
Abstract
Sentiment analysis has become a prevalent issue in the research community, with researchers employing data mining and artificial intelligence approaches to extract insights from textual data. Sentiment analysis has progressed from simply classifying evaluations as positive or negative to a sophisticated task requiring a fine-grained multimodal analysis of emotions, manifestations of sarcasm, aggression, hatred, and racism. Sarcasm occurs when the intended message differs from the literal meaning of the words employed. Generally, the content of the utterance is the opposite of the context. Sentiment analysis tasks are hampered when a sarcastic tone is recognized in user-generated content. Thus, automatic sarcasm detection in textual data dramatically impacts the performance of sentiment analysis models. This study aims to explain the basic architecture of a sarcasm detection system and the most effective techniques for extracting sarcasm. Then, for the Arabic language, determining the gap and challenges.
Introduction
With the adoption of new communication and global networking habits, social media has become an essential part of the contemporary world. Social media is not only used by the young generation; all generations are indeed trending toward it. Businesses and institutions have quickly recognized the value of publicly accessible data on websites like Facebook, Twitter, Instagram, Reddit, and others. They have started mining these gold mines to understand public opinions and interests and to keep abreast of the worldwide trembling market. Twitter is undoubtedly the most popular microblogging platform among the general population, business communities, and academic researchers. Since its launch in 2006, the number of Twitter users has increased significantly. There are 396.5 active Twitter accounts worldwide, more than 50% of whom use the site daily and produce more than 650 million daily tweets. Users of Twitter share tweets, which are limited to 140 characters. Tweets are brief messages that are frequently sent containing text, images, videos, or links. Twitter is used by individuals to communicate with friends and family to share routines, build a community network, and get political and sporting news. Besides, companies are monitoring Twitter to collect consumer feedback and adapt their market strategies.
Twitter played a significant role in the Arab Spring and other instances of civil disturbance in the Arab region. According to globalmediainsight.com, nearly 30 million people in Saudi Arabia will be active users of Twitter in 2022. Saudi Twitter users represent about 72% of the total internet users. Furthermore, Arabic is the official language of 24 countries in North Africa, the Middle East, and the Arabian Peninsula. There are three forms of the Arabic language: Classical, Modern Standard, and Colloquial. Most pre-modern literary works were written in classical Arabic, which is the language of the holy Quran. However, most publications, from newspapers to novels, as well as traditional broadcasts like news programs, educational programs, and political speeches, utilize Modern Standard Arabic, which deviates slightly stylistically and lexically from Classical Arabic. In addition, people employ a variety of dialects in daily communication that vary from region to region, even within the same nation.
Natural Language Processing (NLP) is a computational discipline aiming to give machines the intelligence to interpret and analyze natural human language. Given the diversity and complexity of languages, there are numerous applications for NLP, and when it comes to Arabic, they are even more sophisticated. Arabic is a Semitic language written from right to left, unlike Latin and English. Therefore, Arabic has an excessive derivational and inflectional properties; most of the words in dialectal varieties are derived from Modern Standard Arabic roots with no rules for emphasis, as stated in references [1, 2], and [3]. There are two forms of sentences in Arabic: nominal, when the subject is the topic (subject-verb), and verbal, when the sentence starts with a verb followed by an explicit or implicitly implied subject (verb-subject). The translation of both the nominal and verbal forms of Arabic into English gives a single nominal form. Thus, the free order and diversity of grammatical rules in Arabic are common challenges to NLP tasks.
Dialect Arabic is mainly used in social media and Twitter to write textual messages. Dialect or Vernacular Arabic can be grouped into five general categories: Egyptian, Maghrebi, Levantine, Mesopotamian Arabic, and Arabian Peninsula Arabic. Moreover, Arabic orthography is not straightforward because the shape of a single letter can change according to its place in a word. The way a letter is written at the beginning of a word is not the same as the middle or the end. Additionally, Arabic texts occasionally include orthographic marks called diacritics to aid in spelling words for novices or young readers or just to add more style to the text. For example, while in Arabic, “ ” are three letters employed as vowels, some diacritical marks take the place of short vowels. The presence of diacritics in Arabic words change completely the meaning as in the word (
” are three letters employed as vowels, some diacritical marks take the place of short vowels. The presence of diacritics in Arabic words change completely the meaning as in the word ( A character, To twist
A character, To twist  ). Thus, many techniques of stemming and lemmatization are devoted to the Arabic language to enhance parsing text and reduce noise from social media data [4–6].
). Thus, many techniques of stemming and lemmatization are devoted to the Arabic language to enhance parsing text and reduce noise from social media data [4–6].
Sentiment analysis is one of the most active fields of NLP. Over the past few years, interest in sentiment analysis in Arabic has dramatically helped to construct resources and develop approaches tailored to the particular morphological and cultural characteristics of the Arabic language. Sentiment analysis, also known as opinion mining, entails investigating and evaluating users’ online behavior to ascertain their perspectives on a specific item, service, or entity. Three levels of investigation [7] are employed throughout this process: sentence, aspect, and document. For example, sentiment analysis of Twitter messages is performed at the sentence level to extract the subjectivity of the message and assign a polarity (positive, negative) or a class of emotion to the sentence.
