
Abstract
Multilingual pre-trained language models have achieved impressive results on most natural language processing tasks. However, the performance is inhibited due to capacity limitations and their under-representation of pre-training data, especially for languages with limited resources. This has led to the creation of tailored pre-trained language models, in which the models are pre-trained on large amounts of monolingual data or domain specific corpus. Nevertheless, compared to relying on multiple monolingual models, utilizing multilingual models offers the advantage of multilinguality, such as generalization on cross-lingual resources. To combine the advantages of both multilingual and monolingual models, we propose KDDA - a framework that leverages monolingual models to a single multilingual model with the aim to improve sentence representation for Vietnamese. KDDA employs teacher-student framework and cross-lingual transfer that aims to adopt knowledge from two monolingual models (teachers) and transfers them into a unified multilingual model (student). Since the representations from the teachers and the student lie on disparate semantic spaces, we measure discrepancy between their distributions by using Sinkhorn Divergence - an optimal transport distance. We conduct experiments on two Vietnamese natural language understanding tasks, including machine reading comprehension and natural language inference. Experimental results show that our model outperforms other state-of-the-art models and yields competitive performances.
Keywords
Introduction
Nowadays, with the development of data collection and self-supervised objectives, large pre-trained language models (LMs) have become one of the significant breakthroughs in natural language processing (NLP) and have achieved state-of-the-art results on many tasks. Several works [1–3] focus on building LMs for English and other resource-rich languages because of the enormous amount of training data. But considering 7000+ languages in the world, collecting the corpus for pre-training models is not an easy task because it is time-consuming and requires a significant effort, especially for resource-poor languages. Therefore, people often face difficulty in training models on resource-poor languages due to the scarcity of vocabulary curation and size. The emergence of multilingual pre-trained LMs and their impact has shown surprisingly good cross-lingual effectiveness on many downstream tasks [4, 5]. Many famous multilingual pre-trained LMs, such as mBERT [1], XLM [6], XLM-R [7] extend the monolingual models to hundreds of languages by learning deep linguistic representations from a large multilingual corpus. Hence, multilingual models can generalize on many languages and domains at different granularities by leveraging knowledge from the pre-training corpora. As a result, the models deliver impressive performances on many cross-lingual transfer benchmarks.
Despite the effectiveness of cross-lingual transfer, multilingual models come with their own drawbacks. Even though they have been trained on an enormous amount of corpus, due to the constant number of parameters, the performance on downstream tasks decreases as we add more languages for pre-training. The multilingual models perform worse on resource-rich and resource-poor languages because they lack language-specific capacities [7, 8]. To this end, several recent efforts have introduced language-specific LMs with custom vocabularies that can bring more compact representations from enormous data coming from multiple domains [9, 10] and provide comparable advances. However, building a language-specific LM prevents us from utilizing multilingual power such as cross-lingual transfer between a resource-rich language and its closely related language varieties.
Is it possible for multilingual models to leverage language-specific monolingual models, perform well on supervised tasks, and enable positive language transfer between languages? This motivates us to leverage the power of monolingual pre-trained models to improve the performance of multilingual models for downstream tasks. In this work, we focus on improving Vietnamese sentence representation in natural language understanding (NLU) in particular for machine reading comprehension and natural language inference tasks. Recently, knowledge distillation has emerged as a technique for transferring knowledge between models using the student-teacher framework. We employ the teacher-student framework to leverage the capabilities of language-specific monolingual models and transfer their rich knowledge to a multilingual model. Intuitively, we first fine-tune the language-specific monolingual teachers on downstream tasks and then proceed to distill their knowledge into the multilingual student model.
It is worth noting during the knowledge transferring process, the hidden representation of the teachers and the student models belong to two separate monolingual and multilingual spaces. Inspired by the work of [11], we propose a distillation strategy in which the teacher models try to transfer language and task-specific features to the student model without changing the model architecture. Sinkhorn Divergence [12] – an Optimal Transport measure, can be efficiently utilized for this optimization. Sinkhorn Divergence is a powerful method for comparing distributions that aims to minimize the cost of moving probability mass from a source distribution to a target distribution. It has some nice properties that do not require the two sets of distributions to overlap, unlike other types of divergence such as KL-Divergence. This makes Sinkhorn Divergence an effective solution for transferring knowledge between models, as two different models belong to distinct feature spaces and cannot be directly projected one-to-one. Furthermore, Sinkhorn Divergence enables the utilization of GPUs, allowing the computation of the distillation loss for batches of many samples.
