
Abstract
The speaker diarization task pertains to the automated differentiation of speakers within an audio recording, while lacking any prior information regarding the speakers. The introduction of the self-attention mechanism in End-to-End Neural Speaker Diarization (EEND) has elegantly resolved the issue of overlapping speakers. The Transformer model equipped with self-attention mechanism has shown great potential in collecting global information, yielding remarkable outcomes in various tasks. However, the individual speaker characteristics are predominantly reflected in the contextual information, which conventional self-attention would not adequately address. In this study, we propose a hierarchical encoders model to augment the encoders’ acquisition of speaker information in two distinct ways: (1) Constraining the perceptual field of the self-attentive mechanism with left-right windows or Gaussian weights to highlight contextual information; (2) Utilizing a pre-trained time-delay neural network based speaker embedding extractor to alleviate the shortcomings of speaker feature extraction ability. We evaluate the proposed methods on a simulated dataset of two speakers and a real conversation dataset. The model with the most favorable outcomes among the proposed enhancements achieves a diarization error rate of 7.74% on the simulated dataset and 21.92% on MagicData-RAMC after adaptation. These results compellingly demonstrate the efficacy of the proposed methods.
Introduction
Motivation
Speaker diarization is an important front-end task in speech recognition. The primary objective of speaker diarization is to assign speaker identities to speech segments, essentially determining “Who speaks When” [1]. This technology has broad applications in scenarios where speaker information is essential for ASR, such as automatic transcription of conference and telephone data, automatic tracking, and annotation of the corpus with speaker separation technology [2], as it’s shown in Fig. 1. The findings reported in the literature [3, 4] demonstrate that the incorporation of a speaker diarization module can improve the recognition precision of speech recognition models in handling speech signals containing multiple speakers. Thus, the development of an effective speaker diarization model capable of distinguishing between multiple speakers in a speech signal is deemed crucial.
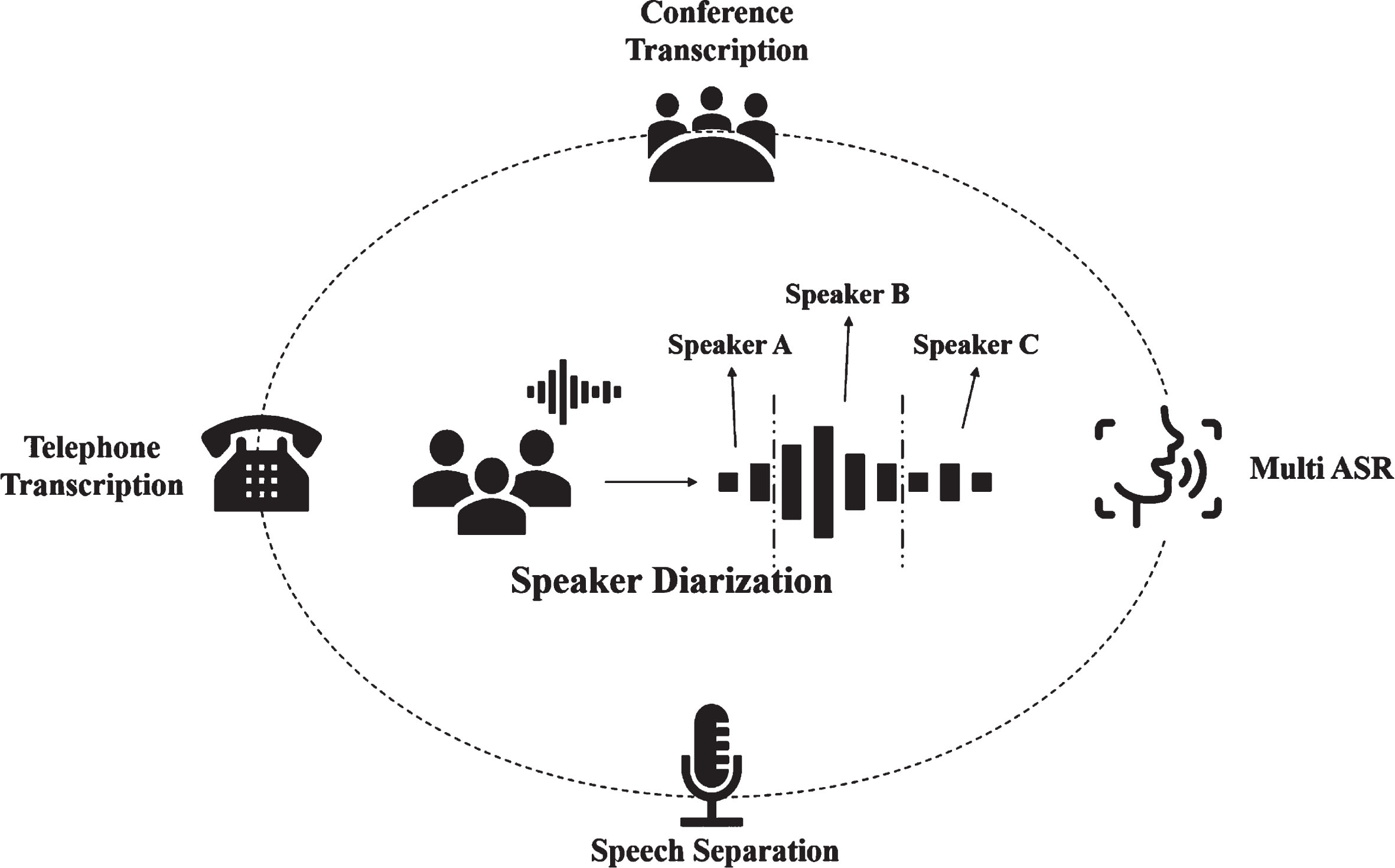
Visual abstract of speaker diarization. The module is capable of distinguishing between speakers in multi-speaker monaural audio signals. It can be applied to various scenarios, such as conference transcription, telephone transcription, speech separation, and multi-speaker speech recognition.
