
Abstract
Human motion style transfer is a technique that aims to apply a desired style to neutral motions, which is an essential aspect of motion generation and retargeting. With the advancement of deep learning networks, significant progress has been made in this field. However, one of the main challenges is preserving the essential features of the original motions, such as velocities and trace, during the style transfer process. To overcome this challenge, we have proposed a novel method called Residual LSTM Generative Adversarial Networks (Res-LGAN) for motion style transfer. The Res-LGAN models consist of a transfer network and a refinement network, which work together to generate smooth and natural stylized motions while preserving key features of the original motions. Additionally, we have introduced a reconstruction loss term to ensure the stylized motions closely retain the features of the original motions. Our experiments demonstrate that the proposed Res-LGAN model outperforms existing state-of-the-art models by generating high-quality stylized motions while preserving the original motion features. To the best of our knowledge, Res-LGAN is the leading method for preserving original content features during motion style transferring.
Introduction
The purpose of human motion style transferring is to stylize neutral motions, and this is a task with significant academic and application value. In research, motion style transferring task is not only an essential part of human motion retarget, but used for motion generation tasks to obtain more diverse types of motions; in application, motion style transferring helps animators generate desired motions with different styles to save time, and game companies can reduce the size of software by using one neutral motion and several pieces of style information instead of employing multiple stylized motions.
Though traditional methods [26, 30] have achieved some level of success, they still have certain shortcomings, such as struggles in processing high-dimensional movement data and a lack of adaptability in dealing with various movement patterns.
With the development of deep learning methods and hardware upgrades, deep learning methods are being applied in an increasing number of research fields [1, 25]. Motion style transfer also greatly improved and received a great deal of research interest. Many throughs have also been made by combining motion generation and retargeting with deep learning networks [12, 29].
Deep learning-based approaches have been widely used in motion style transfer tasks [20, 31]. However, these methods frequently overlook the generated motion’s inconsistencies and artifacts such as foot-sliding and distorted trajectories.
One typical method for achieving motion style transfer is by using a Gram matrix to represent style features, which is inspired by image style transfer [5, 15]. While this approach has strong performance, it comes with extra computation cost.
Therefore, we aim to achieve motion style transfer without the use of Gram matrix, in order to accelerate computation speed, thanks to the powerful generative capacity of GANs.
The generative adversarial networks (GANs)[6] consist of a generator and a discriminator. The aim of training generator is to synthesize a fake data distribution that is indistinguishable from the real data distribution, while discriminator is trained for distinguishing these two distributions. Since the great properties of GANs, these constructions have been widely used in different fields [9, 27], including motion generation and analysis [16, 17].
We have observed that the task of motion style transfer is composed of two main sections: transferring a new style to a neutral motion while ensuring that the features of the original motion are preserved. This is crucial for animators, as characters should move along a fixed trace at given velocities, and for researchers, as many deep learning methods require paired-data to train their networks. Therefore, preserving motion features is crucial for obtaining neutral-style paired-datasets that can be used for further research on motion styles.
As stated before, when it comes to motion style transfer, maintaining the original motion characteristics is key for ensuring the quality of the generated motions.
In order to achieve our goals, we utilize a reconstruction loss that is inspired by energy-based generative adversarial networks (EBGANs) [32] to make certain that the majority of the original features, including velocities, bone length, and trace, are retained.
As we mentioned above, we attempt to use GANs to complete both these tasks. The generator focuses on combining the features of the style and the original motion, while the discriminator’s main task is to determine whether the style of the generated motion is the same as the input style information and that the basic motion features are the same as the original motion. The reconstruction loss plays an important role in feature preservation, so we use both reconstruction loss and adversarial loss to ensure that the generator can generate the desired motions. We chose the CMU Mocap dataset as our dataset because it contains multiple motions and styles, which is ideal for training the model to transfer styles.
In summary, our work has three main contributions: We propose the novel Residual LSTM GAN, called Res-LGAN. In Res-LGAN, a generative adversarial network with Residual LSTM structure works to generate the natural and smooth stylized motions through the input of original motions. The main contribution of Res-LGAN is its ability to complete the task of motion style transfer while preserving the original motion features. We use a reconstruction loss to help maintain the original motion features (such as velocities, bone length and trace) of the generated stylized motions. The Res-LGAN we propose has the capability to generate stylized motions without using a Gram matrix and with minimal additional constraints, which results in reduced computation cost.
