
Abstract
Outlier detection is an important topic in data mining. An information system (IS) is a database that shows relationships between objects and attributes. A real-valued information system (RVIS) is an IS whose information values are real numbers. People often encounter missing values during data processing. A RVIS with the miss values is an incomplete real-valued information system (IRVIS). Due to the presence of the missing values, the distance between two information values is difficult to determine, so the existing outlier detection rarely considered an IS with the miss values. This paper investigates outlier detection for an IRVIS via rough set theory and granular computing. Firstly, the distance between two information values on each attribute of an IRVIS is introduced, and the parameter λ to control the distance is given. Then, the tolerance relation on the object set is defined according to the distance, and the tolerance class is obtained, which is regarded as an information granule. After then, λ-lower and λ-upper approximations in an IRVIS are put forward. Next, the outlier factor of every object in an IRVIS is presented. Finally, outlier detection method for IRVIS via rough set theory and granular computing is proposed, and the corresponding algorithms is designed. Through the experiments, the proposed method is compared with other methods. The experimental results show that the designed algorithm is more effective than some existing algorithms in an IRVIS. It is worth mentioning that for comprehensive comparison, ROC curve and AUC value are used to illustrate the advantages of the proposed method.
Introduction
The relevant research work
One intuitive and popular definition of an outlier was given by Hawkins [21]: “An outlier is an observation that deviates so much from other observations as to arouse suspicions that it was generated by a different mechanism”.
As an important branch of data mining, the purpose of outlier detection is to find objects whose behavior is different from that of normal objects. Outlier detection is widely used in many fields, such as marketing [9], medical diagnosis [16], bioinformatics data [31]. In practical applications, outlier detection is an unsupervised learning problem, because outliers are few and data labeling is expensive [16].
Outlier detection strategies can also be classified as local or global based on the size of their reference set. The well-known Local Outlier Factor scoring algorithm [11] detects outliers based on local density and provides a local outlier score to each data point. For each data point, the LOF score is defined as the ratio of the average density of its neighbors to its own local density. The global unsupervised outlier identification technology may be split into three major types depending on the assumptions used in modeling outliers: clustering-based, statistics-based, and closest neighbor-based techniques. In clustering based technology [38], data that does not belong to any cluster or belongs to a very small cluster is considered as outliers. This method largely depends on the parameter setting of clustering algorithm, and its efficiency is low. In statistical-based technology [12, 41], it is assumed that the data fits a statistical model, and then a test is run to identify the data points that do not fit in the presumed model. In closest neighbor-based technology, each data point is analyzed according to its local neighborhood. The closest neighbor method is distance-based or density-based, depending on which standard is used to identify nearest neighbors and outliers [13]. In the distance-based method [30], a data point far from its nearest neighbor is regarded as an outlier. When the density of different data areas is different, the performance of these methods will be poor. The density-based method not only calculates the local density of each data point, but also calculates the local density of its adjacent points. If the density of a data point is much lower than that of its adjacent points, it is considered an outlier [33].
Granular computing (GrC), proposed by Zadeh [49], is an important tool in artificial intelligence [48]. GrC emphasizes the importance of granulation. Related work is generally combined with the fuzzy set theory [37], rough set theory (RST) [39, 40]. Lin [31] proposed a method for GrC based on neighborhood systems. Yao [44] has looked at certain GrC approaches in the context of neighborhood systems. As a computing method of information processing, GrC provides a theoretical framework for solving the problems in data mining and pattern recognition [32, 45].
Rough set theory (RST) introduced by Pawlak is a tool for handling uncertain information. This theory defines lower and upper approximations, and presents the accuracy of a set by means of two approximations. The accuracy may be applied to quantify the quality of the approximations on decision classes [39]. RST is widely used in attribute reduction [17, 43], pattern recognition [51], classification [25, 50] and data mining [14]. In recent years, RST has attracted many researchers’ attention [1, 22], and its application is mostly related to an information system (IS). It is worth mentioning that topology plays an important role in handling an IS via RST (see [3–5, 35]).
GrC or RST can be applied to outlier detection. In order to make up for the shortcomings of distance-based and density-based methods, outlier detection methods based on RST were also proposed. Although these methods have proved the effectiveness of RST in outlier detection. However, these methods build mathematical models based on equivalence relations, and their detection models are only applicable to nominal feature data. Numerical feature data need to be described before we use these detection models. It increases the time required for data processing and is accompanied by significant loss of information. However, this does not happen when an IRVIS is directly studied with RST and GrC.
Many scholars have developed outlier detection based on GrC or RST. Francisco et al. [19] constructed mathematical framework of outlier detection based on RST. Chen et al. [15] proposed an outlier detection algorithm based on the neighborhood rough set model. Macia-Perez et al. [36] improved outlier detection algorithm based on RST. Jiang et al. [26] presented a GrC-based outlier detection method, which uses the information table-based GrC model to detect outliers. Yuan et al. [46] studied outlier detection methods based on fuzzy rough sets (FRSs). Li [32] gave an outlier detection algorithm for categortical data using GrC. Jiang et al. [29] gave an information entropy-based approach to outlier detection. Gao et al. [20] put forward a relative granular ratio-based outlier detection method in heterogeneous data. In addition, Dey et al. [18] investigated outlier detection in social networks leveraging community structure.
