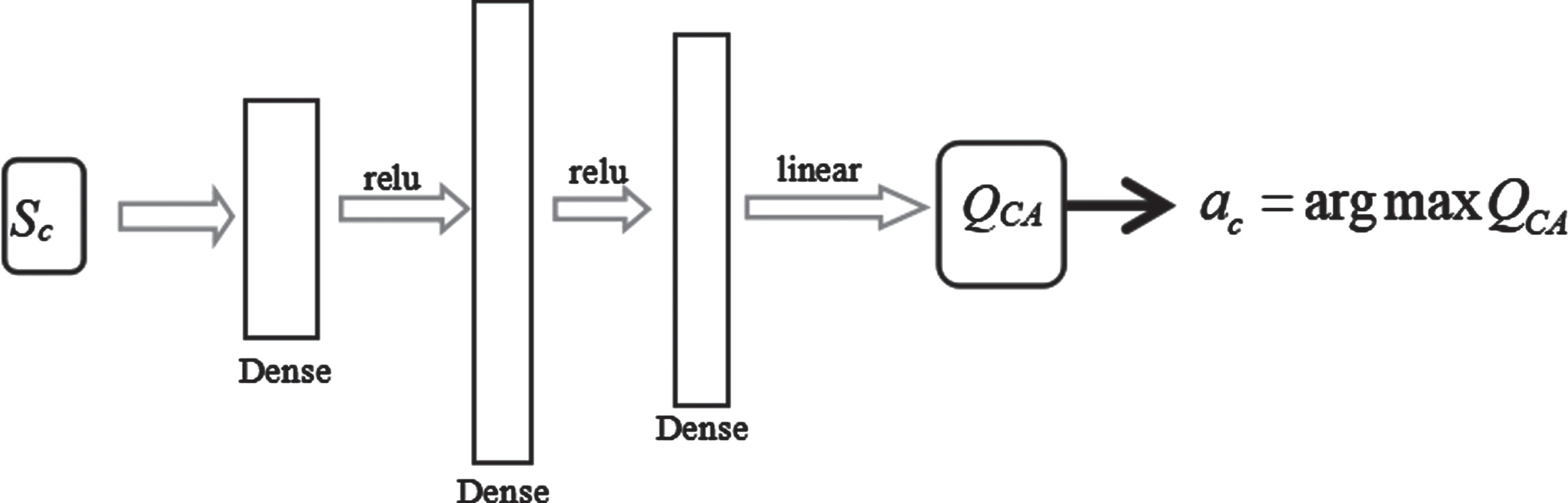
ActNet network structure of AC_agent.
ActNet fits the optimal value function Q
CA
of cooling system status and scheduling action. Select the action corresponding to the maximum Q
CA
value for the cooling system to change the temperature setting of the data center. The ActNet network consists of a fully connected network, with the same amount of computation and parameters, as shown in Formula 3-16.
The value of D here is 3, and the size of the input layer is m + 2, which is consistent with the size of the state space of the AC_agent. The size of the output layer is 5, which is consistent with the size of the action space of the AC_agent. The number of channels in the intermediate network can vary with the size of the data center.
EvalNet of AC_agent and schedule_agent adopts the same network structure, and the input information is the overall state of the data center and the actions of the two agents. The output layer size is 5, which is smaller than that of schedule_agent’s EvalNet (Figure 4-3), as shown in Fig. 6. Refer to Formula 3-8 and 3-9 for parameter quantity and calculation quantity.
