
Abstract
Transformer-based neural machine translation (NMT) has achieved state-of-the-art performance in the NMT paradigm. However, it relies on the availability of copious parallel corpora. For low-resource language pairs, the amount of parallel data is insufficient, resulting in poor translation quality. To alleviate this issue, this paper proposes an efficient data augmentation (DA) method named STA. Firstly, the pseudo-parallel sentence pairs are generated by translating sentence trunks with the target-to-source NMT model. Furthermore, two strategies are introduced to merge the original data and pseudo-parallel corpus to augment the training set. Experimental results on simulated and real low-resource translation tasks show that the proposed method improves the translation quality over the strong baseline, and also outperforms other data augmentation methods. Moreover, the STA method can further improve the translation quality when combined with the back-translation method with the extra monolingual data.
Introduction
Transformer-based Neural machine translation (NMT) has shown the best performance on several language pairs with an end-to-end architecture and large-scale parallel data [1–4]. Consequently, the availability of parallel corpora has an important influence on how well the NMT model performs. However, large-scale parallel corpora are often unavailable for many language pairs, e.g., Turish→English, and even for some domains in high-resource language pairs, it still suffers from the data scarcity issue. It is a time-consuming and expensive job to construct bilingual datasets with high quality manually.
To alleviate this issue, some researchers utilize high-resource language to improve the translation quality of the low-resource NMT model [5–7]. But these methods usually have complex models and computational cost. Naturally, data augmentation (DA) technique is an important trick to generate additional training samples when the available parallel data are scarce, and it has been proved useful in previous works [8–15]. It has been widely used in computer vision, and has achieved progress in neural machine translation. Words replacement are employed to generate augmented data with relatively high quality [9, 11, 12, 16–18]. However, these methods are difficult to use all the possible expanded data due to the data sparsity problem in low-resource languages. Another data augmentation method uses monolingual data [8, 10, 19, 20], e.g., back-translation and self-learning. Nevertheless, to gather and collate the required quantity of monolingual data, these methods require a significant amount of work. Some researchers utilize a synonymous dictionary to replace words in a parallel sentence pairs. However, thesaurus resources are also limited for low-resource languages.
Different from previous work, this paper proposes an effective data augmentation method named STA. It utilizes a target-to-source NMT model and sentence trunks to generate additional sentence pairs, and it does not need to introduce any external monolingual data or synonymous dictionary. Specifically, the main steps of the proposed DA method can be simply summarized as follows: Firstly, constructing a target-to-source NMT model (backward NMT model); Secondly, the constituency parse tree is generated by Stanford CoreNLP [21] for target sentence in the training set and an algorithm of generating sentence trunk is proposed; Next, translating the generated sentence trunks by the NMT model; Finally, two strategies are employed to generate the pseudo-parallel corpus. The method is simple yet effective, and the following is major contributions: To the best of our knowledge, it is the first effort to utilize sentence trunks to augment the training set for NMT tasks; Two DA strategies (Mixtrure and Concatenation) are proposed to augment the training dataset by the pseudo-parallel sentence pairs in the STA method; The STA method improves the performance of the Transformer-based NMT model steadily, especially for long sentences.
The structure of this paper is as follows: the related work is introduced in section 2, and section 3 describes the STA method in detail. Section 4 introduces the experiment and results, and the conclusion is presented in section 5.
Related work
Data augmentation (DA) is a widely used technology in many fields of deep learning, which improves model training. As for neural machine translation (NMT), DA is often used to generate the noisy data to increase the model’s robustness or more diverse training samples to improve translation performance.
One of the DA methods requires the introduction of monolingual data. In terms of using source monolingual data, Zhang and Zong [10] improved the NMT model with the self-learning method. It augmented the training set by translating source sentenecs into the target. As for the target monolingual data, Sennrich et al., [8] proposed a DA method named back-translation, which translates target monolingual sentences into the source to expand the training set. The variant of back-translation has been proven effectively in many works [14, 19, 22, 23]. He et al., [24] extend the back-translation method to use monolingual data from both the source and target sides. Hoang et al., [25] proposed an iterative DA method to ameliorate the BT and the NMT model. A corpus augmentation method is proposed by Zhang and Matsumoto [26], and it segmented lengthy sentences with word alignment, and generated the synthetic parallel data by BT. Imamura et al., [27] generated several source sentences for a target sentence by sampling. All these methods show effectiveness, yet they require additional monolingual data. Different from previous work, the sentence trunks augmentation (STA) method does not need additional monolingual data. It merely extracts the sentence trunk by establishing rules based on the constituency parse tree and constructs pseudo-parallel sentence pairs to augment the training set.
