
Abstract
The purpose of the Chinese similar case matching task is to compare the similarity of two case texts with a given anchor text and find out which text is more similar to the anchor text. In the area of law, it plays an important role and has been of interest to many researchers. Previous approaches have compared legal texts only at the text semantic level, without incorporating article information of law. In addition, the position correlation of words in case texts is often important, but it has not been considered in previous approaches. This paper proposes a method which extracts features from the semantic similarity level and from the level of related articles of law, respectively, to enable similarity comparisons of legal case texts. When similarity comparisons are made at the semantic similarity level, a novel capsule network method is proposed based on siamese structure that introduces the position correlation and the routing mechanism within the capsule network is improved so that deep text features between case pairs can be learned. When similarity comparisons are made at the level of related articles of law, related articles of law are selected and coded and interacted with the case text features to generate legal features. Experiment is conducted with a real-world legal text dataset, and the proposed model outperformed all baseline models, demonstrating effectiveness of the proposed model. Further, to confirm the generality of the improved capsule network proposed in the paper on long text datasets, this paper also carried out experiments on two long text datasets, demonstrating effectiveness of the improved capsule network proposed in the model.
Keywords
Introduction
In a standard legal system, the most similar past cases can provide adjudicatory advice for current cases with similar elements of the case. To arrive at a just verdict, legal practitioners often devote considerable time and effort to searching for precedents that resemble the cases they are currently dealing with. Therefore, finding similar cases automatically from a large number of case texts has become a problem that needs to be addressed. Not only does this reduce the heavy lifting for legal professionals, it also benefits the rule of law. In view of the fast-paced progress of deep learning methodologies, given the significant availability of legal case data in the public domain, the legal field has recently seen a significant surge in the utilization of artificial intelligence (AI) technologies, indicating a growing interest in the application of AI within this domain. Thanks to the development of neural network techniques, legal case matching tasks have also been performed using neural networks and achieved decent performance. Several previous works exist [1, 24] focus on encoding fact descriptions as continuous vectors and then utilizing fully connected layers to compute the similarity of case texts. The former approach encountered difficulties in identifying the most similar text cases due to the nuanced differences between them. Siamese networks and capsule networks have shown promising results in NLP, as evidenced by studies such as [4, 33]. Capsule networks are a group of neural networks that represent the probability of the existence of an object by a vector whose direction represents the property of the object and whose vector length reflects the probability of its property. The properties of these capsule networks are useful for extracting features of multi-element features of legal cases. [11, 28] exploit capsule networks [34] based siamese network to automatically learn some element features of legal texts.
Table 1 shows an example of a legal text. A legal text usually consists of three parts, which we have marked with three separate colors. The first is to the request of the record litigant, then to the record of the description of plaintiff of the facts and reasons, and finally to the record of the facts found at the hearing. After analyzing the legal text, it can be concluded that of the three parts mentioned above, the second part is more important than the first and the last part is more important than the second. Therefore it is feasible to introduce position correlation to improve the performance of the model. However, previous studies have not introduced position correlation into the model. Intuitively, there is a high degree of similarity between cases citing the same or similar article of law, and therefore, article information of law is applied to the model. The previous approaches do not incorporate information of articles of law.
An example of legal text
An example of legal text

This paper proposes a method which extracts features from the semantic similarity level and from the similarity level of related articles of law, respectively, for Chinese legal similarity case matching task. At the semantic similarity level, a novel capsule network method is proposed based on siamese structure that introduces the position correlation and the routing mechanism within the capsule network is improved. The proposed capsule network method interacts the information of the texts that need to be compared after encoding the texts, which has the advantage that the model can focus on the relevant information between two texts, and the features of the more similar texts will be more similar after the feature interaction. The introduction of position correlation can help the model to focus on the features that are in the position with high position correlation and reduce the effect of noisy data in the text on the model. In addition, the proposed improved capsule network approach can improve the feature extraction ability of the model through the introduction of position correlation and the improvement of the routing network, which can help the model to better distinguish the degree of similarity of text pairs. At the similarity level of related articles of law, relevant articles of law are selected and encoded, compared with text features to generate legal features that are applied in subsequent calculations. To be specific, the proposed method includes the fact encoder layer, the capsule network with position layer, feature fusion and comparison layer, output layer. The fact encoder applies convolution neural generate features of fact description and produces primary capsules in capsule network. Then a capsule network with position correlation layer generates element capsules based on the results of primary capsules. Some cases do not provide relevant articles of law at the end of the case, firstly, it is necessary to select some relevant articles of law from the book of articles of law, then encode the articles of law and apply the attention mechanism to interact with the text features to generate relevant features of articles of law. A fully connected layer computes the similarity between the relevant legal text features of two case texts. A feature fusion and comparison layer computes vector distances between features based on their outputs from capsule layers and the article of law layer. A final similarity result is produced by the output layer. In the proposed method, the siamese [33] structure is applied to triplets of the case. In the siamese structure, each case triplet has the same parameters.
Here is a concise overview of the contributions in the paper: (1) A method which extracts features from the semantic level and from the level of similar articles of law is proposed to capture the similarity of text for the matching of Chinese similarity cases.
(2) An approach for fusing position correlation in capsule networks and improving dynamic routing in capsule networks is proposed. The improved capsule network improves the feature correlation of information between text pairs. (3) The knowledge information of law articles is applied to the task of case similarity matching of legal texts at the similarity level of related articles of law to improve the performance of the model. (4) Experiments are conducted with a real-world legal text dataset, and the proposed model outperforms all baseline models, demonstrating that the proposed model is effective. Further, it is proposed to validate the generality of the improved capsule network proposed in the model by utilizing two long text datasets. The result of the experiment indicate that the improved capsule network proposed in the paper is suitable for accomplishing the objective of determining similarity between lengthy documents. The paper is structured as follows: Section 2 concludes with a concise overview of the work related to this topic. Section 3 presents the proposed method. Section 4 reports the experiment results and analysis. Section 5 reports the results of experiments conducted on two Chinese long text similarity datasets to demonstrate the improved capsule network proposed in the paper. Section 6 is the discussion section. Section 7 concludes the paper.
Text similarity matching
The goal of text similarity matching can be thought of as computing the degree of semantic relevance between text pairs [6–9]. Text similarity is the basis of many NLP studies, such as information extraction [10], human-chine dialogue answering [12] and knowledge inference [18], among others. Therefore, the study of matching semantic relevance between texts has recently received attention. In traditional work, some methods are based on artificially designed feature rules, statistics of commonly used words between texts, editing distances, and other methods to calculate similarity matching between texts. Some work is based on embedding models to map text to word embedding [19, 49], and uses word embedding to calculate text similarity. Common word embedding models include Term Frequency Inverse Document Frequency (TF-IDF) [25] and Bag of Words. In recent years, because of the advancing rapidly of the technology of natural language processing, the performance of text coding technology has also been improved, which has improved the problem of sparse lexical vectors and greatly improved the ability to extract semantic representations of text. Affected by this, the model effect of text similarity matching task direction has also been greatly improved [46] proposed an approach for measuring text similarity based on different similarity methods by combining the structure similarity and word-based similarity. Hu et al. [23] introduced CNN, which are often applied to images, to the sentence similarity matching task. Wan et al. [26] introduced a model based on deep learning that applies sentence representations in multiple positions to compute the similarity of two sentences. Wang et al. [27] introduced a matching model based on bilateral multi-view for encoding sentences vectors from two directions to achieve sentence similarity matching. Paheli et al. [50] proposed to augment the PCNet with the hierarchy of legal statutes, to form a heterogeneous network Hier-SPCNet for computing similarity between two legal case documents based on a precedent citation network among case documents (PCNet). Recent transformer models, such as BERT and sentence-BERT, are purely feed-forward (dispensing with recursion), but use position embeddings and self-attention layers to allow an order-sensitive representation of the document to emerge. These networks can be used in different ways to predict document similarity [52]. Wei et al. [55] improved WMD method using the syntactic parse tree, called Syntax-aware Word Mover’s Distance (SynWMD) for text similarity by incorporating word importance and taking inherent contextual and structural information in a sentence into account. Over the years, models based on the siamese network [33] have achieved good performance in many tasks. The same encoder of the siamese network processes the input two sentences by sharing the weights. Siamese networks are widely applied in text similarity comparison tasks. Saedi et al. [47] proposed a Deep-Siamese Bi-LSTM-model for feeding out the embedded vectors from BERT model and predicted the similarity of the text pairs. Viji et al. [48] proposed a new hybridized approach using Weighted Fine-Tuned BERT Feature extraction with Siamese Bi-LSTM model for text similarity. Han et al. [51] introduced the Siamese Attention-augmented Recurrent Convolutional Neural Network (S-ARCNN) that combines multiple neural network architectures for measuring document similarity. In each subnetwork of S-ARCNN, a document passes through a bidirectional Long Short-Term Memory (bi-LSTM) layer, which sends representations to local and global document modules. Revathy et al. [56] proposed a hybrid approach integrating Deep Siamese Bi-LSTM-Bidirectional Long-short term Memory network and GRU-Gated Recurrent-Unit neural network training model for semantic text similarity. Juan et al. [53] applied semantic methods, the cosine similarity algorithm, and fuzzy logic to improve the text similarity matching of documents. The model proposed in this paper applies the siamese network to encode two input legal texts to achieve the text feature extraction task.
