
Abstract
Speech emotion recognition has become the heart of most human computer interaction applications in the modern world. The growing need to develop emotionally intelligent devices has opened up a lot of research opportunities. Most researchers in this field have applied the use of handcrafted features and machine learning techniques in recognising speech emotion. However, these techniques require extra processing steps and handcrafted features are usually not robust. They are computationally intensive because the curse of dimensionality results in low discriminating power. Research has shown that deep learning algorithms are effective for extracting robust and salient features in dataset. In this study, we have developed a custom 2D-convolution neural network that performs both feature extraction and classification of vocal utterances. The neural network has been evaluated against deep multilayer perceptron neural network and deep radial basis function neural network using the Berlin database of emotional speech, Ryerson audio-visual emotional speech database and Surrey audio-visual expressed emotion corpus. The described deep learning algorithm achieves the highest precision, recall and F1-scores when compared to other existing algorithms. It is observed that there may be need to develop customized solutions for different language settings depending on the area of applications.
Keywords
Introduction
Speech Emotion Recognition (SER) is an open research agenda that is laden with many challenges, which have inspired this present study. Emotion is a difficult word to define [1], but some researchers have defined it as a mixture of physiological responses and inner thoughts of people [2]. It plays a pivotal role in influencing the rational actions and decisions that human beings make on a daily basis [3]. The Automatic Speech Emotion Recognition (ASER) has recently become popular because of its many useful applications in Human Computer Interaction (HCI) [4]. The recognition of emotion from speech has recently become an active research theme for applications such as smart health care [5], smart home [6], smart entertainment [7] and other important services. For example, SER can be used to monitor the emotion of agents in a call center in order to control their behavior when talking to customers [8]. There are various methods that have been developed for processing speech emotion over the recent years [9]. Nevertheless, SER is a complex task because it is difficult to accurately identify the correct emotion for a given situation [10]. Furthermore, the distinction between different emotional tones is pretty narrow [11]. There are other important factors that make SER difficult, which include the dependency of emotions on language and culture and selection of relevant features that are required to perform effective emotion recognition [12].
Many traditional speech recognition methods have been proposed in literature over the past decade [13], but most of them use handcrafted features [14] such as prosodic and spectral features [15]. The intrinsic drawback of using handcrafted features is that they sometimes require extra processing steps such as feature selection [16, 17]. This presents an imminent need to replace the current standard methods with models that can adaptively learn low-level features from raw data and high-level features from low-level ones in a hierarchical manner. Such models should be able to remove the over-reliance of choice of features and other preprocessing steps [18]. Recent research has shown that deep learning models can solve some of the above mentioned problems [19]. In particular, deep neural networks have become popular in speech processing tasks such as speaker identification [20], gender identification [21], Alzheimer recognition [22] and many more. A growing interest has been noticed in the application of deep neural networks in speech analysis and language analysis. However, all of these gave us a mind boggling question as to what method can be used to effectively extract salient features from raw speech files?
In this study, therefore, the use of custom 2D-CNN model is described as a feature extraction and speech classification tool for recognising emotion from one second frames in raw spectrogram data. Spectrograms of speech emotion are used in this study for feature generation because they contain acoustic and semantic features that could improve the accuracy of emotion classification task [23]. Moreover, we have performed a comparative analysis of the proposed 2D-CNN deep learning algorithm against Deep Multi-Layer Perceptron (DMLP) and Deep Radial Basis Function Neural Network (DRBFNN) [24]. Experimental results are reported for three benchmark databases of Berlin Database of Emotional Speech (EMO-DB) [25], Ryerson Audio-Visual Database of Emotional Speech (RAVDESS) [26] and Surrey Audio-Visual Expressed Emotion (SAVEE) [27]. The distinctive contributions of this study to the existing research on speech recognition are the following:
The application of DRBFNN and DMLP as feature extraction and classification tools for raw spectrograms to achieve high accuracy values without applying a feature selection algorithm. The validation of DRBFNN as an extremely fast algorithm for training raw spectrum data. The discovery that DMLP is effective in recognising angry, disgust, happy, neutral and sad emotion states. The development of a custom 2D-CNN speech recognition model that can recognise eight basic emotion states with high precision, accuracy, recall and F1-score. The description of a 2D-CNN algorithm that can detect disgust and fear emotion states better than the DRBFNN and DMLP based methods.