Currently, speaker diarization can be realized using two distinct approaches: clustering-based methods [5–7] and end-to-end based methods [8–10]. Both methods have their respective merits and drawbacks. Clustering-based methods have demonstrated their effectiveness in speaker diarization tasks [29–31]. However, they face difficulties in handling overlap-ping speeches because the segmentation stage only considers a single speaker by default. While end-to-end approaches [8–10] have demonstrated the ability to proficiently handle speech overlap and perform well on simulated datasets with high levels of speech overlap, they exhibit suboptimal performance when applied to real-world conversational data with relatively lower levels of speech overlap.
The proposed methods
In light of the limitations of existing methods in addressing speech overlap issues in real conversational audio, this study proposes an improved end-to-end approach that can handle speech overlap naturally and effectively. Specifically, a hierarchical encoder model is proposed to address the limitation of the EEND model [8] in real conversations. The proposed model comprises bottom layers consisting of transformer encoders with different variants of self-attention that can focus on contextual speech. The upper layers comprise regular transformer encoders that extract global information. Additionally, we introduce a pretrained joint speaker embedding extractor to enhance the model’s ability to abstract speaker features. The proposed approach enhances the performance of end-to-end methods on real conversational data while retaining the ability to handle speech overlap.
The main contributions of the proposed methods can be summarized as follows:
The study proposes a method to construct contextual information for data using the lower-level encoders in a hierarchical encoder, by limiting the receptive field of the self-attention. To guide the attention bias of the self-attention mechanism, fixed weight values are injected.
Introducing Gaussian prior probability weights into the self-attention mechanism and removing the fixed-length window constraint on the receptive field, this study controls the range of the self-attention through Gaussian weight values, thereby guiding its attention direction.
To enhance the model’s performance, a feature extractor module based on time-delay neural network (TDNN) [40] for speaker feature extraction was added. The pre-trained feature extractor, which was trained on a large amount of single-speaker speech segments, runs in parallel with the bottom-level encoder in the hierarchical encoder model, providing guidance for the latter’s performance.
Organization
The rest of the paper is structured as follows. Section 2 delineates the distinctions between speaker diarization, speaker verification, and speaker recognition, and provides a comprehensive overview of the two main approaches for speaker diarization currently in use. Section 3 focuses on the related works in the field of speaker diarization and highlights the differences between these works and the proposed method in this paper. Section 4 introduced the proposed hierarchical encoder model, and provided a detailed explanation on variants of self-attention mechanism. Furthermore, we also described the added feature extractor and its role in the model. In section 5, the experimental setup was described, which included an explanation of the dataset and its augmentation, as well as a presentation of the different models and their corresponding parameters. In section 6, the experimental results of each model were presented and compared with existing mainstream methods. Lastly, the proposed method and discuss its limitations and future work were summarized in section 7.
Background
In this section, we will explain the differences between speaker verification, speaker recognition, and speaker diarization.
Speaker verification
Speaker verification (SV) is a crucial technology that enables the authentication of an individual’s claimed identity using their registered voice samples and test speech signals. It finds widespread applications in numerous solutions, ranging from customer identity verification in call centers to contactless facility access, facilitating secure and seamless user engagement. Based on the specific application scenarios, SV can be broadly categorized into two types: text-dependent speaker verification (TD-SV) and text-independent speaker verification (TI-SV). In TD-SV, the spoken content of the test utterance and the enrolled utterance must match, while in TI-SV, there are no restrictions on the spoken content of either the test or the enrollmentutterance.
Speaker recognition
It is a well-established fact that a speaker’s voice carries distinct individual characteristics attributable to their unique vocal anatomy and speaking style. These characteristics include, but are not limited to, the shape of the vocal tract, the size of the larynx, the accent, and the rhythm. These personal traits are inherent to each individual’s voice and can be used to differentiate one speaker from another, rendering speech a valuable means of identifying individuals. The task of speaker recognition is to identify a specific individual using their audio feature information.
Speaker diarization
The primary aim of speaker diarization is to identify and assign speaker identities to individual speech segments, thereby enabling the accurate determination of “who speaks when” within a given audio recording. This process plays a crucial role in various applications of speech processing and analysis, such as meeting transcription, broadcast news indexing, and speaker turn-taking analysis. Currently, there are two main approaches to achieving speaker diarization: modular methods based on clustering and end-to-end methods. Both methods have their respective merits and drawbacks, the specific details will be elaborated in the section 3.
Related work
This section introduces the two mainstream technical approaches in speaker diarization and compare their representative works with the proposed method in this paper.
