
Abstract
The process of fusing different images from various imaging modalities into a single, fused image that contains a wealth of information and improves the usability of medical images in real-world applications is known as medical image fusion. The most useful features from data can be automatically extracted by deep learning models. In the recent past, the field of image fusion has been preparing to introduce a deep learning model. In this work we can achieve the multi-Focus medical image fusion by hybrid deep learning models. Here the relevant health care data are collected from database (CT & MRI brain images). Following the input images are pre-processed using sliding window and the abnormal data is eliminated using distribution map method. Further the proposed work comprises 3 steps, 1) the proposed method is used to extract the features from the input image using the modified Tetrolet transform (MMT), which uses a brain image as an input image. This model is capable of identifying anomalous trends in time series data and automatically deriving from the input data characteristics that characterise the system state.2) Propose a novel hybrid model based on CNN with Bi-LSTM (Bi-directional Short Term Memory) multi-focus image fusion method to overcome the difficulty faced by the existing fusion methods. 3) This hybrid model are used to predict the brain tumor present in the fused image. Finally, experimental results are evaluated using a variety of performance measures. From the results, we can see that our suggested model contributes to an increase in predictive performance while also lowering the complexity in terms of storage and processing time.
Keywords
Introduction
Applications in the field of healthcare have attracted a lot of attention recently. These healthcare applications generate and gather vast quantities of clinical data at an unequalled velocity and scale. The numerous sources of healthcare data include patient hospital records, test results, scan copies, and medical records. These medical equipment must have communication capabilities in order to convey data smoothly. From the gathered smart healthcare data, insights are frequently gained and important data sources are identified using data mining and deep learning techniques. Image fusion has advanced quickly in both military and non-military contexts since its inception in 1985, particularly in the fields of infrared and visible light image fusion, material analysis, remote sensing image fusion, multi-focal image, and medical image. Imaging technology is necessary for diagnosing medical conditions. Medical image fusion research has grown in importance because single mode medical images only offer a little amount of information while clinical diagnosis calls for a substantial amount of data. The categories of single-mode fusion and multimodal fusion include fusion of medical images. Numerous researchers are looking at multimodal fusion because single-modal fusion can only supply so much information.
The ability to use tetrominoes for local augmentation, multi-resolution analysis, sub-banding, and localization in the frequency and temporal domains make the modified tetrolet transform a useful tool for signal and image processing tasks. Novel Modified tetrolet transformation is a new adaptive haar-type wavelet transformation that inserts the block overlap method in the process of image decomposition into the middle of the original tetrolet transform coefficients. Compare with standard two-dimensional wavelet transformation, stationary tetrolet transformation is a new multi-scale geometrical tool based on tetrominoes, which anisotropic image geometric structures can capture information efficiently through multi-direction selection. The suggested approach offers a new algorithm for processing images and enhances redundancy in image decomposition.
Fusion at the feature level is accomplished by extracting the relevant information or features from the images. The process of processing data at a higher level to create data with more information is called feature level fusion. In this type of fusion, complex techniques are used to combine the data that was gathered from the images. Region-based fused is one of the most basic examples of feature-level image fusion. To acquire the fusion of particular aspects of the images, the region of interests is extracted and then fused. Figure 1 explains how feature level image fusion works.

Schematic for feature level image fusion.
Previously, some image fusion method was used to detect brain tumor in CT and MRI images. However, if the resolution of the source images is low, the fused images produced by the traditional fusion method will be low-quality as well. In this study, proposed multi-focus image fusion methods highlights both the feasibility and the advantages of applying CT/MRI fusion technology to the surgical treatment of brain tumor. The non-subsampled Tetrolet transform is used to first divide the source CT and MR images into a number of sub images. Low-frequency coefficients are blended using local energy while high-frequency sub bands are fused using weighted normalised cross-correlation between feature maps provided by the Modified Tetrolet Transform extraction stage. Furthermore, utilising the proposed methodology, challenges with data fusion in healthcare are recognised and investigated.
An innovative MRI/CT brain image fusion algorithm based on modified tetrolet transformation has been designed and put into practise. A new and highly successful combined modality for diagnosis has been created by merging MR and CT brain images. The process of merging two distinct image pairs, such as those obtained by MRI and CT, was initially thought to be possible. The fusion formula, which was developed based on transparency labelling to lessen the computational load, is used to combine those two images. To forecast the irregularities existing in the fused image, a hybrid multi-focus image model called Bi-LSTM (Bi-directional Short Term Memory) is applied.
Notation/symbol/abbreviation
Identify the abnormalities in the brain, such as brain tumor, early-stage psychosis, and anxiety disorders. Previously, the image fusion method was used to detect abnormalities in CT and MRI images. However, if the resolution of the source images is low, the fused images produced by the traditional fusion method will be low-quality as well. In this study, we discuss changing data fusion trends as well as some of the best practises for utilising smart healthcare. Furthermore, utilising the proposed methodology, challenges with data fusion in healthcare are recognised and investigated.The main objective of this research is combining relevant information from two or more images into a single image wherein the resulting image will be more informative and complete than any of the input images.This hybrid model are used to predict the abnormalities present in the fused image. A novel strategy for improving the visual quality of CT and MRI brain images is proposed, the input images are pre-processed using sliding window and the abnormal data is eliminated using distribution map method. Introduce a novel Modified Tetrolet transform (MMT) is used to extract the input image. This model is applied to decomposing the CT and MRI brain images. Followed by the Tetrolet transform the image are decomposed. Time series data can automatically learn the temporal information of unexpected trends using the modified Tetrolet transform. Additionally, it has the ability to automatically extract characteristics from the incoming data that describe the system status. To address the challenges posed by the current fusion methods, propose a unique hybrid model based on CNN with Bi-LSTM (Bi-directional Short Term Memory) multi-focus image fusion. This hybrid model are used to predict the brain tumor present in the fused image. Finally, experimental results are evaluated using a variety of performance measures. From the results, we can see that our suggested model contributes to a reduction in the complexity of time and storage while also improving predictive performance.
Deep learning models can automatically identify the most beneficial aspects in data, avoiding the complexity of manual design. The medical image fusion can be accomplished using a unique hybrid model based on CNN and Bi-LSTM. The efficiency of medical image fusion can be considerably increased with this technique, which can successfully complete batch image fusion operations and meet real-world diagnostic needs. It has a beneficial use in raising forecast accuracy.
Related work
Based on the methodology of Multi Fusion process, the earlier approaches are categorized into two categories as pixel based image fusion and transform based image fusion. The simplest spatial-based method is to take the average of the input images pixel by pixel. However, along with its simplicity, this method leads to several undesirable side effects, such as reduced contrast. To improve the quality of fused image, various approaches are propose in earlier based on the block division if source images. CNN-BiLSTM, a proposed hybrid model combining convolutional neural networks (CNN) and bidirectional long-short term memories (BiLSTM), is presented as a method for predicting anomalies in fused images. In comparison to existing strategies, the proposed CNN-BiLSTM network has the benefit of incorporating the useful characteristics and the embedded relationships in the lengthy time sequences.
This study employed Shandong Province as the study location and measured data to conduct a traditional GIS-based soil quality evaluation in order to evaluate the quick, precise, and practical remote sensing identification approach of cultivated land quality. Then, by categorising various crop rotation techniques and incorporating data from remote sensing, we generated three different types of characteristic indicators utilising the Pressure-State-Response paradigm. For the overall accuracy, which is 86.12%, 93.65%, and 79.18%, the corresponding kappas are 0.66, 0.77, and 0.90. [2] This work uses a big data statistical analysis model to investigate and analyse precision poverty alleviation, and it employs the multisource big data fusion technique to carry out a thorough investigation and analysis of the subject. The study of the problems that come up when big data technology is used to fight poverty and study the development path. [3] In this research, we present a comprehensive graphic representation of the complicated tensor decomposition and transformation processes to facilitate understanding of tensors and tensor decomposition. For readers who are curious about tensors and tensor decompositions, these graphics also act as a general guideline and an excellent place to start. Make a new recommendation for a tensor network-based data fusion technique that can analyse multiple matrices and many tensors simultaneously. To aid readers in understanding and appreciating this technology, we give a brief overview of tensor networks. [4] It is recommended to use a rapid disturbance categorization method that is resistant to issues with low PMU data quality. The univariate temporal convolutional de-noising auto encoder is the foundation for the unique feature extraction technique proposed in this paper (UTCN-DAE). The Softmax classifier and a multi-layered deep neural network are used to categorise the data (DNN). Principal component analysis with multivariate functionality is used for data analysis (MFPCA). [5] To make eigenvectors easier to understand and less susceptible to outliers, the MFPCA is typically written as a minimization problem with both a robustness and a simplicity penalty component. The results of our method can be used as a trustworthy basis for station grouping, correlation analysis, and outlier identification.