Motivation and contributions
We often encounter missing values during data processing. An incomplete real-valued information system (IRVIS) means a real-valued information system (RVIS) with missing values. Due to the presence of the missing values, the distance between two information values is difficult to determine, so the existing outlier detection rarely considered an IS with the miss values.
Considering the treatment of the miss values, this paper first defines a novel distance between two information values in an IRVIS. The idea behind this distance is to introduce the probability distribution under different conditions. Then, the tolerance classes of each object under different attributes are calculated according to the distance formula in an IRVIS, and each tolerance class is regarded as an information granule. According to the upper and lower approximations, the accuracy of the approximation of an information granule is proposed to measure the uncertainty of the information granule. Moreover, the degree of outlierness of an information granule is formulated. Next, the outlier factor of each object is introduced to evaluate the likelihood of an object being an outlier, and the outlier factor detection algorithm based on RST and GrC is presented. Finally, the presented algorithm is compared to seven algorithms: CBLOF [24], DB [30], KNN [42], SEQ [28], NOOF [15], IE [27], FRGOD [47] to show some superiority. Experiments are carried out on 12 data sets downloaded from UCI, and the results shows that the presented algorithm often has the better outlier detection effect.
Based on the above research motivation, the major contributions of this paper can be summarized as follows.
(1) A novel distance between two information values in an IRVIS is defined. This distance considers the missing values.
(2) Based on RST and GrC, the outlier factor of each object is calculated. An outlier detection algorithm in an IRVIS based on RST and GrC is proposed.
(3) The experiment results illustrate the superiority of the proposed algorithm.
The workflow of this paper is depicted in Fig. 1.

The workflow of this paper.
The remainder of this paper is organized as follows. Section 2 describes some preparatory work. Section 3 studies outlier detection in an IRVIS based on RST and GrC, including examples. Section 4 proposes the OF algorithm. Section 5 gives experimental results. Section 6 carries out evaluation analysis. Section 7 summaries this paper.
We look back at binary relations and IRVISs.
Throughout this paper, O and A denote two non-empty finite sets, 2 O means the power set of O and |X| expresses the cardinality of X ∈ 2 O . Put
Recall that R is a binary relation on O whenever R ⊆ O × O. R is called
(1) Reflexive, if (o, o′) ∈ R for any o ∈ O;
(2) Symmetric, if (o, o′) ∈ R implies (o′, o) ∈ R for any o, o′ ∈ O;
(3) Transitive, if (o, o′) ∈ R and (o′, o″) ∈ R imply (o, o″) ∈ R for any o, o′, o " ∈ O.
R is said to be an equivalence relation on O, if R is reflexive, symmetric and transitive; R is called a tolerance relation on O, if R is reflexive and symmetric.
An IRVIS
Let (O, A) be an IS. If there is a ∈ A such that * ∈ V a , here * means a null or unknown value, then (O, A) is called an incomplete information system (IIS).
Let (O, A) be an IIS. For each a ∈ A, denote
An IRVIS (O, A)
∀ a ∈ A, denote
For missing data, we have the following thoughts.
1) Consider “o ≠ o′, a (o) = * , a (o′) ≠ * , a ∈ A”, because “a (o)” is treated as “do not care” condition, thus a (o) has the probability of
2) Consider “o ≠ o′, a (o) ≠ * , a (o′) = * , a ∈ A”, because “a (o′)” is treated as “do not care” condition, thus a (o′) has the probability of
3) Consider “o ≠ o′, a (o) = * , a (o′) = * , a ∈ A”, a (o) and a (o′) both have the probability of
d (a (o) , a (o′)) =
Clearly, P λ is a tolerance relation on O.
Denote
(1) If P ⊆ Q ⊆ A, then ∀ λ ∈ [0, 1], ∀ o ∈ O,
(2) If 0 ≤ λ1 ≤ λ2 ≤ 1, then ∀ P ⊆ A, ∀ o ∈ O,
So Q λ (o) ⊆ P λ (o).
(2) ∀ o′ ∈ P λ1 (o), we have ∀ a ∈ P, d (a (o) , a (o′)) ≤ λ1. Since λ1 ≤ λ2, ∀ a ∈ P, d (a (o) , a (o′)) ≤ λ2. Thus o′ ∈ P λ2 (o).
So P λ1 (o) ⊆ P λ2 (o). □
Moreover, if
Put
(2)
(4) If P ⊆ Q ⊆ A, then ∀ λ ∈ [0, 1], ∀ X ∈ 2
O
,
(5) If 0 ≤ λ1 ≤ λ2 ≤ 1, then ∀ P ⊆ A, ∀ X ∈ 2
O
,
(6)
(1) If P ⊆ Q ⊆ A, then ∀ λ ∈ [0, 1], ∀ X ∈ 2
O
,
(2) If 0 ≤ λ1 ≤ λ2 ≤ 1, then ∀ P ⊆ A, ∀ X ∈ 2
O
,
In this section, we define outliers for incomplete real-valued data via RST and GrC, and then give an example of finding the outliers.
Denote
In Definition 3.1, the approximate accuracy of information granule g to reflect the uncertainty of information granule g, and this can be interpreted as the outlier degree of g under the set of attributes E. Obviously, in IRVIS, information granule g represents the tolerance class of each object o under attribute subset P and
Denote
In Definition 3.2, we use
In Definition 3.3, {a} λ (o) represents the tolerance class under each individual attribute a in A, that is also the information granule g containing object o. This definition illustrates the view that a few objects in the data set are more likely to be outliers. If the tolerance class of object o is small, it is more independent of other objects, so it is more likely to be an outlier.