Clustering based methods
The clustering-based speaker diarization method divides the speaker diarization task into several sub-tasks. A typical clustering-based method typically in-volves several steps, each with its own model: (1) Voice Activity Detection (VAD) [11–13], where a VAD model [14] is used to detect segments of speech that contain voice activity. (2) Segmentation: The speech is segmented into individual pieces containing a single speaker, with speaker rotation detection being performed on the parts of speech previously detected by the VAD model. This step employs two primary methods: segmentation by speak-er-change point detection [15, 16] and uniform seg-mentation [7]. Segments created using the uniform segmentation method must be sufficiently short to assume the absence of multiple speakers [1]. (3) Speaker Embedding: The speaker embedding model extracts speaker features from all the segments produced by the segmentation model, using i-vector [17–19], d-vector [20, 21], or x-vector [5, 23]. This is a critical step in the clustering method, and the speaker embedding model can be trained using a large number of labeled single-speaker utterances. (4) Clustering: A clustering algorithm is used to group the speech segments produced by a single speaker, based on the speaker embedding and similarity measure. Spectral Clustering [24, 25] and Agglomerative Hierarchical Clustering (AHC) based on BIC [26], KL [27], or PLDA [28] are commonly used methods. Clustering based methods have demonstrated their effectiveness in speaker diarization tasks [29–31]. However, they face difficulties in handling overlapping speeches because the segmentation stage only considers a single speaker by default.
End-to-end based methods
With the advent of End-to-End speaker diarization, numerous methods have been proposed [29, 36]. Compared with the clustering based methods, the end-to-end speaker diarization technology based on direct modeling of preprocessed multi-speaker single-channel audio signals can eliminate intermediate and tedious subtasks and avoid error accumulation caused by these subtasks. Therefore, it has advantages in terms of simplicity and efficiency. Indeed, the end-to-end model has a natural advantage in handling the problem of speech overlap. In traditional clustering based methods, speech signals need to be separated first and then clustered, which is a difficult task especially in the case of speech overlap. However, end-to-end models, such as the EEND model [8] mentioned earlier, utilizing a multi-label classification framework, can naturally address the issue of speech overlap. The transformer encoder, introduced by the EEND model to the speaker diarization task, which was initially proposed in [32], has achieved state-of-the-art performance in natural language processing [33], computer vision [34] and automatic speech recognition [35]. The self-attention mechanism in the transformer encoder enables it to equally capture global information. However, in the case of speaker diarization task, single-speaker information is typically reflected in the contextual speech instead of global. Therefore, the self-attention mechanism needs to place greater emphasis on contextual information during speaker information acquisition to enhance the speaker’s modeling ability.
The proposed methods
In sections 3.1 and 3.2, the two main approaches for speaker diarization were presented: clustering based and end-to-end based. To better handle the inevitable problem of speech overlap in real audio, we chose the end-to-end approach for our proposed method, and made improvements to address the issue of poor performance of the EEND model on real data with less speech overlap. As mentioned earlier, the original transformer encoder is capable of equally capturing global information. However, in speaker diarization task, features of the same speaker are more reflected in the context of the audio. Therefore, it is necessary to model the contextual information of the audio in the process of extracting speaker features. It is also necessary to retain the ability of the upper-level encoders to obtain global information to distinguish between different speakers in the entire audio segment.
Thus, a hierarchical encoder model was proposed, with the bottom encoders composed of variants self-attention that can focus on contextual information, and the upper encoders retain the original transformer encoder to obtain global information. Moreover, a feature extractor based on pre-trained time delay neural network was added, which can be executed in parallel with the bottom layer encoders to enhance its learning capability for speaker features. Table 1 presents a comparison among the clustering-based method, the end-to-end method, and the proposed method in this paper.
The similarities and differences between the proposed method in this paper and the related works
The similarities and differences between the proposed method in this paper and the related works
In [8], the EEND model with self-attention was proposed, which incorporates the transformer encoder with a self-attention mechanism [32] into the speaker diarization task. The transformer encoder layers are categorized into two functions: the bottom layers extract the speaker’s features, while the upper layers cluster the speakers. However, the model lacks the ability to extract speaker features effectively. To overcome this limitation, two improvements were proposed. The pipeline of the proposed methods is illustrated in Fig. 2.
