
Abstract
Gait recognition is the process of recognizing a person based on their walking style. Each person’s walking gait is distinctive and cannot be imitated by others. However, the walking motion of a person will be changed based on their behaviour but their walking pattern doesn’t change. In this paper, a novel Clustering based Faster RCNN has been proposed to identify the single, double and multi-gait. The gait images from the publicly available dataset are pre-processed using Multi scale Retinex (MSR) to reduce the noise artifacts. The Faster RCNN is used for extracting the relevant features from the gait images via the two modules namely CNN and RPN. The CNN layers extract the most relevant features as feature maps and RPN is used for creating the bounding boxes for the extracted features. Fuzzy K-means clustering is used to group the features based on their labels, and it specifies the features acquired using CNN and RPN as input. Finally, the Fast RCNN is employed for classifying the gait images into suspicious and non-suspicious walking pattern. The proposed Clustering based Faster RCNN net achieves the high accuracy rate of 98.74% and 99.19% for suspicious and non-suspicious walking pattern respectively. The proposed Clustering based Faster RCNN model was compared with other traditional models like CNN, U-net, Fab net and Fast R-CNN. The proposed Clustering based Faster RCNN model improves the overall accuracy of 8.86% 33.77% 3.12% and 5.48% better than mmGait, LSTM Net, STDNN and RNN respectively.
Introduction
A person’s biometrical characteristic can be categorized into behavioral or physiological characteristics. Biometric features, like the iris, ears, passwords, face, tokens and finger prints, require highly exact detection and a well-managed human interaction to be effective [1]. Gait recognition, which refers to recognizing people by their walking style, can be particularly challenging due to variations in the camera’s point of view and people’s face expressions [2]. People’s appearance might also change as a result of changes in their attire, such as donning a hat or coat or carrying a backpack and handbag [3]. Even though research on gait detection has recently increased, learning discriminative temporal representation is still difficult because the distinctions between silhouettes in the spatial domain are extremely slight [4]. In low-resolution recordings, where other biometrics systems might not work because of a lack of pixels, gait recognition has a great deal of potential for identifying people [5].
When a person is walking with other people, their walking behaviour changes, and when several people are walking together, it becomes more difficult for conventional gait recognition methods. This task has mainly used in security surveillance, such as the identification of suspicious people or activities and the authentication of people [6]. Model-free techniques and model-based techniques are the two basic categories that can be used to divide gait recognition from the perspective of computer vision [7]. Tracking or modeling body parts like thighs, arms, legs and limbs allows model-based techniques to get a number of dynamic or static body characteristics. Gait signatures created using these model parameters are used to recognition and identification of people [8].
A faster R-CNN extracts and detects the ordinary in every frame of the video regardless of whether the pedestrian carries anything or not [9]. RPN and CNN are two different variants of Faster RCNN that have been used to analyze the attribute vectors created from different walking patterns in order to identify the walking styles [10]. Gait recognition is a technique for identifying people based on how they walk. Each person’s walking gait is distinctive and cannot be imitated by others. However, it is complicated to find out the person using their silhouette because the reflection may vary based on the light direction. The walking motion of a person will be changed based on their behaviour but their walking pattern doesn’t change. The main purpose of the study is as follows: A novel Clustering based Faster RCNN has been proposed to identify the single, double and multi-gait. The gait images from the CASIA-B gait dataset are pre-processed using Multi Scale Retinex is used to reduce the noise artifacts. The Faster RCNN is used for extracting the relevant features from the gait images via the two modules namely CNN and RPN. The CNN layers extract the most relevant features as feature maps and RPN is used for creating the bounding boxes for the extracted features. Consequently, Fuzzy K-means clustering uses the features acquired via CNN and RPN as input to group the features according to their labels. Finally, the Fast RCNN is employed for classifying the gait images into suspicious and non-suspicious walking gait based on the clusters from the clustering algorithm.
The remainder of the analysis is divided into the following sections: Section II the literature review is thoroughly explained. Section III the proposed method is described in detail. Section IV the results and discussion part are covered. Section V the conclusion is discussed.
Literature review
In recent years, many studies for gait images are pre-processing, feature extraction and classification strategies have been discussed by the researchers. In this section, a review of a few recent studies is provided.
