
Abstract
This paper proposes a method of using machine learning and an evolutionary algorithm to solve the flexible job shop problem (FJSP). Specifically, a back propagation (BP) neural network is used as the machine learning method, the most widely used genetic algorithm (GA) is employed as the optimized object to address the machine-selection sub-problem of the FJSP, and particle swarm optimization (PSO) is utilized to solve the operation-order sub-problem of the FJSP. At present, evolutionary algorithms such as the GA, PSO, ant colony algorithm, simulated annealing algorithm, and their optimization algorithms are widely used to solve the FJSP; however, none of them optimizes the initial solutions. Because each of these algorithms only focuses on solving a single FJSP, they can only use randomly generated initial solutions and cannot determine whether the initial solutions are good or bad. Based on these standard evolutionary algorithms and their optimized versions, the JSON object was introduced in this study to cluster and reconstruct FJSPs such that the machine learning strategies can be used to optimize the initial solutions. Specifically, the BP neural networks are trained so that the generalization of BP neural networks can be used to judge whether the initial solutions of the FJSPs are good or bad. This approach enables the bad solutions to be filtered out and the good solutions to be maintained as the initial solutions. Extensive experiments were performed to test the proposed algorithm. They demonstrated that it was feasible and effective. The contribution of this approach consists of reconstructing the mathematical model of the FJSP so that machine learning strategies can be introduced to optimize the algorithms for the FJSP. This approach seems to be a new direction for introducing more interesting machine learning methodologies to solve the FJSP.
Keywords
Introduction
As the manufacturing industry is becoming increasingly intelligent and information-oriented, current manufacturing scenarios are evolving into flexible job-shop scheduling scenarios. Therefore, the flexible job-shop problem (FJSP) has attracted increasing attention from researchers and engineers [1].
The FJSP is an extension of the job shop problem (JSP). Unlike the JSP [2], the FJSP enables operations to be processed on any available machine. Therefore, two new challenges are faced in the FJSP: (1) the assignment of each operation to an appropriate machine and (2) further scheduling of the assigned operations on the machines. It extensively exists in many industries, such as automobile assembly, textile manufacturing, chemical material processing and semiconductor manufacturing [3]. The FJSP was proven to be strongly NP-hard in 1993 [4-6]. To date, numerous solutions have emerged, among which the most widely used are evolutionary algorithms (EAs) such as the genetic algorithm (GA), ant colony optimization (ACO) algorithm, and particle swarm optimization (PSO) algorithm [7].
The challenge faced by the current EAs used to solve the FJSP is how the search convergence speed can be improved, especially for large FJSPs. Many algorithms require thousands of iterations before the optimal solution can be fetched. Such low efficiency may hinder their practical application because production scheduling requires rapid responses to changes. Therefore, many scholars have developed optimization algorithms to solve the FJSP.
Thus far, many machine learning methods have provided scientific benefits, but these methods are rarely used to solve the FJSP. Considering the generalization ability of neural network, it is suitable to optimize the initial population generation process for solving the FJSP. This enlightens the concept of hybrid evolution algorithm with BP neural network for the FJSP.
The paper provides the following four contributions: Reconstruction of the FJSP model based on JSON (JavaScript Object Notation) objection representation. A machine learning method, the BP neural network approach, is introduced as an example to optimize the process of the EAs for FJSP. GA is the optimized object for the machine-selection sub-problem of the FJSP, and PSO is the method used for the operation-order sub-problem of the FJSP. The datasets, feature extraction strategy, and training strategies are presented for the machine learning method aimed at FJSP.
The rest of this paper is organized as follows: Section 2 presents the literature review. Section 3 introduces the FJSP model formulation. Section 4 gives an account of the pseudocode implementation and program algorithm flow of our work. As this study is focused on the optimization of the EA solution to the FJSP, Subsections 5.1 and 5.2 introduce the general process of the EA for the FJSP. The GA is currently the most widely used EA. Thus, it is beneficial to the description of this paper as an optimized object. Therefore, this work used the GA to solve the machine-selection sub-problem of the FJSP. PSO has the advantages of fast search speed, high efficiency, and simplicity, so this work chose it to solve the operation-order sub-problem. Aspects 1 and 4 are introduced in Subsections 5.3 and 5.5, respectively.
Literature review
This section describes the literature related to solving the FJSP, focusing on EAs such as the GA, PSO algorithm, ACO algorithm, and simulated annealing algorithm.
The GA is an effective meta-heuristic algorithm for solving combinatorial optimization problems [8] and has also been successfully applied to solve the FJSP. Many studies have been conducted on this topic. Chen et al. [9] developed an algorithm based on a GA and grouped the GA for the FJSP. Luo et al. [10] designed an improved GA in which chromosome coding based on workpiece processes and machining was used to solve the FJSP. Wang et al. [11] applied a GA to flexible workshop scheduling multi-objective optimization. The experiments showed that it could reduce production costs and resource consumption and improve production efficiency and reliability. An et al. [12] proposed an improved nondominated sorting genetic algorithm III with adaptive reference vector (NSGA-III/ARV) to deal with a flexible job-shop rescheduling problem (FJRP) with both new job insertion and machine preventive maintenance (PM). Liu et al. [13] designed a novel multiple populations for multiple objectives framework-based genetic algorithm approach (MPMOGA) to solve the job-shop scheduling problem. Harish
PSO is another widely used method of solving the FJSP because of its simplicity and ability to handle optimization problems efficiently. Gao et al. [14] developed an effective general PSO algorithm for the FJSP, and Ding et al. [15] proposed an improved PSO algorithm to solve the FJSP. They obtained beneficial solutions by improving the encoding/decoding scheme, communication mechanism between particles, and alternate rules for the candidate machines for operations. Gu et al. [16] presented a discrete PSO algorithm with an adaptive inertia weight to solve the multi-objective FJSP, and their comparative results demonstrated its effectiveness and practicality. So far, there have been many variations of PSO such as matrix-based PSO (MPSO) [17], social learning particle swarm optimization with adaptive region search (SLPSO-ARS) [18], pipeline-based parallel PSO (P3SO) [19], triple archives particle swarm optimization (TAPSO) [20], and dynamic group learning distributed particle swarm optimization (DGLDPSO) [21]. They have made great achievement in the area of optimization problems.
Recently, other EAs, such as the ACO and simulated annealing algorithms, have also achieved outstanding performance in solving the FJSP. Huang et al. [22] developed a two-pheromone ACO algorithm for the FJSP, considering the due-window and sequential-dependent setup times of jobs. Rossi [23] proposed an ACO algorithm with reinforced pheromone relationships based on a disjunctive graph model for the FJSP, considering sequence-dependent setup and transportation times. Gao et al. [24] presented a novel shuffled multi-swarm micro-migrating birds optimization algorithm to address multi-resource-constrained FJSP. The experimental results indicated that the proposed algorithm performed better than the existing algorithms when the objective was to minimize the makespan. Kavitha et al. [25] designed a technique based on a social insect method to explain the single-goal FJSP, which focuses on the distinction between two diverse search specialists (insects): males and females. Chiang and Lin [26] proposed a multi-objective EA that utilized effective genetic operators and carefully maintained population diversity for multi-objective FJSP. Gao et al. [27] proposed a discrete Jaya algorithm to handle the flexible job-shop rescheduling problem (FJRP). Harish Garg proposed a new hybrid gravitational search algorithm with genetic algorithm (GSA-GA) for the constraint nonlinear optimization problems with mixed variables and this approach achieved good results [28]. K. Tanmay et al. developed an effective hybrid method using improved teaching–learning-based optimization and Harris hawks optimization (ITLHHO) for solving different kinds of engineering design and numerical optimization problems. The experimental results suggest that ITLHHO significantly outperforms other algorithms [29].
During the last few years, hybrids of various EAs have achieved better results in solving the FJSP. Many studies have been published on this topic. For instance, Li et al. [30] proposed a hybrid algorithm that combines PSO, Tabu search, and genetic operators (mutation and crossover operators) to solve the FJSP. Tang et al. [31] developed a hybrid algorithm that combines PSO and GAs to address the FJSP. Tang et al. [32] presented a hybrid discrete PSO algorithm integrated with simulated annealing, which is decomposed into global and local search phases to solve multi-objective flexible job-shop scheduling with tolerated time intervals and limited starting time intervals. Wang et al. [33] proposed a multi-swarm collaborative genetic algorithm (MSCGA) based on a collaborative optimization algorithm for the FJSP. With a multi-population structure independently evolving into two FJSP sub-problems, the MSCGA achieved good performance. Li et al. [34] designed an improved artificial bee colony algorithm with Q-learning for solving permutation flow-shop scheduling problems. Alawad et al. [35] proposed a new discrete optimization algorithm called Discrete Jaya with Refraction Learning and Three Mutation Methods (DJRL3M) for solving the permutation flow shop scheduling problem. Abed-alguni et al. [36] designed an improved island cuckoo search with elite opposition-based learning and multiple mutation methods (iCSPM2) to solve the permutation flow shop scheduling problem. Alkhateeb et al. [37] developed discrete hybrid cuckoo search and simulated annealing algorithm to solve the job shop scheduling problem.
