
Abstract
A novel approach to enhance software testing through intelligent test case selection is proposed in this work. The proposed method combines feature extraction, clustering, and a hybrid optimization algorithm to improve testing effectiveness while reducing resource overhead. It employs a context encoder to extract relevant features from software code, enhancing the accuracy of subsequent testing. Through the use of Fuzzy C-means (FCM) clustering, the test cases are classified into groups, streamlining the testing process by identifying similar cases. To optimize feature selection, a Hybrid Whale Optimized Crow Search Algorithm (HWOCSA), which intelligently combines the strengths of both Whale Optimization Algorithm (WOA) and Crow Search Algorithm (CSA) is introduced. This hybrid approach mitigates limitations while maximizing the selection of pertinent features for testing. The ultimate contribution of this work lies in the proposal of a multi-SVM classifier, which refines the test case selection process. Each classifier learns specific problem domains, generating predictions that guide the selection of test cases with unprecedented precision. Experimental results demonstrate that the proposed method achieves remarkable improvements in testing outcomes, including enhanced performance metrics, reduced computation time, and minimized training data requirements. By significantly streamlining the testing process and accurately selecting relevant test cases, this work paves the way for higher quality software updates at a reduced cost.
Introduction
Regression testing plays a vital role in software development by ensuring the continued functionality and correctness of software even after code changes have been made. As software systems evolve, effective maintenance strategies are essential to prevent them from becoming obsolete and ineffective. One key aspect of this maintenance is regression testing, which verifies that software updates do not introduce defects that could undermine its performance. In large organizations, regression testing is typically executed by experts who execute or analyse the code [1, 2]. However, this process can be resource-intensive, repetitive, time-consuming, and costly due to the need for re-execution of the entire test suite [3]. To mitigate these challenges, regression test optimization techniques such as test selection and prioritization have been introduced. These techniques involve selecting a subset of test cases that efficiently identify bugs and defects [4]. Test cases can be reordered based on predefined criteria such as code coverage, branches, or fault detection [5, 6]. Alternatively, test case selection involves reducing the number of test cases based on specific criteria [7, 8]. In this work, the focus is on test prioritization to facilitate seamless test case selection. Recently, the application of Machine Learning (ML) techniques has gained traction in driving the test case selection process.
In the realm of ML, classification is typically accomplished using two main techniques: discriminative learning and generative learning. The former displays exceptional performance in terms of supervised learning in many instances. The SVM [9–11], which is based on discriminative learning, has a simple and linear model that maximizes the linear separator margin directly between two sets. Moreover, among several ML approaches, the SVM offers a comparatively exceptional recognition rate. However, on the downside, it is only applicable for solving binary decisions. Thereby, a Multi-SVM technique is employed in this work to support multi-class problems. The ML base test case selection is further enhanced by using metaheuristic algorithms [20–26] for feature selection in test case selection. Some of the prominently used algorithms for feature selection are Differential Evolution (DE) [12], Particle Swarm Optimization (PSO) [13], Genetic Algorithm (GA) [14], Crow Search Optimization (CSO) [15] and Whale Optimization Algorithm (WOA) [16]. When a metaheuristic algorithm is developed, an efficient balance between an exploitation (intensification) and exploration (diversification) phases is required to be accomplished. Hence, hybrid algorithms that combine two prominent metaheuristic algorithms are designed in order to improve algorithm performance. Here, a hybrid algorithm combining WOA and CSA is proposed for enhancing test case selection process. Although the WOA heavily favours exploitation, it fails to adequately implement exploration, resulting in failure to reach global optimal solution in certain cases. The advantage of CSA, on the other hand, resides in its capacity to easily avoid local optima while tackling multimodal, high-dimensional and complex problems. However, its local search capability is not particularly effective [17]. Hence both these algorithms are best suited for hybridization due to their complementary strengths that compensates for the limitations of each other.
Moreover, the test case selection using multi-SVM is improved further with selection of appropriate feature generation and clustering techniques. Here, the context encoder [18, 19], which is a robust and simple technique, is used for feature generation. Additionally, the Fuzzy c-means (FCM) technique is adopted in this work as the data clustering technique. An analysis of recent advanced techniques in testing is provided in Table 1. The literature gap highlighted by the comparative study is the lack of a holistic approach that seamlessly integrates feature extraction, clustering techniques, and a hybrid optimization algorithm for the purpose of test case selection in the domain of software testing. While the existing techniques offer valuable contributions individually, there seems to be a gap in the research landscape where no prior work effectively combines these components to create a unified methodology that can potentially lead to superior testing results. This gap presents an opportunity for the proposed approach to address this limitation and demonstrate its effectiveness in bridging these aspects for enhanced software testing outcomes.
Analysis of recent techniques introduced in testing
Analysis of recent techniques introduced in testing
The proposed approach integrates feature extraction, clustering, and a hybrid optimization algorithm into a unified methodology for test case selection, addressing a gap in the existing literature. The utilization of a context encoder enhances feature extraction accuracy, facilitating the identification of relevant software code features for testing. The application of FCM clustering categorizes test cases into groups, streamlining the testing process by identifying similar cases and thereby improving testing efficiency. The introduction of HWOCSA optimizes feature selection through an intelligent combination of the strengths of WOA and CSA. A novel multi-SVM classifier is proposed, enhancing test case selection accuracy by enabling specialized learning for distinct problem domains, resulting in improved testing outcomes. The experimental results underscore the effectiveness of the proposed approach, showcasing enhanced performance metrics, reduced computation time, and minimized training data requirements.
The proposed approach contributes to higher quality software updates while reducing costs, making the testing process more streamlined and effective. These contributions collectively establish the innovative nature and significance of the proposed work in the domain of software testing.
A test case selection approach based on ML is suggested in this work. The entire process involved in the proposed test case selection approach from data collection, pre-processing, feature generation, feature selection, clustering and classification is illustrated in Fig. 1. This work uses test data related to meta data and provides natural language test case descriptions as inputs for multi-SVM to predict test case selection.
