
Abstract
Data-imbalanced problems are present in many applications. A big gap in the number of samples in different classes induces classifiers to skew to the majority class and thus diminish the performance of learning and quality of obtained results. Most data level imbalanced learning approaches generate new samples only using the information associated with the minority samples through linearly generating or data distribution fitting. Different from these algorithms, we propose a novel oversampling method based on generative adversarial networks (GANs), named OS-GAN. In this method, GAN is assigned to learn the distribution characteristics of the minority class from some selected majority samples but not random noise. As a result, samples released by the trained generator carry information of both majority and minority classes. Furthermore, the central regularization makes the distribution of all synthetic samples not restricted to the domain of the minority class, which can improve the generalization of learning models or algorithms. Experimental results reported on 14 datasets and one high-dimensional dataset show that OS-GAN outperforms 14 commonly used resampling techniques in terms of G-mean, accuracy and F1-score.
Introduction
Currently, data-imbalanced problems have been one of the main obstacles in various applications of machine learning. Imbalanced datasets are commonly widespread [1], which makes machine learning algorithms or models skewed to majority class [2]. However, the minority class could be more meaningful in numerous practical problems [3]. At present, studies mainly solve this problem from two levels, namely algorithmic level and data level.
At the algorithmic level, one tends to adjust the network structure to improve the classification accuracy on the unbalanced data. Ensemble learning is an effective method, such as random forest [4] and XGBoost [5], which integrates several weak classifiers and can avoid the drawback of a single classifier. In [6], a dynamic ensemble learning algorithm based on K-means achieves diverse base classifiers and distance-based dynamic ensemble creates a personalized combinational result for each test sample. Another trend is to optimize the costs of prediction errors or other potential costs with developed conceptualizations or techniques to focus the learning on minority samples. Cost-sensitive model [7] punishes parameters severely if the model misclassifies a minority sample, which can guide the model to pay more attention to the minority class. CS-SVM optimizes the SVM by extending the standard loss function with a constructive procedure [8].
At the data level, resampling method is popular and can be divided into three different strategies, viz. undersampling, oversampling and hybrid sampling. Undersampling deletes some majority samples leading to information loss [9]. Oversampling and hybrid sampling have attracted more attention. Synthetic minority oversampling technique (SMOTE) [10] is well-known as an effective oversampling method. Borderline SMOTE is one of popular variants of SMOTE, and it pays more attention to the minority samples located near the classification boundary [11]. LR-SMOTE avoids the generation of bias sample [12]. SMOTE-NaN-DE is proposed for noisy and borderline samples [13]. There are also some studies oversampling based on the distribution of the minority samples [14].
We notice that most existing oversampling methods directly apply Euclidean distance to sequential data especially to high-dimensional ones [15]. This may not well approximate the underlying characteristics of data. In addition, many methods synthesize new samples only based on the minority samples. However, the size of the minority class is generally low, which indicates that the information they can provide for oversampling is limited or insufficient. It is difficult to determine well the distribution of the minority class with few information. There are so many majority samples containing substantial information but not being fully utilized.
Generative adversarial network (GAN) is a commonly considered image generator since it was introduced in 2014 by Goodfellow [16]. It learns underlying true data distributions from limited available images, and then uses the learned distributions to generate synthetic images. This naturally inspires to investigate the effectiveness of GAN in oversampling minority samples for imbalanced datasets [17]. Mullick et al. employ adversarial oversampling in deep learning systems to mitigate the effects of class imbalance on image datasets [18]. Hao et al. propose an Annealing Genetic GAN to reproduce the distribution of the minority class using only limited data samples [19]. Being an intelligent image generator, it is also applied to industrial defect image generation [20]. Using synthetic images to balance the class distribution is fairly a recent topic that needs to be widely and deeply explored.
However, most GAN-based oversampling methods are currently limited to image generation. As far as we know, there are very few research works for numerical imbalanced datasets. Oh et al. use GAN for oversampling through outlier samples detection and removal from the majority class [21]. Another work different from image generation is to use GAN for tabular data generation [22, 23]. Though research in this area is still in its infancy, GAN can generate high-quality realistic samples through learning probability distributions of numerical datasets.
Inspired by the above discussion, in this paper, we present a new oversampling method based on GAN (OS-GAN) for numerical imbalanced datasets. In this method, GAN assumes the responsibility of extracting salient distribution characteristics of the minority class from some majority samples to expose intrinsic quality of the minority samples to oversampling.
Most existing oversampling methods, such as SMOTE and its variants, are interpolation methods which do not require acquiring any distribution information about the minority class. This is also the challenge they have to face. As a class of machine learning frameworks, GAN provides an alternative solution for oversampling by distribution learning. In OS-GAN, the inputs of the discriminator are all minority samples. No explicit estimation of statistical models or parameters of datasets is required in OS-GAN but distribution of the minority class is learned by training GAN, and then distribution information of the minority class can be incorporated into the synthetic samples. It is made in an effort to preserve the global properties (but not the local properties as other oversampling would) of the underlying probability density function of the minority class.
In a numerical imbalanced dataset, the lack of the minority class and small disjuncts samples make the distribution learning of the minority class very difficult. It has recently been observed that there might be a gray area between classes especially in imbalanced datasets [24]. Samples coming from different classes in the gray area share same space and similar characteristics. So, the inputs of the generator of GAN in OS-GAN are not random noise data but are some selected majority samples. A further advantage of this operation is that it can introduce better inductive information from the majority class for the end-to-end training of GAN, beyond what is provided by the minority class.
OS-GAN dose not select majority samples around the classification boundary for the generator but those that belong to the cluster that includes the center of the minority class. This strategy has the following advantage. Majority samples far away from the classification boundary have obvious difference with he minority samples, and they can be considered as having nothing to do with the minority samples. Majority samples around the classification boundary but far away from the center of the minority class not only provide limited distribution information for GAN but also may mislead distribution learning. Majority samples near the center of minority samples have relatively ambiguous classification characteristics with the minority class. They can be considered as samples with a lot of majority class information and a few minority class information. Therefore, inputting these samples to the generator is to help GAN start learning the distribution of the minority class from these majority samples but not from zero.
The main contributions of this paper are as follows:
The originality of OS-GAN is that it does not perform oversampling or undersampling, but uses GAN as a distribution learning tool to directly generate minority samples. The comprehensive integration of majority and minority classes through training GAN can generate new minority samples according to the characteristics of the entire dataset rather than individual samples.
The paper is organized as follows. Section 2 introduces the related work of GAN. Section 3 describes the proposed method. Section 4 presents details of the experimental results. Section 5 demonstrates the conclusion.
Imbalanced learning
An imbalanced dataset means that there are far more or less samples in one class than in other classes. At present, important techniques include ensemble learning, cost-sensitive learning, choosing right performance metric, oversampling, undersampling, the combination of the last two techniques, etc.
