
Abstract
The use of general target detection algorithms for small-target detection is computationally costly and has a high missed detection rate. A lightweight small-target detection model based on YOLOv5 is proposed to address this issue.First, a maximum pooling layer is introduced to reduce the number of calculations. Second, Shuffle_Conv is designed to replace the ordinary convolutional layer to reduce model parameters. To further compress the model, the Add fusion method is used in the C3 module, while the GAC3 layer is designed with GhostNet. Finally, Mosaic_9 is introduced to improve the small-target detection without increasing the number of calculations. Compared with YOLOv5, computation and parameters of the improved model are reduced by 84.9% and 39.1%, respectively, and the accuracy is improved by 2%, which is more obvious than that of the original model.
Introduction
Smoking is harmful to health and poses a serious risk of fire, which may result in fatality and economic losses. The large number calls for proper management and control of non-smoking public places, which can be achieved using smoking detection algorithms. However, these algorithms fail to detect smoking in small areas because of unable to extract effective features of small targets. Traditional smoking detection methods include smoke sensor detection or artificial detection, but both methods have certain drawbacks. For instance, the infrastructural requirements for using smoke sensors are high. In large public places, the smoke sensors have a limited effect and struggle to function [1, 2]. Similarly, the detection time of traditional detection methods is considerably limited, as detection cannot be performed round the clock. Therefore, it is difficult to exploit traditional detection methods.
As machine learning advances, more model architectures based on convolutional neural networks are constantly being created. A series of basic network models, such as AlexNet, VGG, ResNet, and DenseNet [3], have achieved desirable results in accuracy. However, the size and computational load of the network models make it difficult to perform fast detection. Consequently, creating a lightweight but highly accurate model became a crucial research focus for smoke detection. SqueezeNet [4] adds a 1
Target detection algorithms have evolved from the initial two-stage target detection algorithms, such as Faster R-CNN [7], to the later one-stage target detection algorithms, such as SSD [8]. The YOLO [9, 10, 11, 12]series, until the development of YOLOv5 in 2020, was widely known for its ultra-fast detection speed and became synonymous with target detection algorithms. Shortly after YOLOv4 was proposed, YOLOv5 was proposed; both algorithms are similar, and YOLOv5, which has four versions, can be regarded as an improved version of YOLOv4. Owing to the difference in the number of residual components in the initial CSP module of the network structure, YOLOv5 has different network depths and widths [13]. YOLOv5s is the lightest in the YOLOv5 series; thus, YOLOv5s was selected as the framework for detecting smoking behavior in this study. When using the original YOLOv5s for detection, the number of calculations performed is 15.8 GFLOPS, showing that parameters and calculations is large [14] despite the algorithm’s relative advantages for target detection. To reduce the model weight and improve its accuracy, the following approach was used in this study. (1) The COV
Related technologies
YOLOv5
In addition to its four basic frameworks, the YOLOv5 algorithm has been iterated in different versions, up to v6.2. Each version is an improvement on the previous version in weight and accuracy [17]. From v4.0, the BottleneckCSP module is replaced with the C3 module to eliminate the first convolution of each bottleneck structure for higher inference speed. In v6.0, the focus layer is replaced by the CBL layer, and the C3 module of the backbone is reduced to 6. Further, the computational cost is reduced through several changes, such as using the SPPF layer instead of the SPP layer. YOLOv5v6.0 has the lowest computational cost and higher accuracy. After comprehensively comparing all versions of YOLOv5, we selected YOLOv5v6.0 as the benchmark experimental model in this study. YOLOv5 divides the overall framework of the YOLOv5s model into four sections (Fig. 1): input, backbone, neck, and prediction. Hereafter, “YOLOv5” represents “YOLOv5sv6.0.”