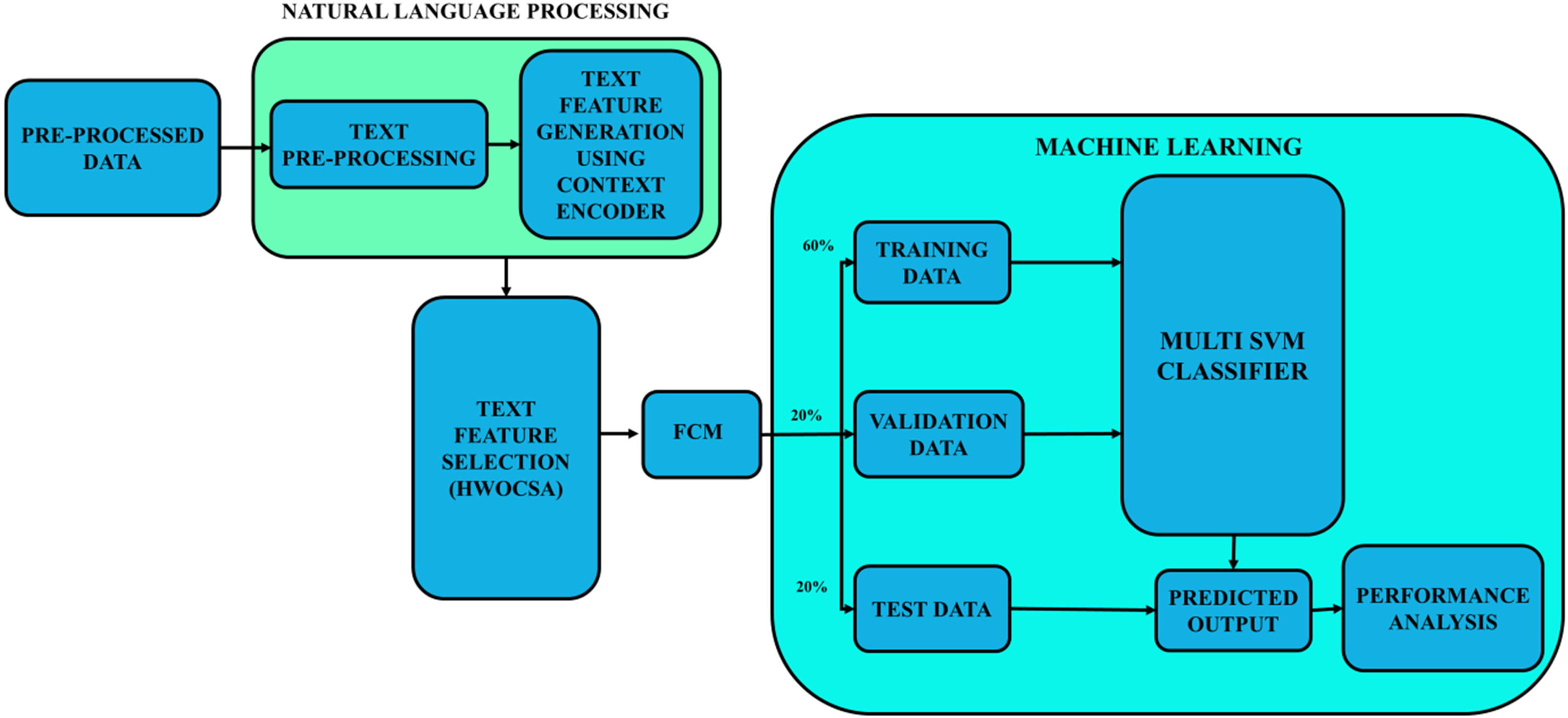
Structure of the proposed test case selection using multi-SVM.
This research involves several key steps. Initially, test cases are determined through data preparation using a dataset containing numerous features. Data pre-processing includes removing irrelevant features and converting categorical data to numerical data. Subsequently, the pre-processed data are put through natural language processing. Here, the data undergoes text pre-processing and text feature generation. The former involves processes such as stop words removal, irrelevant text removal, conversion to lower case and stemming, while the latter uses context encoder for text feature generation. Then the prominent features are selected using novel HWOCSA. After feature selection, the data is subjected to clustering using FCM. The clustered data are then finally classified using multi-SVM. Thus, the appropriate test cases are selected using the proposed ML approach.
Pre-processing
In this work, test data related to meta data is considered, and the inputs provided to multi-SVM consist of natural language test case descriptions for predicting test case selection. Test data selected is authorization micro service test cases, which is based on Oauth2 standard and is prominently used for authorization in industries. The dataset includes numerous features such as the classification target, GIT commit message, bug description, bug ID, defects, automation status, error-prone test cases, test case description, test case title, test case type, release identification number and unique identifier of records. However, only specific features are taken in to account for the proposed work. The redundant test features are removed during the process of feature selection. The final data comprises only the test case title, release identification number, defects, automation status, error prone test cases and test case description. The pre-processed data is then subjected to Natural Language Processing (NLP). The NLP comprises of text pre-processing and text feature generation.
Text pre-processing
In case of text pre-processing, a corpus represented as sparse matrix of numerical features is obtained by conversion of the textual features. The pre-processing approach aims at generating a corpus, which is suitable for the multi SVM.
Removal of irrelevant words: In order to obtain a clean text for successive processing, the irrelevant characters and words are excluded from the data. Transformation to lower case from uppercase: Since both the lower-case and upper-case alphabets have distinct ASCII codes, all the letters are transformed to a common lower-case letters. Stop words removal: In terms of response variables prediction, the role of stop words are insignificant. Stemming words: It is a text normalization technique, which is used to obtain the root word from the inflected word. Through stemming, the Bag of Words feature dimension are successfully reduced.
Text feature generation using context encoder
The statistical text features are generated using context encoder, which aims at predicting the target word on the basis of certain context words. Through selection of suitable rows from W0, the estimation of context words sum of embeddings is achieved. The structure of context encoder is presented in Fig. 2.

Structure of context encoder.
Where, the terms W0 and W1 refers to the parameter matrices of a neural language model and the term t refers to the label vector.
In similar contexts, the same words may appear, resulting in the possibility of replacing synonymous words with each another. The pairwise similarities between words are calculated based on the co-occurrence of context words, resulting in the generation of a similarity matrix.
The similarity scores range between 0 and 1, and these similarities are intended to be saved in word embeddings. It is required that the cosine similarity between the embedding vectors of similar context words is closer to 1. The scalar product of the matrix with word embeddings is given as,
Moreover, Y is also required to approximate S. The word embeddings are required to satisfy the condition,
This is accomplished by computing the Singular Value Decomposition of S in addition to the application of Eigen vectors. The global context vector is evaluated as the average of binary context vector x
ω
i
,
It corresponds to M
ω occurrences of ω in corpus. The embedding of word ω is given as,
Where, a∈[0,1] the context encoder is a robust technique, capable of creating on the spot out of vocabulary embeddings in addition to providing local context-based identification of multiple meaning words.