However, these algorithms for the FJSP can only determine the optimal solutions after algorithm completion, and some may eventually obtain local optimal solutions. In summary, the methods proposed in the existing literature focus on solving only a single FJSP. Consequently, they can only use randomly generated initial solutions and cannot determine whether the initial solutions are good or bad. If judgment can be performed in advance, then some of the initial solutions can be made suboptimal, which will significantly speed up the convergence, rather than taking thousands of iterations to obtain the optimal solutions, as the existing EAs do. In this study, the mathematical model of the FJSP was reconstructed, and machine learning was applied so that a solution could be judged as good or bad in advance. This work applied this approach to generate the initial solutions of the optimization algorithms. Most inappropriate initial solutions could be filtered out in advance, accelerating the convergence of the algorithm and increasing the probability of convergence to the optimal solutions. Thus far, few papers have been published on the use of machine learning methods to solve the FJSP. Ming et al. [38] proposed a method using a knowledge base in which several optimal solutions were stored. These solutions were provided as the initial solutions for rescheduling. However, although directly saving the optimal solutions as the initial solutions may be useful for one particular problem, it is not applicable to other problems. Thus, any change in the number of machines, number of jobs, or other parameters will render these optimal solutions not applicable, making this knowledge base of little significance. Gong et al. [39] used a machine learning method to extract rules to solve the FJSP based on rules and expert systems. However, they directly employed these rules to obtain the final solutions, which resulted in suboptimal solutions rather than optimal ones.
This study collected multiple solutions to several problems to extract features, divided all solutions into relatively optimal solutions and relatively bad solutions, and trained the back propagation (BP) neural network. The generalization ability of this BP neural network can be used to classify the initial solutions of similar problems. In this way, relatively optimal solutions are selected as the initial solutions to reduce the number of optimization iterations and improve the algorithm speed.
Specifically, this work used a combination of a GA and PSO to solve the FJSP, and the fitness of one sub-problem was calculated by another sub-problem. This paper also proposes an optimization method for the particle updating process of the operation-order sub-problem using PSO. Finally, using the BP neural network, an optimization method called BP-GA-PSO is proposed.
FJSP model formulation
The FJSP can be described as follows: a machining system has M machines and N jobs, each job has many different operations, the sequence of operations of the jobs is predetermined, each operation can be machined on multiple machines, and the processing time of each operation varies with the performance of the machine. The scheduling goals are to select the most suitable machine for each operation, determine the optimal processing sequence and start-up time for each operation on each machine, and optimize certain performance metrics of the system. In addition, the following constraints must be satisfied during processing: Only one job can be processed on the same machine at the same time. Each job can only be processed on one machine at a time, and not every operation can be interrupted midway. Sequential constraints exist between the operations of the same job, and no order constraints exist between the operations of different jobs. Different jobs have the same priority.
Therefore, the FJSP can be decomposed into two sub-problems: selecting the appropriate processing machine for all operations of each job and sorting each operation after selecting the machines for all operations. The former is the machine-selection sub-problem, and the latter is the operation-order sub-problem.
The notations used in this paper can be summarized as follows:
Jj: Job index, j = 1, 2,..., n;
nj: Number of operations of job Jj;
Mk: Machine index, k = 1, 2,..., m;
Oij: ith operation of job Jj;
pijk: Processing time of the operation Oij on machine Mk;
Sij: Set of available machines for the operation Oij;
Cij: Completion time of operation Oij;
Cmax: Makespan;
Xijk: Xijk = 1 if machine Mk is selected for operation Oij and 0 otherwise.
Yhgij: Yhgij=–1 if Ohg is executed immediately before Oij, 0 if Ohg and Oij are nonadjacent on machine Mk, and 1 if Ohg is executed immediately after Oij.
gap: Idle-time interval between two adjacent operations;
The formulas of mathematical model of the FJSP are as follows based on recommendations from the literature [40].
Equation (1) is an objective function. Inequality (2) is a precedence constraint. Inequality (3) ensures that there are no overlaps between operations on each machine. Equation (4) computes the length of each idle-time interval. Equations (5)–(7) are the constraints on the decision variables.
The Kacem instances [41] are among the most widely used benchmark instances. The 4×5 Kacem instance is shown in Table 1, where the rows correspond to operations and the columns correspond to machines. A job Ji is formed by a sequence Oi1, Oi2, . . . , O in i of operations to be performed one after another.The mathematical model can be represented by the matrix T.
T = [2,5,4,1,2; 5,4,5,7,5; 4,5,5,4,5; 2,5,4,7,8; 5,6,9,8,5; 4,5,4,54,5; 9,8,6,7,9; 6,1,2,5,4; 2,5,4,2,4; 4,5,2,1,5; 1,5,2,4,12; 5,1,2,1,2].
In this study, the scheduling target was to minimize the maximum completion time, which is currently the most widely used scheduling target. Specifically, the target is to minimize the makespan, that is, the time needed to complete all jobs, which is defined as MK = min{max Ci, i = 1, 2, . . . , n}, where Ci is the completion time of job Ji. Because PSO has the characteristics of simple operation and fast convergence, this work chose PSO as the optimization algorithm.
This section describes how to solve the FJSP with the BP-GA-PSO algorithm to obtain the minimum makespan.
In this study, the trained neural network was applied to the initial solutions of the GA to solve the machine-selection sub-problem of the FJSP. PSO has the advantages of fast search speed, high efficiency, and a simple process, so this work chose it to solve the operation-order sub-problem. This work abbreviate this approach as BP-GA-PSO. Each initial solution array (i) is brought into the trained neural network to determine whether it is relatively optimal. If it is a relatively optimal solution, it is retained. Otherwise, the random function is recalled to regenerate a new solution until a relatively optimal solution is generated. To generate n initial solutions, it is only necessary to loop the function n times. The input parameters are the problem T and relatively optimal-solution coefficient U. In fact, as long as one solution is relatively optimal, it can lead the entire population to evolve in a good direction. The pseudo-code of BP-GA-PSO is as follows:
the pre-trained BP neural network NET_BP will be introduced in Section 5.
gBestOperationOrder[i], which has the minimum makespan value VgBestOperationOrder[i].
Flow charts of the BP-GA-PSO algorithm are shown in Figs. 1 and 2.
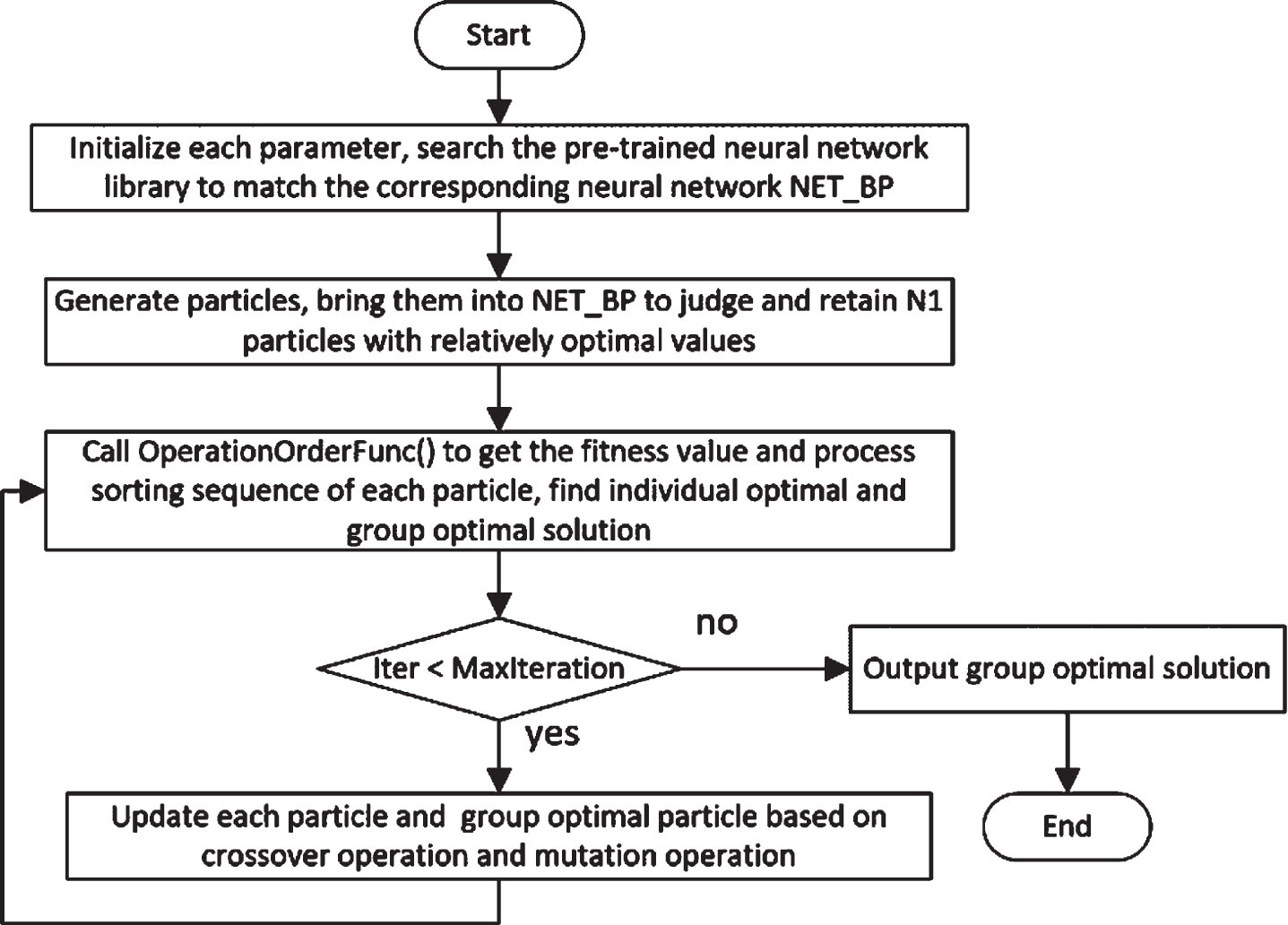
Flow chart of the BP-GA-PSO algorithm for the FJSP.