Ensemble learning combines results or performance of multiple base learners to achieve higher performance than a single classifier, such as Bagging [25] and Boosting [26]. This technique can construct a more stable model and produce better prediction than provided by a single classifier. Cost-sensitive learning uses penalized learning algorithms where the cost of misclassification on the minority class is paid more attention. Penalized-SVM is one of popular methods of this technique [27]. Performance metrics for imbalance datasets not only assesses the classification performance but also guides the classifier modeling [28]. Choosing right metric is challenging for imbalanced classification problems, and generally, precision, recall, G-mean, F1-score and ROC can provide better insight. The widely used technique for imbalanced learning is resampling, i.e. oversampling, undersampling and the combination of them. Oversampling means adding more samples to the minority class, which dose not lose any information but can cause overfitting or poor generalization to the test set [10]. Conversely, undersampling means removing samples from the majority class, which decreases the run-time but lose some information [29].
Generative adversarial network (GAN)
Here we first provide a brief introduction of the GAN, shown in Fig. 1, which is well known for its ability of generating fake data from scratch. The operation process of GAN can be clearly described as a gambling process between two competitors, i.e., be simulated as training two neural networks alternatively. One network is used to generate real-like data and it is referred to as generator (
In most basic GANs, random noise
where
Basic structure of GAN.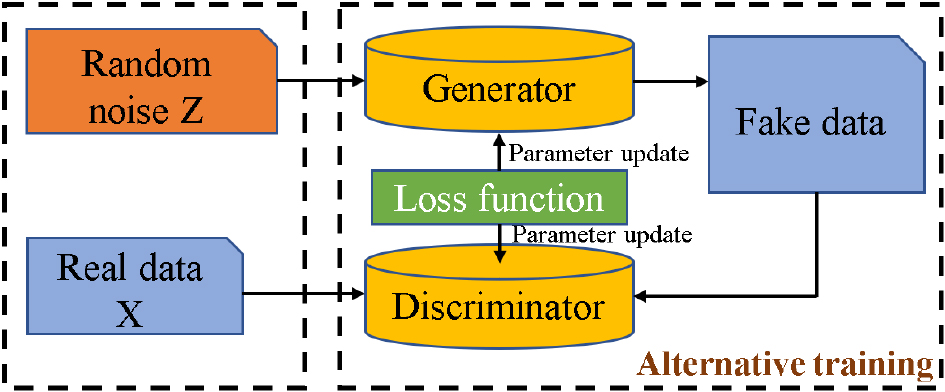
Traditional tasks with GAN
GAN is proposed for generate images at first. Although basic GAN is poor on image task from now to see, it is still an innovative milestone. Besides, researchers use GAN achieve many interesting tasks such as style transfer [31] which can transfer a style of one work to another work and support automatic matting for photos [32].
Additionally, there are also some GAN-variants for speech generation like [33]. Even music can be generated as well [34]. Similarly, the style of music can be transfered as well like image [35].
Besides, there are also some articles propose GAN-variant to address data imbalanced problems. Ref. [36] design experiments to investigate the effect of difficulty factors such as data dimension, class overlap .etc for conditional GAN on image oversampling task. Ref. [37] build an entropyweighted label vector as extra information to help Wasserstein GAN samping minority for high dimensional datasets. However, GAN for tabular dataset with few samples (just several dozens or several hundred) is rare which is what we want to address.
Tabular data generation using GAN
GAN is generally applied to high-fidelity natural image synthesis, but it is rarely used for numerical data. It is extremely difficult to learn the complicated distribution of a numerical dataset of high dimensionality and the sparsity of data points in the feature space causes many troubles in parameter optimizing.
On the other hand, GAN also exhibits some inherent problems in generating numerical data. The major obstacle is the sparsity of numerical data and the mode collapse. In the training process of GAN on the discrete dataset, networks may be caught by vanishing or exploding gradients and the samples generated by the generator are concentrated, which results in the mode collapse [38]. To address these problems, a gradient penalty is applied to the discriminator in DRAGAN [39]. [40] allows the generator consider both the current state of the discriminator and the state of that after several updates. The strategy we use in this paper is to stop the training early.
Another problem is that, GAN need many samples to train before you need it to generate data. Most of tabular dataset with just several minority samples which is not enough to train a GAN well. Therefore, we introduce GAN learn the distribution of minority from majority here which offers a feasible plan.
The proposed oversampling method
Given a binary training imbalanced dataset
By combining the center Training GAN and generating positive samples Translating If necessary, use SMOTE to achieve balance.
The following subsections present details of every step.
Flowchart of OS-GAN.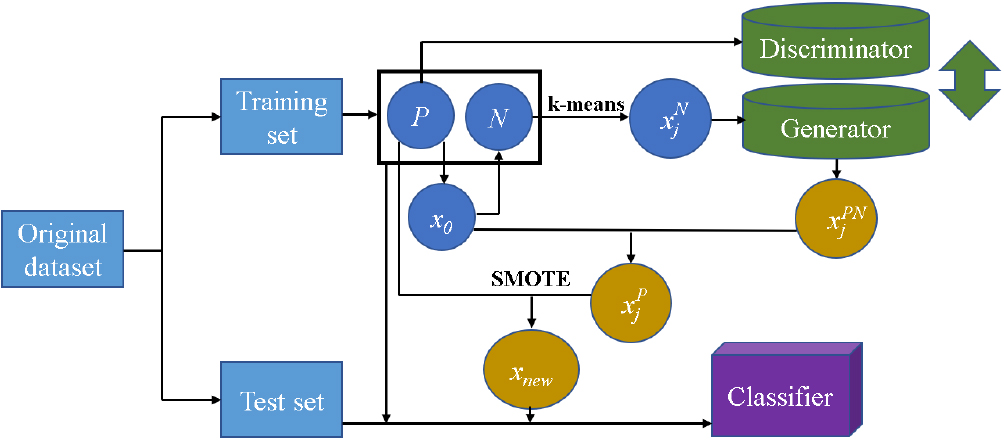
The fundamental difference between OS-GAN and other oversampling methods based GAN is that the inputs of the generator
However, many of the negative samples are too far away from the positive samples, so that there is no substantial relationship between them and the positive class. We need to select some of the negative samples that have the greatest relationship with the positive samples. We first find the center of the positive samples as follows.