Finally, the concept OF λ (o) integrates all the above concepts to give the outlier factor of the object o. Again, since the total subsets of attribute set A is 2|A|, in Definition 3.4 we only use every individual attribute a to make the subset. The outlier factor of o is directly proportional to the degree of outlierness of information granule g containing o. As a result, the larger the outlier factor of object o, the object o may belong to the minority of objects in O.
In this paper, the set of all (λ, μ)-outlier in an IRVIS ia denoted as
The tolerance class of each object
Let g1 = {a1} λ (o1) , g2 = {a2} λ (o1) , g3 = {a3} λ (o1), from Table 2 we have g1 = {o1, o5, o7} , g2 = {o1, o4, o5, o6} , g3 = {o1}
(1) For i = 1, 2, 3, by (3.2), the (E, λ)-accuracy of approximation is calculated as follows:
(2) By (3.3), the corresponding (P, λ)-degree of outlierness could be calculated accordingly:
≈0.6643,
≈0.6413,
≈0.9524 .
(3) By (3.5), the λ-weight function by Definition 3.3 is calculated as follows:
(4) By (3.6), the λ-outlier factor proposed in Definition 3.4 can be calculated as follows:
(5) We can get all λ-outlier factors of every objects:
OF λ (o1) =0.2424, OF λ (o2) =0.3013, OF λ (o3) =0.3656, OF λ (o4) =0.1862, OF λ (o5) =0.2681, OF λ (o6) =0.2651, OF λ (o7) =0.2838.
Given μ = 0.35, we have
Only o3 has an OF λ higher than the threshold μ, and is thus taken as outlier according to Definition 3.5.
This section proposes outlier detection algorithms and analyses their time complexity.
Given an IRVIS (O, A), our method is represented in Algorithms 1 and 2. Algorithm 1 calculates the tolerance class of each object under each attribute to obtain the divided information granules. Algorithm 2 calculates the outlier set.
The time complexity for Algorithm 1 is as follows. In step 4, the time complexity for calculating the d (a (o) , a (o′)) is O (|P| × |O|2), where |P| stands for the number of elements in set P. In step 6, calculate the tolerance class of the object o under attribute set P, which is equivalent to the intersection operation of multiple sets, and its time complexity is O (|P| × |O|). Therefore, the time complexity of the whole algorithm 1 is O (|P| × |O|2 + |P| × |O|), so in the worst case, the time complexity of algorithm 1 is O (|P| × |O|2).
For Algorithm 2, calculation costs for Steps 5 and 7 are O (|O| × |A|), O (|O| × |A| × (|A|-1)) according to Definition 3.1, and those for Steps 9, 10 and 12 are O (|O| × |A|) , O (|O| × |A|) , O (|O|) , according to formula 3.3, 3.5 and 3.6, respectively. Thus, the total time complexity for Algorithm 2 amounts to O (3 × |O| × |A| + |O| × |A| × (|A|-1) + O (|O|). In the worst case, the time complexity of algorithm 2 is O (|O| × |A|2).
Computing P
λ (o)
Computing P λ (o)
1:
2: P λ (o)← ∅
3:
4:
5: Calculate d (a (o) , a (o′)) by formula (2.4)
6:
7: P λ (o) ← P λ (o) ∪ {o′}
8:
9:
10:
return P λ (o).
Calculating the outlier set
1:
2:
3:
4:
5: Obtain tolerance class a λ (o) by Algorithm 1
6: Calculate
7:
8: Calculate
9:
10: Calculate
11: Calculate
12:
13: Calculate OF λ (o) by formula (3.6)
14:
15:
16:
17:
18: return
This section gives experimental analyses.
Experimental setup
The experiments in this section are carried out on a computer equipped with Inter Corei5-7200U processor, frequency of 2.50 GHz, storage of 2.70 GHz and memory of 12 GB. The operating system is Windows 10. The experiments are developed with Python 3.8. Python IDE is Pycharm 2020.2.1.
The performance of all outlier detection algorithms in this section is evalued by the metric proposed by Aggarwal [10]. First, it is clear that those objects belonging to rare classes in each data set are considered outliers. If the given outlier detection algorithm works well, it is expected that these outliers to be over represented in the detected object set.
In other words, for each algorithm, we first calculate the outlier degree of each object in the data set, then arrange the outlier degree in descending order, and set an appropriate threshold. All objects with outlier degree greater than the threshold are selected to become a set of objects to be tested. If there are more objects belonging to rare classes(abnormal classes) in the object set to be tested, the better the performance. It is expected that the outlier degree of objects in all rare classes to be as high as possible, so the easier it is to detect, which means the better the performance of the algorithm.
The appropriate threshold μ mentioned above is obtained according to the proportion of rare classes in each data set. The specific assignment operations will be introduced in different data sets
Data sets
Twelve data sets from UCI Machine Learning Repository are used: Bone marrow transplant children Data Set, Breast Cancer Wisconsin (Original) Data Set, Breast Cancer Wisconsin (Prognostic) Data Set, Computer Hardware Data Set, Glass Identification Data Set, HCV Data Set, CSM 2014 and 2015 Data Set, Airfoil Self-Noise Data Set, Climate Model Simulation Crashes Data Set, Winequality-Red Data Set, Thoracic Surgery Data Set, Blood Transfusion Service Center Data Set.