To summary, the contributions of this paper are described as follows: We propose XLMR-KDDA, a knowledge distillation approach based on Optimal Transport where the multilingual student model learns supervision training signals from two monolingual teacher models at the fine-tuning stage. Our method does not change the model architecture and needs no pre-training procedure, thus making it easy to apply to different languages or different tasks. In practice, the Optimal Transport distance is utilized as a training scheme to optimize the discrepancy loss between the hidden representation of the teacher models and the student model. Our findings indicate that by letting the multilingual model learn from multiple teacher models can result in an overall boost in performance, compared to other strong baselines. We perform a comprehensive analysis and conduct extensive experiments on Vietnamese NLU datasets, namely UIT-ViQuAD and ViNLI. Our results demonstrate substantial improvements over other baselines, thus highlighting the efficacy of our approach. Additionally, we conduct further extensive experiments to explore and evaluate various components within our approach.
The rest of the paper is organized as follows. Section 2 provides backgrounds. Section 3 describes methodology and the training procedure of our model. We discuss experiments results and extensive analysis in section 4. The last section presents our conclusions.
Background
This section presents the backgrounds for our proposed framework. Our goal is to improve the Vietnamese sentence representation on the multilingual model by knowledge transferring from monolingual models.
Multilingual pre-trained language models
Multilingual pre-trained LMs have shown great success in various NLP tasks thanks to their cross-lingual effectiveness. Following the success of Transformer-based architecture [13], several efforts have trained large scale LMs on multiple languages. mBERT is a multilingual variant of BERT [1] that adopts the same training regime by pre-training on 104 languages. Conneau and Lample proposed XLM [6] – a multilingual model pre-trained on a parallel corpus using the translation language modeling objective. XLM-R [7] improves XLM with enormous pre-training data and a better vocabulary; achieving further performance gain on downstream tasks [14, 15]. Recently, mDeBERTa [16] – a multilingual variant of DeBERTa [17], which is pre-trained on the same amount of data as XLM-R. mDeBERTa improves the BERT and RoBERTa models by using disentangled attention and enhanced mask decode which demonstrates its prominent capability on cross-lingual transfer benchmarks. In the meantime, there are many empirical studies that analyze the multilinguality and cross-lingual transfer ability of the multilingual models. They show that a fine-tuned model in one language can be used for another language without relying on any direct cross-lingual supervision [4, 5].
However, many studies point out fundamental limitations of the multilingual models. Conneau et al. [7] observed that scaling the multilingual LMs to a high number of languages only improves the performance to a certain point, after that the performance drops as per language capacity degrades. This is termed as “the curse of multilinguality” or “transfer-interference trade-off”. Also due to this defect, many languages in multilingual models are underrepresented and lag behind their monolingual counterparts in terms of performance on downstream tasks. This can be alleviated by extending per language capacity [7, 18] or further pre-training procedures [19, 20]. Since the model capacity is limited, scaling a bigger model to represent all languages is not practical. To address this, recent works mainly focus on improving performance on one or a set of languages. They have pointed out that monolingual language-specific models pre-trained from scratch achieve better performance than multilingual models, namely Vietnamese [9, 21], Arabic [22], French [23], Finnish [10], Dutch [24], etc. There are some reasons attributed to the increase in performance regarding the multilingual models. For example, monolingual LMs use tailored vocabularies, reduce the need of splitting a word into multiple sub-words, thus avoiding sub-optimal decompositions for other languages [25]. Monolingual LMs often use more pre-training data and this leads to significant improvement in performance, as observed in Li et al. [3].
