
Abstract
Unmanned aerial vehicles (UAVs) play a crucial role in maritime search and rescue missions, capturing images of open water scenarios and assisting in object detection. Previous object detection models have mainly focused on general scenarios. However, existing object detection models have mainly focused on general scenarios, while images captured by UAVs in vast ocean scenarios often contain numerous small objects that significantly degrade the performance of the original models. To address this challenge, we propose a model that can automatically detect objects in images captured by UAVs during maritime search and rescue missions. Our approach involves designing a new detection head with higher resolution feature maps and more comprehensive feature information to improve the detection of small objects. Additionally, we integrate Swin Transformer blocks into the small object detection head, which can improve the model’s ability to obtain abundant contextual information and thus improves the model’s ability to detect small objects. Moreover, we fuse the Convolutional Block Attention Model into the small object detection head to help the model focus on important features. Finally, we adopt a model ensemble strategy to further improve the mean average precision (mAP). Our proposed model achieves a 4.05% improvement in mAP compared to the baseline model. Furthermore, our model outperforms the previous state-of-the-art model on the SeaDronesSee dataset in terms of fewer parameters, lower training costs, and higher mAP.
Introduction
Marine transportation is the most dominant mode of transportation in international logistics. The development of the marine economy has intensified maritime activities. However, the marine scenario is complex. Natural disasters such as high winds, tsunamis, and huge waves can sometimes cause maritime distress accidents [1]. Analysis of a number of maritime accidents shows that search and rescue (SAR) at sea takes too long, leading to people’s disappearance or death due to untimely rescues [2]. Therefore, fast and effective SAR methods are crucial for improving the survival probability of victims in maritime distress accidents [3].
UAVs can quickly reach hard-to-reach areas and cover large search areas in a short period [4]. Using camera-equipped UAVs can quickly cover a wide range of maritime scenarios and provide aerial images of the search area in real-time, so the effective use of UAVs plays an important role in maritime SAR missions. The precise and timely detection of objects in aerial images is one of the most challenging issues in maritime SAR missions [5].
Object detection algorithms for maritime SAR missions rely on a large amount of real training data from UAVs. However, the available datasets from UAVs are mostly limited to object detection in land traffic scenarios, such as VisDrone [6] and UAVDT [7]. Datasets specifically designed for maritime scenarios are primarily focused on remote sensing, which may not provide the required resolution for effective SAR missions [8]. To bridge the gap between ocean-based and land-based visual systems and help develop SAR systems in ocean scenarios, Varga et al. [8] proposed a large-scale open dataset called SeaDronesSee, which consists of images captured in open water environments. Using the SeaDronesSee dataset, Varga et al. [8] conducted extensive experiments on popular object detection models such as Faster R-CNN [9], CenterNet [10], and EfficientDet-D0 [11], using them as baselines. However, the SeaDronesSee dataset contains many small objects due to the aerial UAVs’ capture in large open water scenarios. As a result, the performance of current standard object detection methods is greatly reduced in the SeaDronesSee dataset, which lacks general scenarios. This limitation highlights the inadequate applicability of current object detection models in vast ocean scenarios.
Kiefer et al. [12] proposed that the performance of object detection models can be improved by using more available datasets. However, due to flight limitations, environmental factors, privacy issues, and other restrictions, it is challenging for UAVs to search a wide range of maritime scenarios [8], resulting in a limited amount of publicly available UAV data for maritime SAR missions. To address this issue, Kiefer et al. [12] utilized Grand Theft Auto V as a simulation platform to create a large-scale high-resolution synthetic dataset called DGTA-SeaDronesSee, which is set in virtual open water scenarios. Figure 1 shows the images in the SeaDronesSee dataset and the DGTA-SeaDronesSee dataset, respectively. Subsequently, Kiefer et al. [12] used the DGTA-SeaDronesSee dataset for pre-training the YOLOv5m6 [13], Faster R-CNN, and EfficientDet-D0 models, followed by transfer learning on the SeaDronesSee dataset. The results demonstrated that the performance of the model can be significantly improved by using the additional synthetic datasets. However, it should be noted that the file size of the synthetic DGTA-SeaDronesSee dataset is as large as 687.4G, which is almost 11.5 times larger than the SeaDronesSee dataset (60.2G). Table 1 lists the comparison between SeaDronesSee dataset and DGTA-Seadronessee dataset. Although the model’s performance can be improved with the use of large training datasets, the associated high training cost and huge dataset size may not be the most optimal approach for improvement.

Image samples in SeaDronesSee (a) and DGTA-SeaDronesSee (b) with ground truth annotations. Representative objects are magnified.
Comparison between SeaDronesSee and DGTA-SeaDronesSee
In object detection tasks, the YOLO series models [13–17] always pursue a trade-off between speed and precision in real-time applications. According to our knowledge, YOLOv5 performs better than other object detection models on the SeaDronesSee object detection challenge [18]. Consequently, based on YOLOv5, we design our model by making a series of improvements to it in order to accurately and quickly detect objects in aerial images during maritime SAR missions. We respectively use CSPDarknet53 [19] and PANet [20] as the backbone and neck of our model, which follows the original version of YOLOv5s. In the head of our model, we first design a new object detection head for detecting the numerous small objects in aerial images. To improve the model’s ability to obtain abundant contextual information and thus increase the model’s performance further in detecting small objects, we integrate Swin Transformer blocks [21] into the small object detection head. Then we fuse the Convolutional Block Attention Model (CBAM) [22] into the small object detection head to find attention regions in large coverage images. Finally, we use the model ensemble strategy to improve the average precision further. On the SeaDronesSee dataset, our model’s mean average precision (mAP) result is 33.68%, which outperforms the previous state-of-the-art model(Synth Pretraine YOLO5) with lower training costs and fewer parameters.