where
Diagram of OS-GAN.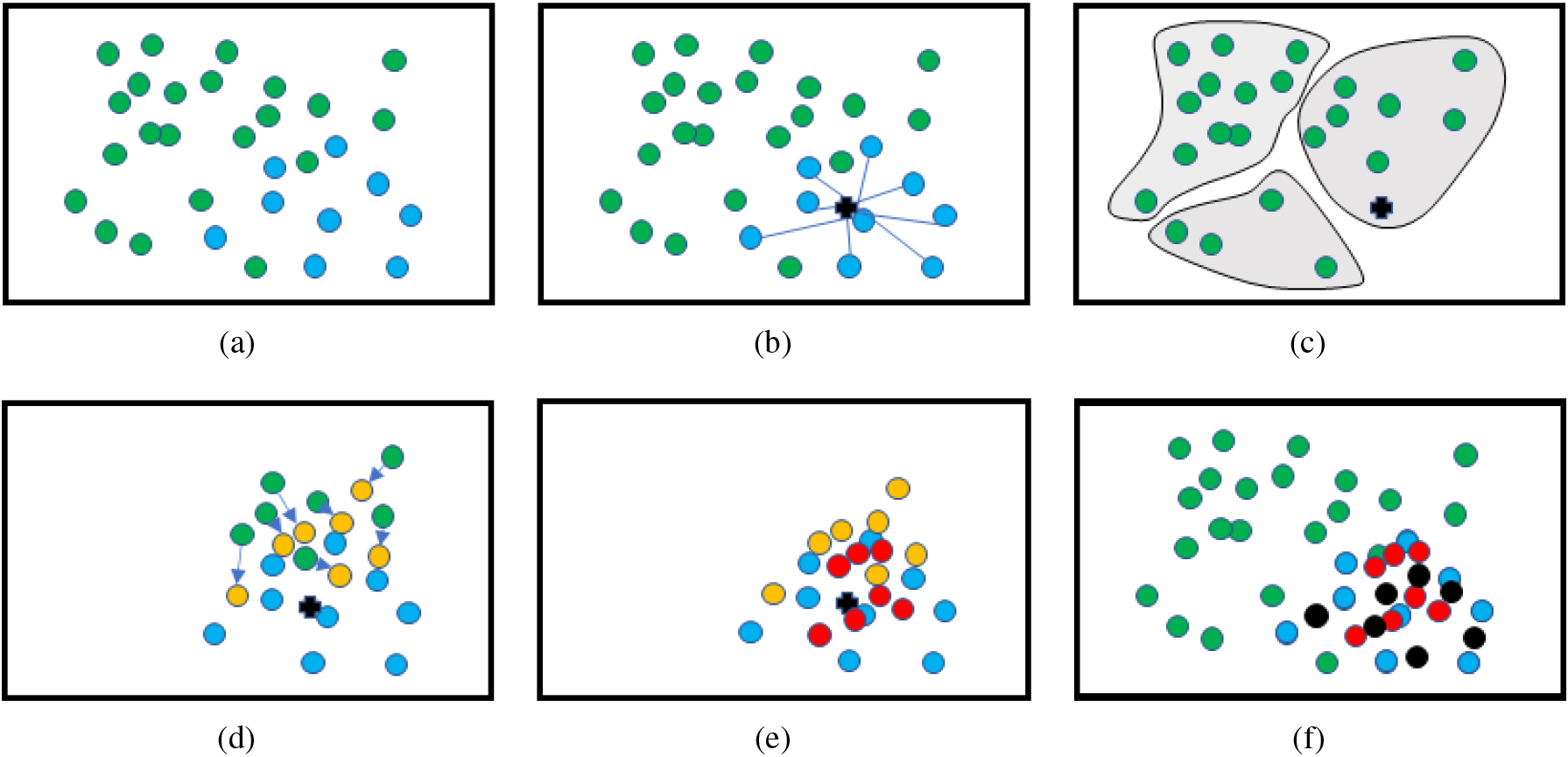
As shown in Fig. 3a, the green and blue points are the negative and positive samples, respectively. The black cross in Fig. 3b is the center
Because we only consider numerical datasets,
All
Early stopping strategy
However, Fig. 3d shows only the ideal result, lots of experiments we performed show that samples generated by GAN from real numerical datasets are concentrated or line up, as shown in Fig. 4a and b, where GANs are trained for 100 epochs on glass4 and yeast6 datasets (the details of these two datasets are listed in Table 1), respectively.
Fake samples generated by GAN on two real-world datasets glass4 and yeast6.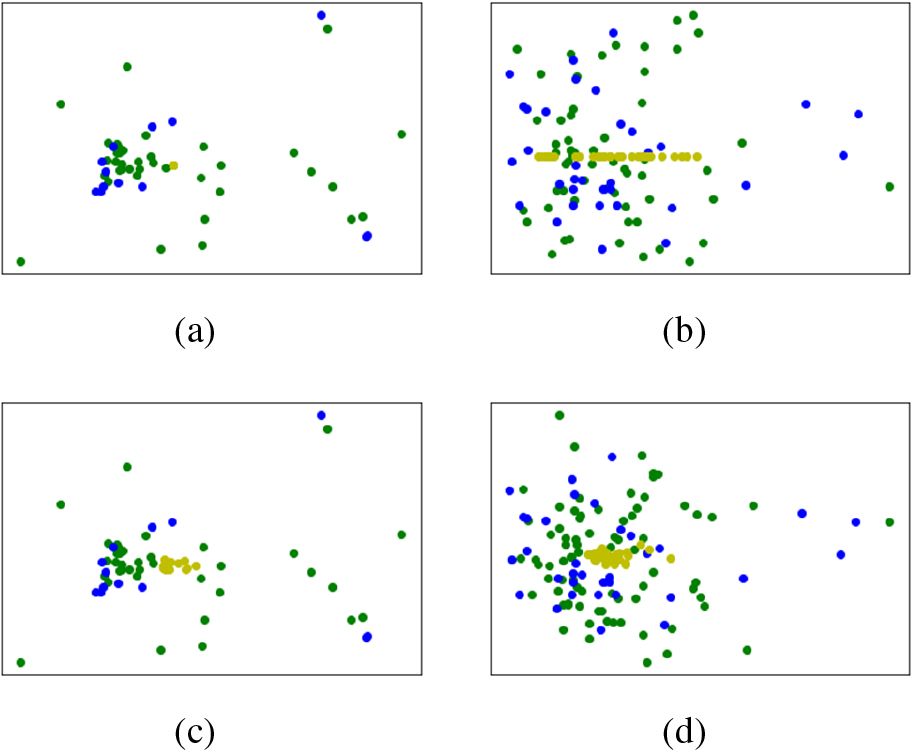
One reason for this phenomenon maybe that the numerical positive samples are scattered in the feature space and the amount of them are so limited that
Our goal is to learn distribution characteristics of the positive class to generate positive samples but not negative samples. So, what we want from GAN are samples containing information of both the negative and positive samples but not a good trained generator. So, we use the strategy of stopping the training early to prevent the over-concentration of fake samples. At the same time, early stopping means the time spent on training GAN can be greatly decreased. Figure 4c and d show the fake sample after GANs are trained 20 epochs on glass4 and yeast6 datasets, respectively.
Although the early stopping strategy can prevent generated samples by GAN from concentrating or lining up, this strategy can also results in insufficient training of GAN, it also brings the risk of too large a gap between the generated samples and the raw positive samples. So, we use the following central regularization to force
shown as red dots in Fig. 3e, where
With the union of
To find a suitable number of synthetic samples,
If
OS-GANepoch
To implement an OS-GAN, most of cost is on training a GAN. The time complexity is obviously
Experimental studies and discussion
In this section, OS-GAN are compared with 14 commonly used resampling methods in terms of three metrics on 14 datasets. Because there are only few positive samples in some datasets, five-fold cross validation is used in our experiments. All results are shown as the average of five-fold cross validation of independent-run ten times.
Datasets and experimental settings
The 14 datasets are collected from KEEL Tool [44] and UCI Repository [45] to demonstrate the performance of the proposed method. The size of these datasets varies from 214 to 1622. The number of features is between 5 and 18. The imbalance ratio (IR) is from 3.25 to 49.69. The description of datasets is shown in Table 1.