Recently, the field of natural language understanding has witnessed rapid development, because of the potent ability of LMs in representing textual data. They have a wide range of applications in natural language understanding, including sentiment analysis, question answering, natural language inference, etc. Through the utilization of pre-trained LMs, natural language understanding is becoming more accessible and effective on comprehension and interpretation of human language.
Knowledge distillation
Knowledge Distillation (KD) is an effective technique that transfers knowledge from a model to another, was first introduced by Hinton et al. [26]. KD aims to train a model, called the student, by exploiting valuable information provided by soft label distribution from another model, called the teacher model. KD has been widely used in a variety of applications in NLP, including model compression [27–29], multi task learning [30, 31], etc. Recent works have investigated methods that align feature spaces between the student and teacher models for a better knowledge transfer. In particular, Wang et al. [32] proposed an application of the KD method that distills the structural knowledge from several monolingual teacher models to the unified multilingual student model in order to solve the problem of the performance gap between monolingual and multilingual model due to capacity limitation. Li et al. [19] focused on learning semantic structure of representation by adopting KD framework to learn rich knowledge from English BERT to improve the multilingual LM. Khanuja et al. [33] enhanced the generalization ability of student models for resource-poor languages by distilling knowledge from multiple multilingual teachers in a task-agnostic setting.
Optimal transport
Optimal Transport (OT) [34, 35] has become popular in NLP due to its ability to compare two different distributions. It has been successfully applied to many applications. For example, Jianqiao Li et al. [36] proposed using OT to capture positional and contextual information of tokens and tackle the problem of exposure bias in text generation tasks. Peggy Tang et al. [37] formulated text summarization as an OT problem, they considered optimizing transportation cost from an optimal summary to a document based on their semantic distributions. Kyle Swanson et al. [38] employed OT as an objective to align inputs in the text matching problem. Recently, OT has been used for KD to transfer knowledge across models. In this line of work, OT is utilized to compute the optimal value to map between semantic spaces and update the student model afterwards. Thong Nguyen et al. [11] investigated transferring knowledge from a monolingual teacher to a multilingual student for the cross-lingual summarization task. Specifically, they proposed a Knowledge Distillation loss using Sinkhorn Divergence for the transfer process. Tulika Bose et al. [39] introduced a new framework that distills the natural language semantic knowledge from multiple teacher networks to a student network using OT.
In our setup, OT distance is employed as a distillation objective to align the feature spaces of the teacher models and the student model, ensuring that OT enables the positive transfer of knowledge between models.
Proposed method
In this section, we formalize our ideas and the training procedure. Our goal is to improve Vietnamese sentence representation in the multilingual model by transferring knowledge from the monolingual models, using the KD framework. One challenge of the knowledge transferring process is that the teacher and the student models come with two different spaces, which makes measuring the discrepancy between them challenging. We need to determine a mapping between their hidden presentations. To address that, we use the Sinkhorn Divergence as the objective for distillation.
Figure 1 demonstrates the overview of our setting, consisting of 3 components: student model, teacher models and training objective.