The main contributions of our work can be summarized as follows: We propose a novel detection head with higher resolution feature maps and more comprehensive feature information to facilitate the model in detecting small objects. We incorporate Swin Transformer blocks into the small object detection head, enhancing the ability of the model to capture abundant contextual information. We integrate the Convolutional Block Attention Model (CBAM) structure into the small object detection head, enabling the model to identify attention regions in images with large coverage. We adopt a model ensemble strategy to further improve the average precision of our model. On the SeaDronesSee dataset, the mean average precision of our model outperforming the previous state-of-the-art with lower training costs and fewer parameters.
SeaDronesSee dataset
SeaDronesSee is the first large annotated dataset based on UAV imagery in open water, specifically designed for object detection in maritime search and rescue missions. Varga et al. [8] captured video and images of swimming activities in open water using various UAVs and cameras, with resolutions ranging from 3480×2160 pixels to 5456×3632 pixels. The images were then carefully annotated and objects were classified into six categories using the DarkLabel [23] labeling tool, including swimmer, floater (swimmer with life jacket), boat, swimmer† (person on boat not wearing a life jacket), floater† (person on boat wearing a life jacket), and life jacket. The distribution of each category in SeaDronesSee is shown in Fig. 4. Figure 2 provides an example of a typical image containing all six categories, while Fig. 3 shows enlarged images of some objects from Fig. 2, albeit with some blurring due to the high resolution of the image.

Example of a typical image that contains six categories.

Examples of objects. These examples are crops from high-resolution images. However, as the objects are small and the images are taken from high altitudes, they appear blurry.
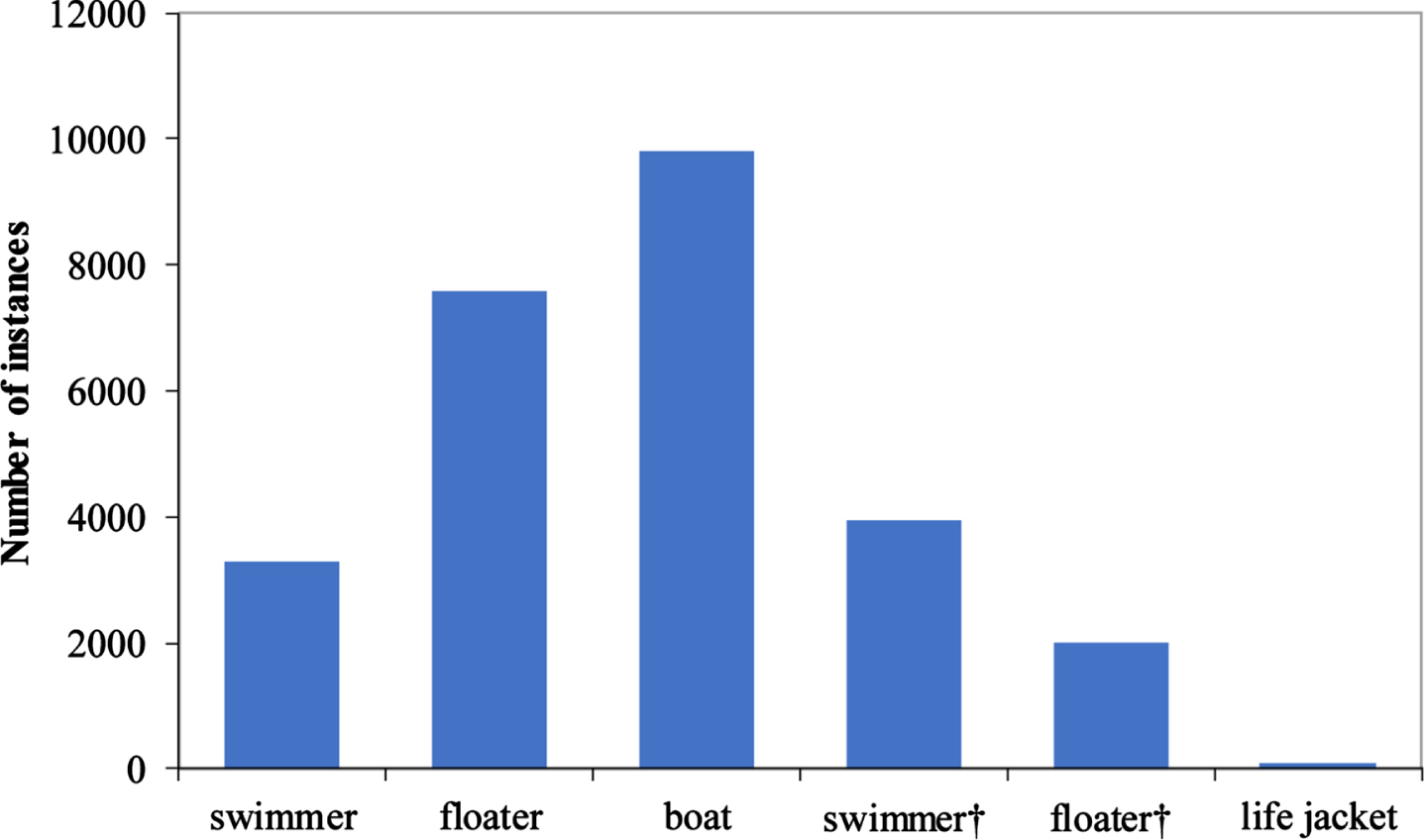
The number of each category in SeaDronesSee.
