
Abstract
Veneer is the critical raw material for manufacturing man-made board products, therefore the quality of the veneer determines the level of the man-made board. However, defects in the veneer may significantly lower its grade. Currently, identifying veneer defects requires manual inspection and subsequent inpainting using a veneer digging machine. Unfortunately, this method only removes the defects of the veneer but ignore the consistency of its texture. To address this issue, we propose a feasible veneer defect reconstruction method that utilizes a texture-aware-multiscale-GAN architecture. Our method performs texture reconstruction of veneer defects to increase the texture information of the reconstructed image while improving the model efficiency, so that generates natural-looking textures in the reconstructed defect areas. The model is trained by end-to-end updating of four cascades of efficient generators and discriminators. We also employed a loss function based on local binary patterns (LBP) to ensure that the restored images contain sufficient texture information. Finally, region normalization is used in the model to enhance the accuracy of the model. Peak Signal to Noise Ratio (PSNR), Structural Similarity Index (SSIM) are used to evaluate the effectiveness of image restoration, the results show that PSNR of the method reacheds 35.32 and SSIM reaches 0.971. By minimizing the difference between the generated texture and that of the original image, our model produces high-quality results.
Introduction
Motivation and incitement
Veneer texture is a natural property that develops during the growth process of wood. Veneer texture is used to identify the type of the wood, the quality of the wood, it is also an important aesthetic feature of the wood products [1, 2]. However, defects can irreversibly damage the veneer texture, so it is important to reconstruct the veneer image. By reconstructing the grain information, the visual aesthetics of the veneer can be enhanced, potentially increasing the economic value of the wood. Image reconstruction task is to fill in missing areas of an image by generating reasonable content or remove unwanted objects from it. This task has attracted considerable interest in the fields of computer vision and pattern recognition research. Unfortunately, the complexity of veneer images makes it difficult to achieve seamless restoration, with problems such as blurring and inconsistencies between the original and restored regions. In addition, it is of great practical significance to enhance the visual aesthetics of the veneer and the potential economic value of the veneer, and to reduce the output rate of waste veneer.
Literature review and research gaps
Existing image reconstruction methods can be classified into two categories: Patch-based texture synthesis methods and feature learning methods based on convolutional neural networks (CNNs) [3]. Patch-based texture synthesis methods involve extracting low-level features, matching and pasting patches [4], then searching for matching patches from known areas of the image to fill in the missing areas, which resulting in more reasonable texture information. However, these methods do not perform well on complex images, such as faces or natural images, and the inpainted results always be blurred. These methods are suitable for images with simple structures or small holes, but generating sufficiently realistic texture features for complex defective images can be challenging.
With the rapid development of computer vision, deep learning methods have made shown remarkable progress in the field of image reconstruction. CNN-based methods, such as contextual encoders, which are capable of learning high-level semantic information from images, while Generative Adversarial Networks (GAN) [5] based methods can overcome the limitations of traditional image reconstruction techniques. Among image reconstruction models, GANs have become the primary model in the restoration field, as they can learn high-dimensional abstract features from large-scale datasets and fill corrupted images with near-realistic alternative content. However, these methods still have limitations, such as the inability to construct accurate spatial information during the learning process or to create blurred textures that are inconsistent with the region surrounding the image. Most current GAN-based restoration models suffer from problems such as loss of image structural information and unrealistic generated textures, often leading to the results blurring or geometric distortion.
To address the above problems, most current GAN-based image reconstruction methods employ a coarse-to-fine structure. Specifically, part of the coarse network stage predicts the complete style of the input image directly from the damaged image [6], and the other part reconstructs the image structure based on edges [7], contours [8]. The fine network stage usually uses information from the predicted or reconstructed image of the coarse network to generate the final plausible image. However, the multi-stage models take up a large amount of computational resources due to the multiple network parameters. Others have borrowed information from the surrounding parts of a defective or damaged image block with the contextual attention mechanism (CAM) [9]. However, CAM still does not ensure continuity of features and also need expensive computational resources.
Except the multi-stage models and contextual attention modules, the training of high-resolution images also requires larger models and a greater number of model parameters, which can become a bottleneck problem in improving the speed of image restoration. Slower training speeds and the need for smaller batch sizes can negatively impact the performance of image reconstruction algorithms due to computational and memory resource constraints [10].
Based on the above analysis, we propose a new framework for deep generation image reconstruction called texture-aware-multiscale-GAN(TMGAN), which aims to improve restoration efficiency while preserving texture features. TMGAN consists of four cascaded efficient generators, each corresponding to an input image of a different resolution. Training starts with a lower resolution image and the size of the generated image is doubled with each subsequent generator using information from the previously generated image. This approach is beneficial because GANs are easier to train GANs on low-resolution images, which converge faster, and improve model stability.
TMGAN eliminates the refinement module to reduce the size of the network and compensates for the resulting loss by using a cascaded training approach and a texture-based loss function. The texture-based loss function is constructed using local binary pattern (LBPs), which minimizes the distance between the LBP of the ground truth images and the LBP of the predicted result, thereby enhancing learning of textures in corrupted areas. As TMGAN does not use complex operations and the refinement module is discarded, it does not require high computational resources.
The main innovations of this article are as follows: Proposing a new GAN-based image reconstruction framework, which introduce four cascaded efficient generators for input images of different resolutions to improve restoration performance while speeding up inference time. An LBP-based loss function is proposed to enhance the texture learning capability of the model and improve the quality of the reconstructed results while maintaining their realism. In order to improve the accuracy of the model and prevent gradient explosion, region normalization is used to handle the effect of spatial distribution on normalization by dividing the pixels into different regions and normalizing the pixels within each region independently. Experiments are conducted on two datasets to demonstrate the effectiveness of the proposed method by comparing it with other state-of-the-art methods.
