
Abstract
Identifying the day instar of silkworms is a fundamental task for precision rearing and behavioral analysis. This study proposes a new method for identifying the day instar of adult silkworms based on deep learning and computer vision. Images from the first day of instar 3 to the seventh day of instar 5 were photographed using a mobile phone, and a dataset containing 7, 000 images was constructed. An effective recognition network, called CSP-SENet, was proposed based on CSPNet, in which the hierarchical kernels were adopted to extract feature maps from different receptive fields, and an image attention mechanism (SENet) was added to learn more important information. Experiments showed that CSP-SENet achieved a recognition precision of 0.9743, a recall of 0.9743, a specificity of 0.9980, and an F1-score of 0.9742. Compared to state-of-the-art and related networks, CSP-SENet achieved better recognition performance with the advantage of computational complexity. The study can provide theoretical and technical references for future work.
Introduction
The silkworm is an insect with high economic value, that is mainly used to produce natural silk, and has been widely reared in China, India, Japan and other countries. The life cycle of silkworms is very short and follows a fixed pattern, where the day instar, which is the age of the silkworm in days, is an important biological indicator. It not only reflects the growth state of the silkworm, but also corresponds with the different breeding requirements. For example, silkworms are dormant after the third day of instar 1, the third day of instar 2, the third day of instar 3 and the fourth day of instar 4, and will spit and cocoon after the seventh day of instar 5, failure to follow this pattern indicates the likelihood of disease occurrence or improper rearing method. In addition, during the rearing process, when silkworms are at different instars, they require different humidity and temperatures to ensure healthy growth, and the amount of mulberry leaves they need varies [1–3]. Therefore, identifying the day instar is a fundamental task for precision rearing and behavior analysis. However, the traditional method for instar recognition mainly relies on daily manual recording, which is inefficient and labor consuming. Therefore, a method to accurately and automatically recognize the day instar is urgently needed.
In recent years, with the rapid development of computer science, deep learning and computer vision have received much attention and have been widely applied in agricultural fields [4–6]. Many studies have been conducted on the recognition of plant leaf diseases, insect or pest species, animal growth behavior, and crop or seed species using convolutional neural networks (CNNs), which have achieved encouraging results [7–9]. In the field of silkworms, Yu et al. [10] proposed a method for the identification of male and female silkworm pupae based on CNN, which obtained better results than traditional methods. Shi et al. [11] used MobileNet to recognize silkworm species, which provided a promising precision. Ding and Chen. [12] presented an image recognition method for silkworm diseases using feature maps slicing and AlexNet architecture. Zhang et al. [13] proposed a cocoon quality detection model based on YOLO v4, which achieved state-of-the-art performance. The above studies have illustrated the broad applications of image recognition and deep learning for the silkworms, but none of them have considered the day instar recognition. To fill this gap, this study focuses on this task using deep learning and computer vision.
Many classic CNNs have been born since 2012. ResNet [14] is one of the most widely influential networks. The residual connection it proposed perfectly avoided the gradient vanishing problem, making deep learning networks deeper and more powerful. It has been used in almost all subsequent algorithms, including CNNs and natural language processing (NLP), and has become a representative achievement that influenced the development of deep learning. CSPNet [15] was developed based on ResNet, which not only inherited the excellent extraction performance of ResNet, but also optimized the residual connection method; therefore, it can provide better recognition accuracy and significantly reduce the computational complexity. CSPNet have been widely used as the backbone network of YOLO networks [16]. We also observed the advantages of the recently prevalent feature fusion and attention mechanisms in various vision tasks, and combined them with CSPNet to design an efficient and accurate network, which achieved a superior recognition result.
The main contributions of this work could be summarized as follows: A new recognition method for day instars of adult silkworms was proposed based on deep learning and computer vision. To the best of our knowledge, this is the first study on this task. An accurate CSP-SENet was proposed based on the feature fusion and image attention mechanism. Experiments indicated that the performance of the CSP-SENet outperformed the state-of-the-art and related networks. An image dataset containing 7,000 images of 14-day instars was constructed.
Related works
Feature fusion in CNNs
Feature fusion has a wide range of applications in CNNs, which can significantly expand the receptive fields and enhance the data representations of the network. Feature Pyramid Network (FPN) [17] adopted a top-down architecture with lateral connections to obtain a high-level feature map at all scales, which improved the detection performance of the object detection algorithms on the COCO benchmark. Path Aggregation Network (PANet) [18] added a bottom-up path augmentation to the FPN to enhance the overall feature hierarchy. Bi-directional Feature Pyramid Network (BiFPN) [19] employed learnable weights to learn the importance of different input features, while repeatedly applying the top-down and bottom-up multi-scale feature fusion. In the application field, Sun et al. [20] presented a multi-level feature fusion network for fruit bearing branch key point detection, which combined features in the same spatial and different spatial sizes. Shi et al. [21] proposed a feature fusion method for the recognition of silkworm diseases based on ResNet-50 and FPN. Dong et al. [22] proposed an automatic method for crop pest detection using multi-scale feature fusion. Wei et al. [23] adopted dilated convolution to obtain multi-scale features and presented a method for pest recognition by fusing multi-scale features. Wang et al. [24] proposed an efficient module for an instance segmentation network in pest monitoring using feature fusion and image attention mechanisms. Xia et al. [25] presented a flower bud detection model for hydroponic Chinese kale using FPN to fuse features extracted by Inception v3. These studies showed that feature fusion is an effective tool to improve the performance. Based on the above works and inspired by the recent development of large kernel models [26, 27]; we proposed a feature extraction and fusion method using the hierarchical large kernels.
