
Abstract
The Fuzzy C-means (FCM) algorithm is one of the most widely used algorithms in unsupervised pattern recognition. As the intensity of observation noise increases, FCM tends to produce large center deviations and even overlap clustering problems. The relative entropy fuzzy C-means algorithm (REFCM) adds relative entropy as a regularization function to the fuzzy C-means algorithm, which has a good ability for noise detection and membership assignment to observed values. However, REFCM still tends to generate overlapping clusters as the size of the cluster increases and becomes imbalanced. Moreover, the convergence speed of this algorithm is slow. To solve this problem, modified suppressed relative entropy fuzzy c-means clustering (MSREFCM) is proposed. Specifically, the MSREFCM algorithm improves the convergence speed of the algorithm while maintaining the accuracy and anti-noise capability of the REFCM algorithm by adding a suppression strategy based on the intra-class average distance measurement. In addition, to further improve the clustering performance of MSREFCM for multidimensional imbalanced data, the center overlapping problem and the center offset problem of elliptical data are solved by replacing the Euclidean distance in REFCM with the Mahalanobis distance. Experiments on several synthetic and UCI datasets indicate that MSREFCM can improve the convergence speed and classification performance of the REFCM for spherical and ellipsoidal datasets with imbalanced sizes. In particular, for the Statlog dataset, the running time of MSREFCM is nearly one second less than that of REFCM, and the accuracy of MSREFCM is 0.034 higher than that of REFCM.
Keywords
Introduction
Pattern recognition theory is a data analysis method that uses computer technology to study sample data without assuming any mathematical model. It consists of two different methods: supervised clustering and unsupervised clustering. Compared to supervised classification, unsupervised classification methods are often more effective in practical problem. In unsupervised classification, the objective is to identify natural groupings within the sample data, assuming that each data point can belong to more than one class. In reality, data points may belong to more than one cluster. Zadeh successfully introduced fuzzy logic to handle this uncertainty, which has made significant strides in cluster analysis. This article focuses on studying clustering problems, particularly in the application of fuzzy clustering methods. Many fuzzy clustering methods have been developed ([1–6]), which utilize fuzzy set theory to partition observational data into multiple clusters. Fuzzy clustering has found applications in various fields such as image segmentation ([7, 8]), weather forecasting [9], medical diagnosis [10], etc. So far, the FCM (fuzzy c-means) algorithm has provided a logical and accurate approach to clustering data [11].
According to the analysis in [12], as the dataset size increase, the computation time of the FCM algorithm increases rapidly. In other words, although the FCM algorithm provides better division quality, it comes at the cost of a slow convergence rate. To address this issue and accelerate the calculation of FCM, the suppressed Fuzzy C-means algorithm (S-FCM) was introduced in reference [4]. This algorithm aims to improve the convergence speed of FCM while maintaining its high classification accuracy. The key step in this algorithm is the selection of an appropriate suppression rate to achieve practical applications. Selecting the proper parameters is crucial as it significantly impacts the performance of clustering algorithms. To address this challenge, several parameter selection schemes have been proposed by scholars ([13–17]).
Furthermore, FCM is a partitioning algorithm that divides observations into C partitions regardless of the presence of noise in the observational data. However, it is common for all clusters to have low membership for noise points. Probabilistic C-means clustering (PCM) can overcome this problem. In the PCM algorithm, there is no interaction between clusters, leading to clustering centers in the PCM algorithm being very close or even overlapping. Additionally, the PCM clustering algorithm lacks much flexibility, and the algorithm needs quite good information to converge to the global minimum. In the literature on fuzzy clustering, many other methods attempt to alleviate the weakness of FCM by adding a regularization function to its objective function. Quadratic regularization [18], adaptive loss regularization [19], symmetric relative entropy [20], and fractional entropy [21] are some well-known regularization functions.
Relative entropy is a measure of the distance between two distributions, and it is commonly used to quantify the degree of dissimilarity between clusters. Furthermore, the relative entropy is a convex function that has been applied as a regularization function in FCM by several researchers, including Z.F. Hao et al. [20], J. Bonilla et al. [22], and F. Salehi et al. [23]. To improve FCM and PCM, Zarinbal et al. introduced relative entropy into the objective function of FCM as a regularization term, resulting in the development of the relative entropy fuzzy c-means (REFCM) clustering algorithm [24]. The REFCM is to minimize the intra-cluster distances while simultaneously maximizing the inter-cluster differences. However, it’s worth noting that the REFCM algorithm is associated with high computational complexity and slow convergence. Furthermore, as the number of clusters increases or when the cluster sizes vary significantly, the REFCM algorithm may exhibit the issue of overlapping cluster centers. Aiming at this problem, this paper proposes modified suppression relative entropy fuzzy C-means clustering (MSREFCM). In selecting the suppression rate, MSREFCM takes into account the impact of each iteration’s results on the suppression rate. Additionally, the MSREFCM algorithm introduces a suppression scheme that incorporates the intra-class mean distance as a selection strategy. Moreover, it utilizes Mahalanobis distance to enhance its applicability to diverse types of data. The proposed method has been tested in multiple experiments and compared with five widely clustering algorithms: FCM [1], S-FCM [4], MSFCM [5], PCM [3], and REFCM [24].
