
Abstract
Point cloud upsampling can improve the resolutions of point clouds and maintain the forms of point clouds, which has attracted more and more attention in recent years. However, upsampling networks sometimes generate point clouds with unclear contours and deficient topological structures, i.e., the problem of insufficient form fidelity of upsampled point clouds. This paper focuses on the above problem. Firstly, we manage to find the points located at contours or sparse positions of point clouds, i.e., the form describers, and make them multiply correctly. To this end, 3 statistics of points, i.e., local coordinate difference, local normal difference and describing index, are designed to estimate the form describers of the point clouds and rectify the feature aggregation of them with reliable neighboring features. Secondly, we divide points into disjoint levels according to the above statistics and apply K nearest neighbors algorithm to the points of different levels respectively to build an accurate graph. Finally, cascaded networks and graph information are fused and added to the feature aggregation so that the network can learn the topology of objects deeply, enhancing the perception of model toward graph information. Our upsampling model PU-FPG is obtained by combining these 3 parts with upsampling networks. We conduct abundant experiments on PU1K dataset and Semantic3D dataset, comparing the upsampling effects of PU-FPG and previous works in multiple metrics. Compared with the baseline model, the Chamfer distance, the Hausdorff distance and the point-to-surface distance of PU-FPG are reduced by 0.159 × 10-3, 2.892 × 10-3 and 0.852 × 10-3, respectively. This shows that PU-FPG can improve the form fidelity and raise the quality of upsampled point clouds effectively. Our code is publicly available at https://github.com/SATURN2021/PU-FPG.
Introduction
Point clouds are the most basic and common representations of 3D scenes, which are used in 3D reconstruction [1–4], automatic driving [5, 6], geological and architectural surveying and other fields widely. However, due to hardware and computational limitations, 3D sensors often produce sparse and noisy point clouds, which are more pronounced for small objects or objects that are far away from the sensor. This brings a massive challenge to subsequent works on point clouds, such as semantic segmentation and object detection. As a task that can improve the resolutions of point clouds, point cloud upsampling converts sparse, incomplete and noisy point clouds into dense, complete and clean point clouds under the premise of retaining the geometry, topology, shape and other characteristics of the point clouds. In recent years, point cloud upsampling has become one of the hot issues in the research direction of point cloud.
Traditional point cloud upsampling algorithms were based on optimization [7–10], which fitted local geometries generally and worked well for smooth surfaces with few features. However, they required various prior information about shapes to constrain the generation of point clouds. Therefore, their methods were less practical. PointNet [11] and PointNet++ [12] demonstrated the feasibility and effectiveness of processing point clouds with deep neural networks. The point cloud upsampling methods based on deep neural networks learned features and structures from data effectively, and required less prior information of data, improving the practicability of point cloud upsampling significantly. In 2018, Yu et al. drew on the multi-layer and multi-scale encoding architecture in PointNet++to propose the first point cloud upsampling network PU-Net [13], which extended the point set implicitly through the multi-branch convolution units in feature space. They did not consider neighboring information however. In 2019, Yifan et al. proposed a patch-based upsampling network MPU [14], which gradually trained cascades end-to-end at different levels of detail. They achieved super-large point cloud upsampling through a series of architecture improvements, including the new dense connection for point-by-point feature extraction, the code allocation for feature expansion and the bilateral feature interpolation for inter-layer feature propagation. However, the feature vectors of the copied points led to the duplication of point set, making generated points gather around the input points. In the same year, Li et al. proposed the point cloud upsampling model PU-GAN based on the generative adversarial network (GAN) [15]. They not only constructed an up-down-up expansion unit in the generator for upsampling point features with error feedback and self-correction, but introduced a self-focus unit to enhance feature aggregation. In addition, they proposed a compound loss that included antagonism, uniformity and reconstruction to encourage the discriminator to learn more potential patterns, improving the uniformity of output points distribution. Their main contributions and performance advantages came from the discriminator, while they paid less attention to the generator. In 2020, Qian et al. incorporated discrete differential geometry into point cloud upsampling and proposed PUGeo-Net [16]. This model generated the upsampling network jointly that encrypted coordinates and normals of point clouds. It used local differential geometry constraints to improve the upsampling results and increased the upsampling points by learning the first and second basic forms of local geometry. However, their approach required additional supervision in the form of normal, which were difficult to obtain in many point clouds. In 2021, Qian et al. proposed a point cloud upsampling model PU-GCN [17] based on graph convolutional networks (GCNs), which regarded the point cloud as a graph and the points as nodes in the graph to utilize topological information of the point clouds. This model combined GCNs with Inception module to extract multi-scale graph structure information of the point clouds. PU-GCN also proposed a new reorganization mechanism NodeShuffle for feature expansion, which could better encode information from neighboring nodes during reorganization. However, PU-GCN fused the same number of neighbor features and did not distinguish them during feature aggregation, resulting in incorrect and biased semantic transmission. PU-GCN also used unified K nearest neighbors (KNN) algorithm, managing to fit the potential graph structure of the point clouds. However, KNN did not fit well on complex point clouds. In addition, the spatial-domain GCNs that had low utilization rate of graph structure information were used in PU-GCN for point feature aggregation. In 2022, Long et al. explored the correlation between patch-to-patch and point-to-point of point clouds, proposing the point cloud upsampling model PC2-PU [18]. This model took adjacent point clouds as supplementary input to compensate for the loss of structural information within a single point cloud. They also introduced a patch correlation module to capture the differences and similarities among patches.