Another category of data augmentation is based on word replacement. Existing methods for word-level data augmentation also include random word swapping and word dropping. Fadaee et al., [11] improved the NMT for low-resource translation by replacing words in the original sentence with the rare vocabulary. Words in the source and target languages are individually replaced by SwitchOut [12] with words that are uniformly sampled from corresponding vocabulary. Artetxe et al., [28] randomly replaced words with adjacent words within a window size. Xie et al., [29] proposed two ways to introduce noise into sentences: randomly substituting words with placeholder words and substituting words with other words that have a comparable frequency distribution across the vocabulary. The alternative words generated by a bidirectional language model or BERT [30, 31] can be used in a sentence instead of the word token. A soft contextual DA method is proposed by Gao et al., [18], which replaces the word representation with the soft distribution. Similar to the Dropout method, the STA method can be seen as word dropping in the sentence, which is constrained by the extraction rules of the sentence trunk. Therefore, the new pseudo-parallel sentence pairs contain less noise than that of simple word dropping.
Method
The data augmentation method named STA (sentence trunks augmentation), generates pseudo-parallel sentence pairs by sentence trunks and back-translation for the original training set. Compared with the original training set, the pseudo-parallel sentences at the source and target sides are concise in length and complete in structure. The two steps of this method are the extraction of sentence trunks as well as the generation and utilization of the pseudo-parallel sentence pairs. The STA method will then be introduced thoroughly in the following.
Generating sentence trunk by constituency parse tree
Previous works pointed out that different words play a different role in a sentence, e.g., Chen et al., [32] divides the words in the sentence into function and content words. Inspired by this simple notion, we hypothesised that certain words establish the fundamental structure of the phrase and describe its primary content, termed sentence trunk. The sentence components and their interrelations can be obtained through syntactic analysis in the NLP community. Therefore, a well-designed algorithm based on the constituency parse tree can be used to extract the sentence trunk.