Complex geological processes have an impact on the spatial structural traits and compositional connections of multivariate geochemical data. [6] The compositional connections and spatial structural elements of multivariate geochemical data are collected and fused using a feature fusion convolutional auto encoder (FCAE) in order to detect abnormal geochemical conditions. By obtaining an AUC of 0.863, a recall of 0.909, and the highest P-A plot intersection point throughout the testing, the FCAE outperformed a number of current models. [7] An information-based multidimensional matching choice strategy for manufacturing service resources is recommended by this study. A case study about the choice to match resources for a body and chassis manufacturing service in a new energy vehicle company is offered at the end. [8] A vegetation greenness index can be produced using a combination of high spatiotemporal resolution data and high temporal frequency data (MODIS) (Landsat). The dependence within and between land cover classes, as well as the spatial misalignment of the data, are all described in the model using a latent multivariate Matern process. [9] Provides a data mining and big data architecture-based model of the English talent that is available for the tourism sector. During the talent training process, information fusion and connection feature mining are coupled to share data and allocate resources. The adaptive grouping of vast amounts of data on the distribution of English-speaking talent in the tourism industry is addressed by the fuzzy clustering method. [10] The one of interest is the well-known data model known as Parametric Big Data Model (ParaDB) for handling multidimensional big data. The ParaDB is completely lacking of this potential capability, in contrast to other standard data models where subset strengthens the system, making it impossible for it to compete on efficiency and effectiveness.
The analysis of artificial intelligence (AI) and machine learning (ML) approaches, together with their advantages and disadvantages, is the first step in gaining a thorough grasp of how to enhance the consistency of renewable energy integration and modernise the entire grid. [11] The impact of weather forecasting on predictions of wind and solar energy has been the subject of extensive investigation. According to the existing research, the average mean absolute percentage error (MAPE) for calculating solar and wind energy is 10.29 percent and 6.7 percent, respectively. [12] They can enhance how financial data from organisations is processed as ideas and technologies like the Internet of Things, big data, cloud computing, and others become increasingly prevalent in day-to-day life. [13] In order to determine the market worth of a property in Philadelphia, it is suggested that urban data, such as metadata and imagery data, be combined with housing qualities. The efficacy of the suggested approach is demonstrated by the experimental findings using data gathered from the city of Philadelphia. [14] Urban planning, traffic control, and environmental monitoring all heavily rely on high-spatial-resolution (HSR) maps of land use. To overcome these difficulties, this work uses the city of Nanjing as a case study to enhance crucial urban land use category mapping techniques. To achieve this, it was crucial to enhance the creation of urban parcels, address the issue of an uneven distribution of point-of-interest (POI) data, take into account the spatial dependency of POI data, and evaluate the effect of training sample size on classification accuracy. [15] Multi-source data will be combined with state-of-the-art machine learning methods to develop within-season yield prediction models for winter wheat in order to overcome these challenges.
A technique for calculating urban poverty using large data from many different sources. The poverty indicators, which are measures of material, economic, and living conditions, were developed using these data. A dataset of the General Deprivation Index (GDI) created from census data was used as a reference to make training RF simpler. The findings demonstrated how consistently high the GDI and MDPI were. We discovered a statistically significant positive spatial autocorrelation in Guangzhou’s poverty situation by analysing the MDPI results. [17] The boundaries of parcels, which were acknowledged as fundamental mapping units, were drawn using OpenStreetMap (OSM). Semantic segmentation of street view images was employed to improve the multi-dimensional description of urban parcels in addition to point of interest (POI), Sentinel-2A, and Luojia-1 night-light data. According to the findings, the spatial distribution of street view components is connected to urban land use. [18] Using a multi-dimensional dataset about Seattle’s building energy performance that was made accessible by the municipal administration, the proposed method is tested for its ability to determine the weather normalised site energy usage intensity of structures. The model is able to correctly estimate the precise value of energy intensity, according to the findings of the 5-fold cross-validation. [19] A method for classifying the usage of urban land that is based on data from multiple sources. To assess the contribution and impact of various aspects, a series of comparative experiments was simultaneously developed. The results showed that using the OSM road network in conjunction with the Gaode road network might greatly improve the categorization results. [20] The Multi-source Heterogeneous Data Analysis (MHDA) technique, which is used to forecast future prices, gathers data from a variety of sources, including investor comments, news event data, and trading data. We first constructed a relation map to aggregate all significant news events from upstream and downstream commodities, in order to precisely quantify the sentiment impact of key news and investor comments during feature extraction.
Based on the concepts of deep learning, convolutional neural networks with atrous convolution is an adaptive data fusion technique for merging data from many sources (FAC-CNN). [21] The parametric rectified linear unit activation function and global average pooling are further techniques used to improve network performance. A centrifugal pump and a commercial fan system are used to test the proposed technology while taking non-manufacturing issues into account. [22] It is presented how to estimate the degree of damage and the remaining useful life of structures using a cutting-edge deep learning algorithm. A long short-term memory regression model is used to evaluate sensor-based the damage’s severity. The influence of different temporal correlations on the precision of damage magnitude predictions is taken into consideration. [23] While the source systems are typically in a healthy state with just occasional flaws, the target computers have fault types that are absent from the source machines. The multi-source transfer learning network (MSTLN), which is composed of a number of partial distribution adaption sub-networks (PDA-Subnets), a multi-source diagnostic knowledge fusion module, and a number of source machines, was proposed as a framework for acquiring and transferring diagnostic knowledge. [24] By meticulously scrutinising data correlation for data fusion and adversarial sample synthesis, the fusion attack methodology allows the adversarial samples of image and LiDAR to be created concurrently from a low-dimension vector. We show that our suggested models are more successful and effective for disassembling autonomous vehicle perception systems than the state-of-the-art. [25] The discovery and characterization of characteristic spectral peaks in samples of rice grains from various sources but from the same cultivar. 80 rice samples from four distinct sources were examined using Raman spectra. Principal component analysis was used to determine the regression coefficients’ first four principal components (PCA). After five iterations, the training samples’ average cyclic test prediction accuracy was 97.5 % ; for the other four, it ranged from 98.75 to 96.25 %.
Proposed method
In this paper, proposed a novel Modified Tetrolet transform (MMT) is used to extract the input image. This model is applied to decomposing the CT and MRI brain images. Followed by the Tetrolet transform the image are decomposed. Time series data can automatically learn the temporal information of unexpected trends using the modified Tetrolet transform. Additionally, it has the ability to automatically extract characteristics from the incoming data that describe the system status. This study proposes an image fusion technique that fuses regional image information with transform nonlinear approximations of the Modified Tetrolet. The algorithm is based on the analysis of numerous image fusion Modified Tetrolet transform techniques.
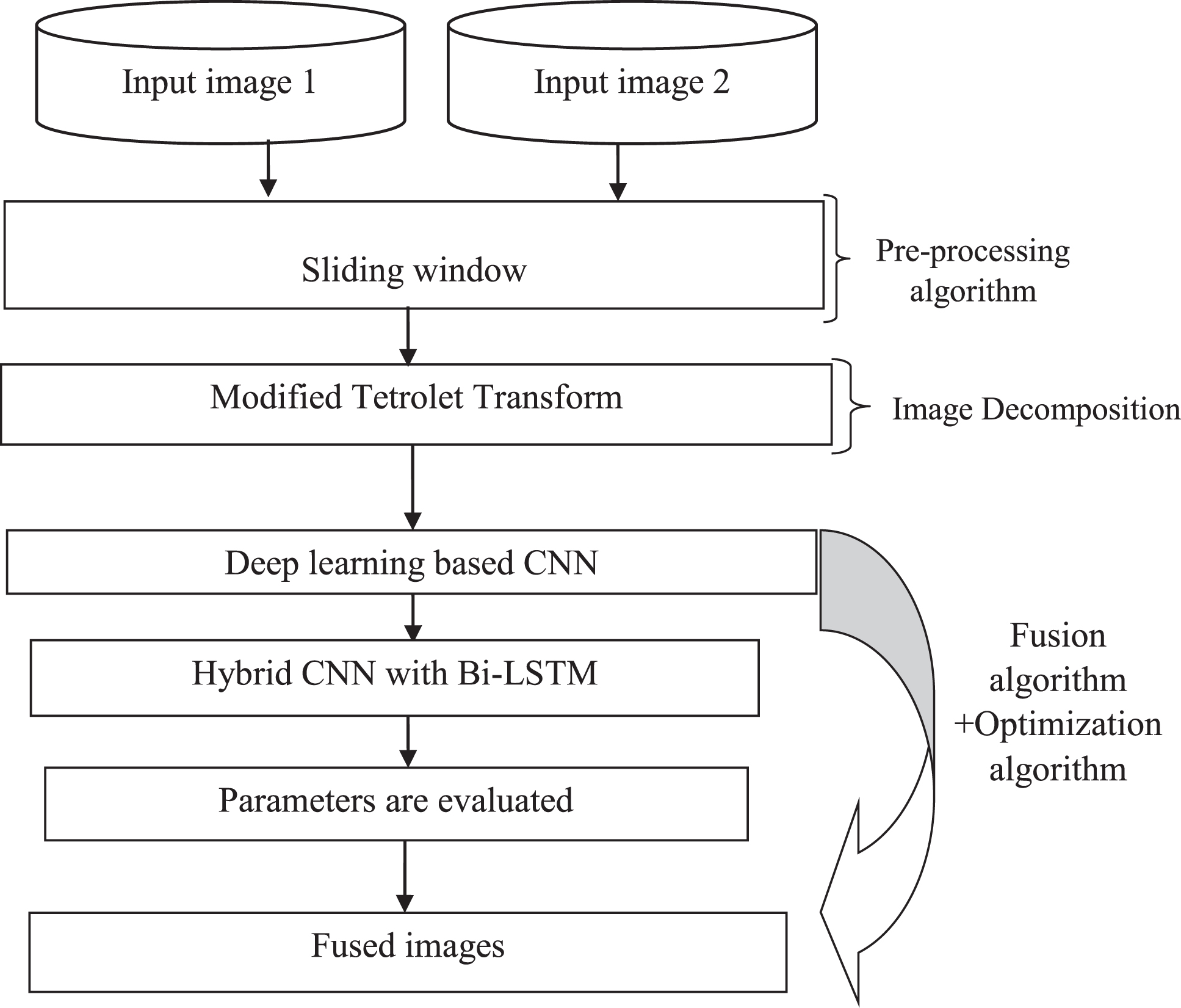
Block diagram.
