
Abstract
Aspect-based sentiment analysis (ABSA) aims to predict the sentiment polarity of a specified aspect in a sentence. Graph neural networks (GNN) based on dependency trees have been shown to be effective for ABSA by explicitly modeling the connection between aspect and opinion terms and exploiting local semantic and syntactic information in the sentence. However, most previous works have overlooked the use of global dependency information. In this paper, we propose a novel Graph Convolutional Network (GCN) with an Interactive Memory Fusion (IMF) mechanism (IMF-GCN) that incorporates both global and local structural information for aspect-based sentiment classification. The IMF mechanism efficiently fuses global and local structural dependency information by assigning different weights to global and local dependency modules. Syntactic constraints are also imposed to prevent the graph convolution propagation unrelated to the target words, further improving the model’s performance. The evaluation metrics used in the paper are accuracy and macro-average F1 scores, and the proposed approach achieves optimal results on three datasets with F1 scores of 79.60%, 82.19%, and 77.75%, which outperform the baseline model.
Problem definition
Introduction
Aspect-based sentiment analysis (ABSA) is distinct from traditional document-based and sentence-based sentiment classification [20]. It aims to predict the sentiment polarity of different aspects in a sentence, including positive, neutral, and negative. For example, in Fig. 1, we illustrate the ABSA task for a sentence with multiple sentiment polarities, where the sentiment polarity is positive for the food aspect and negative for the service aspect. This approach allows for precise aspect classification in a sentence, rather than simply assigning sentiment polarity to the entire sentence.
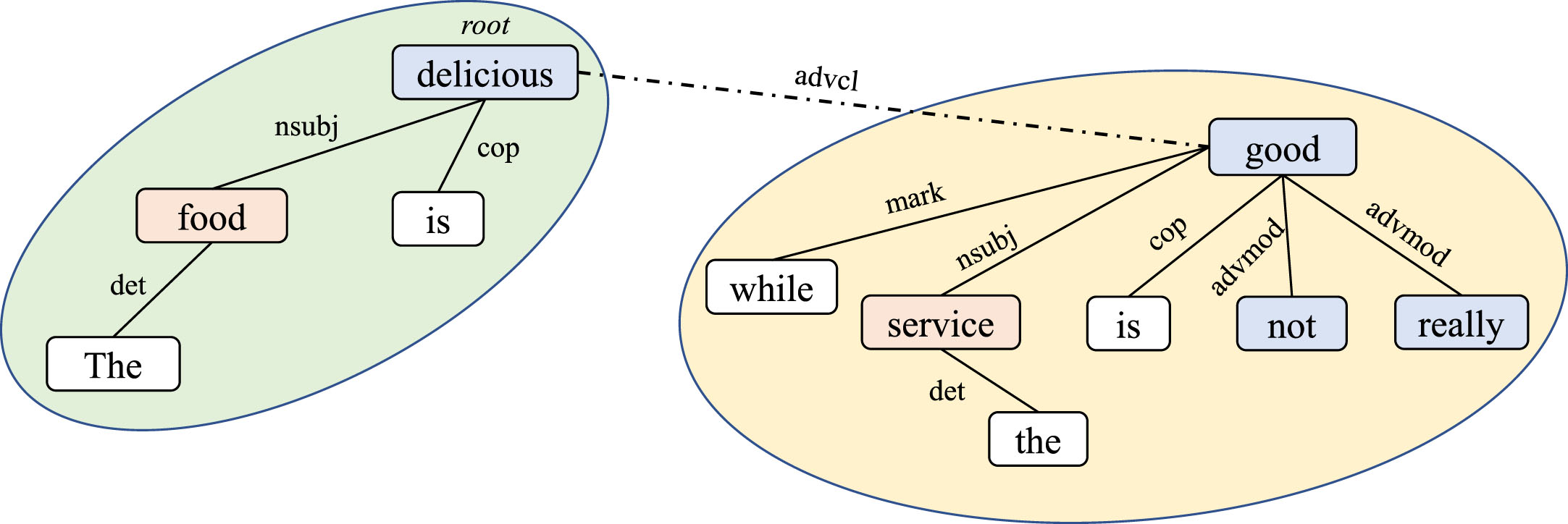
An example sentence in the restaurant dataset and its dependency tree. The orange and blue parts represent aspect terms and opinion terms, respectively.