The rest of this paper is arranged as follows: Section 2 presents in sequence the FCM, S-FCM, MSFCM, PCM, and REFFCM algorithms. Section 3 discusses the proposed MSREFCM algorithm. Section 4 discusses the computational complexity and performance of the MSREFCM algorithm. Finally, Section 5 reports conclusions.
Preliminaries
FCM and PCM algorithms are widely utilized in unsupervised learning to recognize patterns in data. The REFCM algorithm adds relative entropy as a regularization function to the FCM model, which improves its capabilities to deal with noise. S-FCM and MSFCM algorithms adopt a competitive learning mechanism. However, these algorithms can be susceptible to significant center deviations or clustering issues with overlapping clusters as the intensity of noise increases. This section provides a concise overview of the models used by the five algorithms.
FCM algorithm
As one of the most popular clustering algorithms, the objective function of FCM [25] is shown in Equation (1), and the constraints are shown in Equation (2).
Where u
ij
is the degree of membership of jth observation in ith cluster,
Fan et al. proposed the S-FCM algorithm to overcome the slow convergence speed of FCM. In the S-FCM algorithm, the maximum membership degree is rewarded, and the non-winning membership degree is suppressed. This modification can maintain the original order of membership values between clusters. The modification of membership degree is shown in Equation (3).
u pj has the largest membership of all groups, and u ij = αu ij , i ≠ p, where 0 ≤ α ≤ 1.
Since the suppression factor in the S-FCM algorithm is fixed, the performance of S-FCM may be significantly reduced if the parameter α is not correctly selected. To solve this problem, Hung et al. proposed an MSFCM algorithm that can automatically select the appropriate suppression parameters based on the prototype-driven learning method. The selection of the suppression parameter given by them is shown in Equation (4).
Where
1993 Keller et al. [3] Combining possibilistic theory, the possibilistic c-means clustering algorithm was obtained by abandoning the FCM constraint. It only needs
The objective function is shown in Equation (5).
Where η i is a positive number or a penalty factor. Other parameters have the same definitions as before.
To overcome the shortcomings of FCM that its performance deteriorates when the noise of the observation result is large, Zarinbal et al. added relative entropy [26] to the objective function of FCM as the regularization function and proposed the REFCM algorithm [24], whose objective function is shown in Equation (6).
Where θ is the positive coefficient of relative entropy, which determines the degree of influence of relative entropy. The definition of other parameters is the same as before.
Considering W0 (·) as the principle branch of the Lambert-W function, the degree of membership of this observation in ith cluster, u ij , and the center point of ith cluster, v i , are obtained by Equations (7) and (8), respectively [24]:
Where λ j , j = 1, …… , N is the Lagrange multiplier, its formula is shown in Equation (9), and the definitions of other parameters are the same as before.
With this declaration, since the REFCM algorithm can assign low membership to all clusters of noise points, the sum of membership at the noise point is less than 1. Since λ
j
is calculated based on the boundary in the equation, there is no specific membership scheme. Therefore, the
The strategy of suppression behavior
Considering that different regional data will have other effects on clustering results, a more stable suppressive competitive learning algorithm is proposed. The key concept behind this approach is as follows: if the distance between a data point and its cluster center is less than K times the average intra-class distance between the sample and its cluster center, the data point is considered to be in the cluster core, and then the reward measure is performed. On the other hand, if the distance from the data point to the cluster center is greater than K times the average intra-class distance between the sample and the cluster center, it means that the sample does not belong to the cluster core and is suppressed. The average intra-class distance between classes is as follows:
Where
Next, two examples are given to briefly intro-duce the intra-class average distance metric. The number of data points generated is 800 and 1000, respectively, and the number of noise points is 200. The Gaussian radius of the first example is 0.4, and the Gaussian radius of the second example is 0.6. As shown in Fig. 1. In both images, the inner circle represents the \hfilneg circle drawn with the average distance within the class as the radius. The outer circle represents the circle drawn with the cluster kernel as the radius. The radius of the outer circle in Fig. 1 (a) is 1.5 times that of the inner circle, and the radius of the outer circle in Fig. 1 (b) is two times that of the inner circle.