Zhan et al. [24] used 0.3% and 3% as thresholds to distinguish between small, medium, and large objects. An object is defined as a small object when the object area accounts for less than 0.3% of the overall image area. When the object area accounts for between 0.3% and 3% of the image area, the object is defined as a medium object. An object is defined as a large object when the object area accounts for more than 3% of the image area. The COCO dataset [25] is one of the most commonly used datasets for object detection. Based on the definition, Zhan et al. [24] calculated the percentage of small, medium, and large objects in COCO. We calculate the percentage of small, medium, and large objects in SeaDronesSee with the same method. Table 2 lists the percentage of different size objects in MS-COCO dataset and SeaDronesSee. As Table 2 lists, the SeaDronesSee dataset has a large number of small objects compared to the MS-COCO dataset.
Comparison of object sizes between SeaDronesSee and COCO
Figure 5 shows the structure our model. Since there are many small objects in the SeaDronesSee dataset, we first add a new small object detection head for detecting the numerous small objects in the aerial images. Then we integrate Swin Transformer blocks into the small object detection head, enhancing the ability of the model to capture abundant contextual information. We also fuse CBAM to help the model find attention regions in the images. Finally, we adopt the model ensemble strategy to improve the mAP further.
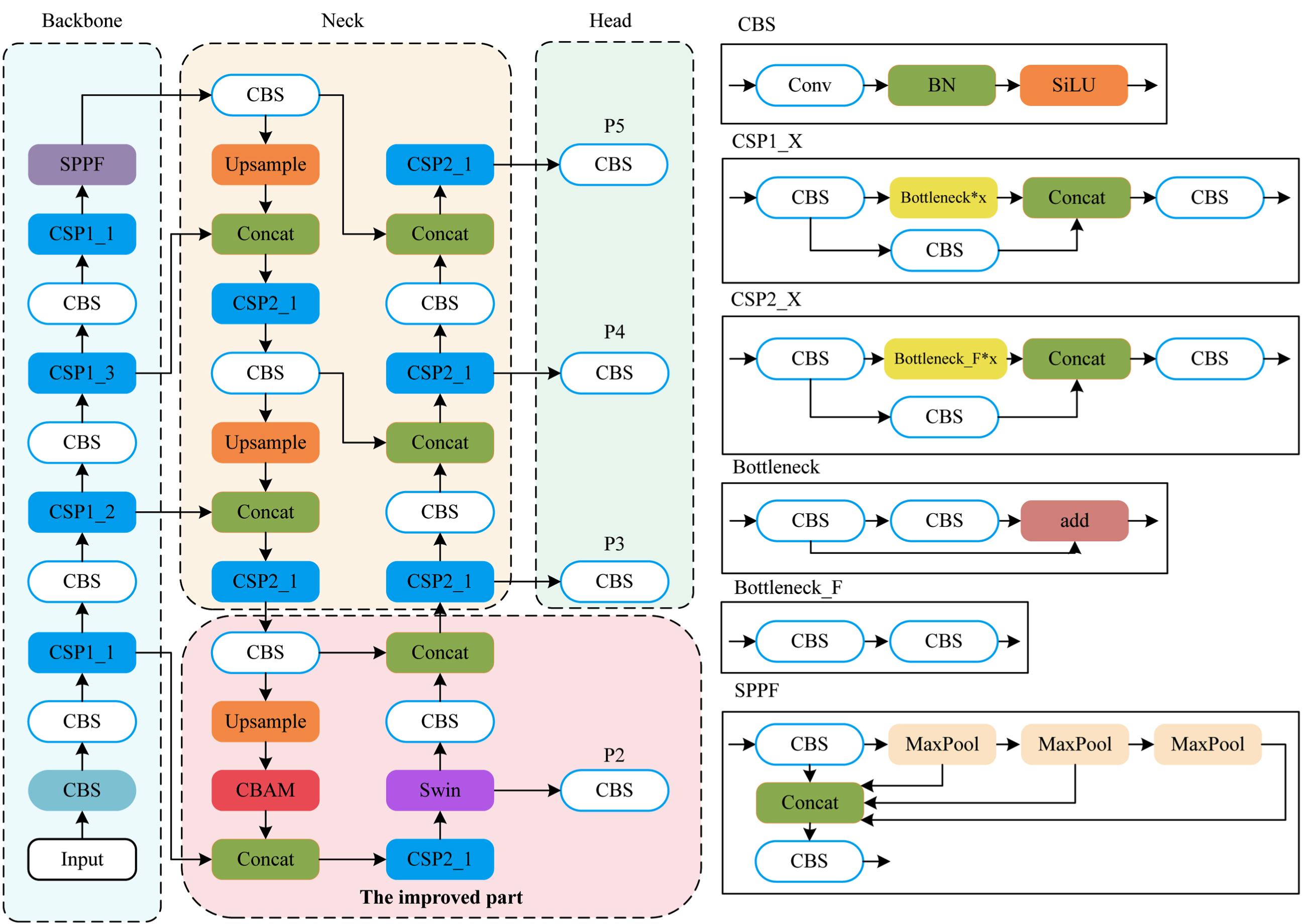
The structure of our model. The structure in the pink background circled with a dotted line is the small object detection head we designed.
The images and annotations in the training and validation sets of SeaDronesSee are made available to researchers, who are free to adjust the data for training their models. The test set only provides images without annotations, and researchers need to use their own models to detect objects in the test set and upload the results to the SeaDronesSee official website to obtain the model’s prediction performance.