extraction of sentence trunk based on the constituency parse tree
extraction of sentence trunk based on the constituency parse tree
Figure 1 shows a constituency parse tree of an English sentence. It uses constituency grammar to identify terminal and non-terminal nodes to denote the structure information of the entire sentence. The content words of a sentence are leaf nodes in the constituency-based parse tree, while non-leaf nodes are the constituent attribute words, which consist of multiple content words of the sentence. The leaf nodes can be represented as the set L = {Do, you, expect, changes, in, the, current, situation, ?}, and the non-terminal nodes can be represented as the set N = {VBP, NP, VP, . . . , NN}.
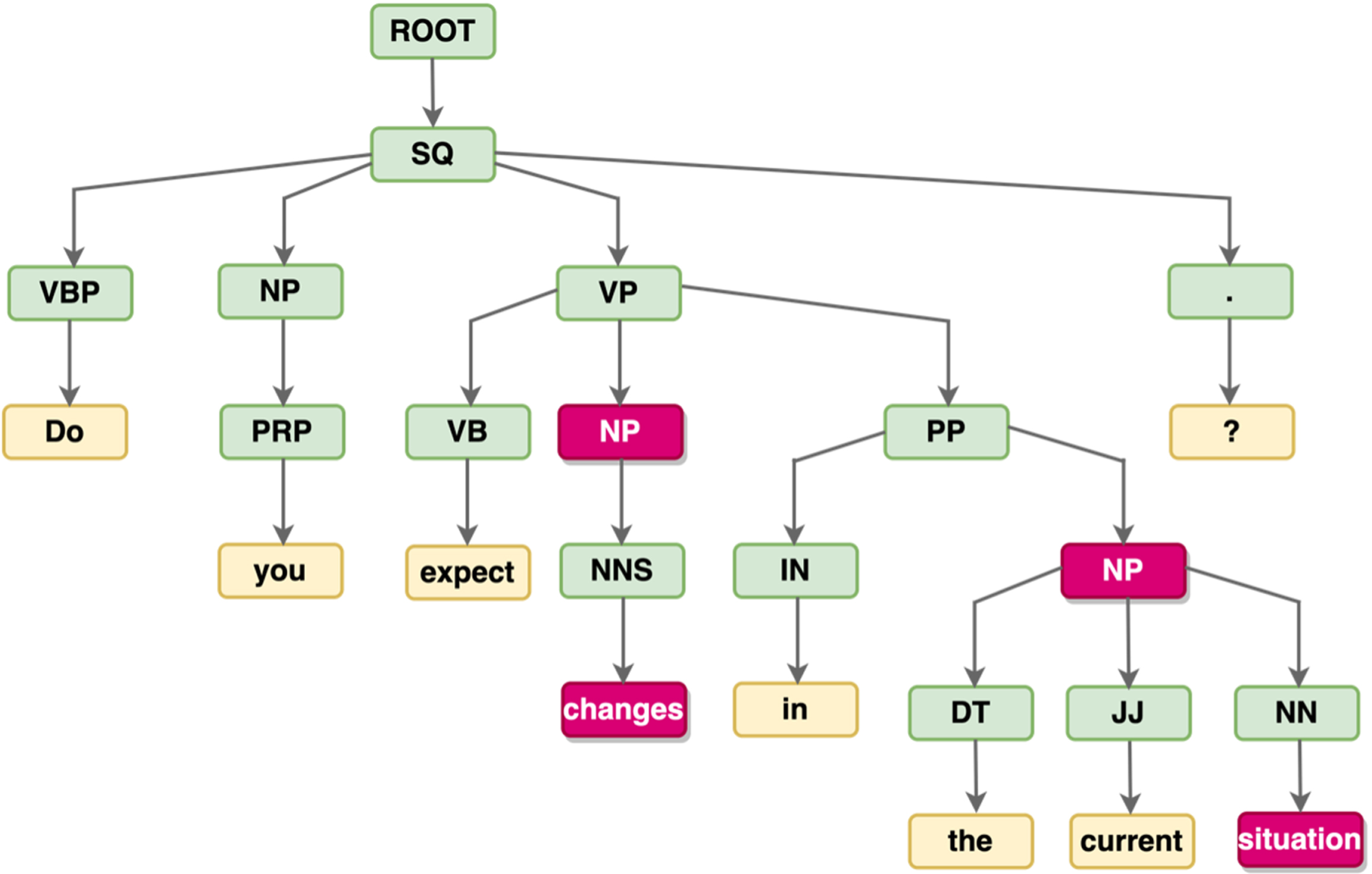
The constituency parse tree of an example sentence.
Given the constituency parse tree of a sentence, algirithm 1 shows the extraction algorithm of the sentence trunk. The sentence trunk of the example in Fig. 1 is “Do you expect changes in situation?”. Note that the sentence trunk may deviate from grammatical rules to some extent.
After the extraction of sentence trunks in original training set, this section introduces the DA method named STA.
Generating pseudo-parallel corpus
As shown in Fig. 2, the method of generating a pseudo-parallel corpus can be briefly summarized as follows:
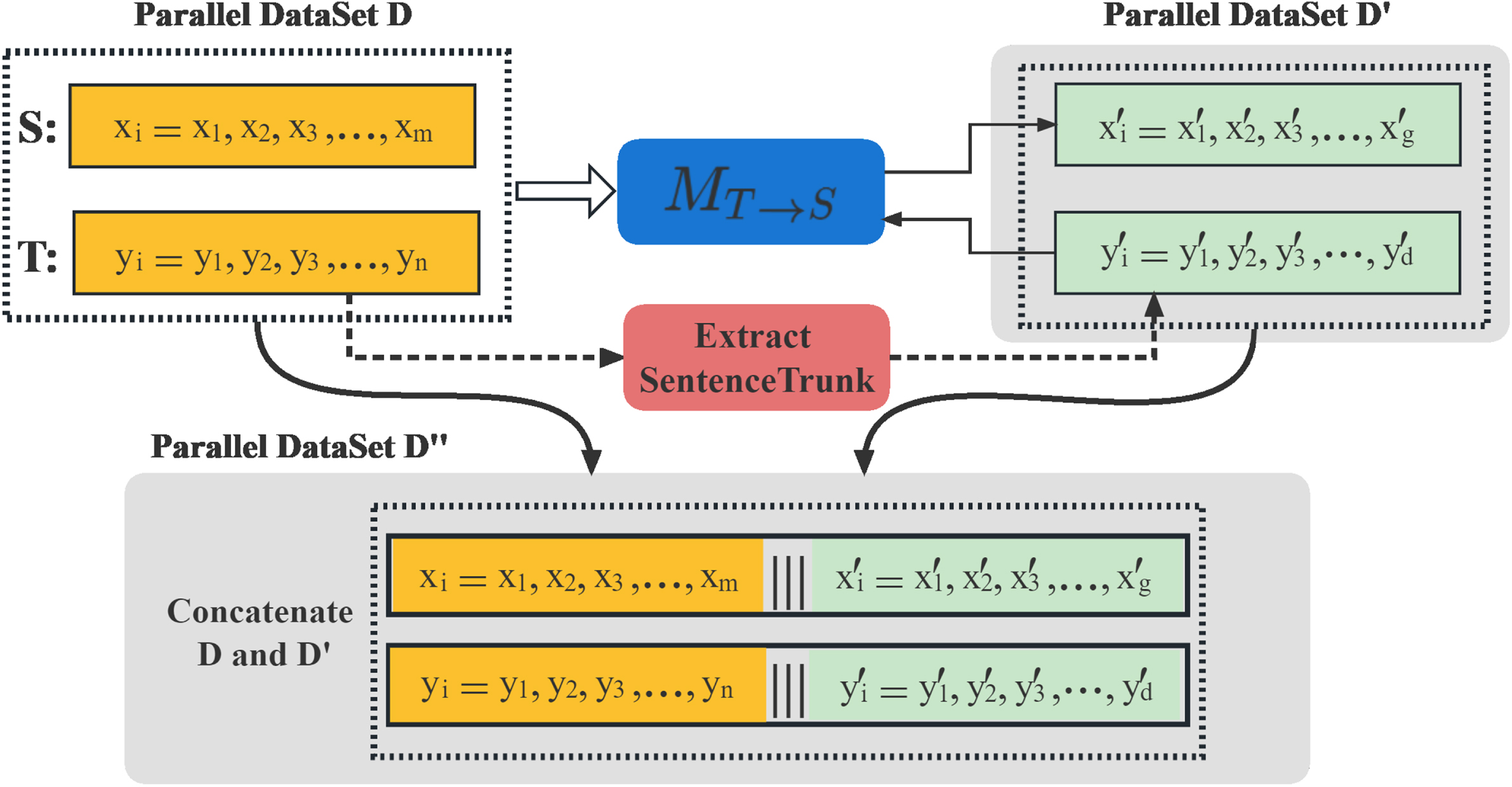
Data augmentation method STA based on sentence trunks.
Given a parallel corpus D ={ x, y }, where x and y represent the source language S and target language T, respectively. Training a NMT model of T → S, and labeling it as MT→S; ∀ (x
i
, y
i
) ∈ D, generating the sentence trunk of y
i
by the extraction algorithm in section 3.1, labelling it as Translating
As shown in Fig. 2, the parallel dataset D denotes the original training set, is the pseudo-parallel corpus that is composed of sentence trunks and corresponding translations. After generating the pseudo-parallel corpus, two data augmentation strategies are employed to augment the training set.
Experiments and results
Datasets and settings
Dataset and pre-processing