In 2021 chen. X., et al., [11] had proposed a false gait sample can be added to existing gait datasets using a Multi-view Gait Generative Adversarial Network, providing useable gait samples for cross-view gait detection methods based on deep learning. The MvGGAN technique improved the ability of gait organization models to be simplified. A comparison of the suggested program’s recognition accuracy when only genuine samples under 90 are offered, both with and without fake samples.
In 2020 Meng. Z., et al. [12] had proposed the gait of 95 participants would be “seen” by two mmWave radars in two different environments over the course of about 30 hours in this first-of-its-kind mmWave gait data collection. In contrast to traditional camera-based methods, mmWave-based gait identification has the distinct benefit of maintaining effectiveness in non-line-of-sight situations, such as in the absence of light in the presence of obstructions. For instances involving a single person, the mmGaitNet can reach 90% accuracy, while for cases involving five coexisting people, it can achieve 88% accuracy.
In 2020, Makihara, Y., et al. [13] had suggested a network to evaluate the phase of the single input image, and the network to reconstruct the gait cycle uses the calculated phase. This reduced an encoded feature’s dependence on the phase of that specific image. An example of this method is a phase-aware gait cycle reconstructor. A good trade-off between recognition and reconstruction accuracy is achieved by concurrently optimizing the recognition and PA-GCR networks.

The overall process of the proposed methodology.
In 2021 Zhao, X., et al., [14] had suggested PoseGait, a model-based gait recognition technique. Gait recognition is a stimulating yet exciting task in biometrics. RNN/LSTM nor CNN can effectively extract spatio-temporal gait feature with the help of combining two losses. The best recognition rate for the pose feature is 60.92% if there is no difference.
In 2019 Zhang, Z., et al., [15] had proposed the use of an autoencoder-based network and a multi-layer LSTM called GaitNet with innovative loss functions to clearly separate pose features from visual appearance. Frontal-View Gait dataset with an effort on frontal-view walking gait identification. This network outperforms our approach by 81.2% on the all procedure of the FVG dataset, achieving a recognition accuracy of 65.4% TDR at 1% FAR.
In 2019 Singh, J.P., et al., [16] had suggested the dataset is divided into two categories i.e., Single-Gait (SG) same subjects walk alone and Multi-Gait (MG) subjects walk in a group. This dataset’s goal is to examine how a person’s stride changes depending on whether they walk with others or by themselves. So, they created a new database which focused on multi-Gait occlusion situation and the CAISA-B dataset achieved 75% accuracy.
In 2018 Gadaleta, M. and Rossi, M., [17] had unveiled IDNet, a user authentication system that makes advantage of motion data gathered by smartphones. A smartphone with a trustworthy block for extracting the walking cycle independent of direction, walking cycles of these into a multi-stage authentication method, and one-class SVMs to classify the coherent integration. In less than five walking cycles, IDNet produced misclassification rates that were less than 0.15 percent.
In 2018 Tong, S., et al. [18] had suggested a multi-view spatial-temporal deep neural network (STDNN) for recognizing gaits. A temporal feature network and spatial feature network a make up the STDNN (SFN). In order to establish the identity of the person, an innovative approach is used to integrate the recognition scores obtained by SFN and TFN. The highest recognition scores were 95.67% for STDNN.
In 2017 chen, X., et al. [19] had proposed that human graphlets be used in a tracking-by-detection method to derive an individual’s whole silhouette. After that, a latent conditional random field (L-CRF) model creates features that are consistent and discriminatory. A new constriction is added to the model’s training in the latent structural support vector machine architecture in order to enhance the concert of multi-gait recognition on the OU-ISIR, this technique yields a rate of 94.7%.
In 2020 Hasan, M.M. and Mustafa, H.A., [20] had proposed a RNN network to effectively train the network for reliable gait recognition by devising a number of techniques and a GRU architecture. They designed a unique gait feature descriptor that is invariant to covariate factors and achieved comparable performance to techniques that call for expensive 3D poses or the calculation of the gait energy image (GEI). This method achieved average development of approx 10% with CCR of 93.34% from PSTN.
Due to the presence of several covariate elements, such as different perspective angles, changes in clothes, walking speeds, load carriage, etc., the classic approaches for distinguishing individual people from gait remain a difficult topic in computer vision research. The proposed clustering based Faster RCNN method mainly focused on identify the single, double and multi-gait.