The distribution of objects among the six classes in the training and validation sets of SeaDronesSee is imbalanced. As shown in Fig. 6, there are significant disparities in the proportions of different objects in the training and validation sets, with variation ranges from 3:1 to 41:1 among different classes. To address this issue, we restructure the dataset to ensure a more balanced proportion of each class between the training and validation sets, with a ratio of 4:1. Additionally, due to the limited number of samples in the life jacket class, we appropriately increase the training set proportion of this class during the dataset restructuring process, to enable better feature learning of the life jacket class by the model.
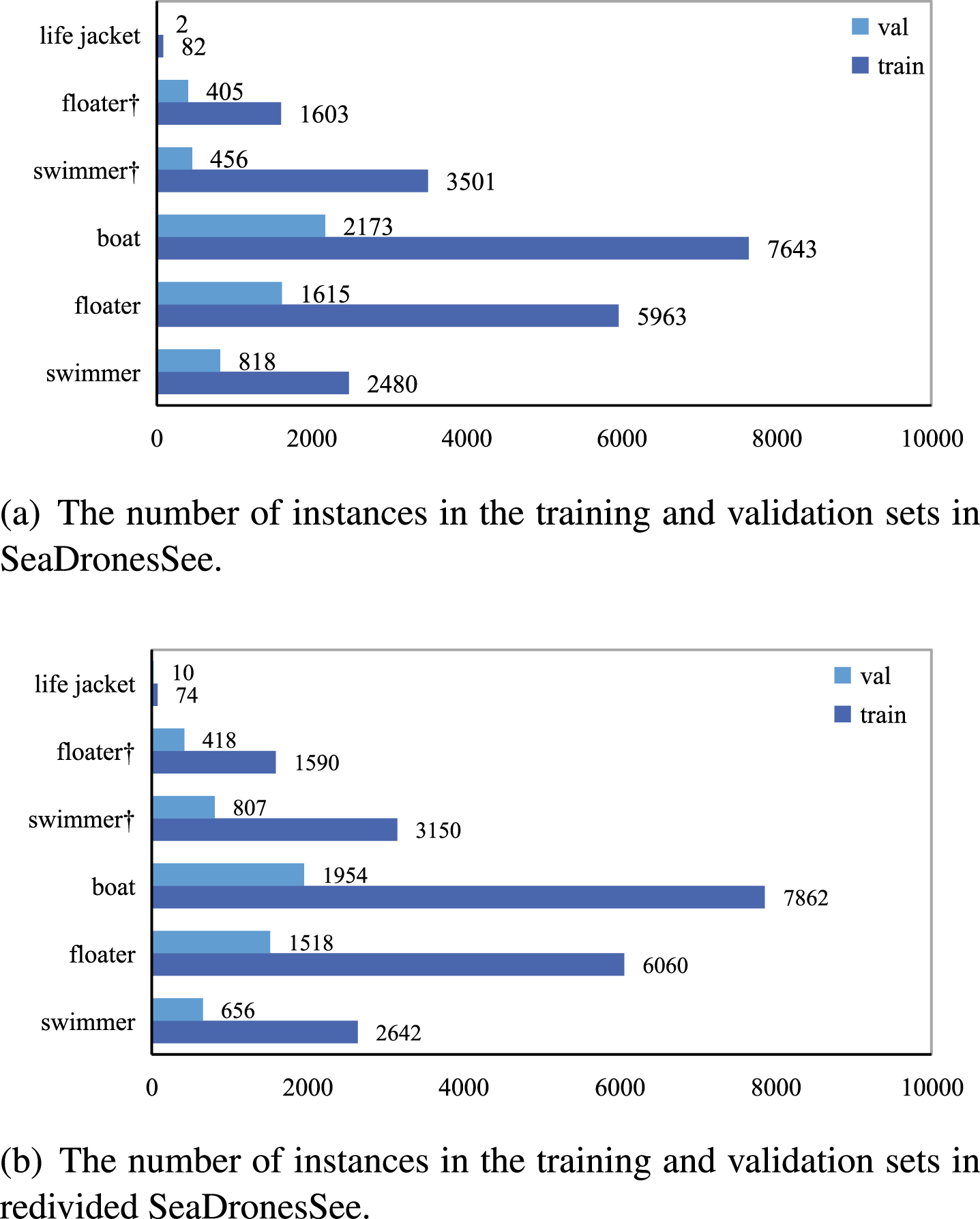
The number of instances in the train set and verification set.
YOLOv5s has three detection heads P3, P4, and P5. However, the feature maps corresponding to these three detection heads have low resolution, lack low-level feature expression, and weak fine-grained feature representation, which is not conducive to the model learning the features of small objects [24]. Therefore, we add a new detection head with higher resolution feature maps and more completed feature information to the original three detection heads to facilitate the detection of small objects.
Due to the limited area and feature information of small objects, they are typically detected in shallower feature maps. As listed in Table 3, when the input image size is 640×640, the feature map size of P2 is 160×160 after a 4× down-sampling operation. Similarly, the feature map size of P3 is 80×80 following an 8× down-sampling operation, while the feature map size of P4 is 40×40 following a 16× down-sampling operation. Finally, the feature map size of P5 is 20×20 after a 32× down-sampling operation. The feature map size gradually decreases from P2 to P5 as the down-sampling multiplier increases. Therefore, P2 is more suitable for detecting small objects, while P5 is more suitable for detecting large objects.