The remainder of this paper is organized as follows. The related work is reviewed in Section 2. The full architecture and the approach are detailed in Section 3. The experimental results and evaluations are presented in Section 4. Finally, the conclusions are drawn in Section 5.
Related work
Current status of image reconstruction research
The existing image reconstruction methods can be divided into two main categories: traditional learning methods and deep learning methods. Traditional methods are implemented using diffusion-based or patching techniques. Diffusion-based techniques, which propagate information from neighbouring regions to the damaged regions [11, 12]. However, the above approaches may not be effective in generating textures for large or complex holes, which have high overhead in terms of memory and time. To overcome this limitation, Yeh [6] has focused on speeding up the image reconstruction and extending them to handle more complex cases. However, traditional learning methods only extract low-level features and therefore fail to understand the semantic structure of an image, resulting in lower performance in many cases.
Learning-based approaches have greatly benefit from the rapid development of deep neural networks (DNNs) and GANs, which have been used on large-scale datasets [13, 14] to learn semantic information about images. These methods use encoder-decoder architectures to directly predict missing pixel values. The Context Encoder (CE) [15] was the first method to attempt to use adversarial learning to fill a square hole in the center of an image, but it suffered from significant artefacts and ambiguity in the results. For this reason, Nazeri et al. [7] proposed two discriminators to ensure global and local image consistency, but this method requires a subsequent processing step to ensure colour coherence around the square holes. The subsequent processing step is replaced by attaching a coarse-texture network to another refine-texture network, which uses a Contextual Attention Mechanism (CAM) into the fine-texture network. This approach searches for the set of surrounding background patches with the highest similarity to the coarse image in order to enhance semantic coherence. However, due to the use of rectangular regions for training, pixel continuity cannot be ensured. Hassanpour et al. [16] solved this problem by adding a coherent semantic attention layer to the fine network to handle free-form masks. However, the time overhead is high due to the high computational resources required to perform the complex operation. Cheng et al. [17] proposed using compressed and stimulated residual networks in the generator and discriminator to reduce the number of parameters. In addition, they proposed a joint context-aware loss to produce more realistic textures. Kim et al. [18] introduced a fusion block that generates a flexible alpha combination mapping to combine corrupted and undamaged pixels. In addition, they used the U-Net of the embedded fusion block to handle non-harmonic region boundaries. Li et al. [19] used global and local discriminators to build a fusion network to produce semantically coherent images.
Other approaches have used multi-stage architectures to reduce the complexity of the image restoration problem by providing additional information to the model. Creswell et al. [20] introduced a two-stage architecture that predicts segmentation labels to generate plausible images of foreground objects. Cheng et al. [17] proposed a three-stage architecture that used incorporates contour information to maintain the boundary between foreground and background objects. He et al. [21] proposed another two-stage architecture to predict edges to monitor the effect of model predictions while recovering the image structure. Peng et al. [22] added appearance flow to the second stage to establish long-term correlation between hidden and contextual regions. Ukwuoma [23] proposed a coarse-to-fine architecture which predicted a high-resolution coarse image in the first stage and then used a fine generator with a multi-scale discriminator to generate a smooth image. However, some of these methods can significantly increase computational complexity and inference time, such as the use of an attention layer in the fine network. Therefore, reducing the model size without compromising the quality of the generated images is of great importance. The proposed restoration algorithm in this article does not use CAM or a coarse-to-fine architecture, resulting in reduced inference time and plausible results.
Generative adversarial networks
Generative Adversarial Networks (GANs) consists of two parts: a generator and a discriminator. The generator is used to simulate the distribution of the training data, while the discriminator is used to distinguish between the training set and the data generated by the generator. In recent years, GANs have achieved great success in image restoration tasks and in modelling complex computer vision problems, including video generation, graph-to-graph conversion and modulation classification. Despite their excellent performance, GANs can be difficult to train quickly as the current training method involves optimizing the parameters of two neural networks independently in a high-stakes task. The first network is a generator that generates new samples similar to real data, and the discriminator network is optimized to distinguish between fake and real data. the loss function of a GAN is defined as follows.
Where z can be a vector sampled from a Gaussian distribution in a random image generation task or an image in an image to image conversion task, x is a real data sample, G (·) is a generator network, and D (·) is a discriminator network.
This article designs a new end-to-end image reconstruction framework, TMGAN, which utilizes GANs and LBP operators. TMGAN overcomes issues of unstable training, suboptimal restoration performance and slow inference time by employing a cascaded GANs architecture. Additionally, an LBP-based loss function is employed to enforce constraints task and ensure that fine-grained textures are properly generated.
TMGAN is one of the first studies to apply cascaded generators and discriminators in the field of image reconstruction, which involves four cascaded generators and discriminators. The framework employs low-resolution images to train encoder-decoder generators that generate sample images similar to the original image distribution. As the training progresses, the output of the pre-trained generators are used as input to the subsequent high-resolution generators. This strategy allows the previous low-resolution generator to facilitate the latter in learning consistent global image features using the filled regions of the previous low-resolution image, while also generating structural information about the corrupted regions. On the other hand, directly training GANs on high-resolution images is difficult to converge and negatively impact model performance. This is because the generator is different to generate images that include fine-grained texture features of the ground truth image, causing the discriminator to reject most of the generated images [24].
Model structure
Using images of different resolutions can help the network to learn the global structure of an image at multiple scales. The model structure of TMGAN is shown in Fig. 1. The training process starts with a 32×32 resolution image, where the defective images and masks are concatenated in the channel dimension and then fed into a generator corresponding to a specific resolution. The output of the generator and the ground truth image are then passed to PatchGAN [25] discriminator, which learns by adversarial learning in order translate the distribution learned by the generator to the true distribution.
