
Abstract
Textual Question Answering targets answering questions defined in natural language. Question Answering Systems offer an automated approach to procuring answers to queries expressed in natural language. The need for Multilingual Question Answering without performing machine translation is ever existing. Besides that, automating tasks with the help of technology to assist humans, has been the main aim of research in recent years. This paper presents an automated answer evaluation system for reading comprehension-based questions in the Hindi language without requiring translation in any other language. The system accepts text, question, and handwritten answer of a student in the form of an image for answer evaluation. This is accomplished by developing a textual question-answering system for reading comprehension. It is an extractive approach that utilizes RoBERTa transformer model and fine-tunes it for Hindi question-answering. The answer to the question is extracted as a span from the provided text. Further, a handwritten text recognizer model is developed employing a Convolutional Recurrent Neural Network with Connectionist Temporal Classification module along with two layers of Bidirectional LSTM. Experimentation is performed using existing as well as self-created datasets to show the effectiveness of the proposed approach. An accuracy of 98.69% is obtained on the self-created Hindi-QA dataset and the proposed system outperformed the other existing methods. The paper also discusses potential research directions in the field.
Keywords
Introduction
Question Answering (QA) is a computer science discipline within the fields of Information Retrieval (IR) and Natural Language Processing (NLP). It is a task of answering questions in natural language. These answers can either be generated or extracted from a given context. Generative QA involves the generation of answers, which requires searching for documents that may contain the answer and then generating the answer. However, the focus of the system presented in this paper is on Machine Reading Comprehension (MRC) based QA which is an extractive technique. It involves the extraction of the answer from a given context.
At present, the development of education systems and education-related technologies, to help the students, teachers, and the entire administration to function smoothly and efficiently without spending a lot of time to achieve tasks, has been growing tremendously. Artificial Intelligence and Machine Learning have become popular fields for solving many problems based on human intelligence to reduce time spent by a human doing tasks that today machines and algorithms can do equally well. A system for automated checking of answer sheets of students can be of great help to the teachers. Handwritten Text Recognition (HTR) model can be employed to recognize and convert handwritten text into digital format. This paper presents a system for the extraction of handwritten text from an image, that contains the answer written by the student and verifies the answer for correctness, and provides a score for the written answer. The main focus of the work presented in this paper is to handle the automated valuation of Reading Comprehension based questions. To cater to the task, first, a Question Answering System for Machine Reading Comprehension is presented followed by the HTR model. Together, these models create an automated answer valuation system.
To increase the reachability and usefulness of the model it is important that the Question Answering System can understand and extract answers from multiple languages. The main aim of this research is to increase the usefulness of already existing question-answering models by creating one single model capable of handling different languages. The presented Question Answering system can handle multiple languages like English, Hindi, Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese and returns an appropriate answer for the question in that language. Although the QA system is a Multilingual Question Answering model, the target of the work presented in this paper is the valuation of Reading comprehension questions, particularly in the Hindi language.
The question-answering system is provided with a paragraph and a question for extraction of answers from the given passage. The provided paragraph and question are assumed to be the same as those given to the students. The answer written by the student (in the form of an image) is provided as input to the HTR model to obtain the digital version of the answer. The digital answer is then compared with the answer provided by the QA system. Based on the correctness of the answer, the marks are allocated.
The main contributions of the work presented in this paper are summarized below:
A system for question-answering based on textual content is presented. As input, the given QA system takes a text and a question. The answer is a span taken from the provided text. To test the model’s performance on real-world data, a Hindi-QA dataset is created. Performance comparison on existing datasets is performed to confirm the effectiveness of the model. An HTR model for extracting handwritten text from images is developed. This module recognizes the answer written in the image is used to obtain the digital version of the word. The marks allocation module is presented that compares the extracted text (obtained from the HTR model) with the predicted answer (obtained from the QA system). Experimentation on existing datasets and on self-created dataset demonstrating the efficacy and applicability of the proposed system in real-world scenarios.
The paper is organized as follows. Section 2 presents the literature review and discusses the required background model. The proposed approach is discussed in Section 3 followed by discussion on the datasets used in Section 4. Experimentation and results are presented in Section 5. Section 6 discusses the possible future direction and emerging research topics in the field that have the potential to further advance the research area. Finally, Section 7 concludes the paper.
In this section, we review the literature on textual question-answering and HTR models for the Hindi language. Hindi is the fourth most spoken language in the world. It is a very popular Indic script and is used by about 400 million people in India and other countries [1].
Textual question-answering
Textual question-answering aims to find the answer to a question and is a popular natural language processing task. Most of the work in textual-QA is in the English language due to the availability of datasets and there have been few efforts to address other languages and multilingual question-answering.
A restricted domain multilingual QA system is presented in [2]. It utilizes Universal Networking Language (UNL) [3] to convert the contents of a document (Hindi or English) into an intermediate language. Initially, the answer type is determined by analyzing the question. The answer template is converted to UNL expression. The UNL expression of the question is matched with the documents to determine the answer. The UNL expression of the answer is converted back to Hindi or English. An accuracy of 60% is reported.
Gupta et al. [4] have proposed a Multi-domain Multi-lingual Question-Answering (MMQA) system for English and Hindi languages. It focuses on factoid and short descriptive questions. A dataset is created comprising 250 articles each for English and Hindi languages. For answering questions in Hindi they are first translated into English using Google Translate and then the answer is found. The system mainly has the following modules: question processing, question classification based on CNN and RNN, question formulation by stop word removal, passage retrieval, and extraction of answers from the identified passage.
Patrick Lewis [5] presents MLQA, a multi-way aligned extractive QA evaluation approach. It caters to 7 languages, namely English, Arabic, German, Spanish, Hindi, Vietnamese and Simplified Chinese. It consists of over 12K QA instances in English and 5K in each other language, with each QA instance being parallel between 4 languages on average. MLQA is built using a novel alignment context strategy on Wikipedia articles and serves as a cross-lingual extension to existing extractive QA datasets. The Hindi-English cross-language question-answering system utilizing newspaper articles is presented in [6]. The question is accepted in English, it is analyzed and the keywords are translated into Hindi language using a bilingual dictionary. The answer is searched in newspaper articles based on the Hindi keywords. The answer is translated back to English and presented as the result. Another cross-language system is presented in [7]. However, all the above discussed systems require language translation to an intermediate language or other natural languages.
A machine learning approach for Hindi Language QA is presented in [8]. The system is divided into three phases: Accessing natural language query; where the input query is read, preprocessed, and get tokenized. It is followed by the feature extraction phase; where specific feature vectors are identified from the results of the previous phase and finally the Classification phase; where the Naïve Bayes classifier has been used, along with the knowledge base already stored in the system.