Details of datasets
Details of datasets
Three classifiers, namely support vector machine (SVM) [46], multilayer perceptron (MLP) [47] and random forest (RF) [4], are used to assess the efficiency of resampling methods. From a large number of experimental results, the coefficient
Figure 5 shows the sensitivity of OS-GAN to the balanced level parameter
When it comes to GAN, in the following experiments, the leaning rate of
All experiments are implemented in Python 3.6 software and run on a computer with an i7-8750H CPU, 8.00 GB of RAM and 64-bit operating system. To evaluate the performance of resampling methods, three metrics, accuracy (Acc), F1-score (Fm) and G-mean (Gm) [48] are introduced based on the confusion matrix shown in Table 2.
Confusion matrix
The sensitivity of OS-GAN to the balanced level parameter 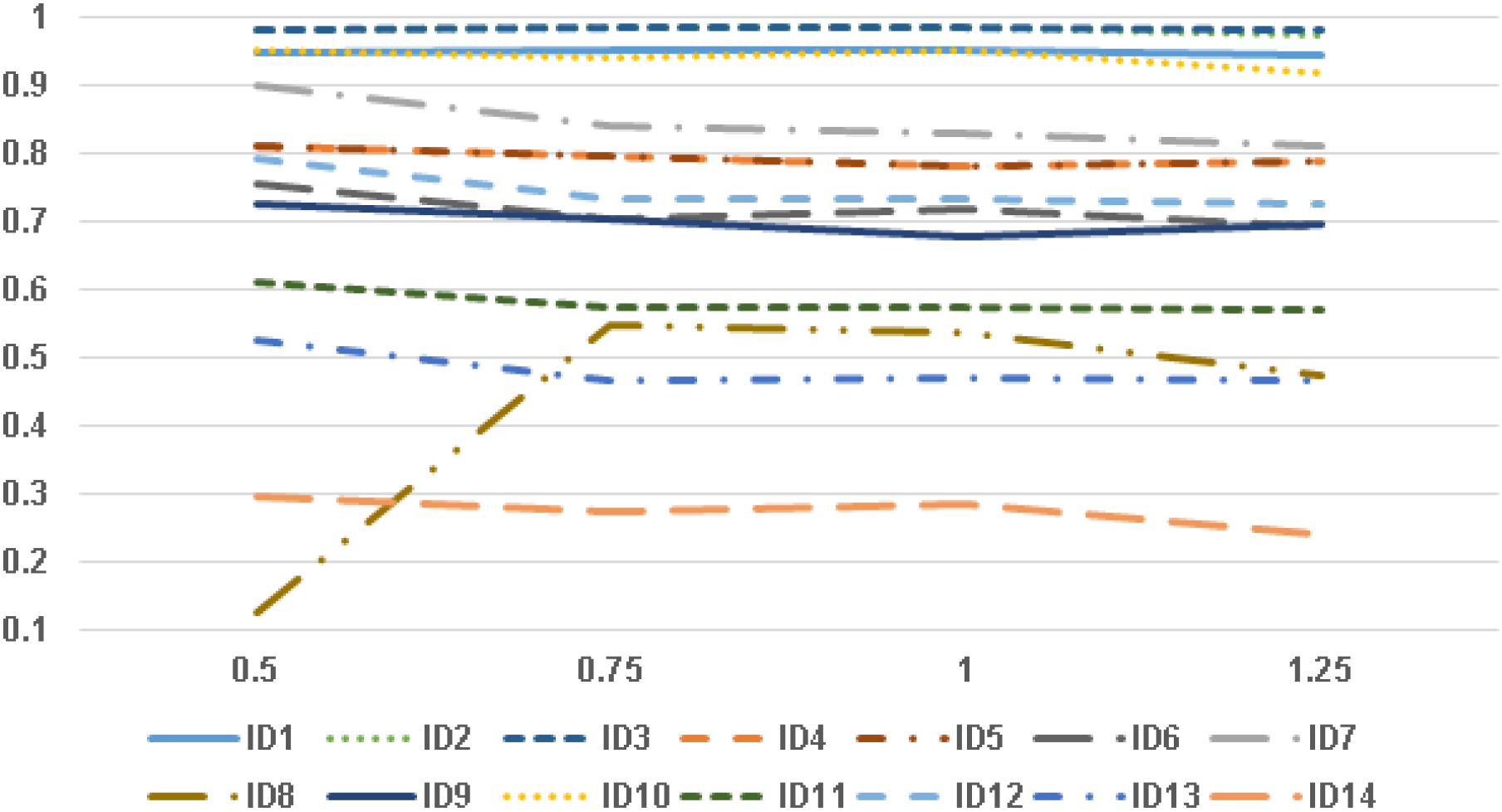
Acc represents the ratio at which the algorithm predicts correctly, but is not reliable enough on unbalanced datasets. It is defined as following:
45 combinations of three classifiers with 15 comparison resampling methods are shown in Table 3 where OS-GAN is abbreviated as OG. Among these comparison methods, SMOTE [10], RandomOversampling (RO) [49] and borderline-SMOTE (BS) [11] are classical oversampling methods; RandomUndersampling (RU) [29] and NearMiss (NM) [50] are two classical undersampling methods; Tomek-SMOTE (TS) [51] is a top hybrid sampler; self-organizing map oversampling (SOMO) [52], MCT [53], adaptive semi-unsupervised weighted oversampling (ASUWO) [54], CCR [55], SMOTE-D (SD) [56] and kmeans-SMOTE (KS) [57] are recent top performer oversamplers. Although unrolled generative adversarial networks (URG) [40] and generative adversarial minority oversampling (GAMO) [58] are two popular GAN-based oversampling methods for image generation, they are included in the comparison to explore their performance on numerical datasets.