The detection layer sizes of P2, P3, P4 and P5 when the input image size is 640×640
The detection layer sizes of P2, P3, P4 and P5 when the input image size is 640×640
The percentage of small objects in the SeaDronesSee dataset is as high as 41.34%. Due to the small size of these objects, their feature information is limited, resulting in difficulties in accurate recognition. Transformer encoder blocks have been shown to be capable of capturing global information and abundant contextual information in object detection tasks [27]. Contextual information plays a crucial role in object detection, and effective utilization of contextual information can greatly improve the performance of object detection algorithms, especially for detecting small objects with limited cues [26]. However, if we add the Transformer block to all heads of YOLOv5, the computational complexity of the model will be excessively high.
Based on the Equation 1, where N head is the number of attention heads, L seq is the sequence length, and D is the dimension per head. (H, W) is the resolution of the feature map. We can see that the computational complexity of the Transformer block is proportional to the square of the feature map size. Only considering the increase in computational complexity brought by Transformer. The total complexity can be calculated as:
Therefore, choosing the appropriate detection heads to add Transformer, rather than adding Transformer to all detection heads, can effectively reduce the computational complexity of the model. However, the computational complexity of the Transformer is quadratic with respect to the image size, and despite our efforts to mitigate the increase in computational complexity, it still significantly adds to the training burden.
Swin Transformer [21] is a hierarchical Transformer that employs a shift window scheme to limit the self-attention computation to non-overlapping local windows. As shown in Equation 3, Swin Transformer allows for cross-window connections, resulting in a self-attentive computational complexity that is linearly related to the image size. Therefore, as shown in Fig. 7, we further improve the Transformer in the detection head by replacing it with two consecutive Swin Transformer blocks, aiming to further alleviate the training burden.
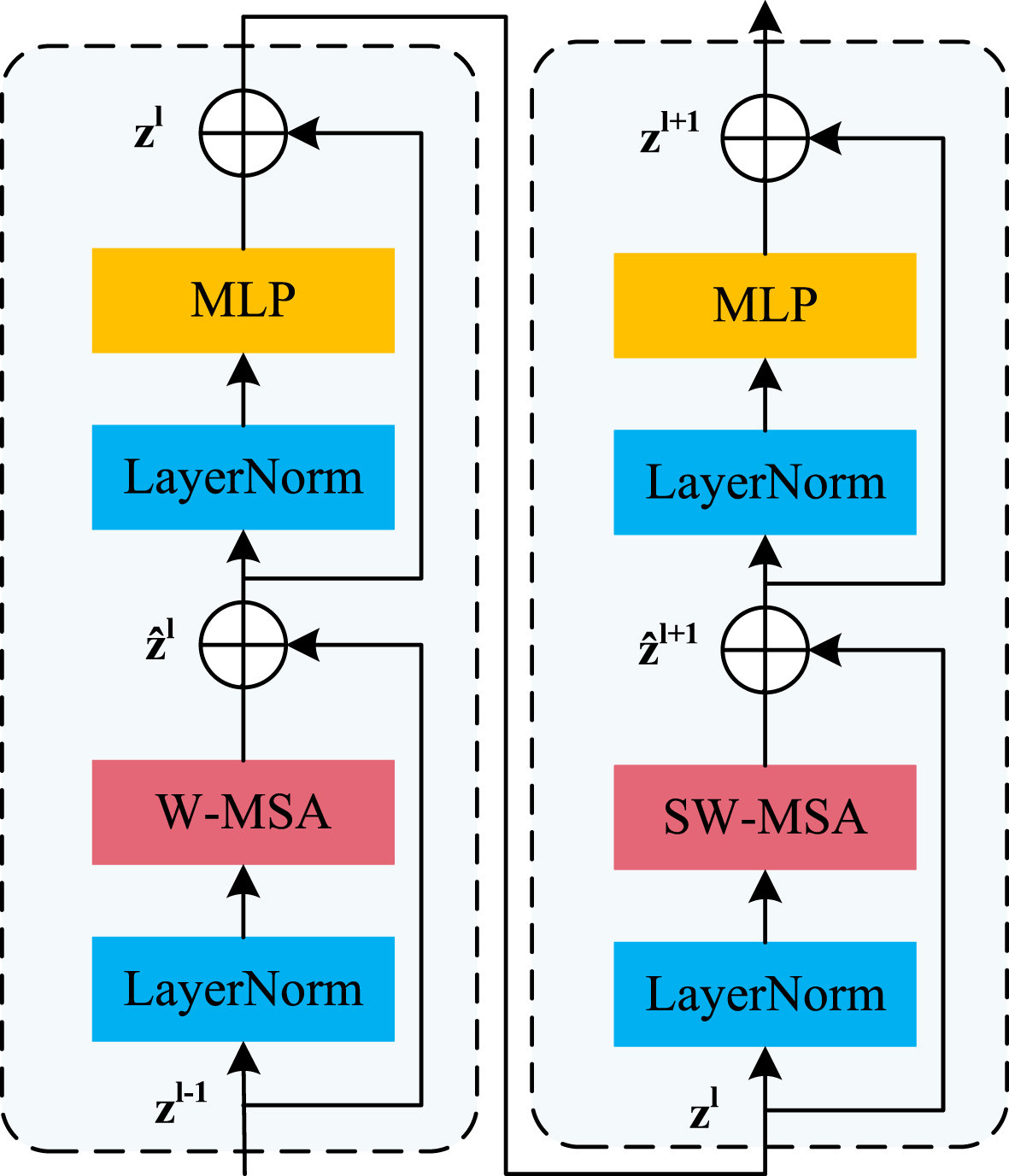
Two successive Swin Transformer Blocks. W-MSA and SW-MSA are multi-head self attention modules with regular and shifted windowing configurations, respectively.