YOLOv5sv6.0 framework.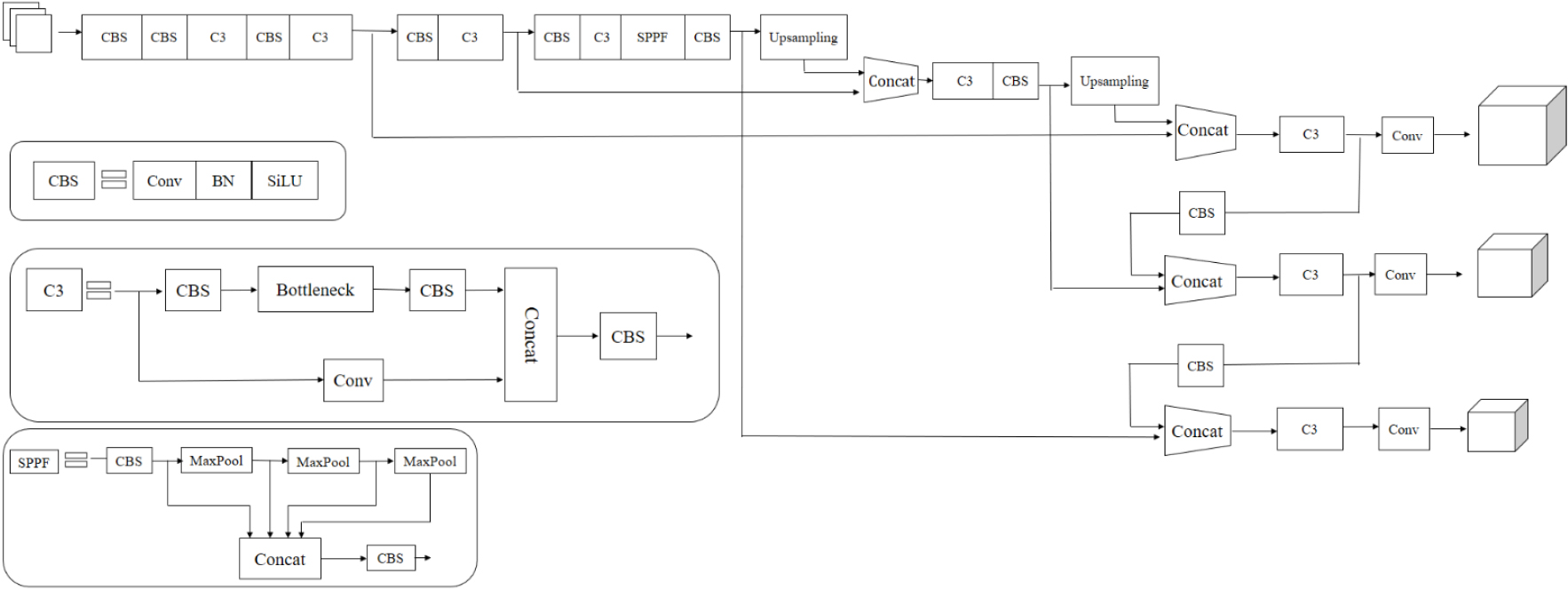
YOLOv5 uses mosaic [18] as the input, randomly cropping, scaling, and stitching four images in the training set. Algorithms prior to YOLOv5 lack adaptive anchor boxes and adaptive image scaling functions. Before training, YOLOv5 outputs the predicted frame according to the anchor frame parameters set in advance; the predicted frame is then compared with the real frame to update the iterative model parameters. When inputting a picture, the commonly used target detection methods scale the input dataset to a fixed size. Owing to the different lengths and widths of the input data, the filling effect also differs, and numerous black borders may affect the detection effect. The adaptive image scaling function solves this problem by determining the minimum number of black border fillings required to improve the detection speed.
In the backbone section, the image is first passed through a CBL module with a 6
In the neck section, YOLOv5 uses the FPN
In the prediction section, YOLOv5 outputs three anchors of different sizes. Typically, 20
The focus layer [20] was proposed for YOLOv5 for slicing and stitching the feature maps. The focus acts as a special down-sampling method, which reduces the dimension of the feature map through the down-sampling layer and avoids over-fitting. Subsequently, v6.0 used the CBL layer to replace the focus layer. Although the computational cost of the model was reduced, the CBL layer neither reduced the dimension nor removed redundant information. Considering that the feature map can reduce the dimension and the number of calculations, the maximum pooling layer was introduced, and the CBR_Maxpooling layer replaced the CBL layer to improve the model performance. The CBR_Maxpooling layer comprises convolution
Shuffle_Conv
Currently, several lightweight networks reduce the number of computations by replacing ordinary convolution layers with group convolution or depthwise separable convolution. However, because of the dispersion of channels, many convolution kernels are used for their respective channels, resulting in incomplete image feature information; moreover, no connection exists between channels, which not only increases the number of computations but also causes a loss of effective information. To address this problem, channel shuffling was introduced in ShuffleNet [21]. After group convolution, channel shuffling is used to flatten the features in the form of tensors to realize information interaction between channels, as shown in Fig. 2.