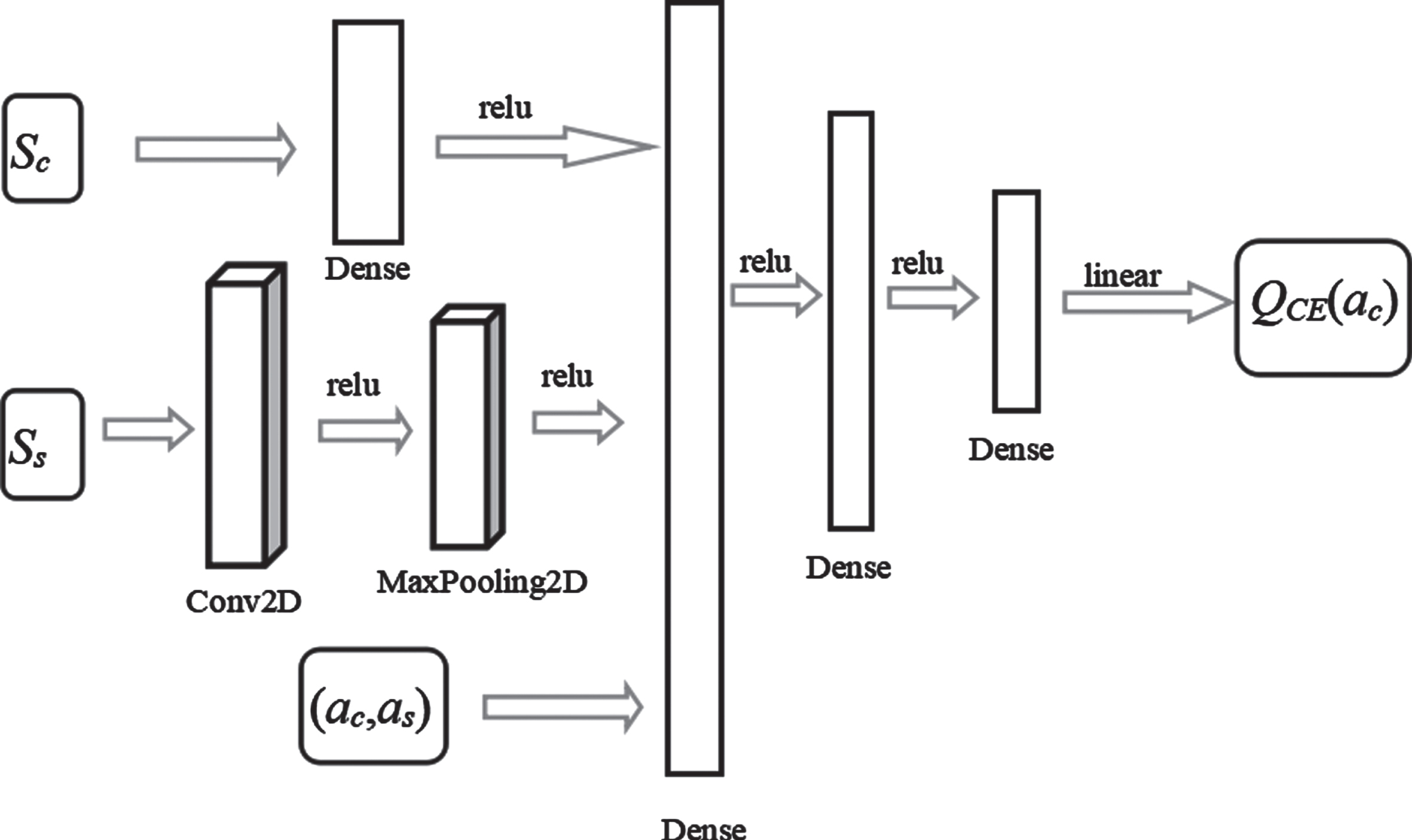
EvalNet network structure of AC_agent.
Similar to the working principle of EvalNet of schedule_agent, EvalNet of AC_agent also uses a hybrid network to fit the value function Q CE of the joint state (including data center state and the actions of two agents). The loss functions of ActNet and EvalNet networks are constructed with Q CE values to update the parameters, so that the decisions made by ActNet are close to the global optimization while maximizing their cumulative rewards. This can reduce the total energy consumption of the data center while reducing the energy consumption of the cooling system.
The data center multi-agent system of MADDQN, schedule_agent and AC_agent both have two DQN networks, namely, the action network ActNet and the evaluation network EvalNet. ActNet and EvalNet are both dual network structures including the primary network and the target network. ActNet inputs local state, outputs Q value to select action, EvalNet inputs global state and actions of two agents, and outputs evaluation value to update network. MADDQN algorithm adopts centralized training and decentralized execution. In the process of centralized training, both DQN networks of the two agents participate in the work; During execution, we can only use the trained ActNet to control the data center.
Before training, the parameter of each network is initialized randomly, and two experience playback pools are established to store the state transition data of two agents. D
s
storage the schedule_agent’s state transfer data
In the training of multi-agent reinforcement learning, each agent does not make decisions at the same time. In the data center environment, first use the ActNet of schedule_agent to select actions and determine whether the actions are effective. If the action is invalid, non operation will be performed and the next time step will be started; When the action is valid, the AC_agent’s ActNet starts to select actions to regulate the cooling system. When the schedule_action and AC_action completes the regulation, the status change is recorded.