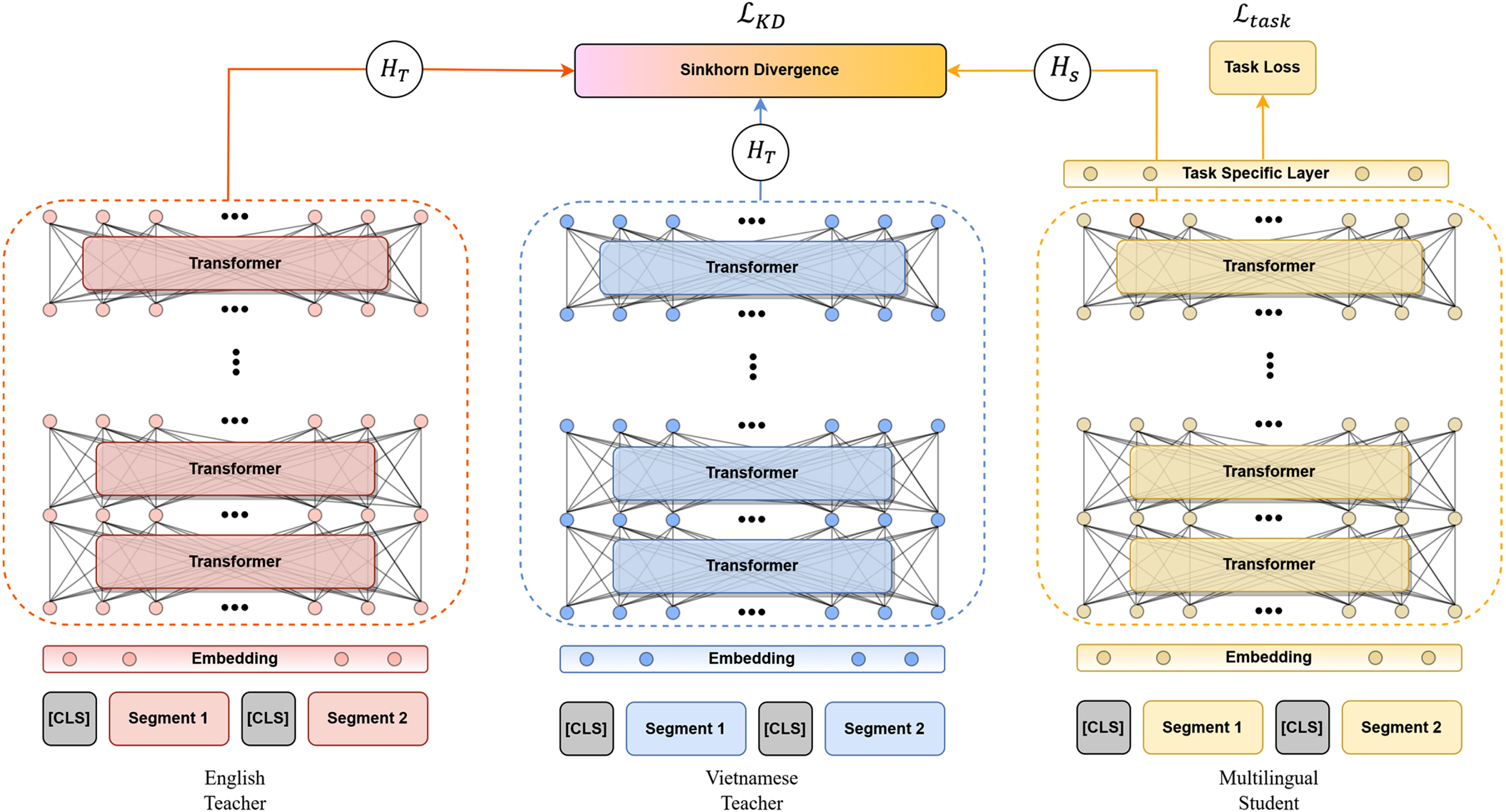
Illustration of our proposed framework KDDA. The figure shows our pipeline, including a student model (Multilingual XLM-R) and two teacher models (the Vietnamese PhoBERT and the English RoBERTA). Note that in each training iteration, only one monolingual model is utilized as the teacher.
This work focuses on two Vietnamese NLU tasks, which consists of: machine reading comprehension (MRC) and natural language inference (NLI). The two tasks are formulated as follows:
An example of UIT-ViQuAD dataset on MRC task (English translation included)
An example of UIT-ViQuAD dataset on MRC task (English translation included)

An example of ViNLI dataset on NLI task (English translation included)

As shown in Figure 1, we present the inputs as a single packed sequence x of length L, where x consists of two segments for the tasks. We then use pre-trained LMs (PLM) to obtain the contextualized embedding H of the input:
Where
Let
Notice that only the student model parameters θ S are updated during knowledge distillation. So, we detach H T from the computational graph.