The radius of the core in (a) is 1.5 times the mean distance within the class, and the radius of the core in (b) is two times the mean distance within the class.
In addition, in the initial iteration, the average distance within the class is larger, the clustering kernel is larger, and the data clustering within the clustering kernel will compete for comparison, thus rewarding the winning membership and punishing the non-winning membership. As iteration progresses, the average distance within the class gradually decreases, and the clustering kernel gradually decreases until the clustering center is correctly located. The clustering kernel finds most of the corresponding data and gradually eliminates noise interference.
In this paper, we have introduced the intra-class average distance metric to mitigate the shift of the cluster center caused by noise points. Furthermore, we have proposed the concept of a clustering kernel to identify the core data of each class and facilitate the rewarding of winning membership degrees while punishing non-winning membership degrees. This approach actively attracts the center and enhances the iteration speed of the algorithm. At the same time, it avoids the unreasonable correction of the membership degree of close-range noise and enhances the robustness of the algorithm.
In addition, if the α value is incorrect, the corrected maximum membership value may be greater. For multi-class clustering, the clustering center is easy to deviate from, which is obviously inappropriate. As a result, we employed the suppression strategy of selecting suppressor α [13] based on the data distribution structure. The key idea of the selection process is to use the clustering validity function to determine the α parameter, which makes the suppression scheme more reasonable. The formula for selecting α according to the data distribution structure is shown in Equation (11).
For the X ={ x1, …, x
n
} dataset, the fuzzy partition entropy [32] is defined as
In addition, the Euclidean distance metric used in FCM and PCM is only applicable to clustering spherical or elliptical data sets. To improve the universality of FCM, Gustafson et al. proposed the Gustafson-Kessel clustering (GK) ([33–35]) algorithm, which uses Mahalanobis distance instead of Euclidean distance in FCM. The Mahalanobis distance calculation formula is shown in Equation (12). The GK algorithm is more suitable for ellipsoid and linear data sets than the FCM algorithm. Therefore, we replace Euclidean distance in the REFCM algorithm with Mahalanobis distance.
Where A
i
is positive definite and det(A
i
) = r
i
, r
i
> 0, it is a norm matrix describing the shape of cluster v
i
.
Therefore, the MSREFCM clustering algorithm proposed in this paper can use the competitive learning mechanism to change the membership value in each iteration. As shown in Equation (13).
The fuzzy membership is modified by Equation (13) so that the membership value of all non-winners is multiplied by a so-called suppression rate α (0 ≤ α ≤ 1), and the winner’s membership increases accordingly. When α = 0, MSREFCM becomes an algorithm similar to HCM. When α = 1, the MSREFCM and REFCM algorithms are consistent.
Furthermore, the MSREFCM method employs the Mahalanobis distance. The proof of this theorem can be found in Appendix A.
MSREFCM clustering algorithm:
Step 1: Fix the number of clusters c (2 ≤ c ≤ N), the degree of fuzziness m, and the relative entropy coefficient θ.
Step 2: Determine the initial membership u(0) and the center point v(0), setting L = 0. Repeat the following steps until
Step 3: Update d ij by Equation (12).
Step 4: Update λ j by Equation (9).
Step 5: Update u(L) by Equation (7).
Step 6: Modify u(L) by Equations (11) and (13).
Step 7: Update v(L) by Equation (8).
Step 8: Increment L.
The flowchart of MSREFCM is shown in Fig. 2.
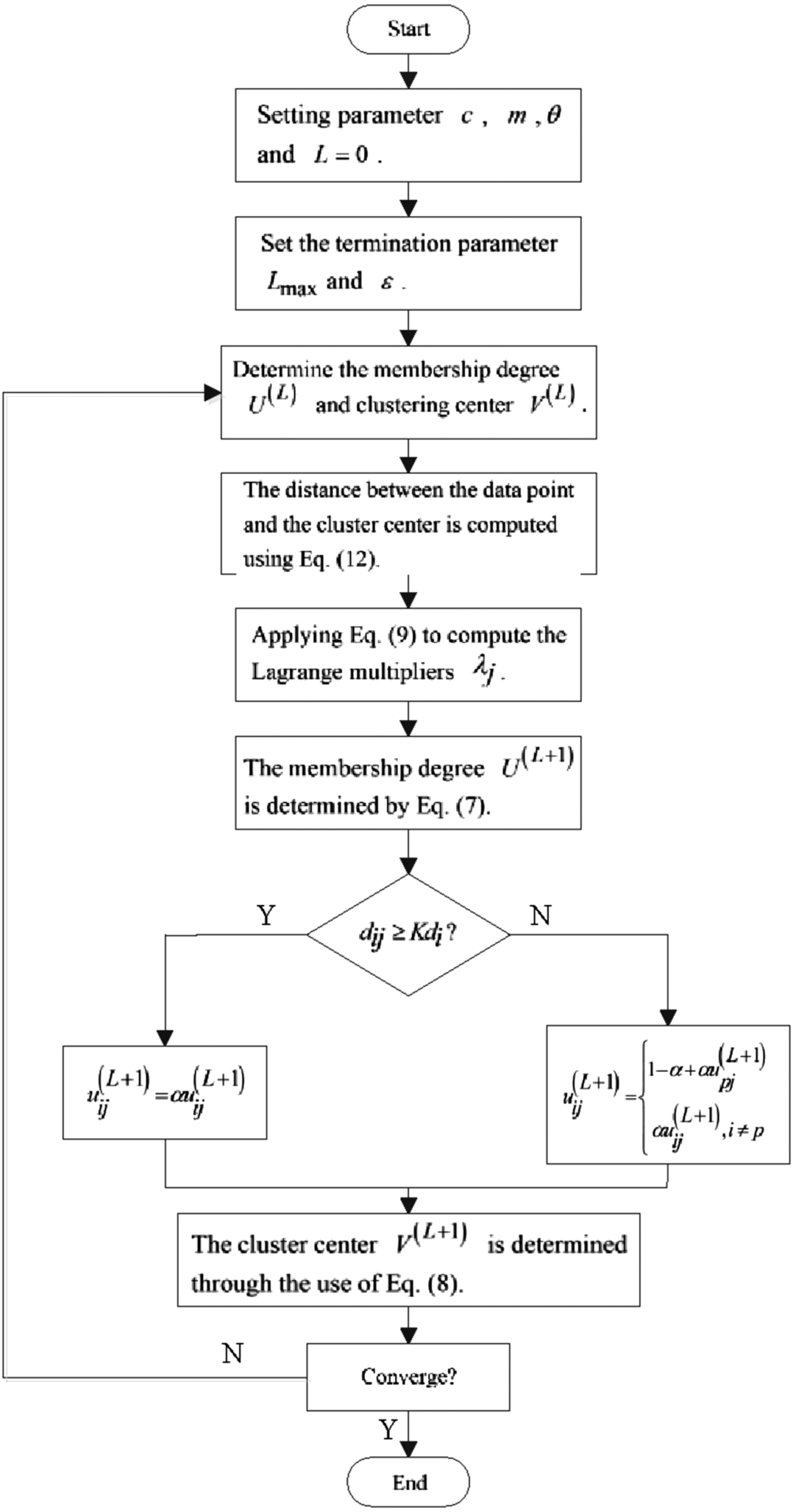
The flowchart of MSREFCM.
In the previous paper [4], the cluster with the most significant membership value of sample x j among all clusters is denoted as pth cluster, and pth cluster is regarded as the winner cluster, so the membership degree of sample x j belonging to cluster p is represented as u pj . In this paper, the sample x j belongs to the cluster within the cluster kernel, which is denoted by the winner pth cluster, and its membership degree is expressed as u pj . The other clusters are called non-winning clusters, and the degree of membership of the observed value x j to the non-winning cluster is denoted u ij , i ≠ p.
In the suppression strategy, we introduced the concept of clustering kernels to identify the core data of each cluster, rewarding in data in the kernel dominating and other data being punished. The membership degree of the non-winning cluster data is proportionally suppressed by the product of α, while the membership degree of the winning cluster data is amplified. According to Equations (7) and (9), the relationship between sample x
j
and membership degree is not only related to the distance from cluster center v
i
to sample x
j
, but also to the Lambert-W function value of the distance from sample x
j
to cluster i. The built-in Lambert-W function can be denoted
As shown in Fig. 3, where v1, v2 and v3 are the centers of the three clusters. The observed value x
j
is within the cluster core of the cluster center v1 (the blue circle represents the cluster core of v1), and outside the cluster core of the cluster centers v2 and v3, then the winner cluster is v1. At this time, the membership of the winner cluster will be rewarded, that is, the distance d1j from x
j
to v1 should be shortened to