The attribute values of these data sets are real-values. There are missing values in the six data sets: Bone marrow transplant children Data Set, Breast Cancer Wisconsin (Original) Data Set, Breast Cancer Wisconsin (Prognostic) Data Set, HCV Data Set, CSM 2014 and 2015 Data Set and Winequality-Red Data Set. Other data sets need data missing preprocessing to achieve the purpose of studying IRVIS. And the missing rate parameters are analyzed in the process of data missing preprocessing.
Concretely, a real-valued data set D could be regarded as an IS (O, A) (see Definition 2.1). The determinate value of object o under attribute a is a (o); while the missing value of object o under attribute a is *. This way the data set is transformed into an IRVIS.
Each data set contains a small fraction of objects that is deemed as “rare class”, and such classification usually involves some semantics under certain context, such as in the background of wing noise tests the instances of high noise are taken as outliers.
Table 3 summarizes the data set used in this experiment. Firstly, all data sets without missing attributes are preprocessed by randomly missing attribute values. Then, in order to better conduct outlier detection experiments, it is necessary to treat abnormal classes as minority classes and normal classes as majority classes. Therefore, abnormal objects only make up a small portion of the entire data set. Furthermore, if the data set has an ID attribute, although it is a real value attribute, it is not considered. As shown in Table 3, the “data sets” column represents the name of each corresponding data set; The “dimensions” column represents the size of the corresponding data set attribute set; The “objects” column represents the size of the experimental object set corresponding to each data set; The “outlier ratio” column represents the proportion of abnormal objects in each data set.
Statistics of the public benchmark data sets
Statistics of the public benchmark data sets
A brief comparison between all the outlier detection algorithms is shown in Table 4.
Comparison among outlier detection methods
Comparison among outlier detection methods
Figure 2 shows the scatter plot distribution of all data sets, with the abscissa representing the object number and the ordinate representing the size of the outlier factor calculated by the OF outlier detection algorithm in each scatter plot. The red dot represents the true outlier, and the red dashed line represents the corresponding threshold horizontal line under the data set. The calculation method is to first calculate the outlier factor of each object based on the designed algorithm, and then sort it in descending order according to the value of the outlier factor. Under the premise of each data set, there is a outlier ratio (see Table 3). The size of outlier factor in descending order of outlier ratio is taken as the threshold horizontal line.
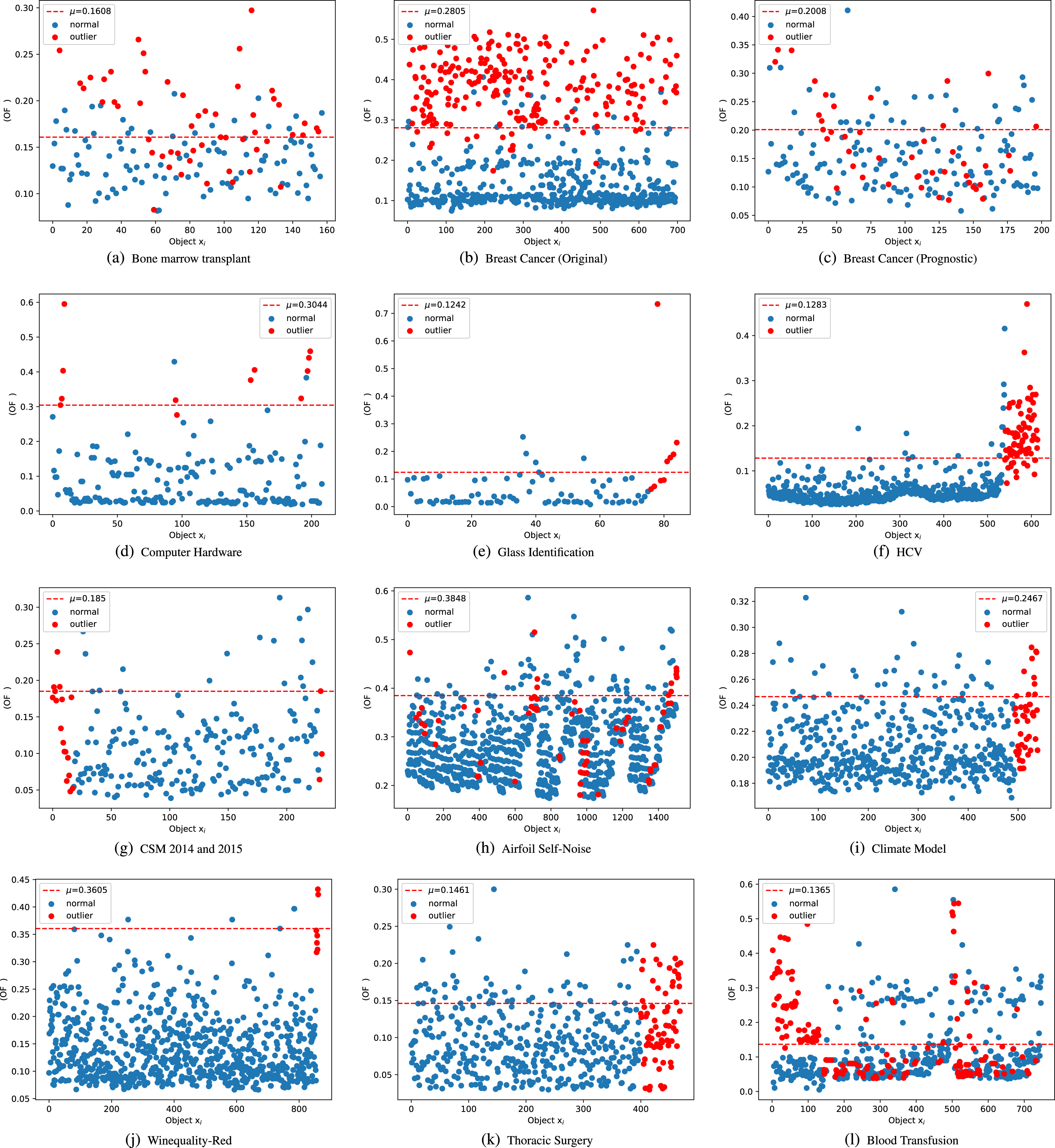
Scatter chart results.