The discussion of related work is succinctly presented in Section 2 to demonstrate the originality and relevance of this study. The details about material and methods of this study are given in Section 3. The study results are well articulated in Section 4. Conclusions of the present study and possible future extensions are discussed in Section 5.
The related studies previously reported are reviewed to demonstrate the uniqueness and relevance of this study and to identify a possible gap. Yoon et al. [28] proposed a model that uses two Bi-directional Long Short-Term Memory (BLSTM) to obtain salient representation of vocal utterances. They proposed an attention mechanism referred to as multi-hop. They trained their model to automatically infer the correlation between the modalities and obtained a weighted average accuracy of 76.5%. Fayek et al. [29] proposed a deep learning model based on CNN that uses spectrograms as input features of speech signals. The proposed model achieved 64.78% accuracy using the Interactive Emotional dyadic MOtion CAPture (IEMOCAP) database [30]. In [31], an attention-based CNN Long Short-Term Memory (LSTM) fully connected Dense Neural Network (DNN) layer (CNNLSTM-DNN) model was introduced and tested on IEMOCAP dataset that achieved an average accuracy of 87.2%. They conducted experiments using a five-fold cross validation and the results were consistent with neutral, happiness, sadness, surprise and questioning emotions. In a similar vein, [32] employed a variant of WaveNet encoder to extract features in speech utterances and used a deep Residual Network (ResNet) to extract features from video signals. They fused these features using Multimodal Compact Bilinear (MCB) pooling to form a joint feature vectors for speech signal. The LSTM network was used to determine voice activity and they obtained an average accuracy of 91.52%.
A sparse autoencoder-based feature transfer learning method for SER was proposed in [33]. Several databases were used, including the EMO-DB and eNTERFACE database, which achieved an accuracy of 59.1% [34]. Zhu et al. [2] developed a novel classification method by combining Deep Belief Networks (DBN) and Support Vector Machine (SVM). They performed feature extraction using DBN and fed the extracted features to their DBN ensemble model, which achieved 95.8% classification accuracy using the Chinese Academy of Sciences (CAS) database. Zhang et al. [35] developed two CNN models for classifying emotions using video and audio files. The first CNN model was used to extract features from the mel-spectrograms generated from audio signals. The second one was used to process the corresponding video recordings. The extracted features were fused and fed to a deep fully connected neural network to classify anger, joy, sadness, surprise, fear and disgust emotions using Ryerson Multimedia Research Lab (RML) dataset to obtain an accuracy of 74.32%. In [36], an end-to end model for emotion recognition from raw audio signal was proposed, wherein the features were extracted from raw audio files using CNN. These features were then fed to an LSTM network to capture the temporal information in the data using the REmote COLlaborative and Affective (RECOLA) interactions dataset. Their proposed method outperformed handcrafted features on the RECOLA database achieving an accuracy of 74.1% in recognising arousal.