In recent years, lots of exploration have been made to effectively model the semantic relevance between aspect and contextual words in sentences. [15, 35] and [23] use the attention mechanism [7] to model the relevance between aspect and context in a sentence. It assigns the weight to each word in the sentence to capture the importance of the word for the target word. The aspect in the sentence consists of one or more words. Therefore, [31] and [29] proposed the use of Convolutional Neural Network (CNN) [32] to solve the above problem through convolutional operations on words in sentences to capture target sequences composed of multiple words. Since CNN and Recurrent Neural Network (RNN) [21] prioritize locality and sequentiality, the model can effectively capture syntactic and semantic dependency information of the target word for multiple words. However, they lack the mechanism to deal with long distance dependence of words in the sentence and may lead to wrong classification of the model. In recent years, the dependency tree has captured the syntactic dependency relationship between two words in the sentence that are far away from each other. Therefore, the graph neural network (GNN) [10] based on dependency trees have attracted increasing attention. In these works, [6] construct the graph convolutional networks (GCN) by using dependency tree of sentences and utilizing syntactic structure information to model the dependency relation of long-range words. [2] design graph attention network related to the target word, but it is the local attention that only consider the importance of the target word with its neighbor nodes and ignore the global information of the sentence.
Although the aforementioned works have achieved satisfied results, they are limited in that they rely excessively on exploiting local dependency information, such as positional, sequential, or syntactic dependency constraints of target words in the sentence, while largely ignoring global structural dependency information. Recent research [12] and [22] has shown that utilizing global dependent information can significantly improve the performance of text classification.
Motivated by the aforementioned challenges, we propose a Graph Convolutional Network guided by an Interactive Memory Fusion mechanism (IMF-GCN) to address the issue of incorporating both global and local dependency information. Specifically, the IMF-GCN framework efficiently fuses local and global dependency information by using a self-attention mechanism to capture the global dependency attention of the sentence, an aspect-aware attention mechanism and local syntactic constraints to capture local dependency attention, and an interactive memory fusion (IMF) mechanism to fuse these two sources of information into a final representation for classification. The resulting representation is fed to a softmax classifier.
In summary, the following are the major contributions of this work:
(1) We use aspect-aware attention and self-attention mechanism to acquire local dependency and global dependency information separately, which thus solved the problem of incomplete information.
(2) To fully integrate global and local dependency information, an interactive memory fusion layer is proposed to learn the final representation of local and global dependencies.
(3) Through extensive experiments on SemEval 2014 and Twitter datasets, it shows that IMF-GCN effectively combines global and local dependency feature, and achieves higher performance than the baseline model with F1 scores of 79.60%, 82.19% and 77.75%.
Aspect-based sentiment analysis
Aspect-based sentiment analysis is a fine-grained sentiment classification task. Early research work usually relied on traditional classification models such as SVM [16, 27]. In recent years, the neural network models have received increasing attention due to their ability to learn text representation directly from data by skipping the step of extracting feature engineering.
In particular, [8] proposed a deep memory network for aspect-based sentiment analysis. The model is composed by multiple computational layers with shared parameters and each layer is an attention model based on target words and context. [35] gives different attention scores for each part of the sentence, utilizing an attention mechanism to keep the model focused on the part that is more important to the target word. [26] propose a network composed of a multi-layer attention mechanism that is integrated with a recurrent neural network to capture the sentiment feature of target words that are distant from the option term. [9] introduced an interactive attention mechanism to yield feature representations of target words and contexts. Some recent work also proposed that employing a convolutional neural network to capture the case where aspect terms are multiple words can yield more competitive performance. For example, [29] employ a convolutional neural network and a gate control mechanism. In particular, two separate convolutional layers are used in the embedding layer to obtain the output representation of the context.