Figure 3 shows the detection rate comparison chart of all data sets. The proposed algorithm (OF) has excellent outlier detection effect on the four data sets of Breast Cancer (Original), Computer Hardware, HCV and Winequality-Red. The detection rate line chart also shows that the front is almost the same slope upward, and then becomes stable until all outliers are found. For example, among the first 80 objects detected after sorting by outlier factors in descending order on the Breast Cancer (Original) data set, they are actually all abnormal points. At this time, the detection rate reaches 100%. If you add another 20 objects and take the first 100 objects, the number of real outliers is 98, which is equivalent to misjudging only two objects. In the comparison chart of the detection rate of the remaining data sets, it can also be clearly seen that the proposed algorithm (OF) is always in the first echelon, with either the front detection rate leading or the back detection rate leading. Overall, the proposed algorithm is better than the existing algorithms.
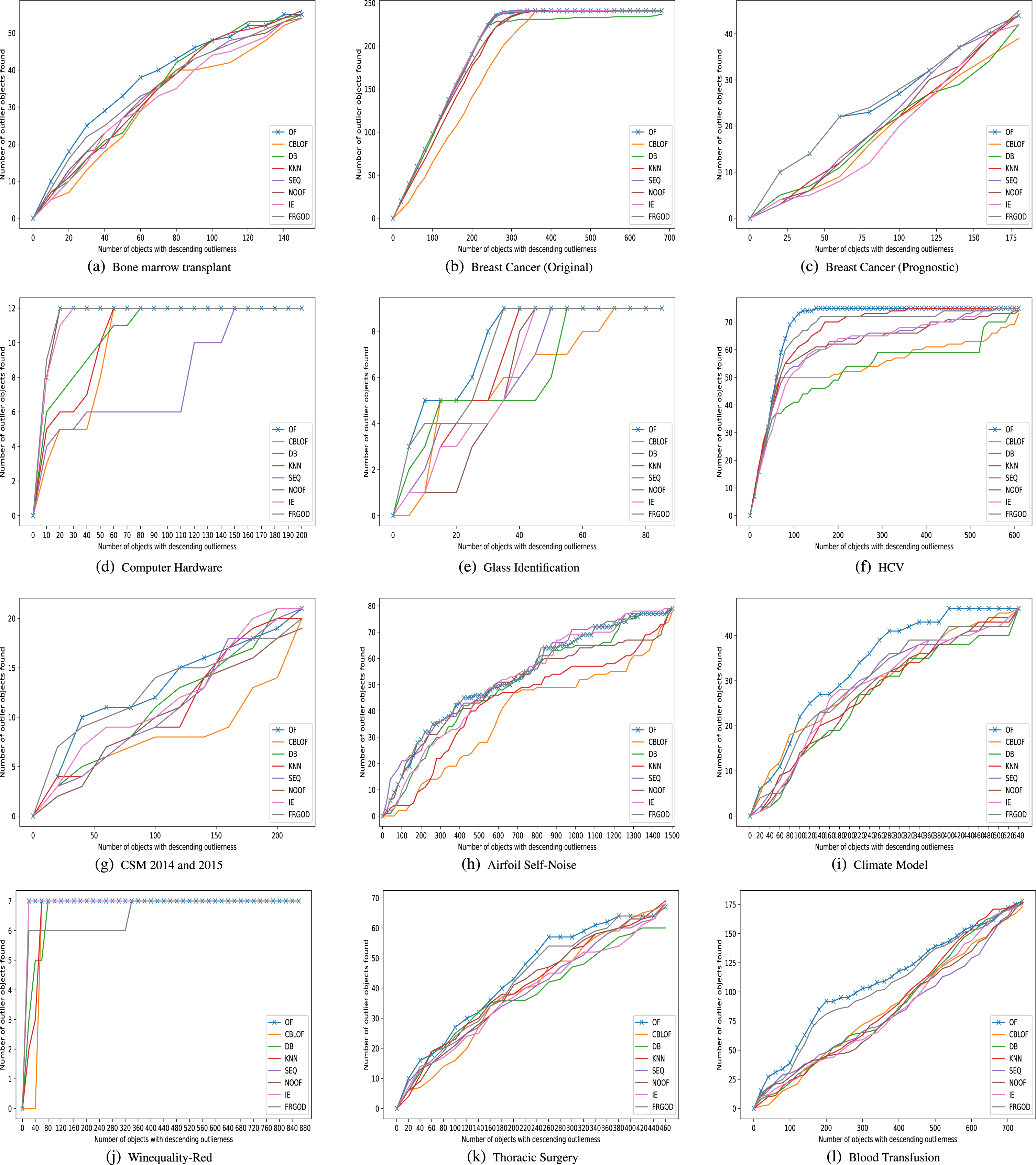
Comparison results of detection rate.