In this section, a novel Clustering based Faster RCNN has been proposed to identify the single, double and multi-gait. In the pre-processing stage, Multi Scale Retinex is used to reduce the noise artifacts. The Faster RCNN is used for extracting the relevant features from the gait images via the two modules namely CNN and RPN. The CNN layers extract the most relevant features as feature maps and RPN is used for creating the bounding boxes for the extracted features. Consequently, Fuzzy K-means clustering uses the features acquired via CNN and RPN as input to group the features according to their labels. Finally, the Fast RCNN is employed for classifying the gait images into suspicious and non-suspicious walking gait based on the clusters from the clustering algorithm.
Dataset description
Dataset description
In this paper, the CASIA-B dataset has been used. This dataset contains a total 124 subjects and 110 sequences per subject. There are 10 sequences for each of the 11 viewpoints (0°, 18°, 180°). The walking condition consists of five sequences of normal walking (N), three sequences of walking with a bag (WB), and two sequences of walking while wearing a coat or jacket (WC) for each subject. For example, there are 11×(5 + 3+2)=110 sequences for each subject. Totally, 1364 images are available in CASIA-B dataset.
Pre-processing is an important role for reducing the noise and enhancing the various changes in gait images. SSR is extended by MSR which is a colour constancy and dynamic range compression-based image processing algorithm that is inspired by human perception. The MSR algorithm, which is a linear weighted summary of the single-scale Retinex method, is expressed exactly in the following formula.
Where the normalization factor K m = 1/(∑ y ∑ z F (y, z)) and c n are the scales that control the extent of the surround. The number of scales required, the weight values and the scale values, the three obvious questions about MSR. The experiments have given that three scales are enough for most of the weights, and images can be equal. The Common static scales include 15, 80, and 250. As a result of not knowing how an image scales up against actual scenes, these are more experimental than theoretical. The weights can be changed to provide more emphasis on either colour rendition or dynamic range compression.
The proposed model focused on Clustering based Faster RCNN net to identify the single, double and multi-gait. The clustering based Faster RCNN model is an integration of clustering for cluster the features based on their labels and the Faster RCNN is used for extracting the relevant features from the gait images via the two modules namely CNN and RPN.
Faster RCNN
The Faster RCNN is used for extracting the relevant features from the gait images via the two modules namely CNN and RPN. The CNN layers extract the most relevant features as feature maps and RPN is used for creating the bounding boxes for the extracted features. First, image feature maps are retrieved as one of the object detection approaches using a set of basic relu with pooling layers and conv using Faster R-CNN. The fully linked layers and RPN layers have the same feature maps. CNN has both a pooling layer and a convolution layer. The structure of clustering based Faster RCNN is shown in Fig. 2.