Graph convolutional networks
Although the above work has made some progress, there are limitations in dealing with second-order or multi-order semantic and syntactic relations between tokens in sentences. To solve this problem, the approach of using dependency trees with graph convolutional network is becoming increasingly popular.
For example, some recent works [6] applied dependency trees of sentences to GCN networks to obtain rich representations on dependency trees. [13] learn the knowledge graph-aware recommendation problem by capturing higher-order structural and semantic information in knowledge graph. When computing the representation of given entity in knowledge graph, the neighbor information is combined with the bias to better capture the local features of the target word. [3] proposed a new graph-aware model that uses syntactic dependencies to refine graphs, deriving graphs focused on aspect to capture the relationship between aspect terms and context. [4] constructed a sentiment enhancement graph by combining external knowledge from the SenticNet module to learn the sentiment information between aspect words and opinion words.
Proposed model
This section describes the details of the IMF-GCN. In particular, the global dependency module and local dependency module based on the IMF-GCN model framework and the solution using graph convolutional networks are introduced. Figure 2 gives an overview of IMF-GCN.
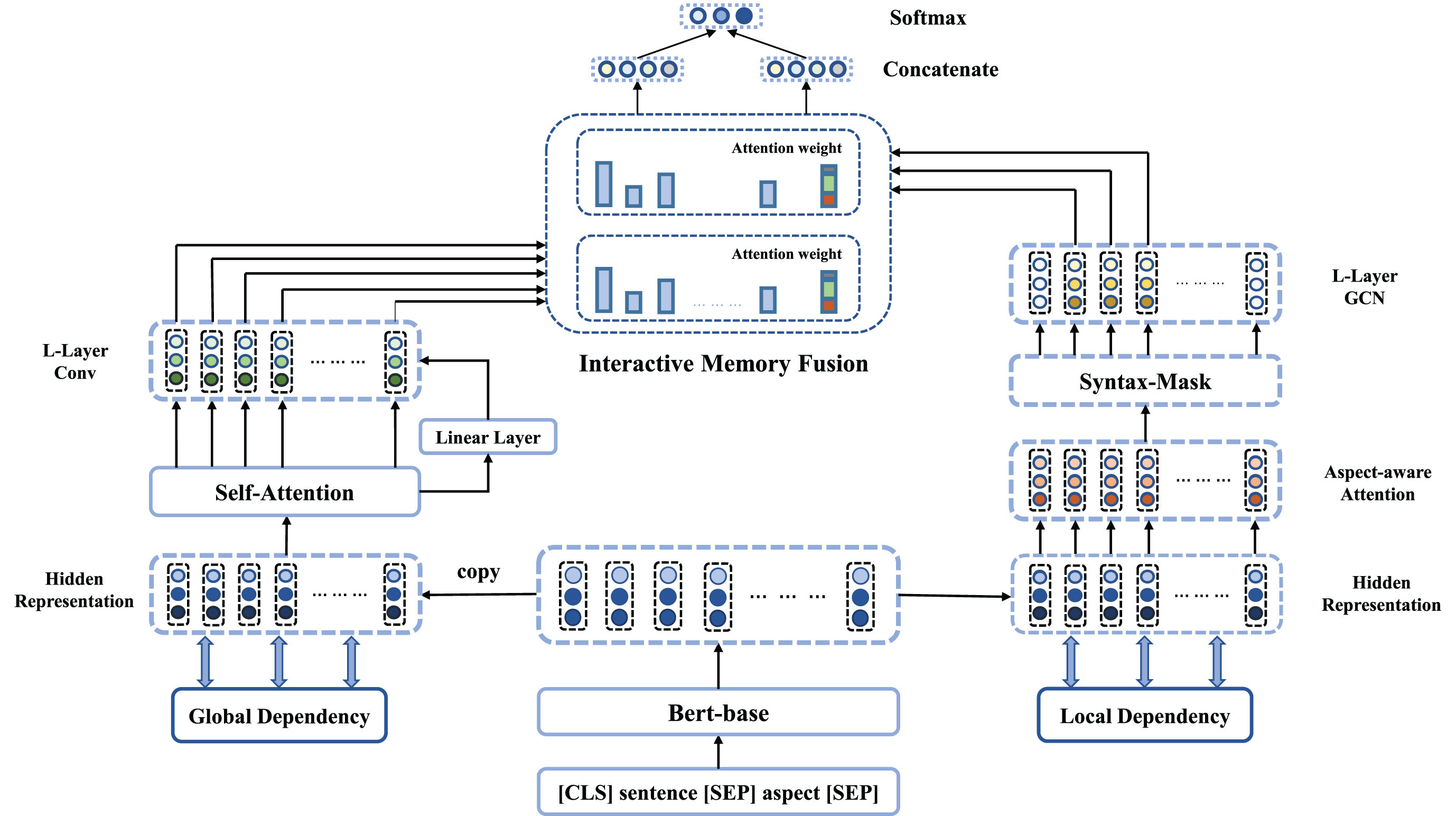
The proposed architecture of IMF-GCN.