The state transfer data of the schedule_agent is stored in Ds, the state transfer data of the AC_agent is stored in Dc.
When a certain amount of experience data has been stored in the experience playback pool, a small batch of state transition data is randomly selected to update the four main networks of the two agents. The target value of the schedule_agent is set to
The target value is given by the target network of EvalNet. EvalNet inputs the global state at the next moment and the estimated next joint action. The next joint action is estimated by the target network of ActNet, and is obtained by Formula 3-18 and 3-19.
The output of EvalNet target network is the value function of executing the joint action in the global state. The goal of multi-agent joint training is to optimize the global value function. Therefore, the target value is used to update ActNet and EvalNet at the same time to gradually achieve global optimization. The loss function of ActNet is Formula 3-20.
Then, every step C, we copy the parameters of the main network of ActNet and EvalNet to the corresponding target network. The ActNet is updated in real time, while the EvalNet is updated once per step C.
AC_agent and schedule_agent network updating process are similar, and use MADDQN algorithm to jointly train the two agent. The specific process of agent is shown in Table 1.
Multi-agent joint training algorithm
The MADDQN algorithm consists of four DQN networks. In each iteration of the training process, the action strategy is formulated by the action network, and the value function is obtained by the evaluation network to update the parameters of each network. This is repeated until the good action network (ActNet) is trained for the two agents.
For MADDQN algorithm, the training time mainly comes from the process that agents use networks to calculate Q values and update each network parameter. The time consumption of other steps can be ignored. Therefore, the main determinants of time
complexity are the number of cycle iterations and the amount of network computing. The time complexity of MADDQN algorithm can be expressed as O(T*M*Time2). T refers to the number of time steps in each round, M refers to the number of training rounds, and Time2 is the sum of the computation of four networks of two agents, as shown in Formula 3-8 and 3-16. The space complexity is O(Space2 + 2 N). Space2 represents the sum of the parameters of the four networks, which can be obtained by referring to Formula 3-9 and 3-16. N represents the capacity of the experience playback pool.
Simulation environment construction
Currently, the commonly used data center simulation software includes CloudSim, EnergyPlus, 6SigmaDC, etc. CloudSim is mainly used to simulate the management of virtual machines and does not involve temperature. EnergyPlus and 6SigmaDC pay attention to the energy consumption management and temperature control of rooms and lack the management of the details of the internal operation status of the cluster.
For the verification of Overall Energy Consumption Optimization algorithm for Data Center Based on Deep Reinforcement Learning, we use the data center energy consumption simulator developed by our team as the simulation platform [34]. The simulation framework is suitable for the data center energy consumption optimization algorithm based on temperature perception. It integrates 6Sigmaroom [35] as the thermal coupling relationship simulation platform. It uses the real-time data or historical data of the computer room and the real task set to test the energy consumption of different temperature aware energy consumption optimization algorithms.
Combined with the actual computer room data, the data center simulation environment set in this paper includes a CRAC and a cabinet, as shown in Fig. 7. The left side of the figure shows the CRAC. The agent sets the temperature according to the cooling strategy, and the cold air is transmitted from the floor to the air inlet of the server. The right side is the cabinet, which contains 10 servers. The agent distributes jobs to the server according to the scheduling strategy, and the hot air from the server’s air outlet flows back from the rear to the air inlet above the CRAC.

Schematic diagram of simulation environment.
The initial setting temperature of CRAC is set to 28°C. Suppose the experiment is conducted in summer, and the initial ambient temperature is set to 30°C. The initial inlet temperature of each server is equal to the ambient temperature. 10 servers are placed in the cabinet. Each server provides three resource services, namely CPU, memory and disk. After the job arrives, it enters the waiting queue, and its length is set to 10. When the waiting queue is full, the job enters the backlog queue, and its length is set to 20. The statistics of job sets are shown in Table 2.
Data set statistics
When multi-agent interacts with the environment, different agents do not make decisions at the same time. Only when the scheduling action is effective, the AC_agent can select action.