SENet with applications
Squeeze-and-Excitation Network (SENet) [28] is a pioneering algorithm for image attention mechanisms that allows the network to focus on the key information and suppress the noise. Researchers have conducted numerous studies using SENet to enhance the capability of the networks, with encouraging results. GhostNet [29] and MobileNet v3 [30] took advantage of SENet to achieve state-of-the-art performance in a lightweight manner. ECANet [31] replaced the fully connection of SENet with a 1D convolutional layer and achieved superior recognition results. Qi et al. [32] proposed a tomato leaf diseases detection method by adding SENet to the backbone of YOLO v5. Zhou et al. [33] used MobileNet and SENet for ore image classification and provided competitive results. Yue et al. [34] proposed a few-shot learning method for synthetic aperture radar image recognition, in which SENet was integrated into a recognition network to enhance the expression capability of the features. Kushnure and Talbar [35] utilized SENet to recalibrate the fused features to capture prominent details of modified high-level features in medical image segmentation. Zhang et al. [36] proposed a MobileNetV2-SENet-based method to identify fish school feeding behavior, which provides better performance than other lightweight networks. Consequently, SENet can significantly improve the effectiveness of CNNs in various tasks. This prompted us to design a recognition algorithm using SENet.
Materials and method
Experimental data
The dataset is essential for training the network. To obtain an accurate dataset of the day instar, image collection and dataset construction were performed in real environments.
Image collection
In this study, a specific silkworm variety named Fang·Xiu×Bai·Chun [37], which is mainly reared in Sichuan Province, China, was used as the experimental sample. All silkworms were reared by a professional in a standard rearing house to ensure the accuracy and objectivity in their instar. The number of silkworms was approximately 500. The image collection was carried out at a fixed time (08 : 00 to 10 : 00 a.m.) in the unit of day instar except during the dormant period, which was from April 28 to May 14 2022, i.e., from the first day of instar 3 to the seventh day of instar 5. The collection site was located in the Sericulture of Sichuan Academy of Agricultural Sciences Institute (Nanchong City, Sichuan Province, China). The collection environment was indoor with natural light.
A smartphone whose brand was iPhone 6 (Apple Computer Inc, Cupertino, California, USA), containing 12 million pixels, was used as the image acquisition device. A tripod was utilized to mount the device, the lens was faced straight down and the silkworm larvae maintained their natural posture during image collection. The aspect ratio of the device screen was set to 1 : 1, to ensure that the body shape of the silkworm did not reshape after image resizing. Mulberry leaves were randomly used as the background. Examples of the original images are shown in Fig. 1. The image of each silkworm was collected only once per day, and 7, 000 images of the 14-day instars were collected.

Day instar images of Fang·Xiu×Bai·Chun. (a) ∼ (c) are images of the first day to the third day at instar 3, (d) ∼ (g) are images of the first day to the fourth day at instar 4, (h) ∼ (n) are images of the first day to the seventh day at instar 5.
The size of the original images was 2448×2448 pixels, which was too large for network training. The original images were cropped to a size of 224×224 pixels using bilinear interpolation, and no other preprocessing methods were performed. Each day instar was used as a recognition category, each category contains 500 images, and a dataset of 14 categories was constructed. The dataset was divided into the training, validation, and test sets by the randomly selecting images in a ratio of 6:2:2.
Data enhancement
Data enhancement can effectively enhance the stability of the model and prevent overfitting. Since the silkworm was manually placed on the background for image acquisition during image collection, there were human habits, lighting environment, image background, and other potential influences that could cause overfitting. Therefore, the preprocessing methods containing random rotation, zoom operation, and horizontal or vertical flipping were used to enhance the images in the training set.
As shown in Fig. 2, for a single image, several images were generated using the data enhancement techniques, and only one was randomly used to replace the original image during the training, and the number of images in the training set was not changed.

Example of data enhancement. (a) is the original image, (b) ∼ (f) are the enhanced images.
Due to the high similarity of silkworms in successive instars, it is difficult to distinguish them manually. A strong extraction strategy was required for the network design. Therefore, a powerful module was proposed to realize effective feature extraction for silkworm images.
Effective block for feature extraction and fusion
We designed our feature extraction block based on the basic block of CSPNet. Figure 3 illustrates the basic block of CSPNet and the proposed CSP-SE block.