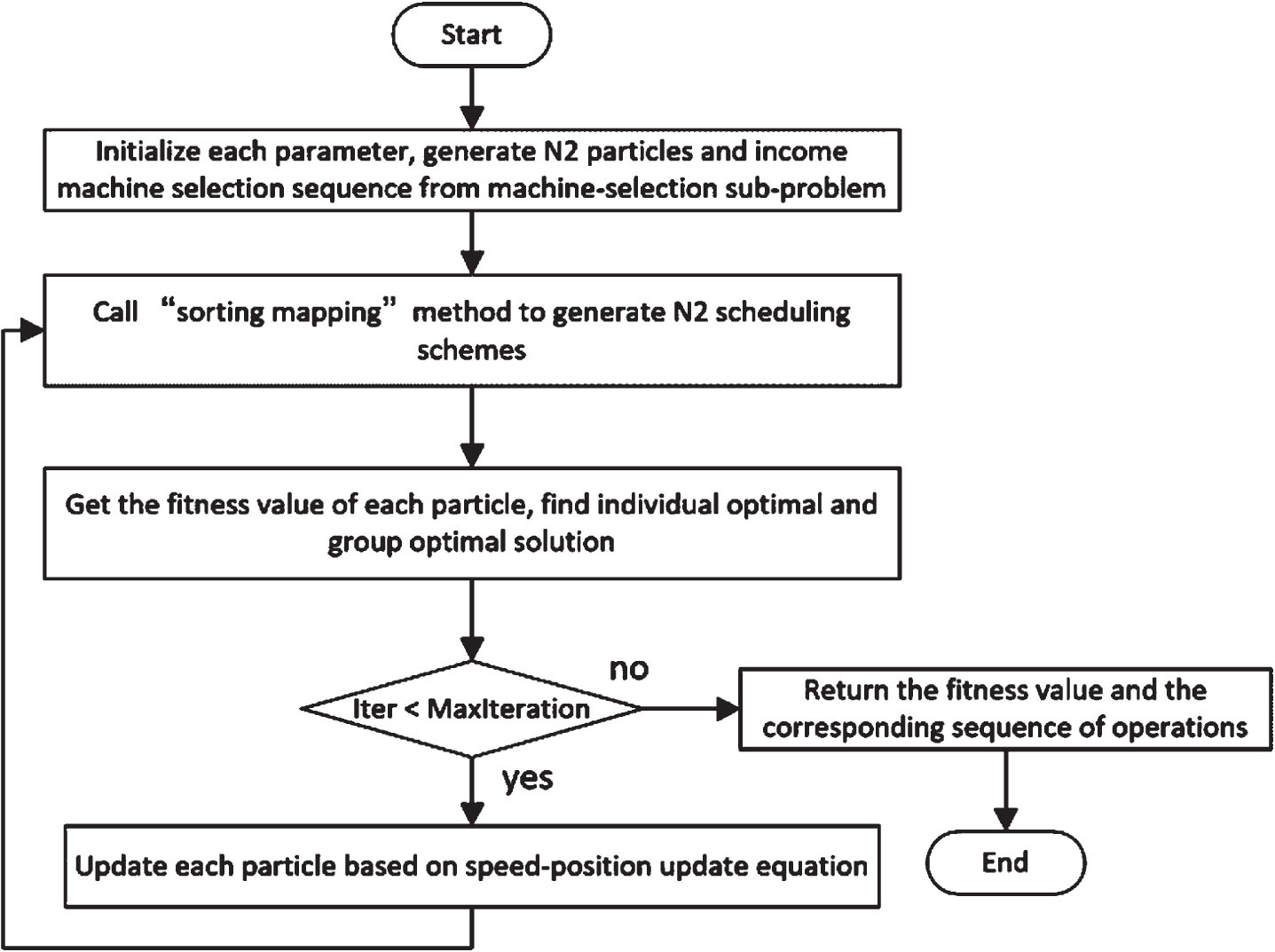
Flow chart of the operation-order sub-problem (OperationOrderFunc).
GA for machine-selection sub-problem
Coding design
To apply a GA successfully to solve the FJSP, an appropriate representation of the particles is essential. For the machine-selection sub-problem in this study, a particle was represented by a chromosome (gene sequence) consisting of a machine-selection sequence. For the problem in Table 1, a gene sequence for machine selection can be expressed as [1 4 2 5 2 6 1 4 5 3 2 3], which means that operation O11 of job J1 selects machine m1 for processing, operation O12 of J1 selects machine m4 for processing, operation O13 of J1 selects machine m2 for processing, operation O21 of J2 selects machine m5 for processing, and the others have the same meaning.
A FJSP (4×5 Kacem instance)
A FJSP (4×5 Kacem instance)
Crossover operation is one effective method of particle updating. Specifically, the particles are updated by exchanging fragments with the group-optimal particles. Two positions are randomly selected on the individual chromosome as marked points, and then the fragments between the marked points are exchanged with the group-optimal chromosomes at the same position. This method ensures that the descendants have legal sequences. Assume that the marked points are 5 and 10, respectively. The crossover operation is illustrated in Fig. 3.

Crossover operation.
For the machine-selection sub-problem, because each operation can be performed by more than one machine, n operations are randomly chosen, and each of the n operations reselects the machine number. The reselected machine number is placed in the corresponding machine-based sequence. To ensure the global nature of the mutation, each reselected machine number for each gene can still be the previous number after the mutation. The gene sequences obtained using this method ensure a legal solution. For example, if n = 2 and the randomly selected operations corresponding to the gene sequence number are two and five, the method is as shown in Fig. 4.

Mutation operation.
Coding design
The operation-based coding method is generally adopted to ensure that the algorithm can obtain globally optimal solutions of the job-shop scheduling problem and has better performance [42].
Operation-based coding represents each operation sequence, and each gene sequence (chromosome) represents a scheduling scheme. All steps of the same job are represented by the same serial number, which is an integer from 1 to n that appears in the gene sequence.
The number of genes encoding this part of the chromosome is equal to the total number of operations, and the operation of each job is represented by the corresponding job number. The number of times the job number appears is equal to the number of job operations. Compiling is performed according to the order in which job numbers appear on the chromosome. Scanning the chromosome from left to right, the kth occurrence of the job number indicates the kth job operation. For the flexible job-shop scheduling problem presented in Table 1, a gene sequence based on the operation code can be expressed as [3 3 4 1 2 3 2 2 4 4 1 1], where 1 indicates an operation of job J1 and 2, 3, and 4 have the same meaning. The three 1 s in the gene sequence represent the three operations of job J1: operations 1, 2, and 3, respectively.
Update strategy for position and velocity vectors
In the standard particle swarm algorithm, the particle position and velocity are updated according to Equations (8) and (9) [43], respectively:
In the above formulas, rand() is a random number generator, a random number in the interval (0, 1) occurs, w is an inertia factor of the degree of influence of the current speed on the speed of the next moment, and c1 and c2 are acceleration constants.
The updating of the position and velocity in the standard PSO algorithm is the key to the algorithm, but it is designed for the optimization of problems in the continuous domain. It does not apply to the JSP, which is a discrete-domain problem. Therefore, many researchers have changed this step. The most widely used method is to treat a chromosome as a particle directly and then to introduce the steps of the GA to crossover, mutate, and select the chromosome to transform a continuous problem into a discrete problem. The entire process is too complicated and does not take full advantage of the PSO. This paper proposes a scheduling sequence generation method, called “sorting mapping,” while maintaining the accuracy of PSO. The particle updating process still uses Equations (8) and (9) and runs in a continuous space.
Taking the problem of three jobs with two operations for each job as an example, this work introduce the following method.
Step 1: Randomly generate 3*2 unequal real numbers in the interval (0, 1), and suppose that one of the particles is
Step 2: The sort() function in Equation (10) sorts the six real numbers in
Step 3: According to the position and velocity updating formulas of the PSO (Equations (8) and (9)),
For the machine-selection sub-problem, most of the running time of the algorithm is spent here because its iterative evolution is implemented by the value returned by the operation-order sub-problem. The initial population of the GA applied to the FJSP is randomly selected, which causes the algorithm to iterate many times to obtain optimal solutions. The method proposed in this study can obtain a better initial population, reducing the number of iterations to the optimal solutions. To determine the commonality between the optimal solutions of such FJSPs, this work introduce one of the most widely used machine learning methods, the BP neural network. Accordingly, it is necessary to generate samples, extract features, and train the BP neural network to make effective use of the generated BP neural network to predict optimal solutions. Most importantly, a method of clustering and reconstructing the FJSPs is necessary. Considering that JSON can conveniently and intuitively describe a class of problems and has the advantage of wide use in industrial scenarios, this work introduced JSON into this method. This study performed model reconstruction for the FJSP, called the JSON-FJSP.