However, due to the advancement in Deep Learning and its success researchers have applied deep learning-based techniques for QA in the English language. Also recently, the Bidirectional Encoder Representations from Transformers (BERT) has become a benchmark in NLP tasks because it reads text simultaneously in both directions rather than sequentially (from left to right). Prior training for BERT focuses on the goals of language modeling and next-sentence prediction. It is thereafter trained to carry out particular NLP tasks. Various variants of BERT like m-BERT, ALBERT, RoBERTa, etc. are trained on a vast corpus of language-specific data.
A BERT Based Multilingual Machine Comprehension in English and Hindi is presented in [9]. They utilized multilingugal BERT (m-BERT) with fine-tuning. BERT, ALBERT, and SPANBERT are utilized in [10] for question answering of Tweets in English.
Recently, a Hindi and Tamil dataset was qurated by Google [11], that lead to focus on Hindi language question answering. Experimentations on various settings with XLM-RoBERTa model is presented in [12]. The first model is a cross-lingual version of XLM-RoBERTa that has only been fine-tuned on the SQUAD [13] dataset. The second model is based on the pretrained RoBERTa model, but it uses a customised Indic tokenizer instead of a classification head. The hyperparameters are then optimized and fine tuned on the ChAII dataset. The third model is built on XLM-RoBERTa but has been fine-tuned and trained on the Indic dataset. The paired RoBERTa models outperformed the XLM-RoBERTa models because the training data was more focused according to the task, as opposed to the XLM-RoBERTa models, which contained a lot of data that did not include in Hindi pairs.
Multilingual Contrastive Training for Question-Answering in Low-resource Languages (MuCoT) is proposed in [14]. It utilizes m-BERT fine-tuned on SQUAD and ChAII dataset with results on Hindi question-answering. Namasivayam et al. [15] performed experimentation by fine-tuning XLM-RoBERTa on Hindi data from SQUAD, MLQA datasets. Further, they also fine-tuned MuRIL [16] and found it to give the best performance.
We investigate the possibility of utilising a transformer model for our purpose because transformer models have demonstrated high performance in question-answering. Next, we discuss the most basic transformer model-BERT, which serve as the foundation for further discussion in the paper.
BERT transformer model
Transformers are pre-trained on large volume of text data, which allows them to learn rich representations of language. These pre-trained models can be fine-tuned on specific tasks with relatively small amounts of task-specific data, making them highly effective for a wide range of NLP tasks without the need for extensive data and computational resources. Moreover, the fine-tuning may be accomplished with a small number of epochs.
BERT [17] is a language model that was trained on a huge and diverse corpus of text from the internet. BERT training is divided into two stages: pre-training and fine-tuning. BERT is pre-trained on a huge amount of text data to gain an understanding of the language. This pretraining stage aids BERT in the development of contextual word embeddings. After pretraining, BERT can be fine-tuned on specific downstream tasks, such as natural language understanding, Question-answering, language generation, etc. A task-specific dataset is required for fine-tuning.
Further, BERT employs two training techniques named Masked LM and Next Sentence Prediction (NSP). First, 15% of the words in the input word sequence are altered and replaced with a [MASK] token. The model then attempts to predict the masked words using the context provided by the non-masked words in the sequence. After which, for Next Sentence Prediction (NSP), the model learns to predict whether the second sentence in a pair of sentences will come after the first one in the original document. A [CLS] token is added at the start of the first sentence and a [SEP] token is added at the end of each sentence. A positional embedding is added to each token to indicate its position in the sequence and a sentence embedding is added for the two sentences to capture their sequence.
In this paper, we experiment with transformer-based models since they can be fine-tuned with fewer resources on smaller datasets after pretraining to maximize their performance on particular tasks and achieve good accuracy.
Handwritten text recognition for Hindi langauge
Summary of Significant methods in HTR
Summary of Significant methods in HTR
There is considerable work in recognition of the printed Hindi language text [21]. However, very less work exists in Hindi handwritten text recognition. The reason is the lack of availability of large datasets. Some researchers targeted the recognition of only Hindi numbers [22, 23, 24]. It is important to recognize characters, words, and sentences for complete digitization. A comprehensive review of text recognition in various languages can be found in [25]. We discuss the literature on Hindi character recognition. Table 1 shows a summary of significant work in HTR in the Hindi language.
A Zernike moment feature-based approach for Hindi character recognition using an artificial neural network for classification is proposed in [19]. Perwej et al. [26] used Characteristic Loci features and a backpropagation-based neural network for the recognition of handwritten characters. A quadratic classifier for the recognition of characters and numbers in the Hindi language was proposed in [18]. For feature extraction, a bounding box is created for the input character followed by contour extraction to create chain code. A 196 dimension size feature is obtained which is sampled down to obtain the final 64 dimension feature by application of the Gaussian filter. Chaudhuri et al. [26] proposed a soft computing-based Hindi text recognition model using HP Labs India Indic Handwriting dataset comprising 29,970 characters and numbers. Various pre-processing techniques such as binarization, noise removal, skew detection and correction, character segmentation, and thinning are applied, followed by feature extraction using discrete Hough transformation. The feature-based classification into various Hindi characters is performed utilizing soft computing techniques like rough fuzzy multilayer perceptron (RFMLP), fuzzy support vector machine (FSVM), fuzzy rough support vector machine (FRSVM), and fuzzy Markov random fields (FMRF). A CNN-RNN hybrid architecture is presented in [B], that employs a spatial transformer network (STN) for input transformation to remove geometric distortion. STN is followed by a set of residual convolutional blocks and stacked bi-directional LSTM layers. Finally, the CTC layer is used for transcribing the labels. It comprises 18 convolutional layers. In this paper, we also consider the IIIT-HW-Dev dataset since it is a word-level dataset, and others are character-level datasets.
This section discusses the proposed Question Answering System for Machine Reading Comprehension dataset using Text Recognition for the Hindi Language. In particular, an automated system for evaluating the answer written by hand is presented. The overview of the proposed system is shown in Fig. 1. A question and text (or context) are provided as input to the QA system that extracts a span of words as output corresponding to the answer to the input question. This answer is compared with the handwritten answer, which is first converted to digital form using a Handwritten Text Recognition (HTR) model. The comparison helps in determining if the written answer is correct or not and also assists in score computation. To accomplish the task of extraction of text from the image, we explore the option to use a deep learning neural network and finally give a score to the answer. Further, the QA system uses a Natural language processing (NLP) technique capable of handling multiple languages. Next, we discuss the modules of the proposed approach: Textual Question Answering (textual-QA), Handwritten Text Recognition, and Answer Evaluation.
Textual question answering
Textual-QA involves extraction of the answer span from the given context. To accomplish this a Multilingual QA model is built using transformer-based RoBERTa model.
