
Abstract
In speech technology, a pivotal role is being played by the Speaker diarization mechanism. In general, speaker diarization is the mechanism of partitioning the input audio stream into homogeneous segments based on the identity of the speakers. The automatic transcription readability can be improved with the speaker diarization as it is good in recognizing the audio stream into the speaker turn and often provides the true speaker identity. In this research work, a novel speaker diarization approach is introduced under three major phases: Feature Extraction, Speech Activity Detection (SAD), and Speaker Segmentation and Clustering process. Initially, from the input audio stream (Telugu language) collected, the Mel Frequency Cepstral coefficient (MFCC) based features are extracted. Subsequently, in Speech Activity Detection (SAD), the music and silence signals are removed. Then, the acquired speech signals are segmented for each individual speaker. Finally, the segmented signals are subjected to the speaker clustering process, where the Optimized Convolutional Neural Network (CNN) is used. To make the clustering more appropriate, the weight and activation function of CNN are fine-tuned by a new Self Adaptive Sea Lion Algorithm (SA-SLnO). Finally, a comparative analysis is made to exhibit the superiority of the proposed speaker diarization work. Accordingly, the accuracy of the proposed method is 0.8073, which is 5.255, 2.45%, and 0.075, superior to the existing works.
Introduction
The humans express their ideas and information through speech, which is being a tool for communication. Recently, a massive count of audiovisual content is being generated from diverse sources like broadcasting radio, meetings, TV channels and lectures as well [10, 11, 12, 13, 14, 15, 16]. Owing to the technological development the virtually unlimited storage capacity is maintained for generating, storing and delivering the audio visual contents with cheaper prices. In this context, there is a necessity to have an affordable and suitable content management model to retrieve and search the information. In the case of speech, the amount of data seems to be bulky and the manual handling of data is complex. Therefore, it is necessary to have an automatic human language processing model that can efficiently search, index and access the information sources. While compared to the text documents, it is challenging to search as well as assess the information contents in the audio due to its computational complexity and time consumption. Therefore, the need for automated processing is essential for searching, indexing and accessing the contents spoken at a particular period of time. Moreover, the multi-party dialogue problems (where more than two peoples are engaged in a conversation) are serious issues while assigning temporal segments of speech. One obvious solution to this issue is speaker diarization [17, 18, 19].
The art of splitting the audio signal into homogeneous segments based on the identity of the speakers is referred as Speaker diarization. It is utilized for estimating the audio stream on “who speak what and when” [20, 21, 22, 23, 24]. It is well suited for information retrieval in many real-life applications like speaker recognition, auxiliary video segmentation, multimedia summarization, telephone and broadcast meetings and so on. The audio sources in all these application include speech signals from speakers, non-speech signals, music, channel characteristics and background noises. In the speaker diarization system, the speaker clustering, speech activity detection and speaker segmentation is considered as crucial components. The speech signals are classified from the non-speech signals like music, noise in the speech activity detection phase [42]. On the basis of the speaker identities the audio stream is split into uniform segments in the segmentation phase [25, 26]. The mechanism of associating the same speaker’s segmented speech is done in the speaker clustering process.
In recent days, the speech diarization with the Dravidian languages is gaining more attention. Telugu is the 3
The major contribution of this research work is:
An optimized CNN based speaker segmentation process is introduced in this research work, where the weight and activation function of the model is optimized by a new algorithm. Proposing a new Self Adaptive Sea Lion algorithm for solving the optimization issue mentioned in this work.
The rest of the paper is arranges as: Section 2 addresses the literature works undergone in speaker diarization. Section 3 tells about proposed Telugu speaker diarization: an architectural description. The feature extraction, speech activity detection and speaker segmentation is described in Section 4. The results acquired with the proposed work are discussed in Section 5 and this paper is concluded in Section 6.
Related works
In 2017, Ramaiah and Rao [1] have developed a novel speaker diarization system by amalgamating the concepts of both the Holoentropy with the eXtended Linear Prediction using autocorrelation Snapshot (HXLPS) and Deep Neural Network (DNN). The HXLPS was developed by blending the Holoentropy concept with the XLPS. The Voice Activity Detection (VAD) method has detected the non-speech signals from the speech signals. Then, the Universal Background Model (UBM) model was utilized for obtaining i-vector representation corresponding to each of the segments. To the speaker’s signals, the labels were assigned using DNN. The outcomes had exhibited better diarization performance in terms of DER.
In 2018, Zewoudie et al. [2] have proposed the utilization of Voice-Quality Features (V-QF) for i-vector and GMM based speaker diarization systems. The long-term and the short-term cepstral features were extracted using the proposed voice-quality features. The speaker clustering was accomplished via the delta dynamic features. As a resultant there has observed a substantial DER improvement in the proposed work.