Slang and idioms are frequently used to condense a lengthy message and adhere to Twitter’s character limit because of the informal writing style and non-standard language of social networks. Using humor or sarcasm is another common way for users of social networks to communicate their opinions. Sarcasm is a figurative language that wraps a deeper meaning in simple words. It is common to need a thorough investigation of the cognitive, social, and context layers and the sentence’s grammatical structure to deduce the hidden sarcasm. So even humans find sarcastic tweets difficult due to their intricacy. As a result, the area of automatic sarcasm detection is expanding and strives to provide computational algorithms and strategies to infer sarcasm and improve sentiment analysis precision.
The rest of the paper is organized as follows: Section 2 presents the background to automatic sarcasm detection showing the foundations of defining sarcasm and the task of automatic sarcasm detection. Next, in Section 3, we describe the principal method to perform this task. Then, Section 4 shows the most cited datasets for Arabic and other languages. Section 5 focuses on approaches used for Arabic sarcasm detection before concluding in Section 6.
Background
Before detailing the framework for automatic sarcasm detection, we first investigate the definition of sarcasm and the formulation of this issue in the NLP tasks.
Definition of sarcasm
The Oxford dictionary defines the term sarcasm as “a way of using words that are the opposite of what you mean in order to be unpleasant to somebody or to make fun of them” while the Macmillan dictionary states that sarcasm is “the activity of saying or writing the opposite of what you mean, or of speaking in a way intended to make someone else feel stupid or show them that you are angry”. Both definitions are equivalent in some sense. Thus, sarcasm can be described as a statement of incongruity or contradiction between the literal meaning and the intended message. Typically, the literal meaning presents the use of positive words while the intended message is negative. An example of this is “I Love Mondays … back to work”, in almost all cases, people do not like to come back to work after the weekend, so Monday is not a favorite day in reality. The literal meaning of this utterance can lead to misinterpretation if one does not share the same contextual layers.
Communication using sarcasm is quite complex [8]. Even for humans, it can be challenging to recognize sarcasm since it requires understanding the situation’s context [9] and the speaker’s social and emotional backgrounds. Also, cognitive conditions may influence the understanding of a message. Because sarcasm is a figurative language [10] that employs linguistic devices like metaphor, hyperbole, ambiguity, and other similar schemes, it can be used to criticize, insult, or as a familiarity form of speaking [11]. For various reasons, sarcasm is sometimes associated with irony or humor. It differs from verbal irony, as the latter is characterized by paralinguistic features, such as facial grimaces, body gestures, and voice intonation like heavy stress and lowering the speaking tempo [12]. The existence of these clues is very critical in recognizing verbal irony. Being able to detect sarcasm in social media content has a significant impact on sentiment analysis. When sarcasm is misunderstood, a text that involves a discrepancy between the words employed and the intended meaning is misclassified by being given the positive polarity. In summary, sarcasm occurs in textual data when there is an incompatibility between the factual situation and the surface meaning of the sentence. This conflict can be found in five scenarios outlined below: A positive surface sentiment with a negative intended meaning [13]: It is the most widely spread sarcasm in everyday communication and hence on social networks. To infer this kind of sarcastic utterance, it is necessary to know the background and the culture. An example could be “ An opposing surface sentiment with a positive intended meaning [14]: this type of sarcasm is rarely encountered on Twitter and is characterized by using words known to be negative to express a positive feeling, such as in the example “ A contradiction between a fact and the text [15 16]: A text is considered sarcastic if it is the opposite of an apparent reality, as in the example “ Sarcasm deduced from the lexical analysis [17]: Hashtags are explicit markers used in Twitter to self-label a tweet. Tweets on Twitter contain expressly defined keywords called hashtags, which frequently serve as categorization labels or metadata in addition to the tweet’s body language. Therefore, it is supposed that the author understands well what sarcasm is when using hashtags like “#sarcasm”, “#sarcastic”, or “#not” to infer sarcasm. An example could be “ A behavioral analysis of likes and dislikes of the user [11, 18]: It is difficult to determine whether a statement like “
 ,
,  (Ziyash is extraordinary, he puts the ball directly on the post)”.
(Ziyash is extraordinary, he puts the ball directly on the post)”. (You are horrible at cooking)”.
(You are horrible at cooking)”. (exclusive news I got the miss universe award)”.
(exclusive news I got the miss universe award)”. (Al-Sissi is the best president in Egypt’s history #not).
(Al-Sissi is the best president in Egypt’s history #not). (I really appreciate the latest flowery dress trend)” is sarcastic if we do not know the author’s personal preferences. Based on the history of his previous tweets, an analysis of his behavior is automatically conducted to determine a prediction for sarcasm.
(I really appreciate the latest flowery dress trend)” is sarcastic if we do not know the author’s personal preferences. Based on the history of his previous tweets, an analysis of his behavior is automatically conducted to determine a prediction for sarcasm.
