
Abstract
In the field of finance, deep learning techniques have been extensively researched for predicting stock prices. In this research, we propose a novel approach for predicting stock price movements using a combination of reviews and historical price data for SBI and HDFC stocks. As market volatility is influenced by numerous factors, it is crucial to consider it while predicting stock prices. To capture the interactions between the price and text data effectively, we create a fusion mix and utilize a hybrid information mixing module, designed using BERT and BiLSTM, to extract the multimodal interactions between the time series and semantic features. The proposed model, the hybrid information mixing module, is based on a multilayer perceptron and achieves high accuracy in predicting price fluctuations in highly volatile stock markets. Future research can extend this approach to include additional data sources and explore other deep learning techniques for better performance.
Introduction
Financial Markets consist of the prediction of stock markets as an external topic. The financial crisis which happened in 2008, this situation was considered an extreme case that disturbs the stability of the market as discussed in [1]. In the history of stock markets, various methods were proposed such as technical analysis, time series analysis, and fundamental analysis as introduced in [2]. The present state of the art shows the rapid development in the area of computer science, especially in machine learning and deep learning field which are applied to the stock market and are presented by [3]. Researchers are hoping to understand the stock market dynamics by learning algorithms from the field of deep learning and machine learning. One of the attractive topics used for forecasting includes the fusion of techniques from deep learning and financial data of time series.
Many researchers have concluded that investor sentiment is considered the most important factor for predicting stock trends. The investor’s sentiment text is mostly found in large amounts in news articles and websites. It is said that one of the most influential drivers for abruptly changing the attitude of the stock market is investor reviews and news. Investor sentiment is considered the key factor which reflects willingness and expectations from the trends of the stock market to predict the yield from the market as discussed by [4]. However, the most crucial factor is the time required for analysis of the reviews written by humans, as the basic requirement of financial analysts is that they monitor constantly and evaluate for the decision-making purpose of whether to sell or purchase the stock. Another factor to be considered is the amount of data available which is generated by various resources. In short two problems arise, the time required for the analysis of financial reviews and the amount of data. Prolonged reading is required for large amounts of financial information along with analysis of time, in contrast, the response time must be reduced and less financial textual data are to be analyzed. Thus, one of the solutions to the problem makes it difficult for the other problem to resolve using traditional techniques as discussed in [5].
Recently, an attention mechanism-based model BERT, which is the present state-of-art, has the capacity of processing eleven NLP tasks as presented by [6]. The evolution of a new state-of-art model includes the addition of an output layer for its fine-tuning. The paper, by [7], consists of a model which predicts preliminary outputs using BERT resulting in better performance and achieving a good hit rate as compared with CNN (Convolution Neural Networks) and word embeddings.
Recently, one of the subfields of ML (Machine Learning) known as Deep Learning is the upcoming research area that has shown promising results in the field of prediction. Researchers previously considered either only numeric data or solely textual data for predicting stock market trends. But these methods had few limitations as the stock market movements are volatile, especially the Stock Market responds to external factors as well. The investors before concluding, generally consider both the aspects of numeric and textual data. In [8], the research is based on deep learning techniques which are applied to the Thai stock market where both numerical and textual data are utilized. The main challenge in this paper was to perform downstream tasks on the Thai corpus where tokenization problems appeared due to Thai characters as they do not have space in between words. Another challenge was that the sentences in Thai news headlines were short. Therefore, the context of the news headlines was difficult to predict. Hence, the pre-trained model is the requirement in the present era to overcome such textual problems.
In this study, we propose an innovative method to forecast stock price movements by integrating data from HDFC and SBI stocks with news data sourced from Stocktwits, which provides comprehensive information on Indian Stock Market stocks. Given that the stock market is influenced by diverse factors, including news and market trends, accurately predicting stock prices requires careful consideration of market volatility. We employ BiLSTM-based models to analyze patterns of stock market volatility in HDFC and SBI stock data. Moreover, we exploit the contextual details present in news data by incorporating Bidirectional Encoder Representations from Transformers (BERT) into our prediction model. By doing so, we effectively capture the textual information pertaining to the stock market, enhancing the accuracy and reliability of our predictions.
Following the extraction of time-series and semantic features from HDFC and SBI stock data, we combine them to form a mixed feature that encompasses multimodal information. To enhance the prediction performance of stock price movements, we introduce a hybrid information mixing module consisting of two multilayer perceptron (MLP) blocks. This module facilitates effective interaction between the mixed features, strengthening the interplay between the price and text data features.