The next step is to suggest a brand-new hybrid model based on CNN with Bi-LSTM (Bi-directional Short Term Memory) multi-focus image fusion to get around the challenges that the present fusion approaches face. To foretell the anomalies contained in the combined image, a hybrid model is applied. Finally, experimental results are evaluated using a variety of performance measures. From the results, we can see that our suggested model contributes to a reduction in the complexity of time and storage while also improving predictive performance.
The sliding window collects data in the first step, and the fresh measurement data are added to the sliding window’s random matrix S rightmost column vector x(T) in the fresh sample phase. The sliding window matrix is then normalised using the formula to get the normalised matrix X
n
= (x
ij
) m,n (1). The matrix has a zero expectation value and a one variance.
Where
Feature extraction is an, approximate reasoning method to recognize the tumour shape and position in MRI image. In the existing method many algorithms were developed for feature extraction. But they are not good for all types of the combined CT and MRI images. In earlier studies, the images features aren’t extracted properly, therefore we applied the Novel Modified Tetrolet Transform approach to solve the problem. After completed the pre-processing step, a novel Modified Tetrolet transform (MTT) is used to extract the brain input image. This model is applied to decomposing the CT and MRI image. Followed by the Tetrolet transform the image are decomposed. Time series data can automatically learn the temporal information of unexpected trends using the modified Tetrolet transform. When compared to the currently used approaches, our innovative Modified Tetrolet Transform methods accurately extract the features from CT and MRI images.
Tetrominoes are forms produced by combining four squares so that at least one edge connects with each other. The iconic computer game classic Tetris popularised the tiling problem with Tetrominoes. For disjoint covering of a 4 4 board with four Tetrominoes, there are 117 solutions. We compute 1174 > 108 as a rough bottom bound of feasible tilings for an 8 8 board. The algorithm employs a modified Tetrolet-based picture de-noising algorithm. Following the commencement of the process, we must initialise temporary memory storage for the output image. Then we’ll cycle through the Tetrolet partitions we’ve chosen. Within the loop, we will perform the fundamental steps of Tetrolet-based image de-noising for all partition scenarios. After the loop is completed, we must recover the image from all of the specified partitions. This study used the salience/match measure fusion rule with a threshold based on the most significant high-frequency coefficients. According on simulations of CT and MRI images as well as practical data, the recommended method delivers better fusion performance and visual effects than the wavelet transform and Modified Tetrolet transform fusion methods.
There are four squares of equal sizes connecting each tetrominoes. A 4×4 block division of an image with Xraise . 5ex1em/emlower . 25ex2i ; jN
i
; jraise . 5ex1em/emlower . 25ex41 with N raise . 5ex1em/emlower . 25ex4 2P ; P2N occurs in the tetrolet transform. The local structure is enhanced by rotational and reflective features of the four free tetrominoes that cover each block. Bijective mapping (L) is used along with these four tetrominoes’ respective orders to map them in a certain order (0, 1, 2, 3). The discrete basis functions are defined as follows for every subset of tetrominoes (I
v
):
When applied to
Tetrolet’s fundamental concept is inherited from standard 2-D haar wavelets. The version of standard haar wavelets is enhanced by infects tetrolets. The 2-D haar wavelets allow a 4 × 4 block with four fixed 2 × 2 squares to be covered. This is a very in efficient way to cover the block as it does not take into consideration the local image structures during the covering. On the other side, for the tetrolets, it has been shown that with any four tetrominoes there are 117 feasible methods to cover a 4 × 4 block.
Four squares are joined together so that at least one edge of each square touches the other to make tetrominoes. The well-known video game “Tetris” made the tiling issue with Tetrominoes widely known. Figure 3 depicts the so-called free tetrominoes, five different shapes that disregard rotations and reflections.

The 5 free Tetrominoes: O - I - T - S - L.
When extracting features from CT and MRI brain images, the modified Tetrolet Transform is utilised. When compared to the currently used approaches, our innovative Modified Tetrolet Transform methods accurately extract the features from CT and MRI images. Proposed modified Tetrolet Transform methods accurately extract the tumour shape and position in CT and MRI images when compared to Tetrolet Transform methods.
The input brain images, such as MRI and CT, are first divided into four sub bands using the haar wavelet transform. Energy compression, a greater SNR, fewer features, and other benefits are provided by fusion employing transforms over more straightforward methods. Image pixels can be compared to the transform coefficients. Wavelets are used to localise temporal frequency, perform multi-scale and multi-resolution operations, and more. In this stage, we take as input two different types of medical imaging (MRI namely (P) and CT namely (Q)). These images are broken down into a single level using the wavelet transform.
CNN with Bi-LSTM (Bi-directional short term memory) multi-focus image fusion method
To overcome the problems that the current fusion approaches encounter, a novel hybrid model based on CNN and Bi-LSTM (Bi-directional Short Term Memory) multi-focus picture fusion is proposed. This hybrid model are used to predict the abnormalities present in the fused image. In this paper, an effective deep learning method was utilized to demonstrate its distinctive and fascinating problem-solving techniques. It is referred to as the long short-term memory due to its memory-oriented features.
Convolutional neural network
In, CNN method for multi-focus-image-fusion is presented. Figure 1 is the CNN model used for fusion. It can be seen that each branch in the network has three convolutional layers and a max-pooling layer. The convolutional and max-pooling layers are considered as feature extraction.
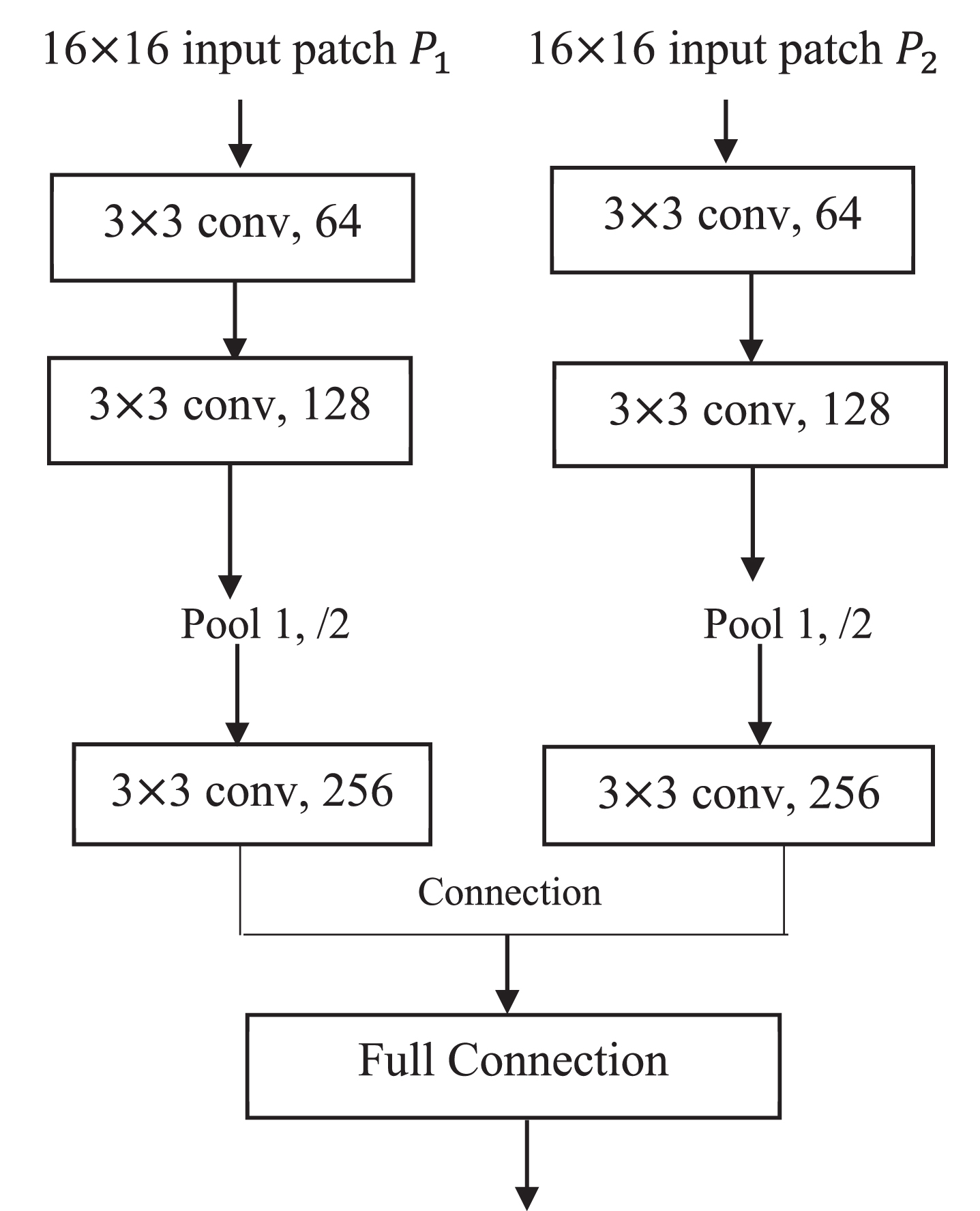
CNN model.