Given a sentence-aspect pair (s, a), where s ={ s1, s2, . . . , s n }. a ={ a1, a2, . . . , a m } is an aspect which is also a sub-sequence of the sentence s. In particular, the sentence may comprise one or more aspects corresponding to different emotional polarities, i.e., positive, neutral or negative. Here, each aspect can consist of one or more words. ABSA aims to predict the emotional polarity of a given aspect via extracting opinion term related to the aspect term from the context. The paper uses the pre-trained model BERT [14] as a sentence encoder. For the BERT encoder 1 , and adopt “ [CLS] sentence [SEP] aspect [SEP] ” as input. Finally, the final layer of the encoder output is obtained as the hidden state, represented by H in the text, and used as input to the global and local dependency modes.
Local dependency attention
Aspect-aware attention
Based on aspect-oriented feature, a retrieval-based attention mechanism is used to yield a contextual representation of the target-oriented values. The idea is to retrieve important features related to aspect semantics in context, so, we propose an aspect-aware attention mechanism that treats aspect terms as query to calculate attention scores for learning local semantic relationships:
Note that semantics and syntax are indispensable features of the sentence. This section will introduce the syntactic mask matrix [36], and combine the local syntax and semantics of a sentence to produce a new matrix representation. The first step is to mask each fully connected graph according to different syntactic distances. The syntactic dependency tree is considered as an undirected graph, where each token is a node. Then, the distance between nodes v
i
and v
j
is defined as d (v
i
, v
j
). Since there are multiple paths between nodes in the syntactic dependency tree, the distance of the shortest path is defined as D:
In order to obtain local semantic and syntactic features, this paper fuse them and use activation functions to generate corresponding weight representations and feed it to the GCN layer:
Based on the work of traditional CNN and graph embedding, GCN is an effective CNN variant that operates directly on the graph [28]. Given a graph with n nodes, the adjacency matrix
Where W
l
is a weight matrix, b
l
is a bias term, and σ is an activation function (e.g., ReLU). A
ij
indicates whether the i-th node is connected to the j-th node. The final output representation of the l-layer GCN is
Self-attention
The self-attention [1] mechanism computes the attention score of each matrix pair in parallel and captures the semantic correlation between arbitrary two tokens of a single sentence. The formula involves a query and a key:
Where matrices Q, K and V are all homologous but not equal to the output of encode layer, while W
Q
, W
K
and W
V
are learnable weight matrices. In addition, d is the dimensionality of the input feature. where
Aspect-based sentiment analysis aims to extract and classify one or more aspects in a sentence, and the aspects may contain multiple tokens. Therefore, the convolution layer (Conv) is applied to extract aspect terms composed of multiple tokens to improve the learning ability of n-gram features. The n-gram features of aspects with multiple tokens are learned by defining multiple layers of Conv, using K filters in each layer. The detailed calculations are as follows:
The IMF layer is an interactive memory fusion mechanism that we propose as one of the key components of the IMF-GCN model. The main purpose is to learn the final representation of local and global dependency relation in the text by interacting the output of the local and global dependency module with the hidden state of the context of the encoder to extract important features related to the semantics and syntax of the sentence. IMF-GCN achieves effective learning of local and global dependency relation in the sentence through the construction of IMF layer and is able to capture the local correlations between local and global context.