45 combinations of three classifiers with eight comparison resampling methods
45 combinations of three classifiers with eight comparison resampling methods
Visualization of oversampling process with OS-GAN on synthetic dataset and ID 6.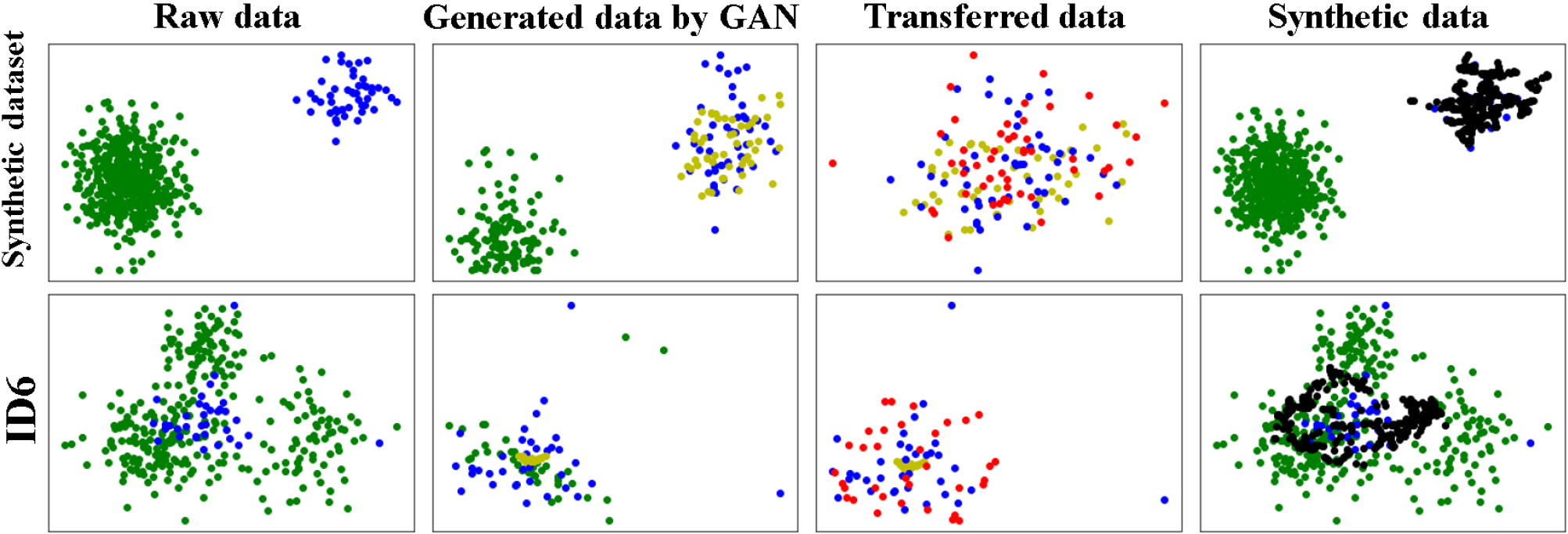
In order to gain insight into the effect of OS-GAN, the two rows of Fig. 6 show the visualization of the oversampling process with OS-GAN on a two-dimensional synthetic dataset and the real world dataset ID6, respectively. The two subfigures in the first column of Fig. 6 are the raw datasets and the negative and positive samples are shown with the green and blue points, respectively. Each class of the synthetic dataset are subject to the 2-dimensional Gaussian distribution. The second column shows the generated data by GAN. The third column shows the transferred data from the generated data by (3). The last column shows the totally rebalanced dataset with SMOTE. According to the results, OS-GAN not only generates positive samples around the region of classification boundary, but also generates positive samples scattered out of the domain of the original positive class. This can strengthen the ability of generalization of classifiers and is not what traditional SMOTE-variants can do.
Test Gm (%) of 45 approaches on ID1-ID5 datasets
Test Gm (%) of 45 approaches on ID6-ID10 datasets
Test Gm (%) of 45 approaches on ID11-ID14 datasets
Because there are too many numbers to show, the test Gm results of 45 approaches on 14 datasets are shown in Tables 4–6. The best values are shown in bold. In accordance with these three tables, OS-GAN gets at least one best result on each dataset. The remaining results of OS-GAN are close to the best, and there is no the worst. We also find that if the IR of dataset is over than 10 or the size of the dataset is relatively large, the more times OS-GAN wins. This may because that GAN is a statistic learner and the larger the number of samples, the better the learning effect. Datasets with a high IR can provide more information for OS-GAN than datasets with a low IR because of the majority samples selection technique in OS-GAN. In addition, the standard deviations of approaches with OS-GAN are low, which indicates that our method is stable. There is no doubt that OS-GAN outperforms other resampling methods in terms of the metric Gm that plays an important role in evaluating imbalance learning.
Test Acc of 45 approaches on the 14 datasets.
Figure 7 shows the test Acc of 45 approaches on the 14 datasets. Our proposed method is shown in black. As we can see that SG, MG and RG are at the top on almost all datasets. Especially, RG outperforms other approaches on 12 datasets, which means that OS-GAN fits well with random forest. The high Acc means that OS-GAN keeps the ability of identifying negative samples while improving the stability of detecting positive samples of machine learning models or algorithms. We also find that the two classical undersampling methods, RU and NM, not only produce less values but also are unstable on datasets with high IR. This may be due to the loss of information caused by removing some negative samples. Except for these two undersampler, the GAN-base oversampling method URG does not perform as well as the other approaches.
Test Fm (%) of 42 approaches on the 14 datasets.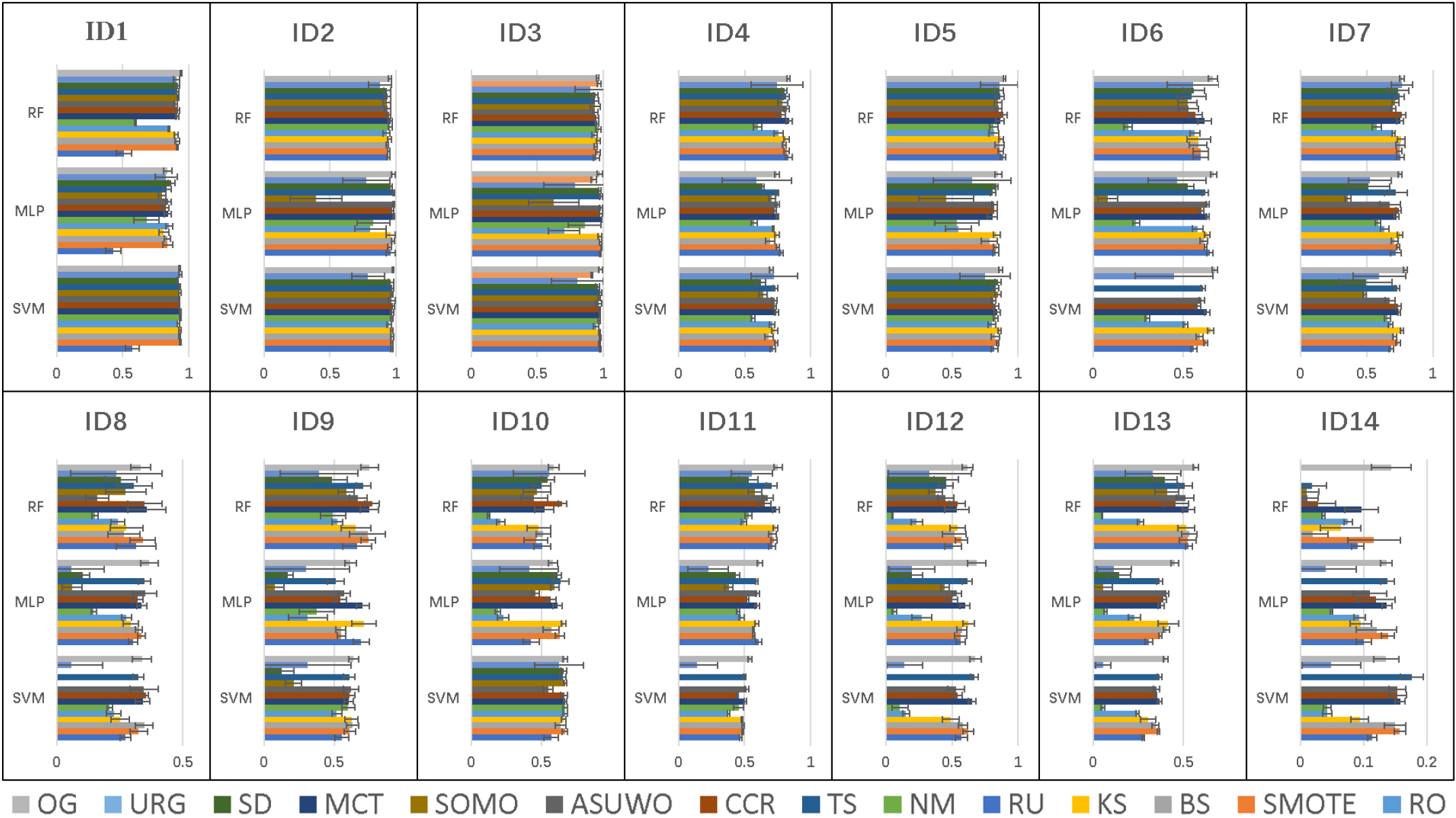
Figure 8 shows the test Fm of 42 approaches on the 14 datasets. We notice that the performance of GAMO is very poor in Gm where 14 results are zero. This phenomenon attracts us to its AUC values because AUC can provide an aggregate measure of performance across all possible classification thresholds. By the cross validation, most average AUC values of GAMO on 14 datasets close to 0.5. This means that approaches with GAMO being the oversampler have no discrimination capacity to classification problems. So there is no need to further analyze its performance in Fm. According to Fig. 8, OS-GAN gets the highest Fm values in many times. With the increase of IR, the number of times OS-GAN surpasses other approaches is increasing. We also can find that there is little difference in the performance of most approaches on datasets with low IR, such as on ID 1–4. But the difference becomes apparent if IR is great. This means that resampling methods produce different balanced results and classifiers are sensitive to the balanced data. So, selecting a good and appropriate resampling method is extremely important for classification problems.