As discussed in Section 2, transformer models have brought about a significant advancement in natural language processing and various other machine learning tasks due to their unique architecture and capabilities. As tranformer models can be fine-tuned with less amount of task-specific data and require a very few epochs for fine-tuning, we have utilized transformer model and fine-tuned it for the QA task.
System overview.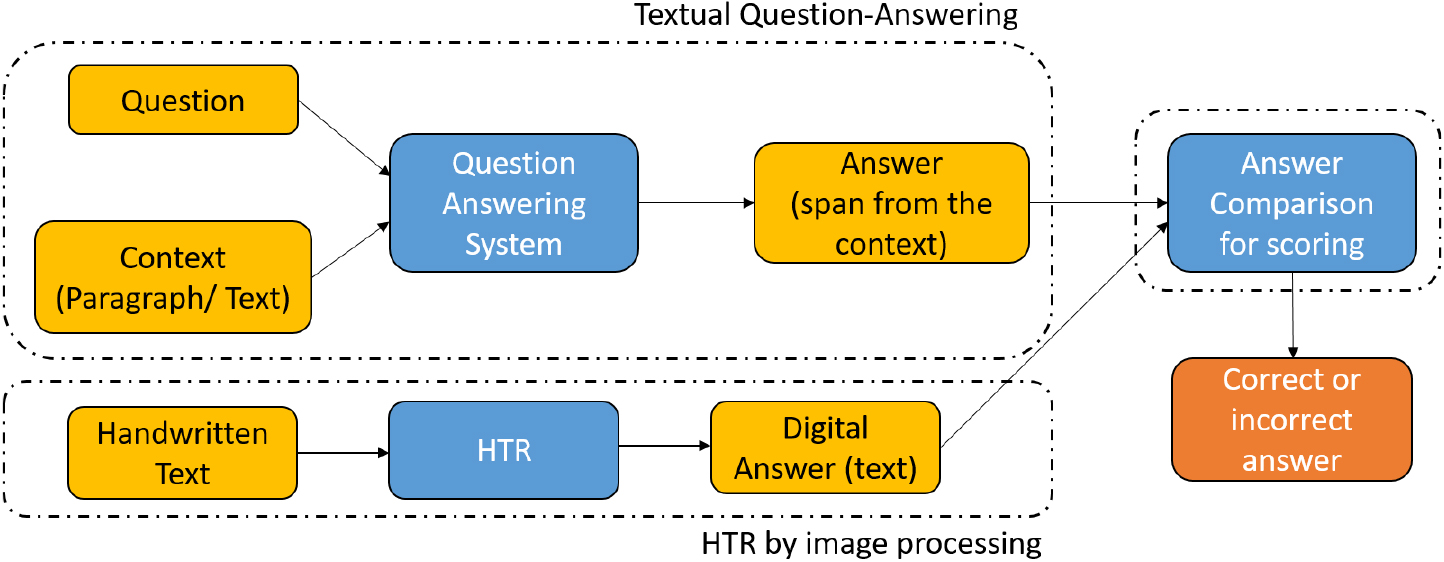
Various transformer models have been utilized for NLP tasks like BERT, m-BERT,ALBERT, RoBERTa, etc. as discussed in Section 2. Since, our focus is span extraction from the given context, we have employed RoBERTa (A Robustly Optimized BERT Pretraining Approach), a transformer-based language model performing textual-QA. It utilizes self-attention and processes input to generate contextual representations of words in a sentence.
Next, we discuss the RoBERTa model and present the rationale for selection of RoBERTa model over alternative models. After which the proposed textual-QA model that utilizes RoBERTa model is discussed.
RoBERTa [27] is an improved version of BERT with significant improvements to the pre-training phase. It is trained for longer sequences using a dataset ten times larger than that used to train the BERT model, with an increased number of iterations. In the pre-training of RoBERTa, the Masked LM part is done using a dynamic masking approach instead of static masking as done in BERT, and instead of NSP module, a sentence order prediction (SOP) task is used.
Dynamic masking is a more adaptive approach in which the masked tokens are changed during training. At the start of training, a few tokens are masked. This masking, however, changes with each epoch. This introduces more variation into the training data, making the model more robust to different input sequence lengths. SOP is performed by packing full sentences sampled contiguously from one or more documents, such that the total length is at most 512 tokens. Inputs may cross document boundaries. When one document is completed, the sampling of sentences from the next document is continued, and a separator token is inserted to demarcate the documents. The NSP loss is also removed.
Rationale for selection of RoBERTa model
As detailed above, RoBERTa model is an improvement of BERT and other variants of BERT. It is trained on a significantly larger and more diverse corpus of text data compared to BERT. Futher, it omits the Next Sentence Prediction (NSP) task, which was part of BERT’s pre-training objective. Removing NSP training allows RoBERTa to focus more on learning the core contextual language representations, resulting in improved performance. It uses a dynamic masking strategy where it randomly masks out and replaces tokens during pre-training. In contrast, BERT uses static masking with fixed probabilities. This dynamic masking approach makes RoBERTa more robust.