Previous learning-based point cloud upsampling methods failed to pay attention to or solve the problem of the upsampled point clouds with incorrect and unclear contours and boundaries as well as deficient topology structures. These abnormal semantic features will affect the utilization value of point clouds profoundly. This paper focuses on the above problem, i.e., the problem of insufficient form fidelity of the upsampled point clouds. Firstly, local coordinate difference, local normal difference and describing index are designed to estimate the form describers of point clouds and further fuse more reliable features, so as to make the form describers multiply in the vicinity based on correct semantic information. Secondly, multi-level KNN graph building suitable for complex point clouds is proposed to replace the traditional unified KNN to build more realistic and accurate graph structures of the point clouds. Finally, the spectral-domain GCNs applicable to directed graphs are cascaded to enhance the perception of model toward graph information in the process of feature aggregation.
Our upsampling model PU-FPG is obtained by combining these 3 parts with point cloud upsampling networks. Experimental results show that our model can improve the form fidelity of the upsampled point clouds effectively. In addition, PU-FPG has significantly improved in various metrics. Our main contributions are as follows: We design local coordinate difference, local normal difference and describing index to estimate the form describers of the point clouds, rectifying the feature aggregation of the form describers with more reliable and relevant neighboring information. We design multi-level KNN graph building for complex point clouds to gain more realistic and accurate graph structures of the point clouds. We use additional spectral-domain GCNs which are adapted to directed graphs to enhance the perception of model toward graph information in the process of feature aggregation. Our upsampling model PU-FPG is obtained by combining these 3 parts with point cloud upsampling networks. Experiments on PU1K dataset and Semantic3D dataset show that our model can improve the form fidelity of upsampled point clouds effectively.
Related works
Learning-based point cloud upsampling
The learning-based point cloud upsampling methods learned features and structures from data effectively, and had low prior requirements on data, promoting the development of point cloud upsampling significantly and expanding application scenarios of point cloud upsampling.
In 2018, Yu et al. proposed the first point cloud upsampling network PU-Net [13], which mapped the input point clouds to feature space to obtain feature vectors. Then, they expanded the dimensions of the feature vectors and transformed redundant dimensions into points through reorganization, realizing the expansion of point set. Finally, they mapped the point set in the feature space to 3D Euclidean space, achieving the point cloud upsampling at a fixed magnification. The network structure of PU-Net was relatively simple and reasonable. Though PU-Net ignored neighboring information and had unnecessary resolution loss due to the down-sampling operation, the framework of PU-Net, i.e., feature extraction, feature expansion and coordinate reconstruction, were widely used in learning-based point cloud upsampling models.
In the same year, Yu et al. proposed the first edge-aware merging network EC-Net [19] to solve the problem of insufficient sensitivity of the network to edges. By designing a regression component that simultaneously returned point coordinates and point-to-edge distances as well as an edge-aware joint loss function, the network could focus on the detected sharp edges and achieve more accurate upsampling. Though EC-Net focused on the edges and proposed an effective model, the marked edges it required were often difficult to obtain.
In 2019, Yifan et al. proposed a progressive network MPU [14], which replicated input point patches in multiple steps so as to achieve super-large point cloud upsampling and further suppress noise and retain details. However, MPU copied the feature vectors of the points, resulting in the duplication of the features of the point set and making the generated points gather around the input points. In addition, the computing consumption of MPU was expensive due to the gradual nature of it.
In the same year, Li et al. proposed the first GAN-based point cloud upsampling model PU-GAN [15], proving that the geometric structures of sparse points were easily lost. PU-GAN constructed an up-down-up expansion unit in the generator to upsample point features with error feedback and self-correction. They also introduced a self-focus unit to enhance feature aggregation. Their main contributions and performance advantages came from discriminators, while they paid less attention to generators.
In the same year, Ye et al. proposed Meta-PU [20] that supported point cloud upsampling with any scale factor using a single model. They used residual plot convolution blocks to form a backbone network and learned a meta-subnet to adjust the weight of residual plot convolution blocks dynamically. The farthest sampling block was used to sample different number of points, realizing the point cloud upsampling with any scale factor.
In 2020, Qian et al. incorporated discrete differential geometry into point cloud upsampling to propose the point cloud upsampling model PUGeo-Net [16], learning the local parameterization and normal direction of each point. Specifically, PUGeo-Net generated dense points in 2D parameter domain at first. Then, they projected the 2D points into 3D space using linear transformation. Finally, they twisted the tangent plane to obtain 3D points on the object surface. PUGeo-Net also realized the regression of normals of the points. However, additional supervision in the form of normal required in PUGeo-Net were difficult to obtain.
In 2021, Li et al. considered the point cloud upsampling as a multi-target task. They proposed the point cloud upsampling network Dis-PU [21] with 2 cascaded subnetworks, i.e., dense generator and space refiner. The dense generator inferred a rough but dense output that described the potential surface roughly. The space refiner further fine-tuned the rough output by adjusting the position of each point.
In 2022, Long et al. explored the correlation between patch-to-patch and point-to-point of the point clouds. They proposed the point cloud upsampling model PC2-PU [18], which took adjacent point clouds as supplementary input to compensate for the loss of structural information within a single point cloud. They also introduced a patch correlation module to capture the differences and similarities among patches.
In the same year, Qian et al. proposed a new end-to-end learning-based point cloud upsampling framework MAFU [22], which analyzed the point cloud upsampling problem from the perspective of formularization and attributed the goal of the problem to determining the interpolation weight and higher-order approximation error explicitly. MAFU designed a lightweight neural network, which could adaptively learn the interpolation weight and high-order refinement of the unified and sorted interpolation by analyzing the local geometric structures of the input point clouds.
In the same year, Feng et al. proposed a new point cloud representation method Neural Points [23] and achieved arbitrary-factored upsampling. The model extracted deep local features of the points and constructed the neural field through the local isomorphism between the 2D parameter domain and the 3D local point cloud patch. Finally, local neural fields were integrated to form a global surface. The point clouds can be upsampled at any magnification by down-sampling on the learned global surface.