In the realm of stock market prediction, the utilization of hybrid approaches that integrate both textual and numerical data holds immense potential for enhancing prediction accuracy. However, the adoption of such hybrid models is accompanied by a host of challenges that need to be addressed. In contrast to traditional approaches that rely solely on numerical data, hybrid models seek to incorporate sentiment-rich textual information extracted from news articles, social media, and financial reports. While this incorporation presents a novel opportunity to capture nuanced market sentiments, it also introduces complexities related to data preprocessing, alignment, and integration. Moreover, the extraction of meaningful features from the amalgamation of textual and numerical data proves intricate and requires advanced natural language processing and feature engineering techniques.
Our methodology aims to capture the multimodal interaction between the time-series features of HDFC and SBI stock data and the semantic features of the news data. This is accomplished by leveraging the mixed feature and the hybrid information mixing module. By considering the unique characteristics of each data type, our approach contributes to improved accuracy in predicting stock price movements.
Our approach brings two significant contributions to the field. Firstly, we employ both BiLSTM and BERT techniques to extract time-series and semantic features from the price and text data, respectively. This enables us to capture the distinct attributes of each data type and generate a mixed feature with multimodal information. Secondly, we propose a hybrid information mixing module, which offers a simpler structure compared to transformer-based models, while effectively incorporating MLP blocks to accurately predict stock price movements.
The paper consists of sections organized as follows: Section II provides a detailed review related to forecasting methods. Section III provides a detailed description of models which are used for the proposed approach; Section IV provides the details about the dataset and methodology used Section V describes the proposed work in different parts; Section VI Results depicts the experiments performed using the proposed model, evaluation measures for calculating the accuracy of the proposed model and experimental results along with a comparative study of different baseline models and Section VII concludes the research conducted and discusses the future scope.
Literature review
This section provides a brief overview of various stock market trend forecasting methods, which can be classified into three distinct categories. The first category pertains to methods that rely on textual sentiments, where the analysis is conducted using text data. The second category focuses on numerical data, employing statistical and quantitative approaches for forecasting. Finally, the third category involves the fusion of both numeric and textual sentiments, combining the two types of data to enhance the accuracy and effectiveness of the forecasting methods.
Unsupervised feature-based approaches
The learning representation including neural and non-neural network for words have been an agile area of research for decades. The pre-trained embeddings are considered an integral part of Modern NLP as it has shown significant improvement over the word embeddings that were to be learned from scratch. The pre-training of word embeddings which is the main objective of using language models performs training from left to right and differentiates between incorrect words and context. Unsupervised feature-based approaches which have coarser granularities include generalizing into paragraph embeddings for sentence embeddings. The prior work as discussed in [7] included ranking candidates into previous and next sentence representation including generations from both the directions left and right or by using autoencoder which has a denoising effect for derived objectives. Thus, to make the sentence representation and embeddings clear Language model came into the picture.
ELMo i.e., Embeddings from Language Model consists of LSTM (Long Short-Term Memory) which is trained in both directions, and a language model generated which understands the sense of the word which occurs next as well as previous and is considered as a step ahead. In ELMo, generalization is performed on embeddings of traditional words from different dimensions. In this language model, the representation of each token is based on its context which means representations that are concatenated from right to left and left to right. The architectures which are task-specific and existing, integrate these word embeddings which are contextually based and use advanced ELMo, for many important benchmarks in NLP such as opinion mining, named entity recognition, and question answering. In this paper, LSTMs are used to perform learning and are utilized for contextual representations for predicting a single word in both contexts right and left for the selected task. ELMo is also one such language model, which uses feature-based LSTMs and they are not deep bi-directional models as shown in [9].
Unsupervised feature-based on fine-tuning
The word embeddings from the unlabeled text are the way of working for feature-based approaches for pre-training. Recently, pre-training of contextual tokens generated from documents or sentences from the text data which is unlabeled are fine-tuned further to a supervised downstream task. Learning requires fewer parameters if learning is performed from scratch, hence, such approaches were proved to be advantageous. This advantage gave much achievement to the OPENAI GPT (Generative Pre-trained Transformer) model as state-of-art which resulted from GLUE (General Language Understanding Evaluation) as a benchmark for various tasks on the sentence level. Auto encoder and left-to-right modeling are the objectives used by such models for pre-training as included in [10].
BERT model was introduced as a bi-directional language model which is pre-trained. This model addressed the constraint of unidirectionality by introducing MLM (Masked language Modelling) and NSP (Next Sentence Prediction) phases which improved the performance of the model. The BERT model presumes that the tokens which are masked are independent and can be predicted using unmasked tokens only. XLNet language model was introduced recently to improve the weakness of the BERT model by applying Transformer-XL which included masked positions with dependency. XLNet uses permutation language modeling as shown in [11].