At present, the application of multi-agent in data center management is rare. There are mainly three reinforcement learning methods to solve the cooperative strategy of multi-agent systems: the first is to learn all agents as a whole. It represents both the IT system state and the cooling system state as one-dimensional information and directly combines them for learning, and then separates the scheduling and cooling actions according to the results. The network structure is a simple multilayer fully connected neural network, which we call the original DQN method; The second is that each agent uses a single agent to train independently without interaction. In this paper, we use DQN to implement two different proxy schedules_ agent and AC_agent, each independent training to control the data center. There is no interaction between them. We call it IDQN (Independent DQN) method; The third way is to use centralized training and decentralized execution. The MADDQN proposed in this study is based on this idea. In addition, we also implement the two methods of Schedule and Hybrid_DQN for comparative tests. Schedule is a single agent method, which only schedules tasks for IT equipment without temperature regulation. Hybrid_DQN is an extension of the first method. It uses the design idea of Fig. 4. schedule_agen to extract the server and temperature information using convolutional neural network and MLP respectively. It is an optimized DQN method.
We used a training set containing 500 operations to train the above five algorithms for 300 rounds, and used the same workspace and reward function. The changes of reward function, total energy consumption and PUE are shown in Figs. 8–10.
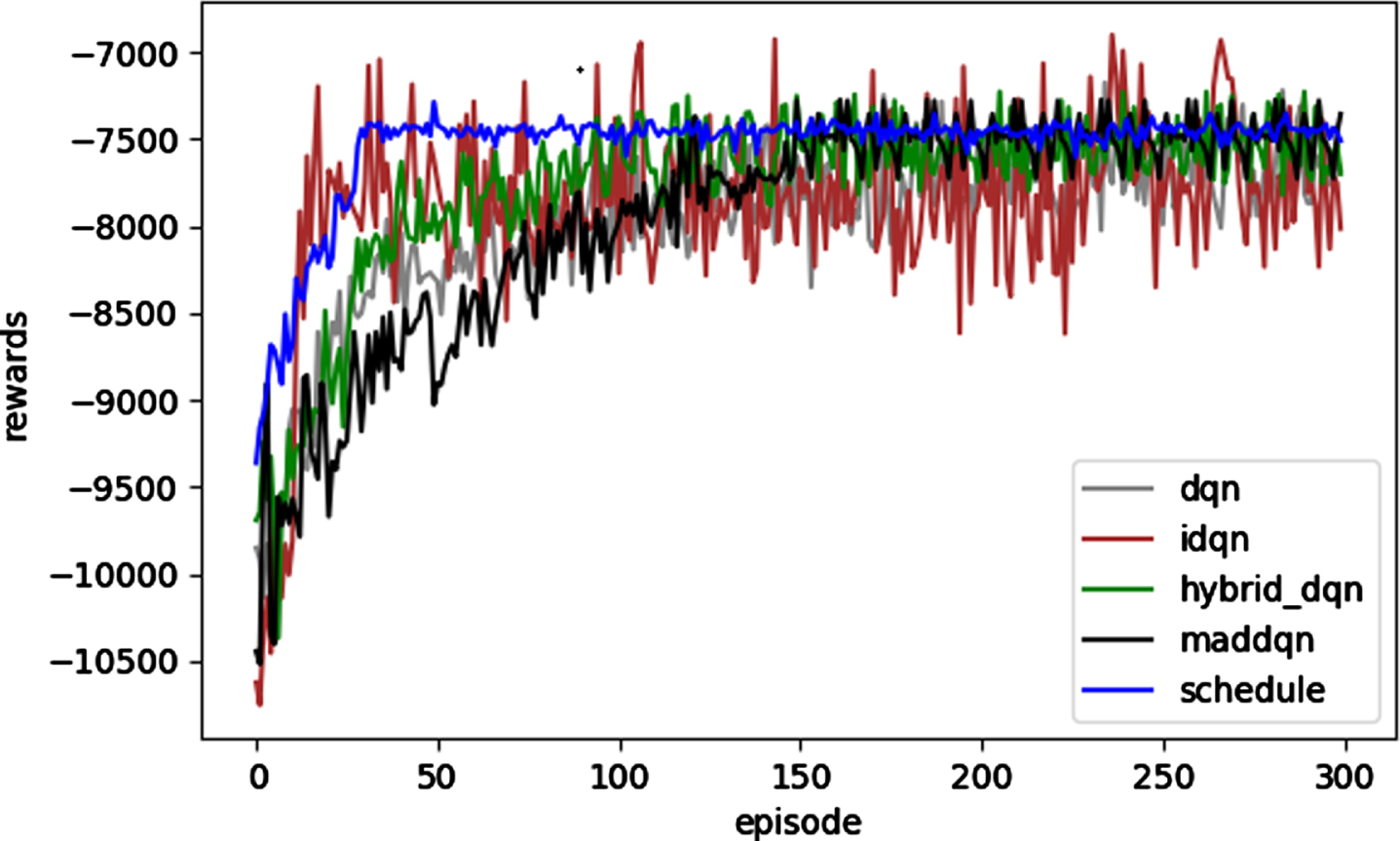
Reward changes during training.