Attention mechanisms can help models focus on important features and suppress unnecessary ones [22]. CBAM is a simple and effective attention module that can be widely used to improve the representation power of convolutional neural networks. As shown in Fig. 8, there are two sequential submodules in CBAM module, namely channel attention module and spatial attention module. In our model, we fuse the CBAM structure into the small object detection head to help it focus on important features of small objects.
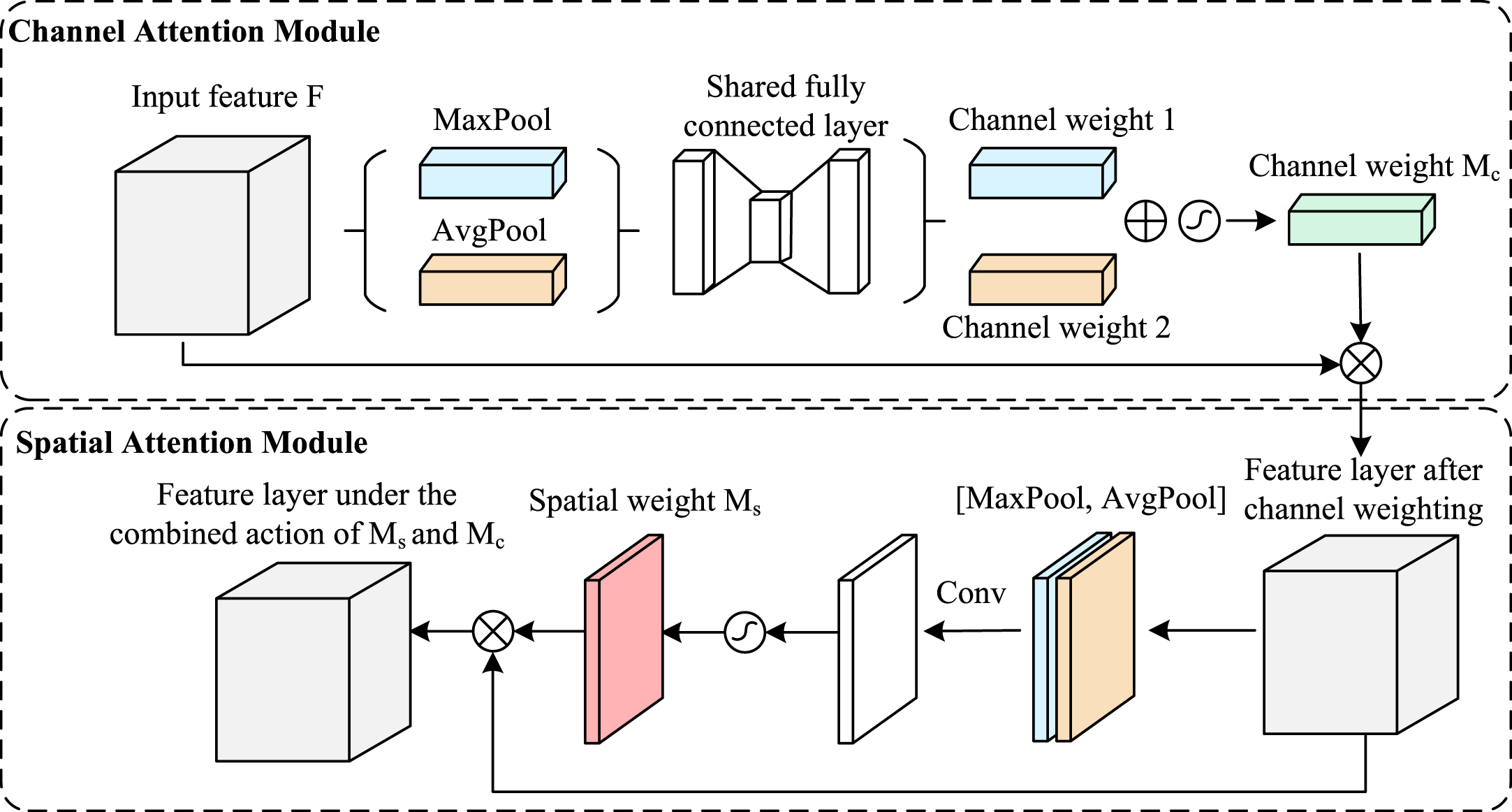
The structure of CBAM.
In the channel attention module, max-pooling and average-pooling operations are performed on every single feature map in the input module. Then, the results of max-pooling and average-pooling are processed using a shared fully connected layer. Finally, the processed results are added, and the results after the sigmoid operation are used to obtain the weight of each channel.
In the spatial attention module, the average-pooling and max-pooling operations are applied along the channel axis, and the results are then concatenated. The channels are adjusted by convolution with the number of channels of 1. Finally, the results after the sigmoid operation are used to obtain the weight of each feature point.
The channel attention is computed as:
Model ensemble can seek the wisdom of the crowds in making predictions and is a commonly used method to improve the robustness and precision of models [28]. During our experiment, we try to integrate two models with the highest performance (M2 and M4 in Table 7). First, obtaining different prediction boxes using different models and then using Non-Maximum Suppression [29] to aggregate these prediction boxes to select the box with the highest confidence level.