Transfer learning from supervised data
The primary intention of Transfer Learning is to enable the developers and researchers to use this technique of pre-training the models which are developed by others and perform a few modifications on them. The main reason for increased accuracy is the use of the methods for Transfer Learning in NLP and mainly for Opinion Mining and Sentiment Analysis. If the training data available is limited, still Transfer Learning leverages the information extracted from a big corpus or dataset to increase efficiency. Opinion Mining summarization and machine translation are wide areas in which transfer learning manifests the effective working of supervised tasks using big datasets. This [12] paper, introduces a method of deep transfer learning for the domain of the stock market based on LSTM for prediction.
In this [13] paper, stock market movement prediction is done using the Selective Transfer Learning with Adversarial Training (STLAT) model which applies transfer learning. This model introduced two aspects namely a method for pre-training and fine-tuning for stock prediction and a module for data selection so that selection of relevant samples for training can be done correctly.
Trends prediction using only historical stock price information
Forecasting of financial data based on time series using Machine Learning methods is much more popularly studied. The techniques specifically SVM (Support Vector Machines) and (KNN) K-Nearest Neighbor are mostly used for stock domain index prediction. The combination of KNN and SVM was popularly used for the Chinese stock market as discussed in [14]. An optimal solution was introduced by [15] in which a neural network was used to develop the model in which PSO (Particle Swarm Optimization) was introduced which predicted the trends. Further to improve the performance, Generic Algorithm, probabilistic SVM, and AdaBoost were introduced by [16]. There are many more approaches proposed which resulted in a good performance.
The work proposed by I. Markovic et al. [17], developed a hybrid model in which the integration of weighted kernel least squares SVM and the analytical hierarchical process was done. In this L. Lei [18] paper, researchers found that the fusion model developed by fusing rough set and wavelet neural network performed better. The fusion model proposed by Jigar Patel et al. [19] significantly contributed to the prediction of stock market trends. This particular fusion model incorporated Random Forest (RF), Artificial Neural Network (ANN), and Support Vector Machine (SVM) techniques at various stages, focusing on CNX Nifty and S&P indices as part of its analysis. Y. Xu et al. [20] introduced a model that combined Logistic Regression (LR), Support Vector Machine (SVM), and Artificial Neural Network (ANN) to predict the trends of the next day. Similarly, Ying Xu et al. [21] proposed a novel fusion model for Chinese stocks, integrating two prediction models based on K-means clustering and ensemble learning. This fusion approach significantly improved the prediction accuracy by leveraging the strengths of both techniques.
In addition to the previously mentioned techniques, Machine Learning (ML) and Deep Learning (DL) are also extensively employed and have demonstrated superior performance. Deep learning, a subset of Machine Learning, plays a crucial role in extracting high-level features from the represented data. Hence, as these deep learning methods have performed better in comparison with ML (Machine Learning) methods, their usage has been extensive in many applications like computing vision, stock market prediction, image processing, etc.
Many DL (Deep Learning) methods have been introduced based on analyzing financial data with time series. In this paper, [22] researchers developed a model in which historical time series financial data was combined with stock-related technical indicators to perform a prediction of the stock market price movement. In [23], a model is proposed in which a Restricted Boltzmann Machine (RBM) along with many classifiers, was combined for the prediction of the short-term stock market trend. Also, in [24], the model was developed by combining generalized autoregressive conditional heteroscedasticity (GARCH) and LSTM (Long Short-term Memory) to predict the volatility of stock price movement. A model was proposed by [25], which integrated FS (feature selection) and LSTM the for prediction of closing stock price in which four stock data the of Shenzhen Component index were taken and a feature set was constructed using 17 technical indices. It was concluded that the FS-LSTM improved the overall accuracy of the system and the forecast value of stock prices. The stock market prediction was done using three frameworks by [26] based on AM (Attention Mechanism) namely AT-RNN, AT-GRU, and AT-LSTM in which selection and focus on key information from stock-related data was performed. Recently, many methods based on CNN are proposed by researchers which achieve good performance in stock market prediction. For example, [27] proposed a method in which stock technical indicators were converted to 2D images, and a CNN-based novel method was applied for the prediction of stock price. CNN and LSTM were combined by [28] to a new network model in which CNN was adopted for extracting features and LSTM was applied to predict stock price movement from the extracted features. The results depicted that the CNN-LSTM method is much more reliable for stock forecasting and gave better prediction accuracy.