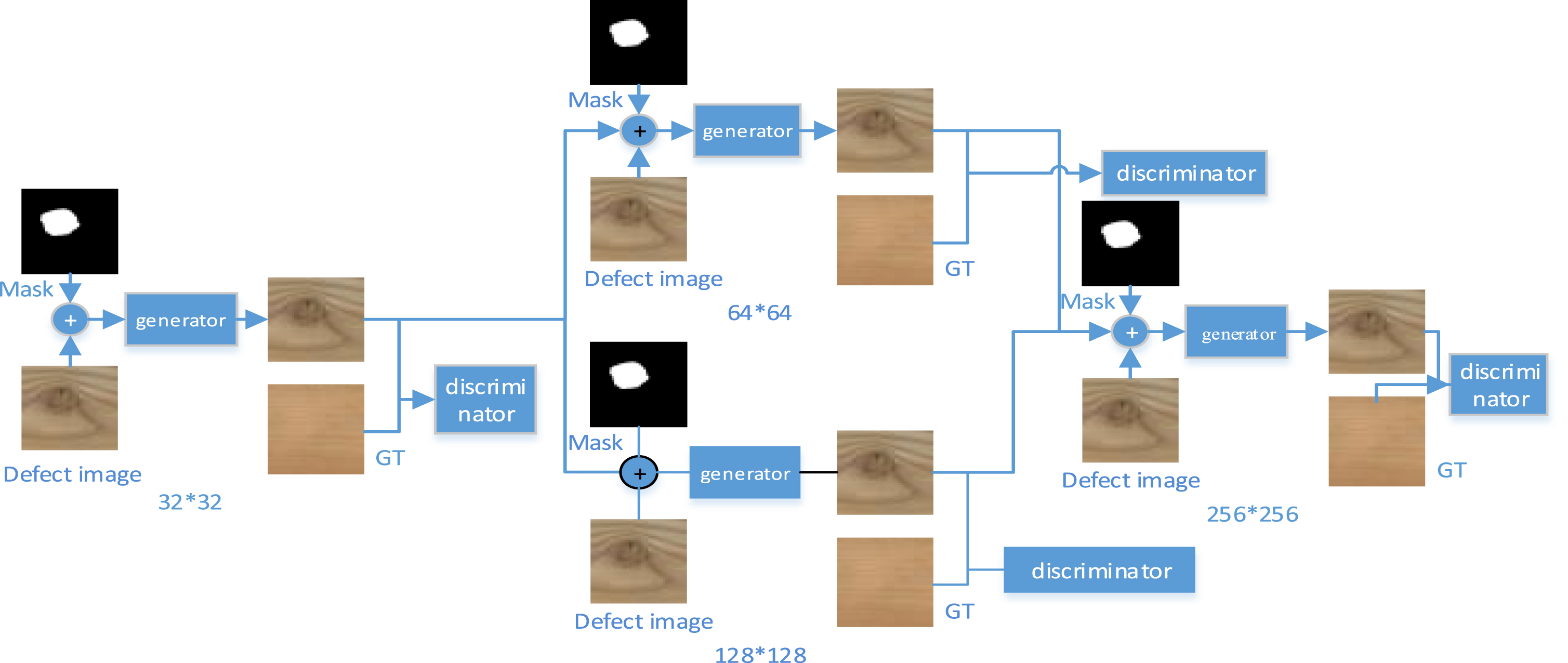
Schematic diagram of the model structure.
During training, different quantitative metrics and loss values are monitored and visualized. The training is stopped when the metrics become stable and the generated images are visually satisfactory to be used as input for the next resolution. This indicates that the generator network has converged. In the second step, the output of the pre-trained generator at 32×32 resolution is used to train the next two high-resolution networks (64×64, 128×128). The generator network at this resolution contains three sub-networks. The first sub-network takes the original defective image and the masked channel connection results as inputs, and the second sub-network, and the generator predicted image at 32×32 resolution as input. The last sub-network connects the feature maps produced by the previous two sub-networks to produce the final image (64×64, 128×128). Similarly, the same approach is followed for the final resolution (256×256), with the generator using the output images from the previous two generators. For example, for a generator with an input of 256×256, the feature extraction network contains four sub-networks, as shown in Fig. 2. The first sub-network receives the original input, i.e. the real image and mask are channel stitched for feature extraction; the second sub-network receives the restoration result of the 128×128 generator with resolution and performs feature compression, the third sub-network receives the restoration result of the 64×64 sub-network with resolution and compresses the features to 32×32, the output structures of the previous four networks are channel stitching and send it to the decoding network.