The effect of suppression behaviour in MSREFCM.
In Section 4.1, we introduce the complexity of FCM, S-FCM, PCM, MSFCM, REFCM, and the MSRFCM algorithm proposed in this paper, along with the parameter settings and running environment of the algorithm. In Section 4.2, we verify the effectiveness of the proposed algorithm using 8 synthetic datasets, 2 UCI datasets, and 2 image datasets.
Performance evaluation
Kolen and Hutcheson mentioned that FCM is asymptotically running in time O (Nc2p) [27], where N is the number of p-dimensional observations and c is the number of clusters. The computational complexity of PCM algorithm is O (Nc2p) The computational complexity of the S-FCM algorithm and the MSFCM algorithm is O (Nc2p) + O (2Nc). The computational complexity of the REFCM algorithm obtained by adding relative entropy to FCM is O (Nc2p) + O (2Nc log(Nc)). In addition, the overall complexity of the MSREFCM clustering method proposed in this paper is O (Nc2p) + O (2Nc log(Nc)) + O (2Nc). Therefore, compared with FCM, S-FCM, MSFCM, and REFCM methods, although the proposed method increases the complexity of the algorithm, the idea of competitive learning improves the convergence speed and reduces the running time.
Under different data conditions, the MSREFCM algorithm will be compared with the FCM, S-FCM, PCM, MSFCM, and REFCM algorithms. These clustering methods have the following properties: (1) FCM, m = 2, (2) S-FCM, m = 2.5, α = 0.5, (3) PCM, m = 2.5, (4) MSFCM, m = 2.5, β = 0.005, (5) REFCM, m = 2.5, θ = 1.5, (6) MSREFCM, m = 2.5, θ = 1.5. To measure and compare the ability of the proposed methods to identify accurate results, the Kwon validity measure V k (c) [28], Separation coefficient V SC [29], Partition coefficient and exponential separation V PCAEC [30], the overall F-measure for the entire data set F*, the normalized mutual information NMI, and the adjusted Rand index ARI [31], accuracy, iteration number, and computing time criteria are applied.
The smaller the V k (c) and V SC values, the better. The V PCAEC index describes the compactness and separation of clusters by the fuzzy membership function and the relative value of the central distance of an exponential structure. F*, NMI, and ARI measure how well the two data distributions match. The higher the value of V PCAEC , F*, NMI, and ARI, the better. In addition, we tested this model on a system with 8 processors, 16.0 GB of RAM, and a 512 GB SSD, and the CPU frequency is 2.90 GHz.
Experiments
In this section, the first eight experiments are synthetic datasets, the ninth and tenth experiments are UCI datasets, and the last two experiments are image datasets. In the experiment on the synthetic datasets, we verified that MSREFCM has lower convergence times and higher classification accuracy through
Synthetic datasets
(