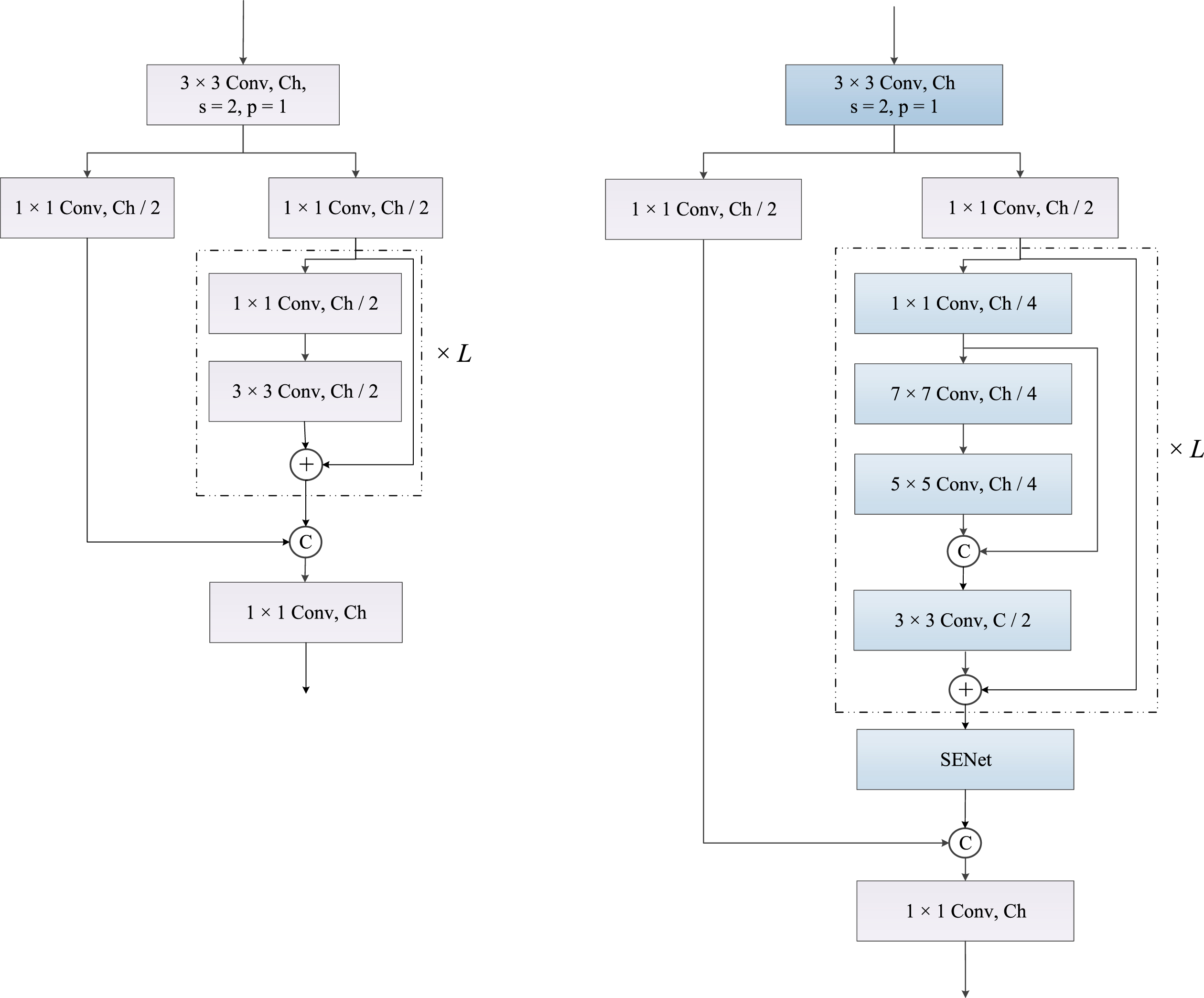
Structure of the CSP block and the proposed CSP-SE block. The “3×3 Conv” refers to the 3×3 convolutional layer, the “Ch” means the number of channels, the “s” is stride, the “p” is padding, the “+” is the addition of feature maps, the “C” is the concatenation operation.
As shown in Fig. 3, when using the proposed block to extract the feature, for the input X with the dimension of W × H × C, where W, H and C denote the width, height, and channel sizes, respectively. First, two 1×1 convolutional layers were used to reshape the feature map, resulting in two sub-feature maps with the dimension of W × H × C/2. The formula is as follows:
Then, the feature extraction was conducted mainly on the one of them, a 1×1 convolutional layer was utilized to reshape the dimension to W × H × C/4, followed by two stacked 7×7 and 5×5 convolutional layers. This hierarchical kernel was used to expand the receptive fields of the network. A conventional 3×3 convolutional layer was adopted after the identity connection. The residual connection was adopted to combine the input and output feature maps. The formula is as follows:
The network depth is increased by adjusting the number of loops of Z1, denoted by “×L” in Fig. 3.