Results and discussion
Experimental environment
To verify the performance of our model, we experiment in the same hardware and software environment. All the experiments are run on a server with two 16C32T Intel(R) Xeon(R) Gold 5218 CPU @ 2.30 GHz, two NVIDIA(R) Tesla(R) V100S with 32G video memory each, and 188 GB RAM. The Operating System is Ubuntu 18.04.1, the CUDA version is 10.2, and the cuDNN version is 7.6.5. The open-source machine learning library is PyTorch 1.11.0, the torchvision version is 0.12.0, and the Python version is 3.7.0.
Evaluation metrics
Since the labels of the SeaDronesSee test set are not publicly available, researchers need to upload their predictions on the test set to the SeaDronesSee website to evaluate the model’s test performance. We can find the model’s performance on different evaluation metrics in the leaderboard on SeaDronesSee’s official website. There are five evaluation indicators on the leaderboard: AP, AP50, AP75, AR1 and AR10. Table 4 lists the meaning of each metric. All results in this article are taken from the SeaDronesSee leaderboard.
Evaluation index of object detection
Evaluation index of object detection
The mAP is each category’s average AP, and the mAR is each category’s average AR. Because the SeaDronesSee dataset consists of six objects, the AP and AR on the leaderboard actually refer to the mAP and mAR, respectively.
The performance of YOLOv5s and our model on the SeaDronesSee dataset is compared as shown in Table 5.
Performance analysis of our model and YOLOv5s
Performance analysis of our model and YOLOv5s
By employing a small object detection head, integrating two successive Swin Transformer blocks, fusing CBAM, and using a model ensemble strategy, the result of mAP50, mAP75, mAP, and mAR1 improves by 5.79%, 5.24%, 4.05%, and 2.7%, respectively. The performance improvement of our model can be more clearly reflected in Fig. 10.
Figure 9 shows the detection results of YOLOv5s and our model in actual scenarios. As shown in Fig. 9(a), YOLOv5s does not detect the floater object in the lower left corner, incorrectly detects a floater object in the lower left corner as a swimmer object, and misses two swimmer objects in the image. In Fig. 9(b), our model correctly detects all objects, which is significantly better than YOLOv5s. As shown in Fig. 9(c) and (d), our model detects the floater† object, while YOLOv5s does not detect this object. There are three swimmer† objects in the bottom of Fig. 9(e) and (f). YOLOv5s only detects one of them, while our model detects all of the objects.

Visualization results of YOLOv5s and our model.
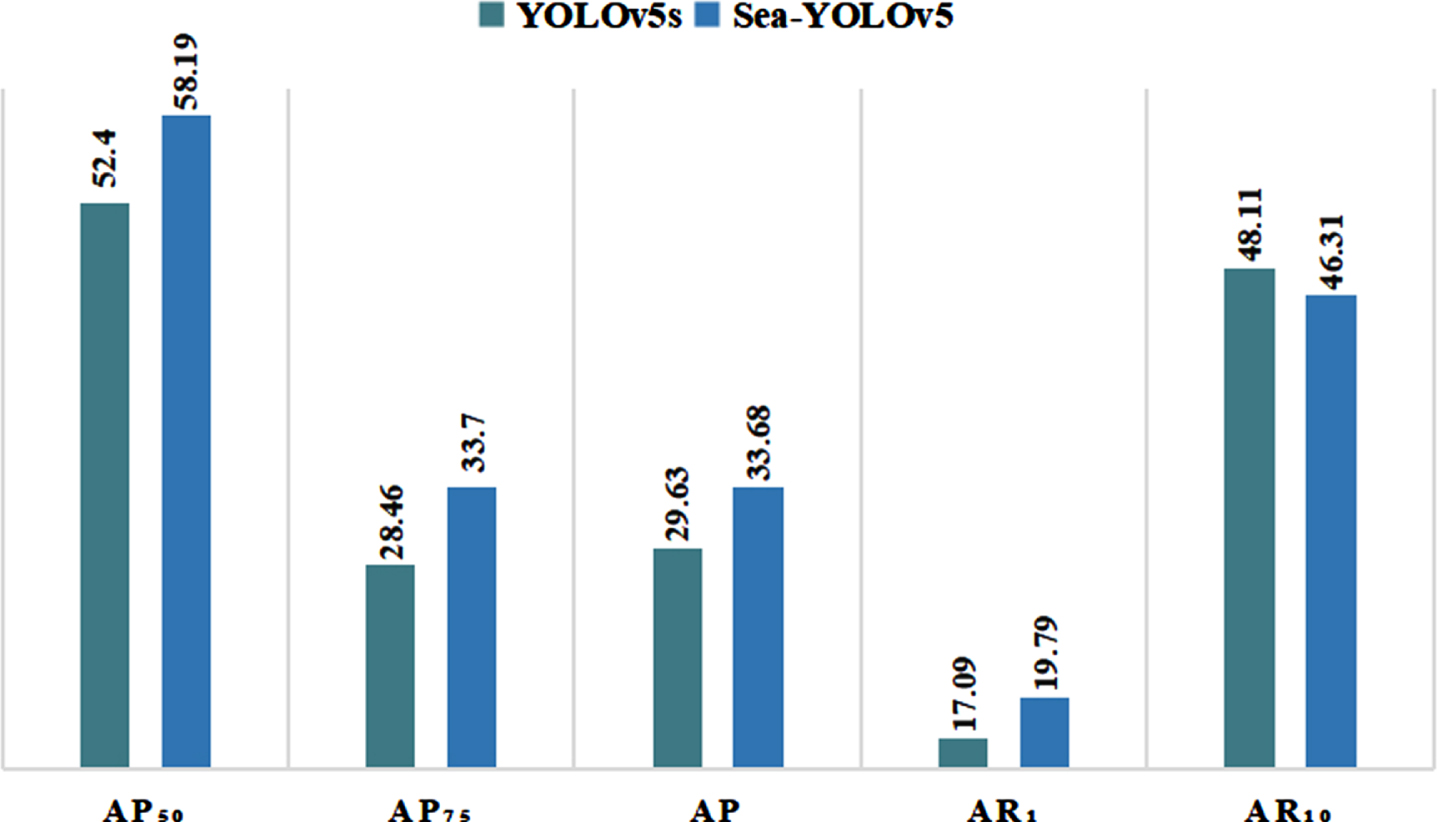
Performance analysis of YOLOv5s and our model.