Previous works including the above managed to solve different problems in point cloud upsampling. MPU [14] and Dis-PU [21] introduced cascaded networks to solve the problem that it was difficult for a single level network to achieve multiple goals. However, their cascaded networks were neither flexible nor easy to train [24]. PU-GAN [15] and PUFA-GAN [25] considered learning the point clouds by the powerful modeling ability of GAN when the point clouds were uneven and sparse. However, GAN was difficult to train and had poor interpretability. Neural Points [23] and FSU [26] achieved arbitrary-factored upsampling to improve the flexibility of trained models when multiple upsampling rates were required. However, the deviation of their models was inevitable because of the finite numbers of 2D planes when fitting curved surfaces. L2G-AE [27] and SPU-Net [28] tried to construct self-supervised point cloud upsampling models to meet the challenge that it was hard to obtain real-scanned dense point clouds with high quality as the ground truth supervision at times. However, the effects of their models were influenced by the inconsistency of scales between training data and testing data.
We summarize the existing learning-based point cloud upsampling models roughly in Table 1, where the GCN-based models will be introduced in
Summary of existing learning-based point cloud upsampling models
Summary of existing learning-based point cloud upsampling models
Although graph data is a kind of non-Euclidean data, it generally exists in real life and can naturally express the data structures, such as transportation network, World Wide Web and social network. Point clouds have potential graph structures which can be obtained approximately by supervised learning methods such as GraphVAE [29] and MolGAN [30], and unsupervised methods such as unified KNN. The graph structures of point clouds can truly reflect the topological structures of objects in an ideal situation. The local structure of each node in the graph data is different, so the translation invariance is no longer satisfied, making it very challenging to define convolutional neural networks on the graph data. In order to process and utilize these graph data, many graph convolutional networks have been proposed. In the construction of convolution kernel, graph convolutional networks can be divided into spectral-domain GCNs (based on convolution theorem) and spatial-domain GCNs (based on aggregation function).
In spectral-domain GCNs, Spectral Networks [31] solved the problem of convolution operation on the graph and the problem of computing the time complexity of convolution operation. However, Spectral Networks encountered the problems of long time-consuming spectral decomposition of Laplace matrix and lack of local information. ChebyNet [32] used polynomials to link the convolution kernel with the eigenvalues of the Laplace matrix, avoiding the spectral decomposition of the Laplace matrix. ChebyNet reduced the number of parameters to be learned, achieving multilevel local distance preservation. However, it was difficult to choose the polynomial order in ChebyNet. Besides, the problem of high time complexity caused by large-scale matrix multiplication was also intractable. Kipf et al. [33] simplified the calculation formula greatly through multiple approximations and avoided the original large-scale matrix multiplication operation, enabling it to learn multi-hop information of nodes flexibly by increasing the network depth. However, the increase in the number of network layers in [33] might lead to over-smoothing. In addition, although many approximations were applied to simplify the calculation, they also led to inadequate utilization of some adjacency relations and graph structure information. The spectral-domain GCNs also had strong constraints on the graph, i.e., the graph must be undirected. This constraint stemmed from the fact that the spectral-domain GCNs could only construct the Laplace matrix through the symmetric adjacency matrix, which limited the application of spectral-domain GCNs in many aspects. In the potential graph structures of point clouds, edges not only represent the connection among nodes, but mean the direction of information aggregation. In general, the aggregation of point cloud nodes information is not bidirectional, therefore the potential graph structures of point clouds should be directed graphs. Although the directed graph can be relaxed into an undirected graph and then inputted into the spectral-domain GCNs, the directed information and some degree information of the graph will be lost, resulting in distorted output results. DGCN [34] solved the problem that the directed graph could not use the spectral-domain GCNs by transforming the adjacency matrix of the directed graph into 3 symmetric adjacency matrices, preserving the directional information in the graph to a large extent at the same time.
In the spatial-domain GCNs, GraphSAGE [35] expanded GCNs into inductive learning tasks by training the function of aggregating node neighbors, playing a generalization role for unknown nodes. DGCNN [36] designed EdgeConv module to perform dynamic image convolution on point clouds. DeepGCNs [37] not only introduced residual connection, dense connection and expansion convolution into GCNs, but trained the deep GCNs architecture successfully. The spatial-domain GCNs allowed the input of directed graphs, but its utilization of the information of the graph structures was lower than that of the spectral-domain GCNs.
We combine additional spectral-domain GCNs with original spatial-domain GCNs to adapt directed graphs and enhance the perception of model toward graph information in the process of feature aggregation.
Point cloud upsampling based on graph convolutional networks
Due to the powerful ability encoding local and global information, GCNs had been widely used in learning-based point cloud processing tasks, such as classification, segmentation and upsampling [38–40].
In 2019, Wu et al. proposed a data-driven point cloud upsampling network AR-GCN [41] based on graph network and countermeasure loss. They used the local similarity of point clouds and the similarity between low resolution input and high-resolution output. They also used a new loss function which combined Chamfer distance (CD) and image confrontation loss to realize the automatic capture of high-resolution point cloud features.
In 2021, Qian et al. proposed the point cloud upsampling model PU-GCN [17] based on graph convolutional networks. They regarded the point cloud as a graph and the points as the nodes in the graph to utilize the topological information of the point clouds. Besides, they combined GCNs with Inception module to extract multi-scale graph structure information of point clouds. They also proposed a new reorganization mechanism NodeShuffle for feature expansion, which could better encode information from neighboring nodes during reorganization.
Existing GCN-based point cloud upsampling models adopted unified KNN which ignored the difference among neighboring points to build the graph of the point cloud, resulting in the fuzzy semantic information. This problem became more severe when point clouds were complex. We design multi-level KNN graph building for complex point clouds to obtain more realistic and accurate graph structures of point clouds, realizing a more effective feature aggregation.