Textual question answering model
Textual question-answering approach.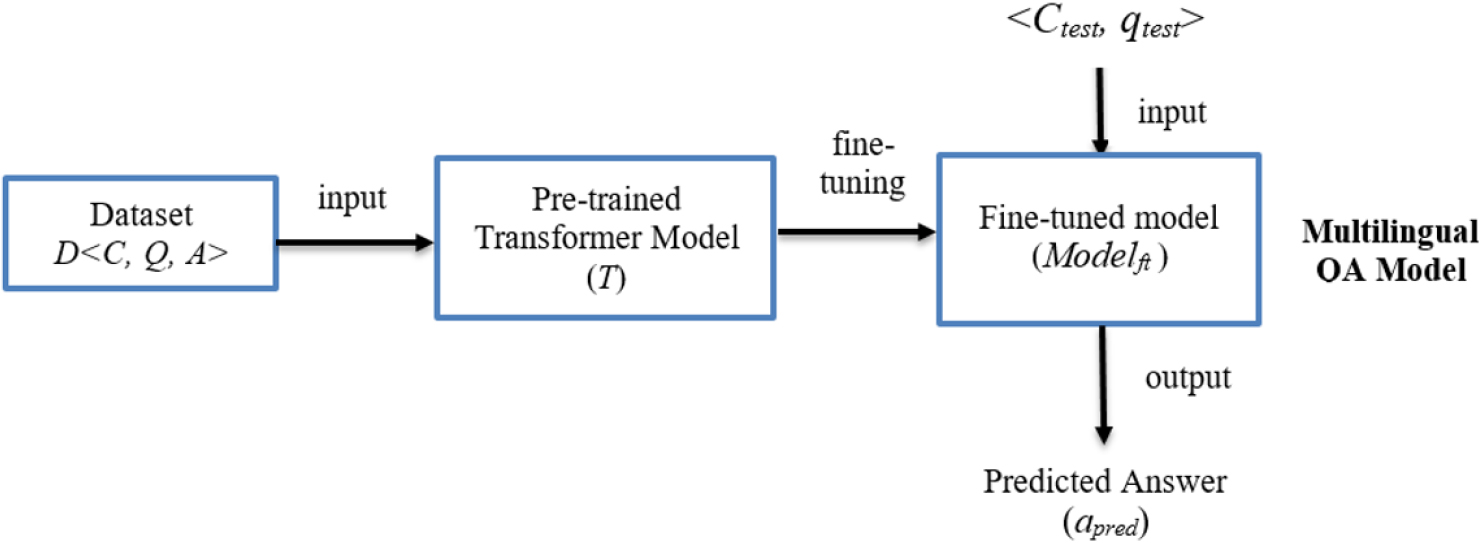
The proposed textual-QA model is presented in Fig. 2. A dataset is provided as input to the transformer model
where
where,
The fine-tuning is done using text from multiple languages (discussed in Section 4) making the
Extraction of handwritten words.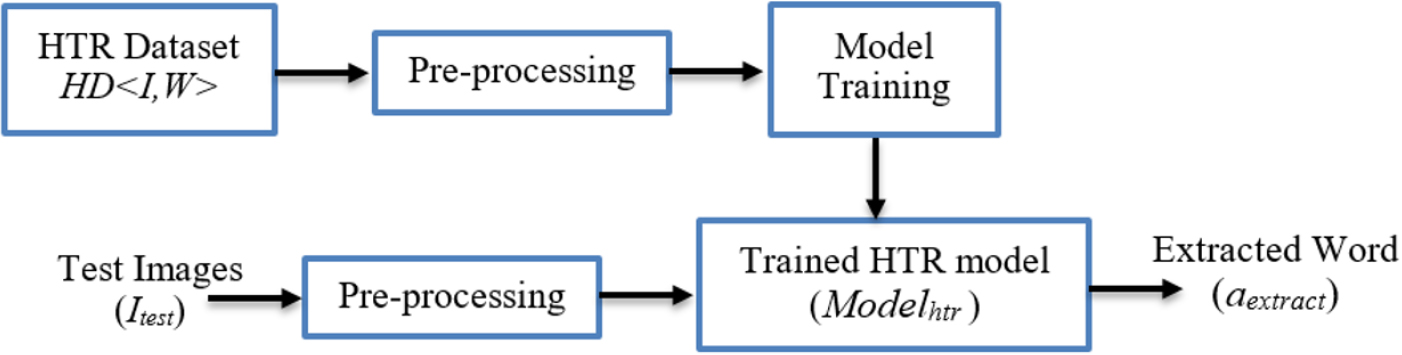
Extraction of handwritten words involves building a Handwritten Text Recognition (HTR) model. The overview of the method is presented in Fig. 3. The HTR dataset
The HTR model is a Convolutional Recurrent Neural Network (CRNN) based model. CRNN involves both Convolutional Neural Network (CNN) as well as Recurrent Neural Networks (RNN). CNN applies convolution operations by sliding a filter across an image to extract features from the image and RNN allows considering data from the past for making predictions. The features from CNN are sent to RNN to examine these aspects sequentially while taking into account prior knowledge to identify certain key relationships between these features that affect the result of word recognition. To further consider the context, a layer in opposite direction can be added to take into account context from the past as well as the future.
Convolutional recurrent neural network based handwritten text recognition model.
The architecture of the proposed HTR model is presented in Fig. 4. A stacked architecture is employed for the design of the model. The image features are extracted using five layer CNN network. It is followed by a two-layer stacked Bi-directional Long Short-Term Memory (Bi-LSTM) along with Connectionist Temporal Classification (CTC) loss [28]. The text is then decoded using CTC decode to obtain the word, character by character. Next, we discuss each module.
Convolution neural network for feature extraction
In CRNN, CNN is regarded as the feature extractor, for extracting features from the images of hand written text. Typically, it is divided into two parts. The first part is application of the convolution operation to extract features and the second part is application of pooling operation to adjust the output of convolutional layer.
A five-layer convolutional neural network is designed for image feature extraction as shown in Fig. 4. Each convolutional block has a 2D convolutional layer that applies Rectified linear unit (ReLu) activation function, and then max pooling.
In the convolutional layer, a filter is applied to the input data to produce feature maps. The filter slides over the input, and at each position, the dot product between the filter and the local region of the input is computed. After which a non-linear activation function ReLU is applied. This can be represented as follows,
where
where,
Further, the maximum pooling layer pools the convolved results to extract important features of the image. The height and width components are changed using the pooling operation. These can be represented as follows,
where,
Recurrent neural network using Bi-LSTM and text recognition
The output of CNN is then passed to RNN module, which comprises of two-layer Bi-LSTM for time-sequence and sequence dependency computations. It generates a probability matrix for characters at each time step. Rather than using LSTM, Bi-LSTM is utilized. LSTM performs transition of the previous hidden state
Mathematically, the LSTM is defined as,
where
As a result, the Bi-LSTM is implemented with two separate LSTM layers for computing
Connectionist temporal classification (CTC) loss and decode
CTC (Connectionist Temporal Classification) [28] is a loss function and decoding algorithm. The CTC loss function is used to train a neural network to learn a mapping between variable-length input sequences and variable-length output sequences. The main difficulty with these types of tasks is that the input and output do not have a one-to-one correlation, making conventional loss functions like mean square error inadequate. The CTC loss introduces a special “blank” label and models the conditional probability of a target sequence given an input sequence. The loss function computes the probability of all possible alignments between the input and output sequences. It aims to maximize the likelihood of the correct alignment.
The Bi-LSTM is used along with the CTC loss. It computes the loss as -log(ground truth text) intending to minimize the negative maximum likelihood path by considering the ground truth text and the output from the Bi-LSTM. Finally, the given labels are used to find the possible paths. The loss for
Decoding is done using the word beam search algorithm to recognize the handwritten text [29]. The algorithm proceeds by finding the beams (candidate characters in our case) at each step. The model provides as output the probabilities of each character at each time step. We consider only the best-scoring character for further processing. A beam width of 50 is used for controlling the number of surviving beams. This process is repeated until the entire output of the model is processed, that is, till the word is recognized. A dictionary of Hindi words is used that restricts the possible words that can be created.
This module is the final step towards building an automatic answer correction system. After obtaining the answer for the given question from the textual-QA model (
if (F-score
Datasets
As discussed in Section 3 the system is divided into: textual-QA, HTR and marks allocation by comparing the correct answer extracted from the textual-QA model and the one written by the student (extracted from HTR model). XQuAD [30] and IIIT-HW-Dev dataset [20] existing datasets are used for training and evaluating the performance on textual-QA and HTR tasks respectively. A hindi question-answering dataset is created for textual-QA task. These datasets are detailed next.
