
Abstract
Pedagogic systems are gaining traction in the provision of training, learning, and continuing professional development (often required to maintain professional qualifications). An essential element in pedagogic systems is the matching of teachers (mentors) and students (mentees). In this paper we present an intelligent context-aware learning system based on profile criteria developed using big data analytic solutions. The proposed system is designed to provide systematic support for mentors based on student profiles. The goal of the proposed system is to match the mentor profiles with the type of pedagogic system, the student profile, the student requirements, and the student’s goals and expectations. The proposed system is predicated on the use of fuzzy logic definitions with a maximal length matching algorithm using expert knowledge. The proposed system implements a mentor (teacher) and mentee (student) matching algorithm based on their profile criteria. The proposed system has been successfully tested by matching mentor and mentee profiles and preferences. Experimental results show that the proposed system can access multi-factorial mentor and mentee profiles, effectively match suitable mentors (teachers) with appropriate mentees (students), and meet the mentee expectations.
Introduction
The provision of education and training requires the design, development, and implementation of pedagogic systems to accommodate learning requirements and the learning goals. For example, pedagogic systems are implemented by academic institutions to provide courses for: (a) tertiary education in full-time and part-time courses delivered face-to-face and on-line, and (b) courses designed and delivered by higher education institutions enterprise (commercial) organisations with courses designed to accommodate for example: full time education, and part-time bespoke courses designed provide, for example: (a) the training of employees to accommodate developments in processes and systems in industry, and (b) courses designed to provide continuing professional development (CPD) which has become compulsory in many professional organisations [such as The Chartered Institute of Building (see: https://www.ciob.org/learning/find-cpd)] where it is a requirement to enable professionally qualified members to retain their professional qualification. Pedagogic systems are essentially dynamic, multi-factorial, and must accommodate the mode of delivery (e.g., face-to-face or on-line), the nature of the course being provided (e.g., tertiary education, the ‘upskilling’ of employees, or CPD). Additionally, courses must be designed to accommodate the academic level of students and their learning styles of students as discussed in [1]. Research has investigated many factors which are increasingly manifest in science and engineering research where socio-economic, socio-political, and socio-technical considerations must be accommodated in computerised systems including pedagogic systems. Such factors are relevant to pedagogic systems implemented during the Covid-19 pandemic where traditional face-to-face teaching was either restricted or not possible. For example, in identifying suitable and appropriate instructors (i.e., teachers), technical and social criteria are important factors in the relationships developed between mentors (teachers) and mentees (students). Such relationships are developed and understood over time and have become increasingly important in on-line pedagogic systems implemented during the Covid-19 pandemic. Relationships developed between mentors and mentees are important in that the sharing of knowledge and experience can be mutually beneficial. This paper presents a novel approach to ‘mentor’- ‘mentee’ (student) reporting based on fuzzy logic implements with a ‘maximal length matching algorithm’ using expert knowledge. The proposed method set out in this paper is designed to improve ‘mentor’ and ‘mentee’ collaborative activity by the application of context matching based on the ‘mentor’ and ‘mentee’ profile criteria. In experimental testing the proposed algorithm has been evaluated along with the mentor pedagogic management system using ‘real-world’ case studies. The results demonstrate that the proposed approach can optimise the mentor search process in the pedagogic management system based on the context-aware profile criteria. The contribution made by this study includes:
• The application of intelligent context-awareness to the identification of appropriate ‘mentor’- ‘mentee’ relationships,
• The provision of an effective improvement is training reporting,
• The application of a novel method to improve pedagogic systems with the capability to generalise to a broad and diverse range of domains and systems where ‘mentor’- ‘mentee’ matching is required.
This paper is divided into five sections: the introduction sets out the background and motivation for the study with the related research set out in Section 2 where research and algorithms that have been used to solve matching problems is addressed. Section 3 shows our proposed model with the related experimental testing described in Section 4. The paper closes with a discussion and concluding observations.
Related research
Traditional pedagogic systems research has investigated many forms of teaching and learning including training projects. In a study analysing training report accuracy Magorzata Baran and Roland Zarzycki [2] analyzed 392 people using a combination of methods such as demographic analyses with a comparative implemented in parallel. The expected results (scores) compared the actual results (the accuracy of the training report) with the mentor and “non-opinion mentor” view to assess the accuracy of the report. Further research by Magorzata Baran shows that mentoring raises mentee success, resulting in quicker job growth, higher income levels, and improved levels of engagement and happiness in the public and at work [3]. In this section other related research studies are addressed which consider research in the field. Research has investigated profile compatibility issues in a broad and diverse range of domains including: online dating applications, the filtering of CVs’, identification of soccer players, etc. An overview of significant research ([4–7, 29] addressing matching algorithms is set out in tabulated form in Table 1 where an overview of the references related research in group decision making [8] is provided. Rhodes & DuBios in a paper entitled “Mentoring Relationships and Programs for Youth” [9] have considered the relationship between mentors and training activities and have observed that mutually beneficial results for both mentees and mentors have been realised. Megginson et al. in [10] have studied mentoring in Action and practical guidelines for managers; mutually beneficial results have been reported in the range: 40% for mentees, 27% for mentors, and 33% for the promoting organizations. The observations of Rhodes & DuBios [9] and Megginson et al. demonstrate the relevance and utility of mentoring for all stakeholders in pedagogic systems. Interesting studies include “candidate resume review recruiting” [7] where Racz et al. describe the skills employers require to identify resumes (CVs’) with the correct profile and skills. Racz et al. employ a radical method which compares probabilities based on the maximum entropy of the analysed models using Big data. Martinez-Gil et al. in [6, 11] employ knowledge-based network filters to reflect compatibility in a normalised range [0,1]. An interesting study is presented in [12] where Paoletti et al. address “Top-k Matching Queries for Filter-Based Profile Matching in Knowledge Bases”. In this study the top-k query algorithm is applied over relational databases to find the most effective matching result. Context matching algorithm [13–15] use to apply the behavior of users, finding the matched Covid-19 person in its identification. Some studies using Knowledge Graph [16] and Fuzzy Knowledge Graph [17] in expression of decision making for matching patients in a medical diagnosis. Long et al. [18, 19] has investigated the framework for Big data 4.0 in order to search with its matching huge data sets in both engineering and science areas. Research has considered ‘mentor’ and ‘mentee’ compatibility; however, it is generally an analysis of two-sided matching problems. Haas et al. [4] have conducted a comparative analysis of pairing algorithms for the mentor pairing problem. Haas et al. have proposed a “deferred acceptance” algorithm. An analysis of the “deferred acceptance” algorithm has also featured in a paper entitled “Two-Sided Matching for mentor-mentee allocations Algorithms and Manipulation Strategies” [5]. Hierarchical Pooling using Graph Neural Networks to Enhance Classification Performance in Large Datasets is considered in [20] where Pham et al. conduct a study of large data sets using a graph deep learning approach applied to data classification. The proposed approach has been evaluated using a number of popular and publicly available sensor in schools and enterprises. In advanced training courses, educational personalisation can be applied to future campus-based pedagogic systems [21–23]. Such training courses facilitate either: (a) E-learning using intelligent context matching [24], or (b) E-learning in industry 4.0 [25]. In both cases the management and evaluation of e-learning resources based on both explicit and tacit knowledge can be realised using a picture fuzzy sets method implemented in a rule-based system in the domain of tertiary education [26, 27] and applied picture fuzzy sets in reasoning for improvement of matching patients with solutions in clinic decision support [28]. The research considered demonstrates both the ability to realise profile matching and the capability to generalise to a broad range of diverse domains and systems. The following section introduces the methodology for the approach proposed in this paper.