Similar Case Matching
Ashley et al. [29] proposed a method extracting features, properties in the case document and evaluating the obtained features, not for all sentences. Saravanan et al. [30] built a case ontology that is applied to help model extract text feature. Kumar et al. [31] proposed an approach of calculating similarities using the cosine function between the embedding model and every term found in the legal case document. Raghav et al. [32] applied document similarity fusing the quote information with the aim of finding out the most similar document of the candidate dataset. Hong et al. [45] proposed an approach that incorporates legal features into a model for similar text matching in the legal domain. In this paper, a novel model based on Siamese capsule network with position correlation is proposed to learn features of pairs of legal documents with the semantic matching of similar cases in legal texts.
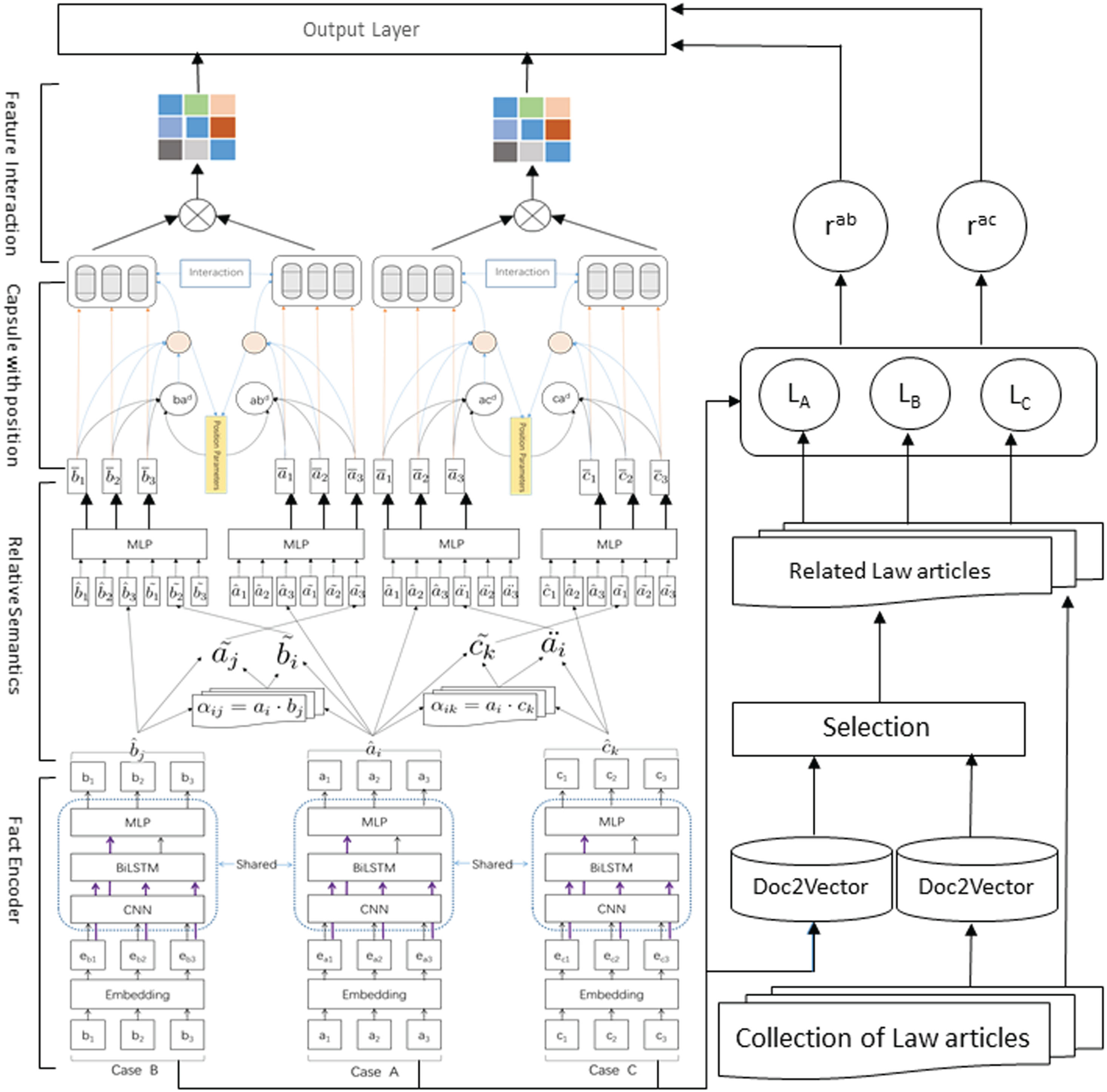
Overview of the proposed method
Fig.1 displays the overview of model, which is designed to process a group of three factual descriptions presented as text. These descriptions are referred to as Case A, Case B, and Case C, respectively. If B is more similar to A, the model outputs 1. If C is more similar to A, the model outputs 0. The proposed approach consists of several layers: Fact encoder. The input sequence is first processed by a pre-trained BERT model to obtain embeddings, which are then further processed by CNN and BiLSTM layers to extract local and contextual features from the text. Capsule network with position layer. This layer applies a capsule network to obtain the feature information of the input text sequence by applying capsule vectors instead of scalars. In this layer, a position structure in capsule network is proposed for learning position information, document embedding and extracting interaction information between the capsules of two text pairs. Texts feature interaction layer. The text feature interaction layer applies the features obtained from the capsule network layer to interact with other text feature representations, resulting in an interaction matrix. Related articles of law selection and enoder layer. The role of this layer is to select legal texts that are similar to the case text and encode them to generate legal text features after interacting with the features of the case text. Output layer. This layer applies a multi-layer perceptron (MLP) classifier to generate final results.
Fact Document Encoder
As input, the model receives a sequence of text characters. The input text serialized representations of case A, B and C are D
A
= (c1, c2, . . . , c
m
), D
B
= (c1, c2, . . . , c
n
) and D
C
= (c1, c2, . . . , c
l
). m, n, l denote the length of case A, B and C. Since the raw legal case data contains a lot of information that is not important for subsequent prediction algorithms, such as intonation and stop words in utterances. This information often interferes with the subsequent prediction algorithm and seriously reduces the accuracy of the algorithm. Therefore, a dictionary of deactivated words and a dictionary of words specific are constructed to the legal industry. The deactivation lexicon is designed to filter out inflectional words and deactivation words that are not useful to the subsequent prediction algorithm. Based on the construction of the above two types of dictionaries, deactivate words is splitted for each utterance in the text. Removing the meaningless words in the original utterance while retaining the legal field terminology, the application of the constructed dictionary can avoid spliting word errors as well as the loss of key words. The lexical deactivation operation can effectively eliminate information that is irrelevant to the subsequent prediction algorithm and retain important textual information. After completing the above processing, the text in paragraphs is processed, each paragraph containing several sentences and each sentence containing several characters. The processed vocabulary is fed into the pre-trained model. The pre-trained BERT model is applied to generate the embeddings e
i
of i-th character in the input case texts A, B, C. The e
i
∈ R
h
represents i-th character embedding generated applying the BERT model. The CNN is applied to learn local features of the input case texts A, B, C. ei:i+j is applied to represent the concatenation of word embedding (e
i
, ei+1, . . . , ei+j) by BERT in case text D, D ∈ {A, B, C}. Multiple kernels with different window sizes (h1, . . . , h
t
, . . . , h
r
) are adopted. In order to generate a convolution vector representing the case text, an operation is introduced that convolves the text with a window of size h
t
, as described by Eq.(1). For each kernel W
t
, convolution operation is applied on the whole input sequence with padding at both ends of the sequence. Local features are extracted by applying a fully-connected layer after concatenating the results of regular operations on different kernels. The following equations are applied to the calculation:
Once the local feature L
i
of i-th word in text and contextual feature H
i
of i-th word have been obtained, a MLP layer can be applied to fuse the local features and context features as the input of the next layer.