Finally, an image attention mechanism (SENet) was imposed to learn more key information and suppress the interference. Two sub-feature maps were concatenated and a 1×1 convolutional layer was utilized to obtain the output. The formula is as follows:
In summary, our CSP-SE block uses channel compression to improve the extraction efficiency, and the hierarchical kernel sizes to obtain the different receptive fields. The large kernel sizes of 7×7 and 5×5 were used to obtain the feature maps of the different receptive fields, and the 3×3 convolutional layer was used to extract more fine-grained information and fuse the features. The image attention mechanism was adopted to achieve the extraction of key information and suppress the interference. Two concatenation operations were used to combine feature maps from the different receptive fields and obtain different semantic information. The pseudocode of the CSP-SE block is presented in Algorithm 1.
The image attention mechanism can direct deep learning networks to focus on the key information, and it mainly contains the spatial and channel attention modules. Because the proposed block has the capability to expand the receptive fields and perform feature fusion in various fine-grained feature maps, that is, it has a strong ability to extract spatial information. Therefore, the channel attention was adopted to obtain key information by recalibrating the channel.
The selected attention mechanism was SENet, which is the pioneering algorithm in this field. As depicted in Fig. 4, for the input feature map X with the dimension of W × H × C, where W, H, and C denote the width, height, and channel sizes, respectively. When calculating the attention weights, a convolutional operation was first used to transform the input into a feature map with the dimension of W × H × C1, and global average pooling was used to generate the channel-wise statistics. The formula is as follows:

Schematic diagram of the SENet. The “FC” represents fully connection.
The two fully connection (FC) layers and the rectified linear unit (ReLU) function were adopted to capture the channel-wise dependencies of the information aggregated in the global average pooling.
Finally, the output was obtained by rescaling w with the channel-wise dependencies using the channel-wise multiplication. The formula is as follows:
Based on the proposed block, a recognition network for the day instar was proposed, namely CSP-SENet. As shown in Fig. 5, CSP-SENet inherits the streamlined structure of general networks, such as ResNet, CSPNet, and MobileNet. The input size of the proposed network was 224×224×3. First, a 7×7 convolutional layer and a 2×2 max pooling layer were utilized to extract the feature map and reduce the dimension, resulting in a feature map with a dimension of 56×56×32. Then, four stages of the proposed blocks were stacked to extract the feature maps, and a feature map with a dimension of 7×7×512 was obtained. The L in the CSP-SE block was set to 2, 2, 6, 2, respectively, to increase the network depth. Finally, an average pooling layer was used to obtain a feature map with the dimension of 1×1×512, and a fully connection was utilized to obtain the recognition result.
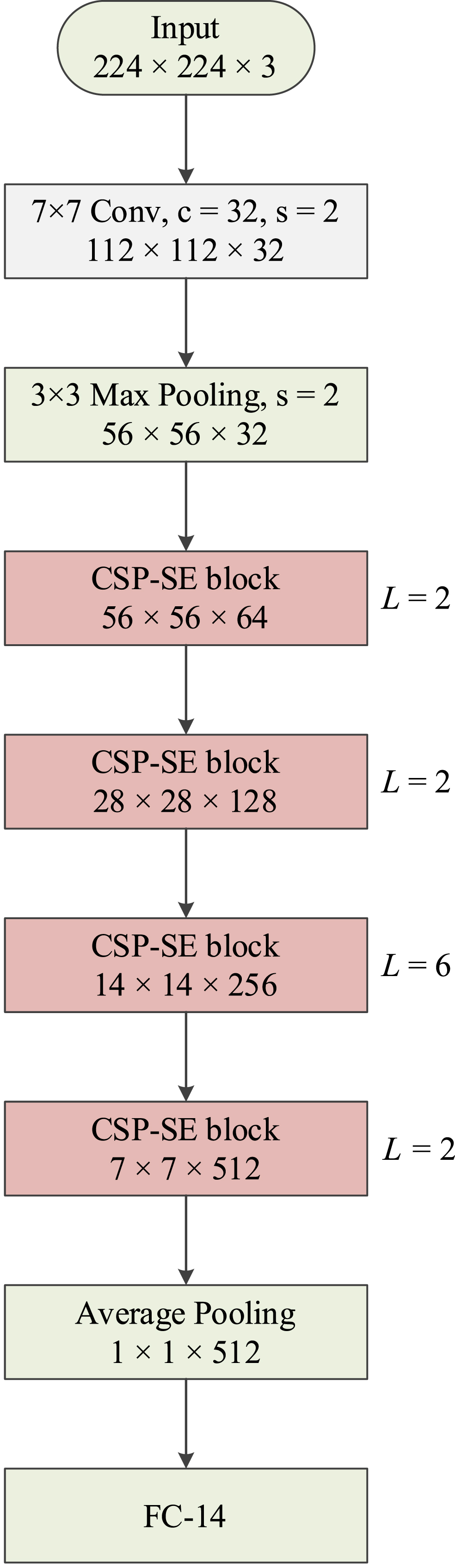
Schematic diagram of our CSP-SENet.