Trends prediction using both textual and numeric information
As the deep learning techniques got advanced, the focus has been given to the learning models based on a neural network that incorporates both financial textual data and quantitative stock data for stock market price prediction. In this paper, [29] recently proposed a model which included both textual and numerical information for the stock index in Thailand. For textual data, they made use of social media and the polarity associated with it. Finally, a multiple regression model is generated which utilizes both the information and another related variable. The [30] paper presented the concept of using two types of information textual and numeric for the prediction of stock market behavior. News headlines were used as textual data to which Word2Vec and CNN are applied, and for numeric data, they made use of technical indicators for the creation of historic price stock data to which LSTM is applied for learning. Finally, the results from both are combined for the prediction of the stock market movement. It analyzed the index prices and sentiments which depicted that sentiment signals which are incorporated in news are reliable and thus are considered accurate predictors of stock market prices. In this paper [31], the work aimed at combining technical analysis as well as fundamental analysis by applying machine learning techniques. For technical analysis indicators were applied while news sentiments were used for fundamental analysis and the trends were predicted for the NASDAQ100 index. In this [32] study the investor sentiment which was taken from Stocktwits and gold returns along with the S&P 500 index was investigated in which it was observed that volatility of the S&P 500 is influenced by gold returns and the sentiments affected returns of S&P 500. Also, [33] studied a combination of CNN and RNN to predict stock trends which included both financial news headlines and stock indicators and it showed that financial news headlines which are in textual format improved the accuracy as compared to the content in the news. Recently, a combination of three different models was proposed by [33] which included SVM, ANN, and an adaptive neuro-fuzzy inference system that performed prediction using public opinions and stock prices. In [34], an examination of signals of the stock market from different websites and blogs was performed, and it was found that the response of investors is much faster and strong toward the positive sentiment. In [35], an investigation of stock market price movement for four different countries using opinions in tweets was done and a better correlation was found between tweets and stock prices.
Currently, the models which incorporate numeric stock data and textual news data are considered largely to support sentiment polarity extraction and it plays an integral part in the prediction of stock trends. Mostly in previous studies, tweets from Twitter have been a big source of information for better performance of opinion mining. However, considering that the sentiment polarity and the news perceive reality which is usually considered as fuzzy and improves the prediction accuracy depicting that the opinions and the reviews cannot be considered as granted. LDA topic model was proposed by [33] in which keyword extraction from tweets was done and opinion mining was performed using the fusion method in which both opinion convergence and news events were incorporated which in turn extended numeric features, ultimately improving the prediction accuracy.
Hence, as per the methods surveyed and discussed above regarding the prediction of stock market trends, the hybrid method is beneficial because it combines both financial textual information along with the stock price for modeling. The increase in the number of data sources can help to achieve better accuracy for the prediction of stock trends with the help of cutting-edge algorithms which can be applied to multiple data sources to get meaningful results. The model in this paper uses the BERT language model which includes transfer learning as few modifications are only required which helps in increasing the accuracy when opinion mining of financial textual data is performed clubbed with Bi-LSTM which is applied for the actual financial numeric data.
Proposed work
This research presents a novel approach for predicting stock price movements by introducing a hybrid information mixing module. The module consists of three main components: a feature embedding module, a hybrid information mixing module, and a binary classifier. Figure 1 provides an overview of the module’s structure. The feature embedding module integrates both price and text embedding, while the hybrid information mixing module consists of a feature-mixing MLP and an interaction-mixing MLP. The binary classifier is then utilized to classify the prediction of stock price movement as either up or down.