Previous works [40, 41] have shown the effectiveness of leveraging the hidden representation of the teacher in the knowledge distillation process. However, utilizing the hidden states presents a difficulty in our setting as the teachers and the student were pre-trained on different kinds of data and belong to two feature spaces. This results in the fact that they cannot be projected one-to-one since disjoined vocabularies. In order to make monolingual and multilingual feature space compatible, we employ the Sinkhorn Divergence as the KD objective:
For the purpose of taking the supervision signal from English and Vietnamese monolingual models, we also have to fine-tune the multilingual student model using cross-lingual data. Specifically, at the beginning of the fine-tuning process, we concatenate the original Vietnamese training data with the English training data as the final training set for the student model. Several works have investigated the cross-lingual transfer effect, showing that leveraging one or more source languages can improve the performance of the target language [42–44]. In our setting, the student model is supervised by the training signal from the hard targets of the training data and the soft targets of monolingual models.
Since the representation of the monolingual teacher models and the multilingual student model lie on two different feature spaces, we propose to use OT to measure the distance between them. We also consider this distance as a transportation cost between two probability measures. OT is a powerful method for transferring probability mass from one distribution to another. Formally, given two distributions: the source distribution α and the target distribution β over the domains
Let α; β are probability distributions that take the form of a sum of Diracs:
Note that each α; β must sum to 1:
Note that in equation (9), α and β are initialized with uniform distribution; ϵ > 0 controls the amount of entropy regularization to interpolate between OT and Maximum Mean Discrepancy. The OT plan can be efficiently approximated by the Sinkhorn-Knopp algorithm [45, 46]. The Sinkhorn-Knopp algorithm is differentiable, making it ideal for any neural network architectures.
In this section, we explain training details and show the experimental results on two Vietnamese NLU benchmark datasets, which are ViQuAD and ViNLI for MRC and NLI, respectively. We also compare our work with state-of-the-art models including XLMRQA [47] and ViReader [48] on the MRC task, and conduct further analysis to prove the effectiveness of our approach based on these benchmarks. In our setting, the models are supervised with cross-lingual training signals from Vietnamese and English data and directly evaluated on Vietnamese.
Datasets
We conduct experiments on two Vietnamese benchmarks datasets for NLU, namely:
At the input layer, the representation must be presented as a single packed sequence, as suggested by [1]. For two tasks, we concatenate two pieces of text with a special [SEP] token and place the [CLS] at the beginning of the sequence. We employ cross-lingual data augmentation for MRC and NLI by using two English datasets namely SQuAD [51] and MNLI [52], respectively. We consider Vietnamese and English as the source languages and Vietnamese as the target language. Table 3 describes the training data statistics.
Model configurations
We employ transformer-based pre-trained LMs with two versions: base and large. All of the student and teacher models share the same architecture: 12 layers, 8 attention heads; 24 layers, 16 attention heads for base version and large version respectively. For the monolingual teachers, we use RoBERTa [2] on English and PhoBERT [9] on Vietnamese. All of the teachers are already fine-tuned on downstream tasks for learning language-specific features. The student model is initialized from XLM-R [7] and followed by a task-specific layer. During the fine-tuning process, we keep the student model parameters trainable, while freezing the teachers’ parameters. For both tasks, we optimize the student model by the AdamW optimizer and search for the best learning rate in the set {1e - 5, 2e - 5, 3e - 5} and the number of epochs is 2. The batch size is 32. We also employ the learning rate scheduler with a linear decay after 10% of training iterations. We set the entropic regularization parameter ϵ to a relatively small number: 0.005, the value of λ parameter in equation (6) is set to 0.3. All the experiments are performed using two T4 GPUs.
We report the results across evaluation benchmarks. Evaluations are performed on fine-tuned models using the test set, based on their performance on the development set. We name our models XLMR-KDDA. We compare our models with XLM-R, XLM-R with cross-lingual data augmentation (XLMR-DA) and the Vietnamese model PhoBERT on both tasks. Specifically, for the MRC task we also compare our model to two other baselines: XLMRQA [47] and ViReader [48] two open-domain MRC systems for Vietnamese.
To measure the performance of our approach, we adapt the commonly used F1 score and Accuracy for the NLI task. For the MRC task, we measure the F1 and Exact Match (EM) scores. In detail, the F1 score measures the number of overlapping tokens (partial match) between the ground truth and the prediction, while the EM score measures the exact matches. We run all tasks three times with different seeds and report the average scores. More detailed results are presented in the following section.