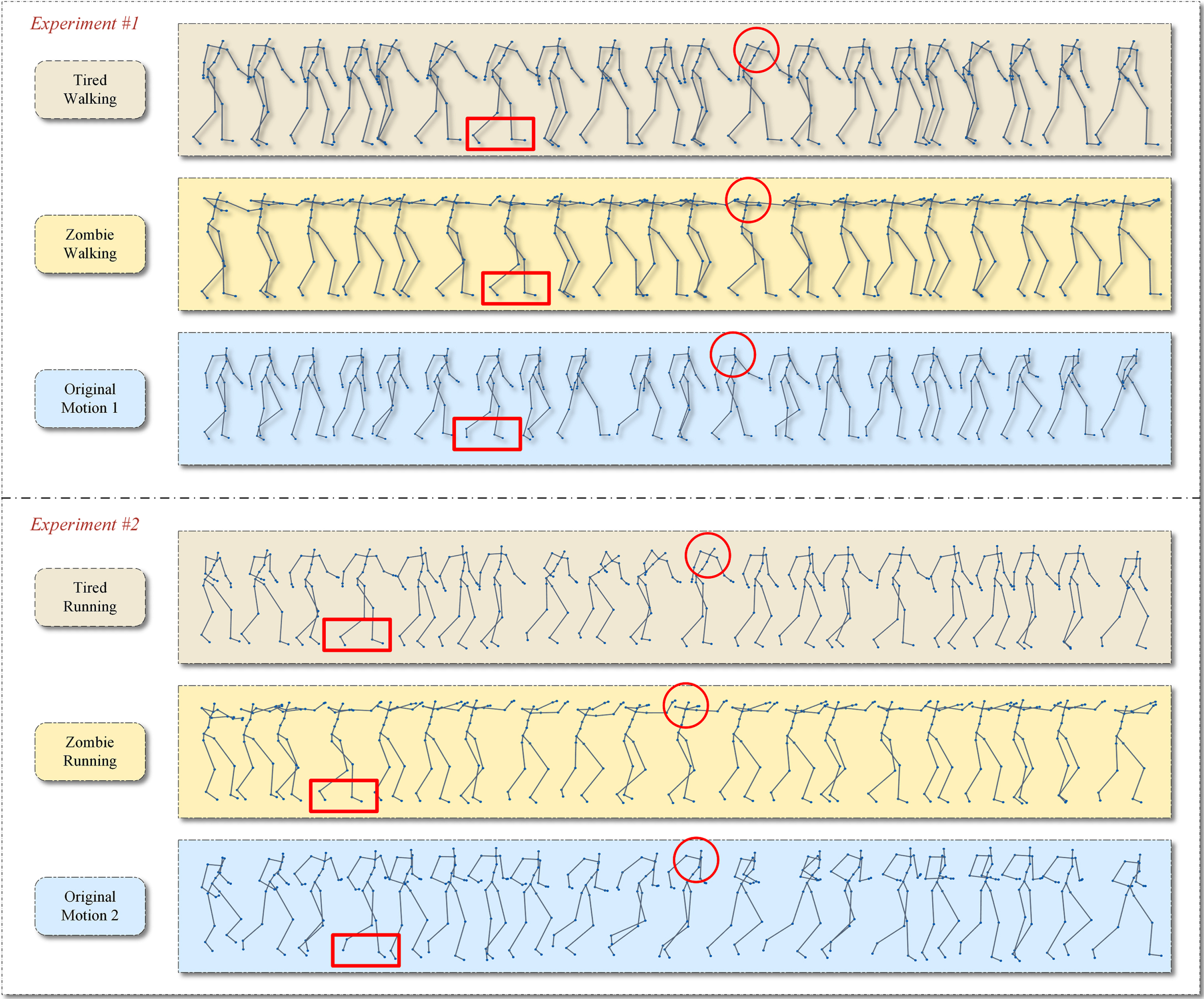
The result of experiment to evaluate the capacity of transferring different styles of Res-LGAN. This figure shows that tired and zombie-like styles transfer to the neutral motions.
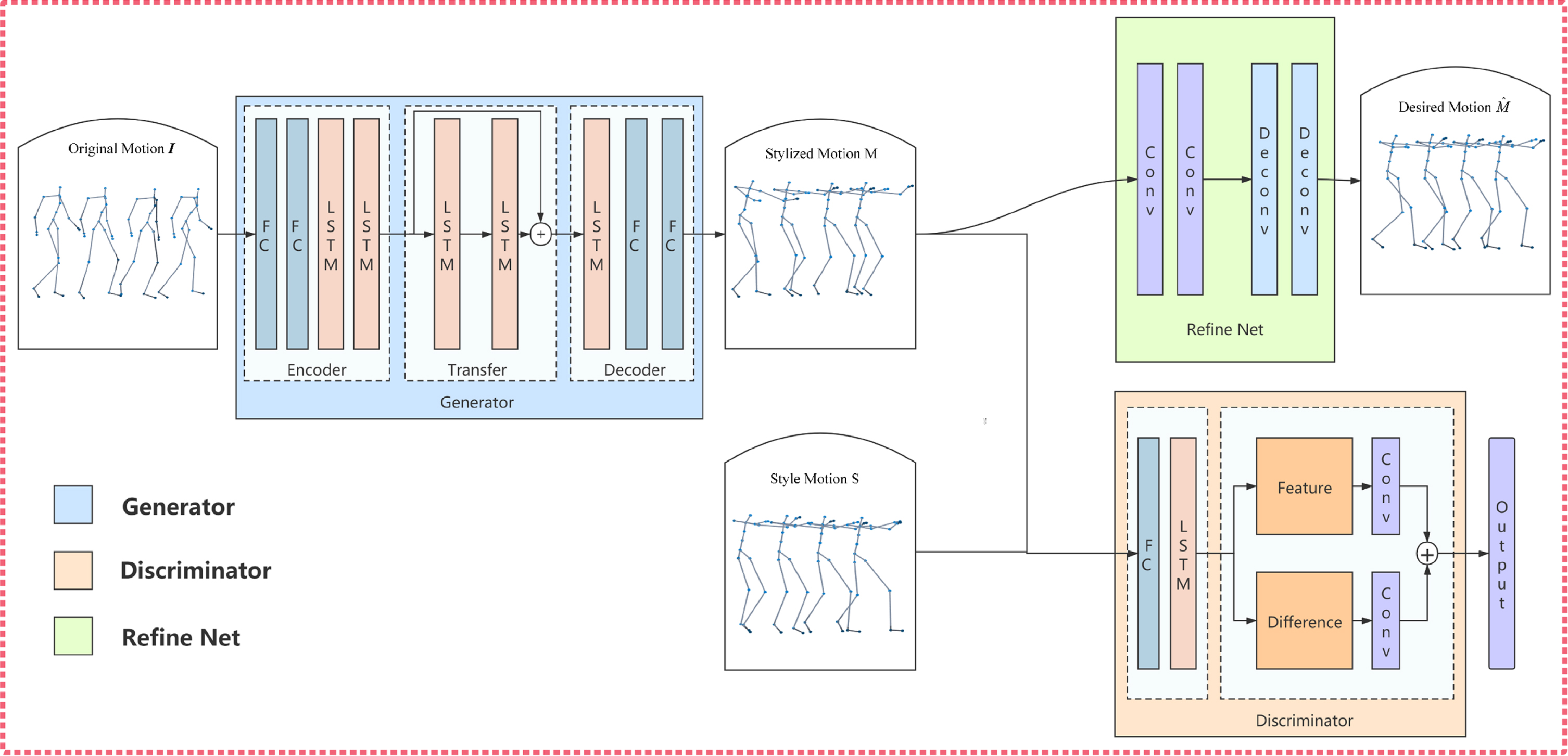
The architecture of Res-LGAN. There are some notations: I: the input neutral motions; S: the input style motions; M: the stylized motions generated by generator G;
Motion style transfer
Motion style transfer is a widely studied problem in computer graphics, which aims to extract a style from a motion clip and apply it to another neutral motion clip. This is useful in various fields such as computer animation and video games, and researchers can also use stylized motions to train networks or conduct further research.