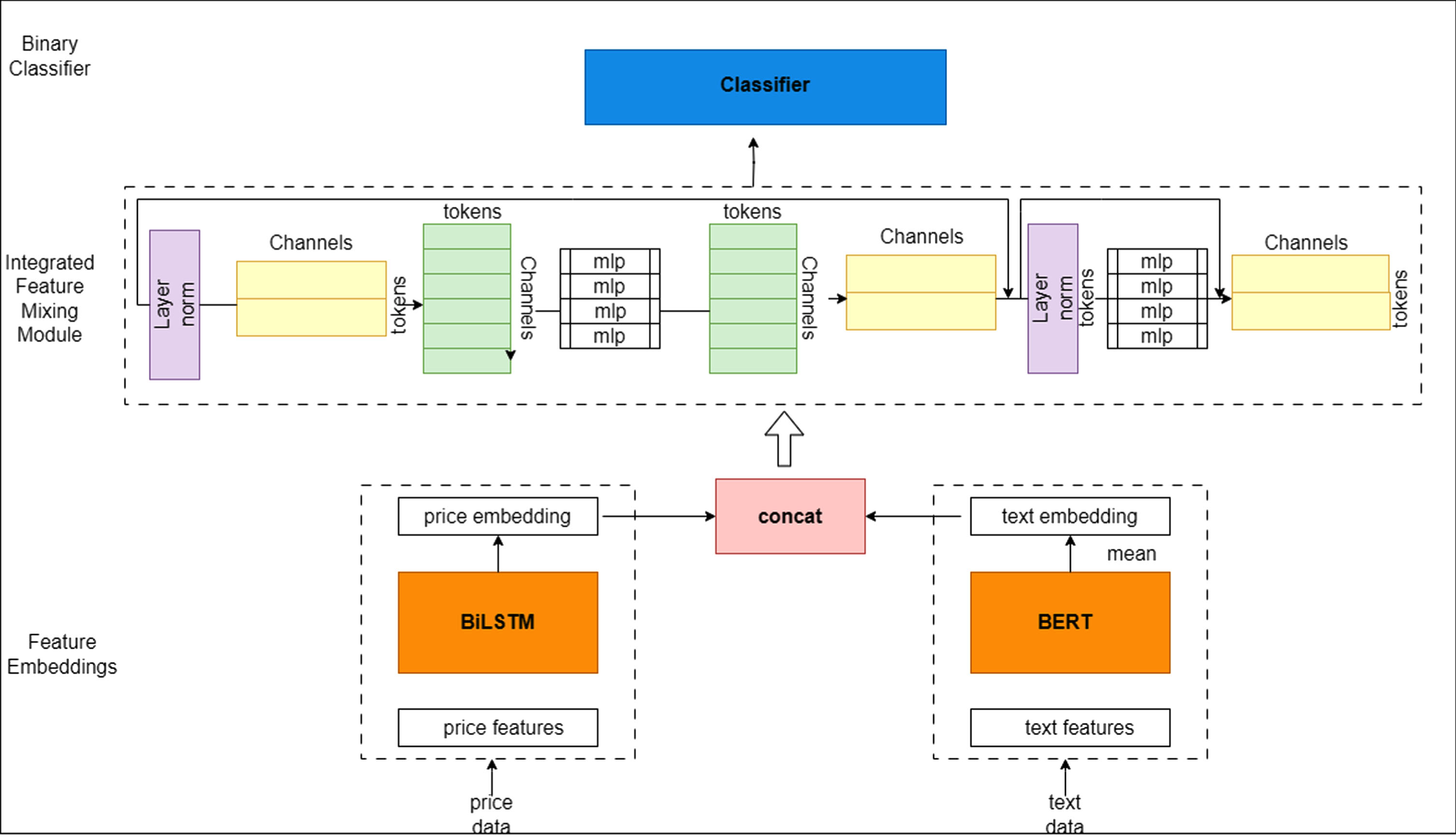
Overall working of the proposed hybrid model (BERT-BiLSTM).
This paper proposes a hybrid information mixing module, which incorporates BiLSTM for time-series analysis, to predict stock price movement. The structure of the hybrid information mixing module is illustrated in Fig. 1, comprising of a feature embedding, hybrid information mixing module, and binary classifier. The feature embedding includes price and text embedding. The price embedding utilizes BiLSTM to extract time-series characteristics from historical price data, allowing for effective analysis of stock market fluctuation signals. BiLSTM, a variant of RNN, is well-suited for analyzing time-series data by utilizing hidden states as memory to capture temporal information history and generate outputs based on network memory. [36]
In order to improve the accuracy of stock price movement prediction, we performed a comparative experiment using various architectures of BiLSTM. The BiLSTM algorithm was chosen due to its ability to effectively learn long-term dependencies and process time-series data. By applying BiLSTM to analyze historical price data, we aimed to capture the sequential dependencies during the trading day and predict stock price movement with greater precision.
To analyze the time-series characteristics of the stock data, the market variables of open, high, low, close (OHLC) prices, and trading volume on trading day i are concatenated into a vector pi ∈ R5. The BiLSTM model is then applied to analyze the time-series features of pi. The output value of the hidden layer of the BiLSTM, represented as bi ∈ RdG, is extracted as the time-series feature for the stock data. Here, bi corresponds to the last hidden state of the BiLSTM for trading day i, and dG represents the hidden dimension of the BiLSTM.
