
Abstract
The amount of used new energy vehicle transactions is increasing quickly as the social economy matures, yet prices are typically low, making it increasingly difficult to select a fair trading system. Enhancing the score function is crucial in order to account for how different people’s attitudes affect the outcome of decisions and to choose an acceptable trading strategy that is applicable to other scenarios and has a favorable impact on transaction flow. The choice of a trading scheme for new energy-using vehicles is usually regarded as a multi-attribute decision problem. In this paper, the Intuitionistic Fuzzy Hybrid Averaging (IFHA) operator integration operator with an improved score function is proposed based on the influence of herd mentality on decision-makers. In order to examine the correlation between the score function and the decision outcome using the Spearman rank correlation coefficient, an application to a real situation and some comparative analyses are provided. The outcomes demonstrate that the decision-making process for used car trading schemes can make use of the proposed improved score function.
Keywords
Introduction
The number of used new energy vehicles being traded is increasing quickly as the social economy develops, yet the prices are typically too low. The selection of a suitable transaction option is a growing source of worry because the decision to transact is typically a multi-attribute fuzzy decision with a burdensome number of decision possibilities for consumers. Atanassov [1] introduced hesitancy into Zadeh [2] fuzzy set theory and proposed an intuitionistic fuzzy set theory that takes into account three aspects of information. Compared with traditional fuzzy sets, intuitionistic fuzzy sets are more practical in dealing with vagueness and uncertainty problems by considering three aspects of information, and are therefore widely used. The Intuitionistic Fuzzy Hybrid Averaging (IFHA) operator not only weights the intuitionistic fuzzy numbers to prevent information loss but also takes into account the importance of data location, making it more suitable for intuitionistic fuzzy multi-attribute decision making. Sensible knowledge is developed in more and more decision-making fields [3]. Yager [4] proposed ordered weighted averaging (OWA) operators for many applications, adding the effect of evaluator optimism to the setting of weights. Liang, Qi, Ding and Leng [5] proposed a hybrid multi-attribute decision making method based on TOPSIS. By incorporating preferences from the standpoint of scheme preferences, He and Liu [6] developed the intuitionistic fuzzy multi-attribute decision-making technique. Chao and Jing [7] synthesized fuzzy hesitation sets and intuitionistic fuzzy sets and proposed hesitation intuitionistic fuzzy sets. Wu, Liu and Wan [8] improved the score function and proposed a new intuitionistic fuzzy ensemble operator. Li and Chen [9] introduced the concept of D-intuitionistic fuzzy hesitation set. Meng, Wang, Zhang and Liu [10] proposed a new intuitionistic fuzzy ensemble operator to improve the score function from the angle that the number of pros and cons is equal. However it doesn’t reflect the reality of the issue, their improvements to the decision-making process are based on the same population of positive and negative views. Rahimi, Kumar, Moomivand and Yari [11] proposed an intuitionistic fuzzy entropy measure for supplier attribute selection and ranking. Thao [12] established the entropy measure and knowledge measure of intuitionistic fuzzy sets based on the divergence test of intuitionistic fuzzy sets. AI-shami, Ibrahim, Azzam and Elmaghrabi [13] proposed SR-fuzzy sets based on intuitionistic fuzzy sets and defined a new score function to rank schemes. Furthermore, there are still limitations in the research on the modified score function for intuitionistic fuzzy theory and fuzzy multi-attribute decision making. Xu [14] proposed a scoring function based on pro and con attitudes for the ranking of schemes. the scoring function proposed by Lin, Yuan and Xia [15] and Wang, Zhang and Liu [16] divided the abstention population into n groups and obtained the expression of the scoring function with parameters after taking the limit. The idea of grouping the abstention population is instructive. Wu, Liu and Wan [8] improved the scoring function by assuming an equal number of yes and no votes and corrected the abstention population for the no population. The score function proposed by Meng, Wang, Zhang and Liu [10] divides the population into three parts, with equal levels of approval and disapproval by default. This improvement motivates us to further subdivide the abstentions on the basis of the three-part division. Ashraf, Ullah, Hussain and Bari [17] classified likelihood into four categories of affiliation, non-affiliation, abstinence, and rejection, further refining the classification of likelihood to interpret information in the form of intervals. Biswas and Joshi [18] used a multi-criteria decision making approach and investigated the impact of prospect theory on investment decisions in a comparative performance evaluation of IPOs with heterogeneous business operations proposition. My research has been greatly influenced by the idea of exploring the influence of psychological expectations on decision making from a behavioral perspective.