XQuAD [30]
The experimentation on textual-QA is performed using the XQuAD dataset. It is a Cross-lingual Question Answering benchmark dataset. The dataset comprises tuples of (question, answer, and context paragraphs). There are 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 [13]. Apart from English, the professional translations of the entire dataset are also available in ten different languages, namely, Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. All of the files in this dataset are in JSON format, which is similar to the SQuAD dataset format. Table 2 shows the average number of tokens per paragraph, question, and answer for each language.
XQuAD tokens
XQuAD tokens
We have merged all these to form a single multilingual dataset of around 14000 question-answer pairs. The dataset is an MCR dataset, in which, the answer to any question is the span from the given context. Apart from the tuple of (question, answer, and context paragraphs), the dataset also contains a start index. The start index specifies the starting character index in the context. However, the end index is not available in the dataset. Thereby, we have applied pre-processed to compute the end index and appended it to the dataset. The end index was computed by considering the answer text, context, and start index.
IIIT-HW-Dev dataset [20]
Sample handwritten words in Devanagari script in the IIIT-HW-Dev dataset [20].
IIIT-HW-Dev dataset is used to train the HTR model. It is a Hindi dataset that contains 9,540 handwritten words in the Devanagari script. It is annotated using UTF-8. For each word, there are about 9 to 10 samples in the dataset. A total of 95,381 word samples are available, these are collected from 12 different individuals with different educational backgrounds and ages. Figure 5 shows sample images from the dataset.
Hindi-QA dataset
Sample of Hindi-QA dataset.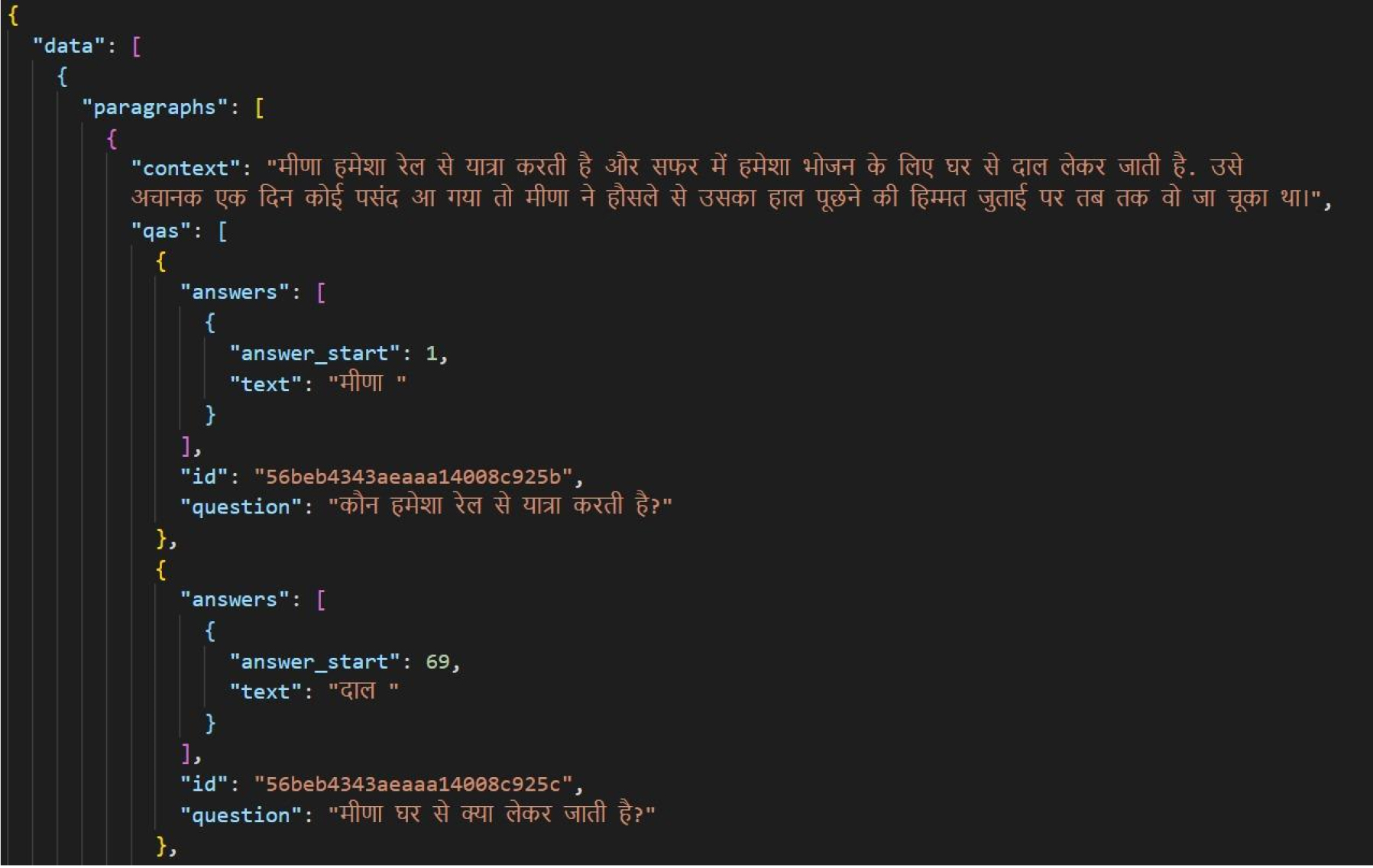
The XQUAD dataset is a general domain dataset which is originally created in English and then translated to 11 different languages. We have created a small dataset called as Hindi-QA. Rather than translating the English text, it is created in Hindi language by native Hindi speakers. The context is in form of short stories and Question-Answer are designed from the context. This is generally the format of asking questions based on MCR in schools. As the overall system is designed for evaluation of handwritten answers of students, Hindi-QA helps to demonstrate the performance on real data. Moreover, no such dataset exists that is specifically designed to handle the MCR task in Hindi language for answer evauation of students.
The dataset comprises of context, question and answer. There are 100 question-answer pairs in the same format as XQUAD. The dataset is in Hindi language and consists of mainly single-word correct answers. Figure 6 shows a context and two questions along with their answers from the dataset.
In this section, the experimentation and the results obtained for the two main modules: textual-QA, HTR are presented. Further, the application of these modules to the overall task of answer evaluation is presented, emphasizing the practical implications on real data in the Hindi language. For model and results evaluation purposes, a simple web app was created using Flask, which is a simple web framework. The performance metrices used to evaluate the model performance are presented first, followed by results and its discussion.
Performance evaluation metrics
Exact Match (EM) Score and F1 Score metrics are used to evaluate the performance of the textual-QA task. The exact match score provides the measure of how similar the two texts are. However, it doesn’t allow variations and checks for exact matches of words. Whereas, the F1-score is based on the computation of precision and recall. These can be expressed as follows,
where,
F1 score captures the precision and recall such that the words chosen as being part of the answer are part of the answer, and EM score is the number of answers that are exactly correct (with the same start and end index).