Furthermore,
The reviews containing semantic information are crucial for comprehending the stock context, while a large volume of stock trend information is extracted from both review data and quantitative analysis. Textual reviews provide factual information and reflect user sentiment towards stocks. It should be noted that daily reviews and historical prices have distinct impacts on stock price movement. [37]
All reviews [r1, r2, r3, … … … … rN] uploaded data on trading day i for each firm captures the stock market trend. The contextual information was extracted using BERT [e1, e2, e3, … … … … eN] for all review data on a trading day i, ev ∈ R(N ×d) is extracted. The semantic feature was obtained by averaging the contextual word embeddings extracted from all review data on a trading day i using BERT, divided by the number of review data N on that day sv ∈ RdB of the review data is generated for a specific trading day i. In addition, the last state of BERT is sv which is hidden, N represents the number of review data available for each corporation on trading day i, and dB denotes the hidden dimension of BERT.
The integration of price data and text data can significantly improve the accuracy of stock price prediction models, as observed by [38], as stocks are influenced by various market signals originating from different sources. However, unlike image data, text data can have variable dimensions, which can cause problems when using an MLP-based model [39]. In order to tackle this challenge, [40] proposed a BiLSTM-based model called BERT to extract semantic features from text data. These features were subsequently combined with time-series features obtained from the price data to form a mixed feature vector xi ∈ RF ×dF, which captures both types of information. The hybrid information mixing module then utilizes this mixed feature vector for further processing.
Our study introduces a hybrid information mixing module comprising two MLP blocks, namely the feature-mixing MLP and interaction-mixing MLP. These MLP blocks are designed to learn the mixed feature, which is created by combining the time-series feature extracted from the price data and the semantic feature derived from the text data. Each MLP block consists of a fully connected layer, followed by a nonlinearity function such as GELU, and another fully connected layer. By leveraging this hybrid information mixing module, the mixed feature xi is learned independently in both row-wise and column-wise directions, effectively generating the mixed features.
Feature mixing BERT-BiLSTM
The Feature-Mixing BERT-BiLSTM module is specifically designed to extract discriminative information from both the price and text data, which are then combined to form the mixed feature matrix. This matrix is structured such that each row represents the channel information of a particular feature, while each column represents an embedding vector. The module operates on all columns xi of the matrix, with each token being inputted through the same module with shared weights across all columns. Through dense matrix multiplication, the weights are shared within the same channel for different tokens. By leveraging this sharing of time-series information and meaningful insights contained within the time-series feature and semantic feature, the module effectively mixes and learns channel information. This enables the Feature-Mixing BERT-BiLSTM to facilitate global communication between different spatial locations through matrix transposition.
The mixed feature x
i
is then passed through the Feature-Mixing BERT-BiLSTM module to produce the output
This process of channel information mixing is performed by the Feature-Mixing BERT-BiLSTM module, which facilitates communication between different tokens. By doing so, the module is able to effectively extract and learn discriminative information. These advancements in channel information mixing have been highlighted in the work by [41].
In contrast to the Feature-Mixing BERT and BiLSTM module, the Interaction-Mixing BERT and BiLSTM module operates on all rows of the matrix xi. Its purpose is to transpose the matrix back to the shape of tokens×channels while sharing weights across all tokens. This module enables the communication between different channels by capturing the correlation between the embedding vectors of each feature. Essentially, the Interaction-Mixing BERT and BiLSTM module treats each token independently, taking individual rows of X as input, thereby facilitating communication across different channels. The module leverages dense matrix multiplication effectively, applied independently to each spatial location, thereby enhancing interaction and promoting information sharing between different channels within each spatial location.
The input x
Feature
to the Interaction-Mixing BERT and BiLSTM module generates x
Interaction
∈ RF×dI. Moreover, dI denotes the hidden dimension of the Interaction-Mixing BERT and BiLSTM module, and W3 and W4 ∈ RF ×dE are the weights of the third and fourth fully connected layers of the Interaction-Mixing BERT and BiLSTM module, respectively. In addition, dE is a hidden dimension in the Interaction-Mixing BERT and BiLSTM module:
By learning the correlation of two embedding vectors through the Interaction-Mixing BERT and BiLSTM module, the correlation between channels of x Feature is mixed to x Interaction .
We obtained the output x
Interaction
by leveraging the hybrid information mixing module that incorporates both BERT and BiLSTM features. The output layer is then passed through a series of operations, including layer normalization, global average pooling, and a fully connected layer, as follows:
Here, LayerNorm applies layer normalization to x Interaction and x norm generates as the output. GAP stands for global average pooling, which takes x norm as input and generates x GAP as its output. FC denotes the fully connected layer, which takes x GAP as input and produces the final classification result, x output .