simple numerical data set.

Membership degrees obtained by applying (a) FCM, (b) S-FCM, (c)PCM, (d) MSFCM, (e) REFCM, (f) MSREFCM methods for the
The average performance comparison of different algorithms in Experiment 1 (standard deviation in bracket)
First, observe the membership graphs of these six algorithms in Fig. 5. Among them, the 8th and 9th data points are noise points, and the membership degrees of the FCM clustering algorithm at these two noise points are both 0.5, which indicates that the distances between these two noise points and the two clustering centers are consistent. FCM cluster centers are [3.343, 3.307] and [14.66, 3.307], and the errors between them and cluster centers [3, 3] and [15, 3] previously set are
Furthermore, as presented in Fig. 5, the membership degree of the REFCM algorithm at these two noise points is 0, indicating a certain level of noise resistance. However, the cluster center of the REFCM algorithm is still shifted compared to the original cluster center. The errors are
Meanwhile, Table 1 shows the best results in bold black. Based on Table 1, we can see that data points 8 and 9 are noise points, and the above six methods can identify the noise. Among the six algorithms, the V k values of REFCM and MSREFCM are the smallest, and the F*, NMI, and ARI values of MSREFCM are the largest. It appears that the MSREFCM algorithm has the best consistency between the actual values and the clustering results generated by the algorithm among these algorithms. In addition, the convergence speed of the MSREFCM algorithm is faster due to the addition of the suppression factor. The MSREFCM algorithm has fewer iterations than the REFCM algorithm.
By and large, MSREFCM algorithm performance is superior to REFCM algorithm performance. In particular, the MSREFCM algorithm has a faster convergence speed and shorter time while maintaining the same classification accuracy.
(