Results
Number of examples in UIT-ViQuAD and ViNLI datasets
Number of examples in UIT-ViQuAD and ViNLI datasets
Results in Exact Match and F1 Score of UIT-ViQuAD MRC task
Results in Accuracy and F1 Score of the ViNLI NLI task
Comparing our method with other baselines, we can conclude that our method notably improves the results on both ViQuAD and ViNLI datasets. The results show that in this setting, the XLMR-KDDA enables positive transfer in three aspects. First, we observe that the performance benefits from additional training data from another language, particularly the XLM-R large gets the highest improvement. All the results from the benchmarks suggest that the multilingual model benefits from positive transfer, i.e., training a multilingual model on multiple language datasets yields greater improvements than training it on a monolingual dataset. This demonstrates that cross-lingual transfer may act as regularization strategy, making the model robust to noise and generalize on the training dataset, as proven in [53]. Second, our KD method utilizing OT improves the results and outperforms other baselines in all settings. The monolingual teacher models provide additional training signals, including language-specific and task-specific features, to the multilingual student model, thereby further boosting its performance. In our case, the student and the teacher features are determined by two feature spaces which are Multilingual and Monolingual spaces, while the OT loss function promotes the learning of a student model that minimizes the transportation cost between the feature sets. This provides an efficient approach for the distillation process without the need of additional mapping between two spaces. Third, our findings suggest that the overall performance of the multilingual student model