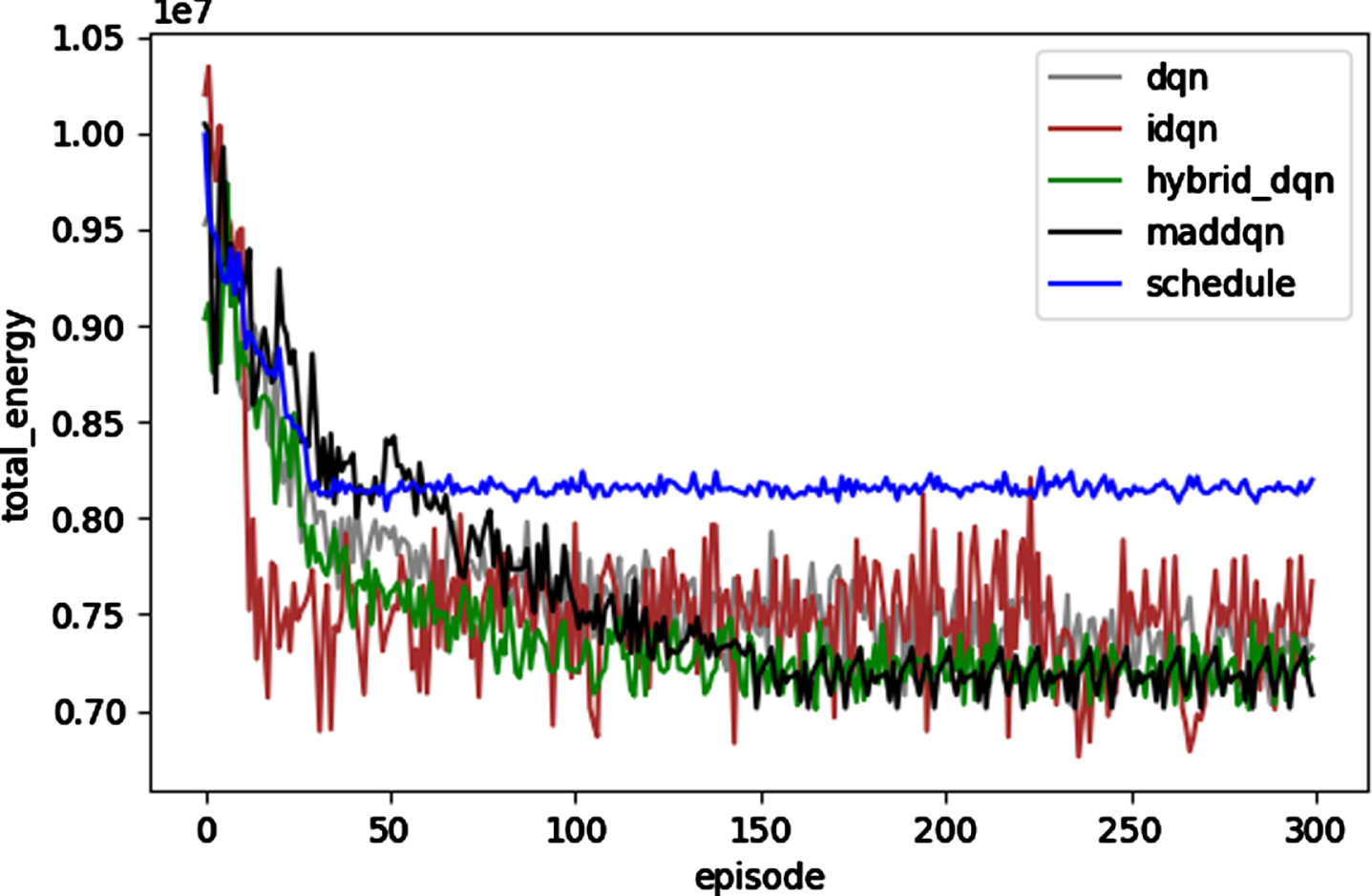
Change of total energy consumption during training.