Several experiments are undertaken on simulated and real low-resource translation tasks to validate the performance of the sentence trunks augmentation (STA) method. It mainly includes Chinese(Zh), Spanish(Es), German(De), Vietnamese(Vi) and Turkish(Tr) to English(En) translation tasks, English to Vietnamese and Turkish translation tasks, which are from the well-known IWSLT14, IWSLT15, and WMT18. All the experiments are based on the transformer [4] that is implemented by the fairseq toolkit [33], and all NMT models are run on a server equipped with GeForce RTX 3090Ti*2.
Table 1 lists the number of sentence of each dataset. For the IWSLT14 De→En translation task, we follow the same training set, test set and pre-processing steps as Gao et al., [18], and we use a shared vocabulary with 10K byte-pair encoding (BPE) [34] types. For the IWSLT14 Es→En task, the settings is consistent with Cheng et al., [35]. For the IWSLT15 Zh→En task, we follow the setting of Werlen et al., [36] with a vocabulary size of 30K for both the source and target sides. For IWSLT15 Vi↔En translation tasks, the data pre-processing setting used by Wang et al., [12] is adopted in this paper. For WMT18 Tr↔En translation tasks, the settings of experiment is consistent with Bugliarello and Okazaki [37].
The number of sentences in each dataset. “Sentence Trunk” denotes the number of successful extraction of sentences
The number of sentences in each dataset. “Sentence Trunk” denotes the number of successful extraction of sentences
For all IWSLT15 translation tasks, we use the standard transformer model. For the IWSLT14 De→En translation task, we adopt the default transformer_small and transformer_base configurations for the neural machine translation (NMT) model, and other IWSLT14 and WMT18 translation tasks, only the default transformer_small configuration is used. For the transformer_small model, It has been determined that the learning rate should be at 5e-4, and the dropout rate should be at 0.3. With regard to the transformer_base model, the values 0.001 and 0.1 have been designated for the learning rate and dropout rate, respectively. β1 = 0.9, β2 = 0.98 and ɛ = 10-9 are used for the Adam optimizer [38]. The value of the beam size is 5 and the value of the maximum epoch is 30 for all translation tasks. The default settings for the other parameters are utilized.