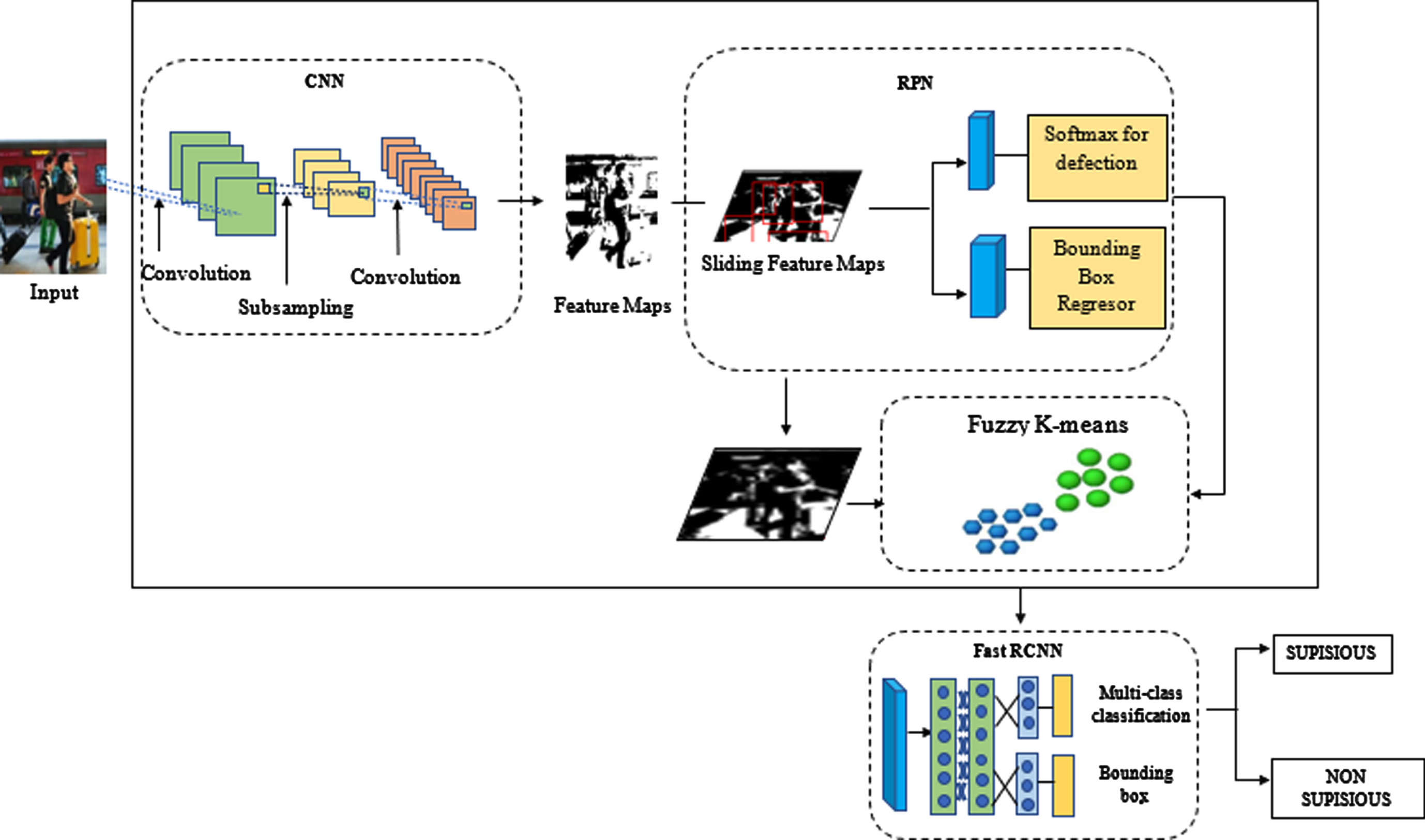
Clustering based Faster RCNN.
3.2.1.1 Convolution Neural Network In Faster-CNN, our proposed network allocates several ROIs of comparable sizes on various feature map levels. The selection of the appropriate ROI to obtain the required information will be complicated by these anchors. Therefore, multi-scale anchors do not need to be specified at each feature level. On each feature map, it is standard procedure to employ a single scale anchor. For example, the size of the anchors on P2, P3, P4, and P5 is 82, 162, 322 and 642, while the multiple aspect ratio is still 1 : 2, 1 : 1, and 2 : 1. In the original image, each level feature map pixel will consequently produce 3 anchors. However, the majority of these anchors continue to be incorrect and have no ROI. The input feature maps and proposals can be obtained by employing a ROI pooling layer.
3.2.1.2 Region Proposal Network The RPN was used to establish regions of interest with anchors for each feature maps. Convolutional feature maps are layered with a small network to build the proposal, which produces a number of rectangular object proposals with an objectness score. To prevent filter or image pyramids, the concept of an anchor box is introduced. The mapping of each region to each reference anchor box that follows enables the detection of objects at various scales. The sliding window is the focus of an anchor that is connected to scales and aspect ratios. In this way, the foreground and background values of the gait image were determined. By using RPN predictions, the anchor chose optimum boundaries for the gait images and fine-tuned their size and position. If many anchors overlap, capture the anchors with the greatest foreground value and discard the others after obtaining the final regional proposal and passing it to ROI Align.
Loss function:
The Faster RCNN is created by combining the Fast RCNN and RPN detector modules. Bounding box regression loss and classification loss make up the total multi-task loss function as defined in Eq.3 with L
cls
and L
reg
functions defined in Eq. (4) and (5).
3.2.1.3 Classification The gait images are classified into suspicious and non-suspicious walking gaits using the Fast RCNN and the clusters from the clustering technique. To expedite the training procedure, Fast R-CNN has been used in place of the traditional technique of detecting regions and running CNN. The region proposals are developed using a tiny sliding window that covers the whole convolution feature map of output layer. Another name for the little sliding window is a lower dimensional feature. The classifier and regression layers, which are both completely connected, are split into these features. The faster RCNN is created by combining the RPN and fast RCNN detector modules.