In this layer, the principle of internal attention is applied to enable the interaction and fusion of information between the two texts being compared. The text A and text B are taken as examples to introduce the calculation of information interaction process. The calculation of the information interaction process between text A and text C is the same operation. The weight of attention for each character is calculated in text A and text B. The weight of attention is defined as ɛ
mn
. In this layer, the attention weight for each input tuple is computed as follows:
This layer takes a document pair A and B as input example to introduce the calculation process of capsule network. It is shown in Algorithm 1, where the pseudocode for the improved capsule network is given. The input of text A and text B in capsule are
Position correlation and document-level embedding
The position parameter p is dynamically adjusted by means of multiple iterations in order to obtain more accurate position importance features in proposed method. Specifically, a position importance parameter p is set and initialised. The parameter p is initialized based on a statistical analysis of the text as follows:
The features generated by the fusion of local and contextual features are applied as input to the capsule network. The original capsule network contains a primary capsule network layer and a digital capsule network layer. We apply the digital capsule layer directly in the proposed capsule structure due to the local features extracted by the convolution layers already fused in the input features of the network.
The position importance parameter p;
The iterative number of dynamic routing: κ;
The iterative number of generating document embedding: τ;
Update step: η
v ab , D ab
1: p ab = p
2:
3: D
ab
=
4:
5:
6:
7: Initialize
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
20:
21:
22:
23:
The general dynamic routing calculation process of the capsule network is as follows:
In order to take position correlation into account in the network structure, the improved dynamic routing of capsule is proposed. The Eq.(26) is improved and the improved equation is as follows:
The output element capsule in section 3.3 are v
ab
, v
ac
, v
ba
and v
ca
. The average pooling operation is applied to obtain the average pooling features of v
ab
, v
ac
, v
ba
, v
ca
. The operation of average pooling is:
Real legal cases are decided according to the relevant applicable legal provisions. We collected a large number of legal articles from law books and applied them to the study of legal text similarity. Some legal case texts give the cited law at the end of the text, and some do not mention the cited law. For those case texts in which no cited law is given, one task that needs to be completed is the need to identify legal texts that are similar to the text of the case. Here, ase A is taken as an example to get the similarity articles of law. Therefore, a number of related articles of law need to be selected broadly according to the type of case. For example, the case A belongs to the civil case text, then we choose the articles of civil law, forming a collection of N law articles L = (l1, l2, . . . , l
N
). The doc2vector method [39] is used to encode the collection of N law articles to generate document document vector of law articles. The doc2vector method also is used to encode legal case A to generate document document embedding of the legal case A. The cosine similarity algorithm is applied to calculate the similarity between the legal case A and each article of law, and results of similarity between articles of law and case A are sorted according to values from the higest to the lowest, the top 3 articles of law are selected as relevant articles of law for that legal text. Assuming that the representation of the selected relevant legal text is L = (l1, l2, l3), the embeddings of articles of law after encoded by doc2vector are denoted as
To accurately predict text B or text C which one is more similar to text A for the given triples (A, B, C), the similarity matching task can be defined a task of binary classification. Specifically, the feature distance between f
ab
and f
ac
is calculated, then the results are fed into a multilayer perceptron network to output the predictions. An MLP layer is applied to exploit the output of an element embedding comparison layer and generate probabilities as follows:
Dataset
We adopt the similar case matching dataset used in the China Artificial Intelligence and Law 2019 competition [1] to evaluate performance of the proposed model. All legal cases in the dataset are related to lending, and the degree of similarity between the texts in the dataset is recognized by legal professionals. A few statistics are presented in Table 2 for the Chinese legal dataset. The symbol maxl means the count number of words in the text that contains the most words, The symbol avgl means the average count number of words that contains the average words. A training dataset, validation dataset, and test dataset make up the dataset. Every element in the triplet is an actual legal case document. Every legal case document contains a description of the facts.
The statistics of Chinese Legal dataset
The statistics of Chinese Legal dataset
For the purpose of comparison with the proposed model, the following models are selected as baseline: Term matching methods (TF-IDF) [25]: TF-IDF is a statistical method used to calculate the importance of a word to a document in a corpus. The TF-IDF technique has found extensive application in the field of natural language processing. Siamese framework based methods BERT [15]. The BERT stands for Bidirectional Encoder Representations from Transformers, and it is a pretrained model that learns from a large scale of the unlabeled corpus. Siamese framework based methods CNN [13] (SiaCNN). A classic convolutional network structure for text similarity task. Siamese framework based methods LSTM (SiaLSTM). A classic recurrent neural network structure for text similarity task. Bidirectional Attention Flow [14]: It applies a multi-stage hierarchical framework that applies character-level, word-level, and context-level granularity to model text. ABCNN [16]. ABCNN is an improvement of BCNN by considering the relationship between two sentences as the introduction of attention in BCNN, adding inter-word contextual information and weighting the information extraction. SMASH-RNN [17]. A siamese hierarchical recursive network model based on multi-depth attention-based that is applied to semantic text matching of long document. It applies the structure of a document to learn the long semantics of the document. IACN [35]. An attention-based capsule network model for textual interactions modulo applying dynamic routing mechanisms for interactions to extract information about the interactions between cases. LFESM [45]. A method for Chinese similar case matching that apply the legal feature vector. In order to compare the results fairly, the extracted features by applying the regular expressions is removed and only kept the rest of the network structure of the model.
Implementation parameters
Similar to [1], this paper applies the accuracy as an evaluation indicator in this paper. The dims of the outputs of BERT and BiLSTM network are equal to 768. The convolution kernels is [1, 5]. The dynamic routing κ is assigned 3, while the capsule element dimensions capsule dim is set to 100 and the number of elements capsules capsule num is 30. Moreover, the dropout with the dropout rate at 0.1 is applied among each layer.
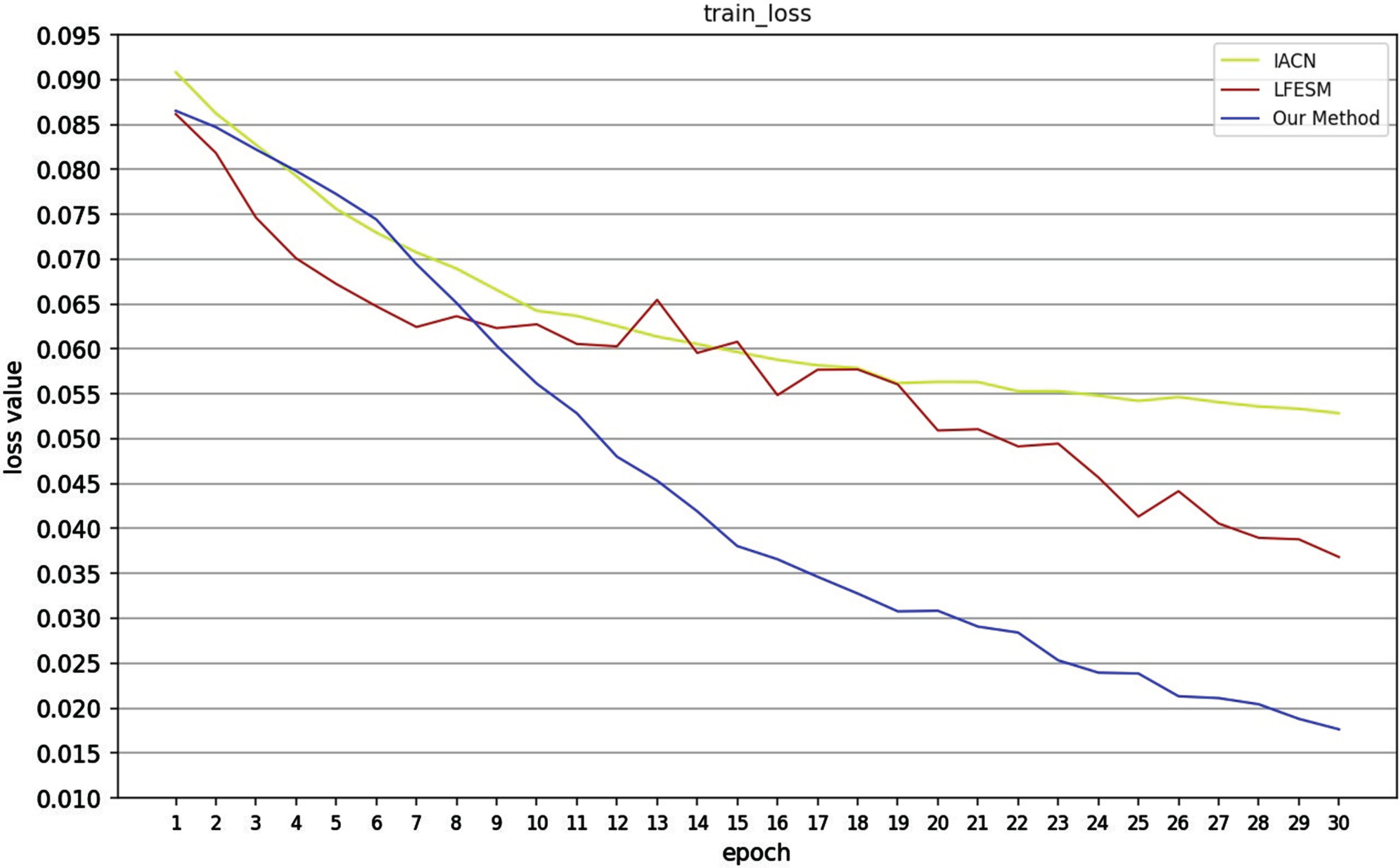
Train loss.