Inspired by self-training [10], for IWSLT15 En→Vi and WMT18 En→Tr translation tasks, we adopt a source-to-target NMT model to translate source sentence trunks. Moreover, to compare with previous data augmentation methods, this paper adopts BLEU [39] and SacreBLEU [40] as the evaluation metric for several translation tasks based on the transformer_base and the transformer_small model. Models with the best performance on the validation set are evaluated. Taking into account of the variance, all experiments are run three times and the median BLEU is reported.
Main results and analyses
Performance on several translation tasks
It is indicated from Tables 2 and 3 that both the Mixture and Concatenation strategies for sentence trunks augmentation (STA) proposed in this paper outperform the baseline. In the IWSLT15 En→Vi translation task, the performance of the Concatenation strategy and the Mixture strategy is close. However, the performance of the Concatenation strategy is significantly better than that of the Mixture strategy in other translation tasks.
Performance on several translation tasks with the BLEU and SacreBLEU metric based on the transformer_small model
Performance on several translation tasks with the BLEU and SacreBLEU metric based on the transformer_small model
Performance on several translation tasks with the BLEU metric based on the transformer_base model
In real low-resource language pairs, e.g., WMT18 Tr→En and IWSLT15 Vi→En translation tasks, compared with the baseline, the BLEU improvements achieved +1.2 and 1.47, respectively. Similar results were found in other translation tasks. It is indicated that the data augmentation method STA could improve the performance significantly on multi-language pairs that are simulated and real low-resource translation tasks.
We perform further experiments, increasing the pseudo-parallel corpus size for augmentation gradually to validate the performance of the NMT model. Four settings are considered: +25%, +50%, +75% and +100%, respectively. As shown in Fig. 3, for all language pairs, both the Mixture strategy and the Concatenation strategy outperform the baseline substantially when increasing the pseudo-parallel data, and the Concatenation strategy achieved better results. Compared with the baseline, the improvements of the Concatenation strategy range from 0.21 in the De→En translation task to 1.67 in the En→Tr translation task.

△BLEU scores (above) for Mixture, and △BLEU scores (below) for Concatenation. The result of De→En is from Table 2.
To validate the performance of the sentence trunks augmentation (STA) method, we compare it with several existing DA methods on three translation tasks. For a fair comparison of the experiments, the same settings are adopted as those in previous work.
For the De→En translation task in Table 4, we evaluate the translation quality with the SacreBLEU metric based on the transformer_small model. It is obvious to find the proposed method in this paper outperforms several other methods. As for the experiments of the De→En translation task in Table 6, the Concatenation strategy also achieves competitive results compared with the Augmentsource+target method used in [41], and outperforms other methods. The experiment results on other translation tasks listed in Tables 4, 5 and 6 also show that the STA method achieves competitive performance compared to other existing DA methods.
Performance of several data augmentation methods on En→Vi translation task with the BLEU metric based on the transformer_base model. (*) is from Wang et al., [12]
Performance of several data augmentation and translation methods on De→En translation task with the BLEU metric based on the transformer_base model. (*) is from Maimaiti et al., [41]
The results of several models are shown in Fig. 4 for varying sentence lengths. Results for all sentence length intervals across every translation tasks demonstrate a substantial improvement in BLEU scores when using the Concatenation strategy (below) compared to the baseline. Nevertheless, the improvement of the Mixture strategy (middle) is only when the sentence length ranges from 11 to 50. We contend that the quality of sentence trunk is not well when the original sentence is too lengthy or too short, therefore the quality of the pseudo-parallel corpus affects the performance of the NMT model.