The task of motion style transfer is challenging because of the complexity of the motion style representation. Current methods for motion style transfer can be broadly categorized into two groups: traditional methods and deep learning methods.
Traditional methods have made significant progress in the field of motion style transfer [26]. These methods typically focus on completing the transfer task in the frequency domain by comparing the differences in the Fourier coefficients of different motions[30]. Another approach involves the use of dynamic models for motion style transfer. Despite some success, traditional methods still have limitations such as difficulty in handling high-dimensional motion data and lack of flexibility in handling different motion styles.
The use of neural network technology for style transfer was first introduced by [5], where it was used to generate art with a similar style to famous paintings. Recently, with the advancement of deep learning, many works have applied deep learning networks to the task of motion style transfer [20, 31]. However, these approaches often neglect the artifacts and inconsistencies of the generated motions, such as foot-sliding or trajectory distortion. Holden and his colleagues [12] proposed a model that uses neural networks and additional constraints to address this issue.
As previously mentioned, when transferring motion styles, preserving the original motion features is also crucial for the quality of the generated motions. Our proposed method Res-LGAN not only addresses the problem of artifacts and unnatural actions but also considers basic motion properties such as velocities and trace, without significantly increasing computation cost.
Generative adversarial networks
Generative adversarial networks (GANs) is a novel approach which based the idea of game theory as the generative model proposed by [6]. Generative adversarial networks have currently been developed greatly and are widely applied in multiple research fields [24, 25]. [28] show that combines RNNs and adversarial training for motion synthesis. Although GANs have powerful generated abilities, they might meet some troubles while training, such as the difficulty of convergence, gradient vanishing. WGAN, introduced by [2, 7], avoid the problems like mode collapse, and provide meaningful learning curves useful for debugging and hyper-parameter searches. Besides, various types of GANs have appeared for different tasks. [3] propose Info-GAN as an information-theoretic extension to the generative adversarial nets in order to learn disentangled representations. Jun-Yan et al. define a new model for the unpaired image to image translation named Cycle-Consistent Adversarial Networks (Cycle-GANs)[33]. They introduce a cycle consistency loss to enhance ability of the model by regularizing structured data with a long history.
[18] introduce an alternative type of GANs called Conditional generative adversarial nets (Conditional-GANs). Conditional-GANs are constructed from the conception of the combination of additional information and input data, and this property can be used for motion style transfer. Our network is different from theirs because our target is transferring style to other neutral motions rather than synthesis a completely new motion. Energy-based GANs introduce an energy view to explain the adversarial architecture in [32]. Our models have the capacity to save the representation and original information of input data inspired by EBGAN and Conditional-GAN.
Residual LSTM
Our decision to use a neural network built with recurrent neural networks (RNNs) and Long Short-Term Memory (LSTM) cells was influenced by previous research [8]. [8] demonstrated the powerful capabilities of RNNs for motion synthesis. While RNNs are effective for sequence processing and have been used in various applications, such as speech recognition and music generation, they do have limitations. RNNs can struggle with long-term memory and may experience issues with gradient vanishing or exploding. Long Short-Term Memory, as proposed by [11], is a novel architecture that can address these limitations and has shown strong performance in tasks such as information extraction, speech processing, and natural language processing (NLP) applications.
It is commonly thought that deeper networks offer better performance, as they can handle more complex representations of data. However, deeper architectures can be difficult to train. Recently, [21] introduced an alternative type of LSTM network, which aims to overcome these difficulties. The Residual LSTM network is similar to convolutional residual networks as proposed by [10], and shows that adding residual connections between LSTM layers can lead to improved capabilities. With this in mind, the generator of our model is constructed with residual LSTM architecture.
Structure of Generator G
Structure of Generator G
We proposed a novel GAN architecture, called Res-LGAN, which is composed of two modules: the transfer-net T and the refine-net R. In detail, the transfer-net consists of a generator G and a discriminator D, which is inspired by the Cycle-GAN architecture as described in [33]. The architecture and working process of Res-LGAN are illustrated in Figure . The generator G receives the original input motions I, while the discriminator D receives the style motions S. By working with D, G is able to generate realistic and stylized motions M. These stylized motions M are then passed on to R, which is responsible for generating natural and stylized motions
Network sructure
We adopted Residual LSTM [21] and Conditional-GAN [18] as our baseline models.