Summary of significant profiling and compatibility issues
Summary of significant profiling and compatibility issues
This section introduces the proposed system. We address the matching problem in Section 3.1 with the system architecture introduced in Section 3.2. The methodology is introduced in Section 4 where we introduce perfect matching, maximal length matching, filter and score criteria, and aggregate score in Sections 4.1, 4.2, 4.3, 4.4 respectively. The evaluation of the proposed approach is set out in Section 5 with case studies and the results provided 6. Limitations and open research questions are addressed in Section 7.1.
The matching problem
There are multiple mentors who have expertise in a broad and diverse range of domains of interest. However, selecting an appropriate represents a significant challenge given the variable nature of mentors qualifications to act as a mentor. Moreover, relationships between mentors (e.g., teachers) and mentees (e.g., students) are driven by many subjective factors that cannot be clearly modeled and evaluated. The challenge considered in this paper is the design and creation of an algorithm capable of addressing the multi-factorial nature of the problem (i.e., mentor and mentee matching) where determining the compatibility between mentors and mentees forms a target to enable the identification of suitable mentors from which a mentee may make an appropriate selection. We may consider the multi-factorial problem in terms of context-matching [30, 31]. Formally:
• Mentee (I) = {Field to be mentored, Company (group, industry etc.) mentee wants to enter, Education (School, department, level e.g., undergraduate or postgraduate), Location }
• Mentor (O) = {Work Experience (Company, Position), Education (School, Faculty or Specialization), Field to mentor, Location, Number of mentees}
From the foregoing discussion we can see that the potential challenge lies in the multi-factorial complexity inherent in achieving compatibility between mentors and mentees which may briefly summarise in Equation 1:
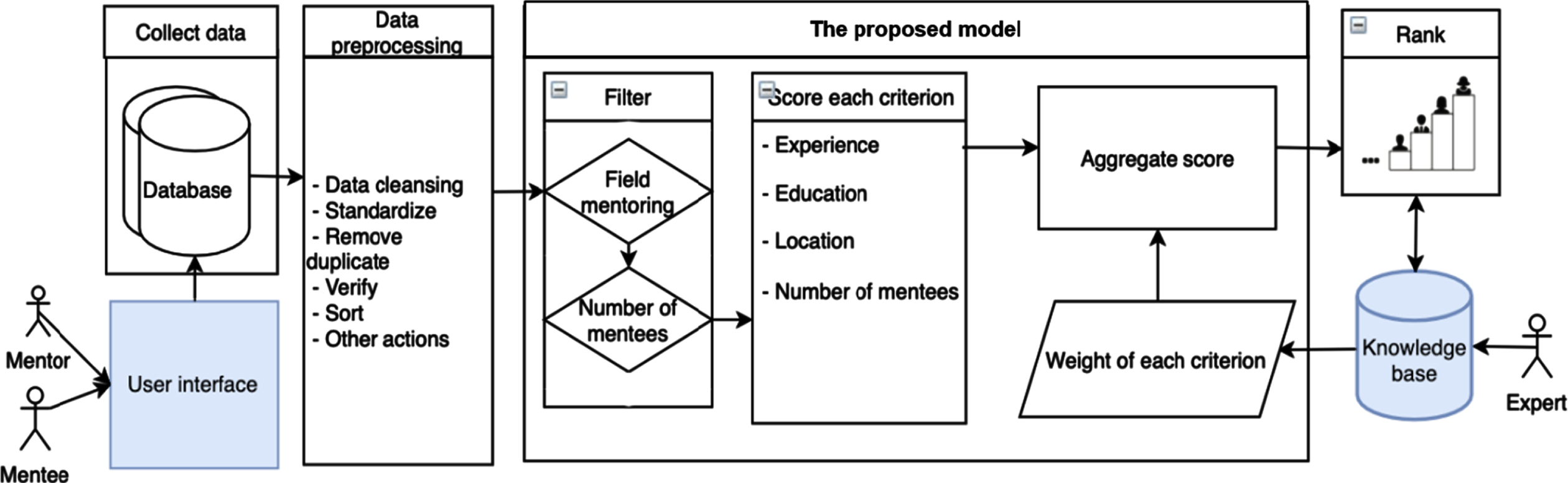
Proposed system architecture for the intelligent pedagogic system.
The algorithm for the proposed method has been designed to: Produce a score for each profile criteria, Average the scores using a weighted average approach, (and) Assign a mentor ranking to the mentee. The results will be presented to potential mentors to enable the weighting to be correctly computed.
Figure 1 presents a conceptual model of the proposed intelligent pedagogic system where a detailed view of the proposed model is provided. Mentors and mentees use the proposed system application to maintain and update their profiles and save the data. Implementing the proposed approach is achieved in the following steps:
• Data cleansing: verify that only correct data is processed,
• Data relating to mentee profiles and mentors currently on the system will be collected from the database system when scoring the match for a mentee.
• Data cleansing: verify that only correct data is processed,
• Standardize: data sets are formatted based on the rules,
• Remove duplicates: similar data is either omitted or removed,
• Verify: unusable data is deleted and data that is unusual is annotated,
• Sort: the data is managed by category,
• Other actions: to increase data quality additional and/or optional rules can be used.
• Filter: Mentors not qualified or eligible for ranking are excluded based on a set of guidelines and guidelines. The filtering criteria are introduced in Section 4.3 (filter and score criteria) where the criteria to be scored and the scoring process is discussed,
• Aggregate score: The weighted average of the criteria will be used to determine the final score. Based on the result(s) and expert opinion(s) the weights will be updated; the aggregation process and equations are introduced and defined in Section 4.4 (aggregate score).
• Rank: The results will be ranked from high to low based on the composite score,
• Experts will then review the results and re-evaluate the results based on their knowledge and experience in order to adjust the weights for each criteria.