In 2019, Karim et al. [3] have introduced an efficient heuristic model by combining the concepts of “Differential Evolution (DE) algorithm and K-means algorithm”. This was done to solve the optimal non-hierarchical clustering problem in the speaker diarization task, especially in the speaker clustering phase. The speaker classification is optimized with two criteria: trace within criterion (TRW) and variance ratio criterion (VRC). In DE algorithm, the classifications of clusters that need to be the optimized were encoded. The evolutionary operators were applied to rearrange the centres in the population. The outcomes of the proposed work had exhibited best efficiency.
In 2020, Diez et al. [4] have presented a complete analysis of speaker diarization with Bayesian Hidden Markov Model. The authors have described the model’s inference and has provided the evaluation in terms of “sensitivity and interactions” of entire model parameters. They have introduced a speaker regularization coefficient (SRC) to control the count of inferred speakers. In addition, the evaluation was done with CALLHOME and DIHARD datasets. The variational inference was driven out of local optima by means of employing the naive speaker model merging strategy.
In 2017, Gebru et al. [5] have developed a novel spatiotemporal Bayesian Fusion based diarization model for several participants who were engaged in a multi-party dialogue. Then, a novel Audio-Visual Fusion (A-VF) method was introduced, where the extraction of Binaural Spectral Features (BSF) were done from a microphone pair. These features were mapped into the image using a supervised audio-visual alignment technique. Finally, the binaural spectral features were classified using the semi-supervised clustering method.
In 2020, Park et al. [6] have projected a new Spectral Clustering Framework (SCF) for speaker diarization, in which the parameters of the clustering algorithm were auto-tuned. The Normalized Maximum Eigengap (NME) values were utilized in the proposed framework to evaluate the number of clusters.
In 2020, Sethuram et al. [7] have developed a new speaker diarization or indexing model for the Telugu language. The features were extracted using MFCC and the clustering process was done using the Optimized ANN. In the Optimized ANN, the training was done using the hybrid concept of Artificial Bee Colony (ABC) and Lion Algorithm (LA). As a consequence, there observed an enhancement in accuracy rate.
Features and challenges of existing speaker diarization approaches
Features and challenges of existing speaker diarization approaches
In 2017, Cyrta et al. [8] have proposed a new deep learningbased speaker diarization. In the context of speaker diarization, they have embedded the low-level speaker using the recurrent CNN architecture. The experimental evaluation of the proposed model had exhibited reduction in the diarization error rate.
In 2019, Gupta et al. [43] have presented an incorporated scheme that produces the opinionated performance on the basis of extractive summaries and graphics from the huge set of reviews of mobile. The presented scheme consist of three major stages like computation of sentiment polarity of all aspect, generates opinionated performance based on extractive summaries and graphical as well as recognition of aspects in the known field. Further, the proposed scheme was executed on dataset of three mobile-reviews and attained higher recall as well as precision when compared with the baseline method.
In 2020, Gupta et al. [44] have utilized diverse conventional techniques based on classification for identifying the emotion of humans and carried out a comprehensive comparative analysis on the basis of mathematical and statistical results. Moreover, an optimal model DSCNN was presented for raw spectrogram, which offered in 61% un-weighted accuracy and for raw spectrogram and for clean spectrogram 79% for the improvement of the human emotion assessment scheme.
In 2017, Piryani et al. [45] have presented aspect-level sentiment analysis on reviews of the movie. Moreover, rule-based linguistic schemes have also been offered that recognize the aspects from movie reviews, calculates the sentiment polarity of that opinion by utilizing the linguistic scheme and place opinion about that aspect. Further, the experiment was carried on the basis of two movie datasets. The outcome showed higher accuracy and was more promising for the utilization of an incorporated opinion profiling system.
The recent fascinating speaker diarization works are discussed in the literature section. The features and challenges of those works are summarized in Table 1. The HXLPS and DNN deployed in [1] attained lower DER. But, here the count of false alarms generated was higher. The GMM- and i-vector in [2] provides the minimum variance. The major drawback of this approach is, the DER performance tends to increase with increase in the count of iterations. The Hidden Markov models in [3] have high-confidence level. To make this approach more significant, the training as well as testing times can be reduced. The Bayesian Hidden Markov Model utilized in [4] reduces the frame rate more effectively and hence increases the accuracy of the diarization. On the other hand, the Sensitivity of the diarization performance can be increased. Further, Spatiotemporal Bayesian Fusion in [5] has the potential of dealing with multiple-speakers, who speak at the same time. But, the major drawback of this approach was its higher computational complexity. The Normalized Maximum Eigengap in [6] avoids hyper-parameter tuning. The Noisy similarity values need to be reduced for making the proposed work more accurate. The ANN+ABC-LA in [7] exhibits lower error rates. To make this approach more attractive for large-scale applications, the loss in data can be reduced. The RCNN utilized in [8] was capable of discriminating between the bigger corpora of speakers. But, here the overall accuracy of the speaker diarization was lower. Thus, all these drawbacks together motivates the current research work to have a better speaker diarization model with higher accuracy and lower DER.
