
Abstract
Aiming at anomaly detection upon a high-dimensional space, this paper proposed a novel autoencoder-support vector machine. The key thought is that using the autoencoder extracts the features from high-dimensional data, and then the support vector machine achieves the separation of abnormal features and normal features. To increase the precision of identifying anomalies, Chebyshev’s theorem was used to estimate the upper of the number of abnormal features. Meanwhile, the dot product operation was implemented in order to strengthen the learning of the model for class labels. Experiment results show that the detected accuracy of the proposed method is 0.766 when the data dimensionality is 5408, and also wins over competitors in detected performance for the considered cases. We also demonstrate that the strengthened learning of class labels can improve the ability of the model to detect anomalies. In terms of noise resistance and overcoming the curse of dimensionality, the former can carry out more efforts than the latter.
Introduction
Usually, anomaly detection is treated as sample identification that does not confirm to the regular patterns or the expected distribution of normal samples [1]. Anomaly detection has been applied in many fields, such as, video surveillance [2, 3], remote sensing [4, 5], and medical diagnosis [6]. Usually, real-world data, e.g., ecological data, economic data, is high dimensionality. Due to high dimensionally of the data, i.e., the so-called the curse of dimensionality, there suffers troubles form mining anomalies, for instance, (i) anomalies easily show anomalous features in a low-dimensional space, instead, those anomalous features become hidden in a high-dimensional space. Most existing detection methods implicitly or explicitly rely on the measurement of the distance between the data, unfortunately, the relative contrast of the distance drops as the dimensionality of the data increases [7–9]. (ii) Anomalies can exist in any of subspaces of a high-dimensional space, because of the rare characteristic of anomalies, anomaly labels are difficult collected in exponential search space.
Some efforts have devoted into the anomaly detection, including deep feature representations-based -based methods, e.g., these methods implemented in [10, 11] gain the superior detection results. Such methods are very good at handling the high dimensionality of the data, since they contain several layers of nonlinear processing nodes to capture the low-dimensional representations of high-dimensional data. And classification-based methods, which do not have to pretreat the data before training the model, e.g., One Class-Support Vector Machine (OC-SVM) [12]. Additionally, Khalid [13–16] et al. proposed the method. From the algorithm level point of view, distance measurement-based methods, reconstructed error-based methods and classification-based methods do not have to pretreat data distributions [17]. From the data level of perspective, deep feature representations-based methods, deep hybrid-based methods can capture the feature representations of the data, which effectively reduce the complex of the search space providing for anomaly detection.
Distance measurement-based methods
Such methods include B-KNN (k-nearest neighbor) [18], KNN [19], etc. Guansong [20] et al. and Hu [21] et al. utilized the random distance in dealing with anomaly detection. They gain better performance in the case of a few number of anomalies [22], and do not specify data distribution assumptions. But unfortunately, they perform not well in handling ‘the curse of dimensionality’, and suffer from failing in high-dimensional noise environment [23]. To improve the detection accuracy, Mao et al. [24] proposed an anomalous method through assessing the changes in angle of data objects, instead of the assessment of the distance between the data.
Reconstructed error-based methods
Points with reconstruction error greater than the preset threshold are considered as anomalies in this strategy. Detected accuracy of such methods relies on the reconstructed errors, such as, Principal Components Analysis (PCA) [25, 26]. Although PCA has outstanding ascendancy in calculating speed and cost, it cannot get good results for nonlinear dependence because of linearly calculated manner. To address this, X. He [27] et al. proposed the fast matrix factorization (MF) for nonlinear dependence. Similarly, the MF in [28] and [29]. MF methods make up the gap of PCA methods, nevertheless, they still have weak capabilities to resist the curse of dimensionality.
Classification-based methods
Classification-based methods are good at projecting high-dimensional data onto a lower-dimensional space so that they work on a simpler data space well [30]. This is beneficial for revealing those hidden anomalies on the projected lower-dimensional space, e.g., the OC-SVM [31–33]. However, such methods may not retain sufficient information for anomaly detection because of fully decoupling during the data projection. Anomalies themselves can provide very little information, once they are completely decoupled, the information may be fully lost.
Deep feature representations-based methods
Deep feature representations-based methods can overcome the curse of dimensionality because of extracting the low dimensional representations of the data, e.g., these methods implemented in [34] and [35], and Deep One-class Classification (DOC) [36]. Auto encoder (AE) are also usually used for anomaly detection, e.g., Sparse AE (SAE) [37], Motion United-AE [38] and Deep Graph Auto-encoder [39]. Due to the design of the loss functions aims at feature extraction, AE is more suitable for data compression or dimension reduction [40].
Deep hybrid-based methods
This type of methods consists of deep network architectures and traditional methods, e.g., Deep Neural Networks-Support Vector Machine (DNN-SVM) [41], deep autoencoder and ensemble k-nearest neighbor (DAE-KNN) [42], and deep autoencoder model combining with hypersphere (DM-HS) [23]. Sangwook [43] et al. proposed K-DNN-SVM method, which utilized the support vector machine (SVM) to judge anomalies in the feature space reconstructed by the K-classification deep neural networks. The detection ability of K-DNN-SVM depends on data volume, when data points are rarity, the quality of the reconstructed feature space is deteriorated. Usually, the deeper the hybrid model is, the better the performance it gains [44]. By contrary, the deeper network architectures need to afford dear cost of tuning parameters and time consuming. Overall, deep hybrid-based methods show natural advantages in addressing anomaly detection for high-dimensional data since they inherit the advantages of deep network architectures and traditional methods.