Nevertheless, the scoring functions proposed by the aforementioned scholars ignore the issue of heterogeneous consumers in the transaction decision process and have the drawbacks of being unable to rank the special fuzzy numbers encountered in the application and the difficulty of determining the parameters with objectivity [19–25]. For the purposes to effectively use many attributes in decision-making, it is essential to incorporate customer price sensitivity and perceived expectations. The goal of this research is to create a new score function that can more effectively handle the issue of differential mental choices brought on by cognitive biases in multi-attribute decision making, which has an impact on transactional decisions. The focus of these activities is therefore discussed below. Utility theory is most importantly incorporated into IFHA. Additionally, each attribute’s weight was determined using data from the study of Xu [26], which facilitated the method’s generalization. Then, an empirical application of this novel approach is provided, and a number of comparison analyses are carried out to illustrate some of its benefits.
The remainder of this paper is organized as follows. Section 2 presents some necessary knowledge of consumer utility and intuitionistic fuzzy set formation operators. The computational steps for improving the score function and proving the proposition of the improved score function are given in Section 3. Section 4 provides a comparative analysis of the Chinese new energy used car trading decision calculus with other score functions. Finally, we conclude this work in Section 5.
Preliminaries
In this section, we introduce the concepts of consumer utility [42], Spearman correlation analysis [18], intuitionistic fuzzy sets [27] and the IFHA operator [8].
In this paper, we focus on the heterogeneous decision behaviour of consumers when faced with different products in a transaction decision, and therefore assume that there is only one distributor in the market, without considering the problem of competition in the distribution channel. There are two types of products in the market: the higher-rated product is marked by the H and its price is marked by PH, while the lower-rated product is marked by the L and its price is marked by PL. Heterogeneous consumers will have different perceived expectations when faced with a transaction decision for a homogeneous product, and since consumers are rational, they will ultimately make a transaction decision based on the utility of the good U. The consumer’s perceived expectation of good H is represented by γ, where a larger γ indicates a higher degree of consumer approval of the good, and the perceived expectation of good L is represented by β γ, where β reflects the consumer’s sensitivity to the price of different goods and β∈(0,1), where a larger β indicates a lower price sensitivity. The utility generated by goods is the difference between the perceived expectation and price. When there are two levels of goods in the market, consumers’ trading decisions are determined by the utility generated by the goods. The utility obtained by purchasing H and L is UL =β γ-PL, UH =γ-PH [43] respectively, and the value of the utility obtained will influence the consumer’s trading decision.
The ordered (μA(x),νA(x)) consisting of subordinate and unaffiliated degrees is called the intuitionistic fuzzy number. Thus the intuitionistic fuzzy set A on X can be regarded as the set of intuitionistic fuzzy numbers, A = {(μ A (x) , ν A (x)) |x ∈ X}.
if s(α1) < s(α2), then α1 < α2; if s(α1) = s(α2), h(α1) = h(α2), then α1 =α2; h(α1) < h(α2), then α1 < α2; h(α1) > h(α2), then α1 > α2.
Where ω= (ω1, ω2, ω3, . . . , ωm)T is the weighted vector of IFHA operator, ωj∈ [0,1](j = 1,2, . . . ,n),
The larger IFHA ω,w the more the corresponding scheme meets the requirements of decision makers.
Spearman’s rank correlation analysis, also known as the rank difference method, is based on the analysis of the basis of correlation between variables in rank information, which is calculated as the difference in the number of ranks. In contrast to the product-difference correlation coefficient, this method does not impose stricter data conditions. It only requires that the ranks of the two observed variables are paired. are paired, and the specific equation is as follows:
Ri and Si in Equation (3) represent the rank of the ith x-value and y-value respectively. The mean of the two variables is denoted by
The t-test is a test of Spearman’s coefficient, which is specified by the equation:
In Equation (4), R represents the correlation coefficient, n represents the sample data size, and the degrees of freedom are n-2. The original hypothesis is not accepted when the t score is greater than t0.05 (n - 2) , and the hypothesis that the correlation coefficient is 0 cannot be rejected when t is less than t0.05 (n - 2) .