Overall architecture of the proposed speaker diarization approach.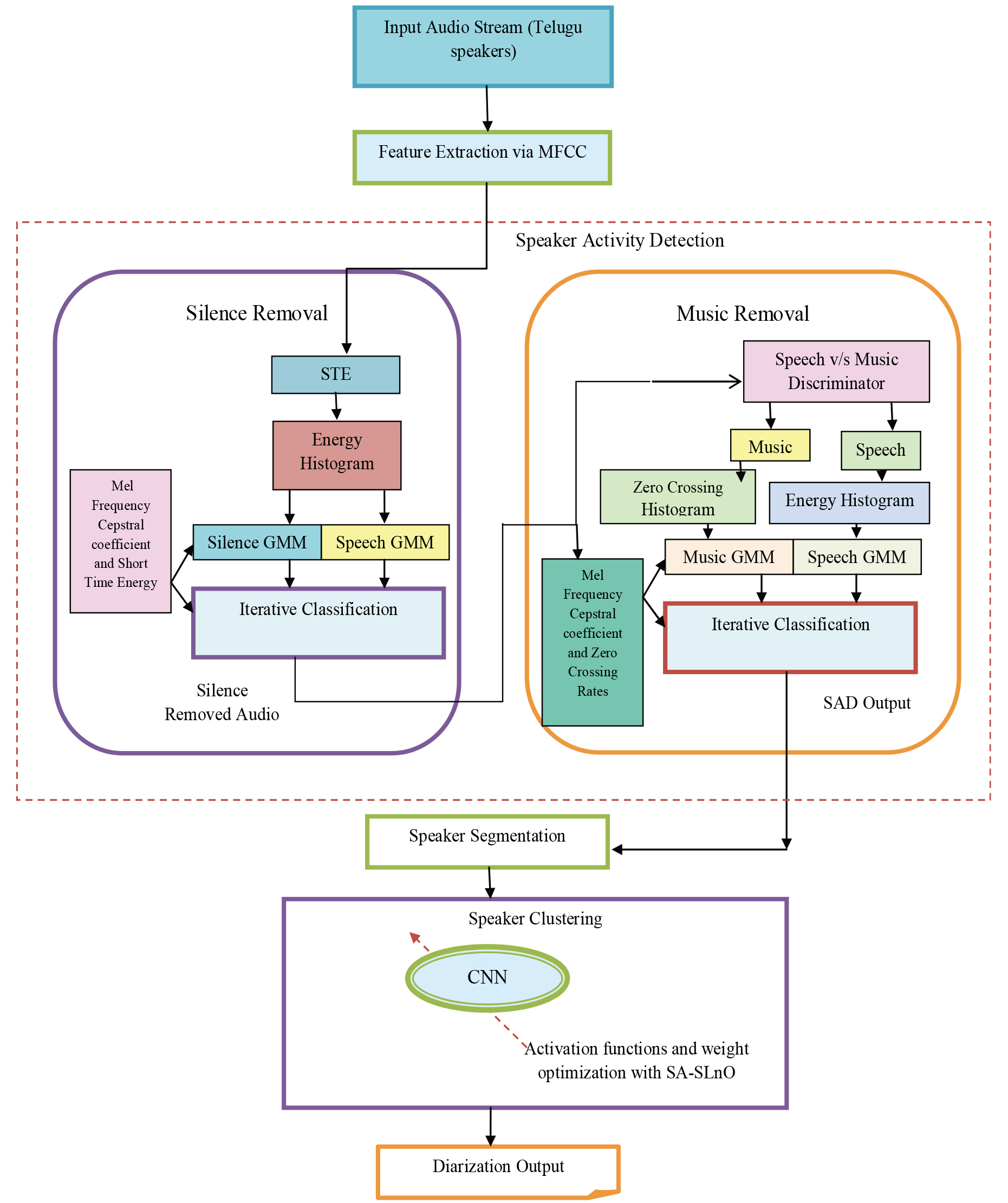
Architecture of proposed Telugu speaker diarization
The speaker diarization belongs to the speech processing category and here the speaker is identified along with the boundary/frame of the speech spoken (i.e. who spoke when), by automatically partitioning the audio signal into homogeneous segments. The Speaker diarization is the combination of both the speaker clustering and the speaker segmentation. In India, the Telugu language is the 3
Step 1 (Data Collection): Initially, the input audio stream corresponding to the multiple Telugu speaker are collected. Let the collected raw speech data (audio signal) is denoted as
Step 2 (Feature Extraction): The MFCC features
Step 3 (Speech Activity Detection): Here, the silence and the music are removed from the extracted features
Step 4 (Speaker Segmentation): Subsequently, the silence removed audio
Step 5 (Speaker clustering): The Segmented audio signal Seg is clustered into
Feature extraction, speech activity detection and speaker segmentation
Feature extraction
MFCC is the renowned audio feature extraction method with less computational complexity. The key objectives of MFCC are exhibited below:
The extracted features Adjusts the frequency and the loudness of sound perceived by the humans. Can capture the “dynamics of phones”. Vocal fold excitation (pitch information) are removed.