The proposed HWOCSA is a combination of both Whale Optimization Algorithm (WOA) and Crow Search Algorithm (CSA). It is effective in identification and selection of the most appropriate variable subset to the target variable.
Crow search algorithm
The CSA is a nature inspired population based approach modelled after the social interaction, characteristics and conduct of crows. In addition to being smart birds, crows tends to live in flocks and conceal their food in hidden places that they can remember and recover even after a long period of time. Furthermore, their self-aware nature enables them to recognize threats and communicate effectively with other crows using complex communication skills. Crows may also engage in food theft by carefully observing the hiding place of food of other crows before stealing it. However, if the concerned crow becomes aware of the thief, it switches its position away from its food for misleading the thief. The population of CSA is made up of N solutions and d problem dimension. The vector that denotes position of each crow in iteration t is given as,
Where, the term If crow j discovers the location of food of crow i, then position of crow j is updated as,
Where, the terms fl and r
i
refers to the flight length and random number respectively. Suppose, if crow i knows about the intention of crow j, it deceives the thief by altering its position.
Both these situations are mathematically represented as,
The schematic representation of the movement of crows during both these conditions is given in Fig. 3. The flight length has a huge impact over searching capability of the crow. The lower and higher values of flight length contribute to local and global search respectively. During the execution of the algorithm, the fitness function of each crow is assessed. Then a crow updates its position in accordance to fitness value. The new location is also evaluated for its feasibility. On the basis of the following equation, the memories of crows get updated,

Schematic representation of the movement of crows.
The WOA is a metaheuristic algorithm, which is modelled after the food foraging and hunting behaviour of humpback whales. This algorithm is primarily based on the bubble net hunting behaviour of the humpback whales. This algorithm entails three phases, which are
Encircling prey: The whales, which are the search agents, encircle their prey after identifying their locations. Then, from a randomly produced search agent set, the best candidate search agent set is identified by WOA. With respect to the best candidate, other search agents also update their location. This entire process is expressed as,
Where, the coefficient vectors are specified as
Where, the variable Exploitation phase: This is the phase during which the bubble-net hunting takes place. The two techniques involved in this phase are spiral updating position and shrinking encircling technique. Through linear decreasing of variable
Parameter specification of HWOCSA
Where, distance between prey and whale is specified as
Where, the random number is specified as p. Exploration phase: The global search process is conducted in this phase and this phase is based on the vector value
Where, the location of randomly chosen whale is specified as X rand .
In this work, a novel HWOCSA approach is used for text feature selection, in which WOA and CSA operate in a simultaneous manner in case of the proposed hybrid algorithm. It incorporates the benefits of both algorithms and generates promising results in terms of solution quality and convergence speed. The algorithm to be executed is selected on the basis of a threshold value, which is a random value ranging between 0 and 1. In this work, 0.5 is selected as the threshold value considering a balance between exploring the search space sufficiently and terminating the algorithm in a timely manner. Moreover, with this threshold value, the algorithm converges to an acceptable solution while avoiding premature convergence or excessive computation time. For a threshold value greater than 0.5, the CSA is executed and the WOA is executed in case of a threshold value lesser than 0.5. Figure 4 gives the flowchart of the HWOCSA. The steps for the implementation of HWOCSA is,
Initialization of the constants including iterations, variables and population in addition to the lower and upper bound. A matrix representing the variables and population size is created. The initial population is expressed as
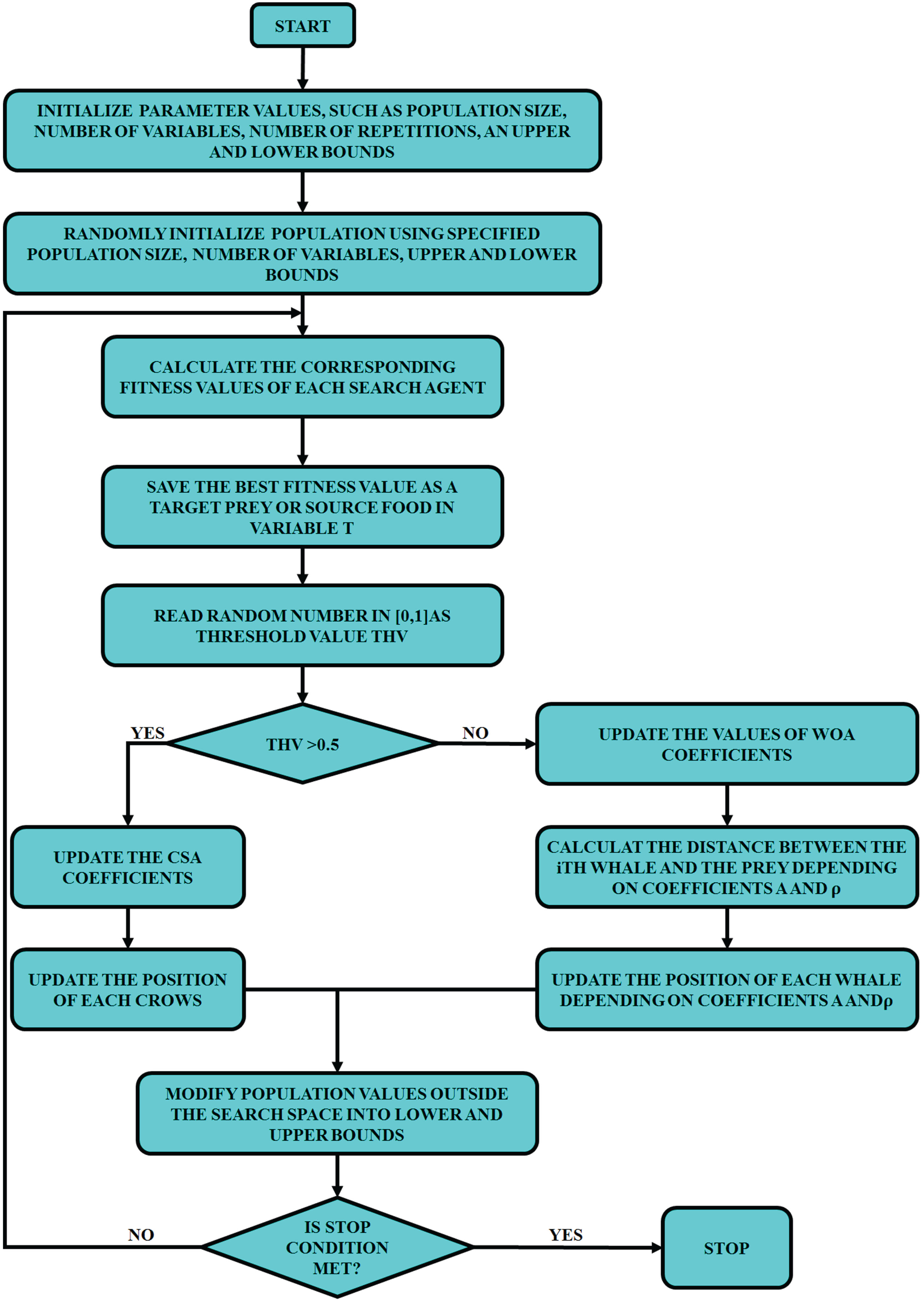
Flowchart of HWOCSA.