The following is a JSON-FJSP:
{
“jobNumber”: IJobNum,
“machineNumber”: IMachineNum,
“validatedMaxProcessingTime”:
IMaxProcessingTime,
“operationList”: [
IJ1,
IJ2,
. . .
IJIJobNum
]
}
The corresponding descriptions of each field of the JSON-FJSP are shown in Table 2.
Description of each field of a JSON-FJSP
Description of each field of a JSON-FJSP
For the “operationList” field, the following conditions need to be met:
A JSON-FJSP is a series of FJSPs in which individual FJSPs can be constructed. These individual FJSPs can be used as samples to train the neural network. Such a neural network can be applied to the optimization of the JSON-FJSP.
To introduce the methodology proposed in this paper conveniently, this work used the JSON-FJSP as the research object called JSON-FJSP_Sample1 temporarily. The 4×5 Kacem instance belongs to JSON-FJSP_Sample1.
{
“jobNumber”: 4,
“machineNumber”: 5,
“validatedmMaxProcessingTime”: 12,
“operationList”: [
2,
3,
3,
4
]
}
The following is a comparison of the initial solution generation process of the GA-PSO algorithm without BP neural network filtering with that of the GA-PSO algorithm after BP neural network filtering. Taking a one-dimensional particle as an example, this work generated six one-dimensional particles. As can be seen from Fig. 5, because the unfiltered initial solution is randomly generated, the positions of these six particles are randomly distributed, and the positions corresponding to their fitness values are far from the optimal position, which means that more iterations are required to reach the optimal position in the later evolution process.
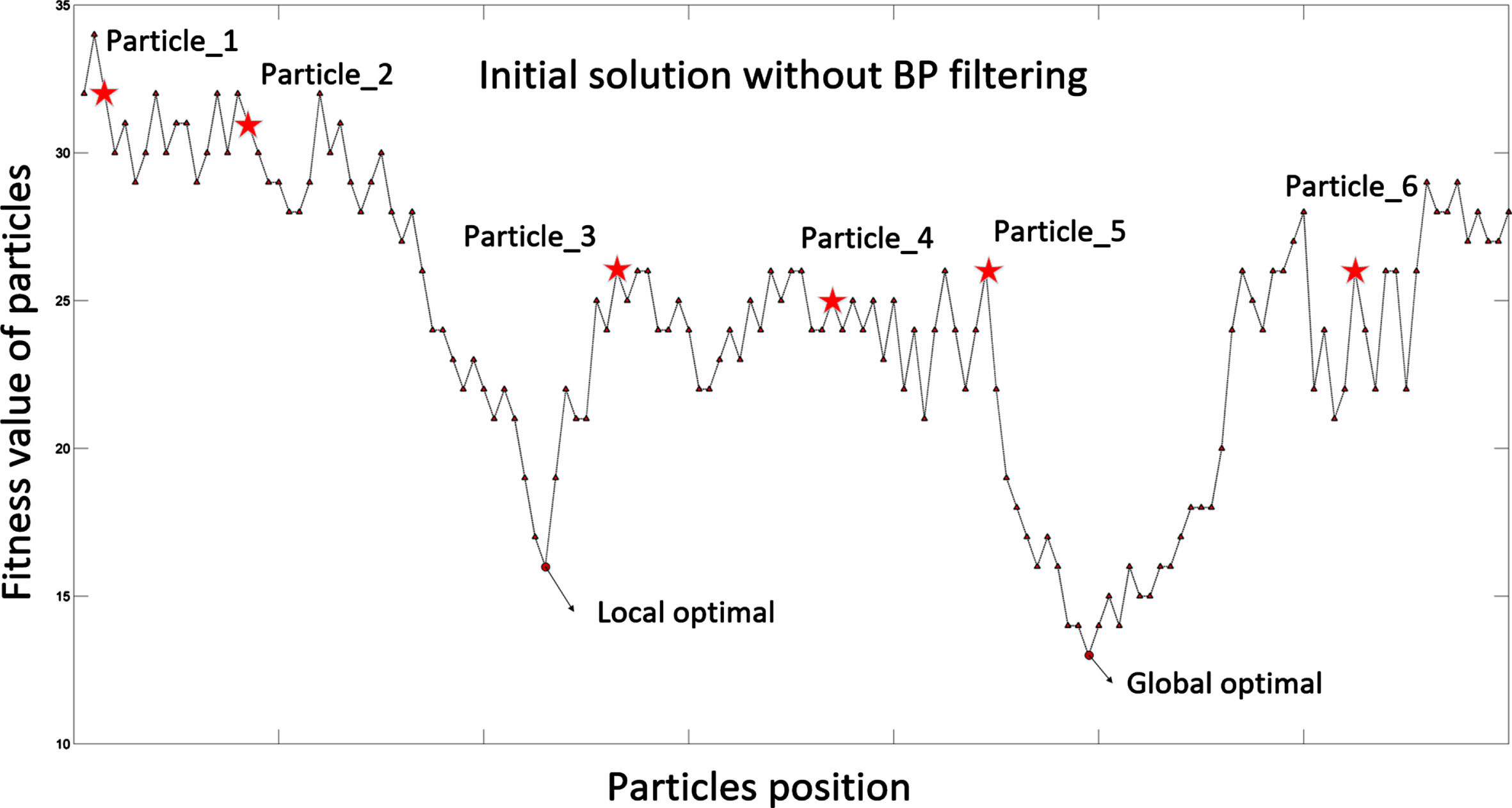
Initial solution generation process of the PSO algorithm without BP neural network filtering.
As shown in Fig. 6, the filtered particles are distributed in better positions, that is, the positions of the sub-optimal solution mentioned in the paper. They only require a few iterations, that is, short moving distances, to reach the optimal position.
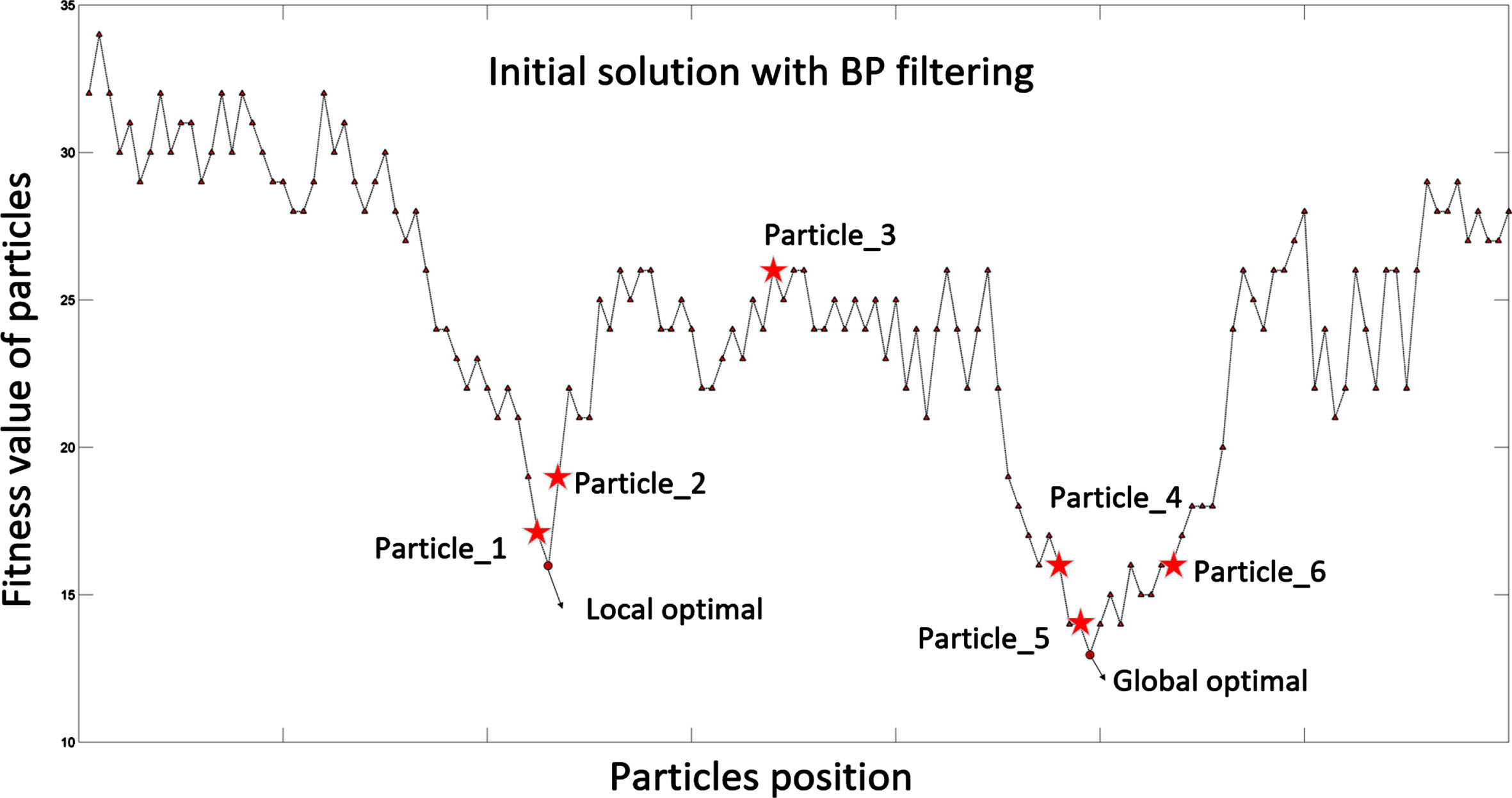
Initial solution generation process of the PSO algorithm after BP neural network filtering.