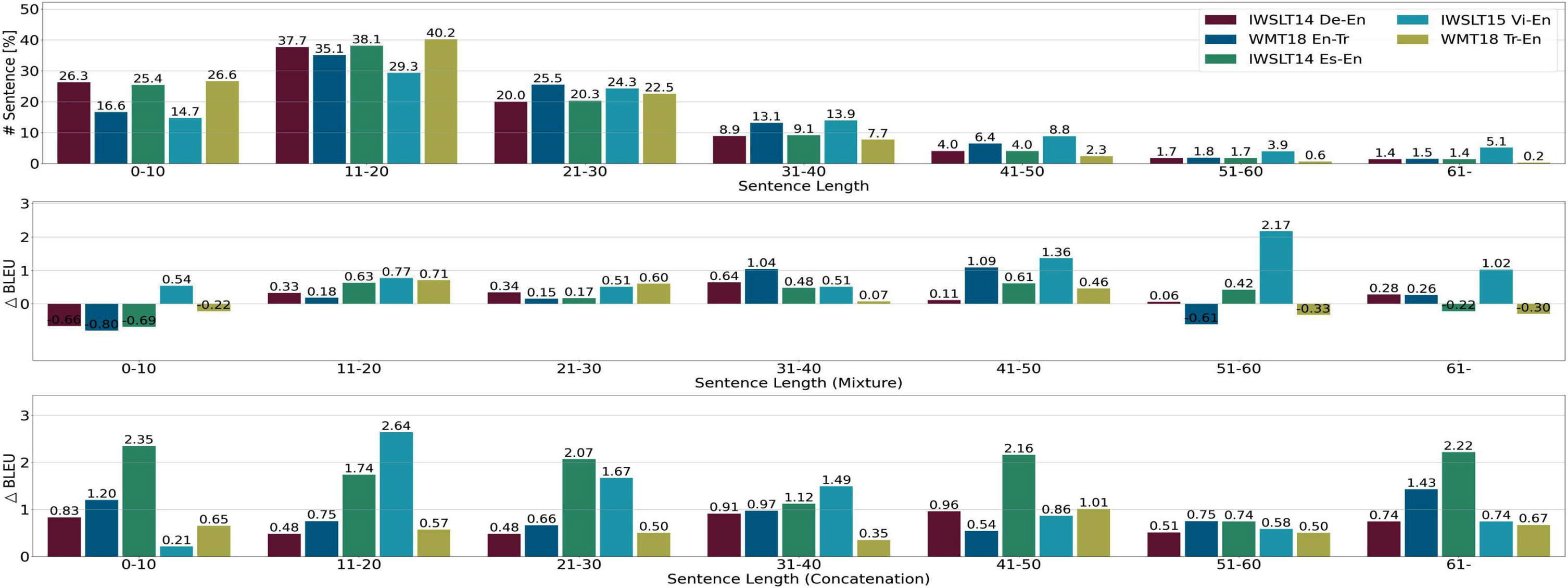
Analysis by sentence length: percentage of test set (above), △BLEU scores (middle) for Mixture, and △BLEU scores (below) for Concatenation. The result of De→En is from Table 2.
It is indicated that the Concatenation strategy performs better for long sentences than the Mixture strategy. The Concatenation strategy works well for both the short and long sentences. We contend that the length of the pseudo-parallel corpus generated by Concatenation is longer than that of the original training set, thereby improve the ability of the NMT model to translate long sentences.
To validate the convergence of the sentence trunks augmentation (STA) method, we calculate the BLEU score on the validation set and the training loss in different epoch on two translation tasks. It is shown in Figs. 5–6 that the STA method can converge faster than the baseline. Specially, it can be seen that the Concatenation strategy can achieve a better BLEU score and lower loss at the beginning of the training process, and the STA method can speed up the convergence. In our opinion, enriching the diversity of the training data with the pseudo-parallel sentence pairs, the neural machine translation model can perform better.
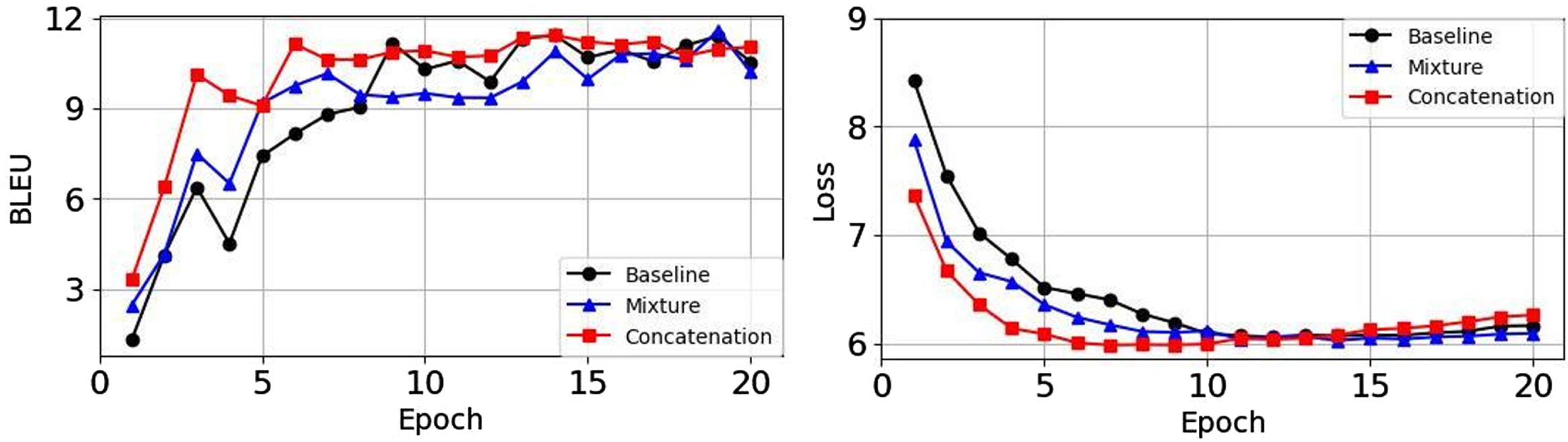
BLEU score (left) and training loss (right) in different epoch on Zh→En translation task.