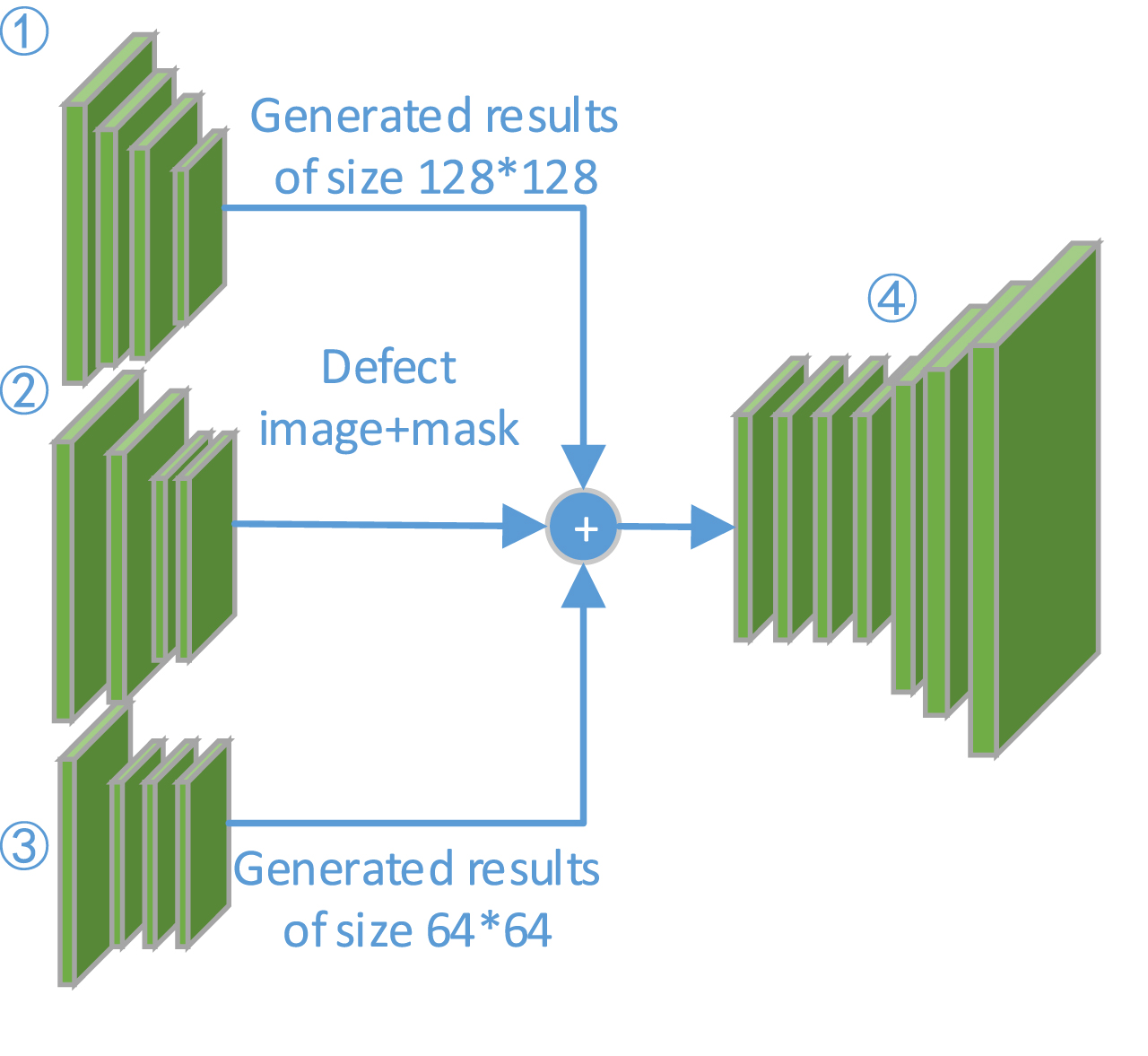
256 x 256 resolution generator architecture.
The structure of the generator network with different inputs is shown in Fig. 3. Conv denotes the convolutional operation, where 3×3/1 signifies the convolutional kernel size of 3×3 and the step size of the convolutional operation is 1, 64×2 indicates that 64 convolutional kernels are used and the module is stacked twice. Tcon denotes the upsampling operation. All generators are fully convolutional networks, and no pooling operations are used. All networks use only two convolutional kernel sizes, 3×3 and 1×1, with the same number of layers for different input sizes of the image or restoration map sub-networks.
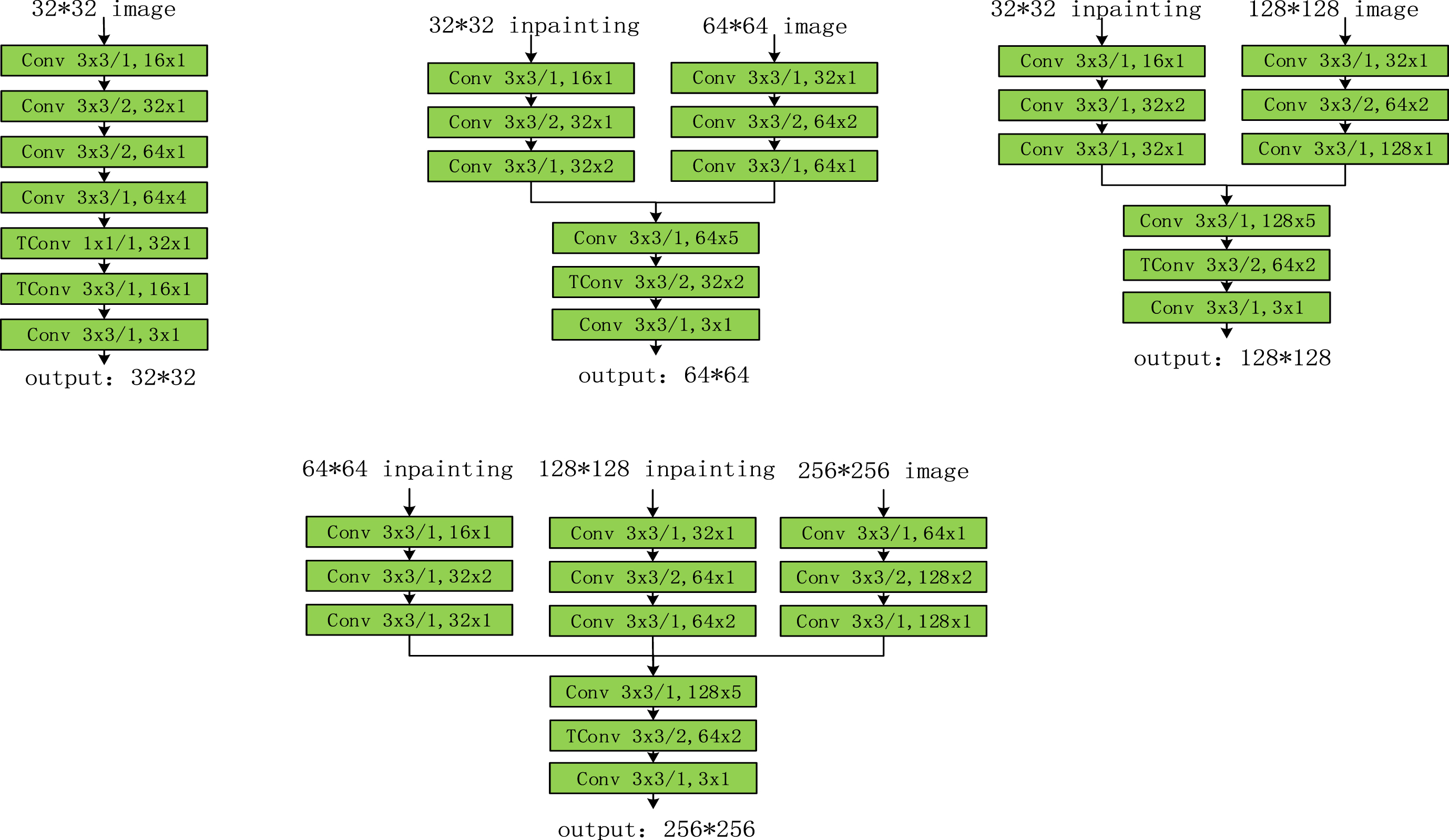
Detailed structure of generator networks with different input sizes.