Where, the number of variables is specified as d, the population size is specified as n and the position of crows or whales is specified using the term X
ij
. The target prey or the crow position is saved as the best search agent. The selection of the threshold value. Execute CSA if the threshold value is greater than 0.5. Execute WOA if the threshold value is lesser than 0.5. Update the coefficients. Adjust the search agents’ positions based on the coefficients. Repeat the steps until the stop criterion is satisfied.
The pseudocode of the proposed HWOCSA is,
The complexity analysis of the HWOCSA algorithm is broken down into following components:
Initialization: O(1)
Population Creation: O(N*D)
Best Search Agent Initialization: O(1)
Threshold Selection: O(1)
Algorithm Execution: O(G*P*I*D)
Where, G is the number of generations, P is the population size, I is the number of iterations within each optimization algorithm (WOA or CSA) and D is the number of dimensions (features).
Coefficient Update: O(G*I)
Position Adjustment: O(G*P*D)
Total Complexity: O(G*P*I*D) + O(G*I) + O(G*P*D) = O(G*P*I*D)
The complexity analysis shows that the overall complexity of the HWOCSA algorithm is dominated by the algorithm execution phase, which includes the execution of WOA and CSA algorithms in a hybrid manner over multiple generations, with each generation having a population of search agents. The following conclusions are deduced from the complexity analysis: HWOCSA algorithm maintains a balance between exploration and exploitation. The HWOCSA algorithm’s complexity lies in its ability to adapt to different problem dimensions (features) and population sizes. As the complexity grows linearly with the number of dimensions and population size, HWOCSA handles diverse and complex optimization tasks by adjusting these parameters accordingly. The HWOCSA algorithm’s complexity analysis suggests its potential for scalability. The execution complexity directly impacts the algorithm’s convergence speed and solution quality. By combining WOA and CSA, the HWOCSA algorithm aims to harness the strengths of both algorithms to achieve faster convergence to high-quality solutions.
Despite the complexity associated with the execution of both WOA and CSA, the HWOCSA algorithm’s focus on text feature selection enhances its efficiency in identifying relevant features. This indicates that HWOCSA can effectively navigate through high-dimensional feature spaces to select the most pertinent features for text analysis.
Clustering using FCM
In FCM, the data samples with a membership degree are assigned to every clusters. The cluster centres are obtained after the datasets are partitioned into M fuzzy clusters and this data clustering approach is based on Euclidean distance:
Where, the training sample is specified as
For every pattern, the membership degree is normalized,
The cluster centres are moved to a suitable location in dataset through iterative updating of membership degrees and cluster centres on the basis of Equation (21) and Equation (22) for every training point
Where, the weighting exponent is specified as m∈[1, ∞]. After clustering, the classification process is carried out using multi-SVM.
The SVM exhibit excellent generalization capability when using the rules based on the structural risk minimization principle. Thereby, it extracts a small training data subset known as support vectors. SVM is suitable for binary classification and in order to support multiple classifications, multi-SVM is used in this work. Multi-SVM is a machine learning algorithm capable of addressing high-dimensional and non-linear problems in test case selection. This process involves selecting a subset of test cases from a larger set, reducing the time and resources required while ensuring adequate test coverage. Multi-SVM works by dividing the larger set of test cases into smaller subsets and training a separate SVM model for each subset. Each SVM model is trained to classify test cases as either selected or not selected for running based on a set of features which are extracted from the test cases. The features can include code coverage, branch coverage, and execution time, among others. Once the SVM models are trained, they are used to predict which test cases should be selected for running based on the features of the test cases. The predictions from each SVM model are combined using a voting mechanism to select the final set of test cases.
The training of the multi-SVM aims to classify the test cases and improve accuracy. For the purpose of training, the following aspects are considered:
The punctuations and stop-words have to be handled for the generation of enhanced accuracy. The data imbalance has to be managed for the creation of more balanced dataset. The parameters of multi-SVM have to be tuned for obtaining varying accuracy values for the same input.
The classification module of the presented multi-classifier is primarily based on the concept of training a SVM for every group patterns Dj obtained from original data set partition. Thus, each classifier, in this sense, understands a problem domain subspace and develops into a local expert for that subdomain. A number of 299 test cases are taken as sample data in which 199 test cases are used for training and 100 test cases are used for testing.
Individual SVM training
The following two operations forms the basis of SVM concept:
An input vector is nonlinearly mapped in high-dimensional feature space, concealed from the output and input. Creation of an optimal hyperplane to facilitate the separation of features.
Each classifier is employed as a SVM with nonlinear transformation from input space to feature space using radial basis functions:
Where, the width parameter is specified as σ. The SVMs in the multi-classifier method are trained individually in parallel.