Mixing process of channel.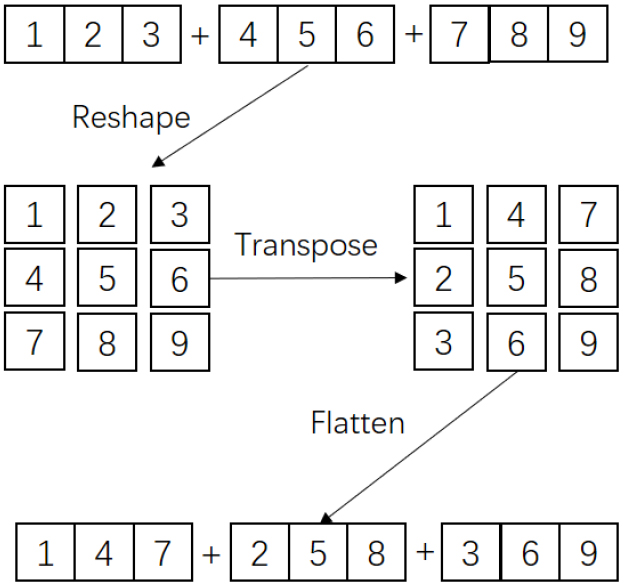
As shown in Fig. 2, the channels are first divided into three groups and numbered 1 to 9. The 1-dimensional channel is expanded into a 3-dimensional channel using the reshape operation, after which the channel is transposed without increasing computational cost. The information interaction between different channels is then analyzed, and the flatten operation is used to reduce the dimension, re-splicing it into a new feature map. Several lightweight networks use depthwise separable convolutions. A network model considers its MAC as well as FLOPS. For instance, point convolution is computationally costly. Let
ShuffleNet has two versions: ShuffleNetV1 and ShuffleNetV2. Depth convolution (DWConv) is an extreme case of group convolution (GConv). Excessive use of GConv increases the model capacity and consumes more MAC. As shown in Eq. (2), where
ShuffleNetV2 reduces the use of group convolution and replaces group convolution with ordinary convolution. As shown in Fig. 3, the feature map is processed using ordinary convolution
Ordinary convolution 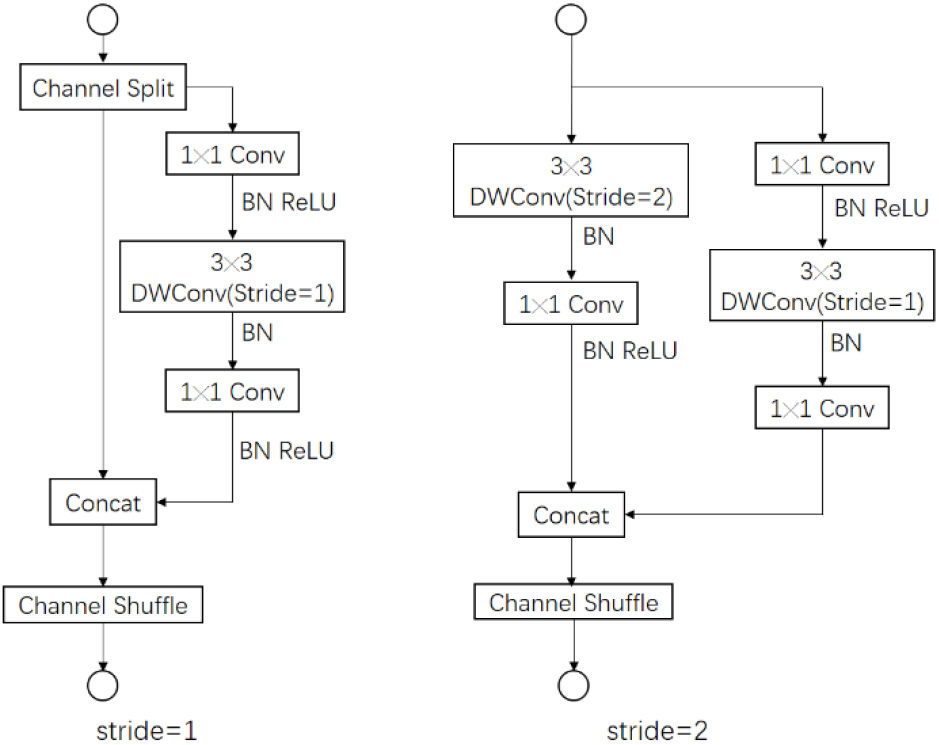
C3 is implemented on the structure of CSPNet. The CSP structure divides the feature map into two branches and fuses the feature information through a hierarchical collapse. Fusion methods are of two main types: Concat and Add, which are used to integrate the feature map information. CSP [22] uses Concat to fuse the information of the output layer with the feature framework extracted by convolution. Channels are merged to increase the dimension of the information. Add acts only increases the amount of information. The image dimension does not change, but the amount of information in each dimension increases. Therefore, Add can be regarded as a special form of Concat, where the number of calculations is half that of Concat. Therefore, we replaced Concat in C3 with Add and designed AC3 to replace the C3 layer in the backbone part.