Methodology
In this paper, we focus on the problem of the upsampled point clouds with incorrect and unclear contours and boundaries as well as deficient topological structures, i.e., the problem of insufficient form fidelity of the upsampled point clouds. Local coordinate difference, local normal difference and describing index of points are designed to search for the form describers, i.e., the points located at edges, contours or sparse locations, so as to rectify the feature aggregation of form describers with more reliable neighboring features. This constitutes our rectification network based on form describer (RNFD). Multilevel KNN graph building (MKGB) is used to replace the traditional unified KNN on complex point clouds to build more complex, real and accurate graph structures of point clouds, so that the model can learn more accurate topological structures of objects according to the built graphs. Graph aware feature aggregation (GAFA) enhances the perception of model toward graph information in the process of feature aggregation by using additional spectral-domain GCNs which are suitable for directed graphs, enabling the model to fully learn semantic information and topological information from more complex graph structures. Our upsampling model PU-FPG is obtained by combining these 3 parts with point cloud upsampling networks.
The model structure of PU-FPG is shown in Fig. 1. RNFD finds the form describers of the input point clouds accurately and use more reliable neighboring features in the process of feature aggregation to obtain the extended and rectified feature N × C0. The rectified feature N × C0 is used to rectify the feature learned by the original graph convolutional networks, where ⊕ in the figure represents the concatenation of feature dimensions. In addition, MKGB can get the complex and real graph structure of the point clouds approximately. Then, GAFA learns more detailed topological information N × C2 of the input point clouds from the graph structure. The rectified feature N × (C0 + C1) is inputted into Inception DenseGCN [17] to extract multi-layer and multi-scale feature. The result from Inception DenseGCN and topological feature acquired by GAFA are fused to obtain N × C3. Subsequently, the fused feature of the points is used by Nodeshuffle to reorganize and expand the point set to obtain the extended point set rN × C3 in the feature space. Finally, multilayer perceptrons (MLPs) are used as coordinate regressor to achieve point cloud upsampling in 3D Euclidean space.

Structure of PU-FPG.
The form describers of point clouds refer to those points that are roughly located on the sharp edges, contours or extremely sparse positions of objects, which can describe the boundaries and topological information of point clouds accurately. During point cloud upsampling, points tend to multiply around themselves to obtain upsampled points according to the feature representations of them. However, points fuse the features of the same number of neighboring nodes and do not distinguish these features in the process of feature aggregation. As a result, a large number of incorrect and irrelevant features are fused in the process of feature aggregation of the form describers. The form describers multiply around themselves based on incorrect semantic information finally, leading to insufficient form fidelity of upsampled point clouds. Therefore, it is necessary for us to search for the form describers of point clouds and rectify the process of feature aggregation of them to fuse correct and relevant semantic information.
In this paper, we define 3 statistics of points, i.e., local coordinate difference (LCD), local normal difference (LND) and describing index (DI), to realize form describer searching (FDS) of point clouds. These statistics can reflect information such as the positions and sparseness of points in the point clouds to a certain extent.
LCD and LND can reflect the positions and sparseness of points. For each point p i in the point cloud, the larger LCD (p i ) and LND (p i ), the more likely p i is a point that can describe the boundaries and topology information of the point cloud accurately, i.e., the form describer. Empirically, LCD is better at finding points in sparse locations, while LND is more sensitive to points at the boundaries and contours of the objects. Therefore, the form describers can be found by the complementarity of these 2 statistics accurately.
DI combines LCD and LND of p i linearly to measure the degree to which p i is a form describer. The parameter λ is used to weigh the importance of LCD and LND. In FDS, DI of each point in the point cloud is calculated to obtain the sample distribution of DIs. Empirically, M points with the largest DIs are selected to constitute the set of form describers. According to the process of FDS, we can define the set of form describers of a point cloud definitely.
Algorithm 1 shows the process of FDS. Given a 2D virtual point cloud, as shown in Fig. 2, the arrow indicates the direction of normal of each point. The information of each point, including coordinate, normal, LCD, LND and DI, is given in Table 2. Note that the normals are unitized. We set k = 2 in both (1) and (2) and set λ = 1 in (3). The searching effects of LCD, LND and DI on the virtual point cloud are shown in Fig. 3, where the letters marked in the points represent the degrees to which the points are identified as form describers. The points marked as

Positions and normals of the points of the 2D point cloud.

Searching effect of form describers on 2D virtual point cloud using our statistics.
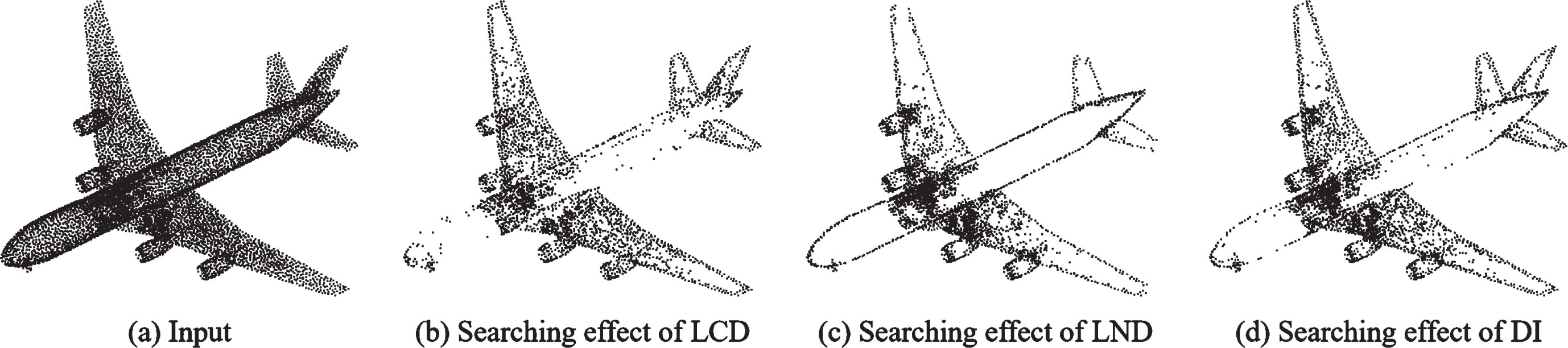
Searching effect of form describers on 3D real point cloud using our statistics.