The architecture of our transfer module is based on the idea of Residual LSTM [21], which is an improved LSTM module as mentioned above. The generator G is adapted from Residual LSTM and contains a down-sampling encoder, a transfer module, and an up-sampling decoder. The encoder module is used to obtain the representations of the original motions. As previously mentioned, LSTM can handle the spatial-temporal representations of the input data. Therefore, the encoder is constructed with two linear layers and two LSTM layers. The decoder module is used to reconstruct the motion data, similar to the decoder of the refine network. However, unlike the refine network, the decoder of the generator is constructed with linear layers and LSTM layers. The core of our model is the transfer module of the generator, which consists of a stacked residual containing two LSTM layers. The transfer module has the capacity to stylize motions in the hidden space. The residual connection does not add any additional parameters. Therefore, compared to bi-directional LSTM layers, residual LSTM does not increase the complexity of our model. The structure of the generator G is shown in Table 1. The D consists of a feature module and a difference module. In order to precisely handle differences between real motion data and generated motion data, we use a trick by comparing differences of motions. We denote dif as the differences between adjacent frames, which is used to compare the difference between adjacent poses. By applying this trick, the capacity of the discriminator is obviously improved. The structure of the discriminator D is shown in Table 2
Structure of Discriminator D
Structure of Discriminator D
Structure of Refine Net R
R is only a simple convolutional auto-encoder since convolutional neural networks (CNNs) have achieved particular success in learning motion manifolds. In the process of generating desired motions, only using adversarial loss does not guarantee that the generated motions are natural and smooth, such as wrong bone length and discrete locomotion. Inspired by [14] which is widely used in modifying artificial motions, we pre-trained the refine network R, which consists of a few convolution and pooling layers to handle motion features in the latent space. The structure of the refine net R is shown in Table 3.
The primary objective of Res-LGAN is to generate stylized motion based on the original, neutral motion while preserving its basic features. In order to achieve natural and smooth motion, we employ three loss functions to optimize our models. In addition to the standard adversarial loss used in GANs, we utilize a refinement loss with L2 norm to modify the generated motions, and a reconstruction loss to preserve the characteristics of the original motion. In GANs, the generator and discriminator engage in a minimax game, where the generator (G) attempts to generate natural motion that is indistinguishable from real motion for the discriminator (D).
where generator G tries to minimize the loss function Eq. 2 while discriminator D tries to maximize it.
where M is generated from G (I) and generator G tries to minimize Eq 3.
To pre-train the refine net, we use ground truth motions C as input and encode them to the hidden space. We then decode them back to reconstruct
while the full loss function for G is:
Training the Res-LGAN model
LSTM can handle the spatial-temporal representations of the input data. The use of a residual structure makes the model easier to optimize and increases the accuracy of the model by increasing the depth, while avoiding the gradient disappearance problem caused by increasing the depth of the model. Due to the characteristics of the residual structure, the input data can be directly passed to the output data, and the model only needs to learn the change between the output data and the input data, which not only ensures the integrity of the data but also simplifies the learning goal and difficulty of the model. Use the differences between adjacent frames to improve the capacity of the discriminator. The reconstruction loss is a new loss proposed in this paper, with the aim of preserving as much of the original motion characteristics as possible.
The input motions are constructed at a rate of 240 frames per second and each posture consists of 21 joints in 3D Euclidean space. Additionally, we include three additional variables to represent basic features of motion (turning, forward, and sideway velocities), resulting in a total of 66 DOFs per pose of the total sequences. The refine-net will be pre-trained first with a learning rate of 0.00001 using the Adam optimizer. Then, we use the RMSprop optimizer method for training the transfer-net. Our model is trained using a GTX 1050Ti. The learning rate of G is set to 0.00001 for the first 200 epochs and is exponentially decayed, while the learning rate of D is set to 0.00001. We train and test Res-LGAN on the CMU Mocap dataset. The size of the output motions is 66 × 240. The algorithm for training Res-LGAN is outlined in Table 4.
Experiments
Dataset
We chose the CMU Mocap dataset [4] on which to perform motion style transfer using Res-LGAN.
Experiment results
To compare Res-LGAN with state-of-the-art methods, we reproduce and train the model of Fast Style Transfer [12] and Real-Time Motion Style Transfer [23]. Both models also consider preserving motion features, but unlike our Res-LGAN model, they adopt additional constraints. The results are evaluated qualitatively on the CMU Mocap dataset. Additionally, we conduct an ablation study on the proposed reconstruction loss function (and the refine net) to evaluate their effects.