To avoid the accumulation of convolution layers, AC3 is combined with GhostNet, which was proposed in CVPR2020 to solve the problem of using limited computing resources to generate numerous feature maps. The usual approach to improving accuracy is to increase the number of convolution layers and parameters. Although the approach improves accuracy, it is resource-intensive. In the conventional convolution operation, the calculation amount is
The concept of a ghost module is proposed in GhostNet, comprising conventional convolution, ghost feature map generation, and feature map splicing.
After the conventional convolution operation, m intrinsic feature maps are obtained, and the number of calculations in this process is As shown in Eq. (3), the ghost feature map
The intrinsic feature maps obtained in step (1) are connected through identity to the ghost feature map obtained in step (2) to obtain the final output. We compare the ghost module with the ordinary convolution, and the operation kernel is set as
Because
GAC3 framework.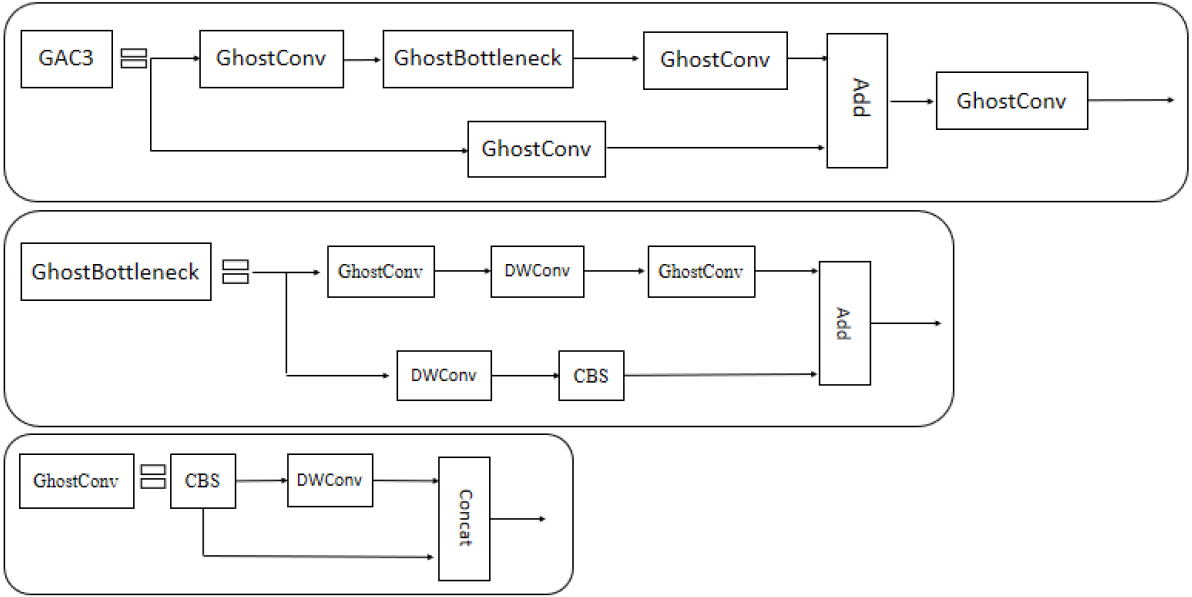
YOLOv5 is widely used today; for example, many engineering-level applications use it for target detection tasks [23]. However, from the perspective of current research and application, YOLOv5 can still be further optimized [24]. In the Table 1, the From column refers to the output from the upper layer, and Arguments refers to the number of input and output channels, convolutional kernel size, step size, and other details for each layer. Table 1 shows that this study mainly optimizes the Backbone part of YOLOv5.