Triangle1 data with noise.

The obtained cluster center obtained by applying (a) FCM, (b) S-FCM, (c)PCM, (d) MSFCM, (e) REFCM, (f) MSREFCM methods for the
The average performance comparison of different algorithms in Experiment 2 (standard deviation in bracket)
The results of Fig. 7 (f) demonstrate the proposed algorithm’s good robustness in the presence of significant noise. In terms of performance improvement, Table 2 shows that the MSREFCM algorithm improves the convergence speed of the REFCM algorithm by introducing a ‘suppression’ strategy. Further, the algorithm introduces a clustering kernel, uses Mahalanobis distance to find the core data of each class through each iteration, and rewards and punishes its winning membership degree and non-winning membership degree so as to actively attract the center and improve the iteration speed of the algorithm. At the same time, the unreasonable correction of the membership degree of close-range noise is avoided, and the robustness of the algorithm is improved.
(

9 cluster data sets with noise.
According to Fig. 9, we can see that FCM, S-FCM, PCM, MSFCM, and REFCM algorithms cannot effectively handle noise points. The proposed algorithm can improve convergence speed while maintaining classification performance. Because MSREFCM first calculates membership and then suppresses it. Equation (13) reveals that the membership formula enhances inter-cluster relationships via competitive learning. In the design of the competitive suppression learning strategy, MSREFCM uses the cluster validity function to determine the suppression rate and suppress non-winning members or typical members outside the cluster core without destroying the original order between clusters. Therefore, even when a noise point is near the cluster, the proposed “suppression” strategy still effectively hinders the noise point.

The obtained cluster center obtained by applying (a) FCM, (b) S-FCM, (c)PCM, (d) MSFCM, (e) REFCM, (f) MSREFCM methods for the
(

16 cluster data sets with noise.