Here, a total of M classifiers is trained for M subsets that are obtained by partitioning dataset D. An input vector
According to the above equation, the class probability
In order to evaluate the effectiveness of the proposed multi-SVM approach in comparison to other testing methodologies, a comprehensive set of experimental results were conducted and analysed across various parameters. These experiments encompassed computation time, branch coverage, fault detection effectiveness, and code coverage. To ensure the robustness and relevance of the findings, a carefully constructed synthetic dataset is employed. This dataset is curated from a diverse range of historical source code projects, thereby encompassing a wide spectrum of scenarios and use cases that are representative of real-world software systems. The details about the dataset is provided in Table 3. The synthetic dataset is meticulously designed to include a variety of code structures, functions, and modules that are commonly encountered in software development projects. This diversity ensures that the experimental outcomes are not biased towards specific coding styles or project types. Additionally, the dataset is intentionally constructed to incorporate potential challenges and complexities that software systems often encounter during their lifecycle, including intricate control flows, varying levels of code complexity, and diverse usage scenarios.
Details of the dataset
Details of the dataset
By creating a synthetic dataset that mirrors the complexities of real-world software, the experimental results presented in this study offer insights that can be extrapolated to actual software systems. The dataset’s diversity and comprehensiveness contribute to the reliability and applicability of the conclusions drawn from the experimental analysis, strengthening the research’s implications for practical software testing scenarios.
An amount of time needed to test software using best test cases chosen by suggested method is measured as time consumption.
The time consumption comparison using strategies like Random Forest (RF), Decision Tree (DT), SVM and Multi-SVM is illustrated in Fig. 5. From figure it is observed that, DT approach attains consumption time of 0.8 s, RF attains 0.78 s, SVM attains 0.64 s and multi-SVM approach attains 0.5 s. The analysis underscores the superiority of the multi-SVM approach in minimizing time consumption during the selection of test cases. This streamlined time consumption enables more frequent testing cycles and expedites the feedback process for any modifications made to the software system. The efficiency gain not only enhances the overall development process but also empowers development teams to be more responsive in addressing evolving requirements and issues in the software.
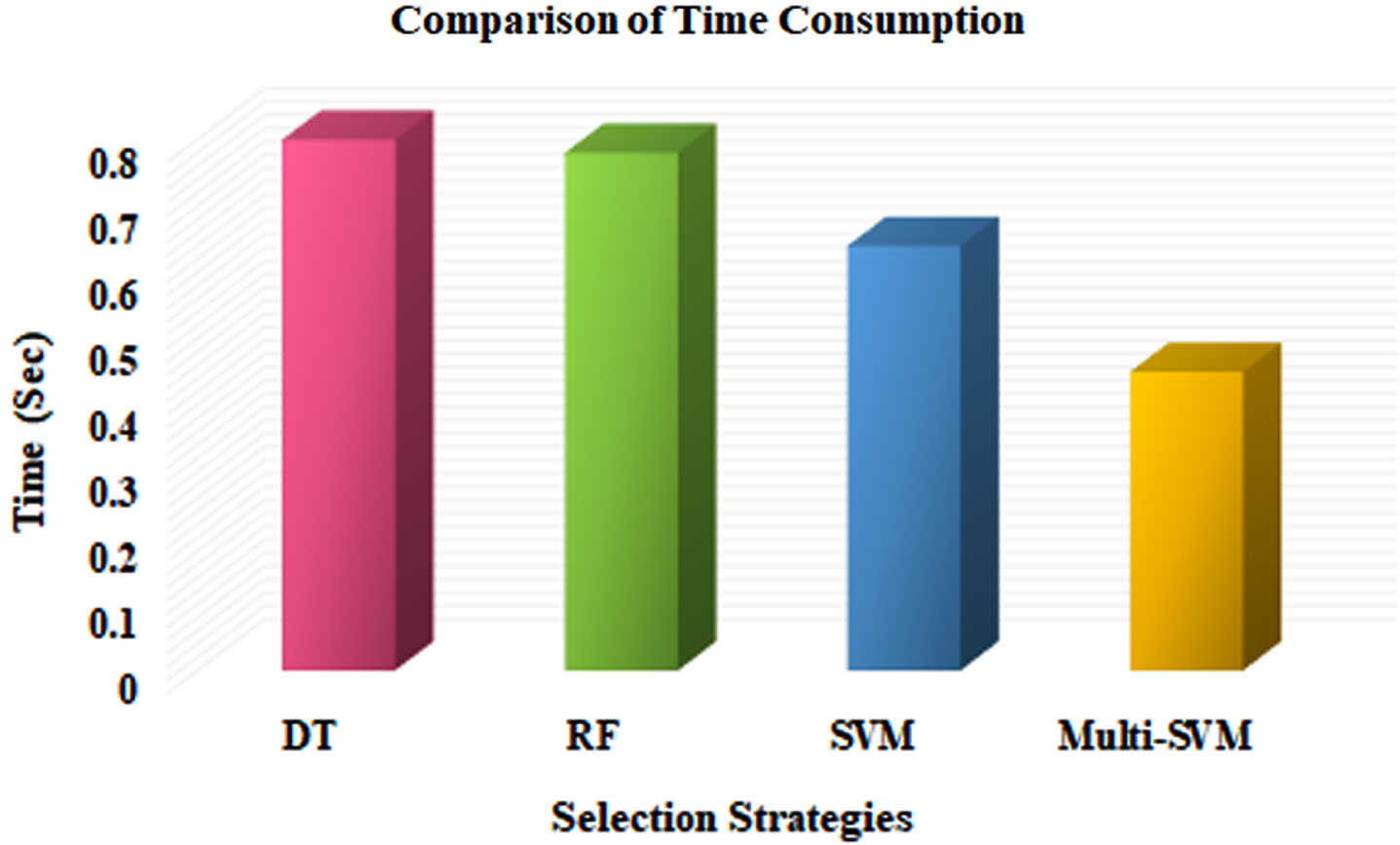
Graphical representation of time consumption.
DDE serves as a crucial indicator in assessing the effectiveness of testing methodologies by quantifying the ratio of detected defects to the total defects introduced during a specific testing phase. In the presented study, DDE is meticulously calculated for a range of approaches, including DT, RF, SVM, and the proposed multi-SVM algorithm. As showcased in Fig. 6, the DDE values achieved by the aforementioned approaches were systematically compared. The results revealed noteworthy insights into their respective performance. Notably, DT exhibited a DDE of 60%, indicating its efficiency in detecting defects. RF surpassed this with an enhanced performance of 79.65%, showcasing improved defect detection capability. SVM further demonstrated an even higher DDE of 84.56%, highlighting its robustness in identifying defects within software systems. However, the most remarkable achievement was observed in the proposed multi-SVM approach, which attains a DDE of 95.6%. This substantial enhancement in defect detection efficiency underscores the significant contribution of the multi-SVM approach in identifying defects accurately.