General operations such as batch normalization and ReLU function were used to normalize and activate the feature values after each convolutional layer.
The experiments were performed on a Dell Precision 5820 workstation with an Intel® core I7-9800X processor, RTX2080 Ti GPU with 11 G memory, and the CUDA-10.0 computational platform. The operating system was Windows10 Professional 64 bit, the programming language was Python 3.7, the programming environment was Jupyter Notebook, and the deep learning framework was Pytorch. In the course of the experiments, categorical cross-entropy was used as the loss function, and Adam was used as the optimizer. The number of mini batch-size was 32, and the number of epochs was 300. The initial learning rate was 0.001, and was multiplied by 0.8 to reduce it if the loss value did not decrease in five consecutive iterations.
All networks were trained on the training and validation sets, and the recognition results were calculated using the test set. The precision, recall, specificity, and F1-score were taken to reflect the recognition performance. The calculation formula are as follows:
Recognition results of our CSP-SENet
In this section, our CSP-SENet was trained and evaluated on the constructed dataset, and the loss value and accuracy on the training and validation sets were recorded to evaluate the convergence effect.
Figure 6 depicts the loss value and accuracy during the training process on the training and validation sets. The loss value was considerably high and the accuracy was extremely low at the initial stages of training. As the epoch increased, the loss decreased, and the accuracy increased sharply. The model reached relative stability after 150 epochs. The loss value reached about 0.1 and 0.2, and the accuracy reached about 99% and 97% in the training and the validation sets, respectively, at the end stages of training.
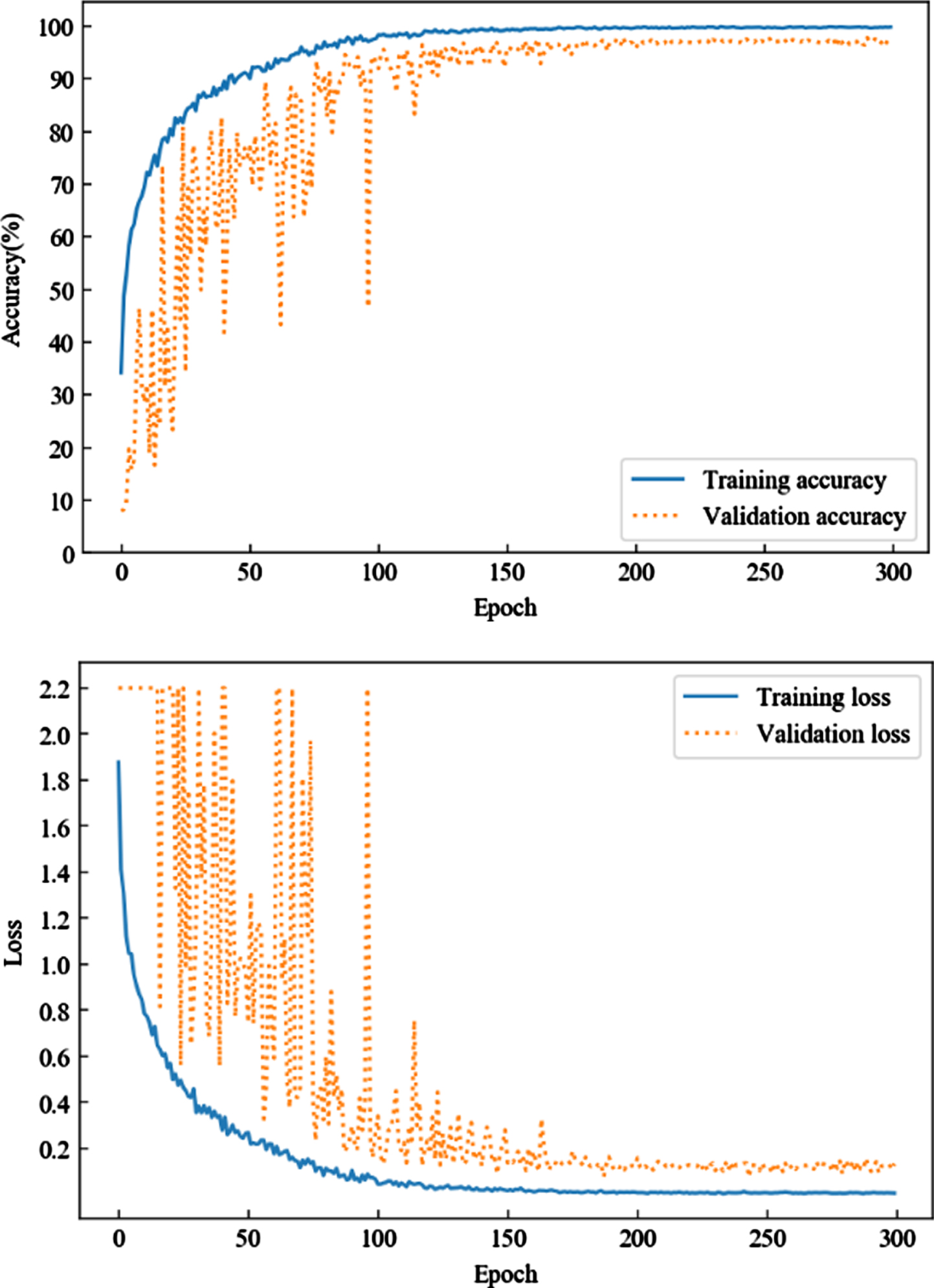
The loss value and accuracy during the training process in the training and validation sets.