The proposed algorithm can also ensure the globality of the results and avoid falling into local optimal solutions through partial filtering. For example, as shown in Fig. 6, this work only filter out five of these six particles to make them suboptimal solutions; particle 3 is randomly generated, and the generation of particle 3 guarantees globality. In fact, it is not necessary to filter out many suboptimal solutions because a few suboptimal solutions can cause the particle swarm to move to the optimal solution position faster. Simultaneously, the filtration cost can be reduced.
The particles for solving the FJSP in this study are multi-dimensional, but the principle is the same as that described above.
Feature extraction
This section discusses the identification of features that determine whether a solution is relatively optimal, considering the generation of random scheduling problems for JSON-FJSP_Sample1.
For JSON-FJSP_Sample1, this work constructed 10 FJSPs, of which 6 FJSPs were used as training sets, and 4 FJSPs were used as test sets. For each FJSP, a processing time ti,j (1 ≤ ti,j ≤ 12) was randomly generated on each machine for each operation. The solutions obtained by the six scheduling problems were different; therefore, the concept of the “relatively optimal-solution interval” was introduced. For a certain scheduling problem P(i), the completion time of its corresponding optimal solution is Tbest(i), and the completion time of a suboptimal solution is Tsub(i); then, the “relatively optimal-solution coefficient” is U = Tsub(i)/Tbest(i) and the relatively optimal-solution interval is [1, U].
The solution in the relatively optimal-solution interval is regarded as a good solution and marked as 1, and a solution that is not in the relatively optimal-solution interval is regarded as a bad solution and marked as 0. This process constructs a model that applies neural networks to solve classification problems, and the relatively optimal-solution interval is applicable to any scheduling problem in the JSON-FJSP. In this study, through multiple data attempts and verifications, 1.4 was chosen as the relatively optimal-solution coefficient for JSON-FJSP_Sample1, and the experimental verification process will be given later.
Six hundred machine-selection sequences were generated for each FJSP. Some were in the relatively optimal-solution interval, and the others were not. The 600 machine-selection sequences were converted into 600 training samples under the corresponding features of each scheduling problem, for a total of 3600 training samples.
Because this work regarded minimizing the completion time as the scheduling target, the feature selection was directly or indirectly related to time. Because which features were useful were not known at the beginning, this work listed as many features as possible. Next, this work extracted features that were useful for solving the problem.
The feature selection path map (FSP) and sparse-error contrast curve (SET) are two useful visual tools proposed by Benoít et al. [44] to assist feature extraction effectively. As shown in the left part of Fig. 7, the FSP displays the best feature subset for each subset size, with each column corresponding to a subset size and blue cells corresponding to the selected features. The SET on the right side of Fig. 7 shows the error for the corresponding feature subset. From these images, a suitable subset of the features can be selected. These diagrams indicate which features are useful for obtaining the correct results and which features are not worth extracting. The features obtained in this study are listed in Table 3, and the corresponding descriptions are as follows:
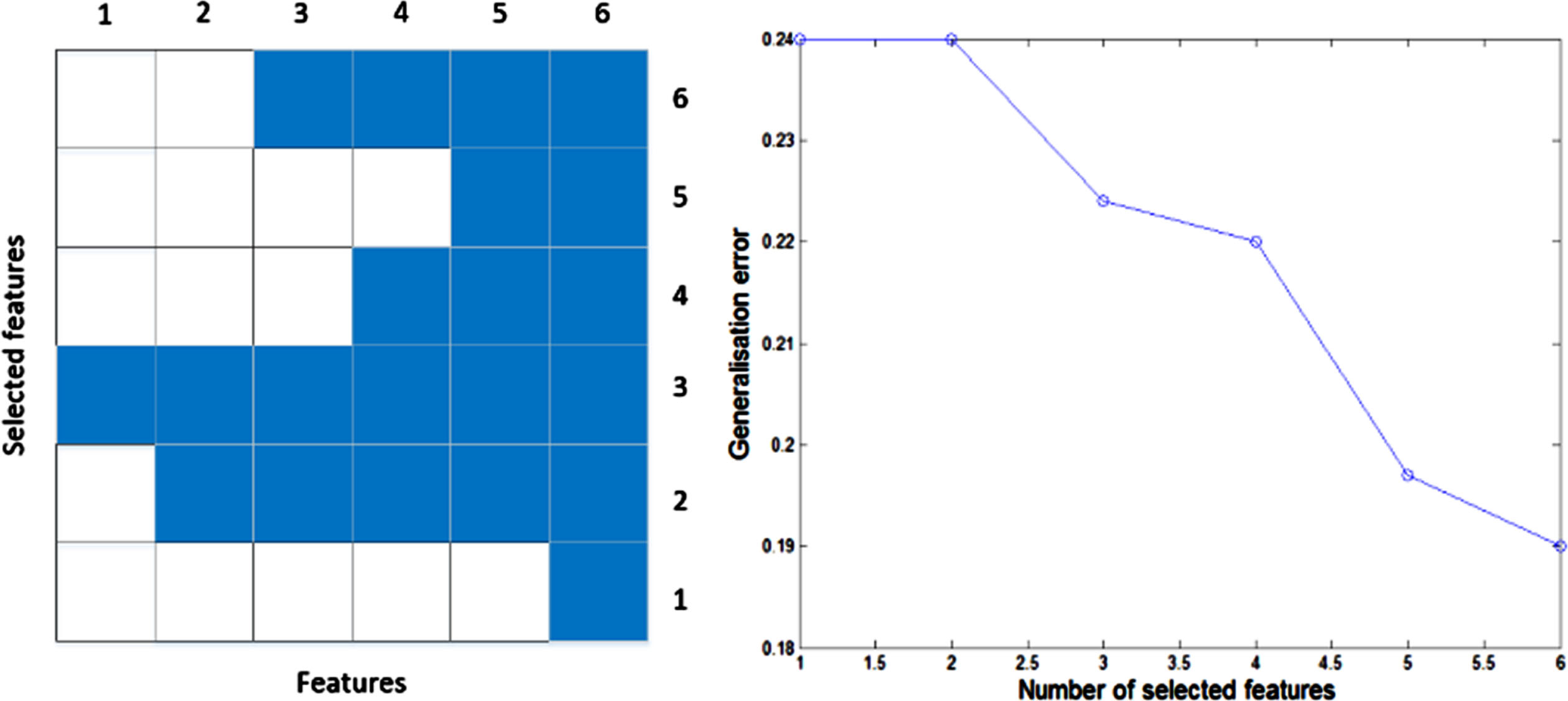
Feature Selection Path Map (FSP) and Sparse-Error Contrast Curve (SET) for feature extraction.
Features that have been obtained in this paper
Feature 1: For a certain machine-selection sequence and its corresponding scheduling problem matrix T, count(i) is the number of times i appears in the sequence, count_min(i) is the number of times i corresponds to the shortest time in T, and Feature 1 is D(count(i)/(2count _ min(i))), where the function D() represents the variance.
Feature 2: Tsum _ chose is the total processing time of selected machines, Tsum is the total time of T, and Feature 2 is Tsum _ chose/Tsum;
Feature 3: countmin _ machine _ times is the number of times each operation of selecting the machines with the shortest processing time is performed, counttimes is the number of all operations, and Feature 3 is countmin _ machine _ times/counttimes.
Feature 4: the maximum processing time of the selected machines divided by the minimum processing time of the selected machines.
Feature 5: the maximum processing time of the selected machines divided by the second maximum processing time of the selected machines.
Feature 6: the number of times the same job selects the same machine, divided by the total number of operations.
This work randomly generated 3600 samples of six problems for neural network training and then randomly generated the seventh problem for prediction. The FSP and SET were drawn by implementing the prediction process for the seventh problem, as shown in Fig. 7. The detailed training and prediction processes are presented in the Subsection 5.2.2.
As can be seen from Fig. 7, as the number of features increases, the prediction error decreases; thus, all features obtained previously should be retained.
The model used in this study was a three-layer BP neural network. The error BP algorithm was used to learn the neural network model. The BP neural network structure is shown in Fig. 8 [45]. In the figure, the input layer contains m neurons corresponding to X={x1, x2,..., x m }, the number of neurons in the hidden layer is n, and the output layer is a single neuron (whether it is a relatively optimal solution). The values of m and n are assigned later.