An end-to-end visual audiovisual fusion system that jointly learns to extract features directly from pixels, audio waveforms and performs classification using Bidi-rectional Gated Recurrent Units (BGRUs) has been reported [37], which obtained 98% accuracy in recognizing speech. Kim et al. [38] proposed 3-Dimensional CNNs (3D CNNs) to learn spectro-temporal features for recognizing speech emotions. They designed the 3D CNNs to learn short and long-term spectro-temporal features with a moderate number of parameters. They did a comparative analysis of the proposed method and other state-of-the-art methods using seven datasets, including RECOLA and EMO-DB. Their proposed model improved the accuracy of detecting sad emotion state by 17%. Fayek et al. [23] presented a SER system that makes use of Deep Neural Networks (DNNs). Their novel approach was used to recognize emotions from one second frames of raw speech spectrograms that achieved a classification accuracy of 60.53% using the eNTERFACE dataset. They also achieved a classification accuracy of 59.7% when they tested their model on the SAVEE dataset. In [39], a stochastic gradient descent optimized DNN was proposed using only three emotion states of angry, neutral and sad from the EMO-DB dataset. They used raw data without applying feature selection techniques and their trained model achieved an overall validation accuracy of 96.97%. Han et al. proposed a novel approach in [40], where they used segment-level features such as Mel-Frequency Cepstral Coefficients (MFCC), pitch period and harmonic to noise ratio and utterance-level features to recognize speech emotions. They used DNN to develop emotion probabilities in all the speech segments. The developed probabilities were then used to create the utterance-level features that were fed to the Extreme Machine Learning (ELM) based classification algorithm. They applied these techniques on the IEMOCAP database [30], achieving an accuracy of 54.3%. In [41], it was observed that CNN is sensitive to the sequence of images and that the deep learning model learns a dictionary of features that are portable across various languages. Furthermore, the researchers discovered that combining Recurrent Neural Network (RNN) with deep CNN can result in a notable increase in accuracy. In their work they applied Multiple Kernel Learning (MKL) to CNN to achieve a classification accuracy of 96.55% with feature selection.
Several methods have been suggested by various researchers for the purpose of recognising emotion through speech. Some authors in the literature have developed deep learning ensemble algorithms to improve classification accuracy and results were indeed promising. However, the problem with this assortment of methods as described in the literature is that they are more concerned with classification accuracy. The nature of the problem of speech emotion recognition requires more with regards to performance benchmarks. The analysis of SER models requires a profound evaluation that can be achieved through the use of precision, recall, F1-score and processing time. Most of the work in the literature was silent in this regard, yet the use of the above mentioned performance benchmarks is key to the evaluation of SER models.
Furthermore, the evaluation of a SER model requires an in-depth analysis of each and every one of the emotions involved. From the literature survey, it is apparent that recognising fear and disgust is quite a big problem. The importance of emotions can vary based on the application domain. For example, fear is an important emotion when developing a SER model for a police call centre. In the same vein, disgust is very important in environments that require an evaluation of customer satisfaction. In addition, some of the methods suggested in the literature involve the use of transfer deep learning models such as Resnet that are pre-trained models. The problem with these models are that if they are used to develop new applications on a new set of data that they have never been exposed to, the following problems can arise. The developed model will inherit certain innate problems of transfer learning models. The models may need time to learn new data patterns because they are pre-trained using google images that do not involve audio spectrogram images.
In addition, handcrafted features have been widely used in speech processing that have yielded some fantastic results. However, these are not suitable for use in recognising emotion through speech when data is huge. The advent of deep learning models has remarkably shown improvements in the processing of large amounts of data. Consequently, this inspired us to develop a custom 2D-CNN deep learning model that is robust enough to recognize disgust and fear emotion states with high precision, recall, F1-score and accuracy.
Material and methods
The material for this study involves the experimental datasets that were employed to validate the proposed custom 2D-CNN algorithm. The datasets are Emodb, Ravdees and Savee, which are subsequently discussed. The study methods follow three main phases, which are spectrogram generation (preprocessing), feature extraction and feature classification [42]. Spectrogram generation involves the conversion of raw audio data to spectrogram representation. Feature extraction involves the extraction of salient features from the spectrogram. Feature classification is the last phase that involves a comparative analysis of the proposed algorithm against the existing Deep MLP (DMLP) and Deep RBFNN (DRBFNN) learning methods implementation of Keras and Tensorflow in python. Python gives the flexibility to prescribe the number of layers, optimizers to use and many other functionalities to adjust DMLP or DRBFNN, thus transforming it into a DNN deep learning algorithms. Figure 1 illustrates the set of phases that were followed in conducting the experiments of this study. The figure depicts the components of audio data, spectrogram generation, feature extraction and feature classification, which are subsequently described.