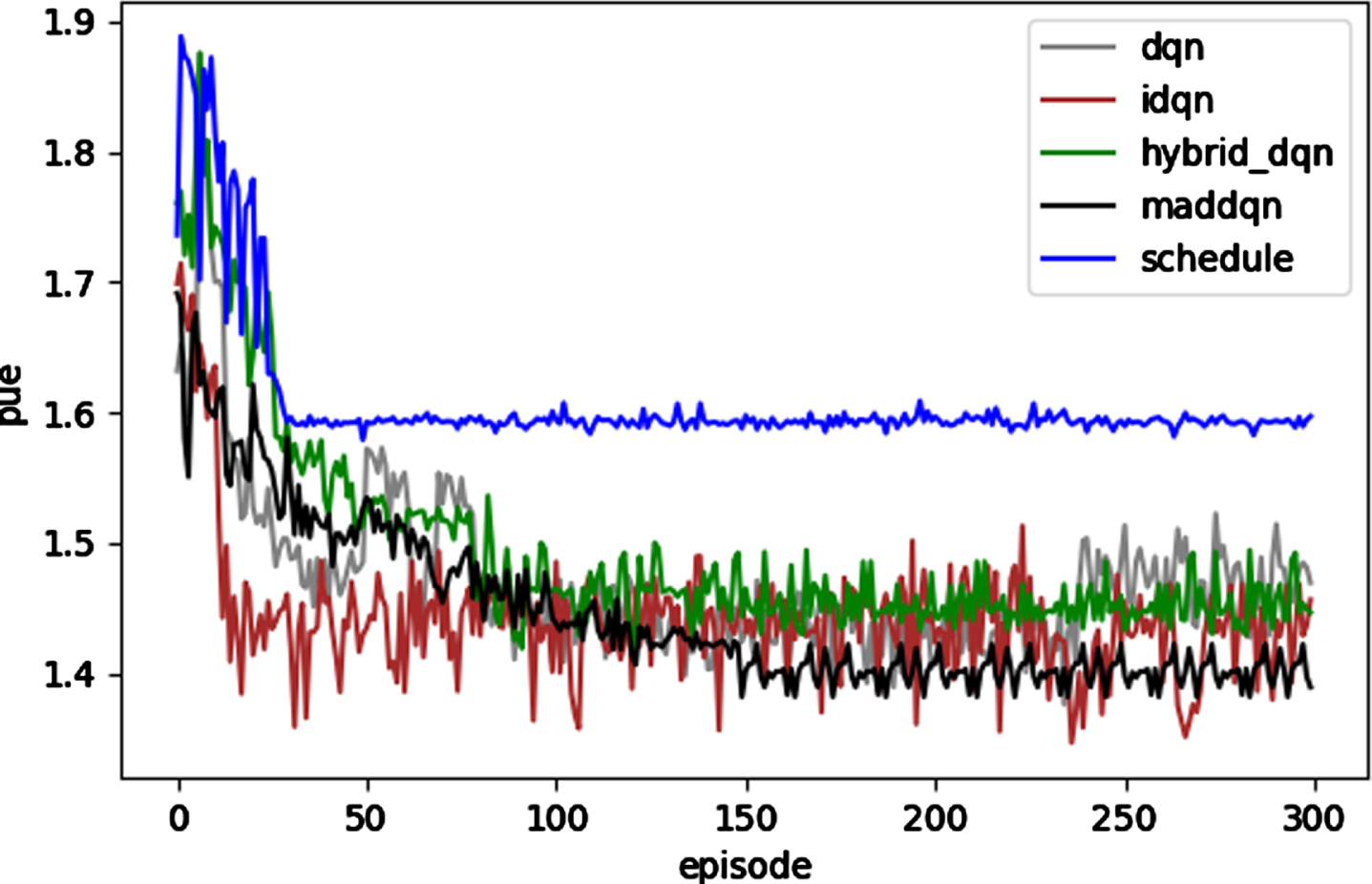
PUE changes during training.
It can be observed from Fig. 8 that with the increase of the number of training rounds, the Schedule algorithm converges fastest because it only schedules server tasks and does not adjust air conditioning. The Independent DQN algorithm cannot converge because each agent is trained independently, focusing only on its own behavior and ignoring the impact of the environment. DQN, Hybrid_DQN algorithm and MADDQN algorithm can converge, Hybrid_DQN converges around the 100th round, MADDQN converges around the 150th round, and DQN converges between the two, about the 120th round. This is due to Hybrid_DQN adopts convolutional neural network, which has better feature extraction ability, so it converges earlier than the original DQN. The MADDQN algorithm has a complex network structure, with many training parameters and computation. Each agent needs to learn the behavior of the other agent, and the interaction process with the environment is more complex, so the convergence process of the algorithm is relatively slow.