The filtering stages of MFCC are shown in Fig. 2. The elaboration of these stages are depicted below.
General architecture of MFCC.
The collected raw speech signal is subjected to the several stages of filters of MFCC [37] for feature extraction.
Pre-emphasis: The input data
Framing: The pre-emphasised signal is split into smaller segments equal sizes of 20–30 ms referred as frames
Windowing: The frames
Fast Fourier Transform (FFT): The time domain signal acquired after windowing is converted into frequency domain by FFT. The outcome from FFT is a periodogram or a spectrum.
Mel-Frequency Cepstrum (MFC): It is based on the “linear cosine transform of a log power spectrum” and it is computed using Eq. (2).
Where, freq (Hz) is the frequency of the signal and the perceived frequency is denoted as
Discrete Cosine Transform (DCT): To the transformed Mel frequency coefficients, the DCT is applied for producing the cepstral coefficients set. In general, DCT is employed for reducing the redundancy presented in the audio information and for enhancing the speed of the system. DCT is computed using Eq. (3).
Here,
In this research work, the 2 decoupled stages are utilized for implementing the SAD subsystem. Initially, from
Silence removal: In this research work, the silence (i.e. Removal of non- audible from audible signals) is removed from Music removal: This bootstrap segmentation prevents loss of informative speech, and so it is utilized in this research work. The features like STE and Zero Crossing Rates (ZCR) are extracted from
The Window-growing-based segmentation (WinGrow) is a popular distance-based segmentation approach, which is employed in this research work for measuring the distance between two audio segments. The Bayesian Information Criterion (BIC) is utilized for evaluating the two hypotheses: (a) in the feature space, the two segments (
Speaker clustering with optimized CNN.
(a) One-change-point detection: Initially, the single speaker change is investigated from the starting point of the audio stream by fixing the search window size
In this work, optimized CNN [39, 40] is used to cluster the segmented speech signal seg into
Where,
Further, the shift-invariance is achieved by the pooling layer
Here,
The fitness or objective fixed in speaker clustering is determined in Eq. (9), where the loss indicates the error function of CNN as defined in Eq. (8). The input solution to the proposed algorithm is weight
The traditional Sea Lion Algorithm (SLnO) is based on the hunting behavior of sea lions. It is good in solving the complex optimization problems, but suffers from lower convergence and minimization accuracy. Therefore, in this research work, an improved version of SLnO referred as SA-SLnO is introduced for achieving the more accurate speech diarization by fine tuning act and Wt of CNN. The steps followed in SA-SLnO are described below:
Solution encoding.
Step 1 (Initialization): The population Pop of search agent (Sea lion) is initialized. The count of iterations denoted as iter and its maximal count of iterations is denoted as
Step 2: Compute the fitness of the search agents using Eq. (9).