According to a linguistic perspective, text-based sarcasm typically has one or more of the following characteristics: propositional, embedded, illocutionary, like prefixed, hyperbole, and dropped negation. Although these features do not indicate ironic tweets [19], they can be used to spot utterances that might be. Here is a quick breakdown of these characteristics: Propositional sarcasm: In propositional sarcasm, implicit feelings are concealed within a statement. In order to interpret a sentence’s sentiment, it is crucial to understand its context. Deprived of its context, a sentence can be misclassified as positive or negative. For example “ Embedded sarcasm: This kind of sarcasm appears when the statement comprises words that depart from its intended meaning and convey an oddity, like in the sentence “ Illocutionary sarcasm: a sincere statement accompanied by additional language context cues, such as glares, raised voices, and stressed-out tones. Emojis or hashtags are some examples of those signs on Twitter. Like prefixed sarcasm: This type of sarcasm is simpler to spot. It forms a declarative sentence and begins with a sarcastic signaler like “like” or “certainly” before making the sarcastic remark. The signaler is flipping the sentiment of the utterance. E.g “ Sarcasm as a hyperbole: A sign of sarcasm could be hyperbole or excessive exaggeration used for emphasis. Interjections and intensifier words [20], are frequently employed to highlight expectations of the text (wow, waah, oooh, what...). Depending on the situation, an author’s comment, “ Sarcasm as a dropped negation: A statement is written without a negation expression in dropped negation. This typically takes the form of a positive outlook in the face of challenging circumstances.
 (what a great morning)” could not be classified without its situational context.
(what a great morning)” could not be classified without its situational context. (That restaurant is spotless, I would never come back there)”, the action of leaving the restaurant is inconsistent with the word “clean”.
(That restaurant is spotless, I would never come back there)”, the action of leaving the restaurant is inconsistent with the word “clean”. (He is like Benkiran)”. Here the person in the statement is compared to a politician.
(He is like Benkiran)”. Here the person in the statement is compared to a politician. (wow you are such a great swimmer)” could be seen as a genuine compliment or a sarcastic criticism. Hyperbole can be used to flag assertions for additional study, but it is insufficient on its own to assess whether a statement is ironic.
(wow you are such a great swimmer)” could be seen as a genuine compliment or a sarcastic criticism. Hyperbole can be used to flag assertions for additional study, but it is insufficient on its own to assess whether a statement is ironic.
Automatic sarcasm detection
Automatic sarcasm detection is a milestone research area within sentiment analysis [21]. It is considered by the majority of scholars to be the most challenging sentiment analysis assignment. In order to reduce bias in the classification of sentiments and to improve assessment measures, the objective is to develop automatic algorithms to detect sarcasm in textual data. Figure 1 illustrates the position of automatic sarcasm detection in relation to the disciplinary fields of NLP, text mining, and sentiment analysis.
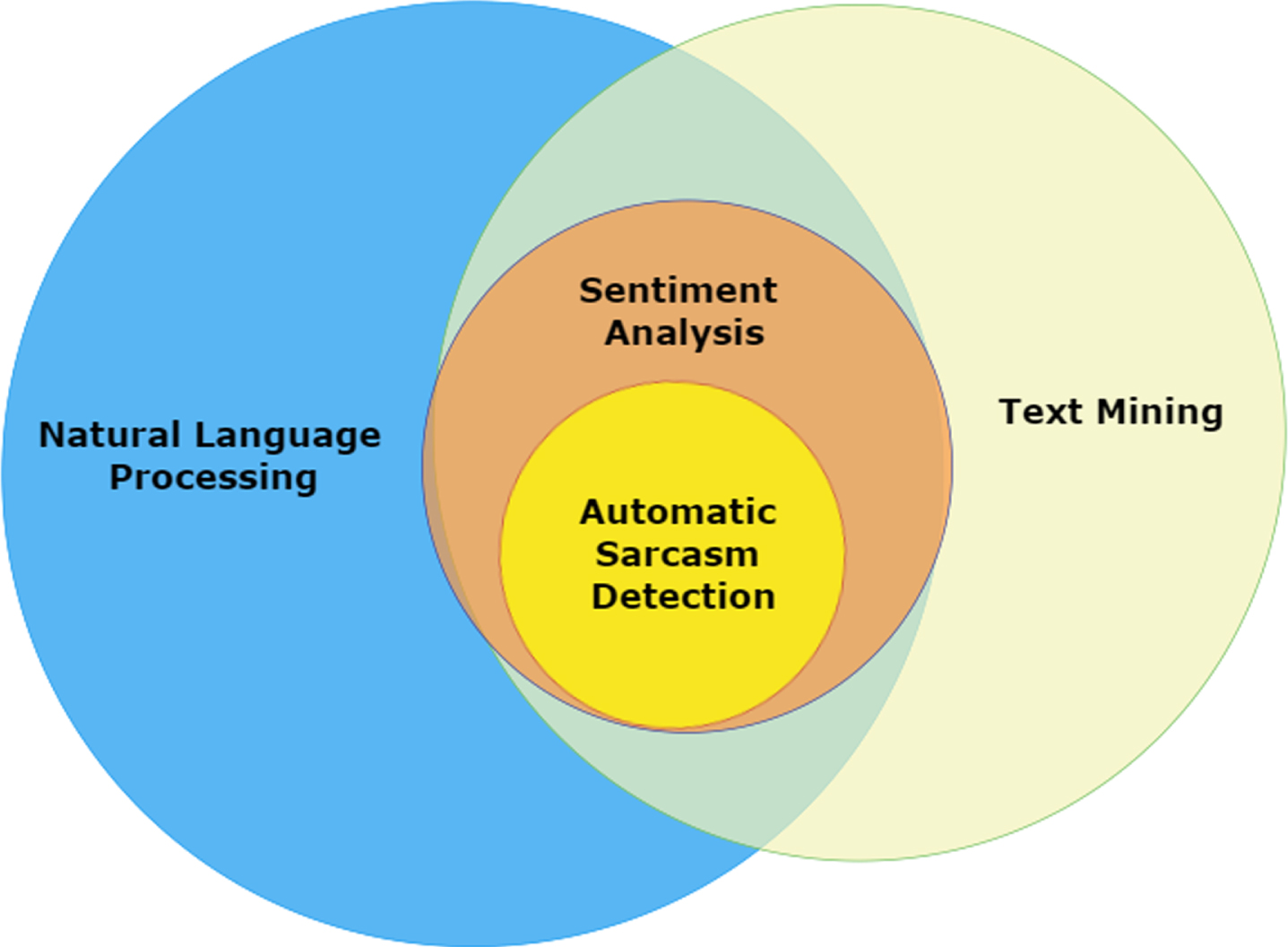
Automatic Sarcasm Detection task.