The model weight that achieved the best accuracy on the validation set was used for model testing. To observe the details of the recognition results, a confusion matrix was adopted to visualize the results. As shown in Fig. 7, the labels “3-1” to “5-7” represents the days from the first day at instar 3 to the seventh day at instar 5, the horizontal coordinate denotes the prediction results of the trained model, and the longitudinal coordinate refers to the true label of each category. The number in the diagonal of the matrix indicates the number of correct recognitions, and the other cells represent the number of incorrect recognitions.
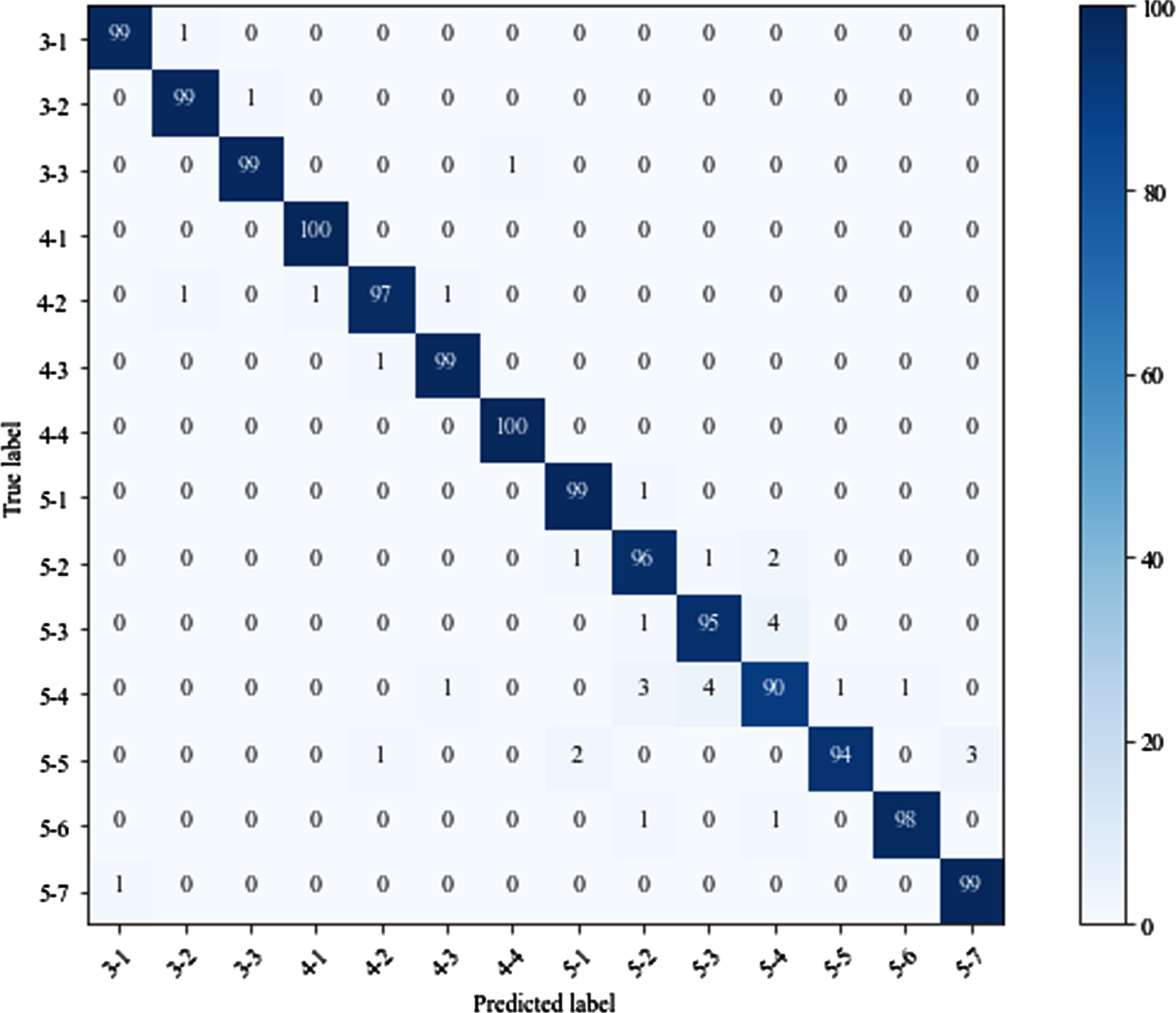
The confusion matrix of CSP-SENet.