The following is a comparison table of different algorithm detection rates for 12 data sets. Each table compares the experimental results of OF algorithm, CBLOF algorithm, DB algorithm, KNN algorithm, SEQ algorithm, NOOF algorithm, IE algorithm, and FRGOD algorithm at different detection stages. Bold font represents the best detection effect at the current detection stage. Here, the “top ratio” is ratio of the number of objects specified as top-k outliers to that of the objects in the data set. The “coverage” is ratio of the number of detected rare classes to that of the rare classes in the data set.
Experimental results in Bone marrow transplant data set
Experimental results in Breast Cancer Wisconsin (Original) data set
Experimental results in Breast Cancer Wisconsin (Diagnostic) data set
Experimental results in Computer Hardware data set
Experimental results in Glass Identification data set
Experimental results in HCV data set
Experimental results in CSM 2014 and 2015 data set
Experimental results in Airfoil Self-Noise data set
Experimental results in Climate Model Simulation Crashes data set
Experimental results in Winequality-Red data set
Experimental results in Thoracic Surgery data set
Experimental results in Blood Transfusion data set
For an IRVIS (O, A), the missing information values are randomly distributed on all attributes, and the incomplete rate of (O, A) (denoted by β) is defined as
Where m represents the number of data set attributes and n represents the number of data set objects. Firstly, choose to analyze the incomplete rate parameters on the data sets that do not have missing values, which are six data sets Airfoil Self-Noise, Computer Hardware, Glass Identification, Climate Model Simulation Crashes, Thoracic Surgery and Blood Transfusion Service Center respectively, and convert the data sets into information systems. Then, among all the attribute information values, we delete 2%, 4%, 6%, 8%, 10%, 12%, 14% and 16% randomly, and we call the created data ‘β-IRVIS’ respectively, whose β = 0.02k (k = 1, 2, ⋯ , 8) .
Next, we conduct a comparative experiment to see the efficiency change of outlier detection under different incomplete rates. The results are shown in the following three-dimensional diagram 4. where the X-axis represents β = 0.02k (k = 1, 2, ⋯ , 8) incomplete rate change and the Y-axis represents the Number of objects with descending outlierness. The Z-axis represents the Number of outlier objects found.
In all these data sets, the greater the incomplete rate, the lower the efficiency of finding outliers. The reason is that if there are more missing values in the information system, which indicates that the information given by the information system is more fuzzy. That leads to the outlier information originally separated by itself is also covered up by too much missing value information, making it more difficult for the outlier to be detected. Therefore, when studying the structure of information system, we should try to avoid the occurrence of too many missing values, or find an effective method to deal with missing values.
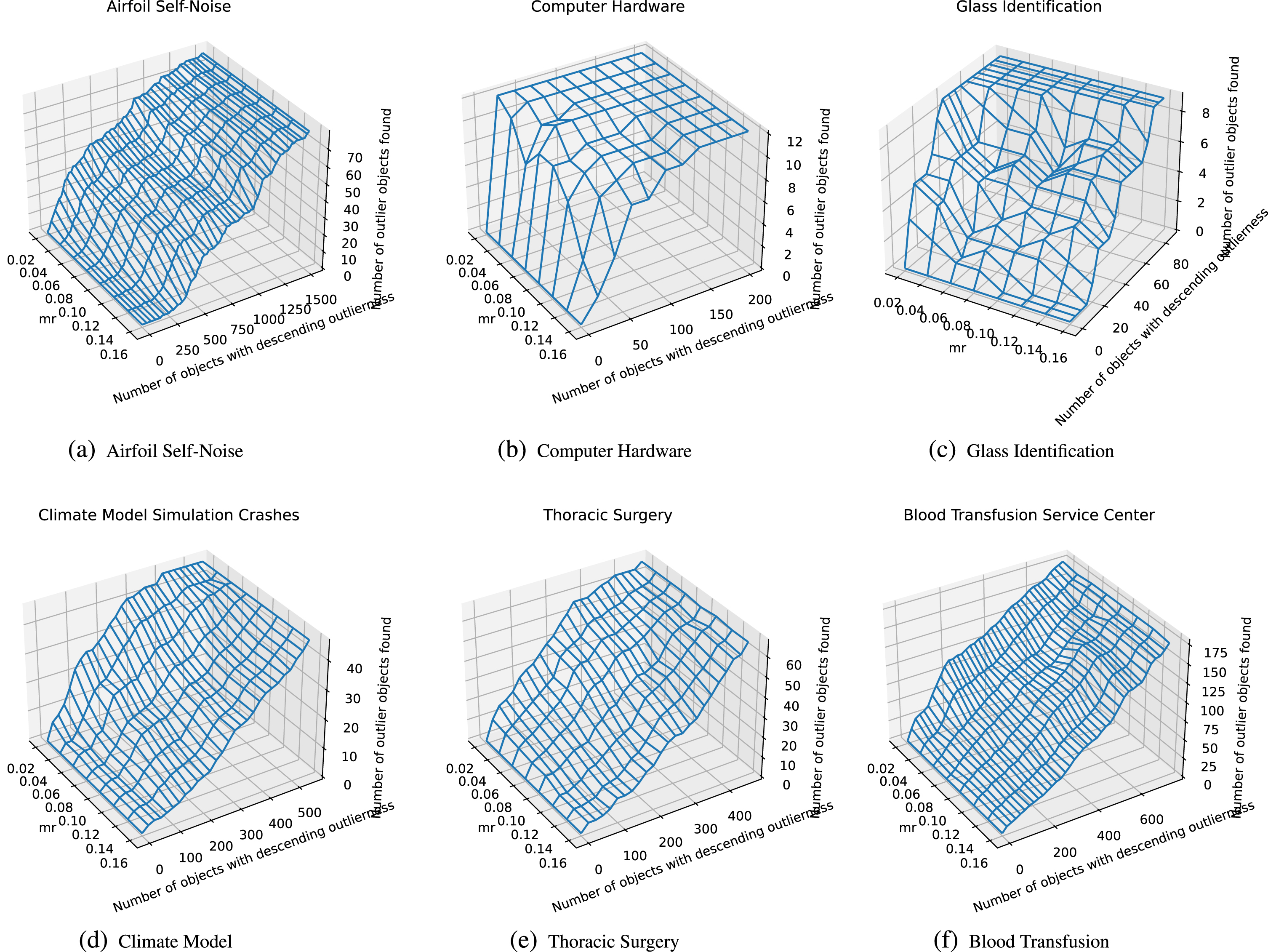
Comparison chart of missing rate analysis.