Improved overall structure of YOLOv5
Improved overall structure of YOLOv5
Dataset production and experimental configuration
The datasets used were crawled Baidu and Google images, screenshots of actors smoking in movies, and mobile phone photographs of people smoking. The images were labeled by labeling to obtain a dataset for the experiment, with people who are not smoking used as the interference item. The batch size of all experiments was 32, and 200 epochs were performed.
Dataset analysis.
The dataset for the experiment had 4,880 images, and the ratio of the training set to the test set was 8:2, as shown in Fig. 5. The target of the experiment was smoking. The target distribution in the dataset was relatively concentrated, and the dataset was dominated by small targets.
The experimental configuration used in the experiment is presented in Table 2, and subsequent experiments were performed using the configuration.
Experimental configuration
Smoking detection belongs to the detection of small target. The difficulties in small-target detection include the availability of a few features, high positioning accuracy, few existing datasets, and small target aggregation [25]. Some people have added attention mechanisms and small-target detection layers to the model for optimization [26]. However, the parameters, computation, and complexity of the model will all increase. By using data augmentation, the model can be optimized without increasing computational costs. As shown in Table 3, the number of parameters and calculations of YOLOv5 is increased after adding several attention mechanisms; the calculation cost is also increased significantly after adding a small target detection layer. Modifying the data enhancement method of the model to Mosaic_9 does not increase the number of computations and parameters.
Addition of different detection layers to YOLOv5
Addition of different detection layers to YOLOv5
When training the neural networks, the sample data require enhancement to improve its generalization and robustness [27]. The data can be enhanced by flipping, rotation, zooming, cropping, translation, or noise increment [28]. In Section 1, we note that YOLOv5 uses Mosaic for data enhancement. Mosaic randomly selects a reference point, and four images are formed into a large picture around the reference point, as illustrated in Fig. 6. The large picture is called “canvas.” Mosaic divides the canvas into four areas and places one image in each area. The picture does not exceed the boundaries of the canvas: the part within the canvas is filled with shadows, while the part exceeding the canvas is cut out. To improve the detection ability of the model for small targets, Mosaic was improved to Mosaic_9, which randomly cuts and splices nine images simultaneously to enhance the diversity, robustness, and detection capability of the model.