Methodology
In this section we address the processes which combine to create the methodology. We introduce perfect matching in Section 4.1 with maximal length matching addressed in Section 4.2. Filter and score criteria are considered in Section 4.3 with aggregate score introduced in Section 4.4. Section 5 presents the evaluation of the proposed approach with results set out in Section 6.
Perfect matching
Focusing on the criteria of the companies (groups, industries, etc.) that the mentee wants to pursue, the mentor’s work experience in those companies will be used to evaluate the compatibility between the mentor and mentee.
• Let set (S = {s1, s2, … s n }) be a limited set of companies (groups, industries, etc.) (and)
• A mentee with (I = {i1, i2, … i n }) represents the companies (groups, industries, etc.) in which the mentee wants to work for, where (i1, i2 . . . i n ∈ S), so I is a subset of (S) (and)
• A mentor (O = {o1, o2, … o n }), where (o1, o2 . . . o n ∈ S), and is also a subset of (S) representing the work experience in which the mentor(s) have expertise and experience.
The task is to evaluate the compatibility of each mentor with mentee I based on the mentee’s desired criteria and the mentor’s work experience.
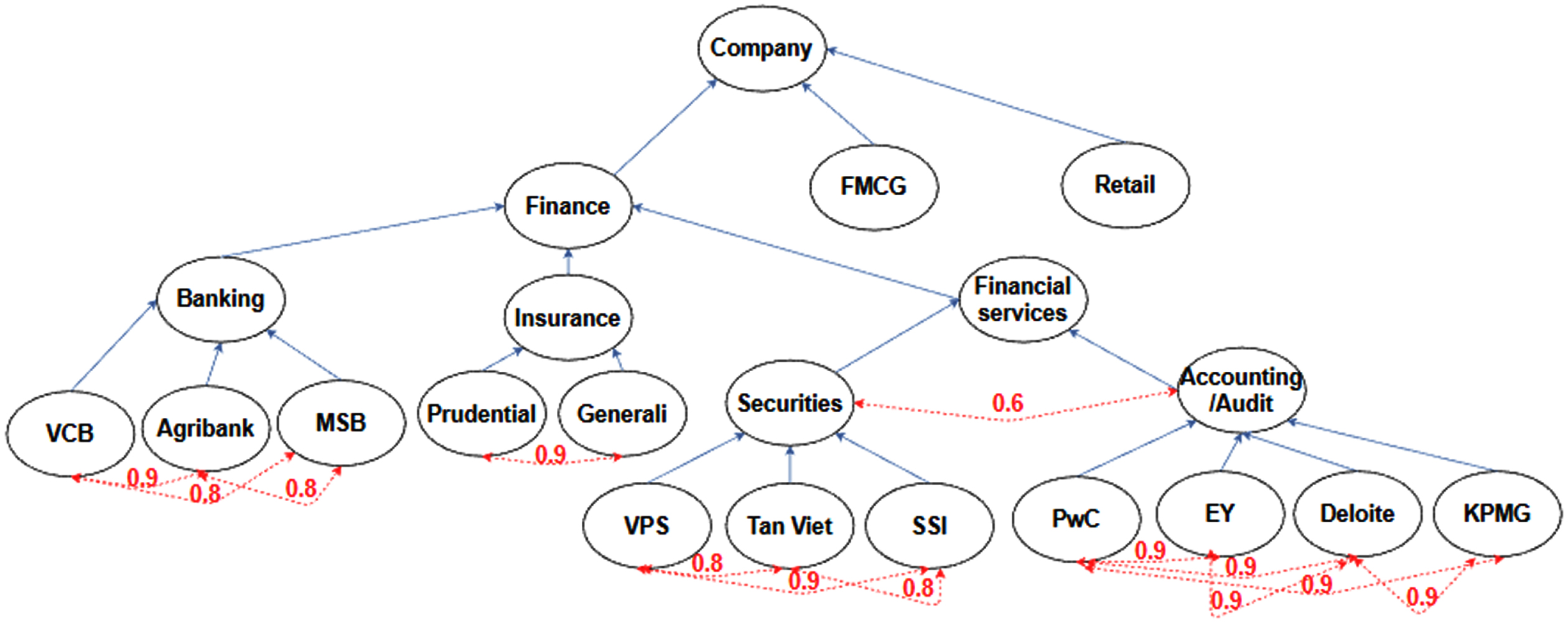
The figure shows the company hierarchy (group, industry etc.). From the figure we can see the tree structure of the model with the components making up the factors to be considered along with the related mentor mentee compatibility scores.
Mentee I = {PwC, KPMG}
Mentor O1 = {EY, Deloite}
Mentor O2 = {PwC, VPS}
Mentor O3 = {KPMG, VCB}
Mentor O4 = {SSI, VPS}
Mentor O5 = {PwC, KPMG}
where EY, Deloite, PwC, VPS, KPMG... are names or common names of companies.
A simple idea proposed in [32] to evaluate the compatibility of a mentor with a mentee is through a formula:
Based on the formula given, we can see that the values of (O2) and (O3) are equal to 0.5, while the values of (O1) and (O4) are 0. This shows that there is no clear differentiation between(O1) and (O4), and similarly between (O2) and (O3). However, since the goal is to rank the compatibility of mentors with mentees, we need to avoid such cases where the values do not provide a clear distinction to give the best results. It is evident that although O1 and I have both expressed their desire and experience in the accounting/auditing industry, the result is 0. Therefore, we need to add more knowledge to re-evaluate (O1) and differentiate between (O2) and (O3), as well as (O1) and (O4)
Assuming that the companies (groups, industries, etc.) in (S) form a hierarchical system. There are several ways to represent this hierarchical system, such as logical description [33], resource description framework Schema [34], or logic programming [32]. Here we will use logical description and obtain the result as shown in Fig. 2.
Let (⪯) be a parent-child relationship (subsumption) on (S). Let (s i ), (s j ) be two elements of (S), then (s i ⪯ s j ) if (s i ) is a specific (particular) instance of (s j ). This means that if a person has experience in (s i ), then they also have experience in (s i ) because (s j ) is more general than (s i ). Let (⪯ d ) denote the specific direct relationship, that is, (s i ⪯ d s j ) if and only if (s i ⪯ s j ) and (∄ s k ∈ S) such that (s k ≠ s i , s k ≠ s j ) and (s i ⪯ s k ⪯ s j ). For each company (group, industry, etc.) in (S), there is a unique parent. In (S), there is a parent-child relationship and each child has a unique parent, so this hierarchy is called a crystal network, denoted by (S, ⪯). In Fig. 2, the solid lines represent the parent-child relationship and are called main edges.