In this section, ROC curve and AUC standard are used to evaluate the experimental results, and Friedman test is performed.
The confusion matrix is required to draw the ROC curve. The confusion matrix is shown in Table 17. There are 4 possible outcomes in the prediction of outliers: an outlier taken as outlier(true positive, TP), an outlier taken as inlier (false negative, FN), an inlier taken as outlier (false positive, FP) and an inlier taken as inlier (true negative, TN).
Confusion matrix for predicting an outlier
Confusion matrix for predicting an outlier
Accordingly, the true positive rate (TPR) and false positive rate (FPR) could be defined as follows:
AUC is the area under the ROC curve, which means that a positive sample and a negative sample are randomly selected from all samples. The probability of positive sample prediction by the model is P1, and the probability of negative sample prediction is P2. AUC is the probability of P1textgreaterP2 (with higher values being better).
The ROC results in Fig. 5 indicate that the proposed algorithm is stable in all data sets, and its ROC curve is higher to the left compared to other algorithms. A clearer and more powerful conclusion can be drawn from the AUC results table, as shown in Table 18. Each data set in the table corresponds to a bold number that represents the AUC value calculated by the best performing outlier detection algorithm in the current data set. The last row in the table shows the average ranking of all algorithms, and the proposed OF outlier detection algorithm has the highest average ranking, indicating its good detection performance in multiple data sets.
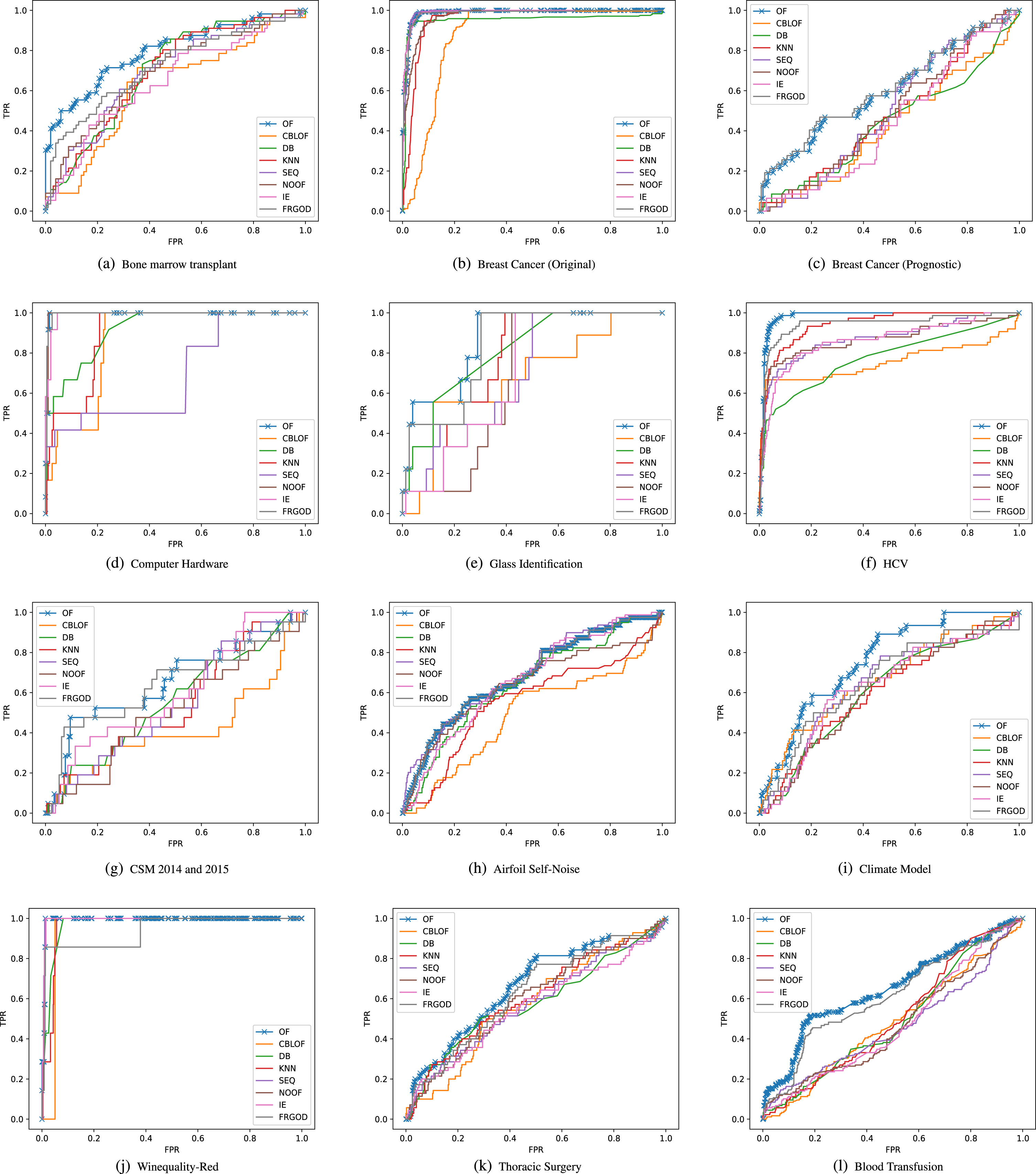
ROC results.