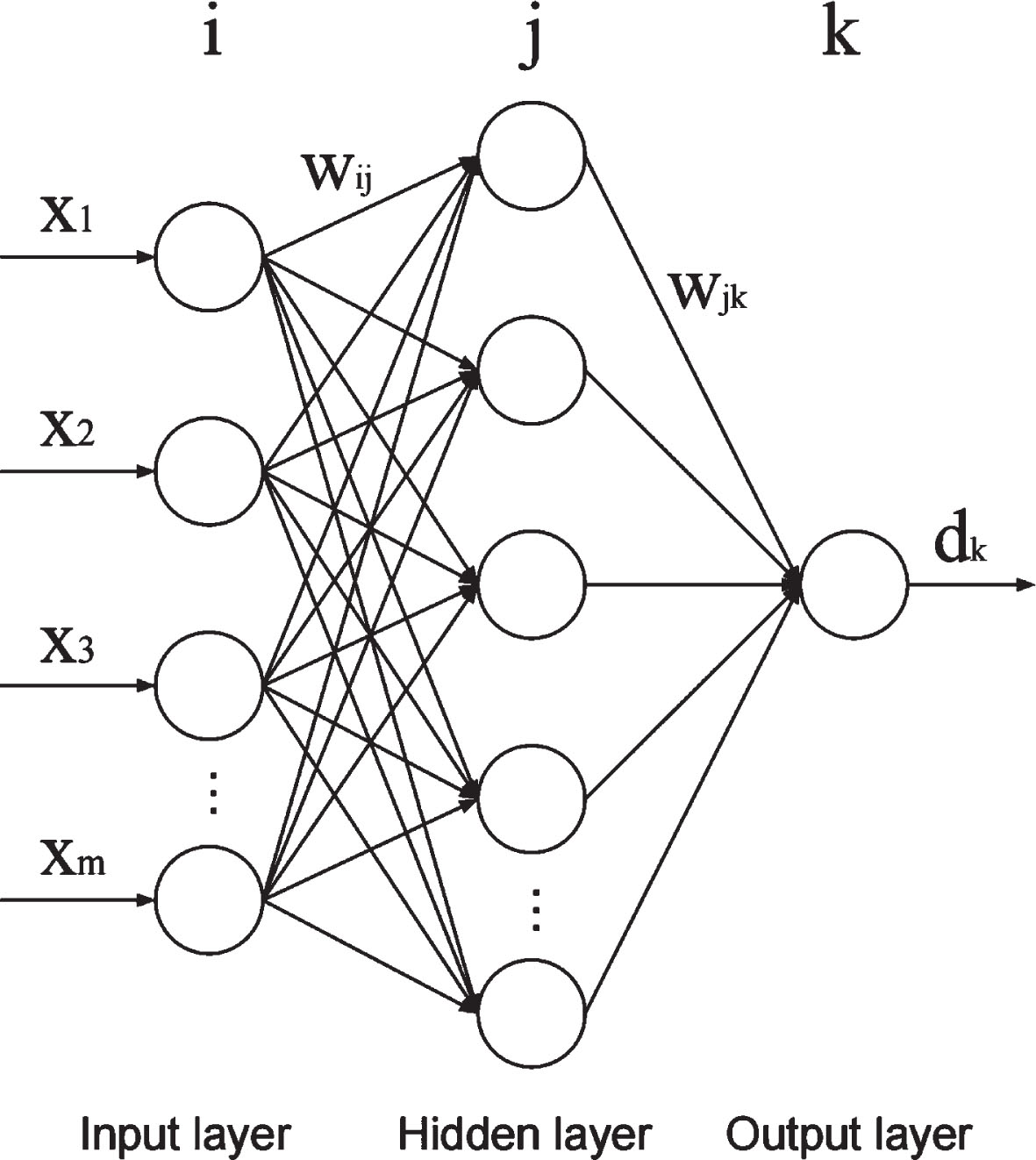
Three-layer BP neural network structure.
The input parameter set for the model was obtained by converting the machine-selection sequences into training samples under the corresponding features. However, because different feature parameters have different units and orders of magnitude, in order to eliminate the influence of different units and data magnitudes on the model prediction results, data normalization was performed before the parameters are input into the network model to ensure that the parameters were of the same order of magnitude [46]. Normalization was implemented using the calculation method shown in Equation (12), where X represents the current value; Xmin and Xmax represent the minimum and maximum values, respectively; and Y is the normalized value. The normalized data range is [0, 1].
The training and test sets were carefully designed. Neural network training was performed using 3600 samples generated by six problems, and Test 1, Test 2, and Test 3 were randomly generated; Test 4 was the 4×5 Kacem instance. Each problem yielded 600 solutions. These problems were divided into four groups for the prediction.
These problems are presented in Table 4. The prediction results and related experimental data are as follows.
Tale 4 Training sets and test sets of JSON-FJSP_Sample1
Each problem in the training sets (Train 1–6) had 600 samples, of which 470 were used to train neural networks (70% of 470 samples were training sets, 15% were test sets, 15% were validation sets), and 130 were used for prediction. The three randomly generated problems (Test 1–3) and the problem of the 4×5 Kacem instance (Test 4) were used as prediction sets. Table 5 shows that the trained BP neural network has an extremely high predictive accuracy of approximately 91%. That is, with this trained BP neural network, one can determine in advance whether a solution is good or bad with approximately 91% accuracy.
Prediction results
The relatively optimal-solution coefficient is used for solution classification, which directly affects the predictive accuracy. If the relatively optimal-solution coefficient is too small to be close to 1, all the relatively optimal solutions will be optimal solutions. Because the number of optimal solutions in the sample is not large, the features of the optimal solutions cannot be learned sufficiently. If the relatively optimal-solution coefficient is too large, then the features of the relatively optimal solutions will be overwhelmed, and the relatively optimal solutions will not be distinguished well. Therefore, the optimal solution coefficient should be chosen appropriately. The following describes the relationship between the relatively optimal-solution coefficient and predictive accuracy.
Figure 9 shows that when the relatively optimal-solution coefficient is 1.4, the predictive accuracy of the relatively optimal solutions, predictive accuracy of the relatively bad solutions, and overall predictive accuracy are all relatively high, so this value is the best in all respects. Therefore, the relatively optimal-solution coefficients of all experimental data in this study were set to 1.4.
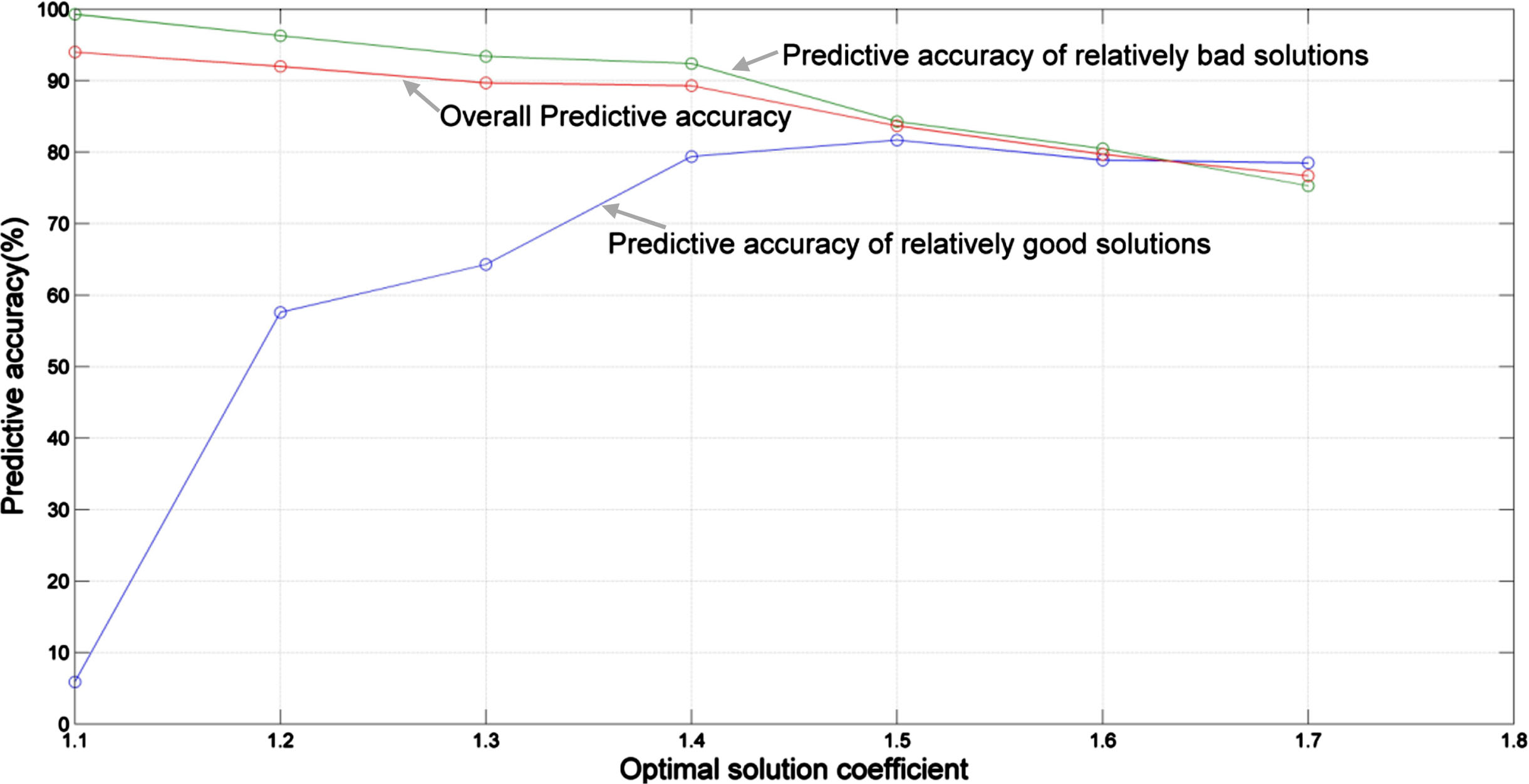
Relationship between the relatively optimal-solution coefficient and predictive accuracy.