Existing scoring functions
An intuitionistic fuzzy number (μ α,ν α) = (0.6,0.2) in a particular voting scheme means: If ten people vote for a certain scheme, six people vote for it, two people vote against it, and two people remain neutral.
The score function s(α) [29] is used to evaluate the intuitionistic fuzzy number in the scheme, and the result represents the decision maker’s satisfaction with the scheme. The equation is as follows:
Where s(α) is the score value of α, s(α) ∈ [0,1].
From Equation (5), we can see that the value of the score function is related to the degree of membership and the degree of non-membership, and the larger the difference between them, the larger the score value of α, and therefore the larger the fuzzy number α, and the decision scheme can better meet the requirements of the decision maker. However, the traditional score function sometimes cannot judge the size of intuitionistic fuzzy numbers [29], as shown in Example 1.
From the line of Equation (5), s(α1) = 0.7–0.1 = 0.6, s(α2) = 0.6–0.0 = 0.6, s(α1) = s(α2). Using exact functions according to the conditions of definition 3, h(α1) = 0.7 + 0.1 = 0.8, h(α2) = 0.6 + 0.0 = 0.6, h(α1) > h(α2), therefore α1 > α2, that is, scheme α1 is superior to scheme α2. However, 60% of the people in favour of scheme α2 are abstainers. Compared with 70% of the people in favour of scheme α1 and 10% of the people against scheme α1, the actual scheme α2 is superior to scheme α1, and the results of the calculation of the traditional score function are inconsistent with the actual situation.
The traditional score function does not take into account the influence of abstainers on decision outcomes, which has limitations in practical application to scheme decision-making. Wang, Zhang and Liu introduced the influence of abstainers on decision outcomes into the score function and modified the score function as follows [16]:
Equation (6) considers the influence of three groups of people who agree, disagree, and abstain on the decision outcomes; the degree of membership, non-membership and hesitation degree are μ α, ν α and 1–μ α –ν α, respectively. The higher the value of SW(α), the more the scheme meets the requirements of the decision-maker. Compared with the traditional scoring function, Liu’s improved scoring function cannot fully discriminate the size of the particular intuitionistic fuzzy number in Example 1.
Based on the inadequacy of the traditional scoring function, Liu and Wang proposed a scoring function that divides the abstainers into n groups and takes the limit of the improved scoring function to obtain:
Compared to Equations (6) and (7), the influence of abstainers on the decision outcomes is also taken into account. However, the weights a and b of
π
a in the score function are difficult to give objective values, and their practical application is also limited. Based on the shortcoming that the weight of Liu’s improved score function cannot be given objectively. Wu [30] modified the weight value of
π
a by the difference between for and against and proposed an improved score function s′ (α):
s′ (α) comprehensively considers the three groups of people who agree, oppose and abstain, which also overcomes the shortcoming that the weighting cannot be given objectively. However, the score function modifies the people who abstain from the group of people who oppose the group, which may lead to inaccurate decision making results in practical application and restrict its application in actual decision-making.
A review of the existing research on the score function shows that the assumption of an equal number of people with positive and negative opinions is not factual, which affects the accuracy of the score function; moreover, the decision results are more subjective from the perspective of preferences. In view of these shortcomings, our study introduces a consumer utility model that no longer classifies the decision population, but analyses the population as a whole, thus avoiding the inaccuracy of the decision results caused by subjective classification. Due to the different perceived expectations caused by cognitive biases, the heart choice will have a greater impact on the decision. The overall consideration of the differences before the decision options, based on the utility derived from the different options, can increase the accuracy of decisions on similar options and provide consumers with a reference for their decisions. The improved scoring function is as follows:
Compared with the scoring function in Equation (8), based on the consumer utility model, the new scoring function uses 1–
π
α to represent the consumer’s price sensitivity β, the membership degree μ
α to represent the consumer’s purchase expectation γ, and the non-membership degree ν
α to represent the product price p. The higher the degree of hesitation, the higher the sensitivity of consumers to the current price; the higher the degree of membership, the higher the expectation of consumers to buy the product; the higher the degree of non-membership, the higher the product price and the influence of consumers’ purchase expectations. If consumers buy goods L, the effect of consumers is UL=(1–
π
α)×μ
α–ν
α, if they buy goods H, the utility of consumers is UH=μ
α–ν
α. When consumers make trading scheme decisions, they comprehensively consider the utility of commodity L and commodity H and take the intermediate value
Comparison of calculation results of several score functions
It can be seen from Table 1 that, compared to other scoring functions, the calculated results of the improved scoring function do not contradict the actual situation, and the calculated results are consistent with objective facts.