Although the training process of MADDQN converges relatively slowly, the converged algorithm after training performs well in reducing the total energy consumption. It can be seen from Figs. 9 and 10 that among the five algorithms, the Schedule algorithm only controls the tasks of IT equipment and does not operate the refrigeration equipment, so it cannot achieve good energy saving effect; The IDQN algorithm is unstable because the two agents run independently without interaction. The energy saving effect of these two algorithms is obviously not as good as that of the other three coordinated energy saving algorithms. Because Hybrid_DQN and MADDQN both adopt the method of combining convolutional neural network with MLP to extract features, the energy saving effect is better than the original DQN; Hybrid_DQN and MADDQN have very similar effects in reducing total energy consumption, but MADDQN has more advantages in improving PUE and scalability.
After the algorithm converges, use the test set in Table 4-1 to test each algorithm. In all five algorithms, agents interact with the environment in the same way as in training, while MADDQN algorithm is different. During the training, both the action network (ActNet) and the evaluation network (EvalNet) of the two agents in MADDQN participate in the training, but only the action network will be run after the training is successful. Each agent selects actions according to its own state, and no longer needs to interact with each other. The comparison results are shown in Fig. 11.
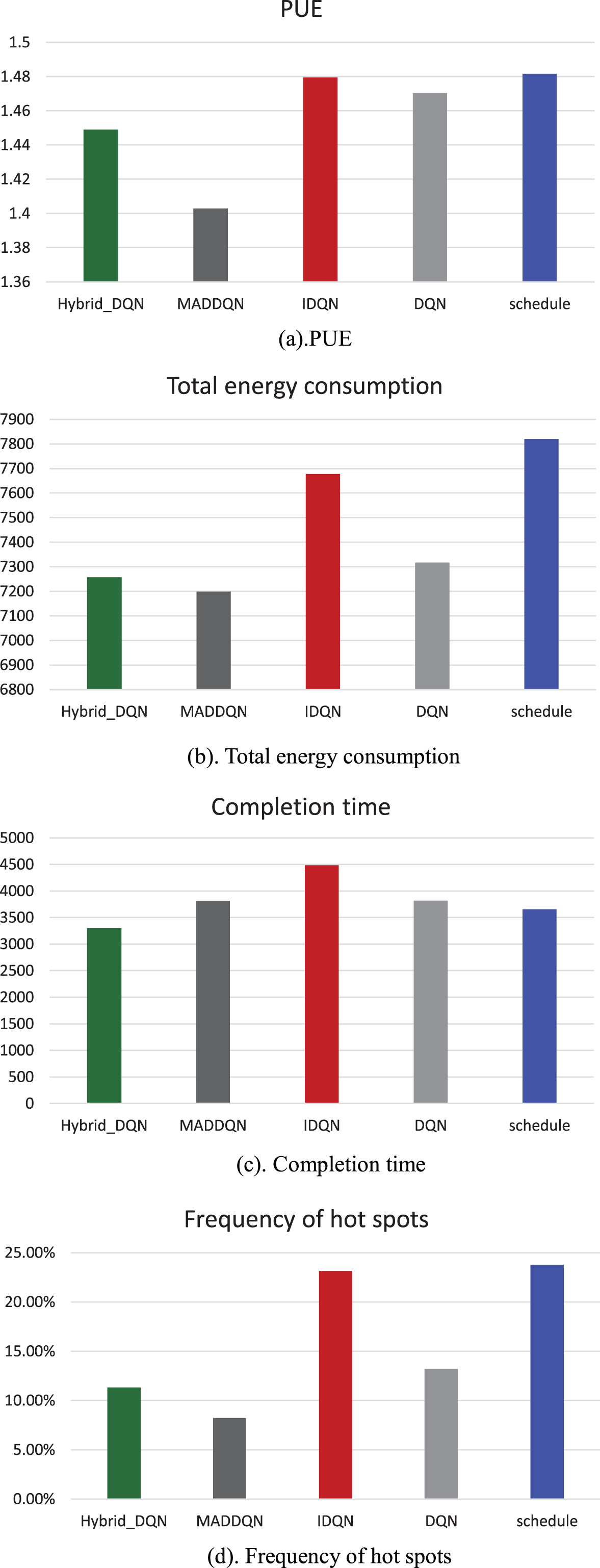
Algorithm performance comparison.