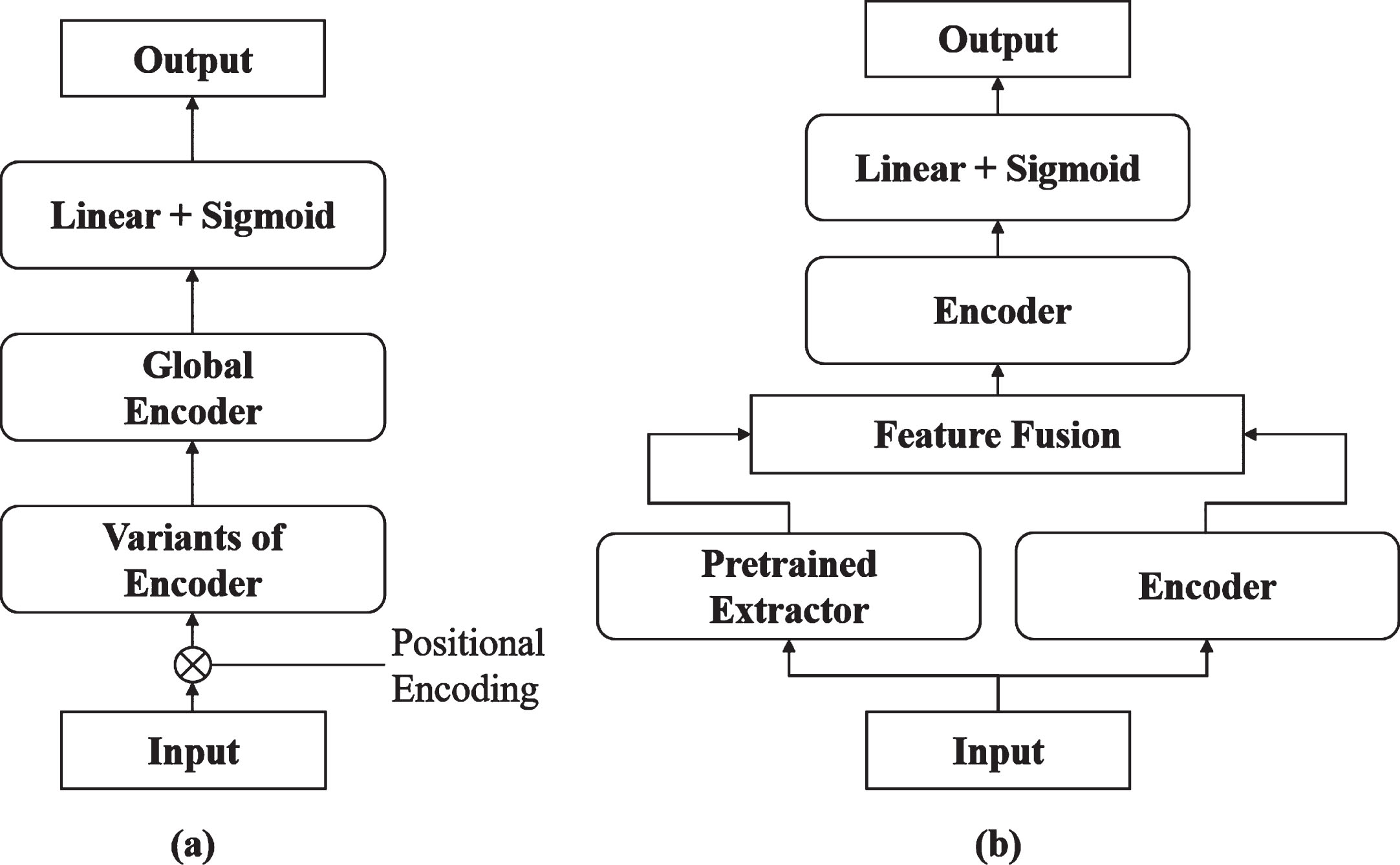
Pipeline of proposed methods: (a) Hierarchical encoders model with variants of encoder and global encoder. (b) EEND model with pretrained speaker embedding extractor.
The self-attention function maps a query vector and a set of key - value pairs to an output vector, as shown in Fig. 3(a). Here, the query, keys, values and output are all vectors. The output vector is calculated as a weighted sum of the values, where the weight assigned to each value is determined by a compatibility function of the query with the corresponding key. Mathematically, this can be formulated as follows:
The description of self-attention mechanism. (a) The original self-attention. (b) The variants of self-attention.
The self-attention mechanism captures the relation of the current position with all global positions. However, in speech-related tasks like speaker diarization, contextual information is more crucial than boundary information due to the coherent nature of speech. Therefore, treating all positions equally with a normal self-attentive mechanism, as shown in Fig. 4(a), should be avoided, and attention should be focused on the positions related to the current one. To address this issue, a weight matrix was added to limit the scope of the self-attention, as depicted in Fig. 3(b). The proposed hierarchical encoders model with variants of encoder and global encoder is illustrated in Fig. 2(a).
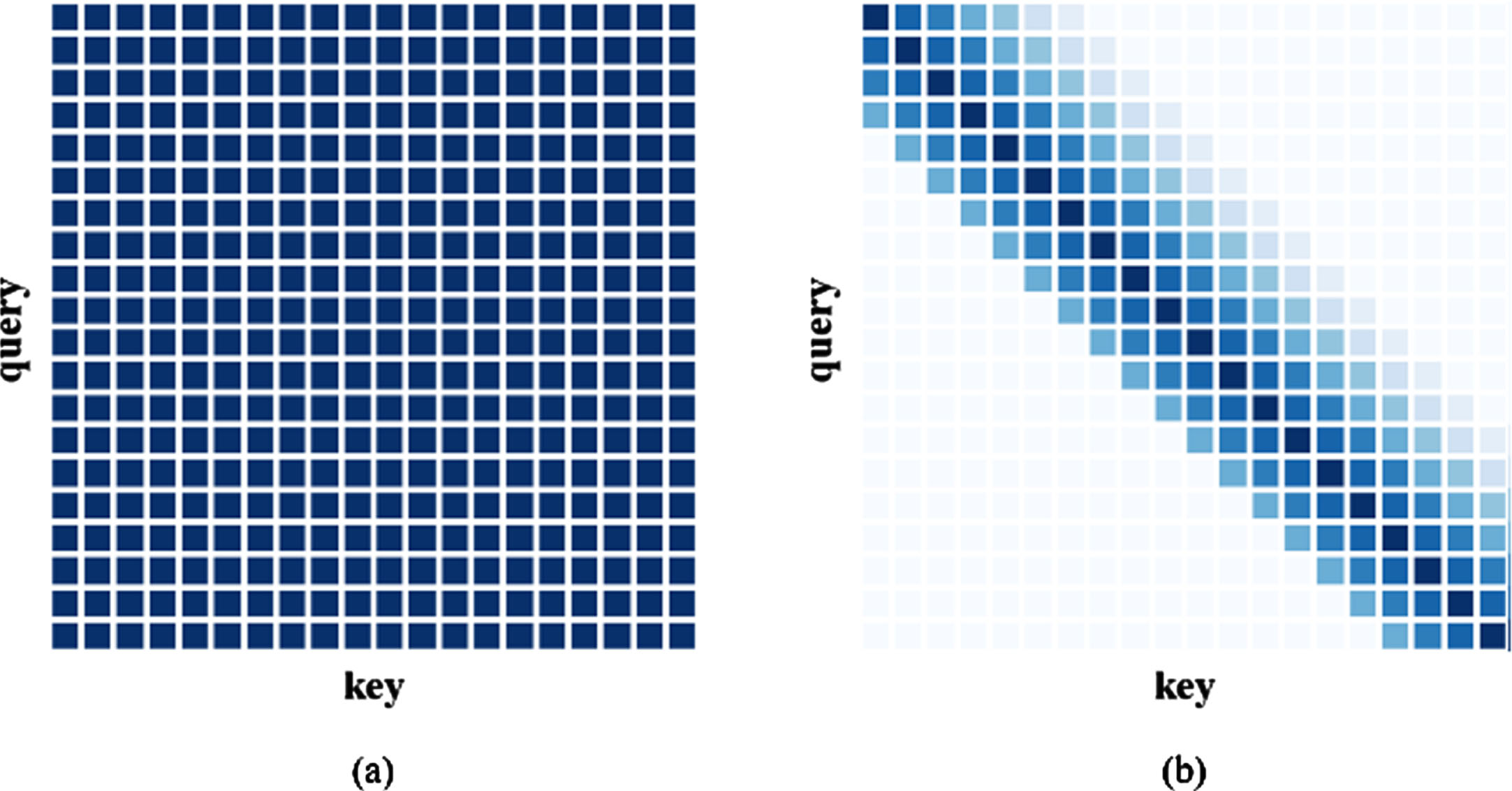
Self-attention scores with weight mask. The darker colors represent higher weights of attention scores. (a)Global self-attention with equal weights. (b)Contextual self-attention with windows of different length at both side and decreasing weights.