The obtained cluster center obtained by applying (a) FCM, (b) S-FCM, (c)PCM, (d) MSFCM, (e) REFCM, (f) MSREFCM methods for the
Therefore, as can be seen from Figs. 9 and 11, the ability of the FCM, S-FCM, and MSFCM algorithms to detect noise points will be weakened as the cluster size increases from 9 to 16. That is, the robustness of these algorithms is poor. The PCM algorithm and the REFCM algorithm will appear as clustering center overlap phenomena, which is not appropriate. The MSREFCM algorithm improves the clustering center overlap problem of the REFCM clustering center algorithm by calculating the mean intra-class distance metric of the last iteration. In addition, the MSREFCM algorithm improves the convergence speed of the REFCM algorithm by introducing a suppression strategy.
(

12 cluster data sets with noise.
When the dataset’s cluster size is inconsistent, all of the FCM, S-FCM, PCM, MSFCM, and REFCM algorithms obtain overlapping cluster centers. Only MSREFCM can effectively classify clusters and handle noise points. Additionally, Fig. 13(e) illustrates that the REFCM algorithm obtains two overlapping centers for datasets of various sizes. Therefore, the MSREFCM algorithm can overcome the center’s coincidence phenomenon of REFCM clustering owing to the incorporation of a suppression factor based on data distribution structure selection and clustering kernel suppression strategy. The algorithm identifies core data for each class during each iteration. Then it actively rewards and punishes winning and non-winning members, thus attracting the center and accelerating the iteration speed. Furthermore, it avoids undue correction of membership degrees in close-range noise, resulting in increased anti-noise robustness of the algorithm.

The obtained cluster center obtained by applying (a) FCM, (b) S-FCM, (c)PCM, (d) MSFCM, (e) REFCM, (f) MSREFCM methods for the
(

6 cluster data sets with noise.

The obtained cluster center obtained by applying (a) FCM, (b) S-FCM, (c)PCM, (d) MSFCM, (e) REFCM, (f) MSREFCM methods for the
The six clustering datasets in experiment six are all bar data. FCM, S-FCM, PCM, MSFCM, and REFCM algorithms cannot achieve good results in six kinds of clustering noise data sets. In Fig. 15, the final classification result of the FCM algorithm is similar to an ellipsoid, so the algorithm is not suitable for strip data sets. The classification results of the S-FCM algorithm are consistent with those of the FCM algorithm, which are ellipsoids. The classification results of the PCM algorithm in six bar data sets tend to have five classes, which shows that the algorithm will have the phenomenon of overlapping clustering centers for bar data sets. The classification results of the MSFCM algorithm are similar to those of ellipsoids; the algorithm is not suitable for strip data sets. The REFCM algorithm will exhibit a classification error phenomenon, which may be due to noise interference. The main reasons are as follows: The first reason is that all five algorithms use Euclidean distance measurement and cannot handle bar datasets well. In addition, the second reason is that FCM, S-FCM, PCM, and MSFCM methods are sensitive to noise data. However, the MSREFCM algorithm can overcome the consistency problem between these algorithms and the noise sensitivity of bar data. The MSREFCM algorithm proposed in experiment six has a center deviation of 1.88 on six clustering datasets.
(

2 cluster data sets with noise.

The obtained cluster center obtained by applying (a) FCM, (b) S-FCM, (c)PCM, (d) MSFCM, (e) REFCM, (f) MSREFCM methods for the
The data set in
(

2 cluster data sets with noise.

The results of
From the results of Experiment 8, under different fuzzy degrees m, the suppressed factor α gradually decreases and tends to be stable with the increase in the number of iterations of the algorithm. Under the appropriate fuzzy degree, the membership degree gradually becomes clear with the increase in the number of iterations. Therefore, choosing the correct fuzzy degrees is very important for the clustering results. In Fig. 19 (a), (e), (i), and (m), when m = 2.5 and m = 3.5, the number of iterations is the least, that is, the number of iterations is 12. Figure 19 (b), (f), (j), and (n) represent the second iteration membership result diagram. From the diagram, as the fuzzy degree increases, the initial value of the suppressed factor α will gradually decrease. In addition, in the membership diagram in Fig. 19 (c), (g), (k), and (o), when m = 2.5, the membership classification is more obvious. Finally, in Fig. 19 (d), (h), (l), and (p), when m = 3.5, the algorithm cannot correctly classify the data set. The reason is that when the fuzzy degree becomes larger, the suppressed factor becomes smaller, so the suppression factor changes too fast in the iterative process. As a result, we consider that the fuzzy degree m is best between [2, 3]. In this study, the value of fuzzy degree m is set at 2.5.
(
The average performance comparison of different algorithms in Experiment 9 (standard deviation in bracket)
The average performance comparison of different algorithms in Experiment 9 (standard deviation in bracket)
(
The average performance comparison of different algorithms in Experiment 10 (standard deviation in bracket)
Tables 2 and 3 demonstrate that the majority of parameters employed in the MSREFCM algorithm are optimal. In comparison to the REFCM algorithm, MSREFCM significantly reduces the number of required iterations while maintaining a high level of accuracy. This results in decreased convergence time. Overall, the performance of the MSREFCM algorithm is superior to that of the REFCM algorithm on both synthetic and UCI datasets.
Imagery is an important means for humans to obtain, express, and transmit information. Therefore, image processing has been widely used in medicine, remote sensing, and other fields. In the image segmentation process, the image will be divided into different homogeneous regions with similar attributes. The MSREFCM algorithm is similar to the REFCM algorithm, which is divided into different clusters according to their color components or pixel intensity level. However, the MSREFCM algorithm can better improve classification performance. In this article, we will conduct two experiments to scrutinize the advantages of the MSREFCM algorithm in processing images.
(