From the running results, we can see that the Schedule method is not as good as other algorithms in terms of energy consumption, PUE, and hot spots, but it runs faster because it only regulates jobs. The multi-agent independent training method IDQN can not converge in the training process due to the lack of interaction between systems, so the performance in terms of total energy consumption, PUE and hot spot frequency in the test results is not good enough. Its effect is only slightly better than Schedule. Moreover, the IDQN algorithm uses multi-agent distributed execution, so it also requires a long running time. Hybrid_DQN is the optimization algorithm of DQN, which has certain improvement compared with DQN in all aspects, but it is still inferior to our MADQN algorithm. Due to the more complex interaction process between different agents, MADDQN takes a little more time to complete all tasks, but it has better effects in reducing hot spots, reducing total energy consumption, and improving energy efficiency.
The advantage of MADDQN algorithm is excellent scalability. It transforms the research of data center from a whole to two subsystems. When the scale of the data center expands and clusters, air conditioners or other equipment increase, corresponding agent can be added to control them. When adding agents, the previously established network structure and state space need not be changed too much. By adding the interactive information of the new agent in the training process, the cooperative training of all agents can be realized. Of course, as the number of agents increases, the interaction information will become more and the joint training time will become longer. However, because of the centralized training and decentralized execution method, the new system only needs to complete a collaborative training process once, and the subsequent execution process is only related to the local data of each agent, and the running time of the system will not increase significantly with the increase of agents. It has good scalability and availability.
IBM put forward the idea of autonomic computing in 2001. It investigates how system can achieve specified “control” out-comes on their own, without operator intervention, such as: self-configuration, self-optimisation, self-protection and self-healing. The next generation computer system can be established with the help of AI/ML technology to realize the deployment and integration of virtual machines and jobs, realize the ability to independently detect and resist potential network attacks and intrusions, and self detect, evaluate and recover from errors without human intervention. With the help of AI/ML technology, the “self-*” systems can enhance its own performance by successfully completing computational jobs, detect and prevent harmful assaults on the autonomic coordinator managing the overall system and discover, evaluate and recover from errors on its own, without the need for human intervention. This “self-*” property’s primary advantage is lower total cost. There will also be a reduction in the number of people needed to maintain the systems and will save deployment and maintenance costs, time, and boost IT system stability [36].
Autonomic computing has made some progress in cloud, fog, edge, serverless and quantum computing. Among them, reinforcement learning, because it focuses on online learning and does not need to give any data in advance, makes it very suitable for the management of multi task and multi device systems in the data center. Reinforcement learning is goal driven, learns through "trial and error", and tries to maintain a balance between exploration-exploration. It obtains action reward (feedback) from the environment to learn information, and automatically updates model parameters. Among them, reinforcement learning is very suitable for the management of multi task and multi equipment systems in the data center because it focuses on online learning and does not need to give any data in advance. Reinforcement learning (RL) approaches like Q-learning and State-Action-Reward-State-Action (SARSA) have been used to study Migrating VMs or containers in the data center. In this paper, we use the multi-agent reinforcement learning method to achieve the collaborative energy saving of data center tasks and refrigeration equipment. Although it remains a challenge in practical contexts where there are many requests, it is also the trend of the next generation of computing in the future.
Conclusions and future work
This paper proposes a global energy optimization algorithm MADDQN based on heterogeneous multi-agent reinforcement learning. First, different networks are designed for scheduling agent and cooling agent. Build the overall energy consumption optimization framework of MADDQN, and determine the interaction process between each agent and the environment; Then the state action space, reward function and different network structures are designed for each agent; Finally, centralized training and decentralized execution are adopted to simplify the interaction process between different agents. In the data center simulator designed by our team, the algorithm MADDQN proposed in this paper is compared with the multi-agent independent training algorithm and the hybrid dqn network algorithm. It is proved that MADDQN algorithm can not only reduce the total energy consumption of the data center, but also further improve energy efficiency.
This research has made phased progress in algorithm research, but it is still based on the data center simulation environment. Although we use real data for simulation, it does not fully represent the actual data center. Therefore, the algorithm can be verified in the real data room in future work. In addition, our algorithm only implements two agents. In the future, with the increase of data center size, the multi-agent framework designed in this paper can expand more agents, including job scheduling of multiple clusters or the control of multiple air conditioning units, and even the cooperative optimization between different data centers.
Footnotes
Acknowledgment
This work is supported by National Key Research and Development Plan of China. (No. 2017YFB1001701).