Building upon the work of [34] which proposed sliding-window-attention with a window size that can be flexibly adjusted to focus attention on the contextual information of the current token, a novel self-attention mechanism with decreasing weights towards the window was introduced. To control the length of information acquisition, two hyperparameters d L and d R were introduced to control the size of the left and right windows, respectively. Experimental results have demonstrated that unequal attentional window lengths on both sides can yield better performance on speaker diarization tasks.
The window located to the left of the current frame with a length of was designated as the “back-ward-window”, while the window positioned to the right with a length of was referred to as the “for-ward-window”. After conducting experiments, it was discovered that setting the length of the backward-window to half that of the forward-window led to superior performance. Mathematically, this can be expressed as:
the w ij is the weight value determined by the distance to the current frame. The b ij is the bias to mask out information outside the window with -∞ and to keep the attention results in the window with 0. Weights and biases were added to the result after the dotted product of query and key in the self-attentive mechanism by generating a mask matrix, as shown in Fig. 4(b).
In the previous section, the attention mechanism was discussed, which involved the use of windows with decreasing weights from the center to the boundary. This naturally reminds us of a gaussian distribution. In the field of natural language processing, a gaussian transformer model was proposed in [38], which has been successful. Taking inspiration from this, the fixed weights and biases were replaced with dynamically generated weights that conform to a gaussian distribution. As a result, the restriction of attention windows for contextual information was eliminated. Consequently, the self-attention mechanism can acquire not only more contextual information but also a small amount of distal information.