The output of Fig. 1 is a 2-dimensional vector that is the two scores of the input image patches P1, P2, which is fully connected with a 256-dimensional vector. The 2-dimensional vector produces a probability distribution on two classes. The fully connected layer can be deemed as classification. Then, the softmax loss function is applied to gain the value of the score map. The network can process the source images of any size as a whole without dividing them into small patches. The result of the CNN model is the score map that represents the pixels’ sharpness level.
Image 1 and Image 2, these two images are fed to a pre-trained CNN to acquire the score map. Every value of the score map that represents the focus level of a set of 16 × 16 patches of I1 is between 0 and 1. Each patch is averaged to obtain the pixel value of the corresponding position of the weight map E, i.e., the weight of the patches. The flow chart for generating the weight map E is shown in Fig. 5.

The proposed activation map representation diagram’s flowchart.
Computed tomography and magnetic resonance imaging (CT/ MRI) fusion is used increasingly in the surgical treatment of brain tumor. The merging of these complementary modalities provides excellent visualization of the tumor shape and recognize the position in CT and MRI image using novel multi-focus image fusion method. The process of combining two or more images with different focal points from the same scene into an all-focus composite image is known as multi-focus image fusion. I n this study, we assume that there are two multi-focus source images, that the source images have been registered, which means that the objects in all images are geometrically aligned, and that the source images are available. In Fig. 6, the bi-directional short term memory (Bi-LSTM) picture fusion method employing CNNs is described. The steps of the complete fusion procedure of the method this paper suggests are as follows: Two low-resolution pictures A and B are scaled to the correct size using bi-cubic interpolation. Our objective is to produce a fused image Y with a resolution equal to the high-resolution image from the ground truth. Although A and B are the same size as the desired high-resolution image, we nonetheless refer to them as low-resolution images for ease of display. 64 network filters that have already received training convolve the source images A and B. 64 feature maps, designated as F1 (A) and F1 (B), are included in the first layer’s output. Each local image patch is projected onto a 64-dimensional feature, where each feature represents a network filter or basis, as a result of the convolution operation carried out on the image domain. The sparse coding solver-like approach can be implemented by projecting the patch onto a (low-resolution) dictionary. One layer CNNs may be utilised to represent the sparse-coding. These devices are intended to represent the most prominent characteristics of the local image, much like CNNs that employ Bi-LSTM (Bi-directional Short Term Memory) network filters or bases.They can serve as dictionary atoms or wavelet bases in sparse representation. Thus, by fusing the local feature maps F1 (A) and F1 (B) together, we can achieve information fusion (B). The above analysis can be used to assist us create fusion rules. When fusing multiple focus images, we anticipate that the focus regions of all the source photos will be chosen to create the fused image. As a result, the fusion weights produced in Section 3 are fused straight away with the first layer feature maps of diverse source images.
The fused first layer feature mappings F1 are serially propagated to the second CNNs with Bi-LSTM nonlinear mapping layer and the third reconstruction layer to form the final high-resolution fused all-in-focus image.
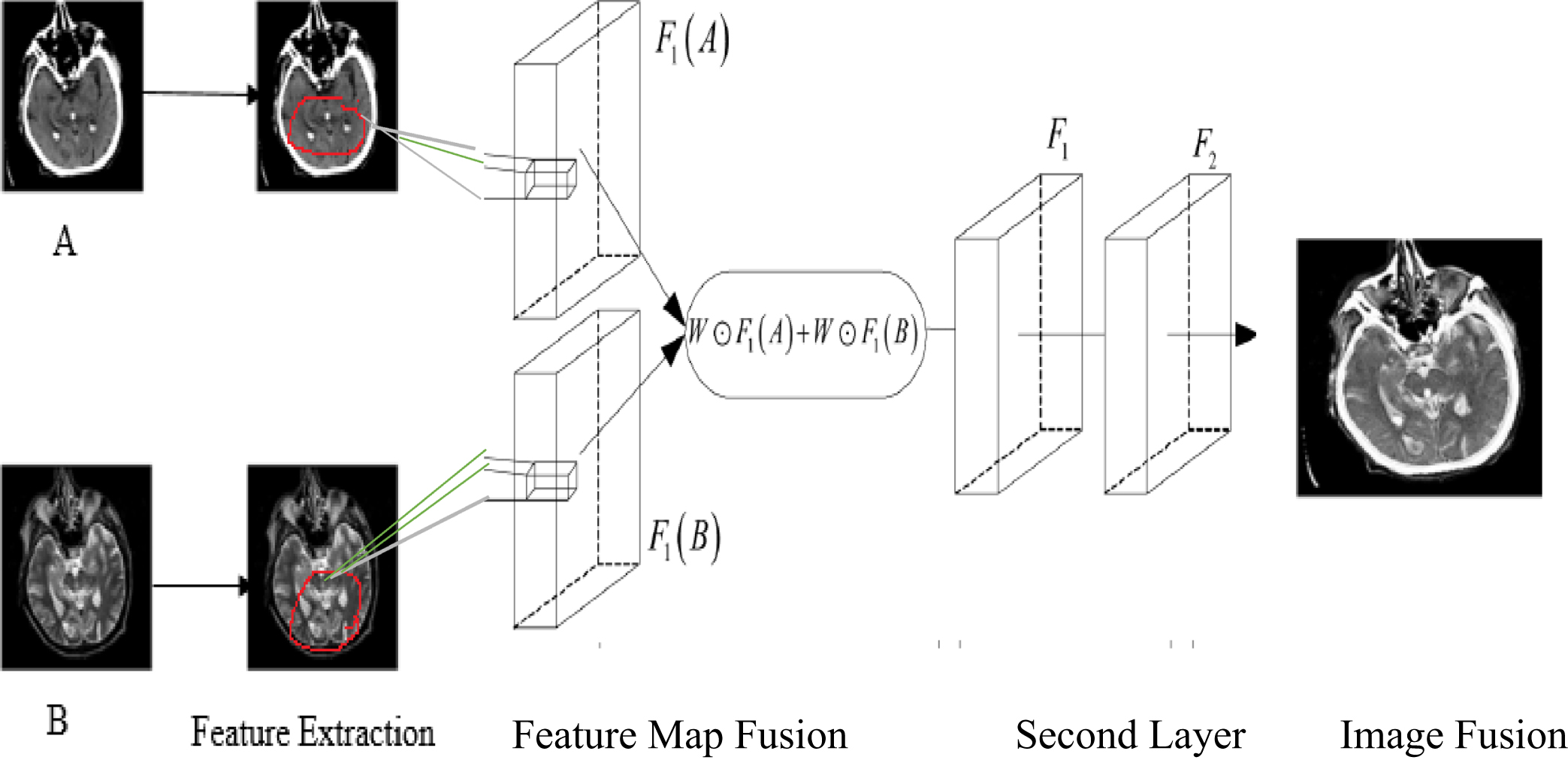
The framework of the proposed CNN with Bi-LSTM (Bi-directional Short Term Memory) multi-focus image fusion.
The hybrid CNN with Bi-LSTM is a deep learning technique that analyses data well and extracts the crucial traits required for prediction. This method extends the Convolutional Neural Network (CNN). To solve the “vanishing gradient” problem of the original CNN structure, the forerunners developed the new network structure of LSTM. The different layers as well as their parameters values of the proposed network structure are depicted as follows: Sequence Folding Layer CNN is made up of a convolutional layer, a batch normalisation layer, and a ReLU layer with 30 filters and a 5-by-5 filter size. With the suggested network, two series of the aforementioned structural layers are used. The Sequence Unfolding Layer restores the sequence structure of the input data after sequence folding. A Bi-LSTM network with 350 hidden units that only outputs the last time step. A fully connected layer of size 9 (the number of classes), followed by a softmax layer and a classification layer
The acronyms x t are used to represent the input sequence, ht-1 for the previous block output, Ct-1 for the previous LSTM block memory, and b f for the bias vector. W Stands for the logistic sigmoid function and represents specific weight vectors for every σ input, where stands for the input. In Fig. 7, the suggested hybrid CNN with Bi-LSTM network’s structure, together with the arrangement and graph of its layers, are depicted.