BLEU score (left) and training loss (right) in different epoch on the Vi→En translation task.
The back-translation (BT) method is widely adopted to augment the training set for many low-resource neural machine translation (NMT) tasks. In order to evaluate the robustness of the sentence trunks augmentaion (STA) method, we perform several experiments by combining the STA method with the BT method with extra monolingual 100k English sentences from the WMT14 translation task. Therefore, another pseudo-parallel corpus was generated by the monolingual data with the target-to-source NMT model.
As can be seen in Table 7, the NMT model performs noticeably better when utilising the BT method with the additional monolingual data in comparison to the baseline. In fact, it performs so well that it even outperforms the STA(Mixture) and STA(Concatenation) methods in the Vi→En translation task. We contend that the BT method with extra monolingual data enriches the diversity of the training set compared with the STA method. However, when combining the STA method with the BT method, the NMT model further improves the translation quality. Consequently, it can be seen that BT and STA are independent factors that improve the translation quality.
Performance of back-translation (BT) compared to and combined with sentence trunks augmentation (STA)
Performance of back-translation (BT) compared to and combined with sentence trunks augmentation (STA)
It has been proven that the Concatenation strategy steadily improves the performance of all the translation tasks in previous experiments. Reviewing the Concatenation strategy from another perspective, the original training set makes up the first half of the pseudo-parallel corpus, while the sentence trunks make up the second. It is uncertain whether the improvement brought by the original data replication or the sentence trunk. To address this issue, we copy parallel sentences in the training set that the sentence trunk of the target side is extracted successfully as the additional parallel corpus, and combine it with the original training set. This method is named Double. Figure 7 shows the improved performance of several data augmentation methods on corresponding translation tasks compared with the baseline. Unexpectly, we find that the performance of the Double strategy even outperforms the Mixture strategy. It is obvious that the improvement brought by the Concatenation strategy is better than that of the Double strategy. The phenomenon proves the effectiveness of the proposed Concatenation strategy.

△BLEU scores for different translation task. The result of the De→En is from Table 2.
In order to verify whether the performance of the STA method is affected by the result of the syntactic analysis, we take another parser [42] proposed by Berkeley to test it on two translation tasks. The experimantal results are listed in Table 8. It can be seen that the STA method achieves a stable improvement compared with the baseline when using two different syntactic parsers. The results show that the STA method is stable and robust.
Performance of different parser on two translation tasks with the BLEU metric
Performance of different parser on two translation tasks with the BLEU metric
In fact, sentence trunks extracted by the STA method may deviate from grammatical rules. Ungrammatical sentence trunks can be regarded as a data noice, which improves the robustness of the model.
We analyse the source sentence length of the training set under two strategies (Mixture and Concatenation) proposed on different translation tasks. The experimental results are displayed in Fig. 8. We can find that the proportion of each interval of sentence length is more balanced for the Concatenation strategy compared to the baseline. However, the Mixture strategy aggravates the trend of unbalanced distribution of original training set. we content that increasing long sentences for the training set, results in the better ability of the NMT model to deal with long sentences. This conjecture is also consistent with the experimental results in section 4.2.4.