The HTR model is evaluated based on Accuracy that is the measure of fraction of text classified by the model which are correct.
The performance of textual-QA is assessed on existing dataset-XQUAD and on the created dataset Hindi-QA.
Results on XQUAD
The task of textual-QA is accomplished by, first, training a pre-trained transformer model on a combined multilingual dataset, XQUAD (refer to Section 4). Experiments are conducted utilising a variety of pre-trained transformer models, including BERT, m-BERT, DistilBERT, ALBERT, RoBERTa-base, and RoBERTa-large, to demonstrate the effectiveness of the proposed textual-QA technique. These models were fine-tuned for 5 epochs with a batch size of 32 and a learning rate of
Time required to fine-tune the models
Time required to fine-tune the models
Results of question answering on hindi and English language from XQUAD dataset
The time required for fine-tuning each of the models using XQUAD is presented in Table 3. The trained model
Effectiveness of using combined XQUAD dataset
To further show the effectiveness of training the model on a combined set of all languages (as discussed in Section 4) rather than just on a single language, experiments were carried out by fine-tuning the pre-trained models only on a specific language from the XQUAD dataset. Table 5 shows the model performance when fine-tuning is done using only English and only Hindi language question-answer pairs from the dataset.
Model performance when trained only using hindi/English QA pairs from XQUAD dataset
Comparision of performance on English question-answer pairs from XQUAD dataset in two settings. S-trained and tested only using English QA pairs, C-trained on combined dataset of 11 languages and tested on English QA.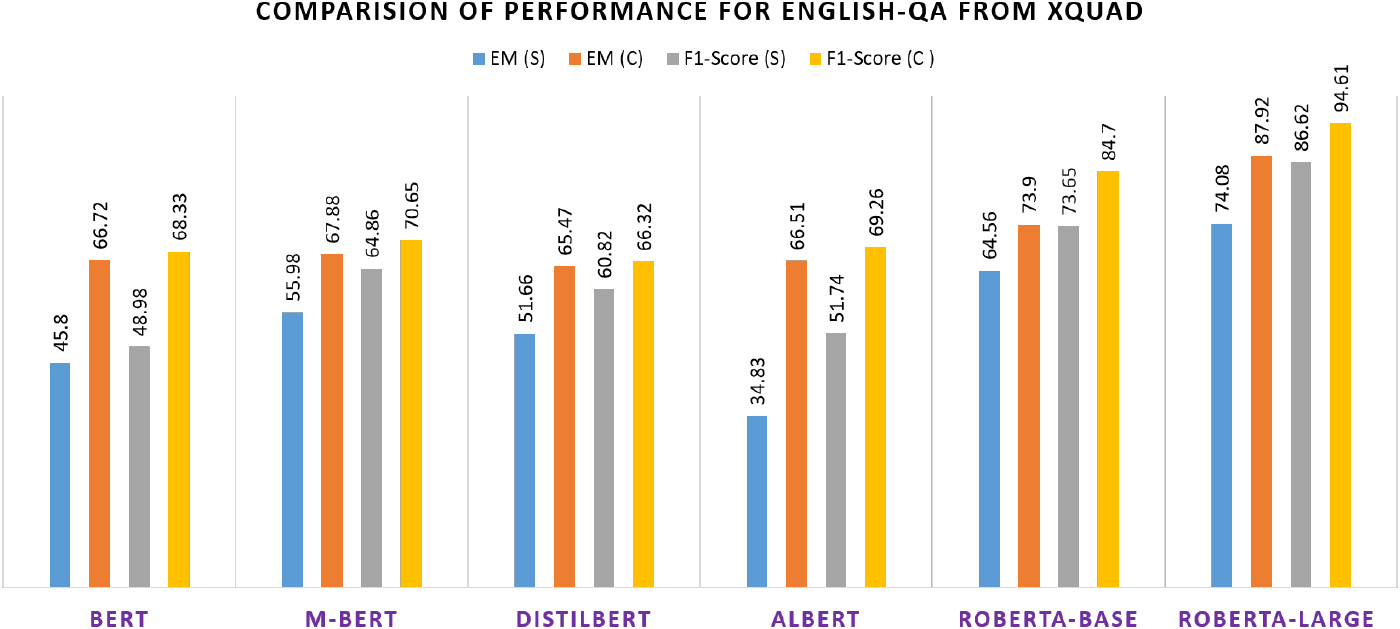
Comparision of performance on Hindi QA from XQUAD dataset in two settings. S-trained and tested only using Hindi QA pairs of XQUAD, C-trained on combined dataset of 11 languages and tested on Hindi QA from XQUAD.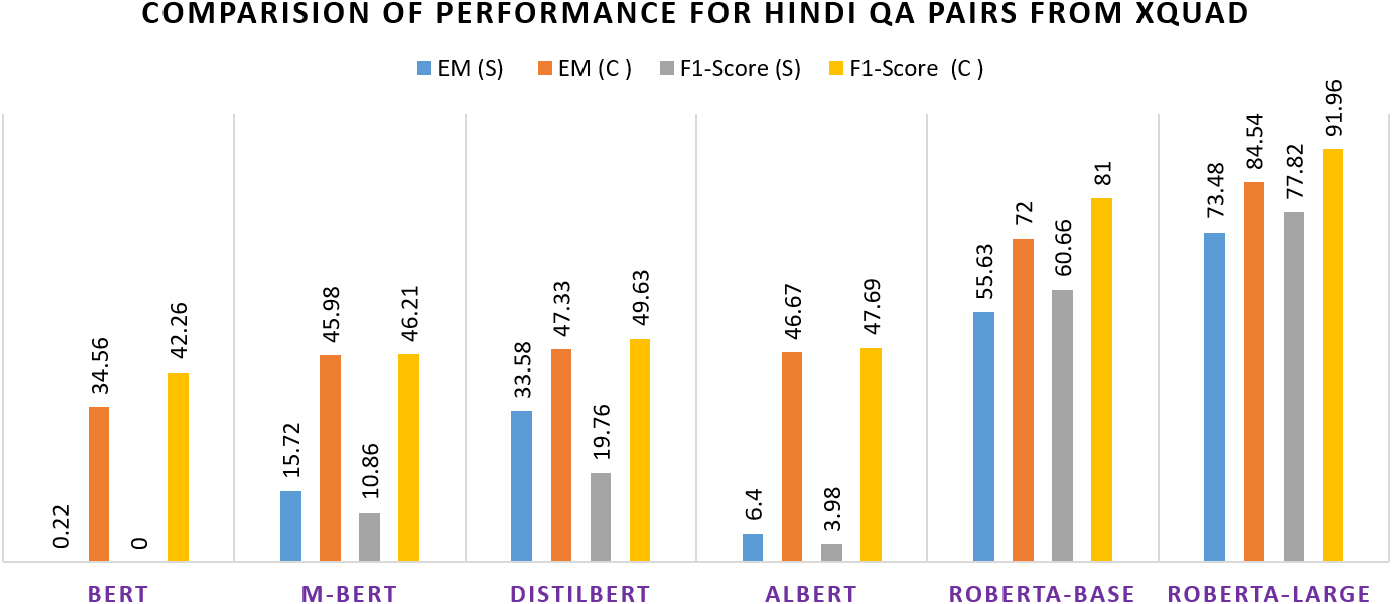
Comparative analysis is presented in Figs 7 and 8. It is observed that the performance of all the models improves considerably when trained on a combined dataset of all languages from XQUAD. This is also evident from the comparison of Tables 4 and 5. Thereby, rather than training only using specific language, trained model on a combined dataset offers more comprehensive language representation and is further used as the final model for next steps.