The output of the regressors is a region border with geographic coordinates (q, r, H, W).
Where, W*, H*, q*, p* are the ground truth bounding box centre, width, and height and qa,p
a
, Ha,, W
a
are the height, centre, and width of anchor.The argmax switches are utilized by the reverse function of the ROI pooling layer to determine the partial derivative of the loss function with respect to each input variable a
j
Where, every mini-batch ROI p and for output unit b
qr
, the partial derivative
Where, F is the filter bank, q is the image tensor input, f is the filter number, k is the layer number, N number of filters, m and n are the spatial coordinates and r convolution output.
The function of the object identification method was estimated by average precision.
Where recall-n = [0, 0.1, 0.2, , 1.0]
Where, N
C
, N
r
normalized weighted parameters and weighted by a balance parameter for the outputs of the r and c layers, u
j
j
th
an object, v
j
vector with four local coordinates for the predicting bounding box and the projected probability of the anchor, I anchor’s index in a mini-batch, L
c
classification loss,
Fuzzy K-means clustering to group of data based on walking while wear a coat, typical walking and carrying bag. The lower body joints’ gait, however, is primarily changed when walking with other people. Additionally, the maximum accuracy is obtained when all joints are combined. The baseline method, however, does not capture enough dynamic gait information with its 14 joints, resulting in a lower recognition accuracy than our suggested method based on dense trajectories.
In terms of fuzzy K-Means clustering, squared l2-standard loss is complex due to the huge deviations. Therefore, introduce the proposed clustering model’s adaptive loss function. Given l1-norm, squared l2-norm and arbitrary vector m are defined as,
Generally, the squared l2-standard loss function is sensitive to large outliers but insensitive to tiny outliers. In contrast, l1-standard loss is sensitive to minor outliers but insensitive to large outliers. In order to address the aforementioned problem, the adaptive loss function for vector g is introduced.

Example of the adaptive loss function using various.
The suggested approach combines nonnegative spectral clustering and fuzzy K-Means into a single model. To improve the quality of attraction graph, the similarity matrix is created specially by investigating the data and cluster structures. Fuzzy K-Means clustering is described as the process of assigning data points to each cluster with a given level of membership.
Where number of clusters is C, fuzzy membership is Z ∈Rn×c. Moreover, μ
K
is the clustering centroid matrix and centroid of the K-th cluster is C = [μ1, μ2, …μ
C
] ∈ Rd×c. The membership degree of the j-th sample’s connection with the j-th group is represented by each item of matrix Z. The square l2-norm is replaced with the robust loss-norm in order to address the issue of outliers’ sensitivity and enhance clustering performance. Problem is modified as
The neutral function in achieves improved strength regardless of large or little losses because to the adaptive -norm, which acts as an interruption between the l1-norm and l2-norm.
The experimental setup for this research was created using the deep learning toolbox in MATLAB. In this section accuracy, precision, recall, specificity and F1 score are the different metrics used to evaluate the proposed Clustering based Faster RCNN Network. Moreover, the proposed Clustering based Faster RCNN Network was also compared with other traditional network and state-of-art models.
Performance analysis
In this work, specificity, accuracy, precision, recall, and F1 score were used as the basis for the performance analysis calculations.
False-positives, false-negatives, true-positives, and true-negatives are denoted by FP, FN, TP, and TF respectively.
The performance of proposed model for three classes that includes suspicious and non supiscious. The proposed approach achieved higher accuracy of 0.987 and 0.991 for s supiscious and non supiscious. The proposed approach achieved higher specificity of 0.965 and 0.977 for suspicious and non supiscious and precision is 0.961 and 0.954 for suspicious and non-suspicious. The proposed approach achieved higher recall of 0.985 and 0.957 for suspicious and non supiscious and F1 score is 0.934 and 0.969 for suspicious and non supiscious that can be measured via TPR and FPR parameters. The overall accuracy of 0.987 and the overall specificity of 0.962 and precision, recall and F1 score is 0.979,0.929 and 0.941.
Figure 4 shows that the proposed model has achieved high accuracy in both training and testing accuracy, and loss is shows in Fig. 5. The performance is based on the specificity, recall, accuracy, precision and F1 score, and the accuracy obtained by the proposed model is 98.76%.