Misrecognition of more than three images included: four images of the third day at instar 5 were recognized as the fourth day at instar 5. There were 3 and 4 images of the fourth day at instar 5 that were recognized as the second and third day at instar 5, respectively, and three images of the fifth day at instar 5 that were recognized as the seventh day at instar 5. Based on these results, it can be observed that the images of the adjacent day in an instar are more likely to be misrecognized due to their high similarity, and the images of instar 5 are more likely to be misclassified. This corresponds to real situations where it is more difficult to distinguish the day instar by the appearance in late instar 5 due to the growth of the silkworm.
Table 1 reflects the details of the recognition results for each category according to the confusion matrix. The best results were found for “4-1” and “4-4,” while the lowest results were found for “5-4.” In summary, CSP-SENet achieved a precision of 0.9743, a recall of 0.9743, a specificity of 0.9980, and an F1-score of 0.9742 on the test set of 1400 images.
Recognition results were proposed by CSP-SENet
To verify the recognition capability of the proposed network, several state-of-the-art networks, including DarkNet-53 [38], CSPNet [15], ResNet-50 [16], and Swin Transformer [39], were selected for comparison with CSP-SENet.
Comparison results of CSP-SENet with other state-of-the-art networks
Comparison results of CSP-SENet with other state-of-the-art networks
In this section, two types of related networks have been used for comparison with our CSP-SENet, one of which is the combination of CSPNet with image attention mechanisms, such as CSPNet+ECA [40], CSPNet+CBAM [41] and CSPNet+CANet [42], and the other is the application networks of SENet, such as GhostNet [26] and MobileNet v3 small [27].
Table 3 summarizes the results of the selected networks. It can be observed that by adding CBAM, CANet, and ECANet to CSPNet, the recognition precision can be increased without significantly increasing the number of parameters and the computational burden. However, the performance of these networks on the dataset was not as good as that of CSP-SENet alone. Meanwhile, due to the use of lightweight design, GhostNet and MobileNet have significant advantages over CSP-SNet in terms of the number of parameters and GFLOPs, but their recognition results were relatively limited. These results illustrated the recognition performance of the proposed method.
Comparison results of CSP-SENet with other related networks
Comparison results of CSP-SENet with other related networks
To reflect the effectiveness of the crucial components of the proposed method, we decomposed the CSP-SE block into four different structures and then used them to build different networks with the same configuration as CSP-SENet (same number of convolutional kernels and L) for training and testing to verify the recognition effect of each structure. As shown in Fig. 8, the first of these structures was to add SENet to the CSP block (Method I), the second was our CSP-SE block without SENet (Method II), and the third was to use two 3×3 convolutional layers to replace the 7×7 and 5×5 convolutions in the CSP-SENet block (Method III). In addition, we also tested changing the number of each stage L in CSP-SE from 2 : 2: 6 : 2 to 2 : 3: 5 : 2 (which is the same ratio as ResNet-50) (Method IV).