In this section, the proposed method is compared with baseline methods on the Chinese legal dataset. The experiment result is shown in Table 3 and the train loss of proposed model and some baselines over training epochs on train dataset is shown in Fig.2. The valid accuracy of proposed model over training epochs on validation dataset is shown in Fig.3. The test accuracy of proposed model over training epochs on test dataset is shown in Fig.4. From this table 3, the following results can be obtained: (1) The performance of traditional statistical methods (TF-IDF) is inferior to that of models based on deep learning. The reason is that the word embedding representatives generated by the TF-IDF model are sparse and lack rich semantic information. (2) The reason for this is that BERT cannot extract deep features of the text and lacks the ability to extract rich semantic information. (3) Compared with the traditional model, the deep learning model SiaCNN, BiDAF, SiaLSTM, IACN, LFESM can extract depth level of semantic text information of legal text. (4) The proposed model outperforms the baseline models. Specifically, the proposed model achieves 2.7% and 3.14% improvement in development and testing, respectively, over the LFESM that is the best baseline model. As shown in Fig.2, the loss value of the proposed model on the training set decreases relatively quickly as the training batches increase, and loss value of the proposed method is consistently lower than the other models in the figure after the 8-th batch. This indicates that the proposed model outperforms the baseline models. The proposed model exhibits an increase in accuracy on the validation dataset as the number of training batches increases, as depicted in Fig.3. Eventually, the model surpasses the baseline model in terms of validation accuracy.
Experiment results of comparing with baseline models on Chinese legal dataset
Experiment results of comparing with baseline models on Chinese legal dataset
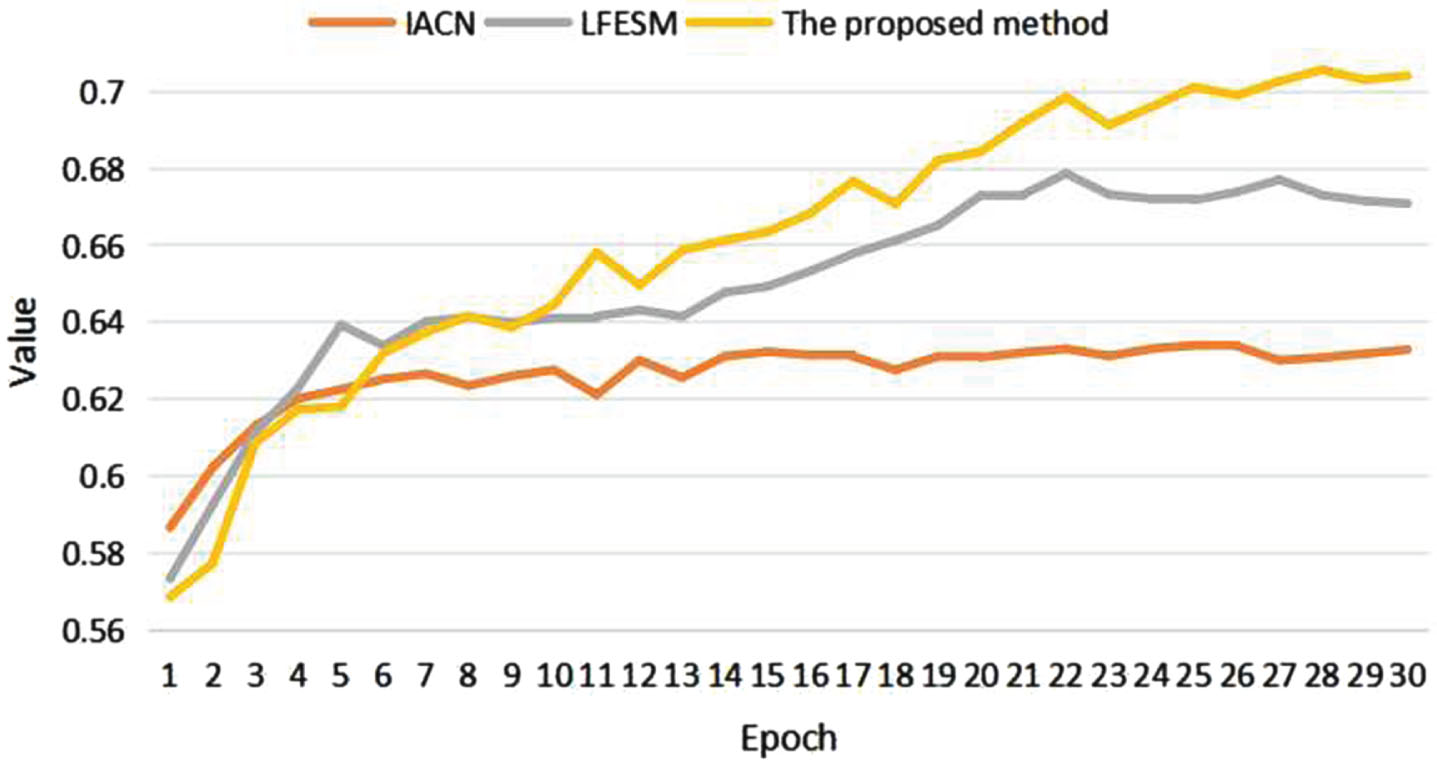
Eval accuracy.