Unlike most of the tasks, the image restoration task is divided into regions to be restored and intact regions, the existing normalisation methods are normalised to all the regions, but are prone to mean and variance bias, so Region normalization (RN) [26] is used and the image pixels are divided into two regions using a mask to avoid the impact of the statistical differences between the two regions on the training of the model.
Assuming that the input features X ∈ RN×C×H×W, N, C, H, W are the number, dimension, height, and width, respectively, the formulas are as follows:
The mean and standard deviation for each subregion are shown below:
Where m represents the region index, |
The mean and standard deviation of each small region are calculated:
Finally, the normalization of each small area is combined together.
The discriminator utilized in this paper is the same as PatchGAN,and the network structure is illustrated in Fig. 4. The parameters in the figure have the same meanings as those in Fig. 3. Specifically, for input sizes of 32×32 and 64×64, n = 32, for input images of 128×128 and 256×256 resolutions, n = 64.
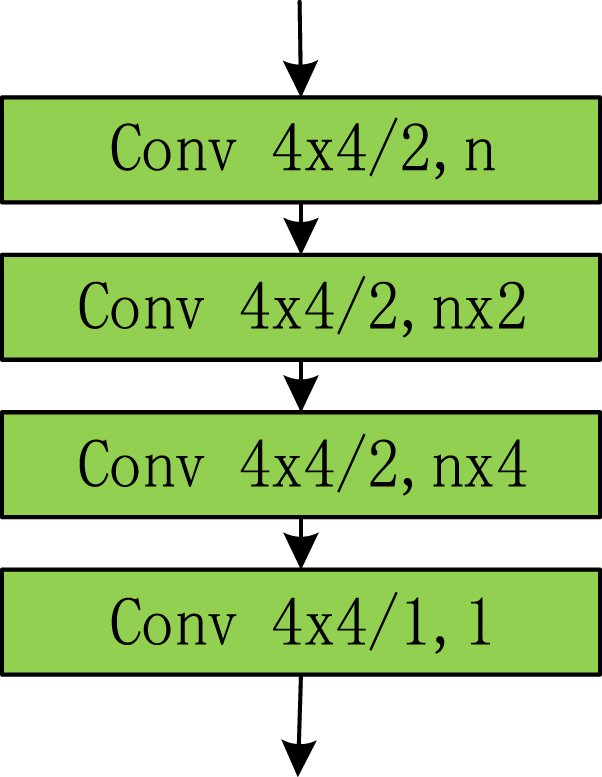
Detailed structure of the discriminator network.
Early reconstruction methods based on deep learning assumed that CNNs could automatically learn the texture and semantics of images without requiring further supervised training. However, recent research has shown tt this strategy does not necessarily hold for GAN-based approaches. To address this issue, Isola et al. [27] proposed discriminative modules and class supervision have been used to improve the acquisition of fine-grained features. Other GAN-based restoration methods have added or predicted edge information to ensure that true texture information is obtained. However, it is difficult to determine the appropriate threshold for a Canny edge detector that can preserve texture in both complex and simple images. Furthermore, in some cases, edge information may not provide enough texture detail, such as in the case of facial skin and homogeneous backgrounds. Based on this, TMGAN introduces a manually designed feature, the LBP texture operator, which as a new image restoration loss function to improve the learning of richer texture feature.
However, the original LBP algorithm has a fixed radius of the window and cannot extract texture features of different sizes and frequencies, for this reason this chapter makes use of the improved circular LBP algorithm. The circular LBP algorithm is capable a neighbourhood of any radius size and extends the square into a circle on which an arbitrary number of equally spaced sampling points can be specified. The various operators are shown in Fig. 5.

Example of calculation with different LBP operators.
Where P for
Where (x
p
, y
p
) is the coordinates of the p sample point. Since the sampling points of the circular LBP algorithm are distributed on a circle, it is not guaranteed that the coordinates of each sampling point are integers, and for this reason a bilinear interpolation method needs to be used to solve the problem. For points with non-integer coordinates, the coordinates are rounded up and down, respectively, to x0, y0, x1, y1, to obtain four coordinates, and the actual sampled point coordinates are calculated according to the following formula:
Figure 6 shows an example of the 3×3 LBP operator, which traverses each pixel in a grey-scale image, analyzes the pixel values in the 3×3 neighbourhood around that pixel, and compares the magnitude of each pixel value in the neighbourhood with the value of the central pixel. In this way, the 8 points in the 3×3 neighbourhood are compared to produce an 8-bit binary number, which is arranged sequentially to form a binary number, which is the LBP value of the central pixel. The resulting binary number is converted to a decimal number and replaced with the pixel value at the corresponding position in the binary image, resulting in an LBP image.

Example of 3×3 LBP calculation process.