Beyond that, support vector machine (SVM)-based architectures are also used for anomaly detection, e.g., Sparse SVM [45], the SVM [46]. SVM-based architectures can gain superior detected results on the low-dimensional data, while they easily suffer the limitation of linear inseparability on the high-dimensional data, since the features obtained are quite limited for building the proper classification boundaries [23]. From the point view of structures, shallow structures being similar to SVMs are failure to extract the dependencies between variables [47]. SVMs can take advantages in anomaly detection once there provide favorable low-dimensional space environments for them.
Motivations
The motivation of this work is to mine a limited number of potential anomaly instances upon a high-dimensional space, and to provide the insights for anomaly detection. Additionally, to propose some measures in improving detection precision, we also discussed the relative importance of the effect indicators noise and data dimensionality. Given that these complementary advantages between auto encoders and SVMs, this is very valuable to develop the hybrid model of both aiming at anomaly detection on high-dimensional data. The hybrid model not only better captures robust features from the input data, but also has the ability of distinguishing the potential anomalies. Hence, this paper proposes a novel autoencoder-support vector machine. Using the autoencoder extracts the features from high-dimensional data, then the support vector machine achieves the separation of abnormal features and normal features. To increase the precision of anomaly detection, using Chebyshev’s theorem estimates the upper of abnormal feature quantity. Furthermore, the dot product operation is also implemented to strengthen the learning of the model for class labels.
Contribution
We summarize main contributions of this work, as follows The proposed model resists the curse of dimensionality to a certain extent since the dot product operation strengthens the ability to learn the class labels. Noise has more negative effects on anomaly detection accuracy than data dimensionality does, so that the former can carry out more efforts than the latter in improving detection accuracies.
The rest of this paper is organized as follows. The proposed method is illustrated in Section 2. The experimental details are illustrated in Section 3. Section 4 exhibits experimental results and the discussion. Section 5 draws a conclusion.
Methodology
Background
Raghavendra [48] et al. define that anomaly is defined as an observation that deviates so significantly from other observations as to arouse suspicion from the view of data distribution. Figure 1 visualizes the definition of high-dimensional anomalies that are projected onto 2-dimensional space, where point P1 and point P2 and these points in the region R2 are defined anomaly instances. These points in the region R1 are regarded as normal instances.
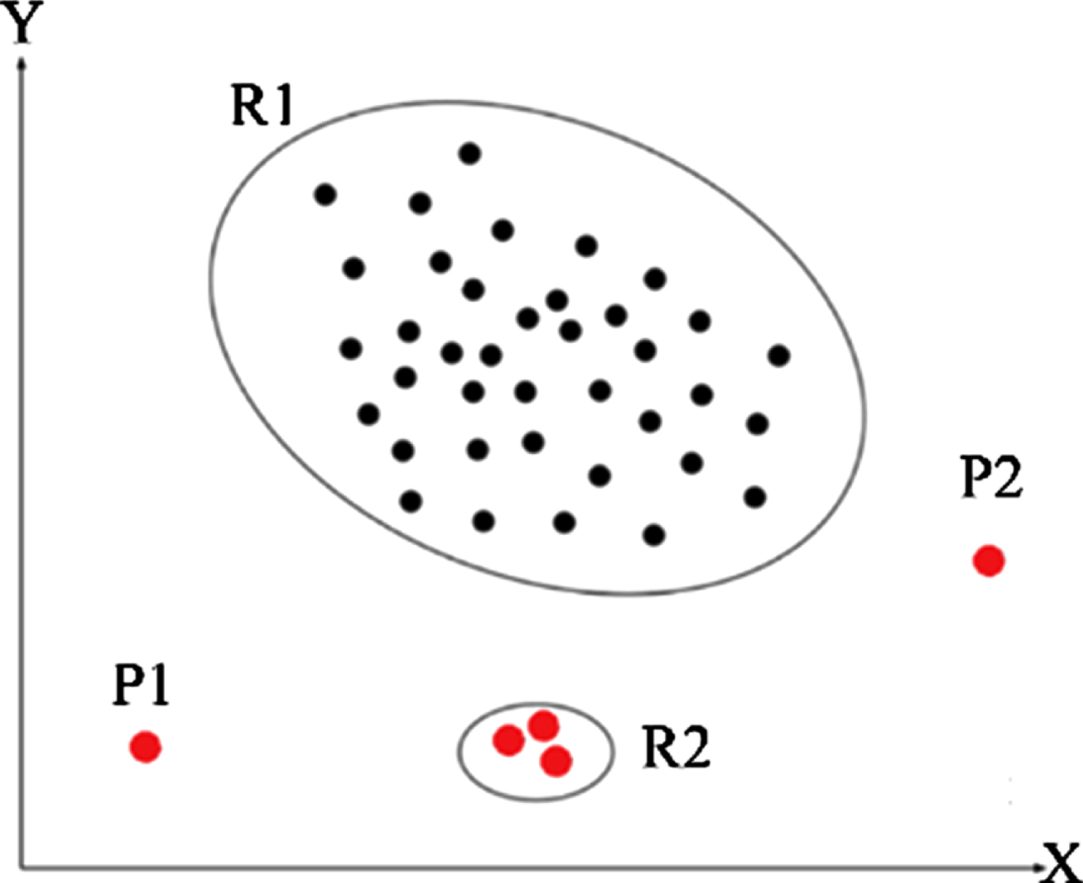
Definition of anomalies. It is cited by the [1]. Red circles are regarded as anomaly instances. Black circles are normal instances.