In the stock price movement classification task using BERT and BiLSTM, the binary classifier aims to predict the direction of stock price fluctuations. The label is set by comparing the closing price
The output of the hybrid information mixing module undergoes layer normalization, followed by global average pooling, and finally, a fully connected layer to generate the final classification result. The output of layer normalization is denoted by x
norm
, and the output of global average pooling is denoted by x
GAP
. The final classification result is obtained by passing x
GAP
through a fully connected layer and applying the sigmoid function. The binary cross-entropy loss, denoted as BCE loss, is employed to compute the discrepancy between the predicted value denoted as
Dataset
In this investigation, we conducted a comprehensive analysis of the hybrid information mixing module by leveraging the Stocktwits dataset and stock price data from two prominent Indian companies, HDFC and SBI. The Stocktwits dataset encompasses a vast collection of social media messages specifically related to stock trading, while the stock price data was sourced from the National Stock Exchange of India.
To ensure data quality, we filtered out samples that were missing price data or social media messages, resulting in a refined dataset comprising 503 trading days spanning from January 1, 2014, to January 1, 2016, for HDFC and SBI. The price data incorporated historical OHLC prices (open, high, low, close) and trading volume.
For model training and evaluation, the dataset was split into training and validation sets in an 8 : 2 ratio. To capture temporal dependencies effectively, we employed a window size of 30, meaning that the binary classifier was tasked with predicting the stock price movement for the closing price of the next trading day based on the data from the previous 30 days.
Training
In our proposed model, we employ a BiLSTM layer with 768 hidden units to capture the time-series characteristics present in the historical price data. For the BERT layer utilized to extract semantic features from the text data, we set the hidden layer dimension to 768 as well.
Within the hybrid information mixing module, we incorporate an MLP with a hidden dimension of 768 and 8 layers. This MLP facilitates the fusion and interaction of the extracted features from both the time-series and semantic domains.
During training, the model undergoes 30 epochs using the AdamW optimization method with a learning rate of 2e-5 and an epsilon value of 1e-8. We utilize a batch size of 32 for efficient computation. All experiments are conducted using one NVIDIA GeForce RTX 3090 GPU.
Evaluation measures
For evaluating the accuracy of our stock price movement prediction, we rely on the confusion matrix-based metric. This metric allows us to assess the performance of our model by considering four key elements: true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN). From these elements, we calculate the accuracy, which measures the proportion of correct predictions in relation to the total number of predictions.
Stock price fluctuations
A comparative experiment was conducted to evaluate the performance of the proposed hybrid information mixing module, which combines BERT and BiLSTM, in predicting stock price movement. The performance of the module was compared with existing state-of-the-art models in the field. The results, as shown in Table 1, indicate that the hybrid information mixing module achieved a performance of 68.98%, surpassing all other models, including those that solely rely on either time series or text features. This outcome demonstrates the module’s ability to effectively capture the multimodal interaction of price and text data features, reflecting market signals and improving stock price movement prediction. The models compared in this study, along with their corresponding experimental results, are presented in Table 1.
Comparative analysis of experimental accuracy
Comparative analysis of experimental accuracy
In their work, [42] introduce StockNet, a novel framework that leverages variational autoencoders (VAEs) to integrate both text and price signals for stock prediction. This approach combines neural variational inference to address complex posterior inference challenges and incorporates a temporal auxiliary to capture predictive dependencies effectively. By jointly modeling text and price data, StockNet offers a powerful solution for stock prediction tasks.
Multipronged Attention Network for Stock Forecasting (MAN-SF)
Through text data and historical price signals, the model jointly learns relevant information temporarily. [43] propose a multipronged attention network for predicting stock price movements. This network architecture effectively combines complex temporal signals from various sources, including financial data, social media, and interstock relationships. The model leverages a hierarchical temporal approach and incorporates a graph neural network to capture and integrate these signals. By doing so, it enables a comprehensive analysis of the interplay between different factors in stock price prediction.
Hybrid Attention Network (HAN)
proposed a stock price movement prediction model based solely on text data. The model utilizes GRU (Gated Recurrent Unit) and attention mechanisms to analyze online news and predict stock price trends. The model is designed with three key principles in mind for news-oriented stock price trend prediction: sequential context dependency, diverse influence, and effective and efficient learning. By incorporating these principles, the model aims to capture the sequential nature of news data, account for various factors that influence stock prices, and achieve accurate and efficient learning for stock price prediction.