In the specific implementation, TMGAN employs an LBP layer to minimize the LBP loss between the true value and the predicted image. The LBP operator is robust changes in lighting and invariant to changes in greyscale. However, LBP is a non-differentiable iterative function and cannot be optimized using back propagation. For this reason a convolution layer with fixed weights is used to convert this problem to a matrix multiplication operation. As a result, LBP does not increase the learning parameters of the network and does not add excessive additional computational overhead. The specific implementation is similar to that used in the literature [28]. It should be noted that the LBP loss is only used at the last resolution (256×256) to speed up the inference time.
The design of the loss function has an important impact on the effective training of the model. The loss function in this chapter contains is three parts, which are constraining the overall restoration similarity of the image by the difference between the real image and the predicted image, training the GAN by adversarial loss, and learning the texture details of the image by texture loss constraint.
Let In×n and Mn×n be the truth image and the corresponding mask, where n is the size of a square image. Similarly, let Gn×n (·) be the generator generating the network and the output On×n. Let Gray (·) be a function that converts a colour image to a greyscale image. Let LBP (·) be a differentiable LBP layer that converts a greyscale image to an LBP image. The output image grams for the different resolution generators are expressed as:
Experimental setup
The methods proposed in this chapter are compared qualitatively and quantitatively with a number of state-of-the-art methods, including Context Encoder (CE) [15], a multi-scale high-resolution image restoration model (HR) [29] and Contextual Attention Mechanism (CAM) [9]. These methods have pre-trained models, save training time and computational resources, and achieve very competitive results on public datasets through different mechanisms.
The veneer image dataset uses images from Wood-Auth [31] and select 12 different tree species to construct the dataset. The veneer defect dataset was captured using the image acquisition equipment built in the lab, and the raw images were captured using the image acquisition equipment built in the lab, and the raw images were captured using the OscarF810CIRF industrial camera’s to capture the surface defects of the veneer. When the veneer moves forward on the conveyor belt, the infrared sensor triggers the signal from the CCD camera, which is illuminated using the LED equalization plate to capture the Veneer defect image. The system structure is shown in Fig. 7.

Veneer data automatic acquisition equipment.
This device captured 2730 veneer defect images, including 1000 live nodes, 860 dead nodes and 870 wormholes. The larger the number of samples in the training s of the deep learning model, the better its training effect, so the traditional data enhancement techniques were used in the training process: rotating, cropping and flipping the images in terms of spatial transformation. After the enhancement of all defective images was completed, a total of 41,354 images were obtained for the veneer texture dataset and 16,380 images were obtained for the defective dataset. Each image was used to generate a total of 5 masks at random positions with a percentage of 10%, 20%, 30%, 40% and 50%. the generated dataset was divided into a training set and a test set, where 80% of the images were used for training and 20% for testing. To maintain consistency in image size, the veneer images were scaled uniformly to 256×256.
The experimental models in this paper are based on Pytorch [32] and trained on one GPU: NVIDIA 2080TI. In this chapter, the Adam optimizer is used for optimization with hyperparameters α=0.5 and β=0.9. The learning rate of the generator and the discriminator is fixed to 10–4 and the training parameters are shown in Table 1.
Training parameters
Region normalization was used in all convolutional layers of the discriminator. The weights of all previous networks were frozen while training the generator and discriminator at the current resolution. During the testing phase, the mask images were classified into four categories based on the ratio of hole size to the image size: 10% – 20%, 20% – 30%, 30% – 40% and 40% – 50%.
This section provides a qualitative comparison of the effectiveness of the different methods by comparing their effectiveness in repairing defective images. The restoration results of the different methods in the Places2 public dataset are given in Fig. 8. From left to right the results are shown for the damaged images and CE, HR, CAM, TMGAN and the ground truth undamaged images. Some of the image areas are shown enlarged in order to see clearly the differences between the generated images.

Reconstruction results of different methods on public datasets.
As can be seen in Fig. 8, CE produces significant artefacts that result in a change in the structure of the restored image relative to the original image. HR has better results by using multi-scale high-resolution images to predict edges to recover the overall structure of the image, but visual artefacts are still evident in the zoomed-in regions. Although CAM uses its introduced attention module to produce plausible and smooth images with global consistency, loss of colour difference structure is still observed and is more pronounced for texture details, such as the failure to capture tree branch textures in the zoomed region in the first row, and the failure to generate mountain textures in the second row. Compared to the above methods, the method in this chapter shows a very realistic texture structure in all the missing areas, which qualitative analysis from a visual perspective shows to be superior to the other three restoration models.
To further demonstrate the effectiveness of the proposed method, the three comparison methods and the method proposed in this chapter were used for image restoration of the veneer dataset, and the results are shown in Fig. 9. As can be seen from the figure, the restoration results of CAM have been able to capture the texture details of the images compared to the more serious blurring problems of the first two methods, but there is some texture inconsistency as shown in the third row of Fig. 9. In addition, there is some colour inconsistency in the restoration results from CAM. In contrast, the TMGAN restoration results not only capture a sufficiently clear texture, but also the restored image area maintains a more consistent colour continuity with the rest of the image. These results further demonstrate the effectiveness of the proposed method.

Reconstruction results of different methods on veneer images.
The effectiveness of image restoration is not fully judged by visual judgment, but also from the evaluation indexes to prove the effectiveness of the restoration effect. To evaluate the performance of TMGAN, we calculated the mean square error (MSE), peak signal to noise ratio (PSNR), and structural similarity (SSIM) between the generated image and the original image [33]. MSE is a measure of the difference between two images, with a lower MSE indicating a closer match between the images. The value can be calculated as follows:
Where m and n represent the height and width of the image, I represents the original image, K represents the restored image.
Among them,
Where μ x μ y represent the mean of images x and y, σ x σ y represent the standard deviation of images x and y, σ xy represents the covariance between images x and y, c1c2 and c3 are constants.