Pang [49] et al. define that anomaly detection is regarded as the procedure of detecting data instances that significantly deviate from the majority of data instances. Similarly, we give the definition of anomaly detection in this work. The details of symbols are interpreted in Appendix Table 3.
The scheme contains feature extraction stage, feature separation stage and class label output stage. Because complex high-dimensional space is not beneficial for the searching of anomalies, using the encoder extracts the low-dimensional features from X in feature extraction stage. By doing so, favorable space environments can be created for anomaly detection. Utilizing the SVM separates anomaly and normal features in feature separation stage. And the number of anomaly features are estimated by the Chebyshev’s theorem to promote the separated precision. Finally, the decoder sends out the learned class labels in class label output stage. The details are as follows.
(1) Feature extraction
The autoencoder with multiple hidden layers is designed to extract features, illustrated in Fig. 2. The error e PO between the prediction and the output is obtained, and the label vector V label is generated according to the prediction results. Thereafter, e PO and V label implement the dot product operation, where ⊗ represents the dot product operation. The results of the dot product are added the loss function. The label vector V label is to strengthen the model to learn normal class labels. If the predicted result is normal, there generates a normal class label +1, and let V label = [1]. Similarly, if the predicted result is anomaly, there generates an abnormal class label -1, and let V label = [0]. Label vector V label is a unit vector consisting of zero and 1. Eq. (1) gives the loss function L function of the autoencoder.
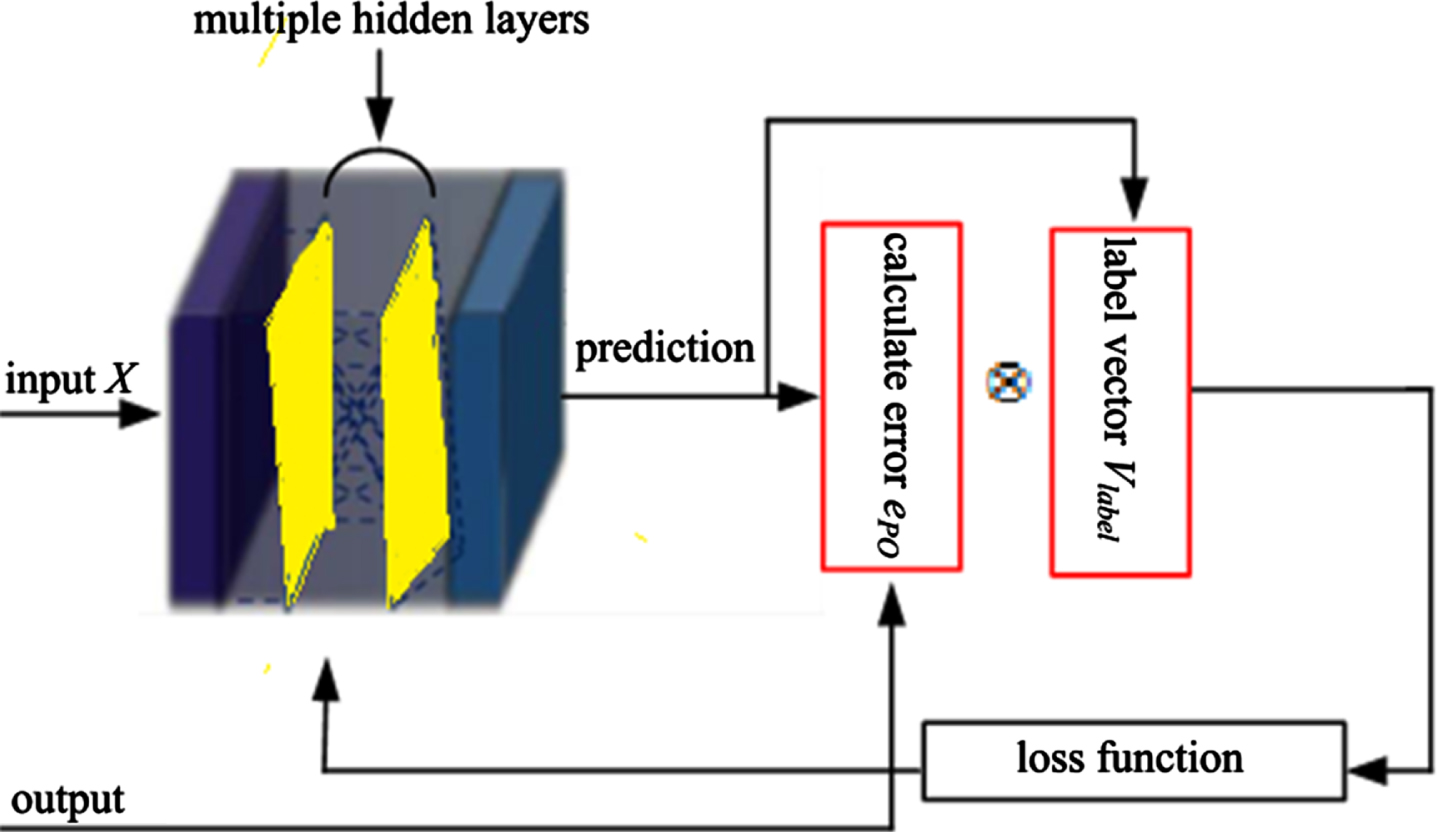
The autoencoder. It has multiple hidden layers, and the dot product operation is introduced.