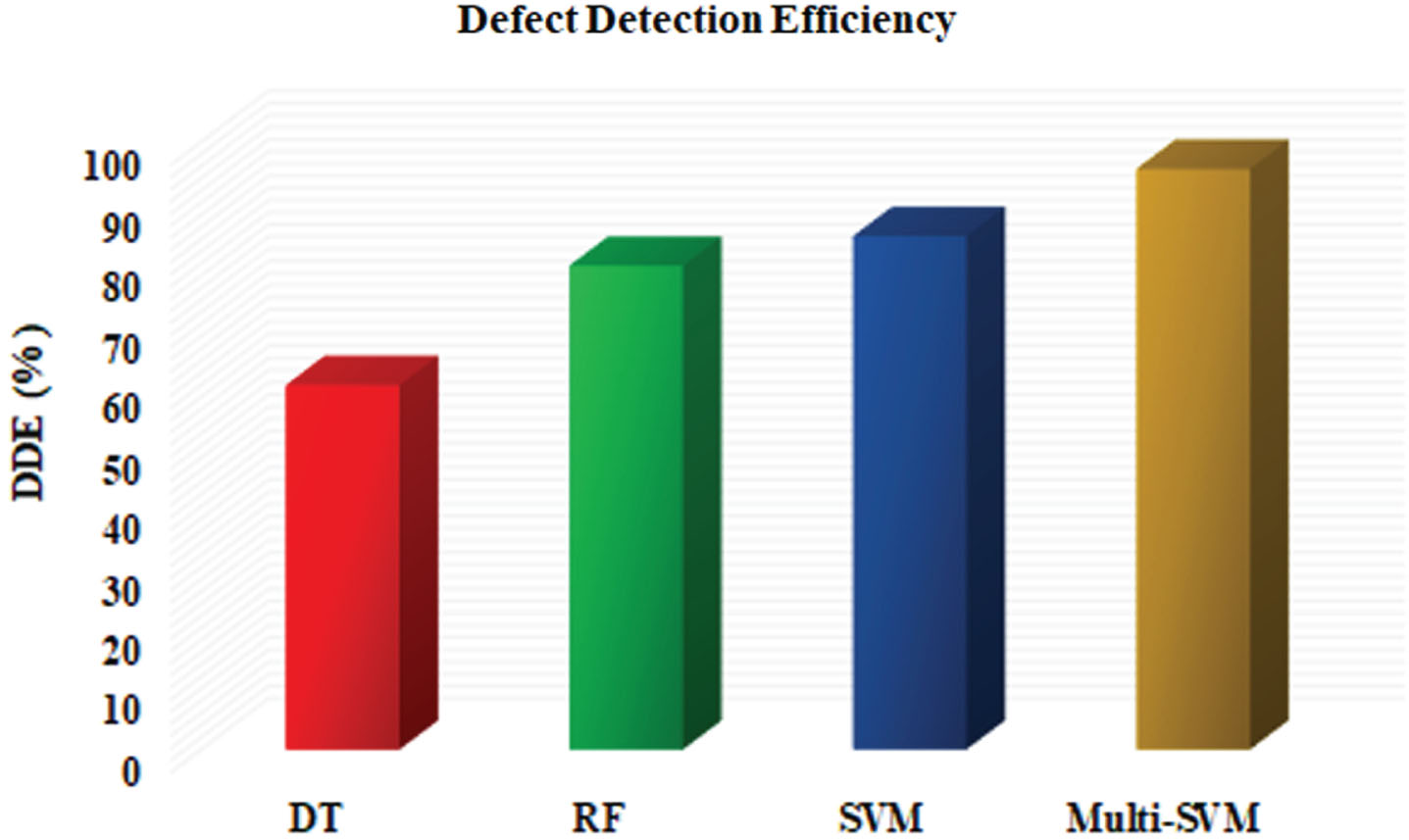
DDE comparison.
The detailed analysis elucidates that the multi-SVM approach outperforms its counterparts, showcasing superior defect detection capabilities. The considerable difference in DDE values substantiates the effectiveness of the proposed methodology in addressing the complexities and challenges inherent in software systems. This not only bolsters confidence in the reliability of the proposed algorithm but also reinforces its potential for utilization in practical software testing scenarios.
Code coverage is a critical metric that provides insights into the extent to which a program’s source code is exercised during the execution of a designated test suite. It helps gauge the thoroughness of testing by revealing which portions of the code have been executed and which remain untested. In essence, code coverage serves as a yardstick to assess the quality and effectiveness of testing methodologies.
The comparison using DT, RF, SVM and Multi-SVM for code coverage is depicted in Fig. 7. Generally, the code coverage should be high for selecting best test case. In comparison 15% is attained using DT, 27% using RF, 33% by SVM and the proposed multi-SVM achieves the best code coverage of 40% resulting in improved classification when compared with other strategies. The improved code coverage achieved by the proposed multi-SVM strategy reflects its proficiency in selecting test cases that effectively exercise a greater portion of the code. This capability is pivotal in identifying potential defects, bugs, or vulnerabilities that might otherwise remain hidden under less extensive testing scenarios. The robust code coverage achieved by the multi-SVM approach contributes to enhanced software quality and reliability, positioning it as a promising solution for robust testing and software validation.