Specifically, for the construction of the IMF layer, an aspect-specific mask layer is first applied to the output of the local dependency module to mask the state of non-aspect words to zero, and then an attention interaction is performed between the output of the mask layer and the output of the global dependency module. This process ensures that the IMF layer concentrate only on aspect-related features and captures the relevant dependency relationship between the local and global context. where the output of the mask layer is H
mask
= { 0, 0, . . . , hasp+1, . . . , hasp+m, 0, . . . , h
n
} , defined as,
Where asp is the index of aspect terms, and m is the length of aspect terms. W1 is a trainable parameter, and H is the final output of the encoding layer. Therefore, the local dependency attention weight and final representation are calculated as:
Accordingly, the final representation of the global dependency is computed as,
After the final representations of local and global dependencies are obtained, they are fed into a fully connected layer and followed by a softmax function to yield a probability distribution over polarity decision space:
In summary, the introduction of IMF can effectively enhance the modeling capability of IMF-GCN and improve the performance of natural language processing tasks such as text classification and sentiment analysis.
Finally, the standard cross-entropy loss is used as our objective function:
Datasets
Experiments on aspect-based sentiment analysis were conducted by using three benchmark datasets, including the SemEval 2014 Task 4 [25] for restaurant and laptop reviews and Twitter from [19]. Each aspect is labeled by one of three sentiment polarities, positive, neutral or negative. Statistics for the three datasets are summarized in Table 1.
Statistics of the datasets
Statistics of the datasets
For IMF-GCN, this paper initialize the word embeddings using a 300-dimensional GloVe vectors [17]. The dimension of the hidden state of BERT is set to 768. All sentences are parsed by Stanford parser. The number of GCN layers for syntactic dependency trees and text graphs is set to 2, which is the best setting found in multiple experiments. The model utilize Adam as the optimizer with a learning rate of 0.002, and batch size is 32. This paper execute 3 experiments with random initialization and report the average performance. In addition, the dropout function is applied to the input of the encoding layer and the dropout rate is set to 0.3. The model is implemented via PyTorch, and all experiments were done on hardware with an NVIDIA GeForce GTX 2080TI.
Evaluation metrics
For evaluation, the performance of aspect-based sentiment analysis was assessed using accuracy (ACC) and macro-average F1 scores (F1). ACC: The percentage of samples correctly predicted among all samples is named accuracy. It is defined as:
F1: In our experiments, macro-averaged F1 [12] is used to assess the average F1 across all different labels. Defined as:
In order to fully evaluate the performance of the model, the proposed method is compared with the state-of-the-art baseline in this paper. BERT [14] is the basic pre-trained BERT model, which adopts “[CLS] sentence [SEP] aspect [SEP]” as input. SA-GCN+BERT [30] is a GCN model based on BERT and dependency trees, which adopt selective attention to discover important words to infer the aspect representation. AEN-BERT [34] is an attention encoder network based on the pre-trained BERT model, designed to resolve aspect polarity classification. R-GAT+BERT [18] is an R-GAT model employing a pre-trained BERT instead of a BiLSTM as an Encoder. DGEDT+BERT [11] common consider planar representation and graph-based representation via dependency graph enhanced dual-transformer networks. BERT4GCN [24] integrates grammatical sequential features from PLM of BERT and syntactic knowledge of dependency graphs. T-GCN+BERT [33] uses dependency types to distinguish different relationships in the graph and learns contextual information from different GCN layers with attention layer integration. SSEGCN [36] propose a syntactically and semantically enhanced graph convolutional network for integrating syntactic and semantic information of sentences.