These results indicate that our model outperforms the original YOLOv5s model in terms of detection.
To verify the effectiveness of the method proposed in this paper, we conduct ablation experiments on each improvement, and the experimental results are listed in Tables 6 and 7.
Performance of YOLOv5s on the same test set after redividing the SeaDronesSee
Performance of YOLOv5s on the same test set after redividing the SeaDronesSee
Ablation study on the test set of SeaDronesSee
As listed in Table 6, we re-divide the SeaDronesSee dataset so that the ratio of each type of object’s number in train set to validation set is 4 to 1. Because the number of life jacket classes is so small, we also appropriately increase the number of life jackets in train set. After re-dividing the SeaDronesSee dataset, the result of mAP50, mAP75, mAP, and mAR1 improves by 2.08%, 3.61%, 2.16%, and 1.43%, respectively. This validates the effectiveness of the re-division of SeaDronesSee dataset.
As listed in Table 7, after adding the small objects detection head, the mAP50, mAR1, and mAR10 of the M1 is improved by 0.76%, 0.64%, and 2.32%, respectively. By comparing M1 and M2, we find that after integrating Swin Transformer blocks into the small object detection head, the mAP50, mAP75, mAP, mAR1, and mAR10 of the M2 improves by 1.17%, 1.05%, 1.44%, 0.26%, and 0.39%, respectively. When comparing M1 and M3, it can be found that the mAP50 and mAP of M3 increases by 0.97% and 0.59%, respectively. Compared with M2, the mAP50, mAP75, mAP, and mAR1 of the M4 improves by 0.88%, 0.12%, 0.16%, and 0.25%, respectively. Finally, the model M5 which is trained by integrating all methods achieves the best test results. Compared with YOLOv5s, which is trained with the same dataset, the mAP50, mAP75, mAP, mAR1, and mAR10 of the model improves by 3.71%, 1.63%, 1.89%, 1.27%, and 4.03%, respectively. The results of the above ablation experiments demonstrate the effectiveness of all our improvements.
To verify the model’s performance, we compare our model with the other models on the SeaDronesSee dataset. The comparison results are shown in Table 8.
Performance comparison of different models on the SeaDronesSee dataset (sorted by mAP) as of August 28, 2022. More details can be found on the SeaDronesSee leaderboard (https://seadronessee.cs.uni-tuebingen.de/leaderboard
Performance comparison of different models on the SeaDronesSee dataset (sorted by mAP) as of August 28, 2022. More details can be found on the SeaDronesSee leaderboard (https://seadronessee.cs.uni-tuebingen.de/leaderboard
As listed in Table 8, prior to our model, Synth Pretrained YOLOv5m6 is the best model on the SeaDronesSee object detection challenge leaderboard. The Synth Pretrained YOLOv5m6 uses YOLOv5m6 as the base model and uses up to 687.4G of synthetic data to pre-train YOLOv5m6 and then transfer-trained on the SeaDronesSee dataset. The results show that compared with the original YOLOv5m6, the Synth Pretrained YOLOv5m6 has improved mAP50, mAP75, mAP, mAR1, and mAR10 by 2.02%, 4.34%, 1.20%, 0.76% and 1.62%, respectively. However, the improved performance of the Synth Pretrained YOLOv5m6 comes at the cost of a huge training dataset and high training costs. Our model is based on the YOLOv5s lightweight model and integrates different improvement strategies to improve the model’s performance. On the SeaDronesSee dataset,our model outperforms the Synth Pretrained YOLOv5m6 with lower training costs and higher mAP.
Up to now, it can be seen from the leaderboard that our model is the best performer among all the models based on the improved yolo series.
The SeaDronesSee dataset represents the first large annotated UAV dataset based on open water, making it a valuable resource for training object detection algorithms to support UAVs in maritime Search and Rescue (SAR) missions. However, similar to other UAV datasets in the field, the SeaDronesSee dataset also presents certain limitations. Specifically, the presence of numerous small objects in the dataset poses challenges for object detection performance. To address this limitation, we have designed a new detection head with higher resolution feature maps and more comprehensive feature information, integrated Swin Transformer blocks for improved contextual information, incorporated CBAM structure to aid in identifying attention regions in large coverage images, and adopted a model ensemble strategy to further enhance performance. As of August 28th, 2022, our model has set a new record in the SeaDronesSee object recognition challenge, achieving higher mean Average Precision (mAP) compared to the previous state-of-the-art model according to experimental results on the test set. Despite these achievements, there are still several limitations to our study. The dataset used in this study, although the largest of its kind in open water, may still have limitations in terms of diversity and representativeness. In future research, efforts should be made to address these limitations and explore the potential of other tasks beyond object detection.
Footnotes
Acknowledgments
This work is supported by the National Science and Technology Major Project, China (Grant No. 2021YFB0300104) and the key program of National Science Fund of Tianjin, China (Grant No. 21JCZDJC00130).