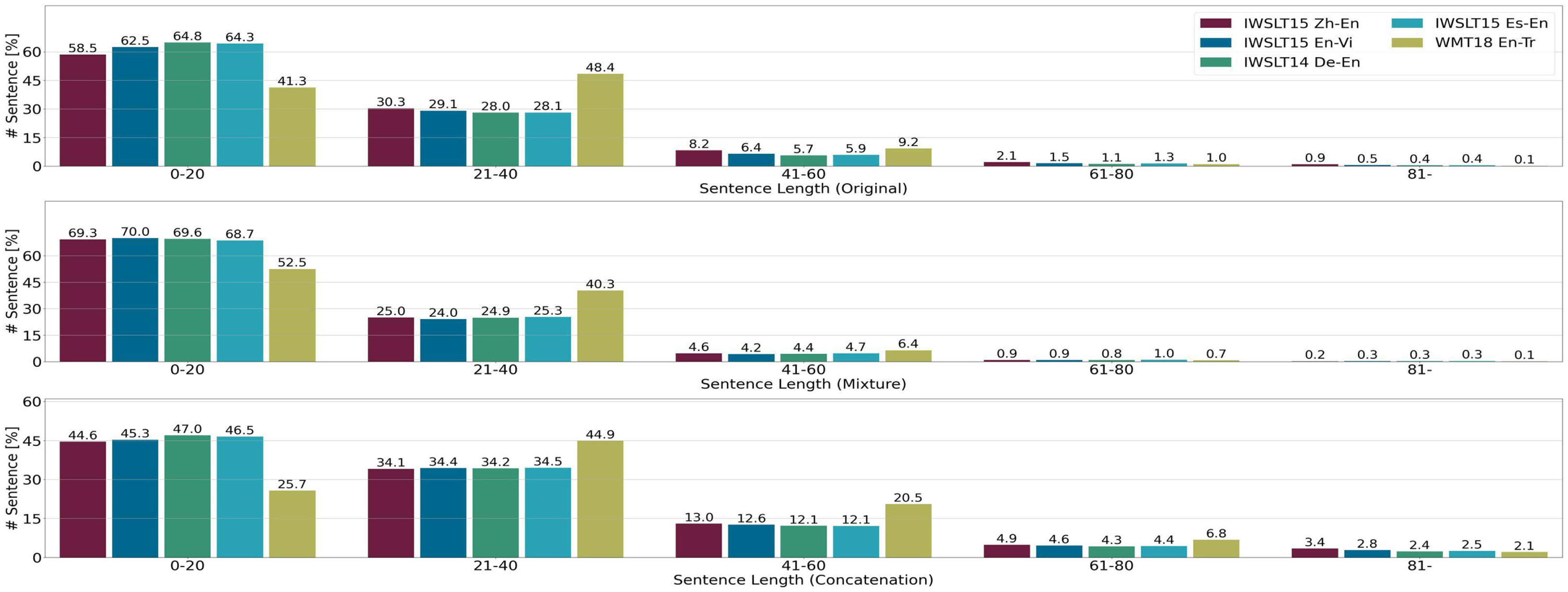
Analysis by source sentence length in training set: percentage of training set for Baseline, percentage of training set (middle) for Mixture, and percentage of training set (below) for Concatenation.
Table 9 shows a case in which the STA method works well, whereas Table 10 shows a case in which the translation quality deteriorated. Compared with the reference, the translation quality of the STA (Mixture) and STA (Concatenation) is better than that of the baseline in Table 9, although the translations are not perfect. It is obvious that the STA method results in better performance of the neural machine translation model. In Table 10, there is a repetitive output error in the translation of the STA (Concatenation) strategy. Nevertheless, the error is not seen in the translation of the baseline. In the case of short sentences of the test set, this type of inaccuracy occurs several times. This suggests that the ability to output long sentences may lead to unnatural output repetition due to the attempt to generate long sentences. A sample sentence listed in Table 11 is the translation from Turkish to English. The translation generated by the STA method are closer to the corresponding reference compared to the baseline, alghough the translation quality can yet be better. Therefore, it is demonstrated that the STA method plays a positive role in low-resource language translation tasks.
An German example of the effectiveness of the STA method
An German example of the effectiveness of the STA method
An German example where the STA method may cause errors
A Turkish example of the effectiveness of the STA method
This paper proposes a straightforward yet effective method named STA to augment the training set of neural machine translation for low-resource language pairs. By utilizing sentence trunks derived from the constituency parse tree on the training set as well as back-translation, the Mixture and Concatenation strategies are employed to generate the pseudo-parallel corpus. Experimental results on simulated low-resource language pairs (e.g., German→English) and real low-resource language pairs (e.g., Turkish↔ English) show substantial improvements in STA method over the strong baselines. In addition, the experimental results indicate that the STA method is more competitive than other available data augmemtation approaches. In future work, we intend to investigate data augmentation methods with smaller granularity, e.g., n-gram, and to continue studying our method in other natural language processing generating tasks, such as text summarization.
Footnotes
Acknowledgments
We would like to thank anonymous reviewers for their valuable comments. And thank Jiarui Li for his helpful advice to improve the paper. This research was supported by grants 2021-YKLH-12 and 2022-YKLH-18 from the Natural Science Foundation of Liaoning Province, China.