Here we will demonstrate that the improved scoring function still satisfies the proposition of the scoring function, thus justifying and validating the improved scoring function.
μ
α =1, ν
α =0< = > s(α) =1; μ
α =0, ν
α =1< = > s(α) =-1.
If
π
α = 1-μ
α-ν
α and S
λ(α) = 1, μ
α2 +μ
α +μ
α *ν
α - 2ν
α-1 = 0, Under the condition 0≤μ
α ≤ 1 and 0≤ ν
α ≤ 1: when μ
α =ν
α, μ
α =ν
α = -1/2≠0 or μ
α =ν
α = 1, the above equation does not hold; when μ
α < ν
α, μ
α+μ
α*ν
α-2ν
α < 0, μ
α2-1 < 0, so μ
α2+μ
α+μ
α *ν
α-2ν
α-1 < 0, the above equation does not hold; when μ
α> ν
α, to make the equation hold, there is μ
α2+μ
α+μ
α *ν
α-2ν
α-1 = 0. Because -1≤μ
α2+μ
α-1≤1, -1≤μ
α*ν
α-2ν
α≤0, so μ
α = 1 and ν
α = 0.
The proof of theorem 1 (2) is similar to that of (1).
Therefore, S λ (α) increases monotonically concerning μ α.
In the same way,
Thus S λ (α) decreases monotonically concerning ν α.
The same reasoning gives.
So S λ(α1) > S λ(α2).
For multiple attribute decision making problems, let Y = {Y1, Y2, …, Y
m
} be the scheme, G = {G1, G2, …, G
m
} is the property set, ω= (ω1, ω2, ω3, . . . , ωm)T is the weight vector of the attribute, ω=(ω1, ω2, ω3, . . . , ωm)T, ω
j
∈ [0,1](j = 1,2, . . . ,n),
The characteristic of scheme Yi with respect to the attribute Gj is represented by the intuitionistic fuzzy number dij(μij,νij), therefore μij denotes the degree to which scheme Yi satisfies attribute Gj, and vij denotes the degree to which scheme Yi does not satisfy the attribute Gj. When the indicators include indicators of different dimensions, in order to make the indicators of different dimensions comparable, the original data are standardised using Equation (15) in Atanassov [36]. The specific equation is:
Where Gi is a benefit-based indicator, and Gj is a cost-based indicator, i = 1,2,..,5; j = 1, 2, …, 5, 6.
Therefore, the characteristic information of all schemes Yi(i = 1,2, . . . ,m) concerning all attributes Gj(j = 1,2, . . . ,n) can be expressed by an intuitionistic fuzzy matrix D=(dij)m *n. Where dij(μij,νij), μij ∈ [0,1], νij ∈ [0,1], μij+νij ≤ 1. See Table 2.