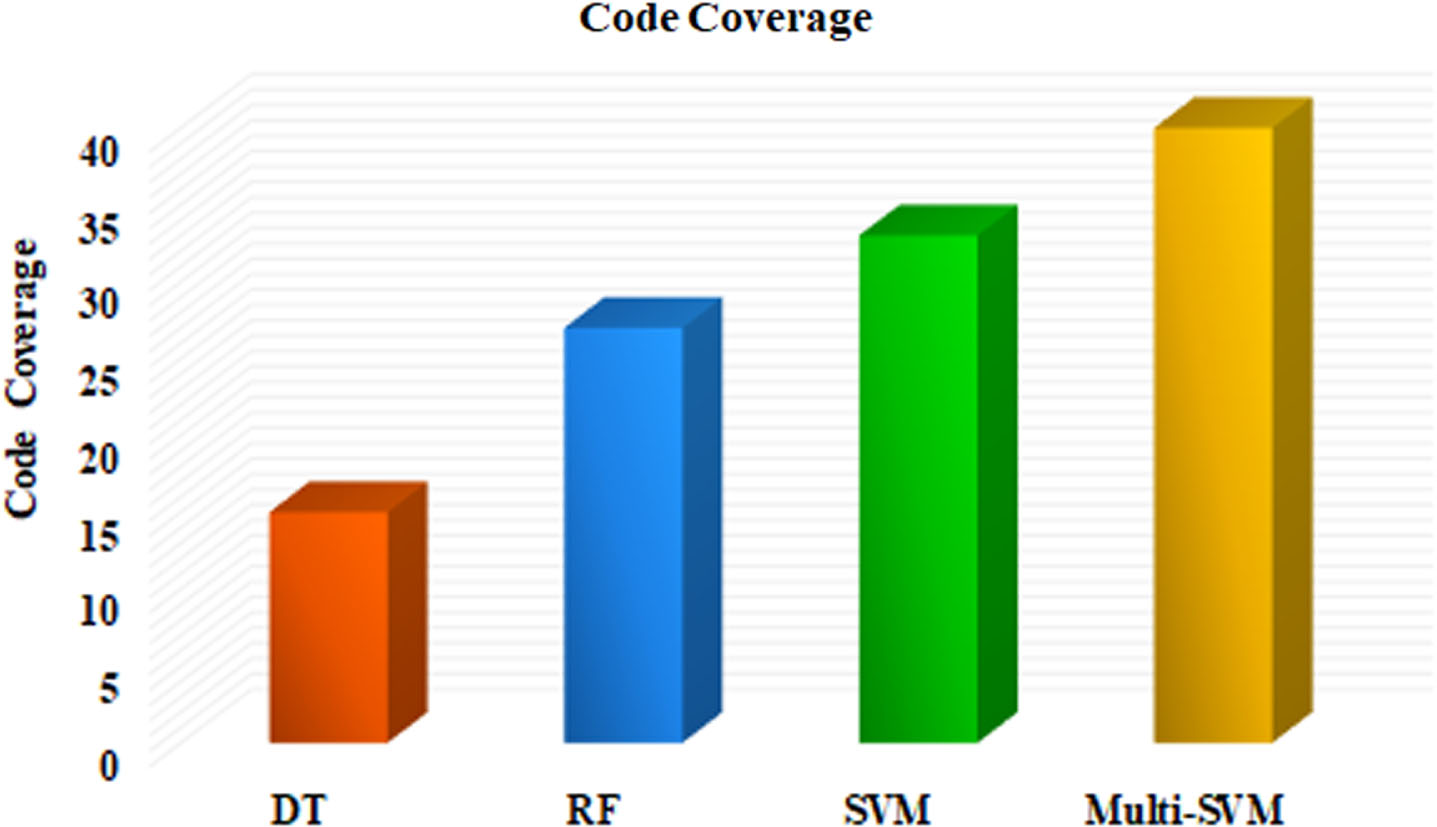
Comparison of code coverage.
In the evaluation of test specifications and coverage metrics, a crucial aspect of software testing is the measurement of branch coverage –a metric used to gauge the extent to which a program’s source code is executed during a specific test suite’s execution. This metric is vital in assessing the thoroughness of testing methodologies and their effectiveness in exploring various code paths.
The branch coverage for five different strategies is illustrated in Fig. 8. Upon close examination of the depicted comparison, a clear pattern emerges: the proposed multi-SVM strategy exhibits superior branch coverage when compared to the other strategies. This observation highlights the potential of the multi-SVM approach to explore a greater variety of code pathways, leading to a more comprehensive testing process. The consistent trend of the multi-SVM approach outperforming the other strategies in terms of branch coverage underlines its ability to effectively navigate intricate control flows and complex logic within the codebase.
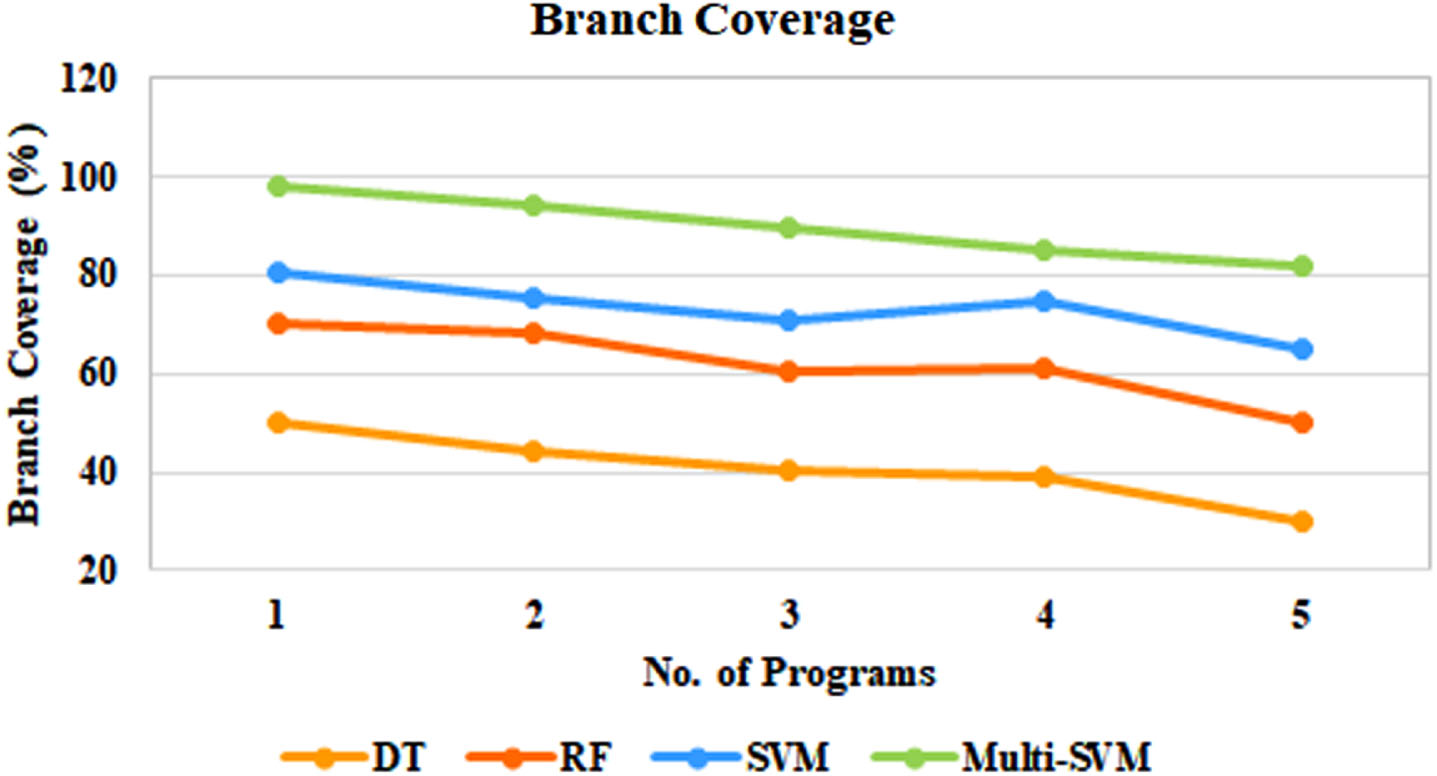
Branch coverage comparison.