The higher the value of PSNR and SSIM, the better the restoration effect, and the lower the value of MSE, the better the restoration effect, Table 2 presents the experimental results of the different methods on the Places2 dataset. As shown in the table, CE performs the worst among the three metrics for different mask sizes. HR outperforms the CE algorithm, indicating that using multi-scale image textures can enhance the restoration performance. CAM achieves the best results among the three compared methods, indicating that the attention mechanism is equally effective in enhancing the results. Overall, TMGAN achieves the optimal results for seven of the 12 mask sizes for the three metrics. For the small mask case metrics, TMGAN and the optimal CAM method have similar performance, except for the case where the mask size is between 10% – 20% according to the MSE metric. In the other four suboptimal cases, the performance drop relative to the optimal performance ranges from 0.03 to 5%. In addition, it can be seen from the results that TMGAN performs better than CAM at large mask scales, indicating that the multi-scale parallel cascade structure proposed in this paper can effectively handle the restoration of large-scale masked images. The above results demonstrate the effectiveness of the proposed method. Figure 10 provides a more intuitive display of our model’s performance for various mask sizes on the Palces2 dataset.
Different methods restore results on the Palces2 dataset
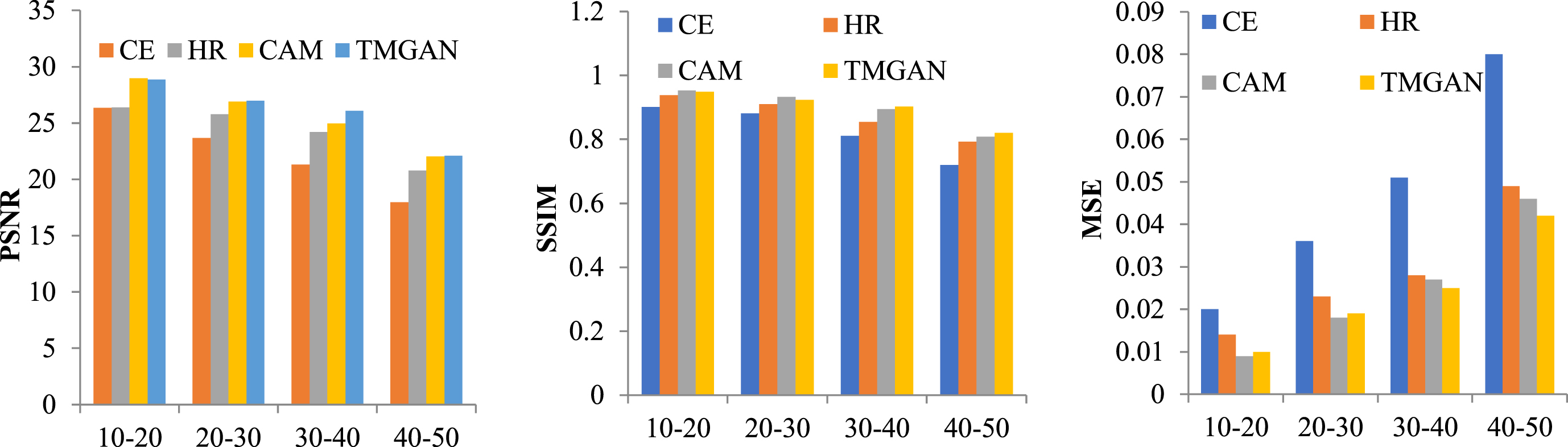
Effect of relative make sizes on the Palces2 dataset.
Table 3 shows the experimental results of the different methods on the veneer defect data. As can be seen from the table, similar to the results of Places2, CE gives the worst results among the four mask sizes for the three metrics, with relatively significantly better results for HR than CE, again indicating that multi-scale is an effective strategy for improving repair performance. Similarly, CAM gave the best results of the three compared methods, obtaining three optimal results out of 12 cases. The proposed method, TMGAN, obtained 9 best results for 12 cases and almost the same results as CAM for the next best case, demonstrating the effectiveness of the proposed method. Figure 11 shows the performance of our model for various mask sizes on the veneer dataset.
Different methods restore results on the veneer dataset
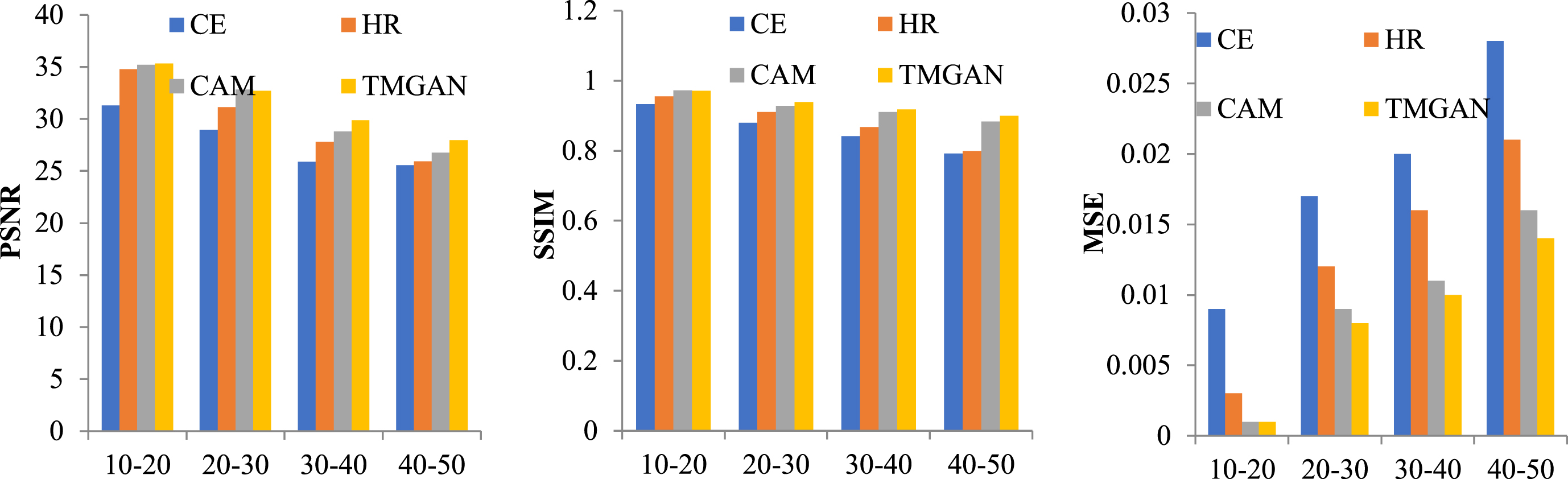
Effect of relative make sizes on the veneer dataset.