The structure of LSTM.
The hybrid CNN with Bidirectional Long Short-Term Memory (Bi-LSTM) is advantageous for learning a network from the entire time series at each time step because it learns bidirectional long-term dependencies between time steps. For handling input sequences in both directions, a hybrid CNN with Bi-LSTM is used. It is made up of two layers of recurrent networks, the first running the input sequence forward and the second backward.
The hybrid CNN with Bi-LSTM network is able to learn in-depth details about the past and present order of data points since both layers are linked to the same output layer. The output sequence, h→ and h↔ as shown in the following equations, is computed by combining the forward and backward hidden sequences computed by these two sub-layers,
In this method,
Python is a programming language that may be used for a wide variety of numerical and computer applications, and it is also used in the investigations. It gauges how well the image fusion performance works. On a Windows PC running Microsoft Windows 7 Professional, an Intel (R) Core i5 processor running at 1.6 GHz, 4 GB of RAM, and the proposed image fusion is performed. Additionally, Precision, Recall, and F-score measures are utilised for this purpose to compare the accuracy and efficiency of suggested hybrid CNNs using the Bi-LSTM. The 378 real time MRI images and 331 real time CT images is collected from the Pranav Diagnostics Centre in Nagercoil and Take 389 standard MRI images and 192 standard CT images for the results (Table 2). Use both real time images and standard dataset images are used to predict the abnormalities present in the fused image. In this paper, an effective deep learning method was utilized to demonstrate its distinctive and fascinating problem-solving techniques. It is referred to as the long short-term memory due to its memory-oriented features.
Dataset details
Dataset details
Real time images: (Source:https://blkhospitals.wordpress.com/2019/03/25/different-types-of-brain-tumor/).
The suggested multi-focus image fusion approaches differ from the existing image fusion method in terms of computing. This section contains the experiments we run to test the effectiveness of the suggested model using the CT and MRI datasets. To merge medical images, a unique hybrid model based on Bi-LSTM and CNN can be used (Fig. 8).

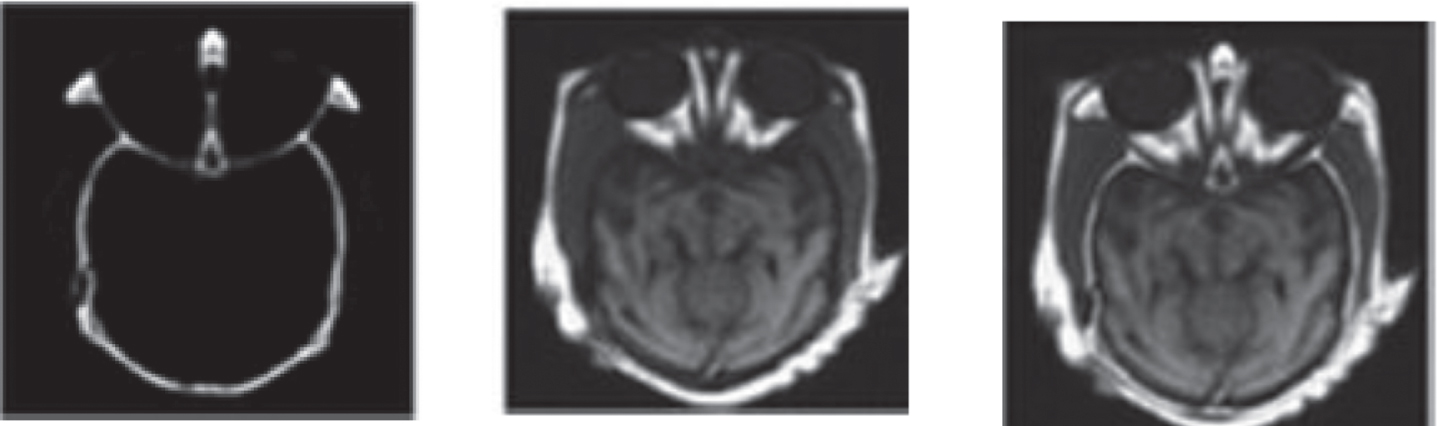
Segmented image of benign case sample 2 (a) Input image (b) Pre-processed image (c) Segmented image (d) Tumor Extracted image.
Comparison of different image fusion methods using brain images. (a) CT image (b) MR image (c) fused image by the CNNs with Bi-LSTM.
A few fusion errors can be seen in and around the CT region using the DWT approach. In the CSMA approach, we can also see information fusion loss. CNN provides improved visual quality as compared to the methods previously stated, but the overall contrast of the image is decreased. Overall, using our suggested hybrid CNNs with Bi-LSTM technique, the relevant data from the MRI and CT is retained with the least amount of fusion loss. Figure 10 compare the outcomes of the fusion of 23 pairs of fatal brain images utilising MRI-CT using various methods, including the suggested method.
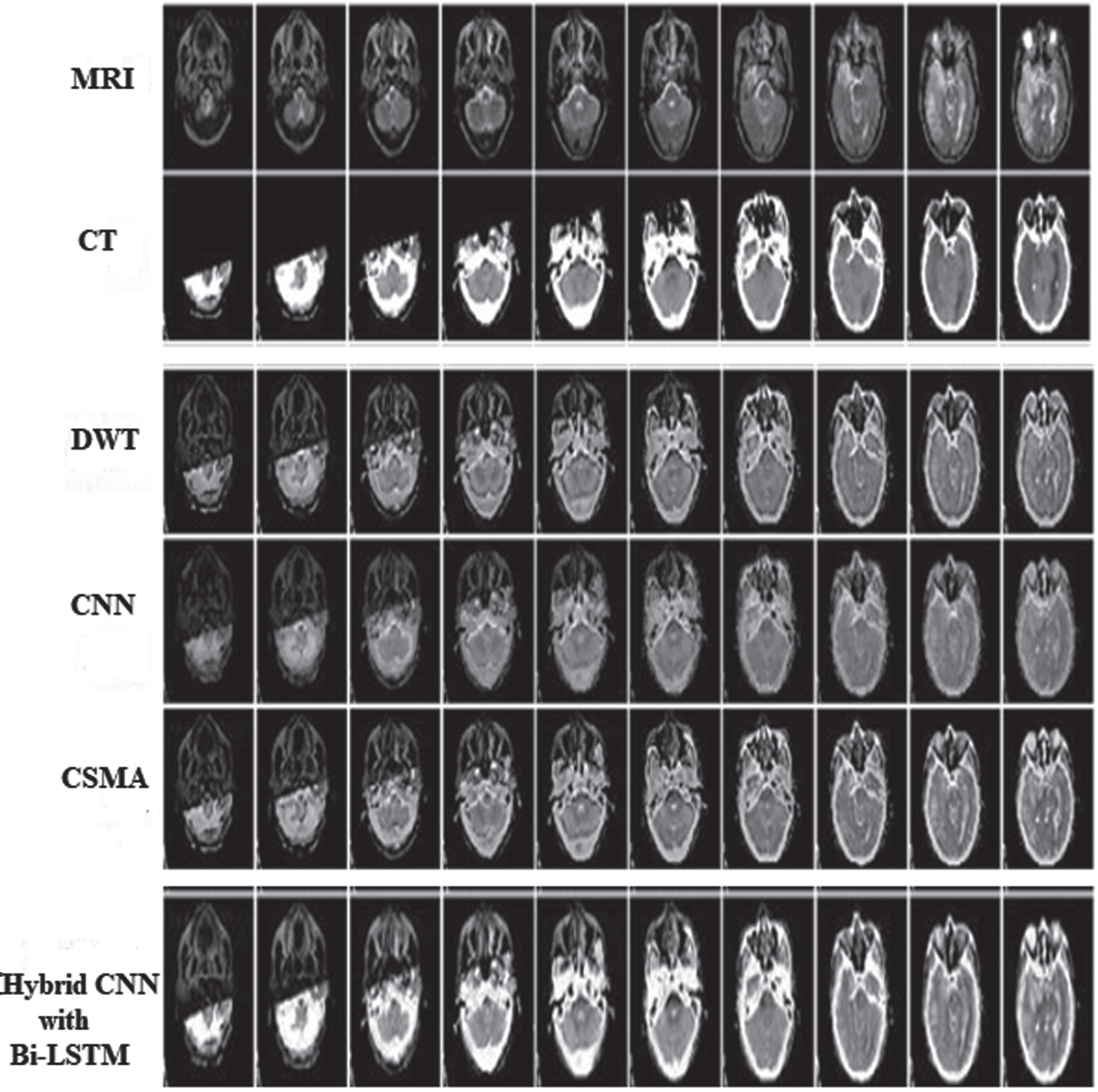
The results of various methods on first 10 pairs of MRI-CT images.
The computation of the proposed hybrid CNNs using Bi-LSTM algorithm distinguished with the discrete wavelet transform. A number of measures were used, including Precision, Recall, F-Score, Mean-Square Error (MSE), Peak Signal-To-Noise Ratio (PSNR), and correlation, to evaluate the effectiveness of the present and new techniques. These metrics are shown in equations from (10–15).