Flow chart of the proposed study methods.
The databases that were utilized in this study to validate the performance of the proposed custom 2D-CNN algorithm are EMO-DB [25], RAVDESS [26] and SAVEE [27].
Emodb
The acted EMO-DB speech corpus [21] consists of 535 German vocal utterances. It is a multiclass speech emotion database that consists of seven different acted emotions, which are anger, joy, sadness, neutral, boredom, disgust and fear. The dataset is a collection of ten professional native German-speaking actors made of voices of five females and five males that were asked to simulate these emotions. The simulations were recorded in an anechoic chamber using a high-quality recording equipment. The recordings were produced at a sampling rate of 16 kHz with a 16-bit resolution and mono channel. The version of EMO-DB used in this study consists of 340 audio files. Each of the audio files is approximately 3 seconds long. The angry class constitutes of 127 audio files as shown in Fig. 2. The happy class has a total of 72 class, while 79 vocal utterances were recorded in the neutral class and the sad class consists of 62 audio files.
Emodb dataset.
The RAVDESS speech corpus [26] is a collection of validated multimodal speeches and songs. It consists of speeches of 24 professional gender balanced actors with 12 females and 12 males. These actors were recorded speaking two similar statements in a neutral North American accent. This database comprises of 8 speech emotion classes that comprise of angry, happy, neutral, calm, sad, surprised, fear and disgust expressions. The 24 recorded vocal utterances consist of three modality formats, which are Audio-only (16 bit, 48 kHz .wav), Audio-Video (720p H.264, AAC 48 kHz, .mp4), and Video-only (no sound). The angry, calm, disgust, fear, happy and sad emotion classes constitute of 192 audio files each while the surprise class contains a total of 184 files a shown in Fig. 3. Only 96 files were recorded in the neutral emotion state.
Ravdess dataset.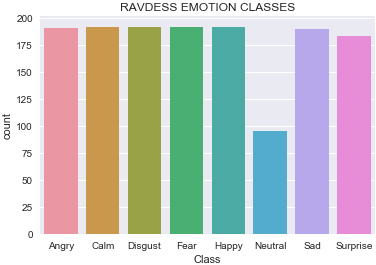
The SAVEE dataset [27] is an audio-visual database that comprises 480 British English vocal utterances. These vocal utterances were recorded from four male actors in seven different emotions, which are anger, disgust, fear, happiness, sadness, surprise and neutral. The recordings were done in an advanced media laboratory with high quality audio-visual equipment. The neutral class consists of 120 audio files and all the other remaining classes have a total of 60 audio files each as illustrated in Fig. 4.
Savee dataset.
EMO-DB spectrograms showing four emotion states.
Spectrograms of speech emotions were generated in this study to provide input to 2D-CNN, DMLP and DRBFNN classification algorithms for feature extraction, instead of using handcrafted features [43] such as MFCCs. Spectrograms are spectral representations of speech signals [44]. The application of speech spectrogram data transforms SER problem to an image processing task for which different image processing methods abound. The short-time Fourier transform spectrograms were generated using Hamming window frames as done in [18]. The Hamming window frames used were of length 25 milliseconds. Subsequently, 12.5 milliseconds stride were applied to the original speech waveforms, including both voiced and unvoiced components. Spectrograms representing spectral magnitudes for blocks of frames of time duration of 1 second with a stride of 10 milliseconds between blocks were calculated using Librosa, which is a speech processing python package. The audio files of the experimental databases were converted to spectrograms when the above processes were applied and results are shown in Figs 5–7.
Ravdess spectrograms.
Savee spectrograms.