We have presented ways to add knowledge to the ‘sub-side’ hierarchy. However, given that these edges can form cycles in the hierarchy, to address this we have used the fuzzy filter definition method as discussed in [35, 36].
Definitions
In this section we set out definitions with an illustrative example which measures a relevance score.
• Let (G = (V, :E)) be a directed weighted graph with (V) representing a finite set of non-empty nodes,
• Let (E = {E I ∪ E E } ⊆ V × V) represent the set of edges,
• Each node represents a company (group, industry, etc.).
• An edge ((e i = (v i , v j ) ∈ E I )) (set of main edges) links a company (group, industry, etc.) (v i ) to a company(group, industry, etc.) (v j ) if (v i ) is a subset of (v j ).
• Additionally: (e e = (v i , v j ) ∈ E E ) (set of secondary edges) denotes a conditional dependence between (v i ) and (v j ).
Specifically, if a mentor has worked at company (v i ), then they also have certain knowledge about company (v j ) in the same industry group (this type of edge is called a secondary edge).
Set (ω : E → [0, 1]) be a weighting function that assigns weights to all edges, with the main edges (e i ∈ E I ) have (ω (e i ) = 1) and all sub-edges (e e ∈ E E ) for the weight (ω (e e )) representing the conditional probability between the starting point and the end node of the edge. The edge weights can be derived based on the experimenters or experts.
• Let (G = (V, E I ∪ E E )) be a directional graph with side weights of (ω : E → (0, 1]) and a network crystals of (S, ⪯). If (V = S) and every (v i , v j ∈ V) have ((v i , v j ) ∈ E I ) if and only if (v i ⪯ d v j ), we claim (G) is based on (S, ⪯) [7].
• Let (s, t ∈ V) denote two nodes, and (p E (s, t)) represent all directional paths between (s) and (t) as shown in Equation 3:
• Call (I ⊆ V) a set of companies (groups, industries...),
• The set of all companies (group, industry,...) accessible from (I) through directed paths containing only edges from (E I ) is defined as the extension of (I) from (E I ),
• To make a fuzzy set, add (1.0) to each extension node as shown in Equation 7:
• Let (O ⊆ V) be a set of companies (group, industry,...). The extension of (O) from (E) (including (E I ) and (E E )) is defined as the set of all companies (industry, industry groups...) available from (O) through directed paths containing edges, and assigning the length of the longest path between the node and the elements of (O) to each element of the extension set as expressed in Equation 8:
We can determine the appropriate value between
Using the example shown in Section 4.1 we can measure the score corresponding to the match between mentors and mentees based on the work experience criteria using the extension set [following extending] of (I) and (O1) as follows:
•
•
•
•
As we can see, after expanding the initial mentee set (I = {PwC, KPMG}), additional elements such as (Audit/Accounting, FinancialServices, Finance) have been added and extended from (PwC, KPMG) through the main edges as shown in Fig. 2 with the corresponding value of (1.0) as done by (extend
E
I
(I)). As for the mentor set (O = {EY, Deloitte}), similar to the extension from (I), the elements (Audit/Accounting, Financial Services, Finance) have been extended from (EY,Deloitte) through main edges and assigned values of (1.0). Meanwhile, (PwC, KPMG, Securities) have been extended through auxiliary edges, and their fixed values have been calculated using the method (extend
E
(O)). The intersection of
The above result has provided us with a more accurate evaluation of the compatibility between a mentor and mentee based on the desired criteria and the mentor’s work experience.
When mentors are ranked relative to their compatibility with mentees the mentees CV (work experience, qualifications) and interest in a particular domain or a specific organisation (company, group, industry, etc.) and the mentees work experience and qualifications are appropriate and relevant to that company or organisation we will evaluate the following factors:
•
•
•
•
•
The criteria listed above should be weighed when evaluating the match between mentors and mentees. Other criteria such as age, interests, gender... are not possible to consider under the present situation. The following processes implemented in our proposed approach will be used in the evaluation of the factors:
•
•
•
Aggregate score
To compute the aggregate score we implement the following:
• Let
• We use the Equation 10 to calculate the final ranking, which calculates the compatibility between mentors and mentees:
To evaluate the proposed approach to effectively match mentees with mentors in a compatible and meaningful relationship we have used an experimental case study. Section 5.1 addresses the case study with the dataset set out in Section 5.1.1. The results are documented in Section 6. Consideration of the study and the reported results are addressed in Section 7 where the limitations and open research questions (ORQ) and future directions for research are discussed in Section 7.1.
Case study
The experimental case study is based on ‘real-world’ data provided by the
The dataset
There are 2652 records in the database, and 167 mentors in economic sectors (note: one mentor can mentor many different fields). Mentors are predominantly located in Hanoi where there are 71 registered mentors and Ho Chi Minh City where there are 89 registered mentors. Figure 3 models the mentor data by location.