Intuitionistic fuzzy matrix D
The steps of the Intuitionistic Fuzzy Hybrid Averaging operator multi-attribute decision making method based on the improved score function are as follows:
Numerical example
With the development of the modern economy and the improvement of living standards, new energy vehicles have developed rapidly, especially in China, supported by the policies of the Chinese government. The increase in the number of new energy vehicles has promoted the vigorous development of the used new energy car market compared with traditional fuel vehicles. There is no reasonable transaction evaluation method for the trade decision of used new energy cars. The trade decision of used new energy cars affects and restricts the development of the used car market and limits the circulation efficiency of used cars. To improve the efficiency of used car trade decisions, make different trade decision making schemes for different groups of people, improve the problem of undervalued prices of new energy second-hand cars, and provide appropriate solutions for used car trade decisions. Then, make an effective trading scheme to solve the second-hand car trading decision. In this section, the Intuitionistic Fuzzy Hybrid Averaging operator based on an improved score function can be applied to the decision making of used new energy car trading schemes. As different traders want to choose a used new energy car that best suits their trading preferences, six indicators are selected through a questionnaire survey: total engine power (G1) , manufacturer’s guide price (G2), battery capacity (G3), brand (G4), driving range (G5) and service life (G6) as reference indicators for traders when purchasing new energy used cars. The degree of preference of decision makers for the above six indicators is determined by a questionnaire survey, and five schemes Yi(i = 1,2,3,4,5) are designed according to the different degrees of preference. Scheme Y1 mainly takes into account the total power and the range of the engine; scheme Y2 mainly takes into account the range and the time of use; scheme Y3 mainly takes into account the manufacturer’s recommended price, brand, and use time; scheme Y4 mainly takes into account the battery capacity, the brand and the time of use; scheme Y5 mainly takes into account the total power of the engine and the manufacturer’s recommended price.
Based on the results of the questionnaire trader voting hypothesis Yi(i = 1,2,3,4,5) under attribute Gj(j = 1,2,3,4,5,6) trader age, gender and trader preferences and other characteristic information is represented by intuitionistic fuzzy numbers, according to trader preferences to determine the attribute weights for ω= (0.35,0.25,0.18,0.12,0.07,0.03)T, intuitionistic fuzzy matrix D = (dij)5 *6 as shown in Table 3.
Intuitionistic fuzzy matrix D
Intuitionistic fuzzy matrix D
Since G2 and G4 are cost indicators, and G1, G3, G5, and G1 are benefit indicators, to make the indicators of different dimensions comparable, the cost indicators are transformed into benefit indicators by Equation (15). Thus, the intuitionistic fuzzy decision matrix D = (dij) 5*6 is transformed into a normalised intuitionistic fuzzy decision matrix
Normalized intuitionistic fuzzy decision matrix D′
The attribute values of the decision scheme.
Weighted intuitionistic fuzzy decision matrix
According to Xu’s [14] research on the weighted attribute values of schemes, the attribute values are sorted according to their size, and then the position vector of the IFHA operator is determined as ω= (0.0865,0.1716,0.2419,0.2419,0.1717,0.0865)T by using the IFHA operator equation according to the number of attributes n = 6. By assigning different weights to the data to eliminate as much as possible the influence of other factors on the decision result [31], the comprehensive attribute value of the scheme Yj=(i = 1,2,3,4,5) is obtained
The score value of
Comprehensive attribute values of schemes
The score value of the score function
According to the score value of the score function in Table 7, the ranking result of the selection scheme is S λ(d4)> S λ(d5)> S λ(d3)> S λ(d1)> S λ(d2), so Y4 > Y5 > Y1 > Y3 > Y2 and the best scheme is Y4. Battery capacity, brand, and life time are more important for consumers.
In this section, we compare the decision results obtained by the improved score function with those obtained by the transmission score function to illustrate its superiority.
First of all, we compare the improved score function with the method in Atanassov [7]. For Atanassov [7], the calculated results are S(Y1) = 0.409, S(Y2) = 0.383, S(Y3) = 0.428, S(Y4) = 0.711, S(Y5) = 0.657. Therefore, the ranking order is Y4 > Y5 > Y3 > Y1 > Y2. Secondly, we compare the improved score function with the method in Atanassov [24]. For Atanassov [24], the calculated results are S(Y1) = -0.0.39, S(Y2) = –0.139, S(Y3) = –0.021, S(Y4) = 0.458, S(Y5) = 0.336. Therefore, the ranking order is Y4 > Y5 > Y3 > Y1 > Y2. Finally, we compare the improved score function with the method in Atanassov [37]. For Atanassov [37], the calculated results are S(Y1) = 0.289, S(Y2) = 0.210, S(Y3) = 0.254, S(Y4) = 0.646, S(Y5) = 0.601. Therefore, the ranking order is Y4 > Y5 > Y3 > Y2 > Y1.