Where ζ is an activation function. w, b are the weight and the bias, respectively. x
i
,
(2) Feature separation
Normal features and abnormal features can be separated in the extracted features, due to the difference between the both, the SVM can separate them. The SVM can be given as follows
Where ξ is a slack variable. θ > 0 is just a penalty item and is not a training parameter. y
i
is the feature in definition 1. c
i
is the corresponding label of y
i
.
Using Lagrange function [53] covert Eq. (3) into Eq. (4) according to KKT (Karush-Kuhn-Tucker) [53]. As follows
Where α i > 0 is the Lagrange multiplier. κ is a positive definite (p.d. in Lemma2) kernel function satisfying the Mercer theorem (i.e., Lemma 1). The [53] gives the derived procedure.
The Matern52 kernel [54] is use as the kernel of the SVM, since it can make the radius to be warping concave and non-decreasing [54, 55], more areas with small radii can be observed.
Where r1, r2 are the kernel parameter and kernel radius, respectively. A1, A2, A3 are constants.
(3) Abnormal feature estimation
The Chebyshev’s theorem, i.e., Lemma 3, estimates the number of abnormal features because of determining the upper regarding the percentage of the data that exists within λ number of standard deviations from the mean [52]. That is, the Chebyshev’s theorem can estimate that the percentage of abnormal feature quantity is lower than 1/λ2 [52]. Hence, let parameter θ in Eq. (3) be not greater than 1/λ2, that is, Eq. (3) is converted into Eq. (6), as follows
Figure 3 displays the architecture of the model, which consists of the encoder module, the SVM module and the decoder module. The encoder module is used to extract the features from the input data, which corresponds to the feature extraction stage in Section 3.2. Using the SVM module separates abnormal features from normal features, corresponding to the feature separation stage. The decoder module sends out the learned class labels, similarly, this corresponds to the class label output stage.

The architecture of the model. Encoder module and decoder module contain multiple hidden-layers, respectively.
Since the proposed model consists of the autoencoder and the SVM, namely AESVM, the objective function O (L
function
, f) of AESVM contains the loss function L
function
of the autoencoder in Eq. (1) and the function f of SVM in Eq. (4), having that
Algorithm 1 displays the training of AESVM. The benchmark dataset is divided into training set B train and validation set B val in step 1. The optimal parameter values is obtained in the procedure of step 2 to step 16, where the optimal hidden-layer quantity ϒ Opt is obtained in the procedure of step 4 and step 12. Similarly, the optimal neuron quantity Π Opt is obtained in step 3 to step 15. After gaining the optimal parameter values, using training dataset TrainingSet trains AESVM, illustrated in step 17 to step 22. Through iteratively learning the objective function O (L function , f), the hyper parameters are updated. Then, the training is terminated until the hyper parameters can converge. Once AESVM is trained well, training accuracy TrainingAcc and class label C are sent out.
Algorithm 1. Training of AESVM.
Datasets
Ten high-dimensional UCI (University of California Irvine) datasets were selected from different data dimensions, including two benchmark datasets B1, B2 and eight validation datasets U1-U8, as shown in Table 1. Benchmark datasets B1 and B2 are used to test parameters of AESVM. Datasets U1-U8 are used to verify AESVM and competitors. The ten datasets were pretreated by the manner in [56].
Details of ten UCI datasets
Details of ten UCI datasets
We also generated 5 high-dimensional datasets without noise, denoted S1-S5, and 5 low-dimensional datasets containing noise, namely N1-N5. The ten synthetic datasets are used for verify the effects of noise and data dimensionality on detection performance, illustrated in Table 2. For the ten UCI and the ten synthetic datasets, the 70% of them were used for the training of our model, and the rest 30% were used for testing of our model.