Information of each point in the 2D virtual point cloud
Since form describers describe the boundaries and topology information of point clouds accurately, the feature aggregation strategy of them should be conservative, otherwise the upsampling model is likely to generate incorrect new boundaries based on incorrect feature representations. Nearby neighbors are more reliable compared with the neighbors far away, because they are more likely to contain correct and relevant semantic information, i.e., small local structures are more reliable than large local structures. In this paper, the importance of small local structures is emphasized in the process of feature aggregation to realize the rectification of feature representations of form describers.
Specifically, an independent deep graph convolutional network is introduced as a rectification network to learn feature representations of small local structures of form describers conservatively. The rectification network has the same structure as the feature embedding network of all nodes and runs in parallel. We integrate the feature representations of the form describers learned by the rectification network into the corresponding part of the feature representations learned by the feature embedding network by way of summation, realizing the rectification in the process of feature aggregation of the form describers. The structure of our RNFD is shown in Fig. 5. Note that the rectified feature M × C0 is extended to N × C0 in order to ensure the consistence of shape of rectified feature and feature learned by the feature embedding network. Specifically, zero vectors are used to fill the tensor to ensure that the positions of the rectified feature of the form describers remain unchanged throughout the point cloud.

Structure of RNFD.
Point clouds have latent graph structures that can describe the topology of objects accurately in the ideal situation. The following graph convolutional network learns the topology of the point clouds by using the graph structure information of the point clouds. The upsampled point clouds with high form fidelity are obtained finally.
Traditionally, the graph structure of a point cloud is built by unified KNN. This algorithm uses a simple strategy to build the graph structure of a point cloud, i.e., to find the same number of neighbors for each point, which is suitable for building the graph structure on the flat and simple surface of the objects. However, unified KNN is likely to generate overfilled graphs on the sharp edges and holes of the objects, which cannot depict the topological structures of the objects accurately. This fuzzy semantic information and incorrect graph structures will mislead the subsequent graph convolutional network, making it learn incorrect semantic information of point clouds. Therefore, improving the building method of the graph structures of the point clouds is conducive to the subsequent graph convolutional network for point cloud learning, obtaining the upsampled point clouds with high form fidelity finally.