Finally, the final ranking results of the three scoring function schemes are shown in Table 8.
The score value of the score function
The score value of the score function
Based on the data in Table 8, Spearman’s rank correlation was calculated between the score values and the score function, and the decision scheme, and the correlation was found to be statistically significant, as shown in Table 9.
Correlation between Score values, Score functions and Decision options
**Correlation is significant at the 0.01 level(2-tailed). *Correlation is significant at the 0.05 level(2-tailed).
Table 9 shows that the score function and decision option variables pass a two-tailed t-test with a significance probability level of 0.008 for the score function at the 0.01 significance level and 0.017 for the decision option at the 0.05 significance level. Two conclusions can be drawn: There is a relatively significant negative correlation between the score value and the score function. The negative correlation is due to the addition of the effect of consumer utility to the score function, which increases the volatility of the score values. Based on the volatility, it is possible to select the worse decision solution and negative factors from similar solutions, thus increasing the accuracy of the decision. Optimal solution selection is based on ideal conditions, but actual decision situations can be more complex. In addition to providing the consumer with the best option, negative information affecting the decision option must be analysed to make the results more realistic. There is a more significant positive correlation between the score value and the decision options. The positive correlation is due to the fact that the improved score function is more applicable to multi-option choices, which can effectively solve the distress caused by multi-attribute choices. Although more decision options can provide consumers with more choices and satisfy different consumer needs. However, in the case of cognitive bias, the large number of similar decision options increases the influence of consumers’ mental choices on the decision. This is at odds with rational judgement. Therefore, the results of our analysing are reasonable, and analyzing the decision options in terms of consumers’ access to utility as a whole and integrating different consumer preferences for comprehensive consideration will increase the accuracy of the decision.
We numbered Atanassov [7, 37] and the improved score function sequentially 1,2,3,4 and compared them to analyse the fluctuation of the score values. From Fig. 2 and Table 8, it can be concluded that the improved score function is more sensitive to different decision options.
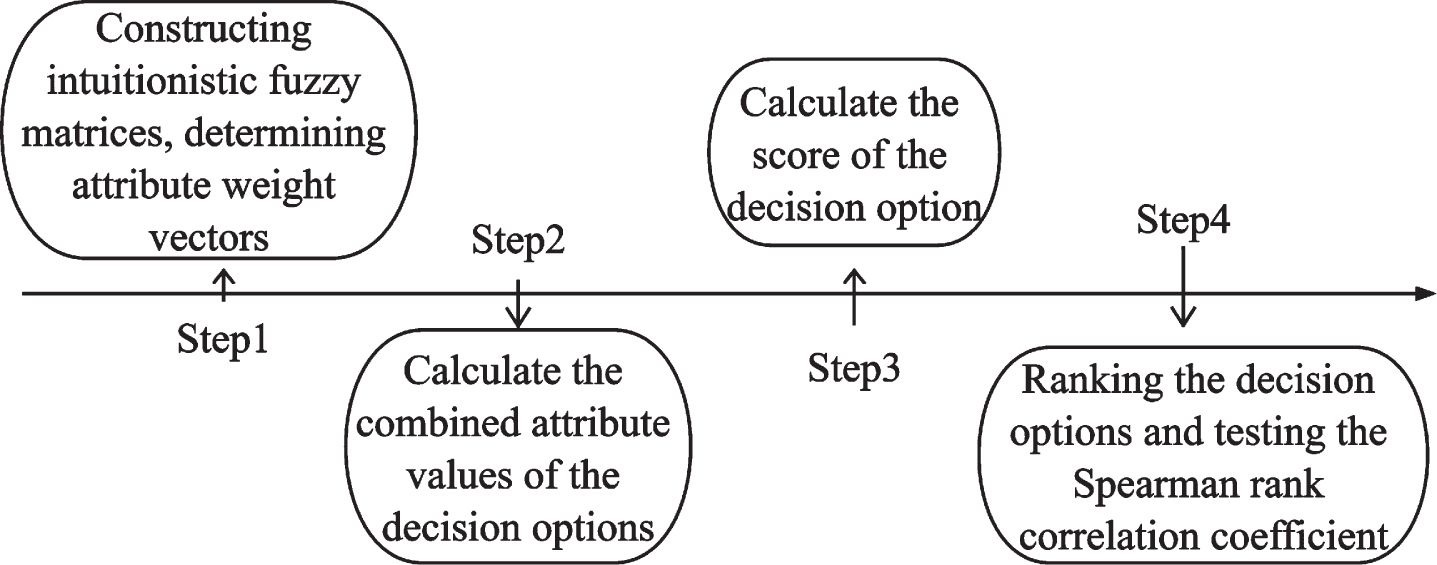
The process of decision-making based on a herding psychology improved score function for trading decisions.