Details of ten synthetic datasets
Based on the architecture of AESVM, these competitors were considered, including deep hybrid-based methods DNN-SVM [41] and DAE-KNN [42], distance measurement-based method B-KNN [18], reconstructed error-based method MF [27], classification-based method OC-SVM [31], deep feature representations-based method SAE [37]. In addition, to verify the effort of the proposed dot product operation, we also designed a benchmark model referring to AESVM, namely BM-AESVM. Noting that benchmark model BM-AESVM has the same architecture and parameter configurations as AESVM, but without importing dot product operation.
We carefully studied AESVM parameters of having effects on learning results. Sigmoid function is used as the activation function of AESVM. Since the output of Sigmoid is just zero or 1, it is more suitable for the judgment of abnormal and normal instances. Studies indicate that neuron quantity is hard to be determined by experience [57]. Hence, the number of neuron Π ∈ {10, 30, 50, 70, 90, 100, 150} is determined within a certain range through validation testing. Similarly, the number of hidden-layer ϒ = {1, 2, 3, 4, 5, 7, 10, 20, 30} is determined within a certain range through validation testing. For the six competitors, we utilized the parameters provided by the corresponding literature.
Assessment metrics
Accuracy metric, F1-score metric and G-score metric are used as the evaluated indicators.
Where TP, TN are the proportion of correctly predicted anomaly instances and correctly predicted normal instances, respectively. FP, FN are the proportion of incorrectly predicted anomaly instances and incorrectly predicted normal instances, respectively.
Experiment I. Parameter testing. To test parameters Π, ϒ of AESVM and BM-AESVM, the two models were run on benchmark datasets B1 and B2. Then, the run results were analyzed.
Experiment II. Ability comparisons of anomaly detection. To compare AESVM with competitors, they were run on validation datasets U1-U8, and the results were observed.
Experiment III. Affected indicators of detection accuracy. To analyze the effect factors noise and data dimensionality, the AESVM and the competitors were run on the ten synthetic datasets S1-S5 and N1-N5, and then we observe the results.