Feature extraction is the process of converting raw data to a data set that presents a reduced number of attributes containing the most discriminatory information. The original goal of the process was to reduce the data dimensionality, remove redundant information and convert data to a format that is more appropriate for subsequent classification. Research has shown that a classification model is as good as the features used in the classification process. Most of the solutions suggested in the literature employ the end-to-end technique in which raw audio files are fed into classification models. Based on the literature survey we observed that this method yields low accuracy scores because of the inefficient feature extraction process involved. This is why we have decided to evaluate our custom 2D-CNN deep learning algorithm using spectrograms as our core features. The spectrogram generation process is important because it has helped in generating the required spectrograms that were fed to the deep learning models for feature classification.
Feature classification
CNNs are one of the most popular techniques used in various feature classification tasks such as text processing and image classification [45]. The networks apply a series of filters to raw pixel data to extract and learn higher level features in images. These are the features that a CNN model can use to classify images [46]. CNNs were introduced towards the end of 20
Basic architecture of custom 2D-CNN algorithm.
Figure 8 shows the basic architecture of the custom 2D-CNN for processing spectrogram images of emotion. In this study, we have used the Keras Application Programming Interface (API) with TensorFlow on the backend to develop the proposed custom 2D-CNN. Since the spectrograms generated in the preprocessing stage were in RGB format, we had to convert them to grey scale for efficient processing. In this study, we have implemented a deep neural network consisting of convolutional and fully connected layers to classify speech emotion from three labeled datasets, which are EMO-DB, RAVDESS and SAVEE. The labeled datasets consist of spectrogram images of size 28
It is extremely difficult to distinguish speech emotion visually through observing the spectrogram images because the difference between spectrograms for each emotion state is small. Consequently, 2D-CNN is applied to extract features from raw spectrogram images of speech emotion. The parameter settings of the proposed custom 2D-CNN are listed in Table 1. The filter size used to develop the proposed model is 4*4 for the first two convolutional layers. The remaining two layers employed a 3*3 filter size. A 2*2 max-pooling was applied for each convolutional layer. The first fully connected layers had 256 units while the second one had 128 units. The softmax classifier was used in the end to identify speech emotion states.