For the purpose of this study, we conducted an electronic search on six academic databases, including Web of Science, IEEE Explore, Science Direct, Springer, Google Scholar, and Scopus. The analysis considers the publications between 2011 and 2022. The search strategy for the literature on “Automatic Sarcasm detection on Twitter” from the chosen databases was defined using various appropriate keywords. Sarcasm identification, sarcasm detection, sarcastic text, sarcasm in microblogs, sarcasm in social platforms, sarcasm on Twitter, irony detection, and irony on Twitter, All prior keywords were combined with either Arabic or English as we conducted the search in both languages. Figure 2 clearly highlights the growing interest in automatic sarcasm detection, especially over the last five years. The figure emphasizes that there is a significant disparity in research devoted to English compared to Arabic. The years 2021 and 2022 represent the peak period for research in Arabic.

Evolution of publications about Arabic and English Sarcasm Detection.
This paper is the first overview that tries to gather the works in this field in order to draw the main lines of research and the possible directions for improvement. In the research process we have established, we have found several exciting literature reviews that deal with automatic sarcasm detection for the English language.
Joshi et al. discussed various methods for automatically detecting sarcasm and noticed a need for more research on prefixed, illocutionary, and implicit sarcasm [22]. They also raised concerns about data skew and the effect of sarcasm detection on sentiment analysis. According to the study, culture affects how sarcasm is encoded and decoded, and there is a correlation between the use of numbers in a text and its sarcastic attitude. Being the initial review of 2016, automatic sarcasm detection did not widely employ deep learning techniques. The study presented in [23] is a systematic review of 40 works in the literature published between 2008 and 2019. The authors discussed the datasets used, the feature engineering, and preprocessing methods. Having considered automatic sarcasm detection as a classification problem, it presents the main classification techniques for social media data. The authors of [24] addressed the issue from a feature selection angle, and they highlighted that although SVM is used extensively as opposed to Naive Bayes and logistic regression, the results are still challenging and we need to better understand the behavior and emotion in order to best recognize sarcasm. Recent work in [25] concluded that deep learning approaches have become highly explored in recent years and that the publicly reported datasets are limited to Twitter and Reddit data. It suggests using ensemble-learning methods, exploring new context-related features, and providing new datasets from other open sources than social networks with multimodal data to overcome the challenges of automatic sarcasm detection.
For the intention of handling the issue of automatic sarcasm detection, Kanakam et al. [26] concentrated on machine learning techniques. The work included research of the techniques employed, the performance as stated, the drawbacks of each technique, and the features leading to the best outcomes. However, neither the benchmarked datasets nor the assessment measures present a baseline for the assessed research. A large number of high-quality articles on automatic sarcasm detection using Twitter data were recently analyzed by Moores et al [27]. Data annotation and sarcasm’s context were the two main problems they found. The ability to recognize sarcasm requires shared knowledge background, which is very difficult to obtain. By showing a significant regression of classifiers like SVM, they also noted a decreased use of transformers in favor of LSTSM and CNN models. Other studies are presented in [28–34].
Automatic sarcasm detection frameworks are based on four key components depicted in Fig. 3: data collection, data preparation, feature engineering, and classification. We detail each component of the framework in the following subsections.

The process of sarcasm detection.
Data collection is the first step in any sarcasm detection project. On social networks, the amount of data on the Internet is hindered by accessibility and privacy restrictions. Twitter is an online microblogging site that enables users to share messages of 280 characters after its recent update. Twitter is a powerful source of data since it allows accessing data via its developer’s API, commonly used to construct the most popular datasets. A tweet is composed of several elements, among which the most important for the task of automatic sarcasm detection is the hashtag used to index the phrases or words in the tweets. Fortunately, Twitter APIs provide tools for collecting data from Twitter from a Twitter developer account, either by scrapping data or using software APIs such as Tweepy https://www.tweepy.org/. These options can generate a dataset that is either a broad, untargeted sample of what is available or a set of targeted samples based on hashtags, usernames, and location. In order to collect data with sarcastic intentions, researchers often use hashtags like “#sarcasm”, “#sarcastic”, “#not,” “and #irony”.