Mosaic_9 canvas order.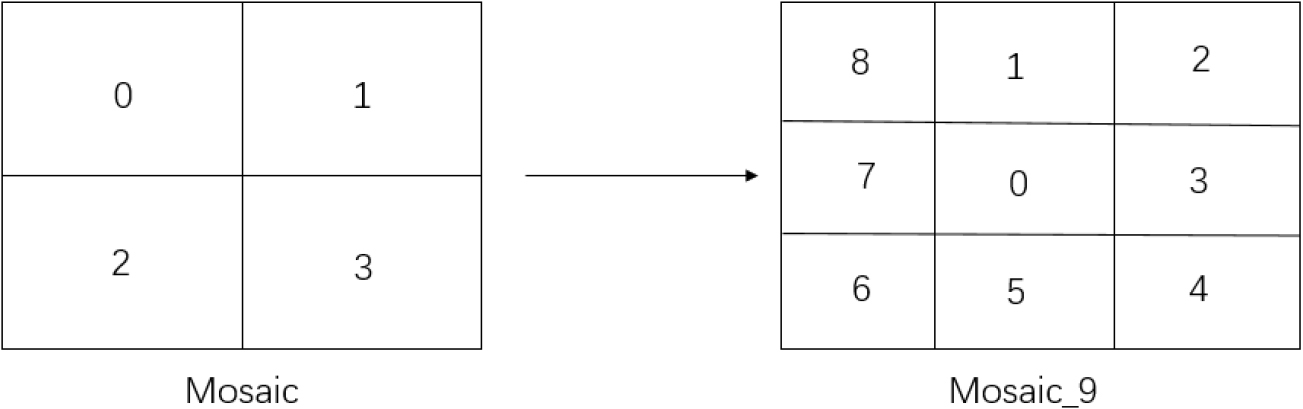
Table 4 shows a comparison of the performance of different improved models of YOLOV5. After adding the CBR maximum pooling layer to the model, the number of calculations was reduced by 37%. Replacing the CBR layer with the downsampling function of the maximum pooling layer has a significant effect on reducing the number of calculations. By further adding Shuffle_Conv to the model, group convolution reduced the model parameters by 81%; the channel shuffle technology prevented the loss of effective features in the feature map to maintain the model accuracy.
In Table 4, the numbers in parentheses refer to the number of GAC3 layers used by YOLOv5. When the backbone and head sections were replaced with GAC3 layers, the model was compressed to 5M, but the accuracy was also reduced by 4%. As shown in Table 4, YOLOv5_CBR_Shuffle_GAC3(4) performed better than YOLOv5_CBR_Shuffle_GAC3(8) in model accuracy, number of parameters, number of computations, and model size. A comparison of all improved models shows that the optimal improved model was YOLOv5_CBR_Shuffle_GAC3(4), where the backbone part of YOLOv5 is replaced by the GAC3 layer. The model has a size of 7.5M, 4,280,718 parameters, and 2.4 GFLOPs calculations. Compared with YOLOv5, the parameters of the improved model were reduced by 60.9%, the number of calculations was reduced by 15.1%, and the size was compressed by nearly 50%, with a 2% increase in accuracy.
Comparison of different improved frameworks of YOLOv5
Comparison of different improved frameworks of YOLOv5
Accuracy of improved model and YOLOv5.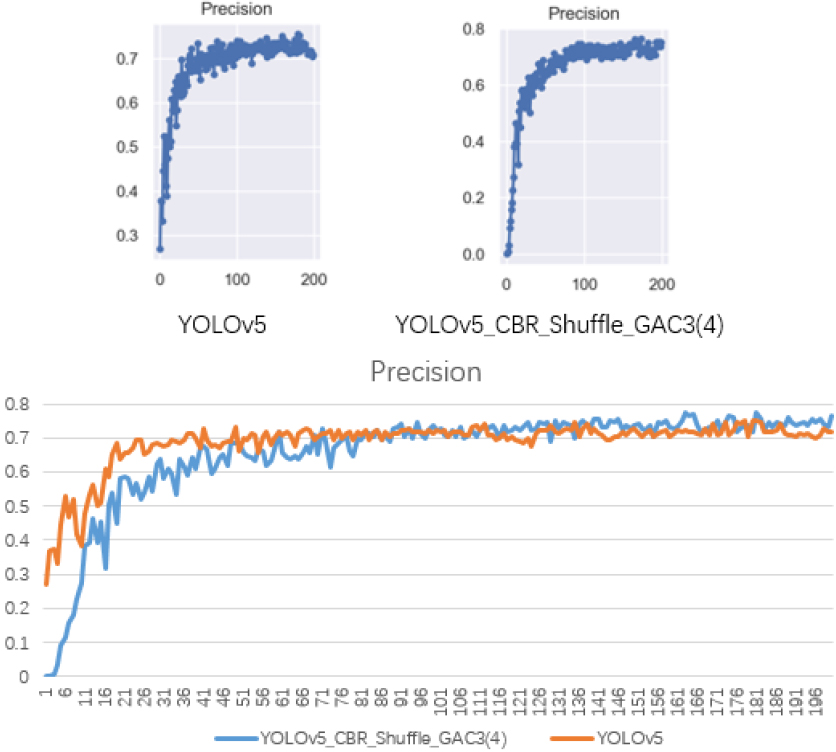
Figure 7 illustrates the training results of YOLOv5 and YOLOv5_CBR_Shuffle_GAC3(4) in 200 epochs in the same experimental environment. Because YOLOv5_CBR_Shuffle_GAC3(4) uses YOLOv5 pre-training weights, the initial accuracy was low, as shown in Fig. 7. As the number of training rounds increased, the accuracy of the model increased and gradually became stable. The accuracy of the improved model also gradually approached 80%, whereas that of YOLOv5 was approximately 75%, and the training effect of the improved model was better than that of YOLOv5.