Rope and the main object of the image obtained by (b) FCM, (c) S-FCM, (d) PCM, (e) REFCM, (f) MSREFCM method.

Cactus and the main object of the image obtained by (b) FCM, (c) SFCM, (d) PCM, (e) REFCM, (f) MSREFCM method.
In this paper, we propose a modified suppressed relative entropy fuzzy c-means clustering algorithm by using suppressive factors, clustering kernel and Mahalanobis distance. The problem of overlapping cluster centers in REFCM algorithm is improved when the number of clusters increases and clusters of different sizes.
Furthermore, the MSREFCM algorithm effectively handles elliptical, cross, and strip data sets. Experimental results demonstrate that the proposed method maintains high accuracy while requiring fewer iterations than the REFCM algorithm on synthetic and UCI datasets. Thus, it is highly recommended to use the MSREFCM algorithm when processing noisy data, including but not limited to ellipsoidal, cross, and bar datasets.
Funding statement
This work is supported by the National Natural Science Foundation of China (No. 62071378, 62071379, 62106196), the National Natural Science Basic Research Plan in Shaanxi Province of China (2021JM-461) and ‘New Star Team of Xi’an University of Posts and Telecommunications, China’, No. xyt2016-01.
Appendix A
The three necessary conditions for optimized are
Firstly, by setting the gradient of J concerning U to zero, the first-order necessary condition for optimality is found. That is:
By solving
When you solve y ij in Equation (16) you get:
Therefore, the membership degree of each observed result in each cluster will be:
Where W0 (·) is the main branch of the Lambert-W function [36], which is defined as the satisfied formula W (Z) exp(W (Z)) = Z.
So, Equation (18) is rewritten as:
Secondly, by setting the gradient of J concerning λ j to zero, the first-order necessary condition for optimality is found. That is:
The binding Equation (19) can be obtained:
Since the membership degree and the Lagrange multiplier are completely related, it is obvious that the exact solution will not be obtained by solving this equation with λ j . Therefore, we need to find the boundary of λ j . This problem can be studied from both u ij ≥ 0 ∀ i, j and u ij ≤ 1 ∀ i, j perspectives.
When u
ij
≥ 0 ∀ i, j,
The image of the Lambert function is shown in Fig. 22, which has two branches W0 (·) and W-1 (·). Obviously, the domain has two different trends in [- raise0.7ex1 / lower0.7exe, 0]. When the Lambert function takes values in [- ∞ , -1], the monotonic decreasing function is obtained, and when the Lambert function takes values in [- 1, 0], the monotonic increasing function is obtained.

Two branches of W (Z), blue is W0 (Z), red is W-1 (Z).
So, Equation (22) is rewritten as:
Therefore, the lower bound of the Lagrange multiplier λ j is defined as:
When u ij ≤ 1 ∀ i, j, there is:
Therefore, the lower bound of the Lagrange multiplier λ j is defined as:
Thus, based on Equations (24) and (26), the lower bound for λ j would be:
Finality, by setting the gradient of J concerning V to zero, the first-order necessary condition for optimality is found. That is:
It can be obtained from Equation (30).
For the optimal membership functions (
So, define the fuzzy covariance matrix for Γ i by