Data annotation
Supervised learning for Natural Language Processing tasks and, in consequence, automatic sarcasm detection needs annotated data to build a dataset that will help train the algorithms and map the inputs and outputs within a computational function. Since annotation is generally done by humans, we need to compare the given labels or annotations for several reasons, including validating and refining annotation guidelines and schemes, locating ambiguities or problems in the source, or making the process of annotation reproducible. Different comparison methods are possible, such as statistical modeling of annotator discrepancies, formal agreement measures calculation, or qualitative analysis of the annotations. After collecting the data, the first step is to write the guidelines or instructions to guide the annotators by defining the annotation categories, explaining each category with concrete examples, focusing on exceptional situations, and defining the operation’s objective. After choosing annotators from the same culture and native speakers of the target language, we first calculate the degree of reliability. Once the method has been shown to be reliable, it can be applied to the entire piece of content by a single annotator. Typically, reliability is evaluated on a sample of the material to be annotated. Several prerequisites must be satisfied before the agreement may be seen as a sign of dependability. The measure used to show how much the annotators were in agreement while labeling a certain category is called Inter-Annotator Agreement[35, 36]. Two metrics, Cohen and Fleiss’ Kappa (equation 1), are often employed in manual annotations. Cohen’s κ: two annotators annotating each instance with a category. This measure is used to validate pair annotations. Fleiss’ κ: each instance was annotated n times with a category. This metric is used to measure the agreement between three raters or more.
Where Kappa is calculated with the formula:
Po is the hypothetical probability of chance agreement, and Pe is the relative observed agreement among annotators. The agreement is better when Kappa is close to 1.
For manual annotation and following the requirements of each project, one can use hired annotators or annotators who are part of the project team or rely on crowdsourcing [37, 38] services such as Amazon Mechanical Turk, Upwork, or other similar services. Figure 4 summarizes the main phases of manual annotation for automatic sarcasm detection.

Flowchart of sarcasm dataset annotation.
The second possibility to annotate data for automatic sarcasm detection is remote supervision [11, 39, 40], this mechanism is based on Twitter users self-labeling their tweets using hashtags such as “#sarcasm”, “#not”, “#sarcastic”. It is assumed that the user is well aware of the hashtag and uses it in the right place. Thus, tweets are collected through Twitter API using predefined hashtags.
The last and least used way to annotate data is automatic labeling based on machine learning algorithms [41] that will recognize patterns from human-annotated or author-annotated data to deduce annotations from the remaining data.
The method of reducing noise from data collection is known as data preparation. The data collected from various platforms, such as Twitter, Maktoob, and Facebook, is dispersed and unstructured. As a result, data preprocessing is one of the most critical processes in detecting sarcasm. The most prominent preprocessing techniques are data tokenization, stop words deletion, lemmatization, or stemming words, and POS parsing. Transforming sentences into words is, referred to as tokenization, available in several free libraries. The terms are converted into their stem or root form during stemming and lemmatization. The stop words or words that are less significant for sarcasm identification, such as prepositions, pronouns, and conjunctions that are the most used in the language (Arabic or English), would be removed during the stop word replacement method. Other cleanings are sometimes performed to reduce noise, like removing duplications, URLs, retweets, user mentions, or emoji.
Feature extraction
Several methods are used at this stage to extract features from a cleaned data set. In sarcasm detection systems, methods based on the frequency of words to award a relative score, such as TF-IDF, N-gram, and Bag of words, are employed. However, because sarcasm detection is context-dependent, methods based on contexts, such as Word embedding and transformers, yield better results.
The chosen features depend on the sarcasm’s subtype; these include lexical [42] elements like nouns, verbs, and adjectives. Syntactic characteristics are predicated on the presence of expressions or words well known to express sarcasm. Features of semantics [43] and hyperbole [12], such as using intensifiers or exaggeration statements. The most common pragmatic features [17] are hashtags, punctuation, exclamation points, and so for. The final pattern-related feature is based on the order of words or the frequency of a particular word or sentence.
Feature selection
Feature selection is a dimensionality reduction technique in which relevant features are selected, and unnecessary or redundant features are removed. Reduced input dimensionality can increase performance by lowering the model’s learning speed and complexity or enhancing the classification’s generalization and accuracy. In addition to reducing the overall cost of measurement, finding appropriate features helps improve understanding of the sarcastic utterances.
From a taxonomic point of view, feature selection methods can be grouped under four main categories: Wrapper methods: The Wrapper methodology considers selecting feature sets as a search issue in which several combinations are created, assessed, and contrasted. A predictive model is utilized to assess a set of features and provide model performance scores. The classifier determines how well the Wrapper technique performs. Based on the classifier’s output, the best subset of characteristics is chosen. An example of those methods is Recursive Feature Elimination (RFE) [44]. Wrapper methods are much more computationally expensive than filter methods, but they can detect feature interactions, making them more accurate. Filter methods: Those methods pick up the intrinsic properties of features using statistical measures independently of the learning algorithms. Information Gain [45] and Chi-Square are the most commonly used for sarcasm detection. Filter methods offer the benefit of being computationally efficient and providing a quick way to identify relevant features. However, they may not take into account feature redundancy, feature interactions, or multicollinearity of features. Embedded methods: Also known as the intrinsic methods, they extract the best features during the training phase. An example is the LASSO regression algorithm [46]. The advantages of using embedded methods include increased reliability of feature estimates compared to a single filter or wrapper algorithm, reduced overfitting, no need for feature scaling, and robustness to outliers. However, there are some drawbacks to using embedded methods, such as decreased interpretability, higher computational cost and memory consumption, and difficulty in handling categorical features. Hybrid methods: They encompass the shortcomings of each one using both filtering and wrapping methods [47]. We rank the feature set using a filter method first and then reduce it using a wrapper method.