can be enhanced by letting it learn from multiple monolingual teachers simultaneously. These monolingual supervising signals contribute to a diverse and comprehensive understanding of the relationships between different languages from various perspectives, thus helping the generalization process. Our study has led us to the conclusion that by simultaneously modeling the soft label distribution from the monolingual teachers with their corresponding hard label distribution, results in a more flexible and positive transfer. This transfer is learned without making any modifications to the original model architecture, thereby demonstrating the effectiveness of the proposed approach.
It is also worth mentioning that the monolingual models perform worse than multilingual models using the same training data. Except for the evaluation of the PhoBERT-base on ViNLI development dataset, we only observe deterioration in performance with XLM-R. One possible reason for this is that the superior performance of XLM-R is attributed to the enormous amount of Vietnamese pre-training data (7 times bigger than PhoBERT), which aligns with the findings in the previous work [3].
In order to shed more light on the contribution of each component in the OT-based knowledge distillation settings, in this section, we study the performance of the student model under different configurations. We inspect (1) the student’s performance with different teachers, (2) the distillation strategies, and (3) the trade-off between hard targets and soft targets.
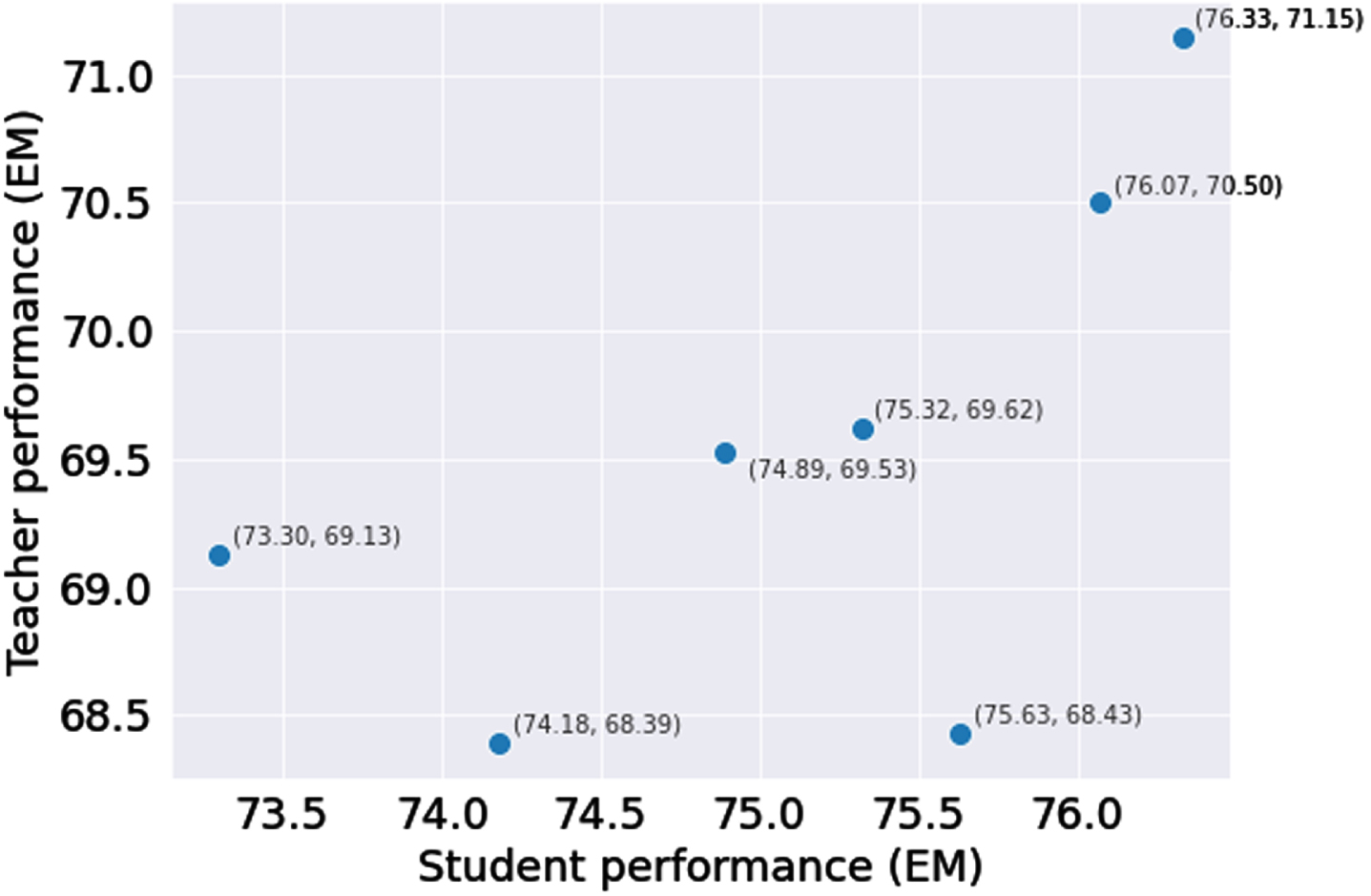
Exact Match score on the UIT-ViQuAD dataset for different Vietnamese teacher models.
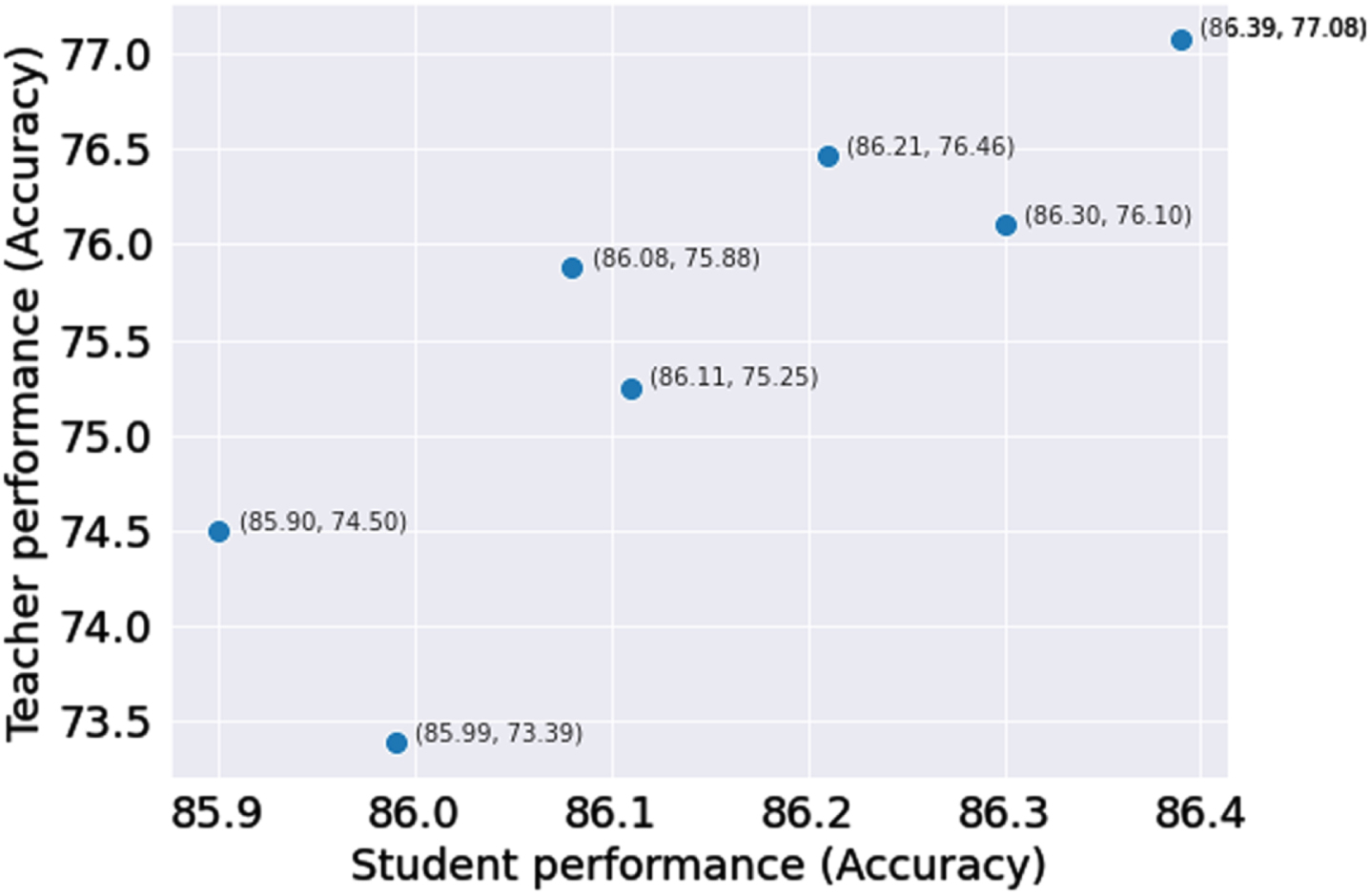
Accuracy score on the ViNLI dataset for different teacher.
Performance on UIT-ViQuAD and ViNLI using different OT objectives