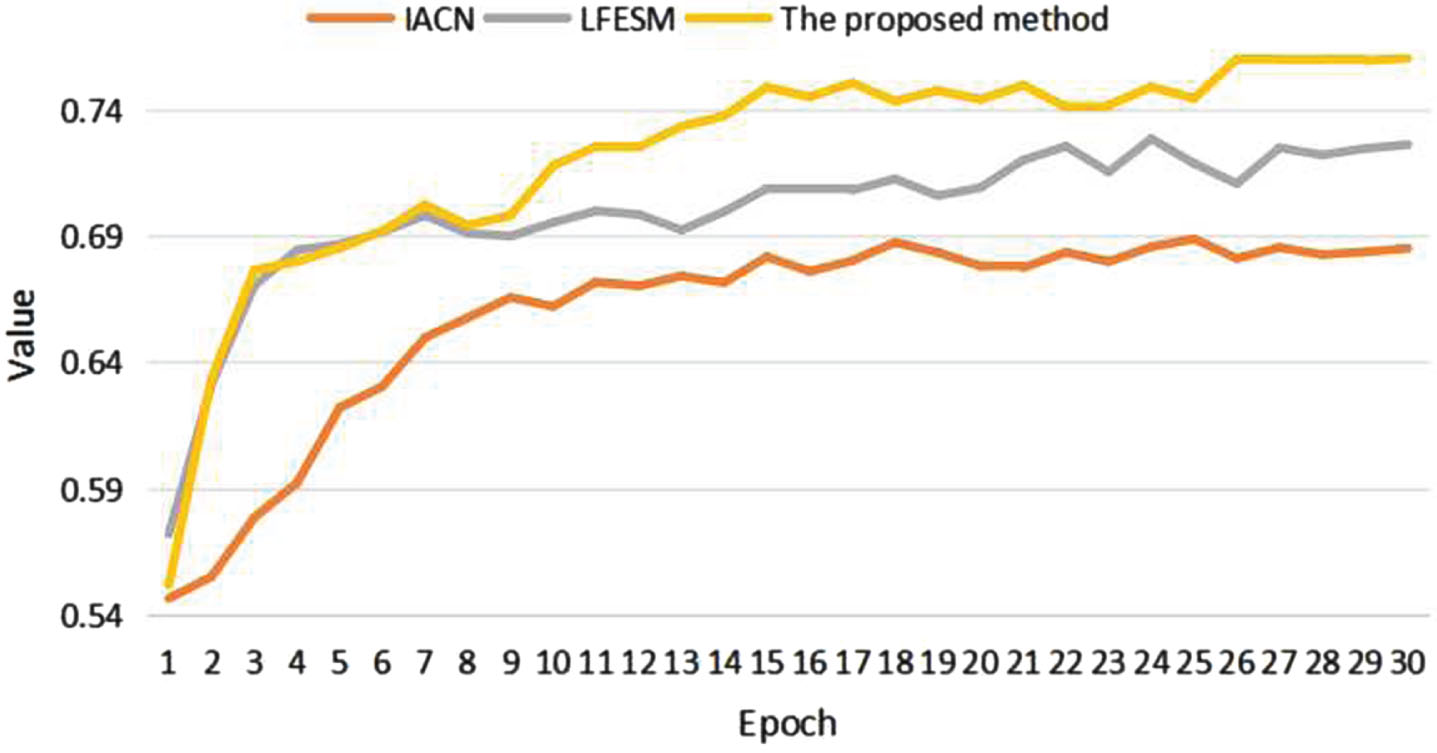
Test accuracy.
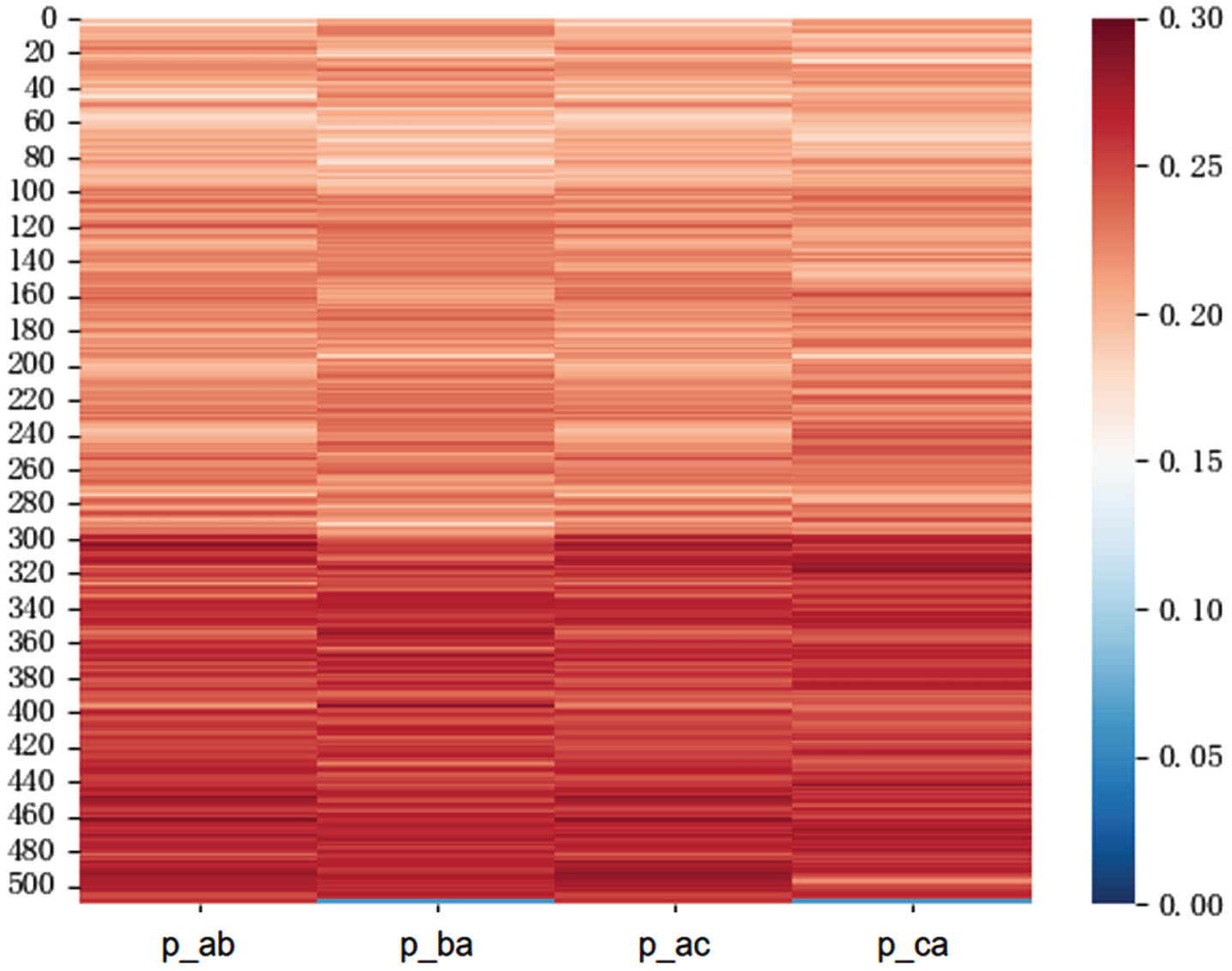
Distribution of position correlation. p ab , p ba , p ac , p ca axes are represented as text A interacting with text B, text B interacting with text A, text A interacting with text C, and text C interacting with text A, respectively. The vertical axis represents the positions of words in the document.
Based on our analysis, there appears to be a consistency between model loss and accuracy changes on validation and test datasets. We determined that this phenomenon is because the larger the change in the loss function, indicating that the ability of model to extract features is then enhanced, and the difference between the probabilities of the results of the two classes produced by the output layer is continuously amplified as training proceeds, while the model will choose the class with the highest probability when making predictions. Thus there is a consistency between the change in the loss value and the change in the accuracy rate. An example is given below to illustrate this. The model outputs two sets of category outcomes with probabilities of P (label = 0) =0.8, P (label = 1) =0.2, and P (label = 0) =0.6, P (label = 1) =0.4. The difference between the probabilities of the two categories in first group is 0.6 and the difference between the probabilities of the two categories in second group is 0.2. For both sets of these two data, the model output for the prediction category is P = 0. The model therefore calculates the same accuracy for both groups data. Assuming that P = 0 is the correct result, the loss value of model can be smaller for the first group data compared to the second group data. In back propagation using the first group data, the model can update the parameters better. As the model is trained, a model with good performance can increase the difference between the probabilities of the generated outcome labels, which in this example is P (label = 0) and P (label = 1).
Fig.5 illustrates the map of position correlation after interaction between text pairs in the dataset. Specifically, the value of the i-th row in the p ab column in the figure indicates the correlation between the feature embedding of the information generated by the interaction and fusion of text A and text B and the feature embedding of the position i-th obtained after the generation. From Fig.5, it can be seen that the later the position of the feature embedding is, the higher the feature correlation with the feature embedding of the whole text. The reason for the low correlation of the last part of the p ba and p ca columns in the figure is that the lengths of text b and text c are less than the value of the longest length of the text set in the model, so the correlation of this part is low.
The proposed model achieves such good results because the proposedr model first extracts the contextual semantic information of the text using the BERT model. Then CNN and LSTM networks are applied to extract both local semantic and contextual feature information of the text. A multilayer MLP network is used in fusing the local and contextual feature information, which has the advantage of maintaining the rotational invariance of the feature information. We introduce position correlation of the text into the capsule network to enhance the learning features ability of the model. Furthermore, the dynamic routing is improved in the capsule network by focusing not only on the features of the current text when extracting text feature information, but also incorporating the relevant features of the text with which it is compared, so that the improved capsule network can extract relevant feature information between text pairs. In addition, if two cases are similar even though the semantic level, the similarity is low, but the related articles of law are similar, the similarity between the two cases is usually higher. Therefore, the information of legal texts related to the cases is also used in the proposed method to help the model to determine the similarity between the cases in terms of legal texts. In order to validate the effectiveness of the proposed modules, some ablation experiments are performed, the results of which are given in the next section.