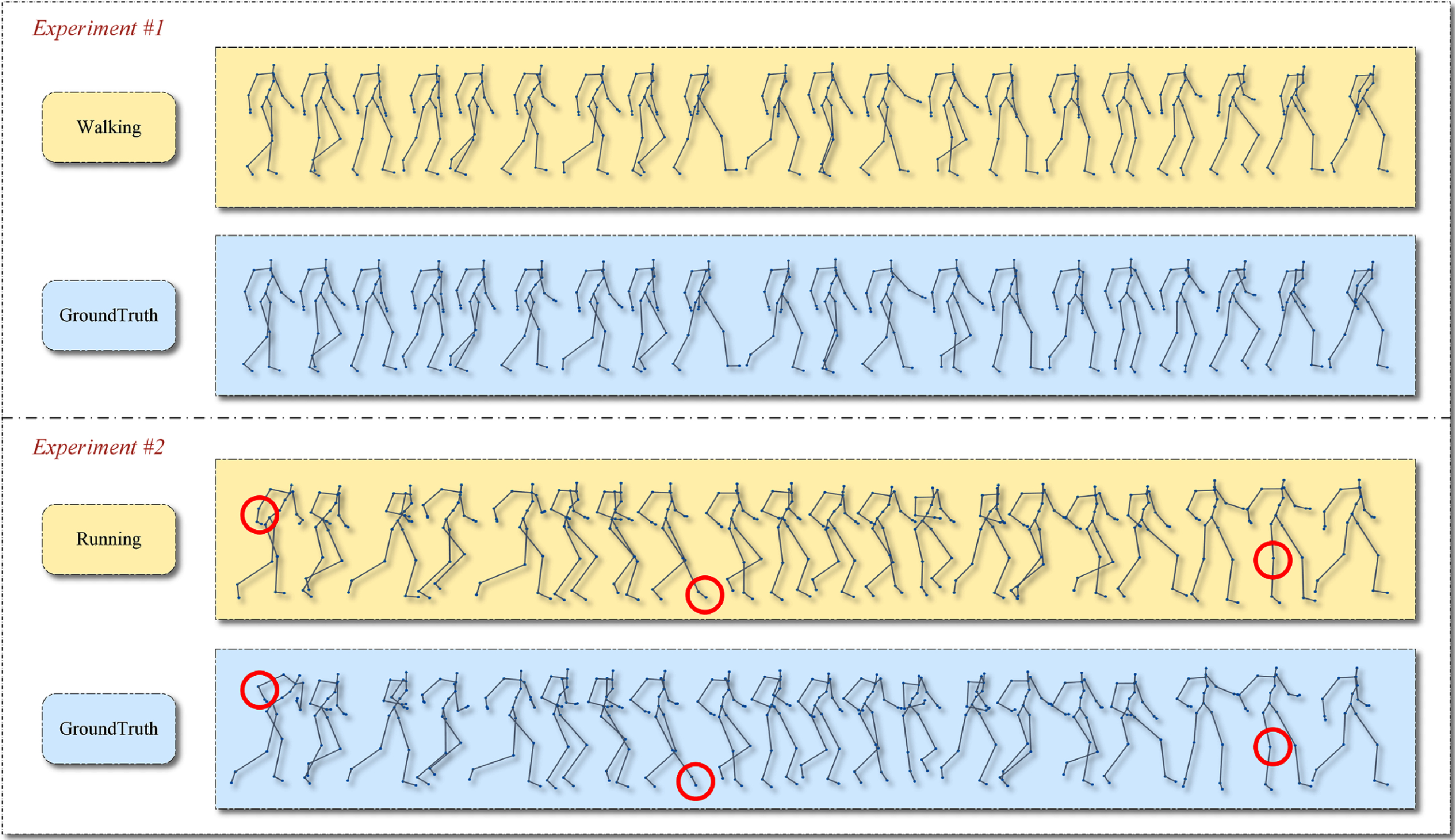
The result of experiment to evaluate the capacity of preserving original features of Res-LGAN. This figure shows walking and running motions in our experiments.
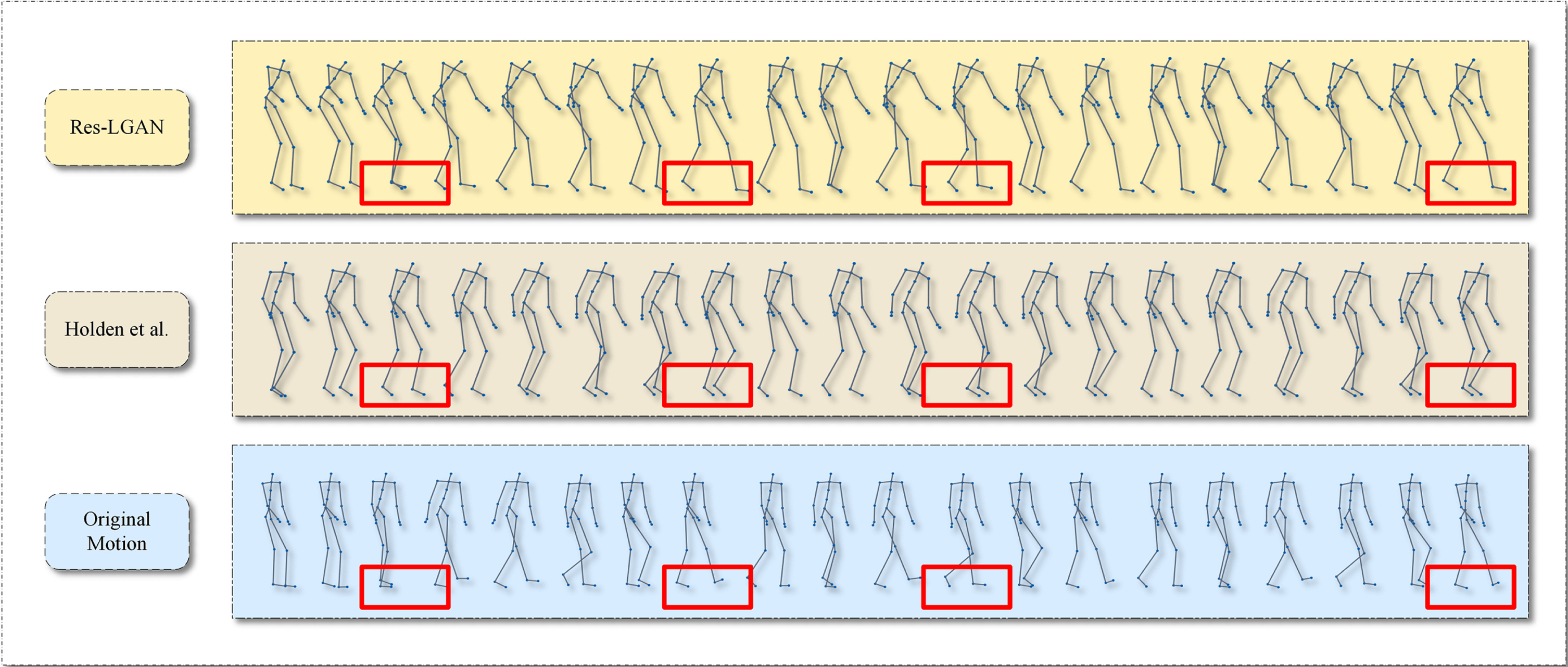
The result of experiment to evaluate the capacity of transferring styles of Res-LGAN. This figure shows the results of Fast Neural Transfer[12] and Res-LGAN for transferring tired style to the same neutral motion.