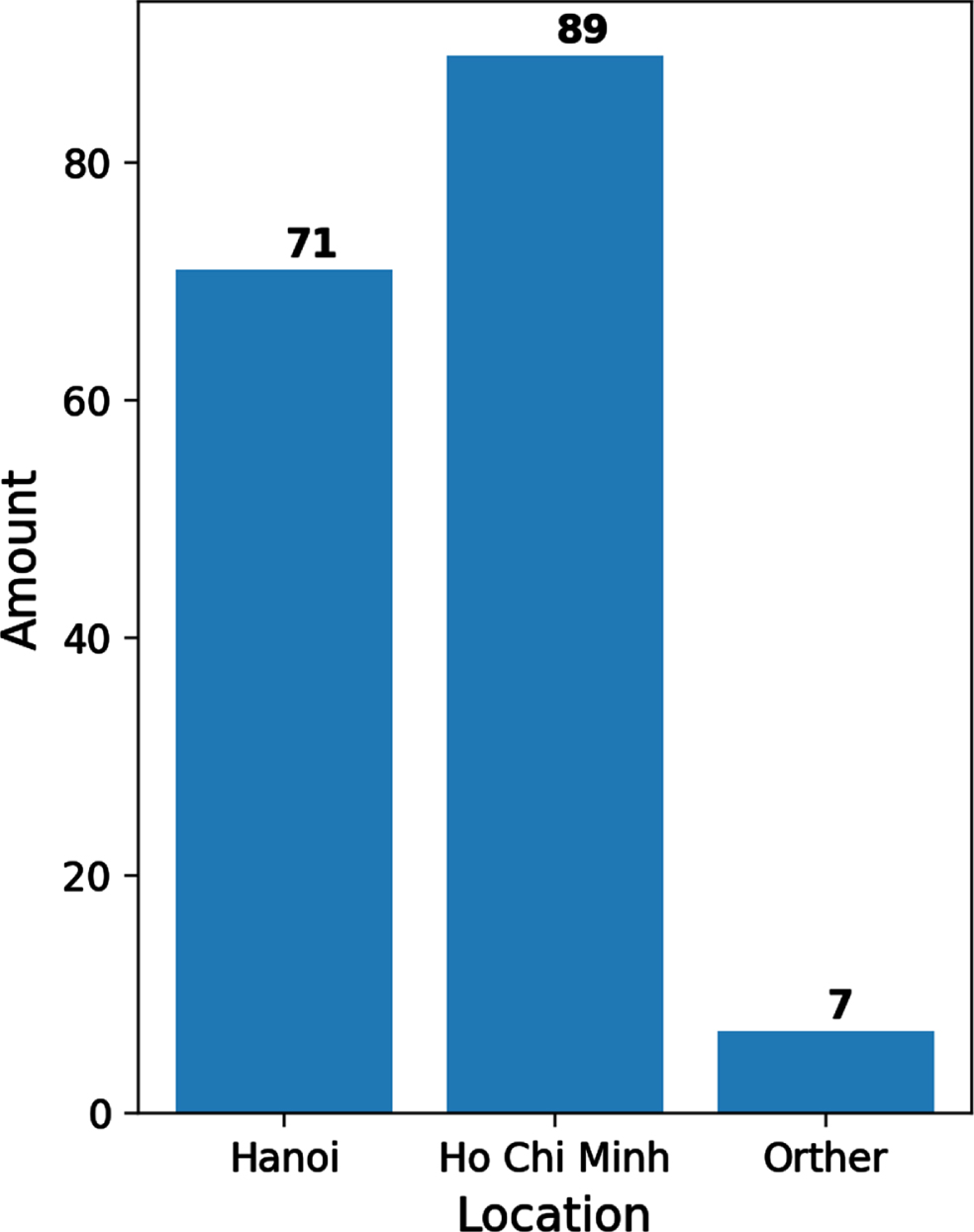
Mentor data by location.
The dataset includes mentors from a range of domains to reflect the diversity in mentoring capabilities. Figure 4 models the mentor data based on the domain of the mentor (the field of expertise). The range of mentoring expertise and qualifications used in the experimental case study is as follows:

Mentor data by domain and field of mentoring expertise.
• 39 mentors [note: one mentor can choose many different mentoring fields] in the domain of finance and banking,
• 64 mentors from the domain of marketing and sales,
• 16 mentors in from the domain of accounting and audit.
• 24 mentors in the supply chain array,
• 31 mentors in the domain of human resources (personnel),
• 8 mentors in management consulting, (and)
• 23 mentors in other domains and areas of expertise.
There are additional available mentors, Fig. 5 models the mentor data by university. The range of mentoring expertise and qualifications used in the experimental case study is as follows:
• 53 mentors from Hanoi Foreign Trade University,
• 19 mentors from Ho Chi Minh Foreign Trade University,
• 23 mentors from National Economics University, (and)
• Additional mentors from other universities in Hanoi and Ho Chi Minh including overseas students and other provinces.

Mentor data by university.
Mentors are drawn from a number of large multi-national organizations in a variety of domains and industries to maximise the available mentoring expertise. Figure 6 models the broad and diverse range available mentoring expertise by organisation (company) with mentor data by connection pairs by field modeled in Fig. 7. There are:

Mentor data by organisation (company).
• 372 existing mentor-mentee matches,
• 86 pairs of connections in finance and banking,
• 103 pairs of connections in marketing and sales,
• 31 pairs of matches in accounting and auditing,
• pairs of connections in human resources,
• 57 pairs of supply chain connections,
• pairs of management consulting connections, (and)
• 36 pairs of connections in other fields.
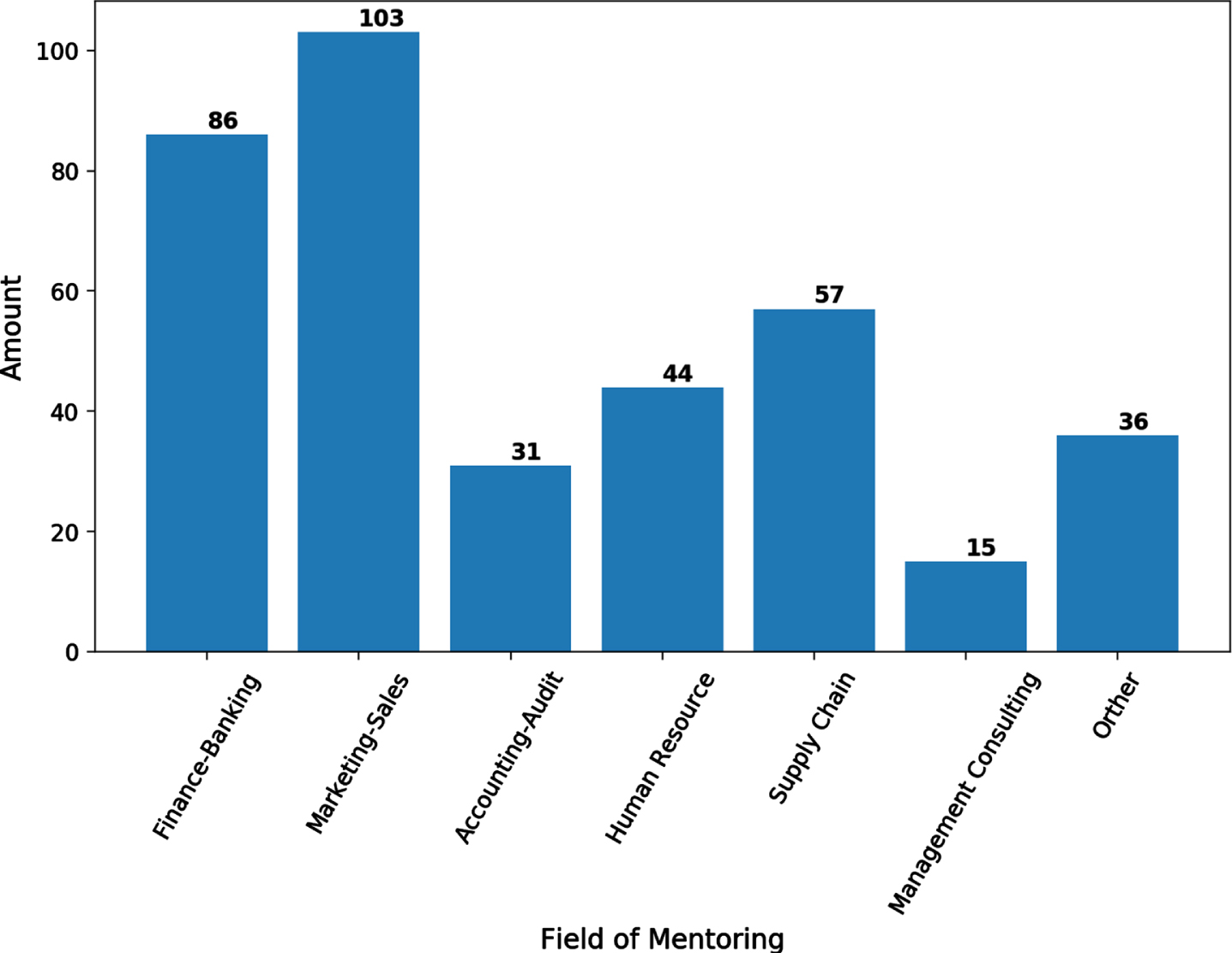
Mentor data showing connection pairs by field.