In summary, Feature selection is a complex area of research and many studies have been conducted to determine the best methods. The choice of feature selection method depends on the problem, domain, and data. A common approach is to start with one or more embedded methods to see what they produce. It is unlikely that models using intrinsic feature selection will select the same predictor subset, especially if linear and nonlinear methods are being compared. If a non-linear intrinsic method has good predictive performance, then a wrapper method combined with a non-linear model can be used. Similarly, if a linear intrinsic method has good predictive performance, then a wrapper method combined with a linear model can be used. When dealing with large datasets and no existing model to produce satisfactory results, filter methods can be employed to select the most effective features.
Classification
Sarcasm detection can be reduced to a binary classification task if there are two categories: sarcastic or not. Alternatively, multi-way classification in case there is several categories of sentiments, including sarcasm. Besides, Sarcasm classification can be performed by four methods depicted in Fig. 5: lexicon-based methods, machine learning methods, rule-based methods, and deep learning methods.

Sarcasm detection methods.
When evaluating the automatic sarcasm detection approaches, the following metrics are reported: Accuracy: is the proportion of correct predictions to total predictions.
Since data available for sarcasm are mostly imbalanced, other metrics, like precision, F1-score, recall, are used to give a better evaluation. Precision: is the total number of correct results divided by the number of all returned results. Precision measures the number of tweets that have successfully been classified as sarcastic over total number of tweets that are classified as sarcastic. Recall: is the number of correct results divided by number of results that should have been returned. F1-score: It considers both precision and recall to calculate the score. Formula for F-score is 2*[(precision*recall)/ (precision+recall)].
Datasets
In this section, we present a selection of English and Arabic datasets to compare their size, collection method, and use for automatic sarcasm detection.
Arabic datasets
The problem of automatic sarcasm detection is a very recent issue in Arabic. Arabic is one of the most morphologically complex languages due to its inflectional nature. Given the high immersion of Arabic in social networks, several shared tasks have been organized to handle sarcasm detection in Arabic. Not far away, the first shared task on irony detection in English was organized during Sem-Eval 2018 [48]. Two classification issues were addressed: the first one is the detection of sarcastic tweets, and the other one, in addition to the classification of tweets, finds the type of irony expressed. The best F1 score obtained on the former task is 0.71 against 0.51 for the latter.
The 11th meeting of the Forum for Information Retrieval Evaluation 2019 [49] was organized in India, and it involved the first sarcasm detection task in the Arabic language. The forum shared the IDAT dataset that consisted of 5030 tweets collected using Arabic hashtags “ ”, “
”, “ ”, “
”, “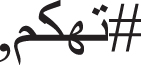 ”, “
”, “ ” (Masquerade, Mockery, Taunt). Ten participants submitted their run for the binary classification task; their approaches consisted of machine and deep learning methods with different techniques for feature weighting ranging from a traditional bag of words to sophisticated embeddings. The best F1 score measure was obtained by an ensemble model [50] combined with TF-IDF n-gram features showing that traditional ensemble methods outperformed the deep learning techniques for this task.
” (Masquerade, Mockery, Taunt). Ten participants submitted their run for the binary classification task; their approaches consisted of machine and deep learning methods with different techniques for feature weighting ranging from a traditional bag of words to sophisticated embeddings. The best F1 score measure was obtained by an ensemble model [50] combined with TF-IDF n-gram features showing that traditional ensemble methods outperformed the deep learning techniques for this task.
The paper [51] introduced a domain-specific corpus collected from political tweets. Initially, the authors used the names of political candidates in the presidential elections in Egypt and the US. Then they collected the tweets containing them based on the same hashtags as in the paper [49] for sarcastic tweets and without those hashtags for non-sarcastic tweets. The imbalanced dataset resulting from the collection and cleaning process contains 5479 tweets, of which 1733 are ironic. Moreover, it contains a mix of modern standard Arabic and dialectal Arabic, especially Egyptian. For validation purposes, the authors constructed four groups of features: surface, sentiment, shifter, and internal context features, and obtained satisfactory results similar to those obtained for English, French, and Japanese, with an F1 score of 0.72%.
The Sixth Arabic Natural Language Processing Workshop (WANLP 2021) [52] involved two projects: identifying sarcasm and sentiment in the Arabic language. WANLP-21 had 40 groups of participants with one shared dataset called the ArSarcasm [53]. This dataset contains 10547 tweets. 1687 are sarcastic and labeled for sentiment and dialect. The approach adopted for the ArSarcasm dataset’s constitution differs from the previous ones. The authors considered the re-annotation of datasets commonly used in the literature for subjectivity and sentiment classification, the ASTD [54] and Sem-Eval 2017 [55]. In addition, the authors used a crowdsourcing method by sharing the guidelines with Arabic annotators to label the datasets according to three labels: sentiment, sarcasm, and dialect type.
Abuteir et al. [56] collected a balanced dataset consisting of 10000 sarcastic tweets that were posted between 2010 and 2020. The dataset is about sports and politics. It was compiled using hashtags synonymous with sarcasm or irony expressed in standard Arabic or dialectal Arabic and was automatically annotated by the tweeters. In a similar work, the authors of [57] presented the first Moroccan dataset that also handles sarcastic tweets. The Moroccan Sentiment Twitter Dataset (MSTD) contains 2188 sarcastic tweets manually annotated by three native speakers. A similar dataset was collected in the context of COVID-19 called the AraCOVID19-SSD. This dataset considers sentiment analysis and sarcasm detection of over 300k collected tweets containing terms related to the COVID-19 virus in Arabic. The distribution of the dataset is imbalanced, with 1802 sarcastic tweets and 3360 non-sarcastic tweets. Experiments showed that the SVM classifier and the Arabert [58] transformer yielded very successful results for the sarcasm detection task reaching an F1-score of 0.95.