Ablation experiment. To verify the effort that the proposed dot product operation strengthens the learning of the model to class labels. In Experiment II, the ablation was supplemented.
The corresponding algorithms of these models are developed by using Python 3.8 in Tensorflow 2.0 of Linux operating system, then they were run on the Server with Intel i5 3.4 GHz CPU, 32 G memory.
Results and discussion
Parameter testing
Figure 4 unveils the testing results of the parameters, showing that our model AESVM and the benchmark model BM-AESVM obtain the best performance values in metrics Accuracy, F1-score and G-score when the number of neurons Π is equal to 50, and that of hidden layers ϒ is equal to 4. In Fig. 4(a), as the number of neurons start to increase from 10 to 50, the performance both AESVM and BM-AESVM augment. Once the values of neuron scale exceed 50, the two models decline in detected performance, this is because they happened over-fitting. Similarly, in Fig. 4(b), the number of hidden layers reach 4, the optimal performance is obtained for the two models. These demonstrate that the performance of AESVM and BM-AESVM gains the optimization when Π and ϒ reaches a certain scale on all considered case. Consequently, let Π, ϒ be equal to 50 and 4 in subsequent experiments, respectively.
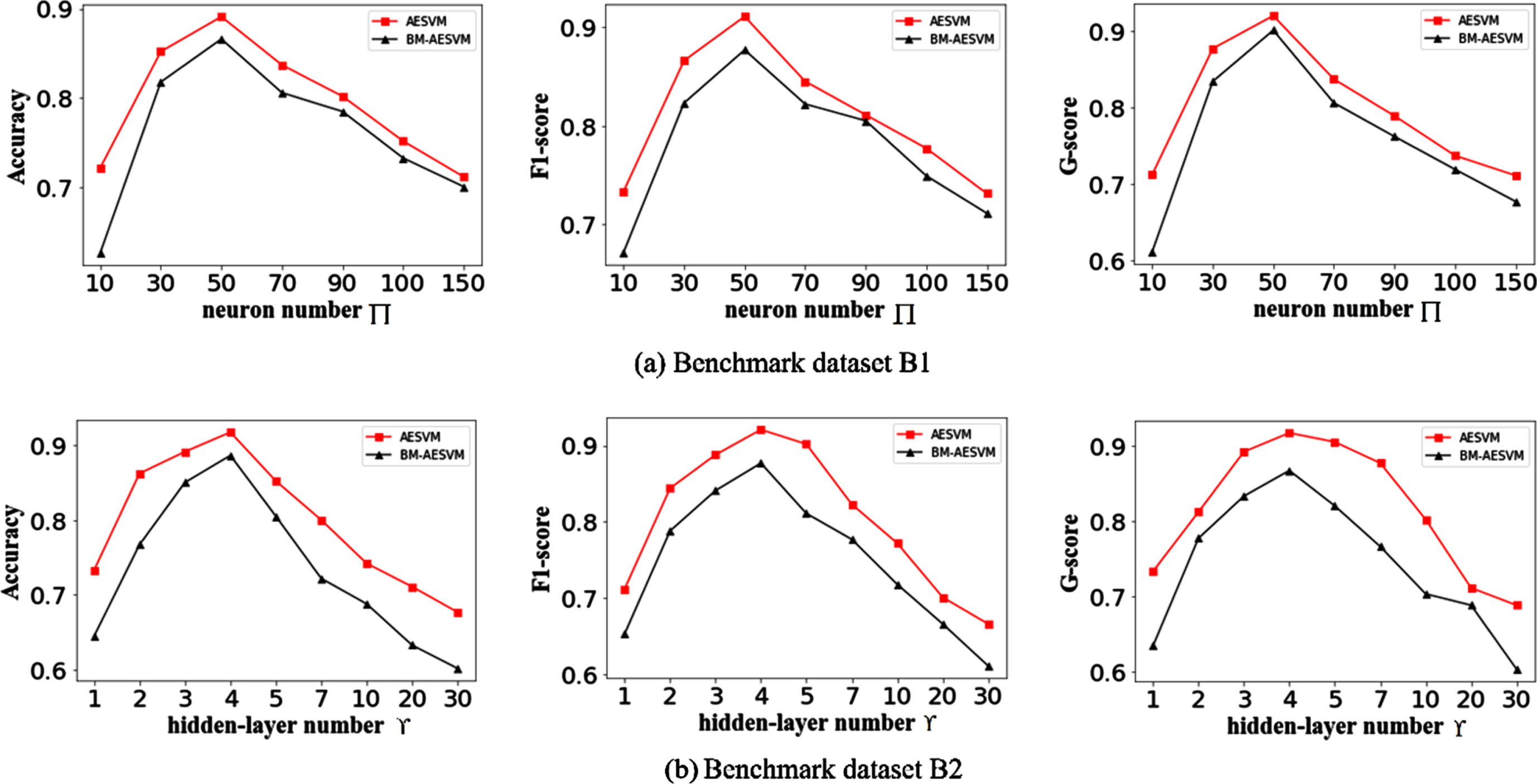
Results of parameter testing on benchmark datasets. (a) displays the testing of neural neuron quantity on dataset B1. (b) displays the testing of hidden-layer scale on dataset B2.
Results in Fig. 5 show that AESVM outperforms four competing models on most datasets, e.g., U3-U8. Especially, on dataset U8 (dimension = 5408, anomaly ratio = 0.86%), AESVM has outstanding advantages over the competitors. This means that AESVM suffers less negative effects caused by the curse of dimensionality in handling anomaly detection for high-dimensional data. These detection results obtained by distance-based measurement, e.g., B-KNN and MF, are not as good as the other competitors on most datasets, which mean that distance-based measurement is not suitable for the anomaly detection for high-dimensional data.
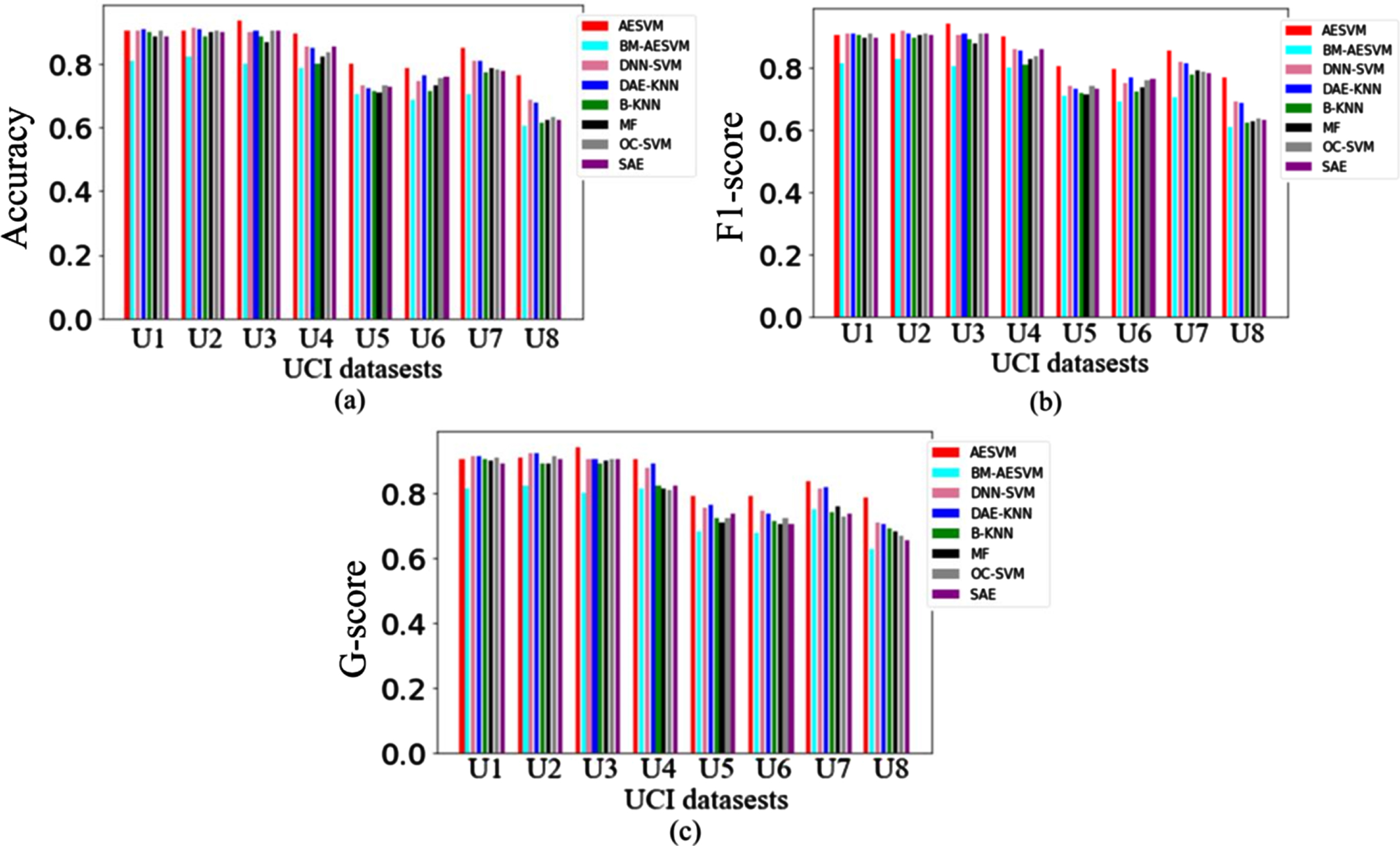
Detected results on the eight UCI datasets. (a), (b) and (c) display the detected results using different assessment metrics.