In practice, the speed of machine repair of defective areas is extremely important for industrial applications. Table 4 shows the amount of floating point operations, the model parameters in millions and the GPU inference time in milliseconds. The computing platform is an Intel(R) Core(TM) i7-9750 H CPU @ 2.60 GHz and an NVidia Quadro T2000 GPU. for a fair comparison, the average inference time was obtained by averaging all models tested 100 times on the same hardware. As can be seen from Tables 1 and 2, the performance of the method proposed in this chapter outperforms the three compared methods. In addition to this, TMGAN has only 3.4M parameters and 28.9 (GFLOPs), which is the lowest number of parameters, computation and inference time among the four methods. In addition, CAM has 24.1M parameters and 177 (GFLOPs), which is due to the fact that CAM uses an expensive attention mechanism layer in the refinement network, which greatly increases the number of parameters and GFLOPs.
Comparison of the number of parameters and inference time for different methods
Comparison of the number of parameters and inference time for different methods
The reason for the small number of TMGAN parameters comes from two sources, one being the discarding of the refinement module, which greatly compresses the network. The second is that although LBP adds an LBP layer, the parameters of this module are solidified and do not need to be trained. In terms of inference time, the models in this chapter show the best results, highlighting the efficiency of the proposed method.
In order to further demonstrate the effectiveness of the method and to analyze the contribution of each part to the overall method, four aspects of the ablation experiments are carried out: the influence of the LBP loss function and the shape of the LBP operator are investigated, the performance of the four generators is analyzed, and the quality of the generated textures is evaluated.
1. Effectiveness of LBP loss
To analyze the contribution of the proposed LBP loss function to the overall methodology, two models were set up, the first one using only the proposed network architecture, while the second one added the LBP loss function to constrain the prediction of missing regions, and qualitative and quantitative results for both setups are given on veneer data. Table 5 shows that the LBP loss improves the performance compared to the case without LBP.
In addition, as can be seen in Fig. 12, the addition of the upper LBP layer clearly restores the image texture, and the comparison is more obvious in the restoration results of the first row of images.
2. Effect of LBP radius

The effect of LBP loss. From left to right, shows original image, masked image, the model trained without LBP, our result, respectively.
Figure 12 and Table 5 show that the addition of LBP loss can improve the visualisation and quantitative results of the restoration to a certain extent, while different radii in the LBP algorithm have an important impact on the algorithm performance. In order to further analyse the effect of the texture images obtained at different radii on the restoration model, it was verified through experiments, as shown in Table 5. From the table, it can be seen that when R is 3, better results are achieved in both metrics, while as the radius increases, larger radius loses more contour details, resulting in performance degradation.
3. Performance analysis of four generators
The restoration model in the paper investigates different receptive fields by optimising the parameters of four progressive generators. The high-resolution generator benefits from previous restoration image results generated by the lower generator to learn the global structure of the image. In order to compare the image restoration results of different generators, the output images of different generators are given on veneer defect data, as shown in Fig. 13. As can be seen from Fig. 13, the quality of the image restoration improves as the dimensionality of the generator input increases, and more meaningful texture information appears. Overall, the high-resolution image texture is closer to the un-lossy regions of the image. Although the lower resolution images are blurry and do not provide clear texture details, they restore the global structure of the image, which helps to estimate the damaged pixels at the next resolution.

Intermediate images generated by different scale generators.
Comparison of inpainting performance with different parameters
In this section the proposed method is applied to the restoration of defective images captured in actual industrial production. The experiments were carried out on three randomly selected defect type images respectively and the restoration results are shown in Fig. 14. The three types of defects are wormholes, live knots and dead knots. The corresponding mask as well as the restore results correspond to the second and third columns of Fig. 14, respectively.

Restoration results of the proposed method for veneer defect image.
As can be seen from the results in Fig. 14, TMGAN is basically able to obtain globally consistent texture features when repairing defective images, which is of great importance for practical industrial applications. For example, for the repair of the wormhole in the first row, the repair result shows obvious consistent features with the texture around the wormhole. Similar to the first row, the repair results for the second row for a live knot, again have significant globally consistent texture features. In contrast, the repair results for the third row of dead knots have less pronounced textural features than the first two, but still maintain consistency. It should be noted that the restored image has some colour differences from the original image due to the design of the loss function which mainly emphasises the loss of texture.
This paper proposes an efficient end-to-end GAN-based image reconstruction framework which uses a cascaded generator approach to stabilize training and improve inpainting performance. The method takes different resolution images as input for each generator, then passes the output of the lower resolution generator to the higher resolution generator as input. So that the higher-resolution generator can obtain global information from the restored images of the previous low-resolution generator. In addition, the proposed LBP loss function simultaneously constrains image restoration and texture detail generation. Quantitative and qualitative results on both the public dataset and the veneer defect dataset show that the method generates images with global structural consistency and fine texture, and significantly speeds up the computation time while maintaining repair effectiveness. Therefore, using the images generated by as veneer defect restore template can improve the utilization of veneer and veneer-based panels, and then reduce the waste of resources.
Footnotes
Acknowledgments
The work was supported by the “Heilongjiang Provincial Natural Science Foundation of China”, grant number: YQ2020C018, and by “The Fundamental Research Funds for the Central Universities”, grant number: 2572019BF08.