In this section, the result obtained on Hindi-QA is discussed. The dataset is divided into training and test set of 80% and 20% respectively. It is clear from the discussion in Section 5.2.1 that the RoBERTa-large model outperforms the other models. As a result, RoBERTa-large model is used for further experimentation on our created Hindi-QA dataset. Additionally, it was shown that the models trained on a combined dataset perform better. Thereby, we employ the model that was produced in the previous section and further fine-tune it using the training set of Hindi-QA rather than only fine-tuning the RoBERTa-large model on the Hindi-QA dataset. This led to further improvement in the model performance. The F1-score obtained for the final model on the test set of Hindi-QA is
Sample result of textual-QA by entering a new paragraph and a question to obtain answer for a real data.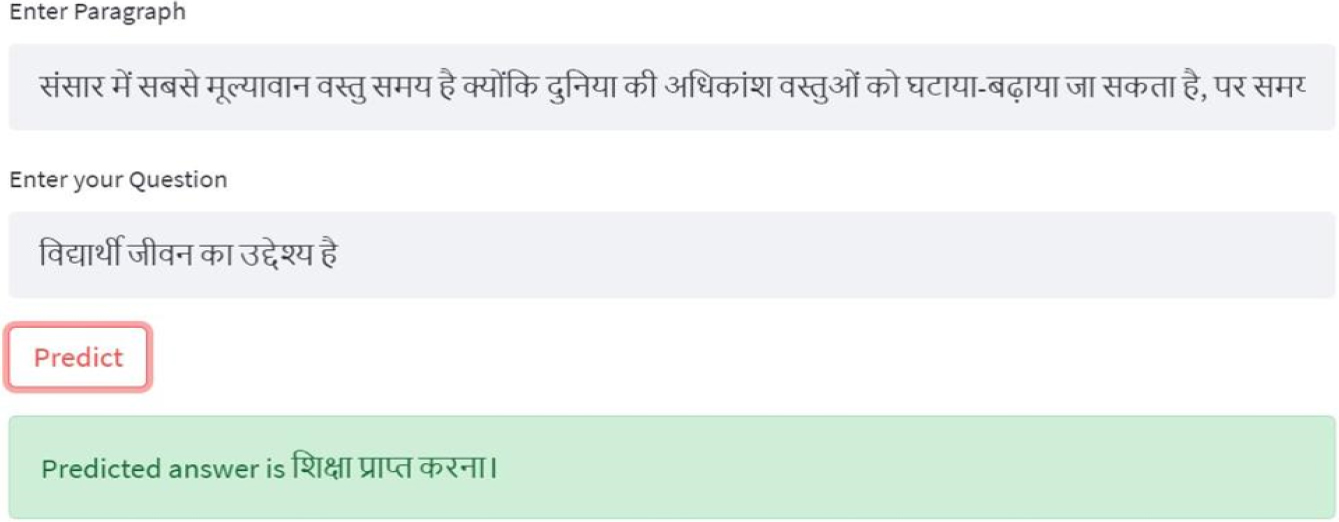
A sample answer for context and question are shown in Fig. 9. The system requires entering the context/paragraph as input along with the question in the Hindi Language. It then predicts the answer to the given question by extracting a span from the given context.
To further, validate the performance of the proposed model, we performed experimentation on a recently released dataset called Challenge in AI for India (ChAII) – Hindi and Tamil Question Answering [11]. The dataset includes context, question and answer in Hindi and Tamil language. The training set has 740 Hindi and 364 Tamil examples. The test set comprises of 816 examples.
Evaluation metric used
There is very less work on the dataset, and researchers have employed Jaccard similarity as the evaluation metric. Thereby, we have also evaluated the results using the same metric for ease of comparision. Jaccard similarity coefficient is defined as,
where, A and B are sets of predicted aswer and ground truth answer. A Jaccard score of 0 means that none of the characters are the same between the predicted answer and the correct answer, and a score of 1 means that the two are identical.
Results
Our model is obtained by employing the fine-tuned RoBERTa-large model (obtained in Section 5.2.1 using the combined XQUAD dataset) and further fine-tuning it using the training set of ChAII dataset. The model is fine-tuned for 4 epochs with learning rate of
Results of textual-QA on ChAII dataset
The comparision is done with the following methods:
As observed in Table 6, our approach performs better than the other methods. This is because the model was fine-tuned on combined set of 11 languages as opposed to just one language. Therefore, as discussed in Section 5.2, the results here are also indicative of the same fact that fine-tuning using combined XQUAD dataset is more effective and provides better representation of language. This is also evidant by comparing the results with the best performing model [15], which is trained only using Hindi QA pairs from the datasets used.
Accuracy of HTR model on IIIT-HW-Dev
Accuracy of HTR model on IIIT-HW-Dev
The HTR model was developed by training the CRNN network (as discussed in Section 3.2) on the IIIT-HW-Dev dataset (refer to Section 4). 80 percent dataset was used for training and the remaining 20 percent for testing. Initially, pre-processing of handwritten input images is done by applying gray scaling and resizing techniques. The input image is resized to 128
Although, there is a considerable amount of work in devanagri script character recognition, there is very less work in word-level recognition in Hindi language. Based on the presented result, our model outperforms the existing method on this dataset.