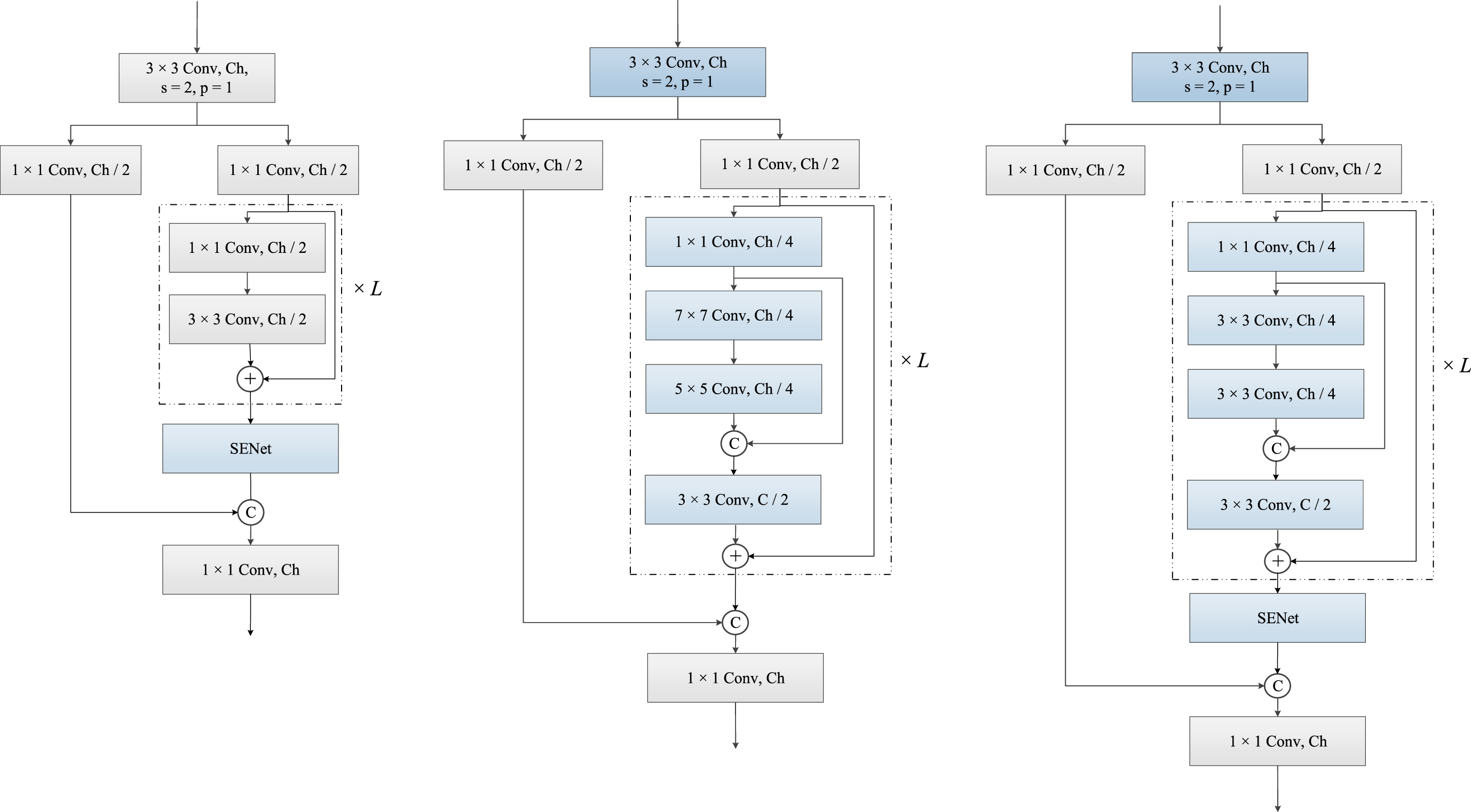
Three structures for ablation analysis.
Table 4 reports the comparison results for the different components. It can be observed that when SENet was added to CSPNet, and compared to the results of original CSPNet, the recognition precision, recall and F1-score increased by 0.0135, 0.0139 and 0.0118, respectively. When SENet was removed from our CSP-SE block, and compared to the result of CSP-SENet, the recognition precision, recall and F1-score were decreased by 0.0122, 0.0123 and 0.0123, respectively. This demonstrated the effect of SENet on recognition performance. Second, when the 3×3 convolutional layers were used to replace the 7×7 and 5×5 convolutional layers in the CSP-SE block, the recognition precision, recall, and F1-score were decreased by 0.0186, 0.0186, and 0.0186, respectively, demonstrating the effect of the feature fusion from the different receptive fields. Finally, when the stage L in the four stages was changed from 2 : 2:6 : 2 to 3 : 3:6 : 6, the recognition precision, recall, and F1-score were reduced by 0.0036, 0.0036 and 0.0038, respectively, thus demonstrating the role of the stage ratio.
Comparison results for different components
This study proposes a new method for the day instar recognition of adult silkworms based on feature fusion and image attention mechanisms. The images from the first day of instar 3 to the seventh day of instar 5 were photographed using a mobile phone under real rearing conditions, and a dataset containing 7 000 images was constructed for recognition. An effective module was proposed based on the feature fusion from the different receptive fields and the image attention mechanism to realize the extraction of diversified features and key information, and a network was presented using the proposed module. Based on the experimental results, the following specific conclusions can be drawn: A recognition method for the day instar of adult silkworms was proposed, which can fill the gaps in this field and provide a theoretical reference for related work on the recognition of silkworms and other insects. A CSP-SENet was developed based on CSPNet and SENet, in which feature fusion from different receptive fields and SENet were adopted to improve the recognition performance. The experiments demonstrated the advantages of CSP-SENet, which has better recognition precision and cheap computational cost.
However, our study still has some shortcomings. The dataset contains only images of one silkworm species, and the number of images and categories in the dataset need to be further expanded. The key visual and behavioral characteristics of each day age, such as dormancy, food ringing, molting, and spitting, were not sufficiently considered, and the depth of research on the day age recognition needs to be further enhanced. For these reasons, in the follow-up study, we plan to further enrich the dataset to include more images of silkworms. At the same time, we will also focus on studying some key behavioral traits during the silkworm’s growth to expand the practical implications of the study.
Footnotes
Acknowledgments
This study was supported by the Open Competition Mechanism to select the best Candidates from Sichuan Academy of Agricultural Sciences(1 + 9KJGG008); Natural Science Foundation of Sichuan, China (2023NSFSC0498) and the National Modern Agricultural Industrial Technology System Special Project (CARS-18).