BP neural network performance test
To test the performance of the BP neural network obtained previously, this work compared BP-GA-PSO and GA-PSO on the 4×5 Kacem instance (Test 4), as shown in Table 6. Furthermore, this work performed the comparison between BP-GA-PSO and MOGA on the the 4×5 Kacem instance (Test 1), as shown in Table 7. BP neural network is the machine learning method introduced in this study. This work verified the effectiveness of the machine learning method by comparing the performance of the algorithm with and without a BP neural network. The former is BP-GA-PSO, and the latter is GA-PSO. The parameter values were as follows: the initial population number was 100, the number of iterations was 200, and the neural network was the single hidden layer neural network described in the previous section. The number of input layer neurons m was six, the number of hidden layer neurons n was 25, and the relatively optimal-solution coefficient U was 1.4.
Initial solutions and results comparison of Test4
Initial solutions and results comparison of Test4
Initial solutions and results comparison of Test1
For the 4×5 Kacem instance (Test 4), Cmax is 11, and the corresponding fitness value of the relatively optimal-solution is ceil (11*1.4) (the ceil() function obtains the largest integer not less than the argument), yielding 16 as the fitness value of the relatively optimal-solution. This work used GA-PSO and BP-GA-PSO to generate 100 initial solutions, and the fitness values of the first 20 initial solutions are listed Table 6. Sixteen of the initial solutions obtained by BP-GA-PSO are relatively optimal, whereas the number of relatively optimal solutions among the initial solutions obtained by GA-PSO is 0. In other words, the initial population of BP-GA-PSO is much better than that of GA-PSO because the BP neural network has judged the initial solutions in advance and maintains the relatively optimal solutions. In addition, the BP-GA-PSO results are statistically investigated with the Wilcoxon rank-sum test, the Wilcoxon W is 251 and the asymptotic significance is less than 0.001 which means the data obtained by BP-GA-PSO differs significantly from the one by GA-PSO.
For the 4×5 Kacem instance (Test 1), Cmax is 14, and the corresponding fitness value of the relatively optimal-solution is ceil (14*1.4) (the ceil() function obtains the largest integer not less than the argument), yielding 20 as the fitness value of the relatively optimal-solution. This comparison used BP-GA-PSO and GA-PSO to generate 100 initial solutions, and the fitness values of the first 20 initial solutions are listed Table 7. Seventeen of the initial solutions obtained by BP-GA-PSO are relatively optimal, whereas the number of relatively optimal solutions among the initial solutions obtained by MOGA is 0. In other words, the initial population of BP-GA-PSO is much better than that of MOGA because the BP neural network has judged the initial solutions in advance and maintains the relatively optimal solutions. Furthermore, the BP-GA-PSO results are statistically investigated with the Wilcoxon rank-sum test, the Wilcoxon W is 210.5 and the asymptotic significance is less than 0.001 which means the data obtained by BP-GA-PSO differs significantly from the one by MOGA.
To test the performance of BP-GA-PSO further, this work compared its results with those of other well-known algorithms using two sets of benchmark studies: ten BRdata instances [4] and five Kacem instances.
For the first set of data, the BRdata instances, this work repeatedly ran BP-GA-PSO 10 times and listed the best results. Table 8 compares the makespans of the optimal solutions of BP-GA-PSO and those in the literature (TS [4], PVNS [47], MOGA [48], PSO+TS [30], and P-EDA [49]). For the ten instances of BRdata, the best results obtained by BP-GA-PSO are equal to or less than those obtained by other algorithms. For the MK01 instance, BP-GA-PSO outperforms TS and is on par with the other four algorithms. For instance, in MK02, the BP-GA-PSO outperformed TS, PSO+TS, and MATSLO. For instance, in MK03, BP-GA-PSO outperformed TS and MATSLO. For the MK04 instance, the makespan 60 obtained by the BP-GA-PSO dominates the other four algorithms, as the PVNS does. For MK05 and MK06, the BP-GA-PSO outperforms the others. For M07, the BP-GA-PSO gets the makespan 139 which equals the one by MOGA and is better than the other four algorithms. For MK08, our algorithm and the others get the same result. For M09, the BP-GA-PSO gets the makespan 307 which equals the one by PVNS and is better than the other four algorithms. For MK10, our algorithm is a little worse than PVNS, but is better than the other four algorithms.
Comparison of results on Bandimarte instances
Comparison of results on Bandimarte instances
For the second set of data, the Kacem instances, this work repeatedly ran BP-GA-PSO 10 times and listed the best results.
Table 9 compares the best and average values between BP-GA-PSO and those in the literature (AL+CGA [50], BBO [51], BEDA [52], KBACO [53], ABC [54], HDE-N2 [55] and SEA [56]). In Table 9, the following notations are used:
Comparison result for the Kacem instances
BBO: on a 2.4 GHz CPU and 4GB RAM. BEDA: on a 3.2 GHz CPU. KBACO: on a 2.4 GHz CPU and 1 GB RAM. TSPCB: on a 1.6 GHz CPU and 512 MB RAM. ABC: on a 2.83 GHz CPU and 3.21 GB RAM. BP-GA-PSO: on a 2.6 GHz CPU and 8.0 GB RAM. HDE-N2: on a 2.83 GHz CPU and 15.9 GB RAM.
From Table 9, it can be concluded that BP-GA-PSO is not worse than the other algorithms and is even better than several improved algorithms. Further, BP-GA-PSO can obtain an optimal solution with a 100% success rate.
Figure 10 compares BP-GA-PSO and several effective algorithms, including BBO [51] and MOGA [48], for a 10×7 Kacem instance. BP-GA-PSO can quickly obtain the best makespan with very few iterations.
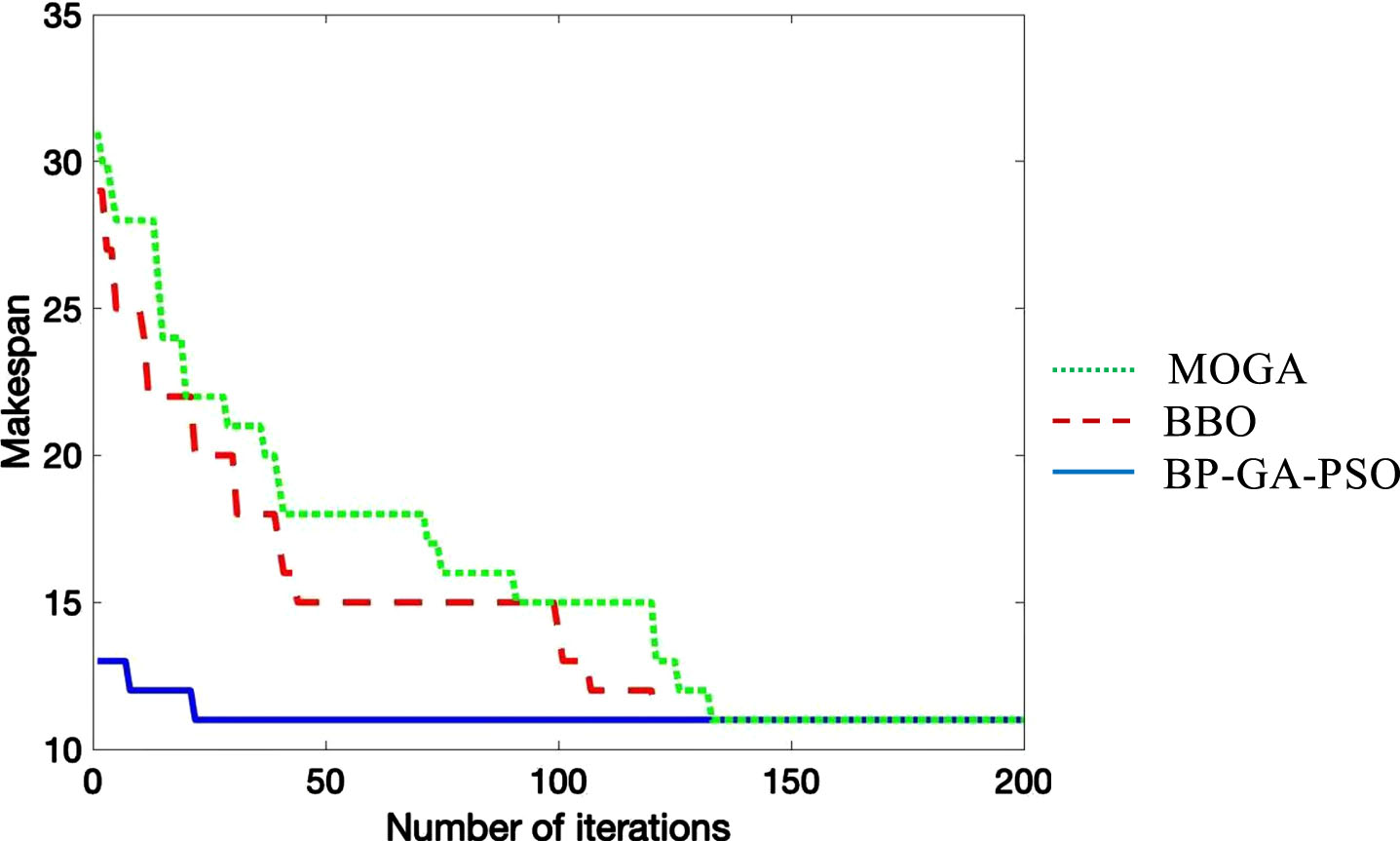
The comparison of convergence between MOGA, BBO and BP-GA-PSO on 10×7 Kacem instance.