Researchers highlighted many limitations of distant supervision as a method to construct sarcasm datasets. First, the position of the hashtag in the tweet creates a significant ambiguity. Sometimes, a tweet refers to sarcasm, but the implied message is not sarcastic. Besides, tweeters may need clarification about the different devices of figurative language. Finally, a tweet labeled as sarcastic can contain humor or stance or even be a fact.
Consequently, automatic annotation utilizing ground truth labeling is inaccurate and could lead to biased data. Manual annotation, however, requires a lot of time and resources and can result in linguistic and contextual inconsistencies. Therefore, the work considers creating an open-domain corpus based on Twitter data to overcome these two limitations. Initially extracting a dataset of 1.4M, automatic processing of retweets, URLs, and short tweets cleaning was carried out to reduce the noise. As a result, the authors selected a dataset of 5358 tweets and annotated 4809 as ironic.
Najla et al employed 35 keywords from the Saudi dialect to scrap tweets with ironic intentions. They started from the assumption that irony and sarcasm are relevant to the same phenomena on social media. The annotation was based on crowdsourcing, and the team employed seven annotators meeting conditions of age, familiarity with Twitter, and belonging to Saudi Arabia to understand the texts better. After cleaning the collected tweets and the two rounds of annotation, they could annotate 19810 tweets, of which 8089 are labeled as ironic. In order to set a baseline system, they conducted experiments based on machine and deep learning models. The best F1-score was obtained by the AraBert model with a measure of 0.71, showing that the Bert transformer is most relevant when dealing with irony or sarcasm.
Table 1 Below presents some datasets addressing sarcasm in many languages, with a focus on the Arabic language.
Datasets addressing Sarcasm in Arabic and other languages
Datasets addressing Sarcasm in Arabic and other languages
Machine learning approaches
Most sarcasm detection problems are reduced to a classification task. Natively, the researchers used mathematical machine learning models to handle this task. Karoui et al. [51] employed a supervised learning method to classify ironic tweets. They represent four feature categories: surface, sentiment, shifter, and internal contextual features. For the experimentation phase, they run a classification task under the Weka toolkit using the traditional algorithms Support Vector Machines (SVM), Naive Bayes (NB), Logistic Regression (LR), and Random Forest (RF). The results showed that the best accuracy was given by the Random Forest classifier in combination with all groups of features. Furthermore, alghadhban et al. [71] proposed a Naive Bayes Model to classify sarcastic tweets using the Weka Software. The reported accuracy was 65.91% on a small manually generated dataset. The authors of [72] collected a corpus of 20000 tweets composed from Modern Standard Arabic (MSA) and Dialectal Arabic (DA), with a balanced distribution (10000 sarcastic tweets and 10000 non-sarcastic tweets). For their experiments, they used three classification algorithms: NB, LR, and RF, and benchmarked a set of features to conclude that the length features gave the best performance in combination with punctuation features and unigrams. An accuracy of 89,17% yielded by the NB algorithm suggested that the combination of baseline and structural features is very informative to improve results regarding the sarcasm identification task.
According to the study reported in [69], the SVM classifier with a bag of words vectorization method gave a high F1-score exceeding 0.95 for the AraCovid dataset, and the authors owe this result to the quality of annotating the dataset being verified manually after the automatic collection based on hashtag markers. Similarly, the Work of Nayel and al. [73] proposed SVM based classifier to handle the task of Sarcasm and Sentiment Analysis. The model achieved a relatively high accuracy for the sarcasm classification task with 84.22% showing that SVM is an accurate classifier even when it comes to complicated tasks. Unlike the previous works, Murad et al. [74] considered both scenarios of binary and multiclass classification for a dataset containing 2989 sarcastic tweets. They reported results from using six state-of-the-art machine learning models Passive-Aggressive Classifier as (PAC), Logistic Regression Classifier (LRC), Random Forest Classifier (RFC), Linear SVC Classifier (LSVC), Decision Tree Classifier (DTC), and K Nearest Neighbor Classifier (KNNC). The LSCV classifier outperformed other classifiers in terms of the evaluation metrics with an accuracy of 84%.
Deep learning approaches
Detecting sarcasm in social networks is a complex task. Besides recognizing whether the sentiment has a positive or negative orientation, the purpose is to derive a sarcastic intention from an utterance. Feature engineering in automated systems based on machine learning algorithms hinders obtaining efficient accuracies. In recent years, researchers addressing this issue for the Arabic language have turned their attention to deep learning methods and transformers.
Authors [53]conducted tests based on a Bidirectional Long Short Term Bi-LSTM model followed by a fully connected layer and Mazajak embedding [75] to establish a baseline while proposing the ArSarcasm dataset. Their poor F1-score of 0.46 demonstrates how difficult it is to identify sarcasm in written messages [76] collected a dataset from the Twitter scrapper. This dataset contains a balanced schema of 5620 ironic tweets. For feature extraction, they employed a pre-trained word embedding Word2Vec of 300D embeddings. The embedding layer is linked to the neural network model. They experimented using Convolutional Neural Networks (CNN) and Bi-LSTM models, and they reported that two layers of CNN produced the best F1-score of 0.87. Because of its capacity to recognize invariant position features and to feed the output of each layer to the subsequent layer regardless of its position, these results demonstrated that CNN models might be pretty good at identifying sarcasm in text.