Step 3: while
Step 4: On the basis of the objective function (minimization of loss in CNN), shown in Eq. (9), compute the fitness of the overall iteration and identify the best fitness
Step 5: If
Here, the distance between the sea lion and the prey (target) is denoted as
Step 6: if
Where,
Step 7: if
Where,
Step 8: Now find the best fitness of the corresponding iterations by computing the objective function. The resultant best solution acquired is denoted as
Performance Evaluation of the proposed and existing works for speaker diarization under Test case 1 (a) Accuracy, (b) DER, (c) FDR and (d) FNR.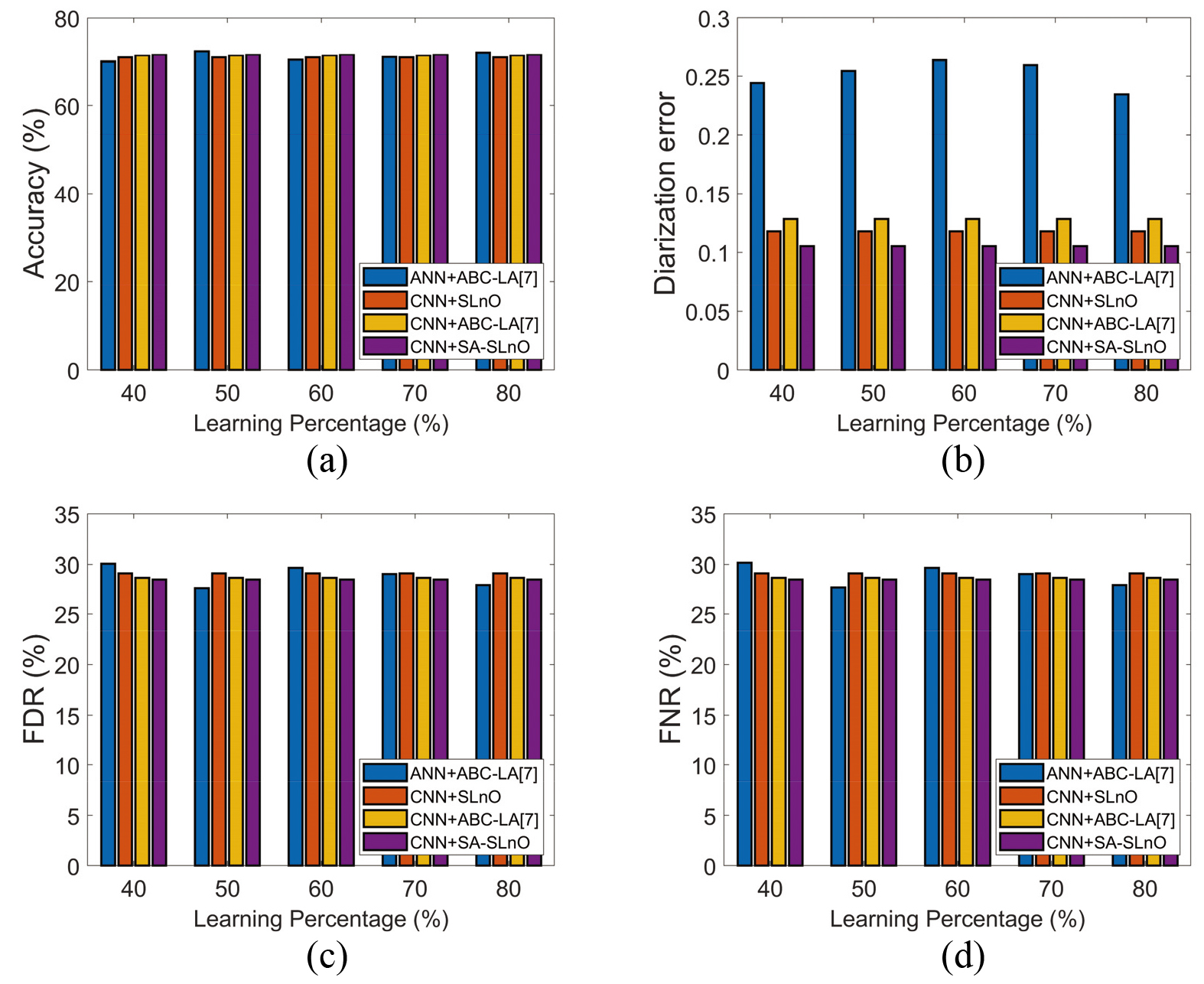
Step 6: Terminate.
Simulation procedure
The proposed speaker diarization model with the aid of the SA-SLnO based CNN was implemented in MATLAB and the results acquire were noted. The collected audio signal from Telugu language is split into five Test Cases: “Test case 1, Test case 2, Test case 3, Test case 4 and Test case 5”, respectively. The presented work model (SA-SLnO with CNN) is compared over the traditional models like ANN+ABC-LA, CNN+SLnO and CNN+ABC+LA. The evaluation is made in terms of accuracy, False Discovery Rate (FDR), diarization error, False Negative Rate (FNR), and False Positive Rate (FPR), respectively All the evaluations are done by varying the learning percentage from 40 to 80, respectively.
Performance analysis for Test case 1
In this section, the performance analysis is done for Test case 1 with respect to the accuracy, FDR, diarization error, FNR, and FPR, respectively The corresponding results are shown in Fig. 5. The accuracy of speaker diarization is the key parameter that decides the potential of the proposed work. The accuracy of the presented work is higher for certain variations in the learning percentage. When learning percentage
Overall performance of the proposed and exiting works for speaker diarization: Test case 1
Overall performance of the proposed and exiting works for speaker diarization: Test case 1
Performance Evaluation of the proposed and existing works for speaker diarization under Test case 2 (a) Accuracy, (b) DER, (c) FDR and (d) FNR.