Performance analysis of proposed method

Training and Testing accuracy of proposed method.

Training and Testing loss of proposed method.
The comparative assessment was conducted among four prior deep learning networks is demonstrated in Table 3.
Comparison between traditional deep neural networks
Comparison between traditional deep neural networks
According to Table 3, traditional networks like CNN, Google Net, and Mobile Net require a lot of parameters to get those results, which raises the complexity level of each network. But the Faster R-CNN only utilize a smaller number of parameters so the complexity is reduced. Moreover, small number of flops are used in the proposed model that results in the low computational time when compared to the prior methods. Hence, the complexity structure of the proposed model is slightly high when compared to the light weight deep learning networks like shuffle net.
In this division, a comparison between the proposed model and conventional deep learning networks is also conducted. Based on a performance comparison with existing methods, this technique outperforms them in terms of productivity. Performance is evaluated using F1 score, precision, specificity, recall, and accuracy. The proposed model is compared with three different deep learning algorithms in this comparison analysis.
Table 4 illustrates that the results attained in terms of overall accuracy rate. From Table 4 the traditional networks like CNN, U-net, Fab net and Fast R-CNN obtains less accuracy compared to the Faster R-CNN. Faster R-CNN preserves the high accuracy ranges of 98.78%. The accuracy obtained by CNN, U-net, Fab net and Fast R-CNN is 97.68% 96.76% 95.67% and 94.21% respectively. The specificity obtained by CNN, U-net, Fab net, Fast R-CNN and Faster R-CNN is 95.46%96.48%93.64% 91.38% and 97.53%. Precision is obtained by CNN, U-net, Fab net, Fast R-CNN and Faster R-CNN is 94.63% 93.53% 91.45% 92.15% and 95.21% Recall is obtained by CNN, U-net, Fab net, Fast R-CNN and Faster R-CNN is 92.42% 93.37% 87.76% 90.61% and 94.67% F1 score is obtained by CNN, U-net, Fab net, Fast R-CNN and Faster R-CNN is 90.56% 92.34% 86.98% 88.85% and 92.85% The Faster R-CNN net’s accuracy rate is higher than that of the existing models. Thus, it is clearly seen that Clustering based Faster R-CNN model performs better than other techniques.
Comparison between traditional deep learning networks
According to Table 5, the proposed Clustering based Faster RCNN model improves the overall accuracy of 8.86% 33.77% 3.12% and 5.48% better than mmGait, LSTM Net, STDNN and RNN respectively.
Comparison between proposed and the existing models
The specificity obtained by mmGait, LSTM Net, STDNN and RNN is 87.48% 62.10% 91.38% and 89.37% The proposed clustering-based faster RCNN model achieved a specificity of 94.28% The precision obtained by mmGait, LSTM Net, STDNN and RNN is 89.48% 69.17% 90.13% and 90.89% The proposed clustering-based faster RCNN model achieved a precision of 95.39% The proposed clustering-based faster RCNN model achieved a Recall of 93.29% The proposed clustering-based faster RCNN model achieved a F1 score of 91.38%
In this paper, a novel Clustering based Faster RCNN approach has been proposed to identify the single, double and multi-gait. From CASIA-B gait dataset, we choose single, double and multi-gait images are pre-processed using Multi scale Retinex (MSR) to reduce the noise artifacts. Finally, the Fast RCNN is employed for classifying the gait images into suspicious and non-suspicious walking gait based on the clusters from the clustering algorithm. The proposed Clustering based Faster RCNN net achieves the high accuracy rate of 98.74% and 99.19% for suspicious and non-suspicious walking gait respectively. The proposed Clustering based Faster RCNN model was compared with other traditional models like CNN, U-net, Fab net and Fast R-CNN. The proposed Clustering based Faster RCNN model improves the overall accuracy of 8.86% 33.77% 3.12% and 5.48% better than mmGait, LSTM Net, STDNN and RNN respectively. The complexity structure of the proposed model is slightly high when compared to the light weight deep learning networks, since the complexity can be reduced to achieve stable performance in multi-gait recognition. In future, the accuracy of the proposed model can be improved by using the advanced deep learning networks or optimization algorithms.
Footnotes
Acknowledgments
The authors with a deep sense of gratitude would thank the supervisor for his guidance and constant support rendered during this research.