Note that DI can quantify the positions and sparsity of points. For point pairs with large differences in positions and sparsity, the numbers of neighbors of them should be some difference to build a more realistic and accurate point cloud structure. Empirically, for points that are close to the edges and outlines of the objects and have large degrees of sparsity, i.e., points with larger DIs, selecting fewer neighbors can describe the local topology more realistically. For points located in the center of the objects and with small degrees of sparsity, i.e., points with smaller DIs, appropriate increases in the numbers of neighbors will help to make more and correct use of local structure information to generate a more uniform point cloud.
FDS can find the point set consisting of points with large DIs. Therefore, FDS can be used multiple times to divide the input point cloud into several disjoint levels according to the values of DIs of the points, i.e.,
and
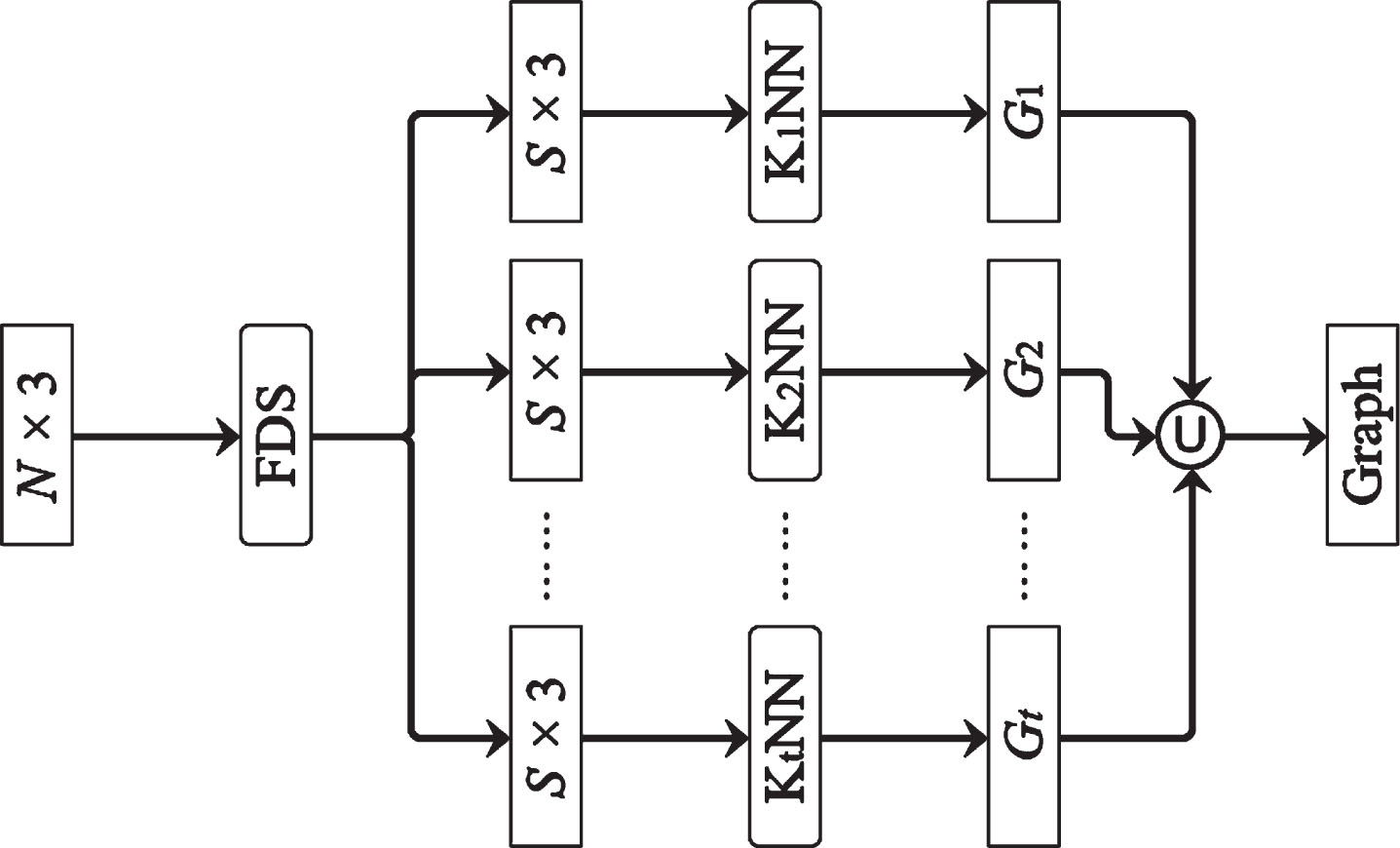
Structure of MKGB.
The complete graph structure realizes a more realistic and accurate representation of the topological structure information of the point clouds through a variety of subgraph structures, which is helpful for the subsequent graph convolutional network to utilize the topological structure information of the point clouds, obtaining the upsampled point clouds with high form fidelity finally.
The spatial-domain GCNs are often applied to point clouds. These methods manage to learn neighboring feature representations of points to perceive the detailed topological structures of objects. However, spatial-domain methods do not incorporate graph structure information including node degrees, edge weights, etc., and are only suitable for learning simple graph structures. The graph structure of the point cloud is a description of the topological structures of the object, which is generally more complex, especially for those objects with more complex topological structures. Therefore, spatial-domain methods often have very limited ability to learn the graph structures of complex point clouds. It is likely to learn fuzzy and biased detail topology, which leads to the insufficiency of form fidelity eventually.
The method [33] proposed by Kipf et al. is in the spectral domain, which effectively integrates the degrees of nodes and the weights of edges in the process of learning the neighboring feature representations of points, making full use of graph structure information. The calculation formula of the graph convolution layer of the spectral-domain methods is
We directly introduce the theories in DGCN [34] for the convenience of reading. Given a directed graph
The first-order adjacency matrix A
F
is obtained by symmetrizing the adjacency matrix A, which describes the neighboring information of each node. As shown in
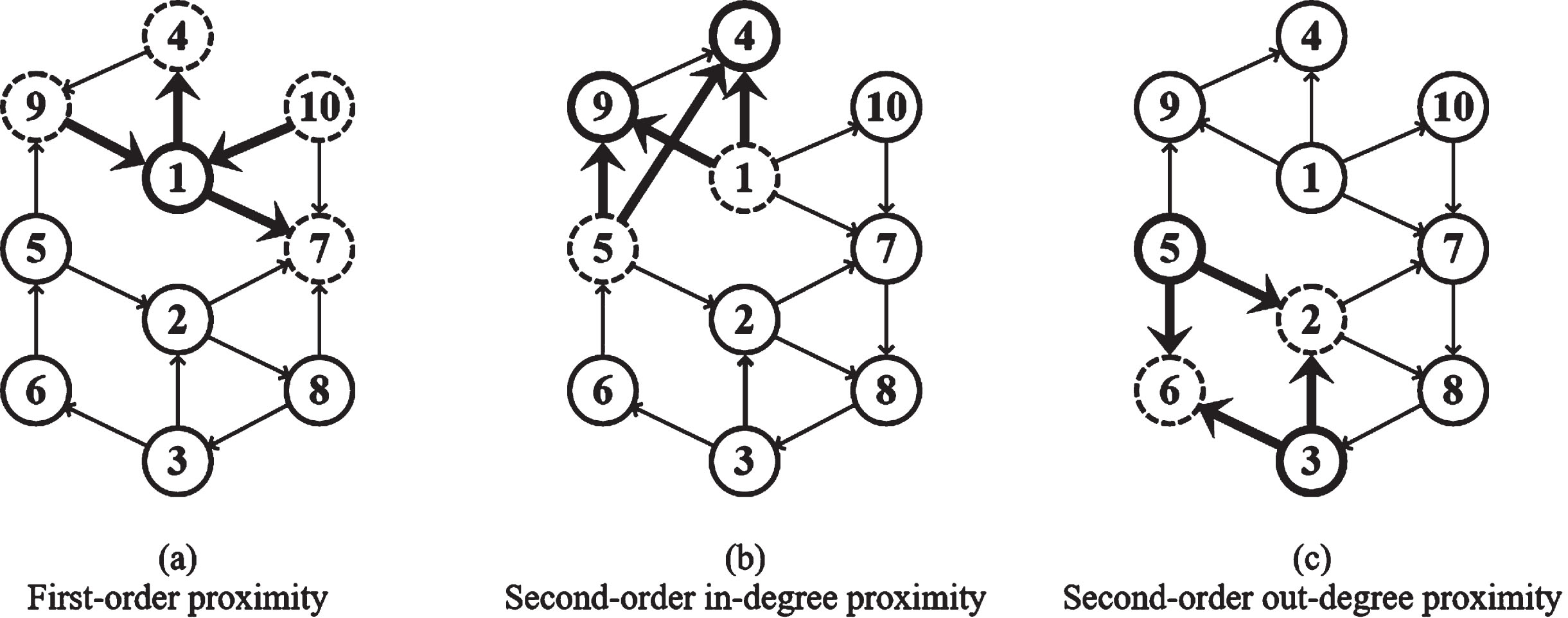
Node proximity.