The suggested hybrid CNNs with Bi-LSTM algorithm successfully combines the pixels from several modalities and is used to maximise the important pixels using hybrid CNNs with Bi-LSTM. As a result, it offers a higher PSNR value than the current algorithm for the provided brain images. The computed value of the hybrid CNNs with Bi-LSTM and Discrete Wavelet Transform (DWT) for Multimodal Medical Image Fusion is shown in Table 3. The greatest pixel value is assigned to the corresponding pixel of resultant fused image and selected the parameters value based on the fused image.
Performance evaluation of Hybrid CNNs with Bi-LSTM and Discrete Wavelet\\ Transform (DWT)
The effectiveness of the medical image fusion using the hybrid CNNs with Bi-LSTM algorithm is described in detail for various pictures used in the fusion. The performance graph makes it evident how the offered dataset’s levels of accuracy compare. The experiment’s findings show that the suggested hybrid algorithm is less accurate than the present method and has superior accuracy. The proposed Modified Tetrolet transform is performed to efficiently extract the best features and fuse similar pixels. It significantly enhances accuracy for the provided brain images more than the current method.
In CNN with Bi-CLSTM, the convolution operation is followed by max-pooling similarly to CNN, and we set the size and number of convolution kernels based on empirical data to be 3 × 3 and 32, respectively. We set the state of the Bi-LSTM to zeros without losing generality. Table 4, where d and p denote the number of dropout and pooling, and Bi-LSTM denotes forward and backward CLSTM, respectively, provides a detailed breakdown of each layer’s dimensions in Bi-CLSTM.
The dimension of each layer in Bi-CLSTM
Comparison of MSE’s performance against CNNs with Bi-LSTM in a hybrid approach is made. In the fusion findings for various types of images, it is a method for estimating an unseen quantity, and the results are shown in Fig. 11. In the Hybrid technique for Multimodal medical image fusion, the Peak signal to noise ratio establishes the greatest value that may be used to construct the image against the noise; its performance is shown in Fig. 12.
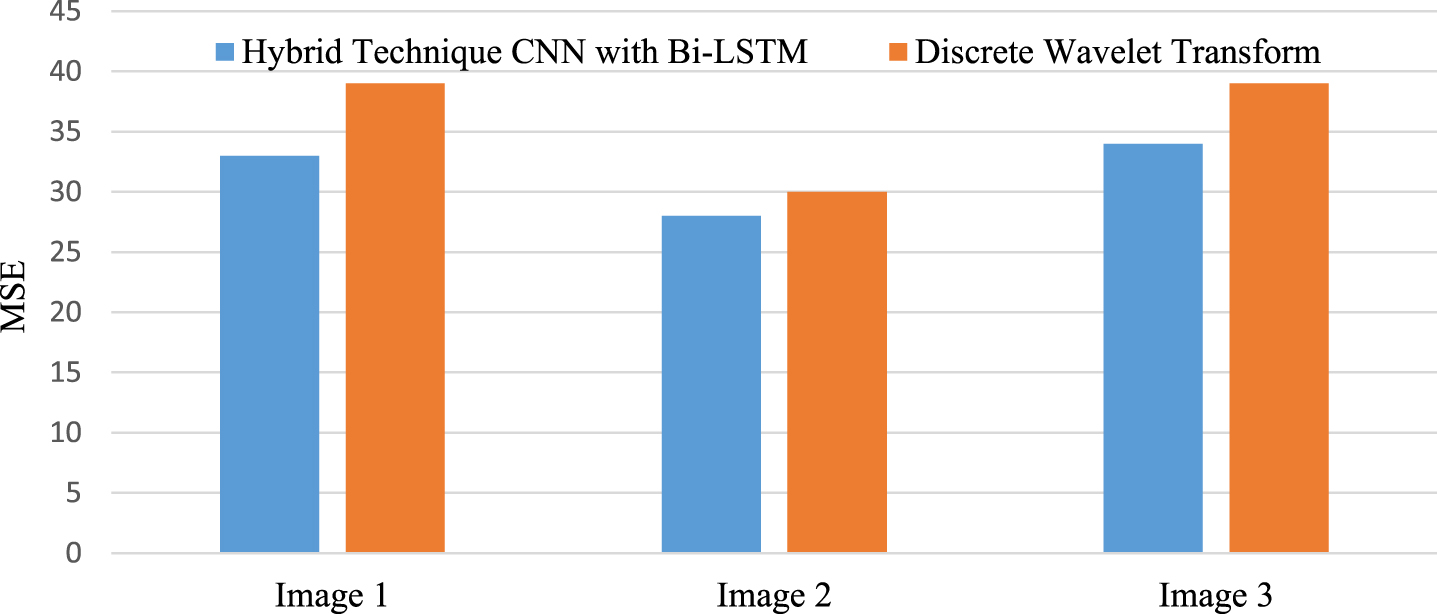
Performance Analysis of MSE against Hybrid Technique CNNs with Bi-LSTM and Discrete Wavelet Transform (DWT) algorithm.
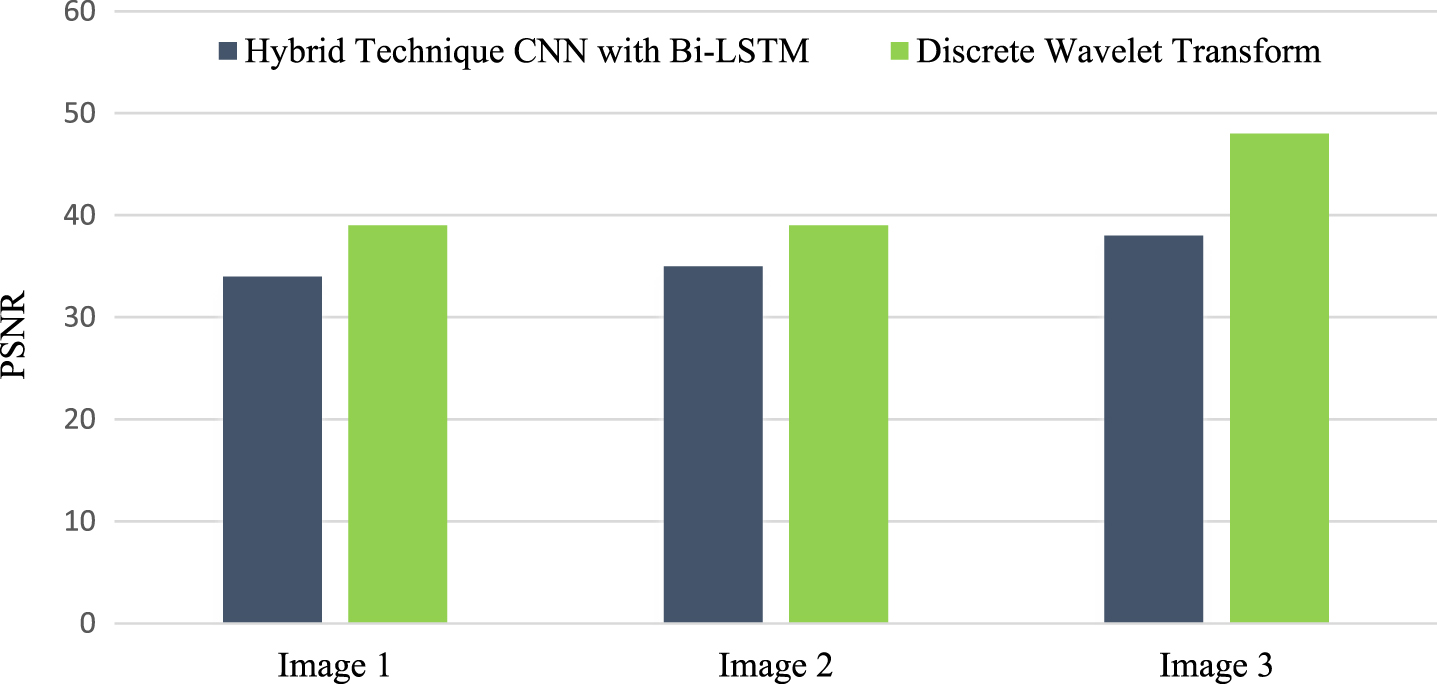
Performance Analysis of PSNR against Hybrid Technique CNNs with Bi-LSTM and Discrete Wavelet Transform (DWT) algorithm.
The three images used to illustrate the correlation for the CNNs using Bi-LSTM algorithm show that the outcomes of image fusion versus the current methods vary most, as shown in Fig. 13.