Overall performance
To show the validity of IMF-GCN, compare the performance of our model with previous work where accuracy and macro-averaged F1 were used as evaluation metrics and report the results in Table 2. The experiment results indicate that our IMF-GCN model attains the best performance on all three datasets, which proves the superiority of our model. Our model adopts an architecture based on graph convolutional networks and an interactive memory fusion mechanism that fuses structural information at the global and local dimensions, which in turn improves the performance of sentiment classification. Specifically, our approach captures the local semantic features of the sentences by designing aspect-aware attention mechanisms with the target word as the query key of the attention mechanism. The local syntactic and captured semantics are fused together using a syntax-based GCN network to form the local dependency module of the sentence. The global dependency module uses a self-attentive mechanism to capture the global semantics of the sentence, because the target word already knows its degree of association with other words, and thus can be better solved in multilayer convolutional networks for sentences where the target word is multiple words. In particular, we propose an interactive memory fusion method that effectively combines the local dependency module and the global dependency module so that the model fully considers the syntactic and semantic features of the sentences. On the other hand, a pre-trained model is used in this paper, and to be fair, we only compare with work using the pre-trained model. The experiment proves that the IMF-GCN can learn more syntactic and semantic knowledge to enhance the ABSA ability.
Comparison of experimental results. The best two metrics are shown in bold. “-" means not reported
Comparison of experimental results. The best two metrics are shown in bold. “-" means not reported
Ablation study
As shown in Table 3, an ablation study of the model is performed to investigate the impact of each component (e.g., global dependent modules and local dependent modules) and to check the validity of the different modules in IMF-GCN. The IMF-GCN is the best performing baseline model. Firstly, it can be observed that by removing the local dependency module, the accuracy of the model decreases rapidly, resulting in a decrease of 3.34%, 1.80% and 2.16% on Laptop, Restaurant and Twitter, respectively, indicating that the model lacks the ability to learn the local semantics and syntax of the sentences. Next, by removing the aspect-aware attention mechanism in the local dependency module, we find that the metrics do not drop significantly relative to the local dependency module. The lack of global dependency and the lack of aspect-aware attention have similar performance, showing that the model is relatively more focused on the local features of the sentences. It is worth noting that the lack of self-attention degrades the performance of the model, leading to the conclusion that the global semantics of the sentence are equally important for ABSA. Notably, when the model removes the interactive memory fusion method, the model performance decreases substantially, with accuracy rates on Laptop, Restaurant, and Twitter decreasing by 4.62%, 2.13% and 2.70%, respectively, which confirms that the effective integration of local and global dependencies is essential. In summary, the results of the ablation experiments show that each module is of indispensable value to our overall model architecture.
Experimental results of ablation study
Experimental results of ablation study
In order to obtain a more comprehensive understanding of how our model works and its ability to accurately classify aspect-based sentiment, we present a case study with multiple test samples. The predictions made by T-GCN, R-GAT, and IMF-GCN for various aspects in a specific sentence are shown by Table 4 2 . In the table, T-L denotes the label of aspect in the sentence, P-L denotes the label of model prediction, and R indicates the judgment whether the model is correctly classified. The first sample is “I have a good battery life, so I take it without a cord.”, which contains two aspects “battery life” and “cord”. The sentiment polarity of “battery life” is natural, while the sentiment polarity of “cord” has a positive affective polarity, and such a strong contrast may interfere with the predictive power of the model. The second sample is “I prefer apple juice vinegar because it tastes good and the texture is both soft and not sticky.”, which has multiple opinion terms that can, to a certain extent, interfere with the model’s recognition of semantic associations. The third sample is “You may need to special order a bag.”, and the model generally has difficulty in making correct predictions for sentences in which the opinion term is positive, but the sentiment polarity is neutral. The last example is “Then HP sends it back to me with the hardware screwed up, not able to connect.”, which contains two aspect terms, but the sentence only expresses the emotional polarity of one target word. The IMF-GCN correctly predicts all four samples, which reflects that the IMF-GCN model effectively combines local and global dependency information. To sum up, our IMF-GCN excels at handling complex sentences with multiple sentiment words or target words that can disrupt semantic association recognition. The ability to consider the overall sentence semantics is also crucial in ABSA, and our model efficiently combines local and global dependency information for precise predictions.