The results of the ablation experiments are reported in this section. A series of experiments utilizing various variant models is performed on a Chinese legal dataset. The objective of these experiments is to showcase the performance of each module included in the proposed model.
Impact of module structure
Capsule. The improved capsule network of the proposed method is replaced with the original capsule network, which does not introduce position correlation. Cap_Atten. The position correlation structure is removed. When updating the routing information in the capsule network, only the attention information between two text pairs is considered. w/o law. Structures related to information about legal articles are removed from the model.
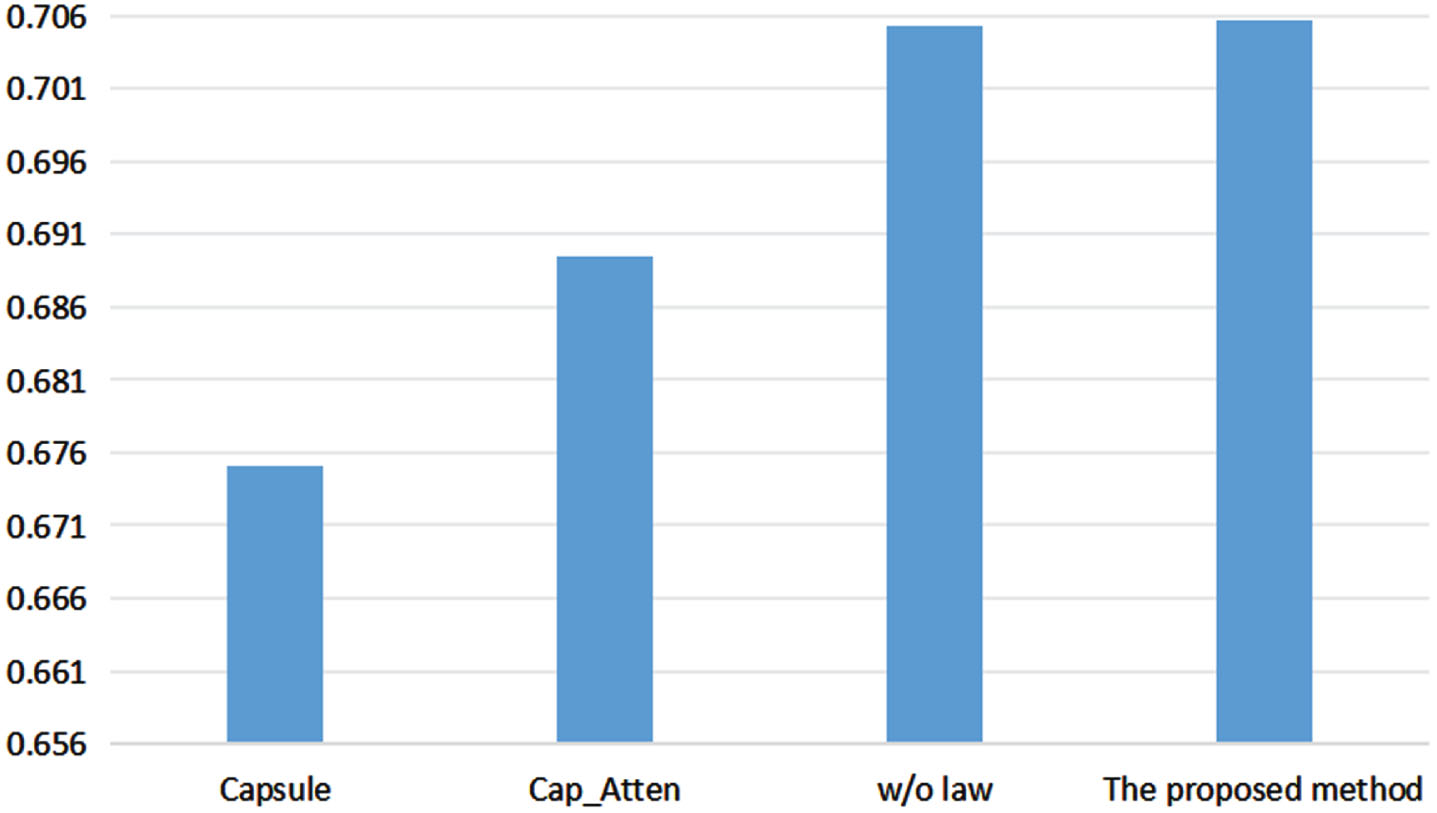
Accuracy of ablation study on validation datasets.
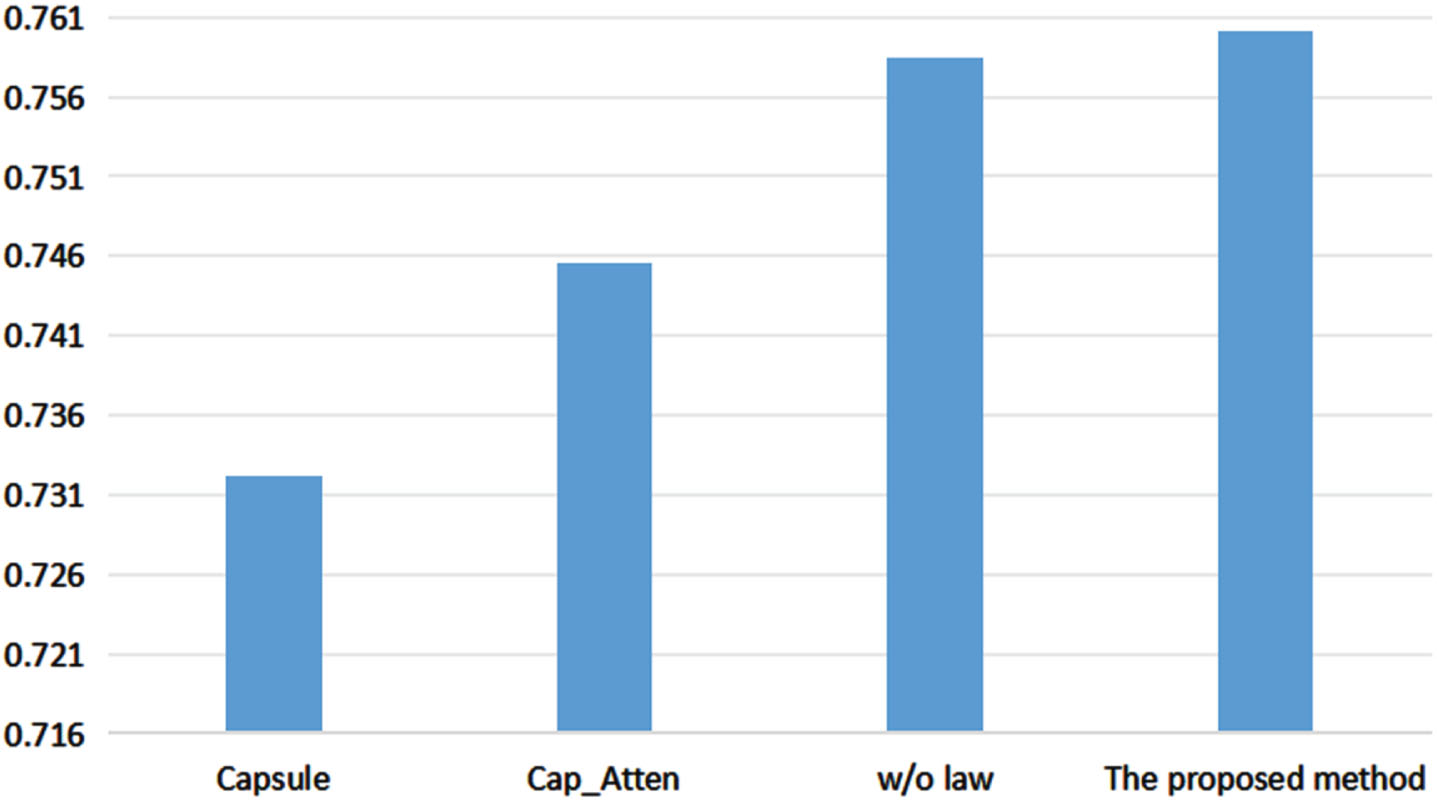
Accuracy of ablation study on test datasets.