For Test case 2, the performance of the presented work and the existing works are compared in terms of accuracy, FDR, diarization error, FNR, and FPR, respectively The outcomes are graphically shown in Fig. 4. In the case of accuracy, the performance of the presented work from Fig. 6a is higher and hence said to be suitable for speaker diarization. In the case of accuracy, the presented works is 23%, 3.8% and 5.125 better than ANN+ABC-LA algorithmbased speaker diarization, CNN+SLnO based speaker diarization and CNN+ABC+LA based speaker diarization, respectively. In addition, the DER of the presented works is the lowest for every variation in the learning percentage. The DER performance at 40
Overall performance of the proposed and exiting works for speaker diarization: Test case 2
Overall performance of the proposed and exiting works for speaker diarization: Test case 2
Performance Evaluation of the proposed and existing works for speaker diarization under Test case 3 (a) Accuracy, (b) DER, (c) FDR and (d) FNR.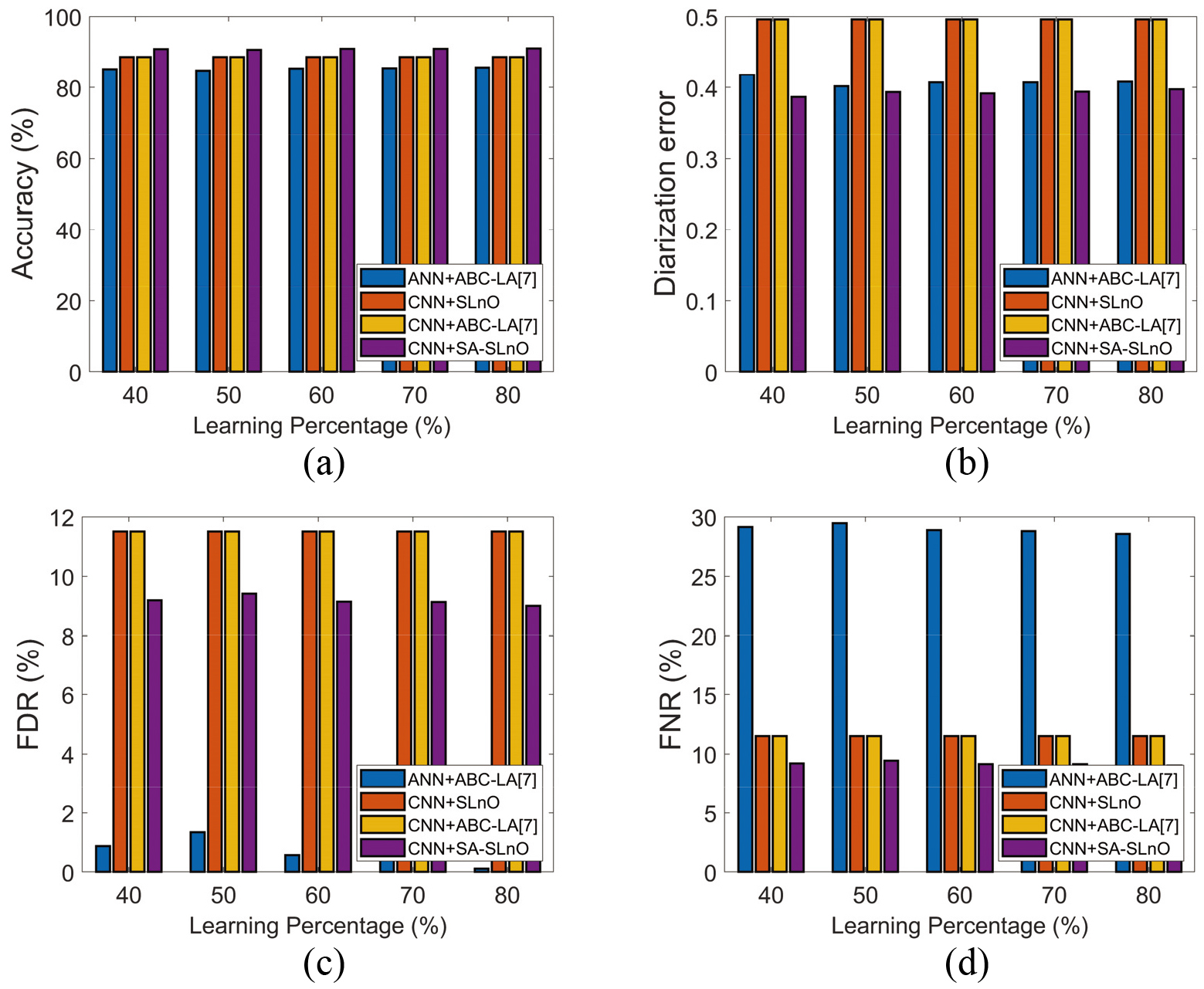
The presented telugu speaker diarization model is compared over the existing works for Test case 3 and the results acquired in terms of accuracy, FDR, diarization error, FNR, and FPR, respectively are shown in Fig. 7 On observing, 80
Overall performance of the proposed and exiting works for speaker diarization: Test case 3
Overall performance of the proposed and exiting works for speaker diarization: Test case 3
Performance Evaluation of the proposed and existing works for speaker diarization under Test case 4 (a) Accuracy, (b) DER, (c) FDR and (d) FNR.