Assuming that the weights conform to a Gaussian distribution, they can be assigned a Gaussian prior to correct the importance of attention scores around the current frame. A Gaussian distribution with a mean of and a variance of was selected to limit the receptive field and assign weights, as shown in Fig. 5(a). Another Gaussian distribution with a mean of but a variance determined by the length of the product of the query and key was also chosen to obtain as much contextual and boundary information as possible, as depicted in Fig. 6(b). The probability density function can be expressed as follows:
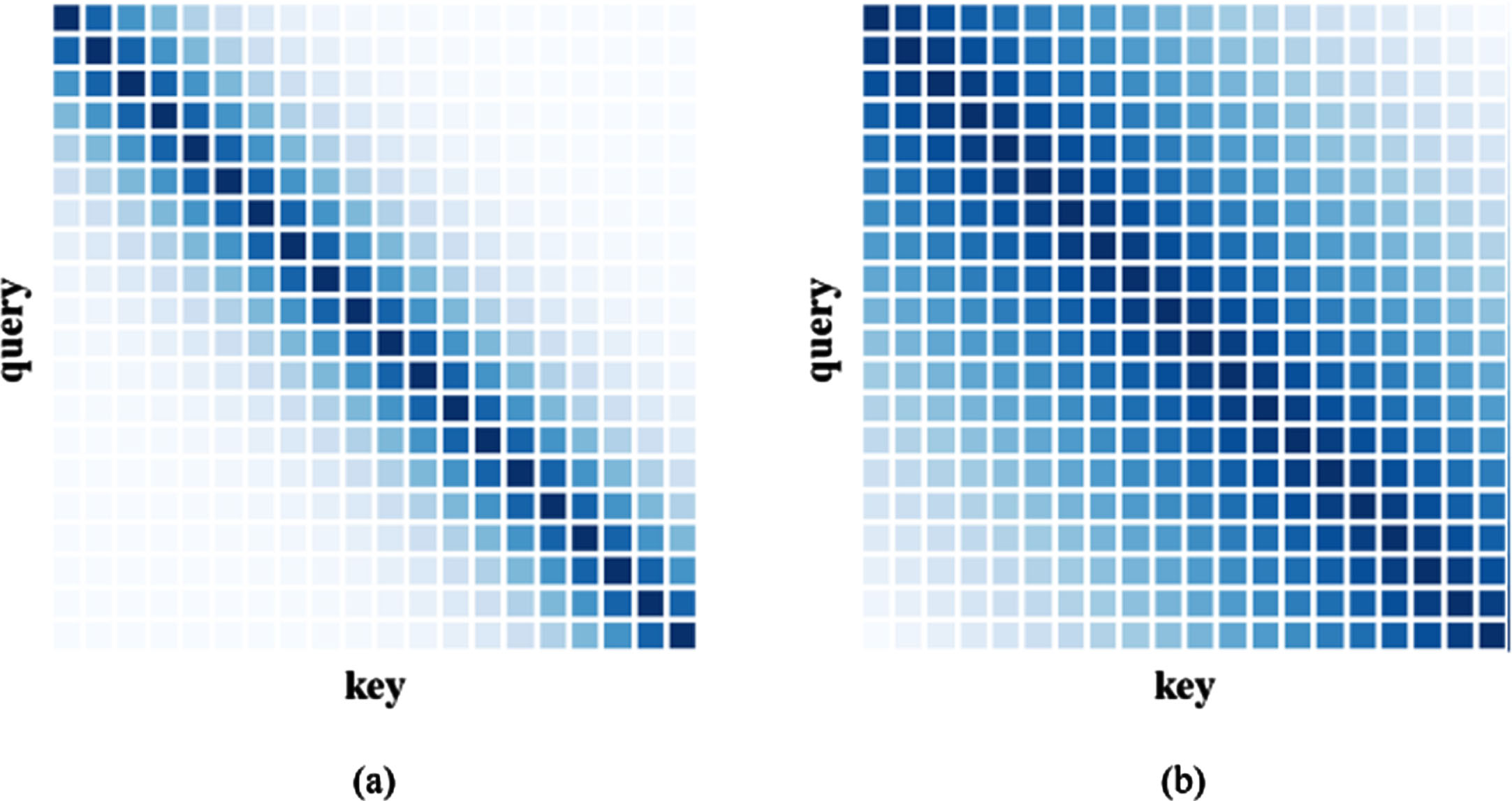
Constraint self-attention with Gaussian weights. The darker colors represent higher weights of attention scores. (a) Gaussian weights mask with μ = 0 and σ2 = 4. (b) Gaussian weights mask with μ = 0 and dynamic σ2.
Where d
ij
is a random variable, means the distance from i to j. Then insert the gaussian prior ∅ (d
ij
) as weight, Equation (2) can be described as:
Clustering-based methods typically extract speaker embeddings from segmented speech using a speaker embedding extractor. It has been shown that pre-trained speaker embedding extractors can effectively capture the speaker’s characteristics. Therefore, in this study, a Time Delay Neural Network (TDNN)-based speaker feature extractor was introduced to work in parallel with the transformer encoders, and perform two stages of feature fusion before forwarding to the subsequent layer. The pipeline of the joint EEND and speaker embedding extractor is illustrated in Fig. 2(b).
The speaker embedding extractor was pre-trained with an AAM-Softmax classifier to enable information extraction from the speaker. These vectors generated by the pre-trained extractor can serve as guidance for the lower transformer encoder. Prior to feeding into the global transformer encoder, two parts of feature fusion were implemented on the two generated features from the pre-trained extractor and transformer encoders. The TDNN-based speaker feature extractor can be described as follows::
Where SE
R
es2Block is the same as it’s in [39].
Where MLP is a fully connected layer that projects the speaker’s embedding to 256-d, which is the same as the output of transformer encoder.
Feature fusion refers to the technique of combining different features or features from different modalities to obtain a more comprehensive and accurate representation of information. Feature fusion techniques are widely used in fields such as computer vision [45], bioinformatics validation [46], and underage verification [47].
In this paper, we perform feature fusion between speaker embeddings extracted from the bottom-level encoder and speaker embeddings extracted from the pre-trained feature extraction module. Specifically, to fuse the second-level features from the feature extractor with the millisecond-level features extracted by the bottom encoders. Therefore, we establish a correspondence between batches of second-level features and corresponding batches of millisecond-level feature vectors with the same time duration. The two sets of features with established correspondence are concatenated and then mapped to a 256-dimensional feature vector using a fully connected layer.