A.Omar et al [77] proposed an enhanced model based on artificial neural networks (ANN) and the feature selection method Particle Swarm Optimization (PSO). They optimize the accuracy from 82.12% to 86.85% after the PSO feature reduction. The suggested system showed greater accuracy than the model described in [53] that uses word embedding feature representation, despite being based on the TF-IDF feature representation, which is utilized to compute the numerical values corresponding to the features without taking into account the context. Moreover, in an attempt to handle multilingual sentiment analysis, Touahri et al. [78] constructed a set of sarcastic features through manual analysis of tweets from two multi-dialect datasets. These features include hashtag features, sarcasm indicators, mixed features, exclamation marks, and laughter indicators. They used the deep learning models RNN (Recurrent Neural Networks) and LSTM (Long Short Term Memory) for classification and achieved 80.36% accuracy.
Transformers models
To process text corpora, Transformers offer thousands of pre-trained models for Natural Language Processing tasks, specifically for sentiment analysis, categorization, information extraction, question answering, summarization, and translation. Because it was a powerful translation model and trained considerably more quickly than its forerunners, The Transformer represented a revolution when it was first introduced. Nevertheless, most significantly, it has impacted NLP and the pre-trained models it has stimulated.
Table 2 presents the tasks shared around sarcasm detection in Arabic. Primarily, the three tasks considered three different datasets with Deep Learning, Ensemble Learning, and Transformers models. The F1-score metrics are relatively low compared to the performance of systems in English.
Tasks on Arabic Sarcasm detection and their best results
Tasks on Arabic Sarcasm detection and their best results
i.https://edinburghnlp.inf.ed.ac.uk/workshops/SemEval2022/train.Ar.csv.
ii.https://github.com/iabufarha/ArSarcasm-v2/tree/main/ArSarcasm-v2.
In order to alleviate the need for large-scale data for the Arabic NLP tasks. The team of Zhang et al. [79] proposed a purely deep learning model based on fine-tuning the pre-trained bidirectional encoders from transformers (BERT) on data from six tasks, including Author Profiling and Deception Detection, Emotion Detection, and Sentiment Analysis in Arabic tweets. They improved their model to handle multidialectal data by further training on a Twitter dataset composed of random dialects. This system was ranked fourth with an F1 score of 0.824. Multi-Task Learning (MTL) was also the system’s core module provided by [80], while the tasks concerned Sentiment Analysis and Sarcasm Detection on the ArSarcasmv2 dataset. The authors proved that the MARBERT-based system with MTL configuration outperformed the single-task model and obtained an F1-score of 0.662. Anshul et al. [81] first preprocessed the ArSarcasm-v2 dataset by changing and deleting several text components from the initial corpus. Then, they performed experiments using several iterations of the AraELECTRA and AraBERT transformer models, both of which were previously trained on Arabic text. The best-reported F1-score for the Arabic sarcasm detection task is 0.855 using the AraBertv2-base model. Hengle et al. [82] demonstrated that their hybrid system performed better for sarcasm detection than the standalone AraBERT model. The system is composed of three layers. The first concatenates the pre-trained Mazajak embeddings at the sentence level. Then the representation is passed to the CNN-BiLSTM ensemble to get a sentence representation followed by the AraBERT model that constructs the contextualized tweet representations. Thus, this combined system showed the efficiency of incorporating embedding from static models to the BERT transformer instead of training on large-scale Arabic datasets. The team [83] showed that increasing the size of datasets’ size directly impacts the improvement of results. Thus, they proposed different approaches for data augmentation, such as extending datasets, creating new instances with word embedding, or relying on token repetition. For the models, they trained the Electra and BERT Transformers while adding or removing a BiLSTM layer with or without attention. Finally, the BERT CAMeLBERT-Mix model performed the best by showing stability for the Arabic sarcasm detection task with 0.87 in accuracy and the other tasks.
In the following, we present a summary of the tasks commonly known in the research community for sarcasm detection in Arabic, showing the model that won the first rank and the reported measures.
Sarcasm is difficult to detect in social network data, and even human users sometimes need to interpret sarcasm better. Sarcasm can be nuanced, especially when dealing with textual content containing noise, short sentences, and idioms that overcome the character limit. Moreover, it is tough for users to identify and produce sarcastic content. On the other hand, algorithms are also unable to identify sarcasm without indicating markers such as the hashtags #sarcasm, “irony and so forth.
Throughout the studies reviewed, we observe that context influences recognizing sarcasm in a text. Deprived of its context, it is highly challenging to determine whether an utterance is sarcastic or not.
We discovered that the majority of datasets addressing this issue have an unbalanced distribution with a low representation of the sarcastic class, particularly for the Arabic language. For this reason, the most reliable metric is the F1-score, which considers balancing the classification of the various classes of sarcasm, whether they are considered positive or negative, as well as the types of sarcasm. The reported measures, however, still need to be higher and, in the best circumstances, do not reach 0.7. Recent works in shared tasks demonstrated that ensemble machine-learning techniques could be very effective and less expensive than deep learning or Transformers models for this task.
Lastly, because algorithms learn by doing, getting very high ratings for novel forms of sarcasm is challenging. As a result, researchers are trying to increase dataset size and provide more Arabic resources.