Boxplots of the results of 15 resampling methods on the whole dataset.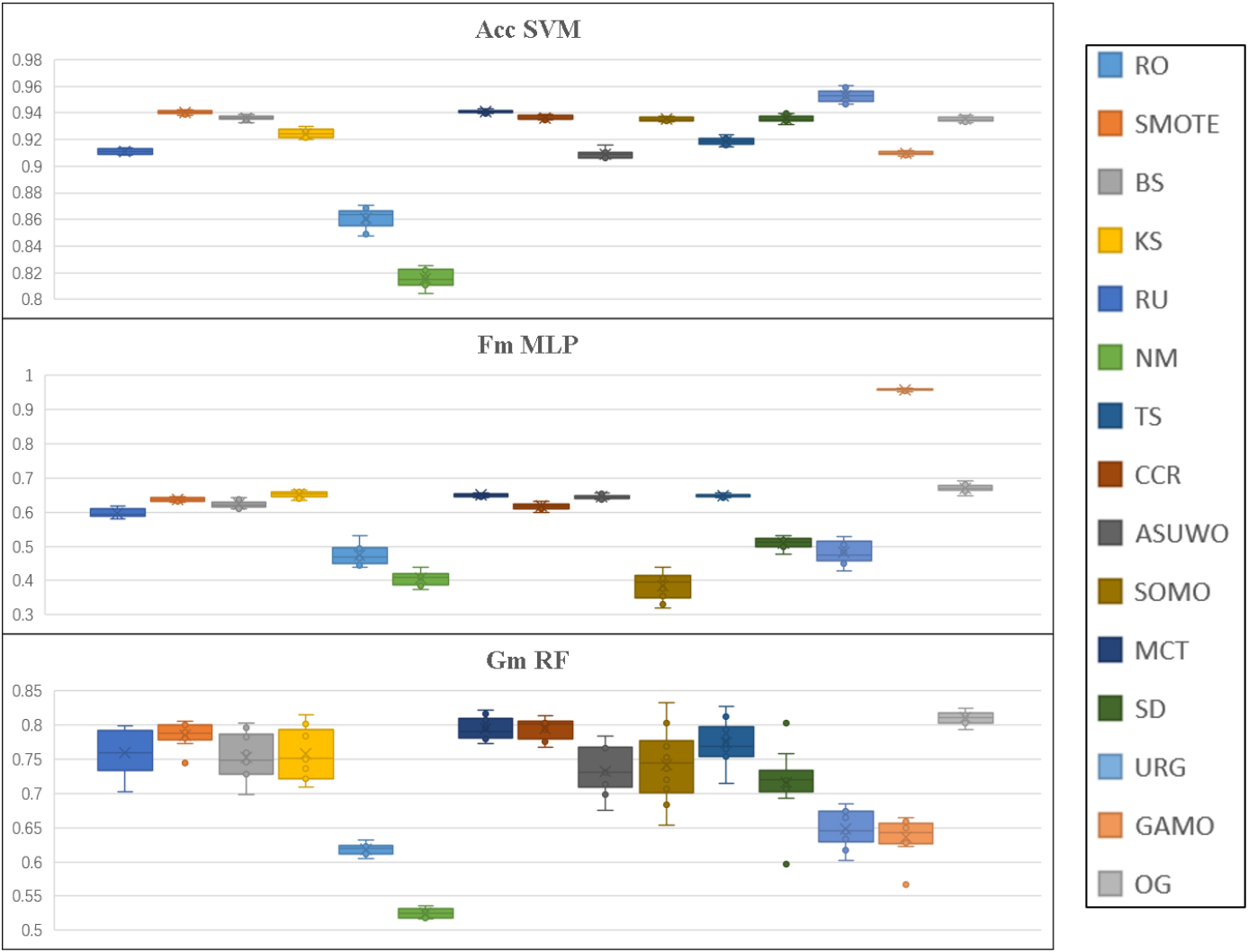
Figure 9 shows the boxplots of the results of 15 resampling methods on the whole 14 dataset. The results are the average of Acc, Fm and Gm of 14 datasets in each time of ten-independent-run. The first picture illustrates the average Acc of SVM with different resampling methods. The second one and the third one show the information which is similar to the first one according to the subtitles. In the terms of Acc of SVM, the best resampling method is the GAN-based URG. But OS-GAN outperforms other 14 methods on the whole dataset in terms of Fm and Gm, and the the standard deviation of OS-GAN is apparently less than others. This means that OS-GAN is competitive and pragmatic.