Mentee data by university.
Mentees are drawn from a range of institutions, the list of institutions and the mentee numbers are set out below. Figure 8 models the mentee data by institution (university).
• 109 mentees from Hanoi Foreign Trade University,
• 41 mentees from Ho Chi Minh City Foreign Trade University,
• 31 mentees from Ho Chi Minh University of Economics,
• 58 mentees from National Economics University,
• 35 mentees from the Academy of Finance, (and)
• Additional mentees from Hanoi University of Science and Technology and the other universities.
The largest body of mentees (35%) are drawn from undergraduate degree programs with third year students (preparing investigating internships in preparation for a job search), 4th year students preparing to graduate make up (29%) of the population of mentees, and college students from year two make up 16% of the population. Figure 9 shows a pie chart setting out the relative proportions of mentees by the status of the students e.g., year and alumni) for the population of mentees.
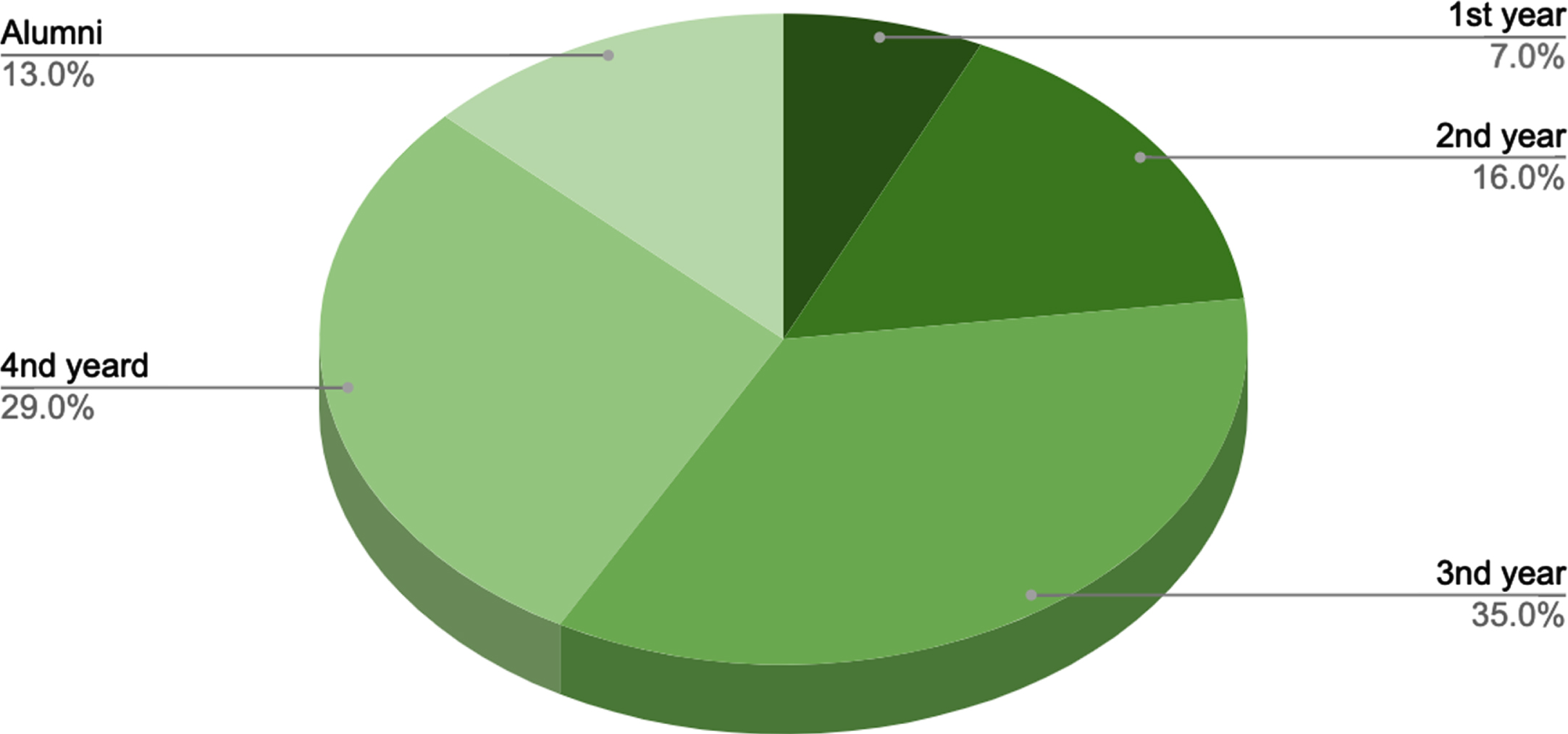
Mentee data by school year.
In this section we set out the results of the analysis derived from the case study. Based on mentoring expert advice the score for the criterion of the number of mentees should be as follows:
• for zero (no) mentees the score = 1,
• for one mentee the weighted score = 0.8,
• for two mentees the weighted score = 0.3,
• for three mentees the weighted scores are equal (to filter out mentor scores).