Detailed architecture of the proposed custom 2D-CNN algorithm
DRBFNN validation accuracy on EMODB.
In this study, we have built a custom 2D-CNN deep learning algorithm consisting of convolutional, pooling and fully connected layers. The algorithm was trained with standardized input dataset cleared of silent segments using mini-batches of size 28. Moreover, it was experimentally tested against two other algorithms based on RBFNN and MLP on EMODB, RAVDESS and SAVEE benchmark speech emotion databases. Benchmark has been used to come up with an in-depth analysis that informs the development of SER systems across a variety of platforms such as mobile devices and desktop computers. The standard performance metrics of processing time, validation accuracy, validation loss, precision, recall and F1-score were used in the experimental study.
Accuracy analysis of three classifiers on speech emotion spectrograms dataset
Accuracy analysis of three classifiers on speech emotion spectrograms dataset
DRBFNN validation accuracy on RAVDESS.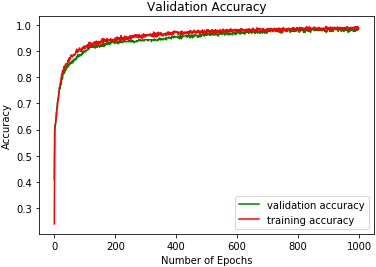
DRBFNN validation accuracy on SAVEE.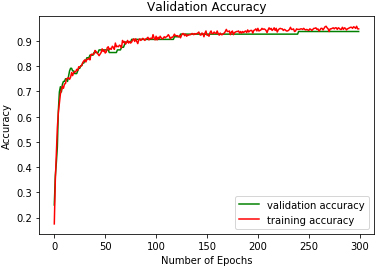
DMLP validation accuracy on EMODB.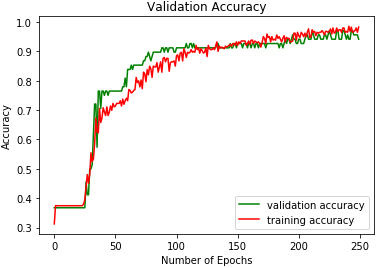
DMLP validation accuracy on RAVDESS.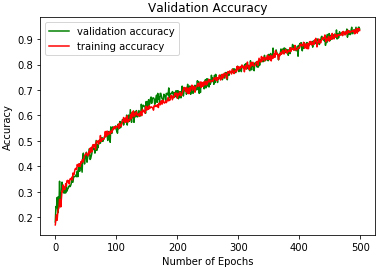
DMLP validation accuracy on SAVEE.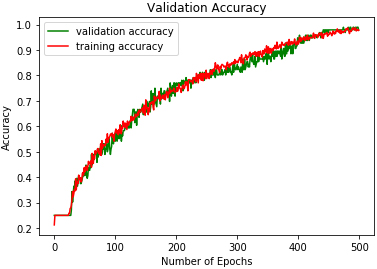
2D-CNN validation accuracy on EMODB.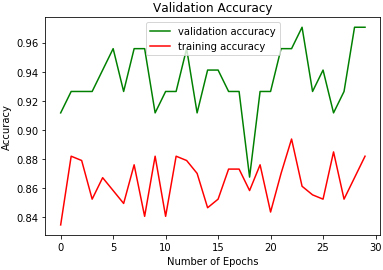
2D-CNN validation accuracy on RAVDESS.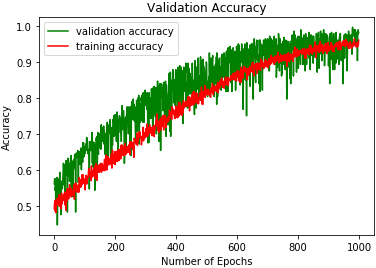
2D-CNN validation accuracy on SAVEE.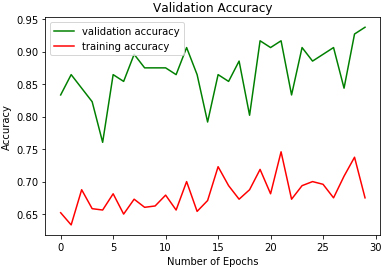
The study experiments were conducted on a computer with an i7 2.3 GHz processor and 8 GB of RAM. Table 2. Figures 9 to 17 show the validation accuracies obtained using the three classifiers investigated. DRBFNN obtained the highest validation accuracy score of 97.05% on EMODB database. The 2D-CNN yielded the lowest validation accuracy of 93.51% while 94.11% accuracy was achieved using DMLP as shown in Figs 10 and 11. The results changed when the classifiers were applied on RAVDESS database, wherein the highest validation accuracy of 98.22% was achieved using 2D-CNN and accuracy of 98.22% was achieved with DRBFNN. DMLP produced the lowest validation accuracy in this regard as illustrated in Fig. 13. However, it obtained the highest score of 97.91% when the classifiers were applied to the SAVEE database. This time 2D-CNN was outperformed by DRBFNN because it obtained an accuracy score of 90.2% while the later achieved 93.75% validation accuracy as shown in Figs 16 and 17.