Case Study
Case Study
In this section, the model study the affect of setting the number of layers of the graph convolutional network and convolutional layers between 1 and 6 on the laptop, restaurant, and twitter datasets. As shown in Fig. 3, the experimental results show that our model achieves the best performance with the number of layers of GCN equal to 2 and the number of layers of Conv equal to 4. In particular, when the layer of GCN is set to 1, the model can only learn the first-order semantic and syntactic information of each token in the sentence. However, when the number of GCN layers is large, the node representation will be too smooth and generate more redundant information, thus reducing the performance of the model. With the increase of Conv layers, the multiple convolution operations can iteratively extract more complex features from low-level features, and thus the model can achieve the equal (or even greater) level of performance with fewer parameters. However, too many layers can lead to overfitting of the model, so this paper set an optimal number of layers for the model.

The effect of GCN and Conv layers on performance (ACC values and F1 scores) in the three datasets.
In Table 5, We make confusion matrix for each dataset, in order, laptop, restaurant and twitter. Those samples that were misclassified were analyzed. In the laptop dataset, the number of misclassified positive sentiments is much larger than the other two sentiments, which may be due to the model being too "confident" in learning positive sentiments, which means that the decision boundary of the model may be more inclined to label some neutral or negative texts as positive rather than the other way around. In the restaurant dataset, observing that too many positive sample numbers are available for each category in the confusion matrix may lead to poor performance of the model. The problem can be mitigated by considering increasing the sample size of the other two categories or by using a sample balancing approach. The number of error classifications was almost consistent across sentiment in the twitter dataset. The misclassification of positive categories as neutral or negative may be due to the fact that the texts contain expressions or words whose emotional polarity is difficult to judge, such as irony, sarcasm, hyperbole, etc. The classification of neutral category errors as positive or negative may be due to the model not accurately capturing the subtle changes of emotion in the text or the presence of ambiguity in the text.
Confusion Matrix
Confusion Matrix
In natural language processing, there are many other factors that affect the performance of the model. First, our model currently only considers syntactic and semantic dependency information between aspect and opinion terms in a single sentence. However, in real-world scenarios, aspects and opinion terms may be distributed in multiple sentences or even paragraphs. In such cases, our model may not be able to capture the full context and make accurate predictions. Therefore, we plan to investigate the use of discourse-level information, such as core inference parsing and coherence relations, to better capture the global context and improve the performance of our model. Second, our proposed model is still subject to uncertainty and noise in practical applications, such as misspelled words, slang expressions, and negation. Therefore, we plan to explore ways to address these challenges by adding uncertainty-aware mechanisms, such as Bayesian neural networks or Monte Carlo dropouts, to our model to make it more robust and reliable. Overall, we believe that addressing these challenges and limitations, and further improving our proposed model, will enhance its applicability and usefulness in real-world scenarios.
Future plans
In future work, we consider three plans to improve the model performance or to address the issues faced in the discussion.
Firstly we can improve the performance of the model by further fine-tuning the model parameters or introducing new features to further improve the performance in the area of sentiment analysis. The second is that data augmentation techniques can be used to increase the training data of the model to further improve the robustness and generalization ability of the model. Finally we can investigate different graph convolutional network structures, interactive memory fusion mechanisms, in order to understand which factors are most critical to the effectiveness of sentiment analysis tasks and further optimize the algorithms.
Conclusion
In this paper, the aspect-based sentiment classification problem is investigated and proposed a new model, a graph convolutional network guided by an iinteractive memory fusion mechanism (IMF-GCN), to solve this problem. Our Model construct graph convolutional neural networks on dependency trees to extract local syntactic dependencies and distances of sentences, and obtain global and local semantic information through attentional mechanisms. In addition, we divide the information obtained to local dependent attention and global dependent attention as output, and fuse the above two modules through the interactive memory fusion mechanism. Experimental results on three public datasets show that the method is effective.