Overall performance of the proposed and exiting works for speaker diarization: Test case 4
Performance Evaluation of the proposed and existing works for speaker diarization under Test case 5 (a) Accuracy, (b) DER, (c) FDR and (d) FNR.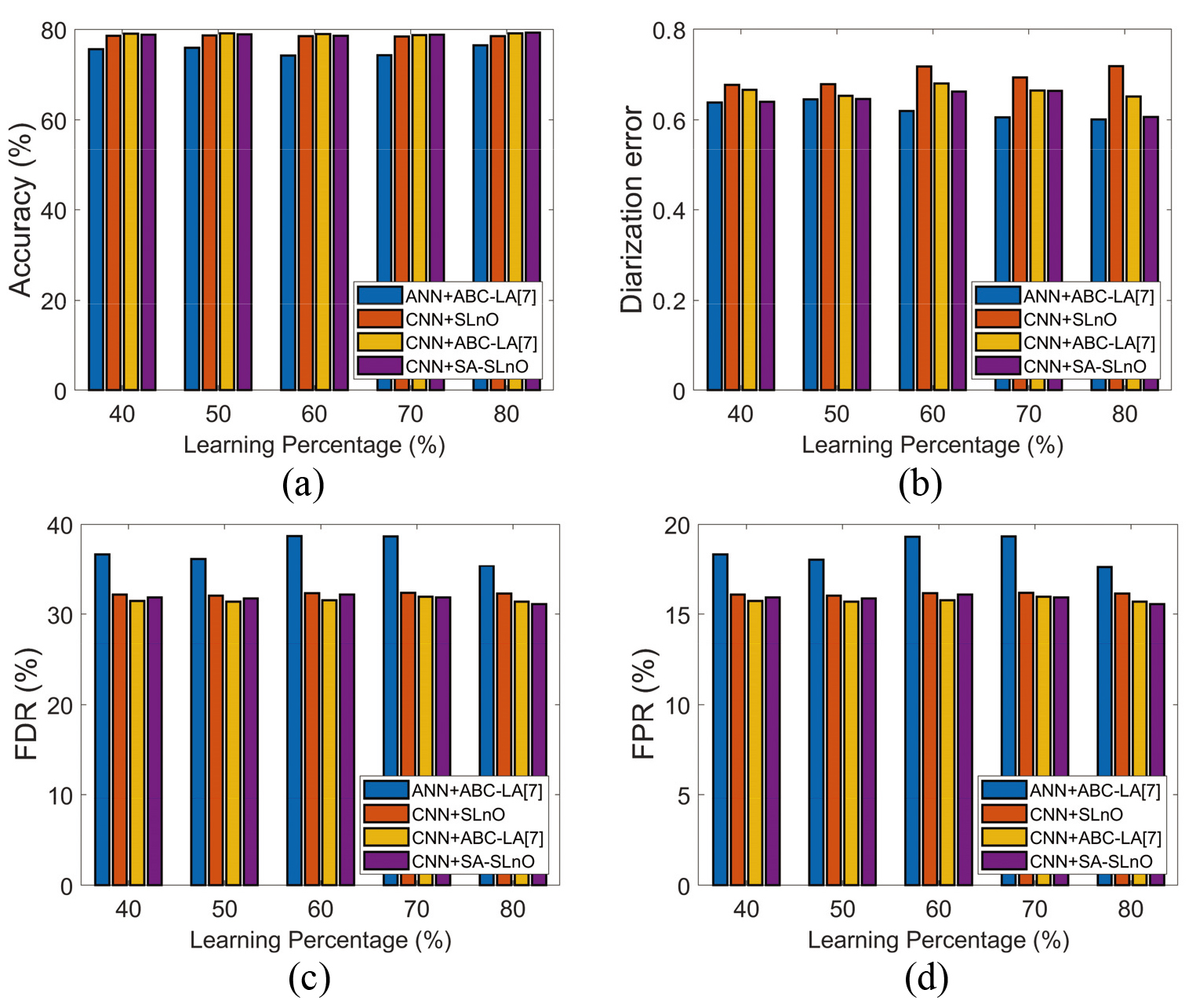
Figure 8 shows the performance evaluation of both the presented and the existing works. The accuracy measure decides the selection of the diarization approach. In Fig. 8a, the accuracy of the presented work is 9.09%, 6.8% and 3.45 better than ANN+ABC-LA algorithm based speaker diarization, CNN+SLnO based speaker diarization and CNN+ABC+LA based speaker diarization, respectively at 80
Overall performance of the proposed and exiting works for speaker diarization: Test case 5
Overall performance of the proposed and exiting works for speaker diarization: Test case 5
Overall DER performance of the proposed speaker diarization and exiting works for Test case 1, Test case 2, Test case 3, Test case 4 and Test case 5
The outcomes acquired under test case 5 are exhibited in Fig. 9. The accuracy of the presented work is higher for every variation in the LP. Thus, portrays itself suitable for speaker diarization. Then, in case of DER, the proposed work attains lower value. On observing the 80
DER performance
The DER performance is the common measure discussed in most of the literature works [1, 2, 5, 6, 7, 8] . Among them, very few counts of works have satisfied the required level of DER. But, in those works the accuracy of speaker diarization was not met. By taking this as a challenge, the proposed speaker diarization work has achieved both the maximization in accuracy as well as minimization in DER performance. The DER performance for all the test cases is shown in Table 6. The proposed speaker diarization works achieves the lowest DER performance in all the five test cases. The DER performance achieved by the presented work is 0.10523 for test case 1, 0.61 for Test case 2, 0.39 for Test case 3, 0.25 for test case 4 and 0.53 for test case. Among all these, the lowest DER is recorded under Test case 1. From this evaluation, it is proved that the presented work is better with less DER performance and the maximized accuracy rate.
Conclusion