First, we select neutral motions to evaluate the motion quality and the original content preservation ability of our Res-LGAN. We use two different types of motions (running and walking) with a neutral style from the CMU Mocap dataset as input. The results are shown in Figure 3. As Res-LGAN is trained using neutral motions, it is easy to observe whether the features of the original motions are preserved. From Figure 3, it can be seen intuitively that Res-LGAN can synthesize motions that are close to the content of the ground truth, although some joints in the running actions have changed bone angles. Our Res-LGAN model behaves like an auto-encoder when it is trained using neutral motions. This model can confidently handle the human motion manifold and has the capacity to preserve motion features.
Next, we evaluate both the content preservation ability and the style transfer ability of different models. In this section, we focus on the style transfer ability assessment, so we choose the same type of motion with varying styles, including tired and zombies-like styles. The experimental results are shown in Figure 4. As shown in Figure 4, the model of [12] achieves motion style transfer while changing the pace of the original motion, while the generated motions of Res-LGAN have a pace that is closer to the original. In short, Res-LGAN, which we proposed, can transfer style to the neutral motion and preserves more original features, resulting in more precise stylized motions which animators and researchers desire.
Furthermore, we test the ability to transfer different styles to different neutral motions as is shown in Figure 1. It can be seen that both tired and zombies-like styles are transferred successfully.
In conclusion, our Res-LGAN model can transfer different styles to different neutral motions and preserves more original features, resulting in more precise stylized motions which animators and researchers desired.
According to [30], difference of style is highly correlated in the frequency domain magnitude component regardless of what kinds of motions. Therefore, we build on this idea to evaluate the capacities of Res-LGAN model quantitatively by comparing frequency domain magnitude component and time domain signals.
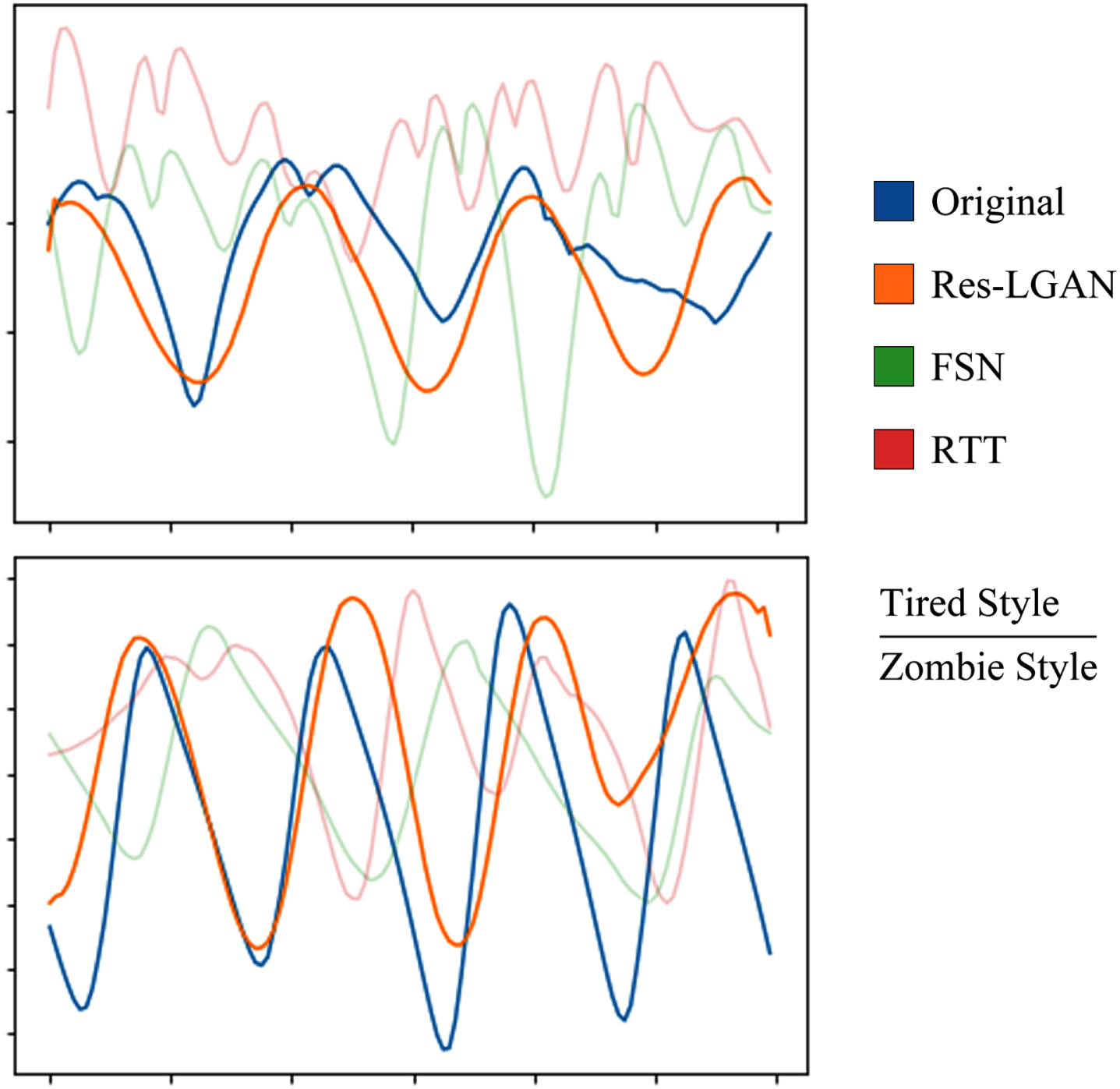
Time domain signals of results. Top: Tired motions; bottom: Zombie-like motions.