Sample result of QA in Hindi language on real data.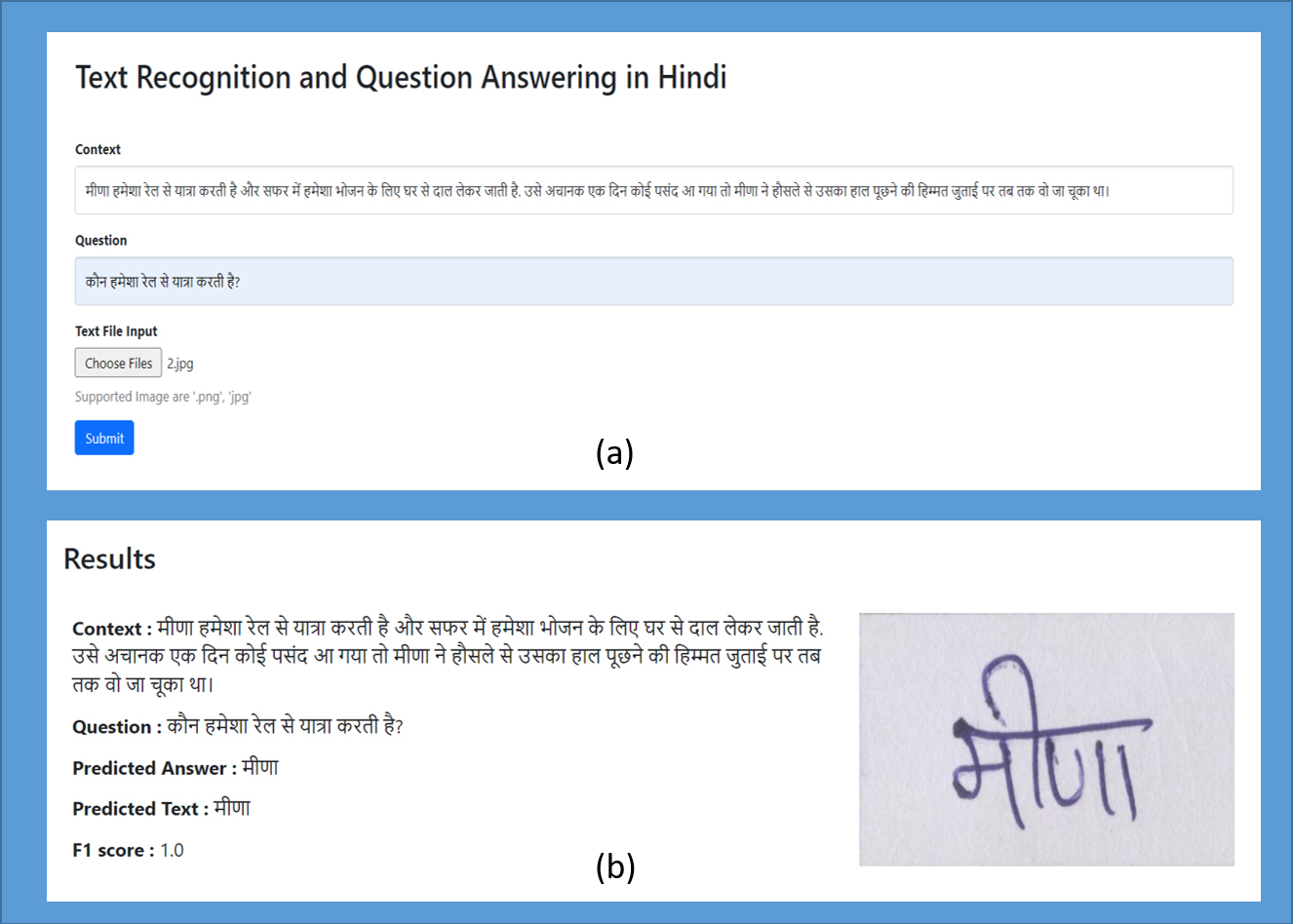
Further, the task of answer evaluation is performed by comparing the answer extracted from the image with the answer predicted by the QA model. When comparing answers, lower and upper-case matches are taken into account to see if the expected and actual results exactly match.
For model and results evaluation, a web app was created using Flask. Context (Paragraph), Question, and Images (for recognition) are given as input in the web app to obtain the answer evaluation. Sample evaluation on real data is presented in Figs 10 and 11.
Sample results of QA in Hindi language on real data.
Figure 10a shows the inputs required and Fig. 10b shows the obtained result along with the entered inputs. The entered context, question and images are displayed. The predicted answer (
Another result for two questions is shown in Fig. 11. For the first question
In this section, we discuss the possible future direction and emerging research topics in the field that have the potential to further advance this research area.
Future scope
Future Scope of the work presented in this paper is discussed below:
Currently, the text recognition model can extract only one-word text. Thereby, limiting the answer evaluation to a single-word answer. As a future scope, the model for recognizing a line or paragraph as an answer can be built to further enhance the answer evaluation system. The Hindi-QA dataset can be further extended to include more context and question-answer pairs, to further improve the model accuracy. Although, the focus is on Hindi language, the system can be developed in various languages. The XQUAD dataset used for fine-tuning the textual-QA models is in 11 languages. We have further finetuned it using Hindi question-answer pairs. Further fine-tuning in other languages can lead to an efficient multi-lingual system. The work presented in this paper is on Machine reading comprehension type of questions. Other type of questions like multiple choice questions, open answer questions can also be addressed. Additional module of automated QA pair generation from the given text can help in additional practice and undestanding of students.
The application areas of the proposed system are presented next.
The proposed system can be very useful in education sector. It can be used in schools by training it on the textbook content, providing assistance to teachers and students. It can help in designing Interactive textbooks for students offering explanations and additional information. A chatbot for any educational institute can be built for answering common queries of students.
The potential research directions in textual-QA are as follows:
BiQue a German-nglish bilingual textual QA-ystem is presented in [34]. It is an open-domain bilingual QA-System for English target document collections and German source language questions. In [35], discriminative adversarial neural networks are used to address cross-language task of question-uestion similarity reranking in community question answering. The question can be either in English or in Arabic, and the questions it is compared to are always in English. A Cross-Lingual Product Question Answering system called xPQA is presented in [36]. It is a cross language question answering system that supports 12 Languages.
In this paper, an answer evaluation system for the Hindi language is presented. The paper tries to connect the research outcomes to the real-world application of an automated answer evaluation system, highlighting its potential to assist students and educators. A question-answering model is built along a handwritten text recognition model for the automated evaluation of answers written by the student. For question answering on the Hindi dataset, the model built using the Roberta-large pre-trained model, trained on the combined 11 language XQUAD dataset gave the highest performance in comparison to other models. It is further fine-tuned on the Hindi-QA dataset to further improve the performance of the model. Based on the results of the experiments, it can be concluded that fine-tuning the RoBERTa model with question-answering datasets in multiple languages and then fine-tuning it specifically with the Hindi-QA dataset outperforms other methods that fine-tune only using Hindi pairs, only English pairs, or English and Hindi pairs. The text recognition model is built using Convolutional Recurrent Neural Network, which extracts the handwritten Hindi text from the image. The outputs from these two models are then compared to obtain the evaluation of the answer using the F1-score.
Declaration of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Dataset availability
The datasets generated during the current study are available from the corresponding author on request.