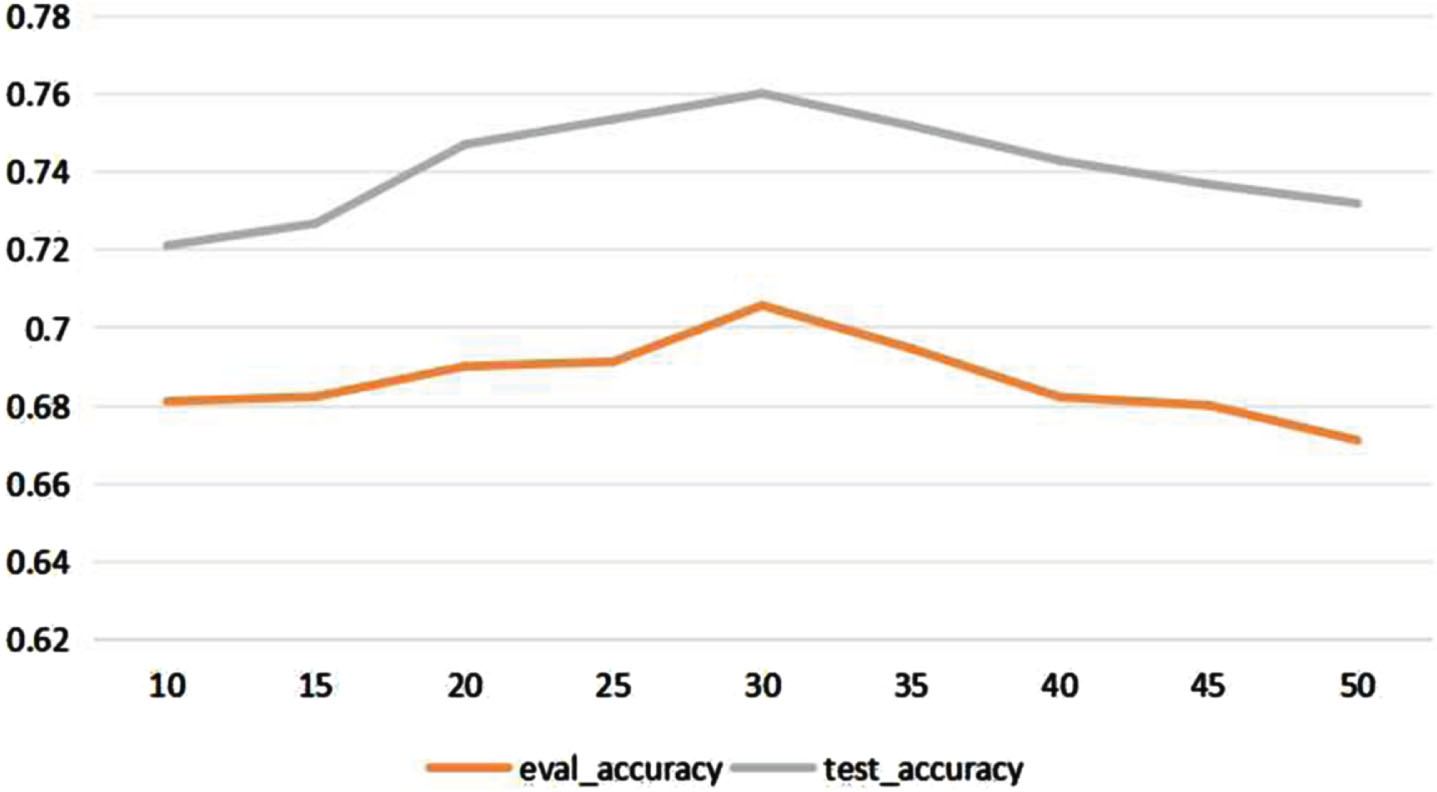
Accuracy of The proposed method with different number of element capsule on validation and test dataset
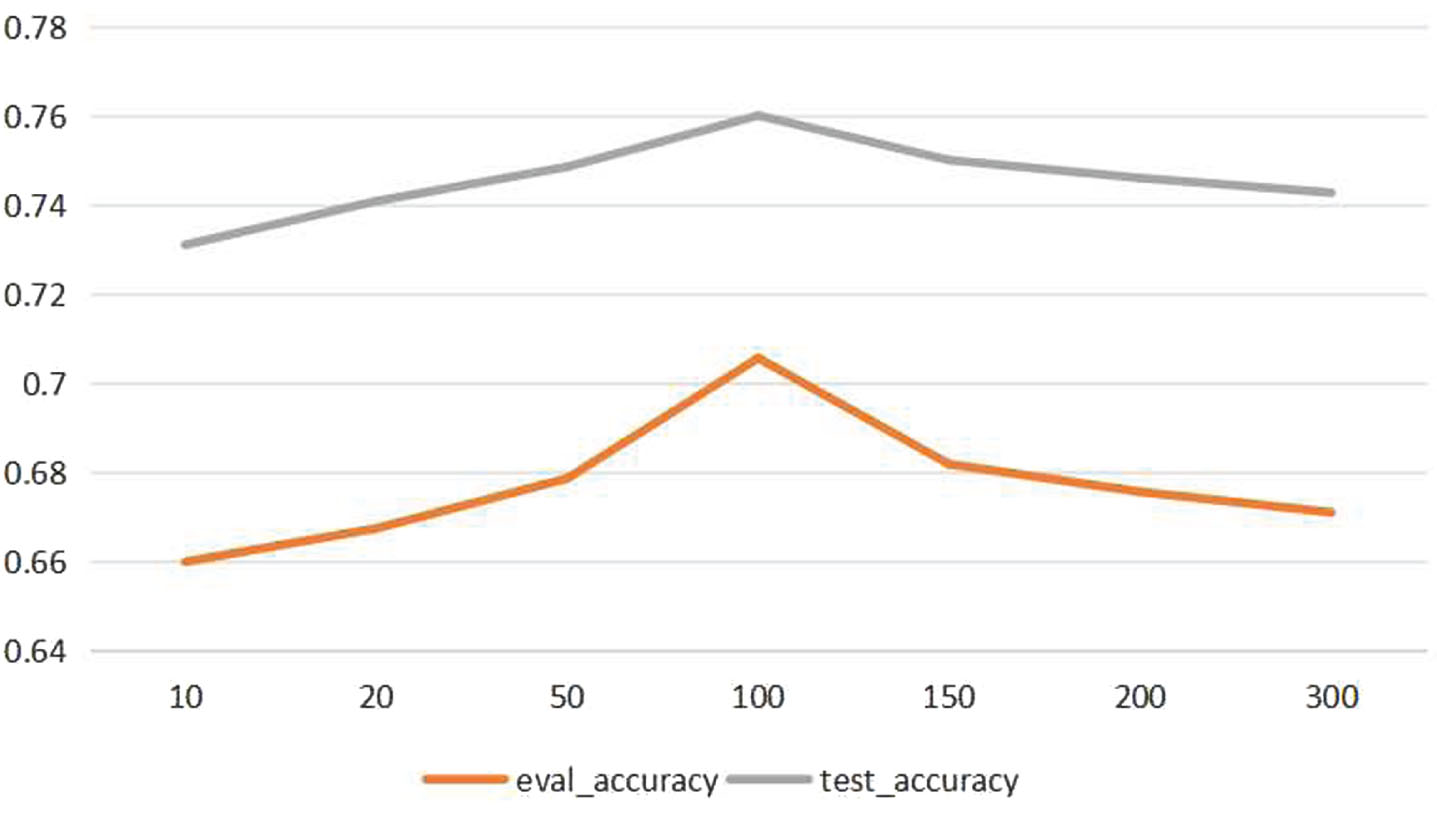
Accuracy of The proposed method with different dimension of element capsule on validation and test dataset
The accuracy results of the above three methods and the proposed method on the test dataset, respectively, are shown in Fig.6 and Fig.7. On the validation dataset, this Cap_Atten model improves the accuracy over the Capsule model by 1.72%, and the proposed capsule network improves the accuracy over the Cap_Atten model by 1.9%, and the proposed model in this paper improves the accuracy over the w/o law model by 0.04%. On the test dataset, the Cap_Atten model improves the accuracy over the Capsule model by 2.94%, the proposed capsule network improves the accuracy over the Cap_Atten model by 1.89% and the proposed model in this paper improves the accuracy over the w/o law model by 0.16%.