and
respectively, where
The first-order adjacency matrix A
F
only retains the undirected information of the graph, while the second-order in-degree adjacency matrix A
S
in
and the second-order out-degree adjacency matrix A
S
out
calculated through the weighted directed edges in the graph retain the directed information of the graph. Therefore, these proximity matrices highly preserve the full information of the graph. It is easy to verify that A
F
, A
S
in
and A
S
out
are all symmetric matrices, thus they can be used for full utilization by spectral-domain methods, i.e.,
where
We fuse the graph structure feature representations of these 3 adjacency matrices to obtain the complete graph structure feature representations of the nodes. We also use the parameters α, β to weigh the importance of different graph structure feature representations, i.e.,
The structure of GAFA is shown in Fig. 8. Note that multiple DGCNs are cascaded to extract multi-layer features.
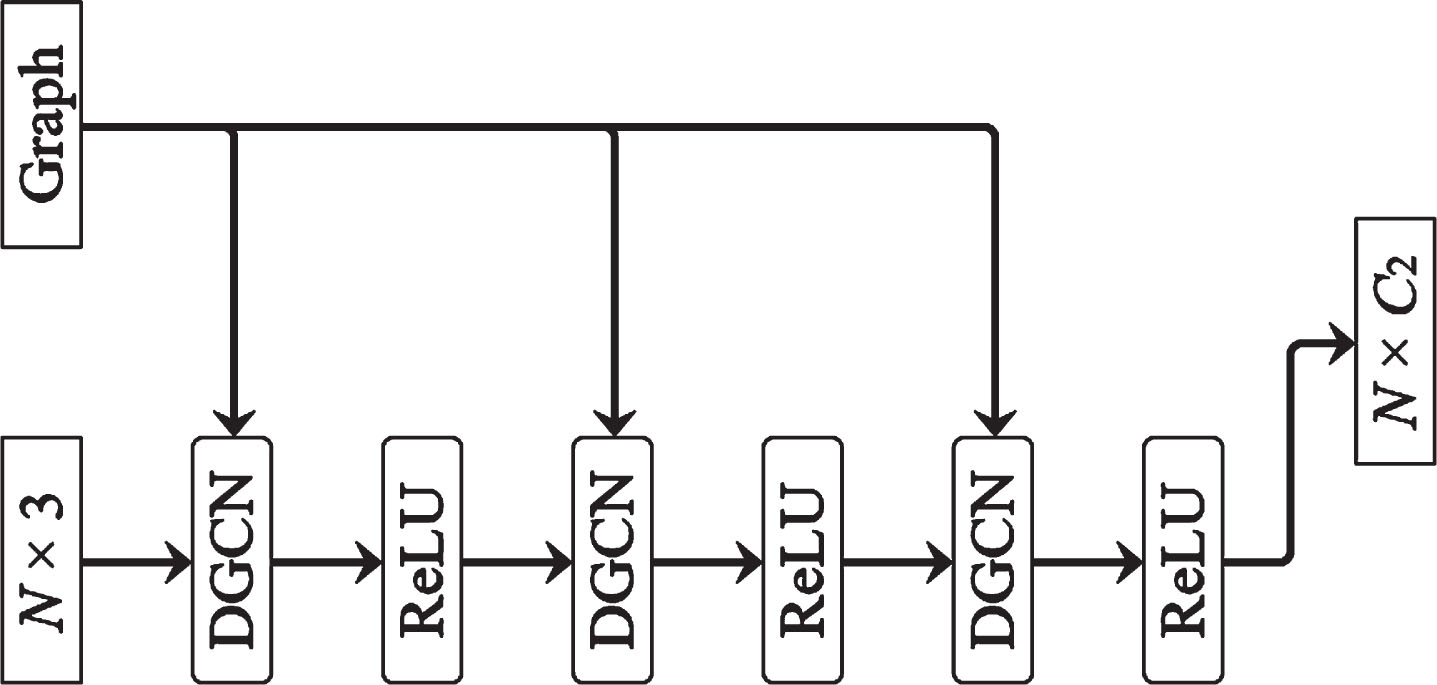
Structure of GAFA.
Our GAFA enhances the ability of graph convolutional network to learn the graph structures of complex point clouds, so that the model can make full use of the graph structure information of point clouds, obtaining the upsampled point clouds with high form fidelity.
Our model is trained and tested on PU1K [17] dataset. Quantitative and qualitative experimental results are reported as well. We also provide qualitative experimental results on the real-scanned dataset Semantic3D [42] to prove the practicability of our PU-FPG in practical scenarios. In addition, abundant ablation studies are conducted to verify the effectiveness of the proposed RNFD, MKGB and GAFA in solving the problems of the insufficient form fidelity of the upsampled point clouds.
Dataset
PU1K dataset
PU1K consists of 1147 3D models, which are divided into 1020 training samples and 127 test samples, covering a large number of 3D object semantic ranges. The training set consists of 120 3D models of PU-GAN and 900 3D models of ShapeNetCore [43]. The test set includes 27 3D models of PU-GAN and more than 100 3D models of ShapeNetCore.