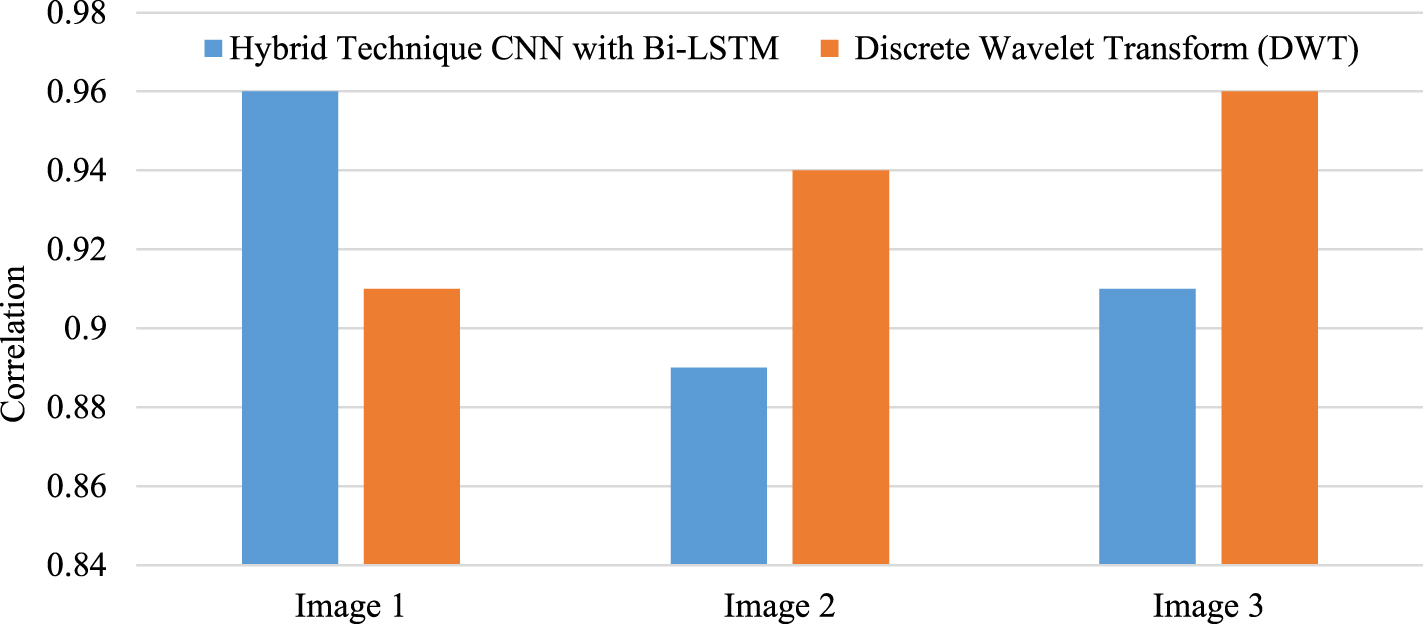
Performance Analysis of correlation against Hybrid Technique CNNs with Bi-LSTM and Discrete Wavelet Transform (DWT) algorithm.
We train and test various deep learning techniques on a Windows machine running Microsoft Windows 7 Professional, an Intel (R) Core i5 CPU clocked at 1.6 GHz, and 4 GB of RAM in order to evaluate their computational effectiveness. Table 5 [26] demonstrates that Hybrid CNNs with Bi-LSTM require less training and testing time than -CNN and LSTM. In addition, training or testing Hybrid CNNs with Bi-LSTM is quicker than CNN with LSTM.
Computation time (min.) of CNN, LSTM and Hybrid CNNs with Bi-LSTM methods on two datasets
The average F-Score accuracy of the suggested Hybrid CNN with Bi-LSTM algorithm is compared to that of the Bi-LSTM and DWT algorithms in Fig. 14 against the proportion of the training datasets used in each of the aforementioned scenarios to the total training data.
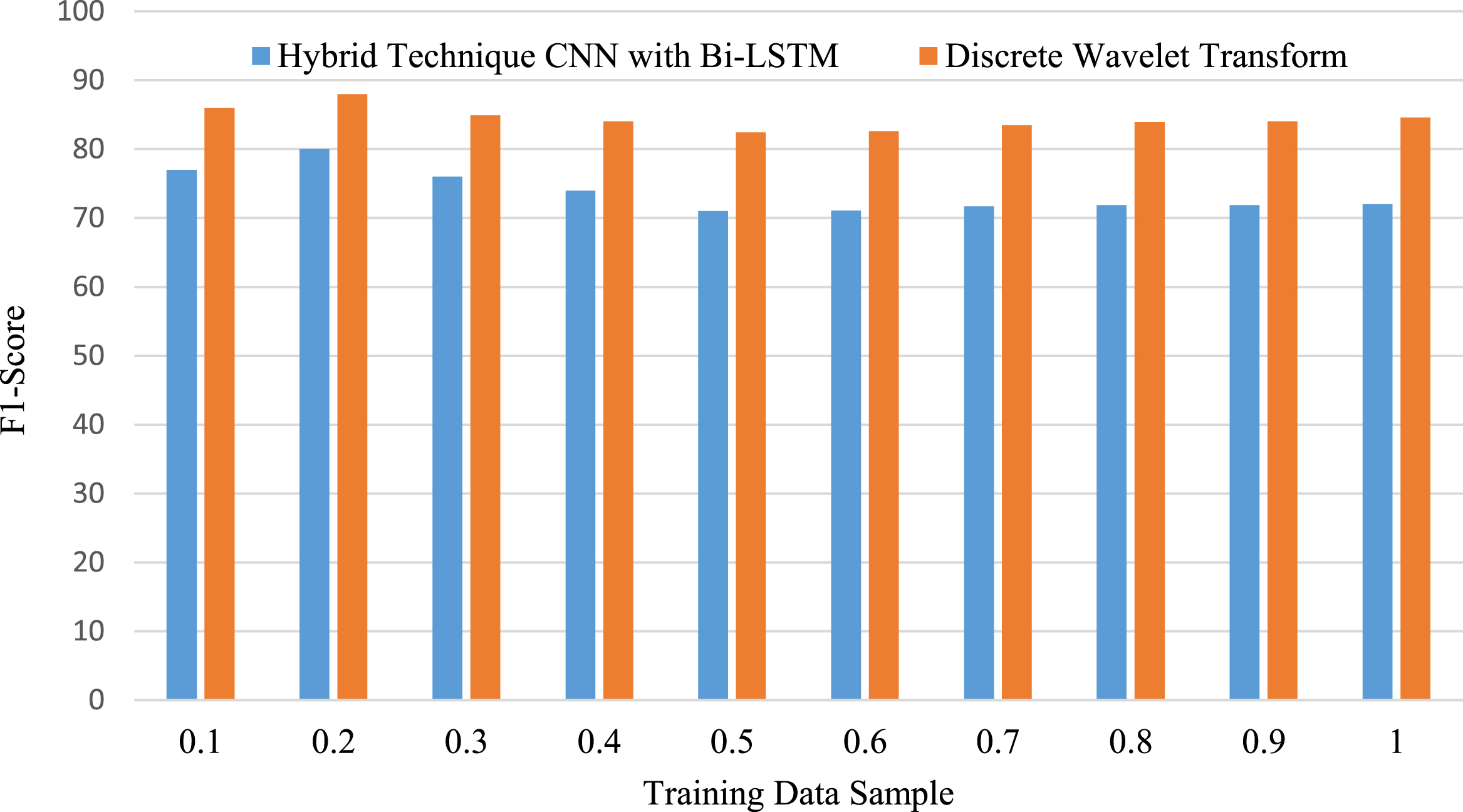
F-Score vs the ratio of training samples applied in various training situations, hybrid CNN with BiLSTM network is superior to DWT and Bi-LSTM approach.
Regarding the ratio of training datasets used in each of the aforementioned scenarios to the total training data, the proposed Hybrid CNN and Bi-LSTM network contrasted with the CNN and Bi-LSTM technique [26]. Table 6 contrasts the suggested Hybrid CNN and Bi-LSTM algorithm’s image fusion accuracy with the accuracy of the other classifiers.
Comparing the Suggested Hybrid CNN and Bi-LSTM image fusion accuracy to that of the CNN,\\ Multivariate Functionality with Principal Component Analysis (MFPCA) and Feature Fusion\\ Convolutional Auto Encoder (FCAE) while using various training samples cases
The size of the local image patch is left as a free option in the suggested technique. The performance of multi-focus image fusion and multi-model image fusion to evaluate the effects of the parameter Comparisons of the fused findings with multi-model image fusion and parameter multi-focus image fusion are shown in Fig. 15.