Based on the experimental results, the hybrid information mixing module incorporating BERT and BiLSTM outperforms previous models such as StockNet, MAN-SF, and HAN in terms of accuracy. The proposed module improves the accuracy by approximately 16.79%, 12.13%, and 19.97% when compared to these models, respectively. This significant improvement demonstrates the effectiveness of analyzing and capturing the multimodal interaction of information within the mixed feature matrix, which combines time-series features and semantic features using the hybrid information mixing module with BERT and BiLSTM. The results affirm that the MLP-based hybrid information mixing module with BERT and BiLSTM is highly efficient in predicting stock price movement.
Impacts of hybrid mixing module
In this study, we conducted experiments to compare the performance and effectiveness of classical methods such as LSTM and GRU networks in stock price prediction, as well as the hybrid information mixing module itself. To evaluate the performance, we replaced the hybrid information mixing module with a BiLSTM network and compared it with a transformer encoder to examine the potential of replacing attention mechanisms with MLP architectures in NLP.
The results showed that the hybrid information mixing module outperformed both the BiLSTM network and the transformer encoder, indicating its effectiveness in capturing multimodal information for stock price movement prediction. The hybrid information mixing module achieved a performance improvement of approximately 6.92% compared to BiLSTM. Furthermore, it outperformed the transformer-based method using self-attention by approximately 16.99%, despite having a simpler structure.
These findings demonstrate that the two MLP blocks in the hybrid information mixing module effectively combine and leverage the multimodal information in the mixed feature, leading to improved stock price prediction performance. The hybrid information mixing module proves to be more effective than BiLSTM alone, and it offers a promising alternative to the transformer-based approach by achieving comparable or even superior performance with a simpler architecture.
Comparative analysis
In this study, we utilized BiLSTM as the algorithm of choice for analyzing price data, replacing the use of GRU and LSTM. BiLSTM, being a variant of LSTM, offers the advantage of processing input sequences in both forward and backward directions, thereby enabling it to capture more comprehensive contextual information and enhance model performance.
To evaluate the performance of BiLSTM in comparison to other algorithms in stock price movement prediction, namely GRU and LSTM, we conducted a comparative experiment for price embedding. The results of this experiment are summarized in Table 2.
Comparative analysis of price embeddings
Comparative analysis of price embeddings
The experimental findings demonstrate that BiLSTM achieves higher accuracy compared to LSTM and GRU, with a notable performance of 71.23%. This outcome indicates that BiLSTM serves as a superior algorithm for price embedding and effectively captures the market signals associated with historical price volatility in the prediction of stock price movements.
This research aims to develop a deep learning model for forecasting stock market trends in the Indian stock market, specifically for stocks SBI and HDFC. The model incorporates numerical data, historical stock prices, and textual data, representing investors’ sentiments. The utilization of an Attention-based architecture is a promising approach in this context.
This paper focuses on the task of predicting stock price movements by extracting time-series and semantic features and subsequently creating a mixed feature using a hybrid information mixing module. The hybrid information mixing module combines two characteristics and effectively blends the multimodal information present in the mixed feature. To evaluate the performance and effectiveness of the module in time-series analysis, BERT and BiLSTM networks are employed, and their performance is compared to the classical methods of LSTM and GRU.
The hybrid information mixing module comprises feature-mixing and interaction-mixing MLPs, which operate independently row-wise and column-wise. This enables them to enhance the interaction between the two data characteristics present in the mixed feature, thereby improving the prediction of stock price movements. The proposed hybrid approach, which integrates text and numeric data using BERT-BiLSTM models for stock market prediction, holds significant practical implications for various stakeholders in the financial domain. Investors can leverage the model’s predictions to make informed decisions on portfolio adjustments and stock trading, enhancing their ability to respond to rapidly changing market conditions. Financial institutions can incorporate the model’s insights into algorithmic trading strategies, enabling automated and data-driven trading decisions. Additionally, the approach offers early detection of market-moving news events, contributing to risk management strategies and minimizing potential losses. However, practical implementation faces challenges such as data quality assurance, model adaptability to evolving market dynamics, and the need for ongoing model maintenance. By addressing these limitations and emphasizing concrete applications, this research contributes to the enhancement of investment decision-making, trading strategies, and risk mitigation in the real-world financial landscape.
In future research, we plan to incorporate additional data sources that impact stock market volatility and enhance the hybrid information mixing module’s ability to analyze the influence of additional variables on stock market trends. We intend to include company relationship data to extract the degree of relationship and pattern of influence between different companies, generating tri-multimodal information that encompasses three distinct types of data related to the stock market. Subsequently, we will apply the improved hybrid information mixing module to blend this tri-multimodal information and conduct a comprehensive study to predict fluctuations in the stock market. This approach will involve extracting three different types of interactions and capturing the dynamic correlation present in the market.