Experimental setup
Data
The EEND method uses a different training set compared to Clustering based methods. While Clustering based methods train their speaker embedding neural network on single speaker utterances, the EEND method is trained on speech from multiple speakers. In [8], simulated speech audio was used as the training set, with two speakers simulated using the same method and enhancements made for the overlapping part in this paper. Additionally, the EEND method can also be trained on real speech conversations that contain speaker overlap. Therefore, to ensure the proposed model can effectively handle the issue of speech overlap while performing well in real conversations, the model was trained on simulated dataset and adapted on real speech dataset.
Real speech dataset
In the experiments, the proposed models were trained on a simulated dataset generated from real conversations. The real conversations were obtained from the MagicData-RAMC dataset [41], which is an open-source dataset consisting of richly annotated Mandarin conversational (RAMC) speech. This dataset contains 180 hours of recorded telephone conversations, with a sampling rate of 16 kHz. The 180 hours of recordings in the dataset consist of 351 conversations, comprising a total of 219,325 segments. On average, each conversation lasts 30.8 minutes and has around 625 speech segments. The speakers in this dataset are evenly distributed in terms of gender and geography, ensuring an even representation.
Simulated dataset
As previously mentioned, the EEND method can be trained using simulated speech mixtures. In this paper, the method for generating simulated mixtures described in [8] was utilized. The MagicData-RAMC [41] dataset was used as the set of utterances for the simulation, with a sampling rate of 16 kHz. The simulated mixtures included a total of 663 speakers, with each mixture consisting of two speakers. The mixtures were divided into a training set and a testing set.
The MUSAN [42] corpus was utilized to intro-duce background noises to the simulated mixtures during the generation process. The background noises that were annotated in the corpus were randomly selected during the generation process. Similarly, the 10,000 room impulse responses used were selected from the simulated room impulse response dataset [43].
A total of 100,000 simulated training set mixtures, each containing 10–20 utterances from two speakers, were generated for the experiment. Similarly, a validation set of 500 mixtures with the same configuration was also generated.
Model information
All proposed models were trained for 100 epochs on the simulated dataset and the average of the last ten epochs was taken. The models were then adapted to the MagicData-RAMC_train dataset. Adam optimizer [44] with 100,000 warm-up steps and an initial learning rate of 10e-3 was applied to train the models. The input to the models was 23-dimensional log-Mel-filterbanks with a 20-ms frame length and 10-ms frame shift, and the batch size was set to 64. Each of the transformer encoders comprised 256 hidden units with a dropout rate of 0.1.
VB-x model
The baseline model for the speaker diarization task in the MagicData-RAMC dataset is the Variational Bayes HMM x-vectors [5], which comes with a pre-trained model. In this study, the VB-x model was selected to represent the clustering-based methods for comparison with the end-to-end method.
EEND with self-attention
The present study employs an End-to-End neural speaker diarization model, which was originally proposed in [8] and is utilized as the baseline model in this experiment. From among all model versions, a 4-layer transformer encoders model was chosen, with each layer consisting of 4 heads and 256 hidden units. In recognition of the significance of contextual information for speaker diarization tasks, a positional encoding module was added to the model for comparison purposes. This module utilizes trigonometric functions to augment the input with position-al information.
EEND with proposed methods
The conventional EEND model discussed earlier consists of 4 transformer encoders, with the bottom two focused on extracting speaker information and the remaining two on clustering. However, to enhance the model’s ability to extract speaker information, a novel Contextual Self-Attention with decreasing weights (CSA) approach was introduced. Specifically, two encoder layers were replaced with four layers of CSA, which allows the self-attention mechanism to restrict its attention to contextual information and place greater emphasis on it. The window-size, which controls the self-attention mechanism’s field of view, was set to different values as a hyperparameter to evaluate the model’s performance. Additionally, a fixed set of weights, determined by the distance to the current frame within the same window-size, was applied.
Contextual self-attention with decreasing weights (CSA): Two encoder layers were replaced with four layers of CSA to enable the self-attention mechanism to limit the view on contextual information and have emphasis in contextual information. The window-size is a hyperparameter that controls the field of view of the self-attention mechanism, and different sizes of windows were set to observe the performance of the model. The weights are a fixed set of constants determined by the distance to the current frame under the same window-size.
Self-attention with Gaussian weights (GSA): In this study, two encoder layers were replaced with four layers of GSA, which represents an improvement on the weight value of CSA. GSA has the ability to generate weight values dynamically based on the distance with the Gaussian probability density function. Furthermore, the window used to restrict the view in CSA can be replaced with the weight values generated by GSA. A Gaussian distribution with μ = 0 and σ2 = 4 was selected to emphasize the contextual information of the self-attention. However, the value of σ2 is also determined by the length of the attention score matrix, which can broaden the view of GSA.
Joint EEND and Speaker Embedding Extractor (EEND-SE): A joint EEND and speaker embedding extractor was utilized as a complementary component to the primary model. The module was pre-trained to ensure that it possessed the capability to extract speaker information. It runs in parallel with the bottom encoders and sends the fused features of the two parts to the subsequent stage.
Results
EEND with self-attention
After observing the importance of the positional relationship of input sequences in the speaker diarization task, a positional encoding module was incorporated into the transformer encoder [32]. However, its performance did not match that of the EEND model without positional encoding. Although the positional encoding allowed the model to learn the positional information between sequence elements, it failed to convey the relevance of the context to the current frame. The model’s performance was evaluated on Simu_test, and MagicData_test, and the results are presented in Table 4. Adding positional encoding to the EEND model did not improve its performance, indicating that more precise utilization of contextual information is necessary to enhance the model’s efficacy. The original EEND model has excellent ability to handle the speech overlap problem and has a minimum number of parameters and calculations, as it’s shown in Table 3. However, EEND model’s performance appears to diminish when presented with authentic conversational data featuring reduced levels of speech overlap, as it is presented in Table 2.