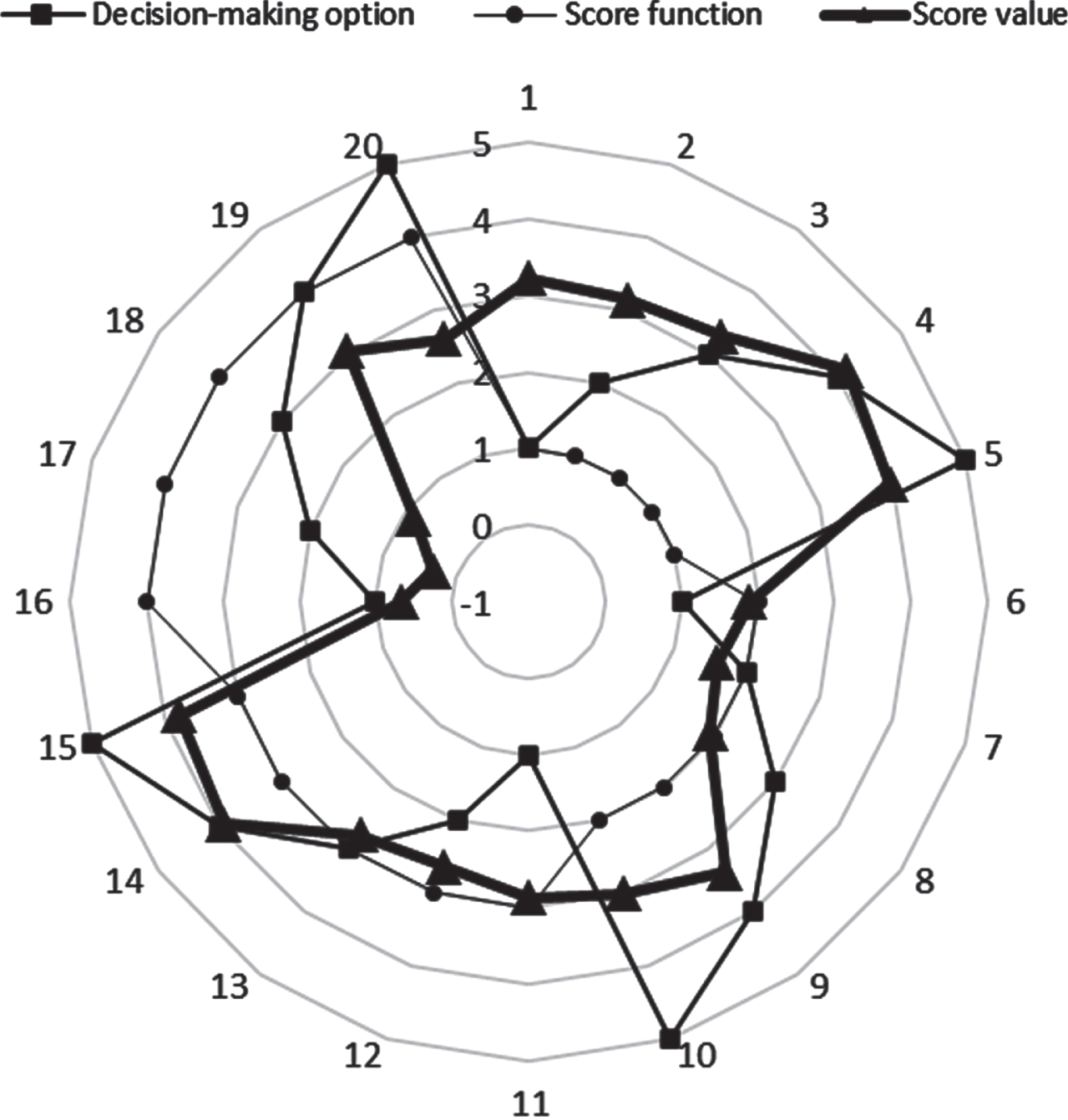
Sensitivity analysis.