The mean values and standard deviations of Fm of RG on ID2, ID5 and ID11 in terms of different 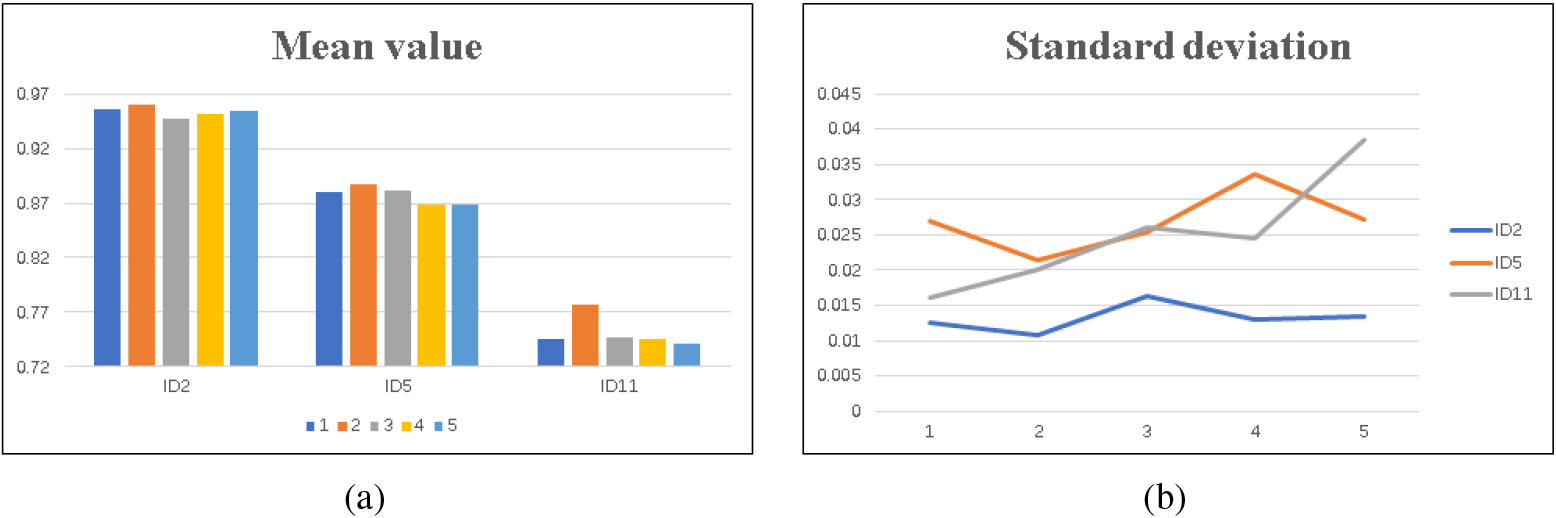
From above experimental results, if GAN-based oversampling methods are directly applied on numerical datasets, the performance is barely satisfactory. The proposed method works well not only because GAN learns the data distribution, but also because of what happens after sample generating by GAN. This indicates that there is still a fundamental difference between image data and numerical data if GAN is used to oversample.
To explore the influence of the parameter
The above numerical experiments are implemented on datasets with moderate dimension. To explore the performance of OS-GAN on high-dimension datasets, we conduct our method on a 90-dimension dataset,
The performance of OS-GAN on a high-dimension dataset:
To evaluate the robustness of our proposed algorithm, we add some noisy samples into positive class of ID2 dataset through fliping the label of negative samples. The noisy ratio is set to 5%, 10% and 20%, respectively. The relative error e is introduced to mesure the rate changes of Acc, Fm and Gm, which can be derived as follows.
where
The relative errors of metrics on ID2 with noise
Acc of classifiers with MGAN, TGAN and OG on 14 datasets.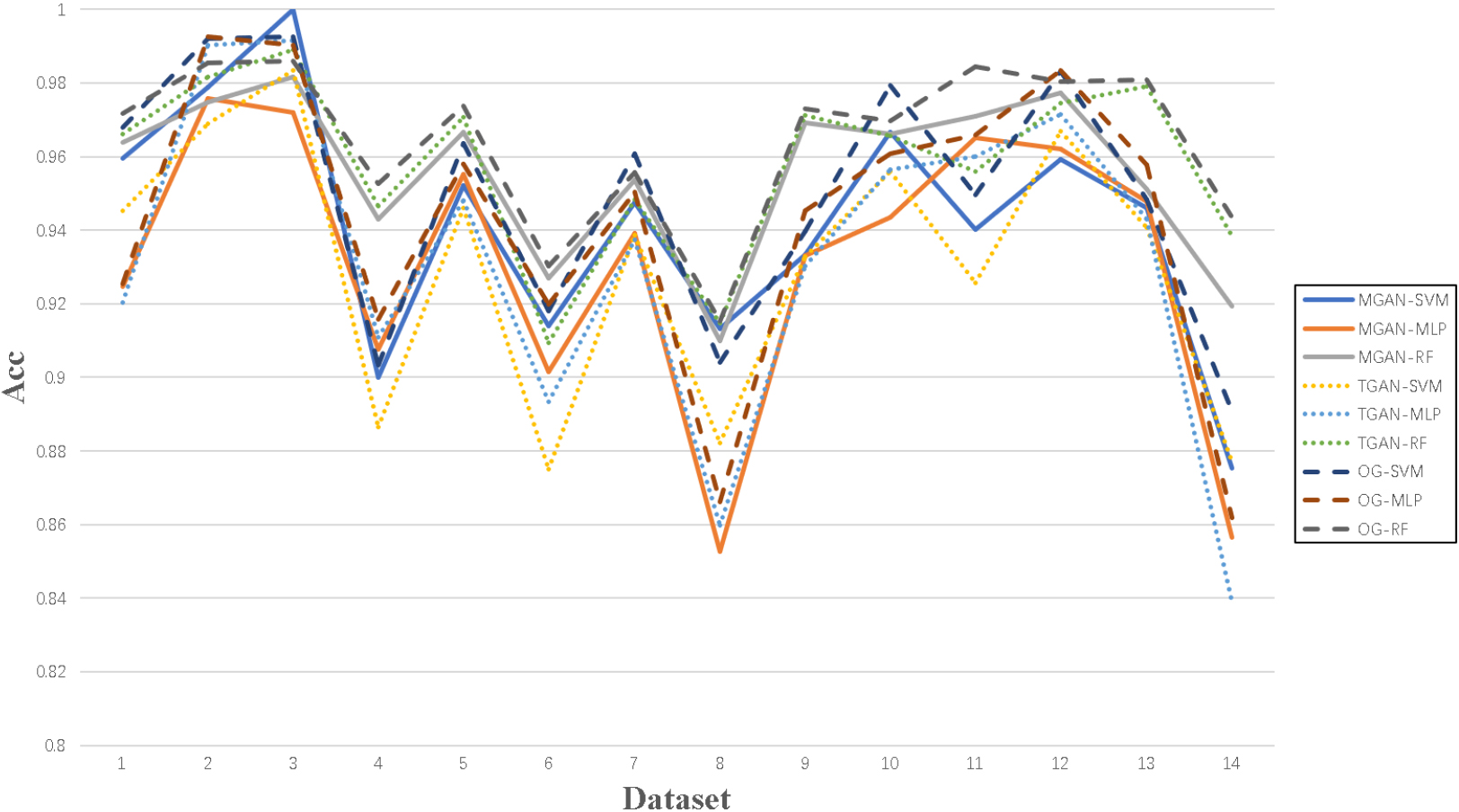
Table 8 shows the results of robustness test. The relative errors of Acc and Gm are sufficiently low and definitely acceptable. Although the relative errors are large in terms of 20% noisy ratio, they are still less than the noisy ratio. This shows that OS-GAN is robust and can effectively counteract noise.