The results of proposed models and baseline model that trained on simu_train and tested on MagicDta_test\\ after adapted on MagicData_train. The model of VBx is a pre-trained model provided by [41]
The results of proposed models and baseline model that trained on simu_train and tested on MagicDta_test\\ after adapted on MagicData_train. The model of VBx is a pre-trained model provided by [41]
The proposed hierarchical encoder model, which incorporates a variant of self-attention, was evaluated on simu_test, MagicData_dev, and MagicData_test datasets, and the results are presented in Table 2. The proposed models utilize variant of self-attention to emphasize contextual speaker information and employ global self-attention to merge speaker features. Furthermore, the impact of positional encoding on the proposed models is analyzed and the results are shown in Table 4.
The proposed method in this paper is compared with existing methods in terms of the paramrs, FLOPs, and train time. The VB-x model was not tested due to the lack of data required for training data, and the rest of the experiments were conducted on a server with a 3090 graphics card
The proposed method in this paper is compared with existing methods in terms of the paramrs, FLOPs, and train time. The VB-x model was not tested due to the lack of data required for training data, and the rest of the experiments were conducted on a server with a 3090 graphics card
Performance differences between proposed models with or without positional encoding. The CA-EEND window-size is 32
As previously mentioned, although the positional encoding allows the model to capture location information, adding it directly did not lead to improved performance in real speech audio. However, when combined with the variant of self-attention, the positional encoding enabled the model to achieve better performance in real speech conversations.
In the experiments conducted on contextual self-attention with decreasing weights (CSA), various window sizes were chosen to investigate the impact of limiting the length of the input sequence on the model’s performance. The experimental results indicated that the contextual self-attention model demonstrated significant improvement compared to the baseline model. Additionally, different window sizes had an impact on the model’s performance, with the lowest DER rate of 21.92% achieved on MagicData_test when the window size was set to 32, exhibiting a 34.9% enhancement over the baseline model, as depicted in Table 2. These findings supported the hypothesis that contextual information is more critical for the current frame than boundary information. Furthermore, the contextual self-attention model with decreasing weights exhibited the ability to obtain local information. Nonetheless, the quantity of parameters and computational demands of the model have substantially escalated due to the need to calculate the weights on the self-attention layer and add bias to the redundant information, as in Table 3..
Constraint self-attention with Gaussian weights
In the evaluation of the constrained self-attention model with gaussian weights (GSA), two types of σ2 were separately tested: dynamically generated and fixed. As shown in Table 2, the model did not perform well when dynamically generated σ2 was used to extend the view of the model. This is because the proportion of high weight elements in the central part, which is determined by the σ2, did not help the model to identify the contextual information of the speaker. However, when σ2 was fixed, the high weights were limited to a smaller number of elements to ensure that the attention was focused on context. The fixed σ2 values resulted in better performance. When σ2 was set to 4, the DER on MagicData_test achieved 25.86%, but increased to 9.27% on simu_test. Moreover, from Table 3, it is known that owing to the requirement for computing Gaussian weight values, the number of parameters and computational complexity of this approach have markedly amplified.
EEND with speaker embedding extractor
In this section, we evaluated the performance of EEND-SE on simu_test and MagicData_dev, respectively, and the results are presented in Table 5. The proposed model exhibited a significant improvement of 15% in DER compared to EEND without joint SE. However, the training time required for the proposed model increased considerably, nearly threefold that of EEND without SE, as it’s shown in Table 3. While this approach can yield improvements, it comes at a high cost.
Results of EEND model with or without speaker embedding extractor on simu_test and MagicData_dev
Results of EEND model with or without speaker embedding extractor on simu_test and MagicData_dev
In the speaker diarization task, while end-to-end methods have the ability to naturally address the overlapping issue, they are not always effective in real conversations where the amount of overlap is minimal. As the continuous nature of audio primarily reflects the characteristics of individual speakers in contextual sequences, a positional encoding module was incorporated into the EEND model, albeit with a consequent rise in the DER of evaluation to 44.40% on the M agicData_test dataset. However, while the positional encoding module provides the model with the position relationship of the input sequence, it cannot instruct the model on the significance of contextual information. The proposed CSA or GSA, which assigns weights to the self-attention module, enables the EEND model to capture local information. By combining the positional encoding module with the proposed EEND variant with self-attention, we achieved 21.92% and 12.13% on the MagicData_test and MagicData_dev datasets, respectively, signifying the model’s ability to capture features present in contextual speech. The proposed enhancements in both directions were successful, with the best results in each direction exhibiting a DER improvement of 34.9% and 15% over the baseline.
Nevertheless, in scenarios involving tasks with a substantial degree of contextual relevance in the input, delving into the model’s potential for contextual information modeling presents a promising avenue for further investigation. Ultimately, while the proposed approach has achieved commendable precision, the unresolved concerns surrounding the end-to-end paradigm and its applicability to the adaptable speaker predicament necessitate further refinement and improvement, which we intend to undertake in our future research endeavors.