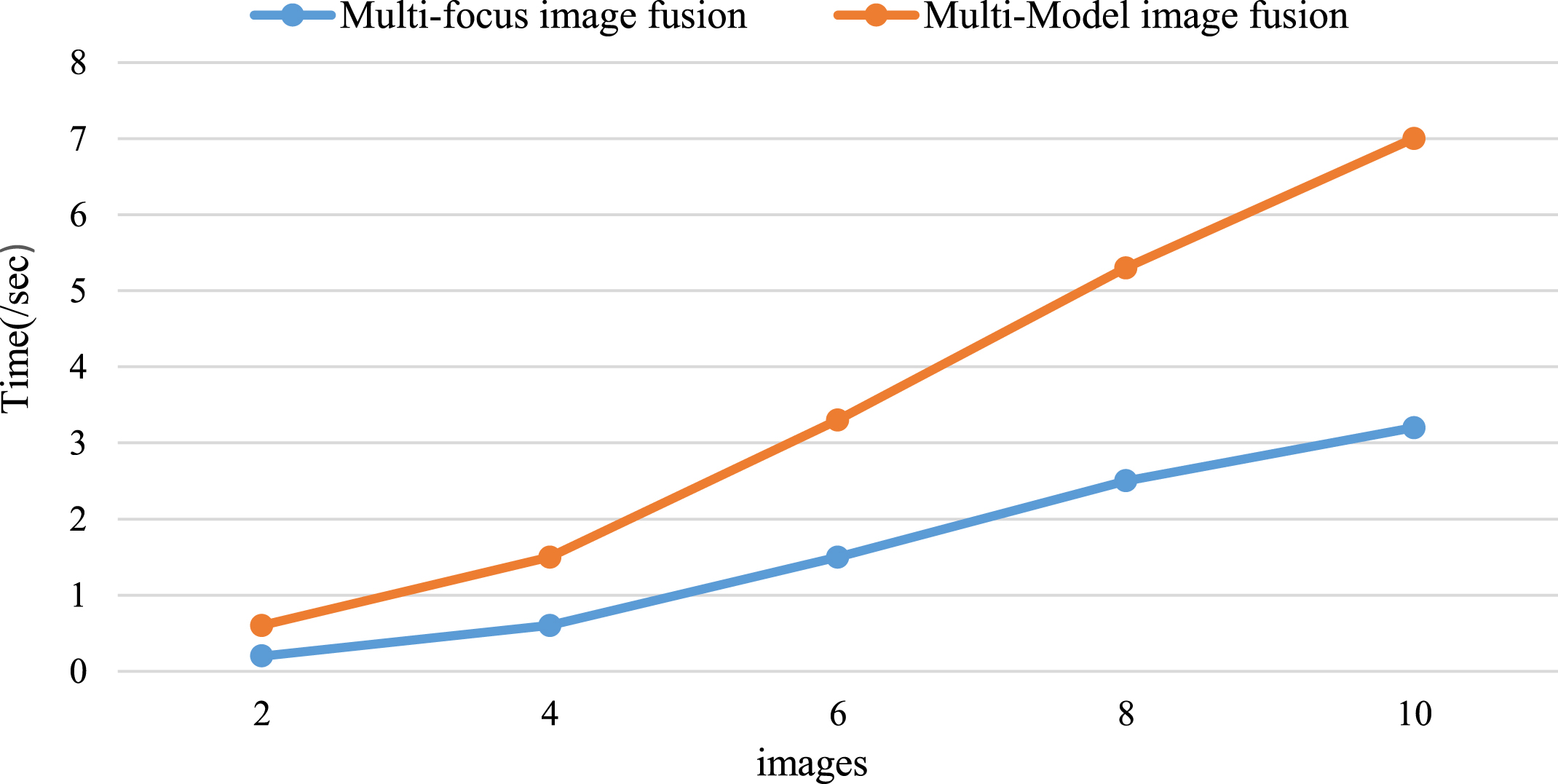
Compared multi-focus image fusion and Multi-model image fusion time of image fusion.
Table 7 displays these outcomes. The SML-based fusion rule is somewhat outperformed by the proposed method in terms of Q and Q E . Values. As a result, the suggested technique has less structural distortion and more edge information transfer. The three images used to illustrate the correlation for the CNNs and Bi-LSTM algorithm show where the most variation between the findings of the Image Fusion and the current methods, as shown in Fig. 10, lies.
MRI and CT images are used to quantitatively compare the proposed method to Energy and SML-based fusion rules in the area of Modified Tetrolet Transforms
Performance of the suggested method was compared to that of the discrete stationary wavelet transform (Discrete-SWT), dual tree complex wavelet transform (DT-CWT), discrete wavelet transform (DWT), and Convolutional neural network-based multimodal image fusion (CNN-MIF). As can be seen in Table 8, a comparison of several medical picture fusion approaches.
Different medical image fusion techniques are compared
Using the two training instances mentioned above, comparisons were done between CNN and Bi-LSTM measurements and the outcomes of the suggested Hybrid CNN and Bi-LSTM. Figure 16 shows, respectively, the accuracy of the proposed Hybrid CNN and Bi-LSTM algorithms in contrast to those of the Bi-LSTM and CNN techniques, as well as the proportion of the training datasets used in each of the aforementioned scenarios to the total training data.
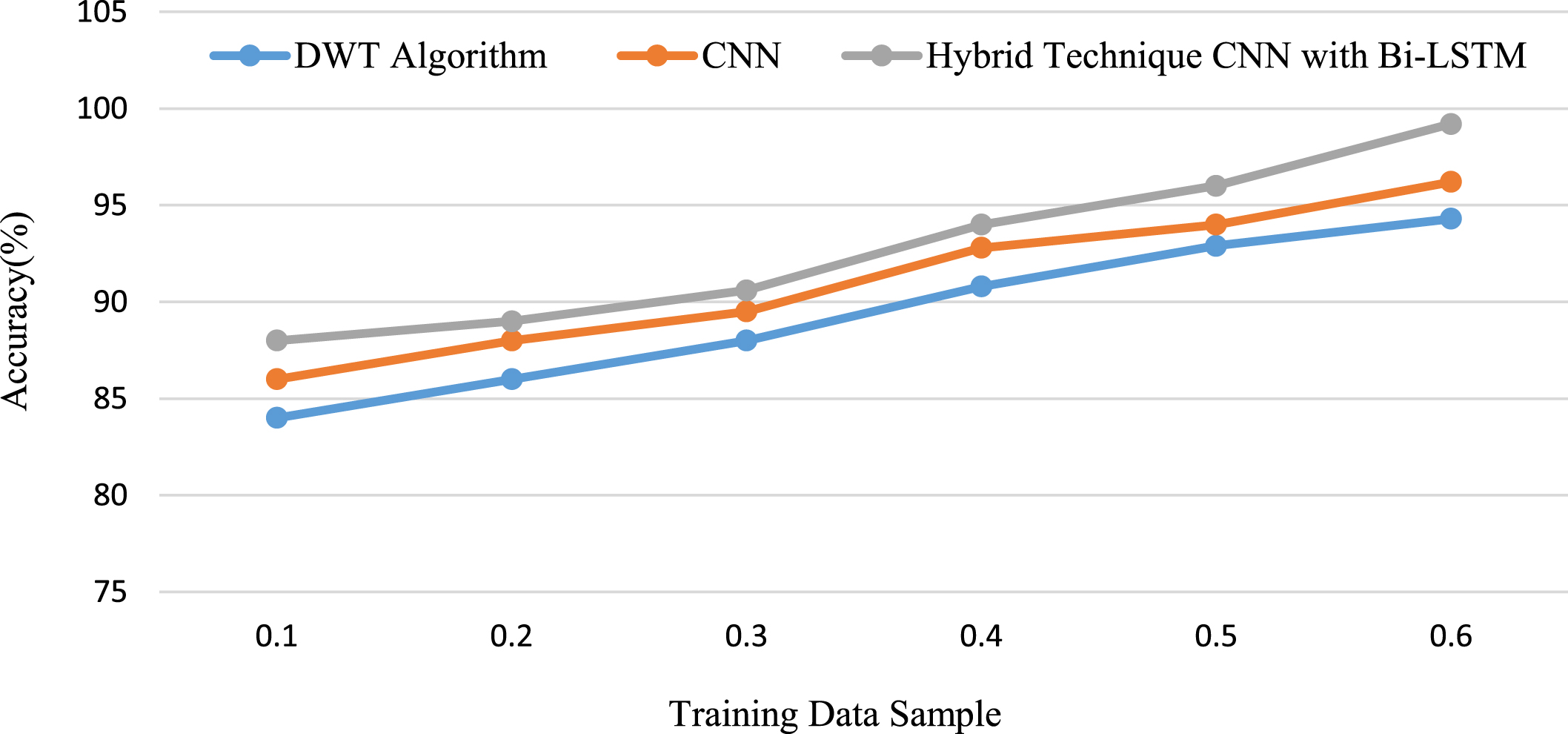
Proposed Hybrid CNN and Bi-LSTM algorithm to the Bi-LSTM and CNN technique of training samples used in various training cases.
Introduced a novel Modified Tetrolet transform (MMT) is used to extract the input image. Proposed a novel hybrid CNN with Bi-LSTM (Bi-directional Short Term Memory) multi-focus image fusion technique to get over the problems with the current fusion techniques. This hybrid model is employed to predict the brain tumor contained in the fused image. Based on the hybrid CNN with Bi-LSTM, we created and used a unique MRI/CT medical image fusion technique. A novel and very efficient combination diagnostic modality is now available thanks to our successful integration of MR and CT images into a single fused image. The technique of merging two separate image pairs, such as those obtained by MRI and CT, was initially thought to be possible. Those pair of images is fused together using fusion formula, which formulated based on transparency labelling to reduce the computational load. Finally, experimental results are evaluated using a variety of performance measures. From the results, we can see that our suggested model contributes to a reduction in the complexity of time and storage while also improving predictive performance. The proposed method could be improved further by pre-processing the CT picture and then combining the generated image with the MR image. The proposed strategy can be expanded to anatomical and functional medical fusion. This situation demonstrates the effectiveness and benefits of using CT/MRI fusion technology in brain tumour surgery.