The high level of performance for multi-SVM are shown in Table 4 utilising cross validation to distinguish between training and testing sets. The value of k is changed for k fold cross validation, ranging from 2 to 15. It is obvious that the testing accuracy is highest for k = 8 and is 86.94%.
Performance result of multi-SVM for cross validation
The proposed HWOCSA is evaluated for its effectiveness in text feature selection by comparing against five prominent metaheuristic algorithms: DE, PSO, GA, CSA and WOA. The outcomes of the comparison results are tabulated in Table 5 and it is analysed on the basis of the standard deviation and mean value of the fitness function.
Performance comparison of HWOCSA in contrast with other algorithms
Performance comparison of HWOCSA in contrast with other algorithms
The proposed HWOCSA outperforms another metaheuristic algorithms in terms of fitness, accuracy, sensitivity and specificity. However, in terms of computational speed, WOA has the lowest computational time. Moreover, the CSA also has a quicker computational time than HWOCSA. The proposed HWOCSA takes comparatively more time in discovering the best solution owing to its hybrid structure. Furthermore, it is also observed that a proposed HWOCSA has significantly better computational time than DE, PSO and GA.
Table 6 presents the results of the proposed HWOCSA validation on a set of benchmark functions. The table provides a clear overview of the superior performance of the proposed HWOCSA across various benchmark functions, substantiating its effectiveness as an optimization algorithm and highlighting its potential for applications in diverse optimization tasks.
Validation of algorithm on benchmark functions
Table 7 offers a comprehensive evaluation of the proposed algorithm’s performance on a diverse set of complex optimization problems. The assessment covers Solution Quality, Convergence Speed, and Robustness across various problem domains. The HWOCSA algorithm demonstrates remarkable proficiency in addressing intricate challenges. It achieves high-quality solutions rapidly and robustly for problems such as the Traveling Salesman, Quadratic Assignment, Knapsack, and High-Dimensional Rastrigin. It excels in Engineering Design, neural network hyperparameter optimization, Portfolio Optimization, Supply Chain Optimization, and Scientific Model Parameter optimization, showcasing a consistent balance between quality, speed, and robustness. The algorithm’s adaptability is evident in Multi-objective Optimization, where it consistently delivers high performance. Overall, this evaluation underscores the algorithm’s versatility and effectiveness across a broad spectrum of demanding optimization scenarios.
Performance of proposed HWOCSA algorithm on complex optimization problems
In Table 8, the Wilcoxon test results show the p-values obtained for the comparison of the proposed HWOCSA algorithm against other algorithms in terms of various metrics like fitness, accuracy, sensitivity, specificity and computational time. Similarly, the ANOVA test results provide the p-values for the same comparisons. The lower the p-value, the stronger the evidence against the null hypothesis, indicating a significant difference in performance. these statistical analyses underscore the exceptional performance of the proposed HWOCSA algorithm across a range of metrics, positioning it as a promising optimization solution in comparison to its counterparts.
Statistical test results for proposed HWOCSA algorithm
As evident from the Table 9, the HWOCSA algorithm outperforms all other considered hybrid algorithms, achieving the highest accuracy of 0.9887 while requiring the shortest computational time of 0.415 seconds. This table showcases the remarkable capabilities of HWOCSA in optimization tasks.
Performance comparison of hybrid algorithms
This study has presented a comprehensive overview of the test case selection process through the application of a machine learning approach. By utilizing the context encoder for feature extraction and FCM clustering, the methodology demonstrates its effectiveness in enhancing test case selection. The incorporation of the innovative HWOCSA further contributes to improved feature selection, resulting in optimized test case outcomes. Notably, the experimental results underscore the significance of these developments, showcasing substantial achievements in training time reduction by 0.5 seconds, accompanied by an impressive efficiency rating of 95.6%.
The pivotal contributions of this work revolve around its ability to harness the potential of multi-SVM for test case selection, leading to a remarkable 40% increase in code coverage and improved branch coverage. The evaluation of performance metrics under varying fold values reinforces the superiority of the multi-SVM approach, achieving a commendable accuracy rate of 86.94%. These achievements mark significant milestones in enhancing the efficiency, accuracy, and effectiveness of test case selection processes.
Future directions
Looking ahead, there are several promising avenues for extending and enhancing the proposed approach. One potential future direction is to explore the application of the technique in diverse software domains and larger-scale projects, assessing its scalability and adaptability. Additionally, investigating the integration of other advanced optimization algorithms could further refine the feature selection process. Furthermore, incorporating dynamic learning strategies into the approach could potentially enhance adaptability to evolving software systems.
Limitations
It is important to acknowledge the limitations of the proposed method. While the Multi-SVM approach demonstrates substantial accuracy, its performance might be influenced by the nature and complexity of the software system under consideration. Furthermore, the effectiveness of the approach could vary when applied to different problem domains, potentially requiring domain-specific adjustments. Additionally, the efficiency gains achieved through feature selection and test case reduction should be carefully weighed against any potential loss of comprehensive coverage. The proposed method’s applicability in various domains might be constrained by factors such as the nature of the data and the complexity of the problem. Additionally, the performance could be influenced by the availability and quality of features in different application scenarios, potentially affecting the effectiveness of the context encoder and clustering techniques.