Validation loss analysis of three classifiers on speech emotion spectrograms dataset
DRBFNN test loss on EMODB.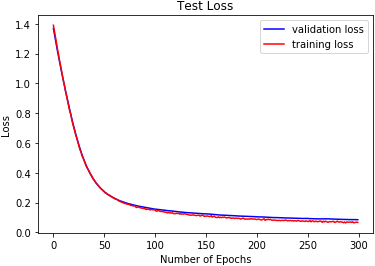
DRBFNN test loss on RAVDESS.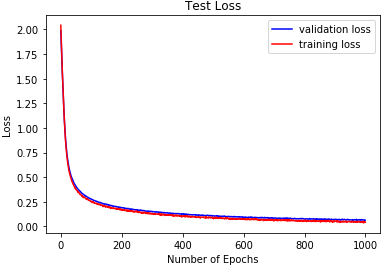
Training time in seconds of three classifiers
DRBFNN test loss on SAVEE.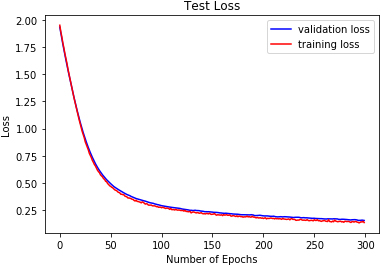
The reported results in Table 3 and Figs 18 to 26 show the test losses obtained using the three classifiers. DRBFNN recorded the lowest test loss of 0.085 when the classifiers were applied to the EMODB. The 2D-CNN obtained test loss of 0.121 while DMLP achieved 0.112. When the classifiers were applied on the RAVDESS dataset, the test losses recorded show that DRBFNN (0.063) performed better than the other classifiers. For the SAVEE database, DMLP recorded the lowest test loss score of 0.124 while the highest test loss was obtained using the 2D-CNN. The combined validation accuracy and test loss results show that DRBFNN is the overall best performing classifier. This is because it achieved the highest accuracy scores on EMODB and RAVDESS databases and it yielded the lowest test loss scores on the same databases.
DMLP test loss on EMODB.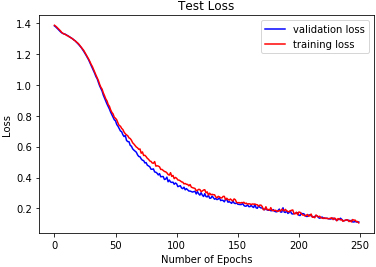
DMLP test loss on RAVDESS.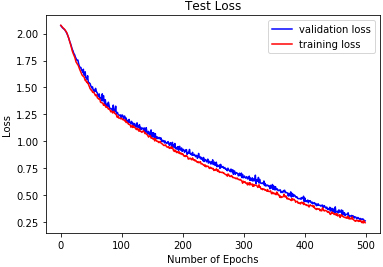
DMLP test loss on SAVEE.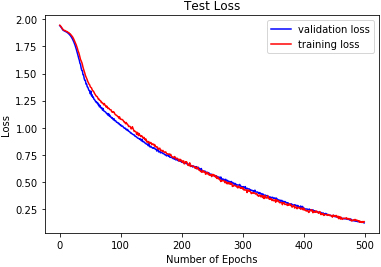
2D-CNN test loss on EMODB.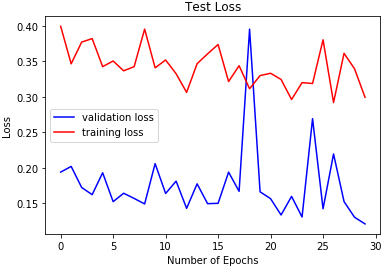
2D-CNN test loss on RAVDESS.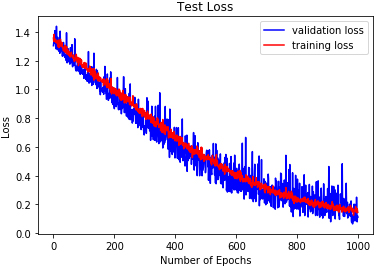
2D-CNN test loss on SAVEE.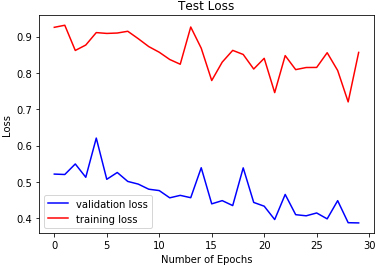
Table 4 shows that DRBFNN is the fasted performing classifier in terms of the training time because it processes over a thousand spectrograms in just 57.4 seconds on RAVDESS database. When DRBFNN was implemented on the three datasets, the training was done in a single run, wherein the classifier ran only once. In addition, DMLP recorded shorter processing time of 66 seconds on RAVDESS database. In addition, the classifier ran once, which shows that it can be implemented in real time systems. However, 2D-CNN was quite taxing in terms of the training time. It processed the RAVDESS spectrograms for 25200 seconds, which translates to approximately 7 hours. Moreover, the deep learning model ran five times to improve the accuracy and this took 35 hours, which translates to approximately a day and 9 extra hours.