The prediction results of YOLOv5 and YOLOv5_CBR_Shuffle_GAC3(4) are presented in Fig. 8(a) and (b). When detecting a single target, both models have the same detection effect, and both detect smoking behavior.
Close single-target detection effect.
Figure 9(a) and (b) refer to YOLOv5 and YOLOv5_CBR_Shuffle_GAC3(4), respectively. The models achieved a poor detection effect in detecting multiple long-range targets. The data enhancement method of YOLOv5_CBR_Shuffle_GAC3(4) is Mosaic_9, significantly improving its multi-target detection ability (Fig. 9(c)). The model was considerably compressed, and the desired detection effect was achieved. YOLOv5_CBR_Shuffle_GAC3(4)–Mosaic_9 is hereafter referred to as “YOLOv5#.”
Remote multiple target detection effect.
To further measure the performance of the algorithm, YOLOv5# was compared with other phase target detection algorithms using the same experimental equipment. The results are presented in Table 5. All performance aspects of YOLOv5# were compared with those of the more mature YOLO series. The detection accuracy of YOLOv3-tiny [29] and YOLOv4-tiny [30] increased by 8% and 9%, respectively. The number of parameters, number of calculations, and model size had varying degrees of decline. Aside from the YOLO series algorithms, YOLOv5# achieved 6% higher accuracy than SSD and obtained an absolute advantage in other aspects. Compared with the tiny version in the latest YOLOv7 [31], YOLOv5# had 20% higher accuracy under the same experimental conditions and outperformed YOLOv7-tiny in other performance aspects.
The data enhancement method of YOLOv5# was changed to Mosaic_9, which optimized the detection effect and increased the number of parameters, the number of calculations, and the model size. However, the detection accuracy hardly changed. YOLOv5# not only considerably compressed the computational cost of the model, but also achieved a 77.57% detection accuracy, indicating the effectiveness and economy of the model improvement.
Comparison of different algorithms
Comparison of different algorithms
According to actual application scenarios of smoking behavior, YOLOv5# was designed to detect small targets of smoking behavior. The popularity of lightweight networks has attracted research attention to reducing the computational cost of machine learning models. Thus, the CBR maximum pooling layer was used to reduce the dimension of YOLOv5#. The group convolution and channel shuffle techniques reduces the number of model parameters while maintaining the model accuracy. The lightweight C3 layer replaced with the Add function was then combined with GhostNet to compress the model parameters and size further. Experiments showed that the detection accuracy of YOLOv5# was improved from 75% to 77%. The introduction of Mosaic_9 over Mosaic improved the detection effect of the model without increasing the computational cost while enhancing the small-target detection ability of the model. These results show that YOLOv5# considerably reduces the computational cost, maintains the detection accuracy index of YOLOv5, effectively improves the detection ability of the model and value in practical applications.
Footnotes
Acknowledgments
Basic Research Business Fee Project (Excellent Innovation Team Project). Project Name: Deep learning behavior recognition fall detection research. Project Number: 2022CXTD04. Graduate Innovation Fund Program. Project Name: Research on Smoking Behavior Detection Based on YOLOv5s Algorithm. Project Number: XY2023024. Project Name: Zhangjiakou Cigarette Factory Co., Ltd.