Performance on UIT-ViQuAD and ViNLI with different λ parameters
In the present study, we introduce a framework that utilizes knowledge distillation from monolingual models to a multilingual model for the purpose of improving the representation of Vietnamese sentences. To achieve this objective, we leverage the Optimal Transport (OT) objective to minimize the discrepancy between the feature spaces of the student model and the teacher models. Specifically, the proposed framework seeks to distill the knowledge obtained from two monolingual teacher models and transfer it to the multilingual student models. Our results show that the approaches make competitive enhancements in the performance or even outperform other baselines on two Vietnamese NLU benchmarks, including NLI and MRC. Our study contributes to the promotion of research on resource-poor languages such as Vietnamese, where the main challenge is the lack of resources, including annotated corpora and other lexical resources. The proposed approach could also serve as a baseline for future research and help catalyze further improvements in the field of NLU for resource-poor languages.
In future work, we will conduct further experiments to explore the impact of the approach on other NLP tasks, such as natural language generation. Besides, we will employ other OT algorithms in our framework for Vietnamese NLU tasks.
Footnotes
CRediT author statement
Phu Xuan-Vinh Nguyen & Thu Hoang-Thien Nguyen: Conceptualization, Methodology, Software, Validation, Writing - Original Draft, Visualization. Ngan Luu-Thuy Nguyen & Kiet Van Nguyen: Resources, Writing - Review & Editing, Supervision, Project administration.
Acknowledgement
This research is funded by Vietnam National University HoChiMinh City (VNU-HCM) under grant number DS2022-26-01.