Two basic hyperparameters are applied in the proposed model: the number of capsules capsule num , the dim of the capsule capsule dim . The effect of the above two hyperparameters is investigated for the performance of the proposed model. The capsule num in the experiment are set to [10, 50] and the capsule dim in the experiment to [10,20,50,100,150,200,300]. The results of the experiments on the Chinese legal dataset are depicted in Figs.8 and Fig.9. Fig.8 demonstrates that the performance of the model improves as the number of capsules increases, provided the number of elemental capsules is less than 30. The accuracy of the proposed model is highest when the number of elemental capsules is 30. When capsule num is greater than 30, the performance of the model becomes worse as the number of capsules increases. Fig 9 shows that when capsule dim is less than 100, the accuracy of the model becomes better as the number of capsules increases. The best accuracy is obtained when capsule dim is 100. When capsule dim is greater than 100, the accuracy of the model deteriorates as the number of capsules increases.
Analysis of sample
Table 4 shows two documents, document B and document C, which are derived from the triplet data as the documents in Table 1. The document in Table 1 is called Document A. Document B and document C are compared with document A and are used to determine document B and document C, which one is more similar to A.
In this example, document A and document C are more similar than document A and document B. Document A and document C in the factual description of the part of the similarity, are about business mismanagement and lending disputes, the form of borrowing for a one-time borrowing of the required amount, while document B is divided into a number of borrowing; borrowing by virtue of the text, document A and document C are issued a loan note, while the text of the B halfway through the signing of the relatively formal "Loan Agreement," and ultimately the text of document A and document C, the starting date of the interest rate from the first borrowing date, document B starting date from the formal signing of the agreement. In the end, both document A and document C have interest dates from the date of the first loan, and Text B has an interest date from the date of the formalization of the agreement. document A and document C both contain for interest rate adjustment, document A because the defendant did not repay the principal in a timely manner and no repayment of money during the recovery period, the interest rate was eventually adjusted upward, document C, the plaintiff also in the late adjustment of the interest rate. In document B, the parties did not disagree on the interest rate, which remained at 2%.
An analysis of Documents A, B, and C reveals that the similarity of the above expressions is manifested in the descriptions of the "Facts and Reasons" and "Facts Found by the Court" sections. This indicates that the words in each position in the text do not have the same relevance to the text as a whole. The section describing the "facts as found by the court" is the most important section when making text comparisons, followed by the section describing the "facts and reasons", and finally the section describing the "plaintiff’s claim". In other words, the content in the "Facts Found by the Court" section had the highest position relevance, the content in the "Facts and Reasons" section was the second most relevant, and the text in the "Description of Plaintiff’s Claims" section had the lowest position correlation. This result also matches the position correlation results shown in Fig.5, indicating that position correlation information can be introduced into the network to improve model performance. The "Description of Plaintiff’s Claim" and "Facts and Reasons" sections contain some noisy data, which is not conducive to the ability of model to learn features of the whole text. In addition, by fusing the features between text pairs with information interaction, the model can obtain a better feature representation of the text. Since the common points between document A and document C are more than those between document A and document B, after the operation of Eq.(17) and Eq.(18), so the fused document embeddings
Document B and Document C
Document B and Document C

Additional test is carried out in this section to assess the generality of the improved capsule network proposed in the paper on two long document datasets, known as CNSE and CNSS, which are publicly available, as mentioned in the paper by Liu et al. [36].
Datasets
The CNSE dataset and CNSS dataset consist of long-form news articles in Chinese collected from mainstream Chinese Internet news providers and contains many topics from various fields. There are two datasets available: CNSE and CNSS. The CNSE dataset consists of 29,063 pairs of news articles that are labeled based on whether they agree on the topic or not. On the other hand, the CNSS dataset contains 33,503 pairs of news articles that are labeled based on whether they agree on the topic or not. As in a prior study [36], the training, development, and test datasets in this paper are split in the same proportions. Specifically, 60% of the data is used for training, 20% for development, and the remaining 20% for testing. Table 5 displays the statistical information for CNSE and CNSS.
The statistics information of CNSE dataset and CNSS dataset
The statistics information of CNSE dataset and CNSS dataset
To test the performance of the proposed model, this paper has compared it with a range of competing baseline methods. These methods can be classified into two classes. One class is similarity matching via deep neural network models with a representational or interaction focus, including DSSM [37], CDSSM [38], DUET [40], MatchPyramid [41], ARC-II [42] and ARC-I [42]. Another class is similarity matching based on term similarity, including BM25 [43], LDA [44] and SimNet [36].
The input to the proposed method is three files, while the data for this dataset are two long files and no additional legal text information is required for input. Therefore, the proposed model is needed to modify for application to this dataset. Structures related to information of legal articles are removed from the model. The fact encoder is modified to encode two long documents instead of three documents. The interaction layer then focuses between two documents. With this modification, the proposed model is directly applied to the document similarity matching task of two documents. The other hyper parameters remain the same as the experimental parameters set in Section 4.3.
Experimental results and analysis
The experimental results are shown in Table 6. It can be seen that the proposed method outperforms the baseline model on both datasets. The performance improvement can be attributed to the fact that the proposed method applies a capsule network with position correlation to transform long text into multiple text semantic units and there is contextual location relationship information between the text units, and the improved routing in the capsule network is able to consider the interaction between texts when updating the parameters. Both of these points can help to improve the performance of model.
Experimental results of different methods on CNSE and CNSS datasets
Experimental results of different methods on CNSE and CNSS datasets
Currently, there are some difficulties in the task of legal text similarity matching. The first is that in the process of model training, the similarity distance between text A and text B in some instances may be equal to that between text A and text C, and the model is prone to errors in predicting such data. Therefore extracting the deep features of legal texts more effectively and increasing the differences between the features between text pairs can help improve the accuracy of the model. Secondly, the text length is relatively long, and in this paper we need to discard some words when we use BERT to encode the text, which has the disadvantage of losing some information and is not conducive to the model learning document level information. To improve this problem, in the future we consider introducing hierarchical coding networks to encode the text to improve the accuracy of the model. In this paper, we apply cross entropy as a loss function to convert the text similarity matching task into a classification task. In order to improve the accuracy of legal text similarity matching, we consider proposing a new loss function for similarity comparison of triple data in future studies. Currently the topic model is applied to various text tasks, and we will also explore how to extract the topics and keywords of legal texts and apply the extracted words topics and keywords to the legal text matching task in the future. In this paper, there is still a lot of room for improvement in the method of calculating the similarity between the text and the relevant legal text, and how to better combine the information of the legal text into the model needs to be continued research.
Couslusion
A novel approach for Chinese SCM task integrating articles of law and using a siamese structure capsule network that incorporates position correlation is proposed in this paper. The reason for applying capsule networks is that they are inherently better able to focus on the position of the text compared to other networks, while the position correlation of the text is introduced into the network to better enhance the ability of capsule network to extract text features. At the same time, the position correlation is continuously updated as the network is trained, and the updated information can be used to compute feature embeddings for the entire document. The generated document embeddings can in turn improve the performance of the model. This paper has enhanced the method for updating dynamic routing parameters in the capsule network to compare the similarity of text pairs. Unlike previous approaches, which only consider the current text information, this updated approach takes into account the information of the texts being compared as well. Law article information is also applied to the model. The introduction of law article information can help the model to determine the similarity of cases in terms of laws regulations. The proposed model is tested on a real-world legal case similarity matching dataset, and the results demonstrate its superior performance compared to current baselines, achieving state-of-the-art accuracy. To further validate the generality of the improved capsule network proposed in the paper by utilizing two long text datasets, and the result indicates the generality of the improved capsule network proposed.
Conflict of interest
The authors declare that they have no conflict of interest.
Authors’ contributions
Methodology, material preparation, data collection, and analysis are performed by Zhe Chen. Zhe Chen write the draft of the manuscript, Lin Ye and Hongli Zhang do the supervision, reviewing, Yunting Zhang comments on versions of the manuscript.
Acknowledgement
This work is supported by the National Natural Science Foundation of China (NSFC) under Grant 61872111.