Following the previous work, Poisson disk sampling is used in the original mesh to generate input and ground truth point cloud pairs. In addition, 50 point cloud patches are cut from each 3D model as the input when training the network, i.e., a total of 51000 point cloud patches are used for training. Each patch includes 256 points as training input and 1024 points as ground truth. Each input point cloud containing 2048 points and each ground truth point cloud containing 8192 points are used as paired test data.
Semantic3D dataset
Semantic3D provides a large labelled 3D point cloud data set of natural scenes with over 4 billion points in total. It also covers a range of diverse urban scenes: churches, streets, railroad tracks, squares, villages, soccer fields, castles to name just a few. The point clouds Semantic3D provides are scanned statically with state-of-the-art equipment and contain very fine details.
We manually cut point cloud patches with exact semantic information from Semantic3D. These patches are used as the input point clouds to conduct qualitative experiments in practical scenarios.
Loss function
In this paper, we use CD as the loss function to minimize the difference between the upsampled point cloud and the ground truth. Given 2 point clouds P and Q, Chamfer distance of them is defined as
We follow the previous work and select CD, Hausdorff distance (HD) and point-to-surface distance (P2F) as evaluation metrics in order to facilitate comparison. The smaller the values of these metrics, the better the model generates upsampled points. All models are trained and tested on the same computer with a single NVIDIA Tesla V100-32 G GPU and Intel Xeon E5-2698 v4 CPU.
Implementation details
In all experiments, we train PU-FPG for 200 epochs with batch size 64 on NVIDIA Tesla V100-32 G and set the input number of points N = 256. In our RNFD, the number of form describers M = 64, and the compromise factor λ = 0.95. In our MKGB, we use FDS for t = 4 times, and the numbers of neighbors selected at each level are set to k1 = 8, k2 = 12, k3 = 16 and k4 = 20. In our GAFA, we use the tradeoff parameter α = 0.85 and β = 1. In addition, we use the Adam optimizer and set the learning rate to 0.001 and beta to 0.9. Similar to the previous work, normalizing, rotating, scaling and random perturbation are all used in the point clouds to enhance the data. We train PU-Net, MPU, PU-GAN, PU-GCN and PU-FPG on PU1K for multiple times to ensure the stabilities of them. In our experiments, the upsampling factor r = 4.
Quantitative experimental results
Table 3 shows the mean quantitative results in multiple experiments of PU-Net, MPU, PU-GAN, PU-GCN and PU-FPG on PU1K. Here we note that we cannot compare with the works in 2022 such as [18] and [23], since the dataset we used is different from those they used. Although PU-FPG needs more training parameters compared with the state-of-the-art model PU-GCN, PU-FPG has significantly improved in other metrics, where CD is reduced by 0.159 × 10-3, HD is reduced by 2.892 × 10-3 and P2F is reduced by 0.852 × 10-3. The experimental results show that our proposed PU-FPG can improve the form fidelity of the upsampled point clouds effectively, thus raising the quality of the upsampled point clouds.
Quantitative experimental results
Quantitative experimental results
Results on PU1K
Qualitative upsampling comparison results of PU-Net, MPU, PU-GAN, PU-GCN and PU-FPG on PU1K are shown in Fig. 9. In

Qualitative experimental results on PU1K.
Qualitative upsampling comparison results of PU-Net, MPU, PU-GAN, PU-GCN and PU-FPG on Semantic3D are shown in Fig. 10. In

Qualitative experimental results on Semantic3D.
Abundant ablation studies are conducted to verify the contribution of RNFD, MKGB and GAFA in improving the quality of point cloud upsampling. We conduct the following experiments on PU1K and ensured that all experimental parameters are consistent. Table 4 shows the effects of our proposed parts individually and in combination. The experimental results show that the combination of the 3 parts we proposed, i.e., PU-FPG, can produce the highest quality upsampled point clouds.
Experimental results of ablation study
Experimental results of ablation study
In this paper, we focus on the problem of the upsampled point clouds with incorrect and unclear contours and boundaries as well as deficient topology structures in the process of point cloud upsampling, i.e., the problem of insufficient form fidelity of the upsampled point clouds. Firstly, we manage to make the form describers of the point clouds multiply near themselves according to correct semantic information. To this end, 3 statistics of points, i.e., LCD, LND and DI, are designed to estimate form describers of point clouds and further rectify the process of feature aggregation of them with more reliable neighboring features. This constitutes our rectification network based on form describer. Secondly, multilevel KNN graph building divides all points into several disjoint levels according to the above 3 statistics and apply KNN algorithm to the points of different levels respectively to build more realistic and accurate graph structures, so that the graph convolutional network can fully utilize potential graph structures of point clouds. Finally, to enhance the perception of model toward graph information, graph aware feature aggregation fuses cascaded networks and more graph information and add them to the process of feature aggregation in order that the network can deeply learn the topology of the object. Our model PU-FPG is obtained by combining these 3 parts with point cloud upsampling networks. Abundant quantitative and qualitative experiments prove that PU-FPG can improve the form fidelity and raise the quality of upsampled point clouds effectively.
In the future, we will combine more statistical methods with our DI to search for form describers more precisely. Besides, designing a mechanism to balance LCD and LND adaptively will be beneficial as well. Moreover, searching for outliers and reducing their weights in feature aggregation will also help improve the form fidelity of upsampled point clouds.
Footnotes
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgments
This research was funded by the National Natural Science Foundation of China (no. 62072024 and 41971396), the Projects of Beijing Advanced Innovation Center for Future Urban Design (no. UDC2019033324), R&D Program of Beijing Municipal Education Commission (KM202210016002 and KM202110016001), the Fundamental Research Funds for Municipal Universities of Beijing University of Civil Engineering and Architecture (no. X20084 and ZF17061), and the BUCEA Post Graduate Innovation Project (PG2022144 and PG2023143).