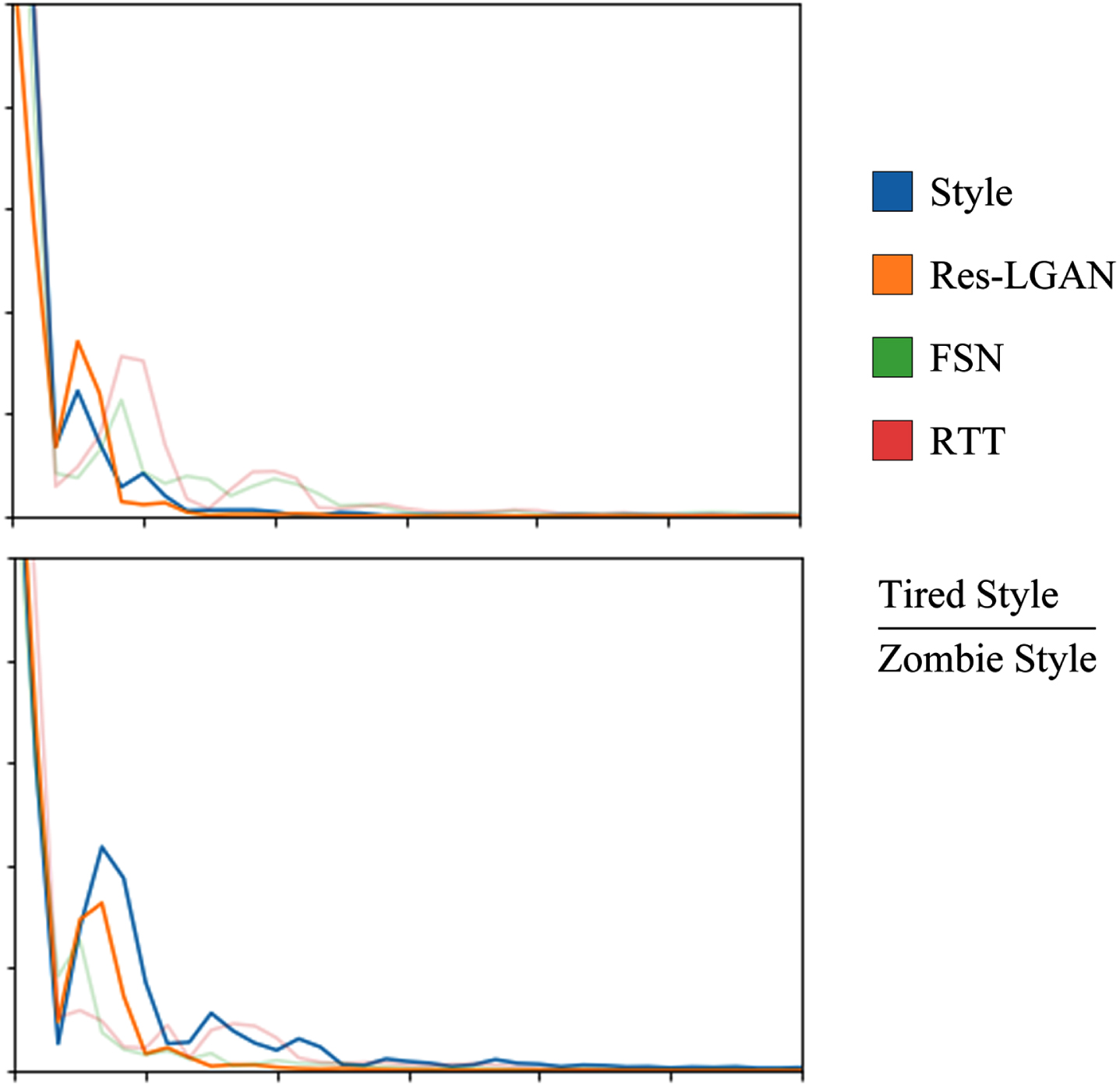
Frequency domain magnitude component of results. Top: Tired motions; bottom: Zombie-like motions.
First, we compare the differences of the time domain signals of each body joints (hips, spine, neck and head) which belong to the generated motions and original neutral motions to evaluate the feature-preserved ability of our model.
The Figure 5 illustrates a data sequence of the hip joint, with the position information of the joint node on the ordinate axis and the slope of the data curve indicating the motion rate of the joint. As depicted, compared to [12] and [23], the Res-LGAN model curve exhibits a high level of consistency with the original motion curve, with the overall rate of change remaining consistent with that of the original motion. In stylized movements, each joint typically requires corresponding changes. For instance, a "tired" style of movement would entail greater fluctuations in the hip joint, as opposed to the more regular movement seen in a normal walk. As a result, there may be slight variations in the joint position at certain points in time. However, it can be inferred from the figure that the Res-LGAN generated stylized motion preserves the time-domain information of the hip joint to a significant extent, thus effectively maintaining the essential characteristics of the underlying motion.