Figures 11 and 12 show the Gantt charts of the optimal solutions obtained by BP-GA-PSO when solving the 4×5 and 10×10 instances, respectively. This work obtain 11, which is the makespan of the best-known solution for the 4×5 instance, and 7, which is the makespan of the best-known solution, for the 10×10 instance.
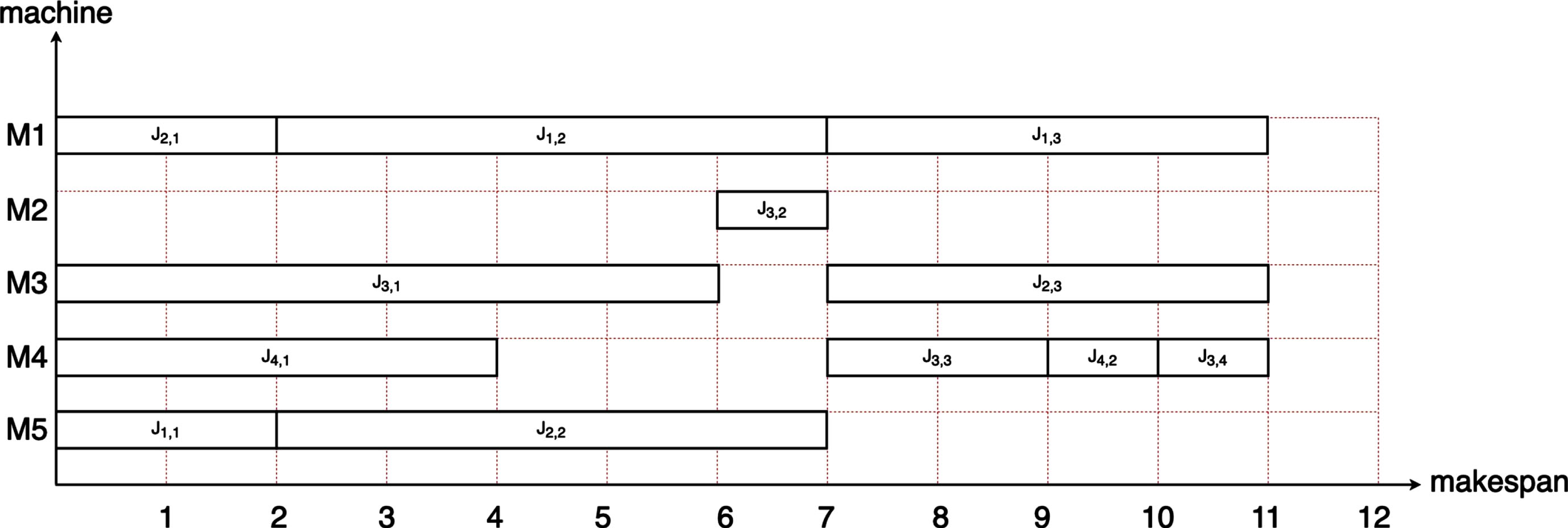
The Gantt chart of instance 1 (4×5).
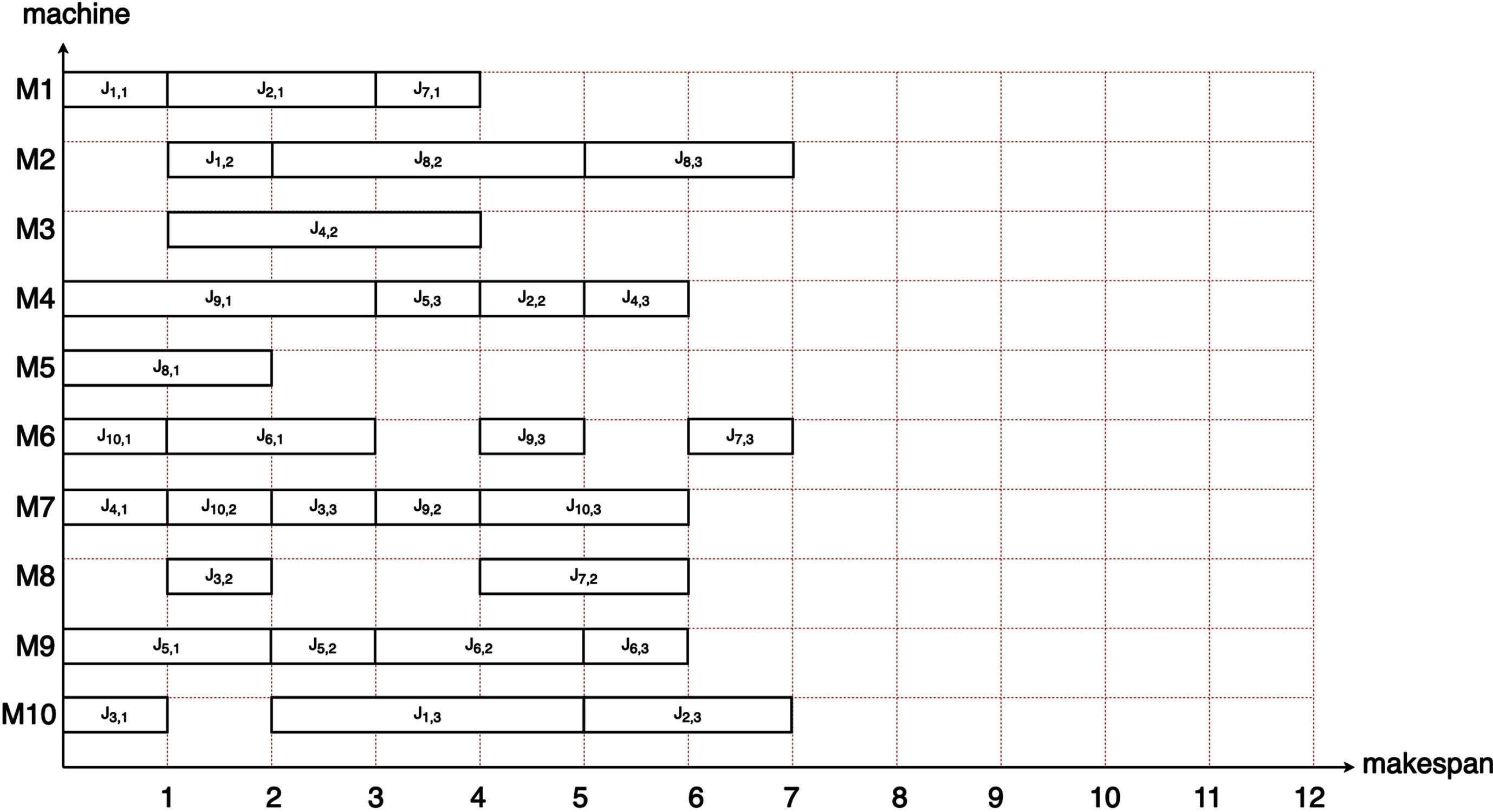
The Gantt chart of instance 4 (10×10).
This study addressed one of the most challenging combinatorial problems: the FJSP. The JSON-FJSP is proposed and a machine learning method to optimize the solutions is introduced. The FSP and SET were also introduced into the feature extraction process; thus, some valuable features were extracted. The pre-trained BP neural network was verified to optimize the initial population, accelerate the convergence of the algorithm, and improve the probability of convergence to the optimal solution.
The originality of this approach consists of reconstructing the mathematical model of the FJSP so that machine learning strategies can be introduced to optimize the algorithms for the FJSP. This reconstructed model (JSON-FJSP) seems to be a new direction for introducing more interesting methodologies to solve the FJSP. Thus far, many machine learning methods have provided scientific benefits, but these methods are rarely used to solve the FJSP. The BP-GA-PSO approach for the FJSP proposed in this study proved to be feasible and effective.
The approach proposed in this article can not only be applied to the FJSP with the goal of “shortest processing time”, but also to the FJSP with other goals, bringing a new optimization concept to the solution of these problems.
The disadvantage of this approach proposed in this paper is that a large number of sample training is required to obtain the corresponding BP neural networks before the algorithm is implemented. However, these trainings are done offline in advance, the efficiency of the algorithm is not affected.