Results of ablation experiments in Fig. 6 show that the detection ability of AESVM is superior to that of BE-AESVM. Particularly, there are significant differences in detection performance as the dimensions of dataset U1-U8 increases. Unfortunately, on dataset U8 (dimension = 5408), BE-AESVM obtains poor detection performance. This implies that even the hybrid model based on deep network structures is vulnerable to negative effects of high dimensions. By contrary, AESVM suffers less such negative impact because of implementing the dot product operation. Together, these confirm that the proposed dot product operation is beneficial for the model to resist the curse of dimensionality to a certain extent.
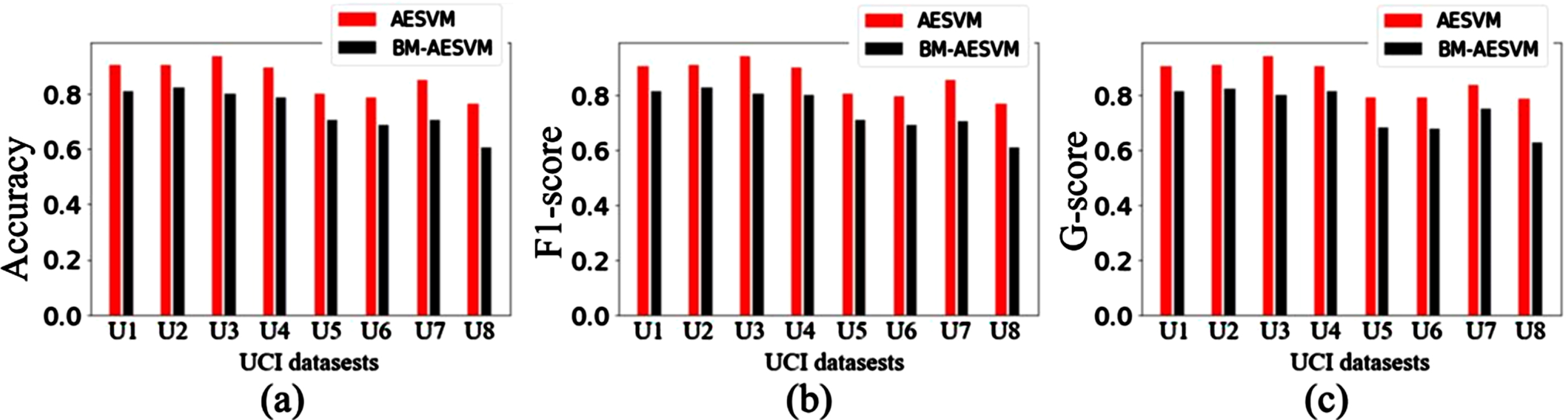
Results of ablation experiments.
Figure 7 unveils that the eight models (AESVM, the benchmark model BE-ASESVM and the six competitive models) begin to drop in detection performance as noise ratio increases or when data dimensionality increases. Nevertheless, AESVM is still better than BE-ASESVM and the six competitors in detection performance. Because our AESVM utilized the Chebyshev theorem to estimate the number of anomalies, which alleviates noise interference to a certain extent. Compared Fig. 7(a) with Fig. 7(b), it can be seen that the noise has more negative effects on the eight methods than data dimensionality does. Hence, suppressing noise interference is more effective than overcoming the curse of dimensionality in improving detection accuracy.