The weights of the above criteria are obtained using the proposed method based on the following percentages. In the experiment, the weighting for each criteria is set out in Fig. 10:
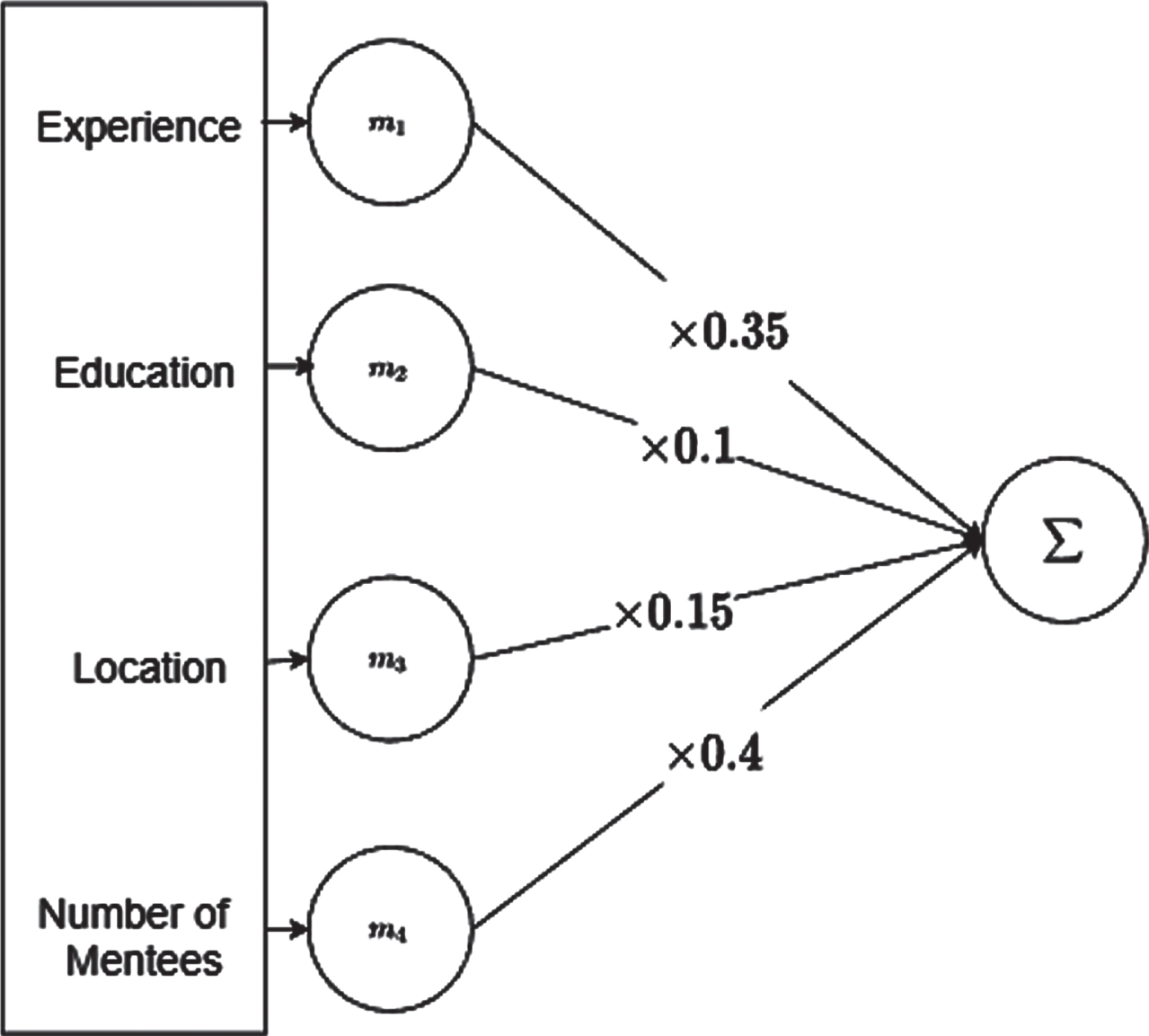
The weighting for each criteria.
• Work experience = 35%
• Education = 10%
• location= 15%
• The number of mentees at any one time = 40%
Note that work experience (35%), education (10%, location (15%), and number of mentees (40%) are the weights optimized as presented in section 4. Through experimentation and based on the experience and knowledge of experts are obtained weights, the average representation is 90% based on the experience and knowledge of experts. The results are described in the Fig. 10.
Consider the following example where there is one mentee and a range of mentors as follows:
• Mentee I = {PwC, FTU,Accounting-Audit, Hanoi}
• Mentor O1 = {[KMPG, EY], FTU, Accounting-Audit, Hanoi, 1 }
• Mentor O2 = {VPS, FTU, Finance-Banking, HCM, 1}
• Mentor O3 = {[VCB, MSB], NEU, Finance-Banking, Hanoi, 0}
• Mentor O4 = {EY, NEU, Accounting-Audit, Hanoi, 1}
• Mentor O5 = {EY, FTU, Accounting-Audit, HCM, 1}
• Mentor O6 = {PwC, NEU, Accounting-Audit, HCM, 2}
• Mentor O7 = {PwC, FTU, Accounting-Audit, Hanoi, 3}
• Mentor O8 = {VPS, FTU, Accounting-Audit, HCM, 1}
• Mentor O9 = {[VCB, MB], AOF, Accounting-Audit, Hanoi, 2}
• Mentor O10 = {Deloitte, NEU, Accounting-Audit, HCM, 2}
Based on the weighting, we can calculate: (a) the score, and (b) the ranking of mentors that match mentees as set in Table 2. Mentor (O1), mentor (O4), and mentor (O5) are the three top ranked mentors in the Table 2, which we refer to as mentee(O). In assessing the compatibility, the majority of matching between mentors and mentees will be clear and unambiguous. However, if we use only a perfect compatibility measure, the ranking for mentors that match the mentee will be as shown in Table 3. While the results tabulated in Tables 2 and 3 differ (the results for Mentor (O4) and Mentor (O6) were not clearly demarcated in Table 3) we would argue that the measure of compatibility remains relevant and useful in practical ‘real-world’ mentoring.
Table of scores and mentor rankings
Table of scores and mentor rankings based only on perfect matching
We have considered the matching of mentors (i.e., teachers) and mentees (i.e., students) in the context of pedagogic systems which are gaining traction in the provision of training, learning, and continuing professional development. Pedagogic systems, implemented in both academic and enterprise organisations, must be to accommodate for example: (a) full time education, and (b) part-time education including training courses designed to provide continuing professional development and the training of employees to accommodate developments in processes and systems in industry. Research has investigated societal factors which increasingly play a significant role in science and engineering research. Such research has addressed common social learning activities including relationships developed between mentors and students which were important in on-line pedagogic systems implemented during the Covid-19 pandemic where traditional face-to-face teaching was either restricted or not possible. Relationships developed between mentors and students are important in that the sharing of knowledge and experience is facilitated resulting in mutual benefit. The improvement of the mentor / mentee matching process this paper presents an intelligent learning system based on context-aware profile criteria developed using big data analytic solutions. The proposed system is designed to provide systematic support for mentors based on student profiles. The goal of the proposed system is to match the mentor profiles with the type of pedagogic system, the student profile, and the student requirements and expectations. The proposed system implements a mentor / mentee matching algorithm based on their profile criteria. The proposed system is predicated on the use of fuzzy logic definitions with a maximal length matching algorithm using expert knowledge to refine and improve the matching method. The approach presented in this paper has been evaluated using experimental testing. The evaluation is addressed in Section 5 with the dataset described in Section 5.1.1 and the results provided in Section 1. Experimental results show that the proposed system provides an effective basis upon which quantifiable measures of compatibility between mentors and mentees to achieve appropriate matching with mentee expectations met.