AUC results
Here we have 8 algorithms and 12 data sets. Considering that each algorithm has a performance ranking on each data set, each algorithm corresponds to a ranking number. The Friedman test and Nemenyi test are also conducted to compare whether there were significant differences between multiple algorithms. Two statistics need to be calculated, namely
The comparison of different algorithms with Nemenyi test are shown in Fig. 6. The OF algorithm has the lowest ranking mean under each data set, which is significantly different from the six algorithms with higher ranking.
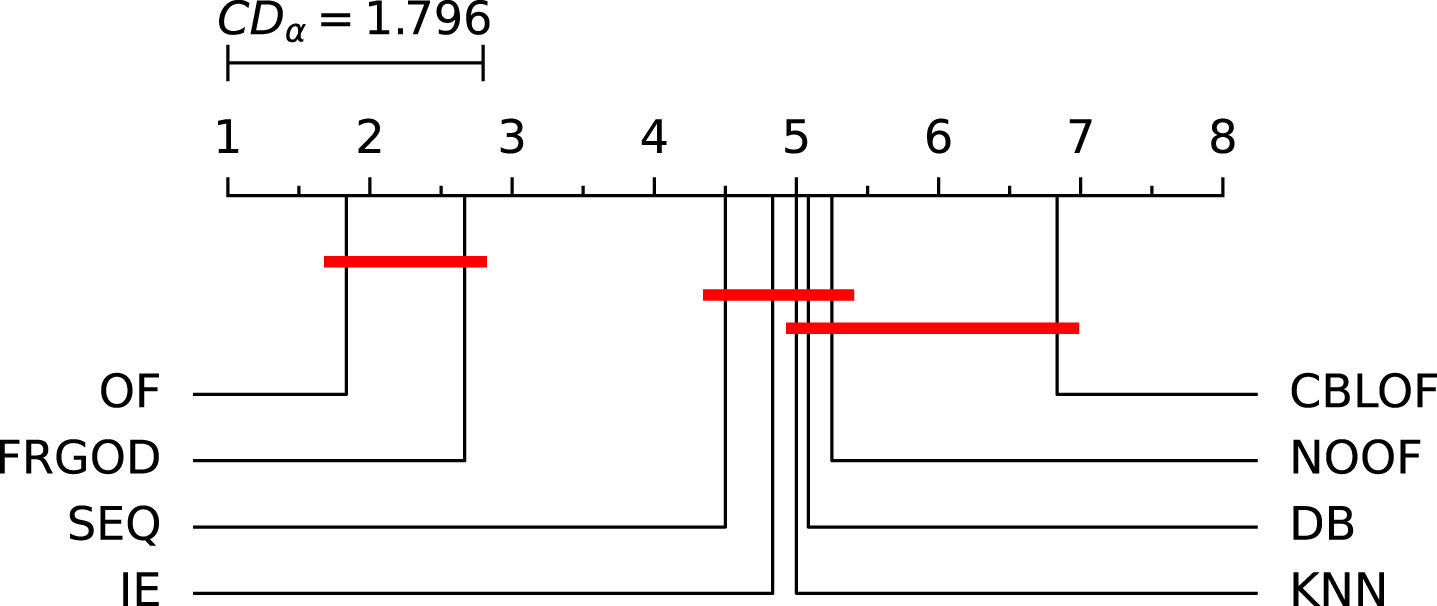
Nemenyi test result.
Combining the advantages of RST and GRC, this paper has studied the outlier detection method in an IRVIS. A method for calculating the outlier factor of each object has been constructed. The corresponding outlier detection algorithm has been proposed. Several experiments on twelve data sets have been carried out. When the performance of the other six algorithms fluctuates with different data sets, the proposed algorithm remains relatively stable and has certain robustness. This shows that the performance of the proposed algorithm is better than the other six algorithms. In future work, we will consider optimizing the proposed algorithm to reduce the computational time while the performance of the algorithm is maintained, and study outlier detection for hybrid data.
Footnotes
Acknowledgments
The authors would like to thank the editors and the anonymous reviewers for their valuable comments and suggestions, which have helped immensely in improving the quality of the paper. This work is supported by Guangxi First-class Discipline Statistics Construction Project Fund and Natural Science Foundation of Guangxi Province (2021GXNSFAA220114).