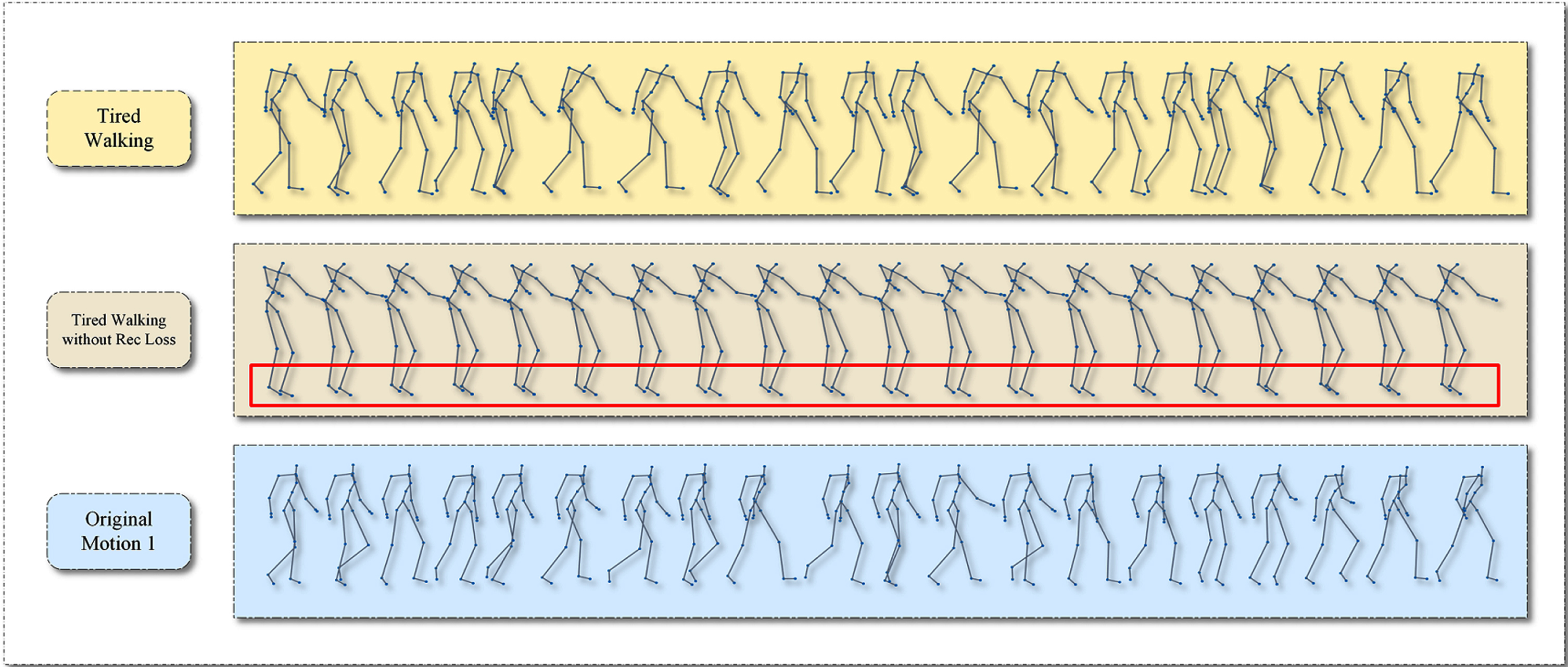
The ablation study to evaluate the reconstruction loss function.
Then we compute frequency domain magnitude component to evaluate style transferring ability of Res-LGAN. Because the key joints of different style are different, we choose different joints group for them. For example, we select shoulder and hands for tired style while forearm and hands for zombie style. Figure 6 shows the frequency domain magnitude component of these two style motions.
As can be seen from the Figure 6, the Res-LGAN model is most similar to the frequency domain amplitude component curve of the input style movement. Due to differences in original movement speed, direction, and other information, the model makes some exaggerations or convergences when generating stylized movement, resulting in amplitude max values not being entirely consistent with the input style movement. However, overall, the model still conforms to the desired movement style.
According to the quantitative evaluation above, our Res-LGAN model achieves motion style transfer task in preserving the features of original motions.
We choose two different styles and two different actions (tired and zombies; walking and running) to evaluate the capacity of the proposed reconstruction loss. As is shown in Figure 7, the motions generated by Res-LGAN without reconstruction loss do not contain enough motion features.
In summary, the reconstruction loss function effectively helps Res-LGAN generate motions that are more consistent with the features of the original input motions compared to Res-LGAN without reconstruction loss.
In this paper, we introduce a new model, Res-LGAN, for motion style transfer. Unlike prior methods, our model is able to generate stylized motions while simultaneously preserving the original motion features. Additionally, by eliminating the use of the Gram matrix, the computation efficiency of the model is significantly enhanced. The network of Res-LGAN is composed of a transfer module T and a refine module R, which collaborate to produce natural and seamless stylized movements. To tackle the problem of preserving original features, we include a reconstruction loss as our feature preservation loss to optimize the generator G during training. Our results and evaluation experiments demonstrate that Res-LGAN achieves comparable results with other motion style transfer methods in transferring motion styles while preserving original motion features. Additionally, qualitative evaluations indicate that Res-LGAN preserves original motion features to a greater extent. The ablation study also highlights the importance of the reconstruction loss function in preserving the original motion features. This work has significant and valuable applications in multimedia, particularly in motion retargeting and generation studies, and is widely used in the CG movie and game industries.
Our Residual LSTM Generative Adversarial Network (Res-LGAN) has accomplished the crucial objectives of human motion style transfer: effectively transferring style while maintaining the integrity of the original motion information. However, for complex actions, additional repair networks may be necessary to correct errors in the generated stylized motion. Without these repairs, the resulting stylized motion may exhibit jittering issues. Future research will focus on optimizing the structure of the transfer network and elevating the quality of model-generated stylized motion to improve or integrate the repair network.