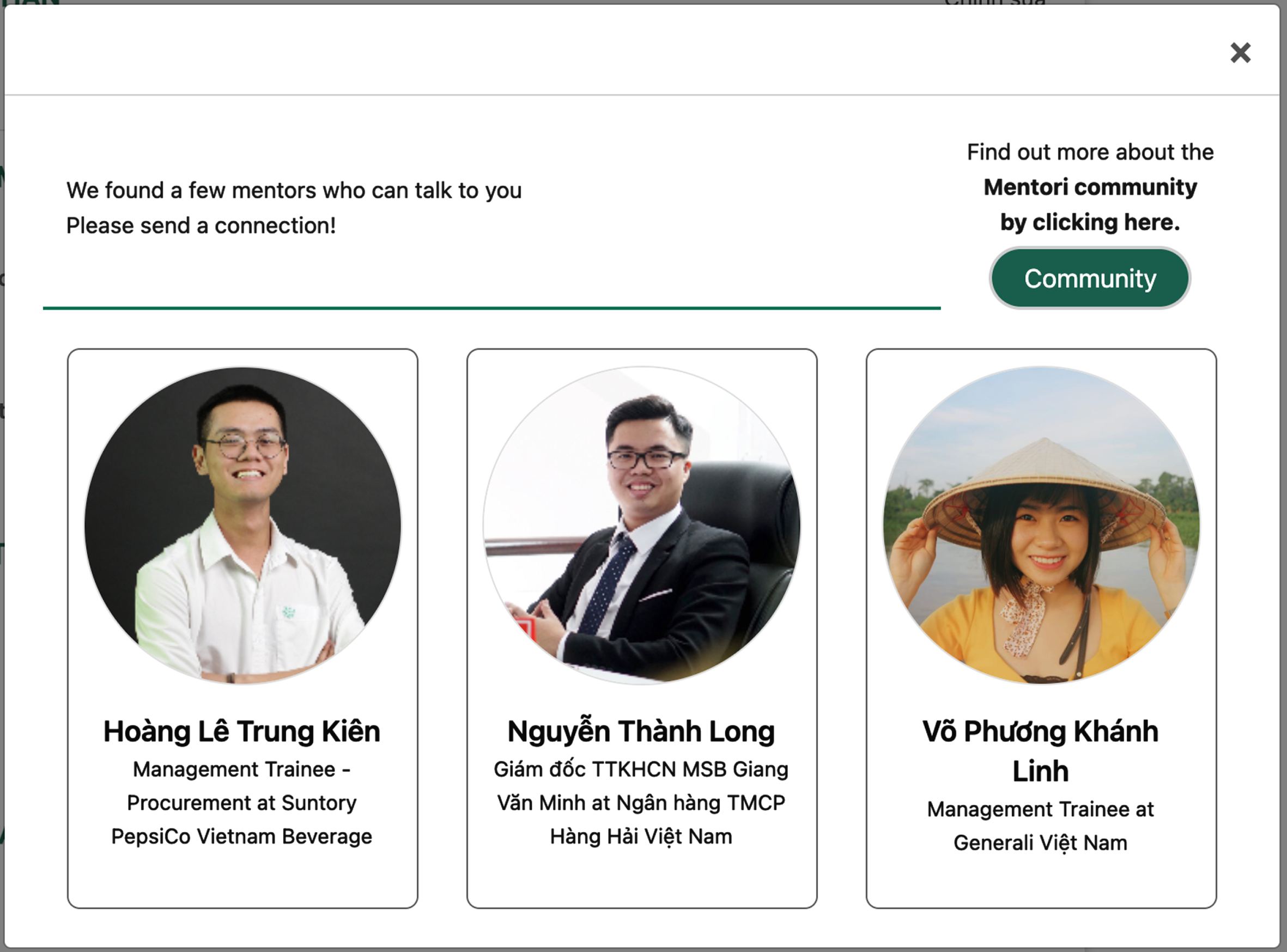
The interface on a screen to introduce suitable mentors.
In this study we have designed and implemented a web interface as shown in Fig. 11 which is designed to show mentors along with their qualifications and expertise. The interface shown in figure 11 represents ate web portal and a mentee, by clicking on the “Community” button will, will see potential mentors which can be tested for compatibility.
In conducting this study many research questions have been answered. However, as with all such research there open research questions (ORQ) and the related directions for future research. To improve ‘mentor’ and ‘mentee’ matching, as with all context-aware scenarios, the range of possible parameters is almost limitless and highly dynamic. We propose to investigate increasing the potential range of parameters [in a diverse range of domains and systems] to determine matching and profile compatibility. In Section 1 we have observed that results tabulated in Tables 2 and 3 differ and some results in Table 3 are not clearly demarcated. To improve the matching performance we will investigate reinforcement learning along with the use of natural language processing (NLP) to improve the granularity in the matching criteria. Additionally, we will investigate improving the assessment for the textual criteria such as introducing or explaining what the mentee encountered to enhance the knowledge graph and develop the algorithm to optimize the weights and improve the mentor query algorithm to match the ‘mentee’ based on the profile parameters and criteria.
Concluding observations
We have considered the issues the ‘mentor’ and ‘mentee’ matching problem. While there are published studies, such methods have limitations as discussed in this paper. We have set out our novel proposed novel approach to ‘mentor’ ‘mentee’ (student) reporting based on fuzzy logic implements with a ‘maximal length matching algorithm’ using expert knowledge implemented using big data analytics. In experimental testing the proposed approach has been evaluated with ‘real-world’ case studies; the results demonstrate that the proposed method can optimise the mentor search process in the pedagogic management system based on context-aware profile criteria. In this research a novel algorithm designed to optimize mentor-mentee matching, the related search process, and a mentor management system based on the profile criteria has been developed. The proposed method effectively enables mentoring activities and we posit that the proposed approach provides an effective basis upon which ‘mentee’ (student) can be matched to an appropriate ‘mentor’ (teacher). Moreover, while the proposed method has been shown to be effective for pedagogic systems, the underlying principles that drive the approach have the capability to generalise (using the appropriate parameters) in a diverse range of domains and systems where we would argue that the measure of compatibility remains relevant and useful in practical ‘real-world’ mentoring systems.
Footnotes
Acknowledgment
The Authors express their gratitude to the Ministry of Science and Technology (MOST) of Vietnam for sponsoring this research through a state-level project: Research on building a digital transformation model for Smart schools, Code KC-4.0-06/19-25.