A novel speaker diarization approach was introduced in this paper by following three major phases: Feature Extraction, SAD, and Speaker Segmentation and Clustering process. Initially, from the input audio stream (Telugu language), the MFCC based features were extracted. Subsequently, in SAD, the music and silence signals were removed. Then, the acquired speech signals were segmented for each individual speaker. Finally, the segmented signals were subjected to speaker clustering process, where the Optimized CNN was used. To make the clustering more appropriate, the weight and activation function of CNN were fine–tuned by a new SA-SLnO. Finally, a comparative analysis is made to exhibit the superiority of the proposed speaker diarization work. The proposed speaker diarization works achieves the lowest DER performance in all the five test cases. The DER performance achieved by the presented work is 0.10523 for Test case 1, 0.61 for Test case 2, 0.39 for Test case 3, 0.25 for Test case 4 and 0.53 for test case. Among all these, the lowest DER is recorded under Test case 1. However, the presented model cannot use the visual features, like head-pose tracking, as well as head pose estimation. In future our work will be extended to integrate richer visual features, to improve the detection of speech turns based on gaze In addition, to deal with more multifaceted scenarios concerning tens of participants we will consider wearable devices, or distributed sensors
Footnotes
Nomenclature
| Abbreviation | Description |
|---|---|
| MFCC | Mel Frequency Cepstral coefficient |
| SAD | Speech Activity Detection |
| LPCC | Linear Predictive Cepstral Coefficients |
| ANN | Artificial Neural Network |
| PLP | Perceptual Linear Predictive |
| GMM | Gaussian mixture model |
| HXLPS | Holoentropy with the eXtended Linear Prediction using autocorrelation Snapshot |
| DNN | Deep Neural Network |
| VAD | Voice Activity Detection |
| UBM | Universal Background Model |
| DER | Diarization error ratio |
| DE | differential evolution |
| TRW | trace within criterion |
| VRC | variance ratio criterion |
| LA | Lion Algorithm |
|---|---|
| ABC | Artificial Bee Colony |
| MSR | Missed Speech Rate |
| FASR | False Alarm Speech Rate |
| BIC | Bayesian Information Criterion |
| FDR | False Discovery Rate |
| FPR | False Positive Rate |
| FNR | False Negative Rate |
| SA-SLnO | Self Adaptive Sea Lion Algorithm |
| SLnO | Sea Lion Algorithm |
| MCC | Mathews Correlation Coefficient |
| NPV | Negative Predictive Value |
| V-QF | Voice-Quality Features |
| A-VF | Audio-Visual Fusion |
| BSF | Binaural Spectral Features |
| SCF | Spectral Clustering Framework |
| NME | Normalized Maximum Eigengap |
| CNN | Convolutional Neural Network |
| FFT | Fast Fourier Transform |
| MFC | Mel-Frequency Cepstrum |
| DCT | Discrete Cosine Transform |
| SAD | Speaker Activity Detection |
| STE | Short Time Energy |
| ZCR | Zero Crossing Rates |