Tables 5–7 depict precision, recall and F1-score obtained from the three classifiers using Emodb, Ravdess and Savee benchmark databases. The proposed custom 2D-CNN obtained 100% precision scores, except in the calm and fear emotion states. The highest overall precision of 98%, recall of 98% and F1 score of 98% were recorded by the classifier. The highest scores were achieved using DMLP on SAVEE database, where 98% was obtained for each benchmark metric. DMLP was seen to be more effective in recognising angry, disgust, happy, neutral and sad emotion states because the model obtained perfect scores of 100%. In addition, DMLP obtained the best precision score in recognising angry emotion state. DRBFNN was efficient in recognising happy emotion state (96%) when it was applied on EMODB database. It performed better than all the other classifiers in detecting happy emotion. However, 2D-CNN achieved the best overall precision of 97%, recall of 97% and F1-score of 97%. The model obtained perfect precision scores of 100% in recognizing neutral and sad emotion states.
Precision, recall and F1-score analysis on Emodb spectrograms
Precision, recall and F1-score analysis on Savee spectrograms
Precision, Recall and F1-score analysis on Ravdess spectrograms
Table 8 shows a comparative analysis of the results obtained in this study and results from related work. In particular, Table 8 shows that features extracted from raw spectrograms have more discriminative power, especially when fed to artificial neural network models. The proposed 2D-CNN algorithm performs better than others, especially when compared to those algorithms that utilize CNN with spectrogram features. However, the apparent limitation of the custom 2D-CNN algorithm is learning time constraint. Certain authors have argued that faster learning algorithms may acquire more training samples, but only when they are more effective will they achieve higher performance on unseen testing data [49]. This work places a strong emphasis on tradeoff between method efficiency versus method accuracy. However, improving on the processing speed of custom 2D-CNN is an exhilarating work for the future.
Comparison of the proposed method with related methods from the literature
In this paper, we have introduced 2D-CNN deep learning algorithm and presented a comparative analysis of its performance with deep learning based DMLP and conventional DRBFNN. Three popular speech emotion databases were used in this study, which are EMODB, RAVDESS and SAVEE. These databases were chosen because they include different languages and accents. We have carried out a series of experiments in our quest to develop a model that recognizes emotion states such as anger, happiness, sadness, calmness, fear, neutral, disgust and surprise. One of the main objectives of this study was to explore the performance of deep learning models and DRBFNN in extracting features for classifying various emotion states. The results obtained show that the proposed custom 2D-CNN model is quite effective in recognising almost all of the above mentioned emotions. However, we have observed that the proposed model is resource intensive as shown by the long processing time. Moreover, it was noted that DRBFNN and DMLP are extremely fast, which makes them ideal for use in computing environments that have low specification requirements such as handheld devices. However, these may not be a viable option when classifying vast amounts of data [19].
In addition, we have observed that the classifiers investigated in this study perform differently when applied to corporal with different languages. For example, DRBFNN achieved the highest precision of 100% in recognising happiness in utterances spoken in the German language while achieving the lowest score of 70% in recognising the same emotion state in the Northern American language. This gave us the impression that there may be need to customize a speech recognition model based on the nature of the target market and application. The results obtained in this paper are quite interesting. However, the major limitation is that the experimental study was conducted using acted speech datasets. Furthermore, the speech datasets were free of noise because the recordings were done using state of the art recording equipment. There is a possibility that there can be major differences between working with acted and real data. Recently, new features have been used to recognize emotion such as breath [54]. In future work, we would like to explore this technique further and improve on the processing speed of the 2D-CNN. Moreover, we would like to evaluate CNN as a feature extraction tool in speech emotion recognition systems.
Footnotes
Acknowledgments
This work was supported by Durban University of Technology through the ICT and Society Research Group.