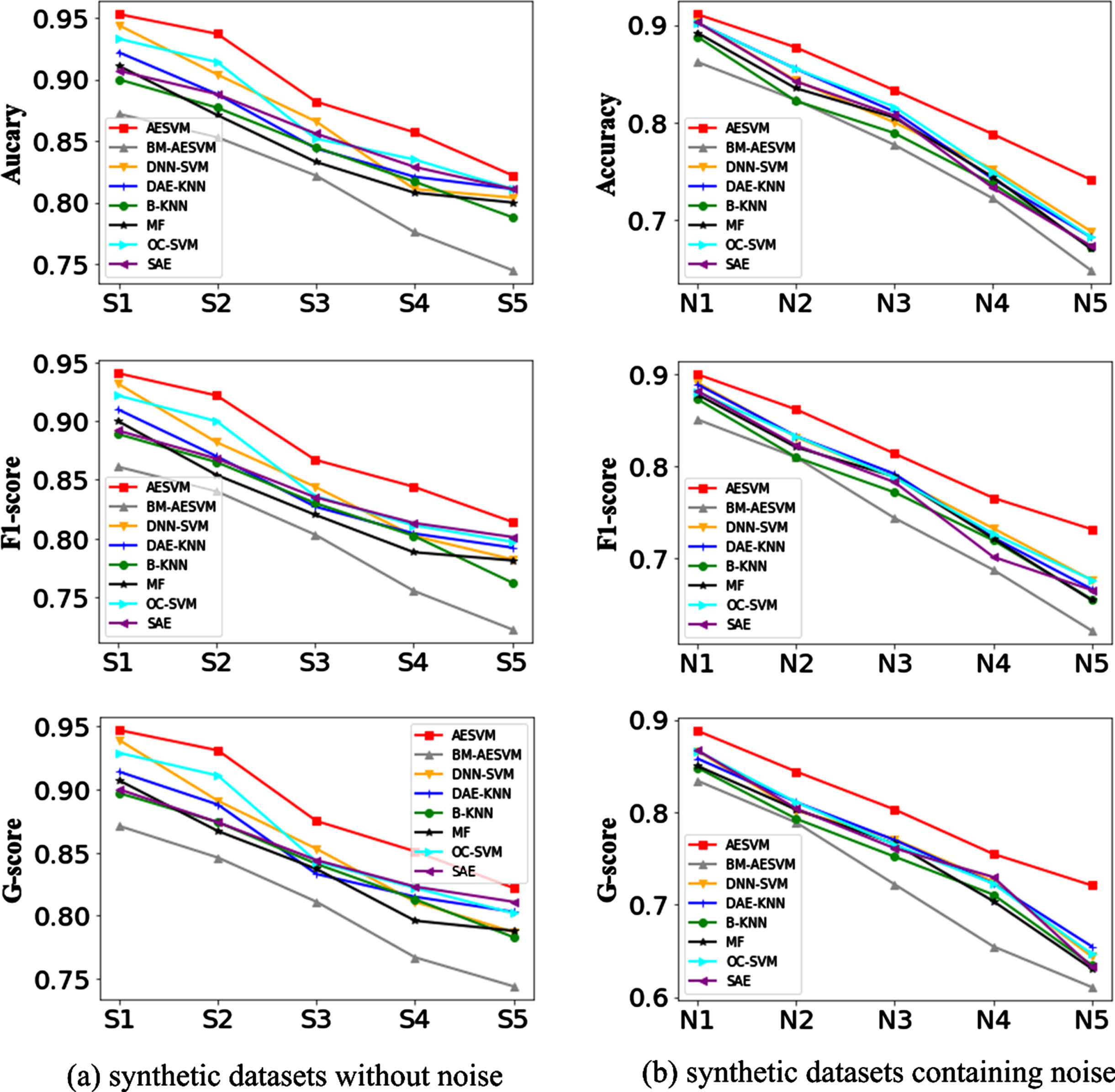
Comparison of negative indicators.
Conclusion
This paper proposed a hybrid method of combining the autoencoder with the SVM aiming at anomaly detection upon a high-dimensional space. The key thought is that using the autoencoder extracts the features from high-dimensional data, then the SVM achieves the separation of abnormal features and normal features. To increasing the mined precision of abnormal features, Chebyshev’s theorem is used to estimate the upper of the number of abnormal features. Meanwhile, the dot product operation is proposed to strengthen the learning of the model to class labels. Experiment results show that our method gain that the detected accuracy is 0.766, when the data dimensionality is 5408. Numeral results indicate that our method defeats competitors in detected performance for the considered cases. The findings indicate that the reinforcement learning of class labels improve the ability of detectors to detect anomalies. In terms of noise resistance and overcoming the curse of dimensionality, the former can carry out more efforts than the latter. In future work, we will explore anomaly detection under noise interference. Noise can mask anomalies so that anomalies encounter much trap during mining process.
Data availability
Data will be made available on request. The data is cited at http://archive.ics.uci.edu/ml/datasets.php?format=&task=&att=&area=&numAtt=&numIns=&type=mvar&sort=nameUp&view=table
Ethical approval
This manuscript does not contain any studies with human participants or animals performed by any of the authors.
Competing interests
The authors declare no conflict of interest.
Contributions
Zhuo Jiang proposed the methodology and wrote the manuscript. Xiao Huang implemented the source code. Zhuo Jiang, Rongbin Wang designed the experiment.