Several useful observations can be made from this paper. First, when comparing the scores, it can be seen that although the best and worst options are the same, the ranking for the intermediate options is not the same. It can be seen that the Atanassov [7] and Atanassov [37] scores for the decision options are generally stable and do not differ significantly from one decision option to another. On the other hand, the scores of Atanassov [24] and The improved score function fluctuate significantly, and the ranking of the decision options in the middle is not the same. It is difficult to extend their use in practical applications. Our improved score function can better reflect the difference in utility obtained by decision makers for homogeneous goods in the presence of cognitive biases, and can more accurately select the better option and negative factors to provide input to consumer decisions.
The multi-attribute decision problem is a difficult task due to the complexity of the objective situation and the different psychological expectations resulting from cognitive biases. This study examines, the influence of consumer utility on transactional decisions from a behavioural economics perspective. Consumer decision behaviour is mainly driven by different perceived expectations due to cognitive biases. The score function of the comparison group does not take into account the effect of utility, and decisions made in the presence of cognitive biases are susceptible to mental choices. Instead of classifying the decision population, we design a method that considers the differences between transaction options as a whole and ranks them from the perspective of the utility consumers receive in their transaction decisions, compensating for the deviations between the assumptions of the other score functions in classifying the decision population and the actual situation, avoiding the loss of decision information and minimising the subjective arbitrariness of decision makers. A new intuitive fuzzy multi-attribute decision making method based on utility theory is proposed by introducing a mean modified score function for the utility obtained by heterogeneous consumers from homogeneous goods, and using the improved score function to make a comprehensive evaluation of the transaction options; in combination with the IFHA operator. To verify the effectiveness of the improved score function, the correlation between the score value and the score function as well as the Spearman rank correlation coefficients of the decision options are verified by analysing the correlation between the score value and the score function. A comparison was also made with the ranking of the scenarios in the comparison group. The results show that the improved scoring function is more comprehensive and realistic for the decision population, ensuring the reasonableness and validity of the decision results. Decision-making is not only about choosing the best solution but also about finding the influencing factors that affect the decision. It is also about finding the influencing factors that affect the decision, providing a more informed view when faced with a complex choice. The improved score function is more sensitive to different decision options and provides consumers with more information about their decisions. However, our work has some shortcomings. In this paper, we use the given attribute values to rank the decision alternatives, and although we introduce the consumer acquisition utility to correct the decision, this may still have some impact on the precision of the decision.
In future work, the determination of attribute weights can be further investigated and the use of Pythagorean Hesitant Fuzzy Number (PHFN) to represent attribute values can be explored. This paper used given objective attribute weights based on the number of attributes, which may affect the scope of application in the future. Future research can consider Pythagorean Hesitant Fuzzy Number (PHFN) to represent attribute values, which can reflect the decision-making information in a more detailed and comprehensive way; and establish an optimisation model to determine the attribute weights through the dispersion rate of the original decision-making information to avoid information bias. In addition, future research could investigate the effect of the retailer’s sales probability on the decision outcome and further improve the accuracy of the decision method through a combined analysis of the two. In addition, the design method has been applied to many other uncertain environments [32–35] and can be used to solve multi-attribute decision problems such as project selection [36–45].
Footnotes
Acknowledgments
This paper is supported by the National Natural Science Foundation of China (No: 12261007). Guangxi University of Science and Technology PhD Fund Project University Science and Technology PhD 19Z431 Study on the Carbon Neutral Potential of ELV Metal Parts Recycling and Automobile Industry Research on the Linkage and Enhancement of Technical Standardisation Capability.