Section 5.2 shows OS-GAN can beat most of baselines on 14 benchmarks. However, most of baselines are implemented based on SMOTE or GAN for image. Here we choose two state of the art GAN samplers that are similar to OS-GAN to present. Ref. [59] propose an oversampler (MGAN) based on GAN learning information from majority class that is similar to OS-GAN. Ref. [23] focus on tabular data with GAN (TGAN). We would do an experiment like Section 5.2 on abovementioned 14 public datasets to explore deeply. Figure 11 shows OS-GAN is better for few samples with high imbalance ratio. In addition, the performance of OS-GAN is satisfactory compared with other similar configurations.
Ablation experiment
To evaluate the performance and importance of central regularisation and reparative SMOTE, we do an ablation study which investigates the performance of OS-GAN without regularization (OG-R) and OS-GAN without SMOTE (OG-S). Figure 12 shows the Gm of RF with OG, OG-R and OG-S on 14 datasets. In conclusion, regularisation is better for datasets with high overlapping or datasets with complex distribution while SMOTE is better for datasets with high imbalance ratio, especially, the dataset with complex distribution and fuzzy classification boundary. This experiment shows both central regularisation and reparative SMOTE are necessary in most cases to increase the performance of OS-GAN.
Gm of ablation study of OS-GAN on 14 datasets.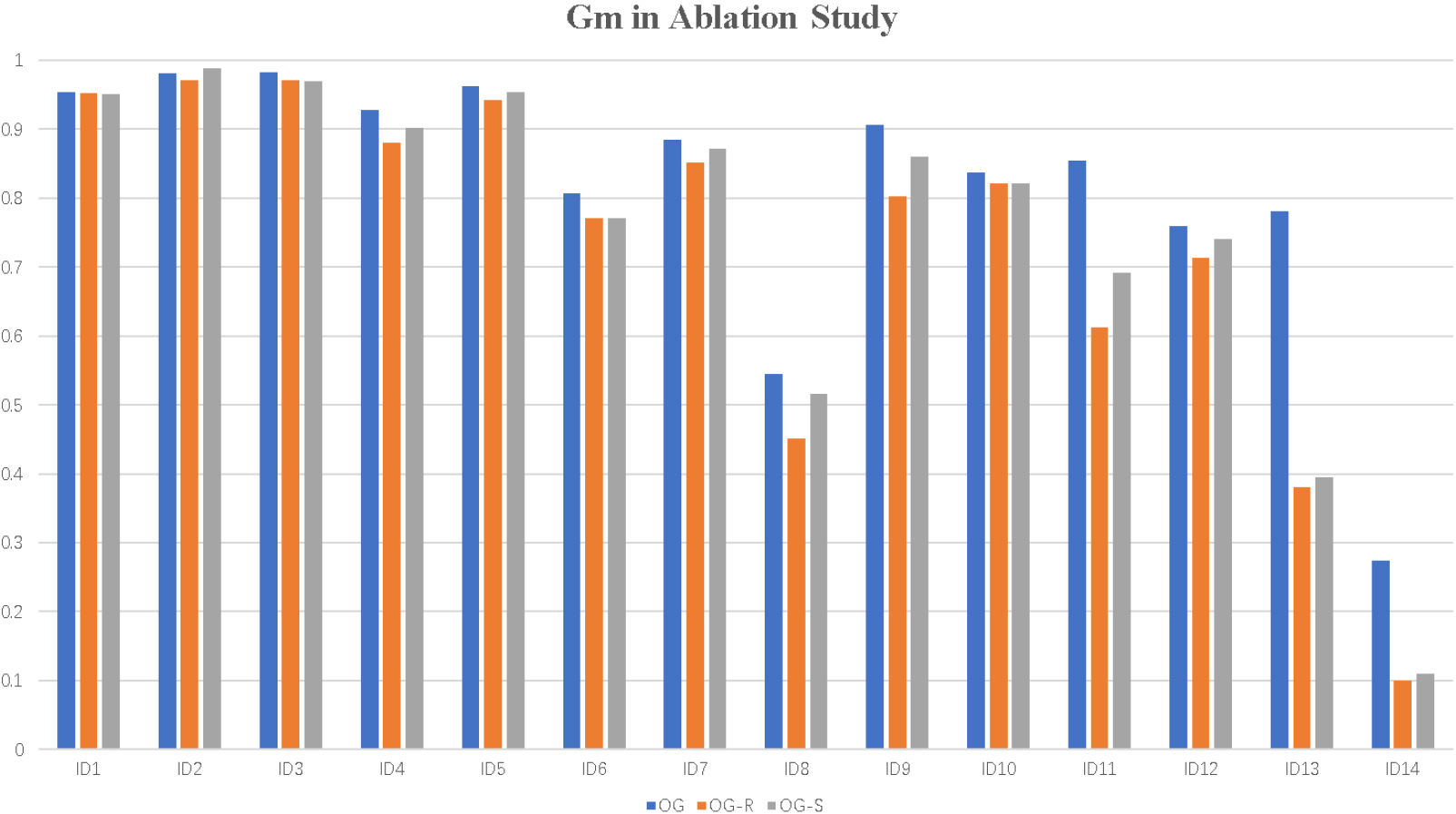
Although the original intention for OS-GAN is to address binary classification task, we explore the efficiency of OS-GAN on multi-class classification as well. First of all, two multi-class datasets are built with ecoli2 and ecoli3 datasets which share the same characteristics. The first dataset is named
Sampling process is as follows. Firstly, oversampling e3 with the number of e3 and that of e4
The performance of OS-GAN on two multi-class datasets
Table 9 shows the performance of OS-GAN on two multi-class datasets. The results are satisfactory on the two multi-class datasets using OS-GAN with the oversampling process we mentioned above. In conclusion, OS-GAN can be used on multi-class task conveniently with class-wise sampling process without changing the binary sampling structure of algorithm.
The paper presents a new oversampling method, OS-GAN, where GAN is used on numerical datasets to learn the distribution of the positive class through converting some negative samples into positive-liked ones. Since fake samples generated by GAN are concentrated or line up, an early-stop learning strategy is adopted in GAN. After that, a further operation based on the center of positive class is executed to modify the generated data by GAN, which allows synthetic samples to carry distinguishing positive characteristic. OS-GAN abstracts information from both negative and positive classes to rebalance the dataset and to improve the generalization of classifiers. In the light of the results of experiments on 14 benchmark datasets and one high-dimension dataset, our method outperforms 14 commonly used resampling methods in terms of G-mean, accuracy and F1-score. This manifests that OS-GAN can effectively generate positive samples with the information of the negative class as well as the positive class. Further investigation may include exploring a new method to exploit the negative information to sketch further distribution characteristics of datasets.
Footnotes
Acknowledgments
This work was supported in part by the National Key R&D Program of China under Grant 2018AAA0100300, the National College Student Innovation and Entrepreneurship Training Program Support Project under Grant 20211014110020, in part by the Fundamental Research Funds for the Central Universities under Grant DUT22YG236, in part by the National Natural Science Foundation of China under Grant 11201051, 62172073, 62076182.
Declaration of competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.